汇编系列文章已经更新了三篇,每一篇都是笔者用心总结,希望对你有帮助
之前的文章我们主要聊了一些基本的汇编指令,并且通过一个名为 Debug 的调试软件,让我们看到了内存中是如何存储指令和数据的,在学习了这些之后,我们就可以了解汇编程序了。
程序的执行过程
首先通过一个示意图给大家介绍一下程序的执行过程,我们以 C 语言一个简单的 hello.c 程序为例。
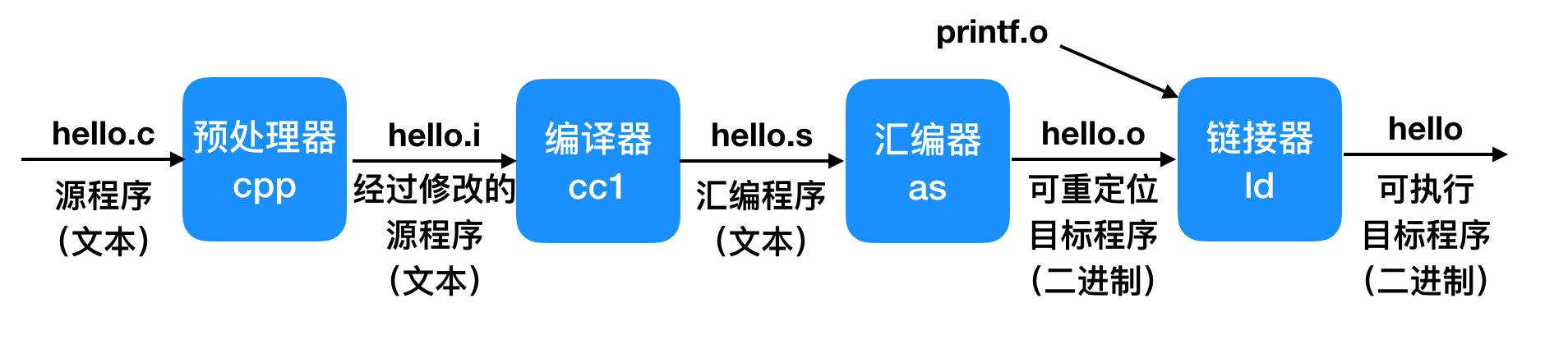
这就是一个完整的 hello world 程序执行过程,会涉及几个核心组件:预处理器、编译器、汇编器、连接器,下面我们逐个击破。
- 预处理阶段(Preprocessing phase),预处理器会根据开始的
#字符,修改源 C 程序。#include <stdio.h> 命令就会告诉预处理器去读系统头文件stdio.h中的内容,并把它插入到程序作为文本。 - 然后是
编译阶段(Compilation phase),编译器会把文本文件hello.i翻译成文本hello.s,它包括一段汇编语言程序(assembly-language program)。
汇编语言是非常有用的,因为它能够针对不同高级语言来提供自己的一套标准输出语言。
- 编译完成之后是
汇编阶段(Assembly phase),这一步汇编器会把 hello.s 翻译成机器指令,把这些指令打包成可重定位的二进制程序(relocatable object program) 放在 hello.c 文件中。 - 最后一个是
链接阶段(Linking phase),这个阶段就是用链接器把翻译过后的程序合并在一起,生成在操作系统上直接运行的可执行文件的过程。
所以,一般来说,可执行文件包括两个方面
- 程序和数据,这些是构成可执行文件的基本信息。
- 相关的描述信息,比如空间多大,程序有多大等,这些是构成可执行文件的必要因素。
认识汇编程序
同样的,先上一则汇编代码,然后下面再慢慢概述。
assume cs:code
code segment
mov ax,1234H
add ax,ax
mov bx,1111H
add bx,bx
code ends
end
这段汇编代码有几个地方你可能不太了解,不过 mov、add 指令你应该知道是什么意思(如果你看完笔者之前文章并进行了仔细研究的话)。
构成汇编程序的指令分为两种:一种是汇编指令,一种是伪指令,汇编指令就是我们上面提到的 mov 、add 指令,这些指令有实际的意义,比如 mov 就是移动寄存器或者数据,add 就是对寄存器或者数据进行加法操作。而且 mov 和 add 这类汇编指令在内存中有对应的机器码存在,最终会有 CPU 执行。而伪指令没有实际的意义,它们指令简单的定义一个程序段,这些伪指令会由编译器来直接解释,它们在内存中没有对应的机器码,所以不会由 CPU 来执行。
上面提到的伪指令有三种,即
code segment
......
