����Ŀ¼
- һ���м���Ķ���
- �����м���Ŀ���
- ����MySQL��NoSQL
- ΪʲôҪʹ�� Memcached
- �ġ��ֲ�ʽϵͳ
һ���м���Ķ���
�м��һ�ʵ�����
�м����������һ�γ����� 1968 ���ڵ¹��Ӷ���ʩ�������˾ٰ�� NATO �������̴�� ��������һ�ݱ����С�
�������ʽȷ������������(Software Engineering)�ĸ���,ͬʱ��̽����������ơ������ͷַ������⡣
�м���Ķ���
�м��(Ӣ��:Middleware),�����м�����н��,��һ���ṩϵͳ������Ӧ������֮�����ӡ���������������֮��Ĺ�ͨ������,Ӧ���������Խ����м���ڲ�ͬ�ļ����ܹ�֮�乲����Ϣ����Դ���м��λ�ڿͻ����������IJ���ϵͳ֮��,�����ż�����Դ������ͨ�š� �C ά���ٿ�
ʲô�����м��
���ǰ����������һЩ������������һЩ�����м���ĸ���
- ҵ��ƽ̨�����м��,ҵ��ƽ̨�Ǵӷ�����ӽdz������ͬʱ֧�Ŷ��ҵ��,ҵ��֮�����Ϣ���γɽ�������ǿ��ƽ̨��
- Ӫ�����߲����м��,Ӫ��������ֱ�������������������û����������߲������
- ����/�������߰������м��,����/�������߰����ڸ��ֳ����ij��������г�����һЩ���ù�����(����)�ļ���,�������������뱾����
- SaaS �����м��,SaaS(Software as a Service) �������һ����������ģʽ,�����û���װ,ͨ���������߷��ʵ�һ�ַ���ģʽ��
- PaaS �����м��,PaaS(Platform as a Service) �������з���ƽ̨��Ϊһ�ַ���,�ṩ��������ƽ̨(ǿ����������ϵͳ������ϸ�ڵ�runtimeƽ̨)��
���йؼ�
�Ӷ�������ܽ�����еļ����ط�
-
����:����������
-
���ò㼶:ϵͳ������Ӧ������֮�䡢����������֮��;�����ͻ�����ϵͳ����֮��ļ�����Դ������ͨ�š�
-
�������:�м��ΪӦ����������,Ӧ������Ϊ�����û�����,�����û�����ֱ��ʹ���м����
�м���ĺô�
�м���ܸ��ͻ�����ʲô?
Ϊ�ϲ�Ӧ�������Ŀ����ṩ��ݵġ����伴�õķ����ͼ��������,���̿�������;���εײ�runtime�IJ���;��ʡӦ�ñ�����ϵͳ��Դ,�������гɱ���
������
ʲôʱ��ʹ���м��
�����м���Ķ�������֪���м��������������ϵͳ֮��ķ���,��ô����ʲôʱ��ʹ�����м��,����Щ�ط��õ����м���ˡ����Dz�������һ��http�������������һ����
�����������������һ����ַʱ,����ͨ�� DNS ������Ŀ�����ע��Ĺ���IP��ַ
����Ŀ������ web ������������� Tengine ֮��,����һ���Ĺ���ת����Ŀ�����A��
����Aͨ�� RPC��� Dubbo �������B�Ľ�����м����,���Ҵ� Tair �����ж�ȡ��������,������
����A����ʹ�� Druid ͨ�� TDDL д��������� MySQL Master �ڵ�Ȼ�ؽ��
�첽������ Canal ͨ��ģ�� Binlog ���Ӹ��Ƶ�ԭ��,Ѹ�ٽ����� Binlog ���Ѳ��·�����Ϣ���� RocketMQ
����Cͨ�� RocketMQ ���ѵ��¼�֮��,ͨ���������� ConfigServer ��ȡ���IJ��Խ��ж�Ӧ���Ե��¼�������
�������������ʹ����һϵ�е��м����Эͬ�������������������,��web������������� Tengine��RPC��� Dubbo������ Tair�����ӳ� Driud�����ݿ������ TDDL��Binlog ͬ������ Canal����Ϣ���� RocketMQ���������� ConfigServer��
���û����м��
- ·����web������:������ת������������ͨ�����ݵķ������� �类ҵ��㷺ʹ�õİ������ Nginx �з��� Tengine�������ڲ��ļ���ʽ·�ɷ��� VipServer
- RPC���:����ʱ����Զ�̷�����ÿ�ܡ���grpc, Thrift, ����� HSF, Dubbo, SOFA-RPC
- ��Ϣ�м��:֧���ڷֲ�ʽϵͳ֮�䷢�ͺͽ�����Ϣ�������� �� Apache kafka, Apache RabbitMQ, NSQ, ���������Դ�� Apache RocketMQ
- �������: �ֲ�ʽ�ĸ������ݴ洢��,һ�����ڴ�洢���� ���� Tair,ҵ��� Redis, Memcached, Ehcache
- ��������:����ͳһ����������Ŀ���������õ�ϵͳ���� ���� Nacos��Я�� Apollo���ٶ� Disconf
- �ֲ�ʽ����:����IJ����ߡ�֧������ķ���������Դ�������Լ�����������ֱ�λ�ڲ�ͬ�ķֲ�ʽϵͳ�IJ�ͬ�ڵ�֮�ϡ� �� ���� seata����Ѷ DTF
- �������:�ֲ�ʽ�������ṩ��ʱ��������š��ֲ�ʽ�����ȹ��ܵ�ϵͳ���� ���� SchedulerX��ҵ�� xxl-job������ elastic-job������ TSP
- ���ݿ�� ����֧�ֵ������ݺͷֿ�ֱ��� TDDL,���ݿ����ӳ� Driud, Binlog ͬ���� Canal �ȡ�
�м���Ʋ�Ʒ
������ʱ���ĵ���,������˾��ҵ��������Ǩ��;Ϊ�����Ͽͻ��ܹ���ݵ�ʹ���ȶ���Ч���м������,�Ƴ��̿�ʼ�����������Ļ����м�������ƻ�,����֧�Ÿ������Ͽͻ�������ҵ��Ŀ���������
�����м���Ŀ���
ʲô���м������?
���Ź���������ҵ�ķ�չ,���ڻ�������˾��ģԽ��Խ��,ҵ��Խ��Խ����,��֮ʹ�ô������м������ߺ�̨�������ܡ��ɴ˲������м��������ά����Ա��
��Ȼ,��С��˾,�м��,���绺��,MQ,RPC �ȷ���,�����������ҵ����Ա�Լ�ά��,����ί�е�������ƽ̨��ά(֧��һЩ����)����,�����̨�������� 200 ��,�����ͻ��齨�Լ����м���������ܹ��Ŷ�,����ά����̨�����������ܹ����м����
�����ģ�Ĺ�˾,�����ڸ��ָ�����ԭ��(����,KPI),���Լ������м��,������С���Ҫ���м���Ŷ���Ҫ�������Ա��
�м��������Ա��Ҫ��Щ����?
��Ȼ��Ҫ�м��������Ա,��ô�м��������Աһ���������Ƹ��?��Ƹ��Ҫ����ʲô?
ͨ��,һ����˾�ڸտ�ʼ�齨�м���Ŷӵ�ʱ��,����ӹ�˾�ڲ���ѡ��Ӣ�˲�,������ѡ���м������Ȥ���˲š���ʱ��,������û����ؾ���,������Ȼ�л�����뵽�м�������С���֮,�����û���м����������,��ͨ����Ƹ�ķ�ʽ�����м����ҵ,��ô��Զ���,����Щ���ۡ�
��ô,����,��������м������,��,��û���м����������,��,��Ĺ�˾Ҳû���齨�м���ŶӵĴ��㡣
����ôͻ��?
��: ���ۡ����۵���Ĺ�˾���м���Ŷӡ�
������漰����һ���м���Ŷ���Ҫ��Щ���ܡ���Ϊ���ۿ϶���Ҫ����,��������Ե����м����λ,��ô��Ȼ,����Ҫ���м�������֪ʶ��
����,����һ��,������ֹ���ȷ��ʱ��,��ʹ���м��,Ҳ�кܶ�����,����������һ��,���ܲ��Ǻ�ȷ��
- ���������м��,���� RPC ����м��,�����۶�,��·��,�ֲ�ʽ�������ĵȵȡ�����Դ� SpringCloud ���ҵ���صIJ�Ʒ����Ȼ����Ҳ�кܶ�����IJ�Ʒ��
- �洢�м��,���绺��,MQ�ȵ�,����洢�漰���ֲ�ʽ(ͨ�������漰),��ôҪ����Խϸߡ�
- ���� Proxy,���������ݿ�,���� Cache,���Ǹ��ִ洢,ͨ�����������غ�������,�Ƚϼİ취����ʹ�� Proxy ���д���,��Ӧ������ʹ�ü�Ⱥ���������ܿ���,����ͨ����ʹ�����ܽϸߵIJ�Ʒ,���� goLang,C++ �ȡ�Java �ij�����������Ч��,������ط�Ȩ�ز���
- ���ֲַ�ʽ�м��,���� ZK ����,����Ҹ�����Ϊ�Ѷ��ǽϴ�ġ��ֲ�ʽ���������������бȽ����ѵ�һ���㡣�ر����漰���洢��һ���ԡ�
- �������,k8s,docker��,�������Ѿ��Ǵ�������,��ʵ��Ҳ���Ǻܶ�😀(��������˵��)��
�ص�֮ǰ�Ļ���: һ���м����������Ҫ��Щ����?
- ���Ի������� Java ����Ա�ĽǶ�,����ͨ������:����,����,JVM,Netty,IO��NIO(mmap,sendfile)
- ���������,�����м��������Ա������ OS ��,���Լ��������Ҳ�ز�����,�����ļ�ϵͳ(IO/����),�����߳�,�ڴ������
- �������,���̨����Ա,�϶�Ҫ��������Ϥ��,��Ϥ�� Linux ���Ų���������,��Ϥ Epoll ԭ���ȡ�
- �ֲ�ʽ���֪ʶ,�������������ݱ�����,�ֲ�ʽ֪ʶ�ز�����,CAP, Paxos,Raft,zab,2pc,3pc,base�ȵȡ�����ܸ�����Щ����д��ʵ�ִ��롣
- ��Ϥ��Դʵ��,��ʹ����ҵ����Ա,��Ҳ 100% ��Ӵ���Դ��Ŀ,���� Spring,��ô,ͨ������Ҫ�����ֳ��õĿ�Դ��������̵�����,����֪����ԭ��,Ҳ�������ơ��Ӵ�ĽǶȿ�,��ÿ���������ܵı���,��ƺ�ȡ��,��С�ĽǶȿ�,��ÿ����ܵ��ڲ�ʵ��ϸ��,����Щ��Ȥ�ĵط�(ͨ�����ֿ�ܶ�����������Ż�)��
- �˽���ҵ�����,�м����ҵ��ҵ�����в�ͬ,ÿ���м���İ汾���������ø�����Ŀ������Dz�Ŀ(���� iPhone ������),�˽�������,�����˽���ҵ����,����Ϊ��ҵ���졣
��γ�Ϊ�м��������Ա?
