C语言第七章――数据类型
引子:sizeof的用法
- 是一个运算符,给出某个类型和变量在内存中所占据的字节数
sizeof(int)sizeof(i)- 是静态运算符,它的结果在编译时刻就已经决定了
- 不要在sizeof的括号中做运算,这些运算不会做的,即只看结果是什么类型的,不会真的去做计算,比如sizeof(a++)这种事情a不会++,但sizeof(a+1.0)确实是会先把int a转化为double 然后再得出double的大小
C语言的类型


整数
关于几种整数类型、
整数那一张ppt,每种数据类型是几个字节
下面是用自己的电脑来看这些数据类型的
#include<stdio.h>
int main()
{
printf("%ld\n",sizeof(char));
printf("%ld\n",sizeof(short));
printf("%ld\n",sizeof(int));
printf("%ld\n",sizeof(long));
printf("%ld\n",sizeof(long long));
printf("%ld\n",sizeof(float));
printf("%ld\n",sizeof(double));
printf("%ld\n",sizeof(long double));
return 0;
}
我这台电脑的运行结果是
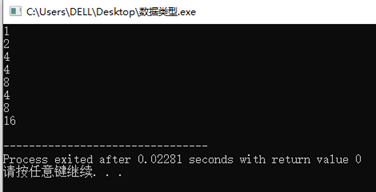
关于为什么int和long根据计算机和编译器有不同的结果?
如下图,int想要表达的就是一个寄存器的大小,寄存器通过总线一次性可以把这么多的数据给了RAM,所谓“这么多的数据”即一个int,int就是用来表达寄存器的
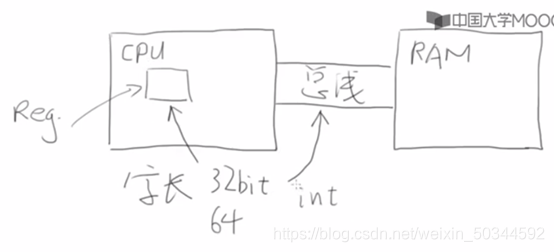
计算机内整数是如何表达的
引子:
- 计算机里一切都是二进制,他是什么取决于我们怎么看待它!!!
- 所有的类型最终的意义是我们通过什么方式去看待它,而不是表明他是怎么表达的
原码和补码
负数是由补码表示的
以一个字节(8位)举例
0-> 0000 0000
1-> 0000 0001
现在要找到一个数是-1,使得,-1+1=0,即
1111 1111+0000 0001-> 1 0000 0000
而第九位无法表达,因此,其实是255+1->256,然而这里的256因为无法表达第9位,而变成了0,这里的1111 1111本来是255,也就变成了-1
即
- 对于-a来说,补码就是0-a,实际上是2n-a,n是这种类型的位数
对应在上面的例子中,对于-1来说,补码就是0000 0000-0000 0001=1111 1111,(0-1=-1)实际上是(1 0000 0000-0000 0001=1111 1111注意有溢出的1)28-1=255
- 1111 1111被当作纯二进制数的时候是255,被当作补码来说是-1(再次反应的是引子中说的,在于我们怎样看待它)
- 补码的意义在于拿原码和补码就可以加出一个带溢出的0,进行的运算仍然是纯二进制的运算
整数的范围――关于越界
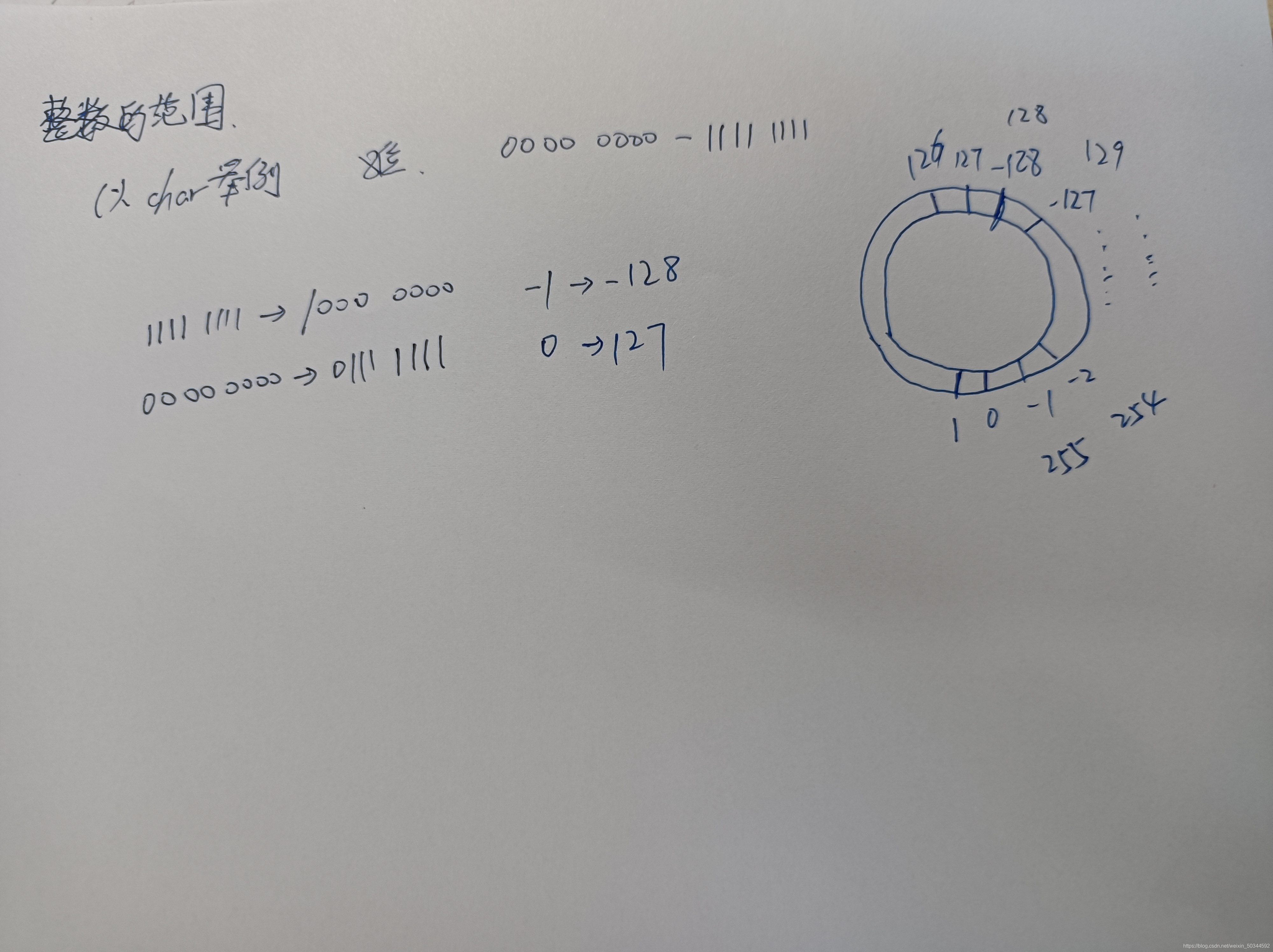
如图,正是因为char所表达的范围变成了一个圆,所以才会有
- 同样是8位,只能表示256个数,但char表示的是则是-27到27-1(即-128~127,即上图中圆的内圈),而unsigned char表示的则是0到28-1(即0~255,即上图中圆的外圈)
- char中,127+1=-128,127+2=-127
- unsigned char中,255+1=0,0-2=254
整数的格式化输入输出
只有两种%d %ld 如果表示无符号的则是%u,%lu
- 所有int和比int小的数都用%d
- 比int大的都用%ld
