���Ƕ�֪��,C�������ж�����������,��Ȼ���Dz�֪�����ǵĴ洢Ҳ��ʹ������,���˽��˵ײ��ԭ�����������绢������
֮ǰ����ѧϰ�����»�����������:
char //�ַ���������
short //������
int //����
long //������
long long //����������
float //�����ȸ�����
double //˫���ȸ�����
�������Ǿ���ѧϰ���������ڴ��еĴ洢��
����
��������Ҫ֪��:�ַ���ʵ����Ҳ������
ԭ�롢���롢����
�����Ǵ���һ�����ͱ�������ֵʱ,�����ڴ����������洢����?
������е����������ֱ�ʾ����,��ԭ�롢����Ͳ��롣
���ֱ�ʾ�������з���λ����ֵλ������,����λ������0��ʾ������,��1��ʾ������
�����������ֱ�ʾ����������ͬ��
- ԭ��:ֱ�ӽ������ư�������������ʽ����ɶ����ƾͿ��ԡ�
- ����:��ԭ��ķ���λ����,����λ���ΰ�λȡ���Ϳ��Եõ��ˡ�
- ����:����+1�͵õ����롣
������ԭ���������붼��ͬ��
����������˵:���ݴ���ڴ�����ʵ��ŵ��Dz��롣
��������ʱҲ���ò����������,����ܻ���,��ô�鷳,ΪʲôҪ������?����Ϊ,����Ҫ��һ������Ѽ���ת��Ϊ�˼ӷ�,�������������,
�������5-4,ת��Ϊ����5+(-4):

��������Ľ������1,˭���뵽�����뵽���ַ�����������ô�뵽����?
̫������!
������VS�Ϲ۲������������ڴ��еĴ洢:
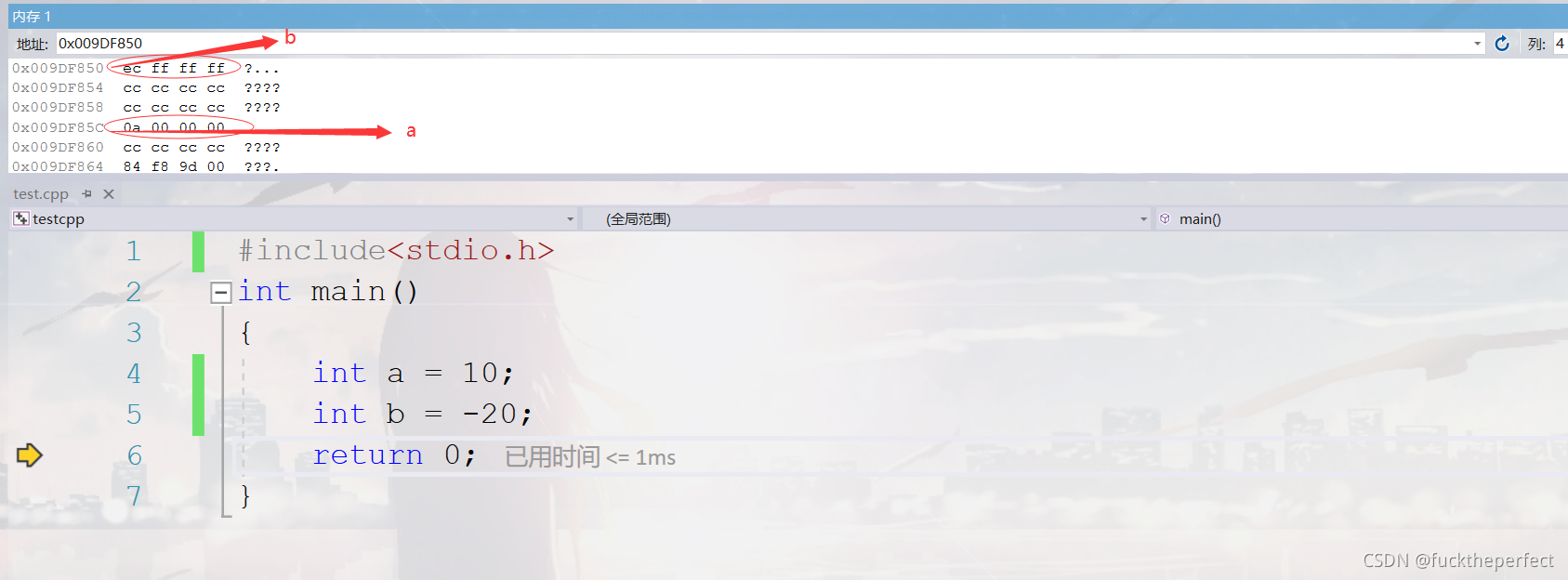
���ǻᷢ��:����ְ�,�洢˳���Ƿ���?���漰���������С����
��С���ֽ���
ʲô�Ǵ�С��?