code ends
segment 和 ends 是一组成对出现的指令,而且这一对指令必须成对出现,缺了谁都不行。这一对指令定义了一个段,segment 标识着段的开始,ends 标识着段的结束。code 表示段的名称,段名称可以随意替换。
汇编程序由多个段组成(至少包含一个段),这些段被用来存放代码、数据或者当做栈空间来使用。上面例子代码中的段由代码组成,所以叫代码段。
除了段之外,汇编程序还需要有 assume ,这同样是一条伪指令,它的意思是假设,它假设某一段寄存器和某个段相关联,通过 assume 来说明这种关联关系。assume 不用深入理解,我们只要知道编程时将特定用途的段和相关寄存器关联起来即可。
end 是一段汇编程序结束的标志,它也是一条伪指令,编译器在编译汇编程序的过程中,遇到 end 就会停止编译,所以,如果我们汇编程序写完了,就需要在程序的末尾加上 end ,表示程序的结束。
在汇编程序中,除了汇编指令和伪指令,还有一种标号,比如上面代码中的 code,标号位于 segment 的前面,作为段的名称,这个段的名称最终将被编译、连接处理为一个段的段地址。
再次提醒下,注意这里不要搞混了 end 和 ends ,ends 是和 segment 一起使用的表示汇编段,而 end 是汇编结束的标识。
所以总结下,用汇编语言编写的源程序,包括伪指令和汇编指令,伪指令是由编译器来执行,汇编指令可以翻译成机器代码并最终由 CPU 执行。
以后,我们可以将源程序文件中的内容称为源程序,将源程序中最终由计算机执行、处理的指令或数据,称为程序。程序最先以汇编指令的形式存在于原程序中,然后经过编译、连接后转变为机器码,存储在可执行文件中,如下图所示
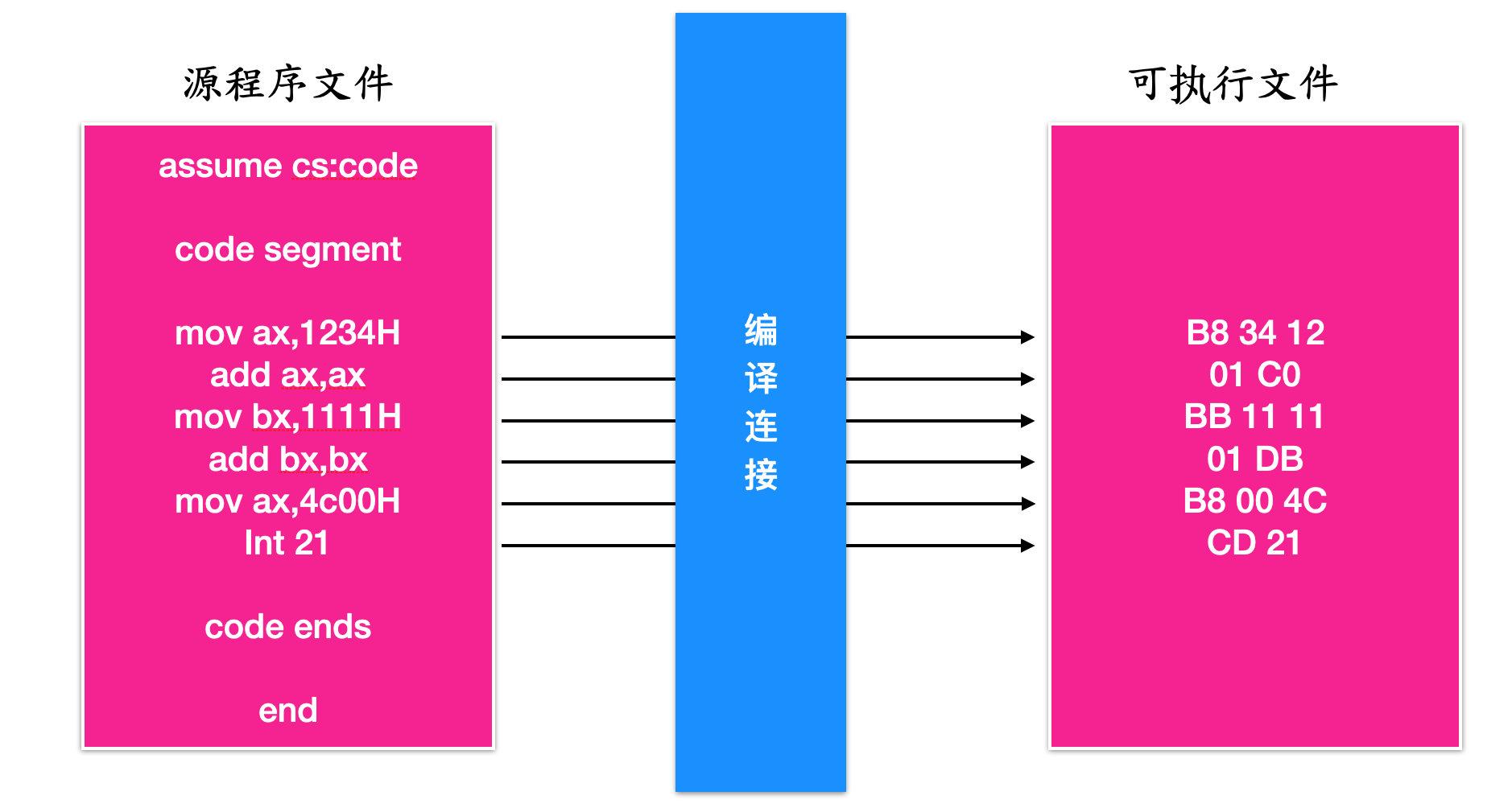
所以,总结一点来说,编写一个汇编程序主要分为下面这几步
- 首先定义一个段 ,比如 code、abc 等
- 在段中写入汇编指令
- 指出程序在何时处结束
- 标号要和寄存器关联起来。
- 程序返回(后面要说)
程序返回
一个完整的程序是要有返回条件的,程序只有在执行完相关代码后,执行返回条件,让出 CPU 执行权,操作系统才会分配时间片给其他程序,程序不能一直霸占着 CPU 不放,这是一种资源的浪费,而且一直占用着 CPU,也会导致程序崩溃。
