??ǰ��Ļ�??
🔵🔵🔵��Һ�!
��ƪ������Ϊ�˺��������ļ��汾��ͨѶ¼�����ġ�֮ǰ������Ȼ�Լ��װ�ͨѶ¼��������,ʹ�����Զ�̬�����ڴ�,����ֻҪһ�ر�,���ݾͻᶪʧ,������Ǹij��ļ���,��ô���ݴ洢���ļ���Ͳ��ᶪʧ�ˡ�
🔵🔵🔵���ݳ־û�
��ҪͨѶ¼�������ܱ���,���漰���ݳ־û������⡣����һ�����ݳ־û��ķ�����,�����ݴ���ڴ����ļ�����ŵ����ݿ�ȷ�ʽ��ʹ���ļ����ǿ��Խ�����ֱ�Ӵ���ڵ��Ե�Ӳ����,���������ݵij־û���
🔵🔵🔵��˱�ƪ����,�������ҽ����й�C���Զ��ļ��Ķ�д��
👋Hi~ o( ̄�� ̄)����������������Ա
👀 �ܸ��˼�����O(��_��)O! 🌱 �������ڷ�ѿ�С�
🎉��ӭ��ע🔎����👍�ղ�??����📝
📌����������ԭ��,CSDN��!📆��ʱ��:🌴2021��10��10��🌴
💞? ����ˮƽ����,������ִ���,һ��Ҫ��ʱ��֪����Ŷ o( ̄�� ̄)o!��л��л!
📫���������� gitee,ƽ������д�ij�����붼�����档
🔵C���Գ��������Ԥ����🔵
🔷 һ���ļ�����
1. �ļ�
1.1ʲô���ļ�?
�ļ�:�����ϵ��ļ���
�����ڳ��������,����һ��̸���ļ�������:�����ļ��������ļ�(���ļ����ܵĽǶ��������)��
1.2�����ļ��������ļ�
- 🔹�����ļ�
����Դ�����ļ�(��Ϊ.c),Ŀ���ļ�(windows������Ϊ.obj),��ִ�г���(windows������Ϊ.exe)�� - 🔹�����ļ�
�ļ������ݲ�һ���dz���,���dz�������ʱ��д�����ݡ�
�������������Ҫ���ж�ȡ���ݵ��ļ�,����������ݵ��ļ���
🔹�ٸ�����:
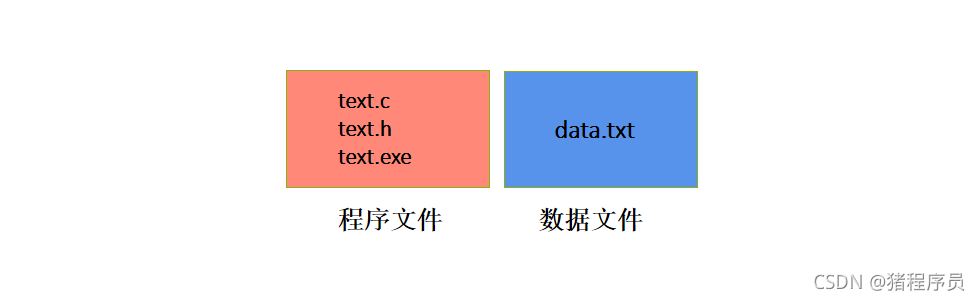
����ǰ�������������ݵ���������������ն�Ϊ�����,�����ն˵ļ�����������,���н����ʾ����ʾ���ϡ���ʵ��ʱ�����ǻ����Ϣ�����������,����Ҫ��ʱ���ٴӴ����ϰ����ݶ�ȡ���ڴ���ʹ��,���ﴦ���ľ��Ǵ������ļ���
1.3�ı��ļ��Ͷ������ļ�
�������ݵ���֯��ʽ,�����ļ�����Ϊ�ı��ļ����߶������ļ���
- �������ڴ����Զ����Ƶ���ʽ�洢,�������ת������������,���Ƕ������ļ���
- ���Ҫ�����������ASCII�����ʽ�洢,����Ҫ�ڴ洢ǰת������ASCII�ַ�����ʽ�洢���ļ�������
���ļ���
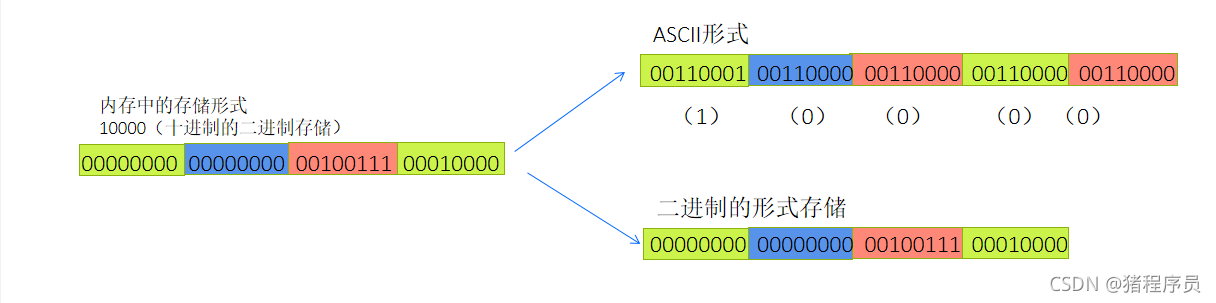
һ���������ڴ�������ô�洢����?