���(�洢)ģʽ,��ָ���ݵĵ�λ�������ڴ�ĸߵ�ַ��,�����ݵĸ�λ,�������ڴ�ĵ͵�ַ��;
С��(�洢)ģʽ,��ָ���ݵĵ�λ�������ڴ�ĵ͵�ַ��,�����ݵĸ�λ,,�������ڴ�ĸߵ�ַ�С�
Ϊʲô���д�С��?
Ϊʲô���д�С��ģʽ֮����?
������Ϊ�ڼ����ϵͳ��,���������ֽ�Ϊ��λ��,ÿ����ַ��Ԫ����Ӧ��һ���ֽ�,һ���ֽ�Ϊ8 bit��������C�����г���8 bit��char֮��,����16 bit��short��,32 bit��long��(Ҫ������ı�����),����,����λ������8λ�Ĵ�����,����16λ����32λ�Ĵ�����,���ڼĴ������ȴ���һ���ֽ�,��ô��Ȼ������һ����ν�����ֽڰ��ŵ����⡣��˾͵����˴�˴洢ģʽ��С�˴洢ģʽ��
����:һ��16bit ��short ��x ,���ڴ��еĵ�ַΪ0x0010 , x ��ֵΪ0x1122 ,��ô0x11 Ϊ���ֽ�, 0x22 Ϊ���ֽڡ����ڴ��ģʽ,�ͽ�0x11 ���ڵ͵�ַ��,��0x0010 ��, 0x22 ���ڸߵ�ַ��,��0x0011 �С�С��ģʽ,�պ��෴�����dz��õ�X86 �ṹ��С��ģʽ,��KEIL C51 ��Ϊ���ģʽ���ܶ��ARM,DSP��ΪС��ģʽ����ЩARM��������������Ӳ����ѡ���Ǵ��ģʽ����С��ģʽ��
��Щ���������и��˽���С�
��ϰ
���³�������н����ʲô��?
unsigned int i;
for(i = 9; i >= 0; i--)
{
printf("%u\n",i);
}
������ѭ����ӡ!
Ϊʲô��?
����֪��unsigned long������û�з���λ,���ǵ�i=0ʱ,i�C����˶����Ƶ�
11111111111111111111111111111111,������������,��������ӡ,����ѭ����
ע��:������ʹ��������ʱ���п��ܻ���ִ�������,�������һ��ҪС�ĵ�ʹ����Щ��������
�������Ľ������ʲô��?
int main()
{
char a[1000];
int i;
for(i=0; i<1000; i++)
{
a[i] = -1-i;
}
printf("%d",strlen(a));
return 0;
}
����:255
����֪��strlen����Ľ�����־�ǡ�\0��,����Ӧ��ASCII��ֵ��0,��char������ֻ��8λ,���Ǽ����֪a[0]=-1,a[1]=-2����a[127]=-128,��������,������������һ������,-128����ô��ʾ����?���ǿ�������Ϊ,������10000000����-128,Ȼ��,a[128]=127,���Ƿ���,���ֵ��Ȼ�ֻ�����!
�����ž���a[255]=0;��strlen��õ�ֵΪ255��
��ʵ,����ֻҪ����������,���ܰ���ס�������ڴ��еĴ洢��
������
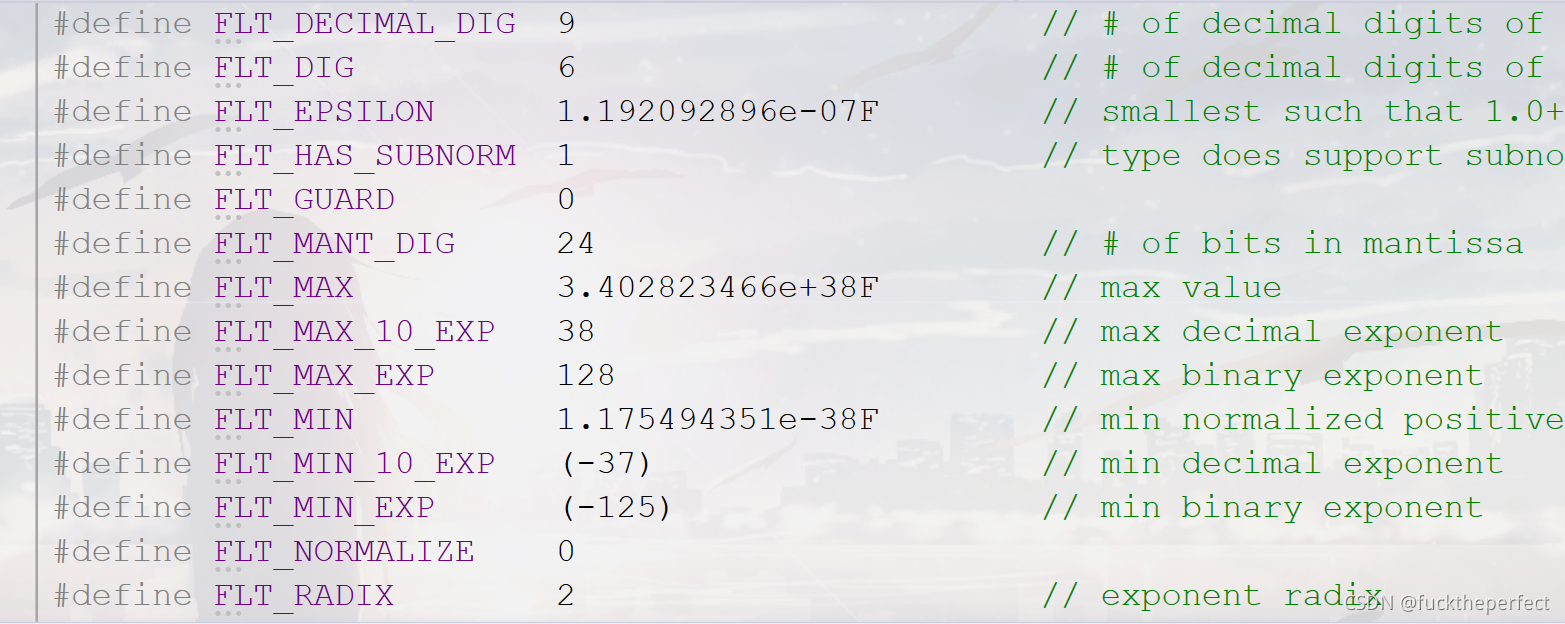
����֪��,��������float,double������,��float.h�ļ���,���ǿ��Կ����ܶ���ڸ������ļ��Ķ���:
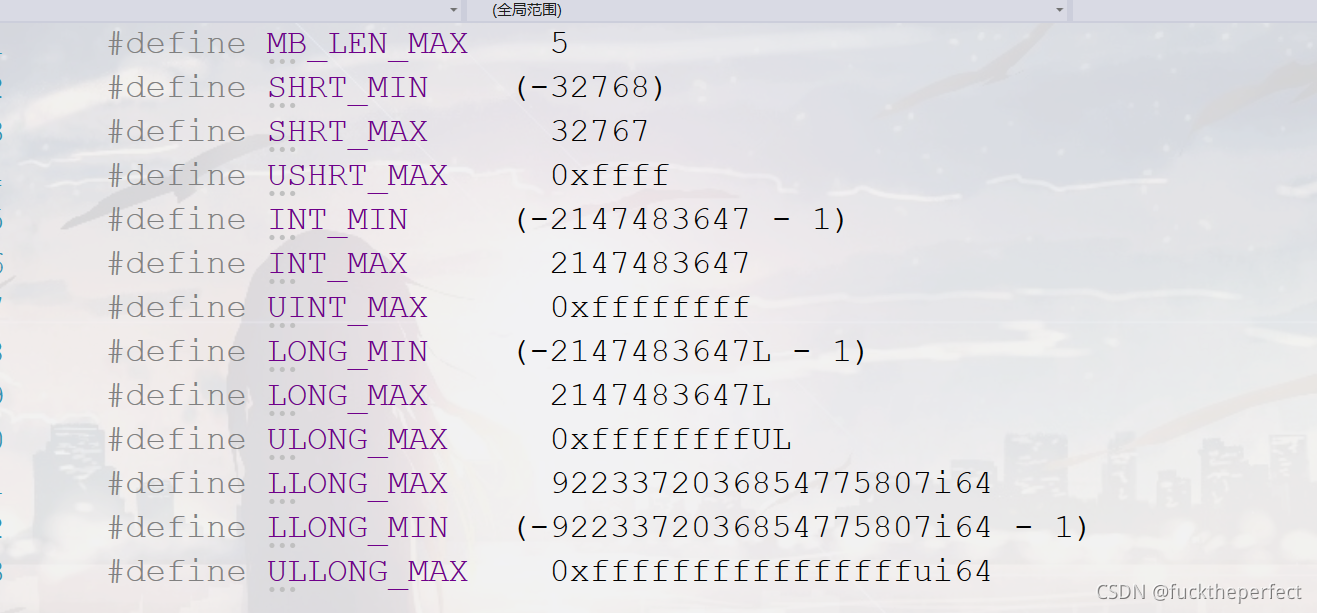
**����:**��limits.h�ļ��п��Կ����ܶ������������Ķ���:
���ڸ������Ĵ洢,�����ȿ�һ�δ���:
int main()
{
int n = 9;
float *pFloat = (float *)&n;
printf("n��ֵΪ:%d\n",n);
printf("*pFloat��ֵΪ:%f\n",*pFloat);
*pFloat = 9.0;
printf("num��ֵΪ:%d\n",n);
printf("*pFloat��ֵΪ:%f\n",*pFloat);
return 0;
}
����������:

��ô��,�Dz��Ǻ��±�?
