��·��,����Ϸû��ǰ;��,hhhh
C++�˹���
C++������������̲���
�ಿ��
-
����������������:��װ���̳�����̬
��װ:�����ض�������Ժ�ʵ��ϸ��,��������ӿ�,�����ڳ��������ԵĶ����ĵķ��ʼ���
�̳�:����̳и������������Ϊ,ʹ���������(ʵ��)���и�������Ժͷ���,������Ӹ���̳з���,ʹ��������и�����ͬ����Ϊ
��̬:ָ��ͬ����Ϣ���費ͬ�Ķ����������ͬ�Ķ��� -
��ķ���Ȩ��:private��protected��public
private:��private�������εij�Ա����ֻ�ܱ�����ķ�������Ԫ��������,���ຯ��������,�������������з�װ�̶�����ߵ�,һ����˵,Ӧ�þ����ܽ���ij�Ա��������Ϊprivate����������,���ٳ�Ա�����ı�¶,ֻ�ṩgetter��settter������������,�����������İ�ȫ��
protected:protected�������εij�Ա�����ͳ�Ա�������Ա�����ij�Ա��������,���Dz��ܱ������������,������ͨ�������ij�Ա����������ʡ�����,��Щ��Ա���Ա�����ĺ�������Ԫ��������,���public��Ա ����һ������ʹ�������ֱ�ӷ��ʵ�����
public:��public���������εij�Ա�����ͺ������Ա���ĺ���������ĺ�������Ԫ����,Ҳ��������Ķ���������,������ʹ�ó�Ա����������ʡ��������Ԫ����,�����Ǹ������Ԫ����,Ҳ�����Ǹ������Ԫ��ij�Ա���� -
�����������ϵ
�������Ϊ:�����ȹ���Ȼ�������,����ж������,��������˳��
��������Ϊ:����������,����������� -
�����dz����������
�������һ�㷢���������г�Ա����Ϊָ���ʱ��
���:���ǽ�ָ����ָ�������ڴ�����������Ϊ
dz����:ֻ����ָ��ı�����Ϊ(��ʵ���ƶ������»������õ�) -
��������Щ����?����Ĵ�С?
�����еĺ�������Ĭ�ϵ�����������:ȱʡ���캯����ȱʡ�������캯����ȱʡ����������ȱʡ��ֵ�������ȱʡȡַ�������ȱʡȡַ����� const
����Ĵ�С�ᱻ����Ϊ1,��Ϊ����Ҳ�п��ܱ�ʵ����,��ʵ�����Ķ�����Ҫ����Ψһ�ڴ��ַ�ġ���˿���Ĵ�С�ᱻ����Ϊ1���ܱ�֤ʵ������ʱ��ӵ��Ψһ���ڴ��ַ -
����ƶ����庯��
һ����˵��Ҫ���ƶ����캯�����ƶ�����������ԭ����ʵ������dz��������,�����¿����ڴ�ռ俽�����������,����ֱ�ӻ����ʱ������ڴ�,ʡȥ����ʱ����Ŀ���Ȼ���ٸ�ֵ��ôһ����ʱ�����IJ��衣������Ч�������ܡ�����Ҫע��,ʹ���ƶ�������Ҫ��ԭ��ָ����һ���ڴ��ָ����Ϊ��,�������������ڴ�й¶ -
�麯�����(�ؿ���)
ֻҪ���������麯��,��ô�ڸ���ʵ����������ڴ沼����,�ͻ����ͷ����һ����ָ��(��СΪϵͳλ��,32Ϊ4�ֽ�,64Ϊ8�ֽ�)����ָ���ָ��һ�����(�����ȫ�ִ洢��,��Ϊһ��������ж�����һ��),Ȼ��ñ����ָ���ֻ�ָ��ͬ���麯����ַ��
������д���麯�������¿���һƬ�ڴ�,���Ҹ�������е�ָ��,����ָ����Ĺ���ĺ�����ַ,�ú�����ʽҲ��������̬��
�麯����֧�ֶ�̬����Ҫ�IJ���,���������������:

-
����ڴ����
�ڴ������Ϊ������ڴ�ķ���Ч�ʶ����ڵĶ���������intel 32λcpu,ÿ���������ڶ��Ǵ�ż��ַ��ʼ��ȡ32λ���ڴ�����,������ݴ�ŵ�ַ���Ǵ�ż����ʼ,����ܳ�����Ҫ�����������ڲ��ܶ�ȡ����Ҫ������,�����Ҫ���ڴ��д������ʱ���ж���
�ڴ������һ���ȽϼĹ���(�������ܶ�,�����������������):

-
���ء���д������
����:��ָͬһ�ɷ������ڱ������ľ��в�ͬ�����е�ͬ������,����ע��������
��д:��ָ���������д������¶���ĺ���(������,�����б�,����ֵ���Ͷ�����ͬ�����б���д�ĺ���һֱ),һ���ڻ����б�����Virtual����
����:��ָ������ĺ�������������ͬ���Ļ��ຯ��(ֻҪͬ��,���ܲ����б��Ƿ���ͬ�ͻ�����) -
���캯���ܷ�Ϊ�麯��?��������Ϊʲôһ��Ҫ���麯��?