�ַ�һ����ASCII��ʽ�洢,��ֵ�����ݼȿ�����ASCII��ʽ�洢,Ҳ����ʹ�ö�������ʽ�洢��
��������10000,�����ASCII�����ʽ���������,�������ռ��5���ֽ�(ÿ���ַ�һ���ֽ�),��
��������ʽ���,���ڴ�����ֻռ4���ֽ�(VS2013����)��
🔹���Դ���:
#include <stdio.h>
int main()
{
int a = 10000;
FILE* pf = fopen("test.txt", "wb");
fwrite(&a, 4, 1, pf);//�����Ƶ���ʽд���ļ���
fclose(pf);
pf = NULL;
return 0; }
2. C�������
1.4ʲô����?
��:�Ǹ�����ĸ���,�Ƕ���������豸�ij���,�������ݵ�����/������������ԡ������ķ�ʽ���С��豸�������ļ�,����,�ڴ�ȡ�
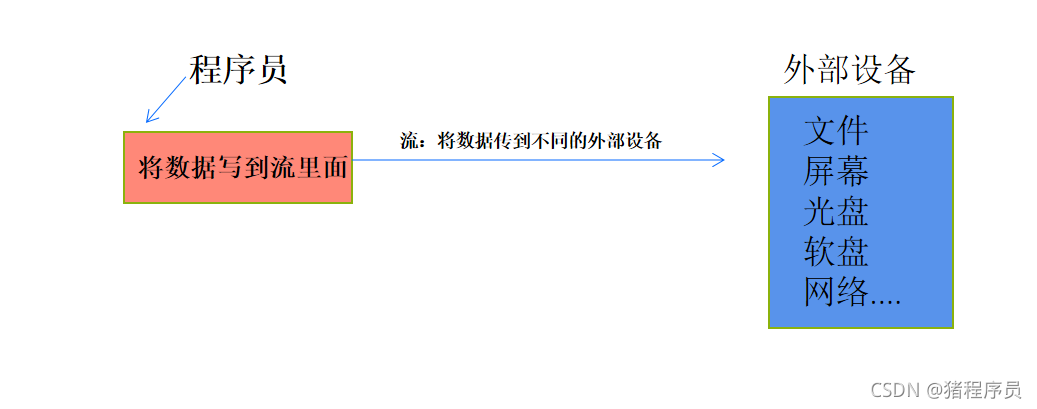
C���Եij���,ֻҪ����������Ĭ�ϴ�������:
stdin���� ��������(standard input stream)?���ڶ�ȡ��ͨ���������
�ڴ����������Ϊ�Ӽ������롣scanf��getchar�Ⱥ������������ж�ȡ�ַ���stdout���� �������(standard output stream)?����д����ͨ���������
�ڴ����������Ϊ�������ʾ�����档printf��puts ��putchar �Ⱥ������������д���ַ���stderr���� ��������(standard error stream)?����д�����������
�ڴ����������Ϊ�������ʾ�����档
🔷ע:�������������Ͷ���FILE *
1.5�ļ�ָ��
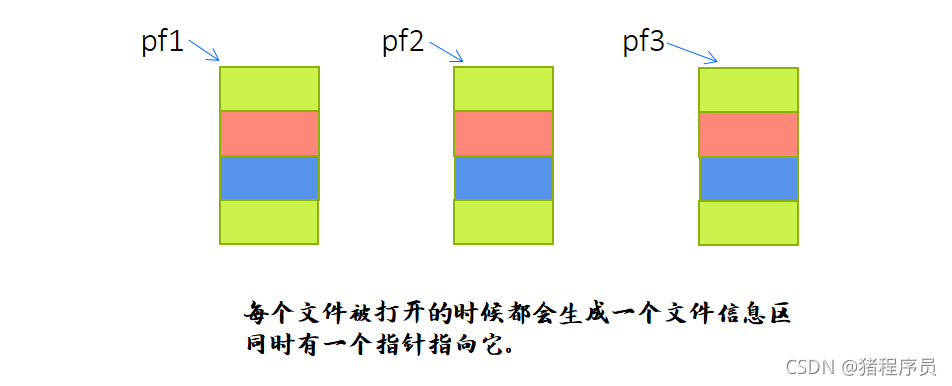
�����ļ�ϵͳ��,�ؼ��ĸ����ǡ��ļ�����ָ�롱,��ơ��ļ�ָ�롱��
🔷�ļ�ָ��:ÿ����ʹ�õ��ļ������ڴ��п�����һ����Ӧ���ļ���Ϣ��,��������ļ��������Ϣ(���ļ�����
��,�ļ�״̬���ļ���ǰ��λ�õ�)����Щ��Ϣ�DZ�����һ���ṹ������еġ��ýṹ����������ϵͳ
������,ȡ��FILE.
