Ŀ¼
���
��2003��C++��ίԱ�������ύ��һ�ݼ��������(���TC1),ʹ��C++03��������Ѿ�ȡ����C++98��ΪC++11֮ǰ������C++�����ơ���������TC1��Ҫ�Ƕ�C++98���е�©��������,���Եĺ��IJ�����û�иĶ�,�������ϰ���Եİ��������ϲ���ΪC++98/03������C++0x��C++11,C++��10��ĥһ��,�ڶ������������ϵı�ɺɺ���١����C++98/03,C++11������������ɹ۵ı仯,���а�����Լ140��������,�Լ���C++03����Լ600��ȱ�ݵ�����,��ʹ��C++11�����Ǵ�C++98/03����������һ�������ԡ���Ƚ϶���,C++11�ܸ��õ�����ϵͳ�����Ϳ��������ӷ����ͼ��������ȶ��Ͱ�ȫ,�������ܸ�ǿ��,��������������Ա�Ŀ���Ч�ʡ�
�б���ʼ��
C++98��{}�ij�ʼ������
- ��C++98��,������ʹ�û�����{}������Ԫ�ؽ���ͳһ���б���ʼֵ�趨������
int array1[] = {1,2,3,4,5};
int array2[5] = {0};
����һЩ�Զ��������,ȴ��ʹ�������ij�ʼ��������:
vector v{1,2,3,4,5};
����ͨ������,����ÿ�ζ���vectorʱ,����Ҫ�Ȱ�vector�������,Ȼ��ʹ��ѭ�����丳��ʼֵ,�dz������㡣C++11�������ô�����������б�(��ʼ���б�)��ʹ�÷�Χ,ʹ����������е��������ͺ��û��Զ��������,ʹ�ó�ʼ���б�ʱ,�����ӵȺ�(=),Ҳ�ɲ����ӡ�
�������͵��б���ʼ��
ע��:�б���ʼ��������{}֮ǰʹ�õȺ�,��Ч���벻ʹ��=û��ʲô����
// �������ͱ���
int x1 = { 10 };
int x2{ 10 };
int x3 = 1 + 2;
int x4 = { 1 + 2 };
int x5{ 1 + 2 };
// ����
int arr1[5]{ 1,2,3,4,5 };
int arr2[]{ 1,2,3,4,5 };
// ��̬����,��C++98�в�֧��
int* arr3 = new int[5]{ 1,2,3,4,5 };
// ������
vector v{ 1,2,3,4,5 };
map<int, int> m{ {1,1}, {2,2,},{3,3},{4,4} };
return 0;
�Զ������͵��б���ʼ��
- ����֧�ֵ���������б���ʼ��
class Point
{
public:
Point(int x = 0, int y = 0): _x(x), _y(y)
{}
private:
int _x;
int _y;
};
int main()
{
Pointer p1={ 1, 2 };//��ʽ����ת��(�������)
Pointer p{ 1, 2 };
return 0;
}
- ���������б���ʼ��
���������Ҫ֧���б���ʼ��,�������(ģ����)����һ����initializer_list���Ͳ����Ĺ��캯�����ɡ�ע��:initializer_list��ϵͳ�Զ������ģ��,����ģ������Ҫ����������:begin()��end()�������Լ���ȡ������Ԫ�ظ����ķ���size()��
#include <initializer_list>
template
class Vector {
public:
// ��
Vector(initializer_list l): _capacity(l.size()), _size(0)
{
_array = new T[_capacity];
for(auto e : l)
_array[_size++] = e;
}
Vector& operator=(initializer_list l) {
delete[] _array;
size_t i = 0;
for (auto e : l)
_array[i++] = e;
return this;
}
// ��
private:
T _array;
size_t _capacity;
size_t _size;
};
���������Ƶ�
Ϊʲô��Ҫ�����Ƶ�
�ڶ������ʱ,�����ȸ���������ʵ������,����������������,����Щ����¿��ܲ�֪����Ҫʵ��������ô��,��������д�����ر���,����:
short a = 32670;
short b = 32670;
// c�������short,��������ݶ�ʧ,����ܹ��ñ���������a+b�Ľ���Ƶ�c��ʵ������,�Ͳ����
������
short c = a + b;
int main() {
std::map<std::string, std::string> m{ {��apple��, ��ƻ����}, {��banana��,���㽶��} };
// ʹ�õ�������������, ����������̫����
//std::map<std::string, std::string>::iterator it = m.begin();
//����ʹ��auto�Ƶ����ʹ��볤��
auto it = m.begin();
//auto�Ƶ��ǰ�˫�н�,�����֪�����ض��������,�ή�ʹ���Ŀɶ���
while (it != m.end())
{
cout << it->first << " " << it->second << endl;
++it;
}
}
C++11��,����ʹ��auto�����ݱ�����ʼ������ʽ�����Ƶ�������ʵ������,���Ը��������д�ṩ����㡣��������c��it�����ͻ���auto,�������ͨ������,���Ҹ��Ӽ�ࡣ
decltype�����Ƶ�
Ϊʲô��Ҫdecltype
autoʹ�õ�ǰ����:����Ҫ��auto���������ͽ��г�ʼ��,������������Ƶ���auto��ʵ�����͡�����ʱ�������Ҫ���ݱ���ʽ�������֮���������ͽ����Ƶ�,��Ϊ�����ڼ�,���벻������,��ʱautoҲ������Ϊ����
template<class T1, class T2>
T1 Add(const T1& left, const T2& right)
{
return left + right;
}
������ü���֮������ʵ��������Ϊ�����ķ���ֵ���;Ͳ������,������Ҫ�������������֪�������
ʵ������,��RTTI(Run-Time Type Identification ����ʱ����ʶ��)��
C++98��ȷʵ�Ѿ�֧��RTTI:
- typeidֻ�ܲ鿴���Ͳ����������ඨ������
cout << typeid(it).name() << endl;
��ȡit������

- dynamic_castֻ��Ӧ���ں����麯���ļ̳���ϵ��
����ʱ����ʶ���ȱ���ǽ��ͳ������е�Ч�ʡ�
�������һ����it������ͬ�Ķ���:
auto it1=it
decltype(it) copy;
//�������Ƕ���һ����it������ͬ�Ķ��� auto�DZ���ʱ,ͨ����ʼ�������Ƶ�
//decltype�DZ���ʱͨ�������Ƶ�
void fun(auto it);//���ﶨ�����,auto������������������,����������ֵ����
//auto��Ҫ����ʱ�Ƶ����� ������
//�ײ�ʵ���DZ����ָ����Ҫ�Ƚ���ռ֡
Ĭ�ϳ�Ա��������
��C++�ж��ڿ��������������һЩĬ�ϵij�Ա����,����:���캯�����������캯������������ء�����������&��const&�����ء��ƶ����졢�ƶ���������Ⱥ����������������ʽ������,��������������������Ĭ�ϰ汾����ʱ�������Ĺ�����ܱ�����,������������˴������Ĺ��캯��,��Ҫʱ����Ҫ���岻�������İ汾��ʵ�����εĶ�������ʱ������������,��ʱ�ֲ�����,������ɻ���,����C++11�ó���Ա���Կ����Ƿ���Ҫ���������ɡ�
��ʽȱʡ����
һ����Ե��ǹ��캯��
��C++11��,������Ĭ�Ϻ��������������ʱ����=default,�Ӷ���ʽ��ָʾ���������ɸú�����Ĭ�ϰ汾,��=default���εĺ�����Ϊ��ʽȱʡ������
class A
{
public:
A(int a) : _a(a)
{}
// ��ʽȱʡ���캯��,�ɱ���������
A() = default;
// ����������,�����ⶨ��ʱ�ñ���������Ĭ�ϸ�ֵ���������
A& operator=(const A& a);
private:
int _a;
};
A& A::operator=(const A& a) = default;
int main()
{
A a1(10);
A a2;
a2 = a1;
return 0;
}
���û�� A() = default;����ڶ���a2�����ͳ�����,��=default���εĺ�����Ϊ��ʽȱʡ������
ɾ��Ĭ�Ϻ���
C++98 ������/������-��ֻ������ʵ��(��ֹ����Ĭ�ϵ�)+����˽��(��ֹ�����ⶨ��)
һ����Ե��ǿ������캯����ֵ
�������Ҫ����ijЩĬ�Ϻ���������,��C++98��,�Ǹú�������private,���Ҳ�������,����ֻҪ��������Ҫ���þͻᱨ������C++11�и���,ֻ���ڸú�����������=delete����,���ָʾ�����������ɶ�Ӧ������Ĭ�ϰ汾,��=delete���εĺ���Ϊɾ��������
class A
{
public:
// ��ʽȱʡ���캯��,�ɱ�����ɾ��
A() = delete;
private:
int _a;
};
int main()
{
A a2;
return 0;
