����Ŀ¼
C++�ؼ���
C++�ܼ�63���ؼ���,C����32���ؼ���

�����ռ�
��C/C++��,�����������ͺ���Ҫѧ������Ǵ������ڵ�,��Щ������������������ƽ���������ȫ����
������,���ܻᵼ�ºܶ��ͻ��ʹ�������ռ��Ŀ���ǶԱ�ʶ�������ƽ��б��ػ�,�Ա���������ͻ������
��Ⱦ,namespace�ؼ��ֵij��־��������������ġ�
�����ռ䶨��
���������ռ�,��Ҫʹ�õ�namespace�ؼ���,����������ռ������,Ȼ���һ��{}����,{}�м�Ϊ����
�ռ�ij�Ա��
- ��ͨ�������ռ�
namespace N1 // N1Ϊ�����ռ������
{
// �����ռ��е�����,�ȿ��Զ������,Ҳ���Զ��庯��
int a;
int Add(int left, int right)
{
return left + right;
}
}
- �����ռ�Ƕ��
namespace N2
{
int a;
int b;
int Add(int left, int right)
{
return left + right;
}
namespace N3
{
int c;
int d;
int Sub(int left, int right)
{
return left - right;
}
}
}
- ͬһ���������������ڶ����ͬ���Ƶ������ռ�,����������ϳ�ͬһ�������ռ��С�
namespace N1
{
int Add(int left, int right)
{
return left + right;
}
}
namespace N1
{
int Sub(int left, int right)
{
return left - right;
}
}
// ʹ��ʱ��ϳ�ͬһ�������ռ���
namespace N1
{
int Add(int left, int right)
{
return left + right;
}
int Sub(int left, int right)
{
return left - right;
}
}
ע��:һ�������ռ�Ͷ�����һ���µ�������,�����ռ��е��������ݶ������ڸ������ռ���
�����ռ�ʹ��
�����ռ��ʹ�������ַ�ʽ:
- ȫ��ֱ��չ����ȫ��
namespace N
{
int a;
double b;
}
using namespace N;//�������ռ�N�����г�Ա����
int main()
{
a = 5;
printf("%d\n", a);
return 0;
}
�ŵ�:���������㡣 ȱ��:���Լ��Ķ��屩¶��ȥ��,������������Ⱦ
- ����ÿ�������ռ��еĶ���ʱ,ָ�������ռ�
namespace N
{
int a;
double b;
}
int main()
{
N::a=10;
printf("%d\n", N::a);
return 0;
}
�ŵ�:������������Ⱦ�� ȱ��:�������鷳,ÿ������ȥָ�������ռ�
- ֻ�ѳ��ø�չ��
namespace N
{
int a;
double b;
}
using N::b;//�������ռ��еij�Աb����
int main()
{
b = 3.14;
printf("%.2lf\n", b);
return 0;
}
����1��2�Ž������
C++����������
ѧϰC����ʱ��������д�ij���������Ļ�����hello world,������������C++��ʵ��һ���
#include<iostream>
using namespace std;
int main()
{
cout << "hello world" << endl;
return 0;
}

˵��:
- ʹ��cout�����(����̨)��cin������(����)ʱ,�������< iostream >ͷ�ļ��Լ�std�������� �䡣
ע��:���ڱ��⽫���й�����ȫ������ʵ��,������.h����ͷ�ļ���,ʹ��ʱֻ�������Ӧͷ�ļ�
����,��������ʵ����std�����ռ���,Ϊ�˺�Cͷ�ļ�����,ҲΪ����ȷʹ�������ռ�,�涨C++ͷ��
������.h;�ɱ�����(vc 6.0)�л�֧��<iostream.h>��ʽ,�����������Ѳ�֧��,����Ƽ�ʹ��
