第二講:std::allocator
標準庫的興起,意味我們可以擺脫內存管理的繁複瑣屑,直接使用容器。但是容 器背後的分配器(allocator)攸關容器的速度效能和空間效能。我將比較 Visual C++, Borland C++, GNU C++標準庫中的 allocator,並深入探索其中最精巧的 GNU C++ allocator 的設計。
西北有高楼,上与浮云齐
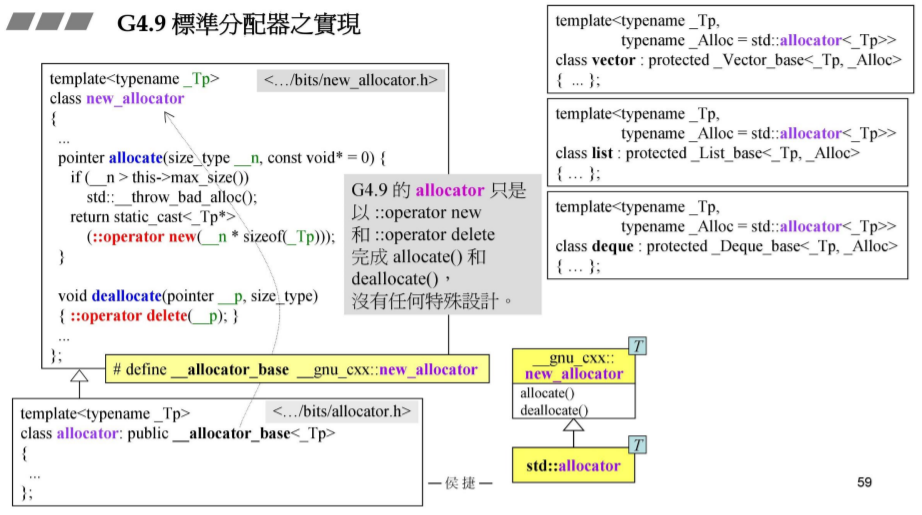
G4.9 std::allocator 标准分配器之实现
和以前的分配器一样 用 operator::new 和 operator::delete 完成分配
G4.9 pool_allocator
用了vector的分配器 —— 省掉了cookie

G2.9 std::alloc 运行模式
std::alloc里的操作是,先创出一个可放置16种大小【以8为倍数关系】的总记录链表,即8~128的16种大小。超出这个大小范围的则std::alloc不为其服务分配内存【每一大段带cookie,小段共享所处大段的cookie】,而是调用malloc去分配内存【每个内存都带cookie】
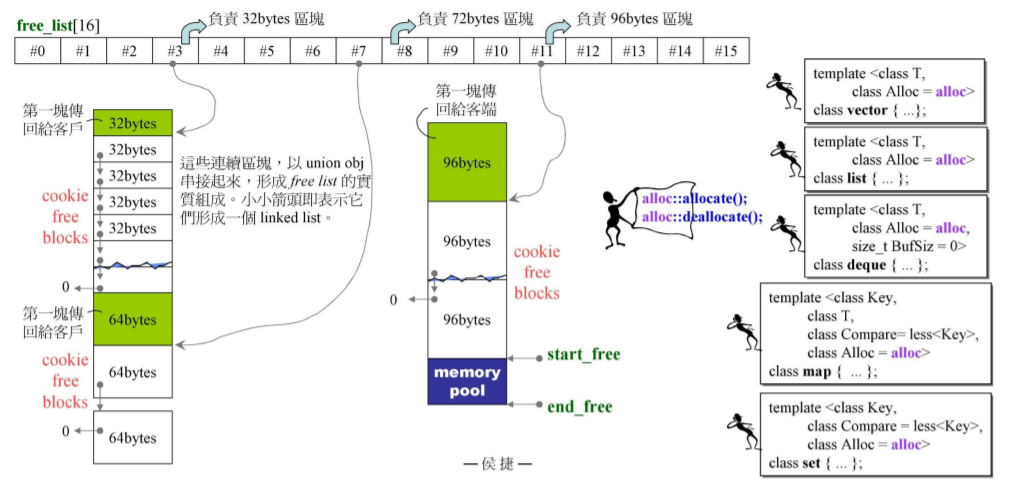
#0记录大小为8的数据类型,
#1记录大小为16的数据类型 …
#15记录大小为128的数据类型,
- 如果此时需在容器vector中放入一个类型大小为30的元素,则编译器会将其大小调节为8的倍数即调整到32而放入 #3 所malloc出的一大段free list的第一小片中,且此时free list1的头指针向下移一位,则剩下19小段是空的。而在这 #3下所malloc分配得的一大块内存中是带有头尾两个cookie的,然后其实际生成大小为32 * 20 * 2,前20个用来存放32大小的元素数据,而后一半则作为战备池提供后续放置元素使用。
