一、基础
1.语言概述
1.1.机器语言
机器语言是一组0和1系列组成的指令码,这些治理码是由CPU制作厂商规定的,然后发布请程序员遵守。因此不同型号的计算机指令系统即机器语言是不相通的,按一种计算机的机器指令编制的程序不能再另一个计算机上运行
1.2.汇编语言
汇编语言是一种人类可以比较轻松掌握的编程语言,只是机器不懂,但可以由一类程序将汇编语言翻译为机器语言,不同CPU的汇编语言也不同,因此汇编语言编写的程序必须记住是在什么CPU上编写的,这工作量依然较大
1.3.面向过程的语言
汇编语言和机器语言都是面向机器的,机器不同,语言也不同。而高级语言不再关注底层的计算机硬件,把主要精力放在了程序设计上,高级语言要执行也需要由一个翻译程序将其翻译成机器语言,这就是编辑程序。高级语言解决问题的方法是,分析出解决问题所需要的步骤,把程序看成数据被加工的过程。基于这类方法的程序设计语言被称为面向过程的语言,C语言就是一种面向过程的程序设计语言
2.程序的开发周期
产生一个 .exe的可执行文件需要经过:编辑源代码(.c),编译源代码(.obj),连接目标程序,最后生成一个可执行文件
编辑源代码
一篇由汉字,英文,标点符号或者其他可以从键盘输入的字符组合内容被称为文本,能够进行文字编辑工具的软件被称为编辑器,源代码就是程序员输入编写的,符合 C 语言语法规则的文本。一般用扩展名 .c 表示其为一个 C源代码文件,源代码文件简称源文件,也可以称为源程序,只要能输入文字的文本编辑软件都可以作为源代码编辑器。
编译 C 源代码
编译是把 C 语言源代码翻译成用二进制指令表示的目标文件,目标文件和机器语言还有一段距离。编译过程由 C 编译系统提供的编译程序完成。编译程序简称编译器,编译程序运行后,自动对源程序进行句法和语法检查,当发现问题后就将错误类型和所在位置显示出来,用户可以再利用编辑器对源程序进行修改,修改之后重新编译,直至通过为止,如果未发现句法和语法方面的错误,就自动形成目标代码,并对目标代码进行优化后生成目标文件
目标文件的扩展名为 .obj,它是目标程序的文件类型标识,不同的编译系统,或者不同版本的编译程序,它们的启动命令不同,生成的目标文件也不同,扩展名有时候也不一定相同,当然格式也不相同,但是作用相同
连接目标文本
多个源代码文件经过编译后产生了对应的多个目标文件,此时还没有将其组合装配成一个可以运行的整体,因此计算机依然不能执行,连接过程是用连接程序将目标文件,第三方目标文件,C 语言提供的运行时的库文件连接装配成一个完整的可执行的目标程序。连接程序简称连接器。
可执行程序文件的扩展名为 .exe,是可执行程序的文件类型标识,绝大部分系统生成的可执行文件的扩展名为 .exe,程序员开发程序,除了要编写自己的代码外,有时会使用其他人提供的库文件,如果要编写一个 mp3播放器软件,对于 mp3 解码部分,因为已经由现成的第三方代码库做好了这些事情,可以直接拿来使用。
运行程序
运行程序是指将可执行的目标文件投入运行,以获取程序处理的结果,如果程序运行结果不正确可以重新回到第一步,对程序进行编辑修改,编译和与运行,运行程序与C语言本身已经无关
3.第一个C程序
下面的程序从标准输入读取文本并对其进行修改,然后写到标准输出。程序手写读入一串列标号,这些列标号成对出现,表示输入行的列范围,这串列标号以一个负值结尾,作为结束标志,剩余的输入行被程序读入并打印,然后输入行中被选中范围的字符串被提取出来并打印,第一列的列标号为0
/*
**这个程序从标准输入中读取输入行并在标准输出轴打印这些行
**每行的输入行后面是改行的一部分内容
**
**输入行的第一行是一串列标号,串的最后以一个负数结尾
**这些列标号成对出现,说明需要打印的输入行的列的范围
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_COLS 20 /*每行处理的最大列号*/
#define MAX_INPUT 1000 /*每个输入行的最大长度*/
int read_column_numbers(int columns[],int max);
void rearrange(char *output,char const *input,int n_columns,int const columns[]);
int main(void)
{
int n_columns; /*进行处理的列标号*/
int columns[MAX_COLS]; /*需要处理的列数*/
char input[MAX_INPUT]; /*容纳输入行的数组*/
char output[MAX_INPUT]; /*容纳输出行的数组*/
/*读取列标号*/
n_columns=read_column_numbers(columns,MAX_COLS);
/*读取,处理和打印剩余的输入行*/
while (gets(input)!=NULL){
printf("Orignal input: %s\n",input);
rearrange(output,input,n_columns,columns);
printf("Rearranged line: %s\n",output);
}
return EXIT_SUCCESS;
}
/*读取列标号,超出范围不予理会*/
int read_column_numbers(int columns[],int max)
{
int num=0;
int ch;
/*取得列标号,如果所读取的数小于0则停止*/
while (num<max && scanf("%d",&columns[num]) == 1 && columns[num] >=0)
num+=1;
/*确认已经读取的标号为偶数个,因为它们是成对出现的*/
if (num%2 !=0){
puts("Last column number is not paired.");
exit(EXIT_FAILURE);
}
/*丢弃该行中包含最后一个数字的那部分内容*/
while ((ch= getchar()) != EOF && ch !='\n')
;
return num;
}
/*处理输入行,将指定列的字符连接在一起,输出行以NUL结尾*/
void rearrange(char *output,char const *input,int n_columns,int const columns[])
{
int col; /*colunms数组的下标*/
int output_col; /*输出列计数器*/
int len; /*输入行的长度*/
len=strlen(input);
output_col=0;
/*处理每对列标号*/
for (col=0;col<n_columns;col+=2){
int nchars = columns[col+1]-columns[col]+1;
/*如果输入行结束或输出行数组已满,就结束任务*/
if (columns[col]>=len || output_col==MAX_INPUT-1)
break;
/*如果输出行空间不够,只复制可以容纳的数据*/
if (output_col+nchars>MAX_INPUT-1)
nchars =MAX_INPUT-output_col-1;
/*复制相关的数据*/
strncpy (output+output_col,input+columns[col],nchars);
output_col+=nchars;
}
output[output_col]='\0';
}
3.1.1.空白和注释
注释符号以 /* 开始,以 */ 结束,但不能嵌套,在其他的语言中可以把一段代码注释掉,使其不起作用,但是在 C 语言中,如果这段代码内部原先就有注释存在,这样做就会出问题,更好的办法是使用 #if 语句
#if 0
statements
#endif
3.1.2.预处理指令
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_COLS 20 /*每行处理的最大列号*/
#define MAX_INPUT 1000 /*每个输入行的最大长度*/
这些是预处理指令,因为它们是有预处理器解释的,预处理器读入源代码,根据预处理指令对其进行修改,然后把修改过的源代码递交给编译器。在例子程序中,预处理器用名叫 stdio.h 的库函数头文件中的内容替换第一条 #include 指令语句,其结果仿佛就是 stdio.h 的内容被逐字写道源文件的那个位置,第二条第三条指令的功能类似,只是所替换的头文件不同
stdio.h 头文件使我们可以访问 标准 I/O 库中的函数,这组函数用于执行输入和输出。stdlib.h 定义了 EXIT_SUCCESS 和 EXIT_FAILURE 符号。我们需要用 string.h 头文件提供的函数来操纵字符串
int read_column_numbers(int columns[],int max);
void rearrange(char *output,char const *input,int n_columns,int const columns[]);
这些声明称为函数原型,它们告诉编译器这些以后将在源文件中定义的函数的特征,这样在函数被调用时,编译器就可以对它们进行准确性检查,每个原型以一个类型名开头,表示函数返回值的类型,跟在类型名后的是函数名,再后面是函数期望接收的参数,参数的名字并非必需,给出参数的名字只是提示它们的作用
rearrange 函数接受四个参数,前两个参数都是指针,指针指定一个存储与计算机内存中的值的地址,第二个和第四个参数被声明为 const,这表示函数将不会修改函数调用者所传递的这两个参数,关键字 void 表示函数不返回任何值,在其他语言中,无返回值的函数被称为过程
3.1.3.main()函数
int main(void)
{
int n_columns; /*进行处理的列标号*/
int columns[MAX_COLS]; /*需要处理的列数*/
char input[MAX_INPUT]; /*容纳输入行的数组*/
char output[MAX_INPUT]; /*容纳输出行的数组*/
/*读取列标号*/
n_columns=read_column_numbers(columns,MAX_COLS);
/*读取,处理和打印剩余的输入行*/
while (gets(input)!=NULL){
printf("Original input: %s\n",input);
rearrange(output,input,n_columns,columns);
printf("Rearranged line: %s\n",output);
}
return EXIT_SUCCESS;
}
每个 C 程序都必须有一个 main() 函数,函数体内首先定义了四个局部变量,分别是整型标量,整型数组以及两个字符数组。在 C 语言中,数组参数是以引用的形式传递的,也就是传址调用,而标量和常量则是按值传递,在函数中对标量参数的任何修改都会在函数返回时丢失,因此被调用函数无法修改调用函数以传值形式传递给它的参数,然而当被调用函数修改数组参数中的一个元素时,调用函数所传递的数组就会被实际地修改
gets函数从标准输入读取一行文本,并把它存储于作为参数传递给它的数组中,一行输入由一串字符组成,以一个换行符结尾,gets函数丢弃换行符,并在该行的末尾储存一个 NUL 字节(一个 NUL 字节是指字节模式为全0的字节,类似’\0’这样的字符常量)。然后,gets函数返回一个非 NULL 值,表示被成功读取,若返回 NULL 表示读取完毕
尽管在 C 语言中并不存在 “string” 数据类型,但在整个语言中有一个约定:字符串就是一串以 NUL 字节结尾的字符,NUL 是作为字符串终止符,它本身并不被看作是字符串的一部分,字符串常量就是源程序中被双引号括起来的一串字符
NUL 是 ASCII 码字符集中 ‘\0’ 字符的名字,它的字节模式为全 0 ,NULL 指一个其值为 0 的指针,它们都是整型值,其值也相同,所以它们可以互换使用。NULL 在头文件 stdio.h 中定义,并不存在预定义的符号 NULL,如果想使用它而不是字符常量’\0’,必须自行定义
printf 执行格式化的输出,常用格式代码:
%d:以十进制形式打印一个整型值
%o:以八进制形式打印一个整型值
%x:以十六进制形式打印一个整型值
%c:打印一个字符
%s:打印一个字符串
%f:输出 float 变量,输出保留 6 位小数
%lf:输出 double 变量,输出保留 6 位小数
%nd:以 n 字符宽度输出整数,宽度不足用空格填充
%0nd:以 n 字符宽度输出整数,宽度不足用 0 填充
%.nf:输出浮点数,精确到小数点后 n 位
3.1.4.read_column_numbers 函数
int read_column_numbers(int columns[],int max)
{
int num=0;
int ch;
/*取得列标号,如果所读取的数小于0则停止*/
while (num<max && scanf("%d",&columns[num]) == 1 && columns[num] >=0)
num+=1;
/*确认已经读取的标号为偶数个,因为它们是成对出现的*/
if (num%2 !=0){
puts("Last column number is not paired.");
exit(EXIT_FAILURE);
}
函数的声明必须于程序中调用时的指定完全相同,第一个参数数组可以接收任意长度的参数,但无法确定数组长度。接下来声明了两个变量,第二个变量并未初始化,更准确的说,它的初始值是一个不可预料的值,但函数对这个变量所执行的第一个操作就是赋值
scanf 函数从标准输入轴读取字符,并根据格式字符串对他们进行转化,类似于 printf 函数的逆操作,返回值是函数成功转换并存储于参数中的值的个数,在使用时需要注意:
1.由于 scanf 函数的实现原理,所有标量参数的前面必须加上一个 “&” 符号,数组前不需要加上 “&” 符号,但是如果数组参数中出现了下标引用,也就是说实际参数是数组的某个特定元素,它的前面也必须加上 “&” 符号
2.它的格式代码于 printf 函数的格式代码相似但不完全相同:
%d:读取一个整型数值 变量类型:int
%ld:读取一个长整型数值 变量类型:long
%f:读取一个实型值(浮点数) 变量类型:float
%lf:读取一个双精度实型值 变量类型:double
%d:读取一个字符 变量类型:char
%s:从输入中读取一个字符串 变量类型:char 型数组
前五个格式代码用于读取标量值,变量参数的前面必须加上"&"符号,使用所有格式码(除%c)之外,输入之前的空白(空格,制表符,换行符等)会被跳过,值后面的空白表示该值的结束。因此用 %s 格式码输入字符串时,中间不能包含空白,除出现 %c 外,其他格式输入符都会跳过中间的空格,但是一旦遇到非空格时,就会继续读入,如果不符合格式码会产生错误
因此实例代码中 scanf("%d",&columns[num]) 读入字符,根据格式码 %d 将这些数字中的某一个转换为一个整数,结果存储在指定的数组元素(columns[num])中,转换后返回 1 这个值,不管文件读完还是下一次输入的字符无法转换为整数,循环都会终止
标准并未硬性规定 C 编译器对数组下标的有效性进行检查,而且绝大多数 C 编译器确实也不进行检查。因此,如果需要进行数组下标的有效检查必须自行编写代码
&& 是"逻辑与"操作符,若左边的表达式为假,右边的表达式便不再进行求值
puts 函数是 gets 函数的输出版本,它把指定的字符串写入标准输出并在末尾添加一个换行符
/*丢弃该行中包含最后一个数字的那部分内容*/
while ((ch= getchar()) != EOF && ch !='\n')
;
getchar() 函数从标准输入读取一个字符并返回它的值,如果输入中不再存在任何字符,函数就会返回常量 EOF(在stdio.h中定义),用于提示文件的结尾,读取字符后将其赋给ch,然后与 EOF 进行比较,加上括号可以保证赋值操作先于比较操作进行,这行语句表示读入的文本不是结尾字符,也不是换行符,循环才继续进行,这样循环就能剔除掉当前输入行最后的剩余字符
ch 被声明为整型,而实际我们用它来读取字符,这是因为 EOF 是一个整型值,它的位数比字符类型要多,把 ch 声明为整型可以防止从读取的字符以外地被解释为 EOF。但同时,这也意味着接收字符的 ch 必须足够大,足以容纳 EOF,这就是 ch 使用整型值的原因,字符只是小整型数,用一个整型变量容纳字符值并不会引起任何问题
while 循环的循环体没有任何语句,仅仅完成 while 表达式的测试部分就足以达到目的,所以循环体无事可干,while 语句之后的单独一个分号称为空语句,它就是应用于目前这个场合
3.1.5.rearrange函数
/*处理输入行,将指定列的字符连接在一起,输出行以NUL结尾*/
void rearrange(char *output,char const *input,int n_columns,int const columns[])
{
int col; /*colunms数组的下标*/
int output_col; /*输出列计数器*/
int len; /*输入行的长度*/
这些语句定义了 rearrange 函数并声明了一些局部变量,前两个参数被声明为指针,但在实际调用时,传给它们的为数组名,这是因为数组名作为实参时,传递给函数的实际上是一个指向数组起始位置的指针,也就是数组在内存中的地址,也就是数组名作为参数时具备了传址调用的语义,函数可以按照操作指针的方式来操作实参,也可以像使用数组名一样用下标来引用数组中的元素
但传址调用时如果修改了形参数组的元素,它实际将修改实参数组对应的元素,因此将 columns 声明为 const 有两方面的作用,首先,它声明该函数的作者的意图是这个参数不能被修改,其次,它导致编译器去验证是否违背该意图,因此第四个参数不必担心因传址调用而使得数组中的元素被修改
len=strlen(input);
output_col=0;
/*处理每对列标号*/
for (col=0;col<n_columns;col+=2){
C 语言中的 for 语句更像是 while 语句的一种常用风格的简写法,包含三个表达式(都是可选的),第一部分是初始部分,只在循环开始前执行一次,第二个表达式是测试部分,每次循环都要执行一次,第三部分是调整部分,每次循环都要执行,但它在测试部分之前执行,相当于下面的while循环
col=0
while(col<n_columns){
col+=2
}
int nchars = columns[col+1]-columns[col]+1;
/*如果输入行结束或输出行数组已满,就结束任务*/
if (columns[col]>=len || output_col==MAX_INPUT-1)
break;
/*如果输出行空间不够,只复制可以容纳的数据*/
if (output_col+nchars>MAX_INPUT-1)
nchars =MAX_INPUT-output_col-1;
/*复制相关的数据*/
strncpy (output+output_col,input+columns[col],nchars);
output_col+=nchars;
strncpy 函数把选中的字符从输入行复制到输出行的下一个位置,strncpy 函数的前两个参数分别是目标字符串地址和源字符串的地址,在上面的例子里,目标字符串的位置是输入数组的起始地址向后偏移output_col列的地址,源字符串的地址是输入数组起始地址向后偏移columns[col]个位置的地址,第三个参数指定需要复制的字符数,输出列计数器随后向后移动 nchars 个位置
output[output_col]='\0';
}
循环结束后,输出字符数串以一个 NUL 字符作为终止符
3.1.6.补充
在编写程序前还需要了解:
putchar 函数与 getchar 函数相对应,它接收一个整型参数,并在标准输出轴打印该字符(字符在本质上也是整型),它们是非格式化输出和输入函数
在函数库里存在许多操纵字符串的函数,下面是最常用的几个,除特别说明,这些函数的参数既可以是字符串常量也可以是字符型数组名,还可以是一个指向字符的指针
strcpy 函数与 strncpy 函数类似,但它没有限制需要复制的字符数量,它接收两个参数:第二个字符串参数将被复制到第一个字符串参数,第一个字符串参数将被覆盖,strcat 函数也接收两个参数,但它把第二个字符串参数添加到第一个字符串参数的末尾,在这两个函数中,它们的第一个字符串参数不能是字符串常量,而且必须确保目标字符串有足够的空间
在字符串内进行搜索的函数是 strchr,它接受两个参数,第一个是字符串,第二个是一个字符,这个函数在字符串参数内搜索字符参数在字符串内的第一次出现位置,成功就返回这个位置的指针,失败返回一个 NULL 指针。strstr 函数的功能类似,但它的第二个参数也是一个字符串,它搜索第二个字符串在第一个字符串中第一次出现的位置
4.基本概念
4.1.环境
在 ANSI C 的任何一种实现中,存在两种不同的环境,翻译环境中,源代码被翻译为机器指令,执行环境中它指向实际代码,这两种环境不必在同一台机器,例如,交叉编译器就是在同一台机器上运行,但它产生的可执行代码运行于不同类型的机器上
源代码(源文件)经过编译形成目标代码,链接器将多个目标代码捆绑在一起,形成单一完整的可执行程序。链接器同时也会映入标准函数库中任何被用到的函数。
编译本身也包含多个过程,首先预处理器处理,然后源代码进行解析,这个阶段是大多数错误产生的阶段,随后生成目标代码,如果在编译程序的命令行中加入了要进行优化的选项,优化器会对目标代码进行进一步优化
程序的执行也要经历几个阶段,首先程序载入内存,这个任务由操作系统完成,那些不是存储在堆栈中的尚未初始化的变量将在此时得到初始值,然后执行便开始,在宿主环境(具有操作系统的环境)中,通常一个小型的启动程序于程序链接在一起,它负责处理一系列日常事务,如收集命名行参数以便程序能够访问它们,接着便调用 main 函数。在绝大多数机器里,程序将使用一个运行时堆栈,它用于存储函数的局部变量和返回地址,程序中同时也可以使用静态内存,存储在静态内存中的变量在程序的整个执行过程中将一直保留它们的值
程序的最后一个阶段就是程序的终止,它可以是多种不同的原因引起的。正常终止就是 main 函数返回,有些执行环境允许程序返回一个代码,提示车光绪为什么停止执行
4.2.词法规则
词法规则决定你在源程序中如何形成单独的字符片段,也就是标记,一个ANSI C程序由声明和函数组成,函数定义了需要执行的工作,声明则描述了函数或函数将要操作的数据类型,注释可以散布于源文件的各个地方
标准未规定 C 环境必须使用哪种特定的字符集,但它规定字符集必须包括英语所有的大写和小写字母,数字0-9以及一些符号,字符集还必须包括空格,水平制表符,垂直制表符,格式反馈字符和换行符,这些字符被称作空白字符,因为它们被打印时出现的时空白不是记号
标准还定义了三字母词,三字母词是几个字符序列,合起来表示另一个字符,三字母词使 C 环境可以在缺少一些必须字符的字符集上出现,例如 ??( 代表 [,两个问号开头再尾随一个字符。
另外 C 源代码中可能会使用某个特定字符,但这个字符再环境里有特别的意义,K&R C 定义了几个转义序列或字符转义,ANSI C 在它的基础上又增加了几个转义序列,转义序列由一个反斜杠加上一个或多个其他字符组成,如下几个例子:
\a 警告字符,它将奏响终端铃声或产生其他一些可以看见或听见的信号
\b 退格键 \f 进纸字符 \n 换行符 \r 回车符 \t 水平制表符 \v 垂直制表符 \ddd 表示1-3个八进制数字 \xddd 表示1-3个十六进制数
二、数据
程序对数据进行操作,下面会描述它的各种类型,特点和如何声明它,还会描述变量的三个属性:作用域,链接属性和存储类型
2.1.基本数据类型
在 C 中,仅有四种基本数据类型:整型,浮点型,指针和聚合类型(如数组和结构),,其它类型都由它们的组合派生而来
2.1.1.整型
整型包括字符,短整型,整型和长整型,它们都分为有符号和无符号两种版本,规定整型值相互之间大小的规则很简单:长整型至少应该和整型一样长,整型至少应该和短整型一样长,长整型不得比短整型短,下面是一些变量的最小范围: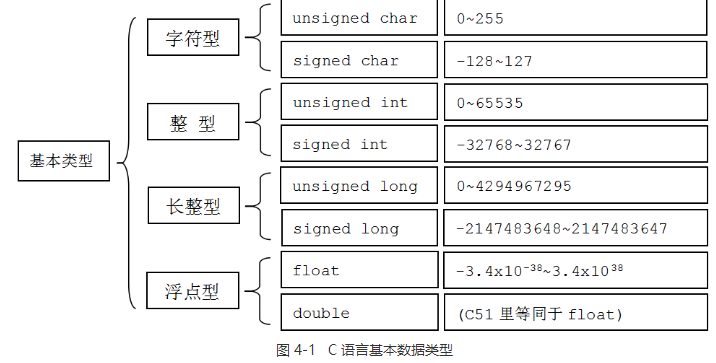
头文件 limits.h 说明了各种不同的整数类型的特点
尽管设计 char 类型变量的目的是为了让它们容纳字符型值,但字符在本质上是小整型值,缺省的 char 要么是 signed char,要么是 unsigned char,这取决于编译器,因此不同机器上的 char 可能由不同范围的值,只有程序使用的 char 型变量的值位于 signed char 和
unsigned char 的交集中,这个程序才是可移植的,在一个把字符当作小整型值的程序中,显式声明这类变量可以提高可移植性,但是可能效率会受损,另外还有库函数把他们的参数声明为 char,如果你把参数显示声明为 signed char 或 unsigned char 可能会出现兼容性问题。当可移植性十分重要时,最佳的方案是把存储于 char 型变量的值限制在signed char 与 unsigned char 的交集内,并且只有当 char 型变量显示声明为 signed char 或 unsigned char 时,才对它执行算术运算
负数的二进制表示规则:负数的绝对值所有位取反再加一,二进制转负数:除去符号位减一,然后按位取反
整型常量
整型常量(声明为 const 的变量)与普通变量类似,区别是它在被初始化后值不能再改变。
整型常量出现时,它的类型取决于常量时如何书写的,可以通过后缀来改变默认规则,如在整数常量后面添加字符 L 或 l 可以使整数被解释为 long 整型值,加字符 U 或 u 可以指定为 unsigned 整型值,十进制整型常量可以是 int,long,unsigned long,在默认情况下,它是最短类型但能完整容纳这个值。
另外还有字符常量,字符常量是用单引号括起来的单个字符,说明符是 char,每个字符以一个字节的 ASCII 码的形式存放在变量的存储单元之中的它们的类型总是 int,不能再后面添加后缀,如果一个多多字节字符常量前有一个 L ,它就是宽字符常量,当运行环境支持一种宽字符集时,就有可能使用它们。
枚举类型
枚举类型就是指它的值为符号常量,而不是字面值的类型,它们以下面这种形式声明:
enum Jar_Type {CUP,PINT,QUART,HALF_GALLON,GALLON};
这个语句声明了一个类型,称为 Jar_Type,这种类型的变量按下面方式声明:
enum Jar_Type milk_jug,gas_can,medicine_bottle;
如果某种特别的枚举类型的变量只使用一个声明,可以把上面两条语句合并为:
enum Jar_Type {CUP,PINT,QUART,HALF_GALLON,GALLON}
milk_jug,gas_can,medicine_bottle;
这种类型的变量实际上以整型的方式存储,这些符号名实际值都是整型值,这里 CUP 是0,PINT 是1,以此类推。适当时候,可以为这些符号名指定特定的整型值:
enum Jar_Type {CUP=8,PINT=16,QUART=32,HALF_GALLON=64,GALLON=128};