���캯������Ϊ�麯��,�麯���ĵ�����Ҫ�麯����ָ��,����ָ�����ڶ�������ݿռ���;�����캯������Ϊ�麯��,��ô���ڶ���δ����,��û���ڴ�ռ�,��û���麯������ַ���������麯���������캯���ˡ�
��������һ��Ҫ���麯������Ҫԭ����Ϊ�˷�ֹ�ڴ�й¶��

�ڴ�������
- C++�ڴ����:ջ����������ȫ��/��̬�洢���������洢����������
ջ��:��ִ�к���ʱ,�����ھֲ������Ĵ洢��Ԫ��������ջ�ϴ���,����ִ�н���ʱ,��Щ�洢��Ԫ�ᱻ�Զ��ͷš�ջ�ڴ�������������ڴ�������ָ���,���Ч�ʺܸ�,���Ƿ�����ڴ���������
����:������Щ��new������ڴ��,���ǵ��ͷŲ������������,����Ӧ�ó���ȥ���ơ�һ��һ��new�Ͷ�Ӧһ��delete���������Աû���ֶ��ͷŵ���һ���ڴ�,��ô���������,����ϵͳ�����н���һ������
ȫ��/��̬�洢��:��C++��,ͳһ���ȫ�ֱ����;�̬������һ���ڴ�ռ䡣ȫ��/��̬�洢���ڵı����ڳ��������Ѿ�������ڴ�ռ䲢��ʼ��������ڴ��ڳ�������������ڼ䶼���ڡ���Ҫע�����,�����洢���ڲ�����û�г�ʼ���ı���,�������û��ȥ����ʼ������,��ô����ᰴ��Ĭ�Ϸ�ʽ��ʼ����Щ����
�����洢��:�洢��һ�����ַ�������,���Ͻ��仮�ֵ���ȫ�ִ洢��,ͳһ��Ϊ��������(�Ҿ��ö���,ֻҪ��֪�������������ܷ���һ�����)��Ҫע�����,�ֲ������Dz����ڳ����洢���ġ�
������:������ϵͳ���ص��ڴ�ʱ,���п�ִ�еĴ��뱻���ص�������,Ҳ�д����,�洢����Ĵ���ָ���������ʱ,����������ݲ��ɱ���ֻ���Ա�ִ�С�ͬʱ,��һ�������ǹ�����,Ŀ����Ϊ���ö�����еij������ֻ����һ�ݴ��븱��,��Լ�ռ� - �ڴ�й©
����һ����˵���ڴ�й¶����ָ���ϵ��ڴ�й¶�ˡ�һ��˵�Ķ��dz���������һ����ϵ��ڴ�Ȼ������ȷ�ͷŻ������ͷź������ÿ�ָ����������ָ���������ܶ���֮,ֻҪ���ڴ����������ʵ�����Ա����Ϊ�ڴ�й¶�� - ����ָ���Ұָ��
����ָ��:��ָ��ָ��һ���ڴ�ռ�,������ڴ�ռ䱻�ͷź�,��ָ����Ȼָ����Ƭ�ռ�
Ұָ��:��ָ��ָ����ȷ��ָ��,��û��ͨ����ʼ���õ���ָ�� - ����ָ��
����ָ�����Ϊ�˽���ڴ�й¶��������ֵ�ָ�롣�����֮,����ʵ��һ����,ͨ�������������ͷŵ��Լ���ָ����ڴ�ռ䡣ͬʱ,�����Է�ֹ����ͷ�ͬһ�ڴ�ռ�,�Լ���ֵ����ת������������
����ָ��������:auto_ptr(ò���Ѿ�����),unique_ptr�Լ�shared_ptr,weak_ptr,unique�Ƕ���ָ���share�ǹ�����Դָ��,��Щʱ�������˺һ��share_ptr
�ؼ������
-
new��delete��malloc��free
new��delelte��C++�Ĺؼ���,��malloc��free�ǿ⺯��,��Ҫͷ�ļ���֧��
ʹ��new��������������ڴ�ʱ,����ָ���ڴ���С,����������������Զ�����,��malloc����Ҫ��ʽ���ƶ��ڴ��С
new�������ڴ����ɹ�ʱ,���ص��Ƕ������͵�ָ��,�����ϸ������ƥ��,�����������ת��������new�Ƿ������Ͱ�ȫ�ԵIJ���������malloc�ڴ����ɹ����ص���void*,��Ҫͨ��ǿ������ת����void*ת����������Ҫ������
new�ڴ����ʧ��ʱ,���׳�bad_alloc�쳣����malloc�᷵��Null
new�������ڴ�,����ù��캯��,��ʼ�������ء�delete������,��黹�ڴ�
new��delete�������ض�malloc����������
