Ŀ¼
- һ��C���Ի���������
- 1. gcc�������������������,�ֱ���ʲô����?
- 2.ʲô�ǻص�����?
- 3.��ַ�ܷ�ʹ�� printf�����е� %u��ʽ��ӡ?
- 4.�ṹ���빲����(������)������
- 5. static��const��volatile�ؼ�����ʲô����?
- 6.���������Ͷ������������
- 7.��ֵ�븳��ֵ��ʲô��ͬ?
- 8.�ֲ�������ȫ�ֱ����ܷ�����
- 9.�������һ���Ѿ���������ⲿ����
- 10.ȫ�ֱ����;ֲ������Ĵ洢��ʽ��ʲô����?
- 10-����:�ڴ�ķֶ�
- 11. const �� # define ����к��ŵ�?
- 12.������ָ���������ʲô?
- 13.Ϊʲô��Ϊ�����βε������ָ����Ի���?
- 14.�βκ�ʵ����ʲô����?
- 15.ָ�롢����͵�ַ֮��Ĺ�ϵ�ǵ�ʲô?
- 16. voidָ����ǿ�ָ����?����ʲô����?
- 17.���ڴ�ϢϢ��ص���Ҫ��������Щ?
- 18. #include<> �� #include���� ��ʲô����?
- 18.0 gcc����
- 19. x=x+1 , x+=1 , x++ �ĸ�Ч�ʸ�?
- 20.Ϊ�������ͱ�����ֵʱ,��������Ӧ����ת��?
- ����Linux����
- 1. �ַ��豸�����豸���ܵ�����Linux���и�ͳ�ƽ�ʲô?
- 2.�鿴һ���ļ������ͳ��õ��м��ַ�ʽ
- 3.Linux�³��õİ�װ����?
- 4.�ֱ����shell���shell��shell�ű�
- 5.printf��scanf�������Ƿ���ͬһ���ļ�
- 6. Linux���õ��ļ�ϵͳ����?��β鿴�ļ�ϵͳ����?
- 7. windows����û���ļ�ϵͳ?�ļ�ϵͳ�к�����?
- 8.ͷ�ļ��Ϳ��ļ�һ�����ĸ�·����?
- 9.ϵͳ�������ͬ�����ļ�
- 10.ϵͳ�������ͬ�Ľ��̡�
- 11.�鿴�ļ�����Щ����
- 12.�����ļ���Ȩ��
- 13.ʲô�Ƿ�������?
- �������ݽṹ
- ��. IO����
- 1.��IO���ļ�IO����?
- 2.������ָ��?--�ļ�ָ�롢�ļ���ָ��
- 3.����ϵͳ����?
- 3.1 �����⺯��
- 4.������̬��Ͷ�̬�������?
- 5.��ν�����ִ��ֱ�������ں�̨?
- 6.���̵�״̬
- 7.ʲô�ǽ�ʬ����?
- 7-8.�¶�����
- 8.���������ӽ����е�дʱ��������?
- 9.���߳̽϶���̵�����?
- 10.�̳߳ص�ʹ��?----�ٿ���
- 11.�̳߳ص���ɲ���?
- 12.�̵߳�ͬ���������?
- 13.������������ʵ��ԭ��?
- 14.�����������龰?
- 15.�����ź�����ԭ��?
- 16.�������̵�ͨ�Ż���?
- 17.�ܵ���ͨ��ԭ��?
- 18.�û����̶��źŵ���Ӧ��ʽ?
- 19.�����ڴ�ͨ��ԭ��?
- ��. ������
- 1. ISO�߲�����ͨ�Žṹ��TCP/IP�IJ�����ͨ�Žṹ
- 2. tcpͨ�ŵ���ȱ��
- 2.3 TCPΪʲôҪ������������
- 3. udpͨ�ŵ���ȱ��
- 4. pool��select������(select poll epoll������)
- select��poll��epoll���Ƶ��ص�
- 5. ioģ�����ļ���
- 6. ���ʵ��tcp����������
- 7. ���糬ʱ���ı��ʺ�ʵ�ַ�ʽ
- 8. TCP ����������
- 9. UDP����������
- 10. UDP����ͨ����Ҫע����Щ����
- 11. ��ô���ļ��������ı�־λ--�ļ�״̬��־λ
- 12. sqlite���ݿ�Ļ���ʹ��,������ɾ�IJ�
- 13. ����UDP�����������ʵ������Ⱥ��
- 14. ���ߴʵ����ʵ�ֲ�ѯ����
- 15. TCP��UDP������
- 16. OSI�߲�����ģʽ,ÿ�����Ҫ����,��Ҫ��Э��
- 17. TCP ճ��
- 18. TCP���������ֺ��Ĵλ��ֱַ�����,��Ҫ��ʲô
- 19. ���ʵ�ֲ���������,������������ʵ�ַ�ʽ��ʲô��ͬ
- 20.�̺߳ͽ��̵�����,���̺߳Ͷ���̱�̵��ص�
- ��.C++
- 1. new��delete��malloc��free��ϵ
- 2. delete�� delete []����
- 3. C++����Щ����(��������ص�)
- 4. ��������ʱҪ���ø��������������?
- 5. ��̬,�麯��,���麯��
- 6. �����溯���ķ���ֵ(��)----��ô������--
- 7. ʲô�ǡ����á�?������ʹ�á����á�Ҫע����Щ����?
- 7-8. ������ָ�������
- 8. �������á���Ϊ �������� ����Щ�ص�?
- 9. ��ʲôʱ����Ҫʹ�á������á�?
- 10. �������á���Ϊ��������ֵ���͵ĸ�ʽ���ô�����Ҫ���صĹ���?
- 11. �ṹ�������к�����?---C����������
- 12. ���������:
- 13. ����(overload)����д(overried,�е���Ҳ���������ǡ�)������?
- 14. ���ļ������ֻ����intialization list(��ʼ���б�) ��������assignment?
- 15. C++�Dz������Ͱ�ȫ��?
- 16. main ����ִ����ǰ,����ִ��ʲô����?
- 17. �����ڴ���䷽ʽ�Լ����ǵ�����?
- 18. �ֱ�д��BOOL,int,float,ָ�����͵ı���a �롰�㡱�ıȽ���䡣
- 19. ��˵��const��#define ���,�к��ŵ�?--C����-11��
- 20. ����������ָ�������?--C����-12��
- 21. int (*s[10])(int) ��ʾ����ʲô?
- 22. ջ�ڴ������ֳ�����
- 23. ��������ת��ָ���ڴ��ַ
- 24. int id[sizeof(unsigned long)];�������?Ϊʲô?
- 27. �ڴ�ķ��䷽ʽ�м���?---���� 17
- 28. ������������������麯��,�����ʲô����?
- 29. ȫ�ֱ����;ֲ�������ʲô����?����ôʵ�ֵ�?����ϵͳ�ͱ���������ô֪����?
- ��. ARM��ϵ�ṹ���
- 1. ������һ��ARM���������ص�,����˵��5�����ϵ��ص㡣
- 2. ARM�ں��ж����ֹ���ģʽ?��д����Щ����ģʽ��Ӣ����д,�м����쳣ģʽ,�м�����Ȩģʽ,cortex_aϵ���м�����Ȩģʽ,���ֹ���ģʽ
- 3. ARM�ں��ж��ٸ��Ĵ���,����һ��
- 4. ARMͨ�üĴ�����,��3���Ĵ���������ܺ�����,��д�����ǵ����ֺ����á�
- 5. ������һ��CPSR�Ĵ��������Bit����������á�
- 6. ʲô��������?�������ı�����ʲô
- 7. ����BLָ����תʱLR�Ĵ����������ʲô����?�������ԭ��
- 8. ������һ��ʲô�Ǵ������ֳ�,��ν��б����ֳ�?
- 9. ATPCSĬ��ʹ�õ���ʲôջ?--����ջ(ARMҲ��)
- 10. ʲô����ջ����ջ,ʲô����ջ����ջ?
- 11. ��д��һ��������ARM�����ж�ָ��,����Ҫ���������á�
- 12. ������һ��ARM��ϵ���쳣�������ĸ��
- 13. ��д��һ��ARM�������ɵ�bin�ļ�ӳ���а�����Щ����?
- 14. �����˵����ARM�������Ͻ���һ���жϴ������ж��쳣�����IJ��졣
- 15. ������쳣�жϴ�������ʱ,��ͨ��ʲô��ɳ�ʼ������,��Щ��ʼ���ľ��岽����ʲô?
- 16. uboot����Ҫ����
- 17. uboot���������������ں˵�?
- 18. uboot���������̵���Ҫ����ʲô
- 19. bootcmd��bootargs����uboot��������������
- 20. linux�ں˵���������
- 21. uImage,zImage,vmlinux������
- 22. Kconfig,.config,Makefile�����ļ�֮��Ĺ�ϵ
- ��. ϵͳ��ֲ
- 1. Linux�ں���������---ͬ�� ��.20
- 2. ʲô��bootloader?��Ƕ��ʽϵͳ����bootloader��������ʲô?
- 3. Ϊʲô������Զ�Ӳ��ƽ̨�������Զ�C����ȴ���Բ�����Ӳ��ƽ̨?
- 4. ʲô�����������?
- 5. Linuxƽ̨�µĿ�ִ���ļ���ʲô��ʽ?
- 6. ʲô���������?
- 7. ����nfs����ĸ���������?
- 8. ����һ��װ��linux�ں˵Ŀ��������������?
- 9. ����uboot����Ҫ��������Щ?
- 10. uboot������û�������?
- 11. ����uboot��bootcmd��������������?--��.19
- 12. ����uboot��bootargs��������������?--��.19
- 13. ����ʲô��ƽ̨��ش���ʲô��ƽ̨�ش���?
- 14.�������linux/uboot֧�ָ���Ӳ��ƽ̨?
- 15. �������ubootʹ���ʺ��ض��Ŀ�����ƽ̨?
- 16. ��α���uboot���ɶ������ļ�?
- 17. ����uboot����������?
- 18. ����ϵͳ����������Щ?
- 19. �������linuxԴ��ʹ���ʺ��ض��Ĵ�����?
- 20. ��make menuconfig��������Щ�������Ա�ѡ������״̬����Y��,��N��,��M��������״̬�ֱ���ʲô����?
- 21. ��α��뱻ѡ��Ϊ��M��ѡ�������ģ��?
- 22. �����豸��������?
- 23. ��д�豸���ļ�����Ҫ������ʲô?
- 24. ������ν�һ���ں�Դ�������е�����������뵽�ں���?
- 25. ������ν�һ���Լ���д������������뵽�ں���?
- 26.���ں������������������̨�Ѿ���ʼ������һ�����ʲô��ʽ�������ں�?
- 27. linux�ں�����������������ʲô������ӡϵͳ��������Oops?
- 28. linux�ں�����������������ijЩ������ӡϵͳ��������Oops,��������Ҫ��ӡ��Щ����?
- 29. ����ʲô���ļ�ϵͳ?ʲô�и��ļ�ϵͳ?
- 30. ��������Ϊʲôһ�㲻��Ҫ��װ��̬��?
- ��. ��������
- 1. ʲô��ģ��?
- 2. �����������
- 3. �ַ��豸������ܱ������?
- 4. ʲô�Dz���,�����в�����̬��ԭ������Щ?
- 5. �����̬��;������Щ?�ֱ���ʲô�ص�?
- 6. ������IOģ���м���?
- 7. ���linux�豸ģ�͵���Ҫ����?
- 8. �ַ��豸���������linux�豸ģ���Ƿ�ì��?
- 9. platform�ܹ��ֱ��Ϊ�ĸ�����?����ͨ��ʲô����ƥ��
- 10. �豸����platform�ܹ��Ƿ���ì��?
- 11. ΪʲôҪ���жϷ�Ϊ���°벿?���°벿��������Щ?
- 12. ����������tasklet������?
- 13. �ں����ڴ���亯���ֱ�����Щ?�ֱ���ʲô�ص�?
- 14. �ں˵���
- 15. �ַ��豸�����Ŀ��
- 16. �ַ��豸�Ϳ��豸�������豸������
- 17. �����;�̬����,��Щ�������־�̬,�����̬�ķ���,�Լ�����,ʹ�ó�����---�����4��
- 18. ���������ź���������
- 19. ̸̸����ж�������,���������ĵ�����
- 20. �жϵͰ벿��Ҫ����ʲô
- 21. Platfprmƽ̨��������ģ��
- 22. IIC��ϵͳ�������
- 23. ������ϵͳ�������
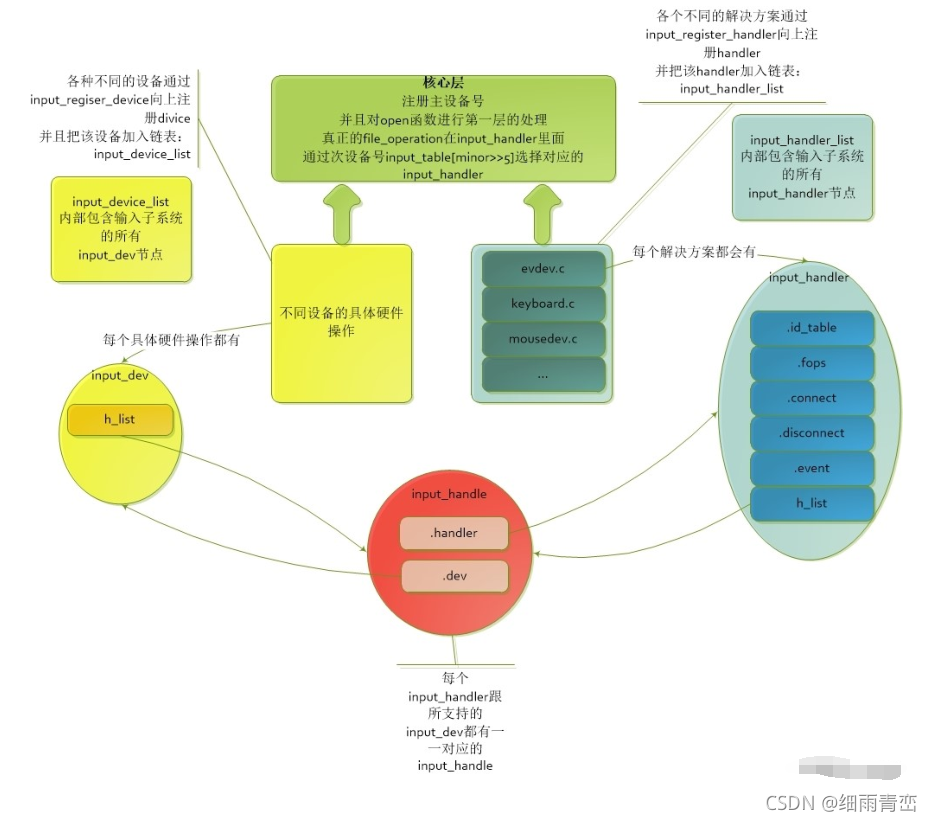
һ��C���Ի���������
1. gcc�������������������,�ֱ���ʲô����?
gcc����������������������IJ�,�ֱ��� Ԥ������ ���롢 ��ࡢ ����
Ԥ����:����Դ�ļ��е�#ifndef��#include��#define��Ԥ��������,�ýλ�����һ���м��ļ�.i
��Ҫ����'�궨���滻','ͷ�ļ�չ��','ע��ɾ��'��,'������'�����
gcc -E hello.c �Co #����ʹ��-Eѡ������.i�ļ�
##��ע�⡿�� -o,ֻ�����ն˴�ӡһ��չ���Ĵ���,Դ�ļ����ᷢ���ı�
����:gcc��Ԥ�������'���'�����'�������'����,�������.i,��������ɻ�������ļ�.s
������Ƿ��д� , �����������:(���벽��) ����-->�ʷ�����-->�������-->ͳ�Ʒ���-->���(�ٽ���)
gcc -S hello.i �Co hello.s #��û�� -o �������ɶ�Ӧ�� .s �ļ�
���:�������ѱ��������'�������'���ɾ���CPU�ϵ�Ŀ�����('��������')������������ļ�.s,���Ŀ������ļ�.o��.obj , ����:(��ಽ��)->ͳ�Ʒ���-->�������ű�
#������ļ����ɻ�����(����ɶ������ļ�)
gcc �Cc hello.s �Co hello.o
#-c ��ʾ�����ӿ�,��û�� -o �������ɶ�Ӧ��.o �ļ�
����:��'���Ŀ�����ģ��'���ӳ�һ��'���Ŀ�����'ģ�顣����Ŀ������ļ�.0(��������Ŀ������ļ������ļ�����������),�㼯��һ����ִ�еĶ����ƴ����ļ�
#���ӿ⺯��,����һ����ִ���ļ�
gcc hello.o �Co hello #�� -o ������ a.out ��ִ���ļ�
# E S c ---> i s o
2.ʲô�ǻص�����?
�ص���������һ��ͨ��'����ָ�����'�ĺ��������Ե�'һ��������Ϊ����'ʹ�õ�ʱ��,����������ǻص�������
#������ָ�� ��Ϊ�����IJ��� �ĺ���
int (*p)(int,int) ------ > # int my_sub(int a,int b)
һ��'�����IJ���'��һ��'����ָ��',�����������'��������ĸ�'����,'ȡ����'�����������ʱ,��'�ĸ��������β�'�ĺ���ָ�븳ֵ
3.��ַ�ܷ�ʹ�� printf�����е� %u��ʽ��ӡ?
%u �Ǵ�ӡ���ŵ�ʮ���Ƶ�����,��ַ�DZ��������ŵ�16���Ƶ�,���Կ��Դ�ӡ���Dz��Ƽ�
����%p�������
4.�ṹ���빲����(������)������
���Ƚṹ���빲���嶼��'��������',���ǵ�'��Ա����'�����Զ���Ϊ'��ͬ����'�ġ�
�ṹ�����ͬʱ�洢���ֱ�������,����ͬ��ͬһ��ʱ��ֻ�ܴ洢��ʹ�ö���������͵�һ��,����һʱ��,�������ͱ��ı��,ԭ���ı������ͺ�ֵ����������
�������������ͬһ�����������ʹ�ö��ָ�ʽ,���Խ�ʡ�ռ䡣'���г�Ա����һ���ڴ�ռ�',ÿ����Ա��'��ַ��ͬ'
'�ṹ��Ĵ�С'�Ǹ���ÿ����Ա�����Ĵ�С������ȷ����,��'������Ĵ�С'�Ǹ������ij�Ա�����Ĵ�Сȷ����
5. static��const��volatile�ؼ�����ʲô����?
static:��ֹ����̬
1.����ȫ�ֱ���:����ֻ�ڱ�ģ���ڿɼ�,'��������',����'����ֻ���ڱ��ļ�'(��ǰ.c)��ʹ��
�ڶ��岻��Ҫ�������ļ�������ȫ�ֱ���ʱ,����static�ؼ����ܹ���Ч�ؽ��ͳ���ģ��֮������,���ⲻͬ�ļ�ͬ�������ij�ͻ,�Ҳ�����ʹ�á�
2.���ξֲ�����:������ȫ�������������ڴ�ռ�,'�ӳ���������������',�������������
3.���κ���:������ʹ�÷�ʽ��ȫ�ֱ�������,�ں����ķ�������ǰ����static,���Ǿ�̬����,'��������',����'�ú���ֻ���ڱ��ļ�'(��ǰ.c)��ʹ��
��̬����ֻ�������������ļ��пɼ�,�����ļ��������øú���,��ͬ���ļ�����ʹ����ͬ���ֵľ�̬����,����Ӱ�졣
const:ֻ��
C��������:��const���εı�����'ֻ������',���ʻ��DZ���,
���˳���Ϊ������,����ͨ�������������ڳ���������������ֵ,������÷�����ͨ����һ����
C++��������:��const���εı���,�������ͳ�ʼֵ��ֱ�ӷŵ����ű���,��ʹ�ñ�������ʱ���ֱ�Ӵӷ��ű��ж�ȡ��ֵ�������C������,��C++��������const���εı��������dz�����
//const ����˭ ˭���ܱ�----- ���� *p ֵ���ܱ�,����ָ�� ���Ըı�
// ----- ���� p p��ָ���ܱ� ���� *p��ֵ ���Ըı�
const int *p; //ֵ���ܱ�,����ָ�� ���Ըı�
int const *p; //ֵ���ܱ�,����ָ�� ���Ըı�
int * const p; //p��ָ���ܱ� ���� *p��ֵ ���Ըı�
const int * const p; //p��ָ���ܱ� ���� *p��ֵ ���Ըı�
volatile :��ֹ�������Ż�
volatile�ؼ��������ı���,�������Է��ʸñ����Ĵ����'���ٽ����Ż�',�Ӷ������ṩ�������ַ���ȶ����ʡ�
�� volatile ����,�ùؼ��ֵ������Ƿ�ֹ������ֱ����CPU�Ĵ����л�ȡֵ,���ڴ������¶�ȡ
6.���������Ͷ������������
����'�������ڴ�ռ�',
����'�����ڴ�ռ�'����Ҳ�п���ͬʱΪ���ṩ'��ʼֵ'��
#ע��:��������,�ǿ��ٵ�ַ�ռ��˵�
7.��ֵ�븳��ֵ��ʲô��ͬ?