符号名被当作整型常量处理,声明为枚举类型的变量实际上是整数类型,这个事实意味着可以给 Jar_Type 类型的变量赋诸如 -623 这样的字面值,但是要避免以这种方式使用枚举,因为把枚举变量同整数无差别地混合在一起使用会削弱它们值的含义
枚举类型一般指定第一个元素的数值大小,后面的数值大小会依次递增,相当于用了很多 #define 来定义了数字的名称,而且避免了麻烦
基本使用:
#include <stdio.h>
void main()
{
int a,b,c,d;
unsigned u;
a=12;
b=-24;
u=-10;
c=a+u;
d=b+u;
printf("a+u=%d,b+u=%d\n",c,d);
}
声明无符号整型(unsigned)是将内存空间的第一位也存放了数据,而不是符号,可以存放的整数范围比有符号的大了一倍
#include <stdio.h>
void main()
{
unsigned int a=30;
printf("%u\n",a );
/*用无符号整型表达了负数,而且格式化输出符号也将其解释为无符号整型,就会出现问题*/
unsigned int b=-30;
printf("%u\n",b );
/*之所以能用无符号整型表示负数是因为 pintf 函数会根据格式化符号将数据进行转换(解释) %u 解释为 unsigned int %d 解释为 int*/
unsigned int c=-1;
printf("%d\n",c );
printf("%u\n",c );
int d=-1;
printf("%d\n",d );
printf("%u\n",d );
}
/*30
4294967266
-1
4294967295
-1
4294967295*/
整型溢出(从高位开始一直到能容纳的数字之间的数直接被抛弃):
#include <stdio.h>
void main()
{
short int a,b;
a=32767; /*0111111111111111*/
b=a+1; /*1000000000000000*/
printf("%d,%d\n",a,b); //printf的 %d 进行了格式转换
}
#32767,-32768
不使用 printf 进行输出,理解高位抛弃
#include <iostream>
#include <cstdio>
using namespace std;
int main()
{
unsigned int n1 = 4294967295;
cout << n1 << endl;
unsigned int n2 = n1+3;
cout << n2 << endl;
return 0;
}
//4294967295 0xffffffff 是最大容纳值
//2 0xffffffff+2=0x1000000002,将高位的1舍弃,产生 000000002,输出 2
字符类型:
#include <stdio.h>
void main()
{
char a,b;
a=120;
b=121;
printf("%c,%c\n",a,b);
printf("%d,%d\n",a,b);
}
/*x,y
120,121*/
小写字母换成大写字母:
#include <stdio.h>
void main()
{
char a,b;
a='a';
b='b';
a=a-32;
b=b-32;
printf("%c,%c\n",a,b);
printf("%d,%d\n",a,b);
}
/*A,B
65,66*/
2.1.2.浮点类型
诸如 3.14159 和 6.203*10^23这样的数值无法按照整数存储,第一个非整数,第二个超出了计算机整数所能表达的范围。但是可以用浮点数的形式存储,它们通常以一个小数以及一个以某个假定值为基数的指数组成,如 .3243F * 16^1,.314159 * 10^1 都表示 3.14159
它在内存中的存放形式:符号+,小数部分 .314159,指数部分 1
浮点数包括 float,double,long double类型,通常这些类型分别提供单精度,双精度以及某些支持扩展精度的机器上提供扩展精度,ANSI 标准仅仅规定 long double 至少和 double 一样长,double 至少和 float 一样长。标准同时规定了一个最小范围:所有浮点类型至少能够容纳从 10^-37 到 10^37 之间的任何值
头文件 float.h 定义了 FLT_MAX,DBL_MAX,LDBL_MAX ,分别表示 float,double,long double 所能存储的最大值,FLT_MIN,DBL_MIN,LDBL_MIN 分别表示 float,double,long double 能够存储的最小值。这个文件另外还定义一些和浮点值的实现有关的某些特性的名字,例如浮点数所使用的基数,不同长度的浮点值的有效数字位数等
浮点数字面值总是写成十进制的形式,它必须有一个小数点或指数,也可以两者都有。浮点数字面值再默认情况下都是 double 类型的,除非它的后面跟一个 L 或 l 表示它是一个 long double 类型的值,或者跟一个 F 或f 表示它是一个 float 类型的值
浮点数类型的舍入误差(达到最大范围后,再进行处理也会舍去而看上去是没进行处理):
#include <stdio.h>
void main()
{
float a,b;
a=123456.789e5;
b=a+20;
printf("%f\n",a);
printf("%f\n",b);
}
/*12345678848.000000
12345678848.000000*/
不同类型的数值运算(char,shotr―>int―>unsigned―>long―>double):
#include <stdio.h>
void main()
{
float PI=3.14159;
double s,r=5;
s=r*r*PI;
printf("%d\n",s);
printf("%g\n",s);
}
/*1342177280*/
/*78.5398*/
2.1.3.指针
变量的值存储在计算机的内存中,每个变量都占据一个特定的位置,内存位置都由地址唯一确定并引用,指针只是地址的另一个名字。指针变量就是一个其值为一个(一些)内存地址的变量,C 有一些操作符,可以获得变量的地址,也可以通过一个指针变量取得它所指向的值或数据结构
指针常量
指针常量和非指针常量在本质上是不同的,因为编译器负责把变量赋给计算机内存中的位置,程序员事先无法知道某个特定的变量将存储到内存中的哪个位置,因此,你通过操作符获得一个变量的地址,而不是直接把它的地址协程字面值常量的形式
字符串常量
C 语言存在字符串的概念:它就是一串以 NUL 字节结尾的零个或多个字符。字符串通常存储在字符数组中,这也是 C 语言没有显式的字符串类型的原因,由于 NUL 字节是用于终结字符串的,所以在字符串内部不能有 NUL 字节。不过在一般情况下,这个限制不会造成问题。字符串常量(不像字符常量)的书写方式是用一对双引号包围一串字符,而且可以是空的
K&R C:
在字符串常量的存储形式中,所有的字符和 NUL 终止符都存储于内存的某个位置,K&R C 并未提及一个字符串常量中的字符是否可以被程序修改,但它清楚地表明具有相同的值的不同字符串常量在内存中是分开存储的。因此,许多编译器都允许程序修改字符串常量
ANSI C:
ANSI C 则声明如果对一个字符串常量进行修改,其效果是未定义的。它也允许编译器把一个重复出现的字符串常量存储于一个地方,这就使得修改字符串常量变得极为危险,因此对一个常量进行修改可能殃及程序中的其他字符串常量。因此 ANSI 编译器不允许修改字符串常量,或者提供编译选项,让你可以自行选择是否允许修改字符串常量。如果要修改字符串,请把它存储于数组中
程序中使用字符串常量会生成一个 “指向字符的指针常量” 。当一个字符串常量出现于一个表达式中,表达式所使用的值就是这些字符所存储的地址,而不是这些字符本身。因此,可以把字符串常量赋给一个"指向字符的指针后",后者指向这些字符所存储的地址,但是,不能把字符串常量赋给一个字符数组,因为字符串常量的直接值是一个指针,而不是这些字符本身
可以使用 char a = ‘a’ 而不能 char a = “a” 因为一个char字符常量在内存中只有一个字节,只占八位,“a” 在内存中的存储形式为 a\0 ,每一个字符占据一个一个字节(八位),字符都被翻译成 Unicode 编码的数字,内存中不存在字母,只存在数字
2.2.基本声明
变量声明的基本形式是:说明符 声明表达式列表,说明符用于描述被声明标识符的基本类型,也可以用于改变标识符的默认存储类型和作用域。signed 关键字一般只用于 char,其他整型类型在默认情况下都是有符号数,至于 char 是否是 signed,则因编译器而定
2.2.1.初始化
在一个声明中,可以给标量变量指定一个初始值。自动变量(存储在堆栈中)和静态变量(存储在普通内存中)的初始化存在一个重要的差别。
在静态变量的初始化中,我们可以把可执行程序文件想要初始化的值放在当程序执行时变量将会使用的位置。当可执行文件载入内存时,这个以及保存了正确初始值的位置将赋给那个变量。完成这个任务并不需要额外的时间,如果不显式指定初始值,静态变量将初始化为0
自动变量的初始化需要更多开销,因为当程序链接时还无法判断自动变量的存储位置。事实上,函数的局部变量在函数每次调用时都可能占据不同的位置。基于这个理由,自动变量没有默认的初始值,而显式的初始化将在代码块的起始处插入一条隐式的赋值语句
这造成了四种结果:首先,自动变量的初始化较之赋值语句效率并无提高。除了声明为 const 的变量之外,在声明变量的同时进行初始化和先声明后赋值并无效率之别。其次,这条隐式的赋值语句使自动变量在程序执行到它们所声明的函数(或代码块)时,每次都将初始化。这个行为与静态变量很不相同,后者只是在程序开始执行前初始化依次。其三,由于初始化在运行时执行,可以使用任何表达式作为初始化值,例如下面的程序。最后,除非对自动变量进行显式的初始化,否则当自动变量创建时,他们的值总是垃圾
int func(int a)
{
int b=a+3
}
2.2.2.声明简单数组
为了声明一个一维数组,在数组名后面要跟一对方括号,方括号里面是一个整数,指定数组中元素的个数
int values[20];
可以解释为 名字 values 加一个下标,产生一个类型为 int 的值(共有20个整型值),这个声明表达式显示了一个表达式中的标识符产生了一个基本类型的值。C 的编译器并不检查程序对数组下标的引用是否在数组的合法范围之内,一个良好的经验法则是:如果下标值似乎从那些已知是正确的值计算得来,那么无需检查它的值,如果一个用作下标的值是根据某种方法从用户输入的数据产生来的,那么在使用它之前必须进行检测,确保它在有效范围之内
2.2.3.声明指针
声明表达式也可用于声明指针,在 C 语言的声明中,先给出一个基本类型,紧随器后的是一个标识符列表,这些标识符组成的表达式,用于产生基本类型的变量
int *a;
这条语句表示表达式 *a 产生的结构类型是 int,知道 * 操作符执行的是间接寻址以后,可以推断 a 是一个指向 int 的指针
char *message="hello world!";
这条语句把 message 声明为一个指向字符的指针,并用字符串常量中的第一个字符的地址对该指针进行初始化
2.2.4.隐式声明
C 中有几种声明,它的类型名可以省略。例如,如果函数不显式声明返回值的类型,它就会默认返回整型
2.3.typedef
C 支持一种叫做 typedef 的机制,它允许为各种数据类型定义新的名字,typedef 声明的写法和普通声明基本相同,只是把 typedef 这个关键字出现在声明的前面
char *ptr_to_char; /*声明 ptr_to_char 为一个指向字符的指针*/
typedef char *ptr_to_char; /*将 ptr_to_char 作为指向字符的指针类型的新名字*/
ptr_to_char a; /*声明 a 是一个指向字符的指针
2.4.常量
ANSI C 允许声明常量,常量的样子和变量完全一样,只是值不能修改,可以通过 const 关键字来声明常量。既然常量的值无法被修改,也就无法把任何东西赋值给它,使它一开始拥有一个值有两种方法:声明时对它进行初始化或函数中声明为 const 的形参在函数被调用时会得到实参的值,当涉及指针变量时,有两种东西都可能成为常量:指针变量和它所指向的实体
int *pi; /*pi是一个普通的指向整型的指针*/
int const *pci /*pci是一个指向整型常量的指针,可以修改指针的值,但是不能修改它所指向的值*/
int *const cpi /*cpi是一个指向整型的常量指针,指针是常量,无法修改,但可以修改它所指向的整型的值*/
int const *const cpci /*指针和它所指向的值都是常量,不允许修改*/
#define 指令是另一种创建名字常量的机制,例如下面的两个声明都为 50 这个值创建了名字常量
#define MAX_ELEMENTS 50;
int const max_elements=50;
在这种情况下,使用 #define 比使用 const 变量更好,因为只要允许使用字面值常量的地方都可以使用前者,比如声明数组的长度,而 const 变量只能用于允许使用变量的地方
2.5.作用域
当变量在程序的某个部分被声明时,它只有在程序的一定区域内才能被访问,这个区域由标识符的作用域 scope 决定。编译器可以确认四种不同类型的作用域:文件作用域,函数作用域,代码块作用域和原型作用域。
位于一对花括号之间的所有语句称为一个代码块,任何在代码块开始位置声明的标识符都具有代码块作用域
在 K&R C 中,函数形参的作用域开始于形参的声明处,位于函数体之外。如果在函数体内部声明了名字于形参相同的局部变量,它们将隐藏形参,这样一来,形参便无法被函数的任何部分访问。ANSI C 避免了这种错误,它把形参的作用域设定为函数最外层的那个作用域(也就是整个函数体)。这样声明于函数最外层作用域的局部变量无法和形参同名,因为它们的作用域相同
任何代码块之外声明的标识符都具有文件作用域,它表示这些标识符从它们的声明之处到源文件的结尾处都是可以访问的
原型作用域只适用于在函数原型中声明的参数名,在原型(与函数的定义不同)中,参数的名字并非必需
函数作用域只适用于语句标签,语句标签用于 goto 语句。基本上,函数作用域可以简化为一条规则:一个函数中的所有语句标签必唯一
2.6.链接属性
当组成一个程序的各个源文件被分别编译之后,所有的目标文件以及那些从一个或多个函数库中引用的函数链接在一起,形成可执行程序。然而,如果相同的标识符出现在几个不同的源文件中时,标识符的链接属性决定如何处理在不同文件中出现的标识符。标识符的作用域与它的链接属性有关,但两个属性并不相同
链接属性一共有 3 种:external(外部),internal(内部),none(无)。没有链接属性的标识符(none),总被视为独立个体,也就是说,该标识符的多个声明被当作独立的不同个体。属性 internal 链接属性的标识符在同一个源文件内的所有声明中都指同一个实体但是在不同源文件中的多个声明分属于不同的实体。属性 external 链接属性的标识符在几个源文件中都表示同一个实体
typedef char *a;
int b;
int c (int d)
{
int e;
int f (int g);
}
在默认情况下,b,c,f 的链接属性为 external,其他为 none。
关键字 extern 和 static 用于在声明中修改标识符的链接属性和存储类型,如果某个声明在正常情况下具有 external 链接属性,在前面加上 static 可以使它的链接属性变为 internal,如 static int b,可以声明变量b为当前源文件私有,不能被其他文件所访问。在函数体内部的变量,其链接属性默认为 none,前面加上 static 不改变链接属性(只有原来链接属性为 external 才可以),而改变其存储类型,由自动变量改为静态变量。具有 external 链接属性的实体在其他语言中称为全局实体,它的存储类型一定是静态存储类型,即在程序开始执行前进行初始化。
extern 关键字的规则更为复杂,一般而言,它为一个标识符指定 external 链接属性,这样就可以访问在其他任何位置定义的这个实体。
当 extern 关键字用于源文件中一个标识符的第一次声明时,它指定该标识符具有 external 链接属性,但它用于该标识符的第二次后以后的声明时,它并不会更改由第一次声明所指定的链接属性,下面是一个例子:
static int i;
extern int i; /*第二次声明无效,i 的链接属性还是 internal
2.7.存储类型
变量的存储类型是指存储变量值的内存类型,变量的存储类型决定变量何时创建,何时销毁以及它的值将保持多久。有三个地方可以用于存储变量:**普通内存,运行时堆栈,硬件寄存器。**在这三个地方存储的变量具有不同的特性
变量的默认存储类型取决于它的声明位置。在代码块之外声明的变量总是存储于静态内存中,也就是不属于堆栈的内存,这类变量称为静态变量。这类变量无法为他们指定其他的存储类型,静态变量在程序运行之前创建,在程序的整个执行期间始终存在,它们始终保持原先的值,除非给它赋一个不同的值或者程序结束
在代码块内部声明的变量默认存储类型是自动的,也就是说它存储于堆栈中,称为**自动变量。**有一个关键字 auto 就是用于修饰这种存储类型的,但它极少使用,因为代码块中的变量在默认时就是自动变量。在程序执行到声明自动变量的代码块时,自动变量才被创建,当程序的执行流离开代码块时,这些自动变量便自行销毁。代码块再次执行时,这些自动变量在堆栈中所占据的内存位置可能与原先不同
对于在代码块内部声明的变量,如果给它加上关键字 static,可以使它的存储类型从自动变量变为静态变量,具有静态存储类型的变量在整个程序执行过程中一直存在,而不仅仅在声明它的代码块的执行时存在。需要注意,修改变量的存储类型不表示修改变量的作用域,它仍然只能在代码块内部按名字访问,函数的形式参数不能声明为静态,因为实参总是在堆栈中传递给参数,用于支持递归
关键字 register 可以用于自动变量的声明,提示它们应该存储于机器的硬件寄存器而不是内存中,这类变量称为寄存器变量。通常,寄存器变量比存储在内存的变量访问起来效率更高。但是编译器不一定要理睬 register 关键字,如果有太多的变量被声明为 register,它只选取前几个实际存储于寄存器中,其余的就按普通自动变量处理,如果一个编译器自己有一套寄存器优化方法,它也可能忽略 register 关键字,其依据是由编译器决定哪些变量存储于寄存器中比人脑的决定更为合理一些
在典型情况下,你希望把使用频率最高的那些变量声明为寄存器变量。在有些计算机中,如果把指针声明为寄存器变量,程序的效率将得到提高。你可以把函数的形式参数声明为寄存器变量,编译器会在函数的起始位置生成指令,把这些值从堆栈中复制到寄存器中。但是,完全有可能,这个优化措施所节省的空间和时间的开销还抵不上复制这几个值所用的开销
寄存器变量的创建和销毁时间和自动变量相同,但它需要一些额外的工作。在一个使用寄存器变量的函数返回之前,这些寄存器先前存储的值必须恢复,确保调用者的寄存器变量未被破坏,许多机器使用运行时堆栈来完成这个任务。当函数执行开始时,它把需要使用的所有寄存器的内容保存到堆栈中,当函数返回时,这些值再复制回寄存器中
在许多机器的硬件实现中,并不为寄存器指定地址。同样,由于寄存器值的保存和恢复,某个特定的寄存器在不同的时刻所保存的值不一定相同。基于这些理由,机器并不提供寄存器变量的地址
三、语句
C 实现了其他现代高级语言所具有的所有语句,但 C 语句还是存在一些不同之处。例如,C 并不具备专门的赋值语句,而是统一采用"表达式语句"代替。switch 语句实现了其他语言中 case 语句的功能,但其实现方式非比寻常
3.1.空语句
C 最简单的语句就是空语句,它本身只包含一个分号。空语句本身并不执行任何任务,但有时还是有用的。它所使用的场合就是语法要求出现一条完整的语句,但并不需要它执行任何任务
3.2.表达式语句
C 并不具备专门的赋值语句,赋值就是一种操作,就像加法和减法一样,所以赋值就在表达式内进行,只要在表达式的后面加一个分号,就可以把表达式变为语句。有的语句看似"没有效果",只是表示表达式的值被忽略,而关注于它所执行的工作,这类作用称为"副作用"
3.3.代码块
代码块就是位于一对花括号之内的可选的声明和语句列表。代码块的语法是非常直接了当的,代码块可以用于任何要求出现语句的地方。
3.4.if 语句
C 的 if 语句和其他的 if 语句相差不大。它的语法(花括号可以省略)如下:
if (expression)
{
statement
}
else
{
statement
}
括号是 if 语句的一部分,而不是表达式的一部分,因此必须出现
C 的 if 语句和其他语言的 if 语句只有一个差别:C 并不具备布尔类型,而是用整型来代替,零值为假,非零值为真。else 语句从属于最靠近它的不完整 if 语句,如果想让它从属于其他语句,可以用花括号实现代码块
3.5.while 语句
C 的 while 语句也和其他语言的 while 语句有许多相似之处,唯一真正存在差别的地方在于它的 expression 部分,和 if 语句类似,下面是它的语法(花括号可以省略)如下:
while (expression)
{
statement
}
3.6.break 和 continue 语句
在 while 循环中可以使用 break 语句,用于永久终止循环,也可以使用 continue 语句,它用于永久终止当前的那次循环。出现在嵌套循环的内部,它只对最内层的循环起作用,无法影响外层循环的执行
3.7.for 语句
C 的 for 语句比其他语言的 for 语句更为常用。事实上,C 的 for 语句是 while 循环的一种极为常用的语句组合形式的简写法,语法如下
for (expression1;expression2;expression3)
{
statement
}
expression1 为初始化部分,expression2 为条件部分,expression3 为 =调整部分,也可以使用 break 和 continue,continue 可以把控制流直接转移到调整部分。for 语句的执行过程几乎和下面的 while 语句一模一样
expression1;
while (expression2)
{
expression3;
}
3.8.do 语句
C 语言的 do 语句非常像其他语言的 repeat 语句,它很像 while 语句,只是它的测试在循环体执行后才进行,所以这种循环至少执行一次。所以当需要循环体至少执行一次时,选择 do 语句。下面是它的语法:
do
{
statement
}
while (expression);
3.9.switch 语句
C 的 switch 语句类似于其他语言的 case 语句,但有一个方面存在着重要的区别,下面是它的语法:
switch (expression)
{
statement-list
}
贯穿于语句列表之间的是一个或多个 case 标签,形式如下:
case constant-expression:statement
每个 case 标签必须具有一个唯一的值。常量表达式,是指在编译期间进行求值的表达式,它不能是任何变量。这里的不寻常之处是 case 标签并不把语句列表划分为几个部分,它们只是确定语句列表的进入点,可以使用 break 语句来直接跳转到语句列表,continue 在 switch 中没有任何作用,每个 switch 语句中只能出现一条 default 子句,它会在 case 都不满足时执行
3.10.goto 语句
要使用 goto 语句,必须在希望跳转的语句前加上语句标签,语句标签就是标识符后面加个冒号,包含这些标签的 goto 语句可以出现在同一个函数的任何位置。
goto 语句是一种危险的语句,但是,在一种情况下,即使在结构良好的程序中,使用 goto 语句也非常合适:跳出多层循环
while (condition1){
while (condition2){
while (condition3){
goto quit;
}
}
}
quit:;
要想在这种情况下避免使用 goto 可以有两种方案:设置一个状态,在每个循环都进行检测,另一种是把所有循环放到一个单独的函数中,当想要直接从最内层循环跳出时,用 return 离开这个函数
四、操作符和表达式
C 拥有品类繁多的操作符,这个特定使它很难被精通
4.1.操作符
4.1.1.算术操作符
C 提供了所有常用的算术操作符:+ - * / %,除了 %,其余都既适用于整型,又适用于浮点型,/ 操作符的两个操作数都为整型,他将做整除运算,其他情况都执行浮点数除法,% 为取模运算。
整数进行除法时,结果也是整数
#include <iostream>
#include <cstdio>
using namespace std;
int main()
{
int a = 10;
int b = 3;
double d = a/b;
cout << d << endl;
d = 5/2;
cout << d << endl;
d = 5/2.0;
cout << d << endl;
d = (double)a/b;
cout << d << endl;
return 0;
}
/* 3
2
2.5
3.33333*/
4.1.2.移位操作符
移位操作只是简单地把一个值的位向左或向右移动。左移时,值最左边的几位被丢去,右边多出来的空位补 0 ;右移时,可以选择两种方案:一种是逻辑移位,左边移入的位用 0 填充;另一种是算术移位,左边移入的位由原先该值的符号位决定,符号位位1,则移入的位均为1,否则移入的均为 0 ,这样能够保证原数的正负形式不变。左移符号为 <<,右移为 >>,两个操作数都必须是整型,当移位的数字为负数时,它的结果不能预测,取决于编译器,因此使用了这类移位的程序是不可移植的
标准说明无符号值(八位都用来存储数字)所执行的所有移位操作都是逻辑移位,而对于有符号值的移位方式,取决于编译器。一个程序如果使用了有符号数的右移位操作,它就是不可移植的,下面的程序可以测试机器编译器的移位方式:
4.1.3.位操作符
位操作符对它们的操作数的各个位执行 AND,OR,XOR 等逻辑操作,分别对应 &,|,^,它们要求操作数为整数,它们对操作数的位进行指定的操作,每次对左右操作数的各一位进行操作
下面的语句可以把指定位设置为 1
value = value | 1 << bit_number
下面的语句把指定的位清零
value = value &~ (1<<bit_number)
下面的语句对指定的位进行测试,如果该位已经被设置为 1,则表达式的结果为非零值
value & 1 << bit_number
4.1.4.赋值
赋值操作符用一个等号来表示,赋值是表达式的一种,它的值就是左操作数的值。需要注意的是:a = x= y+3,并不能保证 a 和 x 被赋予相同的值,如果 x 是一个字符型变量,那么 y+3 的值就会被截去一段,以便容纳于字符类型的变量中,那么 a 所赋予的值就是这个被截短之后的新值。在下面的这个错误中,这种截短正是问题的根源所在:
char ch;
...