🔷�����ļ�����رռ����д����
�����ļ��Ļ�������:
- ���ļ�
- �����ļ�
- �ر��ļ�
1. �ļ��Ĵ���ر�
ANSIC �涨ʹ��fopen���������ļ�,fclose���ر��ļ���
2.1�ļ���
Ϊ�˷������,�ļ���ʶ������Ϊ�ļ�����һ���ļ�Ҫ��һ��Ψһ���ļ���ʶ,�Ա��û�ʶ������á�
�ļ�������3����:�ļ�·��+�ļ�������+�ļ���
🔷����:
c:\code\test.txt
2.2���ļ�
�ļ��ڶ�д֮ǰӦ���ȴ��ļ�,��ʹ�ý���֮��Ӧ�ùر��ļ���
�ڱ�д�����ʱ��,�ڴ��ļ���ͬʱ,���᷵��һ��FILE*��ָ�����ָ����ļ�,Ҳ�൱�ڽ�����ָ����ļ��Ĺ�ϵ��
🔷����:
struct _iobuf {
char *_ptr;
int _cnt;
char *_base;
int _flag;
int _file;
int _charbuf;
int _bufsiz;
char *_tmpfname;
};
typedef struct _iobuf FILE;
���������ǽ��ṹ��struct _iobuf������ΪFILE�����ṹ��������������Dz���Ҫ�˽⡣
��ͬ��C��������FILE���Ͱ��������ݲ���ȫ��ͬ,���Ǵ�ͬС�졣
ÿ����һ���ļ���ʱ��,ϵͳ������ļ�������Զ�����һ��FILE�ṹ�ı���,��������е���Ϣ,ʹ���߲��ع���ϸ�ڡ�
һ�㶼��ͨ��һ��FILE��ָ����ά�����FILE�ṹ�ı���,����ʹ���������ӷ��㡣
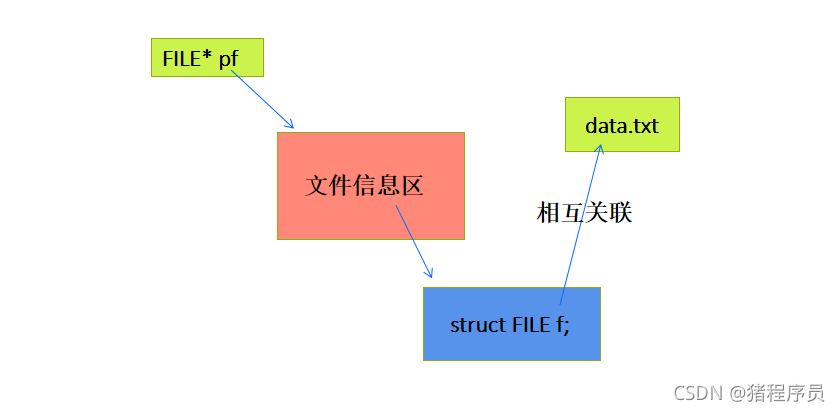
�������ǿ��Դ���һ��FILE*��ָ�����:
FILE* pf; //�ļ�ָ�����
����pf��һ��ָ��FILE�������ݵ�ָ�����������ʹpfָ��ij���ļ����ļ���Ϣ��(��һ���ṹ�����)��
ͨ�����ļ���Ϣ���е���Ϣ���ܹ����ʸ��ļ���Ҳ����˵,ͨ���ļ�ָ������ܹ��ҵ������������ļ���
//���ļ�
FILE * fopen ( const char * filename, const char * mode );
����:
| ���� | ���� |
|---|---|
| ͷ�ļ� | stdio.h |
| ����ֵ | �ɹ�:����һ��FILE *��ָ�롣��ʧ��: ���ؿ�ָ��null |
����filename | ����Ҫ���ļ�·�����ļ��� |
����mode | �ļ�ģʽ(���ַ�����ʽ����) |
| ���� | ���ļ� |
FILE* pf = fopen("data.txt", "r"); //���ļ�
if(pf==NULL)
{
perror("fopen"); //������ļ�ʧ�ܴ�ӡ������Ϣ
}
🔷fopen��ز�����:
2.3�ļ�ʹ�ò�����
| �ļ�ʹ�÷�ʽ | ���� | ���ָ���ļ������� |
|---|---|---|
| ��r��(ֻ��) | Ϊ����������,��һ���Ѿ����ڵ��ı��ļ� | ���� |
| ��w��(ֻд) | Ϊ���������,��һ���ı��ļ� | ����һ���µ��ļ� |
| ��a��(��) | ���ı��ļ�β�������� | ����һ���µ��ļ� |
| ��rb��(ֻ��) | Ϊ����������,��һ���������ļ� | ���� |
| ��wb��(ֻд) | Ϊ���������,��һ���������ļ� | ����һ���µ��ļ� |
| ��ab��(��) | ��һ���������ļ�β�������� | ���� |
| ��r+��(��д) | Ϊ�˶���д,��һ���ı��ļ� | ���� |
| ��w+��(��д) | Ϊ�˶���д,����һ���µ��ļ� | ����һ���µ��ļ� |
| ��a+��(��д) | ��һ���ļ�,���ļ�β���ж�д | ����һ���µ��ļ� |
| ��rb+��(��д) | Ϊ�˶���д��һ���������ļ� | ���� |
| ��wb+��(��д) | Ϊ�˶���д,�½�һ���µĶ������ļ� | ����һ���µ��ļ� |
| ��ab+��(��д) | ��һ���������ļ�,���ļ�β���ж���д | ����һ���µ��ļ� |
🔷����·�������·��
- ����·��
����д��������·����
FILE* pf = fopen("F:\\VS2019\\Project1\\Project1.txt", "r");
- ���·��
�����ڵ�ǰ�����в��Ҹ��ļ���
FILE* pf = fopen("Project1.txt", "r");
2.4�ر��ļ�
//�ر��ļ�
int fclose ( FILE * stream );
����:
| ���� | ���� |
|---|---|
| ͷ�ļ� | stdio.h |
| ����ֵ | ����(��ʾ�ر������ļ�ָ������,����EOF��ʾ�ļ��ر�ʧ��) |
���� fclose | ��Ҫ�رյ��ļ�ָ�� |
| ���� | �ر��ļ� |
🔷�ٸ�����:
/* fopen fclose example */
#include <stdio.h>
int main ()
{
FILE * pFile;
//���ļ�
pFile = fopen ("myfile.txt","w");
//�ļ�����
if (pFile!=NULL)
{
fputs ("fopen example",pFile);
//�ر��ļ�
fclose (pFile);
}
return 0; }
2. �ļ��Ķ�д

| ���� | ������ | ������ |
|---|---|---|
| �ַ����뺯�� | fgetc | ���������� |
| �ַ�������� | fputc | ��������� |
| �ı������뺯�� | fgets | ���������� |
| �ı���������� | fputs | ��������� |
| ��ʽ�����뺯�� | fscanf | ���������� |
| ��ʽ��������� | fprintf | ��������� |
| ���������� | fread | �ļ� |
| ��������� | fwrite | �ļ� |
🔷ע: �������������������˼-----���������ļ����������ڱ��������
???? fputc
�ı��ļ��ַ��������,�÷��뺯��putchar����һ����
int fputs ( const char * str, FILE * stream );
����:
| ���� | ���� |
|---|---|
| ͷ�ļ� | stdio.h |
| ����ֵ | ����(��ʾ����ַ�ASCII��,����EOF��ʾ���ʧ��) |
����str | ��д�����ַ� |
����stream | �����(���ַ�д��Ŀ����,�紫�ļ�ָ��������ļ�,��stdout�������Ļ��) |
| ���� | ���ļ������һ���ַ� |
🔷�ٸ�����:
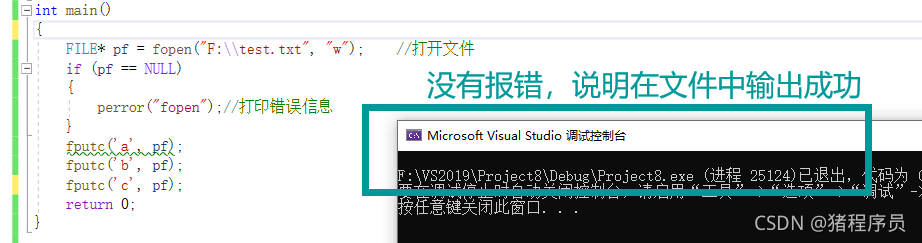
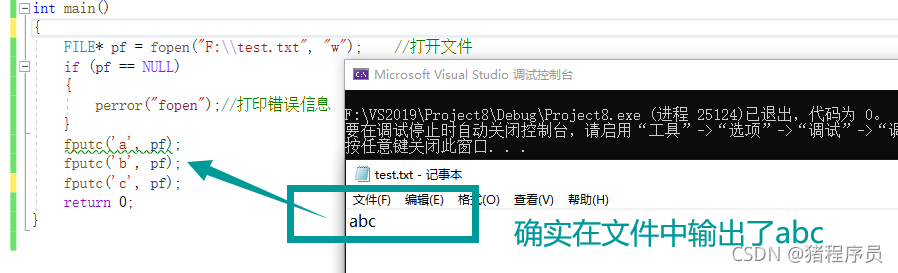
int main()
{
FILE* pf = fopen("F:\\test.txt", "w"); //���ļ�
if (pf == NULL)
{
perror("fopen");//��ӡ������Ϣ
}
fputc('a', pf);
fputc('b', pf);
fputc('c', pf);
return 0;
}
🔷�پٸ�����:
��Ȼ�������������������˼,������ǰ����ڱ�������Կ���:
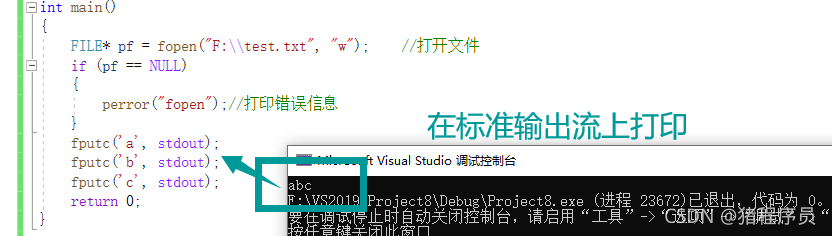
int main()
{
FILE* pf = fopen("F:\\test.txt", "w"); //���ļ�
if (pf == NULL)
{
perror("fopen");//��ӡ������Ϣ
}
fputc('a', stdout);
fputc('b', stdout);
fputc('c', stdout);
return 0;
}
???? fgetc
�ı��ļ��ַ����뺯��,�÷��뺯��getchar����һ����
int fgetc ( FILE * stream );
����:
| ���� | ���� |
|---|---|
| ͷ�ļ� | stdio.h |
| ����ֵ | ����(��ʾ�����ַ�ASCII��,����EOF��ʾ����ʧ��) |
����FILE * stream | ������(�����ж�ȡ��������,���ļ�ָ���ȡ�ļ�,��stdin��ȡ���̵�) |
| ���� | ���ļ�������һ���ַ� |
🔷�ٸ�����:
int main()
{
FILE* pf = fopen("F:\\test.txt", "w"); //���ļ�
if (pf == NULL)
{
perror("fopen");//��ӡ������Ϣ
}
//��������
fputc('a', stdout);
fputc('b', stdout);
fputc('c', stdout);
//���ļ�(�ֱ������)
int ch = fgetc(pf);
printf("%c ", ch);
ch = fgetc(pf);
printf("%c ", ch);
ch = fgetc(pf);
printf("%c ", ch);
return 0;
}
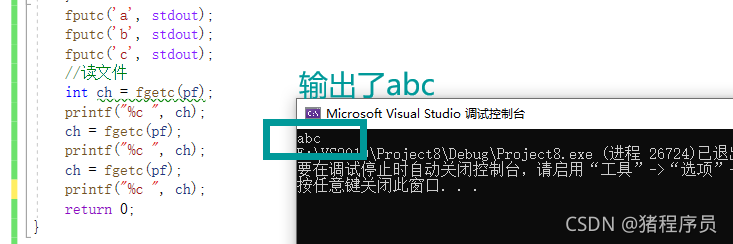
����ļ�ָ��ÿ��һ�ζ����Զ������仯,����ܴ�ӡ��abc.
