д�ڿ�ͷ:
����
�������ij������Ͳ���
�㷨
markdown ���ַ:https://www.zybuluo.com/codeep/note/163962#cmd-markdown-%E5%85%AC%E5%BC%8F%E6%8C%87%E5%AF%BC%E6%89%8B%E5%86%8C
����
bool operator <(struct node &b)const
{
return r-l<b.r-b.l;//�Ⱥſ��ܻ��
}
����ģ��
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define ull unsigned long long
#define il (i<<1)
#define ir (i<<1)+1
#define pb push_back
const int maxn=1e5+5;
inline char nc() {static char buf[1000000],*p1=buf,*p2=buf;return p1==p2&&(p2=(p1=buf)+fread(buf,1,1000000,stdin),p1==p2)?EOF:*p1++;}
inline void read(int &sum) {char ch=nc();sum=0;while(ch<'0') ch=nc();while(ch>='0') sum=(sum<<3)+(sum<<1)+(ch^48),ch=nc();}
ll qsm(ll a,ll b)
{
ll base=a,ans=1;
while(b>0)
{
if(b%2==1)ans=ans*base;
base=base*base;
b>>=1;
}
return ans;
}
ll gcd(ll a,ll b)
{
return b==0?a:gcd(b,a%b);
}
void solve()
{
}
int main()
{
ios::sync_with_stdio(false);
int t;
cin>>t;
while(t--)sovle();
return 0;
}
STL
unordered_mapPostgraduate entrance examinatio
ceil()����ȡ��
floor()����ȡ��
__builtin_popcount()
����һ�����ֵĶ��������ж��ٸ�1.
bitset
#include<bits/stdc++.h>
using namespace std;
#define LL long long
const LL mod = 1000000007;
const int MX = 1e3+1;
bitset<100*100*100+1>ans,t;
int main(){
int n;scanf("%d",&n);
ans[0]=1;
while(n--){
t.reset();
int l,r;scanf("%d%d",&l,&r);
while(l<=r){
t|=ans<<(l*l);l++;
}
ans=t;
}
printf("%d",ans.count());
return 0;
}
�ַ�������
getline(cin,s);
to_string();
stoi/stol/stoll;
���ȶ���
priority_queue <int> q;
q.size();//����q��Ԫ�ظ���
q.empty();//����q�Ƿ�Ϊ��,����1,����0
q.push(k);//��q��ĩβ����k
q.pop();//ɾ��q�ĵ�һ��Ԫ��
q.top();//����q�ĵ�һ��Ԫ��
q.back();//����q��ĩβԪ��
priority_queue<int> da; //�����
priority_queue<int,vector<int>,greater<int> > xiao; //����
pair
��,map��Ȼ����pair ʵ�ֵġ�
#include <iostream>
#include <string>
#include <utility>
#include <map>
using namespace std;
int main() {
pair<string, string> p1("sc0301","С��"); // ��ʽһ,����һ��pair��Ϊp1
pair<string, string> p2 = make_pair("sc0302", "С��"); // ��ʽ��,make_pair��������һ����"sc0302"�� "С��"��ʼ����pair
pair<string, string> p3("sc0303", "��");
pair<string, string> p4("sc0304", "��");
map<string, string> m1; // ����һ����map
map<string, string> m2{ p1,p2,p3,p4 }; // ����һ������pair p1��p2��p3��p4��map
map<string, string> m3{ {"sc0301","С��"},{"sc0302", "С��"},{"sc0303", "С��"},{"sc0304", "С��"} }; // Ч��ͬ��һ��
map<string, string>::iterator it1 = m2.begin(); // �õ�ָ��m2��Ԫ�صĵ�����
map<string, string>::iterator it2 = m2.end(); // �õ�ָ��m2βԪ�ص���һ��λ�õĵ�����
pair<string, string> p11 = *it1; // �õ�m2����Ԫ��{"sc0301","С��"},����һ��pair
string p1_ID = it1->first; // �õ�m2����Ԫ��{"sc0301","С��"}��fisrt��Ա,ѧ��
string p1_name = it1->second; // �õ�m2����Ԫ��{"sc0301","С��"}��second��Ա,����
for (auto p : m2) {
cout << "ѧ��:" << p.first << "; ����:" << p.second << endl;
}
m1.insert(p1); // ��map�в������е�pair
m1.insert({ "sc0302", "С��" }); // �����ֵ��{ "sc0302", "С��" }
m1.insert(pair<string, string> ("sc0303", "С��")); // ����һ������pair����,�����뵽map��
m1.emplace(p1); // Ҫ����Ĺؼ�������������,emplace/insertʲô������
m1.emplace(pair<string, string>("sc0303", "С��")); // Ҫ����Ĺؼ�������������,emplace/insertʲô������
map<string, string>::iterator it = m2.find("sc0301"); // ���ҹؼ���Ϊ"sc0301"��Ԫ��,����һ��������
if (it == m2.end()) { // ��"sc0301"����������,��it����������
cout << "δ�ҵ�!" << endl;
}
else {
pair<string, string> result1 = *it; // �ҵ���
}
int result2 = m2.count("sc0305"); // ���ҹؼ���Ϊ"sc0301"��Ԫ��,���عؼ��ֵ���"sc0301"��Ԫ������
if (result2==0) {
cout << "δ�ҵ�!" << endl;
}
else {
cout << "�ҵ���!" << endl;
}
}
sort����
struct cmp
{
bool operator()(int a,int b)
{
return dist[a]>dist[b];
}
};
friend <��������> <������> (<�����б�>);
friend bool operator<(const node &a,const node &b)
{
return a.x<b.x;
}
bool operator<(node &a)const
{
return y<b.y;//y��ʾ��ǰ�ṹ���ֵ
}
//**���ȶ����෴**
vector
vector<type> name;
a.clear(); //���a�е�Ԫ��
a.back(); //����a�����һ��Ԫ��
a.front(); //����a�ĵ�һ��Ԫ��
vect.size();����������Ԫ�صĸ���
vect.empty();�ж������Ƿ�Ϊ��
a.insert(a.begin()+1,5); //��a�ĵ�1��Ԫ��(�ӵ�0������)��λ�ò�����ֵ5,
��aΪ1,2,3,4,����Ԫ�غ�Ϊ1,5,2,3,4
vect.resize(num);����ָ�������ij���Ϊnum,�������䳤,����Ĭ��ֵ�����λ�á�
����������,��ĩβ�����������ȵ�Ԫ�ر�ɾ����
vect.resize(num,elem);����ָ�������ij���Ϊnum,�������䳤,����elemֵ�����λ�á�
����������,��ĩβ�����������ȵ�Ԫ�ر�ɾ����
vect.push_back(1);//��vector�������Ԫ��1
a.swap(b); //bΪ����,��a�е�Ԫ�غ�b�е�Ԫ�ؽ��������Խ���
vect.pop_back()//ɾ�����һ��Ԫ��
vector<int> vect(a,a+10);//������a�������;
sort(vect.begin(),vect.end());
for(int i=0;i<=b.size()-1;i++)
set
begin() //����set�����ĵ�һ��������
end() ������//����set���������һ��������
clear() ��//ɾ��set�����е����е�Ԫ��
empty() ��//�ж�set�����Ƿ�Ϊ��
max_size() //����set�������ܰ�����Ԫ��������
size() ������//���ص�ǰset�����е�Ԫ�ظ���
rbegin������//���ص�ֵ��end()��ͬ
rend()������//���ص�ֵ��rbegin()��ͬ
#include<bits/stdc++.h>
using namespace std;
const int maxn = 2e5 + 5;
int a[maxn];
int main() {
int n, q;
cin >> n >> q;
set<int>s;
while (q--)
{
int op, id;
cin >> op >> id;
s.insert(0); s.insert(n);
if (op == 1)s.insert(id);
else
{
set<int>::iterator it;
it = s.lower_bound(id);
int len = *it - *(--it);
cout << len << endl;
}
}
return 0;
}
���ֲ���
upper_bound:
//��һ���������������[first, last),���ص�һ������val��Ԫ�����ڵĵ�ַ�����δ�ҵ����,��last;
lower_bound:
//��һ�������������[first, last), ���ص�һ�����ڵ���valԪ�صĵ�ַ,��δ�ҵ�,��last;
binary_search:
//��һ�������������[first, last)��, �ж�val�Ƿ����;
unique
3 3 2 5 2 3 -�� 3 2 5 2 3 3
python�ڿƼ�
eval()����
����ֱ�����ַ�������ʽ��ֵע��:��^��ת��**��;
s = input()
s1=""
for i in range(len(s)):
if s[i]=="^" :
s1=s1+"**"
else :
s1=s1+s[i]
print(eval(s1))
���ú���
�� da��Լ��
ll gcd(ll a,ll b){
return b==0?a:gcd(b,a%b);
}
== __gcd()
������
ll qsm(ll a,ll b)
{
ll base=a,ans=1;
while(b>0)
{
if(b%2==1)ans=ans*base;
base=base*base;
b>>=1;
}
return ans;
}
��̬�滮
��λdp
���� 1:����Ǵ�1->n,��ô���Խ���������ת��Ϊf(n)-f(m-1);
����2:�������νṹ����������,ע��lastת��ʱ������
#include<iostream>
#include<algorithm>
#include<cstring>
#include<vector>
#define ll long long
using namespace std;
const int maxn=20;
ll f[maxn][maxn];
ll K;
void init()
{
for(int i=1; i<=9; i++) f[1][i]=1;
for(int i=2; i<maxn; i++){
for(int j=0;j<=9;j++)f[i][0]+=f[i-1][j];
for(int j=1; j<=9; j++)
{
f[i][j]+=f[i-1][j];
for(int k=j+K; k<=9; k++)
{
f[i][j]+=f[i-1][k];
}
}
}
}
ll dp(ll n)
{
if(!n) return 0;
vector<int>nums;
while(n) nums.push_back(n%10),n/=10;
ll res=0;//������
int last=0;
for(int i=nums.size()-1; i>=0; i--)
{
int x=nums[i];//xΪ��ǰ��λ��
// cout<<i<<" "<<x<<" "<<last<<" "<<res<<endl;
if(i==nums.size()-1)
{
for(int j=0; j<x; j++) //Ҫ���ϱ���һλ>=��һλ,���Դ�last��ʼö��,���ö�ٵ�x,lastΪ��һλ,Ҳ�����λ,����һλ��ö���������Ƶ�
res+=f[i+1][j];
last=x;
continue; //��˵Ľڵ���i+1��λ��(��Ϊ��һλ���±���0)
}
if(x>last)
{
res+=f[i+1][last];
for(int j=last+K; j<x; j++)res+=f[i+1][j];
if(x>last&&x<last+K)break;
last=x;
} //�����ǰ��λ������һλС,��ô����Ķ���������,ֱ��break�˳�
else if(x==last)x=last;
else break;//�����˳�������һ����˵���������ұ���һ�ε�ÿһ��������С�ڵ���ǰһλ����,���++
}
return res;
}
int main(void)
{
ll l,r,L,R;
cin>>l>>r>>K;
init();
cout<<dp(r)-dp(l-1)<<endl;
//cout<<f[4][1]<<endl;
return 0;
}
��������
��������һ����dp?
no!��������Ҳ�ܹ���������,dp�����ڼ��仯����,�����Ч�����Ѿ�����¼����Ϣ������ؼ�,��α�����Ϣ�ĺ�����Ч��Ҳ�ǹؼ���
#include<bits/stdc++.h>
using namespace std;
const int maxn=3e4;
const int maxm=26;
int v[maxn],w[maxn],n,m,res=0,dp[maxm][maxn];
int dfs(int i,int j)
{
if(dp[i][j]!=-1)return dp[i][j];
if(i==m)
{
return 0;
}
else if(j<v[i])res=dfs(i+1,j);
else
{
res=max(dfs(i+1,j),dfs(i+1,j-v[i])+v[i]*w[i]);
dp[i][j]=res;
}
return res;
}
int main()
{
ios::sync_with_stdio(false);
cin>>n>>m;
for(int i=0;i<m;i++)cin>>v[i]>>w[i];
memset(dp,-1,sizeof(dp));
dfs(0,n);
cout<<res<<endl;
return 0;
}
01��������
һά������Ҫ����
��ά��Ҫ�Բ������Ĵ���
bag[j]=maxv(bag[j],bag[j-w[i]]+v[i]);
��ȫ��������
һά������Ҫ����
maxValue[j] = max(maxValue[j], maxValue[j-w[i]] + v[i]);
���ر�������
������01����û��ʲô��ͬ
���鱳������
����һά��ʾ���,��ֻ֤����һ����ѡһ�����߲�ѡ
����
ͬ������
����:ͬ���������m,����mȥ����������a��b���õ�������ͬ,��a��b��ģmͬ��,���� a �� ? b ( m o d ? m ) a\equiv \ b(mod\ m) a��?b(mod?m)?��
����1 a �� b ( m o d ? m ) a\equiv b(mod\ m) a��b(mod?m)���ҽ��� m �O ( a ? b ) m|(a-b) m�O(a?b)
����2 a �� b ( m o d ? m ) a\equiv b(mod\ m) a��b(mod?m)���ҽ�������k���� a = b + k m a=b+km a=b+km
����3 ͬ���ϵ�ǵȼ۹�ϵ
����4 ��a, b, c������,m������,��
a
��
b
(
m
o
d
?
m
)
a\equiv b(mod\ m)
a��b(mod?m),��:
a
+
c
��
a
+
c
(
m
o
d
?
m
)
a
?
c
��
a
?
c
(
m
o
d
?
m
)
a
c
��
b
c
(
m
o
d
?
m
)
a+c\equiv a+c(mod\ m)\\ a-c\equiv a-c(mod\ m)\\ ac\equiv bc (mod \ m)
a+c��a+c(mod?m)a?c��a?c(mod?m)ac��bc(mod?m)
����5 ��a,b,c,d,����,m������,��
a
��
b
(
m
o
d
?
m
)
a\equiv b (mod\ m)
a��b(mod?m),
c
��
d
(
m
o
d
?
m
)
c\equiv d(mod\ m)
c��d(mod?m),��
a
x
+
c
y
��
b
x
+
d
y
(
m
o
d
?
m
)
(
��
��
��
��
)
a
c
��
b
d
(
m
o
d
?
m
)
(
��
��
��
)
a
n
��
b
n
(
m
o
d
?
m
)
(
��
��
��
)
f
(
a
)
��
f
(
b
)
(
m
o
d
?
m
)
(
f
(
x
)
Ϊ
��
��
��
��
��
��
ʽ
)
ax+cy\equiv bx+dy(mod\ m)(���ɼ���)\\ ac\equiv bd(mod\ m)(�ɳ���)\\ a^n\equiv b^n(mod\ m)(������)\\ f(a)\equiv f(b)(mod\ m)(f(x)Ϊ������������ʽ)
ax+cy��bx+dy(mod?m)(��������)ac��bd(mod?m)(������)an��bn(mod?m)(������)f(a)��f(b)(mod?m)(f(x)Ϊ������������ʽ)
(ps:ͬ�������ʮ���ȶ�,�������ԡ�
����6 ��a,b,c,d����,m������,��
- �� a �� b ( m o d ? m ) a\equiv b(mod\ m) a��b(mod?m),��d|m,�� a �� b ( m o d ? d ) a\equiv b (mod\ d) a��b(mod?d)��(ps:��������mͬ��,����m������Ҳͬ��)
- �� a �� b ( m o d ? m ) a\equiv b(mod\ m) a��b(mod?m),�� g c d ( a , m ) = g c d ( b , m ) gcd(a,m)=gcd(b,m) gcd(a,m)=gcd(b,m)?
- a �� b ( m o d ? m i ) , i = 1 , 2 , �� , n a\equiv b (mod\ m_i),i=1,2,\dots,n a��b(mod?mi?),i=1,2,��,n����,���ҽ��� a �� b ( m o d [ m 1 , m 2 , �� , m n ] ) a\equiv b (mod[m_1,m_2,\dots,m_n]) a��b(mod[m1?,m2?,��,mn?]).