��,˵�����м��������Ա��Ҫ��Щ����,��Ȼ,��γ�Ϊ�м��������Ա,�Ͳ��������ˡ�
˵����,���� 6 ����,����Ӳ��ͷ��
- �����Ѿ���ʼ����������˵,��Ҫƽʱ��̵Ļ���,˵������һ��,������ҵ���������,����Ѹ㶨���ŵ���Щ���ݡ�
- ���ڻ�����ѧ��ͬѧ��˵,��ˬ,�������ѧУ(������ָ��ѧ,������֪�Ĵ���,ͨ���dz���/Сѧ�Ϳ�ʼ���,���ⲻ�DZ����)���ѵ�ʱ����ѧϰ,һ�����ĸ㶨��Щ֪ʶ��,�����в�ͬ,������֪ʶ�ﵽ�����ˮƽ,��ô SP offer Ӧ����������� :)
�������ص����Щƽʱ����������,����м����ͬѧ���ġ�
�Ҽ�������һ������ 3 �����ڵ� Java ������Ա,�����������ѵ��,��·����,�ư���,��ר��,������,���㲻�ڴ�,ͨ����һ����̨���������� 200 �˵Ĵ�ҵ��˾,title �� ��Java ��������ʦ��,������һ������Ա������,���� get��set,���� crud,���� html ���,����Ͳ�Ʒͬѧ����,Ҳ����Ͳ���ͬѧ���㡭(�о����������� =_=||)
����������ۡ�
��ô������Ҫ��������:
- ���� Java ����,����Դ��,����Դ��,JVM ԭ��,Netty ԭ��Դ��,IO ���(�漰���㿽���ļ��洢),��Щ���� Java ����,ͨ���DZ���ġ�
- �ֲ�ʽԭ��,������֪������֪ʶ,�����дһ��,���²��տ�Դ��Ҳ�С�
- Դ��,Spring Mybatis Tomcat �ȵ�,��Щ����ͨ���������ȽӴ���,���������↑ʼ��RPC �м����ص�,Dubbo,Motan,SOFA,��һ����,�Ƽ� SOFA��
- ����Ϥ��Ϥ(��ϤָԴ������)�ֲ�ʽ����ز�Ʒ,�������� Java ����,�Ƽ� RocketMQ,Apollo �������ĵȵ��м��,��ʵ������,MQ ��Ը��ӡ�
- ����ϵͳ,ͨ��,�����о����������ʱ,����������ϵͳ������,������Ҫ�ƹ�,����Ū���ס�
- �Լ��IJ�Ʒ,�о������,���繫�ں�,����,��ѧ��Ƶ,GitHub ��Ŀ�ȵ�,��֮,���õó��ֵĶ�����
- �Ӵ�ţ����,�˽���ҵ����ꡣҲ������һ����ֵ���,�������������ҵ,���б�Ҫ����ҵ���������ѧϰ(��������Ȧ�ͺ�)��
����MySQL��NoSQL
֮ǰд��һƪ�������ݿ�Ļ�������:���ݿ������ʹ��C���Թ���һ�����ݿ⡢SQL���ԡ�MySQL
����������NoSQL�ĺ��塣
��ϵ�����ݿ���ʲô?
��ϵ�����ݿ⽨���ڹ�ϵ������ģ�͵Ļ�����,�ǽ����ڼ��ϴ�������ѧ����ͷ������������ݵ����ݿ⡣��ʵ�����еĸ���ʵ���Լ�ʵ��֮��ĸ�����ϵ�����ù�ϵģ������ʾ,�г���ռ�ܴ�ݶ�� Oracle��MySQL��DB2 �ȶ��������ϵģ�͵� DBMS��
��ϵ�����ݿ��������
�ڹ�ϵ�����ݿ���,ʵ���Լ�ʵ������ϵ���ɵ�һ�Ľṹ��������ʾ,�������ṹ��һ�Ŷ�ά����ͼ 1 ��ʾ��ѧ��ѡ��ϵͳ��,ʵ���ʵ�����ϵ�����ݿ��е����ṹ��ͨ��ͼ 2 ��ʾ��
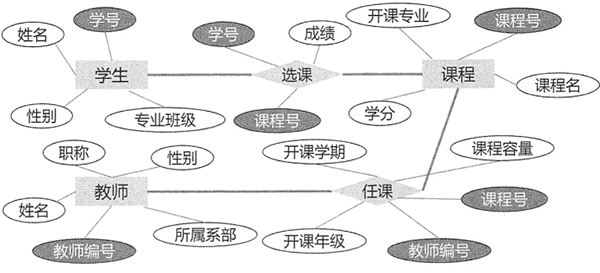
ͼ 1:��ϵ�����ݿ�
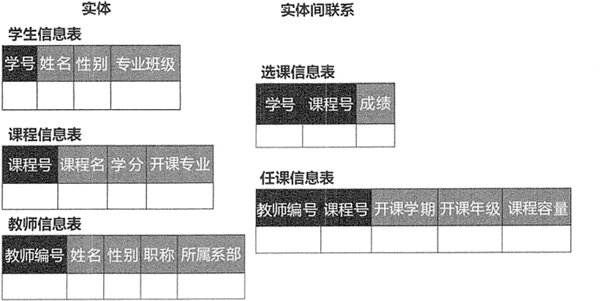
ͼ 2:ѧ��ѡ��ϵͳ���ݿ����ṹ
��ϵ�����ݿ����к��е���ʽ�洢����,��һϵ�е��к��б���Ϊ��,һ�����������ݿ⡣ͼ 3 ��ʾ��Ա����Ϣ�����ǹ�ϵ�����ݿ⡣
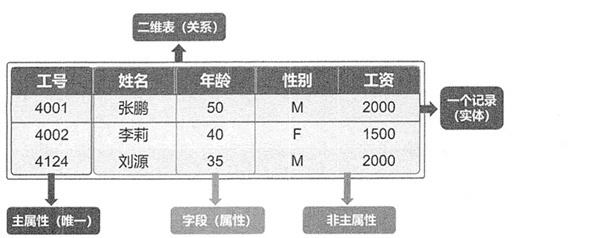
ͼ 3:Ա����Ϣ��
����˵��:
- ��ά��:Ҳ��Ϊ��ϵ,����һϵ�ж�ά����ļ���,����������洢���ݶ���֮��Ĺ�ϵ������������кͺ��������ɡ�
- ��:Ҳ��Ԫ����¼,�ڱ�����һ����������ݼ���,����һ��ʵ�塣
- ��:Ҳ���ֶλ�����,�ڱ�����һ�����е����ݼ��ϡ���Ҳ�����˱��е����ݽṹ��
- ������:��ϵ�е�ijһ������,�����ǵ�ֵΨһ�ر�ʶһ����¼,��Ƹ�������Ϊ�����Ի������������Կ�����һ������,Ҳ�����ɶ�����Թ�ͬ��ɡ���ͼ 1-5 ��,ѧ����ѧ����Ϣ����������,���ǿγ���Ϣ����,ѧ�źͿγ̺Ź�ͬΨһ�ر�ʶ��һ����¼,����ѧ�źͿγ̺�һ������˿γ���Ϣ���������ԡ�
�ṹ����ѯ����
��ϵ�����ݿ�ĺ�������ṹ���IJ�ѯ����(Structured Query Language, SQL),SQL ���������ݵIJ�ѯ�����ݡ�����Ϳ���,��һ���ۺϵġ�ͨ�õ��Ҽ��������ݿ�������ԡ�ͬʱ SQL ����һ�ָ߶ȷǹ��̻�������,���ݿ������ֻ��Ҫָ����ʲô,������Ҫָ������ô��������ɶ����ݿ�Ĺ�����
SQL ����ʵ�����ݿ�ȫ�������ڵ����в���,���� SQL �Բ���֮����ͳ��˼����ϵ�����ݿ���������ġ��Խ�ʯ��,SQL ����ÿһ�α�������ƶ������Ź�ϵ�����ݿ��Ʒ�ķ�չ����
SQL ���������ĸ����֡�
���ݶ�������(DDL)
DDL ���� CREATE��DROP��ALTER �ȶ����������ݿ���ʹ�� CREATE �������±�,DROP ��ɾ����,ALTER �������ݿ������ġ�
����,����ѧ����Ϣ��ʹ����������:
CREATE TABLE StuInfo(id int(10) NOT NULL,PRIMARY KEY(id),name varchar(20), female bool,class varchar(20));
���ݲ�ѯ����(Data Query Language, DQL)
DQL ����������ݲ�ѯ,���Dz�������ݱ��������ġ�
DQL����ṹ����:
SELECT FROM ����1,��2
where ��ѯ���� #������� and��or�� not�� =��between��and��in��like ��;
group by �����ֶ�
having (������������)
order by �����ֶκ���;
���ݲ�������(Data Manipulation Language, DML)
DML ��������ݿ�����������ݷ��ʹ�����ָ�,�� INSERT��UPDATE��DELETE ����ָ��Ϊ����,�ֱ�������롢������ɾ����
������������������:
INSERT ���� (�ֶ�1,�ֶ�2,��,�ֶ�n,) VALUES (�ֶ�1ֵ,�ֶ�2ֵ,��,�ֶ�nֵ) where ��ѯ����;
���ݿ�������(Data Control Language, DCL)
DCL ��һ�ֿɶ����ݷ���Ȩ���п��Ƶ�ָ������Կ����ض��û��˻��Բ鿴����Ԥ������û��Զ��庯�������ݿ������Ȩ��,�� GRANT �� REVOKE ����ָ����ɡ�
DCL �Կ����û��ķ���Ȩ��Ϊ��,GRANT Ϊ��Ȩ���,��Ӧ�� REVOKE �dz�����Ȩ��䡣
��ϵ�����ݿ����ȱ��
��ϵ�����ݿ��Ѿ���չ����ʮ��,������֪ʶ����ؼ����Ͳ�Ʒ����������,��Ŀǰ������Ӧ����㷺�����ݿ�ϵͳ��
��ϵ�����ݿ���ŵ�
- ��������:��ά���ṹ�dz�����������ĸ���,��ϵ������ģ����Բ��������ģ�ͺ���״������ģ�͵�����ģ����˵���������⡣
- ʹ�÷���:ͨ�õ� SQL ʹ�û�������ϵ�����ݿ�dz����㡣
- ����ά��:�ḻ�������Դ�������������������ݲ�һ�µ����⡣��ϵ�����ݿ��ṩ�������֧��,�ܱ�֤ϵͳ���������ȷִ��,ͬʱ�ṩ����Ļָ����ع����������ƺ���������Ľ����
��ϵ�����ݿ��ȱ��
���Ÿ������ҵ��ķ�չ,��ϵ�����ݿ���������Ժ������ݵĴ�������,�������²��㡣
- �߲�����д������:��վ���û��IJ����Է��ʷdz���,��һ̨���ݿ���������������,��Ӳ�� I/O ����,��������ܶ���ͬʱ���ӡ�
- �Ժ������ݵĶ�дЧ�ʵ�:������������̫��,��ÿ�εĶ�д���ʶ����dz�������
- ��չ�Բ�:��һ��Ĺ�ϵ�����ݿ�ϵͳ��,ͨ���������ݿ��������Ӳ�����ÿ�������ݴ���������,��������չ����������չ�ջ�ﵽӲ�����ܵ�ƿ��,��Ӧ�Ի��������ݱ�ըʽ������������һ����չ��ʽ�Ǻ�����չ,�����ö�̨�������ɼ�Ⱥ,��ͬ��ɶ����ݵĴ洢�������ʹ��������ֺ�����չ�ļ�Ⱥ�����ݽ��з�ɢ�洢��ͳһ����,������Ժ������ݵĴ洢�ʹ��������������ڹ�ϵ�����ݿ��������ģ�͡�������Լ���������ǿһ���Ե��ص�,����������ʵ�ָ�Ч�ʵġ�������չ�ķֲ�ʽ�ܹ���
NoSQL���ݿ����������Щ?
