Xctf--Web--Challenge--area Wp
1.baby_web
> 题目描述:想想初始页面是哪个
思路: 先进入网页,看到url为http://111.200.241.244:59979/1.php
结合题目描述,初始页面应该是:index.php,
尝试修改url------>失败,又跳回到1.php
查看源码:没有发现什么,修改为index.php再次查看源码,在network中看到了

其实还有第二种方法
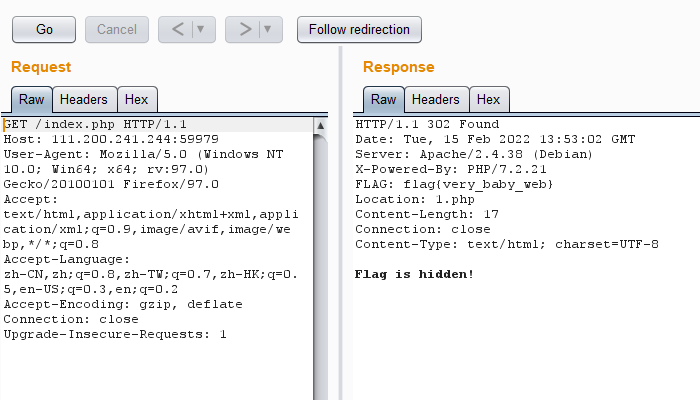
bp抓包,修改网页请求头,sent to repeater go一下,在响应中出现flag
2.warmup
进入环境,只有一张图片,选择查看源码,发现注释
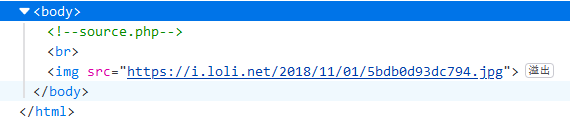
查看该php文件,出现一个checkFile(&$page)函数,这里代码实现的功能是判断参数类型,并对参数进行多次字符串截取函数介绍.
代码中还有一个hint.php,内容为
flag not here, and flag in ffffllllaaaagggg
source.php 中含有文件引入语句include $_REQUEST['file'],
综合以上判断:1:需要file传参、2:checkfile返回值为true(需要将’?'经过url编码两次)、3:文件名为flag not here, and flag in ffffllllaaaagggg
结合几位大神的解答,得到传参值:?file=source.php%253f/…/…/…/…/ffffllllaaaagggg
3.Training-WWW-Robots
网站先列出了一串英文:
`In this little training challenge, you are going to learn about the Robots_exclusion_standard.
The robots.txt file is used by web crawlers to check if they are allowed to crawl and index your website or only parts of it.
Sometimes these files reveal the directory structure instead protecting the content from being crawled.
Enjoy!`
经过翻译是这样:
在这个小小的训练挑战中,您将学习Robots_exclusion_standard。
txt文件被网络爬虫用来检查他们是否被允许爬行和索引你的网站或仅部分网站。
有时这些文件会显示目录结构,而不是保护内容不被抓取。
享受
这里附上robors协议的一个介绍:Robots
既然是robots,那先看看robots.txt文件
是这样的:
** `User-agent: *
Disallow: /fl0g.php
User-agent: Yandex
Disallow: ***
Disallow: /fl0g.php 表示禁止所有爬虫访问 /fl0g.php,那咱们就访问一下这个页面
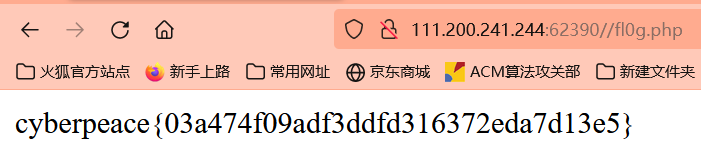
其实这一题和新手区的robots是一样的XCTF新手区