- 比如,继续在容器list中放入一个类型大小为63的元素,则编译器会将其大小调节为8的倍数即调整到64而放入 #7 中,但 #7下并无挂free list,所以跑到前面 #3 提供的战备池去分配空间。此时战备池大小为32 * 20 =640,所以放置64大小的元素时,可以分成640/64=10块,则此时战备池 被划分为10小段,第一段已用来放置元素对象,free list2的指针向下移一位,且剩下9小段是空的。
若此时容器set需要放入一个类型大小为256的元素,则此时已不属于std::alloc的服务范围,则调用的是malloc去分配内存空间。
embedded pointers(内嵌指针)
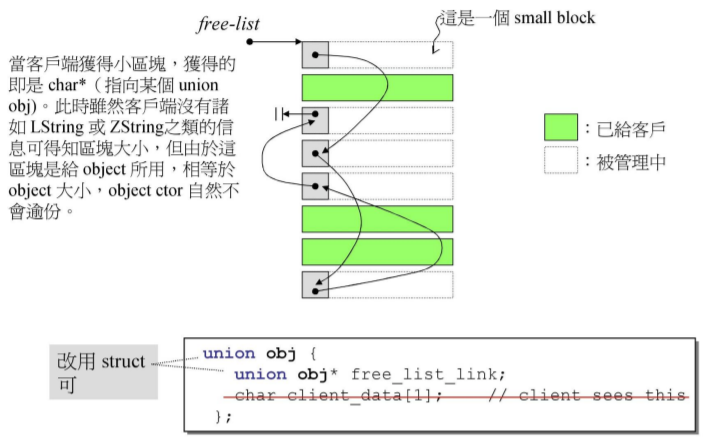
用共用体 —— 当容器开始在free list中放置元素值时,就会覆盖掉整小片,此时指针信息已经覆盖掉了,而且指向free list头端的指针下移一位跳到下一个空的位置。
这里指向空表free list头端的指针是嵌属于一小片空间的一部分,因而不占用额外的内存空间
取第8、12张图 作为 经典过程
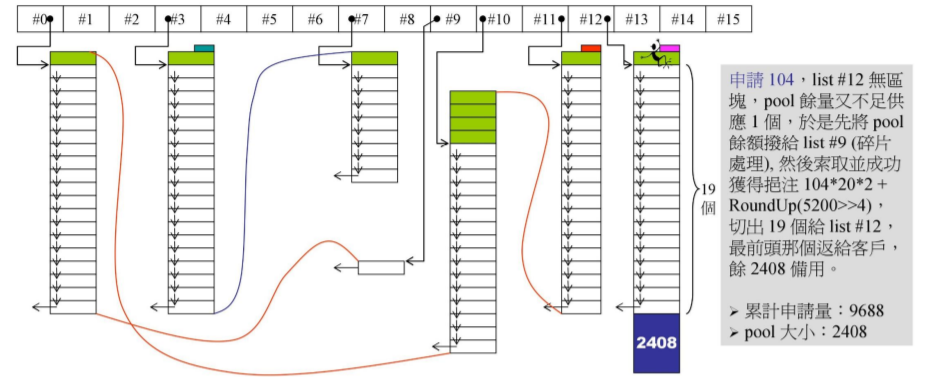
容器申请放置104bytes的元素,则应放置于#(104/8-1)即#12中,而#12中为空,且pool【战备池】有余量80,但此时pool【战备池】余量已不足放入104大小的元素即不可能分割出片段来放置元素,则此80称为碎片。所以将#0下的pool碎片拨给#(80/8-1)即#9下。然后调用malloc创建出带头尾两个cookie的一大段内存空间,
申请量为 104 * 20 * 2 + RoundUp(5200>>4) = 9688:
104 为按所放置容器的元素的大小而设定,20 * 2则是表示每个最多需要切分成20小段,前半段用于存放操作,而后半段则当作pool【战备池】为后续放置提供操作空间。
RoundUp(5200>>4) 表示为上一次累计申请量除以16所得的大小【还要调整为8的倍数】即5200/16=325->328。
因而所得累计申请量为,且除去容器所分配的内存大小104 * 20 = 2080,
最终pool大小为:9688 - 5200 - 2080 = 2408。以上为碎片的处理!
