最近博主开学啦!更新节奏有点跟不上,这里做个检讨~
UU们开学感觉怎么样呢?见到同学或者舍友有没有很开心呢?又可以一起愉快地玩耍咯!
但是玩归玩,学习还是正事,话不多说,开始今天的内容。

在之前的内容中,我们已经把C语言的入门知识进行了一个全面的讲解,并介绍了一些实用的调试技巧,以及函数栈帧的创建和销毁,可以说对于C语言已经算是敲过开门砖了。
那么今天,我们就要开启深入学习C语言的旅程啦!首先解决C语言进阶第一问:数据在内存中是如何存储的?
当然,我们主要探讨的是整型和浮点型这两种类型。

数据类型
C语言中具以下几种基本内置类型:

这里说明一下:
- C语言的基本内置类型只的是C语言本身具有的类型,而库函数本身是不属于C语言的,是独立于C语言之外的。
- C语言是用来决定语言的语法形式的,而库函数是编译器的产商提供,当然库函数的使用是受C语言标准约束的(比如C语言标准规定了一些库函数的函数名、参数类型、返回值类型和函数功能)。
- 这样做的好处是虽然不同编译器实现函数的方式不一样,但是对于我们来说,在不同的编译器下使用函数的方式是一样的。
- 当然在有一些编译器中对一些库函数的支持提供得不是很好,比如在VS编译器下使用scanf函数就可能会报错,需要使用scanf_s。
由于字符类型在存储的时候是按照ASCII码值存储的,所以字符类型也属于整型家族中的一员。
前面我们已经学习了以上这么多的数据类型,并且了解了它们所占内存空间的大小。
我们还要明白,我们为什么要给数据分那么多的类型:
- 我们生活中出了的数除了整数就是小数,所以为了更好地存储这两种类型,数据分为整型和浮点型两大类
- 使用不同的类型时内存开辟的空间大小是不一样的(使用范围也不一样)。我们应该根据数据的大小选择合适的类型,如果选大了,则浪费空间;选小了,则数据无法完整存储。
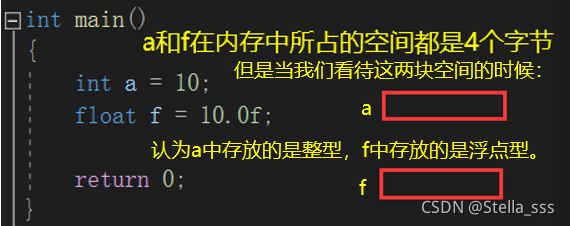
- 不同类型决定了我们看待空间时应该采用哪种视角。即对于内存中不同空间的类型存和取的方式是不一样的。
类型的基本归类
整型家族
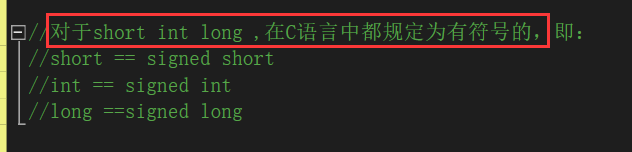
- char
unsigned char
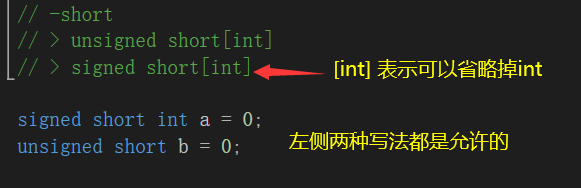
signed char- short
unsigned short [int]
signed short [int]- int
unsigned int
signed int- long
unsigned long [int]
signed long [int]
-long long
unsigned long long [int]
signed long long [int]
注意:

如何理解有符号和无符号:
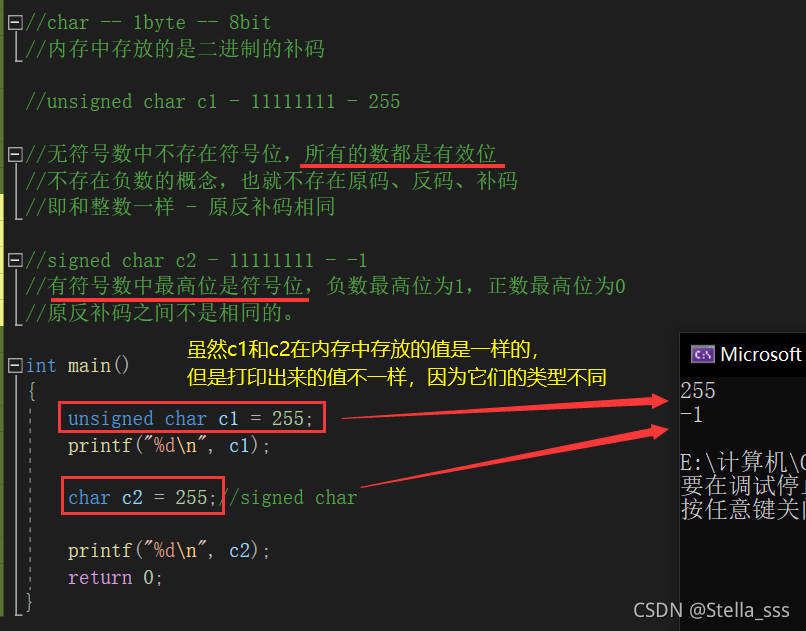
以char类型举例:
这里也说明了不同类型决定了我们看待内存中的值时视角也不同。
同时,我们也可以由此推算出一个类型中最大能放一个多大的数字。
还是以char类型举例:

由此可以得出,有符号的char中可以存放的数的范围是 -128 ~ 127。
相同道理:
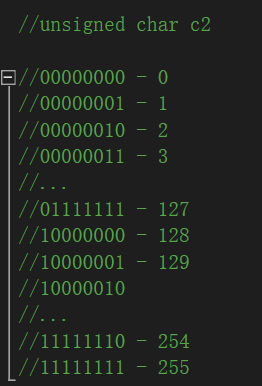
无符号的char中可以存放的数的范围是 0 ~ 255。
同理,我们可以得出short、int 、long等等类型的范围。
浮点型
float
double
这两种类型通常根据数据要求的精度来选择:精度高选择double类型(8个字节),精度低选择float类型(4个字节)。
一般我们更常选择float类型,但是记住噢~3.14默认是double类型哦!
构造类型
除了内置类型之外,还有构造类型,即可以自己创造的类型。
数组类型
结构体类型 struct
枚举类型 enum
联合类型 union
数组类型为什么也属于构造类型呢?
我们来看看数组的类型:
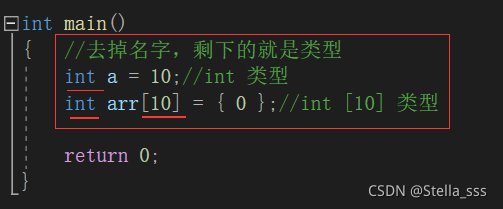