�����ǵ����������м�ֵ���ʲ�֮һ����������ʱ��,�����������ռ����ݵ������������,���Ǵ�ͳ�Ĺ�ϵ�����ݿ��ڿ���չ�ԡ�����ģ�ͺͿ����Է�����ԶԶ�������㵱ǰ�����ݴ�������,���,���� NoSQL ���ݿ�ϵͳӦ�˶�����
NoSQL ���ݿⲻ���ϵ�����ݿ�����������ͬ���ص�,��ѭ��ͬ�ı���NoSQL ���ݿ����Ͷ���,�����㲻ͬ������Ӧ������,���ȡ���˾�ijɹ���
NoSQL ���ݿ����������������������ƺ�ǿһ���Ի���,����ȡ���õķֲ�ʽ���������ͺ�����չ����,������µ�����ģ��,ʹ���ڲ�ͬ��Ӧ�ó�����,���ض�ҵ�����ݾ��и�ǿ�Ĵ������ܡ�
NoSQL ���ݿ������Ϊ�����㻥������ҵ�������������,���������ݾ��д��������������� ���ٻ����ص㡣
����Ϣ��ʱ��������,��������������Ѹ��,���ݼ��Ϲ�ģ��ʵ�ִ� GB��PB �� ZB �ķ�Ծ�����ݲ������Ǵ�ͳ�Ľṹ������,�������˴����ķǽṹ���Ͱ�ṹ������,��ϵ�����ݿ����洢�������ݡ�
���,�ܶ������˾�����з����͵ġ��ǹ�ϵ�͵����ݿ�,����ǹ�ϵ�����ݿ�ͳ��Ϊ NoSQL ���ݿ�,����Ҫ�������¡�
��������ģ��
��������������վ�û���Ϣ������λ�����ݡ��罻ͼ�ס��û����������ݡ�������־�����Լ����������ݵ�,���ڿ��ٸı������ǵ�ͨ�š������桢���ֵ��ճ�����,û��ʹ����Щ���ݵ�Ӧ�úܿ�ͻᱻ�û���������������ϣ��ʹ�÷dz��������ݿ�,�����µ���������,���Ҳ��ᱻ�����������ṩ�̵����ݽṹ�仯��Ӱ�졣
��ϵ�����ݿ������ģ�Ͷ����ϸ�,�����������µ��������͡�����,��Ҫ�洢�ͻ��ĵ绰���롢��������ַ�����е���Ϣ,�� SQL ���ݿ���Ҫ��ǰ֪��Ҫ�洢����ʲô����������ݿ���ģʽ��˵ʮ�ֲ�����,��Ϊÿ�����������ʱ,ͨ������Ҫ�ı����ݿ��ģʽ��
NoSQL ���ݿ��ṩ������ģ�����ܺܺõ�������������,����Ӧ�ÿ���ͨ��������������ģ�ʹ洢���ݶ������ı�;����ֻ�����Ӹ������,����������ݵ�Ǩ�ơ�
��������ǿ
����ҵ��˵,��ϵ�����ݿ�һ��ʼ���ձ��ѡ��Ȼ��,��ʹ�ù�ϵ�����ݿ�Ĺ�����ȴ������Խ��Խ�������,ԭ���������������Ļ���,��������չ�����Ǻ�����չ�ġ���ʹ�����Dz��ʺ���Щ��Ҫ���Ҷ�̬�������Ե�Ӧ�á�
NoSQL ���ݿ��һ��ʼ���Ƿֲ�ʽ��������չ��,��˷dz��ʺϻ�����Ӧ�÷ֲ�ʽ�����ԡ�
�ڻ�����Ӧ����,�����ݿ���������������ݴ洢�����ݷ��ʵ�����ʱ,ֻ��Ҫ���Ӷ�̨������,���û������ɢ����̨��������,���ɼ��ٵ�̨������������ƿ�����ֵĿ����ԡ�
�Զ���Ƭ
���ڹ�ϵ�����ݿ�洢���ǽṹ��������,����ͨ������������չ,����̨������Ҫ�����������ݿ���ȷ���ɿ��������ݵij��������ԡ��������Ĵ����Ƿdz������,������չҲ���ܵ����ơ������������Ľ���������Ǻ�����չ,�����ӷ�������������չ��̨�������Ĵ���������
NoSQL ���ݿ�ͨ����֧���Զ���Ƭ,����ζ�����ǻ��Զ����ڶ�̨�������Ϸַ�����,������ҪӦ�ó������Ӷ���IJ�����
�Զ�����
NoSQL ���ݿ�֧���Զ����ơ��� NoSQL ���ݿ�ֲ�ʽ��Ⱥ��,���������Զ������ݽ��б���,����һ�����ݸ��ƴ洢�ڶ�̨�������ϡ����,������û�����ͬһ����ʱ,���Խ��û������ɢ����̨�������С�
ͬʱ,��ij̨���������ֹ���ʱ,���������������ݿ����ṩ����,�� NoSQL ���ݿ�ķֲ�ʽ��Ⱥ���и߿��������ֱ��ָ���������
�ֲ�ʽ���ݿ�����Щ�ص�?
��������Ҫͨ���ֲ�ʽ�ļ�Ⱥ��ʽ������洢�ͷ��ʵ����⡣�ֲ�ʽϵͳ�ĺ����������ö�̨������Эͬ����,��ɵ�̨������������������,�����Ǹ߲������ߴ�������������
�ֲ�ʽ���ݿ������ݿ⼼�������缼�����ϵIJ���,��ͨ�����缼���������Ϸֿ������ݿ�������һ��,�����������ϵļ��й�����
�ڷֲ�ʽ���ݿ�ϵͳ��,һ��Ӧ�ó�����Զ����ݿ����������,���ݿ��е����ݷֱ�洢�ڲ�ͬ�ľֲ����ݿ���,�ɲ�ͬ�����ϲ�ͬ�� DBMS ���й���,�����ϵ�ṹ����ͼ��ʾ��
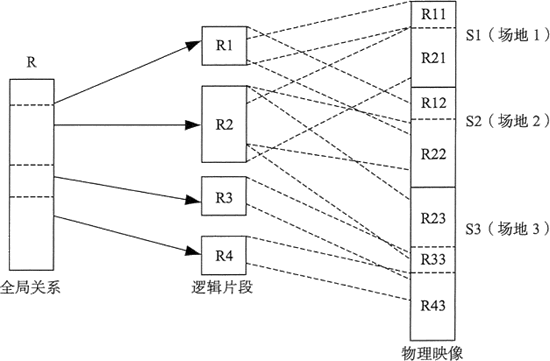
�ֲ�ʽ���ݴ���ʹ�÷ֶ���֮�İ취��������ģ���ݹ�������,���������ݵĻ����ص����¡�
�ֲ���������
�ڷֲ�ʽϵͳ��,���ݲ��Ǵ洢��һ��������,���Ǵ洢�ڼ��������Ķ�������ϡ���������һ������,���DZ������û�����,����һ�� DBMS ͳһ�������û���������ʱ����ָ�����ݴ��������,Ҳ����Ҫ֪���ɷֲ�ʽϵͳ�е���̨����������ɡ�
�������ݵ�������
�ֲ�ʽ���ݵĸ����������������,������Э����ͬ���ֳ�ͻ���û�����ͬʱ,��ij̨���������ֹ���ʱ,�˷������ϵ������������������ϻ��б���,�����ϵͳ�Ŀ����ԡ�
���ֶั���ķ�ʽ���û���˵������,���û�����Ҫ֪�������Ĵ���,��ϵͳͳһ������Э�������ĵ��á�
����Ŀɿ���
�ֲ�ʽ���ݴ��������ظ��Ĺ���,��������˵�����ϵ�����,��ϵͳ��һ�����������������ϲ���ʹ����ϵͳ̱��,�Ӷ������ϵͳ�Ŀɿ��ԡ�
�����ڷֲ�ʽϵͳ��,�����Dz�����, ����ͬ�û�������ͬһʱ���ͬһ����Դ���з���,���Ҫ��ϵͳ֧�ֲַ�ʽ�IJ�������,��֤ϵͳ�����ݵ�һ�¡�
�ֲ�ʽϵͳ���Խ���������ݵĴ洢�ͷ���,�����ڷֲ�ʽ������,���ݿ��������Ϊ���ӵ�����,�������¡�
- �����ڷֲ�ʽ�������Զั����ʽ���д洢,��ô,��Ϊ�û��ṩ���ݷ���ʱ���ѡ��һ������,�����û�����ijһ����������,�����ϵͳ��ÿ���������õ����¡�
- ������ڸ���ϵͳ���и�����Ϣʱ,ij�����������������Ӳ���������ܳ���������䷢�����ϡ������������,���ȷ�����ϻָ�ʱ,�˷������ϵĸ�������������һ�¡�
��Щ������ֲ�ʽ���ݿ����ϵͳ��������ս,�����Ƿֲ�ʽϵͳ���еĸ�����,������Ҫ���ǶԷֲ����ݵĹ���,��������֮���һ�����Լ����ݷ��ʵİ�ȫ�ԡ�
CAP������ʲô?
