stringЪЧSTLжаЕФРр,ЯрБШгкCгябдЕФзжЗћЪ§зщКЭзжЗћжИеы,stringЖдзжЗћДЎЕФДІРэЗНБуКмЖрЁЃ
ЮФеТФПТМ
вЛЁЂзжЗћЕФвЛаЉВЙГф
жкЫљжмжЊгЂЮФзжЗћЕШЗћКХдкМЦЫуЛњжаВЩгУASCIIТыЕФЗНЪНДЂДцЁЃ
ЕЋЪЧЖдгкжаЮФЕШЦфЫћзжЗћ,ASCIIТыдђЮоЗЈБэЪО(вђЮЊвЛИізжНкДцВЛЯТ),ЖдгкетаЉзжЗћ,дђВЩгУUnicodeБрТыУДБъзМ:ЫќЮЊУПжжгябджаЕФУПИізжЗћЩшЖЈСЫЭГвЛВЂЧвЮЈвЛЕФЖўНјжЦБрТы,вдТњзуПчгябдЁЂПчЦНЬЈНјааЮФБОзЊЛЛЁЂДІРэЕФвЊЧѓЁЃЕБШЛUnicodeБъзМЯТзжЗћЪЧСНИізжНк,етбљОЭФмДцЯТДѓВПЗжзжЗћСЫЁЃ
ЕБШЛвВгааТЕФзжЗћаЭwchar_tРДДцДЂСНИізжНкЕФзжЗћЁЃ

ЖўЁЂstringРр
ЯрБШгкCгябд,stringРраЭИќЗћКЯУцЯђЖдЯѓЕФЫМЯы,ЫќНЋstringвдМАГЩдБКЏЪ§ЗХдкСЫвЛИіЭЗЮФМў<string>жа,ЖјПт< iostream >вбОвўЪНЕиАќКЌСЫ<string>ЭЗЮФМў,ЫљвдЮоашЯдЪНв§гУИУЭЗЮФМўвВФмЙЛЪЙгУstringРрЁЃетбљИќЗНБувЛаЉЁЃ
ЯрБШгкCгябдЕФзжЗћЪ§зщЛђзжЗћжИеы,stringИќАВШЋвЛаЉ,зжЗћЪ§зщЛђзжЗћжИеыКмШнвзОЭЛсдННчЗУЮЪЁЃ
СЫНтstringРрзюКУЕФЗНЪНОЭЪЧВщПДЙйЗНЮФЕЕЁЃ stringРр
2.1.stringРрЕФГЃМћЙЙдьКЏЪ§КЭЮіЙЙКЏЪ§
дкC++98жагавдЯТЦпжжЙЙдьКЏЪ§:

ЦфжаБШНЯживЊЕФЪЧФЌШЯЙЙдьЁЂзжЗћДЎЙЙдьКЭПНБДЙЙдьЁЃ
#include<iostream>
using namespace std;
int main()
{
string s1; //ФЌШЯЙЙдь
string s2("hello"); //зжЗћДЎЙЙдь
string s3(s2); //ПНБДЙЙдь
string s4("hello", 1); //ИДжЦзжЗћДЎЧА n ИізжЗћ
string s5("hello", 1, 2); //ДгзжЗћДЎЕквЛИіЮЛжУЭљКѓПНБД2ИізжЗћ
string s6("hello", 1, string::npos); //nposЪЧвЛИіОВЬЌЕФШЋОжБфСПЮЊ-1ВЙТыЮоЧюДѓ ГЌГіГЄЖШдђШЋВППНБД
string s7("hello", 1, 20); //ЭЌЩЯ
string s8(5, 'a'); //гУnИізжЗћЬюГфзжЗћДЎ
string s9 = "hello"; //ЕШМлгкзжЗћДЎЙЙдь,БрвыЦїгХЛЏСЫвўЪНРраЭзЊЛЛЕФЙ§ГЬ
cout << s1 << endl;
cout << s2 << endl;
cout << s3 << endl;
cout << s4 << endl;
cout << s5 << endl;
cout << s6 << endl;
cout << s7 << endl;
cout << s8 << endl;
cout << s9 << endl;
s1 = s8; //жиди=
cout << s1 << endl;
return 0;
}

ЮіЙЙКЏЪ§дђЪЧдкЖдЯѓЯњЛйЪБздЖЏЕїгУ,ЯњЛйПЊБйЕФПеМф:

2.2.Ш§жжБщРњЗНЪН
- ВЩгУЯТБъЕФЗНЪН


size()ЪЧвЛИіЙЋЙВГЩдБКЏЪ§,ЗЕЛиstringЕФГЄЖШЁЃКЭlength()ЯрЭЌЁЃ

- ЕќДњЦїБщРњ
ЕќДњЦїiteratorЪЧstringжаЕФРр,ЫљвдвЊМггђзїгУЯоЖЈЗћЁЃ

begin()ЗЕЛиПЊЪМЕФЯТБъЮЛжУЕФЕќДњЦїЁЃ
ЕќДњЦїЗЕЛиЕФЪЧвЛИізѓБегвПЊЕФЯТБъЧјМф,Ыљвдend()ЗЕЛиЕФВЛЪЧзюКѓвЛИіЪ§ОнЮЛжУЕФЕќДњЦї,ЗЕЛиЪЧзюКѓвЛИіЮЛжУЯТвЛИіЮЛжУЁЃ
C++жаЗВЪЧИјЕќДњЦївЛАуЖМЪЧИјЕФзѓБегвПЊЕФЧјМфЁЃЕќДњЦїЪЧРрЫЦжИеывЛбљЕФЖЋЮї,ЫќЕФгУЗЈОЭЪЧФЃФтжИеыЁЃ
ЕќДњЦїЕФвтвхЪЧБщРњИќИДдгЕФШнЦї,БШШчlistЁЂmapЕШЁЃ
ЗДЯђЕќДњЦї:

ЗДЯђЕќДњЦї++ЕФЪБКђЪЧЕЙзХЭљЧАзпЕФЁЃ
constЖдЯѓжЛФмЪЙгУconstЕќДњЦїБщРњ,constЕќДњЦїЪЧжЛЖС:

iteratorБщРњЦеЭЈЖдЯѓЪЧПЩЖСПЩаДЕФ,const_iterator БщРњconstЖдЯѓЪЧжЛЖСЕФЁЃ
- ЗЖЮЇfor