����ֵ,Ҳ����'��ʼ��',ֻ���ڶ����ʱ�����,ֻ����'=',��ʽΪ
int a = 10;
��ֵ,���ڶ����,�ı������ֵ,����=���������ϸ�ֵ���,��+=��-=��,�Լ�,�Լ�Ҳ�����㸳ֵ��䡣��ʽΪ
a = 200;
#----����**����--Ӧ�ò��������ʰ�(�Զ����ιؼ���)
8.�ֲ�������ȫ�ֱ����ܷ�����
����,�ֲ�����ԭ��
��C++��,����ͨ��'�����ռ�'(�����ռ�)������������ȫ�ֱ���,����ǰ������������� ::
������C������,�����Dz���,����ȫ�ֵ�����������
9.�������һ���Ѿ���������ⲿ����
1.�� extern�ؼ��ַ�ʽ:����һ���������ⲿ����
2.��'����ͷ�ļ�'�ķ�ʽ,�����ڲ�ͬ��C�ļ�������ͬ����ȫ�ֱ���,ǰ��������ֻ����һ��C�ļ��жԴ˱�������ֵ,��ʱ���Ӳ��������
10.ȫ�ֱ����;ֲ������Ĵ洢��ʽ��ʲô����?
1.'������'��ͬ:ȫ�ֱ�����������Ϊ'��������',���ֲ�������������Ϊ'��ǰ������ѭ��'
2.'�ڴ�洢��ʽ'��ͬ:ȫ�ֱ����洢��'ȫ��������'��,�ֲ������洢��'ջ��'
3.'������'��ͬ:ȫ�ֱ����������ں�������һ��,��'��������ٶ�����',�ֲ������ں����ڲ���ѭ���ڲ�,��'�������˳�'��'ѭ���˳�'�Ͳ�������
4.'ʹ�÷�ʽ'��ͬ:ȫ�ֱ���������������'�������ֶ�����'�õ�,���Ǿֲ�����ֻ����'�ֲ�ʹ��'��(�ֲ�����)
10-����:�ڴ�ķֶ�
C���Ծ�������֮���ڴ��Ϊ�����������
1.ջ:�ɱ��������й���,�Զ�������ͷ�,��ź������ù����еĸ��ֲ���,�ֲ�����,����ֵ���������ص�ַ��������ʽ�������ݽṹ�е�ջ��
2.��:���ڳ���̬���������ͷſռ䡣C�����е�malloc��free,C++�е�new��delete�����ڶ��н��еġ����������,����Ա����Ŀռ���ʹ�ý�����Ӧ���ͷ�,������Աû���ͷſռ�,�������������ʱϵͳ�Զ����ա�
3.ȫ��(��̬)�洢��:��ΪDATA�κ�BSS�Ρ�
DATA��(ȫ�ֳ�ʼ����)��ų�ʼ����ȫ�ֱ����;�̬����;
BSS��(ȫ��δ��ʼ����)���δ��ʼ����ȫ�ֱ����;�̬�������������н���ʱ�Զ��ͷš�����,
BSS���ڳ���ִ��֮ǰ�ᱻϵͳ�Զ�����,����δ��ʼ��ȫ�ֱ����;�̬�����ڳ���ִ��֮ǰ�Ѿ�Ϊ0��
4.���ֳ�����:��ų����ַ����������������ϵͳ�ͷš�
5.���������:��ų���Ķ����ƴ��롣
11. const �� # define ����к��ŵ�?
��ͬ��:���߶������������峣����
��ͬ��:
a.'������ʱ��':#define���ڱ����'Ԥ������'չ��,��const����'����'�����е�ʱ��������
b.#defineֻ��'���ַ����滻','û�����ͼ��'��
��const�ж�Ӧ����������,��Ҫ�����жϵ�,���Ա���һЩ�ͼ��Ĵ���
c.�ʹ洢��ʽ����:define'�궨��'ʱ'��������ڴ�',#defineֻ�ǽ���չ��,�ж��ٵط�ʹ��,���滻���ٴ�,������ĺ곣�����ڴ��������ɸ�����;
const�����ڶ���ʱ�����ڴ��з���(�����Ƕ���Ҳ������ջ��),const�����'ֻ������'�ڳ������й�����ֻ��һ�ݱ��ݡ�
�ܽ�:const �� #define ����к��ŵ�
a.const������'��������',���곣��'û����������',���������Զ�ǰ�߽������Ͱ�ȫ���,������ֻ�����ַ��滻,û�����Ͱ�ȫ���,�������ַ��滻���ܻ�������ϲ����Ĵ���
b.��Щ���ɻ��ĵ��Թ��߿��Զ�const�������в���,�����ܶԺ곣�����в��ԡ�
12.������ָ���������ʲô?
��������һ����ַ���� ---> �����Ա���ֵ,Ҳ�����������Լ�,����ƫ��
ָ���DZ������Կ��� ++ -- ,����ƫ��
�����������,����������һ��ָ��,ָ���������ַ,�������ַ �� ������Ԫ�صĵ�ַ �� ������ ��ͬһ����ַ
13.Ϊʲô��Ϊ�����βε������ָ����Ի���?
C���� �β� ��'������''ʵ����'����'ָ�����'��
14.�βκ�ʵ����ʲô����?
��ʽ����:��'���庯��'ʱ,���������������еı�����Ϊ'��ʽ����'���ں�������֮ǰ,���ݸ�������ֵ�������Ƶ���Щ��ʽ������
ʵ�ʲ���:��'���ú���'ʱ,Ҳ��������ʹ��һ������ʱ,���������������еIJ���Ϊ'ʵ�ʲ���',�����ĵ������ṩ�������IJ�����Ϊʵ�ʲ���
15.ָ�롢����͵�ַ֮��Ĺ�ϵ�ǵ�ʲô?
�����DZ�����һƬ'�����ڴ浥Ԫ'�е�,��'������'������Ƭ'�����ڴ浥Ԫ'��'��ַ',
�ڴ浥Ԫ�ĵ�ַ����ָ��,���������Ҳ��һ��ָ��
#�������ɶ������Ԫ�����,Ԫ�ذ����������͵IJ�ͬ,��ռ�����ڴ�Ĵ�СҲ��ͬ��
һ��'����'��Ԫ�ص���ַ��������ռ����'�ڴ浥Ԫ'��'��ַ', 'ָ��'����'�ȿ���ָ��'һ������,'Ҳ����ָ��'һ������Ԫ�ء�
��'������'��'����ĵ�һ��Ԫ��'��'��ַ'����ָ��,ָ���ָ����һ�����顣
�����ʹָ�����ָ���i��Ԫ��,�Ϳ���iԪ����ַ��������
16. voidָ����ǿ�ָ����?����ʲô����?
voidָ����һ������ָ��,���ǿ�ָ��
�����Ա�ʾ����һ�����͵�ָ��(malloc�ķ���ֵ����һ�� voidָ��)
��ָ��һ��Ӧ���������������:
(1) �ÿ�ָ����ֹ�Եݹ�����ṹ�ļ������
(2) �ÿ�ָ����Ϊ��������ʧ��ʱ�ķ���ֵ
(3) �ÿ�ָ����Ϊ����ֵ
17.���ڴ�ϢϢ��ص���Ҫ��������Щ?
(Ұָ�롢ջ(stack)����(heap)����̬��)
Ұָ��:������һ��ָ�����û�н��г�ʼ��,��ָ��ָ����һ����ȷ���Ŀռ�,���ָ���ΪҰָ��
���Ұָ��ļ������
a. �����ָ�����û�б���ʼ��
b. ָ��IJ��������ɱ��������÷�Χ(Խ��)
c. ָ�뱻�ͷŻ���ɾ����,û�б���ΪNULL,Ȼ���ٴα�ʹ��
ջ(stack):ջ����������ֲ�����(ϵͳ�Զ������ͷ�),ջ�ϵ�����ֻ�ں����ķ�Χ�ڴ���,�������н�����Щ����Ҳ�ᱻ����,ջ���ص����Ч�ʸ�,���ռ��С����
��(heap):������malloc()��calloc()���Ⱥ�������new��������õ��ڴ�,��free()������delete()�����ͷ��ڴ桢�ѵ��ص����Ч�ʸ�,����Ա�ֶ������ͷ�,���ռ��С����
#ע��:������������,�ڶ�������Ŀռ�Ҳ���Ա�ϵͳ�ͷ�
��̬��:��̬�����ڱ����Զ�ȫ�ֱ�����static����,��̬�������������������ж�����,�ɱ������ڱ����ʱ������ڴ�
18. #include<> �� #include���� ��ʲô����?
#include<> ֱ���� ϵͳ�Ŀ��� ȥѰ����Ҫ��ͷ�ļ���
#include"" ���ڵ�ǰĿ¼���в���,����Ҳ���,��ȥϵͳ�Ŀ������Ѱ��
18.0 gcc����
-I -I ../include #���ӿ�(�Լ��Ŀ�)//��ĵ�ַ #����ʹ�� -I ��ָʾ�DZ�λ�õ�ͷ�ļ�
-i
-L
-l ���ӵ�������
19. x=x+1 , x+=1 , x++ �ĸ�Ч�ʸ�?
x++ ��ȡx�ĵ�ַ,Ȼ��x����1 x++��Ч�����
x+=1 ��ȡ�Ⱥ��ұߵ�x�ĵ�ַ,����x+1��ֵ,���õ���ֱֵ�Ӵ�����ߵ�x,֮ǰ�Ѷ���,��ʡȥ��ֵ�Ĺ���
x=x+1 �ȶ�ȡ�Ⱥ��ұߵ�x�ĵ�ַ,����x+1��ֵ,Ȼ���ȡ�Ⱥ���ߵ�x��ַ,��Ⱥ��ұߵ�ֵ���ݸ��Ⱥ���ߵ�ֵ
# ++i �� �� i++ ����
1.i++���ص���i��ֵ,++i���ص���i+1��ֵ;
2.i++����������ֵ, ++i ����������ֵ��
20.Ϊ�������ͱ�����ֵʱ,��������Ӧ����ת��?
��ʽ����ת�������еIJ��������Զ�ת��Ϊ��������
ϵͳ�Ὣ�����ͻ��Զ�ת���ɸ����ͽ��м���,Ȼ����Ľ����ֵ����Ҫ����������

����Linux����
1. �ַ��豸�����豸���ܵ�����Linux���и�ͳ�ƽ�ʲô?
Linux һ�н��ļ�
2.�鿴һ���ļ������ͳ��õ��м��ַ�ʽ
ls -l
file [�ļ���]
stat [�ļ���]
����
//��ͨ�ļ����� -
Linux������һ���ļ�����, ���� ���ı��ļ�(ASCII);�������ļ�(binary);���ݸ�ʽ���ļ�(data);����ѹ���ļ�.��һ������Ϊ [-]
//Ŀ¼�ļ� d
����Ŀ¼, ���� # cd �������ġ���һ������Ϊ [d],���� [drwxrwxrwx]
//���豸�ļ� b
���豸�ļ� : ���Ǵ洢�����Թ�ϵͳ��ȡ�Ľӿ��豸,���Ծ���Ӳ�̡�����һ��Ӳ�̵Ĵ�����/dev/hda1���ļ�����һ������Ϊ [b]
//�ַ��豸 c
�ַ��豸�ļ�:�����ж˿ڵĽӿ��豸,������̡����ȵȡ���һ������Ϊ [c]
//�����ļ� s
�����ļ�ͨ�����������������ӡ���������һ�������������ͻ��˵�Ҫ��,�ͻ��˾Ϳ���ͨ����������������ͨ�š���һ������Ϊ [s],��� /var/runĿ¼�п��������ļ�����
//�ܵ��ļ� p
FIFOҲ��һ��������ļ�����,����Ҫ��Ŀ����,����������ͬʱ��ȡһ���ļ�����ɵĴ���FIFO��first-in-first-out(�Ƚ��ȳ�)����д����һ������Ϊ [p]
//�����ļ� l
����Windows����Ŀ�ݷ�ʽ����һ������Ϊ [l],���� [lrwxrwxrwx] ֻ���������ļ� ����l
3.Linux�³��õİ�װ����?
���߰�װ:sudo apt-get install
���߰�װ:sudo dpkg
��װ���� : sudo dpkg -i ������ (install)
�鿴�Ѱ�װ�����İ汾: sudo dpkg -l ������
�鿴������װ��·����Ϣ : sudo dpkg -L ������
ж������ : sudo dpkg -r ������ (������������Ϣ�ᱣ��)
��ȫж�� : sudo dpkg -P ������
4.�ֱ����shell���shell��shell�ű�
shell : �����н�����(����sh,csh,ksh,bash,dash�Ȳ�ͬ�汾���)
shell����:��һ�ֽ��������Ե����������
shell�ű�:��������һ���ļ��� ����.sh ��β���ļ��� �����ŵ���shell����ļ��ϡ�
5.printf��scanf�������Ƿ���ͬһ���ļ�
����
printf �������DZ�������ļ� #--- stdout
scanf �������DZ��������ļ� #--- stdin
#����һ�� ��������� --- stderr
6. Linux���õ��ļ�ϵͳ����?��β鿴�ļ�ϵͳ����?
Linux���õ��ļ�ϵͳ�� ext4,ext3..
�鿴�ļ�ϵͳ���͵�����(�����ĸ�����)
df -T
parted -l
blkid
lsblk -f
7. windows����û���ļ�ϵͳ?�ļ�ϵͳ�к�����?
��!windows�ļ�ϵͳ����fat16,fat32,ntfs,ntfs5.0,winfs��
����:����'�����ʹ洢'�ļ���Ϣ������������Ϊ�ļ�����ϵͳ,����ļ�ϵͳ��
��ϵͳ�Ƕ�����,'�ļ�ϵͳ'�Ƕ�'�ļ��洢���ռ�'����'��֯�ͷ���',�����ļ��洢���Դ�����ļ����б����ͼ�����ϵͳ��
�����˵,������Ϊ�û������ļ�,���롢�������ġ�ת���ļ�,�����ļ��Ĵ�ȡ,���û�����ʹ��ʱ�����ļ��ȡ�
8.ͷ�ļ��Ϳ��ļ�һ�����ĸ�·����?
ϵͳ��'ͷ�ļ�'λ��: /usr/include
��װ���'ͷ�ļ�'λ��: /usr/local/include/
#include<linux/can.h> //��Ӧ /usr/include/linux/can.h
#include<stdio.h> //��Ӧ /usr/include/stdio.h
#include <libusb-1.0/libusb.h> //��Ӧ /usr/local/include/libusb-1.0/libusb.h
ϵͳ��'���ļ�'λ��:/lib/usr/lib
�û�'��װ��'λ��: /usr/local/lib
Ĭ��ֻ������c���Կ�,����ϵͳ�����е��������Լ���װ��,��Ҫ�ڱ���ʱָ�����������ڷ�ϵͳ
�����ͨ��-L��ָ�����ļ�λ�á�
a. C����,����Ҫ-l �Լ�-L,����ʱ�Զ�����/lib/x86_64-linux-gnu/libc.so.6:gcc -o test test.c
b. �����������,��libmath.so:gcc -o test test.c -lm
c.��װ��:��:libusb-1.0.so,gcc -o libusb-test usbtest3.0.c -lpthread -lusb-1.0
d.��ϵͳ����:gcc -o usbtest usbtest.c -L/home/baoli/libusb -lusb
9.ϵͳ�������ͬ�����ļ�
�ļ�������
10.ϵͳ�������ͬ�Ľ��̡�
pid
11.�鿴�ļ�����Щ����
cat �ɵ�һ�п�ʼ��ʾ�ļ����� #-n ������ʾ�к�
tac �����һ�п�ʼ��ǰ��ʾ,#���Կ��� tac �� cat �ĵ���д
more һҳһҳ����ʾ�ļ�����
less �� more ����,���DZ� more ���õ���,��������ǰ��ҳ!
head ֻ��ͷ����,Ĭ��ǰ10��
tail ֻ��β�ͼ���,Ĭ�Ϻ�10��
ls �鿴Ŀ¼�µ��ļ�
file �鿴�ļ�������
12.�����ļ���Ȩ��
chmod : �ı䵵����Ȩ��, SUID, SGID, SBIT�ȵȵ�����
chmod 754 filename
#chgrp : �ı䵵������Ⱥ��
#chown : �ı䵵��ӵ����
13.ʲô�Ƿ�������?
�ֽ�������,
#�����·������������ʱ:�����ļ�λ�÷����仯��ʱ��,���ӻ�ʧЧ(���������ļ����ɴ���)
#�þ���·��������ʱ��:�����ļ������ƶ�������λ��, ���DZ������ļ�(Դ�ļ�)�����ƶ�
�������ݽṹ
1.���ݽṹ��Ҫ�о�����ʲô?
���ݵĸ������ṹ�������ṹ�Լ�����֮��Ĺ�ϵ(��ѧģ��)
�Ը��ֽṹ������Ӧ������
��Ƴ���Ӧ���㷨
�����㷨��Ч��
2.���������������
(���ṹ���ڴ�洢�����ʷ�ʽ�����������)
���ṹ:���Թ�ϵ
�ڴ�洢:������һ�������ĵ�ַ�ռ�,���������Dz������ĵĵ�ַ�ռ�
���ʷ�ʽ:�������ͨ���±�ֱ�ӵķ��ʶ���Ӧ��λ��,����������
���������ɾ��,����λ�ò���,��Ҫ�ڴ��Ƭ���ƶ�,Ч�ʵ�
����,��ɾ���Ͳ��������
˳���:(����)
ԭ��:˳����洢�ǽ�����Ԫ�طŵ�һ���������ڴ�洢�ռ�,��������Ԫ�صĴ�ŵ�ַҲ����(��
������ͳһ)��
�ŵ�:
(1)�ռ������ʸߡ�(�ֲ���ԭ��,�������,�����ʸ�)
(2)��ȡ�ٶȸ�Ч,ͨ���±���ֱ�Ӵ洢��
ȱ��:
(1)�����ɾ���Ƚ���,����:�������ɾ��һ��Ԫ��ʱ,��������Ҫ�����ƶ�Ԫ����������һ��˳��
(2)��������������,�пռ�����,����Ҫ��ȡ��Ԫ�ظ������ܶ���˳�����Ԫ�ظ���ʱ,�����"���"����.��Ԫ�ظ���Զ����Ԥ�ȷ���Ŀռ�ʱ,�ռ��˷Ѿ�
ʱ������ :���� O(1) ,�����ɾ��O(n)
�����洢
ԭ��:�����洢���ڳ������й����ж�̬�ķ���ռ�,ֻҪ�洢�����пռ�,�Ͳ��ᷢ���洢�������,��������Ԫ�ؿ�������,����ռ�洢�ռ��������,һ���ִ�Ž��ֵ(data),��һ���ִ�ű�ʾ����ϵ���ָ��(struct �ṹ��* next)��
�ŵ�:
(1)�����ɾ���ٶȿ�,����ԭ�е�����˳��,����:�������ɾ��һ��Ԫ��ʱ,ֻ��Ҫ�ı�ָ��ָ�ɡ�
(2)û�пռ�����,�洢Ԫ�صĸ���������,����ֻ���ڴ�ռ��С�йء�
ȱ��:
(1)��ȡij��Ԫ���ٶ�����
(2)ռ�ö���Ŀռ��Դ洢ָ��(�˷ѿռ�,���������,malloc����,�ռ���Ƭ��)
(3)�����ٶ���,��Ϊ����ʱ,��Ҫѭ����������,��Ҫ�ӿ�ʼ�ڵ�һ��һ���ڵ�ȥ����Ԫ�ط��ʡ�
ʱ������ :���� O(n) ,�����ɾ��O(1)��
3.����������㷨
1.ѡ��һ��'��'Ԫ��,ͨ��ѡ���һ��Ԫ�ػ������һ��Ԫ��
2.ͨ��һ������(��Ҫ���������)�ָ�ɶ�����������,(�����)����һ���ּ�¼��Ԫ��ֵ���Ȼ�Ԫ��ֵС��(�����)��һ���ּ�¼��Ԫ��ֵ�Ȼ�ֵ��
3.��ʱ'��Ԫ��'�����ź������м�λ��
4.Ȼ��ݹ����,�ֱ������������ͬ���ķ���������������,ֱ��������������
4. hash���ҵ��㷨
���Ҫ�� 'NUM' �����в�������,
��'NUM'/0.75,����������'N',���Դ���һ����'N'��Ԫ�ص�ָ������,Ȼ��'NUM'�����ֱ��'N'ȡ
��,
��ÿһ����������������������Ԫ���±��������,Ȼ����в�����ֱ������Ӧ�������±꼴��
#ʵ�ʽ���
���Ҫ��100�����в�������
Ȼ��100/0.75,����������133,���Դ���һ����133��Ԫ�ص�ָ������
Ȼ��num�����ֱ��133ȡ��,
��ÿһ����������������������Ԫ���±��������,Ȼ����в�����ֱ������Ӧ�������±꼴��
5.�жϵ������Ƿ��л�
ʹ������ָ��,ͬʱָ��ͬһ���ڵ�,Ȼ��һ��ָ��һ��������,һ��ָ��һ����һ��,Ȼ���ж�������ָ����û��ָ��ͬһ���ڵ��ʱ��,���ָ����ͬһ���ڵ� �����л�,�������û��
6.�ж�һ�������ַ����Ƿ�ƥ����ȷ,��������ж���,��ô��?��(([]))��ȷ,[[(()����
ʹ�õ�����ʽջ ��Ϊ���� #---һ�����Ŷ�Ӧһ��ջ
Ȼ���ж� ,����� ( �ͽ�ջ,����� ) �ͳ�ջ
�ж�ִ�����ջ����֮��ķ���ֵ,�������ֵ ���� -1 ,���Ǵ����
�����������ַ���������,�����ջ�ķ���ֵ = 0,��ʾ����ȷ��,�����Ǵ����
��. IO����
1.��IO���ļ�IO����?