当我们定义的数组元素的类型和个数不同时,数组的类型也不同,可以通过sizeof反映出来,所以我们也说数组属于构造类型。
指针类型
int *pi
char *pc
float *pf
void *pv
空类型
void表示空类型(即无类型)
常用于函数的返回类型、函数参数和指针类型
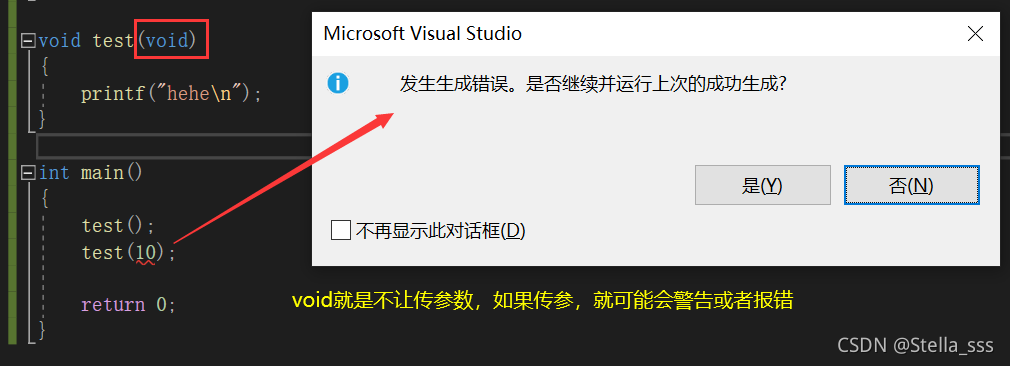
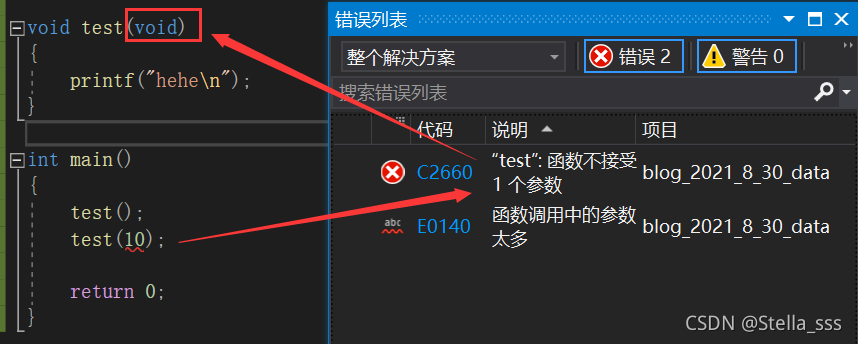
这里说void作为函数参数是什么情况呢?
正常我们在调用函数的时候,如果这个函数不需要传参,则不写参数。
但是如果是一个不需要传参的函数,而我们又给它传参了,函数会怎样呢?在有的编译器中,会报错,但是有的编译器则会接受这种情况。
但是如果我们给参数加上一个void。编译器就会报错或者警告,告诉你不能传参啦!
整型在内存中的存储
我们知道,一个变量创建之后是要在内存中开辟空间的,那么这些变量在内存中到底是怎么存储的呢?
接下来我们就来看看~
首先看看整型在内存中是如何存储的。
我们知道,二进制中有符号的整数有原码、反码、补码三种表示方式。
这三种表示方式都有符号位和数值位两部分。
- 在符号位中,0表示“正”,1表示“负”。
- 在数值位中,正数的原、反、补码相同;负数的三种表示方法各不相同:
原码:直接将二进制按照正负数的形式翻译成二进制。
反码:将原码的符号位不变,其他位依次按位取反。
补码:反码+1得到补码。
我们知道对于整型来说,内存中存放的是该数的补码。
在计算机系统中,数值一律用补码来表示和存储。
但是存放的是补码,而不是原码或者反码呢?
因为,使用补码可以将符号位和数值位作统一处理。
同时,加法和减法也可以统一处理(CPU只有加法器)。
因此,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
比如,我们想计算1-1。但是因为CUP只有加法运算,所以我们可以把表达式写成1+(-1)。

我们可以看到,用原码计算,得不出正确的结果。
但是如果用补码计算,情况就不一样了。
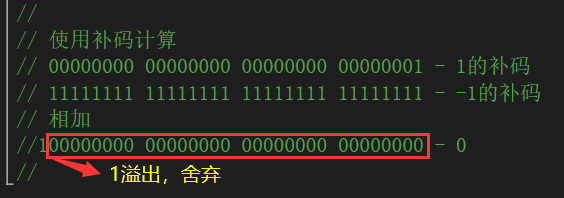
从上图的计算中,我们可以看出,使用补码可以直接对符号位和数值位同一进行处理。
这里有一个有意思的事情:
我们知道原码、反码和补码都是怎么得到的,那么计算一下我们会发现用同样的方法,我们也可以通过补码得到原码。