CAP ��������Էֲ�ʽ���ݿ���Ե�,����ָ��һ���ֲ�ʽϵͳ��,һ����(Consistency, C)��������(Availability, A)�������ݴ���(Partition Tolerance, P)���߲��ɼ�á�
һ����(C)
һ������ָ��all nodes see the same data at the same time��,�����²����ɹ���,���нڵ���ͬһʱ���������ȫһ�¡�
һ���Կ��Է�Ϊ�ͻ��˺ͷ����������ͬ���ӽ�:
- �ӿͻ��˽Ƕ�����,һ������Ҫָ����û���������ʱ���µ�������α������û���ȡ������;
- �ӷ��������,һ���������û��������ݸ���ʱ��ν����ݸ��Ƶ�����ϵͳ,�Ա�֤���ݵ�һ�¡�
һ�������ڲ�����дʱ�Ż���ֵ�����,���������һ���Ե�����ʱ,һ��Ҫע���Ͽ��Dz�����д�ij�����
������(A)
��������ָ��reads and writes always succeed��,���û���������ʱ,ϵͳ�Ƿ�����������Ӧʱ�䷵�ؽ����
�õĿ�������Ҫ��ָϵͳ�ܹ��ܺõ�Ϊ�û�����,�������û�����ʧ�ܻ��߷��ʳ�ʱ���û����鲻�õ��������ͨ�������,��������ֲ�ʽ�������ࡢ���ؾ�������źܴ�Ĺ�����
�����ݴ���(P)
�����ݴ�����ָ��the system continues to operate despite arbitrary message loss or failure of part of the system��,���ֲ�ʽϵͳ������ij�ڵ������������ϵ�ʱ��,��Ȼ�ܹ������ṩ����һ���ԺͿ����Եķ���
�����ݴ��Ժ���չ�Խ�����ء��ڷֲ�ʽӦ����,������ΪһЩ�ֲ�ʽ��ԭ����ϵͳ��������ת�������ݴ��Ը�ָ�ڲ��ֽڵ���ϻ���ֶ����������,��Ⱥϵͳ��Ȼ���ṩ����,������ݵķ��ʡ������ݴ�����Ϊ��ϵͳ�в��öั�����ԡ�
���ϵ
CAP ������Ϊ�ֲ�ʽϵͳֻ�ܼ�����е���������,������ CA��CP��AP �������,��ͼ��ʾ��
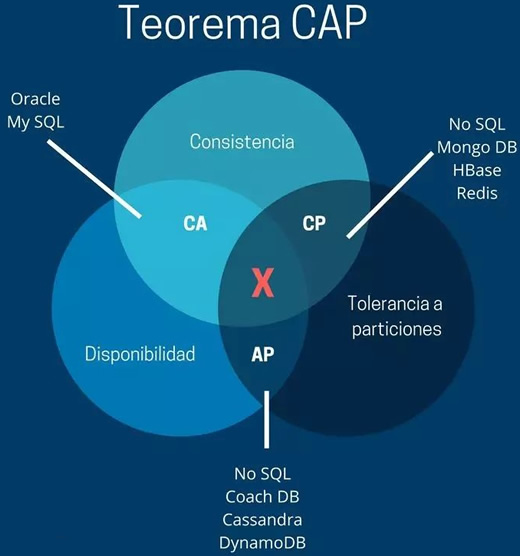
CA without P
�����Ҫ�� Partition Tolerance,������������,��ǿһ���ԺͿ������ǿ��Ա�֤�ġ���ʵ������ʼ�մ��ڵ�����,��� CA �ķֲ�ʽϵͳ��������������������ϵͳ��Ȼ���� CA��
CP without A
�����Ҫ�������,�൱��ÿ��������Ҫ�ڸ�������֮��ǿһ��,�������ݴ��Իᵼ��ͬ��ʱ�������ӳ�,��� CP Ҳ�ǿ��Ա�֤�ġ��ܶഫͳ�����ݿ�ֲ�ʽ������������ģʽ��
AP without C
���Ҫ�����Ը߲���������,�������һ���ԡ�һ����������,�ڵ�֮����ܻ�ʧȥ��ϵ,Ϊ��ʵ�ָ߿���,ÿ���ڵ�ֻ���ñ��������ṩ����,�������ᵼ��ȫ�����ݵIJ�һ���ԡ�
�ܽ�
��ʵ����,�ɸ���ʵ���������Ȩ��,���������������ṩ���÷�ʽ,���û��������ѡ�� CAP ���ԡ�
CAP ���ۿ����ڲ�ͬ�IJ���,���Ը��� CAP ԭ�����ƾֲ�����Ʋ���,����,�ڷֲ�ʽϵͳ��,ÿ���ڵ��������������ܱ�֤ CA ��,������������Ҫ��� AP �� CP��
ACIDԭ����ʲô?
ACID �ǹ�ϵ�����ݿ�����������Ҫ���ص�ԭ��������һ��һ�ºͿɿ�����Ļ�����Ԫ,����Ϊԭ�ӵ�Ԫִ�е�һϵ�����ݿ������ɡ����ݿ��һ��������ʱ���ṩ�������,��������������ֹͣ��ȡ����ع��ȡ�
��ϵ�����ݿ�֧������� ACID ԭ��,��ԭ����(Atomicity)��һ����(Consistency)��������(Isolation)���־���(Durability),������ԭ��֤��������̵������ݵ���ȷ��,�����������¡�
ԭ����(A)
һ�����������ϵ�в������豻����һ������,���еIJ���Ҫôȫ�����,Ҫôһ��Ҳ������ɡ��������������з�������,���ع�������ʼǰ��״̬,��Ҫ���ı�����ݿ��¼���ᱻ�ı䡣
һ����(C)
һ������ָ������ʼ֮ǰ����������Ժ�,���ݿ��������Լ��û�б��ƻ�,�����ݿ��������ƻ���ϵ���ݵ������Լ�ҵ�����ϵ�һ���ԡ�
������(I)
��Ҫ����ʵ�ֲ�������,�����ܹ�ȷ������ִ�е�����˳��һ����һ����ִ�С�ͨ������,һ��δ�������Ӱ������һ��δ�������
�־���(D)
һ��һ�������ύ,��Ӧ�ó־ñ���,������Ϊ������������ͻ��ȡ���������
��������ĸ����Կ��Կ�����ϵ�����ݿ���Ҫ��ǿһ���Ե�,������һ���� NoSQL ���ݿ������ص������Ļ��ơ�ԭ���ǵ����ݿⱣ��ǿһ����ʱ,���ѱ�֤ϵͳ���к�����չ�Ϳ����Ե�����,�����Էֲ�ʽ���ݴ洢����ֻ�ṩ����һ���Եı���,�� BASE ԭ����
BASEԭ��������һ����
BASE ��������� NoSQL ���ݿ���Ե�,���Ƕ� CAP ������һ����(C)�Ϳ�����(A)����Ȩ��Ľ��,Դ��������Լ��ڴ��ģ�ֲ�ʽϵͳ��ʵ�����ܽᡣ�����˼����������ǿһ����,��ÿ��Ӧ�ö����Ը����������ص�,�����ʵ���ʽ�ﵽ����һ���ԡ�
��������(Basically Available)
��������ָ�ֲ�ʽϵͳ�ڳ��ֹ���ʱ,ϵͳ������ʧ���ֿ�����,����֤���Ĺ��ܻ��ߵ�ǰ����Ҫ���ܿ��á�
�����û���˵,���ǵ�ǰ���ע�Ĺ��ܻ�����õĹ��ܵĿ����Խ����ñ�֤,�����������ܻᱻ������
��״̬(Soft-state)
��״̬����ϵͳ���ݴ����м�״̬,������Ӱ��ϵͳ�����������,��������ͬ�ڵ�ĸ���֮�������ʱ�IJ�һ�������
����һ����(Eventually Consistent)
����һ����Ҫ��ϵͳ�����ݸ��������ܹ�һ��,������Ҫʵʱ��֤���ݸ���һ�¡�����,����ϵͳ�еķ�ʵʱת�˲���,���� 24 Сʱ���û��˻���״̬��ת��ǰ���Dz�һ�µ�,�� 24 Сʱ���˻����ݱ�����ȷ��
����һ������ BASE ԭ���ĺ���,Ҳ�� NoSQL ���ݿ����Ҫ�ص�,ͨ������һ����,���ϵͳ�Ŀ������ԡ��ɿ��ԺͿ����ԡ����Ҷ��ڴ���� Web Ӧ��,��ʵ������Ҫǿһ����,�������һ���Զ���ȡ�߿�����,�Ƕ����ֲ�ʽ���ݿ��Ʒ�ķ���
����һ���Կ��Է�Ϊ�ͻ��˺ͷ����������ͬ���ӽǡ�
�ӿͻ��˵ĽǶȿ�
�ӿͻ�������,һ������Ҫָ���Ƕಢ������ʱ���¹���������λ�ȡ������,����һ���������� 5 �����֡�
| һ���Ա��� | ˵�� |
|---|---|
| ���һ���� | ������� A ֪ͨ���� B ���Ѹ�����һ��������,��ô,���� B �ĺ������ʽ����ظ��º��ֵ,��һ��д�뽫��֤ȡ��ǰһ��д�롣����� A �������ϵ�Ľ��� C �ķ�������һ�������һ���Թ��� |
| ����֮��д(Read-Your-Writes) һ���� | ������ A �Լ�����һ��������֮��,�����Ƿ��ʵ����¹���ֵ,�Ҳ��ῴ����ֵ���������һ����ģ�͵�һ�������� |
| �Ự(Session)������ | ������һ��ģ�͵�ʵ�ð汾,���ѷ��ʴ洢ϵͳ�Ľ��̷ŵ��Ự���������С�ֻҪ�Ự������,ϵͳ�ͱ�֤������֮��д��һ���ԡ��������ijЩʧ��������Ự��ֹ,��Ҫ�����µĻỰ,����ϵͳ��֤�����������µĻỰ�� |
| ����(Monotonic)��һ���� | ��������Ѿ����������ݶ����ij��ֵ,��ô�κκ������ʶ����᷵�����Ǹ�ֵ֮ǰ��ֵ�� |
| ����дһ���� | ϵͳ��֤����ͬһ�����̵�д����˳��ִ�С� |
��������һ���ԵIJ�ͬ��ʽ���Խ������,����,������һ���Ժ͡�����֮��д��һ���ԾͿ������ʵ�֡���ʵ���ĽǶ�����,�����ߵ���϶�ȡ�Լ����µ�����,һ����ȡ�����µİ汾,�Ͳ����ٶ�ȡ�ɰ汾,�Ի��ڴ˼ܹ��ϵij�����˵,����ٺܶ����ķ��ա�
�ӷ������ĽǶȿ�
�ӷ��������,��ξ���ؽ����º�����ݷֲ�������ϵͳ,���ʹﵽ����һ���Ե�ʱ�䴰��,�����ϵͳ�Ŀ��öȺ��û�����ȷdz���Ҫ�ķ��档
�ֲ�ʽ����ϵͳ����������:
- N Ϊ���ݸ��Ƶķ�����
- W Ϊ��������ʱ��Ҫ����д�����Ľڵ�����
- R Ϊ��ȡ���ݵ�ʱ����Ҫ��ȡ�Ľڵ�����
��� W+R>N,д�Ľڵ�Ͷ��Ľڵ��ص�,����ǿһ���ԡ�����,���ڵ��͵�һ��һ��ͬ�����ƵĹ�ϵ�����ݿ�(N=2, W=2,R=1),�ܶ���������DZ��������,����һ�µġ�
��� W+R��N,������һ���ԡ�����,����һ��һ���첽���ƵĹ�ϵ�����ݿ�(N=2,W=1,R=1),��������DZ���,���������ȡ�����Ѿ����¹�������,��������һ���ԡ�
���ڷֲ�ʽϵͳ,Ϊ�˱�֤�߿�����,һ������ N��3�����ò�ͬ��N��W��R ���,���ڿ����Ժ�һ����֮��ȡһ��ƽ��,����Ӧ��ͬ��Ӧ�ó�����
���N=W �� R=1,���κ�һ��д�ڵ�ʧЧ,���ᵼ��дʧ��,��˿����Իή�͡������������ݷֲ��� N ���ڵ���ͬ��д���,��˿��Ա�֤ǿһ���ԡ�
��� N=R �� W=1,��ֻ��Ҫһ���ڵ�д��ɹ�����,д���ܺͿ����Զ��Ƚϸߡ����Ƕ�ȡ�����ڵ�Ľ��̿��ܲ��ܻ�ȡ���º������,�������һ���ԡ������������,��� W<(N+1)/2,����д��Ľڵ㲻�ص�,������д��ͻ��
NoSQL���ݿ�����Щ?