����7 �� a c �� b c ( m o d ? m ) , d = g c d ( c , m ) ac\equiv bc(mod \ m),d=gcd(c,m) ac��bc(mod?m),d=gcd(c,m),�� a �� b ( m o d ? m / d ) a\equiv b (mod \ m/d) a��b(mod?m/d)
��չŷ�����
���涨��:���a\b������,��ôһ����������x,yʹ�� a x + b y = g c d ( a , b ) ax+by=gcd(a,b) ax+by=gcd(a,b)?�н�
����:��� a x + b y = 1 ax+by=1 ax+by=1�н�,��ô g c d ( a , b ) = 1 gcd(a,b)=1 gcd(a,b)=1
int exgcd(int a, int b, int &x0, int &y0)
{
if(!b)
{
x = 1, y = 0;
return a;
}
int d = exgcd(b, a%b, y0, x0);
y -= a/b*x;
return d;
}
int main()
{
int a, b;
cin >> a >> b;
int x0, y0;
cout<<exgcd(a, b, x0, y0 )<<endl;
cout<<(x%b+b)%b<<endl;
return 0;
}
�ú����ķ���ֵΪa��b���������d,����x,yΪ����һ��⡣
һ��ͬ���ax + by = c �н�ij�Ҫ����Ϊ g c d ( a , b ) �O c gcd(a,b)|c gcd(a,b)�Oc
�� g c d ( a , b ) �O c gcd(a,b)|c gcd(a,b)�Oc��ͬ����� g c d ( a , n ) gcd(a,n) gcd(a,n)����
x = x 0 + k ? b d x = x_0 +k*\frac{b}{d} x=x0?+k?db?
y = y 0 ? k ? a d y = y_0 -k*\frac{a}{d} y=y0??k?da?
ŷ������
ŷ�������Ķ���
$\phi (n) $ ��ʾ��1��n��,��n�γɻ��ʹ�ϵ�����ĸ�����
ŷ������������
-
��nΪ����ʱ, ? ( n ) = n ? 1 \phi(n)=n-1 ?(n)=n?1
-
ŷ�������ǻ��Ժ���,��������ȫ���Ժ���
ֻ�е� n = p 1 ? p 2 n=p_1*p_2 n=p1??p2? ʱ, ? ( n ) = ? ( p 1 ) ? ? ( p 2 ) \phi(n)=\phi(p_1)*\phi(p_2) ?(n)=?(p1?)??(p2?)
? ( p q ) = ? ( q ) ? ? ( p ) = ( p ? 1 ) ( q ? 1 ) \phi(pq)=\phi(q)*\phi(p)=(p-1)(q-1) ?(pq)=?(q)??(p)=(p?1)(q?1)(RSA�㷨Ӧ��)
-
��n>2ʱ, ? ( n ) \phi(n) ?(n)Ϊż��
��nΪ������k����ʱ, ? ( n ) = p k ? p k ? 1 = ( p ? 1 ) p k ? 1 \phi(n)=p^k-p^{k-1}=(p-1)p^{k-1} ?(n)=pk?pk?1=(p?1)pk?1
֤��,ֻ�õ���xΪp�ı���ʱ,���߲Ų�����,��������������Ϊ p k ? 1 p^{k-1} pk?1��
ͨ�����ϵ����ۿ��Եõ����¹�ʽ,
?
(
N
)
=
N
?
��
i
=
1
n
(
1
?
1
p
i
)
\phi(N) = N*\prod_{i=1}^{n}(1-\frac{1}{p_i})
?(N)=N?i=1��n?(1?pi?1?)
����piΪ������,��ÿ��������ֻ��һ�Ρ�
o(n)��ɸ��ɸ��������ͬʱ����亯��ֵ
��Ҫ�õ���������:
��p����
���pΪx������
��ô ? ( p ? x ) = p ? x ? ( 1 ? 1 p 1 ) ? ( 1 ? 1 p 2 ) ? . . . ( 1 ? 1 p n ) ) = ? ( x ) ? p \phi(p*x)=p*x*(1-\frac{1}{p_1})*(1-\frac{1}{p_2})*...(1-\frac{1}{p_n}))=\phi(x)*p ?(p?x)=p?x?(1?p1?1?)?(1?p2?1?)?...(1?pn?1?))=?(x)?p
���p����x������,��px����
��ô ? ( p ? x ) = ? ( p ) ? ? ( x ) = ? ( x ) ? ( p ? 1 ) \phi(p*x)=\phi(p)*\phi(x)=\phi(x)*(p-1) ?(p?x)=?(p)??(x)=?(x)?(p?1)
phi[1]=1;
for(int i=2;i<=maxn;i++)
{
if(!isprime[i])
{
prime[++cnt]=i;
phi[i]=i-1;//����ֱ�������
}
for(int j=1;j<=cnt&&prime[j]*i<=maxn;j++)
{
isprime[i*prime[j]]=1;
if(i%prime[j]==0)
{
phi[i*prime[j]]=phi[i]*prime[j];//px������
break;
}
else phi[i*prime[j]]=phi[i]*(prime[j]-1);//px����
}
}
����:
6 2
20 8
30 8
100 40
ŷ������
a ? ( n ) �� 1 ( m o d ? n ) s . t . ? g c d ( a , n ) = 1 a^{\phi(n)}\equiv1(mod\ n)\\ s.t.\ gcd(a,n)=1 a?(n)��1(mod?n)s.t.?gcd(a,n)=1
��������
a
p
?
1
��
1
(
m
o
d
?
p
)
a^{p-1}\equiv1(mod\ p)
ap?1��1(mod?p)
��ŷ��������֪����С����Ϊŷ�����������������
Լ��������Լ����
����������ʱ,Ӧ������˼������������
d(n)Ϊ������n�����Ӹ�����
s
u
m
(
n
)
sum(n)
sum(n)ΪԼ��֮��
d
(
n
)
=
(
��
1
+
1
)
?
(
��
2
+
1
)
?
.
.
.
?
(
��
k
+
1
)
��
i
=
1
i
=
��
��
��
��
��
j
=
0
j
=
p
i
��
��
��
��
��
p
i
j
d(n) = (\alpha_1+1)*(\alpha_2+1)*...*(\alpha_k+1) \\ \sum_{i=1}^{i=��������}\sum_{j=0}^{j=p_i��������} p_i^{j}
d(n)=(��1?+1)?(��2?+1)?...?(��k?+1)i=1��i=��������?j=0��j=pi?����������?pij?
N �� 2e9��,���������1600��
�й�ʣ�ඨ��
�й�ʣ�ඨ���Ƕ������ض�����������ͬ������������
�й�ʣ��Ľ�Ϊ�����,��������
��
m
1
,
m
2
,
m
3
,
.
.
.
,
m
r
m_1,m_2,m_3,...,m_r
m1?,m2?,m3?,...,mr?���������ص�������,��ͬ���
x
��
a
1
(
m
o
d
?
m
1
)
x
��
a
2
(
m
o
d
?
m
2
)
x
��
a
3
(
m
o
d
?
m
3
)
��
��
x
��
a
r
(
m
o
d
?
m
r
)
x\equiv a_1(mod \ m_1)\\ x\equiv a_2(mod\ m_2)\\ x\equiv a_3(mod\ m_3)\\ \dots\\ \dots\\ x\equiv a_r(mod\ m_r)
x��a1?(mod?m1?)x��a2?(mod?m2?)x��a3?(mod?m3?)����x��ar?(mod?mr?)
��ģ
M
=
m
1
m
2
m
3
?
?
?
m
r
M=m_1m_2m_3*\dots*m_r
M=m1?m2?m3????mr????��Ψһ��,��Ϊ�й�ʣ�ඨ����
���˼·:
- �� M i = M / m i M_i=M/m_i Mi?=M/mi?���� m i , m j m_i,m_j mi?,mj?����,��� g c d ( M i , m i ) = 1 gcd(M_i,m_i)=1 gcd(Mi?,mi?)=1,�� M i P i �� 1 ( m o d ? m i ) M_iP_i\equiv 1 (mod\ m_i) Mi?Pi?��1(mod?mi?),������չŷ����õ���⡣
- r e s = a 1 M 1 P 1 + a 2 M 2 P 2 + ? + a r M r P r res=a_1M_1P_1+a_2M_2P_2+\dots+a_rM_rP_r res=a1?M1?P1?+a2?M2?P2?+?+ar?Mr?Pr????? ,res��Ϊ��С��
#include<bits/stdc++.h>
using namespace std;
#define ll long long
ll exgcd(ll a, ll b, ll &x, ll &y)
{
if(b==0)
{
x = 1, y = 0;
return a;
}
ll d = exgcd(b, a%b, y, x);
y -= a/b*x;
return d;
}
int main()
{
int n;
cin>>n;
vector<ll>A(n+1),B(n+1);
ll M=1ll,res=0;
for(int i=1;i<=n;i++)cin>>A[i]>>B[i],M*=A[i];
for(int i=1;i<=n;i++)
{
ll x, y;
exgcd(M/A[i], A[i], x, y);//����Ԫ
res = (res + B[i]*M/A[i]*x)%M;
}
cout<<(res+M)%M<<endl;
}
����չ��
����չ������:
����һ������Ϊn������,�ʸ�������ȫ�����е�λ��,����:
123 1
132 2
213 3
231 4
312 5
312 6
���ǽ�ȫ������������ӳ��,�γ�˫�亯����
����˼��:��λdp�ֲ�˼��,��ǰδ��֮ǰ��������ǰλС��������֮���������,��Ҫ�ȸ���С��
������ⲽ��:
- Ԥ�������׳�����
- ��ʼ�ֲ洦��,��ΪҪ֪���м�����δ�����ֲ��ұȵ�����С,���Կ���������״�����Ż���
- ��ʱ�临�Ӷ� o ( n l o g n ) o(nlog_n) o(nlogn?)?
#include<bits/stdc++.h>
using namespace std;
#define ll long long
const ll mod=998244353;
const int maxn=1e6+5;
ll jc[maxn],c[maxn];
inline int lowbit(int x)//��״�����
{
return x&(-x);
}
inline void updata(int x,int y,int n)
{
for(int i=x;i<=n;i+=lowbit(i))c[i]+=y;
}
inline ll getsum(int x)
{
ll ans=0;for(int i=x;i>0;i-=lowbit(i))ans+=c[i];
return ans;
}
void pre_jc()//Ԥ�����׳�
{
ll num=1;jc[0]=1;
for(ll i=1;i<maxn;i++)
{
num=(num*i)%mod;
jc[i]=num;
}
}
int main()
{
ios::sync_with_stdio(false);
pre_jc();
int n;
cin>>n;
for(int i=1;i<=n;i++)updata(i,1,n);
ll res=0;
for(int i=1;i<=n;i++)
{
int num;cin>>num;
getsum(num-1);
res=(res+getsum(num-1)*jc[n-i]%mod)%mod;//���Ĵ���
updata(num,-1,n);
}
cout<<(res+1)%mod<<endl;//res���ж��ٱ��Լ�С,����Ҫ��1
return 0;
}
Burnside ������Polya����
����һ��n��Ļ�,mͿɫ,�ж����ֱ��ʲ�ͬ�ķ���
һ�����֤��:��ֻ����ת��ʱ��(˳ʱ�����ʱ��),����һ����n���ַ��Ļ�,��˳ʱ�����ʱ����ת����λ��,����������n���û�,���Ǽ�����˳ʱ����תk��λ��,���͵�ͬ����ʱ��ת��n-k��λ��,����һ���û�Ϊ:G={��0,��1,��2,��3,��4,��,��n-1},���ʱ�����֤����ʱ����תk��λ��ʱ��k��ѭ���ڵĸ���ΪGcd(n,k),��ÿ��ѭ���ij���ΪL=n/gcd(n,i)��
Polya ������
a
n
s
w
e
r
=
��
i
=
1
n
m
g
c
d
(
i
,
n
)
n
answer = \frac{\sum_{i=1}^{n}m^{gcd(i,n)}}{n}
answer=n��i=1n?mgcd(i,n)?
�����
�����ݷ�ΧС�ڵ���3000 30003000����ʱ,��ֱ�Ӹ����������һ������:C ( n , m ) = C ( n ? 1 , m ) + C ( n ? 1 , m ? 1 ) ֱ�ӵ��Ƽ���,ʱ�临�Ӷ�Ϊ O(n^2).