}

������ɾ�����ι���,ʹ��a2�����塣
class A
{
public:
A(int a): _a(a)
{}
// ��ֹ����������Ĭ�ϵĿ������캯���Լ���ֵ���������
A(const A&) = delete;
A& operator(const A&) = delete;
private:
int _a;
};
int main()
{
A a1(10);
// ����ʧ��,��Ϊ����û�п������캯��
//A a2(a1);
// ����ʧ��,��Ϊ����û�и�ֵ���������
A a3(20);
a3 = a2;
return 0;
}
��ֵ����
��ֵ���ø���
C++98����������õĸ���,���ü�����,���ñ�����������ʵ�幫��ͬһ���ڴ�ռ�,�����õĵײ���ͨ��ָ����ʵ�ֵ�,���ʹ������,������߳���Ŀɶ��ԡ�
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
int main()
{
int a = 10;
int b = 20;
Swap(a, b);
}
Ϊ����߳�������Ч��,C++11����������ֵ����,��ֵ����Ҳ�DZ���,����ֻ�ܶ���ֵ���á�
int Add(int a, int b)
{
return a + b;
}
int main()
{
const int&& ra = 10;
// ���ú�������ֵ,����ֵ��һ����ʱ����,Ϊ��ֵ
int&& rRet = Add(10, 20);
return 0;
}
Ϊ����C++98�е����ý�������,C++11�����ַ�ʽ��֮Ϊ��ֵ����
��ֵ����ֵ
��ֵ����ֵ��C�����еĸ���,��C����û�и����ϸ�����ַ�ʽ,һ����Ϊ:���Է���=��ߵ�,�����ܹ�ȡ��ַ�ij�Ϊ��ֵ,ֻ�ܷ���=�ұߵ�,���߲���ȡ��ַ�ij�Ϊ��ֵ,����Ҳ��һ����ȫ��ȷ��
int & ��ֵ����
int && ��ֵ����
��ֵ:���Էŵ���=����ֵ,һ�������
��ֵ:һ�㲻�����ĵ�һЩֵ������:����,��ʱ����������ʽ����ֵ��
���þ��Ǹ�����ȡ����
��ֵ����һ���������ֵȡ��
��ֵ����һ���������ֵȡ��
int main() {
int a = 0;
int& a1 = a;//��ֵ����һ�����ֵȡ����
const int&a2 = int(1);//const ��ֵ����Ҳ���Ը���ֵȡ����
//��ֵ���ò�����������ֵ����const �ͱ�ɲ����ĵ�,�Ϳ��Ը���ֵȡ����
int&& a1 = int(0);//��ֵ����һ�����ֵȡ����
int&& a2 = move(a);//��ֵ���ò���ֱ�Ӹ���ֵȡ����,���Ǽ���move()���Ը�ȡ������
//��ֵ������ ����ֵ������,������ֵ���ñ���ʹ��move����ֵȡ����
return 0;
}
int g_a = 10;
// �����ķ���ֵ���Ϊ����
int& GetG_A()
{
return g_a;
}
int main()
{
int a = 10;
int b = 20;
// a��b������ֵ,b�ȿ�����=�����,Ҳ�����Ҳ�,
// ˵��:��ֵ�ȿɷ���=�����,Ҳ�ɷ���=���Ҳ�
a = b;
b = a;
const int c = 30;
// ����ʧ��,cΪconst����,ֻ������������
//c = a;
// ��Ϊ���Զ�cȡ��ַ,���c�ϸ���˵��������ֵ
cout << &c << endl;
// ����ʧ��:��Ϊb+1�Ľ����һ����ʱ����,û�о�������,Ҳ����ȡ��ַ,���Ϊ��ֵ
//b + 1 = 20;
GetG_A() = 100;
return 0;
}
��˹�����ֵ����ֵ�����ֲ��Ǻܺ�����,һ����Ϊ:
- ��ͨ���͵ı���,��Ϊ������,����ȡ��ַ,����Ϊ����ֵ��
- const���εij���,������,ֻ�����͵�,����Ӧ�ð�����ֵ�Դ�,����Ϊ�����ȡ��ַ(���ֻ��
const���ͳ����Ķ���,�����������俪�ٿռ�,����Ըó���ȡ��ַʱ,��������Ϊ�俪�ٿռ�),
C++11��Ϊ������ֵ�� - �������ʽ�����н����һ����ʱ�������߶���,��Ϊ����ֵ��
- �������ʽ���н����������һ����������Ϊ����ֵ��
�ܽ�: - ���ܼ�ͨ���ܷ����=����Ҳ����ȡ��ַ���ж���ֵ������ֵ,Ҫ���ݱ���ʽ��������������
�ж�,��������:c���� - �ܵõ����õı���ʽһ���ܹ���Ϊ����,������ó����á�
C++11����ֵ�������ϸ������:
C�����еĴ���ֵ,����:a+b, 100
����ֵ������:����ʽ���м�������������ֵ�ķ�ʽ���з��ء�
��������ֵ���ñȽ�
��C++98�е���ͨ������const����������ʵ���ϵ�����:
int main()
{
// ��ͨ��������ֻ��������ֵ,����������ֵ
int a = 10;
int& ra1 = a; // raΪa�ı���
//int& ra2 = 10; // ����ʧ��,��Ϊ10����ֵ
const int& ra3 = 10;
const int& ra4 = a;
return 0;
}
ע��: ��ͨ����ֻ��������ֵ,����������ֵ,const���üȿ�������ֵ,Ҳ��������ֵ��
C++11����ֵ����:ֻ��������ֵ,һ���������ֱ��������ֵ��
int main()
{
// 10����ֵ,����ֻ��һ������,û�о���Ŀռ�,
// ��ֵ���ñ���r1�ڶ��������,������������һ����ʱ����,r1ʵ�����õ�����ʱ����
int&& r1 = 10;
r1 = 100;
int a = 10;
int&& r2 = a; // ����ʧ��:��ֵ���ò���������ֵ
return 0;
}
����:��ȻC++98�е�const����������ֵ����ֵ����������,��ΪʲôC++11��Ҫ���ӵ������ֵ������?
ֵ����ʽ���ض����ȱ��
���һ�������漰����Դ����,�û�������ʽ�ṩ�������졢��ֵ����������Լ���������,�����������
���Զ�����һ��Ĭ�ϵ�,�����������������߶���֮�����ֵ,�ͻ����,����:
class String
{
public:
String(const char* str =" ")
{
if (nullptr == str)
str = ����;
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
String(const String& s)
: _str(new char[strlen(s._str) + 1])
{
cout << ��String(const String& s)�� << endl;
strcpy(_str, s._str);
}
String& operator=(const String& s)
{
cout << ��String& operator=(const String& s)�� << endl;
if (this != &s)
{
char* pTemp = new char[strlen(s._str) + 1];
strcpy(pTemp, s._str);
delete[] _str;
_str = pTemp;
}
return this;
}
String& operator+=(const String& s) {
cout << ��String& operator+=(const String& s)�� << endl;
return this;
}
String operator+(const String& s)
{
cout << ��String operator+(const String& s)�� << endl;
char pTemp = new char[strlen(_str) + strlen(s._str) + 1];
strcpy(pTemp, _str);
strcpy(pTemp + strlen(_str), s._str);
String strRet(pTemp);
return strRet;
}
~String()
{
if (_str) delete[] _str;
}
private:
char _str;
};
int main()
{
String s1(��hello��);
String s2(��world��);
String s3 = s1 + s2;
//�������Ż�����Ӧ�������ο�������,�����������Ż���һ��
/String s4;
s4 = s1 += s2;/
String s5;
s5 = s1 + s2;
return 0;
}
����:��ֵ����,���һ�ο���(��ο����п��ܻᱻ�Ż�)
��1��ֵ���÷���,����һ�ο�������
��ֵ���õ�����:
<1>�������ô��� �C ���ٿ���+����Ͳ���
<2>�������ô�����ֵ�C���ٿ���
��������:���Ч��+��߳���ɶ���(����Ҫ�ø���ָ��)
��ֵ���þ���Ч�������ä��:��Щ�������ô����÷���

��operator+��:strRet�ڰ���ֵ����ʱ,���봴��һ����ʱ����,��ʱ������֮��,strRet�ͱ�����
��,���ʹ�÷��ص���ʱ������s3,s3�����֮��,��ʱ����ͱ������ˡ���ϸ�۲�ᷢ��:strRet����
ʱ����s3ÿ��������,�����Լ������Ŀռ�,���ռ��д������Ҳ����ͬ,�൱�ڴ���������������
ȫ��ͬ�Ķ���,���ڿռ���һ���˷�,�����Ч��Ҳ�ή��,������ʱ����ȷʵ���ò��Ǻܴ�,���ܷ�Ը� ����������Ż���?