�ļ�IO-ϵͳ����
�ļ�IO�ֱ����� ϵͳ����,���漰������,���ɲ���ϵͳ�ṩ��,Ҳ���� �ں� �ṩAPI(API:�����ӿ�)
�ļ�IO���ļ�����ʹ���ļ�������
�ļ�������:
�ļ��ı�־,��һ��С��'˳�����'�ķǸ��������ں����� ��ʶһ���ض��������ڷ��ʵ��ļ�
'���̼�ͨ��'��ʽ�д����Ҳ��'ͨ���ļ�������'���в�����
�ļ����������ļ�ָ������,Ҳ�����ڱ�ʶһ���ļ�,���ļ�������Ҫʹ���ļ�������
��һ����������ʱ,����ϵͳ��'�Զ�Ϊ��ǰ���������ļ�������'
0 �������ļ�������(stdin)
1 ������ļ�������(stdout)
2 ����������ļ�������(stderr)
��IO-�⺯��
��IO���ǿ⺯��,�⺯���ı��ʻ���ϵͳ����
��IO���� �ļ�IO �Ļ�����,��װ�����ġ�
�⺯�����ϵͳ����,����һ��������,��ִ��ϵͳ����֮ǰ,�Ὣ�����ȱ����ڻ�������,ֻ�е�������ˢ�µ�ʱ��Ż�ִ��ϵͳ����
��IO���ļ�����ʹ���ļ�ָ��,'fp'����һ��FILE�ṹ�����ļ�ָ��������±�
#�ص�
��IO��'����ֲ�Ը�'
��IO��'�ļ�IO'�Ļ�����'��װ��һƬ�ռ����ֽ���������'
FILE �ṹ��(�ļ�ָ��) ����'�ļ�������'�Ļ����Ϸ�װ��'������'
�ļ�ָ��:FILE * #�ֱ���Ϊ�ļ���ָ�� ,��ָ��
2.������ָ��?�C�ļ�ָ�롢�ļ���ָ��
FILE �ṹ��(�ļ�ָ��) ����'�ļ�������'�Ļ����Ϸ�װ��'������
FILEָ��:ÿ����ʹ�õ��ļ������ڴ��п���һ������,��������ļ����й���Ϣ,��Щ��Ϣ�DZ�����һ���ṹ�����͵ı�����,�ýṹ����������ϵͳ�����,ȡ��ΪFILE��
��I/O������в�������Χ����(stream)�����е�,�ڱ�I/O��,����FILE *��������
3.����ϵͳ����?
ϵͳ������Ҫָ�ľ��Ƕ�'Ӳ��'�IJ�������
�û�ͨ��'Ӧ�ò㺯��'����'linux�ں�',linux'�ں�'����'����'Ӳ��
linux�ں������װ�˴�����ϵͳ����,�����û���ͨ��'Ӧ�ò��ϵͳ���ú���'��'�����ں˵�ϵͳ����'
#��ͬ��linux�ں��е�ϵͳ�����Dz�һ����,����ϵͳ���ö�Ӧ�ij�����ֲ�Բ���,һ��Եײ�Ӳ��������Ҫͨ��ϵͳ����
��ִ�нǶȽ�,�����ϲ�API�ӿ�ͨ������'���ж�',���뵽�ں˿ռ�,ִ��'ϵͳ���÷���'����,ͨ��ϵͳ���ñ�
��,�ҵ���Ӧ���ں˺���,�������������,�м��漰��������״̬���л�(�û�̬���ں�̬)
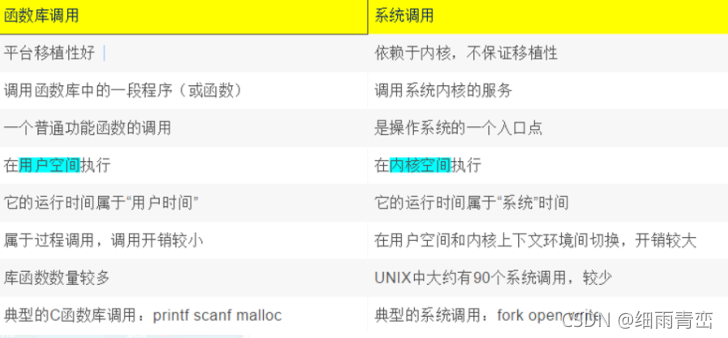
3.1 �����⺯��
�⺯���DZ���Ϊ��ͳһ��ͬ����ϵͳ���ļ������ĺ���
Ҳ����ζ����Ҫ֧��C���Ե�ϵͳ,�⺯����Ӧ����һ����
���Կ⺯������ֲ�Ը���
#ע��:�⺯���ı��ʻ���ϵͳ����,ֻ�����⺯�����ϵͳ���ö��� ������ ,������������������ϵͳ���ô�����
#ֻ�е���������ˢ��֮��Ż�ִ��ϵͳ����
4.������̬��Ͷ�̬�������?
1.��̬���������ӽ�,�����Ŀ��������ļ��ϲ���һ��,�γ�һ������,�������ִ���ļ�������
�ɿ�ִ���ļ��ϴ������,���������ٶ�Ҳ���ǵ��ú������ٶȿ졣����������ʱ��Ҫ����ȥ����ɿ�ִ��
�ļ�����̬������.aΪ���ġ�
2.��̬���������ӽ�,��Ŀ��������ļ��д���һ���⺯������,ָ�����Ŀ⺯������Ϳ�ִ���ļ�
�������������,���ɵĿ�ִ���ļ���С,��Ϊ��Ҫȥ�ⲿ���ú���,�����ٶȽ���,���Ǹ���ʱ������
�±���,ֻ��Ҫ���Ŀ⺯����ʵ�־ͺ��ˡ���̬������.soΪ���ġ�
5.��ν�����ִ��ֱ�������ں�̨?
./** &
ǰ̨��̨�л�
�鿴��̨����: jobs -l
ctrl + z : ��ͣ���̵������̨
����̨��ͣ������'��̨'��������:
bg + % ���к�(ֱ��bgҲ����)
����̨��ͣ����'�õ�ǰ̨����':
fg + % ���к�(ֱ��fgҲ����,��Ϊ��ǰ�ն�ֻ����һ�����Ա���ĵĽ���)
�������ں�̨����:./a.out + &
kill -19 pid �����̺�Ϊpid�Ľ��̱�Ϊֹ̬ͣ
kill -18 pid �����̺�Ϊpid�Ľ��̴�ֹ̬ͣ��Ϊ��̨����
6.���̵�״̬
˯��̬S,����̬R,ֹ̬ͣT,��ʬ̬Z,�ȴ�̬D,����̬,
+: ǰ̨����
<: �����ȼ��Ľ���
N: �����ȼ��Ľ���
L: ���ڴ��ҳ���䲢�����ڴ���,���̵߳�
s: �Ự���鳤
7.ʲô�ǽ�ʬ����?
�ӽ��̽���,���Ǹ�����û�н���,��ʱ�ӽ��̵���Դû���ͷ�(����),����ʱ���ӽ��̳�֮Ϊ��ʬ���� #����Σ��
(��������,��������ʬ,����Σ��)
#������ʬ���̵ķ�ʽ
����1:'�����̽���',��ʱ�Ľ�ʬ���̾ͻ��ɹ¶�����,��Դ�ͻᱻinit���̻���
����2:ʹ��'wait����',�����ȴ��ӽ����˳�,ͬʱ�����ͷŽ�ʬ���̵���Դ,����wait��һ����������,������wait֮��Ĵ���ֻ�е���ʬ���̴�����֮��Ż�ִ��
����3:ʹ��'waitpid����'����Ϊ��������������ʬ���̵���ʹ�÷���������ѭ�����ж��ӽ����Ƿ��˳�,���������û��ѭ��ִ��'waitpid����',����������Դ
����4:������ʬ������õķ�ʽ�ǽ���ź�
7-8.�¶�����
������,������init����Ϊ�ɵ�,�ɵ�������ʬ---û��Σ��
8.���������ӽ����е�дʱ��������?
����fork�����ؿ����˸����̵�������ַ�ռ�,���ִ���ٶ��DZȽ����ġ�
Ϊ�����Ч��
Unixϵͳ����ߴ�����vfork��vforkҲ�����½���,�������������̵ĸ�����
��ͨ��'�������ӽ��̿ɷ�����ͬ�����ڴ�'�Ӷ�αװ�˶Խ��̵�ַ�ռ����ʵ����,��'�ӽ�����Ҫ�ı��ڴ�������ʱ''�ſ���������'�������������"д����ʱ����"(copy-on-write)����
9.���߳̽϶���̵�����?
�߳�ͨ������Ҫͬ����һ����ͨ�Ż���,�߳�ͨ���������̵����ݶ����ͨ��,�̴߳�������Ҫ���ƽ��̵�����,��������
�߳���ת��ʱ����Ҫ�л�4G������ռ�,�����̸߳���
10.�̳߳ص�ʹ��?----�ٿ���
���̼߳�����Ҫ���'��������Ԫ��'����߳�ִ�е�����,�������������ٴ�������Ԫ������ʱ��,���Ӵ�������Ԫ����������
����һ�����������һ����������ʱ��Ϊ:T1 �����߳�ʱ��,T2 ���߳���ִ�������ʱ��,T3�����߳�ʱ��
���:T1 + T3 Զ���� T2,����Բ����̳߳�,����߷���������
11.�̳߳ص���ɲ���?
һ���̳߳ذ��������ĸ�������ɲ���:
1���̳߳ع�����(ThreadPool):���ڴ����������̳߳�,���� �����̳߳�,�����̳߳�,��
��������;
2�������߳�(PoolWorker):�̳߳����߳�,��û������ʱ���ڵȴ�״̬,����ѭ����ִ����
��;
3������ӿ�(Task):ÿ���������ʵ�ֵĽӿ�,�Թ������̵߳��������ִ��,����Ҫ�涨��
��������,����ִ��������β����,�����ִ��״̬��;
4���������(taskQueue):���ڴ��û�д����������ṩһ�ֻ�����ơ�
12.�̵߳�ͬ���������?
����:'ͬһʱ��'ֻ����һ���߳�ִ��,ִ��'��Ϻ�'�����߳���ִ�� --- ������
ͬ��:��'����Ļ�����''��˳��'ִ�� --- �ź��� ��������
13.������������ʵ��ԭ��?
'����߳�'���Ҫ'��'ͬ'һ��������Դ���в���'
'˭��ռ��'��Դ,�ͶԹ�����Դ�IJ���'��������'
'�����߳���Ҫ�ȴ�',����һ���̶߳Թ�����Դ��'����ִ����Ϻ�ͽ���',����֮��
'�����߳�'�Ϳ����ڶ������Դ���в���,
����֮ǰ���ǵ�'����'
'������Ϻ�'���ǵ�'����'
����֮�������߳��ֿ��Բ���,
--�Դ�����--
�ٽ���Դ:����߳�'��������Դ'�����ٽ���Դ,���ĸı��п���Ӱ�쵽�����̵߳�ʹ�ý����
�ٽ���:'����'�ٽ���Դ��'һ�δ���'
14.�����������龰?
�����ĸ���:
���߳��Լ�����̸�����ϵͳ��Դ�������ʲ������ϵͳ�Ĵ���������Ȼ��,'����ִ��'Ҳ�������µ����⡪��--��������ν������ָ'����߳�'��'������Դ'����ɵ�һ��'����(����ȴ�)'',������������,��Щ���̶�������ǰ�ƽ�
������ԭ��:
1.�Բ��ɰ�����Դ�ľ���,�ſ��ܲ�������(��Ŵ�������ӡ��)
2.�����ƽ�˳��Ƿ�,������ͷ���Դ��˳��,Ҳͬ���ᵼ������
15.�����ź�����ԭ��?
�ź�����Ҫ���ͬ������
�ź����ı�����PV����(P��- V��+)
�ź���������һ��������,�Լ���������������,P������V����,P�����Ǽ�����,V�����ǼӲ���,
���ź�����ֵΪ0ʱ,P������������,V����û��Ӱ��
Ĭ���߳��е��ź���PV����ִ��һ��ֻ�ܼ�1����1
16.�������̵�ͨ�Ż���?
���ڵĽ��̼�ͨ�ŷ�ʽ:
�����ܵ� :ֻ������'��Ե��ϵ'�Ľ���
�����ܵ� :'��������'����'�ļ�'����'��ʶ�ں˿ռ�'���ٵ�����
�ź�ͨ�� :�������ź�ʱ,�Խ�������Ӧ�Ĵ�����ʽ---'Ψһ���첽ͨ�Ż���'
SYSTEM V:IPC����
��Ϣ���� :IPC ����,��ϵͳ���н��̿ɼ�,'��������',���Ը������Ͷ�ȡ����
�����ڴ� :'Ч�����','ʵʱ����'һ���ʹ�ù����ڴ汣��
�źŵƼ� :'PV ����',���ͬ������
BSD:
����ͨ�� :ʵ��'��ͬ����'�Ľ��̼�ͨ��
17.�ܵ���ͨ��ԭ��?
�ܵ���Ϊ�����ܵ��������ܵ�,��ԭ������'���ں��п���һ��ռ�',Ȼ������ռ���в���,���ݶ��������ڴ���
�����ܵ�ֻ��������Ե�����ͨ��,ԭ�����ڴ����ļ�ϵͳ�ϲ����ڡ�
�����ܵ��ij���,����Ϊ���ֲ���һȱ�㡣�����ܵ����ļ�������һ��������ļ�,��ȷȷʵʵ�����ļ�ϵͳ֮��,��������'���ݴ�����ڴ���'��
�����ܵ�:
�����ܵ�������'�ں˿ռ俪��һ������',Ȼ����'���������ļ�������',ֻҪ������̿��Եõ��������ļ�������,�Ϳ��Զ�ͬһ���ܵ����в���
�����ܵ���һ��'��˫����ͨ�ŷ�ʽ',��ζ����'�̶��Ķ��˺�д��',���������ܵ��������ڴ��̿ռ䡣���ݵIJ���Ҳ���ڴ档
��Ȼ�����ܵ�����ǰ���̵��������ļ�������,���Կ���ͨ���ļ�IO����������в���
�����ܵ�'ֻ�����ھ�����Ե��ϵ�Ľ��̼�ͨ��',
ԭ������Ϊ�����ܵ���Ȼ����ǰ���̵��������ļ�������,��ô�������ļ��������Ĵ���ֻ���ڵ�ǰ���̵��û��ռ�,��fork֮������Ľ���,��̳�ԭ�������̵����еĿռ�,�������ܵõ��������ļ�������
�ܵ��Ĵ�Сʱ64*1024,�ܵ�д��֮������ڽ���д��Ļ�,�������ȴ�д�롣
�����ܵ�:
�����ܵ�������֮����ڱ��ش���һ���ܵ��ļ�,���ڵ�ǰϵͳ�еĽ��̶��ǿɼ���,
���������ܵ�����ʵ�ֲ���ؽ��̼�ͨ��,���ڴ�����һ���ļ�,���Զ��ļ��������ʾ��Ƕ��ں˿��ٵ��������,ͨ���ļ�IO�Ϳ��Բ���
ע��:�������ܵ�ʱ,�����дȨ��ͬʱ���ڡ�
���ں��ڴ�ռ��ϴ����ܵ�,�ӹܵ�Ϊ�ļ�,���ļ�ʵ�ֲ���,�����ܶ�λ,�ܵ����������ڴ���
18.�û����̶��źŵ���Ӧ��ʽ?
����:���źŲ�����Ե�ǰ����'û���κ�Ӱ��'
ȱʡ:���յ�ǰ'�ź�Ĭ�ϵķ�ʽ'����
��:���յ��źź�ı��亯��ָ��ִ�еĹ��ܺ���,ִ�����Լ��Ĺ���--Ϊ������
#ע��:SIGKILL��SIGSTOP �������ź�ֻ����ȱʡ(Ĭ�Ϸ�ʽ)�ķ�ʽ����,���ܺ���Ҳ���ܲ�
19.�����ڴ�ͨ��ԭ��?
���ں˿ռ�,����һ�������ռ�,�ֱ�ӳ���ͨ�ŵĽ��̵������ַ�ռ���,ʵ�ֶ���в���ͬһ������
�����ڴ���һ����Ϊ��Ч�Ľ��̼�ͨ�ŷ�ʽ,���̿���ֱ�Ӷ�д�ڴ�,������Ҫ�κ����ݵĿ���
Ϊ���ڶ�����̼佻����Ϣ,�ں�ר��������һ���ڴ���,��������Ҫ���ʵĽ��̽���ӳ�䵽�Լ���˽�е�ַ�ռ�
���̾Ϳ���ֱ�Ӷ�д��һ�ڴ���������Ҫ�������ݵĿ���,�Ӷ������ߵ�Ч�ʡ�
���ڶ�����̹���һ���ڴ�,���Ҳ��Ҫ����ij��ͬ������,�绥�������ź�����
�ں�Ԥ��������һƬ��ַ�ռ�,ר�Ÿ�������ͨ��ʹ��,Ȼ����ַ�Ե�ַӳ��ķ�ʽ�����û��ռ䡣����
�ڴ������н��̼�ͨѶ���ٶ����ġ���ͨ����ַ��ӳ��ķ�ʽ�������û���ֱ�Ӳ����ں˲�ĵ�ַ�ϵ�ֵ��
��. ������
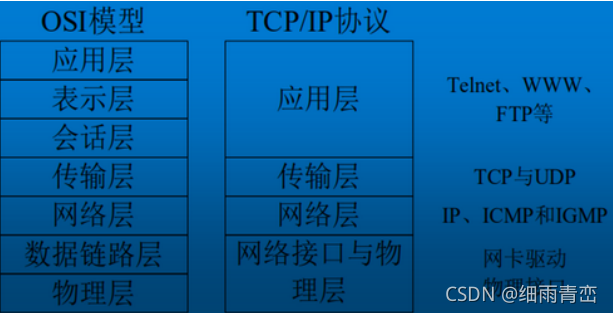
1. ISO�߲�����ͨ�Žṹ��TCP/IP�IJ�����ͨ�Žṹ
ISO�߲�����ģ��
Ӧ�ò�:�����û���Ӧ�ó���,app
��ʾ��:���ݼ��ܡ����ܲ���
�Ự��:���������������������ֺ���������֮�佨����ϵ (������������֮�����ϵ)
�����:�������ݾ��崫��Ļ���(ָ�����ݴ���ķ�ʽ)
�����:��δ�����ν����ݷ���Ŀ������,·�ɵ�ѡ��(���ݷ��顢·��ѡ��)
��·��:��ǰ�����е��������һ�����ݰ�,��֮Ϊһ֡����
������:ѡ�����ݷ��͵�����ý��(���ߡ�����)
TCP/IP�IJ�����ģ��
TCP/IP��ĿǰΪֹ�õ�'��㷺��������ϵ�ṹ'һ��4��
Ӧ�ò�
�����
�����
����ӿ���������
2. tcpͨ�ŵ���ȱ��
TCP(���������Э��)����:��һ��'��������'��'�ɿ�'�Ļ���'�ֽ���'�Ĵ����Э��,�����ṩ��'��
��'��ͨ��(����������������ʧ��������ʧ���������ظ�����ͨ��)
�ŵ�:
TCP����'�ش�����',��ζ��������ݷ��ͳ�������,���ظ�����
TCP�ṩ���Ͽɵķ�ʽ��ʽ�ش�������ֹ���ӡ�
TCP��֤�ɿ��ġ�˳���(���ݰ��Է��͵�˳�����)�Լ������ظ������ݴ��䡣
TCP���������ơ�
������������
�������û�д��͵�,��TCP�ӿڷ���һ������״̬������
TCPͨ�����������������ݿ�ֳɸ�С�ķ�Ƭ�����������ݿ顣���������Ա֪��
ȱ��:
TCP�ڴ�������ʱ���봴��(������)һ�����ӡ�������Ӹ�ͨ�Ž��������˿���,������UDP�ٶ�Ҫ��
2.3 TCPΪʲôҪ������������
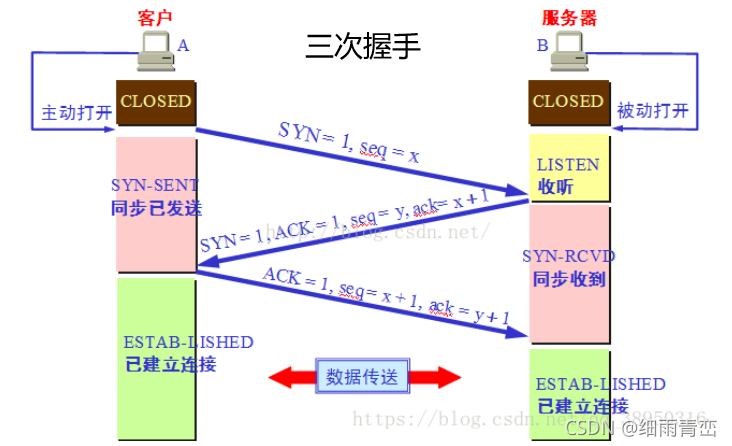
��һ������:'�ͻ���'��'��������'����'��������',TCP��ͷ��SYN��1,�Լ���������к�seqΪx��
�ڶ�������:��'��������'���յ�'�ͻ���'������'����',����SYNΪ1,������ÿͻ��˵�������кź�
��'�ͻ���'���͵�TCP��ͷ��SYN��1,Ӧ�����к�ACK��1,Ӧ�����к�ackΪ�ͻ��˵�������кż�һ(x+1),�Լ���������к�seqΪy��
����������:'�ͻ���'���յ�'��������'��'��������'��'Ӧ��'����'������'����'Ӧ���ź�',Ӧ���־λACK��1,Ӧ�����к�Ϊ��������������кż�һ(y+1)
Ϊʲô������?