顺便做个拓展,如果写出下面的代码,其实就是想表达全部位都是1的时候用无符号数输出,但会发现输出的数字是一样的,这是为什么???
#include<stdio.h>
int main()
{
char c=-1;
int i=-1;
printf("%u %u",c,i);
return 0;
}
答案是unsigned int所能表示的最大值
这就非常好理解了,有以下的说明
注意: 这里需要注意的就是,之前提到过的两点
- int想要表达的就是一个寄存器的大小,寄存器通过总线一次性可以把这么多的数据给了RAM,所谓“这么多的数据”即一个int,int就是用来表达寄存器的就算是char也是一次给RAM一个int的大小
- 所以为什么所有int和比int小的数都用%d也是这个道理,即int和long表示几个字节是由编译器和计算机决定的,这是很有道理的,超过int大小以后,一次给RAM的是一个long的大小,所以
1.int和long表示的是和寄存器相关的事情
2.所有int和比int小的数都用%d,比int大的都用%ld
这两件事情是同一件事情
字符类型char――既是整数类型也是字符类型
'1’的ASCII码是49
#include<stdio.h>
int main()
{
char c;
scanf("%c",&c) ;
printf("%c %d",c,c);
return 0;
}
这里输入:1
输出结果:1 49
#include<stdio.h>
int main()
{
char c;
scanf("%d",&c) ;
printf("%c %d",c,c);
return 0;
}
这里输入:49
输出结果:1 49
!!!
便一目了然了
字符的运算
字符也是可以做类似++这种操作的,毕竟是ASCII码的运算
大小写字母转换
常见的ASCII码可以简单知道一下,比如
- a的ASCII码数值是97,A的ASCII码数值是65。
- ASCII码值中,大小写字母码的关系是对应的大写字母与小写字母之间相差32
- 大写字母码<小写字母码
因此我们就很容易的可以得出来大小写字母的转换公式
- a+‘a’-‘A’ ――把大写字母变成小写字母
- a+‘A’-‘a’ ――把小写字母变成大写字母
注意,根本不需要强记,要充分的理解,可以用a的ASCII码数值是97,A的ASCII码数值是65的例子来理解
浮点数
整数是二进制数,是补码形式
浮点数是编码形式

表达范围
这里的表达范围说的很详细
- 接近0的很小的一个数到很大的一个数,负数一边也是(这表示其实在接近0的很小的一片区域浮点数是表达不了的)
- 0(虽然接近0的小片区域不能表达,但是可以表达0)
- ±inf(正负无穷)
- nan(不存在)
这里用一个例子说明±inf和nan
#include<stdio.h>
int main()
{
printf("%f\n",12.0/0.0);
printf("%f\n",-12.0/0.0);
printf("%f\n",0.0/0.0);
return 0;
}
输出结果:
1.#INF00
-1.#INF00
-1.#IND00
注意:如果是整数printf("%d\n",12/0);其实编译都通不过,但是浮点数中其实定义了0.0可以做分母,专门来这样表示了无穷和不存在的情况
注注意:这里0.0表示的就是0,不能理解成0.0是表示的无限接近0的一个很小的数,所以才能做分母,这样理解是错误的,因为有如下的代码说明0和0.0相等
#include<stdio.h>
int main()
{
int i=0;
double k=0.0;
if(i==k)
{
printf("here!");
}
return 0;
}
确确实实输出了here!那就没话说了,而且浮点数的表达范围明确说可以表达0了
浮点数不能被准确表达!!!