ע��:ʹ��new����һ��Ҫ����delete����,������ñ�������Ϊָ��ָ�����һ������,�����Ƕ������顣��˲�����ö������,�Ӷ�����ڴ�й¶�� -
explict����Ҫ����:��ֹ��ʽ����ת��
����C++֧���Զ��������ת������,����,���Զ�������ת���������캯��(�������ʽ����ת��)ͬʱ���ڵ�ʱ��,���п����ñ���������������,��ʱ����Ҫexplict�ù��캯��ֻ���ڹ������,������������ʽ����ת����
��:��C++11֮��,explict�ؼ���Ҳ֧�ֽ��ö�������캯����

-
static�ؼ���:�������ƴ洢��ʽ�Ϳɼ���
�����α�����ʱ��,static���εľ�̬�ֲ�����ִֻ�г�ʼ��һ��,�����ӳ��˾ֲ���������������,ֱ���������н�������ͷ�
static����ȫ�ֱ�����ʱ��,���ȫ�ֱ���ֻ���ڱ��ļ��з���,�����������ļ��з���,��ʹ��ʹ��extern�ⲿ����Ҳ����
static����һ������,���������ֻ���ڱ��ļ��б�����,���ܱ������ļ�������
�������д��ڲ����ͷſռ�ı���ʱ������������η���ջ�ڴ�ռ������
��̬�������ڴ���ֻ��һ��,������Ϊ���ʵ��������ࡣ
��Ҫע�����,�������������ľ�̬���ݳ�Ա,����Ҫ�����ⶨ��һ�� -
const�ؼ���:�����ؼ���,�����εı���������(��ֻ����)
ʹ��const��ʱ������������:��һ,const�ؼ��־���˭��˭���������ġ��ڶ�,const����һ������ʱ,һ��Ҫ��ʼ��,������ʼ��,��֮���ܳ�ʼ����(������еij���Ա���������ڲ�����֮�г�ʼ��)
����ָ���ʱ��,���������:

���κ�������ʱ:�����εIJ����ں����ڲ����Ա��ı�
���γ�Ա����ʱ:��Ա�������ɱ�,�����ڳ�ʼ���б��н��г�ʼ��
���γ�Ա����ʱ:��Ա�������ܸ����κγ�Ա����
���ζ�������ʱ:���ܸı��κγ�Ա����,����ֻ�ܵ���const���εij���Ա����
ע��:Ϊ�˴���Ľ�׳��,��ȷ��һ�γ�Ա����������ij�Ա������ʱ��,һ��Ҫ��������Ϊconst -
volatile�ؼ���
volatile�ؼ���:���ѱ�����������������ı�����ʱ���п��ܸı�,��˱����ij���ÿ����Ҫ�洢���ȡ���������ʱ��,����ֱ�Ӵӱ�����ַ�ж�ȡ���ݡ����û��volatile�ؼ���,������������Ż���ȡ�ʹ洢,������ʱʹ�üĴ����е�ֵ,�����������ɱ�ij�������˵Ļ�,�����ֲ�һ�µ�����(һ��������ڶ��̱߳��֮��)
6.��������ת��
- static_cast< ����˵���� >(�������߱���ʽ):
- ���ڲ�νṹ�еĻ����������֮��ָ��������õ�ת������������ת��ʱ,�ǰ�ȫ�ġ���������ת��ʱ,�Dz���ȫ��
- ���ڻ�����������֮���ת��,��int->char,��������ת����ȫ��Ҫ������Ա���м��
- �ѿ�ָ��ת����Ŀ�����͵Ŀ�ָ��(new�ؼ��־�ʹ��������ת��)
- ���κ����͵ı���ʽת����void����
- dynamic_cast< type-id >(expression):
- ֻ����������֮��ת��ʱ��ʹ��dynamic_cast,type_id��������ָ��,�����û���void*
- ֻ����������ת������������ʱ����ת����,�������ֶ����ڱ���ʱ�ͽ���ת��
- ʹ������ת���Ļ������Ҫ���麯��,��Ϊ��������ʱ���ͼ��,�������Ϣһ�㶼�洢���麯������
- ��������ת��,dynamic_cast�ǰ�ȫ��(�����Ͳ�һ��ʱ,���������ǿ�ָ��),��static_cast�᷵�����岻����ָ������ڴ���ʵĴ���
- const_cast< ����˵���� >(�������߱���ʽ)