�������ֵ�Ŀ����'ȷ��������'��'�ͻ���'������'�շ�����'������,
��һ�����ֳɹ�˵��'�ͻ���'��'������'������,
�ڶ������ֳɹ�˵��'������'��'�շ�����'������,
���������ֳɹ�˵��'�ͻ���'��'��������'������,
�����������ֵĹ���ȱһ����,����,���˵�������ε����ִ���,���˷���Դ��ʱ��
3. udpͨ�ŵ���ȱ��
UDP(User Datagram Protocol)�û����ݱ�Э��,��'���ɿ�'��'������'��'���ݱ�'Э�顣�����ݷ���ǰ,��Ϊ����Ҫ��������,���Կ��Խ��и�Ч�ʵ����ݴ��䡣
�ŵ�:
1.UDP��Ҫ��һ������
2.UDPû������շ��Ͽ��յ����ݰ�(���ߵ����ݰ�û����ȷ�ִ���Զ��ش�)�������Ŀ�����(û���Զ��ش�����)
3.���UDP��Ŀ�������ڶ�Ӧ�úͿ�����Ϣ
4.��һ�����ݰ�����һ�����ݰ��Ļ�����,UDPҪ������������TDP��С��
ȱ��:
���ɿ�
4. pool��select������(select poll epoll������)
select:
1.select������'����ļ��������ĸ���'�� 1024 ��
2.select������'���ᱻ���',������Ҫ'����'���û��ռ�ı�'����'���ں˿ռ�,'Ч��'�Ƚ�'��'��
3.select��'����״̬������'֮��,'��Ҫ����'���е��ļ�������,�ҵ����õ��ļ�������,�������Ч�ʱȽϵ͡�
poll:
1.poll�������ļ�������'û�и�������'
2.poll��'û�б����','����Ҫ'��������,'Ч�ʸ�'
3.poll��'����״̬������'֮��,'��Ҫ����'���е��ļ�������,�ҵ����õ��ļ�������,�������Ч�ʱȽϵ͡�
epoll:(#����������õ�IO��·���û���)
1.epoll�������ļ�������'û�и�������'
2.epoll'��û�б����',����Ҫ��������,Ч�ʸ�
3.epoll��'����״̬������'֮��,'����Ҫ����'�ļ���������ֱ���õ����õ��ļ���������
select��poll��epoll���Ƶ��ص�
select,poll,epoll����'IO��·����'�Ļ��ơ�
I/O��·���þ�ͨ��һ�ֻ���,����'����'����ļ�������
һ��'ij������������'(һ���Ƕ���������д����),�ܹ�֪ͨ���������Ӧ�Ķ�д������
��select,poll,epoll�����϶���'ͬ��I/O',
��Ϊ���Ƕ���Ҫ��'��д�¼�������'�Լ�������ж�д,Ҳ����˵���'��д'������'����'��,
���첽I/O�������Լ�������ж�д,�첽I/O��ʵ�ֻḺ������ݴ�'�ں�'������'�û��ռ�'---copy to /copy from ��
5. ioģ�����ļ���
����I/O: ��á����Ч�����
������I/O: �ɷ�ֹ����������I/O������,��Ҫ��ѯ
I/O ��·����: ����ͬʱ�Զ��I/O���п���(��һ����������,����������������)
�ź�����I/O: һ���첽ͨ��ģ��(����Ҳ��ѧ����Ψһ��һ���첽IO)
6. ���ʵ��tcp����������
tcp�������Dz�����������ԭ����������������������,
'accept'��������,������Ӧ���ļ�������,
'recv'�����������,
���Կ���ʹ�ø��ӽ��̻��߶��߳�ʵ��tcp����������,Ҳ����ʹ��selectʵ�ֶ���̡����̡߳�select��poll��epoll
7. ���糬ʱ���ı��ʺ�ʵ�ַ�ʽ
'��ʱ���':���� ���� �� ������ ֮��,����һ����ʱ��,
��ʱ�䵽��'֮��'���û��������'һֱ����'
���ʱ��'����'��'û������',����'������'
#����: �Զ�����Ϊ��,�����������������,��������ȡ,���û������,��'һֱ�����ȴ�'
#������: �Զ�����Ϊ��,�����������������,��������ȡ,���û������,��'������������'
ʵ�ַ�ʽ:
����1:ʹ��'setsockopt'ʵ�����糬ʱ��� #��������ѡ��
����2:ʹ��'select'ʵ�����糬ʱ��� #select�����һ������
����3:ʹ��'alarm����'ʵ�����糬ʱ��� #ʹ������
#-------alarmԭ��---------------------------------------------------
alarm��������ʱ���,�����������,���趨��ʱ�䵽��,�����SIGALRM�ź�(�����ź�)����ź�Ĭ��
�Ե�ǰ���̵Ĵ�����ʽ�ǽ�������
������źŵĴ�����ʽ��Ϊ�Զ���,��ִ�����źŴ�������֮��,��������֮ǰ�ļ�������,�����첽ͨ��
����Ĭ�ϵ�����,���ǽ�������Գ�֮Ϊ'����������'
'Ϊ��ʵ�ֳ�ʱ���,����ֻ��Ҫ�ر�������������Լ���==> ִ�����źŴ�������֮��,������ͷ����'
�ر�����������֮���������˳��:
��ʹ��alarm�趨��ʱ�䵽���,����SIGALRM�ź�,ִ���źŴ�������
���źŴ�������ִ����Ϻ�,�������ִ�е�����ִ�еĺ���,���Ǵ���,�����������
#ʹ��sigaction���������źŵ�����
8. TCP ����������
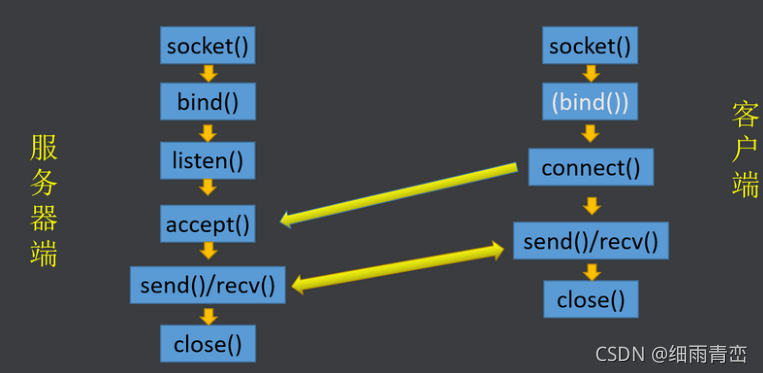
#�����:
�������� socket()
��������������Ϣ�ṹ����� sockaddr_in ===> ��man 7 ip ---> sockaddr_in
�������������������Ϣ�ṹ��� bind()
����������Ϊ��������״̬ listen()
�����ȴ��ͻ��˵����� accept()
����ͨ�� read()/write() �� recv()/send() �� recvfrom()/sendto()
�ر��ļ������� close()
#�ͻ���:
�������� socket()
��������������Ϣ�ṹ�� sockaddr_in
�ͻ��˸������������������� connect()
����ͨ�� read()/write() �� recv()/send() �� recvfrom()/sendto()
�ر��ļ������� close()
9. UDP����������
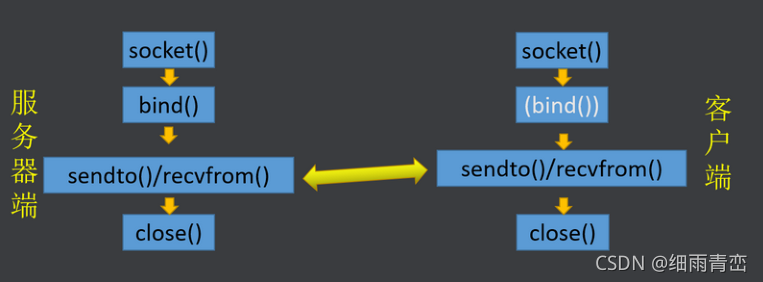
�����:
�������� socket()
��������������Ϣ�ṹ�� sockaddr_in
���������������������Ϣ�ṹ��� bind()
����ͨ�� recvfrom()/sendto()
�ͻ���:
�������� socket()
��������������Ϣ�ṹ�� sockaddr_in
����ͨ�� recvfrom()/sendto()
10. UDP����ͨ����Ҫע����Щ����
�ͻ��˳���:
��Ҫbind��'�Լ��ı�����Ϣ�ṹ��',Ҳ������Ҫָ���Լ��������ļ�,
�������ô��,��������ʶ���յ�������������˭,�ͻ���Ҳ�����յ����������͵�����
11. ��ô���ļ��������ı�־λ�C�ļ�״̬��־λ
����ͨ��'fcntl����'���ļ��������ı�־λ,һ��ִ�ж���д����
int fcntl(int fd, int cmd, ... /* arg */ );
12. sqlite���ݿ�Ļ���ʹ��,������ɾ�IJ�
�������ݿ�:
create table ����(��Ա�� ��Ա����,��Ա�� ��Ա����,...);
�ڳ䵱�����ij�Ա�ĺ���� primary key ,�ڴ�����ʱ��,���������Ա������,�������ظ���
����:Ҳ���Dz���
insert into ���� values('����');//ʾ������
insert into sta values(1000,'admin','123456','12345678901');
ɾ��:
delete from ���� where ����;//���ݺ�������� ɾ�� ��Ӧ������з��������� ��
ʾ��:
delete from stu where id=1002;
��:
update ���� set ��Ҫ���ĵ�ֵ where ����;
ʾ��:
update sta set name='qxy',passwd='12345' where id=1000;
��ѯ:
select ��Ҫ���ҵij�Ա�� from ���� where ����;
ʾ��:
��sta���� ��ѯidΪ1001 �� �ֻ���
select phone from sta where id=1001;
13. ����UDP�����������ʵ������Ⱥ��
�ڿͻ������ӵ���������ʱ��,����һ������(��Ϊ��ȷ���ͻ��˵ĸ���,����������)����ͻ���bind����Ϣ,,Ȼ��Ⱥ����ʱ��,������������������,��ÿ���ͻ��˷�����Ϣ
14. ���ߴʵ����ʵ�ֲ�ѯ����
����˻�ͨ��fopen����,���صĴʵ�
���� ÿ�����ʸ�������������ͬһ��,�м����ÿո�ֿ���,������fgets����ȡһ��,
Ȼ��ʹ��strtok����,��" "�ոָ���,����һ�е����ݽ��вü�,���ڽ�ȡ�����ľ���ÿ�еĵ���,
Ȼ��ʹ��strtok����,�Խ�ȡ����ַ���,�ٴν�����ȡ,��'\n'��Ϊ�ָ���,�õ��ľ�������
ʹ��strcmp����,�Ա�,�ͻ��˴������ĵ���,����ȡ�����ĵ���
�����ͬ,���������巵�ظ��ͻ���
15. TCP��UDP������
TCP��UDP��������
1.TCP��������������UDP��������
2.TCPҪ��ϵͳ��Դ�϶�,UDP����;
3.UDP����ṹ�ϼ�
4.��ģʽ(TCP)�����ݱ�ģʽ(UDP);
5.TCP��֤������ȷ��,UDP���ܶ���
6.TCP��֤����˳��,UDP����֤
UDPӦ�ó���:
1.�������ݱ���ʽ
2.�������ݴ��Ϊ����Ϣ
3.ӵ�д���Client
4.�����ݰ�ȫ��������Ҫ��
5.���縺���dz���,������Ӧ�ٶ�Ҫ���
������ʱ������
1.socket()�IJ�����ͬ ---�������Ͳ�ͬ--TCP(SOCK_STREAM),UDP(SOCK_DGRAM)
2.UDP Server����Ҫ����listen��accept ---UDP�������ӵ�,���Կͻ���Ҳ����Ҫconnect
3.UDP�շ�������sendto/recvfrom���� ---TCP���������ӵ�,ֱ��ʹ��send��from
4.TCP:��ַ��Ϣ��connect/acceptʱȷ�� ---��������Ҳ��
5.UDP:��sendto/recvfrom������ÿ�ξ� ��ָ����ַ��Ϣ
6.UDP:shutdown������Ч
TCP��UDP�����ܽ�:
1��TCP'��������'
UDP��'������'��,����������֮ǰ����Ҫ��������
2��TCP�ṩ'�ɿ�'�ķ���Ҳ����˵,ͨ��TCP���Ӵ��͵�����,���,����ʧ,���ظ�,�Ұ���
UDP�����Ŭ������,��'��'��֤'�ɿ�'����
3��TCP����'�ֽ���',ʵ������TCP�����ݿ���һ�����ṹ���ֽ���
UDP������'����'(���ݱ�)��UDP'û��ӵ������',
����������'ӵ��''����'ʹԴ������'�������ʽ���'(��ʵʱӦ�ú�����,��IP�绰,ʵʱ��Ƶ�����)
4��ÿһ��TCP����ֻ����'�㵽��'��
UDP֧��'һ��һ,һ�Զ�,���һ�Ͷ�Զ�'�Ľ���ͨ��
5��TCP�ײ�����20�ֽ� UDP���ײ�����С,ֻ��8���ֽ�
6��TCP����ͨ���ŵ���'ȫ˫��'��'�ɿ�'�ŵ�(�ڲ��ɿ����ŵ��Ͻ�����һ���ȶ�������),UDP����'���ɿ�'�ŵ�
16. OSI�߲�����ģʽ,ÿ�����Ҫ����,��Ҫ��Э��
Ӧ�ò�:Ϊ�ض�Ӧ�ó����ṩ���ݴ������( TFTP,HTTP,SNMP,FTP,SMTP,DNS,Telnet)
��ʾ��:���ϲ���Ϣ���б任,��֤һ������Ӧ�ò���Ϣ����һ��������Ӧ�ó�������,��ʾ�������ת���������ݵļ��ܡ�ѹ������ʽת����
�Ự��:��������֮��ĻỰ����,������������������ֹ��
�����:�ṩ�˶Զ˵Ľӿڡ�( TCP,UDP)
�����:Ϊ���ݰ�ѡ��·�ɡ�(IP,ICMP,ARP,RARP)
������·��:�����е�ַ��֡,�������( SLIP,CSLIP,PPP,ARP,RARP,MTU)
������:�Զ�����������ʽ������ý���ϴ������ݡ� ISO2110,IEEE802,IEEE802.2
17. TCP ճ��
TCPճ�� -- TCP�ڲ�ʵ����һ�� Nagle�㷨
�Ὣ һ��ʱ���� Ҫ���͵����е����ݱ� ������һ��,��Ϊ һ�����ݰ� �����Է�
�Է��ڽ�������ʱ,recv�ĵ�����������ʾÿ�ν������ݵ����ֵ
���ڷ�������������һ������,����������ÿһ�����ֵ�����
�ͻᵼ��С�ڵ�������������ֵ�Ķ������ճ����һ����յ���������
����:
����1:������ʱ,��֤��ͬ���͵����ݰ�����֮ǰ������һ����
����2:�ڷ�������֮ǰ��ͷ����Ϣ,����Ҫ�������ݵĴ�С,Ȼ��ͷ����Ϣ��Ҫ���͵����ݱ�����һ����
������,ֻҪ��֤ÿ�η��͵����ݴ�Сһ��,�Ͳ�������������
18. TCP���������ֺ��Ĵλ��ֱַ�����,��Ҫ��ʲô
��������:
Ŀ��:ȷ��'������'��'�ͻ���'����'�����շ�����'������,
��һ������˵��'�ͻ���'��'������'������
�ڶ�������˵��'��������'��'�շ�����'������
����������˵��'�ͻ���'��'������'����
��������������һ����ȱһ���ɡ�
�Ĵλ���
TCPЭ����һ��'��������'�ġ�'�ɿ�'�ġ�����'�ֽ���'�Ĵ����ͨ��Э�顣
TCP��'ȫ˫��'ģʽ,
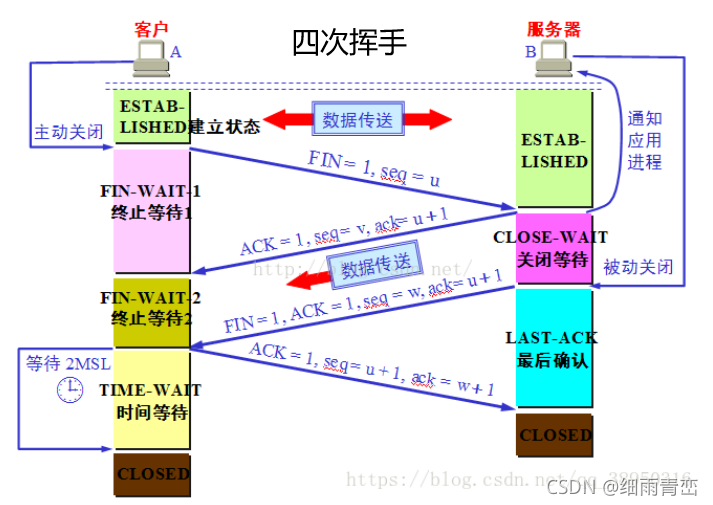
������,
�� Client ����FIN���Ķ�ʱ,ֻ�DZ�ʾ Client �Ѿ�'û������Ҫ����'��,Client ���� Server,���������Ѿ�ȫ�����������;����,���ʱ�� Client ����'���Խ���'���� Server ������;
��Server '����ACK����'��ʱ,��ʾ���Ѿ�֪�� Client û�����ݷ�����,���� Server ����'���Է�������'�� Client ��;
�� Server Ҳ������FIN���Ķ�ʱ,���ʱ��ͱ�ʾ Server Ҳ'û������Ҫ����'��,�ͻ���� Client ,��Ҳû������Ҫ������,֮��˴˾ͻ������ж����TCP���ӡ�
19. ���ʵ�ֲ���������,������������ʵ�ַ�ʽ��ʲô��ͬ
ʵ����Ҫ�����ַ�ʽ:����̲���������,���̲߳���������,I/O���ò���������
20.�̺߳ͽ��̵�����,���̺߳Ͷ���̱�̵��ص�
������'��Դ����'����С��λ,�߳���'����ִ��'����С��λ��
ÿ��'�߳�''����'����������'���̵�������Դ'(���ļ�,�ڴ�ҳ��,�źű�ʶ,��̬������ڴ��)
�̸߳�С,���Ѹ��ٵ�CPU��Դ
(����ϵͳ�����,�����ݻ����߳�,��Ϊ�˸��õ�֧�ֶദ����)
==��
���߳����������˳���ʱ,�����������̶߳��ᱻǿ���˳�
����:
�����dz����'һ��ִ�й���',��һ��'��̬����',�dz�����ִ�й�����'����'��'������Դ'��'������λ',
'ÿһ������'����һ��'�Լ��ĵ�ַ�ռ�',
����������5�ֻ���״̬,������:��ʼ̬,ִ��̬,�ȴ�״̬,����״̬,��ֹ״̬��
�߳�:
�߳���'ϵͳ����'��'������λ',����'��ͬ��'һ�����̵�'�������߳�''��������'��ӵ�е�'ȫ����Դ'��
��ϵ:
'�߳�'��'����'��һ����,һ���߳�ֻ������һ������,��һ�����̿����ж���߳�,��������һ���߳�(�����߳�)��
����:
'��Դʹ��'�ĽǶȳ�����(��ν����Դ���Ǽ����������봦����,�ڴ�,�ļ�,����ȵ�)
��������:'����'�Dz���ϵͳ'��Դ����'��'������λ',��'�߳�'��'������Ⱥ�ִ��'��'������λ'
��������:ÿ��'����'����'����'�Ĵ��������'�ռ�'(����������),����֮����л����нϴ�Ŀ���;
'�߳�'���Կ���'�������Ľ���',ͬһ��'�̹߳���'���������'�ռ�',
ÿ���̶߳����Լ�����������ջ�ͳ��������(PC),�߳�֮���л��Ŀ���С��
��������:�ڲ���ϵͳ����'ͬʱ���ж������'(����);����ͬһ������(����)���ж���߳�ͬʱִ��
(ͨ��CPU����,��ÿ��ʱ��Ƭ��ֻ��һ���߳�ִ��)(�������л�,ʱ��Ƭ��ת)
�ڴ���䷽��:ϵͳ�����е�ʱ���Ϊÿ��'����'���䲻ͬ��'�ڴ�'�ռ�;�����̶߳���,����CPU��,ϵͳ'����Ϊ'�߳�'�����ڴ�'(�߳���ʹ�õ���Դ�������������̵���Դ),�߳���֮��ֻ�ܹ�����Դ��
������ϵ:û��'�߳�'��'����'���Կ�����'���߳�'��,
���һ��'����'����'����߳�',��ִ�й��̲���һ���ߵ�,����'������(�߳�)��ͬ'��ɵ�;
�߳��ǽ��̵�һ����,�����߳�Ҳ����Ϊ��Ȩ���̻������������̡�
��.C++
1. new��delete��malloc��free��ϵ
1.new����ռ��'ͬʱ���Գ�ʼ��', malloc����ռ�ʱ'������ֱ�ӳ�ʼ��'
2.new�������ʼ����'�Զ���0��ʼ��', malloc���������'���ֵ',��
Ҫ'memset'����'bzero'��0
3.mallco/free ��'�⺯��',new/delete ��C++��'�ؼ���'
4.new����ռ�ʱ���Ը�������'�Զ�����ռ��С',��malloc��Ҫ'�ֶ����㴫��'
5.new '���صľ���'��Ӧ���͵�ָ��,��malloc��Ҫ'ǿ������ת��'---���ص���
(void *)
6.new�����'���캯��',malloc����
7.delete�����'��������',free����
2. delete�� delete []����
//�������� ����д�ռ�Ĵ�С Ҳ���Բ�д,��д���� �����˶��� �ͱ��ͷŶ���
deleteֻ�����'һ��''��������',��delete[]�����'ÿһ����Ա'��'����'������
��More Effective C++���и�Ϊ��ϸ�Ľ���:����delete��������������ʱ,��Ϊÿ������Ԫ�ص�����������,Ȼ�����operator delete���ͷ��ڴ档��delete��new����,delete []��new []����
���˵��:�����ڽ�����������,delete��delete[]��������ͬ�ġ������Զ���ĸ�����������,
delete��delete[]���ܻ��á�delete[]ɾ��һ������,deleteɾ��һ��ָ�롣
����˵,
��new������ڴ���deleteɾ��;
��new[]������ڴ���delete[]ɾ����
delete[]���������Ԫ�ص������������ڲ���������û����������,�������ⲻ�����������deleteʱû������,delete�ͻ���Ϊָ����ǵ�������,����,���ͻ���Ϊָ�����һ�����顣
3. C++����Щ����(��������ص�)
���������������� : ��װ �̳� ��̬ -----// �������:��һ�� ����
4. ��������ʱҪ���ø��������������?