<iostream>+std�ķ�ʽ��
Ϊ���������������,C++�����������ݸ�ʽ����,����:���ΨC%d,�ַ��C%c
C++���Զ�ʶ����������
int main()
{
// �Զ�ʶ������
char ch = 'A';
int i = 10;
int* p = &i;
double d = 1.111111;
// �Զ�ʶ�����������
cout << ch << endl;
cout << i << endl;
cout << p << endl;
cout << d << endl;
return 0;
}
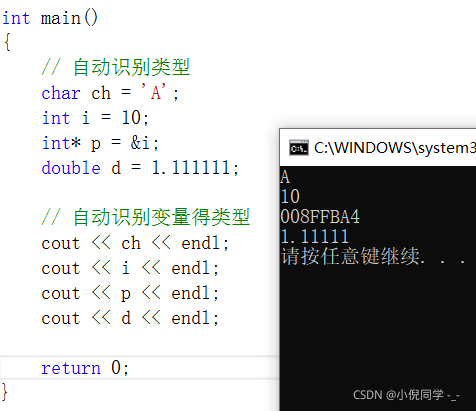
ע��:C++��double����ֻͳ�Ƶ�С������5λ
��ΪC++�Ǽ���C��,�����ڷ���ʱ����printf����C++�������
��:
struct Student
{
char name[10];
int age;
};
int main()
{
struct Student s = { "����", 18 };
cout << "����:" << s.name << " " << "����:" << s.age << endl;
printf("����:%s ����:%d\n", s.name, s.age);
// ������printf��ֱ��
return 0;
}
ȱʡ����
ȱʡ��������
ȱʡ�������������庯��ʱΪ�����IJ���ָ��һ��Ĭ��ֵ���ڵ��øú���ʱ,���û��ָ��ʵ������ø�
Ĭ��ֵ,����ʹ��ָ����ʵ��
void TestFunc(int a = 0)
{
cout << a << endl;
}
int main()
{
TestFunc(); // û�д���ʱ,ʹ�ò�����Ĭ��ֵ
TestFunc(10); // ����ʱ,ʹ��ָ����ʵ��
}
ȱʡ��������
- ȫȱʡ����
�����IJ���ȫ��Ϊȱʡ����
void TestFunc(int a = 10, int b = 20, int c = 30)
{
cout<<"a = "<<a<<endl;
cout<<"b = "<<b<<endl;
cout<<"c = "<<c<<endl;
}
- ��ȱʡ����
�����IJ�����ȫΪȱʡ����
void TestFunc(int a, int b = 10, int c = 20)
{
cout<<"a = "<<a<<endl;
cout<<"b = "<<b<<endl;
cout<<"c = "<<c<<endl;
}
ע��:
- ��ȱʡ��������������������������,���ܼ���Ÿ�
����ʾ��
void TestFunc(int a, int b = 10, int c )
{
cout<<"a = "<<a<<endl;
cout<<"b = "<<b<<endl;
cout<<"c = "<<c<<endl;
}
- ȱʡ���������ں��������Ͷ�����ͬʱ����
- ȱʡֵ�����dz�������ȫ�ֱ���
����ʾ��
void TestFunc(int a, int b = 10, int c = x )
{
cout<<"a = "<<a<<endl;
cout<<"b = "<<b<<endl;
cout<<"c = "<<c<<endl;
}
- C���Բ�֧��ȱʡ����
��������
�������ظ���
��������:�Ǻ�����һ���������,C++������ͬһ�����������������������Ƶ�ͬ������,��Щͬ��������
�β��б�(�������� �� ���� �� ˳��)���벻ͬ,����������ʵ�ֹ��������������Ͳ�ͬ������
int Add(int left, int right)
{
return left + right;
}
double Add(double left, double right)
{
return left + right;
}
long Add(long left, long right)
{
return left + right;
}
int main()
{
Add(10, 20); // ���õ�һ������
Add(10.0, 20.0); // ���õڶ�������
Add(10L, 20L); // ���õ���������
return 0;
}
�������ص�ԭ��
ΪʲôC��֧�ֺ�������,C++֧�ֺ���������?
