一、响应【重点】
在laravel中,响应正常情况下有2个类型:常规的直接响应,另外一个是ajax的响应。
其中展示视图以及直接响应字符串都属于常规的响应。
例如:常规响应
展示视图:
return view(‘welcome’);
直接返回某个字符串:
return ‘hello world’;
提示:在laravel框架中,不允许响应布尔值。
1、ajax请求的响应
语法:return response() -> json(需要json输出的数据); //数据是数组格式,对象也可以
案例:创建一个路由,访问对应的页面之后,获取member表信息,页面输出json格式的响应。
①创建路由
/test11
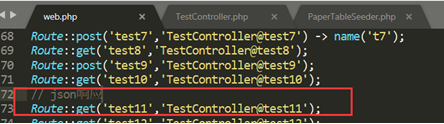
②创建需要的方法并获取基本数据
return response() -> json(需要json输出的数据);
注意:在框架中建议不要再去使用php自带json_encode方法对数据进行json编码。

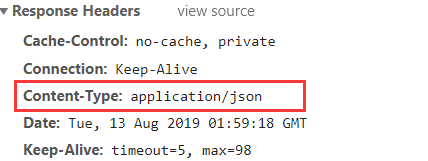
两者的区别,框架自带的json输出方式不会解析当前页面中其他的所有html输出,只会原样输出,如下:

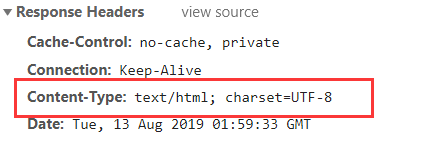
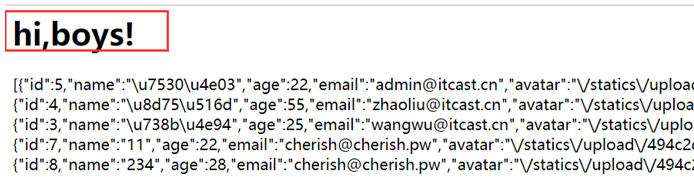
PHP自带的json_encode,则会解析当前页面的其他html标记,效果如下:
2、跳转响应(重定向30x)
在有一些页面,例如同步添加操作,完成操作之后不能停留在当前页面,最好做一个跳转操作,也就是需要一个跳转的响应。
以之前的“上传操作代码”为例:后续比较理想的情况应该是在处理完成之后需要一个跳转提示,告知用户是否成功,成功则应该返回上一页,失败则应该输出错误提示。
两个跳转方式任选一个:
return redirect(路由) -> withErrors([]); 该参数的路由可以是完整的请求路由,也可以是通过route方法+别名获取的路由
return redirect() -> to(路由); 简写成:return redirect(路由)
错误信息的获取与之前自动验证那里的方式一样,通过$errors变量来获取即可。
案例代码:要求更改之前上传文件的方法要求在添加成功之后跳转到首页“/”,失败则返回上一页(test8),携带错误信息

具体的请求的效果:产生了302的请求进行了跳转。

二、会话控制(记忆)
常见应用- 增删改查
session默认存到文件中
session文件的目录:storage\framework\sessions

1、使用Session类
控制器头部引用 use Illuminate\Support\Facades\Session;
由于session类在app.php中已经定义好别名,所以在控制器中引入的时候可以直接use Session

在控制器中直接引入session
Session::put(‘key’, ‘value’); Session中存储一个变量
$value = Session::get(‘key’); Session中获取一个变量
$value = Session::get(‘key’, ‘default’); Session中获取一个变量或返回一个默认值(如果变量不存在)
$value = Session::get(‘key’, function() { return ‘default’; });
Session::all(); Session中获取所有变量
Session::has(‘users’) 检查一个变量是否在Session中存在
Session::forget(‘key’); Session中删除一个变量
Session::flush(); Session中删除所有变量
补充:session方法也可以在视图中使用,如:{{ Session::get(‘code’)}};
案例:编写方法使用上述的语法格式
①编写路由

