��Ͷ���(��)
���6��Ĭ�ϳ�Ա����
һ���������ʲô��Ա��û��,��ô������Ϊ���ࡣ��������ʲô��û����?��ʵ��Ȼ,�κ�һ����,�����Dz�д�������,�����Զ���������6��Ĭ�ϳ�Ա����:
��ƪ���½����⼸��Ĭ�ϳ�Ա�������м��ܡ�
���캯��
1.����
����������һ���������������:
class Date
{
public:
void SetDate(int year = 0, int month = 1, int day = 1)
{
_year = year;
_month = month;
_day = day;
}
void Print()
{
cout << _year << "/" << _month << "/" << _day << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1;
d1.SetDate();
d1.Print();
return 0;
}
����Date��,ÿ�δ�������ʱ���Ե���SetData���������ö��������,�������ÿ�δ�������ʱ����Ҫ���øú���������������Ϣ,δ����Щ�鷳,��ô�ܷ��ٶ�����ͬʱ�ͽ��г�ʼ����?
�������Ҫ�õ����Ĭ�ϳ�Ա�����C���캯���ˡ�
���캯����һ������ij�Ա����,������������ͬ,���������Ͷ���ʱ�ɱ������Զ�����,��֤ÿ�����ݳ�Ա���� һ�����ʵij�ʼֵ,�����ڶ��������������ֻ����һ�Ρ�
2.����
��Ҫע��,���캯����Ȼ��Ϊ���캯��,���������ò���Ϊ��Ա�������ٿռ�,���dz�ʼ����������������:
��������������ͬ��
û�з���ֵ��
���������ٶ���ʵ����ʱ�Զ����ù��캯����
���캯���������ء�
��Ҫע���������ʵ���������ʱ��,����������������(),��������û�в���,��ô��ͳ��˺�������,�ú�����,�ҷ���ֵΪ������
class Date
{
public:
Date()//�εĹ��캯��
{
_year = 0;
_month = 1;
_day = 1;
}
//���εĹ��캯��
Date(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1;//�����εĹ��캯��
Date d2(0, 1, 1);//���ô��εĹ��캯��
Date d3();//��,����ֵΪDate�ĺ�������
return 0;
}
��ʽ���캯��
�������û����ʽ���幹�캯��,��ôc++�����������Զ�����һ���ε�Ĭ�Ϲ��캯��,������û���ʽ�����˹��캯��,��ô���������������ɹ��캯����
��Ҫע����DZ������Լ����ɵĹ��캯���ڳ�ʼ������ʱ����һ��ƫ�ĵĴ���:��������������,���������ᴦ��;�������Զ�������,���������Զ������͵������Լ���Ĭ�Ϲ��캯������������ָ������Ѿ�����õ�����,��:int,double,long�ȵ�;�Զ���������ʹ��struct/class/union��������͡�
����ʲô��˼��?����ͨ�������������������:
class C
{
public:
C()
{
cout << "C()" << endl;
}
private:
int _c;
};
class Date
{
public:
//���û���ʽ�����˹��캯��,��ô����������������
/*Date()
{
_year = 0;
_month = 1;
_day = 1;
}
Date(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}*/
private:
//��������
int _year;
int _month;
int _day;
//�Զ�������
C c1;
};
int main()
{
Date d1;//�����εĹ��캯��
return 0;
}

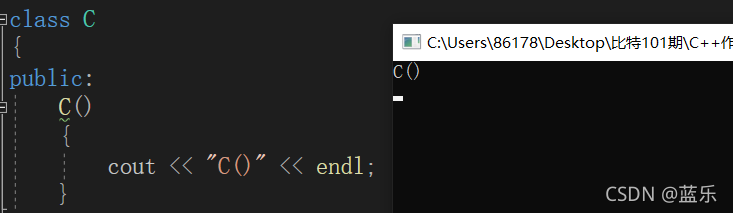
ͨ�����Կ��Է���,d1�������������ͱ�����Ϊ���ֵ,���������õĹ��캯����û�д���,�������Զ�������,���Կ����������������Զ��������е�Ĭ�Ϻ���,����ʵ����������ñ������Լ����ɵ�Ĭ�Ϲ��캯��,���յĽ���������е��������ͱ�����ȻΪ���ֵ,��ô����������������Լ����ɵĹ��캯������ûʲô��?