汇编语言中,实现程序返回的指令只有两行
mov ax,4c00H
int 21H
解释下这两句指令的意思:
mov ax,4c00H 就是把 4c00 移动到 ax,中,INT 21H 是调用系统中断指令,这两句代码起作用的就是 AH = 4CH,意思就是调用 INT 21H 的 4CH 号中断,该中断就是安全退出程序。
到目前为止,我们已经了解到了几种和结束的相关内容,比如段结束,汇编程序结束、还有我们刚刚说的程序返回,下表列出了这三个指令的区别。

程序错误
一般来说,汇编语言的程序错误分为两种:即语法错误和逻辑错误。
语法错误很简单,说白了就是你汇编语言指令写错了,这个程序编译时期就能够发现。
逻辑错误是在运行时发生的,一般不容易被发现,排查起来比较困难,比如下面这段代码不写程序返回就是属于逻辑错误。
assume cs:code
code segment
mov ax,1234H
add ax,ax
mov bx,1111H
add bx,bx
code ends
end
为什么?因为你这段代码没有加程序返回逻辑。类似的这种逻辑错误还有很多,这些错误需要在具体的场景中才能发现。
编写汇编
下面我们开始用编辑器来编写汇编源程序,只要将汇编存储为文本文件,再经过编译器编辑,CPU 运行即可。
我们可以使用多种文本格式来编写汇编程序,比如我们可以使用最简单的文本文件来编写(基于 win7 操作系统环境)
assume cs:codeseg
codeseg segment
mov ax,0123H
mov bx,0456H
add ax,bx
add ax,ax
codeseg ends
end
编写完成后,存储为 .asm 后缀文件,这是一种汇编格式。
编译
一个完整的汇编程序执行流程分为编写、编译、链接和运行,所以接下来我们需要对编写完成的汇编程序进行编译。在编译之前我们需要找到一个相应的编译器,这里我们采用的是 masm 5.0 汇编编译器,执行程序是 masm.exe。
(为了防止大家再从网站上乱找资源,我下载下来放在了网盘中,大家在程序员cxuan 后台回复 masm 即可领取)
说到使用 masm 5.0 的这个过程我踩了很多坑,这里给大家提示下,及时闭坑!!!