(不信你试着算一下!)
所以,由此我们可以看到用补码来存储的好处。
大小端字节序
定义
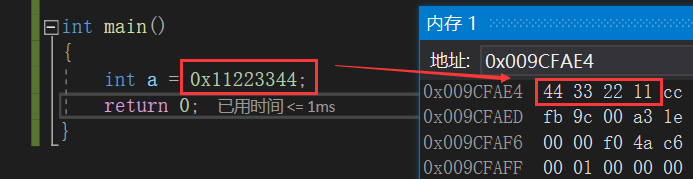
我们看到,a是一个十六进制的数,当我们在内存中查看它的存储情况时,可以发现,它的存放是从低地址开始放44 33 22 11。
对于它们在内存中的存放顺序,其实可以有很多种存放的方式。

但是如果大家都按照自己的想法来写,则整个存储就会乱套,而且如果我们不按照正常的顺序存储时,取出来要获得原来的数就比较麻烦,所以我们最后决定只以下两种存储顺序。
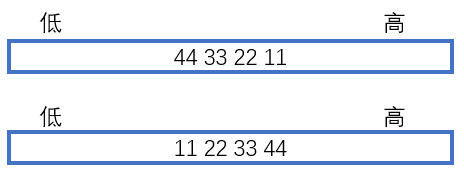
注意:这里的存储顺序是以字节为单位来讨论的。因此,也称字节序。
其中,上面的存储顺序称为小端字节序;下面的存储顺序称为大端字节序。
- 小端字节序存储
把一个数的低位字节的内容,存储在内存的低地址出,把这个数的高位字节的内容,存储在内存的高地址处。- 大端字节序存储
把一个数的低位字节的内容,存储在内存的高地址出,把这个数的高位字节的内容,存储在内存的低地址处。

意义
那么,为什么在存储时还要有大小端之分呢?
这是因为在计算机系统中,内存空间的最小单元是一个字节。所以,如果我们存放的变量大小大于一个字节时,我们就不得考虑每个字节应该以何种顺序存放在内存中了。
那么我们当前的编译器是采取大端存储还是小端存储呢?
别着急,回头看看内存中的值的顺序,就能知道啦!
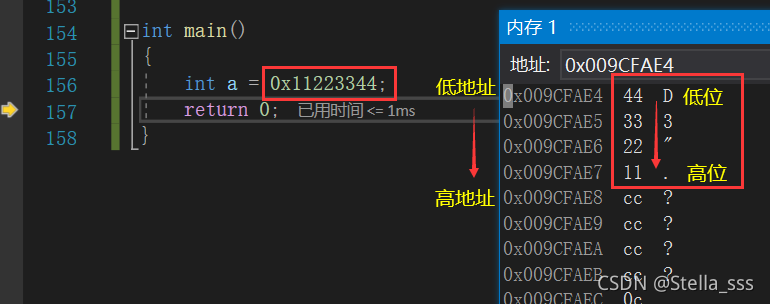
所以,我们当前编译器采用的是小端字节序。
百度曾经出过一道笔试题,让被试者设计一个程序来判断当前机器的字节序。
那么我们应该如何做呢?
我们用1来进行观察。

所以,我们只需要拿出第一个字节,看看里面存的是0还是1就知道了。

当然,我们要实现的是查看一个机器字节序的功能,所以这里我们最好把程序封装成一个函数。

浮点型在内存中的存储
看完了整数在内存中是怎么存储的,那么浮点型在内存中又是怎么存储的呢?
我们接下来就来看看。
首先我们常见的浮点数有:
小数:3.1425926
科学计数法:1E10(1.0*1010)
在浮点型中,我们有float和double两种类型。
而这两种类型的范围,我们用float.h来定义。
如果我们想看整数的最大值(最小值),我们就用INT_MAX(INT_MIN);并在前面包含头文件<limits.h>。