вРДЮШЁШнЦїжаЕФЪ§ОнИГжЕИјe,здЖЏХаЖЯНсЪјЁЃ
ЗЖЮЇforЪЕЯжЕФБОжЪЪЧЕќДњЦї,вђДЫжЇГжЦфЫћШнЦїЕФБщРњЁЃ
2.3.stringГЃгУЕФНгПк
МИИіГЃгУЕФКЏЪ§:
- push_back(ch)
ЮВВхвЛИізжЗћch - append(str)
дкзжЗћДЎКѓзЗМгвЛИізжЗћДЎstr - +=str
дкзжЗћДЎКѓзЗМгвЛИізжЗћДЎstrЁЃжидиСЫ+=.ЁЃЯрБШгкappend,ЪЕМЪжаИќГЃгУ+= - insert(pos,str) insert(pos,n,ch)
дкЯТБъЮЊposЮЛжУВхШывЛИізжЗћДЎstrЁЃЛђепВхШыnИізжЗћchЁЃОЁСПЩйгУinsert,вђЮЊВхШыашвЊХВЖЏЪ§ОнЁЃ - erase(pos,len)
дкЯТБъЮЊposКѓЩОçêЖШЮЊlenЕФзжЗћ,ШчЙћВЛаДposКЭlenдђФЌШЯДгПЊЪМЕФЮЛжУЯђКѓШЋЩОГ§ЁЃ - resize(n,ch)
ИФБфsizeЕФДѓаЁЕНn,capacityвВЛсИФБфЁЃЖрГіРДЕФsizeПеМфдђгУзжЗћchВЙШЋ,ШчЙћВЛаДchдђФЌШЯЮЊ\0ЁЃ - reserve(n)
ИФБфШнСПЕНДѓгкnЕФДѓаЁ,sizeВЂВЛЛсИФБфЁЃ - c_str()
ЛёШЁЖдЯѓжазжЗћДЎЕФЪзЕижЗЁЃ - find(ch/str,pos)КЭrfind(ch/str,pos)
ДгposЮЛжУПЊЪМеввЛИізжЗћЛђепзжЗћДЎ,posВЛаДФЌШЯИј0ЁЃЗЕЛизжЗћЛђзжЗћДЎдкдДзжЗћДЎЕФЯТБъЮЛжУЁЃ
rfindДгКѓЭљЧАевЁЃ - substr(pos,len)
ЗЕЛизжЗћДЎДгposЮЛжУПЊЪМ,ГЄЖШЮЊlenЕФВПЗжЁЃ
ЭЈЙ§findКЭsubstrСНИіКЏЪ§ПЩвдВщевЭјжЗЕФгђУћКЭавщ:
#include<iostream>
using namespace std;
string GetDomain(const string& url)
{
size_t pos = url.find("://");
if (pos != string::npos)
{
size_t start = pos + 3;
size_t end = url.find('/', start);
if (end != string::npos)
{
return url.substr(start, end - start);
}
else
{
return string();
}
}
else
{
return string();
}
}
string GetProtocol(const string& url)
{
size_t pos = url.find("://");
if (pos != string::npos)
{
return url.substr(0, pos - 0);
}
else
{
return string();
}
}
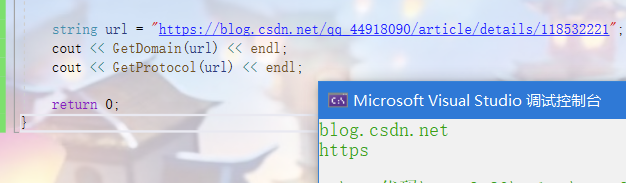
int main()
{
string url = "https://blog.csdn.net/qq_44918090/article/details/118532221";
cout << GetDomain(url) << endl;
cout << GetProtocol(url) << endl;
return 0;
}
- getline(cin,s)
ЭљstringЖдЯѓsжаЪфШывЛаа(АќРЈПеИё),гіЕНЛЛаажежЙЁЃ - reverse(s.begin(),s.end())
ФцжУs,ДЋШыПЊЪМКЭНсЪјЕФЕќДњЦїЁЃ
Ш§ЁЂstringФЃФтЪЕЯж
stringБОжЪЩЯЪЧвЛИіЙмРэзжЗћДЎЕФЫГађБэ(Ъ§зщ),зжЗћДЎЕФНсЮВга\0,ЫљвдВЩгУЫГађБэЕФаДЗЈМДПЩЁЃ
3.1.ЩюЧГПНБДЕФЮЪЬт
stringРрФЃФтЪЕЯжашвЊзЂвтЕФЮЪЬтОЭЪЧЩюЧГПНБД,ЫљвдПНБДЙЙдьКЏЪ§гІИУВЩгУЩюПНБДЕФЗНЪН,вђЮЊаТЕФЖдЯѓвВашвЊПЊБйПеМф,ШчЙћВЩгУЧГПНБДОЭЛсЕМжТЫќУЧжИЯђЭЌвЛПщПеМф,дкЮіЙЙЪБЛсЪЭЗХСНДЮИУПеМфЁЃ


ШчЙћЪЧЩюПНБД:

СэЭт,ИГжЕдЫЫуЗћ=ФЌШЯвВЪЧЧГПНБДЁЃ
3.2.УќУћПеМф
ШчЙћВЛМгУќУћПеМфКЭПтЪЕЯжИєРы,дђЛсКЭПтРяУцЕФstringжиУћЕМжТЮоЗЈЕїгУ,ЕБШЛвВПЩвдИјФЃФтЪЕЯжЕФstringИФРрУћ,етРяВЩгУУќУћПеМфЕФНтОіАьЗЈ,УќУћПеМфЦ№УћЮЊA,ЕБШЛвВПЩвдЦ№Б№ЕФУћзж:
namespace A
{
class string
{
private:
char* _str;//зжЗћжИеы,жИЯђзжЗћДЎ
size_t _size;//МЧТМзжЗћДЎЕФГЄЖШ
size_t _capacity;//МЧТМзжЗћДЎПеМфЕФДѓаЁ
static const size_t npos;//БэЪОзжЗћДЎЕФзюДѓГЄЖШ,ЩшжУГЩОВЬЌГЃСП
};
const size_t string::npos = -1;//дкРрЭтИјОВЬЌГЃСПИГжЕ
}
3.3.ФЌШЯГЩдБКЏЪ§
ЙЙдьКЏЪ§
//ЙЙдьКЏЪ§
string(const char* str = "")
::_str(new char[strlen(str) + 1])//вЊга\0,ЫљвдПЊБйЕФПеМфвЊБШГЄЖШДѓ
, _size(strlen(str))
, _capacity(_size + 1)//вЊга\0,ЫљвдПеМфвЊБШГЄЖШДѓ
{
strcpy(_str, str);//НЋstrжаЕФзжЗћДЎПНЕНthisжа
}
//ПНБДЙЙдь
string(const string& s)
:_str(new char[strlen(s._str) + 1])//вђЮЊга\0,ЫљвдПЊБйГЄЖШ+1ЕФПеМф
,_size(strlen(s._str))
,_capacity(_size+1)
{
strcpy(_str, s._str);//НЋsжаЕФзжЗћДЎПНЕНthisжа
}
//вВПЩвдВЩгУетжжаДЗЈ
//string(const string& s)
// :_str(nullptr)
// ,_size(0)
// ,_capacity(0)//НЋthisЕФзжЗћжИеыжУЮЊПе,ГЄЖШЁЂПеМфДѓаЁжУЮЊ0
//{
// string tmp(s._str);//гУФЌШЯЙЙдьДДНЈвЛИіСйЪБЖдЯѓ,ВЛФмДЋs,ЗёдђЛсЫРбЛЗ
// swap(tmp);//НЋСйЪБЖдЯѓжаЕФЪ§ОнКЭthisНЛЛЛ
//}
ЮіЙЙКЏЪ§
~string()
{
//_sizeКЭ_capacityВЛашвЊжУСу,вђЮЊЖдЯѓЩњУќжмЦкНсЪјетСЉГЩдББфСПОЭУЛСЫ
delete[]_str;
_str = nullptr;
}
жидиИГжЕдЫЫуЗћ=
//вђЮЊЪЧжЕДЋЕн,ЫљвдЛсГіЯжздМКИјздМКИГжЕЕФЧщПі,зжЗћжИеыжИЯђЕФзжЗћДЎЕижЗЛсЗЂЩњИФБф
string& operator=(string s)//вђЮЊЪЧжЕДЋЕн,дкДЋВЮЪБЛсПНБД ЙЙдьвЛИіСйЪБЖдЯѓs
{
swap(s);//НЛЛЛsКЭthis
return *this;
}
//вВПЩвдВЩгУетжжаДЗЈ
/*string& operator=(const string& s)
{
if (this != &s) //ХХГ§здМКИјздМКИГжЕЕФЧщПі
{
delete[]_str;//ЯњЛйдРДЕФзжЗћжИеы_strжИЯђЕФПеМф
_str = new char[strlen(s._str) + 1];//жиаТИј_strПЊБйвЛПщПеМф
strcpy(_str, s._str);//НЋsжазжЗћДЎПНБДЕН_strжИЯђЕФПеМфжа
}
return *this;
}*/
3.4.дЊЫиЗУЮЪКЏЪ§
[]жиди
//[]жиди
//жидиСНИі,вЛИіЦеЭЈЖдЯѓ,вЛИіconstЖдЯѓ
char& operator[](size_t i)//ЗЕЛив§гУПЩвдЖдГЩдББфСПНјаааоИФ
{
assert(i < _size);//ЗРжЙдННч
return _str[i];
}
const char& operator[](size_t i)const
{
assert(i < _size);
return _str[i];
}
findКЭrfind
//ВщеввЛИізжЗћКЭзжЗћДЎ
size_t find(char ch, size_t pos = 0)const
{
assert(pos < _size);
for (size_t i = pos; i < _size; i++)
{
if (_str[i] == ch)
{
return i;
}
}
return npos;
}
size_t find(const char*str, size_t pos = 0)const
{
assert(pos < _size);
const char* ret = strstr(_str+pos, str);
if (ret)
{
return ret - _str;
}
else
{
return npos;
}
}
//ЗДЯђВщевзжЗћЛђзжЗћДЎ
//НЋдзжЗћДЎФцжУШЛКѓИДгУfindКЏЪ§
size_t rfind(char ch, size_t pos = npos)
{
string tmp(*this);
reverse(tmp.begin(), tmp.end()); //ФцжУtmp