�ƶ�����
C++11������ƶ��������,��:��һ����������Դ�ƶ�����һ�������еķ�ʽ,������Ч���������
��ֵ������������������,��ν��?

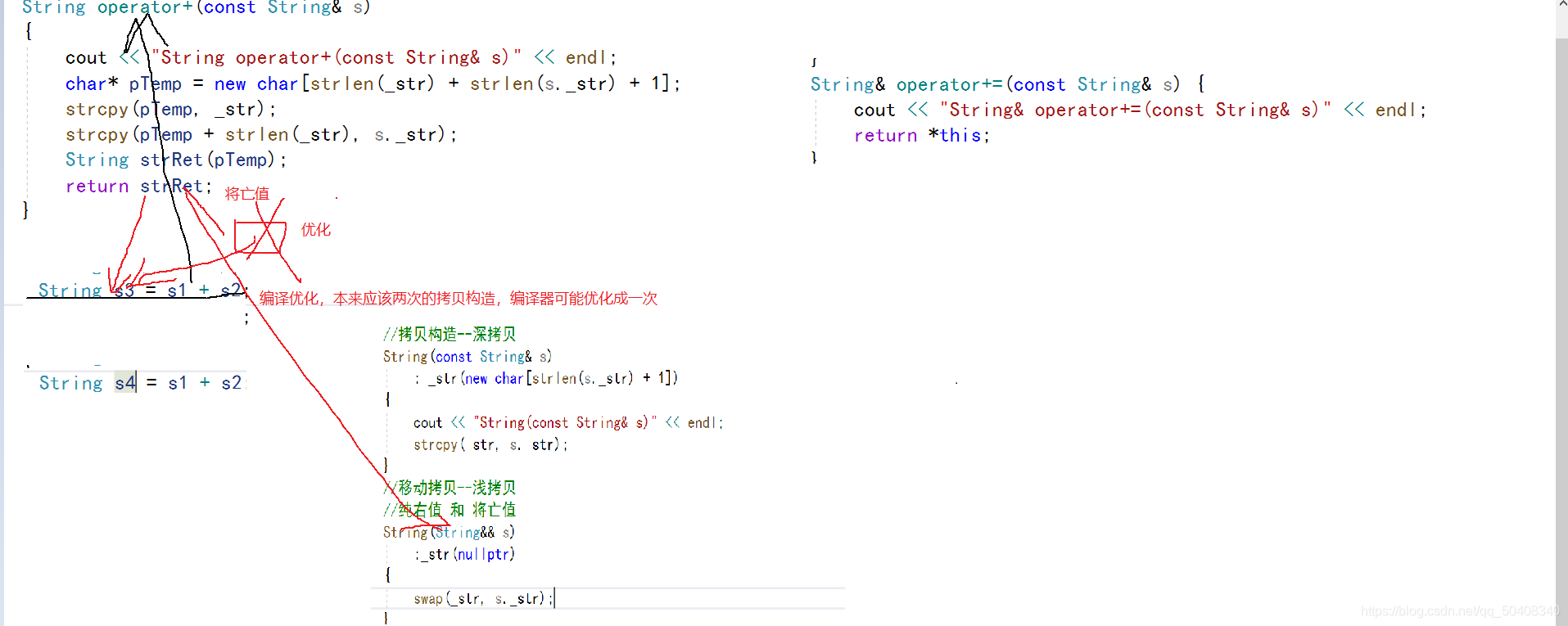
��C++11�������Ҫʵ���ƶ�����,����ʹ����ֵ���á�����String�������ƶ�����:
//��������C���
String(const String& s)
: _str(new char[strlen(s._str) + 1])
{
cout << ��String(const String& s)�� << endl;
strcpy(_str, s._str);
}
//�ƶ������Cdz����
//����ֵ �� ����ֵ
String(String&& s)
:_str(nullptr)
{
swap(_str, s._str);
}
��ΪstrRet��������������ڴ�������ʱ�����ͽ�����,������ֵ,C++11��Ϊ��Ϊ��ֵ,����strRet������ʱ����ʱ,�ͻ�����ƶ�����,����strRet����Դת�Ƶ���ʱ�����С���ʱ����Ҳ����ֵ,���������ʱ������s3ʱ,Ҳ�����ƶ�����,����ʱ��������Դת�Ƶ�s3��,��������,ֻ��Ҫ����һ����ڴ漴��,��ʡ�˿ռ�,�ִ����߳������е�Ч�ʡ�
ע��:
- �ƶ����캯���IJ���ǧ�������ó�const���͵���ֵ����,��Ϊ��Դ��ת�ƶ������ƶ�����ʧЧ��
- ��C++11��,��������Ϊ��Ĭ������һ���ƶ�����,���ƶ�����Ϊdz����,��˵������漰����Դ����
ʱ,�û�������ʽ�����Լ����ƶ����졣
class String
{
public:
String(const char* str =" ��)
{
if (nullptr == str)
str = ����;
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
//��������C���
String(const String& s)
: _str(new char[strlen(s._str) + 1])