��ʵ,������Ϊ�������������ڴ��еĴ洢����ͬ���µ�
�������Ĵ洢����
����һ�������Ƹ���������дΪ(-1)^S * M * 2^E
- (-1)^s��ʾ����λ,��s=0,VΪ����;��s=1,VΪ������
- M��ʾ��Ч����,���ڵ���1,С��2��
- 2^E��ʾָ��λ��
- M���ڵ���1��С��2
ʮ���Ƶ�5.0,д�ɶ�������101.0 ,�൱��1.01��2^2 ����ô,��������V�ĸ�ʽ,���Եó�s=0,M=1.01,E=2��
ʮ���Ƶ�-5.0,д�ɶ�������-101.0 ,�൱��-1.01��2^2 ����ô,s=1,M=1.01,E=2��
����32λ�ĸ�����,���Ĵ洢�ṹ����:

����64λ��Ҳ����:

ǰ��˵��, 1��M<2 ,Ҳ����˵,M����д��1.xxxxxx ����ʽ,����xxxxxx��ʾС�����֡�������ǿ���ʡ��1,ֻ�洢�����xxxxxx,�ȵ���ȡ��ʱ��,�ٰѵ�һλ��1����ȥ���������ǿ�����ʡ��һλ�Ĵ洢�ռ���
E�Ĵ洢
E�Ĵ洢��Ϊ����:
�涨:,�����ڴ�ʱE����ʵֵ�����ټ���һ���м���,����8λ��E,����м�����127;����11λ��E,����м�����1023������,2^10��E��10,���Ա����32λ��������137,��10001001��ʹ�ø�������ʱ���ȡ��E��ֵ�ټ�ȥ127/1023��ʹ��
����,��EȫΪ0��ȫΪ1ʱ����Ƚ����⡣
- ��EȫΪ0ʱ
��ʱ,��������ָ��E����1-127(����1-1023)(�����涨)��Ϊ��ʵֵ,��Ч����M���ټ��ϵ�һλ��1,���ǻ�ԭΪ0.xxxxxx��С������������Ϊ�˱�ʾ��0,�Լ��ӽ���0�ĺ�С�����֡� - ��EΪȫ1ʱ
��ʱ,�����Ч����MȫΪ0,��ʾ�������(����ȡ���ڷ���λs)
������Щ���Dz����̫��,��Ҫ�˽����¹���
���ӵĽ���
��������,���ǾͿ��Խ���ǰ��ij����ˡ�
Ϊʲô0x00000009 ��ԭ�ɸ�����,�ͳ���0.000000 ?
����,��0x00000009 ���,�õ���һλ����λs=0,����8λ��ָ��E=00000000 ,���23λ����Ч����M=000 0000 0000 0000 0000 1001�� ����ָ��EȫΪ0,���Է�����һ�ڵĵڶ�����������,������V��д��: V=(-1)^ 0 ��0.00000000000000000001001��2^ (-126)=1.001��2^(-146) ��Ȼ,V��һ����С�Ľӽ���0������,������ʮ����С����ʾ����0.000000��
�ٿ�����ĵڶ����֡�
����,������9.0���ڶ����Ƶ�1001.0,��1.001��2^3����ô,��һλ�ķ���λs=0,��Ч����M����001�����ټ�20��0,����23λ,ָ��E����3+127=130, ��10000010������,д�ɶ�������ʽ,Ӧ����s��E��M��ʾ�Ķ�������������,�� 0100 0001 0001 0000 0000 0000 0000 0000���32λ�Ķ�������,��ԭ��ʮ����������1091567616 ��
����һ������
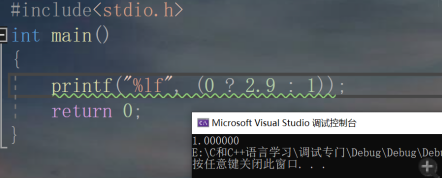
�ҵ��Ʋ�Ӧ����2.9��1����һ������Ϊ��double��,ʣ�µľ��ǽ���ѧ�����ݿ��Խ������,������һ���!
����,�������ǵ�ѧϰ�͵�����,�ڴ��´�һ��ѧϰ!