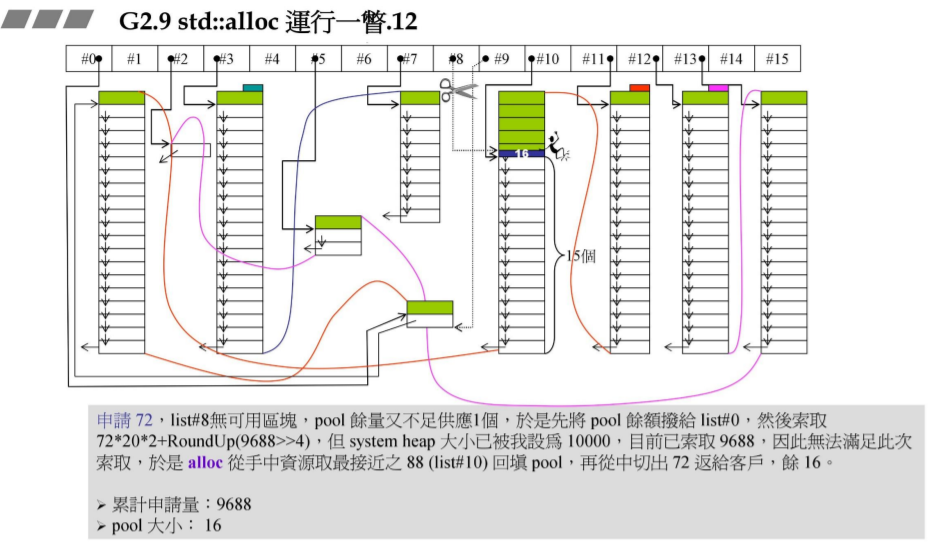
容器申请放置72bytes的元素,则应放置于#(72/8-1)即#8中,但#8中已无可用区块,而pool【战备池】的余量8已不足放入72大小的元素即不可能分割出片段来放置元素,则此8称为碎片。所以将#8下的pool碎片拨给#(8/8-1)即#0下。然后 企图 调用malloc创建出带头尾两个cookie的一大段内存空间,需索取申请量为 72 * 20 * 2 + RoundUp(9688>>4) > 10000 了,则此时索取分配新空间失败:
1.则std::alloc从右边最接近其的#9取资源,但#9此时已空,所以又到#10上索取资源。而#10中仍剩16小段空白区块(每个区块大小为88),则返回#10 free list头端空表的第一块【实际上已是链表的第五块】返回容器并放置元素对象,然后此时#10的free list的指针下移一位指向其free list的第6块了。此时这区块划分为88/72=1块,剩余的88-72=16当作pool【这一区块88的大小已由#8接管了!】。
2.#8返回对应地址给容器并放置元素对象,#8的指针也下移一位直接跳到pool的头端位置即start_free。
3.此时累计申请量仍为9688,pool剩余大小为 16。
G2.9 std::alloc 源码剖析
第一级分配器
在G2.9版本中有第一级分配器,而G4.9中则已经无了:其作用主要是当主要的第二级分配器分配失败时,则调用第一级分配来进行分配内存。
第一级模拟 new handler,G4.9 C++ 用本身设置的 new handler
第一级分配器

第二级分配器
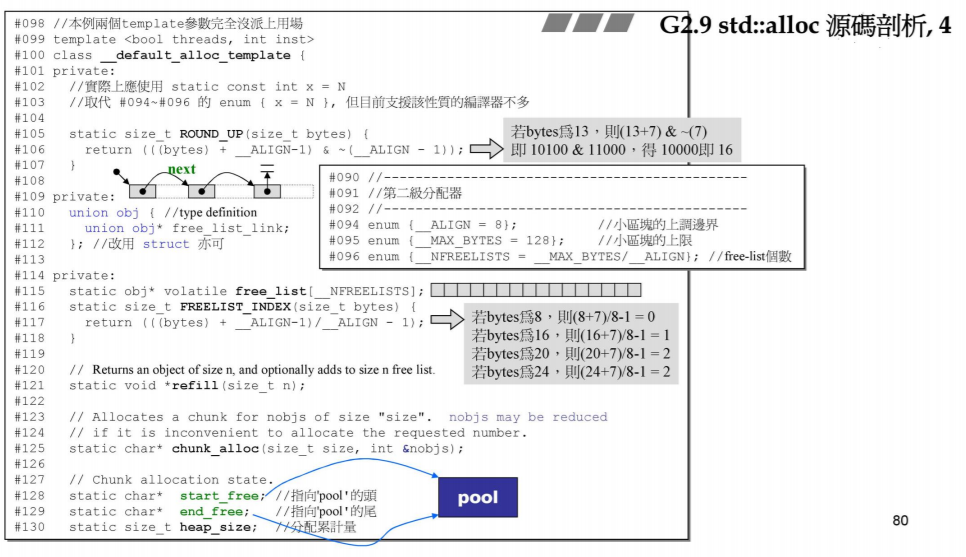
enum {__ALIGN = 8}; // 小区块的上调边界,即为8的倍数【如#0与#1间存放的元素类型大小相差8】
enum {__MAX_BYTES = 128} // 小区块的上限
enum {__NFREELISTS = _MAX_BYTES/__ALIGN}; // free list个数
// 以下两个template参数完全没派上用场
template<bool threads, int inst>
class __default_alloc_template{
private:
static size_t ROUND_UP(size_t bytes){ // 将传入大小上调为8的倍数,即传入bytes为 13 则传入为 16!
return((bytes) + __ALIGN - 1) & ~(__ALIGN - 1); // 即(13+7) & ~(7) --> 10100&11000得10000即16
}
private:
union obj{
union obj* free_list_link; // 实际上为前面说的next指针
}; // 改用 struct 亦可
private:
static obj* free_list[__NFREELISTS]; // 创建一个记录16个编号的链表的指针数组,即存放数组内部的是指针元素。free_list则表示这个数组的起始地址即编号链的起始指针