while ((ch=getchar() != EOF)...
EOF 需要的位数比字符型值所能提供的位数要大得多,这也是 getchar() 返回一个整型值而不是字符值的原因,然而,把 getchar 的返回值首先存储于 ch 中将导致它被截短,然后这个被截短的值提升为整型并与 EOF 比较,将会出现不可预料的错误
4.1.5.单目操作符
C 有一些单目操作符,也就是只接受一个操作数的操作符,下面是它们的使用
! 操作符对它的操作数执行逻辑反操作
~ 操作符对整数类型执行求补操作,原先位 1 的位变为 0,反之变为 1
**- **操作符产生操作数的负值
+ 操作符产生操作数的值,换句话说它什么也不干
& 操作符产生它的操作数的地址
***** 是间接访问操作符,它与指针一起使用,用于访问指针所指向的值
int a,*b; /*声明一个整型变量和一个指向整型变量的指针*/
...
b=&a /*将a变量的地址赋给b指针变量,*b的值则是变量a的值*/
sizeof 操作符判断操作数的类型长度,单位是字节,当操作数为数组名时,它返回数组长度,判断表达式的长度不需要对表达式进行求值,所以 sizeof(a=b+1) 并没有向 a 赋值
类型操作符被称为强制类型转换,它用于显式地把表达式的值转换为另外的类型,它具有很高的优先级,(float) a 可以获得 a 的浮点数值
增值操作符 ++,减值操作符 --,都有两个变型,分别为前缀和后缀,两个操作符的任一变种都需要一个变量而不是表达式作为它的操作数。前缀形式的++操作符出现在操作数的前面,操作数的值被增加,而表达式的值就是操作数增加后的值,后缀则不是这样
int a,b,c,d;
...
a=b=10;
/*增值++的优先级大于赋值*/
c=++a; /*c的值是11*/
d=b++; /*d的值是10*/
抽象地说,前缀和后缀形式的增值操作符都复制一份变量的拷贝。用于周围表达式的值正是这份拷贝(上面的例子中,周围表达式指赋值符号),正是这种情况,解释了下面的操作符不合理,++a 产生了一份 a +1后的拷贝值,当然不能把 10 赋给一个值
++a=10;
4.1.6.关系操作符
这类操作符用于测试各种操作数之间的各种关系。C 提供了所有常见的关系操作符,但这些操作符产生的结果都是一个整型值,而不是布尔值,即1或0
4.1.7.逻辑操作符
&& 表达 and,|| 表达 or,尽管它们的优先级较低,但它仍然会两个关系表达式施加控制,当已经能够确定最后结果时,便不再进行后面的运算,这个行为常被称为 “短路求值”
4.1.8.条件操作符
条件操作符接受三个操作数,它也会控制子表达式的求值顺序,下面是它的用法:
expression1 ? expression2 :expression3
首先计算 expression1,若为真,则整个表达式是 expression2 的值,expression3 不再求值,若 expression1 为假,整个表达式是 expression3 的值,expression2 不再求值,可以读作 expression1 为真吗?是就执行 expression2,否则执行 expression3
4.1.9.逗号操作符
expression1,expression2,expression3,...
这些表达式自左向右逐个求值,整个逗号表达式的值是最后那个表达式的值
4.1.10.下标引用,函数调用和结构成员
C 的下标引用和其他语言的下标引用相似,下标引用操作和间接访问操作表达式是等价的。将函数调用以操作符的方式实现意味着"表达式"可以代替"常量"作为函数名。. 和 -> 操作符用来访问一个结构的成员。如果 s 是个结构变量,那么 s.a 就访问 s 中名叫 a 的成员;当拥有一个指向结构的指针而不是结构本身,而且希望访问它的成员时,就要使用 -> 操作符而不是 . 操作符
4.2.布尔值
C 并不具备显式的布尔类型,使用整数来代替,规则是:零是假,非零值皆为真,但是要避免混合使用整型值和布尔值,即如果一个变量包含了一个任意的整型值,应该显式地对它进行测试
if (value != 0)...
C++中存在布尔值,可以使用 true 或 false:
#include <iostream>
#include <cstdio>
using namespace std;
int main()
{
int a=0,b=1;
bool n=(a++) && (b++); //后缀自加先返回后加,返回a++为0,然后a变成1,由于短路运算,b++不再运算
cout << a << "," << b << endl;
n=a++ && b++;
cout << a << "," << b << endl; //a++和b++都要运算
n=a++ || b++; //b++不被计算
cout << a << "," << b << endl;
return 0;
}
/*
1,1
2,2
3,2
*/
4.3.左值和右值
左值和右值这两个术语是多年前由编译器设计者所创造并沿用至今,尽管它们的定义并不与 C 语言严格吻合。左值就是那些能够出现在赋值符号左边的东西(一般指明了一个特定的位置,也指明了这个位置的值),右值就是能够出现在赋值符号右边的东西(只是指明了一个值),下面这个例子中,a 为左值,因为它标识了一个可以存储结果值的地点,b+25 是右值,因为它指定了一个值
a = b + 25;
它们不能互换,尽管作为左值的 a 也可以当右值,因为每个位置都包含了一个值。然而,b + 25 不能作为左值,因为它并未标识一个特定的位置,注意,当计算机计算 b + 25 时,它的结果必然保存于机器的某个地方,但是,程序员并没有办法来预测该结果会存储在什么地方,也无法保证这个表达式的值下次会存储在那个地方,其结果是,这个表达式不是一个左值(并不是所有表达式都不是左值)。基于同样的理由,字面值常量也都不是左值。
4.4.表达式求值
表达式的求值顺序一部分由它所包含的操作符的优先级和结合性决定,同样,有些表达式的操作数在求值的过程中可能需要转换为其他的类型
4.4.1.隐式类型转换
C 的整型算术运算总是至少以默认的整型类型的精度来进行的。为了获得这个精度,表达式中的字符型和短整型操作数在使用前被转换为普通整型,这种转换称为整型提升。在下面的表达式求值中,b 和 c 先被提升为普通整型,再执行算术加法,加法运算结果阶段存于 a 中
char a,b,c;
a = b + c;
4.4.2.算术转换
如果某个操作符的各个操作数属于不同的类型,那么除非其中一个操作数转换为另一个操作数的类型,否则操作进行。下面的层次体系为 寻常算术转换,如果操作数的类型较低,那么它将首先转换为另一个操作数的类型,再进行计算。浮点数转化为整型时,小数被舍弃
long double > double (float运算时都会转换成double) > unsigned long int > long int > unsigned int > int
4.4.3.操作符的属性
复杂表达式的求值顺序是由 3 个因素决定的:操作符的优先级,操作符的结合性,以及操作符是否控制执行的顺序
? 简单记就是:! > 算术运算符 > 关系运算符 > && > || > 赋值运算符
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LmLhuzhY-1632052464418)(C:\Users\PC\AppData\Roaming\Typora\typora-user-images\image-20210306164150035.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-blf5M9gg-1632052464423)(C:\Users\PC\AppData\Roaming\Typora\typora-user-images\image-20210306164224164.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8nqB8LiV-1632052464430)(C:\Users\PC\AppData\Roaming\Typora\typora-user-images\image-20210306164307198.png)]
两个相邻的操作符的执行顺序由它们的优先级决定。如果它们的优先级相同,它们的执行顺序由它们的结合性决定,除此之外,编译器可以自由决定使用任何顺序对表达式进行求值。只要它不违背逗号,&&,||和 ?操作符所施加的限制
五、指针
5.1.内存和地址
计算机的内存像是一条长街上的一排房屋,每座房子都可以容纳数据,并通过一个房号来标识。在机器上,每一个位置被称为一个字节,每个字节通过地址来标识。为了存储更大的值,我们把两个或多个字节合在一起作为一个更大的内存单位。例如,许多机器以字为单位存储整数,每个字一般由 2 个或 4 个字节组成。由于它们包含了更多的位,每个字可以容纳的整数范围扩大了,但要注意,尽管一个字包含2 个或 4 个字节,但它仍然只有一个地址,至于它的地址是它最左边的那个字节的位置,还是最右边的字节的位置,不同的机器有不同的规定。另一个需要注意的硬件事项是边界对齐。在要求边界对齐的机器上,整型值存储的起始位置只能是某些特定的字节,通常是 2 或 4 的倍数,但这些问题很少影响 C 程序员。高级语言提供的特性之一就是通过名字(也就是变量)而不是地址来访问内存中的位置,但是,名字和内存位置之间的对应关联并不是硬件所提供的,它是由编译器为我们实现的。所有这些变量给了我们一种更为方便的方法记住地址,但是,硬件仍然通过地址访问内存位置
5.2.值和类型
| a | b | c | d | e |
|---|---|---|---|---|
| 112 | -1 | 1078523331 | 100(一个地址编号) | 108(一个地址编号) |
表格中的 a,b,c,d,e,就是变量的名字,它们每一个地址都是一个长度为4个字节的字,下面是它们的声明:
int a=112,b=-1;
float c=4.14;
int *d=&a;
float *e=&c;
a,b 确实存储整数,但是声明 c 为一个浮点数,表格中上它确是一个整数。实际上,该变量在机器中包含了一系列内容为 0 或 1 的位,它们可以被解释为整数,也可以被解释为浮点数,这取决于它们被使用的方式,如果使用的是整型算术口令,这个值被解释为整数,如果使用的是浮点型指令,它们就是浮点数。这表明,不能简单地通过检查一个值的位来判断它的类型,值的类型并非是值本身固有的特性,而是取决于它的使用方式。d 和 e 都被声明位指针,并用其他变量的地址予以初始化。区分变量 d 的地址和它的内容很重要,d 本身是一个变量,标明了一个地址,而它的内容也是一个地址,在这里,房间和街道的比喻不再有效,因为房子的内容绝不可能是其他房子的地址
5.3.间接访问操作符
通过一个指针访问它所指定的地址的过程叫做间接访问或解引用指针,这个用于执行间接访问的操作符是单目操作符 ,要注意,声明指针变量时的 * 和与单目操作符 * 不同,声明指针变量实际上是用 int 来声明的。d 的值是100,而 d 的右值是112,左值是位置100 本身。 *** 指针变量就是这个指针变量值的地址所对应的变量,紧接着编译器可以访问这个变量的值,而&一个变量就是这个变量所代表的地址。简言之, 指针变量返回变量,&变量返回地址
5.4.NULL指针
标准定义了 NULL 指针,它作为一个特殊的指针变量,表示并不指向任何东西。要使一个指针变量为 NULL,可以给它赋一个零值。为了测试一个指针变量是否为 NULL,可以将他与零值进行比较。之所以选择零这个值是因为一种源代码约定。就机器的内部而言,NULL 指针的实际值可能与此不同。在这种情况下,编译器将负责零值和内部值之间的翻译转换
NULL 指针的概念是非常有用的,因为它给出了一个方法,表示某个特定的指针目前没有指向任何东西。例如,一个用于在某个数组中查找某个特定值的函数可能返回一个指向查找到的数组元素的指针,如果该指针不包含指定条件的值,函数就返回 NULL 指针。这个技巧允许返回值传达两个不同片段的信息:有没有找到元素?找到的话是哪个元素?尽管这样的技巧很 常用,但它违背了软件工程的原则。用一个单一的值表示两种不同的意思是一件很危险的事。一种更为安全的策略是让函数返回两个独立的值:状态值和指针
5.5.指针的指针
遇到指针的指针,可以从右向左进行逐层解包,称为双重间接访问
5.6.指针表达式
一个普通的变量出现在等号的右边时,它将会作为右值而返回它的值,当它出现在等号的左边时,它将会作为左值而返回它的地址,&一个变量返回它的地址,但它却不能作为左值,因为这个地址本身是一个值,它并未标明内存中的某个特定位置。++指针变量返回的是指针变量增值后的拷贝,而指针变量++返回的是原来指针变量的拷贝,然后指针变量增值。 * 指针变量++ 的表达式在循环中经常出现,它的执行分为三步:++操作符产生指针变量的一份拷贝,然后++操作符增加指针变量的值,最后,在拷贝的指针变量上执行间接访问操作(还是原来那个没加之前的指针变量),最终产生的结果是,返回表达式中指针变量所对应的变量,指针变量向后推移一个单位
5.7.指针运算
指针加上一个整数的结果是另一个指针,问题是,它指向哪里?如果将一个字符指针加上1,将产生一个指向内存中下一个字符的指针,但是,float 占据的内存空间不止一个字节,如果将一个指向 float 的指针加 1,会发生什么?
答案是,**当一个指针和一个整数量执行算术运算运算时,整数在执行加法运算前始终会根据合适的大小进行调整。这个合适的大小就是指针所指向类型的大小,调整就是把整数值和这个合适的大小相乘。**例如,在某台机器上,float 占据着 4 个字节,在计算 float 型指针加 3 的表达式时,这个 3 将根据 float 的大小进行调整,实际上加到指针上的整型值为12。把3与指针相加使得指针的值增加了3个float的大小,而不是3个字节。换句话说,如果 p 是一个指向 char 的指针,那么表达式 p+1 就是指向下一个 char 的指针;如果 p 是一个指向 float 的指针,那么表达式 p+1 就是指向下一个 float 的指针
5.7.1.算术运算
C 指针的算术运算只限于两种形式。第一种是 指针 +(-)整数。标准定义这种形式只能用于指向数组中某个元素的指针,并且这类表达式的结果类型也是指针。这种形式也适用于使用 malloc 函数动态分配获得的内存,尽管标准中未提及这个事实
数组中的元素存储于连续的内存位置中,后面元素的地址大于前面元素的地址。因此可以得知,对一个指针加一将使它指向数组中的下一个元素,下面的程序可以用于将一个数组中的所有元素初始化为0
#define N_VALUES 5
float values[N_VALUES];
float *vp;
for (vp=&value[0];vp<&values[N_VALUES];)
*vp++=0
第二种形式是指针-指针。只有当两个指针都指向同一个数组中的元素时,才允许从一个指针减去另一个指针,两个指针相减的结果的类型是 ptrdiff_t,它是一种有符号整数类型。减法运算的值是两个指针在内存中的距离(以数组元素的长度为单位,而不是以字节为单位),因为减法运算的结果将除以出租元素类型的长度。例如,如果 p1 指向 array[i] 而 p2 指向 array[j],那么 p2-p1的值是 j-i
5.7.2.关系运算
对指针执行关系运算也是有限制的。用下列关系操作符对两个指针值进行比较是可能的:>=,<=,>,<,不过前提是它们都指向同一个数组中的元素。更具使用的操作符,比较表达式的结构将表明那个指针指向更靠前(后)的位置
六、函数
C 的函数和其他语言的函数相似甚多,但函数的有些方面并不像直觉上应该的那样
6.1.函数声明
有返回值的函数称为真函数,无返回值的函数称为过程类型的函数,它的类型声明为 void。调用函数时向编译器提供函数的特定信息有两种方法:同一源文件的前面出现函数定义或者使用函数原型。函数原型总结了函数定义的起始部分的声明,向编译器提供有关该函数应该如何调用的完整信息。最方便安全的方法是把原型置于一个单独的文件,当其他源文件需要这个函数的原型时,就用 #include 指令包含该文件。当程序调用一个无法见到原型的函数时,编译器便认为该函数返回一个整型值,这种认定可能会引起错误
6.2.函数参数
C 的所有参数均以"传值调用"的方式进行,这意味着函数将获得参数值的一份拷贝。但被传递参数如果是一个数组名,并在函数中使用下标引用该数组的参数,那么在函数中对数组元素修改的是调用程序的数组元素。这是因为数组名的值实际上是一个指针,传递给函数的也是这个指针的一份拷贝,看上去就像是"传址调用"
6.3.递归
当函数被调用时,它的变量空间是创建于运行时堆栈上的。以前调用的函数的变量仍然保留在堆栈上,但它们被再次调用函数的变量所掩盖,因此是不能访问的。许多的问题是以递归的形式解释的,这只是因为它比非递归形式更为清晰。但是,这些问题的迭代实现往往比递归实现的效率更高
6.4.可变参数列表
让一个函数在不同的时候接受数目不同的参数是可以做到的,但存在一些限制可变参数列表是通过宏来实现的,这些宏定义于 stdarg.h 头文件,它是标准库的一部分。这个头文件声明了一个类型 va list 和三个宏:va_start,va_arg,va_end。我们可以声明一个类型为 va_list 的变量,与这几个宏配合使用,访问参数的值。需要注意的是参数列表中需要出现省略号。下面是一个计算平均值的函数
#include <stdarg.h>
#include <stdio.h>
float average(int n_values,...)