'��������'���õĴ�������'������'��������'���������',
Ҳ����˵��'����'�ĵ�'��������'��ʱ��,���������Ϣ�Ѿ�ȫ�������ˡ�
'����'һ������ʱ�ȵ���'����Ĺ���'������Ȼ��'����������'��'����'����;
������ʱ��'ǡ���෴':�ȵ���'�����������'������Ȼ��'���û��������'������
5. ��̬,�麯��,���麯��
��̬:ͨ�� �����'ָ�������'ָ�� ����Ķ���,���Է���'��������д�ĸ����еķ���'��
ʵ�ֶ�̬�ı�Ҫ����:
1.�̳� //---��Ҫ����
2.����ָ�������ָ��������� //---��Ҫһ��ָ�������
3.�麯�� //---��������� ֻ��һ�� ��������� ��Ա
4.������д //---��ԭ���ĺ���
//-----------------------------------------------------------
�麯��:�Թؼ��� virtual ��ͷ�ij�Ա������ '����'��'���庯��'ǰ���� virtual
����'��������'�ж�'������麯��''���¶���'��
//-----------------------------------------------------------
���麯��:��һ���ڻ�����ֻ������,û�ж���ĺ���
���麯��������:��'����'��'Ϊ��'������'����һ������'������,�Ա�'������''������Ҫ'��������'����'����Ϊ�ӿڶ�����
'���麯��''���߱�����'�Ĺ���,һ��'����ֱ�ӱ�����'��
��'����̳�'����'���麯��',��'������'��'�����麯��'��
//----------------------------------------------------------
���'һ������'����'��һ�����麯��',��ô����౻��Ϊ'������'(abstract class)��
'������'�в�������'���麯��',Ҳ�ɰ���'�麯��'��
������'��������'�����������'����'
����'���麯������' ���� '������'
������'������'ʵ��������,����'����'
������'������д������Ĵ��麯��',����'����'
��������Ȼ����ʵ��������,������ͨ���������'ָ�������'ָ������Ķ�����'ʵ�ֶ�
̬'������
6. �����溯���ķ���ֵ(��)----��ô�����بC
int func(x)
{
int countx = 0;
while(x)
{
countx ++;
x = x&(x-1);
}
return countx;
}
�ٶ�x = 9999�� ��:8
˼·:��xת��Ϊ2����,�����е�1�ĸ�����
& : 0 �� ��� & ������ 0 1 �� ��� & ������ ���
����ÿ�ζ��� x �� x-1 ���� & ����,����ÿ��,����Ūûһ�� 1 ,����ֻҪ��x���ʼ�Ķ������м���1 ,Ȼ��ͻ�ִ�м���
9999��ת���ɶ�������,0010 0111 0000 1111 һ��8 ��,8��
���Դ�������:
#include <stdio.h>
int func(x)
{
int countx = 0;
while(x)
{
countx ++;
printf("x = %#x\n",x);
printf("x-1 = %#x\n",x-1);
x = x&(x-1);
printf("��x = %#x\n",x);
puts("------------------------");
}
return countx;
}
int main()
{
int x = 12287;// %#x == 2FFF, ��13��1
int o = 0;
o = func(x);
printf("OK------o = %d\n",o);
return 0;
}
7. ʲô�ǡ����á�?������ʹ�á����á�Ҫע����Щ����?
���þ���ij��Ŀ�������"����"(alias),��Ӧ�õIJ�����Ա���ֱ�Ӳ���Ч����ȫ��ͬ��
����һ��'����'��ʱ��,�м�Ҫ�������'��ʼ��'��
����������Ϻ�,'�൱��''Ŀ�������'��'��������',����Ŀ��'ԭ����'��'������',�����ٰѸ���������Ϊ�����������ı�����
����һ������,'����'�¶�����һ������,��ֻ��ʾ��'������'��Ŀ���������һ��'����',����������һ����������,������ñ�����ռ�洢��Ԫ,ϵͳҲ�������÷���洢��Ԫ�����ܽ�����������á�
7-8. ������ָ�������
1. ���ñ���'��ʼ��' ,ָ�����'����ʼ��'
2. '���ò����Ըı�ָ��' ,ָ�����
3. '������ָ��NULL������', ָ�����ָ��NULL
4. 'ָ��'��ʹ��ǰ��Ҫ'���Ϸ���' ,���ò���Ҫ
8. �������á���Ϊ �������� ����Щ�ص�?
1.����'����'������ �� ����'ָ��'��'Ч��'��һ���ġ�
��ʱ,����������'�β�'�ͳ�Ϊԭ�����������е�'ʵ�α���'��'�����'һ��'����'��ʹ��,
�����ڱ��������ж�'�βα����IJ���'���Ƕ���'��Ӧ��Ŀ�����'(������������)�IJ�����
2.ʹ��'����'���ݺ����IJ���,���ڴ��в�û�в���ʵ�εĸ���,����'ֱ�Ӷ�ʵ�β���';
��ʹ��'һ�����'���ݺ����IJ���,��������������ʱ,��Ҫ��'�βη���洢��Ԫ',�βα�����ʵ�α����ĸ���;
������ݵ���'����',����'���ÿ�������'���������,���������ݵ����ݽϴ�ʱ,��'����'����һ��'����'���ݲ�����'Ч�ʺ���ռ�ռ�'���á�
3.ʹ��'ָ��'��Ϊ������'����'��ȻҲ�ܴﵽ��ʹ�����õ�Ч��,
����,�ڱ���������ͬ��Ҫ��'�βη���洢��Ԫ',����Ҫ�ظ�ʹ��"*ָ�������"����ʽ��������,������ײ��������ҳ�����Ķ��Խϲ�;
��һ����,�����������ĵ��õ㴦,�����ñ����ĵ�ַ��Ϊʵ�Ρ������ø�����ʹ��,��������
9. ��ʲôʱ����Ҫʹ�á������á�?
�����Ҫ����'����'��߳����'Ч��',��Ҫ'����'���ݸ�������'���ݲ�'�ں�����'���ı�',��'Ӧʹ��'�����á�
//��Щ������,������ ������ �βε�ֵ,����ʹ�� ������
������������ʽ:const ���ͱ�ʶ�� &������=Ŀ�������;
int a ;
const int &ra=a;
ra=1; //����
a=1; //��ȷ
10. �������á���Ϊ��������ֵ���͵ĸ�ʽ���ô�����Ҫ���صĹ���?
��ʽ:���ͱ�ʶ�� &������(�β��б�������˵��)
{
//������
}
�ô�:��'�ڴ�'��'������'������ֵ��'����';
(ע��:������Ϊ���ԭ��,����'����һ���ֲ������������Dz���ȡ'�ġ���Ϊ���Ÿþֲ����������ڵĽ���,��Ӧ������Ҳ��ʧЧ,����runtime error!)
ע������:
1. '���ܷ��ؾֲ�����������'���������Բ���Effective C++[1]��Item 31��
��Ҫԭ����'�ֲ�����'����'��������'��'������',��˱����ص�'����'�ͳ�Ϊ��"����ָ"������,��������δ֪״̬��
2. '���ܷ��غ����ڲ�new������ڴ������'���������Բ���Effective C++[1]��Item 31��
��Ȼ�����ھֲ������ı�����������,�ɶ����������(���غ����ڲ�new�����ڴ������),�������������ξ��档
����,���������ص�'����'ֻ����Ϊһ��'��ʱ����'����,��û�б�����һ��ʵ�ʵı���,��ô���������ָ��Ŀռ�(��new����)��'���ͷ�',���memory leak(�ڴ�й©)��
3. '���Է������Ա������',�������'const'������ԭ����Բ���Effective C++[1]��Item 30��
��Ҫԭ���ǵ�'���������'����ij��ҵ�����(business rule)�������ʱ��,�丳ֵ ������ ijЩ�������Ի��߶����״̬�й�,����б�Ҫ����ֵ������װ��һ��ҵ������С�
�������������Ի�ø����Ե�'�dz�������(��ָ��)',��ô�Ը����Եĵ�����ֵ�ͻ��ƻ�ҵ�����������ԡ�
4. '�����������ط���ֵ'����Ϊ"����"������:
��������<<(��ӡ)��>>(��ȡ),����������������ϣ��������ʹ��,
����:cout << "hello" << endl;
�����������������'����ֵ'Ӧ����һ����Ȼ֧���������������������á�
��ѡ��������������:����һ��������ͷ���һ��������ָ�롣
���Ƕ��ڷ���һ��'������',�����������(����)����һ���µ�������,Ҳ����˵,����������<<������ʵ��������Բ�ͬ�����!�������˽��ܡ�
���ڷ���һ��'��ָ��'��������ʹ��<<��������
���,����һ��'����������'��Ψһѡ�����Ψһѡ��ܹؼ�,��˵����'���õ���Ҫ��'�Լ�'�����'�ԡ�---- '���ص�����������'
��ֵ������=���������������������һ��,�ǿ�������ʹ�õ�,
����:x = j = 10;����(x=10)=100;
��ֵ�������ķ���ֵ������һ����ֵ,�Ա���Ա�������ֵ��������ó��������������Ωһ����ֵѡ��
#include<iostream.h>
int &put(int n);
int vals[10];
int error=-1;
void main()
{
put(0)=10; //��put(0)����ֵ��Ϊ��ֵ,�ȼ���vals[0]=10;
put(9)=20; //��put(9)����ֵ��Ϊ��ֵ,�ȼ���vals[9]=20;
cout<<vals[0];
cout<<vals[9];
}
int &put(int n)
{
if (n>=0 && n<=9 ) return vals[n];
else { cout<<"subscript error"; return error; }
}
5. �������һЩ��������,ȴǧ���ܷ�������:
+-*/ ��������������Dz��ܷ�������,Effective C++[1]��Item23��ϸ��������������⡣
��Ҫԭ�������ĸ�������û��side effect,���,���DZ��빹��һ��������Ϊ����ֵ,
��ѡ�ķ�������:����һ��������һ���ֲ�����������,����һ��new����Ķ�������á�����һ����̬�������á�
����ǰ���ᵽ��������Ϊ����ֵ����������,2��3����������������ˡ�
��̬�������������Ϊ((a+b) == (c+d))����ԶΪtrue�����´���
���Կ�ѡ��ֻʣ�·���һ�������ˡ�
11. �ṹ�������к�����?��C����������
12. ���������:
int a=4;
int &f(int x)
{
a=a+x;
return a;
}
int main(void)
{
int t=5;
cout<<f(t)<<endl;// a = 9
f(t)=20; //a = 20
cout<<f(t)<<endl;// t = 5,a = 20 a = 25
t=f(t); //a = 30 t = 30
cout<<f(t)<<endl; }// t = 60
}
//t = 60
13. ����(overload)����д(overried,�е���Ҳ���������ǡ�)������?
�Ӷ�������˵:
����:��ָ�������ڶ��ͬ������,����Щ�����IJ�������ͬ(��������������ͬ,�����������Ͳ�
ͬ,�������߶���ͬ)��
��д:��ָ�������¶��常���麯���ķ�����
��ʵ��ԭ������˵:
����:���������ݺ�����ͬ�IJ�����,��ͬ������������������,Ȼ����Щͬ�������ͳ��˲�ͬ�ĺ���
(���ٶ��ڱ�������˵��������)����,������ͬ������:function func(p:integer):integer;��
function func(p:string):integer;����ô�������������κ�ĺ������ƿ�����������:int_func��
str_func�����������������ĵ���,�ڱ���������Ѿ�ȷ����,�Ǿ�̬�ġ�Ҳ����˵,���ǵĵ�ַ�ڱ�
���ھͰ���(���),���,���غͶ�̬��!
��д:�Ͷ�̬������ء����������¶����˸�����麯����,����ָ����ݸ������IJ�ͬ������ָ��,
��̬�ĵ�����������ĸú���,�����ĺ��������ڱ����ڼ�����ȷ����(���õ�������麯���ĵ�ַ
������)�����,�����ĺ�����ַ���������ڰ�(����)��
14. ���ļ������ֻ����intialization list(��ʼ���б�) ��������assignment?
����ʹ�ó�ʼ�����ij���
1. '��Ա��������'��'���캯���β�����'��ͻʱ;---Ҳ������this���
2.���а���' const '��Ա����ʱ //��Ϊ const ֻ���ڳ�ʼ����ʱ��ֵ
3.���а���' ����' ��Ա���� //���� ֻ����ָ�� �ٲ���
4.���а���'��Ա�Ӷ���'(���а������������ʱ)ʱ
//����ʹ�ó�ʼ���������Ӷ���Ĺ��캯�� ��ɶԳ�Ա�Ӷ���ij�ʼ��
//���캯�� ���г�ʼ�� ��
15. C++�Dz������Ͱ�ȫ��?
���ǡ�������ͬ���͵�ָ��֮�����ǿ��ת��(��reinterpret cast)��C#�����Ͱ�ȫ��
16. main ����ִ����ǰ,����ִ��ʲô����?
ȫ�ֶ���Ĺ��캯������main ����֮ǰִ�С�
17. �����ڴ���䷽ʽ�Լ����ǵ�����?
1) �Ӿ�̬�洢������䡣�ڴ��ڳ�������ʱ����Ѿ������,����ڴ��ڳ�������������ڼ䶼���ڡ�����ȫ�ֱ���,static ������
2) ��ջ�ϴ�������ִ�к���ʱ,�����ھֲ������Ĵ洢��Ԫ��������ջ�ϴ���,����ִ�н���ʱ��Щ�洢��Ԫ�Զ����ͷš�ջ�ڴ�������������ڴ�������ָ���
3) �Ӷ��Ϸ���,��ƶ�̬�ڴ���䡣���������е�ʱ����malloc ��new ����������ٵ��ڴ�,����Ա�Լ������ں�ʱ��free ��delete �ͷ��ڴ档��̬�ڴ���������ɳ���Ա����,ʹ�÷dz����,������Ҳ��ࡣ
18. �ֱ�д��BOOL,int,float,ָ�����͵ı���a �롰�㡱�ıȽ���䡣
BOOL : if ( !a ) or if(a)
int : if ( a == 0)
float : const EXPRESSION EXP = 0.000001
if ( a < EXP && a >-EXP)
pointer : if ( a != NULL) or if(a == NULL)
19. ��˵��const��#define ���,�к��ŵ�?�CC����-11��
20. ����������ָ�������?�CC����-12��
21. int (*s[10])(int) ��ʾ����ʲô?
����ָ������,ÿ��ָ��ָ��һ��int func(int param)�ĺ���
�ص�����
22. ջ�ڴ������ֳ�����
char str1[] = "abc";
char str2[] = "abc";
const char str3[] = "abc";
const char str4[] = "abc";
const char *str5 = "abc";
const char *str6 = "abc";
char *str7 = "abc";
char *str8 = "abc";
cout << ( str1 == str2 ) << endl;//0 �ֱ�ָ����Ե�ջ�ڴ�
cout << ( str3 == str4 ) << endl;//0 �ֱ�ָ����Ե�ջ�ڴ�
cout << ( str5 == str6 ) << endl;//1ָ�����ֳ�������ַ��ͬ
cout << ( str7 == str8 ) << endl;//1ָ�����ֳ�������ַ��ͬ
�����:0 0 1 1
���:str1,str2,str3,str4���������,�����и��Ե��ڴ�ռ�;��str5,str6,str7,str8��ָ��,����ָ��
��ͬ�ij�������
23. ��������ת��ָ���ڴ��ַ
Ҫ�Ծ��Ե�ַ0x100000��ֵ,���ǿ�����(unsigned int*)0x100000 = 1234;��ôҪ�����ó�����ת�����Ե�ַ��0x100000ȥִ��,Ӧ����ô��?
((void ()( ))0x100000 ) ( );
����Ҫ��0x100000ǿ��ת���ɺ���ָ��,
��:(void (*)())0x100000
Ȼ���ٵ�����:
((void ()())0x100000)();
��typedef���Կ��ø�ֱ��Щ:
typedef void(*)() voidFuncPtr;
*((voidFuncPtr)0x100000)();
24. int id[sizeof(unsigned long)];�������?Ϊʲô?
��ȷ ��� sizeof�DZ���ʱ����,����ʱ��ȷ���� ,���Կ��ɺͻ����йصij�����
27. �ڴ�ķ��䷽ʽ�м���?������ 17
28. ������������������麯��,�����ʲô����?
#����������������:
����ָ��delete�ؼ���,��ȷ���տռ䡣
--- ��Ϊ�������������� ֻ�ܵ��� ���� ������
//����ָ��ָ���������ʱ,����������������麯��
//��ôֻ����� �������������,�����������,���Կ��ܻ�����ڴ�й¶
//�������� ���������� �麯��
//������ �������������,������������� ��Ĭ�� ���û������������,�����ڴ�й©
29. ȫ�ֱ����;ֲ�������ʲô����?����ôʵ�ֵ�?����ϵͳ�ͱ���������ô֪����?