static size_t FREELIST_INDEX(size_t bytes){ // 求取所放入bytes大小类型的元素应该放在哪个编号内
return (((bytes) + __ALIGN - 1)/__ALIGN - 1);
// 若bytes为8,则(8+7)/8-1=0
// 若bytes为16,则(8+7)/8-1=1
// 若bytes为20,则(20+7)/8-1=2
// 若bytes为24,则(24+7)/8-1=2
}
// 若所申请放入的编号链表为空,则进行创建
static void* refill(size_t n);
// 在上面refill的创建过程中需要分配一大块内存进行操作切分
static char* chunk_alloc(size_t size, int &nobjs);
// 战备池
static char* start_free; // 指向pool的头
static char* end_free; // 指向pool的尾
static size_t heap_size; // 分配累计量
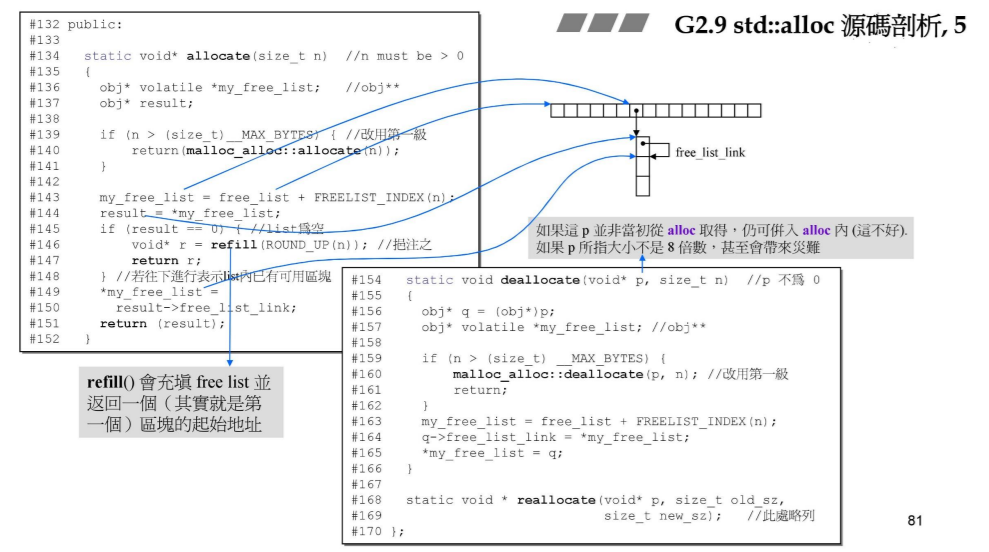
public:
static void* allocate(size_t n){ // n必须大于0
obj* *my_free_list; // obj**,这是指向编号链对应编号位置的指针变量
obj* result; // 指向free list空表第一个空位置的指针变量
if(n > (size_t)__MAX_BYTES){ // 申请放入元素类型大小超出128,则改用第一级分配器
return(malloc_alloc::allocate(n));
}
my_free_list = free_list + FREELIST_INDEX(n); // 指向编号链起始端的指针 + 申请放置元素应落在的编号 = 对应的编号位置(其解引用则是取出对应编号位置下的free list的第一个空位置)
result = *my_free_list; // 编号链的对应编号位置下指向其free list的空表第一个空位置的指针
if(result == 0){ // 若编号链某编号位置下的free list为空,则调用refill进行填充
void* r = refill(ROUND_UP(n));
return r;
}
// 若编号链某编号位置下的free list不为空,
*my_free_list = result->free_list_link; // 则移动对应编号位置下的free list的第一个空位置下移一位
return (result); // 返回当前free list的第一个空位置
}
static void deallocate(void* p, size_t n){ // 传入指针不能为空
// 若传入的指针p,满足其解引用的元素大小在0~128范围内,但p却不是有std::alloc生成的比如是malloc生成的
// 此时传入这里仍可进行处理,虽然其带有cookie但不影响,只是将指针指向修改以下而已