{
/*声明一个名叫var_arg的变量用来访问参数列表的未确定部分*/
va_list var_arg;
int count;
float sum=0;
/*准备访问可变参数,通过调用va_start来初始化,第一个参数是va_list变量的名字,第二个参数是省略号前最后一个有名字的参数*/
va_start(var_arg,n_values);
/*添加取自可变参数列表的值*/
for (count=0;count<n_values;count+=1)
{
/*访问参数,需要使用var_arg,第一个参数是va_list变量的名字,第二个参数是参数列表中下一个参数的类型,返回这个参数值,并使var_arg指向下一个可变参数*/
sum+=va_arg(var_arg,int);
}
/*完成处理可变参数*/
va_end(var_arg);
return sum/n_values;
}
void main(void)
{
float a;
a=average(4,89,87,88,88);
printf("%g\n",a);
}
可变参数必须从头到尾按照顺序逐个访问,不可用一开始就访问参数列表中间的参数。另外,由于参数列表中的可变参数部分没有原型,所以所有作为可变参数列表传递给函数的值都将执行默认参数类型提升。参数列表中至少要有一个命名参数,如果连一个命名参数都没有,就无法使用 va_start,对于这些宏,存在着两个基本的限制,一个值的类型无法简单地通过检查它的位模式来判断,这两个限制就是这个事实的直接结果:这些宏无法判断实际存在的参数的数量,而且无法判断每个参数的类型
七、数组
7.1.一维数组
数组被许多人认为是 C 语言设计的一个缺陷,但是,这个概念实际上以一种相当优雅的方式把一些完全不同的概念联系在一起
7.1.1.数组名
int a;
int b[10];
我们把变量 a 称为标量,因为它是个单一的值,这个变量的类型是一个整数,我们把变量 b 称为数组,因为它是一些值的集合。在 C 中,在几乎所有使用数组名的表达式中,数组名的值是一个指针常量,也就是数组第一个元素的地址,它的类型取决于数组元素的类型:如果它们是 int 类型,那么数组名的类型就是指向 int 的常量指针。只有在两种场合下,数组名并不用指针常量来表示:当数组名作为 sizeof 操作符或者单目操作符 & 的操作数
int a[10];
int b[10];
int* c;
c=&a[0];
表达式 &a[0] 是指向数组中第一个元素的指针,但那整数数组名本身的值,所以下面的语句与 c=&a[0]; 执行的任务是完全一样的
c=a;
数组名并不表示整个数组,而是数组中第一个元素的指针常量(一个地址),因此下面的语句是非法的,不能使用赋值符把一个数组的所有元素复制到另一个数组当中,必须使用一个循环,每次复制一个元素
b=a;
7.1.2.下标引用和指针
C 中的下标引用和间接访问除优先级之外完全相同,当涉及到效率问题时,可以说:下标绝不会比指针更有效率,但指针有时会比下标更有效率,下面两个循环将数组中的所有元素都设置为 0
int array[10],a;
for (a=0;a<10;a+=1)
{
array[10]=0;
}
为了对下标表达式进行求值(每一次),编译器在程序中插入指令:取得 a 的值,并把它与整数的长度相乘
int array[10],*ap;
for (ap=array;ap<array+10;ap++)
{
*ap=0;
}
使用指针的情况有所不同,将 1 与整数的长度相乘只在编译时执行一次,每一次使用指针时,都把编译时产生的结果加在指针上。这个例子说明了指针比下标更有效率的场合:当你在数组中一次一步(或某个固定的数字)地移动时,与固定的数字相乘在编译时完成,所以在运行时所需的指令就少一些。在绝大多数机器上,程序将会更小一些,更快一些
7.1.3.数组和指针
数组和指针并不是相等的。当声明一个数组时,编译器将根据声明所指定的元素数量为数组保留内存空间,然后再创建数组名,它的值是一个常量,指向这段空间的起始位置。声明一个指针变量时,编译器只为指针本身保留内存空间,它并不为任何整型值分配内存空间。而且,指针变量并未被初始化为指向任何现有的内存空间,如果它是一个自动变量,它甚至根本不会被初始化。现在就很清楚,为什么函数原型中的一维数组形参无需写明它的元素数目,因为形参并不为数组参数分配内存空间。因此,下面两个函数原型是相等的
int strlen(char *string);
int strlen(char string[])
7.1.4.初始化
就像标量变量可以在它们的声明中进行初始化一样,数组也可以这样做。唯一的区别是数组的初始化需要一系列的值:
int vector[5]={10,20,30,40,50};
静态初始化和自动初始化
数组初始化的方式类似于标量变量的初始化方式:也就是取决于它们的存储类型。存储于静态内存的数组只初始化一次,也就是在程序开始执行之前。程序并不需要执行指令把这些值放到合适的位置,它们一开始就在那里了。这是由链接器完成的,它用包含可执行程序的文件中合适的值对数组进行初始化。如果数组未被初始化,数组元素的初始值将会自动设置为 0,当这个文件载入到内存中准备执行时,初始化后的数组值和程序指令一样也被载入到内存中。因此,当程序执行时,数组已经初始化完毕
但是,对于自动变量而言,初始化就没有那么简单了。自动变量位于运行时堆栈中,执行流每次进入它们所在的代码块时,这类变量每次所处的内存位置可能并不相同,编译器没有无法对这些位置进行初始化。所以,自动变量在默认情况下是未初始化的。如果自动变量的声明中给出了初始值,每次当执行流进入自动变量声明所在的作用域时,变量就被一条隐式的赋值语句初始化。这条隐式的赋值语句和普通的赋值语句一样需要时间和空间来执行。数组的问题在于初始化列表中可能有很多值,这就可能产生许多条赋值语句。对于那些非常庞大的数组,它的初始化时间可能非常可观。
因此,这里就需要权衡利弊。当数组的初始化局部与一个函数(或代码块)时,应该考虑一下,这程序的执行流每次进入该函数(代码块)时,每次都对数组进行重新初始化是不是值得,不值得的话,可以把数组声明为 static,这样数组的初始化只需在程序开始前执行一次
7.1.5.字符数组的初始化
语言标准提供了一种快速方法用于初始化字符数组:
char message[]="Hello";
它看上去像是一个字符串常量,实际上并不是。下面的语句是真正的字符串常量:
char* message = "Hello";
指针变量被初始化为指向这个字符串常量的存储位置
下面是一个使用数组的例子
#include <iostream>
using namespace std;
// 输入从 2012 年 1 月 22 日开始的某天年月日,返回星期数
int monthDays[13]={-1,31,28,31,30,31,30,31,31,30,31,30,31}; //月份天数
int main()
{
int year,month,date;
int days=0;
scanf("%d%d%d",&year,&month,&date);
for (int y=2012;y<year;++y)
{
if (y%4==0 && y%100!=0 || y%400==0) //判断闰年
days+=366;
else
days+=365;
}
if (year%4==0 && year%100!=0 || year%400==0)
monthDays[2]=29; //目前年份是闰年
for (int m=1;m<month;++m)
days+=monthDays[m];
days+=date;
days-=22;
printf("%d\n",days%7);
}
7.2.多维数组
如果数组的维数不止一个,它就被称为多维数组。在 C 中,多维数组的元素存储顺序按照最右边的下标率先变化的原则,称为行主序。与一维数组类似,多维数组的数组名是指向第一个子数组的指针,下面的语句标识了第二个子数组
int matrix[3][10];
array = *(matrix+1);
由于数组名实际上也是一个指针,因此下面的语句标识了了第二个子数组的第 6 个元素
int a = *(matrix+1)+5;
必须注意,下面的第一条语句是合法的,第二条语句却是非法的
int vector[10],*vp = vector;
int matrix[3][10],*mp = matrix;
因为第二条语句中,mp 被声明为一个指向整型的指针,而实际上 matrix 表示一个指向整型数组的指针。下面的第一条语句可以声明一个指向整型数组的指针,第二条和第三条语句可以声明指针为指向第一个子数组的第一个元素
int (*pi)[10] = matrix;
int *pi = &matrix[0][0];
int *pi = matrix[0];
当多维数组作为函数的参数时,可以使用下面的任一条语句
void fun(int (*matrix)[10]);
void fun(int matrix[][10]);
7.3.指针数组
下面的表达式可以声明一个指向整型的指针数组
int *api[10];
下面的程序可以判断参数是否与一个关键字列表中的任何单词匹配,返回匹配的索引值
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int lookup_keyword(const char *const desired, //指向常量字符的常量指针
const char *keyword[], int const size)
{
const char **p;
for (p = keyword; p < keyword + size; p++)
{
if (strcmp(desired, *p) == 0)
{
return p - keyword;
}
}
return -1;
}
int main()
{
// 创建一个指针数组,每个指针元素都初始化为指向各个不同的字符串常量
const char *keyword[] = {"chen", "gong", "yu", "cai"};
const char *const desired = "cai";
int size = sizeof(keyword) / sizeof(keyword[0]);
printf("size is %d\n", size);
int result = lookup_keyword(desired, keyword, size);
printf("result is %d\n", result);
return 0;
}
八、字符串,字符和字节
字符串是一种重要的数据类型,但是 C 并没有显式的字符串数据类型,因为字符串以字符串常量的性属出现或存储于字符数组中。字符串常量很适用于那些程序不会对它们进行修改的字符串。所有其他字符串都必须存储于字符数组或动态分配内存中
8.1.字符串的长度
字符串就是一串若干个字符,并且以一个位模式为全 0 的 NUL 字节结尾,因此字符串所包含的字符内部不能出现 NUL 字节,NUL 字节是字符串的终止符,但它本身并不是字符串的一部分,所以字符串的长度并不包括 NUL 字节,头文件 string.h 包含了字符串函数所需的原型和声明。
字符串的长度就是它所包含的字符的个数,下面的程序就可以做到
#include <stddef.h>
#include <stdio.h>
size_t strlen(char const *string)
{
int length;
for (length=0;*string++ != '\0';)
length++;
return length;
}
int main()
{
char const *x;
x="abcdefg";
printf("%d",strlen(x));
}
在 string.h 中以及包含了函数 strlen,关于字符串的函数,标准库提供了很多,一般不需要编写字符串函数。对于 strlen,要注意的是它的返回值是一个 size_t 类型的值,这个类型是在头文件 stddef.h 中定义的,它是一个无符号整数类型,在表达式中使用无符号数可能会出现不可预览的结果,例如下面的表达式永远不会成立(无符号数减去无符号数永远不可能为负)
strlen(x)-strlen(y)>=0;
8.2.不受限制的字符串函数
最常用的字符串函数是不受限制的,即它们通过寻找字符串参数结尾的 NUL 字节来判断它们的长度。这些函数一般都指定一块内存用于存放结果字符串,在使用它们时,程序必须保证结果字符串不会溢出这块内存
8.2.1.复制字符串
用于复制字符串的函数是 strcpy(string copy),它的原型如下
char *strcpy(char *dst,char const *src)
这个函数把参数 src 字符串复制到 dst 参数。如果参数 src 和 dst 在内存中出现重叠,其结果是未定义的。由于 dst 参数将被修改,所以它必须是字符数组或者一个指向动态分配内存的数组的指针,不能使用字符串常量。目标参数以前的内容将会被覆盖并丢失,即使新的字符串比 dst 原型的内存更短,由于新的字符串是以 NUL 结尾,所以老字符串最后剩余的几个字符也会被有效地删除
char message[]="Original message";
strcpy(message,"Different");
上面的程序执行后,数组将包含下面第二列的内容,第一个 NUL 字节后面的几个字符再也无法被字符串函数访问,因此可以认完全覆盖
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ‘D’ | ‘i’ | ‘f’ | ‘f’ | ‘e’ | ‘r’ | ‘e’ | ‘n’ | ‘t’ | 0 | ‘e’ | ‘s’ | ‘s’ | ‘a’ | ‘g’ | ‘e’ | 0 |
程序必须保证目标字符串数组的空间足以容纳需要复制的字符串。如果字符串比数组长,多余的字符仍被复制,它们将覆盖原先存储与数组后面的内存空间的值,例如下面的程序将会侵占数组后面的部分内存空间,改写原先存储在那里的值
char message[]="Original message";
strcpy(message,"A different message");
8.2.2.连接字符串
把一个字符串添加到另一个字符串后面可以使用 strcat(string catenate) 函数,它的原型如下
char *strcat(char *dst,char const *src);
strcat 函数要求 dst 参数原先已经包含了一个字符串(可以是空字符串)。它找到这个字符串的末尾,并把 src 字符串的一份拷贝添加到这个位置,如果 src 和 dst 的位置发生重叠,其结果是未定义的,当然也必须保证目标字符串数组剩余的空间足以保存整个源字符串
8.2.3.函数的返回值
strcpy 和 strcat 都返回它们第一个参数的拷贝,就是一个指向目标字符数组的指针,因此可以嵌套使用
strcat(strcpy(dst,a),b);
它和下面的语句一样
strcpy(dst,a);
strcat(dst,b);
8.2.4.字符串比较
比较两个字符串涉及对两个字符串对应字的字符逐个进行比较,直到发现不匹配的为止,那个最先不匹配的字符中较小的那个字符所在的字符串较小,如果一个字符串是另一个字符串的前面的一部分,那么它也被认为小,因为它的 NUL 结尾字节出现得更早,这种比较称为”字典比较"。库函数 strcmp(string compare)用于比较两个字符串,它的原型如下
int strcmp(char const *s1,char const *s2);
如果 s1 小于 s2,函数返回一个小于 0 的值,如果s1 大于 s2,函数返回一个大于 0 的值,如果两个字符串相等,函数返回 0
8.2.5.切分字符串
char *strtok(char *str, const char *delim);
8.3.长度受限的字符串函数
标准函数库还定义了一些函数,它们以另一种不同的方式处理字符串。这些函数接受一个显式的长度参数,用于限定字符数,可以防止长字符串从目标数组溢出,如果位置发生重叠,其结果是未定义的
char *strcpy(char *dst,char const *src,size_t len);
char *strcat(char *dst,char const *src,size_t len);
int strcmp(char const *s1,char const *s2,size_t len);
九、从C到C++
1.引用
//类型名 & 引用名 =变量名;
int n=4;
int &r=n;
//r 相当于 n 的一个别名,修改r或者n,另一个就会改变
//定义引用时一定要将其初始化成引用某个变量
//初始化后,它就会一直引用该变量,而不会再引用其他变量了
//引用只能引用变量,不能引用常量和表达式
利用引用实现交换函数
#include <iostream>
using namespace std;
void swap(int &a,int &b)
{
int temp;
temp=a;a=b;b=temp;
}
int main()
{
int n1=2,n2=3;
swap(n1,n2);
printf("%d%d\n",n1,n2);
}
将函数返回值为引用可以将函数作为左值
#include <iostream>
using namespace std;
int&
getElement(int * a, int i)
{
return a[i];
}
int main()
{
int a[] = {1,2,3};
getElement(a,1) = 10;
cout << a[1] ;
return 0;
}
//10
// const T & 和 T & 是不同类型的变量类型!!!
// T&的类型或T类型的变量可以用来初始化const T &类型的引用
//const T类型的常变量和const T &类型的引用则不能用来初始化 T&类型的引用,除非进行强制转换
2.动态内存分配
p=new T; //T是任意类型名,p是类型为T*的指针
//动态分配出一片大小为 sizeof(T)字节的内存空间,并把内存空间的起始地址赋值给p
int *pn;
pn=new int;
*pn=5;
//用new动态分配的内存空间,一定要用delete运算符进行释放
//delete 指针;
int *p=new int;
*p=5;
delete p;
delete p; //导致异常,一片空间不能被delete两次
//释放数组内存可以使用 delete []p;
3.内联函数/函数重载/
函数调用时有时间开销的,例如,将参数放到栈里,从栈中取出等等,如果函数本身被调用很多次,这个开销会比较大,为了减少函数调用的开销,引入了内联函数机制。编译器处理对内联函数的调用语句时,是将整个函数的代码插入到调用语句处,而不会产生调用函数语句
inline int max(int a,int b)
{
if (a>b) return a;
return b;
}
//对于代码量较少的函数可以使用,如果代码里较多会使得代码的体积增大较多
一个或多个函数,名字相同,参数个数或参数类型不同,就是函数的重载
int max(double f1,double f2){}
int max(int n1,int n2){}
int max(int n1,int n2,int n3){}
//函数重载使得函数命名变得简单
//编译器根据调用函数的实参个数和类型判断该调用哪个函数
4.类与对象
类的大小为类属性大小的总和(不包括函数)
//类的成员函数和类的定义分开写
int Cectangele :: Area()
{
return w*h;
}
类成员的可被访问范围
private 私有成员,只能在成员函数内访问 默认私有
public 公有成员,可以在任何地方访问
protected 保护成员
在类的成员函数内部,能够访问:
当前对象的全部函数,属性
同类其他对象的全部函数属性
在类的成员函数以外的地方,只能访问该类对象的共有成员
#include <iostream>
#include <cstring>
using namespace std;
class CEmployee
{
private:
char szname[30];
public:
int salary;
void setName(char *name);
void getName(char *name);
void averageSalary(CEmployee e1,CEmployee e2);
};
void CEmployee :: setName(char *name)
{
strcpy(szname,name);
}
void CEmployee :: getName(char *name)
{
strcpy(name,szname);
}
void CEmployee :: averageSalary(CEmployee e1,CEmployee e2)
{
cout << e1.szname;
salary=(e1.salary+e2.salary)/2;
}
int main()
{
CEmployee e;
//strcpy(e.szname,"Tom123") 编译出错 [Error] 'char CEmployee::szname [30]' is private
e.setName("Tom");
e.salary=5000;
return 0;
}
设置私有成员的机制,叫 “隐藏”,隐藏的目的是强制对成员变量的访问一定要通过成员函数进行,那么以后成员变量的类型等属性修改之后,只需修改成员函数即可。否则,所有直接访问成员变量的语句都需要被修改
4.1.构造函数
构造函数也是成员函数,它没有返回值。每个类都有构造函数,如果未设置,编译器会自动产生一个没有参数的构造函数。对象生成时构造函数自动被调用,对象一旦生成,就再也不能在其上执行构造函数。一个类可以有多个构造函数
#include <iostream>
#include <cstring>
using namespace std;
class Complex
{
private:
double real,image;
public:
void set(double r,double i);
Complex(double r,double i);
Complex(double r);
}
Complex::Complex(double r,double i)
{
real=r;image=i;
}
Complex::Complex(Complex c1,Complex c2)
{
real=c1.real+c2.real;
image=c1.image+c2.image;
}
每个类都有复制构造函数,如果在定义类时未设置,编译器自动产生构造函数。复制构造函数的参数是类的引用
class Complex
{
private:
double real,image;
}
Complex c1; //调用默认的无参数构造函数
Complex c2(c1); //调用默认的复制构造函数,将c2初始化为与c1一样
//复制构造函数起作用的三种情况
//用一个对象取初始化同类的另一个对象时
complex c2(c1);
complex c2=c1; //初始化语句,非赋值语句,不调用复制构造函数
//如果某个函数有一个参数是A的对象时,该函数被调用时将调用A的复制构造函数
class A
{
public:
int v;
A(int n){v=n};
A(A &a)
{
v=a.v
cout << "Copy constructor called" << endl;
}
}
void Func(A a1){}
int main()
{
A a2;
Func(a2); //调用复制构造函数,参数为a2的引用
return 0;
}
//函数的返回值是类A的对象时,函数返回时,A的复制构造函数将被调用
A Func()
{
A b(4);
return b; //调用复制构造函数,参数为b的引用
}
int main()
{
cout << Func().v << endl; return 0;
}
由于当函数中出现类为参数时会引发复制构造函数调用,开销比较大。所以可以考虑使用类的引用类型为参数,如果希望确保实参的值在函数中不应被改变,那么可以加上 const 关键字
void fun(CMyclass obj_){}
//可以改为
void fun(const CMyclass &obj_){}
类型转换构造函数,**只有一个参数而且不是该类型(不是复制构造函数)。**当需要的时候,编译系统会自动调用转换构造函数,建立一个无名的临时对象(或临时变量)
#include <iostream>
using namespace std;
class Complex
{
public:
double real,image;
Complex (int i)
{
cout << "IntConstructor called" << endl;
real=i;image=0;
}
Complex(double r,double i)
{
real=r;image=i;
}
};
int main()
{
Complex c1(7,8);
Complex c2=12; //调用类型转换构造函数,生成c2(12,0);
c1=9; //调用类型转换构造函数,生成c1(9,0)
cout << c1.real << "," << c1.image << endl;
return 0;
}
4.2.析构函数
析构函数的名字与类名相同,在前面加上 ’ ~ ',没有参数和返回值,一个类最多只能有一个析构函数
析构函数在对象消亡时即被自动调用,可以定义析构函数来在对象消亡前做善后工作,比如释放分配的空间等
定义类时没有写析构函数,编译器会自动生成默认的什么都不做的析构函数
#include <iostream>
using namespace std;
class String
{
private:
char *p;
public:
String()
{
p=new char[10];
};
~String();
{
delete [] p;
}
};
#include <iostream>
using namespace std;
class Demo
{
private:
int id;
public:
Demo(int i)
{
id=i;
cout << "id=" << id << "constructed" << endl;
}
~Demo()
{
cout << "id=" << id << "destructed" << endl;
}
};
Demo d1(1); // id=1constructed
void Func()
{
static Demo d2(2);
Demo d3(3);
cout << "Func" << endl;
}
int main(int argc, char const *argv[])
{
Demo d4(4); // id=4constructed
d4=6; //id=6constructed id=6destructed
cout << "main" << endl;
{
Demo d5(5); //id=5constructed id=5destructed
}
Func(); //id=2constructed id=3constructed Func id=3destructed
cout << "main ends" << endl; //main ends id=6destructed id=2destructed id=1destructed
return 0;
}
4.3.this指针
非静态成员函数中可以直接使用 this 来代表该函数所作用的对象的指针。当 C++ 程序编译时,可以理解为先将类中的成员函数添加了一个 this 指针参数,这使得可以不通过任何对象来调用不需要此对象任何信息的成员函数,相当于Python中的self
4.4.静态成员
普通成员变量每个对象各自有各自的一份,而静态成员变量一共就一份,为所有对象共享
普通成员函数必须作用于某个对象,而静态成员函数并不具体作用于某个对象
不是必须通过某个对象访问静态成员,可以使用:类名::成员名
静态变量和静态函数本质上是全局变量和全局函数。设置静态成员这种机制的目的是将某些类紧密相关的全局变量和函数写到类里面,使他们看上去像一个整体,便于理解和维护
静态成员必须在定义类的文件中对成员变量进行一次说明或初始化,否则编译能通过而链接不能通过
静态成员函数中,不能访问非静态成员变量,也不能调用非静态成员函数
4.5.成员对象和封闭类
成员对象指一个类的成员是其他类的成员有成员对象的类叫封闭类
#include <iostream>
#include <cstring>
#include <cstdlib>
using namespace std;
class Ctyre//轮胎类
{
private:
int radius;
int width;
public:
Ctyre(int r,int w):radius(r),width(w){}//初始化列表
};
class CEngine //引擎类
{
};
class CCar//汽车类 //封闭类
{
private:
int price;
Ctyre tyre; //成员对象
CEngine engine; //成员对象
public:
CCar(int p,int tr,int tw);
};
CCar::CCar(int p,int tr,int w):price(p),tyre(tr,w){};
int main()
{
CCar car(20000,17,255);
return 0;
}
任何生成封闭类对象的语句都要让编译器明白,对象中的成员对象是如何初始化的,具体做法就是:通过封闭类的构造函数的初始化列表
关于封闭类构造函数和析构函数的执行顺序
封闭类对象生成时,先执行所有对象成员的构造函数,然后才执行封闭类的构造函数
对象成员的构造函数调用次序和对象成员在类中的说明次序一致,与它们在成员初始化列表中出现的次序无关
当封闭类的对象消亡时,先执行封闭类的析构函数,然后再执行成员对象的析构函数,次序和构造函数的调用次序相反
4.6.常量对象,常量成员函数
如果不希望某个对象的值被改变,则定义该对象的时候可以再前面加 const 关键字
#include <iostream>
#include <cstring>
#include <cstdlib>
using namespace std;
class Demo
{
private:
int value
public:
Demo();
~ Demo();
};
const Demo obj; //常量对象
在类的成员函数说明后面可以加 const 关键字,则该成员函数成为常量成员函数
常量成员函数在执行期间不应该修改其所作用的对象。因此,常量成员函数中也不能修改成员变量的值(静态成员变量除外),也不能调用同类的非常量成员函数
#include <iostream>
#include <cstring>
#include <cstdlib>
using namespace std;