�������ڲ�ͬ:
ȫ�ֱ������������ʹ���,�����������ٶ�����;
�ֲ������ھֲ������ڲ�,�����ֲ�ѭ������ڲ�����,�˳��Ͳ�����;
ʹ�÷�ʽ��ͬ:
ͨ��������ȫ�ֱ�������ĸ������ֶ������õ�;�ֲ�����ֻ���ھֲ�ʹ��;������ջ����
����ϵͳ�ͱ�����ͨ��'�ڴ�����λ��'��֪����,
'ȫ�ֱ���'������'ȫ�����ݶ�'�����ڳ���ʼ���е�ʱ���ء�
'�ֲ�����'�������'ջ'���� ��
��. ARM��ϵ�ṹ���
1. ������һ��ARM���������ص�,����˵��5�����ϵ��ص㡣
����;
�ͳɱ�,������,RISC�ṹ;
���С;
ָ���;
֧��Thumb(16λ)/ARM(32λ)˫ָ�;
2. ARM�ں��ж����ֹ���ģʽ?��д����Щ����ģʽ��Ӣ����д,�м����쳣ģʽ,�м�����Ȩģʽ,cortex_aϵ���м�����Ȩģʽ,���ֹ���ģʽ
|--> ��Ȩģʽ |---> �쳣ģʽ | --> FIQģʽ(�����ж�)
| | | --> IRQģʽ(��ͨ�ж�)
| | | --> SVCģʽ(��Ȩģʽ)
���� | | | --> Abortģʽ(��ֹ�쳣ģʽ)
ģʽ | | | --> Undefģʽ(δ������쳣ģʽ)
| | | --> Monitorģʽ(��ȫ���ģʽ)
| |---> ���쳣ģʽ---> Systemģʽ(Userģʽ�µ�һ����Ȩģʽ)
|
|--> ����Ȩģʽ --> Userģʽ
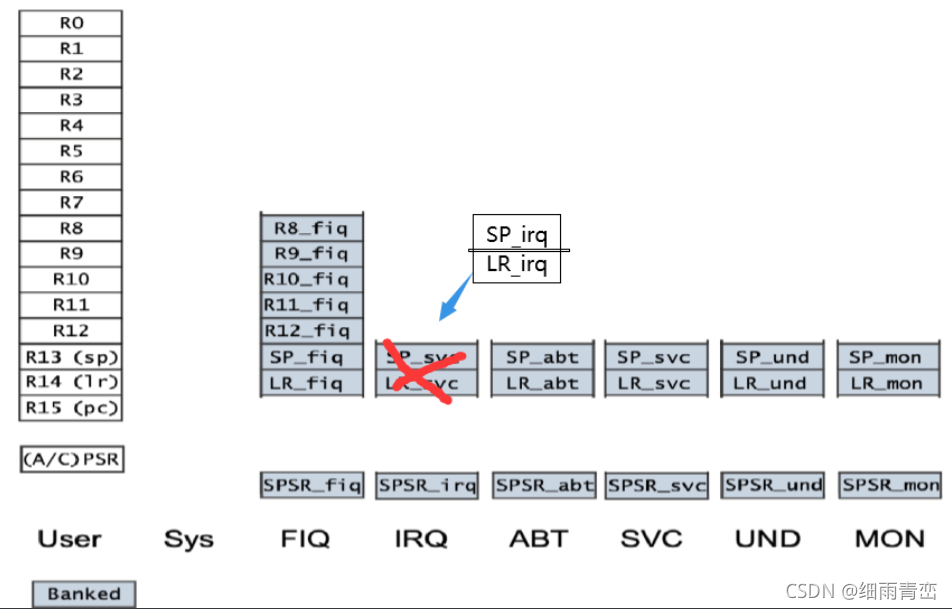
3. ARM�ں��ж��ٸ��Ĵ���,����һ��
ARM��37���Ĵ���,
(1)δ����Ĵ���:R0-R7,��8��;
(2)����Ĵ���R8-R14,����FIQģʽ���е�����һ��R8-R12��5��,����6��ģʽ����һ��R8-R12,��5��,
(3)���������PC��R15�Ĵ���,��1��;
(4)״̬�Ĵ���CPSR,��5������״̬�Ĵ���SPSR,��6��
4. ARMͨ�üĴ�����,��3���Ĵ���������ܺ�����,��д�����ǵ����ֺ����á�
R13:SPջָ��Ĵ���,�����������'ִ��ʱ��ջָ��λ��';
R14:LR�������ӼĴ���,�����������ִ��'BLָ��'��'ģʽ�л�ʱ'��'����'ԭ����'����ִ�еĵ�ַ';
R15:PC���������,ָ��'����ȡָ��ָ��ĵ�ַ'
5. ������һ��CPSR�Ĵ��������Bit����������á�

����λ(ָ��������������Ľ���Ƿ��н�λ,��λ��),
Iλ(IRQ�쳣����λ),
Fλ(FIQ�쳣����λ),
Tλ(ARM/Thumb����״̬),
ģʽλ(����������ģʽ)
N[31] : ָ���'������Ϊ����',Nλ���Զ�'��1',������0.
Z[30] : ָ���'������Ϊ��',Zλ���Զ�'��1',������0.
C[29] :
'�ӷ�':����'��λ',Cλ���Զ�'��1',������0.
'����':����'��λ',Cλ���Զ�'��0',������1.
��λ/��λ:'��32λ'��'��32λ' ��λ���߽�λ��
����64λ�����,��Ҫ��ֳ�����32λ�����мӷ�����,�����32λ,�����32λ,�ڽ��и�32λ����ʱ��Ҫ���ǵ�32λ�Ƿ��н�λ��
V[28] : '����λ'�����仯,Vλ���Զ�'��1',������0.
I[7] : IRQ����λ
I = 0 ������IRQ�ж�
I = 1 ����IRQ�ж�
F[6] : FIQ����λ
F = 0 ������FIQ�ж�
F = 1 ����FIQ�ж�
T[5] : ״̬λ
T = 0 : ARM״̬ --��ִ��ARMָ�
T = 1 : Thumb״̬ ---��ִ��Thumbָ�ARMָ���Thumbָ�����
ARMָ�: ÿ��ָ��ռ4���ֽڵĿռ�
Thumbָ�:ÿ��ָ��ռ2���ֽڵĿռ�
#ARMָ��Ĺ����Ա�Thumbָ��Ĺ��ܸ������ơ�Thumbָ���ָ����ܶ�Ҫ��ARMָ��ߡ�
M[4:0] : ģʽλ
10000 User mode;
10001 FIQ mode;
10011 SVC mode;
10111 Abort mode;
11011 Undfined mode;
11111 System mode;
10110 Monitor mode;
10010 IRQ
#�����ı���
6. ʲô��������?�������ı�����ʲô
Ȼ�������,ѭ�� ����ż�� λ,��� ���Եõ� Ҫ�жϵ��Ǹ���,˵������� ��һ����������
�������ı��� ������ָ���е���
7. ����BLָ����תʱLR�Ĵ����������ʲô����?�������ԭ��
LR�б������ִ����'BL��תָ�����һ��ָ��'�ĵ�ַ��LR������'��Ҫ���س���'ʱ��LR��'��ԭ����ִ�е�λ��'����ִ�С�(�����ֳ�--�ָ��ֳ�)
8. ������һ��ʲô�Ǵ������ֳ�,��ν��б����ֳ�?
ÿ�ֹ���ģʽ�¶�����R0-R15,CPSR��17���Ĵ���,�����ִ�е�ǰ״̬�ͱ�������Щ�Ĵ�����,��Ϊ�������ֳ���
������'ģʽ�л�'ʱ,�������е�һЩ�Ĵ����Ƕ���ģʽ��'���õļĴ���',Ϊ��'��ֹ����'�������Ĵ����е�'ֵ���ƻ�',������Ҫ'����'ԭģʽ�µ�'�������ֳ�',
����STM�����洢ָ��,�Ѵ������ֳ���Ӧ�ļĴ������浽ջ��,����ԭʱ�ٳ�ջ�ָ�(ģʽ�ͷ��ص�ַ)��
���б����ֳ��Ĺ���, Ӳ�������'CPSRģʽ�ı���'��'PC���ص�ַ�ı���',�����Ĵ����ı��湤����Ҫ��������ѹջ���,����'LR'��Ϊ'���ܱ��쳣����������'��BL��תָ��'��',����һ�㶼��Ҫ'����ѹջ'�ٱ��档
9. ATPCSĬ��ʹ�õ���ʲôջ?�C����ջ(ARMҲ��)
10. ʲô����ջ����ջ,ʲô����ջ����ջ?
ջ������: (sp)
��ջ:ջָ��ָ���ջ�ռ�û����Ч������,
ѹջʱ����ֱ�ӽ�����ѹ��ջ�ռ���,
��Ҫ�ٴν�ջָ��ָ��һ���յĿռ䡣
��ջ:ջָ��ָ���ջ�ռ�����Ч������,
ѹջʱ��Ҫ���ƶ�ջָ��ָ��һ���յ�ջ�ռ�,
��ѹ������,��ʱջָ��ָ�����Ȼ��һ������Ч���ݵ�ջ�ռ䡣
��ջ:ѹջʱջָ����ߵ�ַ�����ƶ�,
��ջʱջָ����͵�ַ�����ƶ���
��ջ:ѹջʱջָ����͵�ַ�����ƶ�,
��ջʱջָ����ߵ�ַ�����ƶ�
11. ��д��һ��������ARM�����ж�ָ��,����Ҫ���������á�
SWI 0x1��
SWIָ���'���ж��쳣',ʹ�����ִ������ת���쳣��������ַ0x8,0x1�����жϵ��жϺ�,
���жϴ�������ɸ��ݲ�ͬ���жϺŵ��ö�Ӧ�Ĵ����ӳ���һ��SWI���ж϶����ڲ���ϵͳ��ϵͳ���á�
12. ������һ��ARM��ϵ���쳣�������ĸ��
�쳣�������Ǵ�0x0��ַ��ʼ,һ��32���ֽ�,����8������,������1����������,����7�������Ӧ7���쳣���������תλ��,
��7���쳣������ֱ��Ӧ��5���쳣ģʽ��ÿ����������ŵ�һ�㶼��һ����תָ��,
������ת���������쳣�����������,ͨ��BLָ��,����LDR PC,[PC, #?] �ķ�ʽ������ʵ�ִ�����ת��
13. ��д��һ��ARM�������ɵ�bin�ļ�ӳ���а�����Щ����?
ARM���ɵ�bin�ļ�����:RO,RW ������,ע�� ZI ��һ�㶼���� bin �ļ���ռ�ô洢�ռ䡣
14. �����˵����ARM�������Ͻ���һ���жϴ������ж��쳣�����IJ��졣
�жϴ�������쳣����,��Ҫ���ж���Ҫ��ʼ���ж�Դ���жϿ�����,�жϷ�������ISR��Ҫ�����
ӦPendingλ,����Ҫ�ڽ����жϴ�������һ��ʼ�������
15. ������쳣�жϴ�������ʱ,��ͨ��ʲô��ɳ�ʼ������,��Щ��ʼ���ľ��岽����ʲô?
�������쳣�ж�ʱ,��ARM CORE���һ�¹���,����4����С��
1)����CPSR��SPSR_mode
2)����CPSR��λ
�Ĵ�����״̬����ARM̬
�Ĵ�����ģʽΪ��Ӧ���쳣ģʽ
��ֹ��Ӧ���ж�(������Ҫ��ֹFIQ����IRQ)
3)���淵�ص�ַ��LR_MODE
4)����PCλ��Ӧ���쳣����
16. uboot����Ҫ����
uboot ����bootloader��һ��'��������',���������������ں˵�
��ʼ���ֵ�Ӳ��,Ϊ�ں������ṩ����,
���ں˴��ݲ���
uboot��Ҫ���������ε���:
��һ����:���
����'�쳣������'
��ֹ'mmu'��'cache',��ֹ'���Ź�'
Ӳ��ʱ�ӵ�'��ʼ��','�ڴ�'��'��ʼ��'
���'bss'�� #bss���������洢��̬����,ȫ�ֱ�����
���uboot���������
'��ʼ��C����'���е�'ջ�ռ�'
�ڶ�����:C
���'��Ӳ��'��'��ʼ��','����'�ij�ʼ��,'�ڴ�'�Ľ�һ���ij�ʼ��,'��Դ��'��ʼ�� �ȵȱ�Ҫ'Ӳ����'��ʼ��
���������Ƿ����'����ģʽ'��'������ģʽ'
��ȡuboot��'��������',
ִ��'bootcmd�е�����',
����'���ں˴��ݲ���'(bootargs)
17. uboot���������������ں˵�?
uboot�տ�ʼ���ŵ�flash��,
�����ϵ��,���Զ���'���е�һ���ִ���'����'�ڴ�'��ִ��,
�ⲿ�ִ��븺���'ʣ���uboot����'����'�ڴ�'��,
Ȼ��'uboot����'�ٰ�'kernel���ִ���'Ҳ����'�ڴ�'��,
��������,�ں�������,
���ظ��ļ�ϵͳ,ִ��Ӧ�ó���
18. uboot���������̵���Ҫ����ʲô
uboot������Ҫ��Ϊ������,
��Ҫ��start.s�ļ���,��һ����Ҫ������Ӳ���ij�ʼ��,
����,����'������ģʽ'Ϊ'SVCģʽ','�رտ��Ź�','�����ж�','��ʼ��sdram','����ջ','����ʱ��',��'flash��������'��'�ڴ�','���bss��'��,bss���������洢��̬����,ȫ�ֱ�����,
Ȼ�������ת��start_arm_boot����,�����һ�εĽ�����
�ڶ��αȽϸ���,
���Ĺ�����Ҫ��:
1.��flash�ж����ںˡ�
2.�����ںˡ�
start_arm_boot����Ҫ����Ϊ,
���û���id,
��ʼ��flash,
Ȼ�����main_loop,
�ȴ�uboot����,
ubootҪ�����ں�,��Ҫ����'��������',
��һ����'s=getenv("bootcmd")',
�ڶ�����'run_command(s...)',
����Ҫ�����ں�,��Ҫ����'bootcmd��������'����������,bootcmd��������һ��ָʾ�˴�'ij��flash��ַ'��ȡ�ں˵��������ڴ��ַ,Ȼ������,bootm��
uboot�������ں�ΪuImage,���ָ�ʽ���ں�����'������'���:'�������ں�'��'�ں�ͷ��'���,
'ͷ��'�а����ں��е�һЩ��Ϣ,����'�ں˵ļ��ص�ַ','��ڵ�ַ'��
uboot�ڽ��ܵ����������,Ҫ������Ҫ��,
1,'��ȡ'�ں�ͷ��,
2,'�ƶ�'�ں˵����ʵļ��ص�ַ,
3,�����ں�,ִ��do_bootm_linux
do_bootm_linux��Ҫ����Ϊ,
1,������������,���ض��ĵ�ַ,������������,�����ֱ�Ϊ
setup_start_tag,
setup_memory_tag,
setup_commandline_tag,
setup_end_tag,
�����������Ǿ�֪������Ķ��ڴ洢����Ϣ,
memory��Ϊ���ӵ�'�ڴ��С��Ϣ',
commandlineΪ��������Ϣ,
2,������ڵ�ַ,�����ں�
�����ĺ���Ϊ
the_kernel(0,bd->bi_arch_number,bd->bi_boot_param)
bd->bi_arch_numberΪ���ӵĻ�����,
bd->bi_boot_paramΪ���������ĵ�ַ
19. bootcmd��bootargs����uboot��������������
bootcmd:<���ÿ������'�������Ļ�������'>
�������������һЩ����,��Щ����ڵ���ʱ������,����u-boot������ģʽ��ִ��
setenv bootcmd tftp c2000000 uImage \; tftp c4000000 stm32mp157a-fsmp1a.dtb \; bootm c2000000 - c4000000
//-------------------------------------------------------------------------------
bootargs:�����������Ҫ'���ݸ��ں˵���Ϣ',��Ҫ��������'�ں˷�����Ϣ'��'���ļ�ϵͳ'���ڵķ���
setenv bootargs root=/dev/nfs nfsroot=192.168.1.250:/home/linux/nfs/rootfs,tcp,v4 rw console=ttySTM0,115200 init=/linuxrc ip=192.168.1.222
20. linux�ں˵���������
�ں�������������Ҫ������Щ��?
1> ubootͨ��'tftp����'��'uImage����'���ڴ���(�����ں�)
2> 'uImage'��Ҫ���'�Խ�ѹ'
3> ��ȡcpu��ID��,����ҳ��,��ʼ��MMU,���������ַ�������ַ��ӳ��
4> '���BSS��',bss���������洢��̬����,ȫ�ֱ�����
5> ��ɾ�'�����Ӳ��'��'��ʼ��',��һ����Ӳ����ʼ��< �ڴ�,ʱ��,����,EMMC,nfs�ͻ���....>
5> ��'u-boot��������'���ڴ����'��ȡbootargs����','����'bootargs'����',����������'���ظ��ļ�ϵͳ'��
6> '����'���ļ�ϵͳ
7> ִ�и��ļ�ϵͳ�е�'1�Ž���','linuxrc'����
8> ���˿������linuxϵͳ�����ɹ�

21. uImage,zImage,vmlinux������
�ں˱���(make)֮������������ļ�,
һ��'Image',һ��'zImage',
����'Image'Ϊ'�ں�ӳ��'�ļ�,
��'zImage'Ϊ'�ں�'��һ��'ӳ��ѹ���ļ�',
'Image'��ԼΪ4M,
��'zImage'����2M��----��Ϊѹ����
��ôuImage����ʲô��?----zImage ���˸�ͷ
����'ubootר��'��'ӳ��'�ļ�,������'zImage'֮ǰ'����'һ������Ϊ'64�ֽ�'��'ͷ',
˵�����'�ں˵İ汾'��'����λ��'��'����ʱ��'��'��С'����Ϣ;��'0x40'֮����'zImageû����'��
�������uImage�ļ�?
������uboot��/toolsĿ¼��Ѱ��'mkimage'�ļ�,����copy��ϵͳ'/usr/local/bin'Ŀ¼��,����������������ߡ�
Ȼ�����ں�Ŀ¼������'make uImage',
����ɹ�,�������'arch/arm/boot/'Ŀ¼�·���'uImage'�ļ�,���С��zImage��'64���ֽ�'��
��ʵ����һ���Զ����ֶ�������,
'����'uImage'ͷ��������',u-boot��֪����ӦImage����Ϣ,
���'û��ͷ��'����Ҫ�Լ�'�ֶ�ȥ������Щ����'��
#U-boot��U�ǡ�ͨ�á�����˼��
22. Kconfig,.config,Makefile�����ļ�֮��Ĺ�ϵ
�����ں��ļ�ʱ,��Ҫ����.config�ļ�(make menuconfig --> ѡ����Ҫ������ ),
Ȼ��Makefile�ڱ���ʱͨ��'��ȡ.config�ļ�'��'������Ϣ'��ѡ��Ҫ������ļ�,ѡ�������ļ��ط�ʽ��
.config�ļ������ɿ�ͨ�� make menuconfig ARCH=arm �� make defconfig ��ʽ����,
�����ַ�ʽ����ȥ��Ȼ��ͬ,�������ߵ�ԭ����һ����,����ͨ��Kconfig�ļ����������ġ�
��. ϵͳ��ֲ
1. Linux�ں��������̡�ͬ�� ��.20
1. Linux�ں�'�Խ�ѹ����'
uboot���ϵͳ�����Ժ�,ִ�л�������bootm�е�����;
��,��Linux�ں˵����ڴ��в�����do_bootm���������ں�,��ת��kernel����ʼλ�á�����ں�û�б�ѹ��,��ֱ������;����ں˱�ѹ����,����Ҫ���н�ѹ,��ѹ������kernelͷ���н�ѹ����
ѹ������kernel��ڵ�һ���ļ�Դ��λ����/kernel/arch/arm/boot/compressed/head.S����
������decompress_kernel()�������н�ѹ,
��ѹ��ɺ�,��ӡ����Ϣ��UncompressingLinux...done,booting the kernel����
��ѹ����ɺ�,����gunzip()����(��unlz4()����bunzip2()����unlz())���ں˷���ָ��λ��,��ʼ�����ںˡ�
2. Linux�ں�'��������'
���ں����ӽű�/kernel/arch/arm/kernel/vmlinux.lds��֪,�ں���ں���Ϊstext(/kernel/arch/arm/kernel/head.S)��
�ں˽�ѹ��ɺ�,��ѹ���������stext���������ںˡ�
P.S.:�ں����ӽű�vmlinux.lds���ں����ù����в���,��/kernel/arch/arm/kernel/vmlinux.lds.S�ļ����ɡ�
ԭ����,�ں����ӽű�Ϊ��Ӧ��ͬƽ̨,���������������,����һ������ļ���������ӽű���������
(1)�ر�IRQ��FIQ�ж�,����SVCģʽ������setmode��ʵ��;
(2)У�鴦����ID,�����ں��Ƿ�֧�ָô�����;����֧��,��ֹͣ�����ںˡ�����__lookup_processor_type����ʵ��;
(3)У�������,�����ں��Ƿ�֧�ָû���;����֧��,��ֹͣ�����ںˡ�����__lookup_machine_type����ʵ��;
(4)���uboot���ں˴���ATAGS��ʽ�Ƿ���ȷ,����__vet_atars����ʵ��;
(5)���������ַӳ��ҳ�����˴�������ҳ��Ϊ��ҳ��,���ں�����ǰ��ʹ�á�Linux���ڴ�����и���ϸ��Ҫ��,�������½�������ϸ��ҳ��������__create_page_tables����ʵ�֡�
(6)��תִ��__switch_data����,���е���__mmap_switched���������������
1)�������ݶΡ����bss��,Ŀ���ǹ���C�������л���;
2)���洦����ID�š������롢uboot���ں˴��ε�ַ;
3)b start_kernel��ת���ں˳�ʼ���Ρ�
3. Linux�ں�'��ʼ����'
�˽δ�start_kernel������ʼ��start_kernel����������Linuxƽ̨����ϵͳ�ں˳�ʼ������ں�����
������Ҫ������'���ʣ����Ӳ��ƽ̨��صij�ʼ��'����,�ڽ���һϵ�����ں���صij�ʼ��֮��,
����'��һ���û�����init'���ȴ���ִ�С�����,�����ں�������ɡ�
3.1 start_kernel��������Ҫ����
start_kernel������Ҫ���'�ں���صij�ʼ��'����������������²���:
(1)�ں˼ܹ� ��ͨ��������س�ʼ��
(2)�ڴ������س�ʼ��
(3)���̹�����س�ʼ��
(4)���̵�����س�ʼ��
(5)������ϵͳ����
(6)�����ļ�ϵͳ
(7)�ļ�ϵͳ
start_kernel������⡣
3.2 start_kernel�������еĹؼ�����
(1)setup_arch(&command_line)����'�ں˼ܹ���صij�ʼ��'����,�Ƿdz���Ҫ��һ����ʼ�����衣
����,�����˴�������ز����ij�ʼ�����ں���������(tagged list)�Ļ�ȡ��ǰ�ڴ������ڴ���ϵͳ�����ڳ�ʼ����
command_lineʵ����'uboot���ں�''���ݵ���������������',��uboot�л�������bootargs��ֵ��
��uboot��bootargs��ֵΪ��,command_line = default_command_line,��Ϊ�ں��е�Ĭ�������в���,��ֵ��.config�ļ�������,��ӦCONFIG_CMDLINE�����
(2)setup_command_line��parse_early_param�Լ�parse_args����
��Щ����������'��������в����Ľ���������'��
Ʃ��,cmdline = console=ttySAC2,115200 root=/dev/mmcblk0p2 rw init=/linuxrc rootfstype=ext3;
����Ϊһ���ĸ�����:
console=ttySAC2,115200 //ָ������̨�Ĵ����豸��,���䲨����
root=/dev/mmcblk0p2 rw //ָ�����ļ�ϵͳrootfs��·��
init=/linuxrc //ָ����һ���û�����init��·��
rootfstype=ext3 //ָ�����ļ�ϵͳrootfs������
(3)sched_init������ʼ�����̵�����,�������ж���,���õ�ǰ����Ŀ��̡߳�
(4)rest_init����rest_init��������Ҫ��������:
1)����kernel_thread����������2���ں��߳�,�ֱ���:kernel_init��kthreadd��
kernel_init�߳���'����prepare_namespace����'���ظ��ļ�ϵͳrootfs;Ȼ�����init_post����,ִ�и��ļ�ϵͳrootfs�µĵ�һ���û�����init���û�������4����ѡ����,��command_line��init��·������,���ִ�б��÷�����
��һ����:/sbin/init,
�ڶ�����:/etc/init,
��������:/bin/init,
���ı���:/bin/sh��
2)����schedule���������ں˵���ϵͳ;
3)����cpu_idle����,�������н���idle,����ں�������
2. ʲô��bootloader?��Ƕ��ʽϵͳ����bootloader��������ʲô?