// 即此时std::alloc外的指针内存地址只要满足其解引用元素大小在0~128范围内均可被其回收使用,
// 只不过如果p所指大小不是8的倍数时,可能会导致灾难!!
obj* q = (obj*)p;
obj* my_free_list; // obj**
if(n > (size_T)__MAX_BYTES){ // 传入的元素大小超出128,不属于std::alloc的操作范围,调用的是free
malloc_alloc::deallocate(p, n);
return;
}
my_free_list = free_list + FREELIST_INDEX(n);
q->free_list_link = *my_free_list; // q->next = freeStore
*my_free_list = q; // freeStore = q
}
};
16根指针 —— 不同大小的内存
2根 —— 指向 pool
C语言关键字volatile(注意它是用来修饰变量而不是上面介绍的volatile)表明某个变量的值可能在外部被改变,因此对这些变量的存取不能缓存到寄存器,每次使用时需要重新存取。该关键字在多线程环境下经常使用,因为在编写多线程的程序时,同一个变量可能被多个线程修改,而程序通过该变量同步各个线程。
C++
volatile总是与优化有关,编译器有一种技术叫做数据流分析,分析程序中的变量在哪里赋值、在哪里使用、在哪里失效,分析结果可以用于常量合并,常量传播等优化,进一步可以死代码消除。但有时这些优化不是程序所需要的,这时可以用volatile关键字禁止做这些优化,volatile的字面含义是易变的,
切割就是把指针所指对象 转为 obj再取其next_obj指针 继续切割 ·一而再三…
chunk_alloc
char* chunk_alloc(size_t size, int* nobjs)
{
char* result;
size_t total_bytes = size * (*nobjs); //原 nobjs 改為 (*nobjs)
size_t bytes_left = end_free - start_free;
if (bytes_left >= total_bytes) {
result = start_free;
start_free += total_bytes;
return(result);
} else if (bytes_left >= size) {
*nobjs = bytes_left / size; //原 nobjs 改為 (*nobjs)
total_bytes = size * (*nobjs); //原 nobjs 改為 (*nobjs)
result = start_free;
start_free += total_bytes;
return(result);
} else {
size_t bytes_to_get =
2 * total_bytes + ROUND_UP(heap_size >> 4);
// Try to make use of the left-over piece.