- const_castת�����������Ƴ�������const��volatile����,������Ҫ�ر�ע�����,const_cast���������Ƴ������ij�����,��������ȥ��ָ���������ָ��������õij�����,Ҳ��,��ȥ�������ԵĶ������Ϊָ���������
- reinterpret_cast< ����˵���� >(�������߱���ʽ)
- ǿ������ת����(һ�㲻ʹ��),������ָ�������֮���ת��,Ҳ�������ڲ�ͬ���͵�ָ��/��Աָ��/����֮���ת��
- ǰ�߿���������ָ���д洢������Ϣ���������ض�ƽ̨��,���ָ���������4�ֽڶ����,��ָ����ת�ɵ������������λ(bit)һ����0,��ô�Ϳ���������λ�洢��������
- ���߿�������ͨ����Ա���������ṹ�������ߴ������ṹ�������ʼ�ӳ�Ա(��ź�CPython��_PyObject_CAST����),����C++һ�㲻��Ҫ�õ����֡�
-
override�ؼ���
����ؼ�����Ϊ����д�����ڵġ�����֮������������Ϊ����һ���ܷ��������:���������д������ʽ�Ƿ���ȷ������Ū�����麯��������,�βζ�ʧЧ����� -
decltype�ؼ���
decltype���������ز���������������,�ڴ˹�����,��������������ʽ���ҵõ���������,���Dz���������ʽ��ֵ(��������һЩ����д�������͵ij���,�����Լ�Ҳ��֪����������������Ǹ�ɶ�ij���)
����Ա�
- ������ֵ���á���ָ����úʹ����õ��õ�����
��ֵ����:��ֵ����ʱ,��������ѹջ���Dz����ĸ���,�������Ŀ���������κε��Ķ�ֻ�������ڸ�����,���������ԭ��������ֵ
��ָ�����:������Ҳ��һ�ִ�ֵ����,���ݵ��ǵ�ֵַ,ѹջ����ָ��ĸ������ô�����,�����ٿ���һЩ�ռ䡣����ֵ����64λ����ϵͳ��,long����Ҫʹ��8bit,���Ǵ�ָ�����ֻ��4bit,����֮�����ͨ����ָ�����ȥ�ı����
�����õ���:���ݵ���ʵ�α���,������ʵ�ε�һ���������βε��ľ���ʵ�ε���,���,�����õ���Ҫ����const�������������
ע��,���������ܴ����õĵط��;���������,��Ϊ���Ա���һ�β�������,Ч�ʽϸ�
�������
-
Lambads����ʽ:
C++11֧��дinline����,Ҳ���Ե�������,�൱�ں�����������

���Ǿ���������Sort�������濴����������Զ���������,��ʵϰ��������ʵ����Ҳ�кܶ�ط�����Lambda����ʽ,��������һ������Ҫ���ص�,�ɲο�:Lambda����ʽ���� -
��ֵ����
һ����ƶ�����һ��ʹ��,�൱��ֱ���ñ���ֱ�ӻ����ʱ������ڴ�ռ�Ӷ������һ�εĿ��������������ܡ�
����ж�����ֵ��ʵ��������Щ����:1.��ֵֻ�ܳ����ڵȺ��ұ�,�ܳ�������ߵ�һ������ֵ 2.�����ܲ��ܶԶ���ȡ��ַ,�����ȡ����ַ��һ������ֵ,��ȡ������һ������ֵ
��ֵ����һ�������ƶ����캯�����ƶ���������,�Ϊ&&
std:move()�������Խ�һ����ֵת��Ϊ��ֵ
���ﻹ��һ������ת��������,����ֵ���������ݵĹ����кܿ��ܻ���һ����ֵ,�����Ҫforward()����������ת�� -
auto�Զ��Ƶ�
���ûʲô��˵����,��������forѭ��,������ñ��������������ܳ�����д��ʱ��ʹ��auto,�������ͻ�ȥ�Զ��Ƶ������������� -
�ɱ����ģ��
�Ϊ������,���Խ����������ģ�����,�������Ĵ�������Ϊע�����,ֱ���п��õ�ƫ�ػ��汾Ϊֹ

STL�뷺�ͱ�̲���
����(Containers)
�������¿��Է�Ϊ����:
һ�� ˳������(Sequence Containers):
1.Array(C++11����): ����,�̶����ȵ����顣֮���Խ�Array��װ����һ������,Ŀ����Ϊ������Array���ܵ�STL��ϵ�ṹ�еĸ��ָ����ı���

2.Vector(����):
- Vector����Ϊ����һ������,���ҿ�����̬����,ÿ������ʱ�ڴ��С��չΪ����,��˲�������ԭ������
- C++Vector�ĵײ㿿����ָ��������в���,start,finish,end_of_storage
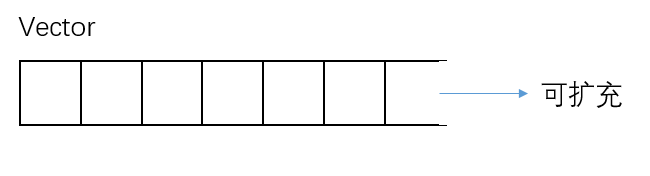
- �ڴ�ռ���ڲ���Ԫ�ص�ʱ������,��������:
- ����2��(��һ�����������,������ƽ̨�ͱ���������)��ԭ�ڴ�ռ��С���ڴ�ռ�
- ��ԭ��Vector�е������������µ�Vector�ڴ�ռ���
- ����ͷ�ԭ����Vector
- ����������,ʹ��ָ���µ�Vector
- ���,ʹ��Vector��ʱ����Ҫ���̬����,��Ϊ������Ƚϴ�Ŀ���(����ǶԹ�����С�и�Ԥ��,������Ӧ���ڴ��С)
3.Deque(˫�˶���)
- Deque�������Ƿֶ�����(��Vectorװ��ָ��ͬ��������ָ����ʵ�ֵ�)
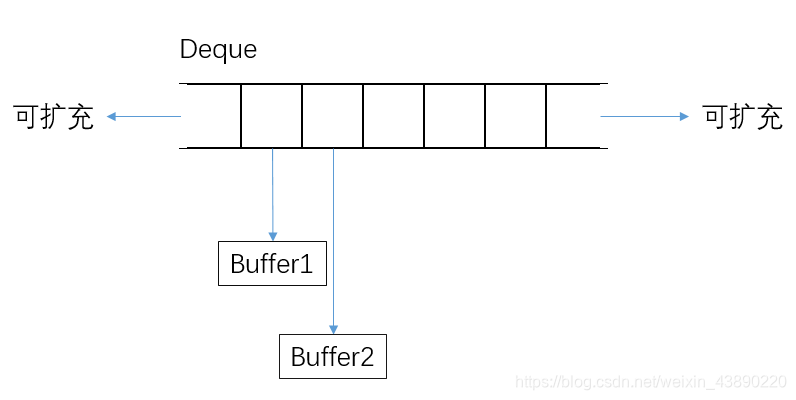
- Deque�ĵ��������ĸ�ָ��,��������random_access_iterator_tag
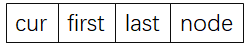
- first��last��ʶ��������buffer�ı߽�
- node�ڴ洢ָ���Vector���ƶ�,��ɻ��������л�
- cur�ǹ���ָ��,ָ������е�ÿһ��Ԫ��
- ����,��������start��finish����������,������ɺ���begin()��end()�Ĺ���(������˵�������curָ��ָ����deque��ͷ��β)
- ��insert()������:
- �������ǰ��,��push_front()����ȥ��
- ���������,��push_back()����ȥ��
- ������������deque�Լ���insert_aux(),���Ȼ���㰲���ǰ����Ԫ�ض�Ǻ�Ԫ�ض�(Ϊ�˽�ʡCopy������),Ȼ��������Ԫ���ٵķ����ƶ�,�ճ���λ�ò���Ԫ��
- ����,deque��������һϵ�еIJ�����ȥģ�������ռ�,���硱-����Ҫ���㻺����������ٸ��ٳ��ϻ�������С,����ټ��ϸ��Ե�Ԫ�ظ���,ͬ��,���С�++�����C����+=��֮��IJ�����ģ�����������洢
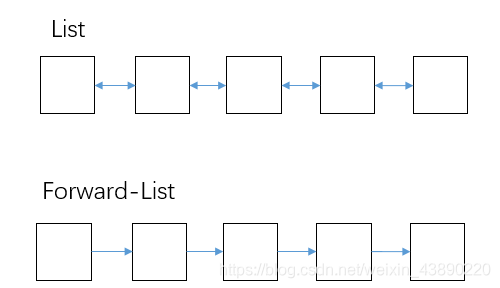
4.List��Forward-List(C++11):
- ûʲô��˵��,����������������ݽṹ��,STLҲ�ṩ������,ע��List��˫������,Forward-List�ǵ�����������(��һ��ָ����ڴ�ռ���Щʱ����ʮ�������洢���ܵ�)
������������(Associative Containers):
1.set��mutiset:
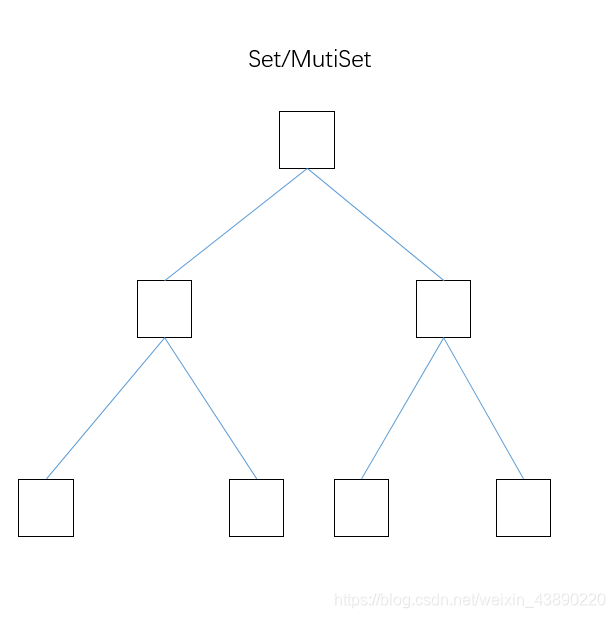
- Set����Key��Value��һ����,������ӳ���ϵ,��MutiSet���ʾһ�����������ͬʱ�洢��ͬ��Key(һ����˵�Dz�����ͬ��)
- �ײ�ʵ���Ǻ����
2.Map��MutiMap
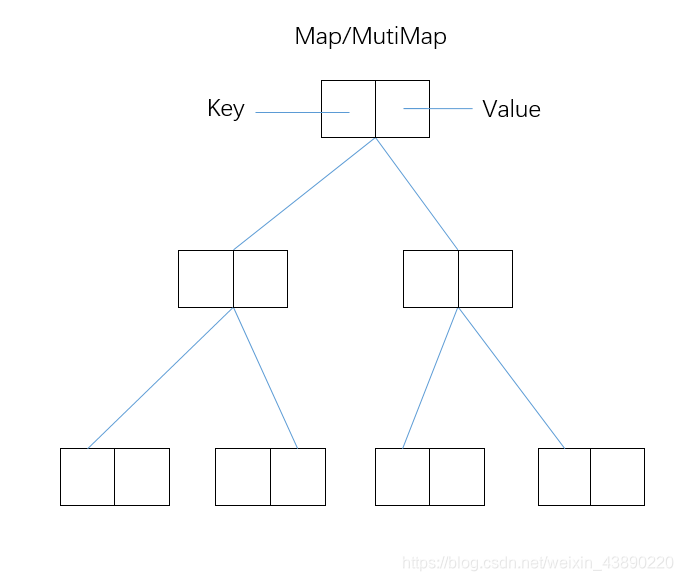
- Map������һ��Key��Ӧһ��Value,Mutiͬ��,�����ж��Key
- �ײ�ͬ��ʹ�ú����
����Unordered Containers(��������,C++11��ʼ����):
��һ��Ҳ���ི,�ֱ���Unordered Set/Unordered Map�Լ����ǵ�Muti,���ǵײ��ʵ�ֵ�����Ҫ�ú��˽�һ�¡�
��һ��������ײ㶼��ʹ��HashTableʵ�ֵ�,Ϊ�˿��ٲ���,ͬʱ,�����ͻ�ķ���ʹ�õ�����ʽ�������(С��һ��,JAVA�ײ�ò��ʹ���˺������ֱ�Ӵ���,ͬ��Ҳ���Խ�ʡ��ͻ����ʱ�IJ���ʱ��)����,Ϊ�˱�֤��ߵIJ���Ч��,һ����Ҫά��Ԫ�غͶ�Ӧ�ҵĸ����������,����,����ҪRehash���õ��µĽ��
������(iterator)
����������ҪĿ����Ǵ������л���㷨����ʱ��Ҫ�ļ����ؼ�����:
1.iterator_category(����������)
2.value_type(Ԫ�ص����)
3.diffence_type(����ı��﷽ʽ)
���������reference_type��pointer_type��Ŀǰû����STL��ʹ�ù�
�㷨�������Щ����ȥͨ���������������ȷ��������ִ����ز�����(���ڵ������п��ܲ���һ����,����һ��ָ��,���Ծ���Ҫ��ȡ����ȥ��ָ��ӵ����Щ��ͬ������)
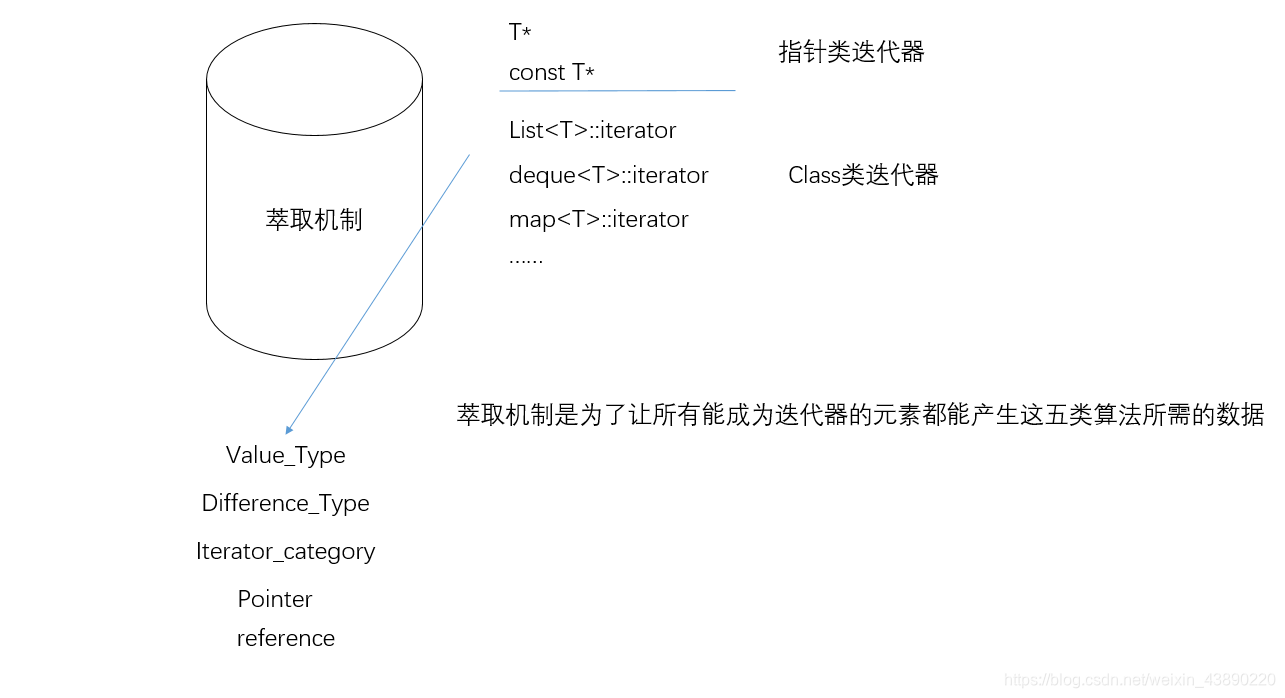
ͬʱ,������������������:

�㷨(algorithm)
�����͵������İ�װ���Ҹ��˵���������Ϊ�˸��õķ������㷨����һ������ʵû�кܶ�Ҫ����,��������sort(),upper_bound(),lower_bound(),next_permutation()�ȵ�����ѧ�Ż��þͺ��ˡ��㷨��ͷ�ļ���
< algorithm >
�º���(Functor)
- �º�������ʹһ�����ʹ�ÿ���ȥ����,һ����˵��ʹ������"()"������ʵ�ֵ�
- ÿһ������ķº������̳���binary_function��unary_function,��Ȼ��������STL����ϵ�ṹ�����������������ģ�������(typedef),�Ӷ������������Եõ���Ӧ����Ϣ
������(adpater)
��STL�����,��������С�ת�����Ľ�ɫ��Adapter�������,��ʵ����һ�����ģʽ����������:��һ��class �Ľӿ�ת��Ϊ��һ�� class �Ľӿ�,ʹԭ����ӿڲ����ݶ����ܺ����� class,����һ������������,������,�º�������������
����������������:���к�ջ(Deque�IJ�ͬ������ʽ)
��������������:���������(Reverse Iterators)
�º�����������:bind()��
������(allocator)
��������C++��Ĭ�Ϸ������Ѿ����ǹ�����,��������û��̫����Ҫ���ܵĶ��������ǽ����Ϸ��������Ҫ˵���ˡ�
�����ڴ������ʵ���൱��ʱ��������Ϊ,��������New�ײ�Ҳ��ȥ����Malloc()����,�����и�������ڴ�����һ�㶼�����Cookie,����Ϊ�˽�Լ�������ڴ�ռ�,��ʵ�Ǻ��б�Ҫ�Լ�����ڴ�����������Ż��ڴ����ܿ����ġ�������Ժ��ҿ��ܻᵥ����������,����ֻ˵һ�ֺ����ʦ���ܵ�,����Ϸ����ܹ����汻��Ϊ�ط������Ľṹ:
�ط�����:

����������һ�����Ĺ�������:����һ���ڴ�,������Ԫ��������ڴ��СΪ50,��ᱻԤ�ȵ���Ϊ56(8bit�ı���),Ȼ��ȥ����56�ֽڴ�С����������ȡ�ڴ�顣������������Ѿ�û���ڴ����,������malloc()�����ϵͳҪ��һ����ڴ�,�и�֮�����ʹ�á�
�������������ô�:
1.��Ч������Malloc()����,��ʡ���ܿ���
2.������Cookie��ռ�Ŀռ�,���������ϴ��ʱ����Խ�Լ�dz�����ڴ�ռ�
������
����������ϴ��
�����������Լ�д��,���ﲻ������������д���˻�ӭָ��~
#include<iostream>
#include<vector>
using namespace std;
//������
class Solution{
public:
void Shuffle(vector<int>& arr);//��ϴ����
void QuickSort(vector<int>& arr);//��������
void HeapSort(vector<int>& arr);//������
void MergeSort(vector<int>& arr);//�鲢����
private:
void QuickSortSup(vector<int>& arr, int ileft, int right);
void HeapKeep(vector<int>& arr, int i, int n);//���Ѻ���
void MergeSortSup(vector<int>& arr, int left, int right);
void MergeHelp(vector<int>&arr, int left, int mid, int right);
};
void Solution::Shuffle(vector<int>& arr) {
int n = arr.size();
for (int i = n-1; i >= 0; i--) {
swap(arr[i], arr[rand() % (i + 1)]);
}
}
void Solution::QuickSort(vector<int>& arr) {
int n = arr.size()-1;//�������ұߵ�Ԫ��
QuickSortSup(arr, 0, n);
}
void Solution::QuickSortSup(vector<int>&arr, int left, int right) {//�ݹ鷽ʽʵ��
if (left > right) {
return;
}
int i = left;
int j = right;
int key = arr[left];
while (i < j) {
while (i<j && arr[j] > key) {
j--;
}
if (i < j) {
swap(arr[i], arr[j]);
}
while (i < j&& arr[i] <= key) {
i++;
}
if (i < j) {
swap(arr[i], arr[j]);
}
}
arr[i] = key;//��ԭ
QuickSortSup(arr, left, i - 1);
QuickSortSup(arr, i + 1, right);
}
void Solution::HeapSort(vector<int>& arr) {
int n = arr.size()-1;
for (int i = n / 2; i >= 0; i--) {
HeapKeep(arr, i, n);
}
for (int i = n; i >= 0; i--) {
swap(arr[0], arr[i]);
HeapKeep(arr, 0, i-1);//ע������,���n�����鳤�ȵĻ�,�Dz��ô�i-1��,forѭ��һ��ʼ��i-1�ͺ�
}
}
void Solution::MergeSort(vector<int>& arr) {
MergeSortSup(arr, 0, arr.size() - 1);
}
void Solution::MergeSortSup(vector<int>& arr, int left, int right) {
if (left >= right) {
return;
}
int mid = left + (right - left) / 2;
MergeSortSup(arr, left, mid);
MergeSortSup(arr, mid + 1, right);
MergeHelp(arr, left, mid, right);
}
void Solution::MergeHelp(vector<int>& arr, int left, int mid, int right) {
int n = right - left + 1;
int* a = new int [n];
int s1 = left;
int s2 = mid + 1;
int i = 0;
while (s1 <= mid && s2 <= right) {
if (arr[s1] >= arr[s2]) {
a[i++] = arr[s2++];
}
else {
a[i++] = arr[s1++];
}
}
while (s1 <= mid) {
a[i++] = arr[s1++];
}
while (s2 <= right) {
a[i++] = arr[s2++];
}
for (int j = 0; j < n; j++) {
arr[left + j] = a[j];
}
}
void Solution::HeapKeep(vector<int>& arr,int i,int n) {
int leftson = i * 2 + 1;
int rightson = i * 2 + 2;
int largest = i;
if (leftson<=n && arr[leftson] > arr[largest]) {
