��C++ѧϰ������(ʮ)Ƕ��ʽ�ڴ����
��ƪ
??��һƪ���������������ϵ��ڴ�,��û���漰�ܶ�ײ��ԭ��;����ʵ�ʹ�����,����һ����Ŀ������Ҫ�����ڴ��ռ��,������ڴ�Ҳ����Ƕ��ʽ�����ϵ��ڴ�;��ƪ���¾ͼ���һ��Ƕ��ʽ�˵�һ���ڴ����;
Linux�ں�ϵͳ�ṹ
��Ҫ��Ϊ���ģ��:
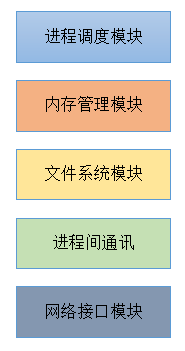
������Ҫ�����ڴ����ģ��,����ģ�鲻������;
�鿴Linux�ڴ�
��Linux������,��ͨ��free -m�鿴�ڴ�ʹ�����;
��ͼ��һ̨rk3326�������ڴ����:

- Mem:��ʾ�����ڴ�ͳ��;
- total:��ʾ�����ڴ�����(used + free);
- used:��ʾ�ܼƷ��������(����buffers��cache)ʹ�õ��ڴ�����,�����в��ֻ��沢δʵ��ʹ��;
- free:δ��������ڴ�;
- shared:�ڴ湲��;
- buffers:ϵͳ���䵫δ��ʹ�õ�buffers����;
- cached:ϵͳ���䵫δ��ʹ�õ�cache����;
- -/+ buffers/cache:��ʾ�����ڴ�Ļ���ͳ��;
- Swap:��ʾӲ���Ͻ���������ʹ�����;
cache
??cache�����ò�ͬ��buffer,�����ٶȼ���,�����еײ��Ż���ʱ,����Ҫ��д����cache���ڴ��������;����ֱ����CPU������,������DDR;
˼����������ѭ��Ч�ʸ�:
// ��һ��ѭ��
int arr[10][100];
for (i = 0;, i < 10; i++)
for (j = 0; j < 100; j++)
arr[i][j] = 8;
// �ڶ���ѭ��
for (i = 0; i <100; i++)
for (j = 0; j < 10; j++)
arr[j][i] = 8;
��Ӳ����������,�ڶ��ֵ�Ч�����,��Ϊ�ڴ����ת������˺ܶ�,����������Ҫע����Ƕ��ѭ����,�����Ѵ��ѭ��д���ڲ�;
buffer
??buffer��������,�����ǿ���һ���ַ�ռ�,���Խ�������Ҫ�õ����ڴ�ռ��ȿ��ٺ�,����buffer���Ա����ڿ��ٶ�дʱ�������;
cache��buffer��һ������:
- cache:�Ѷ�ȡ���������ݱ�������,���¶�ȡʱ������,����Ҫ��ȥӲ�̶�ȡ;���е����ݻ���ݶ�ȡƵ�ʽ���ɸѡ,��Ƶ����ȡ�����ݷ����������ҵ���λ��,�Ѳ��ڶ�ȡ������������,ֱ��ɾ��,��Ҳ��LRU�����㷨��ԭ��;
- buffer:�Ǹ��ݴ��̵Ķ�д��Ƶ�,�ѷ�ɢ��д�������н���,���ٴ�����Ƭ��Ӳ�̵ķ���Ѱ��,�Ӷ����ϵͳ����;
�ڴ油��
�ںܶ�Ƕ��ʽ�����϶����ڴ�����Ĵ���;
˼�������½ṹռ�õ��ڴ�:
struct A{
char a; // 1
char b; // 1
int c; // 4
}
����CPU�ķ������,��64λ������ռ��8���ֽ�,��Ҳ������һЩ���봦��;
���������ڴ�,һЩ����(����N��310)���ͼ�����ݽ��ж���,ͼ��ķֱ���Ҫ����Ӳ��֧�ֵı���,��������������Ч����;
�ܽ�
??��ƪֻ�Ƕ���һƪ�ڴ��һ������,��Ҫ����Linux�е��ڴ�;�ⲿ�ֶ���һЩ�˲ಿ��Ļ����˵�Ƚ���Ҫ,�Ƽ���Բ�ͬ�İ���,������Ҫ���Ķ�API�ĵ�,�˽�����ڴ��API���ٽ��д���Ŀ���;