����֪��,һ��C/C++����Ҫ������������Ҫ�������¼�����:Ԥ���������롢��ࡢ���ӡ�
����֪��,�ڱ���λὫ�����е�ÿ��Դ�ļ���ȫ�ַ�Χ�ı������ŷֱ���л��ܡ��ڻ��λ��ÿ��Դ�ļ����ܳ����ķ��ŷ���һ����ַ(������ֻ��һ������,��������һ��������ĵ�ַ),Ȼ��ֱ�����һ�����ű�������������ڼ�Ὣÿ��Դ�ļ��ķ��ű����кϲ�,����ͬԴ�ļ��ķ��ű��г�������ͬ�ķ���,��ȡ�Ϸ��ĵ�ַΪ�ϲ���ĵ�ַ(�ض�λ)��
��C������,���ν��з��Ż���ʱ,һ���������ܺ�ķ��ž����亯����,���Ե�����ʱ���ֶ����ͬ�ĺ�������ʱ,��������ᱨ������C++�ڽ��з��Ż���ʱ,�Ժ����������������˸Ķ�,�������ܳ��ķ��Ų��ٵ����Ǻ����ĺ�����,����ͨ������������ͺ����Լ�˳�����Ϣ���ܳ� һ������,����һ��,�����Ǻ�������ͬ�ĺ���,ֻҪ����������ͻ�����ĸ����������˳��ͬ,��ô���ܳ����ķ���Ҳ�Ͳ�ͬ�ˡ�
extern ��C��
��ʱ����C++�����п�����Ҫ��ijЩ��������C�ķ��������,�ں���ǰ��extern ��C��,��˼�Ǹ��߱�����,
���ú�������C���Թ��������롣����:tcmalloc��google��C++ʵ�ֵ�һ����Ŀ,���ṩtcmallc()��tcfree
�����ӿ���ʹ��,�������C��Ŀ��û�취ʹ��,��ô����ʹ��extern ��C���������
����
���ø���
���ò����¶���һ������,���Ǹ��Ѵ��ڱ���ȡ��һ������,����������Ϊ���ñ��������ڴ�ռ�,������
���õı�������ͬһ���ڴ�ռ䡣
����& ���ñ�����(������) = ����ʵ��;
int main()
{
int a = 10;
int& b = a; //������aȥ��һ������,��b
b = 20; //�ı�bҲ���Ǹı���a
return 0;
}
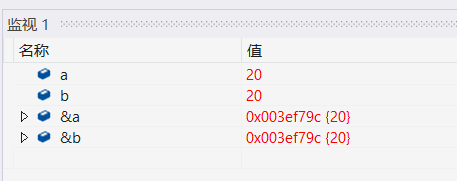
ע��:�������ͱ��������ʵ����ͬ�����͵�
��������
- �����ڶ���ʱ�����ʼ��
����ʾ��:
int main()
{
int a = 10;
int& ra; // ����������ʱ�����
}
- һ�����������ж������
int main()
{
int a = 10;
int& b = a;
int& c = a;
int& d = b;
}
- ����һ������һ��ʵ��,�ٲ�����������ʵ��
int main()
{
int a = 10;
int& b = a;
int c = 20;
b = c;
}
��ʱb��������C���ǽ�C��ֵ����b
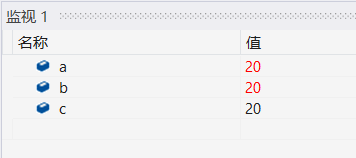
������
int main()
{
const int a = 10;
//int& ra = a; //��������ʱ�����,aΪ����
const int& ra = a;
//int& b = 10; //��������ʱ�����,10Ϊ����
const int& b = 10;
return 0;
}
�����ͱ�const���κ�,���㲻��������,ֻ����һ�������ĵ�ֵ����ʾ����
���õ�ʹ�ó���
- ����������
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
int main()
{
int x = 0, y = 1;
Swap(x, y);
return 0;
}
�����left��x������,right��y������,���ǵĵ�ַ��һ����,����left��right���൱�ڲ���x��y
- ����������ֵ
int& Add(int a, int b)