largest = leftson;
}
if (rightson<=n && arr[rightson] > arr[largest]) {
largest = rightson;
}
if (largest != i) {
swap(arr[i], arr[largest]);
HeapKeep(arr, largest, n);
}
}
void displayVector(vector<int>& arr) {
cout << "arr����ĿǰԪ��Ϊ: ";
for (int i = 0; i < arr.size();i++)
{
cout << arr[i] << " ";
}
cout << endl;
}
int main() {
vector<int> arr = { 1,1,2,3,4,5,6,7,8,8,9,10,-1 };//�ڴ˴����IJ�������
Solution* solution = new Solution();
cout << "��������" << endl;
solution->Shuffle(arr);
displayVector(arr);
solution->QuickSort(arr);
displayVector(arr);
cout << "������" << endl;
solution->Shuffle(arr);
displayVector(arr);
solution->HeapSort(arr);
displayVector(arr);
cout << "�鲢����" << endl;
solution->Shuffle(arr);
displayVector(arr);
solution->MergeSort(arr);
displayVector(arr);
return 0;
}
MyString��
��������б�Ĺ���Ҫ���������,�Ҿ�����
#define _CRT_SECURE_NO_WARNINGS//���strcpy��ʹ��
#include<iostream>
#include<vector>
#include <cstring>
using namespace std;
//ע��strlen���صĴ�С������\0
class Mystring {
public:
Mystring(const char* s=0);
Mystring(const Mystring &str);
Mystring& operator = (const Mystring &str);
friend ostream &operator<<(ostream &o, const Mystring &str)
{
o << str.mystr;
return o;
}
~Mystring();
private:
char* mystr;
int m_size;
};
Mystring::Mystring(const char* s) {
if (s != nullptr) {
m_size = strlen(s);
mystr = new char[m_size+1];
strcpy(mystr,s);
}
else {//��ָ��ʱҪ��������
m_size = 0;
mystr = new char[m_size + 1];
mystr[0] = '\0';
}
}
Mystring::Mystring(const Mystring &str) {
m_size = str.m_size;
mystr = new char[m_size + 1];
strcpy(mystr, str.mystr);
}
Mystring::~Mystring() {
delete[] mystr;
}
Mystring& Mystring::operator=(const Mystring& str) {
//��Ҫ�������Ҹ�ֵ�ж�
if (&str == this) {
return *this;
}
m_size = str.m_size;
delete[] mystr;
mystr = new char[m_size+1];
strcpy(mystr, str.mystr);
return *this;
}
int main() {
char s1[] = "This is first Mystring";
char s2[] = "This is third Mystring";
Mystring mystring1(s1);
cout << mystring1<<endl;
Mystring mystring2(mystring1);
cout << mystring2<<endl;
Mystring mystring3(s2);
cout << mystring3 << endl;
mystring3 = mystring2;
cout << mystring3 << endl;
}