class Sample
{
public:
int value;
void GetValue() const; //常量成员函数
void func();
Sample();
~Sample();
};
void Sample::GetValue() const
{
value=0; //错误,常量成员函数不能使它作用的对象值发生改变
func() //错误,不能调用非常量成员函数
}
如果两个成员函数,名字和参数表都一样,但是一个是 const,一个不是,算重载
常量对象不能调用非常量成员函数,只能调用常量成员函数。非常量对象调用非常量成员函数
4.7.友元
友元分为友元函数和友元类两种
友元函数指:一个类的友元函数(不是这个类的成员函数)可以访问该类的私有成员
#include <iostream>
using namespace std;
class CCar; //提前声明CCar类,以便后面的CDriver类使用
class CDriver
{
public:
void ModifyCar(CCar *pCar) //改装汽车(如果参数CCar对象,就需要把CCar写完整,而不能只声明)
};
class CCar
{
private:
int price;
public:
friend int MostExpensiveCar(CCar cars[],int total); //声明友元
friend void CDriver::ModifyCar(CCar *pcar); //声明友元
};
void CDriver::ModifyCar(CCar *pCar)
{
pCar->price+=1000; //改装后价值增加
}
int MostExpensiveCar(CCar cars[],int total)
{
//求最贵的汽车价格
int tmpMax=-1;
for (int i=0;i<total;++i)
{
if (cars[i].price>tmpMax)
tmpMax=cars[i].price;
}
return tmpMax;
}
友元类指:如果 A 是 B 的友元类,那么 A 的成员函数可以访问 B 的私有成员
友元类之间的关系不能传递,不能继承
十、运算符重载
运算符重载的目的是:扩展C++中提供的运算符的适用范围,使之能作用于对象。同一个运算符,对不同类型的操作数,所发生的行为不同。运算符重载的实质是函数重载,可以重载为普通函数,也可以重载为成员函数。相当于把运算符表达式转换成运算符函数的调用,把运算符的操作数转换成运算符函数的参数,运算符多次重载时,根据实参的类型决定调用哪个运算符函数
#include <iostream>
using namespace std;
class Complex
{
public:
double real,img;
Complex(double r=0.0,double i=0.0):real(r),img(i){};
Complex operator-(const Complex &c);
};
Complex operator+(const Complex &a,const Complex &b)
{
return Complex(a.real+b.real,a.img+b.img); //返回一个临时对象
}
Complex Complex::operator-(const Complex &c)
{
return Complex(real-c.real,img-c.img); //返回一个临时对象
}
int main()
{
Complex a(4,4),b(1,1),c;
c=a+b; //等价于c=operator+(a,b)
cout << c.real << "," << c.img << endl;
cout << (a-b).real << "," << (a-b).img << endl;
//a-b等价于a.operator(b)
return 0;
}
1.赋值运算符‘=’重载
有时希望赋值运算符两边的类型可以不匹配,比如,把一个 int 类型变量赋值给一个 Complex 对象,或者把一个 char * 类型的字符串赋值给一个字符串对象,就需要重载赋值运算符。赋值运算符只能重载为成员函数
#include <iostream>
#include <cstring>
using namespace std;
class String
{
private:
char *str;
public:
String():str(new char[1]){str[0]=0;} //初始化指向空指针
const char * c_str() {return str;}
//对运算符进行重载的时候,好的风格应该是尽量保留运算符原本的特性,如 = 原本就有返回值(左值的引用)
String & operator=(const char *s)
{
if (this = &s)
return *this //避免出现 s=s
//如果直接使用 = 会使两个指针指向同一片内存区域(浅拷贝),从而引发一系列问题
delete [] str;
str=new char[strlen(s)+1];
strcpy(str,s);
return *this;
}
String (String &s)
{
//当编译器使用默认的复制构造函数时,也会出现两个指针指向同一片内存区域(浅拷贝)的情况,用同样的方式解决
str=new char[strlen(s.str)+1];
strcpy(str,s.str);
}
~String(){delete [] str;}
};
2.重载为友元函数
一般情况下,将运算符重载为类的成员函数,是较好的选择。但有时候,重载为成员函数不能满足要求,重载为普通函数,又不能访问类的私有成员,所以需要将运算符重载为友元
Complex operator+(double r);
Complex Complex::operator+(double r)
{
//能解释 c+5,但解决不了5+c(因为5.operator(c)不存在)
return Complex(real+r,img)
}
//但是普通函数又不能访问私有成员,所以需要将运算符 + 重载为友元
friend Complex operator+(double r,const Complex &c); //变成operator+(5,c) 加了friend 就不是成员函数了
3.可变长数组类的实现
#include <iostream>
using namespace std;
class CArray
{
private:
int size; //记录数组元素个数
int *ptr; //记录数组
public:
CArray(int s=0);
CArray(CArray &a);
~CArray();
void push_back(int v);//用于在数组尾部添加一个元素
CArray & operator=(const CArray &a); //重载 = 用于数组对象间的赋值,实现深拷贝操作
int length(){return size;}
int & operator[](int i) //重载中括号运算符,用以支持下标访问数组元素
{
return ptr[i];
}
};
//构造函数
CArray:: CArray(int s):size(s)
{
if (s==0)
ptr=NULL;
else
ptr=new int[s];
}
//深拷贝复制构造函数
CArray:: CArray(CArray & a)
{
if (!a.ptr)
{
//空数组
ptr=NULL;
size=0;
return;
}
//不是空数组
ptr=new int[a.size];
memcpy(ptr,a.ptr,sizeof(int) *a.size);
size=a.size;
}
//析构函数
CArray:: ~CArray()
{
if (ptr) delete [] ptr;
}
//重载 =
CArray & CArray::operator=(const CArray &a) //数组对象=a
{
if (ptr==a.ptr)
return *this;
if (a.ptr==NULL)
{
if (ptr) delete [] ptr;
ptr=NULL;
size=0;
return *this;
}
if (size<a.size) //原有空间足够大,就不用分配新的内存
{
if (ptr)
delete [] ptr;
ptr=new int[a.size];
}
memcpy(ptr,a.ptr,sizeof(int)*a.size);
size=a.size;
return *this;
}
void CArray::push_back(int v)
{
if (ptr)
{
int *temPtr=new int[size+1]; //重新分配内存空间
memcpy(temPtr,ptr,sizeof(int)*size); //拷贝原数组内容
delete [] ptr;
ptr=temPtr;
}
else //原数组为空
ptr=new int[1];
ptr[size++]=v; //加入新元素
}
4.流运算符的重载
ostream & ostream::operator << (int n)
{
//输出n的代码
return *this;
}
ostream & ostream::operator << (ostream &o,const CStudent &s)
{
o << s.nAge;
return o;
}
friend ostream &operator<<(ostream &o,const MyString & s)
{
o << s.p;
return o;
}
friend istream & operator >>(istream &i,Point & p)
{
i >>p.x>>p.y;
return i;
}
5.重载类型转换运算符
#include <iostream>
using namespace std;
class Complex
{
double real,imag;
public:
Complex(double r=0,double i=0):real(r),imag(i){};
operator double () {return real;};
};
int main()
{
Complex c(1.2,3.4);
cout << double (c) << endl;
double n=2+c;
cout << n;
}
//1.2
//3.2
6.自增,自减运算符的重载
后置运算符作为二元运算符重载时,需要多写一个没用的参数:
//重载为成员函数:
T operator++(int);
//重载为全局函数:
T operator++(T2,int);
没有后置运算符重载而有前置重载的情况下,在 vs 中 ,obj++也调用前置重载,而 dev 则令 obj++ 编译出错
#include <iostream>
using namespace std;
class CDemo
{
private:
int n;
public:
CDemo(int i=0):n(i){};
//原生态的前置返回的是操作数的引用,后置返回的是临时对象,这里将函数的返回值设置保持传统
CDemo & operator++(); //用于前置形式
CDemo operator++(int); //用于后置形式
operator int() {return n;};
friend CDemo &operator--(CDemo &);
friend CDemo &operator--(CDemo &,int);
};
CDemo & CDemo::operator++()
{
//前置++
++n;
return *this;
//++s即为s.operator++()
};
CDemo CDemo::operator++(int k)
{
//后置++
CDemo temp(*this) //记录修改前的对象
n++;
return tmp;
//s++即为s.operator++(0)
}
CDemo & operator--(CDemo &d)
{
//前置--
d.n--;
return d;
//s--即为operator--(s)
}
CDemo operator--(CDemo &d,int)
{
//后置--
CDemo tmp(d);
d.n--;
return tmp;
//s--即为operator--(s,0)
}
在重载运算符时要注意:
C++不允许定义新的运算符
重载后的运算符的含义应该符合日常习惯,一般需要进行不断处理的运算符重载需要返回类的引用
运算符重载不改变运算符的优先级
以下运算符不能被重载:. . :: ?: sizeof*
重载运算符 () [] -> 或者赋值运算符 = 时,运算符重载函数必须声明为类的成员函数
十一、继承
继承:在定义一个新的类 B 时,如果该类与某个已有的类 A 相似(指的是类 B 拥有类 A 的全部特定),那么就可以把 A 作为一个基类,而把 B 作为基类的一个派生类(也称子类)。派生类拥有基类的全部成员函数和成员变量,不论是 private,protect,public。但是在派生类的各个成员函数中,不能访问基类中的 private 成员
class CUdergraduateStudent:public CStudent //类名:public 基类名
派生类对象的体积,等于基类对象的体积和派生类对象自己的成员变量的体积之和。在派生类对象中,包含着基类对象,而且基类对象的存储位置位于派生类对象新增的成员变量之前
class CBase //一个对象8个字节
{
int v1,v2;
}
class CDerived:public CBase //一个对象12个字节
{
int v3;
}
1.继承关系和复合关系
类与类之间有三种关系:没关系,继承关系和复合关系
继承关系是 “是” 关系,B是基类A的派生类,那么逻辑上要求:一个B对象也是一个A对象
复合关系是 “有” 关系,类C中 "有"成员变量k,k是类D的对象,则C和D是复合关系,逻辑要求:D对象是C对象固有属性或组成部分
程序中常常通过指针实现 “知道” 关系,如一个人有十条狗的模型
class Master;
class CDog
{
CMaster *pm;
}
class Master
{
CDog *dogs[10];
}
2.派生类覆盖基类成员
派生类可以定义一个和基类成员同名的成员,这叫覆盖。在派生类中访问这类成员时,默认情况是访问派生类中的定义的成员。要在派生类中访问有基类定义的同名成员时,要使用作用域符号 ::
类的保护成员使用 protected 声明,它可以被基类的成员函数,基类的友元函数,派生类的成员函数可以访问当前对象的基类的保护成员
3.派生类的构造函数
class Bug
{
private:
int nLegs,color;
public:
int nType;
Bug(int legs,int color);
void PrintBug(){};
}
class FlyBug:public Bug
{
int nWings;
public:
FlyBug(int legs,int color,int wings);
}
Bug::Bug(int legs,int color)
{
nLegs=legs;
nColor=color;
}
FlyBug::FlyBug(int legs,int color,int wings):Bug(legs,color) //在派生类中初始化基类部分可以用初始化列表
{
nWings=wings;
}
在创建派生类对象时:先执行基类的构造函数,用于初始化派生类对象中从基类继承的成员;再执行成员对象类的构造函数,用于初始化派生类对象中的成员对象;最后执行派生类自己的构造函数。析构顺序与构造顺序相反
4.公有继承的赋值兼容规则
class base{};
class derived:public base{}; //写public表示公有继承,也可以写private或protected,但这两种情况下面的赋值就不能使用
base b;
derived d;
b=d; //派生类的对象可以赋值给基类对象,因为一个派生类对象就必是一个基类对象
base &br=d; //派生类对象可以初始化基类的引用
base *pb=&d; //派生类对象的地址可以赋值给基类指针
在基类声明时,只需列出它的直接基类,派生类沿着类的层次自动向上继承它的间接基类。派生类的成员包括派生类自己定义的成员和直接基类的所有成员和间接基类的所有成员
十二、多态
在类的定义中,前面有 virtual 关键字的成员函数或者派生类和基类中虚函数同名同参数表的函数都是虚函数
class base
{
virtual int get();
}
int base::get(){}
virtual 关键字只用在类定义里的函数声明中,写函数体时不用,构造函数和静态成员函数不能是虚函数
多态有两种表现形式:
1.派生类的指针可以赋给基类指针:
通过基类指针调用基类和派生类中的同名虚函数时:若该指针指向一个基类的对象,那么被调用的是基类的虚函数;若指针指向一个派生类的对象时,那么被调用的是派生类的虚函数。这种机制就叫多态
2.派生类的对象可以赋给基类引用:
通过基类引用调用基类和派生类中的同名虚函数时:若该引用引用的是一个基类的对象,那么被调用的是基类的虚函数;若该引用引用的是一个派生类的对象,那么被调用的是派生类的虚函数。这种机制也叫做多态
要注意在构造函数和析构函数中调用虚函数不是多态
1.多态实例:魔法门之英雄无敌
基本思路:为每个怪物类编写 Attack、FightBack 和 Hurted 成员函数
Attack 函数表现攻击动作,攻击某个怪物,并调用被攻击怪物的 Hurted 函数,以减少被攻击怪物的生命值,同时也调用被攻击怪物的 FightBack函数,遭受被攻击怪物反击
Hurted 函数减少自身生命值,并表现受伤动作
FightBack 成员函数表现反击动作,并调用被反击对象的 Hurted 成员函数,使被反击对象受伤
设置基类CCreature,并且使CDragon,CWolf 等其他类都从CCreature 派生而来
//下面第一个是普通的实现方法,第二个是多态的实现方法
class CCreature
{
protected:
int nPower; //代表攻击力
int nLife; //代表生命值
};
class CDragon:public CCreature
{
public:
void Attack(CWolf *pWolf)
{
//....表现攻击动作的代码
pWolf->Hurted(nPower);
pWolf->FightBack(this);
}
void Attack(CGhost *pGhost)
{
//....表现攻击动作的代码
pGhost->Hurted(nPower);
pGhost->FightBack(this);
}
void Hurted(int nPower)
{
//....表现受伤动作的代码
nLife-=nPower;
}
void FightBack(CWolf *pWolf)
{
//....表现反击动作
pWolf->Hurted(nPower/2);
}
void FightBack(CGhost *pGhost)
{
//表现反击动作的代码
pGhost->Hurted(nPower/2);
}
};
//有n种怪物,CDragon类就会有n个Attack成员函数,以及n个FighteBack成员函数.对其他类也是如此
//如果游戏版本升级,新增了怪物雷鸟 CThunderBird,则程序改动较大
//所有类都需要增加两个成员函数 void Attack(CThunderBird *pThunderBird)和void FightBack(CThunderBird *pThunderBird)
class CCreature
{
protected:
int m_nLifeValue,m_nPower;
public:
virtual void Attack(CCreature *pCreature){}
virtual void Hurted(int nPower){}
virtual void FightBack(CCreature *pCreature){}
};
//基类只有一个Attack成员函数;也只有一个FightBack成员函数,所有CCreature派生类也是如此
class CDragon:public CCreature
{
public:
virtual void Attack(CCreature *pCreature);
virtual void Hurted(int nPower);
virtual void FightBack(CCreature *pCreature);
}
void CDragon::Attack(CCreature *p)
{
//....表现攻击动作的代码
p->Hurted(m_nPower); //多态
p->FightBack(this); //多态
}
void CDragon::Hurted(int nPower)
{
//....表现受伤的动作
m_nLifeValue-=nPower;
}
void CDragon::FightBack(CCreature *p)
{
//....反击动作的代码
p->Hurted(m_nPower/2); //多态
}
//如果版本新增怪物雷鸟,只需要编写新类CThunderBird
//不需要在已有的类里专门为新怪物增加void Attack(CThunderBird *pThunderBird)和void FightBack(CThunderBird *pThunderBird)
//已有的类可以原封不动
int main()
{
CDragon Dragon;
CWolf Wolf;
//派生类的引用可以赋值给基类参数
Dragon.Attack(&Wolf) //调用CWolf::Hurted
Dragon.Attack(&Ghost) //调用CGhost::Hurted
Dragon.Attack(&Bird) //调用CBird::Hurted
}
2.多态实例:几何形体处理程序
输入若个几何形体的参数,按面积排序输出,输出时要指明形状
第一行是几何形体的数目,下面有n行,每行有一个字母c开头
若c是R,表示矩形,后面两个整数位宽高
若c是C,表示圆,后面的一个整数表示半径
若c是T,表示三角形,后面的三个整数表示三条边的长度
#include <iostream>
#include <stdlib.h>
#include <math.h>
using namespace std;
class CShape
{
public:
virtual double Area()=0; //纯虚函数,没有函数体
virtual void PrintInfo()=0;
};
class CRectangle:public CShape
{
public:
int w,h;
virtual double Area()
{
return w*h;
}
virtual void PrintInfo()
{
cout << "Rectangle:" << Area() << endl;
}
};
class CCricle:public CShape
{
public:
int r;
virtual double Area()
{
return 3.14*r*r;
}
virtual void PrintInfo()
{
cout << "Circle:" << Area() << endl;
}
};
class CTriangle:public CShape
{
public:
int a,b,c;
virtual double Area()
{
double p=(a+b+c)/2.0;
return sqrt(p*(p-a)*(p-b)*(p-c));
}
virtual void PrintInfo()
{
cout << "Triangle:" << Area() << endl;
}
};
CShape *pShapes[100];
int MyCompare(const void *s1,const void *s2)
{
double a1,a2;
CShape **p1;
CShape **p2;
p1=(CShape **)s1; //s1,s2是指向pShapes数组中元素的指针,数组元素的类型是CShape *
p2=(CShape **)s2; //故p1,p2都是指向指针类型的指针,类型为CShape **
a1=(*p1)->Area();
a2=(*p2)->Area();
if (a1<a2) return -1;
else if (a2<a1) return 1;
else return 0;
}
int main()
{
int i;int n;
CRectangle *pr;CCricle *pc;CTriangle *pt;
cin >> n;
for (int i=0;i<n;i++)
{
char c;
cin >> c;
switch(c)
{
case 'R':
pr=new CRectangle();
cin >> pr->w >> pr->h;
pShapes[i]=pr;
break;
case 'C':
pc=new CCricle();
cin >> pc->r;
pShapes[i]=pc;
break;
case 'T':
pt=new CTriangle();
cin >> pt->a >> pt-> b >> pt->c;
pShapes[i]=pt;
break;
}
}
qsort(pShapes,n,sizeof(CShape*),MyCompare); //对元素排序,需要用指针指向每个元素,而这里的每个元素都是一个指针,所以是指向指针的指针
for (i=0;i<n;i++)
{
pShapes[i]->PrintInfo();
}
return 0;
}
3.多态的实现原理
"多态"的关键在于通过基类指针或引用调用一个虚函数时,编译时不确定到底调用基类还是派生类的函数,运行时才确定,叫 “动态联编”
在C++ 中,每一个有虚函数的类(或有虚函数类的派生类)都有一个虚函数表,该类的任何对象中都放着虚函数表的指针。虚函数表中列出了该类的虚函数地址,每个对象的大小中多出来的4个字节就是用来放虚函数表的地址的。当出现多态的函数调用语句时,它被编译成一系列根据基类指针所指向的(或基类引用所引用的)对象中存放的虚函数表的地址,在虚函数表中查找虚函数地址,并调用虚函数的指令
#include <iostream>
using namespace std;
class A
{
public:
virtual void Func(){cout << "A::Func" << endl;}
};
class B:public A
{
public:
virtual void Func(){cout << "B::Func" << endl;}
};
int main()
{
A a;
A *pa=new B();
pa->Func(); //B::Func
//64为程序指针为8字节
long long *p1=(long long *) & a;
long long *p2=(long long *) pa;
*p2=*p1; //将a对象虚函数表指针的内容覆盖p2指针指向的内容
pa->Func(); //A:Func
return 0;
}
4.虚析构函数、纯虚函数和抽象类
通过基类的指针删除派生类对象时,通常只会调用基类的析构函数。但是删除一个派生类对象时,应该先调用派生类的析构函数,然后调用基类的析构函数。解决办法:把基类的析构函数声明为 virtual。派生类的析构函数可以 virtual 不进行声明(自动是虚函数)。通过基类的指针删除派生类对象时,首先调用派生类的析构函数,然后调用基类的析构函数。一般来说,一个类如果定义了虚函数,则应该将析构函数也定义成虚函数。或者,一个类打算作为基类使用,也应该将析构函数定义成虚函数。注意,不允许以虚函数作为构造函数
纯虚函数指:没有函数体的虚函数,包含纯虚函数的类叫抽象类。抽象类只能作为基类来派生新类使用,不能创建抽象类的对象
抽象类的指针和引用可以指向由抽象类派生出来的类的对象
class A
{
private:int a;
public:
virtual void Print()=0; //纯虚函数
void func()
}
//A a; 错,A是抽象类,不能创建对象
//A *pa; ok,可以定义抽象类的指针和引用
//pa=new A; 错误,A是抽象类,不能创建对象
class B:public A
{
public:
void f(){cout << "B:f()" << endl;}
};
int main()
{
B b;
b.f();
return 0;
}
在抽象类的成员函数内可以调用纯虚函数(有可能是多态通过派生类调用的虚函数),但是在构造函数或析构函数内部不能调用纯虚函数
如果一个类从抽象类派生而来,那么当且仅当它实现了基类中的所有纯虚函数,它才能成为抽象类
十三、输入和输出模板
1.输入输出流相关的类
istream是用于输入的流类,cin就是该类的对象
ostream是用于输入的流类,cout就是该类的对象,cerr/clog与标准错误输出设备相连
iftream是用于从文件读取数据的类
ofsream是用于向文件中写入数据的类
iostream是既能用于输入,又能用于输出的类
fstream是既能从文件中读取数据,又能向文件中写入数据的类
cin对应于标准输入流,用于从键盘读取数据,也可以被重定向为从文件中读取数据
cout对应于标准输出流,用于向屏幕输出数据,也可以被宠定向为向文件写入数据
cerr/clog对应于标准错误输出流,用于向屏幕输出出错信息。cerr/clog的区别在于cerr不使用缓冲区,直接向显示器输出信息;而输出到clog中的信息会先被存放在缓冲区,缓冲区满或者刷新时才输出到屏幕
#include <iostream>
using namespace std;
int main()
{
int x,y;
cin >> x >> y;
freopen("test.txt","w",stdout); //将标准输出重定向到text.txt文件中
if (y==0)
{
cerr << "error" << endl;
}
else
{
cout << x/y; //输出结果到test.txt中
}
return 0;
}
#include <iostream>
using namespace std;
int main()
{
double f;
int n;
freopen("t.txt","r",stdin);
cin >> f >> n;
cout << f << "," << n << endl;
return 0;
}
在 中有强制类型转换使得 cin 对象能够转化为布尔类型的值,因此它也可以作为判断输入流结束
int x;
while (cin>>x)
{
//...