- masm 5.0 是稳定版本,网络上流传的 6.x 不知道怎么样,我是没运行成功。
- masm 5.0 要在 win7 环境下运行,我使用 win11 测试,程序不兼容,不知道其他版本如何。win7 版本可以正常运行。
安装完成后,我们打开 cmd ,进入下载并解压好的 masm 5.0 文件夹下。
然后直接键入 masm
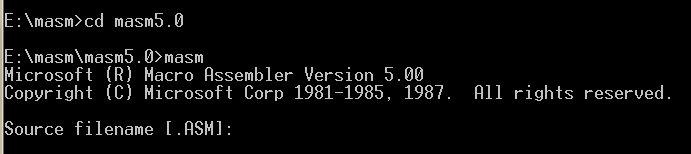
运行 masm 后,首先会显示一些版本信息,然后输入需要被编译的原程序文件名称,这里需要注意一下,[.ASM]提示我们,默认的文件扩展名是 asm,比如我们要编译的源程序文件名是 test.asm,这里直接输入 asm 即可。如果源程序文件不是以 .asm 为后缀,需要输入它的全名,也就是 test.txt。
这里我们输入的是 test,因为我们编写的文件是 .asm 后缀。
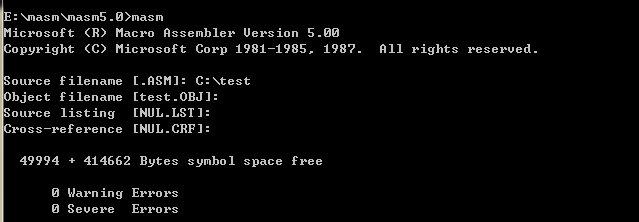
输入源程序文件名后,按 enter 键,程序会提示我们输入要编译出的目标文件名称,目标文件名称是我们对源程序进行编译后的最终结果。Object filename 的后缀名是 .obj,因为 .asm 文件会自动编译为 .obj 文件,所以我们不必再指定文件名,直接按 enter 键,会直接生成 .obj 文件。
确定了目标文件名称后,会出现 Source listing ,这是提示我们要输入列表文件的名称,这个文件是编译器将源程序编译为目标文件的过程中产生的中间结果,可以让编译器不生成这个文件,直接键入 enter 即可。如果编译器要生成这个文件,它的后缀名是 .lst。
然后继续提示出 Cross-reference ,这是提示我们要输入交叉引用文件名称,这个文件和 Source listing 一样,是编译器产生的中间结果,可以不让编译器生成这个文件,我们直接按 enter 即可。如果编译器要生成这个文件,它的后缀名是 .crf。
最后编译器会进行一个结果输出,这个输出结果会显示警告错误和必须要改正的错误,可以从上图中看出来,我们程序没有警告和编译错误。
在输入源程序文件名的时候要指出所在路径,如果遇到 unable to open input file 这个问题,最好把汇编程序直接放在 C 盘,我放在桌面上,也就是 C:\Users\Administrator\Desktop 下,也会出现此错误。
连接
在对源程序编译后得到目标文件后,我们需要对目标文件进行连接,从而得到可执行文件。上一步我们得到了 .obj文件,现在我们需要将 .obj 文件连接成为 .exe 也就是可执行文件。
为了实现我们的需求,我们需要借助微软的 Overlay Linker 3.60 连接器,文件名为 link.exe,这个应用程序不用再次下载(在我公众号回复拿到的软件会包括编译器和连接器,解压后,它们都会在 masm 文件夹下)。
现在我们进入 DOS,cd 到 masm 文件中,键入 link 。
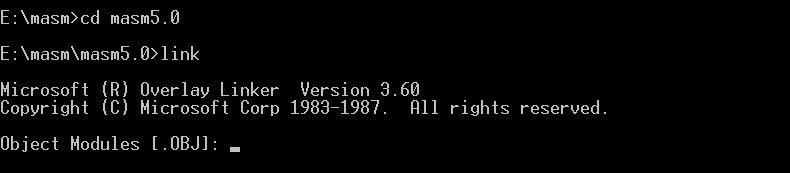
运行 link 后,会出现一些版本信息,然后提示需要被连接的目标文件名称,这里仍需要注意,默认文件是 .obj 结尾,所以如果你需要连接的文件是 obj 文件,就不用输入后缀名,如果不是 obj 文件,则需要输入全名。
我们刚刚编译了一个 test.obj 文件,所以我们直接对这个 obj 文件进行连接。
输入要连接的文件名(这里仍需要输入 obj 所在的路径),按 enter 。