��ϵ�����ݿ��Ʒ�ܶ�,�� MySQL��Oracle��Microsoft SQL Sever ��,�����ǵĻ���ģ�Ͷ��ǹ�ϵ������ģ�͡�NoSQL ��û��ͳһ��ģ��,�����Ƿǹ�ϵ�͵ġ�
������ NoSQL ���ݿ������ֵ���ݿ⡢�������ݿ⡢�ĵ����ݿ��ͼ�����ݿ�,����������ص������ʾ��
| ���� | ��ز�Ʒ | Ӧ�ó��� | ����ģ�� | �ŵ� | ȱ�� |
|---|---|---|---|---|---|
| ��ֵ���ݿ� | Redis��Memcached��Riak | ���ݻ���,��Ự�������ļ���������; Ƶ����д��ӵ�м�����ģ�͵�Ӧ�� | <key,value> ��ֵ��,ͨ��ɢ�б���ʵ�� | ��չ�Ժ�,����Ժ�,��������ʱ���ܸ� | �����ṹ��,ͨ��ֻ�������ַ������߶���������,ֻ��ͨ��������ѯֵ |
| �������ݿ� | Bigtable��HBase��Cassandra | �ֲ�ʽ���ݴ洢����� | ������ʽ�洢,��ͬһ�����ݴ���һ�� | ����չ��ǿ,�����ٶȿ�,�����Ե� | ���ܾ���,��֧�������ǿһ���� |
| �ĵ����ݿ� | MongoDB��CouchDB | Web Ӧ��,�洢�����ĵ������ư�ṹ�������� | <key,value> value �� JSON �ṹ���ĵ� | ���ݽṹ���,���Ը��� value �������� | ȱ��ͳһ��ѯ� |
| ͼ�����ݿ� | Neo4j��InfoGrid | �罻���硢�Ƽ�ϵͳ,רע������ϵͼ�� | ͼ�ṹ | ֧�ָ��ӵ�ͼ���㷨 | �����Ը�,ֻ��֧��һ�������ݹ�ģ |
NoSQL ���ݿⲢû��һ��ͳһ�ļܹ�,���ֲ�ͬ�� NoSQL ���ݿ�֮��IJ���̶�,ԶԶ�������ֹ�ϵ�����ݿ�֮��IJ�ͬ��
����˵,NoSQL ���ݿ��������,һ������� NoSQL ���ݿ��Ȼ�ر�������ijЩ���ϻ���ijЩӦ��,����Щ�����л�ԶԶʤ����ϵ�����ݿ�������� NoSQL ���ݿ⡣
������ NoSQL ���ݿ��Ϊ���¼��֡�
1) ��ֵ���ݿ�
��һ�����ݿ���Ҫ��ʹ�õ�һ��ɢ�б�,���������һ���ض��ļ���һ��ָ��ָ���ض������ݡ�
��ֵģ�Ͷ��� IT ϵͳ��˵,���������ڼ��ײ��𡣼�ֵ���ݿ�����ռ������ݽ��ж�λ,������ͨ���Լ���������ͷ���,��ʵ�ָ����ٵ����ݶ�λ��
2) �������ݿ�
�������ݿ�ͨ������Ӧ�Էֲ�ʽ�洢�ĺ������ݡ�����Ȼ����,�������ǵ��ص���ָ���˶����,��ͼ��ʾ��
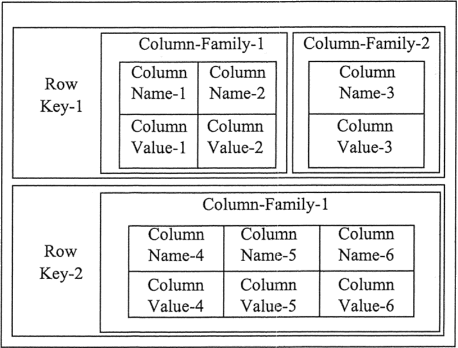
���������ݿ�������������,ÿһ�ж��йؼ��� Row Key,ÿһ���ɶ���������,�� Column-Family-1 �� Column-Family-2,��ÿ�������ɶ������ɡ�
3) �ĵ����ݿ�
�ĵ����ݿ��������� Lotus Notes �칫����,�����ֵ���ݿ����ơ������͵�����ģ���ǰ汾�����ĵ�,�ĵ����ض��ĸ�ʽ�洢,�� JSON��
�ĵ����ݿ���Կ�����ֵ���ݿ��������,����֮��Ƕ��ֵ,��ͼ��ʾ��

�ĵ����ݿ�ȼ�ֵ���ݿ�IJ�ѯЧ�ʸ���, ��Ϊ�ĵ����ݿⲻ�����Ը��ݼ���������,ͬʱ�����Ը����ĵ����ݴ���������
4) ͼ�����ݿ�
ͼ�����ݿ���Դ��ͼ���е�����ѧ,�Խڵ㡢���ڵ�֮��Ĺ�ϵ���洢���������е�����,��ͼ��ʾ��
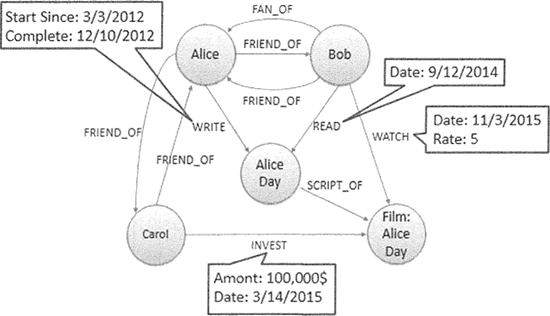
�������˽ṹ���� E-R ͼ,����ͼ��ģʽ��,��ϵ�ͽڵ㱾����������,���� E-R ͼ��,��ϵ��������һ�ֽṹ��
�ڴ����ݿ���ʲô?
�ڴ����ݿ���Ҫ�ǰѴ��̵����ݼ��ص��ڴ��н�����Ӧ������
��ֱ�Ӷ�ȡ�����������,�ڴ�����ݶ�ȡ�ٶ�Ҫ�߳�����������,���,�����ݱ������ڴ����ܹ���������Ӧ�õ����ܡ�
�ڴ����ݿ�ı��˴������ݹ����Ĵ�ͳ��ʽ,����ȫ�����ݶ����ڴ��е��ص������������ϵ�ṹ,���������ݻ��桢�����㷨�����в�������Ҳ��������Ӧ������,���,�����ݴ����ٶ�һ��ȴ�ͳ���ݿ�����ݴ����ٶȿ켸ʮ����
�ڴ����ݿ������ص�����Ӧ�����ݳ�פ�ڴ���,�������ֻ��ʵʱ�ڴ����ݿ���ڴ�������ݽ�����
�������ڴ����ݿ��� Memcached��Redis��SQLite��Microsoft SQL Server Compact �ȡ�
Memcached���Ž̳�
Memcached �� LiveJournal ���� Danga Interactive ��˾�IJ�����?�ƴ��������(BradFitzpatric)������һ���ڴ����ݿ�,�����ѱ�Ӧ���� Facebook��LiveJournal �ȹ�˾������� Web ����������
Ŀǰ�������������ȫ�����,��������������������Ŀ,���Դ˷ֵ����Դ�ͳ���ݿ�IJ�������ѹ����
Memcached ��������Ӧ�Դ���ͬʱ���ֵ���������,������ӵ�ж��ص�����ṹ,�ڹ������Ʒ���,�����������ڴ��е��������µĿռ�,���� HashTable,���� HashTable ������Ч�Ĺ�����
������ʱ����� Memcache �� Memcached ���ֲ�ͬ��˵��,Ϊʲô������������?
��ʵ Memcache �������Ŀ������,�� Memcached �����������˵��������ļ�����һ������Ŀ����,��һ�����������ļ�����
ΪʲôҪʹ�� Memcached
������վ�ĸ߲�����д�ͶԺ������ݵĴ�������,��ͳ�Ĺ�ϵ�����ݿʼ����ƿ����
�����ݿ�ĸ߲�����д
��ϵ�����ݿⱾ�����Ǹ���Ȼ����,�������̷dz���ʱ(����� SQL ��䡢��������)������Թ�ϵ�����ݿ���и߲�����д(ÿ������εķ���),���ݿ�ϵͳ�������ܵġ�
�Ժ������ݵĴ���
���ڴ��͵� SNS ��վ(�� Twitter��������),ÿ������ǧ���������ݲ������Թ�ϵ�����ݿ����,�����һ�������������ݵ����ݱ��в���ij����¼,Ч�ʽ��dz��͡�
ʹ�� Memcached ���ܺܺõؽ���������⡣
���� Web Ӧ�ö������ݱ��浽��ϵ�����ݿ���(�� MySQL ),Web ���������ж�ȡ���ݲ������������ʾ��������������������,���ʵļ���,��ϵ�����ݿ�ĸ����ͻ����,������Ӧ��������վ���ӳ�ʱ�䳤�����⡣
���,ʹ�� Memcached ����ҪĿ����ͨ�������ڴ��л����ϵ�����ݿ�IJ�ѯ���,�������ݿ����������ʵĴ���,����߶�̬ Web Ӧ�õ��ٶ�,��ǿ��վ�ܹ��IJ��������Ϳ���չ�ԡ�
ͨ�������ȹ滮�õ�ϵͳ�ڴ�ռ�����ʱ�������ݿ��еĸ�������,�Դﵽ����ǰ��ҵ�����Թ�ϵ�����ݿ��ֱ�Ӹ߲�������,�Ӷ��ﵽ�������ģ��վ��Ⱥ�ж�̬����IJ�������������
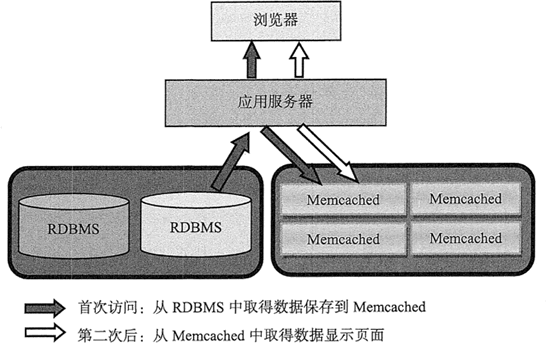
Web ��������ȡ����ʱ�ȶ� Memcached ������,�� Memcached û�����������,�������ݿ���������,Ȼ�� Web �ٰ��������ݷ��͵� Memcached,����ͼ��ʾ��
Redis��ʲô?