但这种判断的方法是可行的,因为浮点运算是有精度的,可以用类似的思路来写代码来说明
#include<stdio.h>
int main()
{
float a=1.23f;
float b=2.34f;
float c=a+b;
if(c==3.57)
{
printf("here!");
}else
{
printf("不相等,c=%.10f,c=%f",c,c);
}
return 0;
}
输出结果是:
不相等,c=3.5699999332,c=3.570000
这里就说明了浮点数不能准确表达,注意这里要在1.23和2.34后面专门加上f来说明是浮点数,而前面的0.0就算加了f,也是和0相等的
- 带小数点的字面量是double而不是float,float需要用f或F后缀来表明身份
这里遇到了一些小的问题:
- 如果去掉f,好像还是会输出here的,是double相等float不相等?
关于输出精度的事情
用例子来说明
#include<stdio.h>
int main()
{
printf("%.3f\n",0.0049);
printf("%.30f\n",0.0049);
printf("%.3f\n",0.00049);
return 0;
}
输出结果:
0.005
0.004899999999999999800000000000
0.000
输出的结果会得出这样几个结论:
- 由第一个和第三个输出的结果得出,输出精度是会四舍五入的
- 第二个结果才是计算机内部真实的这个数,因为0.0049计算机没法准确表达――浮点数计算机没法准确表达,因为数学中的数是连续的,而计算机必须用离散的数来表示
类型转换
自动类型转换
- 当运算符的两边出现不一致的类型时,会自动转换成比较大的类型
- 对于printf,任何小于int的类型都会被转换成int,float会被转换成double(所以这就是输出double的时候并不需要搞一个%lf 只需要%f,都是有原因的)
- 对于scanf,要输入short,需要%hd(所以输入double的时候也要%lf)
强制类型转换
(int)10.2;
注意:强制类型转换的优先级高于四则运算,毕竟是单目运算符
逻辑类型(运算)――特殊的整数运算
- 逻辑类型本身是人为定出来的
- 逻辑类型是特殊的整数类型,逻辑运算是特殊的整数运算
- 逻辑运算优先级
!高于&&高于||(运算优先级要熟悉,见C语言第一章――基本运算这篇文章有总结) - 短路!!!逻辑运算是自左向右进行的,如果左边的结果已经能决定结果了,就不会做右边的运算,这对人来说也是很容易理解的
!a //非
a&&b//与
a||b//或
a>4&&a<6//表示4<a<6
a>'A'&&a<'Z'//判断a是不是大写字母
!age<20//要注意这里是先算非运算,因为是单目运算符
指针
指针会第八章进行单独的讲解
自定义类型
这里留下来的一个问题:
- 自定义类型指的是结构体吗??
八进制和十六进制
表示八进制,前面加0
表示十六进制,前面加0x
int i=012;
int k=0x12;
注意:八进制和十六进制仅仅是如何把数字表达为字符串,与内部如何表达数字无关(内部表达的数字肯定是二进制啊!)
总结:%的输入输出格式
整数
%d 表明输入输出的是十进制(Decimal)
%o 表明输入输出的是八进制(Octal)
%x %X 表明输入输出的是十六进制(Hexadecimal)(因为有字母,输出大写字母时用%X)
%c
%p
浮点数
%f double类型的输出,float类型的输入和输出
%lf double类型的输入(具体查看自动类型转换的后两个点)
%e %E 表示输入输出的是科学计数法,例子如下
#include<stdio.h>
int main()
{
double i=1234.5678;
double k;
scanf("%e",&k);//输入1e-10
printf("%E %e %f\n",i,i,i);
printf("%E %e %f",k,k,k);
return 0;
}
计算结果:
1.234568E+003 1.234568e+003 1234.567800
3.884164E-315 3.884164e-315 0.000000
足以说明用法了(最后一个是0是因为他表达的数跑到精度后面了,如果想要看到他表示的数,可以把%f改成%.16f让他输出小数点后16位的就可以了,这倒不是什么大的事情)是输出精度的事情
总结:逃逸字符(转义字符)
\n
\t 制表位,到固定的位置
\b 回退一格
\
*
"