然后我们就能看到int类型所能存放的最大值啦!
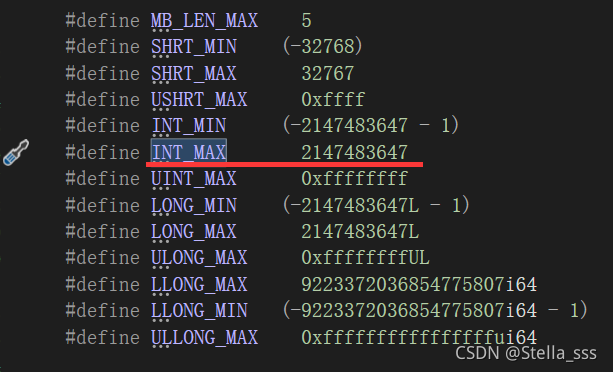
那么,浮点数所能存放的最大最小值是多少呢?
同理,我们可以用FLT_MAX(或者FLT_MIN、DBL_MAX等),引用头文件<float.h>,然后转到定义。
就能得到他们的精度啦~
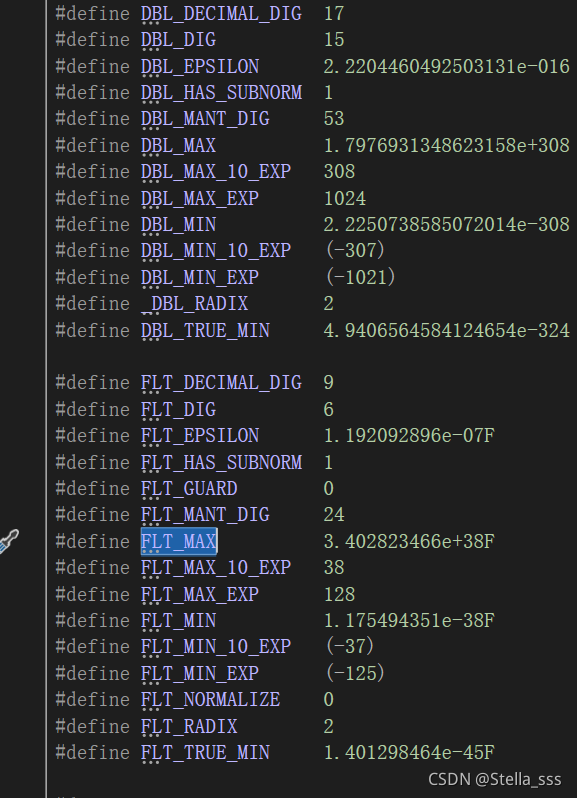
那么在内存中浮点数的存储和整数的存储是一样的吗?
我们可以先通过一段代码来进行验证。
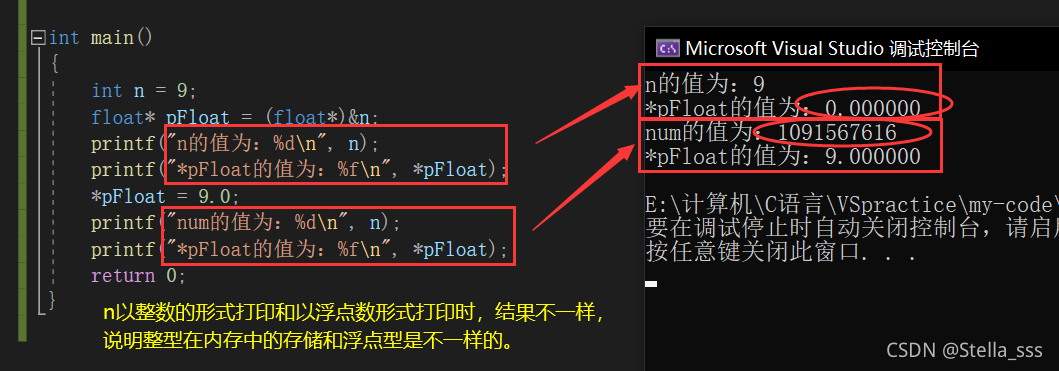
那么如果浮点型的存储和整型不一样,它又是怎么存储的呢?
根据国际标准IEEE(电气和电子工程协会) 754,任意一个二进制浮点数V可以表示成下面的形式:
- (-1)S * M * 2E
(-1)s表示符号位,当S=0,V为正数;当S=1,V为负数。
M表示有效数字,1≤M<2。
2E表示指数位。
我们以小数5.5来举例。