Redis ��һ����Դ�ġ������ܵġ���ֵ���ڴ����ݿ�����ͨ���ṩ���ּ�ֵ�������������㲻ͬ�����µĴ洢����,����������߲㼶�Ľӿ�ʹ�����ʤ���绺�桢����ϵͳ�Ȳ�ͬ�Ľ�ɫ��
��С�ڽ����� Redis ����ʷ������,��ʹ�����ܹ����ٵض� Redis ��һ��ȫ����˽⡣
Redis ��ʷ�뷢չ
2008 ��,�������һ�Ҵ�ҵ��˾ Merzia �Ƴ���һ����� MySQL ����վʵʱͳ��ϵͳ ���� LLOOGG,Ȼ��û�����,�ù�˾�Ĵ�ʼ����������?ɣ������(Salvatore Sanfilippo)������ϵͳ�����ܸе�ʧ��,��������������Ϊ LLOOGG ��������һ�����ݿ�,���� 2009 �꿪�����, ������ݿ����Redis��
�����������в�������ֻ�� Redis ���� LLOOGG ��һ���Ʒ,����ϣ���ø������ʹ����,�����������н� Redis ��Դ����,����ʼ�� Redis ����һ����Ҫ�Ĵ��빱����Ƥ��?ŵ�º�˹(Pieter Noordhuis)һ������� Redis �Ŀ���,ֱ�����졣
���������Լ�Ҳû���뵽,�ڶ̶̵ļ���ʱ����,Redis ��ӵ�����Ӵ���û�Ⱥ�塣Hacked News �� 2012 �귢����һ�����ݿ��ʹ���������,�����ʾ�н� 12% �Ĺ�˾��ʹ�� Redis��
��������������֪��,������ GitHub��Stack Overflow��Flickr����ѩ�� Instagram,���� Redis ���û�������ʹ�� Redis ���û�Խ��Խ��,������Ļ�������˾��ʹ�� Redis ��Ϊ�������档
VMware ��˾�� 2010 �꿪ʼ���� Redis �Ŀ���,�������к�Ƥ��Ҳ�ֱ���ͬ��� 3 �º� 5 �¼��� VMware,ȫְ���� Redis��
Redis ����
�洢�ṹ
�й��ű����Ա�̾���Ķ��߶��ֵ�(���ӳ�䡢��������)���ݽṹһ������Ϥ,���ڴ��� dict[��key��]=��value�� ��,��diet����һ���ֵ�ṹ����,�ַ�����key���Ǽ���,����value���Ǽ�ֵ,���ֵ��п��Ի�ȡ�����ü�����Ӧ�ļ�ֵ,Ҳ����ɾ��һ������
Redis �� Remote Dictionary Server(Զ���ֵ������)����д,�����ֵ�ṹ�洢����,����������Ӧ��ͨ�� TCP ��д�ֵ��е����ݡ�ͬ������ű������е��ֵ�һ��,Redis �ֵ��еļ�ֵ���˿������ַ���,�������������������͡�
��ĿǰΪֹ,Redis ֧�ֵļ�ֵ����������:�ַ������͡�ɢ�����͡��б����͡��������ͺ��������͡�
�����ֵ���ʽ�Ĵ洢�ṹ�볣���� MySQL �ȹ�ϵ���ݿ�Ķ�ά����ʽ�Ĵ洢�ṹ�кܴ�IJ��졣�ٸ�����,�ڳ�����ʹ�� post �����洢��һƪ���µ�����(�������⡢���ġ��Ķ����ͱ�ǩ),������ʾ:
post["title"] = "Hello World!"
post["content"] = "Blablabla..."
post["views"] = 0
post["tags"] = ["PHP","Ruby","Node.js"]
����ϣ������ƪ���µ����ݴ洢�����ݿ���,����Ҫ�����ͨ����ǩ���������¡�
���ʹ�ù�ϵ���ݿ�洢,һ��Ὣ���еı��⡢���ĺ��Ķ����洢��һ������,������ǩ�洢����һ������,Ȼ��ʹ�õ��������������ºͱ�ǩ������Ҫ��ѯʱ����Ҫ����������,���Ǻ�ֱ�ۡ�
�� Redis �ֵ�ṹ�Ĵ洢��ʽ�ͶԶ��ּ�ֵ�������͵�֧��ʹ�ÿ����߿��Խ������е�����ֱ��ӳ�䵽 Redis ��,������ Redis �еĴ洢��ʽ�����ڳ����еĴ洢��ʽ�dz����ơ�
ʹ�� Redis ����һ����������Բ�ͬ�����������ṩ�˷dz�����IJ�����ʽ,��ʹ�ü������ʹ洢���±�ǩ,Redis ���ԶԱ�ǩ�����罻���������ȼ������������
�ڴ�洢��־û�
Redis ���ݿ��е��������ݶ��洢���ڴ��С������ڴ�Ķ�д�ٶ�Զ����Ӳ��,��� Redis ������������������Ӳ�̴洢�����ݿ�����зdz����Ե����ơ���һ̨��ͨ�ıʼDZ�������,Redis ������һ���ڶ�д���� 10 �����ֵ��
�����ݴ洢���ڴ���Ҳ������,����,�����˳����ڴ��е����ݻᶪʧ������ Redis �ṩ�˶Գ־û���֧��,�����Խ��ڴ��е������첽д��Ӳ����,ͬʱ��Ӱ��������ṩ����
���ܷḻ
Redis ��Ȼ����Ϊ���ݿ����,���������ṩ�˷ḻ�Ĺ���,Խ��Խ����˽����������桢 ����ϵͳ�ȡ�Redis ��ν��������ʵ�Ķ����֡�
Redis ����Ϊÿ������������ʱ��(Time To Live, TTL),����ʱ�䵽�ں�����Զ���ɾ���� ��һ������ϳ�ɫ�������� Redis ������Ϊ����ϵͳ��ʹ��,�������� Redis ֧�ֳ־û��ͷḻ����������,ʹ���Ϊ��һ���dz����еĻ���ϵͳ Memcached �����������ߡ�
���� Redis �� Memcached ������һֱ��һ�����ŵĻ��⡣���� Redis �ǵ��߳�ģ��,�� Memcached ֧�ֶ��߳�,�����ڶ�˷������Ϻ��ߵ����ܸ���һЩ��
Ȼ��,ǰ���Ѿ����ܹ�,Redis �������Ѿ��㹻����,�ھ��ֳ����������ܶ������Ϊƿ����������ʹ��ʱ��Ӧ�ù��ĵ��Ƕ����ڹ����ϵ�����,�����Ҫ�õ������������ͻ�־û��ȹ���,Redis ������ Memcached �ܺõ����Ʒ��
��Ϊ����ϵͳ,Redis ������������ռ�õ�����ڴ�ռ�,�����ݴﵽ�ռ����ƺ������һ���Ĺ����Զ���̭����Ҫ�ļ���
����֮��,Redis ���б����ͼ���������ʵ�ֶ���,֧������ʽ��ȡ,���ҿ��Ժ�����ʵ��һ�������ܵ����ȼ����С�ͬʱ,�ڸ��߲�����,Redis ��֧�֡�����/���ġ�����Ϣģʽ,�û����Ի��ڴ˹��������ҵ�ϵͳ��
���ȶ�
���һ������ʹ������̫����,��ʹ���Ĺ����ٷḻҲ���������ˡ�Redis ֱ�۵Ĵ洢�ṹʹ��ͨ�������� Redis ����ʮ�ּ��� Redis ��ʹ����������д����,�������֮�� Redis ���൱�� SQL ֮�ڹ�ϵ���ݿ⡣
����,�ڹ�ϵ���ݿ���Ҫ��ȡ posts ���� id Ϊ 1 �ļ�¼�� title �ֶε�ֵ,����ʹ������ SQL ���ʵ��:
SELECT title FROM posts WHERE id=1 LIMIT 1
���Ӧ��,�� Redis ��Ҫ��ȡ����Ϊ post:1 ��ɢ�����ͼ��� title �ֶε�ֵ,����ʹ�������������ʵ��:
HGET post : 1 title
����,HGET ����һ�����Redis �ṩ�� 100 �������,���dz��õ�ֻ��ʮ����,����ÿ�����������ס��
Redis �ṩ�˼�ʮ�ֲ�ͬ������ԵĿͻ��˿�,��Щ�ⶼ��װ�� Redis ������,�����ڳ������� Redis ���н�����ú����ס�
��Щ��ṩ�˿��Խ���������е���������ֱ������Ӧ����ʽ�洢�� Redis ��(�罫����ֱ�����б����ʹ��� Redis)�ļ���,ʹ�������dz����㡣
Redis ʹ�� C ���Կ���,������ֻ�� 3 ����С��⽵�����û�ͨ���� Redis Դ������ʹ֮���ʺ��Լ���Ŀ��Ҫ���ż�������ϣ����ե�ɡ����ݿ����ܵĿ����߶���,�����ɾ��кܴ����������
Redis �ǿ�Դ��,�н��� 100 ��������Ϊ Redis �����˴��롣���õĿ�����Χ���Ͻ��İ汾��������ʹ�� Redis ���ȶ��汾�����ܷdz��ɿ�,��˶�Ĺ�˾ѡ��ʹ�� Redis Ҳ����ӡ֤�� һ�㡣
Memcached �� Redis �Ƚ�
Memcached �� Redis �ıȽϼ��±���
| ���ݿ� | CPU | �ڴ������� | �־��� | ���ݽṹ | �������� |
|---|---|---|---|---|---|
| Memcached | ֧�ֶ�� | �� | �� | �� | Linux/Windows |
| Redis | ���� | ��(ѹ���� Memcached ��) | ��(Ӳ�̴洢,����ͬ��) | ���� | Linux |
�ġ��ֲ�ʽϵͳ
ʲô�Ƿֲ�ʽϵͳ
�ֲ�ʽϵͳ����һ��ͨ���������ͨ�š�Ϊ����ɹ�ͬ�������Э�������ļ�����ڵ���ɵ�ϵͳ���ֲ�ʽϵͳ�ij�����Ϊ�������۵ġ���ͨ�Ļ�����ɵ������������ɵļ��㡢�洢������Ŀ�������ø���Ļ���,���������������
������Ҫ��ȷ����,ֻ�е������ڵ�Ĵ����������������������ļ��㡢�洢�����ʱ��,��Ӳ��������(���ڴ桢�Ӵ��̡�ʹ�ø��õ�CPU)�߰����ò���ʧ��ʱ��,Ӧ�ó���Ҳ���ܽ�һ���Ż���ʱ��,���Dz���Ҫ���Ƿֲ�ʽϵͳ����Ϊ,�ֲ�ʽϵͳҪ��������Ȿ�����Ǻ͵���ϵͳһ����,�����ڷֲ�ʽϵͳ��ڵ㡢ͨ������ͨ�ŵ����˽ṹ,������ܶ��ϵͳû�е�����,Ϊ�˽����Щ�����ֻ��������Ļ��ơ�Э��,������������⡣����
�ںܶ�������,��Ҫ���ֲ�ʽϵͳ��Ϊ�ֲ�ʽ����(computation)��ֲ�ʽ�洢(storage)��������洢���ศ��ɵ�,������Ҫ����,Ҫô����ʵʱ����(������),Ҫô���Դ洢������;������Ľ��Ҳ����Ҫ�洢�ġ��ڲ���ϵͳ��,�Լ�����洢�зdz��꾡������,�ֲ�ʽϵͳֻ��������Щ�����ƹ㵽����ڵ���ˡ�
��ô�ֲ�ʽϵͳ��ô������ַ�����Щ������ڵ���,�ܼ�˼��,�ֶ���֮,����Ƭ(partition)�����ڼ���,��ô���ǶԼ�����������л�,ÿ���ڵ���һЩ,���ջ��ܾ�����,�����MapReduce��˼��;���ڴ洢,��������һ��,ÿ���ڵ��һ�������ݾ����ˡ������ݹ�ģ����ʱ��,Partition��Ψһ��ѡ��,ͬʱҲ�����һЩ�ô�:
(1)�������ܺͲ���,�������ַ�����ͬ�ķ�Ƭ,�����
(2)����ϵͳ�Ŀ�����,��ʹ���ַ�Ƭ������,������Ƭ�����ܵ�Ӱ��
����������,�з�Ƭ������,����ʵ�����ȴ�������롣ԭ������,�ֲ�ʽϵͳ���д����Ľڵ�,��ͨ������ͨ�š������ڵ�Ĺ���(����crash���ϵ硢������)�Ǹ�С�����¼�,������ϵͳ�Ĺ����ʻ���ڵ�����Ӷ�ָ��������,����ͨ��Ҳ���ܳ��ֶ��������ӳٵ������������һ������ֵġ��쳣�������,�ֲ�ʽϵͳ������Ҫ�����ȶ��Ķ����ṩ����,����Ҫ��ǿ���ݴ��ԡ���İ취,����������߸��Ƽ�(Replication),������ڵ㸺��ͬһ������,��Ϊ�����ľ��Ƿֲ�ʽ�洢��,����ڵ㸴�Ӵ洢ͬһ������,�Դ���ǿ��������ɿ��ԡ�ͬʱ,ReplicationҲ��������ܵ�����,�������ݵ�locality���Լ����û��ĵȴ�ʱ�䡣
������������Distributed systems for fun and profit ��ͼ��������˵����Partition��Replication�����Э���ġ�
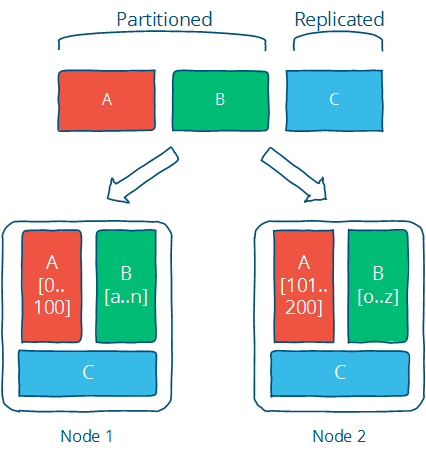
Partition��Replication�ǽ���ֲ�ʽϵͳ�����һ�����ȭ,�ܶ��������ⶼ���������˼·ȥ��������Ⲣ��������,������Ϊ�˽��һ������,��������������,����Ϊ�˿�������ɿ��Ա�֤,����������(���Ƽ�)����������,�����������һ��������ͱ�ú�ͷ��,һ������ϵͳ�ĽǶȺ��û��ĽǶ����в�ͬ�ĵȼ����֡����Ҫ��֤ǿһ����,��ô��Ӱ�������������,��һЩӦ��(������̡�����)�����Խ��ܵġ����������һ����,��ô����Ҫ�������ݳ�ͻ�������CAP��FLP��Щ���۸�������,�ڷֲ�ʽϵͳ��,û����ѵ�ѡ��,������ҪȨ��,��������ʵ�ѡ��
�ֲ�ʽϵͳ��ս
�ֲ�ʽϵͳ��Ҫ��������Э��,����������ս:
��һ,�칹�Ļ���������:
�ֲ�ʽϵͳ�еĻ���,���ò�һ��,�������еķ���Ҳ�����ɲ�ͬ�����ԡ��ܹ�ʵ��,��˴�������Ҳ��һ��;�ڵ��ͨ����������,����ͬ������Ӫ���ṩ������Ĵ�������ʱ���������ֲ�һ������ô��֤�����ͷ����,��ͬ���Ŀ��,���ĸ���С����ս��
�ڶ�,�ձ�Ľڵ����:
��Ȼ�����ڵ�Ĺ��ϸ��ʽϵ�,���ڵ���Ŀ�ﵽһ����ģ,�����ϵĸ��ʾͱ���ˡ��ֲ�ʽϵͳ��Ҫ��֤���Ϸ�����ʱ��,ϵͳ��Ȼ�ǿ��õ�,�����Ҫ��ؽڵ��״̬,�ڽڵ���ϵ�����½��ýڵ㸺��ļ��㡢�洢����ת�Ƶ������ڵ�
����,���ɿ�������:
�ڵ��ͨ������ͨ��,�������Dz��ɿ��ġ����ܵ������������:����ָ��ʱ������������
��ȵ������̵���,����ͨ��������ͷ�۵��dz�ʱ:�ڵ�A��ڵ�B��������,��Լ����ʱ����û���յ��ڵ�B����Ӧ,��ôB�Ƿ���������,����Dz�ȷ����,�����ȷ��������������,���,�Ƿ�Ҫ��������,�ڵ�B����δ���ͬһ������
�ܶ���֮,�ֲ�ʽ����ս������ȷ����,��ȷ�������ʲôʱ��crash���ϵ�,��ȷ������ʲôʱ����,��ȷ��ÿ������ͨ��Ҫ�ӳٶ��,Ҳ��ȷ��ͨ�ŶԶ��Ƿ����˷��͵���Ϣ�����ֲ�ʽ�Ĺ�ģ�Ŵ��������ȷ����,��ȷ���������������,���������ķֲ�ʽ���ۡ�Э������֤�����ֲ�ȷ���Ե������,ϵͳ���ܼ�������������
����,�ܶ���ʵ��ϵͳ�г��ֵ�����,��Դ�����ʱ��äĿ�ֹ�,����������Ǹ�Ӧ�ò�������⡣Fallacies_of_distributed_computing������˼,�����˷ֲ�ʽϵͳ���ֿ��ܵĴ���ļ���:
The network is reliable.
Latency is zero.
Bandwidth is infinite.
The network is secure.
Topology doesn��t change.
There is one administrator.
Transport cost is zero.
The network is homogeneous.
�����ڡ��ֲ�ʽϵͳԭ�����ܡ���ָ��,������Щ�쳣�����ԭ����:����ơ��Ƶ�����֤�ֲ�ʽϵͳ��Э�顢����ʱ,����Ҫ�Ĺ���֮һ����˼����ִ�����̵�ÿ������ʱһ�����������쳣�������ϵͳ�Ĵ�����ʽ����ɵ�Ӱ�졣
�ֲ�ʽϵͳ�����������
����:ʹ�÷ֲ�ʽϵͳ���û���������ϵͳ����ôʵ�ֵ�,Ҳ�����Ķ��������������ĸ��ڵ�,���û�����,�ֲ�ʽϵͳ����߾������û�������֪��������һ���ֲ�ʽϵͳ,�ڡ�[Distributed Systems Principles and Paradigms](http://barbie.uta.edu/~jli/Resources/MapReduce&Hadoop/Distributed Systems Principles and Paradigms.pdf)��һ����,��������ô˵��:
A distributed system is a collection of independent computers that appears to its users as a single coherent system.