??ע:����fgets�����ȡʧ�ܷ���ֵΪEOF,��˿����ж�fgets�ķ���ֵ���ж��ļ��Ƿ��ȡ������
???? fgets
char * fgets ( char * str, int n, FILE * stream );
����:
| ���� | ���� |
|---|---|
| ͷ�ļ� | stdio.h |
| ����ֵ | 🔵��n<=0 ʱ����NULL🔵��n=1 ʱ,���ؿմ�""🔵������ɹ�,�ػ������ĵ�ַ🔵���������������ļ���β(EOF),��NULL |
����str | �ַ���ָ��,ָ��洢�������ݵĻ������ĵ�ַ |
����n | �����ж���n-1���ַ� |
����stream | ָ���ȡ���� |
| ���� | ���ļ�������Ŀ���ַ�����,���������һ���ַ������Զ�����\0 |
int main()
{
FILE* pf = fopen("F:\\test.txt", "w"); //���ļ�
if (pf == NULL)
{
perror("fopen");//��ӡ������Ϣ
}
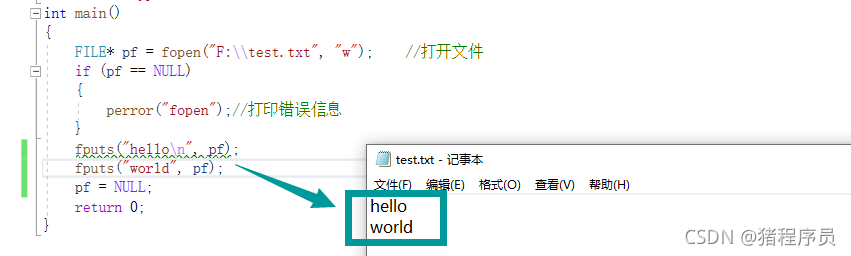
char arr[20] = { 0 };
fputs("hello\n", pf);
fputs("world", pf);
fgets(arr, 20, pf);//fgets��ʹ��
printf("%s\n", arr);
pf = NULL;
return 0;
}
???? fputs
int fputs ( const char * str, FILE * stream );
����:
| ���� | ���� |
|---|---|
| ͷ�ļ� | stdio.h |
| ����ֵ | ����(����EOF��ʾ���ʧ��) |
����str | ��д�����ַ��� |
����stream | �����(���ַ�д��Ŀ����,�紫�ļ�ָ��������ļ�,��stdout�������Ļ��) |
| ���� | ���һ���ַ��� |
🔷�ٸ�����:
int main()
{
FILE* pf = fopen("F:\\test.txt", "w"); //���ļ�
if (pf == NULL)
{
perror("fopen");//��ӡ������Ϣ
}
fputs("hello\n", pf);
fputs("world", pf);
pf = NULL;
return 0;
}
???? fscanf
int fscanf ( FILE * stream, const char * format, ... );
����:
| ���� | ���� |
|---|---|
| ͷ�ļ� | stdio.h |
| ����ֵ | ����(����EOF��ʾ���ʧ��) |
����format | ����������ַ��� |
����stream | ������ |
| ���� | �������ַ�����fscanf��scanf�Ĺ��ܷdz����ơ� |
🔷�ٸ�����:
???? fprintf
int fprintf ( FILE * stream, const char * format, ... );
����:
| ���� | ���� |
|---|---|
| ͷ�ļ� | stdio.h |
| ����ֵ | ����(����EOF��ʾ���ʧ��) |
����format | ��д�����ַ��� |
����stream | �����(���ַ�д��Ŀ����,�紫�ļ�ָ��������ļ�,��stdout�������Ļ��) |
| ���� | �������ַ�����fprintf��printf�Ĺ��ܷdz����ơ� |
🔷�ٸ�����:
struct S
{
int n;
double d;
};
int main()
{
struct S s = { 0};
FILE* pf = fopen("F:\\test.txt", "r"); //���ļ�
if (pf == NULL)
{
perror("fopen");//��ӡ������Ϣ
}
fscanf(pf, "%d %lf", &(s.n), &(s.d));
printf("%d %lf\n", s.n, s.d);
fclose(pf);
pf = NULL;
return 0;
}
???? sprintf
sprintf �� printf ���÷��ϼ���һ��,ֻ�Ǵ�ӡ��Ŀ�ĵز�ͬ����
int sprintf ( char * str, const char * format, ... );
����:
| ���� | ���� |
|---|---|
| ͷ�ļ� | stdio.h |
| ����ֵ | spritnf �����˱��κ����������մ�ӡ���ַ��������е��ַ���Ŀ |
����str | ����str ���ַ�ָ������, |
����format | format Ϊ��ʽ���ַ��� |
����... | ����ǰ�����������̶���,������Խ����������� |
sprintf���� | ���str��ȡ�ַ������ݵ������format�ַ����� |
🔷�ٸ�����:
#include<stdio.h>
struct S
{
int a;
float f;
char name[10];
};
int main()
{
char a[100] = { 0 };
struct S s = { 100,3,14,"zhuzhu" }; //�ṹ��ת�����ַ���
sprintf(a, "%d %lf %s", s.a, s.f, s.name);
printf("%s\n", a);
return 0;