�߾�ȡģ
int b[N],n; //�߾�����,��ʾn
int ksm(int a,int m) {
int ans=1;
for(int i=0;i<n;++i) {
for(int j=0;j<b[i];++j) ans=1ll*ans*a%m;
int tmp=1;
for(int j=0;j<10;++j) tmp=1ll*tmp*a%m;
a=tmp;//��ʮ��
}
return ans;
}
ɸ��
1e6����80000������
1.��ͨ����ɸ
ʱ�临�Ӷ�n2
2.��˹ɸ
ʱ�临�Ӷ�(nloglog n)
3.ŷ��ɸ
ʱ�临�Ӷ�o(n)
int a[maxn],b[maxn],c[maxn],ans=0;
for(int i=2;i<maxn;i++)
{
if(a[i]==0)b[++ans]=i;
for(int j=1;i*b[j]<maxn&&j<=ans;j++)
{
a[i*b[j]]=1;c[i*b[j]]=c[i]+1;
if(i%b[j]==0)break;
}
}
4.min25ɸ
�ռ�n^0.5 ʱ��Ϊ(n^0.75/ln n +n/poly(ln n))һ��1e10;
//������������:
//����sigma(n)Ϊn��������������,��f(n,k)=sum_{i=1}^n (sigma(i^k))
#include<stdio.h>
#include<math.h>
using namespace std;
typedef unsigned long long ull;
typedef long long ll;
const int N=200005;
int T,S,pr[N],pc;
ll n,num[N],m,K;
ull g[N];
bool fl[N];
// ����һ������X�����Ϊ�ڼ������Եõ���Ч��g������
inline int ID(ll x){return x<=S?x:m-n/x+1;}
ull f(ll n,int i){
if(n<1||pr[i]>n)return 0;
ull ret=g[ID(n)]-(i-1)*(K+1);
while((ll)pr[i]*pr[i]<=n){
int p=pr[i];
ull e=K+1,t=n/p;
while(t>=p)ret+=f(t,i+1)*e+e+K,t/=p,e+=K;
// ret= sum{sigma(p^es)([n>1]+f(n/p^es,p)+g[n]-g[num[i-1]]}
// ��Ϊ���ں���g(n,m)��n<=m^2,g(n,m)Ϊ0
// �Ҹ���sigma����������,��������p,��sigma(p^es)=es*k+1
// ���� ret+=(es*k+1)*f(n/p^es,p)+((es+1)k+1)(1<=es&& n/p^es>p)����ǰ���sigma(p^e)*f(n/p^e,p)������һ���sigma(p^e)
// ����������������e<1Ҳ�Ͳ��ؽ�������
i++;
}
return ret;
}
//g[i]����i������������sigma�������
//����ǰ����Ƶ�,ֻ�е�i����ͨ��[n/m]�õ�ʱ,�������
ull solve(ll n){
int i,p,x;ull y;
S=sqrt(n);
while((ll)S*S<=n)S++;
while((ll)S*S>n)S--;
while(m)num[m--]=0;
for(i=1;i<=S;i++)num[++m]=i;
for(i=S;i>=1;i--)if(n/i>S)num[++m]=n/i;
for(i=1;i<=m;i++)g[i]=num[i]-1;
//�˴�g[i]ΪС�ڵ��ڵ�i���������ͨ��[n/m]�õ������������ӵ�����
//���ȼ�ȥ��1����Ϊ1һ����Ϊ��������������������ɸȥ
x=1;y=0;
for(p=2;p<=S;p++)if(g[p]!=g[p-1]){
while(num[x]<(ll)p*p)x++;
//��g'(i,j)Ϊ����ɸ��ɸ��ǰj��������,1��j֮��ʣ����������
//����g'(i,j)=g'(0,j)-sum_{k=0,k<i}(g'(k,[j/p[k+1]])-g'(k,p[k]))
//����p[0]=1,p[i](i>0)��i������
//��g(j)��Ϊg'(i,j)ʹ����p[i]<j&&p[i+1]>j
//����g'(k,p[k])��Ϊk+1
//�������ϵĵ���ʽ�������õ�num[x]>=p^2Ϊֹ,�ʽ��������µ�x
//����ÿ�ζ�Ҫ��ȥ��δȥ����ǰ������g�Գ䵱g'��˴Ӵ���С����
for(i=m;i>=x;i--)g[i]-=g[ID(num[i]/p)]-y;
y++;
}
for(i=1;i<=m;i++)g[i]*=K+1;
return f(n,1)+1;
}
int main(){
int i,j;
//����ɸ
for(i=2;i<N;i++)if(!fl[i]){
pr[++pc]=i;
for(j=i+i;j<N;j+=i)fl[j]=1;
}
for(scanf("%d",&T);T--;){
scanf("%lld%lld",&n,&K);
printf("%llu\n",solve(n));
}
return 0;
}
���ֲ���
#include<bits/stdc++.h>
using namespace std;
const int maxn=16;
const double eps=1e-7;
double a[maxn];
int n;
double f(double x)
{
double res=0,xx=1;
for(int i=0;i<=n;i++)
{
res+=a[i]*xx;xx*=x;
}
return res;
}
int main()
{
double l,r;
cin>>n>>l>>r;
for(int i=0;i<=n;i++)
{
cin>>a[n-i];
}
//for(int i=0;i<=n;i++)cout<<a[i]<<" ";cout<<endl;
while((r-l)>eps)
{
double midl=(r-l)/3+l,midr=r-(r-l)/3;
double ansl=f(midl),ansr=f(midr);
if(ansr>ansl)l=midl;
else if(ansl>ansr)r=midr;
else l=midl,r=midr;
}
//cout<<f(-4.1)<<" "<<f(-4.9)<<endl;
cout<<l<<endl;
return 0;
}
Լɪ������
����,���ھ����Լɪ������,���Ǽ�f(n,m)��ʾ��ʼ��n ����,��m �����ӵ�����˭(��0�ſ�ʼ����)�����е���ʽf(n,m)=(f(n?1,m?1)+k) % n ����k��ʾÿ����k��һ���˳���,ע���Ŵ�0��ʼ��
Ī����˹����
Ī����˹����ʵ������һ������ʽ����������,����Ϊ��Ҫ�������Ļ�,���е�֤�������б�Ҫ�˽�ġ���������һЩ����,�о���ֻ֤����һ��,û�������˽����������ȫ֤��������Ȼ���������������ѧϰ��������,������ȫ֤���������ʵ���ϲ�����Ҫ�ܶ�֪ʶ,�ش���ӡ�
ʵ����,���������֤���õ���һ�����ۺ������֪ʶ��ǰ�ü����ڴ�
https://blog.csdn.net/tomandjake_/article/details/81083051
���ݲ�����,����Ϊ����һҳ�ʼ�����ѧ��,�Լ��Ϳ���Ī����˹���ݵ�֤������ϰ��һ��������ɡ��������һ��ǻ����,��Ȼ,��������ҵĽ��Ͳ���,��ȫ�����Լ�������ʼ�ѧϰ,���������Ƽ��Լ����ʼ�,��Ϊ�����Ϥ��������ѧ����,��ʵ���ĺܿ���һ����Լ�����ʶ���������и�����ŷ���������Ƶ�,û��ѧ��ŷ�������Ļ�,�����Ҳ���Ը��Ӹ�Ч��ѧ����һ�����ݡ�(ע��ʼ���(m,n)=gcd(m,n) )
��,�������⡣����������������
Definition 1 �ɳ˺���:��������f,���� ֻҪgcd(m,n) =1,����f(mn)=f(m)f(n)��
û��, �������ɳ˺�������һ��,ֻҪ��gcd(m,n)=1����������ɳ˾��С�Ȼ������֪����Ψһ�ֽⶨ��,�κ�������n�ɷֽ�Ϊ�����������ݷ���,������Ϊ�ɳ˺���,��
Definition 2 : ������n���������������,��
?
Definition 3 Ī����˹����:
?
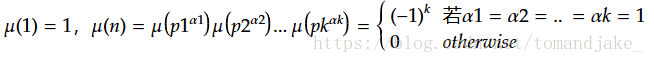
�����е����,�����������,֮�����ǿ��Կ�����������, �����ᵽ����,����֤��,Ī����˹�����ǿɳ˺�����
Ȼ�������ǵ�Ŀ��----Ī����˹���ݶ���:
Theorem 1 Ī����˹���ݶ���: F(n)��f(n)Ϊ��������,����������
?
����
?
֤������:
���ȸ���һ������,

��֪Ϊ�ɳ˺�����
֮����Եõ���һ������

����3֤��:

���Կ���,Ī����˹�����ṩ��һ��F(n)��f(n)������,������֮�����������Ī����˹������֮�����ǻῴ����������ӡ������ȸ�������ɸĪ����˹�����Ĵ���:
int mu[maxn], vis[maxn];
int primes[maxn], cnt;
void get_mu() {
memset(vis, 0, sizeof(vis));
memset(mu, 0, sizeof(mu));
cnt = 0; mu[1] = 1;
for (int i = 2; i <= maxn; ++i) {
if (!vis[i]) { primes[cnt++] = i; mu[i] = -1; }
for (int j = 0; j<cnt&&primes[j] * i <= maxn; ++j) {
vis[primes[j] * i] = 1;
if (i%primes[j] == 0)break;
mu[i*primes[j]] = -mu[i];
}
}
}
Ӧ�þ���:POJ 3904
��Ŀ����n��n��������,�����ҳ����ٸ���ͬ����Ԫ��(a,b,c,d)ʹ�ø���Ԫ����������Ϊ1.
����:
����Ҫ�����,��������Ŀ�����õ���Ī����˹���ݵ�����һ����ʽ:

��ȻҪ�õ�Ī����˹����,�������Ⱦ�Ҫ�ҵ����ʵ�F��f��ʵ����,F��f�Ĺ�ϵ�������������ǿ��Լ���
F(n)Ϊ�ж��ٸ���Ԫ������gcd(a,b,c,d)=n��������
f(n)Ϊ�ж��ٸ���Ԫ������gcd(a,b,c,d)=n
�������ǵ�Ŀ�������f(1), ��ʵ���Ͽ��Կ���F��f������һ��Ī����˹�任�ԡ����˷��ݹ�ʽ,���ǿ���ͨ����F����f,��������F�ܺ���,Ҫ��F(n)����ֻҪ��ԭ�������������ܱ�n���������ĸ���m, ��C(m,4)����F(n)
���ɹ�ʽ,�ɴ����ǿ��Է���
ֱ�Ӽ��㼴�ɡ�
#include<iostream>
#include<cstdio>
#include<string>
#include<cstring>
#include<vector>
#include<stack>
#include<algorithm>
#include<map>
#include<set>
#include<queue>
#include<sstream>
#include<cmath>
#include<iterator>
#include<bitset>
#include<stdio.h>
using namespace std;
#define _for(i,a,b) for(int i=(a);i<(b);++i)
#define _rep(i,a,b) for(int i=(a);i<=(b);++i)
typedef long long LL;
const int INF = 1 << 30;
const int MOD = 1e9 + 7;
const int maxn = 10005;
int n, a[maxn], tot[maxn];
int mu[maxn], vis[maxn];
int primes[maxn], cnt;
void get_mu() {
memset(vis, 0, sizeof(vis));
memset(mu, 0, sizeof(mu));
cnt = 0; mu[1] = 1;
for (int i = 2; i <= maxn; ++i) {
if (!vis[i]) { primes[cnt++] = i; mu[i] = -1; }
for (int j = 0; j<cnt&&primes[j] * i <= maxn; ++j) {
vis[primes[j] * i] = 1;
if (i%primes[j] == 0)break;
mu[i*primes[j]] = -mu[i];
}
}
}
void get_tot() {
memset(tot, 0, sizeof(tot));
for (int i = 0; i<n; ++i) {
int x = a[i];
int m = sqrt(x);
for (int j = 1; j <= m; ++j) {
if (x%j == 0)tot[j]++, tot[x / j]++;
}
if (m*m == x)tot[m]--;
}
}
LL Cn4(int m) {
if (m == 0)return 0;
return 1ll * m*(m - 1)*(m - 2)*(m - 3) / 24;
}
int main()
{
//freopen("C:\\Users\\admin\\Desktop\\in.txt", "r", stdin);
//freopen("C:\\Users\\admin\\Desktop\\out.txt", "w", stdout);
get_mu();
while (~scanf("%d", &n)) {
for (int i = 0; i<n; ++i) scanf("%d", &a[i]);
get_tot();
LL ans = 0;
for (int i = 1; i<maxn; ++i) {
ans += 1ll * mu[i] * Cn4(tot[i]);
}
printf("%I64d\n", ans);
}
return 0;
}
��չŷ�����(����Ԫ)
//��չŷ�����
int exgcd(int a,int b,long long &x,long long &y)
{
if(b==0)return x=1,y=0,a;
int d=exgcd(b,a%b,y,x);//d��ֵʵ���Ͼ���gcd(a,b),�������Ҫ�Ļ����Բ���
return y-=a/b*x,d;
}
//������չŷ��������Ԫ
long long inv(long long a,long long m)
{
long long x,y;
long long d=exgcd(a,m,x,y);
return d==1?(x+m)%m:-1;//�����ʾ�û����Ԫ
}
��������
0x00 ��ƽ�����ϷICG
��һ����Ϸ����:
��������ҽ����ж�
����Ϸ���̵�����ʱ��,����ִ�еĺϷ��ж����ֵ����������
��Ϸ�е�ͬһ��״̬�����ܶ�εִ�(������),��Ϸ��������ж�Ϊ����,����Ϸһ�������������Է�ƽ�ֽ���
��Ƹ���ϷΪһ����ƽ�����Ϸ��
���� Nim �������ڹ�ƽ�����Ϸ,����ͨ��������Ϸ,����Χ��,�Ͳ��ǹ�ƽ�����Ϸ����ΪΧ�彻ս˫���ֱ�ֻ������ӺͰ���,ʤ���ж�Ҳ�Ƚϸ���,����������2������3��
0x01 ����ͼ��Ϸ(����ͼ)
����һ��������ͼ,ͼ����һ��Ψһ�����,������Ϸ���һö���ӡ�������ҽ���ذ���ö����������߽����ƶ�,ÿ�ο����ƶ�һ��,���ƶ����и�������Ϸ����Ϊ����ͼ��Ϸ��
�κ�һ����ƽ�����Ϸ������ת��Ϊ����ͼ��Ϸ�����巽����,��ÿ�����濴��ͼ�е�һ���ڵ�,���Ҵ�ÿ�����������źϷ��ж��ܹ��������һ������������ߡ� ת��Ϊ����ͼ��Ϸ,Ҳ�ƻ��������IJ���״̬ͼ(��Ʋ���ͼ����Ϸͼ)��
����,���������Ϸ�е�ÿһ�ζ���(ÿһ����Ϸ),���Ƕ����Խ���������Ϸͼ�е�һ����ijһ���㵽����Ϊ 0 �ĵ��·����
�����Ϸ��ͼ��ת��,��������ֻ��Ϊ��Ѱ��һ�ֶ�Ӧ��ϵ,�����������ǵ�����Ϸ��ʵ�ʱ���**,ǿ����Ϸ����ѧģ��,����ͻ����Ϸ ����ѧ���ʡ�**
0x02 ���ֱ�ʤ�����ֱذ�
���ֱ�ʤ״̬ : �����ж��Ժ�,������ʣ���״̬��ɱذ�״̬ ��������(��һ���Ƕ���(����)�ľ���)��
���ֱذ�״̬ : ������ô����,���ﲻ���ذ�״̬,���仰˵,���������ô�ж���ֻ�ܴﵽһ�����ֱ�ʤ״̬��������,��ô����(����)��ʤ,���ֱذܡ�
��һ�¾���:
���ֱ�ʤ״̬:�����ߵ�ijһ���ذ�״̬
���ֱذ�״̬:�߲����κ�һ���ذ�״̬
��Ϊ���ǵ�ǰ�ߵ���״̬�������ֵ�״̬h
ͨ�������� Alice ,������Bob ��
����:
���� 2.1: û�к��״̬��״̬�DZذ�״̬��
���� 2.2: һ��״̬�DZ�ʤ״̬���ҽ�����������һ���ذ�״̬Ϊ���ĺ��״̬��
���� 2.3: һ��״̬�DZذ�״̬���ҽ����������к��״̬��Ϊ��ʤ״̬��
�������ͼ��һ��������ͼ,��ͨ������������,���ǿ����ڻ������ͼ��������� O(N+M) ��ʱ��(���� N Ϊ״̬����,M Ϊ����)�ó�ÿ��״̬�DZ�ʤ״̬���DZذ�״̬��
0x03 ��ʤ��ͱذܵ�
�ذܵ�(P��) ǰһ��(previous player)ѡ�ֽ�ȡʤ�ĵ��Ϊ�ذܵ�
��ʤ��(N��) ��һ��(next player)ѡ�ֽ�ȡʤ�ĵ��Ϊ��ʤ��
(1) �����ս���DZذܵ�(P��)
(2) ���κα�ʤ��(N��)����,������һ�ַ������Խ���ذܵ�(P��)
(3)������β���, �ӱذܵ�(P��)��ֻ�ܽ����ʤ��(N��)
0x04 ����ͼ�ĺ�
����һ��DAGͼ<V,E>,��� V ��һ���㼯 S ����:
S �Ƕ�����(�����ڵĵ㻥����ͨ)
����V?S �еĵ㶼����ͨ��һ�����O�� S �еĵ�( V?S ָ S �� V �еIJ���)
��� S ��ͼ V��һ���ˡ�
����: ���ڽڵ��Ӧ SG �����Ϸ�ıذ�̬
��Ϊ Alice ��ǰ�������� S ��,���� S �Ƕ�����,Ҳ����ζ�� Alice ֻ�ܽ����Ӵ� S �ƶ��� V?S
�� Bob�ֿ���ͨ��һ���ƶ������Ӵ� V?S �ƶ����� S,���� Alice �ͺ����DZ�֧����һ��,���Ȱ������ƶ�����û�г��ȵıذܽڵ�,Alice �ذ�,Bob��ʤ!
1.���ϲ���:���ֿ��ƺ����ֵ�����֮��
2.��������:������Сʯ��,������������ijһ����ȡʯ�ӻ��������ȡ��ͬ��ʯ��,ÿ��ȡʯ�ӵĸ���>=1.
int temp = (1.0 + sqrt(5) )/ 2 * (m - n);����Ϊ���վ���ʱ,���ֱذ�;
3.��ķ����:��m��Сʯ��,������������ij����ȡʯ��,ÿ��ȡʯ�ӵĸ���>=1.���ȡ���ߵ�ʤ;
��ÿ����Ʒ��ȫ���������,����õ���ֵΪ0,��ô���ֱذ�,�������ֱ�ʤ��
4.쳲���������:��һ����Ʒ,��������ȡ��Ʒ,��������ȡһ��,����������,�����ܰ���Ʒȡ��,
֮��ÿ��ȡ����Ʒ�����ܳ�����һ��ȡ����Ʒ���Ķ���������Ϊһ��,ȡ�����һ����Ʒ���˻�ʤ��
������:����ʤ���ҽ���n����쳲�������(nΪ��Ʒ����)
FFT ���ٱ任����Ҷ
���� (Convolution)(Convolution) ,ȷ��˵��һ��ͨ���������� f ��g ���ɵ�����������һ����ѧ����.