����չ��:�ֲ�ʽϵͳ�ĸ���Ŀ�����Ϊ�˴������������������������,���������ӵ�ʱ��,�ֲ�ʽϵͳ�Ĵ���������Ҫ��֮���ӡ�����˵,Ҫ�ȽϷ����ͨ�����ӻ�����Ӧ��������������,ͬʱ,�������ģ������ʱ��,���Գ���һЩ����Ļ���,�ﵽ��̬������Ч��
��������ɿ���:һ����˵,�ֲ�ʽϵͳ����Ҫ��ʱ������7*24Сʱ�ṩ����ġ���������ָϵͳ�ڸ�����������ṩ���������,����˵,����ͨ��������ʱ������������ʱ��ı�֪������;���ɿ��Զ���ָ��������ȷ���洢�����ݲ���ʧ��
������:�����ǵ������Ƿֲ�ʽϵͳ,��Ҷ��dz���ע���ܡ���ͬ��ϵͳ�����ܵĺ���ָ���Dz�ͬ��,�����:�߲���,��λʱ���ڴ���������Խ��Խ��;���ӳ�:ÿ�������ƽ��ʱ��Խ��Խ�á������ʵ������ϵͳCPU�ĵ��Ȳ��Ժ���
һ����:�ֲ�ʽϵͳΪ����߿����Կɿ���,һ�����������(���Ƽ�)����ô��α�֤��Щ�ڵ��ϵ�״̬һ��,����Ƿֲ�ʽϵͳ���ò���Ե�һ�������⡣һ�����кܶ�ȼ�,һ����Խǿ,���û�Խ�Ѻ�,������Լϵͳ�Ŀ�����;һ���Եȼ�Խ��,�û�����Ҫ�������ݲ�һ�µ����,��ϵͳ�Ŀ����ԡ������Ժܸߺܶࡣ
��������ۡ�Э��
��������һ�������ṩ����Ĵ��ͷֲ�ʽϵͳ,�û����ӵ�ϵͳ,��һЩ����,����һЩ��Ҫ�洢������,��ô�����������,��������Щ�����������Э����
��һ����������
�û�ʹ��Web��APP��SDK,ͨ��HTTP��TCP���ӵ�ϵͳ���ڷֲ�ʽϵͳ��,Ϊ�˸߲������߿���,һ�㶼�Ƕ���ڵ��ṩ��ͬ�ķ�����ô,��һ��������Ǿ���ѡ���ĸ��ڵ����ṩ����,������Ǹ��ؾ���(load balance)�����ؾ����˼��ܼ�,��ʹ�÷dz��㷺,�ڷֲ�ʽϵͳ��������վ�ķ������涼��ʹ��,����˵,ֻҪ�漰������ڵ��ṩͬ�ʵķ���,����Ҫ���ؾ��⡣
ͨ�����ؾ����ҵ�һ���ڵ�,�������������������û�������,�����п��ܼ�,Ҳ�п��ܸܺ��ӡ�������,�����ȡ����,��ô�ܿ������л����,���ֲ�ʽ����,�������û������,��ô��Ҫȥ���ݿ���ȡ���ݡ����ڸ��ӵ�����,���ܻ���õ�ϵͳ�������ķ���
����,�������A��Ҫ���÷���B�ķ���,���������ڵ���Ҫͨ��,����ͨ�Ŷ��ǽ�����TCP/IPЭ��Ļ�����,����,ÿ��Ӧ�ö���дsocket��һ�����ӡ���Ч������,�����ҪӦ�ò�ķ�װ,�������HTTP��FTP�ȸ���Ӧ�ò�Э�顣��ϵͳ���Ӹ���,�ṩ������http�ӿ�Ҳ��һ�����ѵ����顣���,���˸���һ���ij���,�Ǿ���RPC(remote produce call),�ǵ�Զ�̵��þ����ع��̵���һ������,����������ͨ�ŵ����ϸ��,�����µĽӿ�Ҳ���ӷ��㡣
һ��������ܰ���������,���ڷ���A����һЩ����,Ȼ���ڷ���B������һЩ���������������繺��,�ڶ��������Ϸ���,���˻������Ͽۿ������������Ҫ��֤ԭ����,Ҫô���ɹ�,Ҫô��������������漰���ֲ�ʽ���������,�ֲ�ʽ�����Ǵ�Ӧ�ò��汣֤һ����:ij���غ��ϵ��
����˵��һ����������������,��ʵ�����漰���������,�ֲ�ʽϵͳ���д����ķ���,ÿ���������Ƕ���ڵ���ɡ���ôһ��������ô�ҵ���һ������(��ij���ڵ���)?ͨ������Ҫ��ַ��,��ô��ȡ�����ַ,��İ취���������ļ�д��,����д�뵽���ݿ�,����Щ�����ڽڵ����ݾڵ㶯̬��ɾ��ʱ����,���ʱ�����Ҫ����ע���뷢��:�ṩ����Ľڵ���һ��Э������ע���Լ��ĵ�ַ,ʹ�÷���Ľڵ�ȥЭ��������ȡ��ַ��
���Ͽ��Կ���,Э�������ṩ�����Ļ��ķ���:��һ��ڵ��ṩ���Ƶ���ķ���,ʹ�÷dz��㷺,����������ֲ�ʽ����Э������������ľ���chubby,zookeeper��
�ص��û����������,������������һЩ���ݡ���־,ͨ��Ϊ��Ϣ,����һЩϵͳ���ܻ����Щ��Ϣ����Ȥ,������Ի��Ƽ�����ص�,����ͳ��������������,��Ϣ���������������ߡ���ô��������ô����Ϣ������������,RPC������һ���ܺõ�ѡ��,��ΪRPC�϶���ָ����Ϣ����˭,��ʵ�ʵ�����������߲��������Ҳ������˭�����������Ϣ,���ʱ����Ϣ���оͳ����ˡ�����˵,������ֻ������Ϣ�������淢������,���лὫ��Ϣ������(topic)�ַ�����ע�������������ߡ���Ϣ���������첽������Ӧ�ý�������á�
�����ᵽ,�û����������һЩ����,��Щ������ʵ��¼���û��IJ���ϰ�ߡ�ϲ��,�Ǹ��и�ҵ���IJƸ�����������Ƽ������Ͷ�š��Զ�ʶ����ʹ����˷ֲ�ʽ����ƽ̨,����Hadoop,Storm��,����������Щ���������ݡ�
���,�û��IJ������֮��,�û���������Ҫ�־û�,���������ܴ�,�����ڵ����洢,��ô���ʱ�����Ҫ�ֲ�ʽ�洢:�����ݽ��л��ַ��ڲ�ͬ�Ľڵ���,ͬʱ,Ϊ�˷�ֹ���ݵĶ�ʧ,ÿһ�����ݻᱣ���֡���ͳ�Ĺ�ϵ�����ݿ��ǵ���洢,Ϊ����Ӧ�ò���������·ֿ�ֱ�,�����ö���Ĵ����㡣������NoSql,һ����Ȼ֧�ֲַ�ʽ��
һ���ļܹ�ͼ
������һ������ȷ�ļܹ�ͼ,������ԭ�ֲ�ʽϵͳ����ɲ���(����ֻ�����ֳ�����,�������ֳ�����)
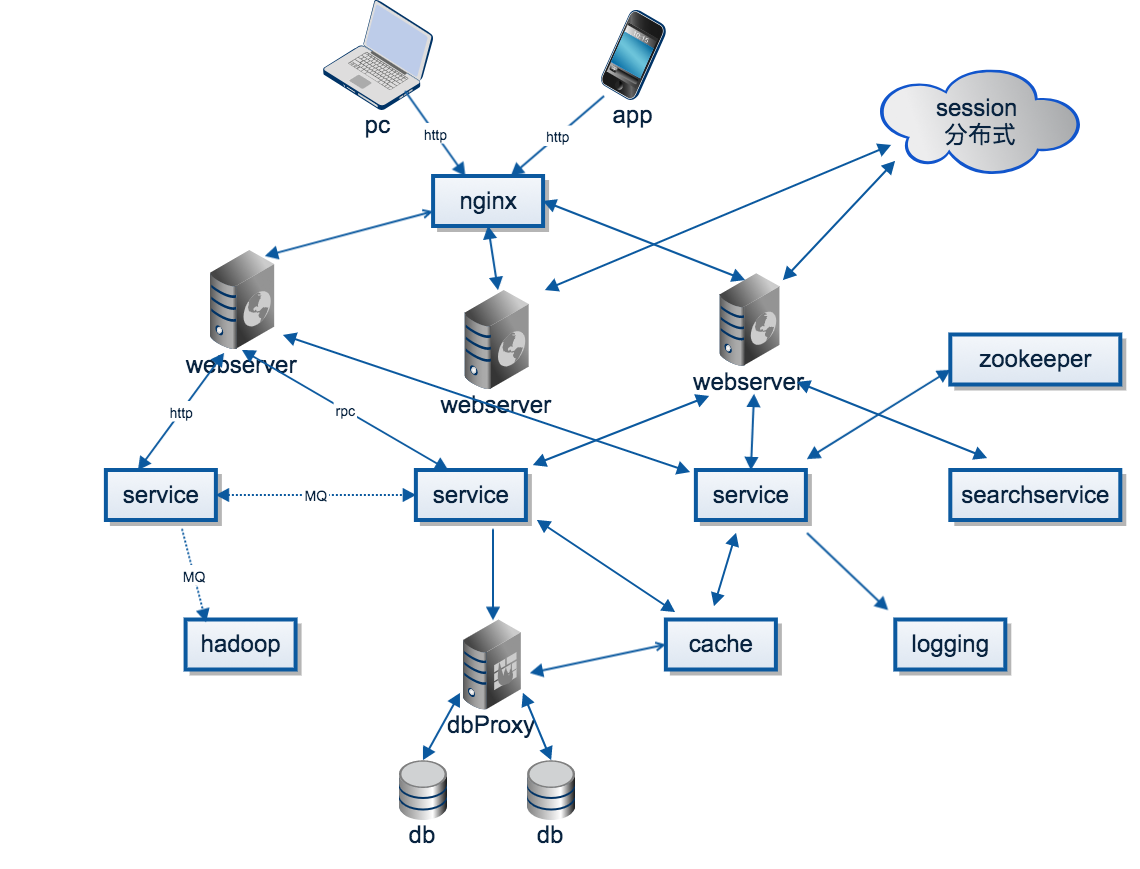
������ʵ��
��ô��������ĸ��ּ���������,ҵ������Щʵ����,������м����С�
��Ȼ,�������Щʵ��,С�������ù�,֪������Ȼ;����˵��,֪��Ȼ;����һ����֮ǰ����δ��,����Ҳ��һ����ȷ,ֻ�Ǵ��������³������ġ�����������,�Ա��պ�����dz��ѧϰ��
- ���ؾ���:
Nginx:�����ܡ��߲�����web������;���ܰ������ؾ��⡢�����������̬���ݻ��桢���ʿ���;������Ӧ�ò�
LVS: Linux virtual server,���ڼ�Ⱥ������Linux����ϵͳʵ��һ�������ܡ��߿��õķ�����;�����������
- webserver:
Java:Tomcat,Apache,Jboss
Python:gunicorn��uwsgi��twisted��webpy��tornado
- service:
SOA������spring boot,django
- ����:
docker,kubernetes
- cache:
memcache��redis��
- ������:
zookeeper��etcd��
zookeeperʹ����PaxosЭ��Paxos��ǿһ����,�߿��õ�ȥ���Ļ��ֲ�ʽ��zookeeper��ʹ�ó����dz��㷺,֮��ϸ����
- rpc���:
grpc��dubbo��brpc
dubbo�ǰ��↑Դ��Java���Կ����ĸ�����RPC���,�ڰ���ϵ�����ܹ���,��ʹ����dubbo + spring boot
- ��Ϣ����:
kafka��rabbitMQ��rocketMQ��QSP
��Ϣ���е�Ӧ�ó���:�첽������Ӧ�ý�������������ϢͨѶ
- ʵʱ����ƽ̨:
storm��akka
- ��������ƽ̨:
hadoop��spark
PS: apark��akka��kafka����scala����д��,����������Ի��Ǻ�ţ�Ƶ�
- dbproxy:
cobarҲ�ǰ��↑Դ��,�ڰ���ϵ��ʹ��Ҳ�dz��㷺,�ǹ�ϵ�����ݿ��sharding + replica ����
- db:
mysql��oracle��MongoDB��HBase
- ����:
elasticsearch��solr
- ��־:
rsyslog��elk��flume
�ܽ�
д��ƪ����,�����������������������ѧϰ�ֲ�ʽϵͳ��,��ʵ��˵,û�к���ͬ�Ĵ𰸡�Ҳ��,��ȷʵ��һ�����Իش�����⡣����,�����Լ�д��һ����,��д����ƪ����,�о��Լ��Ļش�Ҳ�ܻ���,Ҳû��˵���,���������Լ�������һЩָ�������,����,�����˷ֲ�ʽϵͳ�л������ĸ��ּ��������ۡ�Э��,�Լ�ͨ��һ������չʾ���������Э����,���������Ǹ��������ˡ�
���ϵ����ش�,�������ǿ���������,google�������paxosʲô��,���˾��ò��Ǻ�ʵ�á����õĹ���,������һ������İ���,Ȼ���Լ�˼������ʲô����,��������ȥѰ���,��Ѱ��𰸵�ʱ����ȥ�����ġ�
����,Ҳ�кܶ����ᵽ,���պü��������֪ʶ,�����ϵͳ�����������,��ѧϰ�ֲ�ʽϵͳ�Ǵ��������,��һ���Һ���ͬ���ֲ�ʽϵͳ��������˼·������е�,�ܶ��ǰ���о�������,˼�붼����ͬ�ġ����纯��ʽ����е�map reduce֮��Hadoop��MapReduce,������̴洢��raid֮��Partition��Replication,����IPC֮����Ϣ���С