在后期如果使用Laravel框架自带的验证功能模块(Auth)的话,则session就可以不需要使用了。
另外,在laravel框架中还支持快捷函数session(),也可以设置和使用session的。
两个语法:
语法1:设置session
session([key => value]);
语法2:获取session的值
session(key);
三、缓存操作(记忆)
Laravel 为不同的缓存系统提供了统一的 API(在框架中的写法)。缓存配置位于 config/cache.php。在该文件中你可以指定在应用中默认使用哪个缓存驱动。Laravel 目前支持主流的缓存后端如 Memcached 和 Redis 等。
主要方法:
Cache::put()
Cache::get()
Cache::add()
Cache::pull()
Cache::forever()
Cache::forget()
Cache::has()
系统默认是使用文件缓存,其缓存文件存储的位置位于(storage/framework/cache/data):
设置路由:
/test13
创建方法test13
在控制器中先引入:
1、设置缓存
语法:Cache::put(‘key’, ‘value’, $minutes);
Key:键
Value:值
$minutes:有效期,单位是分钟
注意:如果该键已经存在,则直接覆盖原来的值,有效期必须设置,单位是分钟
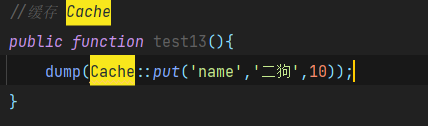
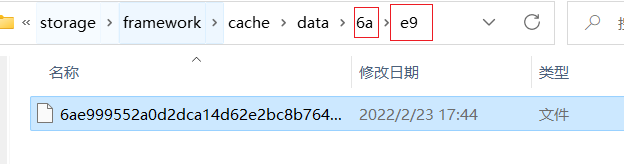
打开文件之后的效果:
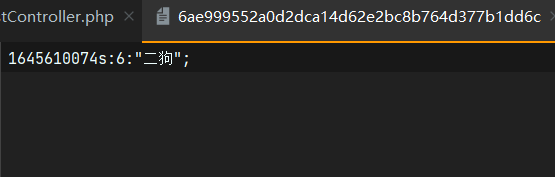
1645610074:表示该缓存项的过期时间的时间戳
S:表示内容是字符串
12:表示内容长度
最后的就是存储的内容
语法:Cache::add(‘key’, ‘value’, $minutes);
Key:键
Value:值
$minutes:有效期,单位是分钟
add 方法只会在缓存项不存在的情况下添加数据到缓存,如果数据被成功添加到缓存返回 true,否则,返回false:
由于之前put已经创建了一个name的缓存,因此使用add再去创建就不会生效
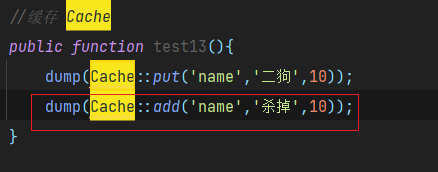

永久存储数据
forever 方法用于持久化存储数据到缓存,这些值必须通过 forget 方法手动从缓存中移除:
Cache::forever(‘key’, ‘value’); 永久存储并不是真的永久,只不过其截至的时间是比较大的值(到2286年)
设置操作:

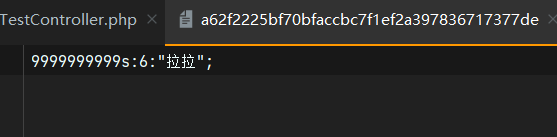
2、获取缓存数据
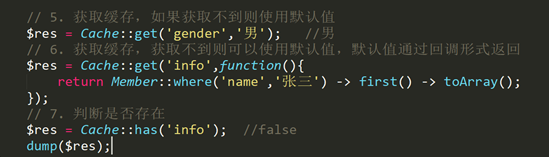
Cache 门面的 get 方法用于从缓存中获取缓存项,如果缓存项不存在,返回 null。如果需要的话你可以传递第二个参数到 get 方法指定缓存项不存在时返回的自定义默认值:
$value = Cache::get(‘key’); 获取指定的key值
$value = Cache::get(‘key’, ‘default’); 获取指定的key值,如果不存在,则使用默认值
可以传递一个匿名函数作为默认值,如果缓存项不存在的话闭包的结果将会被返回。传递匿名函数允许你可以从数据库或其它外部服务获取默认值:
$value = Cache::get(‘key’, function() {
return DB::table(…)->get();
});
检查缓存项是否存在
has 方法用于判断缓存项是否存在:
if (Cache::has(‘key’)) {
//
}
3、删除缓存数据
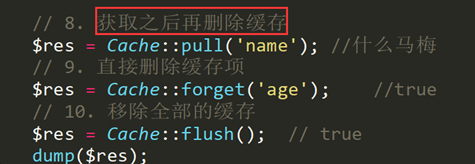
语法:
$value = Cache::pull(‘key’); 从缓存中获取缓存项然后删除,如果缓存项不存在的话返回null,一般设置一次性的存储的数据
Cache::forget(‘key’); 使用forget 方法从缓存中移除缓存项数据
Cache::flush();使用 flush 方法清除所有缓存:并且删除对应的目录
4、缓存数值增加/减少(了解)
increment 和 decrement 方法可用于调整缓存中的整型数值。这两个方法都可以接收第二个参数来指明缓存项数值增加和减少的数目:一般会用作计数器。
Cache::increment(‘key’);
Cache::increment(‘key’, $amount);
Cache::decrement(‘key’);
Cache::decrement(‘key’, $amount);
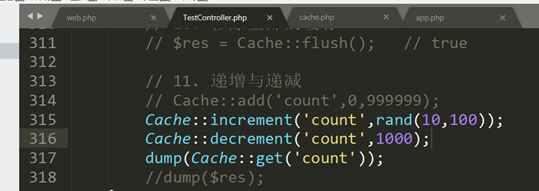
如果用计数器,则在初始化的时候不能使用put和forever,因为这2个方法都会重复的初始化计数器。
5、获取并存储【重点】
有时候你可能想要获取缓存项,但如果请求的缓存项不存在时给它存储一个默认值。例如,你可能想要从缓存中获取所有用户,或者如果它们不存在的话,从数据库获取它们并将其添加到缓存中,你可以通过使用 Cache::remember 方法实现:
$value = Cache::remember('key', $minutes, function() {
return DB::table('users')->get();
});
如果缓存项不存在,传递给 remember 方法的闭包被执行并且将结果存放到缓存中。
如果获取users值是不存在,则可以通过后续的回调代码去执行对应的操作获取其值,并返回,同时会设置一个指定有效期的缓存,方便下次直接使用。比较典型的操作就是在获取微信的accesstoken的时候可以使用。原因是accesstoken本身一天只有2000次的配额,而其有7200s的有效期,在有效期内可以不用去刷新请求。
Demo代码:
public function getAccessToken(){
//从缓存中获取,如果没有过期使用之前的,如果过期则获取最新的
return Cache::remember('access_token',100,function(){
//接口请求地址
$api='https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid='.config('common.appID').'&secret='.config('common.appsecret');
$data=$this->http_get($api);
$tmpArr=json_decode($data,true);
$accessToken=$tmpArr['access_token'];
return $accessToken;
});
}
还可以联合 remember 和 forever 方法:
$value = Cache::rememberForever('users', function() {
return DB::table('users')->get();
});
经常使用的:add/put、get、has、forget、flush、remember。
四、联表查询
联表要求至少得有2张表(除了自己连接自己,自联查询),并且还是存在关系的两张表。
例如:可以建立2张表:文章表、作者表【以目前比较火的网站:知乎】。
文章表(article):
Id 主键
Article_name 文章名称,varchar(50),notnull
Author_id 作者(作者id),int,notnull
作者表(author):
Id 主键
Author_name 作者名称,varchar(20),notnull
①创建迁移文件
#php artisan make:migration create_article_table
#php artisan make:migration create_author_table

②相继编写2个迁移文件的代码
文章表的迁移代码:

作者表的迁移代码:

③执行生成数据表的迁移文件
#php artisan migrate


④模拟数据(通过填充器来实现)
a. 创建填充器文件(可以将多个数据表的写入操作写在一起)
#php artisan make:seeder ArticleAndAuthorTableSeeder

b. 编写数据模拟的代码


c. 需要执行填充器文件
#php artisan db:seed --class=ArticleAndAuthorTableSeeder


案例:要求查询数据表(文章表、作者表),查询出文章的信息包含了作者名称。
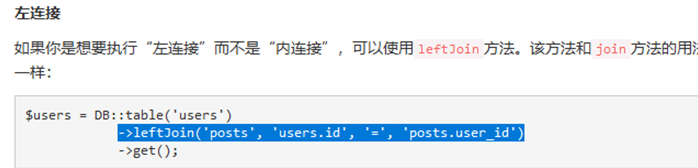
联表查询一共有:内连接(inner)、左连接(left)、右连接(right)。
原始的sql语句:【左外连接】
表:文章表(article)主 t1、作者表(author)从 t2
关联关系:t1.author_id = t2.id
原生的sql:
select t1.id,t1.article_name as article_name,t2.author_name as author_name from article as t1 left join author as t2 on t1.author_id = t2.id;
执行结果:

将上述的sql语句改成链式操作:
语法:DB门面 -> join联表方式名称(关联的表名,表1的字段,运算符,表2的字段)
a. 创建需要的路由

b. 创建test14方法,实现将sql语句改写成链式操作实现刚才的案例效果

显示结果:

五、关联模型(重点+难点)
关联模型就是绑定模型(表)的关系(关联表),后续需要使用联表的时候就可以直接使用关联模型。注意:关联模型必须要创建模型。
1、一对一关系
例如:一篇文章只有一个作者
①创建模型【前提】
#php artisan make:model Article
#php artisan make:model Author
②定义基本的结构代码


③关联模型的关联方法(重点)
注意:在写关联模型的时候要分析出是谁关联谁(类似于联表查询的主、从表),谁做主动关联的模型?当前的案例是文章关联作者,需要关联代码写在主模型中(文章模型中)。
语法:
public function 被关联的模型名小写(){
return $this -> hasOne(‘需要关联模型的命名空间’,’被关联模型的关系字段,’本模型中的关系字段’);
}

关联关系的使用方法:使用动态属性进行调用

动态属性名称就是先前定义的关联方法名称。
案例:通过关联模型的一对一关系查询出每个文章对应的作者名称
①定义需要的路由

②创建需要的方法
控制器中引入需要的文章模型:

操作的代码:

实现的效果:

使用一对一关联关系之后,其可以替代之前写join联表操作。
2、一对多关系
例如:一篇文章有多个评论
由于文章和评论的关系是一对多的关系,所以需要再去创建一个数据表(评论表):
字段id 主键
字段comment 评论内容
字段article_id 和文章的关系字段,文章id
①迁移文件的创建
#php artisan make:migration create_comment_table

②编写迁移文件代码

③执行迁移文件生成数据表
#php artisan migrate

④添加测试的评论内容
a. 创建填充器文件
#php artisan make:seeder CommentTableSeeder

b. 编写填充器文件的代码

c. 执行填充器文件
#php artisan db:seed --class=CommentTableSeeder

执行之后数据表中就会有对应的测试数据:

⑤评论模型创建起来
#php artisan make:model Comment

定义其基本的属性:

案例:查询出每个文章(主)下所有的评论(从)。
关联关系的编写:
public function 被关联的模型名小写(){
return $this -> hasMany(‘需要关联模型的命名空间’,’被关联模型的关系字段,’本模型中的关系字段’);
}
与hasOne方法相比,其只是把方法名称做了变化,其他与之前一致。

编写test16方法实现上述案例的要求:

操作代码:

效果:

3、多对多关系(抽象)
例如:一个文章可能有多个关键词,一个关键词可能被多个文章使用。
当点开关键词链接之后,会发现一个关键下能搜出很多文章。
因此,文章和关键词之间是多对多的关系。
多对多的关系经过拆分之后其实就是两个一对多的关系。由于是双向一对多的关系,因此光靠2张表是无法建立的关系的,需要依靠第三张表建立关系(xx与xx的关系表)。
当前已经存在文章表,因此还需要关键词表和关系表。
关键词表:
字段id 主键
字段keyword 关键词
文章与关键词的关系表:
字段id 主键
字段article_id 文章id
字段key_id 关键词id
简易模拟:
Id 关键词 id 文章id 关键词id
1 芳华 1 1 1
2 冯小刚 2 1 2
3 2 1
①创建需要迁移文件
#php artisan make:migration create_keyword_table
#php artisan make:migration create_relation_table
②编写迁移文件的代码


③执行迁移文件生成数据表
#php artisan migrate

④生成测试的数据
#php artisan make:seeder KeywordAndRelationTableSeeder

编写相关代码:


执行填充器文件:
#php artisan db:seed --class=KeywordAndRelationTableSeeder


⑤创建需要的模型
注意:根据手册中记录的语法要求,不需要给关系表单独的创建模型。
该处只需要单独给keyword创建模型即可
#php artisan make:model Keyword

定义模型的基本内部结构

案例:查询出每个文章(主)下全部的关键词(从)

语法:return $this -> belongsToMany(被关联模型的元素空间路径,多对多模型的关系表名,关系表中当前模型中的关系键, 关系表中被关联模型的关系键);
注意:上述语法提及到的关系键是指在关系表中的字段名。
根据案例的要求,此处的关系映射依旧写在文章模型中:

定义路由:

编写test17方法,实现刚才案例的需要:


建议:后期的联表如果可以用关联模型,尽量使用关联模型。