}
return 0;
//如果前面是从文件输入,比如前面有 freopen("some.txt","r",stdin) 那么,读到文件尾部,输入流就算结束
//如果从键盘输入,则在单独一行输入Ctrl+Z代表输入流结束
istream类的成员函数
*istream & getline(char buf,int bufSize,[char delim]);
从输入列读取 bufSize-1个字符到缓冲区buf,或读到碰到 \n [delim]字符 为止 (哪个先到算哪个)
函数会自动在 buf 中读入数据的结尾添加 \0 。’\n’ 或者 delim 都不会被读入 buf,但会被从输入流中取走。如果输入流中 ‘\n’ 或者 delim 前的字符个数达到或超过了 bufSize 个,就导致读入出错,其结果就是:虽然本次读入已经完成,但是之后的读入就会失败了。可以使用if (! cin.getline(…)) 判断输入是否结束
bool eof() 可以判断输入流是否结束
int peek() 返回下一个字符,但不从流中去掉
istream & putback(char c) 将字符 ch 放回输入流
istream & ignore(int nCount=1,int delim= EOF) 从流中删掉最多 nCount 个字符,遇到 EOF 时结束
2.流操纵算子
使用流操纵算子需要 #include
整数流的基数:流操纵算子 dec,oct,hex,setbase (永久性)
浮点数的精度:precision,setprecision(永久性)
设置域宽:setw,width(一次性)
用户自定义的流操纵算子
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
int n=10;
cout << n << endl; //10
cout << hex << n << "\n" //a
<< dec << n << "\n" //10
<< oct << n << endl; //12
}
precision,setprecision
precision 是 ostream 的成员函数,调用方式为 cout.precision(5)
setprecison 是 流操纵算子,调用方式为 cout << setprecision(5)
它们的功能相同。默认指定输出浮点数的有效位数(非定点方式输出时),指定输出浮点数的小数点后的有效位数(定点方式输出时),都采取四舍五入的方式,可以使用 setiosflags(ios::fixed) 来设置定点方式,实现以小数点位置固定的方式输出,resetiosflags(ios::fixed) 来取消定点方式输出
定点方式:小数点必须出现在个位数后面,例如科学计数法表示就是非定点输出
设置域宽的流操纵算子
设置域宽(setw,width)。两者功能相同,一个是成员函数,一个是流操作算子,调用方式不同:
cin >> setw(4);或者 cin.width(5);
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
int w=4;
char string[10];
cin.width(5);
while (cin >> string)
{
cout.width(w++);
cout << string << endl;//"1234\0" " 5678\0" " 90\0"
cin.width(5);
}
}
还有其他流操作算子有
showpos 非负数要显示正号
setfill(’*’) 填充字符为 *
left/right 左/右对齐
internal 填充字符在中间
用户自定义的流操纵算子
ostream &TabFunc(ostream &output)
{
return output << '\t';
}
cout << "aa" << TabFunc << "bb" << endl;
iostream 里对 << 进行了重载 (成员函数) ostream & operator << (ostream & (*p) (ostream &)),该函数内部会调用 p 所指向的函数,且以 *this 作为参数,hex,dec,oct 都是函数
3.文件读写
创建文件
#include <fstream>
ofstream outFile("clients.dat",ios::out|ios::binary); //文件名,打开方式,文本格式
ofstream fout;
fout.open("clients.dat",ios::out|ios::binary);
文件名可以给绝对路径,也可以给相对路径,没有交代路径信息,就是在当前文件夹下找文件
ios::out 输出到文件,删除原有内容
ios::app 输出到文件,保留原有内容,总是在尾部添加
ios::binary 打开二进制文本(默认打开文本文件)
//判断文件是否创建成功
if (!fout)
{
cout << "File open error!" << endl;
}
文件的读写指针
对于输入文件,有一个读指针;输出文件有一个写指针;对于输入输出文件,有一个读写指针;
标识文件操纵的当前位置,指针在哪里,读写操作就在哪里
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
ofstream fout("a1.out",ios:app); //以添加方式打开
long location=fout.tellp(); //取得写指针的位置
loacation=10;
fout.seekp(location); //将写指针移动到第10个字节处
fout.seekp(location,ios::beg); //从头偏移location
fout.seekp(location,ios::cur); //从当前位置偏移location
fout.seekp(location,ios::end); //从尾部偏移location
}
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
ifstream fin("a1.in",ios::ate); //打开文件,定位文件指针到末尾
long location=fin.tellg(); //取得读指针的位置
location=10L;
fin.seekg(location); //将读指针移动到第10个字节处
fin.seekg(location,ios::beg) //从头偏移location
fin.seekg(location,ios::cur) //从当前位置偏移location
fin.seekg(location,ios::end) //从尾部偏移location
}
因为文件流也是流,所有流的成员函数和流操作算子也同样适用于文件流,下面的程序可以将 in.txt文件中的整数排序后输出到out.txt中
#include <iostream>
#include <fstream>
#include <vector>
#include <algorithm>
using namespace std;
int main()
{
vector<int> v;
ifstream srcFile("in.txt",ios::in);
ofstream destFile("out.txt",ios::out);
int x;
while (srcFile >> x)
{
v.push_back(x);
}
sort(v.begin(),v.end());
for (int i=0;i<v.size();i++)
{
destFile << v[i] << " ";
}
destFile.close(); //一定要关闭
srcFile.close(); //一定要关闭
return 0;
}
二进制读文件
Windows 下打开文件,如果不用ios::binary,则:
读取文件时,所有的 ‘\r\n’ 会被当做一个字符 ‘\n’ 处理,即少读了一个字符 ‘\r’
写入文件时,写入单独的 ‘\n’ 时,系统会自动在前面加一个 ‘\r’,即多写了一个 ‘\r’
ifstream 和 fstream 的成员函数:
*istream & read (char s,long n);
将文件指针指向的地方的n个字节内容,读到内存地址s,然后将文件读指针向后移动n个字节(以ios::in方式打开文件时,文件读指针开始指向文件开头)
*istream & write (const char s,long n);
将内存地址s处的n个字节内容,写道文件中写指针指向的位置,然后文件写指针向后移动n个字节(以ios::out方式打开文件时,文件写指针开始指向文件开头,以ios::app方式打开文件时,文件写指针开始指向文件尾部)
写入120,再读出120
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
ofstream fout("some.dat",ios::out|ios::binary);
int x=120;
fout.write((const char *)(&x),sizeof(int)); //将&x类型强制转换为符合write()参数的类型
fout.close();
ifstream fin("some.dat",ios::in|ios::binary);
int y;
fin.read((char *)(&y),sizeof(int));
fin.close();
cout << y << endl;
}
存储学生信息到二进制信息中
#include <iostream>
#include <fstream>
using namespace std;
struct Student
{
char name[20];
int score;
};
int main()
{
Student s;
ofstream outFile("Student.dat",ios::out|ios::binary);
while (cin >> s.name >> s.score)
{
outFile.write((char *)&s,sizeof(s));
}
outFile.close();
return 0;
}
读取二进制文件中的学生信息
#include <iostream>
#include <fstream>
using namespace std;
struct Student
{
char name[20];
int score;
};
int main()
{
Student s;
ifstream inFile("Student.dat",ios::in|ios::binary);
if (!inFile)
{
cout << "error" << endl;
return 0;
}
while (inFile.read((char *)&s,sizeof(s)))
{
int readedBytes=inFile.gcount(); //看刚才读了多少字节
cout << s.name << " " << s.score << endl;
}
inFile.close();
return 0;
}
#include <iostream>
#include <fstream>
#include <cstring>
using namespace std;
struct Student
{
char name[20];
int score;
};
int main()
{
Student s;
fstream iofile("Student.dat",ios::in|ios::out|ios::binary);
if (!iofile)
{
cout << "error" << endl;
return 0;
}
iofile.seekp(2*sizeof(s),ios::beg); //定位写指针到第三个记录
iofile.write("Mike",strlen("Mike")+1);
iofile.close();
}
拷贝文件程序mycopy
#include <iostream>
#include <fstream>
using namespace std;
int main(int argc, char const *argv[]) //参数个数,参数
{
if (argc!=3)
{
cout << "File name missing!" << endl;
return 0;
}
ifstream inFile(argv[1],ios::binary|ios::in); //读打开文件
if (!inFile)
{
cout << "Source file open error." << endl;
return 0;
}
ofstream outFile(argv[2],ios::binary|ios::out); //写打开文件
if (!outFile)
{
cout << "New file open error." << endl;
inFile.close(); //打开的文件一定要关闭
return 0;
}
char c;
while(inFile.get(c))
{
outFile.put(c);
}
inFile.close();
outFile.close();
}
4.函数模板和类模板
template <class 类型参数1,class 类型参数2,...>
返回值类型 模板名 (形参表)
{
函数体
};
template <class T>
void Swap(T &x,T &y) //各种数据类型的交换函数
{
T tmp=x;
x=y;
y=tmp;
}
int main()
{
int n=1,m=2;
Swap(n,m);
double f=1.2,g=2.3;
Swap(f,g);
return 0;
}
编译器由模板生成函数的过程称为模板的实例化。实例化通过判断参数类型决定实例化哪种函数。也可以不通过参数实例化函数模板
template <class T>
T Inc(T n)
{
return 1+n;
}
int main()
{
cout << Inc<double>(4)/2 ; //2.5
return 0;
}
函数模板也可以重载,只要它们的形参表或类型参数表不同即可。在有多个函数和函数模板名字相同的情况下,编译器如下处理一条函数调用语句
1.先找参数完全匹配的普通函数(非由模板实例化而得到的函数)
2.再找参数完全匹配的模板函数
3.再找实参经过自动类型转换后能够匹配的普通函数
4.上面的都找不到,则报错
匹配函数模板时,不进行自动类型转换
Map模板
#include <iostream>
using namespace std;
template<class T,class Pred> //Pred为函数指针
void Map(T s,T e,T x,Pred op) //将区间[s,e-1]中的元素经过op变换后拷贝到起点为x的区间中
{
for (;s!=e;++s,++x)
{
*x=op(*s);
}
}
int Cube(int x){return x*x*x;};
double Square(double x){return x*x;};
int main()
{
int a[5]={1,2,3,4,5},b[5];
double d[5]={1.1,2.1,3.1,4.1,5.1},c[5];
Map(a,a+5,b,Square);
for (int i=0;i<5;++i) cout << b[i] << ",";
cout << endl;
Map(a,a+5,b,Cube);
for (int i=0;i<5;++i) cout << b[i] << ",";
cout << endl;
Map(d,d+5,c,Square);
for (int i=0;i<5;++i) cout << c[i] << ",";
cout << endl;
return 0;
}
类模板可以生成不同的类,下面是类模板的定义
template <typename 类型参数1,typename 类型参数2,...> //typename和class一样
//类型参数表
class 类模板名
{
//成员函数和成员变量
}
template <class 类型参数1,class 类型参数2,...>
返回值类型 类模板名<类型参数名列表>::成员函数名(参数表)
Pair类模板
#include <iostream>
#include <cstring>
using namespace std;
template <class T1,class T2>
class Pair
{
public:
T1 key;
T2 value;
Pair(T1 k,T2 v):key(k),value(v){};
bool operator<(const Pair<T1,T2> &p) const;
};
template <class T1,class T2>
bool Pair<T1,T2>::operator<(const Pair<T1,T2> &p) const
{
//Pair的成员函数 operator <
return key<p.key;
}
int main()
{
Pair<string,int> student("Tom",19);
cout << student.key << " " << student.value;
}
同一个类模板的两个模板类是不兼容的
5.类模板与派生,友元和静态函数
类模板和派生有四种关系
类模板从类模板派生
#include <iostream>
#include <cstring>
using namespace std;
template <class T1,class T2>
class A
{
public:
T1 v1;T2 v2;
};
template <class T1,class T2>
class B:public A <T2,T1>
{
public:
T1 v3;T2 v4;
};
template <calss T>
class C:public B<T,T>
{
T v5;
}
int main()
{
B<int,double> obj1; //实例化 B<int,double> 和 A<double,int>
C<int> obj2;
return 0;
}
类模板从模板类派生
#include <iostream>
#include <cstring>
using namespace std;
template <class T1,class T2>
class A
{
public:
T1 v1;T2 v2;
};
template <class T>
class B:public A <int,double>
{
public:
T v;
};
int main()
{
B<char> obj1; //实例化 B<char>和A<int,double>
return 0;
}
类模板从普通类派生
#include <iostream>
#include <cstring>
using namespace std;
class A
{
int v1;
}
template <class T>
class B:public A //所有从B实例化得到的类,都已A为基类
{
public:
T v;
};
int main()
{
B<char> obj1;
return 0;
}
普通类从模板类派生
#include <iostream>
#include <cstring>
using namespace std;
template <class T>
class A
{
T v1;
int n;
}
class B:public A<int>
{
public:
double v;
};
int main()
{
B obj1;
return 0
}
类模板与友元
函数,类,类的成员函数作为类模板的友元
void Func1() {};
class A{};
class B
{
public:
void Func(){}
};
template <class T>
class Tmp1
{
friend void Func1();
friend class A;
friend void B::Func();
};
//任何从Tmp1实例化来的类,都有以上三个友元
函数模板作为类模板的友元
#include <iostream>
#include <cstring>
using namespace std;
template <class T1,class T2>
class Pair
{
public:
T1 key;
T2 value;
Pair(T1 k,T2 v):key(k),value(v){};
bool operator<(const Pair<T1,T2> &p) const;
template <class T3,class T4>
friend ostream & operator << (ostream &o,const Pair<T3,T4> & p);
};
template <clsss T1,class T2>
bool Pair<T1,T2>::operator<(const Pair<T1,T2> &p) const
{
return key<p.key;
}
template <class T1,class T2>
ostream & operator << (ostream &o,const Pair<T1,T2> & p)
{
o << "(" << p.key << "," << p.value << ")";
return 0;
}
//任意从template<class T1,class T2> ostream & operator<< (ostream &o,const Pair<T1,T2> &p)生成的函数,都是任意Pair模板类的友元
函数模板作为类的友元
#include <iostream>
#include <cstring>
using namespace std;
class A
{
int v;
public:
A(int n):v(n){}
template <class T>
friend void Print(const T &p);
};
template <class T>
void Print(const T &p)
{
cout << p.v;
}
int main()
{
A a(4);
Print(a);
return 0;
}
//所有从template <class T> void Print(const T &p)生成的函数都会成为类A的友元,自己写的void Print(int a){}不会是A的友元
类模板作为类模板的友元
#include <iostream>
#include <cstring>
using namespace std;
template <class T>
class B
{
T v;
public:
B(T n):v(n){}
template <class T2>
friend class A;
};
template <class T>
class A
{
public:
void Func()
{
B<int> o(10);
cout << o.v << endl;
}
};
int main()
{
A <double> a;
a.Func();
return 0;
}
类模板中可以定义静态成员,那么从该类模板实例化得到的所有类,都包含同样的静态成员
#include <iostream>
#include <cstring>
using namespace std;
template <class T>
class A
{
private:
static int count;
public:
A(){count ++;};
~A(){count--;};
A(A &){count++;};
static void PrintCount() {cout << count << endl;}
};
template<> A(int)::count=0; //实例化需要声明静态成员
template<> A(double)::count=0; //实例化需要声明静态成员
int main()
{
A <int> ia;
A <double> da;
ia.PrintCount();
da.PrintCount();
return 0;
}
十四、标准模板库STL
1.string类
typeof basic_string <char> string;
//使用 string 类要包含头文件 <string>
//string对象的初始化
string s1("hello");
string month="March";
string s2(8,'x');
string s;s='n';
//读取string对象的长度
len=s.length();
//读入和输出
cin >> s;
getline(cin,s);
//可以用=赋值
string s1("cat"),s2;
s2=s1;
//可以用assign函数复制
s3.assign(s1,1,3);//从s1中下标为1的字符开始复制3个字符
//逐个访问string对象的字符
for (int i=0;i<s1.length();++i)
{
cout << s1.at(i) << endl;
}
//成员函数at会做范围检查,而下标运算符不做范围检查
//可以使用+或append连接字符串
s1+=s2;
s2.append(s1,3,s1.size());//从下标为3开始,s1.size()个字符,如果字符串内没有足够字符,则复制到字符串最后一个字符
//可以使用比较运算符或compare比较大小
int f1=s1.compare(s2); //相等返回0,s1大于s2返回1,小于返回-1
int f2=s1.compare(1,2,s3,0,3); //s1[1,2]和s3[0,3]比较
//求字串成员函数 substr
string s1("hello world"),s2;
s2=s1.substr(4,5); //下标4开始5个字符
cout << s2 << endl; //o wor
s1.swap(s2); //将s1和s2交换
s1.find("lo");
//在s1中从前向后查找 "lo" 第一次出现的地方,找到就返回 l 所在位置的下标,找不到返回 string::npos(string中定义的静态常量)
s.rfind("lo"); //从后往前找,返回 l 所在位置的下标
s1.find("ll",1); //从下标为1的位置开始找
s1.find_first_of("abcd"); //在s1中从前往后找,"abcd"中任何一个字符第一次出现的地方,返回字母的位置
s1.find_last_of("abcd"); //在s1中从前往后找,"abcd"中任何一个字符最后一次出现的地方,返回字母的位置
s1.find_first_not_of("abcd"); //在s1中从前往后找,不在"abcd"中任何一个字符第一次出现的地方,返回字母的位置
s1.find_last_not_of("abcd");
s1.erase(5); //去掉下标为5及之后的字符
s1.replace(2,3,"haha",1,2); //替换下标从2开始的的3个字符为"haha"中下标从1开始的2个字符
s1.insert(5,s2,5,3); //将s2中下标为5开始的3个字符插入到s1中下标为5的位置
s1.c_str(); //返回传统的const char *类型的字符串,以'\0'结尾 s1.data()返回char * 而不是 const char *
泛型程序设计就是使用模板的程序设计方法,将一些常用的数据结构(比如链表,数组,二叉树)和算法(比如排序,查找)写成模板,以后则不论数据结构里放的是什么对象,算法阵对什么样的对象,则都不必重新实现数据结构,重新编写算法
标准模板库就是一些常用的数据结构和算法的模板的集合。有了STL,不必再写大多的标准数据结构和算法,并且可获得非常高的性能
STL中的基本概念
容器:可以容纳各种数据类型的通用数据结构,就是类模板
迭代器:可用于依次存取容器中元素,类似于指针
算法:用来操作容器中的元素的函数模板
**sort() **来对一个vector中的数据进行排序
find() 来搜索一个list中的对象
算法本身与它们操作的数据结构类型无关,因此他们可以在从简单的数组到高度复杂容器的任何数据结构上使用
容器都是类模板,分为三种
顺序容器:vector(动态数组),deque(双向队列),list(双向链表)
关联容器:set,multiset,map,mutimap
容器适配器:stack(栈),queue(队列),priority_queue(优先级队列)
对象被插入容器中时,被插入的是对象的一个复制品。许多算法要求对容器中的元素进行比较,有的容器本身就是排序的,所以,放入容器的对象所属的类,往往还应该重载 == 和 < 运算符
2.容器和成员函数
容器并非排序的,元素的插入位置同元素的值无关,有 vector,deque,list 三种
vector
动态数组,元素在内存中连续存放。随机存取任何元素都能在常数时间完成。在尾端增删元素具有较佳的性能(大部分情况下是常数时间),在中间或头部添加元素时间复杂度都是 o(n)
deque
双向队列,元素在内存中连续存放。随机存取任何元素都能在常数时间完成(但次于vector)。在两端增删元素具有较佳的性能(大部分情况下是常数时间)
list
双向链表。元素在内存中不连续存放。在任何位置增删元素都能在常数时间内完成。不支持随机存取
关联容器,插入任何元素都按其相应的排序规则来确定其位置,在查找时有非常好的性能,通常以平衡二叉树方式实现,插入和检索时间都是 o(logn)
set/multiset
set 即集合。set中不允许有相同的元素,multiset中允许存在相同的元素
map/multimap
map与set的不同在于map中存放的元素有且仅有两个成员变量,一个名为 first,一个名为 second,map 根据 first 值对元素进行从小到大排序,并可快速地根据 first 来检索元素。map 不允许 first 值相同,multiset 允许
容器适配器
stack
栈。是项的有限序列,并满足序列中被删除,检索和修改的项只能是最近插入序列的项(栈顶的项)。后进先出
queue
队列,插入只可在尾部进行,删除,检索和修改只允许从头部进行,先进先出
priority_queue
优先级队列。最高优先级元素总是第一个出列
顺序容器和关联容器中都有的成员函数
begin 返回指向容器中第一个元素的迭代器
end 返回指向容器中最后一个元素后面的位置的迭代器
rbegin 返回指向容器中最后一个元素的迭代器
rend 返回指向容器中第一个元素前面的位置的迭代器
erase 从容器中删除一个或几个元素
clear 从容器中删除所有元素
顺序容器的常用成员函数
front 返回容器中第一个元素的引用
back 返回容器中最后一个元素的引用
push_back 在容器末尾添加新元素
pop_back 删除容器末尾的元素
erase 删除迭代器指向的元素(可能会使该迭代器失效),或者删除一个区间,返回被删除元素后面的哪个元素的迭代器
3.迭代器
迭代器用于指向顺序容器和关联容器中的元素,迭代器的用法和指针类似,有 const 和非 const 两种。通过迭代器可以读取它所指向的元素,通过非 const 迭代器还能修改其指向的元素
//定义一个容器类的迭代器的方法
容器类名::iterator 变量名;
//或者
容器类名::const_iterator 变量名;
//访问一个迭代器指向的元素
*迭代器名
迭代器可以通过 ++ 来使其指向下一个元素,如果到达了最后一个元素的后面再使用 ++ 会出错,类似使用 NULL 或未初始化的指针一样
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<int> v;
v.push_back(1);v.push_back(2);v.push_back(3);
vector<int>::const_iterator i;
for(i=v.begin();i!=v.end();++i)
{
cout << *i << ",";
}
cout << endl;
vector<int>::reverse_iterator r; //反向迭代器++向头部前进
for(r=v.rbegin();r!=v.rend();++r)
{
cout << *r << ",";
}
cout << endl;
vector<int>::iterator j;
for (j=v.begin();j!=v.end();++j)
{
*j=100;
}
for (i=v.begin();i!=v.end();i++)
{
cout << *i << ",";
}
cout << endl;
}
若 p 和 p1 都是双向迭代器,则可对 p,p1 进行以下操作
++p,p++,*p,p=p1,p==p1,p!=p1
若 p 和 p1 都是随机访问迭代器,则可对 p,p1 进行以下操作
双向迭代器的所有操作
p+=i 将p向后移动 i 个元素
p-=i 将p向前移动 i 个元素
p+i 返回指向p后面的第i个元素的迭代器
p-1 返回指向p前面的第i个元素的迭代器
p[i] 返回p后面的第i个元素的引用
p<p1,p<=p1,p>p1,p>=p1
vector 和 deque 的迭代器是随机访问迭代器,list 和 set,multiset,map,mutimap 是双向迭代器,容器适配器不支持迭代器
有的算法,如 sort,binary_search 需要通过随机访问迭代器来访问容器中的元素,那么 list 以及关联容器就不支持该算法
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<int> v(100);
int i;
for (int i=0;i<v.size();++i)
{
cout << v[i];
}
vector<int>::const_iterator ii;
for (ii=v.begin();ii!=v.end();++ii)
{
cout << *ii;
}
for (ii=v.begin();ii<v.end(); ++ii)
{
cout << *ii;
}
ii=v.begin();
while (ii<v.end())
{
cout << *ii;
ii=ii+2;
}
}