同理,我们可以写出9.0的表示形式:

我们会发现,其实任何一个浮点数都可以写成这种形式。
那么,只要我们把一个浮点数写成(-1)S * M * 2E这种形式,那么只要我们存储了S、M、E的信息,就能还原出浮点数的值了。
IEEE 754规定: 对于32位的浮点数,最高的1位是符号位S,接着的8位是指数E,剩下的23位为有效数字M。
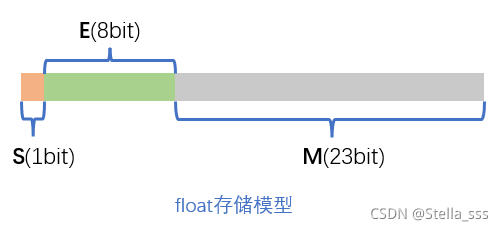
对于64位的浮点数,最高的1位为符号位S,接着是11位的指数E,剩下的52位为有效数字M。

- 此外,IEEE 754对有效数字M和指数E,还有一些特别规定。
因为1≤M<2 即M可以写成1.XXXXXX 的形式,其中XXXXXX表示小数部分。
IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此这个1和它后面的小数点可以被舍去,只保存后面的XXXXXX部分。
比如:当我们要保存1.01的时候,只需要保存01,等到读取的时候,再把前面的1.加上去。
这样,我们就节省了1位有效数字。
以32位浮点数(float)为例,留给M只有23位,将第一位的1舍去以后,等于可以保存24位有效数字,这样精度就得到了提高。
- 那么对于指数E来说,它又是怎么存进去的呢?
我们知道,对于指数E来说,它是可以去负数的,那么对于负数的E在存储的时候,我们又应该如何处理呢?
于是人们又想出了一个办法,不如给这个E加上一个中间数,让E即使是最小的负数,加上这个数之后也不会为负(等于0),那么就不会出现负数的情况了,只要我们取出来的时候再把这个中间数加上就行了。
这样,我们就可以把E作为一个无符号整数了。
如果E为8位,那么它的取值范围就是:0~255,那么它的中间数就是127。
对于11位的E,它的取值范围是0~2047,它的中间数就是1023。
比如:210的E是10,所以保存成32位浮点数时,就保存成10+127=137,即10001001。