�ӹ����϶���:
? h(x)=�ҡ�?��g(��)?f(x?��)d��
�ڶ���ʽ��,��ô�Ͱ��䶨�廮������ʽ,�õ�:
? [����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-E7C3PGsH-1636816370798)(file:///C:\Users\����\AppData\Roaming\Tencent\Users\2211979172\QQ\WinTemp\RichOle\N[VN25XX49A19W$S_AI]L8F.png)]
���� A(x)�� B(x)��Ϊ n?1�ζ���ʽ
�Ƚ���Ȼ����,�����Ǻϲ�ͬ����������,���վ������Ľ��Ӧ���� 2n+1 �
����֪��,ԭ���Ķ���ʽ��ϵ����ʾ��,�������ǽ���ת��Ϊ��ֵ��ʾ�� (dot method)�������ǿ��Ѷ���ʽ F(x)ת��Ϊ����ʽ���� f(x) ,��ô��� n �����Ϳ����� n+1 ����Ψһȷ����������
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-cEIKs1Sc-1636816370806)(file:///C:\Users\����\AppData\Roaming\Tencent\Users\2211979172\QQ\WinTemp\RichOle\P}X1}EMQG2ZQ6KA$}_9`K[J.png)]
����һ������ʽ�˷�����,������ϵ����ʾ����ʱ��, O(n^2)�ĸ��Ӷ���ʱ���㹻��Խ,��FFT����һ����ʹ����ʽ�˷�����O(nlogn)��һ���㷨,�����ԭ����ʵ�dz�����:
��������ʽ��ϵ����ʾ����ֵ,O(nlogn)
��������ʽ�ĵ�ֵ��ʾ����ֵ�˷�,O(n)
��������ʽ�˻��ĵ�ֵ��ʾ����ֵ,O(nlogn)
��������ʽ�˻���ϵ����ʾ��
�����㷨(O(n^3))
Ҫ������,���ȱ���
��������ֵ,�����������������n��������ͬ��x,��������,��ʲô���Ӷ���**O(n^2)**��Ȼ���Dz�ֵ, ��һ���dz���ķ���,�������е�a����δ֪��,��ô�������ͱ���˾���ĸ�˹��Ԫ����,���Ӷ�O(n^3)
������˼,�����������ĸ��Ӷȶ����ٵ��� O(n2)����,ʹ�õ�ǰ����㷨���ܸ��Ӷ�ΪO(n3),�����¿�ʼ���Ǹ�O(n^2)��Ҫ��,��Ҫ����,��Ȼ���ӶȲ���,�Ǿ�ѭ�����Ż�
��ɢ����Ҷ�任
��ֵ��ʾ����һ���ܺõ�����,�����Ǹ������x�����Լ�ѡ��
��ɢ����Ҷ�任��˼·�ǽ�n��x��ֵȡn����λ��(ģ��Ϊһ�ĸ���)
����(����һ��֪ʶ��չ��)
�����,��ʵ����Χ���Dz����ڵ�,������չ��������һ����,��i = ? 1
,���������ܹ�����ʾΪz = x + y ? i z=x+y*iz=x+y?i���������Զ�һ������,��������������(x,y)��ʾ,�����������ж�Ӧ�ĵ�,������������Ǵ�(0,0)��(x,y)��һ�������߶�(ֻ��������ͬѧ��������������),�����������ģ���͵���(0,0)��(x,y)�ľ���
���ڸ�������,����Ҳ�и�������
�ӷ�:(a+bi)+(c+di)=(a+c)+(b+d)i
����:(a+bi)-(c+di)=(a-c)+(b-d)i
�˷�:(a+bi)*(c+di)=(ac-bd)+(ad+bc)i
��Ȼ,C++��ר�ŵ�complex������������,����
���Ƽ�ʹ��!!!
Ϊʲô��?��ΪFFT��������һ���ij���,�������ϵͳcomplex���������,�����Ƽ��Լ���дstruct
�����Ƴ����Ż����FFT
#include<cstdio>
#include<cctype>
#include<cmath>
namespace fast_IO
{
const int IN_LEN=10000000,OUT_LEN=10000000;
char ibuf[IN_LEN],obuf[OUT_LEN],*ih=ibuf+IN_LEN,*oh=obuf,*lastin=ibuf+IN_LEN,*lastout=obuf+OUT_LEN-1;
inline char getchar_(){return (ih==lastin)&&(lastin=(ih=ibuf)+fread(ibuf,1,IN_LEN,stdin),ih==lastin)?EOF:*ih++;}
inline void putchar_(const char x){if(oh==lastout)fwrite(obuf,1,oh-obuf,stdout),oh=obuf;*oh++=x;}
inline void flush(){fwrite(obuf,1,oh-obuf,stdout);}
}
using namespace fast_IO;
#define getchar() getchar_()
#define putchar(x) putchar_((x))
typedef long long LL;
#define rg register
#define complex Complex //��ֹ�Ϳ⺯����ͻ
template <typename T> inline void swap(T&a,T&b){T c=a;a=b;b=c;}
template <typename T> inline void read(T&x)
{
char cu=getchar();x=0;bool fla=0;
while(!isdigit(cu)){if(cu=='-')fla=1;cu=getchar();}
while(isdigit(cu))x=x*10+cu-'0',cu=getchar();
if(fla)x=-x;
}
template <typename T> void printe(const T x)
{
if(x>=10)printe(x/10);
putchar(x%10+'0');
}
template <typename T> inline void print(const T x)
{
if(x<0)putchar('-'),printe(-x);
else printe(x);
}
const int maxn=2097153;const double PI=acos(-1.0);
int n,m;
struct complex
{
double x,y;
inline complex operator +(const complex b)const{return (complex){x+b.x,y+b.y};}
inline complex operator -(const complex b)const{return (complex){x-b.x,y-b.y};}
inline complex operator *(const complex b)const{return (complex){x*b.x-y*b.y,x*b.y+y*b.x};}
}a[maxn],b[maxn];
int lenth=1,Reverse[maxn];
inline void init(const int x)
{
rg int tim=0;
while(lenth<=x)lenth<<=1,tim++;
for(rg int i=0;i<lenth;i++)Reverse[i]=(Reverse[i>>1]>>1)|((i&1)<<(tim-1));
}
inline void FFT(complex*A,const int fla)
{
for(rg int i=0;i<lenth;i++)if(i<Reverse[i])swap(A[i],A[Reverse[i]]);
for(rg int i=1;i<lenth;i<<=1)
{
const complex w=(complex){cos(PI/i),fla*sin(PI/i)};
for(rg int j=0;j<lenth;j+=(i<<1))
{
complex kk=(complex){1,0};
for(rg int k=0;k<i;k++,kk=kk*w)
{
const complex x=A[j+k],y=A[j+k+i]*kk;
A[j+k]=x+y;
A[j+k+i]=x-y;
}
}
}
}
int main()
{
read(n),read(m);
init(n+m);
for(rg int i=0;i<=n;i++)read(a[i].x);//�������ʽA(n+1)��
for(rg int i=0;i<=m;i++)read(b[i].x);//�������ʽB(m+1)��
FFT(a,1),FFT(b,1);//�Զ���ʽ���ֵ
for(rg int i=0;i<lenth;i++)a[i]=a[i]*b[i];//��ֵ���
FFT(a,-1);//�Զ���ʽ���ֵ
for(rg int i=0;i<=n+m;i++)print((int)(a[i].x/lenth+0.5)),putchar(' ');//lenth������,�ͷ���֮���
return flush(),0;
}
/*
1 2
1 2
1 2 1
1 4 5 2
*/
��˹��Ԫ��
��˹��Ԫ�����Է�����
����:
- ��������г����б任Ϊ�������;
- ��ԭ���Է�����;
- ����һ������;
- ��������δ֪��;
- �б�ʾ������ͨ�⡣
const int N = 507, mod = 1e9 + 7;
const double eps = 1e-6;
int n, m;
double a[N][N];
int guass()
{
int c;//��ǰ����ߵ�һ��
int r;//��ǰ�������һ��
for(c = 1, r = 1; c <= n; ++ c){
int t = r;
for(int i = r + 1; i <= n; ++ i){
if(fabs(a[i][c]) > fabs(a[t][c]))
t = i;
}
if(fabs(a[t][c]) < eps)//����0����һ��
continue;
//������һ��(�������һ��)
for(int i = c; i <= n + 1; ++ i)
swap(a[t][i], a[r][i]);
//�Ѹ��е�һ������� 1(����ÿһ�ж�/=��c�е�ֵ)
for(int i = n + 1; i >= c; -- i)
a[r][i] /= a[r][c];
//�м�������(������)ȫ������
for(int i = r + 1; i <= n; ++ i)
if(fabs(a[i][c]) > eps)
for(int j = n + 1; j >= c; -- j)
a[i][j] -= a[r][j] * a[i][c];
r ++ ;
}
if(r <= n){
for(int i = r; i <= n; ++ i)
if(fabs(a[i][n + 1]) > eps)//����,��
return 2;
return 1;//��������
}//�ش�
//��������
for(int i = n; i >= 1; -- i)
for(int j = i + 1; j <= n + 1; ++ j)
a[i][n + 1] -= a[j][n + 1] * a[i][j];
/* ֻҪ������i�е�i�е�ϵ������,���Դӵ�i+1�п�ʼһֱ������n��,
��ΪֻҪ���,���Կ���ֻ����i�е�n+1�е���(b);�����������������еļ�,����һ��forѭ��*/
return 0;
}
int main()
{
cin >> n;
for(int i = 1; i <= n; ++ i)
for(int j = 1; j <= n + 1; ++ j)
cin >> a[i][j];
int t = guass();
if(t == 0){
for(int i = 1; i <= n; ++ i)
printf("%.2f\n", a[i][n + 1]);
}
else if(t == 1)puts("Infinite group solutions");//�������
else puts("No solution");//��
return 0;
}
��˹-Լ����Ԫ��
Լ����Ԫ���ľ��ȸ��á��������,û�лش��Ĺ��̡�
Լ����Ԫ������˼·����:
- 1.ѡ��һ����δ��ѡ����δ֪����Ϊ��Ԫ,ѡ��һ�����������Ԫ�ķ��̡�
- 2.�����������Ԫ��ϵ����Ϊ1��
- 3.ͨ���Ӽ���Ԫ,�����������з����������δ֪����
- 4.�ظ����ϲ���,ֱ����ÿһ�ж����ֻ��һ����ϵ����
�����þ����ʾÿһ��ϵ���Լ����.
�б������˿��ķ��ա�
const int N = 5007;
const double eps = 1e-6;//
int n, m;
double a[N][N];
int guass() {
for(int i = 1; i <= n; ++ i) {//ö����
int maxx = i;
//1.��
for(int j = i + 1; j <= n; ++ j)
//��i����ǰ��δ֪�����˵�iһ�е������ж��Ѿ����Ѿ�����0��,�����ٶ���
if(fabs(a[j][i]) > fabs(a[maxx][i]))
maxx = j;
//2.��
for(int j = 1; j <= n + 1; ++ j)//�ҵ������һ�и���i�л�
swap(a[i][j], a[maxx][j]);
if(fabs(a[i][i]) < eps) return -1;
//3.��
for(int j = 1; j <= n; ++ j)
//�Ѹ�δ֪������i������ȫ������0(��ͨ�ĸ�˹�ǵ�i�����¼�Ϊ0,������Ҫ�ش�)
if(j != i) {
double tmp = a[j][i] / a[i][i];
for(int k = i + 1; k <= n +1; ++ k) //ֻ��Ҫ����i���ұ߾�����,��Ϊ���ȫΪ0
a[j][k] -= a[i][k] * tmp;
} //��˹ - Լ�� ��Ԫ��
} //����õ������ľ���
for(int i = 1; i <= n; ++ i) // k1*a=e1
a[i][n + 1] /= a[i][i]; // k2*b=e2
//�������Ҫ���Ը����ϵ�� <-- // k3*c=e3
return 1; // k4*d=e4
}
int main()
{
scanf("%d", &n);
for(int i = 1; i <= n; ++ i)
for(int j = 1; j <= n + 1; ++ j)
scanf("%lf", &a[i][j]);
int ans = guass();
if(ans == -1) puts("No Solution");
else for(int i = 1; i <= n; ++ i)
printf("%.2f\n", a[i][n + 1]);
return 0;
}
��˹��Ԫ��������Է�����
����һ������n������n��δ֪����������Է����顣
�������е�ϵ���ͳ���Ϊ0��1,ÿ��δ֪����ȡֵҲΪ0��1��
�����������顣
������Է�����ʾ������:
M[1][1]x[1] ^ M[1][2]x[2] ^ �� ^ M[1][n]x[n] = B[1]
M[2][1]x[1] ^ M[2][2]x[2] ^ �� ^ M[2][n]x[n] = B[2]
��
M[n][1]x[1] ^ M[n][2]x[2] ^ �� ^ M[n][n]x[n] = B[n]
const int N = 107, M = 500007, INF = 0x3f3f3f3f;
int n, m;
bitset<120> a[N];
int guass(int n, int m)//n row n �� m col m ��
{
int row = 0, col = 0, maxx;
for(; col < m; ++ col) {
for(maxx = row; maxx < n; ++ maxx)
if(a[maxx][col])
break;
if(maxx == n) continue;
if(a[maxx][col] == 0) continue;
swap(a[maxx], a[row]);
for(int i = row + 1; i < n; ++ i)
if(a[i][col]) //�����һ�������Ļ���һ��ȫ������
a[i] = a[i] ^ a[row];
//for(int j = n; j >= col; -- j)//colǰ�涼��0,����ν
//a[i][j] = a[i][j] ^ a[row][j];
row ++ ;
}
if(row < n) {
for(int i = row; i < n; ++ i)
if(a[i][m])//ì��,���ַ���ij��������0,˵����
return 2;
return 1;//����������
}
//������ξ���,��i�е�i�еı�ʾ��δ֪��x_i��һ����
for(int i = n - 1; i >= 0; -- i) {//��i��,��i�е�i��
for(int j = i + 1; j < m; ++ j)//��j��,�ұ������ж�Ҫ��
a[i][m] = a[i][m] ^ (a[j][m] * a[i][j]);
}
return 0;
}
int x;
itn main()
{
scanf("%d", &n);
m = n;
for(int i = 0; i < n; ++ i)
for(int j = 0; j < m + 1; ++ j) //+1����Ϊ����һ����������(Ҳ���Ǵ�)
scanf("%d", &x), a[i][j] = x;
int res = guass(n, m);
if(res == 0) {
for(int i = 0; i < n; ++ i)
x = a[i][m], printf("%d\n", x);
}
else if(res == 2) puts("No solution");
else puts("Multiple sets of solutions");
return 0;
}
�������ղ�ֵ��
ͼ��
��������
����ֱ��
������Զ����(Ҷ�ӽ��)�ľ��롣
��:������һ��dfs(bfs)�ҵ���ĵ�new,��new������dfs(bfs)������Զ�ĵ�last,new��last��Ϊ����ֱ����
����:����������ܵ�����Զ��,һ��������ֱ����ij���˵㡣
y�ܵ���Ȥ�ⷨ:���¶��Ͽ�����õ���·�ʹγ�·,������Ӽ�Ϊ�·,ȱ�㲻��������·�����Ҷ˵㡣
#include<bits/stdc++.h>
using namespace std;
const int maxn=1e5+5;
#define ll long long
vector<pair<int,ll> >a[maxn];
ll dis=-1e9;
ll dfs(int s, int fa)
{
ll d1=0,d2=0,d=0;
for(int i=0;i<a[s].size();i++)
{
int to=a[s][i].first;ll w=a[s][i].second;
if(to==fa)continue;
ll d=dfs(to,s);
if(d+w>=d1)d2=d1,d1=d+w;
else if(d+w>=d2)d2=d+w;
}
dis=max(d1+d2,dis);
return d1;
}
int main()
{
ios::sync_with_stdio(false);
int n;
cin>>n;
for(int i=1;i<n;i++)
{
int u,v;ll w;
cin>>u>>v>>w;
a[u].push_back({v,w});
a[v].push_back({u,w});
}
dfs(1,0);
cout<<dis<<endl;
return 0;
}
��������
�ҵ����ϵ�һ��������:�õ㵽���������Զ������С��
#include <bits/stdc++.h>
using namespace std;
const int maxn = 1e5 + 5;
#define ll long long
vector<pair<int, ll>> e[maxn];
ll d1[maxn], d2[maxn], up[maxn], prm1[maxn], prm2[maxn];
ll dfs(int s, int fa)
{
for (int i = 0; i < e[s].size(); i++)
{
int to = e[s][i].first;
ll w = e[s][i].second;
if (to == fa)
continue;
ll d = dfs(to, s);
if (d + w >= d1[s])
d2[s] = d1[s], d1[s] = d + w, prm2[s] = prm1[s], prm1[s] = to;
else if (d + w >= d2[s])
d2[s] = d + w, prm2[s] = to;
}
return d1[s];
}
void dfs2(int s, int fa)
{
for (int i = 0; i < e[s].size(); i++)
{
int to = e[s][i].first;
ll w = e[s][i].second;
if (to == fa)
continue;
if (prm1[s] != to)
up[to] = max(up[s], d1[s])+w;//���s�е����L·����to,���N��d2+w,��t�𰸞�d1+w;
else
up[to] = max(up[s], d2[s])+w;
dfs2(to, s);
}
}
int main()
{
ios::sync_with_stdio(false);
//freopen("1.txt","r",stdin);
int n;
cin >> n;
for (int i = 1; i < n; i++)
{
int u, v;
ll w;
cin >> u >> v >> w;
e[u].push_back({v, w});
e[v].push_back({u, w});
}
dfs(1, -1);
//for(int i=1;i<=n;i++)cout<<d1[i]<<endl;
dfs2(1, -1);
ll res = 1e9 + 1;
for (int i = 1; i <= n; i++)
res = min(res, max(up[i], d1[i]));
cout << res << endl;
return 0;
}
/*
5
2 1 1
3 2 1
4 3 1
5 1 1
2
*/
dfs��
��¼dfsʱ��ջ�ͽ�ջ��ʱ��,ͨ����¼��dfs����Խ���ת��Ϊdfs��,�����ø������ݽṹ���������������
dfs���dfs��
int r[maxn],c[maxn];
void dfs(int s,int fa)
{
r[s]=++dfn;
for(aotu it: v)
{
if()
}
c[s]=dfn;
}
����:
�ж������Ƿ���ͬһ����->Ҷ��,������������Ƿ��н�����
- �����������������ġ���������и�����BEFKBEFK,�������ж�Ӧ�IJ�����:BEEFKKFBBEEFKKFB;����CGHICGHI,�������ж�Ӧ�IJ�����:CGGHHIICCGGHHIIC��
- ������(a,b)(a,b)֮���·��,�ɷ�Ϊ�������,��������lcalca��a��ba��b�������������:
1.��lcalca��a��ba��b֮һ,��a��ba��b֮���ininʱ�̵��������outoutʱ�����������·��������AKAK֮���·���Ͷ�Ӧ����ABEEFKABEEFK����KFBCGGHHIICAKFBCGGHHIICA��
2.��lcalca��������,��a��ba��b֮���·��ΪIn[a]��Out[b]In[a]��Out[b]֮����������In[b]��Out[a]In[b]��Out[a]֮������䡣����,����������lcalca!!!����EKEK·��,��ӦΪEFKEFK�ټ���BB������EHEH֮���·��,��ӦΪEFKKFBCGGHEFKKFBCGGH�ټ���AA��
LCA
��������
1.prim��
ʱ��o(n2);?