if (bytes_left > 0) {
obj* volatile *my_free_list =
free_list + FREELIST_INDEX(bytes_left);
((obj*)start_free)->free_list_link = *my_free_list;
*my_free_list = (obj*)start_free;
}
start_free = (char*)malloc(bytes_to_get);
if (0 == start_free) {
int i;
obj* volatile *my_free_list, *p;
//Try to make do with what we have. That can't
//hurt. We do not try smaller requests, since that tends
//to result in disaster on multi-process machines.
for (i = size; i <= __MAX_BYTES; i += __ALIGN) {
my_free_list = free_list + FREELIST_INDEX(i);
p = *my_free_list;
if (0 != p) {
*my_free_list = p -> free_list_link;
start_free = (char*)p;
end_free = start_free + i;
return(chunk_alloc(size, nobjs));
//Any leftover piece will eventually make it to the
//right free list.
}
}
end_free = 0; //In case of exception.
start_free = (char*)malloc_allocate(bytes_to_get);
//This should either throw an exception or
//remedy the situation. Thus we assume it
//succeeded.
}
heap_size += bytes_to_get;
end_free = start_free + bytes_to_get;
return(chunk_alloc(size, nobjs));
}
}
G2.9 std::alloc观念大整理
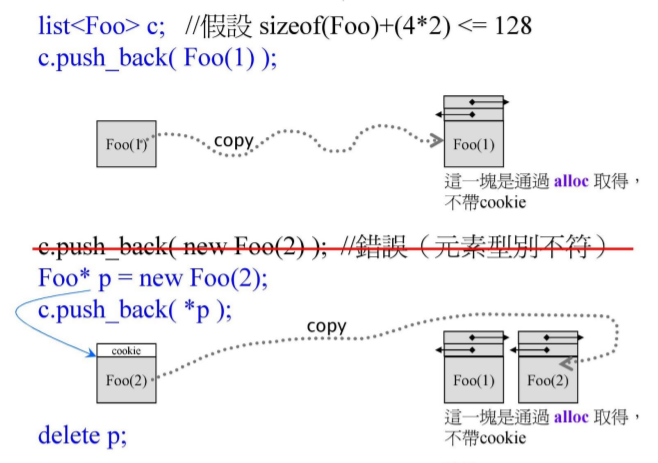
Foo(1)是在stack(栈)中创建出来的临时对象,不带cookie的。由于这个Foo类对象的大小是在0~128范围内的,所以调用std::alloc去申请放入对应编号区下的free list的内存空间。另外由于该内存空间是通过alloc获得的,所以是不带cookie的。
*p是在heap(堆)中创建出来的对象,带cookie的。调用std::alloc去申请放入对应编号区下的free list的内存空间。另外由于该内存空间是通过alloc获得的,所以是不带cookie的【虽然copy进去的*p带cookie】。记住new出的东西,最终要用delete来释放掉内存空间。
示例 —— 元素类型不符
vector<A> a;
a.push_back(new A());
G4.9 pool allocactor 运行观察
通过重载全局的 ::operator new

检讨

answer:
在申请索取量失败时,不去尝试将索取量折半再进行索取而最大程度利用完剩余空间。因为一般场景下,都是多线程的机制,这样子操作会占用了更多的内存空间,会造成对其他线程有影响!
而且,通过上面的操作原理可以知道,调用std::alloc去申请分配内存空间使用时,实际往往各编号区下的free list仍有很多容量【即各free lists链上的小区块都是没被放置元素对象的】,这在std::alloc分配失败时,会达到一个分配内存空间的峰值!!此时通过调用std::alloc操作申请分配内存空间其本身就已经占用了很多内存空间了,若仍采取检讨2的做法,则让其他线程下的可利用内存空间愈加少了!!