{
cout << ��String(const String& s)�� << endl;
strcpy(_str, s._str);
}
//�ƶ������Cdz����
//����ֵ �� ����ֵ
String(String&& s)
:_str(nullptr)
{
swap(_str, s._str);
}
//�ƶ����ƨCdz����
//s2=string(��***");
String& operator=(const String&& s) {
swap(_str,s._str);
return this;
}
String& operator=(const String& s)
{
cout << ��String& operator=(const String& s)�� << endl;
if (this != &s)
{
char pTemp = new char[strlen(s._str) + 1];
strcpy(pTemp, s._str);
delete[] _str;
_str = pTemp;
}
return this;
}
String& operator+=(const String& s) {
cout << ��String& operator+=(const String& s)�� << endl;
return this;
}
String operator+(const String& s)
{
cout << ��String operator+(const String& s)�� << endl;
char pTemp = new char[strlen(_str) + strlen(s._str) + 1];
strcpy(pTemp, _str);
strcpy(pTemp + strlen(_str), s._str);
String strRet(pTemp);
return strRet;
}
~String()
{
if (_str) delete[] _str;
}
private:
char _str;
};
int main()
{
String s1(��hello��);
String s2(��world��);
String s3 = s1 + s2;
String s4 = s1 + s2;
//�������Ż�����Ӧ�������ο�������,�����������Ż���һ��
/String s4;
s4 = s1 += s2;/
String s5;
s5 = s1 + s2;