list 不支持 for (ii=v.begin();ii<v.end(); ++ii),只能用 for (ii=v.begin();ii!=v.end();++ii),也不能使用下标
//算法示例:find()
template<class inlt,class T>
inlt find(inlt first,inlt last,const T& val);
//查找[first,last)中等于val的元素,用==运算符判断相等,找到返回被找到的元素迭代器,否则返回的迭代器等于last
4.vector,deque和list
vector 基本使用
#include <iostream>
#include <vector>
using namespace std;
template<class T>
void PrintVector(T s,T e)
{
for(;s!=e;++s) cout << *s << " ";
cout << endl;
}
int main(int argc, char const *argv[])
{
int a[5]={1,2,3,4,5};
vector<int> v(a,a+5); //将数组容器中的内容拷贝到vector
cout << "1)" << v.end()-v.begin() << endl; //5
cout << "2)";
PrintVector(v.begin(),v.end());
v.insert(v.begin()+2,13); //下标为2处插入13
cout << "3)";
PrintVector(v.begin(),v.end());
v.erase(v.begin()+2); //删除下标为2的元素
vector<int> v2(4,100); //有4个元素,每个元素都是100
v2.insert(v2.begin(),v.begin()+1,v.begin()+3); //v中下标为[1,3)的元素拷贝到v2开头的位置
cout << "5)";
PrintVector(v.begin(),v.end());
v.erase(v.begin()+1,v.begin()+3); //删除v中下标为[1,3)的元素
cout << "6)";
PrintVector(v.begin(),v.end());
return 0;
}
vector 二维数组
#include <iostream>
#include <vector>
using namespace std;
int main(int argc, char const *argv[])
{
vector< vector<int> > v(3);
for (int i = 0; i < v.size(); ++i)
{
for (int j=0; j<4; ++j)
{
v[i].push_back(j);
}
}
for (int i = 0; i < v.size(); ++i)
{
for (int j=0; j<v[i].size(); ++j)
{
cout << v[i][j] << " ";
}
cout << endl;
}
return 0;
}
deque
所有适用于 vector 的才足以都适用于 deque。deque 还有 push_front 和 pop_front 操作,复杂度是 o(1)
list
在任何位置插入删除都是常数时间,不支持随机存取
除了具有所有顺序容器都有的成员函数外,还支持8个成员函数
push_front:在前面插入
pop_front:删除前面的元素
sort:排序(list不支持STL的算法sort)
remove:删除和指定值相等的所有元素
unique:删除所有和前一个元素相同的元素(要做到元素不重复,则 unique 之前还需要 sort)
merge:合并两个链表,并清空被合并的那个
reverse:颠倒链表
splice:在指定位置前面插入另一链表中的一个或多个元素,并在另一链表中删除被插入的元素
list 基本使用
#include <iostream>
#include <list>
#include <algorithm>
using namespace std;
class A
{
private:
int n;
public:
A(int n_):n(n_){};
friend bool operator<(const A& a1, const A& a2)
{
return a1.n<a2.n;
}
friend bool operator==(const A& a1,const A& a2)
{
return a1.n==a2.n;
}
friend ostream& operator<<(ostream& o,const A& a)
{
o << a.n;
return o;
}
};
template <class T>
void PrintList(const list<T> &lst)
{
//不推荐这么写,可以使用两个迭代器作为参数
typename list<T>::const_iterator i;
i=lst.begin();
for (i=lst.begin();i!=lst.end();++i)
{
cout << *i << ",";
}
}
int main(int argc, char const *argv[])
{
list<A> lst1,lst2;
for (int i = 0; i < 5; ++i)
{
lst1.push_back(i);
}
lst1.push_back(2);
lst2.push_back(20);
lst2.push_back(10);
lst2.push_back(40);
lst2.push_back(30);
lst2.push_back(30);
lst2.push_back(40);
cout << "1)";PrintList(lst1); cout << endl;
cout << "2)";PrintList(lst2); cout << endl;
lst2.sort();
cout << "3)";PrintList(lst2); cout << endl;
lst2.pop_front();
cout << "4)";PrintList(lst2);cout << endl;
lst1.remove(2); //删除所有和A(2)相等的元素
cout << "5)";PrintList(lst1);cout << endl;
lst2.unique();
cout << "6)";PrintList(lst2);cout << endl;
lst1.merge(lst2);
cout << "7)";PrintList(lst1);cout << endl;
cout << "8)";PrintList(lst2);cout << endl;
lst1.reverse();
cout << "9)";PrintList(lst1);cout << endl;
lst2.push_back(100);
lst2.push_back(200);
lst2.push_back(300);
lst2.push_back(400);
list<A>::iterator p1,p2,p3;
p1=find(lst1.begin(),lst1.end(),3);
p2=find(lst2.begin(),lst2.end(),200);
p3=find(lst2.begin(),lst2.end(),400);
lst1.splice(p1,lst2,p2,p3); //将[p2,p3)插入p1之前,并从lst2中删除[p2,p3)
cout << "10)";PrintList(lst1);cout << endl;
cout << "11)";PrintList(lst2);cout << endl;
return 0;
}
5.函数对象
如果一个类重载了运算符 “()”,则该类的对象就成为函数对象
#include <iostream>
#include <vector>
#include <algorithm>
#include <functional>
#include <numeric>
using namespace std;
/*
dev c++ accumulate 源代码
template <typename _Inputlterator,typename _Tp,typename _BinaryOperation>
_Tp accumulate(_Inputlterator __first,_Inputlterator __last,_Tp __init,_BinaryOperation __binary_op)
{
for(;__first!=__last;++__first) __init=__binary_op(__init,*__first);
return __init;
}
*/
int SumSquares(int total,int value)
{
return total+value*value;
}
template <class T>
void PrintInterval(T first,T last)
{
for (;first!=last;first++) cout << *first << " ";
cout << endl;
}
template <class T>
class SumPowers
{
private:
int power;
public:
SumPowers(int p):power(p){}
const T operator() (const T& total,const T& value)
{
//计算value的power次方和,加到total上
T v=value;
for (int i = 0; i < power-1; ++i)
{
v=v*value;
}
return total+v;
}
};
int main()
{
const int SIZE=10;
int a1[10]={1,2,3,4,5,6,7,8,9,10};
vector<int> v(a1,a1+SIZE);
cout << "1) ";PrintInterval(v.begin(),v.end());
int result=accumulate(v.begin(),v.end(),0,SumSquares);
cout << "2)平方和 " << result << endl; //在这里相当于0^2+1^2+2^2+...+10^2
result=accumulate(v.begin(),v.end(),0,SumPowers<int>(3));
cout << "3)立方和 " << result << endl;
return 0;
}
6.sort
#include <algorithm>
sort(a+n1,a+n2); //从大到小排序
sort(a+n1,a+n2,greater<T>); //从小到大排序
sort(a+n1,a+n2,rule);
struct rule
{
bool operator() (const T &a1,const T &a2) const
{
//a1排在a2之前
return a1<a2;
}
}
//实例
struct Rule
{
bool operator() (const Point &a1,const Point &a2) const
{
int d1=a1.x*a1.x+a1.y*a1.y;
int d2=a2.x*a2.x+a2.y*a2.y;
if (d1==d2)
{
if (a1.x==a2.x)
return a1.y<a2.y;
else
return a1.x<a2.x;
}
else
return d1<d2;
}
};
2.search
sort(a+n1,a+n2,rule);
bool bindary_search(a+n1,a+n2,n3,rule); //等于表示满足"a必须在b前面"和"b必须在a前面"都不成立 //不确定谁在前谁在后
//如果按个位数排,寻找8可能会认为28是一个结果
T *lower_bound(a+n1,a+n2,n3,rule); //返回一个指针T *p,*p是查找区间中最小的,大于等于"值"的元素,未找到p指向下标为n2的元素
T *upper_bound(a+n1,a+n2,n3,rule); //返回一个指针T *p,*p是查找区间中最小的,必定排在"值"后面的元素的元素,未找到p指向下标为n2的元素
3.multiset/set
#include <set>
multiset<T,rule> st; //定义一个类型为multset的变量st,st里面可以存放 T 类型的数据,并且能自动从小到大排序,开始st为空
st.insert; //插入容器的是值的复制
st.find; //找到,返回一个指向待找值的迭代器,找不到,值为end()
st.erase; //删除迭代器指向的元素
//{1,7,8,8,12,13,13,14,19,21}
st.lower_bound(i); //返回最靠后的迭代器it,使得[begin(),it)中的元素都在i的前面 i=13 返回13
st.upper_bound(i); //返回最靠前的迭代器it,使得[it,end())中的元素都在i的后面 i=8 返回12
multiset<T,rule>::iterator i;
//p是迭代器,相当于指针,可用于指向 multiset 中的元素。访问 multiset 中的元素要通过迭代器
//与指针不同
// multiset上的迭代器可以++,--,用!=和==比较,不可比大小,不可加减整数,不可加减
for (i=st.begin()/*指向st第一个元素的迭代器*/;i!=st.end()/*指向st最后一个元素后面的迭代器(什么都没有)*/;i++)
{
printf(*i)
}
set;//类似multiset,不能有重复(满足"a必须在b前面"和"b必须在a前面"都不成立)元素,可能插入不成功
pair <set<T>::iterator,bool> result=st.insert(i);
for (!result.second) //条件成立说明插入不成功 result.first 是插入的数字
pair <T1,T2>; //等价于下面的结构
struct
{
T1 first;
T2 second;
}
9.multimap/map
#include <map>
multimap<T1,T2> mp;
struct{
T1 first; //关键字
T2 second; //值
}
typedef multimap<int,studentinfo> MAP_STD;
mp.insert(make_pair(st.score,st.info)); //插入
MAP_STD::iterator p=mp.lower_bound(score); //查找 查不到返回mp.begin()
//map不能有关键字重复的元素
//可以使用[],下标为关键字,返回值为first和关键字相同的元素second
//插入元素可能失败
10.容器适配器
容器适配器没有迭代器
stack
stack 是后进先出的数据结构,只能插入,删除,访问其栈顶的元素
可用 vector,list,deque 来实现。默认情况用 deque 实现
template<class T,class Cont = deque<T>
class stack
{
...
};
stack 上可以进行 push 插入,pop 弹出,top 返回栈顶元素的引用
queue
和 stack 基本类似,可用 vector,deque 来实现。默认情况用 deque 实现
template<class T,class Cont=deque<T>
class queue
{
...
};
同样也有 push 在尾部添加元素,pop 弹出头部元素,top 返回头部元素,back 返回队尾元素的引用。先进先出
priority_queue
template<class T,class Container=vector<T>,class Comopare=less<T> >
class priority_queue;
和 queue 类似,可以使用 vector 和 deque 实现。默认使用 vector 实现
priority_queue 通过用堆排序技术实现,保证最大的元素总是在最前面,即执行 pop 操作时,删除的是最大的元素;执行 top 操作时,返回的是最大元素的引用。默认的比较器是 less
#include <queue>
#include <iostream>
using namespace std;
int main(int argc, char const *argv[])
{
priority_queue<double> pq1;
pq1.push(3.2);
pq1.push(9.8);
pq1.push(9.8);
pq1.push(5.4);
while (!pq1.empty())
{
cout << pq1.top() << " "; //9.8 9.8 5.4 3.2
pq1.pop();
}
return 0;
}
#include <queue>
#include <iostream>
using namespace std;
int main(int argc, char const *argv[])
{
priority_queue<double,vector<double>,greater<double> > pq1;
pq1.push(3.2);
pq1.push(9.8);
pq1.push(9.8);
pq1.push(5.4);
while (!pq1.empty())
{
cout << pq1.top() << " "; //9.8 9.8 5.4 3.2
pq1.pop();
}
return 0;
}
容器适配器的成员函数 empty() 可以判断适配器是否为空 size() 返回容器适配器中元素的个数
11.STL算法分类
STL 中大多数重载的算法都是有两个版本的,用 == 判断元素是否相等,或者用 “<” 来比较大小
多出一个类型参数 Pred 和 函数形参 Pred op 通过表达式 op(x,y) 的返回值来判断 x 是否"等于"y,或者 x 是否"小于"y
如下面的有两个版本的 min_element:
iterator min_element(iterator first,iterator last);
iterator min_element(iterator first,iterator last,Pred op);
11.1.不变序列算法
该类算法不会修改算法所作用的容器或对象,适用于顺序容器和关联容器。时间复杂度都是 O(n)
// 约定`表示可以自定义比较器
min; //两个对象中较小的`
max; //两个对象中较大的`
min_element; //区间中最小的`
max_element; //区间中最大的`
for_each; //对区间中的每个元素都做某种操作
count; //计算区间中等于某值的元素个数
count_if; //计算区间中符合某种条件的元素的个数
find; //在区间中查找等于某值的元素
find_if; //在区间中查找符合某条件的元素
find_end; //在区间中查找另一个区间最后一次出现的位置`
find_first_of; //在区间中查找第一个出现在另一个区间的元素的位置`
adjacent_find; //在区间中寻找第一次出现两个连续相等元素的位置`
search; //在区间中查找另一个区间第一次出现的位置`
search_n; //在区间中查找第一次出现等于某值的连续n个元素`
equal; //判断两区间是否相等`
mismatch; //逐个比较两区间元素,返回第一次发生不相等的两个元素的位置
lexicographical_compare; //按字典序比较两个区间的大小`
#include <iostream>
#include <algorithm>
using namespace std;
class A
{
public:
int n;
A(int i):n(i){}
};
bool operator<(const A& a1,const A& a2)
{
cout << "<called" << endl;
if(a1.n==3 && a2.n==7) return true;
return false;
}
int main(int argc, char const *argv[])
{
A aa[]={3,5,7,2,1};
cout << min_element(aa,aa+5)->n << endl;
cout << max_element(aa,aa+5)->n << endl;
return 0;
}
/*
<called 5<3? false min=3
<called 7<3? flase min=3
<called 2<3? flase min=3
<called 1<3? flase min=3
3
<called 3<5? flase max=3
<called 3<7? true max=7
<called 7<2? flase min=7
<called 7<1? flase min=7
7
*/
11.2.变值算法
此类算法会修改区间或目标区间元素的值
值被修改的那个区间,不可用是属于关联容器的
for_each; //对区间中的每个元素都做某种操作
copy; //复制一个区间到别处
copy_backward; //复制一个区间到别处,但目标区前是从后往前被修改的
transform; //将一个区间的元素变形后拷贝到另一个区间
swap_ranges; //交换两个区间内容
fill; //用某个值填充区间
fill_n; //用某个值代替区间中的n个元素;
generate; //用某个操作的结果填充区间
generate_n; //用某个操作的结果替换区间中的n个元素
replace; //将区间中的值替换成另一个值
replace_if; //将区间中符合某种条件的值替换成另一个值
replace_copy; //将一个区间拷贝到另一个区间,拷贝时某个值要换成新值拷过去
replace_copy_if; //将一个区间拷贝到另一个区间,拷贝时符合某个条件的值要换成新值拷过去
#include <iostream>
#include <vector>
#include <list>
#include <numeric>
#include <iterator>
#include <algorithm>
using namespace std;
class CLessThen9
{
public:
bool operator()(int n){return n<9;};
};
void outputSquare(int value){cout << value*value << " ";}
int calculateCube(int value){cout << value*value*value;}
int main(int argc, char const *argv[])
{
const int SIZE=10;
int a1[]={1,2,3,4,5,6,7,8,9,10};
int a2[]={100,2,8,1,50,3,8,9,10,2};
vector<int> v(a1,a1+SIZE);
ostream_iterator<int> output(cout," "); //输出的每一项都是整数,且每一项输出完毕后增加空格
random_shuffle(v.begin(),v.end()); //乱序
cout << endl << "1)";
copy(v.begin(),v.end(),output); //乱序之后的数组 1)9 2 10 3 1 6 8 4 5 7
copy(a2,a2+SIZE,v.begin()); //要保证目标地址有 SIZE 的足够空间
cout << endl << "2)";
cout << count(v.begin(),v.end(),8); //2
cout << endl << "3)";
cout << count_if(v.begin(),v.end(),CLessThen9()); //6
cout << endl << "4)";
cout << *(min_element(v.begin(),v.end())); //1
cout << endl << "5)";
cout << *(max_element(v.begin(),v.end())); //100
cout << endl << "6)";
cout << accumulate(v.begin(),v.end(),0); //193
cout << endl << "7)";
for_each(v.begin(),v.end(),outputSquare); //7)10000 4 64 1 2500 9 64 81 100 4 1827641252163435127291000
vector<int> cubes(SIZE);
transform(a1,a1+SIZE,cubes.begin(),calculateCube);
cout << endl << "8)";
copy(cubes.begin(),cubes.end(),output); //8)4753920 4753920 4753920 4753920 4753920 4753920 4753920 4753920 4753920 4753920
return 0;
}
ostream_iterator<int> output(cout," ");
//定义了一个 ostream_iterator<int> 对象,可以通过cout输出以" "分割的一个个整数
copy(v.begin(),v.end(),output);
template<class init,class Outit>
Outit copy(init first,init last,Outit x);
//本函数对每个在区间(0,last-first)中的N执行一次
// *(x+N)=*(first+N),返回x+N
//下面是copy的源代码
template<class _II,class _OI>
inline _OI copy(_II _F._II _L,_OI _X)
{
for(;_F!=_L;++_X,++_F)
{
*_X=*_F;
}
return (_X);
}
11.3.删除算法
删除一个容器里的某些元素,但不会使得容器内元素减少。可以将所有应该被删除的元素看作空位,用留下的元素从后往前移,一次去填空位,元素往前移后,它原来的位置也就算是空位子,也应由后面的元素来填上,最后,没有被填上的空位子,维持原来的值不变。删除算法不应该作用于关联容器。算法的复杂度都是 O(n)
// 约定`表示可以自定义比较器
remove; //删除区间中等于某个值的元素
remove_if; //删除区间中满足某种条件的元素
remove_copy; //拷贝区间到另一个区间,等于某个值的元素不拷贝
remove_copy_if; //拷贝区间到另一个区间,符合某种条件的元素不拷贝
unique; //删除区间中连续相等的元素,只留下一个`
unique_copy; //拷贝区间到另一个区间,联显相等的元素,只拷贝第一个到目标区间
#include <iostream>
#include <vector>
#include <list>
#include <numeric>
#include <iterator>
#include <algorithm>
using namespace std;
int main(int argc, char const *argv[])
{
int a[5]={1,2,3,2,5};
int b[6]={1,2,3,2,5,6};
ostream_iterator<int> oit(cout,",");
int *p=remove(a,a+5,2);
cout << "1)";copy(a,a+5,oit);cout << endl; // 1) 1,3,5,2,5, 运行过程: 1, ,3, ,5, --> 1,3,5, , ,--> 1,3,5,2,5(空位置填不上了就保持不变)
cout << "2)"<< p-a << endl; //3
vector<int> v(b,b+6);
remove(v.begin(),v.end(),2);
cout << "3)";copy(v.begin(),v.end(),oit);cout << endl; //3)1,3,5,6,5,6,
cout << "4)";cout << v.size() << endl; //4)6
return 0;
}
11.4.变序算法
变序算法改变容器中元素的顺序,但是不改变元素的值,变序算法不适用于关联容器,算法复杂度都是 O(n)
// 约定`表示可以自定义比较器
reverse; //颠倒区间的前后次序
reverse_copy; //把一个区间颠倒后的结果拷贝到另一个区间,源区间不变
rotate; //将区间进行循环左移
rotate_copy; //将区间以首尾相接的形式进行旋转后的结果拷贝到另一个区间,源区间不变
next_permutation; //将区间改为下一个排列`
prev_permutation; //将区间改为上一个排列`
random_shuffle; //随机打乱区间内元素的顺序
partition; //把区间满足某个条件的元素移到前面,不满足条件的移到后面
#include <iostream>
#include <string>
#include <algorithm>
using namespace std;
int main(int argc, char const *argv[])
{
string str="231";
char szStr[]="324";
while (next_permutation(str.begin(),str.end()))
{
cout << str << endl; //312\n321
}
cout << "****" << endl;
while (next_permutation(szStr,szStr+3))
{
cout << szStr << endl; //342\n423\n432
}
sort(str.begin(),str.end());
cout << "****" << endl;
while(next_permutation(str.begin(),str.end()))
{
cout << str << endl; //排列
}
return 0;
}
11.5.排序算法
比前面的变序算法复杂度更高,一般是 O(nlog(n)) 排序算法需要随机访问迭代器的支持 不适用于关联容器和 list
// 约定`表示可以自定义比较器
sort; //将区间从小到大排序`
stable_sort; //将区间从小到大排序
partial_sort; //对区间部分排序,直到最小的n个元素就位`
partial_sort_copy; //将区间前n个元素的排序结果拷贝到别处源区间不变`
nth_element; //对区间部分排序,使得第n小的元素(n从0开始算)就位,且比它小的都在它前面,比它小的都在它后面`
make_heap; //使区间成为一个"堆"`
push_heap; //将元素加入一个是"堆"区间`
pop_heap; //从"堆"区间删除堆顶元素`
sort_heap; //将一个"堆"进行排序,排序结束后,该区间就是普通的有序区间,不再是"堆"了`
#include <iostream>
#include <algorithm>
using namespace std;
class Myless
{
public:
bool operator()(int n1,int n2)
{
return (n1%10)<(n2%10);
}
};
int main(int argc, char const *argv[])
{
int a[]={14,2,9,111,78};
sort(a,a+5,Myless());
int i;
for (i=0;i<5;i++) cout << a[i] << "";
cout << endl;
sort(a,a+5,greater<int>());
for (int i = 0; i < 5; ++i)
{
cout << a[i] << "";
}
return 0;
}
11.6.有序区间算法
要求所操作的区间是已经从小到大排好序的,需要随机访问迭代器的支持。有序区间算法不能用于关联容器和 list
binary_search; //判断区间中是否包含某个元素
includes; //判断一个区间中的每个元素,都在另一区间中
lower_bound; //查找最后一个不小于某值的元素的位置
upper_bound; //查找第一个大于某值的元素的位置
equal_range; //同时获取lower_bound和upper_bound
merage; //合并两个有序区间到第三个区间
set_union; //将两个有序区间的并拷贝到第三个区间
set_intersection; //将两个有序区间的交拷贝到第三个区间
set_difference; //将两个有序区间的差拷贝到第三个区间
set_symmetric_difference; //将两个有序区间的对称差拷贝到第三个区间
inplace_merage; //将两个连续的有序集合原地合并为一个有序区间
#include <iostream>
#include <algorithm>
#include <iterator>
#include <vector>
using namespace std;
bool Greater10(int n)
{
return n>10;
}
int main(int argc, char const *argv[])
{
const int SIZE=10;
int a1[]={2,8,1,50,3,100,8,9,10,2};
vector<int> v(a1,a1+SIZE);
ostream_iterator<int> output(cout," ");
vector<int>::iterator location;
location=find(v.begin(),v.end(),10);
if (location != v.end())
{
cout << endl << "1)" << location-v.begin();
}