Bootloader��'�������س���'��ͳ��,#(Boot :���� Loader : ����)
��Ƕ��ʽϵͳ�ϵ��ĵ�һ�δ���,����Ҫ�����ǽ�'Ӳ����ʼ��'
��һ�����ʵ�״̬����'Ƕ��ʽ����ϵͳ''���ص��ڴ���'ִ�С�
3. Ϊʲô������Զ�Ӳ��ƽ̨�������Զ�C����ȴ���Բ�����Ӳ��ƽ̨?
'��ͬ�Ĵ�����'��Ϊ'Ӳ���IJ���'��'�������Dz�ͬ'��,
'�������'�ǽ�'�������÷���'��ʾ����'��ͬ�Ĵ�����''�������Ҳ��ͬ'��---����������
C������'���ܱ�CPUֱ��ʶ���ִ��'��,����C������Ҫ'�ȱ�����ɻ������'����ִ��,---����������--��C��
�������ʹ�õ���ARM��������ô�����ʱ�����Ǿͽ�'C'�����ARM�Ļ�����,�������ʹ�õ���X86������
��ô�����ʱ�����Ǿͽ�C�����X86�Ļ�����,����'C����'����'������Ӳ��ƽ̨'��
4. ʲô�����������?
'�������'������'һ̨����'��'�༭�ͱ���'����,����'����õij���'�ŵ�'����һ̨����'��ִ�С�
����Ƕ��ʽ������������'�����ϱ༭�ͱ������',������õij���'�����ص�������'ִ�С�
5. Linuxƽ̨�µĿ�ִ���ļ���ʲô��ʽ?
'elf��ʽ'���ļ���linuxƽ̨�³��õ�'�����Ƹ�ʽ'
6. ʲô���������?
��Ϊ'�������'����'��������ʾ������',����'�������'��'������'��'һһ��Ӧ'��,
�������ǿ��Խ�'�������'�����'������',ͬ���������'������'Ҳ����'���Ƴ����',
���ǰ�ͨ�����������Ƴ����Ĺ��̽��������
7. ����nfs����ĸ���������?
NFS(Network File System)��'�����ļ�ϵͳ',
�����������еļ����֮��ͨ��'TCP/IP����''������Դ'��
��NFS��Ӧ����,����NFS�Ŀͻ���Ӧ�ÿ������ض�дλ��Զ��NFS�������ϵ��ļ�,������ʱ����ļ�һ����
8. ����һ��װ��linux�ں˵Ŀ��������������?
һ��װ��linux�ں˵Ŀ������ϵ���
��һ������һ����uboot,
uboot���ȶ�'��Ӳ����Դ'����'��ʼ��',
Ȼ��'�̻�'�ڴ洢���е�'�ں�'�Լ�'����ļ�'�������ص�'�ڴ�'��,
Ȼ��'�ں˿�ʼ����',�ں�'����'��'��Ӳ����Դ���г�ʼ��',�ں˳�ʼ����ɺ��ں˴�ָ��λ��ȥ'���ظ��ļ�ϵͳ'
���ļ�ϵͳ������ɺ�Ϳ��������ϲ��Ӧ�ó��������ϵͳ��������
9. ����uboot����Ҫ��������Щ?
uboot����Ҫ�Ĺ��������¼���
1)'��ʼ��һЩӲ��'Ϊ��������
2)'����'��'����'�ں�
3)��'�ں˴���'
4)ִ���û�����
10. uboot������û�������?
uboot�����û�������ʹ�õ���'setenv'����,
��������������uboot��ipaddr��������Ϊ192.168.1.1�Ϳ���ִ��'setenv ipaddr 192.168.1.1'�����������
11. ����uboot��bootcmd��������������?�C��.19
bootcmd:<���ÿ������'�������Ļ�������'>
�������������һЩ����,��Щ����ڵ���ʱ������,����u-boot������ģʽ��ִ��
12. ����uboot��bootargs��������������?�C��.19
uboot���˿��������ͼ����ں������Ϊ�ں˴���,�����ں˴���һЩ��Ϣ�Ա����ں˵���ȷ����,���ǿ����Ƚ���Щ��Ϣ(������ļ�ϵͳλ�á�����̨��Ϣ��)д�뵽bootargs��������,Ȼ��uboot�ٽ���Щ��Ϣ���ݸ��ں�ʹ�á�
13. ����ʲô��ƽ̨��ش���ʲô��ƽ̨�ش���?
ƽ̨��ش��뼴��'Ӳ��ƽ̨���'�Ĵ���,��'Ӳ��ƽ̨�ı�'��'�������'Ҳ'Ҫ����Ӧ����'��
����һЩ����CPU���Ĵ��������ŵ���ش���,��Ӳ���ı���������Ͳ���������Ҫ����Ӧ���ġ�
ƽ̨�ش�����Ǻ�'Ӳ��ƽ̨��'�Ĵ���,'����Ӳ��ƽ̨�Ƿ�ı�''������붼������'��
ƽ̨���: ��Ӳ��'ƽ̨�йش���'
arch
ƽ̨�ش���: ��Ӳ��'ƽ̨�ش���'
lib
include
drivers
toos
ipc
net
....
14.�������linux/uboot֧�ָ���Ӳ��ƽ̨?
һ�������'��ͬ�Ĵ�����'������'Ӳ���IJ���'��'�����Dz�����'��,
���㴦������ͬ��Χ��Ӳ���豸��ͬ����Ҳ������,
���Ǿ���˵linux/uboot֧�ָ���Ӳ��ƽ̨'������'�����'������'�ܹ�'�������κ�ƽ̨',
������linux/uboot'Դ������'����'����֧�ֵ�Ӳ��ƽ̨'��'����''��д��һ��',
ʹ�õ�ʱ��ǰ����'ʹ�õ���ʲôƽ̨'���Ǿ�'�����Ӧ�Ĵ���'���ɡ�
15. �������ubootʹ���ʺ��ض��Ŀ�����ƽ̨?
��ubootԴ��Ķ���Ŀ¼��ִ��'make <��������>_config'���ɽ������ó�'�ʺ��ض�������ƽ̨'��'uboot'��
���統ǰ�������������origen��ô������Դ��Ķ���Ŀ¼��ִ��make origen_config����������á�
16. ��α���uboot���ɶ������ļ�?
�����úõ�ubootԴ��Ķ���Ŀ¼��ֱ��ִ��'make����'���ɱ���ubootԴ�����ɶ����ƵĿ�ִ���ļ���
17. ����uboot����������?
uboot��Ҫ���������ε���:
��һ����:���
����'�쳣������'
��ֹ'mmu'��'cache',��ֹ'���Ź�'
Ӳ��ʱ�ӵ�'��ʼ��','�ڴ�'��'��ʼ��'
���'bss'�� #bss���������洢��̬����,ȫ�ֱ�����
���uboot���������
'��ʼ��C����'���е�'ջ�ռ�'
�ڶ�����:C
���'��Ӳ��'��'��ʼ��','����'�ij�ʼ��,'�ڴ�'�Ľ�һ���ij�ʼ��,'��Դ��'��ʼ�� �ȵȱ�Ҫ'Ӳ����'��ʼ��
���������Ƿ����'����ģʽ'��'������ģʽ'
��ȡuboot��'��������',
ִ��'bootcmd�е�����',
����'���ں˴��ݲ���'(bootargs)
18. ����ϵͳ����������Щ?
�ڴ����
�ļ�����
�������
���̹���
�豸����
#(����Linux�ں˵Ĺ���)
19. �������linuxԴ��ʹ���ʺ��ض��Ĵ�����?
��linuxԴ����ִ��'make <��������>_defconfig'���ɽ������ó�'�ʺ��ض��Ĵ�����'�Ĵ��롣
��������ʹ�õĴ�������exynos,��ô������linuxԴ�붥��Ŀ¼��ִ������make exynos_defconfig����������á�
20. ��make menuconfig��������Щ�������Ա�ѡ������״̬����Y��,��N��,��M��������״̬�ֱ���ʲô����?
Y--ѡ��'���ں���',�������ں˾Ͱ����˸���������,ͬ���ں˵����Ҳ����֮����
N--'���ᱻ����'���ں�,���������ں�Ҳ��֧�ָ�����
M--'ģ�黯����'���ں���,Ҫ�������������ģ��,�ڱ����ں˵�ʱ�������'���ᱻ����',�����Ե��������һ������ģ��ʹ�õ�ʱ����ʱ���ظ�ģ�顣
21. ��α��뱻ѡ��Ϊ��M��ѡ�������ģ��?
��linuxԴ��Ķ���Ŀ¼��ִ��'make modules'���ɽ�ѡΪ��M�����������������ģ�顣
insmod ����װ�������
lsmod �鿴����
rmmod�����
22. �����豸��������?
�豸��(Device Tree)����'����Ӳ�������ݽṹ',�ڲ���ϵͳ(OS)'������'���豸'��ʼ��'��ʱ��,���ݽṹ�е�'Ӳ����Ϣ''����Ⲣ����'��'����ϵͳ'��
�ں��е�'��������''û��'������'Ӳ����Ϣ',����'�ܽŵ���Ϣ'��'�Ĵ����ĵ�ַ'��,������������'������ȷ������'һ�������Ӳ���豸����,�豸����'ר��'����������'Ӳ����Ϣ'��'�ļ�',��������'�豸��','��������'�Ϳ�������'�����Ӳ��'�豸����'�������ϵ'ʹ��������������
23. ��д�豸���ļ�����Ҫ������ʲô?
�豸���ļ�������������Ӳ����Ϣ���ļ�,
���Ա�д�豸����'��Ҫ����'�Ǹ��ݿ�����Ӳ������Ϣ��
24. ������ν�һ���ں�Դ�������е�����������뵽�ں���?
������'make menuconfig'��'ѡ��'������Ҫ������,
��Ϊ�ں��Դ�������������'û�п������Ӳ����Ϣ',
�������ǻ�Ҫ'����ʵ�ʵ�Ӳ����Ϣ'ȥ'���豸��'�ļ�,
Ȼ��'���±���'�ں˺��豸���Ϳ��Խ��������뵽�ںˡ�
25. ������ν�һ���Լ���д������������뵽�ں���?
�������ǽ��Լ���д��'��������'���뵽'�ں�Դ��'��,
Ȼ���Ķ�Ӧ��'Kconfig�ļ�'ʹ�Լ�д����������'make menuconfig'��������ʾ����,
Ȼ����Ҫ��'��Ӧ��Makefile'ʹ������'��ȷ����',
���ϲ�����ɺ� ����Ϳ��Խ�'����������ں�'��
26.���ں������������������̨�Ѿ���ʼ������һ�����ʲô��ʽ�������ں�?
�������̨�Ѿ���ʼ������һ��ʹ��'printk����'����ӡ�����Լ�����Ϣ
27. linux�ں�����������������ʲô������ӡϵͳ��������Oops?
��linux�ں������������г������¼��������ʱ����ӡ'ϵͳ��������'
1)�ڴ����'Խ��' 2)ʹ��'�Ƿ�ָ��' 3)ʹ����'NULLָ��' 4)ʹ����'����ȷ��ָ��'
28. linux�ں�����������������ijЩ������ӡϵͳ��������Oops,��������Ҫ��ӡ��Щ����?
�����п��Խ�CPU��'�����Ĵ�����ֵ'��'ҳ����������λ��'�Լ�'������Ϣ'��ӡ������
29. ����ʲô���ļ�ϵͳ?ʲô�и��ļ�ϵͳ?
�ļ�ϵͳ��һ��'�����ͷ��ʴ���'��'��������',��'����'��'����',��ͬ'�ļ�ϵͳ'�����ͷ��ʴ��̵�'���Ʋ�ͬ'��
���ļ�ϵͳ��'�������ϵͳ'�������'���ֹ�������'��'���ļ�'��'�ű�'��'����'���ļ��ĵط�
'ʵ��'����'һЩ�ļ�'
30. ��������Ϊʲôһ�㲻��Ҫ��װ��̬��?
����Է�Ϊ'��̬��'��'��̬��'
'��̬��'һ����'�������'��ʱ��'ʹ��'
��'��̬��'һ����'��������'��ʱ��'ʹ��'
��Ƕ��ʽ������һ������ʹ��'�������'�ķ�ʽ,�����DZ༭�ͱ���������ڵ����¶����������ɺ����ص�������ִ��,����'һ�㲻���ڿ�����������',���Կ�����'һ�㲻��Ҫ��װ��̬��'��
��. ��������
1. ʲô��ģ��?
Linux �ں˵�����ṹ�Ѿ��dz��Ӵ�,������������Ҳ�dz��ࡣ
��ᵼ����������,
һ�����ɵ�'�ں˻�ܴ�',
�����������Ҫ�����е�'�ں���������ɾ������',�����ò�'���±����ں�'��
Linux �ṩ��������һ�ֻ���,���ֻ��Ʊ���Ϊ'ģ��(Module)'��ʹ�ñ�������ں˱�����'����Ҫ�������й���',������Щ������Ҫ'��ʹ�õ�ʱ��',��'��Ӧ�Ĵ���'��'��̬�ؼ��ص��ں�'�С�
2. �����������
�ַ��豸���������豸�����������豸����
3. �ַ��豸������ܱ������?
ģ����ز���:
1- �����豸��
2- ע���豸��
3- ��ʼ���ַ��豸����,��д���file_operations�ṹ�弯��
4- ����ע���ַ��豸
ģ��ж�ز���:
1- ȡ��cdevע��
2- ȡ���豸��ע��
4. ʲô�Dz���,�����в�����̬��ԭ������Щ?
����(concurrency)ָ����'���ִ�е�Ԫ''ͬʱ������'��'ִ��',��������ִ�е�Ԫ��'������Դ'(Ӳ����Դ�������ϵ�ȫ�ֱ�������̬������)��'����'��������¾�̬(race conditions)
������̬��ԭ��:��'�������'ͬʱ����'ͬһ��'������'�ٽ���Դ'��ʱ��̬�Ͳ����ˡ�
1.����'����CPU'��˵,���֧��'������ռ',�ͻ������̬��
2.����'���CPU'��˵,�����֮��'����'�ͻ������̬
3.�жϺͽ��̼� �������̬
#(arm)�жϺ��жϼ�������̬ (###�����###)
5. �����̬��;������Щ?�ֱ���ʲô�ص�?
1.˳��ִ��
2.����ִ��
�ж�����:��ֻ�ܽ�ֹ��ʹ�ܱ�CPU�ڵ��ж�,���,�����ܽ��SMP��CPU�����ľ�̬
������ :�ֽ�æ�ȴ������������ڼ䲻����˯�ߵĺ�������,Ҳ������������cpu�ĵ���Ȩ,Ҳ���ܽ��к�ʱ�����������������������
�ź��� :���ں������������ٽ���Դ��һ��,��Ӧ�ò��ź�������һ��
3.������
4.ԭ�Ӳ���
6. ������IOģ���м���?
(1)����ʽIO ���,���,Ч����͵�io����
(2)������ʽIO ��Ҫ���ϵ���ѯ��
(3)��·IO���� �����·�����������������
(4)�ź�����IO �첽ͨ�Ż���,�������жϡ�
7. ���linux�豸ģ�͵���Ҫ����?
ʵ��'Ӳ����ַ��Ϣ'��'��������'���� ----����ô���豸����
8. �ַ��豸���������linux�豸ģ���Ƿ�ì��?
�ַ��豸�������,��ҪΪ��ʹ'Ӧ�ó���'�ܹ�����'������',����'�ײ�Ӳ��'��
linux�豸ģ��ʵ��'Ӳ����ַ��Ϣ'��'��������'����
���Զ��߲���ì�ܡ�
9. platform�ܹ��ֱ��Ϊ�ĸ�����?����ͨ��ʲô����ƥ��
platform���õ�'����'��˼��,��'�豸��Ϣ'��'�豸����'����,��������'����'ģ�� 'devicebus driver'���ƥ��Ĺ��̡�
ƥ��'�ɹ�'֮��ִ��'�����е�probe����',��probe�в���Ӳ������
�������'����'ִ�������е�'remove����'��bus�����ƥ��Ĺ���(bus���ں�ʵ�ֵ�)��
�豸,����,����;
1- ������ƥ��
2- ��id_table������ƥ��
10. �豸����platform�ܹ��Ƿ���ì��?
û��ì��
'�豸��'�Ƕ�'�豸ģ��'��,'Ӳ����Դ'��������,���м�����������ǰ����Դ'�ṹ��',�ij�'�豸���ڵ�'����ʽ��������,�������Ѷ�ϵ��
11. ΪʲôҪ���жϷ�Ϊ���°벿?���°벿��������Щ?
���жϴ�������ֻ����'��̲���ʱ'�IJ���,����'�е�ʱ��'��ϣ�����жϵ�����ʱ��'����Ժ�ʱ�IJ���',�����Ͳ�����ì��,linux�ں�Ϊ�˽�����ì��������'�жϵװ벿'�ĸ��
����Щ'��ʱ����'�ŵ��жϵװ벿��ɡ�---���ǻ��Dz�������ʱ����,��Ϊ��Ȼ���жϵװ벿,��Ҳ�����ж�,���ȼ���һ�����Ҫ��--��
#����:�������жϵ�����ʱ����Ҫȥ�������紫�ݹ���������,��ʱ����һ����ʱ����Ӧ�÷ŵ��жϵװ벿��ɡ��жϵװ벿�Ļ��� ���ж� , tasklet , ��������
12. ����������tasklet������?
tasklet:
tasklet��'����'���ж�ʵ�ֵ�,������ͨ��'����'ʵ�ֵ�,���'û�и���'���ơ�
tasklet������'�ж�������',�����жϵ�'һ������','��������'�ж�ִ�С�
������'��Ժ�ʱ'����,����'����'�����ߵIJ�����
��������:
���ں�������ʱ�������һ��'events'���߳�����߳�Ĭ�ϴ���'����'״̬,������߳���ά��һ��'��������'��
�����'ʹ�ù�������'���������'�ύ������',Ȼ��'����events�߳�',����ȥ���ö������е�'�װ벿��������'���ɡ�
��������'��������'�ж�ִ��,'û�и�������',������'����������'���ڵװ벿���������п�������ʱ,��ʱ,'����'���ߵIJ�����
#-------------------------------------------------------
����:
�������е�'ʹ�÷���'��tasklet�dz�'����'
tasklet������'�������'
��������������'����������'
tasklet����������'����˯��',���������д���������'����˯��'
13. �ں����ڴ���亯���ֱ�����Щ?�ֱ���ʲô�ص�?