}
�����ӡ:
100 3.140000 zhuzhu
�ɴ˿���sprintf���ѽṹ���������и�ʽ������������ת�����ַ�����
???? sscanf
sscanf��scanf����,�������������,ֻ�Ǻ�������Ļ(stdin)Ϊ����Դ,ǰ���Թ̶��ַ���Ϊ����Դ
int sscanf ( const char * s, const char * format, ...);
����:
| ���� | ���� |
|---|---|
| ͷ�ļ� | stdio.h |
| ����ֵ | ���������سɹ���ֵ���ֶθ���������ֵΪ 0 ��ʾû�н��κ��ֶθ�ֵ�� ����ڵ�һ�ζ�ȡ֮ǰ�����ַ�����β,��EOF�� |
����str | ����str ���ַ�ָ������ |
����format | format Ϊ��ʽ������ |
����... | ����ǰ�����������̶���,������Խ����������� |
sscanf���� | sscanf����ַ����ж�ȡһ���ṹ�������� |
🔷�ٸ�����:
struct S
{
int a;
float f;
char name[10];
};
int main()
{
char a[100] = { 0 };
struct S s = { 100,3,14,"zhuzhu" };
struct S tmp = { 0};
sprintf(a, "%d %lf %s", s.a, s.f, s.name);//��һ����ʽ��������ת�����ַ���
printf("%s\n", a);
sscanf(a,"%d %lf %s",&(tmp.a),&(tmp.f),tmp.name);//��a�ַ����е�����ת���ظ�ʽ������
printf("%d %lf %s\n", tmp.a, tmp.f, tmp.name);
return 0;
}
???? fread
size_t fread ( void * ptr, size_t size, size_t count, FILE * stream );
����:
| ���� | ���� |
|---|---|
| ͷ�ļ� | stdio.h |
| ����ֵ | ��������(����ʵ�ʶ�ȡ��������Ŀ��,�������������ڴﵽ����֮ǰ�����ļ���β,���ֵ����С�ڼ�����) |
����ptr | ����ptr ָ��Ŀ���ַ |
����size | size Ϊһ��Ԫ�ص��ֽڴ�С |
����count | count Ϊ��ȡ��Ԫ�ظ��� |
����stream | stream Ϊ�Ѵ��ļ�ָ�� |
| ���� | ��ȡ�ļ� |
🔷�ٸ�����:
struct S
{
int n;
double d;
char name[10];
};
int main()
{
struct S s = { 0};
FILE* pf = fopen("F:\\test.txt", "wb"); //���ļ�
if (pf == NULL)
{
perror("fopen");//��ӡ������Ϣ
}
fread(&s, sizeof(struct S), 1, pf);
printf("%d %lf %s\n", s.n, s.d, s.name);
fclose(pf);
pf = NULL;
return 0;
}
???? fwrite
size_t fwrite ( const void * ptr, size_t size, size_t count, FILE * stream );
����:
| ���� | ���� |
|---|---|
| ͷ�ļ� | stdio.h |
| ����ֵ | ��������(����ʵ�ʶ�ȡ��������Ŀ��,�������������ڴﵽ����֮ǰ�����ļ���β,���ֵ����С�ڼ�����) |
����ptr | ����ptr ָ����д���������ʼ��ַ |
����size | size Ϊһ��Ԫ�ص��ֽڴ�С |
����count | count Ϊ�ܹ�д���Ԫ�ظ��� |
����stream | stream Ϊ�Ѵ��ļ�ָ�� |
| ���� | ������д���ļ����� |
🔷�ٸ�����:
struct S
{
int n;
double d;
char name[10];
};
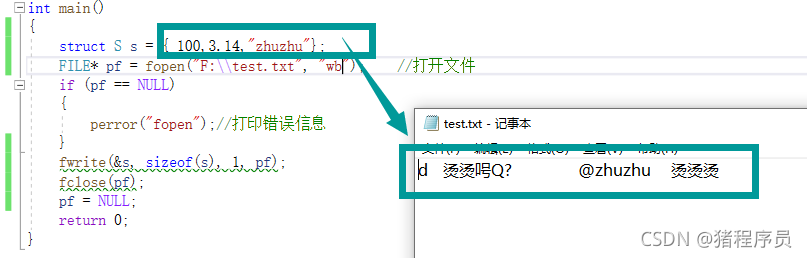
int main()
{
struct S s = { 100,3.14,"zhuzhu"};
FILE* pf = fopen("F:\\test.txt", "wb"); //���ļ�
if (pf == NULL)
{
perror("fopen");//��ӡ������Ϣ
}
fwrite(&s, sizeof(s), 1, pf);
fclose(pf);
pf = NULL;
return 0;
}
🔷���ļ��д�����Ƕ�������Ϣ,��ʾ�����������,��Ȼ���Ƕ�����,���Ǽ�����ܹ���������
🔵🔵🔵��ô��ĿǰΪֹ���Ǿ�ѧ�������������͵�printf��scanf,���ܽ�һ��:
| ���� | ���� |
|---|---|
scanf | �ӱ�������(����)��ȡ��ʽ�������� |
fscanf | ��������������ȡ��ʽ������ |
sscanf | ���ַ����ж�ȡһ���ṹ�������� |
printf | �Ѹ�ʽ������������������(��Ļ)�� |
fprintf | �Ѹ�ʽ����������������������(��Ļ/�ļ�) |
sprintf | �Ѹ�ʽ��������ת���ɶ�Ӧ�ַ��� |
