双亲委派模型
我们在自定义类加载器时发现:
就算不同的类加载器所加载的文件全限定类名相同,也会在各自的类加载器空间也会开辟一个全新的区域,这会导致jvm运行时的混乱;
但是在实际运行时jvm却规避了这种情况的发生,这就是双亲委派模型,(并且在模型中会通过将类文件的全限定类名转换为文件path);
这样就算通过app加载器加载了同名文件,系统也会自上而下的找到已加载的类,从而避免混乱;
线程模型
linux的轻量级线程是由一个线程组下的共享地址所控制;
而我们说创造的线程通常是以1v1,多v1与多v多;
其中1v1在进行线程切换时是利用操作系统界别的切换会导致cpu性能的浪费,可以利用cas来避免线程的切换,但是内核的线程总归是有限的,因此参生了多对1方法,能够提升并发量的上线;
但是当一个线程阻塞会导致这个线程说对应的所有线程堵塞,
多v多能够解决很多缺点,但是难度较高;
锁
乐观锁
乐观锁其实是一种无锁模型,使用的是cas方式所达到的线程安全的模式,利用unsafe类下的方法,利用操作系统级别的原子操作来进行判断;(不需要线程切换,更加高效)
一般来说我们在进行数据安全操作的时候,利用这种方式,只让一个线程完成操作,而其他线程只能通过失败操作来进行(可以使用自旋操作);即在进行数据操作前先进行信号的判断(0-1),通过对未操作数据显示0而操作数据显示1来进行甄别,(这里必须保证在进行数据判断和修改的过程中是原子操作),而cas就能保证这一方式的进行,原因是其调用了cpu级别的操作;
而其余线程进行等待的时候采用自旋的方式进行等候,(适应性自旋指的是如果上一个线程获得了执行权,则这个线程被判断为有可能得到执行权就会继续等待);
需要注意的是在AQS方法里,这里采用了双链表的方式,等候的第一个自旋,其他排队;
悲观锁
悲观锁是我们传统上说的锁结构,其中以对象作为锁;
对象存在着(对象头,实例数据,对齐填充字节)而其中对象头中存在着两个部分(Mark Word和Class Pointer),其中markword 标志位很小32位
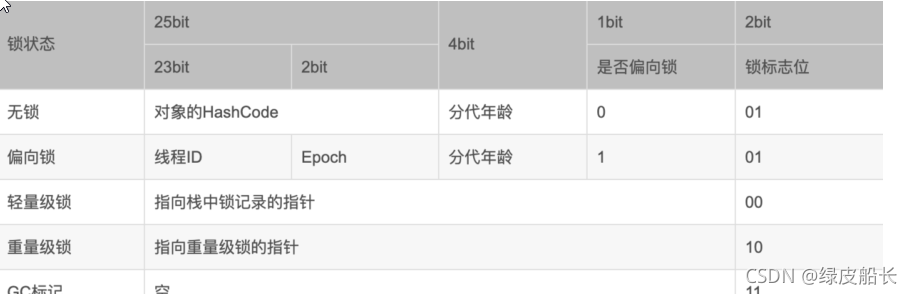
这里显示了四种锁的状态:
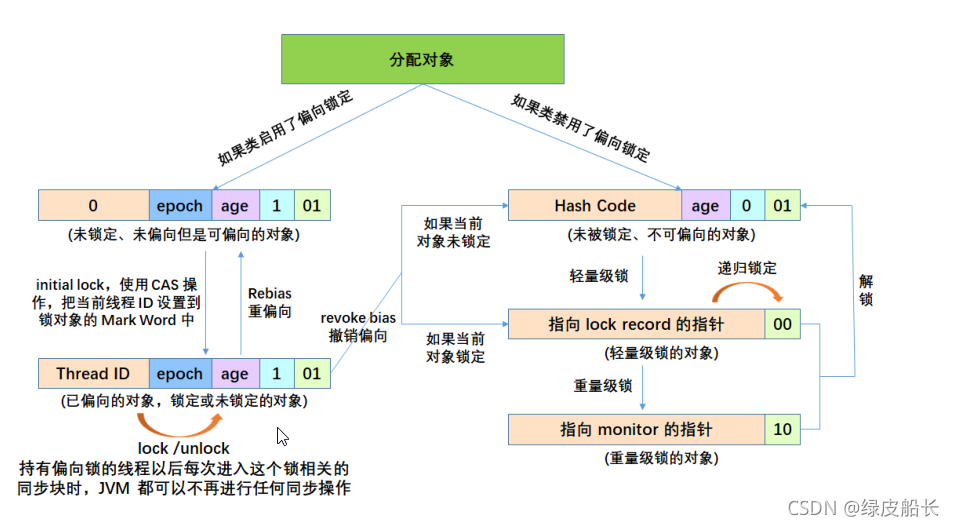
其中(一):无锁,这里包括了,无需数据保护的情况,也包括了上文乐观锁的情况
(二)偏向锁:偏向锁,实际过程中在对数据进行操作的时候,我们希望这个锁不会导致系统状态的切换就能完成,因此在对象锁里记录着某个线程的ID,这样只要是这个线程到来就能进入锁中,然而当多个线程都在进行锁的竞争时,就会升级为轻量级锁
(三)轻量级锁:简单来说,就是线程里的虚拟机栈开辟了一个lockrecord空间来存放标志位的信息,以及一个指针指向标志位,以及尝试使用cas去获得钥匙,如果成功标志位内也会生成一个指针指向这个线程,这样二者就相互认识,其余线程自旋
(四)重量级锁:当自旋的数量超过cpu核数一半的时候就会升级成为重量级锁;通过生成监视器来进行严格的控制
---
在方法区中,先生成类常量池,之后放入到运行时常量池:用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后存放到字符串常量池中。
---