return 0;
}
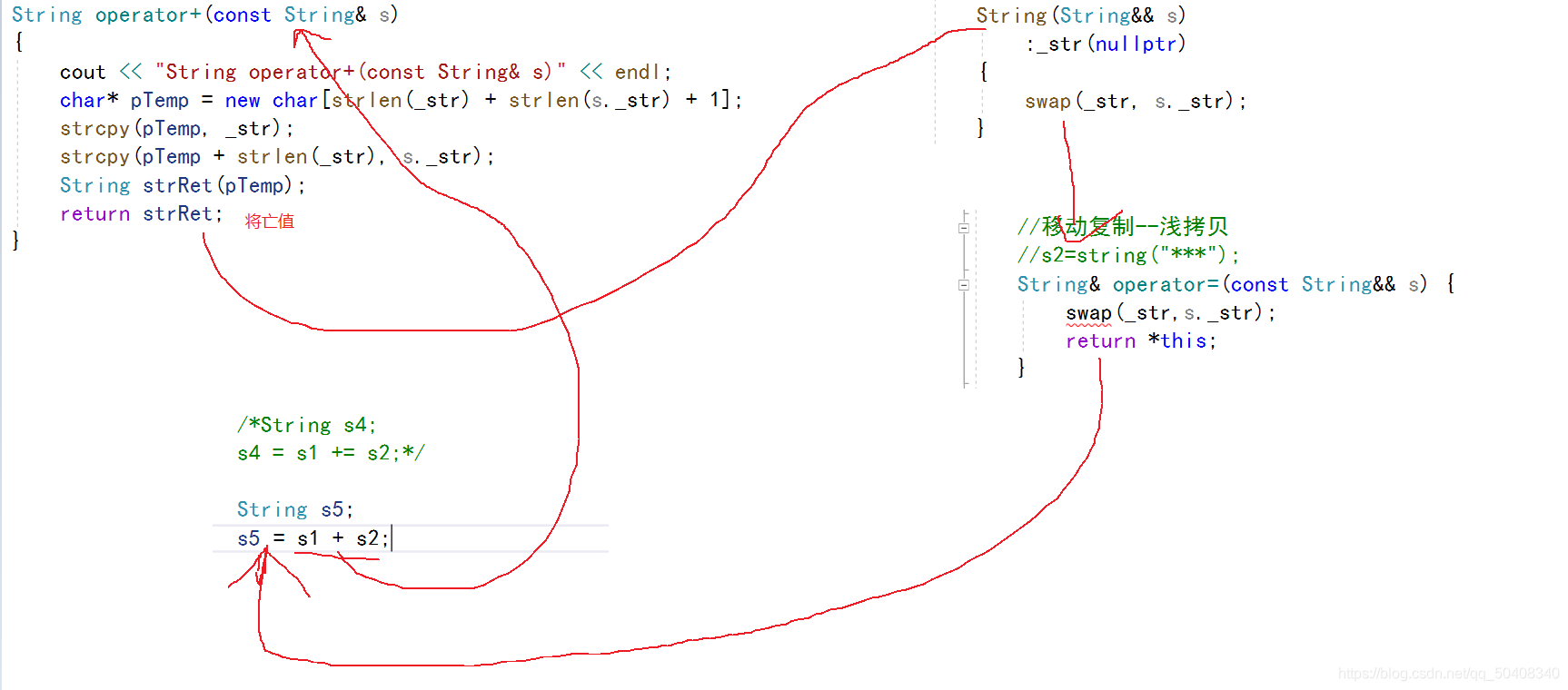
��ֵ���ý����ƶ�������ƶ���ֵ,���ֳ���ֵ����ʱ,���ص�����ֵ(����ֵ)
�ƶ�������ƶ���ֵ,dz����,ת�ƽ���ֵ����Դ,���������,�����Ч��
��ֵ����������
vector v;
v.push_back(��lihua��);//void push_back(_Ty&& _Val)
string str(��li��);
v.push_back(str);// void push_back(const _Ty& _Val)
�ַ�����lihua�����γ�string��ʱ������������ֵ,ͨ���ƶ�������뵽v���,���ַ���str��ͨ������������뵽v����ȥ��
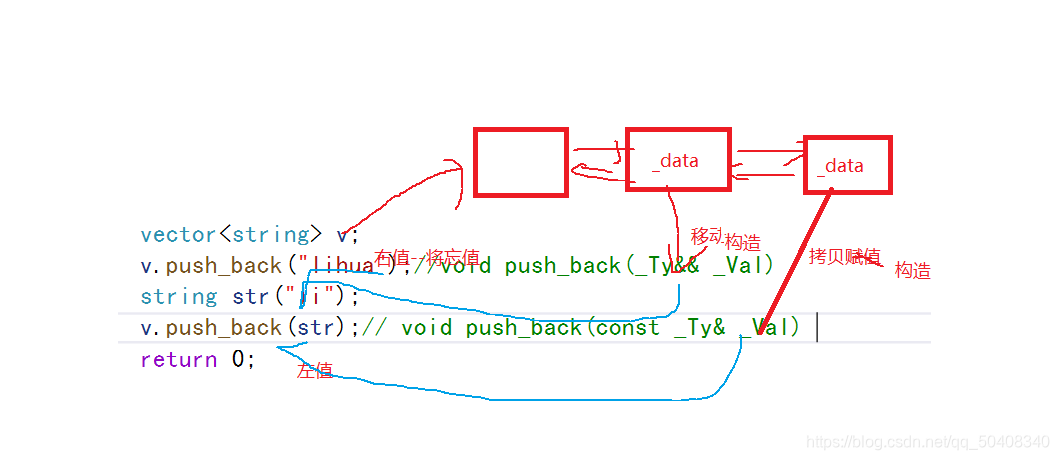
��ֵ����������ֵ
�����,��ֵ����ֻ��������ֵ,����ֵ����һ������������ֵ��?��Ϊ:��Щ������,���������Ҫ����ֵȥ������ֵʵ���ƶ����塣����Ҫ����ֵ��������һ����ֵʱ,����ͨ��move��������ֵת��Ϊ��ֵ��C++11��,std::move()����λ�� ͷ�ļ���,�ú������־����Ի���,�����������κζ���,Ψһ�Ĺ��ܾ��ǽ�һ����ֵǿ��ת��Ϊ��ֵ����,Ȼ��ʵ���ƶ����塣
vector v;
string str(��li1111111��);
v.push_back(str);
string str2(��li1111jdsahdjjdsa111��);
v.push_back(move(str2));
return 0;
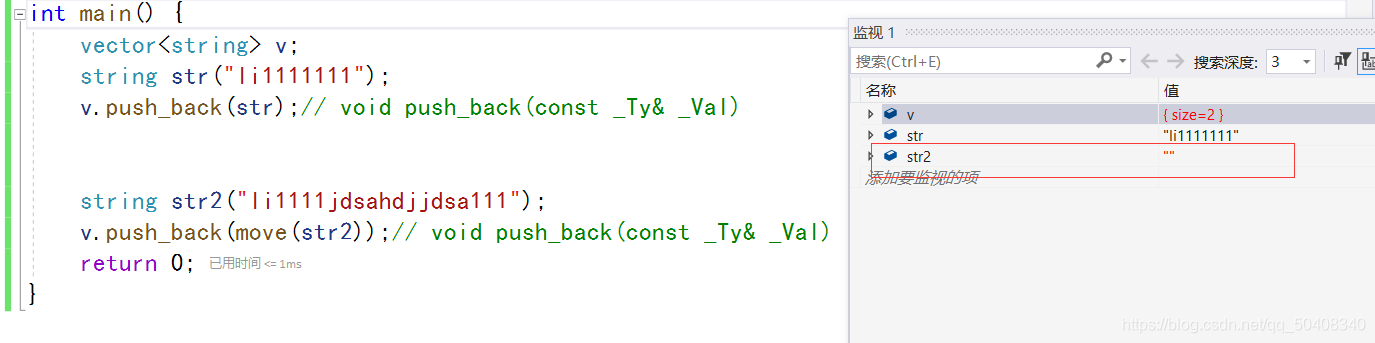
�ַ���str����ֵͨ��������뵽v����,�����ɿ��ַ���,��str2ͨ��move()�������ֵ����,ͨ���ƶ�����str2�е���Դת�Ƶ�v��,��str2�����Ч�ַ���
template
inline typename remove_reference<_Ty>::type&& move(_Ty&& _Arg) _NOEXCEPT
{
// forward _Arg as movable