//ШчЙћposДѓгкзжЗћДЎГЄЖШ,дђНЋposИФЮЊзжЗћДЎзюКѓвЛИіЮЛжУЕФЯТБъ
if (pos >= _size)
{
pos = _size - 1;
}
//ФцжУвдКѓ,posЕФЮЛжУвЊЗЂЩњИФБф
pos = _size - 1 - pos;
size_t ret = tmp.find(ch, pos); //ИДгУfindКЏЪ§
if (ret != npos)
{
return _size - 1 - ret; //ЗЕЛиretОЕЯёЖдГЦКѓЕФЮЛжУ
}
else
{
return npos;
}
}
size_t rfind(const char* str, size_t pos = npos)
{
string tmp(*this);
size_t len = strlen(str); //Д§ВщевЕФзжЗћДЎЕФГЄЖШ
//ПНБДВЂФцжУstr
char* arr = new char[len + 1];
strcpy(arr, str);
int left = 0, right = len - 1;
while (left < right)
{
::swap(arr[left], arr[right]);
left++;
right--;
}
reverse(tmp.begin(), tmp.end()); //ФцжУtmp
//ШчЙћposДѓгкзжЗћДЎГЄЖШ,дђНЋposИФЮЊзжЗћДЎзюКѓвЛИіЮЛжУЕФЯТБъ
if (pos >= _size)
{
pos = _size - 1;
}
//ФцжУвдКѓ,posЕФЮЛжУвЊЗЂЩњИФБф
pos = _size - 1 - pos;
size_t ret = tmp.find(arr, pos); //ИДгУfindКЏЪ§
delete[] arr; //ЯњЛйarr
if (ret != npos)
{
return _size - ret - len; //ЗЕЛиretОЕЯёЖдГЦКѓдйЕїећЕФЮЛжУ
}
else
{
return npos;
}
}
c_str
char* c_str()const
{
return _str;
}
3.5.ШнЛ§КЏЪ§
size()КЭcapacity()
size_t size()const//МгconstЕФКУДІЪЧЦеЭЈЖдЯѓКЭconstЖдЯѓЖМПЩвдЕїгУ
{
return strlen(_str);
}
size_t capacity()
{
return _capacity;
}
reserve
void reserve(size_t n)
{
if (n > _capacity)//ШчЙћашвЊПЊЕФПеМфБШЪЕМЪЕФаЁОЭВЛгУПЊСЫ
{
char* tmp = new char[n+1];
strncpy(tmp, _str,_size+1);//НЋ\0вВвЊПННјШЅ
delete[]_str;//ЯњЛйдРДЕФПеМф
_str = tmp;//жИЯђаТПЊЕФПеМф
_capacity = n+1;
}
}
resize
//ПЊПеМф+ГѕЪМЛЏ,РЉеЙcapacity ВЂЧвГѕЪМЛЏПеМф,sizeвВвЊИФБф
void resize(size_t n, char val = '\0')
{
if (n < _size)
{
_size = n;
_str[_size] = '\0';//nБШЪЕМЪЕФsizeаЁЕФЪБКђжБНгНЋЯТБъЮЊnЕФЕиЗНИФЮЊ\0МДПЩ
}
else
{
// ШчЙћnewSizeДѓгкЕзВуПеМфДѓаЁ,дђашвЊжиаТПЊБйПеМф
if (n > _capacity)
{
reserve(n);
}
memset(_str + _size, val, n - _size);
_size = n;
_str[n] = '\0';
}
}
empty
bool empty()
{
return strcmp(_str, "") == 0;
}
clear
void clear()
{
_size = 0;
_str[0] = '\0';
}
3.6.діЩОВщИФ
гУРДНЛЛЛЖдЯѓжаГЩдББфСПЕФswapКЏЪ§
void swap(string& s)
{
//МггђзїгУЯоЖЈЗћ::ЪЧЮЊСЫЕїгУstdжаЕФswapКЏЪ§,ШчЙћВЛМгдђЪЧздМКЕїгУздМКЫРбЛЗ
::swap(_str, s._str);
::swap(_size, s._size);
::swap(_capacity, s._capacity);
}
етИіКЏЪ§ЕФФПЕФЪЧЮЊСЫНЛЛЛЖдЯѓжаЕФГЩдББфСП,дкНгЯТРДЦфЫћКЏЪ§ЕФЪЕЯжжаБЛЕїгУЁЃ
insert
//ЯТБъЮЊposЮЛжУВхШызжЗћДЎ
string& insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size +len > _capacity)
{
reserve(_size + len);
}
//ХВзжЗћДЎ
char* end = _str + _size;
while (end >= _str + pos)
{
*(end + len) = *end;
end--;
}
strncpy(_str + pos, str, len);
_size += len;
return *this;
}
//ЯТБъЮЊposЮЛжУВхШыnИізжЗћ
string& insert(size_t pos, size_t n, char ch)
{
assert(pos <= _size);
if ((_size+n) >= _capacity)