location=find_if(v.begin(),v.end(),Greater10);
if (location!=v.end())
{
cout << endl << "2)" << location-v.begin();
}
sort(v.begin(),v.end());
if (binary_search(v.begin(),v.end(),9))
{
cout << endl << "3)" << "9 found";
}
return 0;
}
十五、C++新标准
1.统一的初始化方法
int arr[3]{1,2,3};
vector<int> iv{1,2,3};
map<int,string> mp{{1,"a"},{2,"b"}};
string str{"hello world"};
int *p=new int[20]{1,2,3};
struct A
{
int i,j;
A(int m,int n):i(m),j(n) {}
};
A func(int m,int n){return {m,n};};
int main(){A *pa=new A {3,7};}
2.成员变量有默认初始值
class B
{
public:
int m=1234;
int n;
}
3.auto 关键字
auto 用于定义变量,编译器可以自动判断变量的类型
auto i=100; //int
auto k=3434LL; //long long
map<string,int,greater<string> >mp;
for (auto i=mp.begin();i!=mp.end();++i)
cout << i->first << "," << i->second;
class A{};
A operator+(int n,const A&a)
{
return a;
}
template <class T1,class T2>
auto add(T1 x,T2 y)->decltype(x+y) //decltype相当于Python中的type
{
return x+y;
}
auto d = add(100,1.5); //d是double类型
auto k = add(100,A()); //k是A类型
decltype 关键字
int i;
struct A {double x;};
const A *a=new A();
decltype(a) x1; //x1是A*
decltype(i) x2; //x2是int
decltype(a->x) x3 //x3是double&
4**.智能指针 shared_ptr**
头文件
通过 shared_ptr 的构造函数,可以让 shared_ptr 对象托管一个 new 运算符返回的指针,写法如下
shared_ptr<T> ptr (new T); // T 可以是类型
// ptr 可以像 T* 类型的指针一样来使用,不必担心释放内存的事情
多个 shared_ptr 对象可以同时托管一个指针,系统会维护一个托管计数。当无 shared_ptr 托管该指针时,delete 该指针
shared_ptr 对象不能托管指向动态分配的数组的指针,否则程序运行出错
#include <memory>
#include <iostream>
using namespace std;
struct A
{
int n;
A(int v=0):n(v){};
~A(){cout << n << "destructor" << endl;}
};
int main(int argc, char const *argv[])
{
shared_ptr<A> sp1(new A(2)); //sp1托管指向A(2)的指针
shared_ptr<A> sp2(sp1); //sp2也托管指向A(2)的指针
cout << "1)" << sp1->n << "," << sp2->n << endl;
shared_ptr<A> sp3;
A *p=sp1.get(); //get()取得sp1托管的指针,p指向了 A(2)
cout << "2)" << p->n << endl;
sp3=sp1; //sp3也托管A(2)
cout << "3)" << *sp3.n << endl;
sp1.reset(); //sp1放弃托管A(2)
if (!sp1) cout << "4)sp1 is null" << endl;
A *q =new A(3);
sp1.reset(q); //sp1托管q
cout << "5)" << sp1->n << endl;
shared_ptr<A> sp4(sp1) //sp4托管A(3)
shared_ptr<A> sp5;
// sp5.reset(q); //不妥,会导致程序出错,程序并不增加对q的托管计数,程序不知道这里的q和上面一样
sp1.reset(); //sp1放弃托管A(3)
cout << "before end main" << endl;
sp4.reset(); //sp4放弃托管A(3) delete new(A(3))
cout << "end main" << endl;
return 0;
}
5.空指针 nullptr
#include <memory>
#include <iostream>
using namespace std;
int main(int argc, char const *argv[])
{
int *p1=NULL;
int *p2=nullptr;
shared_ptr<double> p3=nullptr;
if(p1==p2) cout << "equal 1";
if (p3==nullptr) cout << "equal 2";
//if (p3==p2) error 类型不匹配
if (p3==NULL) cout << "equal 4";
bool b=nullptr; //b=false;
//int i=nullptr; error
return 0;
}
6.基于范围的for循环
#include <memory>
#include <iostream>
using namespace std;
struct A
{
int n;
A(int i):n(i){}
};
int main(int argc, char const *argv[])
{
int ary[]={1,2,3,4};
for (int & e:ary) //对ary中的每个元素e
{
e*=10;
}
for (int e:ary)
{
cout << e << ",";
}
cout << endl;
vector<A> st(ary,ary+4);
for (auto &it:st)
{
it.n*=10;
}
for (A it:st)
{
cout << it.n << ",";
}
cout << endl;
return 0;
}
7.右值引用和move语义
class A();
A && r=A() //r是右值引用,&&表示右值引用
#include <iostream>
#include <string>
#include <cstring>
using namespace std;
class String
{
public:
char *str;
String():str(new char[1]){str[0]=0};
String(const char * s)
{
str=new char[strlen(s)+1];
strcpy(str,s);
}
String(const String &s)
{
cout << "copy constructor called" << endl;
str=new char[strlen(s.str)+1];
strcpy(str,s.str);
}
String & operator=(const String &s)
{
cout << "copy operator=called" << endl;
if(str!s.str)
{
delete [] str;
str = new char[strlen(s.str)+1];
strcpy(str,s.str);
}
return *this;
}
//move constructor
String(String && s):str(s.str)
{
cout << "move constructor called" << endl;
s.str=new char[1];
s.str[0]=0;
}
//move assignment
String & operator=(String && s)
{
cout << "move operator= called" << endll
if(str!=s.str)
{
delete [] str;
str=s.str;
s.str=new char[1];
s.str[0]=0;
}
return *this;
}
~String(){delete [] str;}
};
template <class T>
void MoveSwap(T & a,T & b)
{
T tmp(move(a)); //std::move(a)为右值,这里会调用move constructor,使tmp指向a的地方,而a指向新的地方
a=move(b); //右值调用move assignment
}
8.无序容器(哈希表)
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{
unordered_map<string, int> turingWinner;
turingWinner.insert(make_pair("Dijkstra", 1972));
turingWinner.insert(make_pair("Scott", 1977));
turingWinner.insert(make_pair("Wilkes", 1967));
turingWinner["Ritchie"] = 1983;
string name;
cin >> name; //输入姓名
unordered_map<string, int>::iterator p = turingWinner.find(name);
if (p != turingWinner.end())
{
cout << p->second;
}
else
{
cout << "Not found";
}
return 0;
}
9.正则表达式
#include <iostream>
#include <regex>
#include <unordered_map>
using namespace std;
int main()
{
regex reg("b.?p.*k");
cout << regex_match("bopggk", reg) << endl;
cout << regex_match("boopggkss", reg) << endl;
return 0;
}
10.lambda表达式
//[外部变量访问方式说明符](参数表)->返回值类型
{
//语句组
};
//外部变量访问方式说明符可以是下面的方式
//[=] 以传值的形式使用所有外部变量
//[] 不使用任何外部变量
//[&] 以引用形式使用所有外部变量
//[x,&y] x 以传值形式使用,y 以引用形式使用
//[=,&x,&y] x,y 以引用形式使用,其余变量以传值形式使用
//[&,x,y] x,y 以传值形式使用,其余变量以引用形式使用
// ->返回值类型也可以没有,没有则编译器自动判断返回值类型
在算法中的简单使用
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
int main()
{
int x = 100, y = 200, z = 300;
cout << [](double a, double b) {return a + b;} (1.2, 2.5) << endl;
auto ff = [=, &y, &z](int n)
{
cout << x << endl;
y++; z++;
return n * n;
};
cout << ff(15) << endl;
cout << y << "," << z << endl;
int a[4] = { 4,2,11,33 };
sort(a, a + 4, [](int x, int y)->bool {return x % 10 < y % 10; });
for_each(a, a + 4, [](int x) {cout << x << " "; });
vector<int> b{ 1,2,3,4 };
int total = 0;
for_each(b.begin(), b.end(), [&](int& x) {total += x; x *= 2; });
cout << total << endl;
for_each(b.begin(), b.end(), [](int x) {cout << x << ""; });
return 0;
}
实现递归求斐波那契数列第n项
#include <iostream>
#include <functional>
using namespace std;
int main()
{
function<int(int)> fib = [&fib](int n) // fib是返回值为int,有一个int参数的函数(求斐波那契数列的函数)
{
return n <= 2 ? 1 : fib(n - 1) + fib(n - 2);
};
cout << fib(5) << endl;
return 0;
}
十六、强制类型转换
static_cast
static_cast 用来比较 “自然” 和低风险的转换,比如整型和实数型,字符型之间互相转换
static_cast 不能来在不同类型的指针之间互相转换,也不能用于整型和指针之间的互相转换,也不能用于不同类型的引用之间的转换
#include <iostream>
using namespace std;
class A
{
public:
operator int() { return 1; };
operator char* () { return NULL; };
};
int main()
{
A a;
int n;
char p[] = "New Dragon Inn";
n = static_cast<int>(3.14); //n的值变为3
n = static_cast<int>(a); //调用a.operator int,n的值变为1
char *k = static_cast<char*>(a); //调用a.operator char*,k的值为NULL;
//n = static_cast<int>(p);编译出错,static_cast不能将指针转换为整型
//p=static_cast<char *>(n);编译出错,static_cast不能将整型转换为指针
}
reinterpret_cast
reinterpret_cast 用来进行不同的指针之间的转换,不同类型的引用之间转换,以及指针和能容纳得侠指针的整数类型之间的转换(内存空间能够容纳得下),转换的时候进行的是逐个比特的拷贝
#include <iostream>
using namespace std;
class A
{
public:
int i, j;
A(int n):i(n),j(n){}
};
int main()
{
A a(100);
int& r = reinterpret_cast<int&>(a); //强行让r引用a
r = 200; //把r的地址写上200
cout << a.i << "," << a.j << endl; //200,100
int n = 300;
A* pa = reinterpret_cast<A*>(&n); //强行让pa指向n
pa->i = 400; //把n的内存写上400
//pa->j = 500; //把n的后四个字节写上500,很可能导致程序崩溃
cout << n << endl; //400
long long la = 0x12345678abcdLL;
pa = reinterpret_cast<A*>(la); //la太长,只取低32位(4个字节)0x5678abcd拷贝给pa
unsigned int u = reinterpret_cast<unsigned int>(pa); //pa逐个拷贝到u
cout << hex << u << endl;
typedef void(*PF1)(int); //函数指针PF1,参数是int,返回值是void
typedef int (*PF2)(int, char*);
PF1 pf1;
PF2 pf2;
//pf2 = reinterpret_cast<PF2>(pf1); //两个不同类型的函数指针可以互相转换
return 0;
}
const_cast
const string 用来去除 const 属性的转换,将 const 引用转换成同类型的非 const 引用,将 const 指针转换为同类型的非 const 指针时用它,例如
const string s="inception";
string &p=const_cast<string&>(s);
string *ps=const_cast<srting*>(&s);
dynamic_cast
dynamic_cast 专门用于将**多态基类(包含虚函数的基类)**的引用或指针强制转换为派生类的指针或引用,而且能够检查转换的安全性。对于不安全的指针转换,转换结果返回 NULL 指针
dynamic_cast 不能用于将非多态基类的指针或引用,强制转换为派生类的指针或引用
#include <iostream>
#include <string>
using namespace std;
class Base
{
public:
virtual ~Base() {};
};
class Derived:public Base{};
int main()
{
Base b;
Derived d;
Derived* pd;
pd = reinterpret_cast<Derived*>(&b); //不安全,但不会提示,仍然赋值
if (pd == NULL)
{
cout << "unsafe reinterpret_cast" << endl;
}
pd = dynamic_cast<Derived*>(&b);
if (pd == NULL) //不安全,会提醒
{
cout << "unsafe dynamic_cast1" << endl;
}
Base* pb = &d;
pd = dynamic_cast<Derived*>(pb); //安全的转换
if (pd == NULL)
{
cout << "unsafe dynamic_cast2" << endl;
}
return 0;
}
十七、异常处理
用 try,catch 处理异常
#include <iostream>
using namespace std;
int main()
{
double m, n;
cin >> m >> n;
try
{
cout << "before dividing" << endl;
if (n == 0)
{
throw - 1; //抛出int异常
}
else
{
cout << m / n << endl;
}
cout << "after dividing" << endl;
}
catch(double d)
{
cout << "catch(double)" << d << endl;
}
catch (int e)
{
cout << "catch(int)" << e << endl;
}
catch(...)
{
cout << "捕获除int和double以外的异常"
}
cout << "finished" << endl;
}
如果函数在执行的过程中,抛出的异常在本函数内就被 catch 捕获并处理了,那么该异常就不会抛给这个函数的调用者;如果异常在本函数中没有被处理,就会抛给函数调用者
#include <iostream>
#include <string>
using namespace std;
class CExption
{
public:
string msg;
CExption(string s):msg(s){}
};
double Devide(double x, double y)
{
if (y == 0)
throw CExption("devided by zero");
cout << "in Devide" << endl;
}
int CountTax(int salary)
{
try
{
if (salary < 0) throw - 1;
cout << "counting tax" << endl;
}
catch (int)
{
cout << "salary<0" << endl;
}
cout << "tax counted" << endl;
}
int main()
{
double f = 1.2;
try
{
CountTax(-1);
f = Devide(3, 0);
cout << "end of try block" << endl;
}
catch (CExption e)
{
cout << e.msg << endl;
}
cout << "f=" << f << endl;
cout << "finished" << endl;
return 0;
}
bad_cast
在用dynamic_cast 进行多态基类对象(或引用)到派生类的引用的强制类型转换时,如果转换是不安全的会抛出此异常
#include <iostream>
#include <stdexcept>
#include <typeinfo>
using namespace std;
class Base
{
virtual void func() {}
};
class Derived :public Base
{
public:
void Print() {}
};
void PrintObj(Base& b)
{
try
{
Derived& rd = dynamic_cast<Derived&>(b);
//此转换若不安全,会抛出bad_cast
rd.Print();
}
catch (bad_cast& e)
{
cerr << e.what() << endl;
}
}
int main()
{
Base b;
PrintObj(b); //抛出异常
return 0;
}
bad_alloc
在用 new 运算符进行动态内存分配时,如果没有足够的内存会引发此异常
#include <iostream>
#include <stdexcept>
#include <typeinfo>
using namespace std;
int main()
{
try
{
char* p = new char[0x7fffffff];
}
catch (const std::exception& e)
{
cerr << e.what() << endl; //bad allocation
}
}
out_of_range
用 vector 或 string 的 at 成员函数根据下标访问元素时,如果下标越界,抛出此异常
#include <iostream>
#include <stdexcept>
#include <vector>
#include <string>
#include <typeinfo>
using namespace std;
int main()
{
vector<int> v(10);
try
{
v.at(100) = 100;
}
catch (const std::exception& e)
{
cerr << e.what() << endl; //invalid vector subscript
}
}
n <= 2 ? 1 : fib(n - 1) + fib(n - 2);
};
cout << fib(5) << endl;
return 0;
}
# 十六、强制类型转换
**static_cast**
static_cast 用来比较 "自然" 和低风险的转换,比如整型和实数型,字符型之间互相转换
static_cast 不能来在不同类型的指针之间互相转换,也不能用于整型和指针之间的互相转换,也不能用于不同类型的引用之间的转换
```c++
#include <iostream>
using namespace std;
class A
{
public:
operator int() { return 1; };
operator char* () { return NULL; };
};
int main()
{
A a;
int n;
char p[] = "New Dragon Inn";
n = static_cast<int>(3.14); //n的值变为3
n = static_cast<int>(a); //调用a.operator int,n的值变为1
char *k = static_cast<char*>(a); //调用a.operator char*,k的值为NULL;
//n = static_cast<int>(p);编译出错,static_cast不能将指针转换为整型
//p=static_cast<char *>(n);编译出错,static_cast不能将整型转换为指针
}
reinterpret_cast
reinterpret_cast 用来进行不同的指针之间的转换,不同类型的引用之间转换,以及指针和能容纳得侠指针的整数类型之间的转换(内存空间能够容纳得下),转换的时候进行的是逐个比特的拷贝
#include <iostream>
using namespace std;
class A
{
public:
int i, j;
A(int n):i(n),j(n){}
};
int main()
{
A a(100);
int& r = reinterpret_cast<int&>(a); //强行让r引用a
r = 200; //把r的地址写上200
cout << a.i << "," << a.j << endl; //200,100
int n = 300;
A* pa = reinterpret_cast<A*>(&n); //强行让pa指向n
pa->i = 400; //把n的内存写上400
//pa->j = 500; //把n的后四个字节写上500,很可能导致程序崩溃
cout << n << endl; //400
long long la = 0x12345678abcdLL;
pa = reinterpret_cast<A*>(la); //la太长,只取低32位(4个字节)0x5678abcd拷贝给pa
unsigned int u = reinterpret_cast<unsigned int>(pa); //pa逐个拷贝到u
cout << hex << u << endl;
typedef void(*PF1)(int); //函数指针PF1,参数是int,返回值是void
typedef int (*PF2)(int, char*);
PF1 pf1;
PF2 pf2;
//pf2 = reinterpret_cast<PF2>(pf1); //两个不同类型的函数指针可以互相转换
return 0;
}
const_cast
const string 用来去除 const 属性的转换,将 const 引用转换成同类型的非 const 引用,将 const 指针转换为同类型的非 const 指针时用它,例如
const string s="inception";
string &p=const_cast<string&>(s);
string *ps=const_cast<srting*>(&s);
dynamic_cast
dynamic_cast 专门用于将**多态基类(包含虚函数的基类)**的引用或指针强制转换为派生类的指针或引用,而且能够检查转换的安全性。对于不安全的指针转换,转换结果返回 NULL 指针
dynamic_cast 不能用于将非多态基类的指针或引用,强制转换为派生类的指针或引用
#include <iostream>
#include <string>
using namespace std;
class Base
{
public:
virtual ~Base() {};
};
class Derived:public Base{};
int main()
{
Base b;
Derived d;
Derived* pd;
pd = reinterpret_cast<Derived*>(&b); //不安全,但不会提示,仍然赋值
if (pd == NULL)
{
cout << "unsafe reinterpret_cast" << endl;
}
pd = dynamic_cast<Derived*>(&b);
if (pd == NULL) //不安全,会提醒
{
cout << "unsafe dynamic_cast1" << endl;
}
Base* pb = &d;
pd = dynamic_cast<Derived*>(pb); //安全的转换
if (pd == NULL)
{
cout << "unsafe dynamic_cast2" << endl;
}
return 0;
}
十七、异常处理
用 try,catch 处理异常
#include <iostream>
using namespace std;
int main()
{
double m, n;
cin >> m >> n;
try
{
cout << "before dividing" << endl;
if (n == 0)
{
throw - 1; //抛出int异常
}
else
{
cout << m / n << endl;
}
cout << "after dividing" << endl;
}
catch(double d)
{
cout << "catch(double)" << d << endl;
}
catch (int e)
{
cout << "catch(int)" << e << endl;
}
catch(...)
{
cout << "捕获除int和double以外的异常"
}
cout << "finished" << endl;
}
如果函数在执行的过程中,抛出的异常在本函数内就被 catch 捕获并处理了,那么该异常就不会抛给这个函数的调用者;如果异常在本函数中没有被处理,就会抛给函数调用者
#include <iostream>
#include <string>
using namespace std;
class CExption
{
public:
string msg;
CExption(string s):msg(s){}
};
double Devide(double x, double y)
{
if (y == 0)
throw CExption("devided by zero");
cout << "in Devide" << endl;
}
int CountTax(int salary)
{
try
{
if (salary < 0) throw - 1;
cout << "counting tax" << endl;
}
catch (int)
{
cout << "salary<0" << endl;
}
cout << "tax counted" << endl;
}
int main()
{
double f = 1.2;
try
{
CountTax(-1);
f = Devide(3, 0);
cout << "end of try block" << endl;
}
catch (CExption e)
{
cout << e.msg << endl;
}
cout << "f=" << f << endl;
cout << "finished" << endl;
return 0;
}
bad_cast
在用dynamic_cast 进行多态基类对象(或引用)到派生类的引用的强制类型转换时,如果转换是不安全的会抛出此异常
#include <iostream>
#include <stdexcept>
#include <typeinfo>
using namespace std;
class Base
{
virtual void func() {}
};
class Derived :public Base
{
public:
void Print() {}
};
void PrintObj(Base& b)
{
try
{
Derived& rd = dynamic_cast<Derived&>(b);
//此转换若不安全,会抛出bad_cast
rd.Print();
}
catch (bad_cast& e)
{
cerr << e.what() << endl;
}
}
int main()
{
Base b;
PrintObj(b); //抛出异常
return 0;
}
bad_alloc
在用 new 运算符进行动态内存分配时,如果没有足够的内存会引发此异常
#include <iostream>
#include <stdexcept>
#include <typeinfo>
using namespace std;
int main()
{
try
{
char* p = new char[0x7fffffff];
}
catch (const std::exception& e)
{
cerr << e.what() << endl; //bad allocation
}
}
out_of_range
用 vector 或 string 的 at 成员函数根据下标访问元素时,如果下标越界,抛出此异常
#include <iostream>
#include <stdexcept>
#include <vector>
#include <string>
#include <typeinfo>
using namespace std;
int main()
{
vector<int> v(10);
try
{
v.at(100) = 100;
}
catch (const std::exception& e)
{
cerr << e.what() << endl; //invalid vector subscript
}
}