/*
*����:unique_powerhouse@qq.com
*blog:https://me.csdn.net/hzf0701
*ע:���������κ�������˽���һ�����������,лл֧�֡�
*
*/
#include<bits/stdc++.h> //POJ��֧��
#define rep(i,a,n) for (int i=a;i<=n;i++)//iΪѭ������,aΪ��ʼֵ,nΪ����ֵ,����
#define per(i,a,n) for (int i=a;i>=n;i--)//iΪѭ������, aΪ��ʼֵ,nΪ����ֵ,�ݼ���
#define pb push_back
#define IOS ios::sync_with_stdio(false);cin.tie(0); cout.tie(0)
#define fi first
#define se second
#define mp make_pair
using namespace std;
const int inf = 0x3f3f3f3f;//�����
const int maxn = 1e3;//���ֵ��
typedef long long ll;
typedef long double ld;
typedef pair<ll, ll> pll;
typedef pair<int, int> pii;
//*******************************�ָ���,����Ϊ�Զ������ģ��***************************************//
int n,m;//ͼ�Ĵ�С�ͱ�����
int graph[maxn][maxn];//ͼ
int lowcost[maxn],closest[maxn];//lowcost[i]��ʾi�����뼯������ľ���,closest[i]��ʾi��֮�����ߵĶ�����š�
int sum;//������С��������Ȩֵ�ܺ͡�
void Prim(int s){
//��ʼ������,��ȡ������Ϣ��
for(int i=1;i<=n;i++){
if(i==s)
lowcost[i]=0;
else
lowcost[i]=graph[s][i];
closest[i]=s;
}
int minn,pos;//���뼯������ı�,pos�����õ���ձ��±ꡣ
sum=0;
for(int i=1;i<=n;i++){
minn=inf;
for(int j=1;j<=n;j++){
//�ҳ�����㼯������ıߡ�
if(lowcost[j]!=0&&lowcost[j]<minn){
minn=lowcost[j];
pos=j;
}
}
if(minn==inf)break;//˵��û���ҵ���
sum+=minn;//������С��������Ȩֵ֮�͡�
lowcost[pos]=0;//����㼯�ϡ�
for(int j=1;j<=n;j++){
//���ڵ㼯���м������µĵ�,����Ҫȥ���¡�
if(lowcost[j]!=0&&graph[pos][j]<lowcost[j]){
lowcost[j]=graph[pos][j];
closest[j]=pos;//�ı��붥��j�����Ķ�����š�
}
}
}
cout<<sum<<endl;//closest�����������Ҫ����С���������������ľ��DZߡ�
}
void print(int s){
//��ӡ��С��������
int temp;
for(int i=1;i<=n;i++){
//����s��Ȼ����,�ʳ�ȥ���Ϊn-1���ߡ�
if(i!=s){
temp=closest[i];
cout<<temp<<"->"<<i<<"��ȨֵΪ:"<<graph[temp][i]<<endl;
}
}
}
int main(){
//freopen("in.txt", "r", stdin);//�ύ��ʱ��Ҫע�͵�
IOS;
while(cin>>n>>m){
memset(graph,inf,sizeof(graph));//��ʼ����
int u,v,w;//��ʱ������
for(int i=1;i<=m;i++){
cin>>u>>v>>w;
//���������,������������ͼΪ����
graph[u][v]=graph[v][u]=w;
}
//��ȡ�����,������Ĭ��ȡ1.
Prim(1);
print(1);//��ӡ��С��������
}
return 0;
}
���·
Dijkstra��Bellman_Ford��SPFA��Floyd
Dijkstra:������ȨֵΪ�Ǹ���ͼ��(��Դ���·��),��쳲������ѵĸ��Ӷ�O(E+VlgV),��ʵ����spfa�����ȶ���,��֤ÿ�γ��ӵ�һ����ȫ�����Ž�;
BellmanFord:������Ȩֵ�и�ֵ��ͼ�ĵ�Դ���·��,�����ܹ���⸺Ȧ,���Ӷ�O(VE)
SPFA:������Ȩֵ�и�ֵ,��û�и�Ȧ��ͼ�ĵ�Դ���·��,�����еĸ��Ӷ�O(kE),kΪÿ���ڵ����Queue�Ĵ���,
��kһ��<=2,���˴��ĸ��Ӷ�֤�����������,��ʵSPFA������Ӧ����O(VE).
Floyd:ÿ�Խڵ�֮������·��
��Ȩͼʹ��dijkstra�㷨,��Ȩͼʹ��SPFA�㷨
SPFA�㷨:
ʱ�临�Ӷ�
����˼��:���ö���,�ж�dp[��ǰ��]��dp[��һ�����]+w�Ĵ�С,���������,���������,visit[]�����Ƿ��ڶ�����,�ھͲ�������ˡ�
�ж�������:���ij���������еĴ�������V������ڸ���(SPFA��������������ͼ)��
��û�и��������������·��,������ʹ��SPFA�㷨,������Dijkstra�㷨��
dijkstra�㷨:�������ȶ�������֤ÿ�θ�������,������֮��㲻���ڳ���
Bellman-ford�㷨:�����ڵ�Դ���·��,ʱ�临�Ӷ���O(VE)
dist[]:��original��������������·������ʼΪ�����,��Ȼ��,��original��original�ľ���Ϊ0��������original��������������·�����ȡ�
pre[]:�����õ������·���е���һ�����㡣
1.��ʼ��:�������ľ���Ϊ0��(dist[original] = 0),��������Ϊ�����
2.�������:ѭ���Ա���E��ÿ���߽����ɳڲ���,ʹ�ö��㼯��V�е�ÿ������v�ľ��볤�ƽ����յ�������̾��볤;
3.��֤�Ƿ�Ȩ��:�ٶ�ÿ���߽����ɳڲ��������������һ�����ܽ����ɳ�,��ô�ͷ���False,�����㷨����True
ͨ����ÿһ�����ɳ�,����n��,ʱ�临�Ӷ�O(VE),�������кܴ���Ż��ռ�,�������ö����Ż�,�Ż�֮����dz������spafa;
floyd�㷨:
0x7fffffff:int �����ֵ
spfa:
#include<iostream>
#include<string.h>
#include<stdio.h>
#include<queue>
#include<cmath>
#define ll long long
#define scf(x) scanf("%lld",&x)
using namespace std;
const int maxn=1e4+4;
const int maxm=5e5+5;
ll head[maxn],dp[maxn];
bool ex[maxn],dd[maxn];//ǰ�����Ƿ��ڶ�����,�������Ƿ�ﵽ��
struct dt
{
ll v;
ll w;
ll next;
}p[maxm];
void zt(ll i,ll u,ll v,ll w){
p[i].w=w;
p[i].v=v;
p[i].next=head[u];
head[u]=i;
}
void spfa(ll s)
{
queue<ll>q;
q.push(s);
ex[s]=true;
dd[s]=true;
while(q.empty()==0)
{
ll n;
dp[s]=0;
n=q.front();
q.pop();
ex[n]=false;
for(ll i=head[n];i;i=p[i].next)
{
if(dp[p[i].v]>dp[n]+p[i].w)
{
dp[p[i].v]=dp[n]+p[i].w;
if(ex[p[i].v]==false)ex[p[i].v]=true,q.push(p[i].v);
}
dd[p[i].v]
=true;
}
}
}
int main()
{
memset(head,0,sizeof(head));
memset(ex,false,sizeof(ex));
memset(dp,0x3f,sizeof(dp));
memset(dd,false,sizeof(dd));
ll n,m,k,u,v,w,s;
cin>>n>>m>>s;
for(ll i=1;i<=m;i++)
{
scf(u);scf(v);scf(w);
zt(i,u,v,w);
}
spfa(s);
for(int i=1;i<=n;i++)
{
if(dd[i])printf("%lld ",dp[i]);
else printf("2147483647 ");
}
/* int sum=1;
for(int i=1;i<=31;i++)sum*=2;
sum-=1;
printf("%d",sum);*/
return 0;
}
dikjstra
���ذ�:
���ذ��djstra��ʱ�临�Ӷ��Ǹ��ȶ���(n^2);
#include<bits/stdc++.h>
#define ll long long
using namespace std;
#define ll long long
const int maxn=1e3+3;
const int maxm=1e5+5;
const ll inf=0x7f7f7f;
ll dis[maxn],n,vis[maxn],S;
ll t[maxn][maxn];//�����ڽӾ����ͼ
void dijkstra()
{
memset(vis,0,sizeof(vis));//��ʼ���������
for(int i=1;i<=n;i++)
{
dis[i]=t[S][i];//���´�����ܵ���ĵ�ľ�����Ϣ
}
dis[S]=0;//��㵽������Ϊ0;
vis[S]=1;int to;
for(int i=1;i<=n;i++)//�ҵ���С�ĵ���Ϊ�µ����
{
ll minn=inf+1;
for(int j=1;j<=n;j++)
{
if(minn>dis[j]&&!vis[j])
{
minn=dis[j];to=j;
}
}
// cout<<"find: "<<to<<" "<<dis[to]<<endl;
vis[to]=1;//�������뵽�Ѿ����µ�������
for(int j=1;j<=n;j++)
{
if(!vis[j])dis[j]=min(dis[j],dis[to]+t[to][j]);//����dis����
}
}
}
int main()
{
ios::sync_with_stdio(false);
int m;
cin>>n>>m>>S;
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)t[i][j]=inf;//��ʼ��ͼ
for(int i=1;i<=m;i++)
{
int u,v;ll w;
cin>>u>>v>>w;
t[u][v]=w;
}
dijkstra();
for(int i=1;i<=n;i++)cout<<dis[i]<<" ";
return 0;
}
djkjstra+���Ż�
#include<bits/stdc++.h>
#define ll long long
using namespace std;
const int maxn=1e5+5;
const int maxm=2e5+5;
struct edge
{
int to,next;
ll w;
}e[maxm*2];
int head[maxn],cnt=0,S;
ll vis[maxn],dis[maxn];int n;
void add(int s,int to,ll w)
{
e[++cnt].w=w;
e[cnt].to=to;
e[cnt].next=head[s];
head[s]=cnt;
}
struct node
{
int pos;ll dis;
bool operator <(const struct node &b)const
{
return dis>b.dis;
}
};
priority_queue<node>q;
void djk()
{
for(int i=1;i<=n;i++)dis[i]=1e17;//dis�ij�ʼ��
dis[S]=0;
q.push({S,0});
while(!q.empty())
{
int s=q.top().pos;q.pop();//�������Ż���ҲҪ��spfaһ����
if(vis[s]==1)continue;vis[s]=1;
for(int i=head[s];i;i=e[i].next)
{
int to=e[i].to;
if(dis[to]>e[i].w+dis[s])
{
dis[to]=e[i].w+dis[s];
if(vis[to]==0)q.push({to,dis[to]});
}
}
}
}
int main()
{
ios::sync_with_stdio(false);
int m;
cin>>n>>m>>S;
for(int i=1;i<=m;i++)
{
int u,v;ll w;
cin>>u>>v>>w;
add(u,v,w);
}
djk();
for(int i=1;i<=n;i++)cout<<dis[i]<<" ";cout<<endl;
return 0;
}
dijkstra+�����Ż�
���Լ��
-
��ʽ��Ŀ��н�
Դ����Ҫ���������:��ԭ�����,һ�����Ա��������еıߡ�
����:
-
�Ƚ�ÿ������ʽ x i < = x j + c k x_i<=x_j+c_k xi?<=xj?+ck?,ת��Ϊһ���� x j x_j xj?�ߵ� x i x_i xi?,����Ϊ c k c_k ck?��һ����
-
�ҵ�һ������Դ��,ʹ�ø�Դ��һ�����Ա��������б�
-
��Դ����һ�鵥Դ���·
���1:������ڸ���,��ԭ����ʽ��һ����
���2:���û�и���,�� d i s t [ i ] dist[i] dist[i],����ԭ����ʽ���һ�����н�
-
-
��������ֵ����Сֵ
����:����������Сֵ,��Ӧ�����·;�����������ֵ,��Ӧ�������·��
����:���ת�� x i < = c x_i<=c xi?<=c,����c��һ������,����IJ���ʽ
����:����һ������Դ��,0,Ȼ����0->i , ������c�ı��ɡ�
���� x i x_i xi?�����ֵΪ��:�����д� x i x_i xi?����,���ɵIJ���ʽ�� x i < = x j + c 1 < = x k + c 2 + c 1 < = . . < = c 1 + c 2 + . . + c k x_i<=x_j+c_1<=x_k+c_2+c_1<=..<=c_1+c_2+..+c_k xi?<=xj?+c1?<=xk?+c2?+c1?<=..<=c1?+c2?+..+ck?? ����������Ͻ�,���� x i x_i xi?�����ֵ���������Ͻ����Сֵ��
Ѱ��ǿ��ͨ����
tarjon�㷨
- ��ȡ����ͼ��ǿ��ͨ����ֻ��Ҫ���Ӳ���ͷ�IJ�����
#include<stdio.h>
#include<iostream>
#include<algorithm>
#define ll long long
using namespace std;
const int maxn=+1e5+1e4+4;
const int maxm=1e5+1e4+5;
int n,m,ans,head[maxn],stack[maxn],top=0,visi[maxn],dfn[maxn],timer=0,low[maxn];ll f[maxn];
int color[maxn],cnt=0;
int u[maxm],v[maxn];
ll quan[maxn],nquan[maxn];ll res=0;
struct edge
{
int to,next;
}e[maxm];
inline void add(int s,int to)
{
e[++ans].to=to;
e[ans].next=head[s];
head[s]=ans;
}
void dfs(int s)//tarjon�㷨���ǿ��ͨ����
{
stack[++top]=s;visi[s]=1;
dfn[s]=low[s]=++timer;
for(int i=head[s];i;i=e[i].next)
{
if(dfn[e[i].to]==0)
{
dfs(e[i].to);
low[s]=min(low[s],low[e[i].to]);
}
else if(visi[e[i].to]==1)low[s]=min(low[s],dfn[e[i].to]);
}
if(low[s]==dfn[s])
{ cnt++;
color[s]=cnt;nquan[cnt]+=quan[s];visi[s]=0;//���DZ�0,qwq!!!!