return ((typename remove_reference<_Ty>::type&&)_Arg);
}
ע��:
- ��ת������ֵ,���������ڲ�û��������ֵ��ת�����ı�,��std::moveת������ֵ����lvalue���ᱻ��
�١� - STL��Ҳ����һ��move����,���ǽ�һ����Χ�е�Ԫ�ذ��Ƶ���һ��λ�á�
class Person
{
public:
Person(char* name, char* sex, int age)
: _name(name)
, _sex(sex)
, _age(age)
{}
Person(const Person& p)
: _name(p._name)
, _sex(p._sex)
, _age(p._age)
{}
#if 0
Person(Person&& p)
: _name(p._name)
, _sex(p._sex)
, _age(p._age)
{}
#else
Person(Person&& p)
: _name(move(p._name))
, _sex(move(p._sex))
, _age(p._age)
{}
#endif
private:
String _name;
String _sex;
int _age;
};
Person GetTempPerson()
{
Person p(��prety��, ��male��, 18);
return p;
}
int main()
{
Person p(GetTempPerson());
return 0;
}
ͬһ���ӿں���,ͨ����ֵ���ú���ֵ�������ֳ���ֵ����ֵ,��ֵ��ʲô?
��T���������͵�ʱ��û��ʲô����
��T���Զ�������,����Ҫϸ��
a.��T��data����ͨ��,���漰���û��ʲô����
b.��T��string,vector list����Ҫ�����ֵ���,�Զ��������ֵ�ֽ�������ֵ,�����������ڿ쵽��,�������ǿ���ʹ���ƶ�����/�ƶ���ֵ,ת����������Դ,�Ͳ���Ҫ�����,Ч�ʵõ�����
C++11������������unorder_XXX��������
�����е�string vector list�ȵ�Ҳ�����ƶ�����/�ƶ���ֵ,��ֵ�dz���,��һ�������Ч��