???? fseek
int fseek ( FILE * stream, long int offset, int origin );
| ���� | ���� |
|---|---|
| ͷ�ļ� | stdio.h |
| ����ֵ | ����(����EOF��ʾ���ʧ��) |
����stream | �ļ���ָ�� |
����offset | ƫ���� |
����origin | ��ʼλ�á��ú���ָ����������ʼλ�õ�ֵ:🔵SEEK_SET🔵SEEK_CUR🔵SEEK_END |
| ���� | �����ļ�ָ���λ�ú�ƫ��������λ�ļ�ָ�롣 |
ע:����origin :
| ���� | ���� |
|---|---|
SEEK_SET | �ļ���ͷ��λ��(�����ļ���Ĭ�������λ��) |
SEEK_CUR | �ļ�ָ�뵱ǰָ���λ�� |
SEEK_END | �ļ�ĩβλ�� |
🔷�ٸ�����:
/* fseek example */
#include <stdio.h>
int main ()
{
FILE * pFile;
pFile = fopen ( "example.txt" , "wb" );`������������Ƭ`
fputs ( "This is an apple." , pFile );
fseek ( pFile , 9 , SEEK_SET );
fputs ( " sam" , pFile );
fclose ( pFile );
return 0;
}
���:
This is a sample. //����δ������гɹ�֮��,example.txt�ı���ͻ������仰
???? ftell
long int ftell ( FILE * stream );
| ���� | ���� |
|---|---|
| ͷ�ļ� | stdio.h |
| ����ֵ | ������(���ؾ����ļ���ʼλ�õ�ƫ������С) |
����stream | Ŀ���ļ�ָ�� |
| ���� | ftell���ڵõ��ļ�λ��ָ�뵱ǰλ��������ļ���ƫ���ֽ��� |
🔷�ٸ�����:
/* ftell example : getting size of a file */
#include <stdio.h>
int main ()
{
FILE * pFile;
long size;
pFile = fopen ("myfile.txt","rb");
if (pFile==NULL) perror ("Error opening file");
else
{
fseek (pFile, 0, SEEK_END); // non-portable
size=ftell (pFile);
fclose (pFile);
printf ("Size of myfile.txt: %ld bytes.\n",size);
}
return 0;
}
���:�˴������ֽ�Ϊ��λ��ӡmyfile.txt�Ĵ�С,��ΪSEEK_ENDʹָ��ָ���ļ�ĩβ��
???? rewind
void rewind ( FILE * stream );
| ���� | ���� |
|---|---|
| ͷ�ļ� | stdio.h |
| ����ֵ | �� |
����stream | Ŀ���ļ�ָ�� |
| ���� | ���ļ��ڲ���λ��ָ������ָ��һ����( ������/�ļ�)�Ŀ�ͷ |
🔷�ٸ�����:
�Ӽ�������һ���ַ�,��д�뵽һ���ļ���,�ٰѸ��ļ����ݶ�����ʾ����Ļ�ϡ�
#include<stdio.h>
int main()
{
FILE *fp;
char ch;
if((fp=fopen("C:\\Users\\dell\\Desktop\\abc.txt","ab+"))==NULL)
{
printf("\nCannot open file\nstrike any key exit\n");
getchar();
return 1;
}
printf("input a string:\n");
ch=getchar();
while(ch!='\n')
{
fputc(ch,fp);
ch=getchar();
}
rewind(fp);
ch=fgetc(fp);
while(ch!=EOF)
{
putchar(ch);
ch=fgetc(fp);
}
fclose(fp);
return 0;
}
rewind(fp);ÿ����һ���ַ�,�ļ��ڲ�λ��ָ������ƶ�һ���ֽڡ�д�����,��ָ����ָ���ļ�ĩβ, ���Ҫ���ļ���ͷ����,���ָ���Ƶ��ļ�ͷ,����rewind()������
🔷�����ļ������ж��뻺��
1. �ļ���ȡ�����ж�
???? feof
int feof ( FILE * stream );
| ���� | ���� |
|---|---|
| ͷ�ļ� | stdio.h |
| ����ֵ | �ļ�����,�ط�0ֵ,����0 |
����stream | Ŀ���ļ�ָ�� |
| ���� | ���ļ���ȡ������ʱ��,�ж��Ƕ�ȡʧ�ܽ���,���������ļ�β������ |
🔷������ʹ�õ�feof
Ӧ����ס:���ļ���ȡ������,������feof�����ķ���ֱֵ�������ж��ļ����Ƿ������
����Ӧ�������ļ���ȡ������ʱ��,�ж��Ƕ�ȡʧ�ܽ���,���������ļ�β������
- �ı��ļ���ȡ�Ƿ����,Ӧ���жϷ���ֵ�Ƿ�Ϊ
EOF ( fgetc ),����NULL ( fgets )
����:
fgetc�ж��Ƿ�ΪEOF