ʵ��Ȼ,����������������ջʵ�ֶ��е���,������˼·��������ջ���ص���֤���е��Ƚ��ȳ�,��������������ṹջ����ջʵ�ֵĶ��еĴ���Ϊ:
class Stack//ջ
{
public:
Stack(int capacity = 4)
{
_a = (int*)malloc(sizeof(int) * capacity);
if (_a == nullptr)
{
cout << "malloc fail" << endl;
exit(-1);
}
_top = 0;
_capacity = capacity;
}
private:
int* _a;
int _top;
int _capacity;
};
struct MyQueue//������ջʵ�ֶ���
{
Stack s1;
Stack s2;
};
���Կ�������MyQueue�����ʵ��������ʱ,����������Stack�еĹ��캯���ֱ�Գ�Ա����s1��s2��ʼ��,���,���������ٶ�����г�ʼ����,�������˵���������ࡣ
�κ�ȫȱʡ�ĺ�����ΪĬ�Ϲ��캯��
�εĹ��캯����ȫȱʡ�Ĺ��캯��������ΪĬ�Ϲ��캯��,������Ҫע�����:�εĹ��캯����ȫȱʡ�Ĺ��캯������ֻ�ܴ���һ��,������Ϊ,������߶����ڵĻ�,��ô��ʵ������������ʱ,�������������ǵ�����һ��������
class Date
{
public:
Date()
{
_year = 0;
_month = 1;
_day = 1;
}
Date(int year = 0, int month = 1, int day = 1)
{
_year = year;
_month = month;
_day = day;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1;//����,��������ʶ��Ҫ������һ�����캯��
return 0;
}
��ʵ�ʹ�����,���Ǹ�������ʹ��ȫȱʡ�Ĺ��캯��,��Ϊ���������εĹ��캯���������
��Ա�������������
����ע������ڶ������ʱ���Ա����ǰ������һ��_,����Ϊ�˷�ֹ�����������:
class Date
{
public:
Date(int year = 0, int month = 1, int day = 1)
{
year = year;
month = month;
day = day;
}
void Print()
{
cout << year << "/" << month << "/" << day << endl;
}
private:
int year;
int month;
int day;
};
int main()
{
Date d1;
d1.Print();
return 0;
}
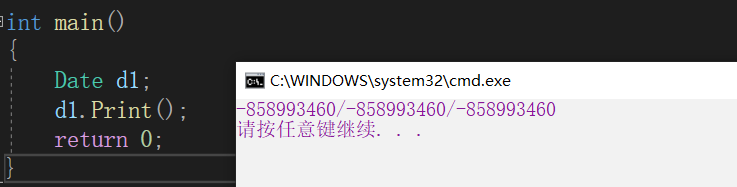
���Կ���,d1�����˹��캯����,���Ա������Ϊ���ֵ��������Ϊ��year = year��������,����year������Ϊ�����β�,ʵ���ϱ������ڴ������ֱ���ʱ,����ѭ�ֲ�����ԭ��,���������ں����β����ҵ���year����,�Ͳ����������������ΧȥѰ�ҳ�Ա�����е�year����,����Print������,�������������β���δ�ҵ�year����,��˼�������������Χ,�ڳ�Ա�������ҵ���year��ʹ��֮��
���,��������Ա����������ʱ��Ҫ��ѭһ���Ĺ淶,��������:(1)�ڱ�����ǰ��_,��_year (2)�ڱ��������_,��year_ (3)�շ巨,��mYear,m��ʾmember��
����,�����������ͨ��ʹ��thisָ����н��,���������Ϊthis->year = year;����ʵ��ʹ�ù�����,��û���ע�س�Ա����������
����
��������c++���Ƶ�ȱ��,������Ĭ�����ɵĹ��캯����������������ͱ�����ʼ��,�����c++11��,�ίԱ���ڳ�Ա��������������һ������,����,����������ͬʱ����ȱʡֵ,����:
class Date
{
public:
Date(int year = 0, int month = 1, int day = 1)
{
_year = year;
_month = month;
_day = day;
}
private:
//ע��,�˴���Ϊȱʡֵ,��Ϊ��������,���dz�ʼ��(����)
int _year = 0;
int _month = 1;
int _day = 1;
};
��������
1.����
�빹�캯�����,����������Լ�һЩ�����������������빹�캯�����෴,����������������ɶ��������,��Ϊ�ֲ���������ٹ������ɱ���������ɵġ�һ�����������������������þ�������,�����������ٵ�ʱ����Զ�������������,����൱�е�һЩ��Դ����������
2.����
����������һ������ij�Ա����,����������:
����������������ǰ����~��
����������������ֵ
һ��������ֻ��һ����������
����������Ϊ��ʽ����,��ôϵͳ���Զ�����Ĭ�ϵ�����������
�빹�캯��һ��,ϵͳ��Ĭ���������������������ͱ������ᴦ��,�����Զ�����������������������������
���,����Date����������,�������ڲ�û��ʲô��Դ��Ҫ����,��˲���Ҫ��������;����Stack��������,���ڲ�����Դ��Ҫ����,�����malloc�����Ŀռ�����ͷ�,�����Ҫʵ������������
����֮ǰ�Ĵ���,��������ջʵ�ֶ�����,��Stack����ʵ���˹��캯������������,��ô��MyQueueʵ����my���������Լ�ʵ�ֳ�ʼ���Ϳռ���ͷ�:
class Stack
{
public:
Stack(int capacity = 4)
{
_a = (int*)malloc(sizeof(int) * capacity);
if (_a == nullptr)
{
cout << "malloc fail" << endl;
exit(-1);
}
_top = 0;
_capacity = capacity;
}
~Stack()
{
free(_a);
_a = NULL;
_top = _capacity = 0;
}
private:
int* _a;
int _top;
int _capacity;
};
struct MyQueue
{
Stack s1;
Stack s2;
};
int main()
{
//���������Լ���mq���г�ʼ���������ռ�
//������Զ����ù��캯������������
MyQueue mq;
return 0;
}
c++�������ڶ����������ڽ���ʱ�Զ�������������
class Date
{
public:
Date(int year = 0, int month = 1, int day = 1)
{
_year = year;
_month = month;
_day = day;
}
~Date()
{
cout << "~Date()" << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1;
return 0;//��������ִ���������ͬʱ��������е���������
}
�������캯��
1.����
�������캯��,����˼��,�����þ��Ǵ���һ���ͱ���������һģһ���Ķ���
�������캯��ֻ�е����β�,���β��ǶԱ������Ͷ��������(һ�㳣��const����),�����Ѵ��ڵ������Ͷ����¶���ʱ�ɱ������Զ����á�
2.����
�������캯��Ҳ������ij�Ա����,��������:
�������캯���ǹ��캯����һ��������ʽ
����ֻ��һ����Ϊ���ô���
�������캯���IJ���ֻ��һ���ұ���Ϊ���ô���,ʹ�ô�ֵ��ʽ����������ݹ���á�
class Date
{
public:
Date()
{
_year = 0;
_month = 1;
_day = 1;
}
Date(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}
Date(Date& d)
{
_year = d._year;
_month = d._month;
_day = d._day;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1;
Date d2(d1);
return 0;
}
��ôΪʲô˵��ֵ�ᵼ������ݹ������?����������Ҫ������ú�����ֵ���β�Ҳ��һ�ֿ���,����˵:

ͬ����,���ڿ������캯��,���β�Ϊ��ֵ����,��ô�����������н�d2��ֵ���β�dʱҲ����ÿ������캯��,��ÿһ�ε��ÿ������캯�����ᾭ�����θ�ֵ����,�Ӷ���������ݹ����:
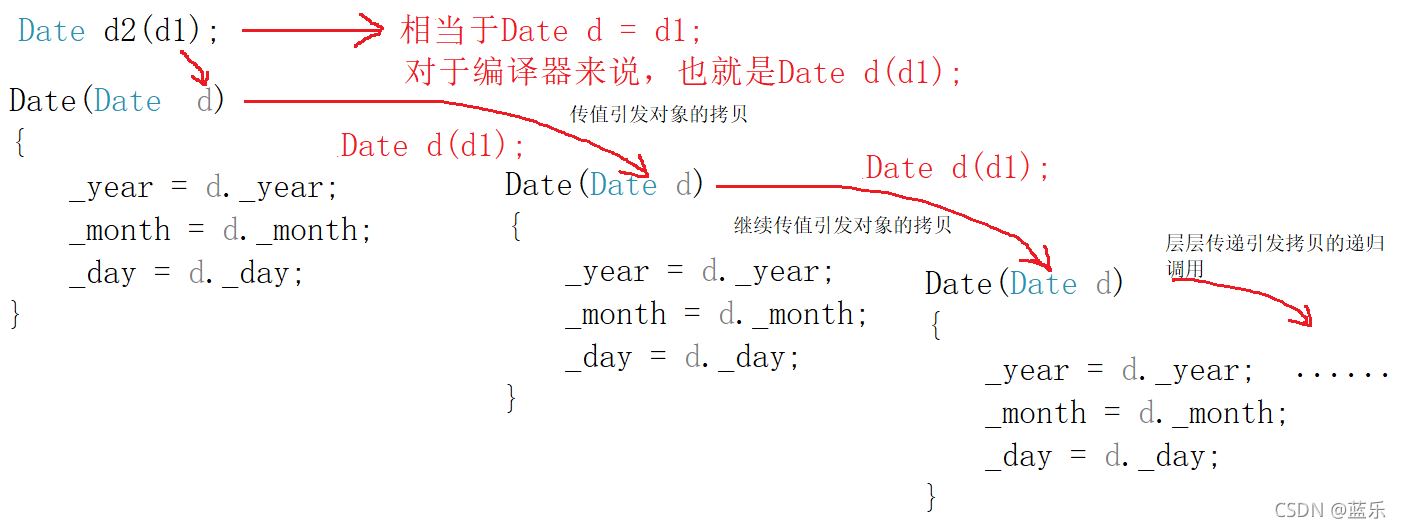
�������þ��ܹ��ܺõĽ���������,���,��ָ��Ҳ���ԴﵽĿ��,����һ�㴫���õĻ�������ǿ����ɶ��ԡ�
��δ��ʽ����,ϵͳ������Ĭ�ϵĿ������캯��
�빹�캯��һ��,��������Լ�û��ʵ�ֿ������캯��,��ô������������Ĭ�ϵĿ������캯��;�����빹�캯����ͬ����,Ĭ�ϵĿ������캯�������������ͺ��Զ������ͱ������ᴦ��:
(1)������������,Ĭ�ϵĿ������캯����Զ������dz����,�������ڴ�洢�е��ֽ���Զ�����п���,Ҳ��ֵ������
(2)�����Զ�������,Ĭ�ϵĿ������캯��������Զ����������Լ��Ŀ������캯����
class A
{
public:
A()
{
_a = 0;
}
A(const A& a)
{
cout << "A(const A& a)" << endl;
}
private:
int _a;
};
class Date
{
public:
Date()
{
_year = 0;
_month = 1;
_day = 1;
}
Date(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}
//����Ĭ�ϵĿ������캯��
/*Date(Date& d)
{
_year = d._year;
_month = d._month;
_day = d._day;
}*/
private:
int _year;
int _month;
int _day;
A aa;
};
int main()
{
Date d1;
Date d2(d1);
return 0;
}
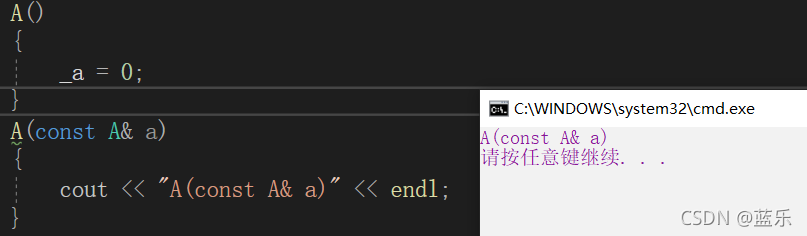
dz������ע������
ͨ����������֪����Ĭ�ϵĿ������캯���ܹ�ʵ��dz����,Ҳ����˵,����Date��������,���������Լ�ʵ�ֿ������캯��ֻ��Ĭ�ϵĿ������캯�����ܹ�ʵ�ֿ���Ŀ��,��ô�Ƿ��ñ������Լ��ĺ���������?