��ҳ(page)���� __get_free_pages ()
������ָ��'������ҳ'�Ľ�����Ϊ����֮һ������
�������ҳ����'�������ں˿ռ�'
�������'����RAM�ռ�'��'����'��
kmalloc
������'����ȷ�ֽ�'��'�ڴ�'��,�밴ҳ������ͬ
vmalloc
����'�����ڴ治һ������'��,��kmallocͬ
14. �ں˵���
a.����ʹ��printk��ӡ�ں���Ϣ,printk�ĵ��Լ�������
#define KERN_EMERG "0" /* system is unusable */
#define KERN_ALERT "1" /* action must be taken immediately */
#define KERN_CRIT "2" /* critical conditions */
#define KERN_ERR "3" /* error conditions */
#define KERN_WARNING "4" /* warning conditions */
#define KERN_NOTICE "5" /* normal but significant condition */
#define KERN_INFO "6" /* informational */
#define KERN_DEBUG "7" /* debug-level messages */
//��ӡ��������������ڹ��˴�ӡ��Ϣ�ġ�
<0> ------------ <7>
��� ������
ֻ�е�'��Ϣ�ļ���'����'�ն˵ļ���'��ʱ����Ϣ'�Ż�'���ն���'��ʾ'
����ͨ��'/proc/sys/kernel/printk' cat ����ļ����鿴
cat /proc/sys/kernel/printk
4 4 1 7
�ն˵ļ��� Ĭ����Ϣ�ļ��� �ն˵���� �ն˵���С����
//ע�� : �ļ����ʱ�� ֻ��ʹ�� echo �ض���,����ʹ�� vim
b. gdb �� addr2line �����ں�ģ��
������������
1.��д��makefile�е�gcc����-Wall -gѡ��,�����������
2.�����ں�ģ���ʱ�����oops,����dmesg ���鿴 panic ���� (����:dmesg |tail -20)
3.�鿴��־����,�ҵ�oops �����Ĺؼ���־,(ע��:���� oops ���Ǵ�ģ��Ļ���ַƫ�Ƴ����ĵ�ַ)
4.�ҵ�oops�����Ļ���ַ,cat /proc/modules |grep oops
5.ʹ�� addr2line �ҵ� oops λ��,(addr2line -e oops.o 0x14,ƫ����=ƫ�Ƶ�ַ-����ַ,�����,0x14����ƫ����)
6.��������н�����ص���Դ��ij��.c�ļ�����к�,Ҳ����֪���˴��뵼�� oops ��λ���ǵڼ���
7.ͨ��objdump ������oops λ��(objdump -dS --adjust-vma=0xffffffffa0358000oops.ko)
8.�ն˴�ӡ�Ľ�����Կ�������������c����,Ҳ����֪���˲���oops���ڴ��ַ��Ӧ��c��������һ��
c. ʹ�ú���BUG_ON(),BUG()��dump_stack()�����ں�
ʹ�÷���:
1.��д�ں�����ģ���ʱ��,����Ҫ�鿴������Ϣ�ĺ����е���BUG_ON(),BUG()����dump_stack()
2.ִ��sudo insmode xxx.ko����kernle��־�¿��Կ������ú����ľ�����Ϣ,������·�����ļ������кŵ�
15. �ַ��豸�����Ŀ��
�ַ��豸:�ṩ������������,Ӧ�ó������˳���ȡ,ͨ����֧�������ȡ,֧�ְ��ֽ�/�ַ�����д
���ݡ�
���豸:Ӧ�ó��������������豸����,���������ȷ����ȡ���ݵ�λ�á�Ӧ�ó������Ѱַ������
���κ�λ��,���ɴ˶�ȡ���ݡ�����,���ݵĶ�дֻ���Կ�(ͨ����512B)�ı������С����ַ��豸��
ͬ,���豸����֧�ֻ����ַ���Ѱַ��
�����豸:�����豸�������豸������,��������պͷ���֡����,����������֡,Ҳ������ip����
��,��Щ���Զ�����������������������������/dev����,������һ����豸��ͬ�������豸��һ��
net_device�ṹ,��ͨ��register_netdevע�ᵽϵͳ��,���ͨ��ifconfig -a��������ܿ�����
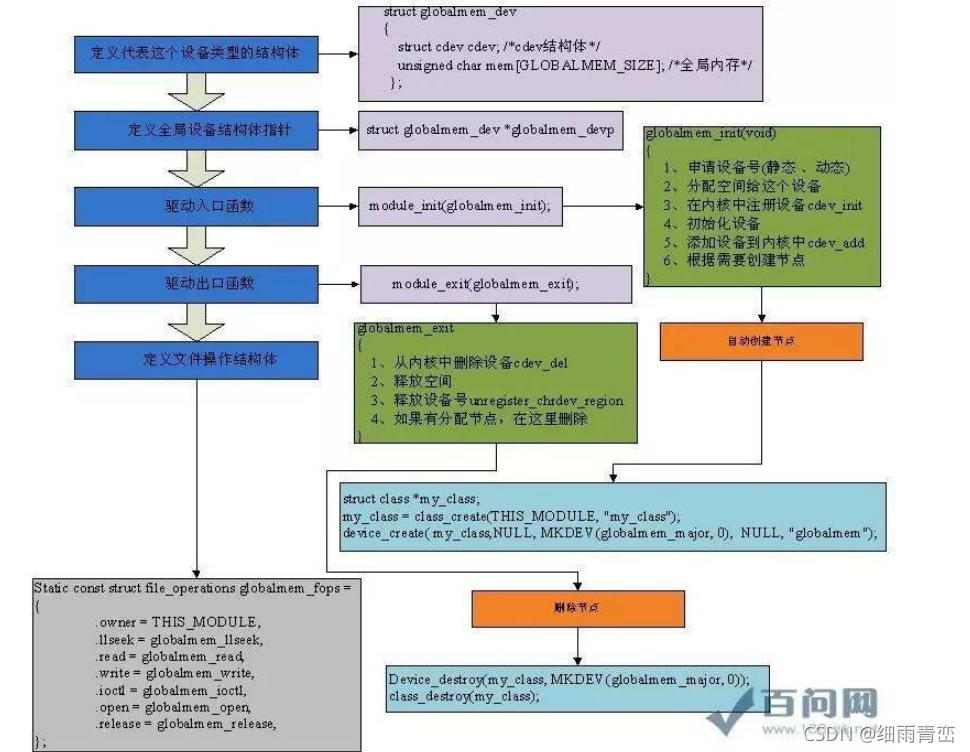
16. �ַ��豸�Ϳ��豸�������豸������
�ַ��豸:
�ṩ������'������',Ӧ�ó������'˳���ȡ',ͨ��'��֧�������ȡ',֧�ְ�'�ֽ�/�ַ�'����д���ݡ�
���豸:
Ӧ�ó������'��������豸����',�����'����ȷ��'��ȡ���ݵ�'λ��'��Ӧ�ó������'Ѱַ'�����ϵ�'�κ�λ��',���ɴ˶�ȡ���ݡ�
����,���ݵĶ�д'ֻ���Կ�(ͨ����512B)�ı���'���С����ַ��豸��ͬ,���豸��'��֧��'�����ַ���Ѱַ��
�����豸:
�����豸��'�����豸'������,������'���պͷ���'֡����,������'����֡',Ҳ������'ip���ݰ�',��Щ���Զ�����������������
������������/dev����(��Ϊ��дLinux�ں�֮ǰ����Э�������),������һ����豸��ͬ�������豸��һ��net_device�ṹ,��ͨ��'register_netdev'ע�ᵽϵͳ��,���ͨ��'ifconfig -a'��������ܿ�����
17. �����;�̬����,��Щ�������־�̬,�����̬�ķ���,�Լ�����,ʹ�ó������������4��
����(concurrency)��ָ'���ִ�е�Ԫ''ͬʱ������'��'��ִ��',������ִ�е�Ԫ�Թ�����Դ�ķ��ʺ��ݵ��¾�̬(race condition)��
�����뾺̬����������:
�Գƶദ����(SMP)�Ķ��CPU;��CPU�ڽ�������ռ���Ľ���;�ж������֮�䡣
��'�������'ͬʱ����'ͬһ��'������'�ٽ���Դ'��ʱ��̬�Ͳ����ˡ�
1.����'����CPU'��˵,���֧��'������ռ',�ͻ������̬��
2.����'���CPU'��˵,�����֮��'����'�ͻ������̬
3.�жϺͽ��̼� �������̬
��������뾺̬��;��:
���ʹ�����Դ�Ĵ��������Ϊ'�ٽ�����(critical section)'',�����̬�ĸ���;�����Ƕ��ٽ����Ļ������,������Ҫ���ж����Ρ�ԭ�Ӳ��������������ź����������塣
1. �����
��CPU���⾺̬��'�취'����'�ж�����',��֤���Է�ֹ�ж�����̼侺̬�����ķ���(�����жϱ����κ���̼��л��Ļ���ʱ���ж�Ҳ�����ε���)��
2.ԭ�Ӳ���
ԭ�Ӳ�����ָ��ִ�й����в��ᱻ��Ĵ���·�����ж�,�ɷ�Ϊ����ԭ�Ӳ�����λԭ�Ӳ�����
3.������
��������Ҫ���SMP��CPU���ں˿���ռ�����,���������Ա�֤�ٽ������ܱ��CPU�ͱ�CPU�ڵ���ռ���̴��š����ٽ��������ܵ��жϺ͵װ벽Ӱ��ʱ,Ӧ��ʹ��������������������
��������æ�ȴ���,����������ʱ,CPU�ͣ��ѭ�����Զ������������Ĺ���,����������ή��ϵͳ�����ܡ�
����ٽ�����������,���ܻᵼ������,�����������ռ���ڼ��ڲ��ܵ���copy_from_user(),copy_to_user(), kmalloc()�Ⱥ�����
4���ź���
�ź�������������ͬ�ĵط����ڵ����̵ò����ź���ʱ,���̻������������״̬��
18. ���������ź���������
������:
��һ�������ȡ����������,����һ������Ҳ���ȡ�����,��ʱ��һ�����̴�������״̬(æ��,ԭ�ش�
ת)
1.���'��˴�����'��Ч
2.������ʱ����Ҫ'����cpu��Դ'
3.��������'��������'��//---> �������Ժ� �ּ�һ��,Ȼ��ͻ�����
4.���������Թ�����'�жϴ�������'��
5.��������'�ڲ�������'��ʱ,��ʱ,�������ߵIJ�������'����
��'copy_to_user/copy_from_user������
6.��������'������ʱ��'��'�ر���ռ'
�ź���:
�ź���:��һ�������ȡ���ź�����,����һ������Ҳ���ȡ����ź���,��ʱ��һ�����̴�������״̬��
1.�ȴ���ȡ�ź����Ľ���'��ռ��cpu��Դ'
2.���'������'��
3.�ź���'�����������'
4.�ź���������'�ٽ������Ժܴ�',����'������'��ʱ����ʱ,�������ߵIJ���
5.�ź���'��������'�жϴ���������
#------------------------------------------------------------------------
���ٽ���'ִ��ʱ��Ƚ�С'ʱ,����������,��������ź���;
'������'���Բ������ٽ�����������'���������Ĵ���',�ź�������;
����ٽ����Ĵ�����'�ж���'ִ��,Ӧ��ʹ��'������'��'�ź�����down_trylock()����'��
19. ̸̸����ж�������,���������ĵ�����
����������:
��������:
����ָ������'�û�̬'�л���'�ں�̬'����Ҫ'�����û�̬ʱcpu�Ĵ����е�ֵ','����״̬'�Լ�'��ջ�ϵ�����',
������'��ǰ���̵Ľ���������',�Ա�'�ٴ�ִ��'�ý���ʱ,�ܹ��ָ��л�ʱ��״̬,����ִ�С�
��������:
����ָ'�л�'��'�ں�̬'��ִ�еij���,�������������ں˿ռ�IJ��֡�
#--------------------------------------------------------------------------------
�������:
�����:
Ӳ��ͨ��'�ж�'�����ź�,�����ں˵����жϴ�������,����'�ں�'�ռ䡣���������,Ӳ����һЩ'�����Ͳ���'ҲҪ���ݸ�'�ں�',�ں�ͨ����Щ���������жϴ�����
�ж����Ŀ��Կ�������'Ӳ������'��������Щ'����'���ں���Ҫ�����һЩ��������(��Ҫ�ǵ�ǰ���жϵĽ��̻�����)
�����:
ִ�����ں˿ռ���жϷ������
20. �жϵͰ벿��Ҫ����ʲô
Ϊ�����ж�ִ��'ʱ�価���ܶ�'���жϴ���'����ɴ�������'֮���ҵ�һ��ƽ���,Linux���жϴ�������ֽ�Ϊ�����벿:���벿(top half)�͵װ벿(bottom half)��
���벿��ɾ������ٵıȽϽ����Ĺ���,������ֻ�Ǽض�ȡ�Ĵ����е��ж�״̬������жϱ�־��ͽ��С��Ǽ��жϡ��Ĺ�����
���Ǽ��жϡ���ζ�Ž��װ벿��������ҵ����豸�ĵװ벿ִ�ж�����ȥ������,���벿ִ�е��ٶȾͻ�ܿ�,���Է��������ж�����
����,�жϴ������������ľ������˵װ벿��ͷ��,��������ж��¼��ľ����������
�װ벿���������жϴ����������е�����,���ҿ��Ա��µ��жϴ��,��Ҳ�ǵװ벿�Ͷ��벿�����ͬ,��Ϊ���벿��������Ƴɲ����жϡ��װ벿�������˵�����Ƿdz�������,������ԱȽϺ�ʱ,����Ӳ���жϷ��������ִ�С�
���ܶ��벿���װ벿�Ľ���ܹ�����ϵͳ����Ӧ����,����,��������ΪLinux�豸�����е��жϴ���һ��Ҫ�������벿���Dz��Եġ�����ж�Ҫ�����Ĺ�����������,����ȫ����ֱ���ڶ��벿ȫ����ɡ�
��ʵ������һ�δ���˵��һ������,�Ǿ���:�ж�Ҫ�����ܺ�ʱ�Ƚ϶�,����ָ�ϵͳ��������,�����жϴ������ж�ִ�зֿ�,Ҳ������˵�ġ��ϰ벿��(�жϴ���)���װ벿(�ж�ִ��)��,��ʵ�������Ǻ���˵���ж������ġ��°벿��һ����tasklet����������ʵ��,���������ж�ʵ���Թ���������ʽʵ�ֵ�
�ж��°벿�Ĵ�������һ���ж�,��λ��ֳ�������������?��Щ���������ϰ벽,��Щ�����°벿?
������һЩ����ɹ����:
���һ�������ʱ��ʮ������,��������ϰ벿��
���һ�������Ӳ���й�,��������ϰ벿��
���һ������Ҫ��֤���������жϴ��,��������ϰ벿��
������������,���Ƿ����°벿��
21. Platfprmƽ̨��������ģ��
�����USB��PCI��I2C��SPI������������˵,platform������һ��'���⡢����'����������,ʵ���в����������������ߡ�
��Ϊʲô��Ҫplatform������?
��ʵ��Linux�豸����ģ��Ϊ�˱����豸������ͳһ�Զ�������������ߡ�
��Ϊ����usb�豸��i2c�豸��pci�豸��spi�豸�ȵ�,������cpu��ͨ�Ŷ���ֱ�ӹ�����Ӧ���������������ǵ�cpu�������ݽ�����,���������ǵ�Ƕ��ʽϵͳ����,���������е��豸���ܹ���������Щ����������,��Ƕ��ʽϵͳ����,SoCϵͳ�м��ɵĶ�����������������ҽ���SoC�ڴ�ռ������ȴ��������������ߡ�
����Linux����ģ��Ϊ�˱���������,����Щ�豸����һ�������������(platform����),��������ʹ����Щ�豸����������,��һЩ�豸û�й��������ϡ�
platform���߹���
(1)�����ṹ��platform_device��platform_driver
(2)����ӿں���(driver\base\platform.c)
// ����ע���豸����
int platform_driver_register(struct platform_driver *);
// ����ж���豸����
void platform_driver_unregister(struct platform_driver *);
// ����ע���豸
int platform_device_register(struct platform_device *);
// ����ж���豸
void platform_device_unregister(struct platform_device *);
������'��ע���豸'����'��ע���豸����'�������һ��'�豸���豸����'��ƥ�����,ƥ��ɹ�֮��ͻ����'probe����',
ƥ���'ԭ��'����ȥ'����'�����µ���Ӧ��'����'���ҵ��ҽ�����������豸�����豸������
(3) platform�����µ�ƥ�亯��,platform_match����platform�������豸���豸������ƥ��ԭ������ͨ�����ֽ���ƥ���,��ȥƥ��platform_driver�е�id_table���еĸ���������platform_device->name�����Ƿ���ͬ,
�����ͬ��ʾƥ��ɹ�ֱ�ӷ���,
����ֱ��ƥ��platform_driver->nameplatform_driver->name�Ƿ���ͬ,��ͬ��ƥ��ɹ�,����ʧ�ܡ�
22. IIC��ϵͳ�������
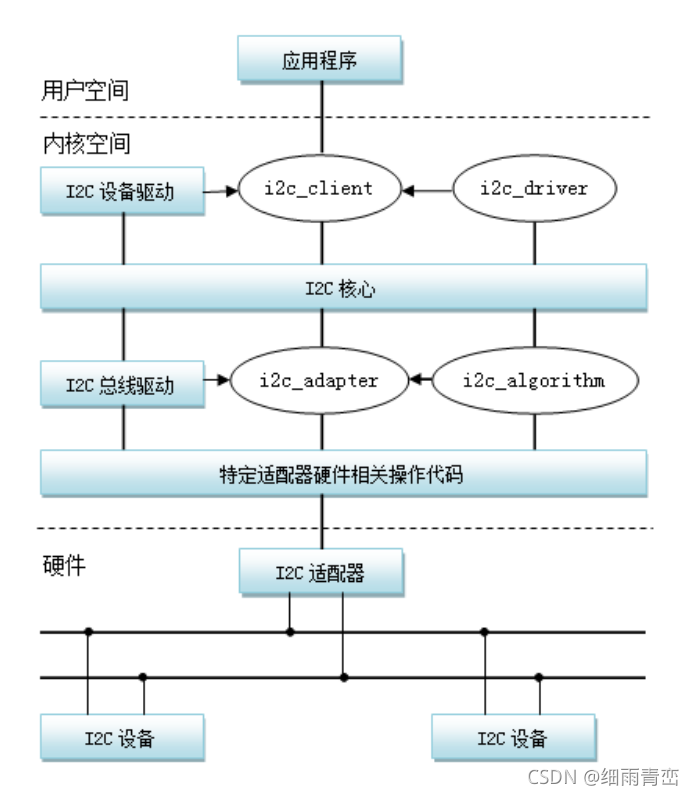
23. ������ϵͳ�������
��ϵͳ�����
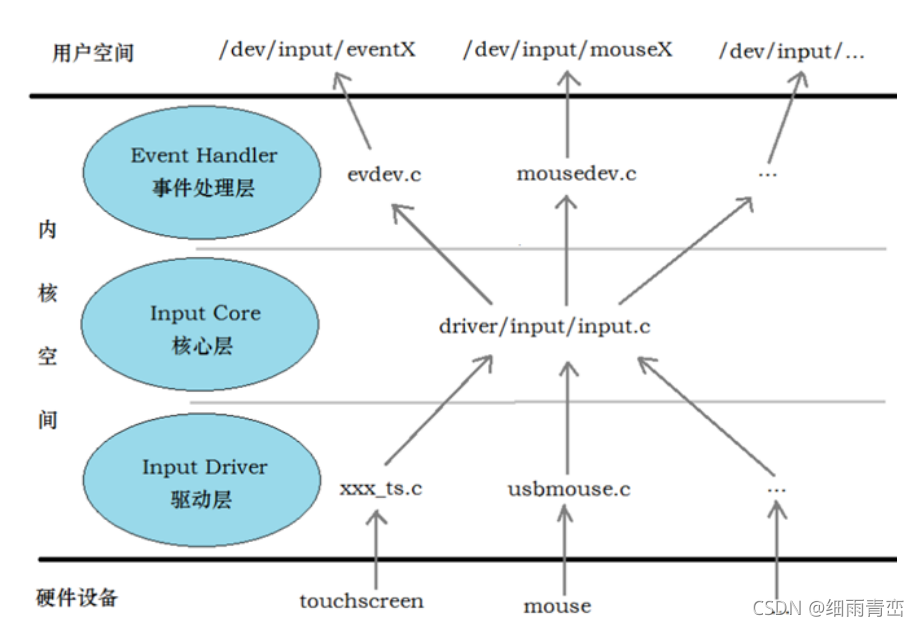
������ϵͳ���¼���������ʾ��ͼ
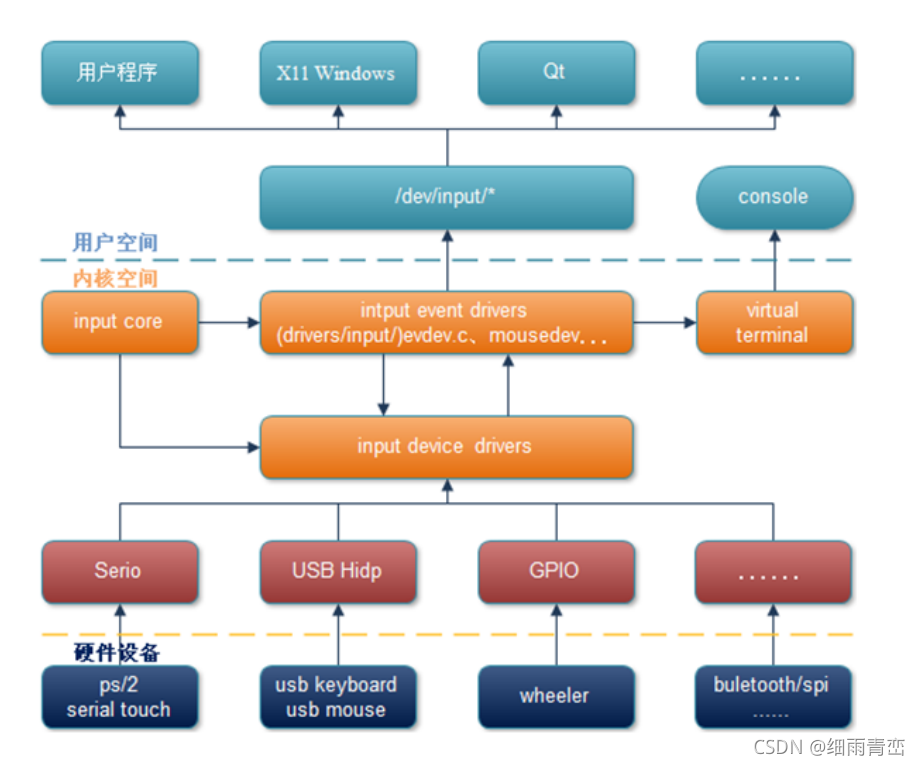
������ϵͳ����