{
static int c = a + b;
return c;
}
ע��:�����������ʱ,���˺���������,������ض���δ����ϵͳ,�����ʹ�����÷���,�����
������ϵͳ��,�����ʹ�ô�ֵ����
��ֵ��������Ч�ʱȽ�
- ����������������
struct A
{
int a[10000];
};
void TestFunc1(A a){}
void TestFunc2(A& a){}
void TestRefAndValue()
{
A a;
// ��ֵ��Ϊ��������
size_t begin1 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc1(a);
size_t end1 = clock();
// ����������������
size_t begin2 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc2(a);
size_t end2 = clock();
// �ֱ���������������н������ʱ��
cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;
cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}
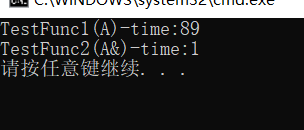
- ֵ�����õ���Ϊ����ֵ���͵����ܱȽ�
#include <time.h>
struct A
{
int a[10000];
};
A a;
// ֵ����
A TestFunc1() { return a; }
// ���÷���
A& TestFunc2(){ return a; }
void TestReturnByRefOrValue()
{
// ��ֵ��Ϊ�����ķ���ֵ����
size_t begin1 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc1();
size_t end1 = clock();
// ��������Ϊ�����ķ���ֵ����
size_t begin2 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc2();
size_t end2 = clock();
// �������������������֮���ʱ��
cout << "TestFunc1 time:" << end1 - begin1 << endl;
cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
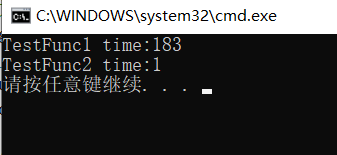
��ֵ��Ϊ�������߷���ֵ����,�ڴ��κͷ����ڼ�,��������ֱ�Ӵ���ʵ�λ��߽���������ֱ�ӷ���,����
����ʵ�λ��߷��ر�����һ����ʱ�Ŀ���,�����ֵ��Ϊ�������߷���ֵ����,Ч���Ƿdz����µ�,������
���������߷���ֵ���ͷdz���ʱ,Ч�ʾ��͡�
���ú�ָ�������
������������þ���һ������,û�ж����ռ�,��������ʵ�干��ͬһ��ռ䡣
int main()
{
int a = 10;
int& ra = a;
cout << "&a = " << &a << endl;
cout << "&ra = " << &ra << endl;
return 0;
}
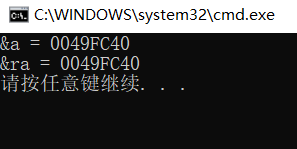
�ڵײ�ʵ����ʵ�����пռ��,��Ϊ�����ǰ���ָ�뷽ʽ��ʵ�ֵġ�
int main()
{
int a = 10;
int& ra = a;
ra = 20;
int* pa = &a;
*pa = 20;
return 0;
}
�������������ú�ָ��Ļ�����Ա�:

���ú�ָ��IJ�ͬ��:
- �����ڶ���ʱ�����ʼ��,ָ��û��Ҫ��
- �����ڳ�ʼ��ʱ����һ��ʵ���,�Ͳ�������������ʵ��,��ָ��������κ�ʱ��ָ���κ�һ��ͬ����ʵ��
- û��NULL����,����NULLָ��
- ��sizeof�к��岻ͬ:���ý��Ϊ�������͵Ĵ�С,��ָ��ʼ���ǵ�ַ�ռ���ռ�ֽڸ���(32λƽ̨��ռ4���ֽ�)
- �����ԼӼ����õ�ʵ������1,ָ���ԼӼ�ָ�����ƫ��һ�����͵Ĵ�С
- �ж༶ָ��,����û�ж༶����
- ����ʵ�巽ʽ��ͬ,ָ����Ҫ��ʽ������,���ñ������Լ�����
- ���ñ�ָ��ʹ��������Ը���ȫ
��������
��inline���εĺ���������������,����ʱC++���������ڵ������������ĵط�չ��,û�к���ѹջ�Ŀ���,
�������������������е�Ч��(����C���Եĺ�)��
һ�㺯���Ļ�����
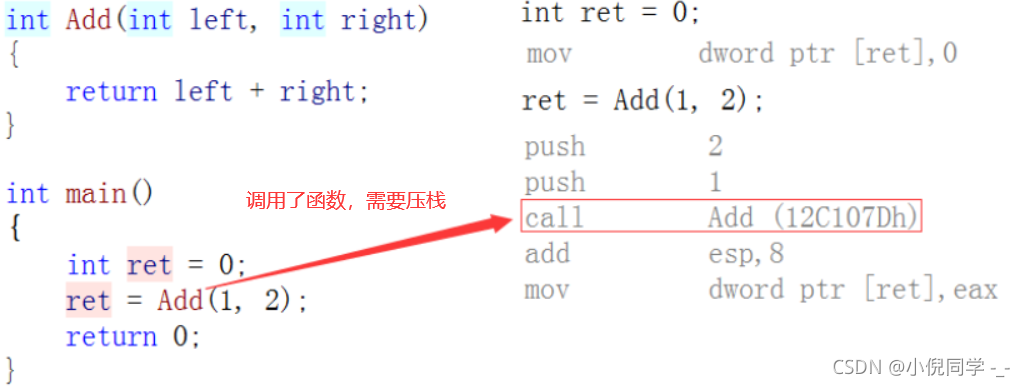
���������Ļ�����
�������������ǰ����inline�ؼ��ֽ���ij���������,�ڱ����ڼ���������ú������滻�����ĵ��á�

����
- inline��һ���Կռ任ʱ�������,ʡȥ���ú�����������Դ���ܳ�������ѭ��/�ݹ�ĺ���������ʹ����Ϊ����������
- inline���ڱ���������ֻ��һ������,���������Զ��Ż�,�������Ϊinline�ĺ���������ѭ��/�ݹ�ȵ�,�������Ż�ʱ����Ե�������
- inline�����������Ͷ������,����ᵼ�����Ӵ�����Ϊinline��չ��,��û�к�����ַ��,���Ӿͻ�
�Ҳ�����
auto�ؼ���
auto���
�����ڵ�C/C++��auto�ĺ�����:ʹ��auto���εı����Ǿ����Զ��洢���ľֲ�����
��C++11��,��ίԱ�ḳ����autoȫ�µĺ���:auto������һ���洢����ָʾ��,������Ϊһ���µ�����ָʾ����ָʾ������,auto�����ı��������ɱ������ڱ���ʱ���Ƶ����á�
int TestAuto()
{
return 10;
}
int main()
{
int a = 10;
auto b = a;
auto c = 'a';
auto d = TestAuto();
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
cout << typeid(d).name() << endl;
return 0;
}
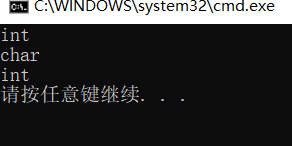
ע��:
ʹ��auto�������ʱ���������г�ʼ��,�ڱ���α�������Ҫ���ݳ�ʼ������ʽ���Ƶ�auto��ʵ����
�͡����auto������һ�֡����͡�������,����һ����������ʱ�ġ�ռλ����,�������ڱ����ڻὫauto�滻Ϊ
����ʵ�ʵ�����
auto��ʹ��ϸ��
- auto��ָ������ý������ʹ��
��auto����ָ������ʱ,��auto��auto*û���κ�����,����auto������������ʱ������&
int main()
{
int x = 10;
auto a = &x;
auto* b = &x;
auto& c = x;
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
return 0;
}

- ��ͬһ�ж���������
����ͬһ�������������ʱ,��Щ������������ͬ������,������������ᱨ��,��Ϊ������ʵ��ֻ��
��һ�����ͽ����Ƶ�,Ȼ�����Ƶ����������Ͷ�������������
void TestAuto()
{
auto a = 1, b = 2;
auto c = 3, d = 4.0; // ���д�������ʧ��,��Ϊc��d�ij�ʼ������ʽ���Ͳ�ͬ
}
auto�����Ƶ��ij���
- auto������Ϊ�����IJ���,��Ϊ����������a��ʵ�����ͽ����Ƶ�
- auto����ֱ��������������
- Ϊ�˱�����C++98�е�auto��������,C++11ֻ������auto��Ϊ����ָʾ�����÷�
- auto��ʵ��������������÷����Ǹ�C++11�ṩ����ʽforѭ��,����lambda����ʽ��
�������ʹ�á�
���ڷ�Χ��forѭ��(C++11)
��Χfor���
��C++98�����Ҫ����һ������,���������·�ʽ����:
void TestFor()
{
int array[] = { 1, 2, 3, 4, 5 };
for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i)
array[i] *= 2;
for (int* p = array; p < array + sizeof(array)/ sizeof(array[0]); ++p)
cout << *p << endl;
}
����һ���з�Χ�ļ��϶���,�ɳ���Ա��˵��ѭ���ķ�Χ�Ƕ����,��ʱ�������������C++11��
�����˻��ڷ�Χ��forѭ����forѭ�����������ð�š� :����Ϊ������:��һ�����Ƿ�Χ�����ڵ����ı���,
�ڶ��������ʾ�������ķ�Χ��
void TestFor()
{
int array[] = { 1, 2, 3, 4, 5 };
for (auto& e : array)
e *= 2;
for (auto e : array)
cout << e << " ";
return ;
}

ע��:����ͨѭ������,������continue����������ѭ��,Ҳ������break����������ѭ��
��Χfor��ʹ������
- forѭ�������ķ�Χ������ȷ����
�����������,���������е�һ��Ԫ�غ����һ��Ԫ�صķ�Χ;���������,Ӧ���ṩbegin��end�ķ���,begin��end����forѭ�������ķ�Χ��
- �����Ķ���Ҫʵ��++��==����
���ǹ��ڵ�����������,֮��������ϸ������
ָ���ֵnullptr(C++11)
C++98�е�ָ���ֵ
�����õ�C/C++���ϰ����,����һ������ʱ��ø��ñ���һ�����ʵij�ʼֵ,������ܻ���ֲ���Ԥ�ϵ�
����,����δ��ʼ����ָ�롣���һ��ָ��û�кϷ���ָ��,���ǻ������ǰ������·�ʽ������г�ʼ��:
void TestPtr()
{
int* p1 = NULL;
int* p2 = 0;
}
NULLʵ����һ����,�ڴ�ͳ��Cͷ�ļ�(stddef.h)��,���Կ������´���:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
���Կ���,NULL���ܱ�����Ϊ���泣��0,���߱�����Ϊ������ָ��(void*)�ij��������۲�ȡ���ֶ���,��
ʹ�ÿ�ֵ��ָ��ʱ,�����ɱ���Ļ�����һЩ�鷳:
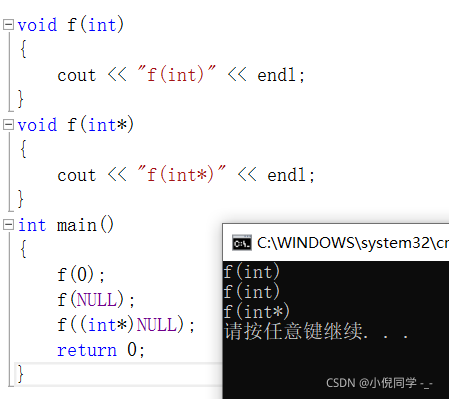
����������ͨ��f(NULL)����ָ��汾��f(int*)����,��������NULL�������0��
��C++98��,���泣��0�ȿ�����һ����������,Ҳ�����������͵�ָ��(void*)����,���DZ�����Ĭ������½��俴����һ�����γ���,���Ҫ���䰴��ָ�뷽ʽ��ʹ��,����������ǿת(void *)0��
�����������C++11����nullptr��Ϊ�ؼ���
- ��ʹ��nullptr��ʾָ���ֵʱ,����Ҫ����ͷ�ļ�
- ��C++11��,sizeof(nullptr) �� sizeof((void*)0)��ռ���ֽ�����ͬ
- Ϊ����ߴ���Ľ�׳��,�ں�����ʾָ���ֵʱ�������ʹ��nullptr