运行时常量池,它是方法区的一部分。Class文件中除了有类的版本、字段、方法、接口等描述等信息外,还有一项信息是常量池(Constant Pool Table),用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后存放到常量池中。
运行时常量是相对于常量来说的,它具备一个重要特征是:动态性。当然,值相同的动态常量与我们通常说的常量只是来源不同,但是都是储存在池内同一块内存区域。Java语言并不要求常量一定只能在编译期产生,运行期间也可能产生新的常量,这些常量被放在运行时常量池中。这里所说的常量包括:基本类型包装类(包装类不管理浮点型,整形只会管理-128到127)和String(也可以通过String.intern()方法可以强制将String放入常量池)
---
当java文件被编译成class文件之后,也就是会生成我上面所说的class常量池,那么运行时常量池又是什么时候产生的呢?
jvm在执行某个类的时候,必须经过加载、连接、初始化,而连接又包括验证、准备、解析三个阶段。而当类加载到内存中后,jvm就会将class常量池中的内容存放到运行时常量池中,由此可知,运行时常量池也是每个类都有一个。在上面我也说了,class常量池中存的是字面量和符号引用,也就是说他们存的并不是对象的实例,而是对象的符号引用值。而经过解析(resolve)之后,也就是把符号引用替换为直接引用,解析的过程会去查询全局字符串池,也就是我们上面所说的StringTable,以保证运行时常量池所引用的字符串与全局字符串池中所引用的是一致的。
-----------
Java中的常量池分为三种类型:
- 类文件中常量池(The Constant Pool)
- 运行时常量池(The Run-Time Constant Pool)
- String常量池
类文件中常量池 ---- 存在于Class文件中
所处区域:堆
诞生时间:编译时
内容概要:符号引用和字面量
class常量池是在编译的时候每个class都有的,在编译阶段,存放的是常量的符号引用。
运行时常量池 ----?存在于内存的元空间中
诞生时间:JVM运行时
内容概要:class文件元信息描述,编译后的代码数据,引用类型数据,类文件常量池。
所谓的运行时常量池其实就是将编译后的类信息放入运行时的一个区域中,用来动态获取类信息。
运行时常量池是在类加载完成之后,将每个class常量池中的符号引用值转存到运行时常量池中,也就是说,每个class都有一个运行时常量池,类在解析之后,将符号引用替换成直接引用,与全局常量池中的引用值保持一致。
字符串常量池 ---- 存在于堆中
字符串池里的内容是在类加载完成,经过验证,准备阶段之后在堆中生成字符串对象实例,然后将该字符串对象实例的引用值存到string pool中(记住:string pool中存的是引用值而不是具体的实例对象,具体的实例对象是在堆中开辟的一块空间存放的)。
在HotSpot VM里实现的string pool功能的是一个StringTable类,它是一个哈希表,里面存的是驻留字符串(也就是我们常说的用双引号括起来的)的引用(而不是驻留字符串实例本身),也就是说在堆中的某些字符串实例被这个StringTable引用之后就等同被赋予了”驻留字符串”的身份。这个StringTable在每个HotSpot VM的实例只有一份,被所有的类共享。