以5.5为例,我们可以在内存中看到它的存储。
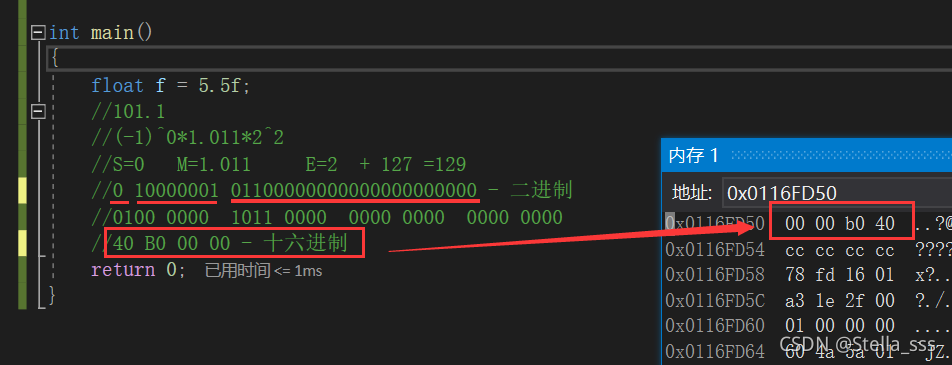
并且我们可以发现,对于浮点数,它在内存中的存储也是有大小端的。
以上,我们就知道了浮点数在内存中是怎么存的了。
那么它又是怎么取出来的呢?
按道理,我们是怎么放进去的,就应该是怎么取出来的。但是由于指数E比较特别,所以再取出来时,又有一些特别的规定。
在内存中取出E时,我们有一下三种情况:
E不全为0或不全为1
这时,E是怎么存进来的,我们就按照原路取出来。
即指数E的计算值减去127(或1023),得到真实值,再将有效数字M前加上第一位的1。
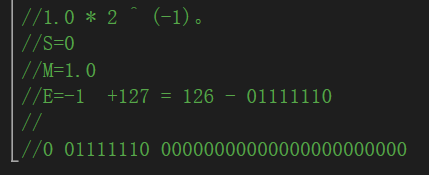
比如: 0.5的二进制形式为0.1,由于规定正数部分必须为1,即将小数点右移1位,则为1.0*2^(-1)。
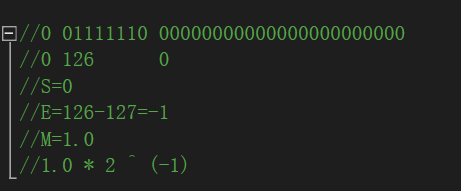
同理,反过来,我们可以通过这个二进制序列得到0.5。
E全为0
当E全为0的时候,说明浮点数的指数E等于-127,而2-127是一个非常非常小的数,已经十分接近于0了。
所以这时候,我们就不再按照原来的计算方式,而是把浮点数的指数E直接记为1-127(或者1-1023), 并且有效数字M不再加上第一位的1,而是还原为0.XXXXXX的小数。这样做是为了表示±0,以及无穷接近于0的很小的数。
E全为1
当E全为1时,则得到的是255,减去127得到的是128,而2128是一个非常大的数。所以这时,如果有效数字M全为0,则该数就表示±无穷大(正负取决于符号位S)
当我们了解完以上浮点型在内存中的存储规则之后,我们就可以理解之前哪个代码打印出来的值了。
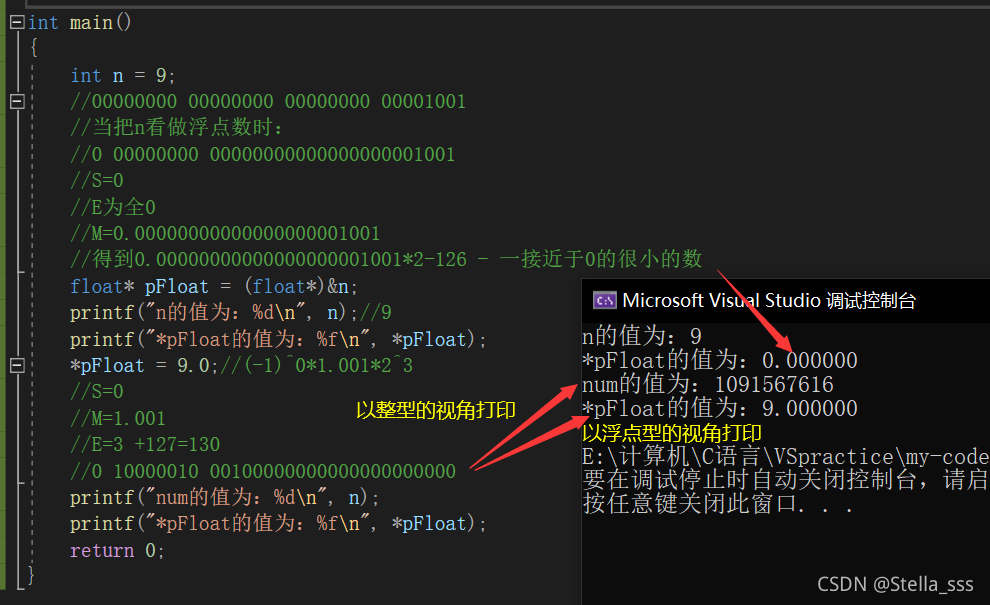
今天的文章就到这里啦!~
你学废了吗?记得点赞收藏加关注,在评论区留下你的脚印~

关注我!一起精进C语言!