��ʵ��Ȼ,����������֪��Stack��,���ֱ�ӵ���ϵͳĬ�ϵĿ������캯��:
class Stack
{
public:
Stack(int capacity = 4)
{
_a = (int*)malloc(sizeof(int) * capacity);
if (_a == nullptr)
{
cout << "malloc fail" << endl;
exit(-1);
}
_top = 0;
_capacity = capacity;
}
~Stack()
{
free(_a);
_a = NULL;
_top = _capacity = 0;
}
private:
int* _a;
int _top;
int _capacity;
};
int main()
{
Stack s1(8);
Stack s2(s1);
return 0;
}
��������,�������к���,���������,����Ϊʲô��?������ΪϵͳĬ�ϵĿ������캯����������һ����s1һģһ����s2:

������֪����������������ڽ���ʱ,ϵͳ���Զ�����������������ռ��������,����s2�Ǻ�ѹջ��,��˻�������,��ʱs2._a��ָ�Ŀռ��Ѿ�free��������ϵͳ��,����s1�����ٴε�����������,���Ѿ��ͷŵ�s1._a��ָ��Ŀռ���һ���ͷ�(ע��,s2._a�ͷ����s1._a��ָ��ԭ�ռ�,��ʱs1._aΪҰָ��),����������ջᵼ�³��������
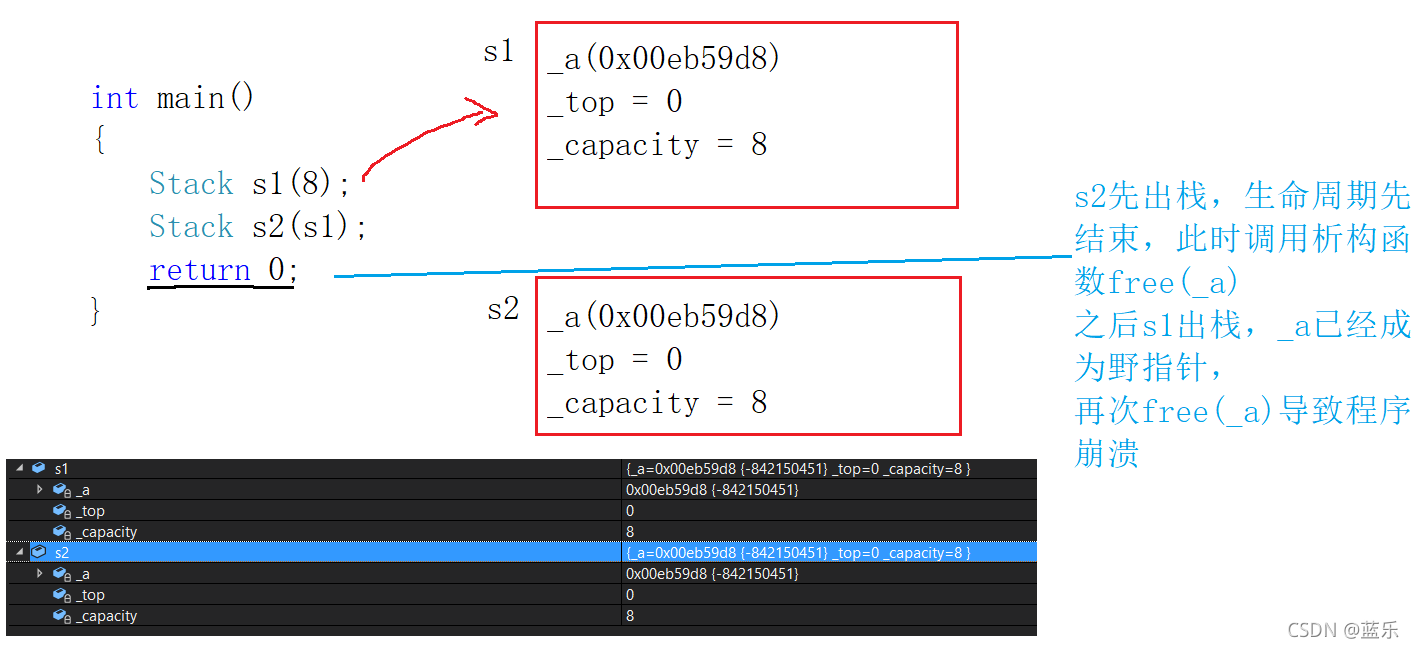
�ɼ�������Ĭ�ϵĿ������캯�������ܽ�����е�����,dz�����ᵼ��һЩ����,��ôҪ��ν��dz�����Ĵ�����������?���Ҫ����֮����ܵ����������ˡ