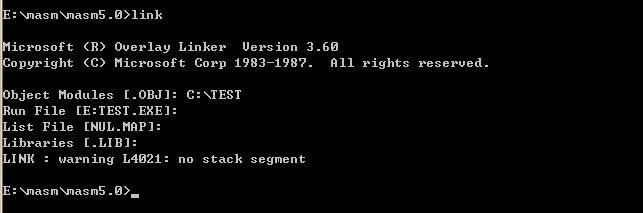
输入 enter 后,会继续来一个三连提示。
第一个提示表明程序继续提示我们输入要生成可执行文件的名称,可执行文件是我们对一个程序进行连接要得到的最终结果,默认的 .exe 文件是 TEST.EXE ,所以我们不再需要指定文件名。这里也可以指定生成可执行文件所在的目录,我们也不需要,继续向下走。
第二个提示是连接程序提示输入映像文件的名称,这个文件是连接程序将目标文件连接为可执行文件过程中的中间结果,也可以让连接程序不生成这个文件,继续向下走。
第三个提示是连接程序提示输入库文件的名称,库文件包含了一些可以调用的子程序,如果程序调用了库中的子程序,就需要指定,否则不需要。
最后会出现一个 waring: no stack segment,我曾一直以为出现这个提示就不会再生成最终执行文件,但是当我仔细检查之后我才发现这只是一个 waning ,最终的执行文件在 masm 文件夹下,我截个图给你看。
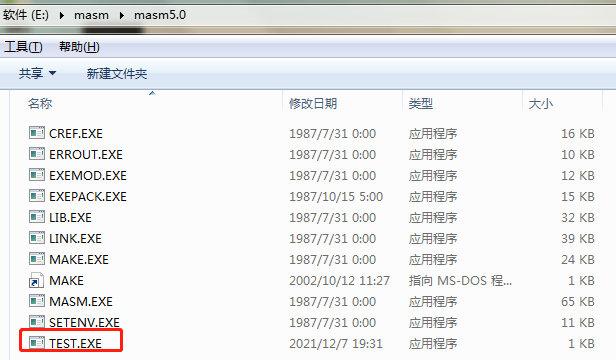
这个提示只是告诉我们没有栈段,我们可以完全忽略这个提示,当然如果你的程序有问题,是无法生成连接之后的文件的。
连接这个过程很有用,归结来说,主要有三个作用
- 当源程序很大时,可以将它分为多个源程序文件来进行编译,每个单独编译之后的目标文件,可以再通过连接将它们连接到一起生成可执行文件。
- 程序中调用了某个库文件中的子程序,需要将这个库文件和目标文件连接到一起生成一个可执行文件。
- 在编译过后生成的机器码文件,其中有些内容还不能直接执行,连接程序需要将这些内容转换为可执行信息,才能够把编译过后的机器码文件,连接成为可执行文件。
执行应用程序
现在我左手一个 asm 文件,右手一个 obj 文件,嘴里叼着一个 exe 文件,所以我就是嘴遁王者。废了半天劲,终于将 asm 搞成 exe 文件了,累屁了,不过先别急着休息,还差最后一步,执行它!
于是我们执行以下 TEST.EXE 文件

我有点蒙,这怎么啥都没有啊,输出结果呢?。。。。。。
细想了一下,哦,我们没有用任何库来向控制台输出信息,我们只是做了一些数据和寄存器的移动、相加操作。
当然我们可以向控制台输出信息,不过这个我们后面在演示。
简单聊聊程序的装载过程
我们大家知道,一个程序如果要执行,就需要装载进入内存,然后 CPU 从内存中取指执行命令。
那么,当我们使用 DOS 的时候,谁负责将可执行程序装载进入内存的呢?
在 DOS 中,有一个叫做命令解释器 command.com 这个玩意儿,它也是 DOS 系统的 shell。
DOS 启动后,会先进行初始化,然后运行 command.com ,command.com 运行后,执行完其他相关任务后,会在屏幕上显示提示符,等待用户输入。
如果用户输入要执行的命令,比如 cd ,taskkill 等,这些命令由 command 执行,执行完成后再次等待用户输入。
如果用户输入要执行的程序,command 会通过文件名找到可执行文件,然后将它载入内存,设置 CS:IP 执行入口,然后 command 暂停运行,CPU 执行程序,程序执行完成后,返回 command ,command 再次等待用户输入。
所以,一个完整的汇编程序的执行过程如下。
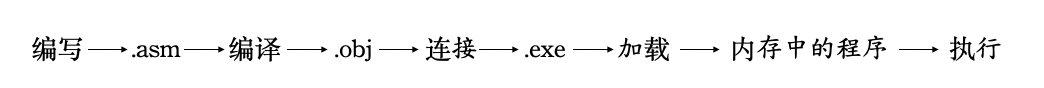
如果这篇文章写的不错并且对你有一些帮助,那我就求个赞呀!