while(stack[top]!=s)
{
color[stack[top]]=cnt;
visi[stack[top]]=0;
nquan[cnt]+=quan[stack[top]];
top--;
}
top--;
}
}
void tp(int s)//���仯���� ,���ð������
{
// cout<<s<<endl;
ll maxsum=0;
if(f[s]!=0)return ;
f[s]=nquan[s];
for(int i=head[s];i;i=e[i].next)
{
if(f[s]==0)tp(e[i].to);
maxsum=max(maxsum,f[e[i].to]);
}
f[s]+=maxsum;
}
inline int read(){
int x=0,ff=1; char ch=getchar();
while(ch<'0'||ch>'9'){if(ch=='-')ff=-1; ch=getchar();}
while(ch>='0'&&ch<='9'){x=x*10+ch-48; ch=getchar();}
return ff*x;
}
int main()
{
n=read();m=read();
for(int i=1;i<=n;i++)cin>>quan[i];
for(int i=1;i<=m;i++)
{
u[i]=read();v[i]=read();
add(u[i],v[i]);
}
for(int i=1;i<=n;i++)if(dfn[i]==0)dfs(i);
for(int i=1;i<=n;i++)head[i]=0;ans=0;
for(int i=1;i<=m;i++)e[i].next=0,e[i].to=0;
for(int i=1;i<=m;i++)
{
int uu=color[u[i]],vv=color[v[i]];
if(uu!=vv)//����һ����ͼ ,������㲻��ͬһ��ǿ��ͨ����������
{
add(uu,vv);
}
}
ll result=0;
for(int i=1;i<=cnt;i++)
{
if(f[i]==0)tp(i);
result=max(result,f[i]);
}
cout<<result<<endl;
return 0;
}
���
�ڸ�����һ������ͼ��,ɾȥij�����ܹ�ʹ��ͼ����ͨ,�õ�㱻��Ϊ���,��һ��ͼ����dfs,�����ʵ�u�ڵ�ʱ,ͼ�����еĵ�ͱ��ֳ�����������,һ�������Ѿ����ʹ���,��һ������δ�����ʹ���,������δ�����ʵĵ�����һ������ֻ����u����ʵ�,��ô��U�㱻��Ϊ��㡣
����ͼ
����ͼ����������������Ⱦɫ������ì��
�������㷨,ƥ�䡢���ƥ�䡢ƥ��㡢����·��
��С�㸲�ǡ�������������С·������(��С·���ظ��㸲��)
���ƥ���� = ��С�㸲��=�ܵ���-��������=�ܵ���-��С·������
����ƥ��,KM(��С������)
����ƥ��(�����)
�������㷨
����ͼ
����ͼƥ��:�����Ϊ��������,ÿ������֮�еĵ�û������������
���ƥ��:ƥ������ı�
�������㷨�����������ͼ�����ƥ���,���ĺ����������������·�����������㷨��ʱ�临�Ӷ�ΪO(VE)
#include<bits/stdc++.h>
using namespace std;
const int maxn=510;
int line[maxn][maxn],used[maxn],nxt[maxn],n,m;
bool find(int x)
{
for(int i=1;i<=m;i++)
{
if(line[x][i]==1&&used[i]==0)
{
used[i] = 1;//cout<<i<<" "<<nxt[i]<<endl;
if(nxt[i] == 0||find(nxt[i]))//������Ů��û�б�ƥ��,�������Ů��ƥ��������ܹ����ҵ������Ů��ƥ�䡣
{
nxt[i] = x;
return true;
}
}
}
return false;
}
int match()
{
int sum=0;
for(int i=1;i<=n;i++)
{
memset(used,0,sizeof(used));//��Ҫ��Ů�����
if(find(i))sum++;
}
return sum;
}
int main()
{
ios::sync_with_stdio(false);
int u,v,s;
cin>>n>>m>>s;
memset(nxt,0,sizeof(nxt));
memset(line,0,sizeof(line));
for(int i=1;i<=s;i++){
cin>>u>>v;
line[u][v]=1;}
int res=match();
cout<<res<<endl;
return 0;
}
������
Dicnic�㷨
#include<bits/stdc++.h>
using namespace std;
#define ll long long
const int maxn=205;//ע�ⷶΧ
const int maxm=5e3+5;
ll n,m,S,T;
ll head[maxn],rad[maxn],dis[maxn],cnt=1;
struct edge
{
int to,next;
ll w;
}e[maxm*2];
void add(int s,int to,ll w)
{
e[++cnt].to=to;
e[cnt].w=w;
e[cnt].next=head[s];
head[s]=cnt;
}
bool bfs()
{
memset(dis,0,sizeof(dis));
queue<ll>q;dis[S]=1;q.push(S);
while(!q.empty())
{
ll u=q.front();q.pop();rad[u]=head[u];
for(int i=head[u];i;i=e[i].next)
{
int v=e[i].to;
if(dis[v]==0&&e[i].w!=0)dis[v]=dis[u]+1,q.push(v);
}
}
return dis[T];
}
ll dfs(int now,ll rem)
{
if(now==T)return rem;
ll tem=rem;
for(int i=rad[now];i;i=e[i].next)
{
int v=e[i].to;rad[now]=i;
if(dis[v]==dis[now]+1&&e[i].w!=0)
{
ll k=min(e[i].w,tem);
ll dlt=dfs(v,k);
e[i].w-=dlt;e[i^1].w+=dlt;
tem-=dlt;
if(!tem)break;//����,��������
}
}
return rem-tem;
}
int main()
{
ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);
cin>>n>>m>>s>>t;
for(int i=1;i<=m;i++)
{
int u,v;ll w;
cin>>u>>v>>w;
add(u,v,w);
add(v,u,0);
}
ll res=0;
while(bfs())res+=dfs(s,1e18);
cout<<res<<endl;
return 0;
}
��С�������Ȩ�պ���ͼ
���Ȩ�պ���ͼ
����:
��һ������ͼ,ÿһ���㶼��һ��Ȩֵ(����Ϊ����0),ѡ��һ��Ȩֵ��������ͼ,ʹ��ÿ����ĺ�̶�����ͼ����,�����ͼ�ͽ����Ȩ�պ���ͼ��
�ⷨ:��������Ա�ת��Ϊ��С������
��Դ��s��ÿ����Ȩ����һ������ΪȨֵ�ı�,ÿ����Ȩ������t��һ������ΪȨֵ�ľ���ֵ�ı�,����ͼԭ���ı�����ȫ��Ϊ����
���Ȩ�պ���ͼȨֵ = ����ȨֵΪ����Ȩֵ֮�� - �����(��С��)
ģ��������:
��Ҫ���Ǵ�s�����ı�Ȩ,���������ɹ�������,˵������һ�������˸���,��ô����Ҫ��ȥ���ߡ�
���ڸ�ͼ,��S��������ȥ�ĵ㼴Ϊ��ѡ����Ȩ,����T����ȥ�ļ�λҪѡ�ķ��ߡ�
�������:���Ͽ�֪Ӧ��ѡ������Դ�������ĵ㡣
����ͼ����ѡ��
������Ŀ:����ȡ��
��С��ģ��
#include<bits/stdc++.h>
using namespace std;
#define ll long long
const int maxn=1e4+4;
const int maxm=4e5+4;
ll a[105][105];
struct node
{
int to,next;
ll w;
}e[maxm*2];
int S,T,n,m,head[maxn],dis[maxn],rad[maxn],cnt=1;
void add(int s,int to,ll w)
{
e[++cnt].to=to;e[cnt].w=w;e[cnt].next=head[s];head[s]=cnt;
e[++cnt].to=s;e[cnt].w=0;e[cnt].next=head[to];head[to]=cnt;
}
bool bfs()
{
memset(dis,0,sizeof(dis));
queue<ll>q;q.push(S);dis[S]=1;
while(!q.empty())
{
int s=q.front();q.pop();rad[s]=head[s];
for(int i=head[s];i;i=e[i].next)
{
int to=e[i].to;
if(dis[to]==0&&e[i].w)
{
dis[to]=dis[s]+1;q.push(to);
}
}
}
return dis[T];
}
ll dfs(int now,ll rem)
{
if(now==T)return rem;
ll tmp=rem;
for(int i=rad[now];i;i=e[i].next)
{
int to=e[i].to;rad[now]=i;
if(dis[to]==dis[now]+1&&e[i].w)
{
ll k=min(e[i].w,tmp);
ll dlt=dfs(to,k);
e[i].w-=dlt,e[i^1].w+=dlt;
tmp-=dlt;
if(!tmp)break;
}
}
return rem-tmp;
}
int main(){
/*��ͼ��Ϊ����ͼ*/
ios::sync_with_stdio(false);
ll sum=0;
cin>>m>>n;S=n*m+1;T=n*m+2;
for(int i=1;i<=m;i++)
for(int j=1;j<=n;j++)cin>>a[i][j],sum+=a[i][j];
for(int i=1;i<=m;i++)
{
for(int j=1;j<=n;j++)
if((i+j)%2==1)
{
add(S,(i-1)*n+j,a[i][j]);//�����е�Ϊ��ɫ�ĵ���������
if(i>1)add((i-1)*n+j,(i-2)*n+j,1e17);//�������������������Ϊinf
if(j>1)add((i-1)*n+j,(i-1)*n+j-1,1e17);
if(i<m)add((i-1)*n+j,i*n+j,1e17);
if(j<n)add((i-1)*n+j,(i-1)*n+j+1,1e17);
}
else
{
add((i-1)*n+j,T,a[i][j]);//�����е�Ϊ��ɫ�ĵ���յ�����
}
}
ll res=0;
while(bfs())res+=dfs(S,1e18);
cout<<sum-res<<endl;
return 0;
}
�����=����
��ѷ����������
����һ��DAG(������ͼ),n���仮��Ϊ�������,���ϴ�ŵ���ͬһ·���ϵĵ�,�������������ٵĻ��ַ�����
��С·��������=|G|-����ͼ���ƥ����(|G|������ͼ�е��ܱ���)
��һ��˼·��,��·�IJ��,��ÿ����������,һ�����,һ������,
���ԭͼ��������֮����һ�������,��ô�ͽ������ͼ�õ�ij�����һ������Ϊ1�ıߵ���һ������,
Ȼ����һ����Դ,����,�ѳ�Դ��ÿ����������,���������,Ȼ�����������
ÿ��·���Ŀ�ͷ���������û��ƥ��ĵ�,���������ʱ���¼һ��ÿ������Ӧ�ij�������ˡ�
��Ҷ��²۴���ûдspecial judge,������vector�ڽӱ�����������,
�����X�mΪ�Լ�����һ��pas���е�����,��Ϊpascal���ڽӱ�д�����Ǵ��˵����ʽǰ����,
ʱ�ճ����Ƚ�С_,дϰ����,�Ͳ�զ��vector�ˡ�
����ͼ����֮һ:��С·��������=������-���ƥ��,���Ӧ�ö�֪����?
�����������
��С���������,�����ڱ�֤���������,���軨�ѵ���С���á�����ÿһ���߶���һ�������ͷ���,����ͨ�����ó�������,����õĵ�λ����,��λ�������Կ�������,��С���ü�Ϊ����*���·����
KM�㷨
1.���Ӷ�o(n4)->o(n3)
2.���÷�Χ:��Ȩ����ͼ�����ƥ�䡣
#include <iostream>
#include <cstring>
#include <cstdio>
using namespace std;
const int MAXN = 305;
const int INF = 0x3f3f3f3f;
int love[MAXN][MAXN]; // ��¼ÿ�����Ӻ�ÿ�������ĺøж�
int ex_girl[MAXN]; // ÿ�����ӵ�����ֵ
int ex_boy[MAXN]; // ÿ������������ֵ
bool vis_girl[MAXN]; // ��¼ÿһ��ƥ��ƥ�����Ů��
bool vis_boy[MAXN]; // ��¼ÿһ��ƥ��ƥ���������
int match[MAXN]; // ��¼ÿ������ƥ�䵽������ ���û����Ϊ-1
int slack[MAXN]; // ��¼ÿ����������ܱ������������ٻ���Ҫ��������ֵ
int N;
bool dfs(int girl)
{
vis_girl[girl] = true;
for (int boy = 0; boy < N; ++boy) {
if (vis_boy[boy]) continue; // ÿһ��ƥ�� ÿ������ֻ����һ��
int gap = ex_girl[girl] + ex_boy[boy] - love[girl][boy];
if (gap == 0) { // �������Ҫ��
vis_boy[boy] = true;
if (match[boy] == -1 || dfs( match[boy] )) { // �ҵ�һ��û��ƥ������� ���߸����������ӿ����ҵ�������
match[boy] = girl;
return true;
}
} else {
slack[boy] = min(slack[boy], gap); // slack ��������Ϊ������Ҫ�õ�Ů�������� �����������ֵ ȡ��Сֵ ��̥������
}
}
return false;
}
int KM()
{
memset(match, -1, sizeof match); // ��ʼÿ��������û��ƥ���Ů��
memset(ex_boy, 0, sizeof ex_boy); // ��ʼÿ������������ֵΪ0
// ÿ��Ů���ij�ʼ����ֵ�������������������ĺøж�
for (int i = 0; i < N; ++i) {
ex_girl[i] = love[i][0];
for (int j = 1; j < N; ++j) {
ex_girl[i] = max(ex_girl[i], love[i][j]);
}
}
// ����Ϊÿһ��Ů�������������
for (int i = 0; i < N; ++i) {
fill(slack, slack + N, INF); // ��ΪҪȡ��Сֵ ��ʼ��Ϊ�����
while (1) {
// Ϊÿ��Ů�������������ķ����� :����Ҳ����ͽ�������ֵ,ֱ���ҵ�Ϊֹ
// ��¼ÿ��ƥ��������Ů���Ƿ���ƥ���
memset(vis_girl, false, sizeof vis_girl);
memset(vis_boy, false, sizeof vis_boy);
if (dfs(i)) break; // �ҵ����� �˳�
// ��������ҵ� �ͽ�������ֵ
// ��С�ɽ��͵�����ֵ
int d = INF;
for (int j = 0; j < N; ++j)
if (!vis_boy[j]) d = min(d, slack[j]);
for (int j = 0; j < N; ++j) {
// ���з��ʹ���Ů����������ֵ
if (vis_girl[j]) ex_girl[j] -= d;
// ���з��ʹ���������������ֵ
if (vis_boy[j]) ex_boy[j] += d;
// û�з��ʹ���boy ��Ϊgirl�ǵ�����ֵ����,����õ�Ů�������ֽ���һ��!
else slack[j] -= d;
}
}
}
// ƥ����� ���������Եĺøжȵĺ�
int res = 0;
for (int i = 0; i < N; ++i)
res += love[ match[i] ][i];
return res;
}
int main()
{
while (~scanf("%d", &N)) {
for (int i = 0; i < N; ++i)
for (int j = 0; j < N; ++j)
scanf("%d", &love[i][j]);
printf("%d\n", KM());
}
return 0;
}
���ݽṹ
Ī���㷨�������ŵı���
Ī�ӨC���ŵı���,����������������ѯ��ʱ,��������������±�����һ���Ĺ���,���ǿ���������?