fgets�жϷ���ֵ�Ƿ�ΪNULL - �������ļ��Ķ�ȡ�����ж�,��ͨ���жϷ���ֵ�Ƿ�С��ʵ��Ҫ���ĸ�����
����:
fread�жϷ���ֵ�Ƿ�С��ʵ��Ҫ���ĸ�����
🔷�ٸ�����(�ı��ļ�������):
#include <stdlib.h>
int main(void) {
int c; // ע��:int,��char,Ҫ����EOF
FILE* fp = fopen("test.txt", "r");
if(!fp) {
perror("File opening failed");
return EXIT_FAILURE;
}
//fgetc ����ȡʧ�ܵ�ʱ����������ļ�������ʱ��,���᷵��EOF
while ((c = fgetc(fp)) != EOF) // ��C I/O��ȡ�ļ�ѭ��
{
putchar(c);
}
//�ж���ʲôԭ�������
if (ferror(fp))//���ferror���ط�01ֵ,˵���ļ���ȡ��������
puts("I/O error when reading");
else if (feof(fp))//���feof���ط�0˵���ж����ļ�ĩβ
puts("End of file reached successfully");
fclose(fp);
}
🔷�ٸ�����(�������ļ�������):
#include <stdio.h>
enum { SIZE = 5 };
int main(void) {
double a[SIZE] = {1.,2.,3.,4.,5.};
FILE *fp = fopen("test.bin", "wb"); // �����ö�����ģʽ
fwrite(a, sizeof *a, SIZE, fp); // д double ������
fclose(fp);
double b[SIZE];
fp = fopen("test.bin","rb");
size_t ret_code = fread(b, sizeof *b, SIZE, fp); // �� double ������
if(ret_code == SIZE) {
puts("Array read successfully, contents: ");
for(int n = 0; n < SIZE; ++n) printf("%f ", b[n]);
putchar('\n');
} else { // error handling
if (feof(fp))
printf("Error reading test.bin: unexpected end of file\n");
else if (ferror(fp)) {
perror("Error reading test.bin");
}
}
fclose(fp);
}
🔷�ܽ�:
feof����;:�ǵ��ļ���ȡ����֮��,�ж��Dz��������ļ�ĩβ����������ferror����;:�ǵ��ļ���ȡ����֮��,�ж��Dz�������������ȡ��������
2. �ļ�������
ANSIC �����á������ļ�ϵͳ�������������ļ��ġ�
��ν�����ļ�ϵͳ��ָϵͳ�Զ������ڴ���Ϊ������ÿһ������ʹ�õ��ļ�����һ�顰�ļ�����������
���ڴ������������ݻ����͵��ڴ��еĻ�����,װ�����������һ���͵������ϡ�
����Ӵ�����������������,��Ӵ����ļ��ж�ȡ�������뵽�ڴ滺����(����������),Ȼ���ٴӻ���������ؽ������͵�����������(���������)��
�������Ĵ�С����C����ϵͳ�����ġ�
???? fflush
int fflush(FILE *stream);
| ���� | ���� |
|---|---|
| ͷ�ļ� | stdio.h |
| ����ֵ | �ļ�����,�ط�0ֵ,����0 |
����stream | Ҫ��ϴ���� |
fflush(stdin) | ˢ�±����뻺����,�����뻺������Ķ�������[�DZ�] |
fflush(stdout) | ˢ�±����������,�������������Ķ�����ӡ��������豸�� |
| ���� | �����д������,��Ҫ��������������������ݽ�������д��ʱ |
🔷�ٸ�����:
#include <windows.h>
//VS2013 WIN10��������
int main()
{
FILE*pf = fopen("test.txt", "w");
fputs("abcdef", pf);//�Ƚ�����������������
printf("˯��10��-�Ѿ�д������,��test.txt�ļ�,�����ļ�û������\n");
Sleep(10000);//������1000����,����10��
printf("ˢ�»�����\n");
fflush(pf);//ˢ�»�����ʱ,�Ž����������������д���ļ�(����)
//ע:fflush �ڸ߰汾��VS�ϲ���ʹ����
printf("��˯��10��-��ʱ,�ٴδ�test.txt�ļ�,�ļ���������\n");
Sleep(10000);
fclose(pf);
//ע:fclose�ڹر��ļ���ʱ��,Ҳ��ˢ�»�����
pf = NULL;
return 0; }
����:
��Ϊ�л������Ĵ���,C�����ڲ����ļ���ʱ��,��Ҫ��ˢ�»������������ļ�����������ʱ��ر��ļ���
�������,���ܵ��¶�д�ļ������⡣
��������д�ò�����������,�������۹�ע��һ��!лл��!