{
reserve(_capacity == 0 ? (_size + n) : (_size + n) * 2);
}
char* end = _str+_size;
while (end >= _str + pos)
{
*(end + n) = *end;
end--;
}
memset(_str + pos, ch, n);
_size+=n;
return *this;
}
push_backКЭappend
void push_back(char ch)
{
//ЗНЗЈвЛ
/*if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);//ПеМфВЛЙЛРЉЕНСНБЖ
}
_str[_size] = ch;
_str[_size + 1] = '\0';
_size++;*/
//ЗНЗЈЖўЁЂжБНгЕїгУinsert
insert(_size,1, ch);
}
void append(const char* str)
{
//ЗНЗЈвЛ
/*size_t len = _size + strlen(str);//МЦЫуВхШыКѓЕФГЄЖШ
if (len >= _capacity)
{
reserve(len);
}
strcpy(_str + _size, str);//Дг_strНсЪјЮЛжУПЊЪМПНБД
_size = len; */
//ЗНЗЈЖўЁЂжБНгЕїгУinsert
insert(_size, str);
}
жиди+=
//ИДгУЮВВхКЏЪ§МДПЩ
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
string& operator+=(const char* str)
{
append(str);
return *this;
}
erase
//ЩОГ§
string& erase(size_t pos,size_t len=npos)
{
assert(pos < _size);
size_t leftlen = _size - pos;
if (len >= leftlen)//posКѓЕФГЄЖШБШвЊЩОЕФГЄЖШаЁ
{
_str[pos] = '\0';
_size = pos;
}
else
{
strcpy(_str + pos, _str + pos + len);//ЩОГ§КѓЪЃгрЕФзжЗћвЦЕНЧАУц
_size -= len;
}
return *this;
}
3.7.ЕќДњЦї
begin()КЭend()ЕќДњЦї
iterator begin()
{
return _str;
}
const_iterator begin()const
{
return _str;
}
iterator end()
{
return _str + _size;
}
const_iterator end()const
{
return _str + _size;
}
3.8.ЗЧГЩдБКЏЪ§жиди
жидиЪфГі<<
ostream& operator<<(ostream& out,const string& s)
{
//вВПЩвдЪЙгУЯТБъБщРњ
/*for (size_t i = 0; i < s.size(); i++)
{
out << s[i];
}*/
//ЪЙгУЗЖЮЇforБщРњ
for (auto ch : s)
{
out << ch;
}
return out;
}
жидиЪфШы>>
istream& operator>>(istream& in, string& s)
{
s.clear();//ЧхПеsРяЕФЪ§Он
char ch;
ch=in.get();//СЌајЪфШы
while (ch != ' ' && ch != '\n')//гіЕНПеИёЛђЛЛааНсЪј
{
s += ch;
ch = in.get();
}
return in;
}
getline
istream& getline(istream& in, string& s)
{
s.clear();//ЧхПеsРяЕФЪ§Он
char ch;
ch = in.get();//СЌајЪфШы
while (ch != '\n')//гіЕНЛЛааНсЪј
{
s += ch;
ch = in.get();
}
return in;
}
3.9.ЙиЯЕдЫЫуЗћжиди
ВЮПМШеЦкРрЕФЙиЯЕдЫЫуЗћжиди,>ЁЂ>=ЁЂ<ЁЂ<=ЁЂ==ЁЂ!=жЛашвЊЪЕЯжГіСНИі,ЦфЫћжБНгИДгУетСНИіМДПЩЁЃ
bool operator<(const string& s1, const string& s2)
{
return strcmp(s1.c_str(), s2.c_str()) < 0;
}
bool operator==(const string& s1, const string& s2)
{
return strcmp(s1.c_str(), s2.c_str()) == 0;
}
//ЪЕЯж<КЭ==,ЦфЫћжБНгжиди
bool operator<=(const string& s1, const string& s2)
{
return s1 < s2 || s1 == s2;
}
bool operator>(const string& s1, const string& s2)
{
return !(s1 <= s2);
}
bool operator>=(const string& s1, const string& s2)
{
return !(s1 < s2);
}
bool operator!=(const string& s1, const string& s2)
{
return !(s1 == s2);
}