��:
[ 1 , 3 ] , [ 1 , 4 ] , [ 1 , 5 ] , [ 2 , 5 ] [1,3],[1,4],[1,5],[2,5] [1,3],[1,4],[1,5],[2,5]��
��Ȼ��˫ָ��!��ʱ�临�Ӷȴ� n 2 n^2 n2�½��� o ( n ) o(n) o(n)��
Ī�Ӿ�������һ���㷨,ͨ��Ԥ����ѯ��˳��,������ʱ�临�Ӷ�,��Ȼ,ǰ�����ܹ�Ԥ����,ǿ�����ߵ���Ŀ����Ī����Ե��
��Ԥ������������:
- ���Ƚ����ݷֿ�,�ֿ��СΪsize
- ����������,����������˵�����ͬһ������,��ô���ǽ��䰴�Ҷ˵��С����
- ������ǵ���˵㲻��ͬһ����,��ô�㰴����˵���������
�����Ǵ���������˳��֮��,ʣ�µľ���֮��˫ָ��������ƶ�����,�������Ӻ�ɾ������𰸵�Ӱ��,Ҳ�ͽ����ˡ�
ll sum = 0;
s[a[1]]++;
for (int i = 1; i <= m; i++)
{
while (l < q[i].l)sum += del(l++);
while (l > q[i].l)sum += add(--l);
while (r < q[i].r)sum += add(++r);
while (r > q[i].r)sum += del(r--);
ans[q[i].id] = sum;
}
��ô��������,��η���Ī���㷨��ʱ�临�Ӷ���?
���ǶԵ�һ�����ѯ��,���ǿ������������,ͬһ���е���˵��ٷ�������,�����ٿ�������,Ȼ���ܵ����Ҷ���˷���,��Ȼ,�Ҷ˵��������,��ֻ����Ʋ�������ô��ʵʱ�临�Ӷ�Ϊ o ( s i z e ? m i + n ) o(\sqrt{size}*m_i+n) o(size??mi?+n),���� m i m_i mi?��ʾ�ٵ�i���е�������.
��ô���������ʱ�临�Ӷ�Ϊ o ( s i z e ? m + n ? ( n s i z e ) ) o(\sqrt{size}*m+n*(\frac{n}{size})) o(size??m+n?(sizen?))?��
#include<bits/stdc++.h>
using namespace std;
#define ll long long
const int maxn = 5e4 + 5;
struct node {
int l, r, id;
}q[maxn];
ll n, m, a[maxn], ans[maxn], l = 1, r = 1, sum, s[maxn], id[maxn], Size;
ll lef[maxn], righ[maxn];
bool cmp(struct node x, struct node y)
{
if (id[x.l] == id[y.l])
{
if(id[x.l]&1)return x.r < y.r;
return x.r>y.r;
}//����,��˵���ͬһ����,���������������� ,����ż���Ż�
return x.l < y.l;//����,������������
}
ll add(int x)
{
ll gs = ++s[a[x]];
return s[a[x]] * (s[a[x]] - 1) / 2 - (s[a[x]] - 1)*(s[a[x]] - 2) / 2;//����Ӱ��
}
ll del(int x)
{
ll gs = --s[a[x]];
return gs * (gs - 1) / 2 - gs * (gs + 1) / 2;//����Ӱ��
}
ll gcd(ll a, ll b)
{
if (a == 0)return b>0?b:1;
return b == 0 ? a : gcd(b, a%b);
}
int main()
{
ios::sync_with_stdio(false);
//freopen("P1494_1.in", "r+", stdin);
cin >> n >> m;
Size = n / sqrt(m * 2 / 3);//�ֿ��С,��Ӱ��ʱ�临�Ӷȡ�
for (int i = 1; i <= n; i++)
{
cin >> a[i];
id[i] = (i - 1) / Size + 1;
}
for (int i = 1; i <= m; i++)
{
cin >> q[i].l >> q[i].r;
q[i].id = i;
lef[i] = q[i].l;
righ[i] = q[i].r;
}
sort(q + 1, q + m + 1, cmp);
ll sum = 0;
s[a[1]]++;
for (int i = 1; i <= m; i++)
{
while (l < q[i].l)sum += del(l++);
while (l > q[i].l)sum += add(--l);
while (r < q[i].r)sum += add(++r);
while (r > q[i].r)sum += del(r--);
ans[q[i].id] = sum;
}
//cout << m << endl;
for (int i = 1; i <= m; i++)
{
ll gs = righ[i] - lef[i] + 1;
if (gs == 1) { cout << "0/1" << endl; continue; }
ll g=gcd(ans[i], gs*(gs - 1) / 2);
//cout <<i<<" "<< ans[i]<<" "<<g << endl;
cout<< ans[i] / g << '/' << gs * (gs - 1) / 2 / g << endl;
}
return 0;
}
#include<bits/stdc++.h>
using namespace std;
const int maxn=2e6+6;
#define ll long long
ll a[maxn],cnt=0,buc1[maxn],buc2[maxn],id[maxn],ans[maxn];
int Size;
struct mo
{
int l,r;
int pos;
bool operator <(const struct mo x)const
{
if(id[l]==id[x.l])
{
if(id[l]&1)return r<x.r;
return r>x.r;
}
return l<x.l;
}
}q[maxn];
int main()
{
int n,m,k;
scanf("%d%d%d",&n,&m,&k);
Size=(int)sqrt(n);
for(int i=1;i<=n;i++)
{
//cin>>a[i];
scanf("%lld",&a[i]);
a[i]^=a[i-1];
id[i]=(i-1)/Size+1;
}
//for(int i=1;i<=n;i++)cout<<a[i]<<" ";cout<<endl;
for(int i=1;i<=m;i++)
{
//cin>>q[i].l>>q[i].r;
scanf("%lld%lld",&q[i].l,&q[i].r);
q[i].pos=i;
}
sort(q+1,q+m+1);
ll l=1,r=1,cnt=0;
buc1[0]=1;
buc2[a[1]]=1;
if(a[1]==k)cnt++;
for(int i=1;i<=m;i++)
{
//cout<<q[i].pos<<endl;
while(r<q[i].r)
{
buc1[a[r]]++;buc2[a[r+1]]++;
cnt+=buc1[a[r+1]^k];
// if(buc1[a[r+1]^k]>0)cout<<i<<" "<<l<<" "<<r+1<<" +"<<buc1[a[r+1]^k]<<endl;
r++;
}
while(r>q[i].r)
{
cnt-=buc1[a[r]^k];
// if(buc1[a[r]^k]>0)cout<<i<<" "<<l<<" "<<r-1<<" -"<<buc1[a[r]^k]<<endl;
buc1[a[r-1]]--;buc2[a[r]]--;
r--;
}
while(l<q[i].l)
{
cnt-=buc2[a[l-1]^k];
// if(buc2[a[l-1]^k]>0)cout<<i<<" "<<l+1<<" "<<r<<" -"<<buc2[a[l-1]^k]<<endl;
buc1[a[l-1]]--;buc2[a[l]]--;
l++;
}
while(l>q[i].l)
{
buc2[a[l-1]]++;
cnt+=buc2[a[l-2]^k];
// if(buc2[a[l-2]^k]>0)cout<<i<<" "<<l-1<<" "<<r<<" +"<<buc2[a[l-2]^k]<<endl;
l--;
buc1[a[l-1]]++;
}
ans[q[i].pos]=cnt;
}
for(int i=1;i<=m;i++)printf("%lld\n",ans[i]);
return 0;
}
2021ţ����
#include<bits/stdc++.h>
using namespace std;
#define ll long long
const int maxn=2e6+6;
#define scf(x) scanf("%d",&x)
int pos[maxn],a[maxn],Size,buc[maxn],cnt,ans[maxn];
struct mo
{
int l,r;
int id;
bool operator <(const struct mo y)const
{
if(pos[l]==pos[y.l])
{
if(pos[l]&1)return r<y.r;
return r>y.r;
}
return l<y.l;
}
}q[maxn];
inline void add(int x)
{
if(buc[a[x]]==0)cnt++;
buc[a[x]]++;
}
inline void del(int x)
{
if(buc[a[x]]==1&&x!=0)cnt--;
buc[a[x]]--;
}
int main()
{
int n,m;
while(~scanf("%d %d",&n,&m)){
Size=sqrt(n);
cnt=0;
for(int i=1;i<=n;i++)scf(a[i]),pos[i]=(i-1)/Size+1,buc[i]=0;
for(int i=1;i<=n;i++)
{
if(buc[a[i]]==0)cnt++;
buc[a[i]]++;
}
// cout<<cnt<<endl;
for(int i=1;i<=m;i++)scf(q[i].l),scf(q[i].r),q[i].id=i;
sort(q+1,q+m+1);
int l=0,r=0;
for(int i=1;i<=m;i++)
{
while(r<q[i].r)del(r++);
while(r>q[i].r)add(--r);
while(l<q[i].l)add(++l);
while(l>q[i].l)del(l--);
ans[q[i].id]=cnt;
}
for(int i=1;i<=m;i++)printf("%d\n",ans[i]);
}
return 0;
}
˫�˶���
struct Deque {
int head, rear, max_length;
int q[DEQUE_SIZE];
// ���캯��
Deque() {
head = 0;
rear = 1;
max_length = DEQUE_SIZE; //�������
}
// ���
void clear() {
head = 0;
rear = 1;
}
// �п�
bool empty() {
if((head + 1) % max_length == rear) {
return true;
}
return false;
}
// ����
bool full() {
if((rear + 1) % max_length == head) {
return true;
}
return false;
}
// �����
int size() {
return (rear - head - 1 + max_length) % max_length;
}
// ���ض���Ԫ��
int front() {
if(empty()) return -1; //������
return q[(head + 1) % max_length];
}
// ���ض�βԪ��
int back() {
if(empty()) return -1; //������
return q[(rear - 1 + max_length) % max_length];
}
// ��β����Ԫ��
void push_back(int val) {
if(full()) return; // ��������
q[rear] = val;
rear = (rear + 1) % max_length;
}
// ���ײ���Ԫ��
void push_front(int val) {
if(full()) return; // ��������
q[head] = val;
head = (head - 1 + max_length) % max_length;
}
// ��βɾ��Ԫ��
void pop_back() {
if(empty()) return; //������
rear = (rear - 1 + max_length) % max_length;
}
// ����ɾ��Ԫ��
void pop_front() {
if(empty()) return; //������
head = (head + 1) % max_length;
}
};
����dp
����ͼ,��Ϊ��
���鼯
int find(int x)
{
if(a[x]==x)return x;
return a[x]=find(a[x]);
}
a[find(x)]=find(y);����
���
#include<cstdio>
#include<iostream>
#include<cstring>
#include<string>
#include<cmath>
#include<algorithm>
#define ll long long
using namespace std;
const ll p=1e9+7;
ll heap[10000007];//ģ���
ll a[10000007];
ll hsize=0;//�ѵĴ�С,Ҳ�Ƕ����һ��Ԫ�صı��
inline ll read(){
ll s=0,w=1;
char ch=getchar();
while(ch<'0'||ch>'9'){if(ch=='-')w=-1;ch=getchar();}
while(ch>='0'&&ch<='9')s=s*10+ch-'0',ch=getchar();
return s*w;
}
inline void _insert(ll node,ll num)//���뺯��,˼·�ǽ�Ԫ�ز��뵽����Ҷ�ڵ�,Ȼ��������,ֱ�����ĸ��ڵ�С����ʱ
{
heap[node]=num;//ֱ�Ӹ���,ʡȥ���жϡ������������,�����ж��н������¸�ֵ
if(heap[node>>1]>num)//�жϸ��ڵ��Ƿ������(������,��)��ע��:node����1ʱ,���ĸ��ڵ�Ϊ0,ֵΪ0,��Ȼ����С,���Բ�����������,�������������
{
heap[node]=heap[node>>1];
_insert(node>>1,num);//��������λ��,�����ݹ�
}
}
inline void _pop(ll node,ll num)//ɾ������
{
heap[node]=num;//���Ʋ��뺯��,ֱ���ȸ�ֵ
if((node<<1)<=hsize&&(num>heap[node<<1]||num>heap[(node<<1)|1]))//��������ӽڵ�,��������һ��С����(���ɽ��н���)
{
heap[node]=heap[node<<1]<heap[(node<<1)|1]?heap[node<<1]:heap[(node<<1)|1];//�ø�С����������,��֤�ѵ��ȶ���
_pop(heap[node<<1]<heap[(node<<1)|1]?node<<1:(node<<1)|1,num);//�ж�Ӧ����һ���ӽڵ�
}
}
int main()
{
ll gs;
ll cz;
ll crs;
ll n;n=read();
for(int i=1;i<=n;i++)
{
ll num;
a[i]=read();
}
ll res=0;ll pop=1;
for(int i=1;i<n;i++)
{
ll r1,r2;
ll q1=1e18,q2=1e18,q3=1e18,q4=1e18;
if(pop<=n)q1=a[pop];
if(pop+1<=n)q2=a[pop+1];
if(hsize==0||q1<heap[1])
{
r1=q1,pop++;
if(hsize==0||q2<heap[1])r2=q2,pop++;
else r2=heap[1],_pop(1,heap[hsize--]);
}
else
{
r1=heap[1],_pop(1,heap[hsize--]);
if(hsize==0||q1<heap[1])r2=q1,pop++;
else r2=heap[1],_pop(1,heap[hsize--]);
}
//cout<<r1<<" "<<r2<<endl;
res=(res+r1+r2)%p;
_insert(++hsize,r1+r2);
}
cout<<res<<endl;
/*for(int zs=0;zs<gs;zs++)
{
scanf("%d",&cz);//���ֲ���
if(cz==1)scanf("%d",&crs),_insert(++hsize,crs);
if(cz==2)printf("%d\n",heap[1]);//�Ѷ���ʹ��Сֵ
if(cz==3)_pop(1,heap[hsize--]);//ע��++��--��λ��(�Ҿ������│�˺þ�/(��o��)/~~,30�ֵ�ͬѧҲ�п����������│��)
}*/
return 0;
}
��״����
����lowbit����α���νṹ,�ǵ��ı��o(log n)
����c[i]����������ijЩ��ĺ�,ʹ������������ζ�����,����Ҫ��ѯʱ,ȡ����Ҫ��c[i],��Щc[i]��ӵļǹ����Dz�ѯ��ǰ�͡�
�����ѯ,������(����ǰ��)
#include<bits/stdc++.h>
using namespace std;
const int maxn=5e5+5;
int c[maxn];//���ȵ������ݳ���
inline int lowbit(int x){return x&(-x);}//ȡ��x�����λ1
inline void update(int x,int y,int n){//�������
for(int i=x;i<=n;i+=lowbit(i))c[i]+=y;
}
inline int getsum(int x){
int ans=0;for(int i=x;i;i-=lowbit(i))ans+=c[i];
return ans;
}
int main()
{
ios::sync_with_stdio(false);
int op,n,m,x,y,num;
cin>>n>>m;
for(int i=1;i<=n;i++){cin>>num;update(i,num,n);}
for(int i=1;i<=m;i++){
cin>>op>>x>>y;
if(op==1)update(x,y,n);
else cout<<getsum(y)-getsum(x-1)<<endl;//��ѯ���Ʋ��,���Dz�ѯǰ��
}
return 0;
}
������,�����ѯ
���ò�������˼��,������ [ a 1 , a 2 , �� �� , a n ] [a_1,a_2,����,a_n] [a1?,a2?,����,an?]?ת��Ϊ [ a 1 , a 2 ? a 1 , a 3 ? a 2 , �� �� , a n ? a n ? 1 ] [a_1,a_2-a_1,a_3-a_2,����,a_n-a_{n-1}] [a1?,a2??a1?,a3??a2?,����,an??an?1?]
���������Ʋ��,����l, r+1;
������ǰ��
#include<bits/stdc++.h>
using namespace std;
#define ll long long
const int maxn = 1e5 + 5;
int n, m;
ll c[maxn];
int lowbit(int x) { return x & (-x); }
void add(int x,int y)
{
for (int i = x; i <= n; i += lowbit(i))c[i] += y;
}
ll getsum(int x)
{
ll ans = 0;for (int i = x; i; i -= lowbit(i))ans += c[i];return ans;
}
int main()
{
ios::sync_with_stdio(false);
cin >> n >> m;
int num1,num2;
cin >> num1; add(1, num1);
for (int i = 2; i <= n; i++)cin >> num2, add(i, num2 - num1), num1 = num2;
while(m--)
{
char op;
cin >> op;
if(op=='Q')
{
int x;
cin >> x;
cout << getsum(x) << endl;
}
else
{
int l, r, x;
cin >> l >> r >> x;
add(l, x); add(r + 1, -x);
}
}
return 0;
}
�߶���
1.���߶���
�����ļ������ѯ
������:������,�ѵ����ĵĵ����,���ݹ��������¶�����,ʱ�临�Ӷ�logn
�����ѯ:�������б�����ѯ�������������,ʱ�临�Ӷ�logn
�����ѯ��������
������:�������߶�����ŵ�����ԭ���������ӵ�num;
�����ѯ;���϶��½���·��num�����
2.�����߶���
�����ĺ������ѯ
������:������Ŀǰ���䱻�������串����,�ͽ����������k*����,���Ҽ����ӳٱ��;
�����ѯ:������push_down�IJ���,���ӳٱ�Ǵ��ݸ�������,���������������sum;������ѯ��ʱ����֮ǰ��ʱ�临�Ӷ���ͬ
�˷��߶���
��������ͬ,���г��м�ʱ��Ҫ�ȳ��ټ�;
st��
#include<iostream>
#include<stdio.h>
#include<cmath>
#include<algorithm>
using namespace std;
const int maxn=2e6+6;
int f[maxn][60];//��Ҫ��ÿռ�,����̫��
double lg2[maxn];
inline int read()
{
int x=0,fa=1;char ch=getchar();
while (!isdigit(ch)){if (ch=='-') fa=-1;ch=getchar();}
while (isdigit(ch)){x=x*10+ch-48;ch=getchar();}
return x*fa;
}
inline int search(int l,int r)
{
int s=lg2[r-l+1]/lg2[2];
return max(f[l][s],f[r-(1<<s)+1][s]);
}
int main()
{
int n,m,l,r;
n=read();m=read();
for(int i=1;i<=n;i++)cin>>f[i][0];
for(int i=1;i<=n;i++)lg2[i]=log2(i);
for(int j=1;j<=lg2[n]/lg2[2];j++)
{
for(int i=1;i<=n&&i+(1<<j)-1<=n;i++)//�߽����-1,j��ʾ��ʱi֮���jλ,����Ҫ��
{
f[i][j]=max(f[i][j-1],f[i+(1<<(j-1))][j-1]);
}
}
for(int i=1;i<=m;i++)
{
l=read();r=read();
printf("%d\n",search(l,r));
}
return 0;
}
�ַ���
string s1;
s1.substr(begin,end);
�������㷨
���������ڽ��������Ӵ�����,�ص����Ӵ�,���Զ�����������Ӵ���������һ��������㷨�����������㷨,�����������ʱ�临�Ӷ�ΪO(n)��
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<iostream>
using namespace std;
const int maxn = 1e6 + 5;
char s[maxn * 2], str[maxn * 2];
int Len[maxn * 2], len;
void getstr() {//�ض����ַ���
int k = 0;
str[k++] = '@';//��ͷ�Ӹ������ַ���ֹԽ��
for (int i = 0; i < len; i++) {
str[k++] = '#';
str[k++] = s[i];
}
str[k++] = '#';
len = k;
str[k] = 0;//�ַ���β����Ϊ0,��ֹԽ��
}
int manacher() {
int mx = 0, id;//mxΪ���ұ�,idΪ���ĵ�
int maxx = 0;
for (int i = 1; i < len; i++) {
if (mx > i) Len[i] = min(mx - i, Len[2 * id - i]);//�жϵ�ǰ�㳬û����mx
else Len[i] = 1;//�����˾���������1,֮���ٽ��в���
while (str[i + Len[i]] == str[i - Len[i]]) Len[i]++;//�жϵ�ǰ���Dz���������Ӵ�,���ϵ�������չ
if (Len[i] + i > mx) {//����mx
mx = Len[i] + i;
id = i;//������
maxx = max(maxx, Len[i]);//������ִ�����
}
}
return (maxx - 1);
}
int main() {
scanf("%s", s);
len = strlen(s);
getstr();
printf("%d\n",manacher());
return 0;
}
�ֵ���(ǰ�������ʲ�����)
#include<bits/stdc++.h>
using namespace std;
int n,m;
struct node
{
int cnt;
int son[26];
bool have;
node()
{
cnt=0;
memset(son,flase,sizeof(son));//̫���DZ��õĺ�
have=false;
}
}trie[800000];
int num;
void insert(string s)
{
int v,len=s.length();
int u=0;
for(int i=0;i<len;i++)
{
v=s[i]-'a';
if(trie[u].son[v]==0)trie[u].son[v]=++num,u=trie[u].son[v];
}
trie[u].have=1;
}
int find(string s)
{
int v,u=0,len=s.length();
for(int i=0;i<len;i++)
{
v=s[i]-'a';
if(trie[u].son[v]==0)return 3;+
}
if(trie[u].have==0)return 3;
if(trie[u].cnt==0)
{
trie[u].cnt++;
return 1;
}
return 2;
}
int main()
{
ios::sync_with_stdio(false);
char name[100];
scanf("%d",&n);
for(int i=1;i<=n;++i)
{
scanf("%s",name);
insert(name);
}
scanf("%d",&m);
for(int i=1;i<=m;++i)
{
scanf("%s",name);
int p=find(name);
if(p==1)
puts("OK");
else if(p==2)
puts("REPEAT");
else if(p==3)
puts("WRONG");
}
return 0;
}
kmpģʽƥ���㷨
ʱ�临�Ӷ�O(n+m)
����:����S�ij���Ϊlen,��S������Сѭ����,ѭ���ڵij���LΪlen-next[len],�Ӵ�ΪS[0��len-next[len]-1]��
(1)���len���Ա�len - next[len]����,������ַ���S������ȫ��ѭ����ѭ�����,ѭ������T=len/L��
(2)�������,˵������Ҫ�����Ӽ�����ĸ���ܲ�ȫ����Ҫ���ĸ�����ѭ������L-len%L=L-(len-L)%L=L-next[len]%L,L=len-next[len]��
��Ϊ3������:
1.prefix_arrary(ÿһλ�Ĵ�ŵ��ǵ�ǰ�ַ��������ǰ��;
2.move prefix_arrary(Ϊ��֮��ƥ�����,�������,��λ��-1);
3.match;
#include<bits/stdc++.h>
bool SUBMIT = false;
using namespace std;
const int inf = 1000;
int nex[inf];
string s,h;
void Getnex(string m)//��kmp�������
{
nex[0]=-1;
int k=-1,j=0;
while(j<m.size())
{
if(k==-1||m[k]==m[j])
{
k++;j++;
nex[j]=k;
}else
k=nex[k];
}
}
int kmp()//��kmp����ƥ��
{
int k=0,j=0;
while(j<h.size())
{
if(k==-1||s[k]==h[j])
{
k++;j++;
}else{
k=nex[k];
cout<<k<<" "<<j<<endl;
}
if(k == s.size())
return j-k;
}
return -1;
}
int main()
{
string s;
cin>>s;
Getnex(s);
for(int i=0;i<=s.length();i++)cout<<nex[i]<<endl;
return 0;
}
AC�Զ���
ac�Զ���:��trie����������ʧ��ָ��,��ƥ��ʧ��ʱ����ת��ʧ��ָ��ָ��ĵط���
ͨ���÷���������ݲ�����ʱ���ϵ���ʧ��
key1:��ι���failָ��?
1.��һ���failָ��ָ����Ǹ��ڵ㡣
2.֮���failָ��ָ����Ǹ��ڵ��failָ��ָ��Ľ����ӽ������Ľ������ͬ�Ľ�㡣
key2:��εõ�fail?
failָ�붼������ָ����ô���ǿ���һ��һ��Ĵ�������failָ��,��ô��һ���failָ�����ֱ�Ӽ̳и��ڵ��fail,��������failһ·���ϡ�
��ô����bfs����ac�Զ�������õ�ѡ��
Trieͼ�Ż�
�����������ֵ�����ijһ֧·һֱƥ����ȥ,�����Ƿ���ƥ������,���ǻ���δ���ָ��?
���ص������?��ôʱ�临�ӶȻ������ӡ�
����Ż�?���ǿ��Խ�ƥ������Ľ������
#include<bits/stdc++.h>
using namespace std;
const int maxn = 1e6 + 6;
int tr[maxn][26], fail[maxn], cnt[maxn], q[maxn], id;
char s[maxn];
void build()
{
int p = 0;
for(int i=0;s[i];i++)
{
int to = s[i] - 'a';
if (tr[p][to] == 0)tr[p][to] = ++id;
p = tr[p][to];
}
cnt[p]++;
}
void get_fail()
{
int hh = 0, tt = -1;
for (int i = 0; i < 26; i++)if (tr[0][i])q[++tt] = tr[0][i];
while(hh<=tt)
{
int ss = q[hh++];
for(int i=0;i<26;i++)
{
int to = tr[ss][i];
if (to == 0)tr[ss][i] = tr[fail[ss]][i];//���ss�����ں��to,��ô�ͽ�to����ָ,ָ���к�̵ġ�
else fail[to] = tr[fail[ss]][i],q[++tt]=to;//������ʧ��ָ��ָ���丸�ڵ����һ����
}
}
}
int main()
{
int n;
scanf("%d", &n);
for(int i=1;i<=n;i++)
{
scanf("%s", s);
build();
}
get_fail();
scanf("%s", s);
int res = 0;
for(int i=0,j=0;s[i];i++)
{
j = tr[j][s[i] - 'a'];
int p = j;
while(p&&~cnt[p])//�Ż�,������cnt����������ֹͣ,���Ƽ��仯
{
res += cnt[p];
cnt[p] = -1;
p = fail[p];
}
}
printf("%d\n", res);
}
/*
4
a
ab
ac
abc
abcd
3
*/
���������Ż�ͳ�ƴ�
#include<bits/stdc++.h>
using namespace std;
const int maxn = 2e5 + 5;
const int L = 2e6 + 6;
int tr[maxn][26], cnt[maxn], fail[maxn], ans[maxn], du[maxn], typ[maxn], id, q[maxn], w[maxn];
char s[L], st[L];
map<int, int>m;
void build(int ty)
{
int p = 0;
for (int i = 0; s[i]; i++)
{
int to = s[i] - 'a';
if (tr[p][to] == 0)tr[p][to] = ++id;
p = tr[p][to];
}
if (typ[p] == 0)typ[p] = ty;
m[ty] = typ[p];
}
void get_fail()
{
int hh = 0, tt = -1;
for (int i = 0; i < 26; i++)if (tr[0][i])q[++tt] = tr[0][i];
while (hh <= tt)
{
int ss = q[hh++];
for (int i = 0; i < 26; i++)
{
int to = tr[ss][i];
if (to == 0)tr[ss][i] = tr[fail[ss]][i];
else fail[to] = tr[fail[ss]][i], q[++tt] = to, du[fail[to]]++;//��¼fail[to]�Ķ�����
}
}
}
int main()
{
int n;
scanf("%d", &n);
for (int i = 1; i <= n; i++)
{
scanf("%s", s);
build(i);
}
get_fail();
scanf("%s", st);
int hh = 0, tt = -1;
for (int i = 0, j = 0; st[i]; i++)
{
j = tr[j][st[i] - 'a'];
w[j] ++;//��Ǹõ㱻�����˼���
}
for (int i = 1; i <= id; i++)if (du[i] == 0)q[++tt] = i;
while (hh <= tt)
{
int ss = q[hh++];
int to = fail[ss];
if (to&&to != ss) {
w[to] += w[ss];
if (du[to] == 1)q[++tt] = to;
du[to]--;
}
}
for (int i = 0; i <= id; i++)ans[typ[i]] += w[i];
for (int i = 1; i <= n; i++)printf("%d\n", ans[m[i]]);
return 0;
}
�Ƽ�������
ģ���˻�
#include <bits/stdc++.h>
#define re register
using namespace std;
inline int read() { //�����Ż�
int X=0,w=1; char c=getchar();
while (c<'0'||c>'9') { if (c=='-') w=-1; c=getchar(); }
while (c>='0'&&c<='9') X=(X<<3)+(X<<1)+c-'0',c=getchar();
return X*w;
}
struct node { int x,y,w; };
node a[1010];
int n,sx,sy;
double ansx,ansy; //ȫ�����Ž������
double ans=1e18,t; //ȫ�����Ž⡢�¶�
const double delta=0.993;//0.993; //����ϵ��
inline double calc_energy(double x,double y) { //��������ϵͳ������
double rt=0;
for (re int i=1;i<=n;i++) {
double deltax=x-a[i].x,deltay=y-a[i].y;
rt+=sqrt(deltax*deltax+deltay*deltay)*a[i].w;
}
return rt;
}//��μ���ϵͳ����?
inline void simulate_anneal() { //SA������
double x=ansx,y=ansy;
t=2000; //��ʼ�¶�
while (t>1e-14) {
double X=x+((rand()<<1)-RAND_MAX)*t;
double Y=y+((rand()<<1)-RAND_MAX)*t; //�ó�һ���µ�����
double now=calc_energy(X,Y);
double Delta=now-ans;
if (Delta<0) { //����
x=X,y=Y;
ansx=x,ansy=y,ans=now;
}
else if (exp(-Delta/t)*RAND_MAX>rand()) x=X,y=Y; //��һ�����ʽ���
t*=delta;
}
}
inline void Solve() { //���ܼ���SA,��С���
ansx=(double)sx/n,ansy=(double)sy/n; //��ƽ��ֵ��ʼ�����ӽ����Ž�
simulate_anneal();
simulate_anneal();
simulate_anneal();
simulate_anneal();
simulate_anneal();
}
int main() {
srand(18253517); srand(rand());srand(rand()); //��ѧsrand
//cout << RAND_MAX;//32767
n=read();
for (re int i=1;i<=n;i++) {
a[i].x=read(),a[i].y=read(),a[i].w=read();
sx+=a[i].x,sy+=a[i].y;
}
Solve();
printf("%.3f %.3f\n",ansx,ansy);
return 0;
}
С����,���ǻ�
���
�����
#include<bits/stdc++.h>
#define ll long long
using namespace std;
int main()
{
ios::sync_with_stdio(false);
ll x,s,res=1;
cin>>x>>s;
for(int i=32;i>=0;i--)
{
int xi=(x>>i)&1;
int si=(s>>i)&1;
if(xi==1)
{
if(si==1)res*=2;
if(si==0)res=0;
}
}
if((x|0)==s)res--;
cout<<res<<endl;
return 0;
}
a + b = a �O b + a & b a+b = a | b + a \& b a+b=a�Ob+a&b