1. 分别利用文件的系统调用read、write和文件的库函数fread、fwrite实现文件复制功能,比较在每次读取一个字节和1024字节时两个程序的执行效率,并分析原因。
1) 进入ubuntu,在桌面新建文件夹 1 用户界面 用以存储文件。
2) 进入此文件夹,新建txt文档,写入超过10k的文本。
3) 在此页面空白处右键进入终端,创建copyfread.c文件:

4)编写代码如下:

5)在终端中输入命令:
gcc copyfread.c -o copyfread_exe //生成可执行文件
6)同一目录下创建copyfread1024.c文件,将第4步源文件中的 #define count 1 改为 #define count 1024后复制粘贴到此文件中,保存并执行第5步。
gcc copyfread1024.c -o copyfread1024_exe
7)同一目录下创建copyread.c文件,编辑代码并保存。
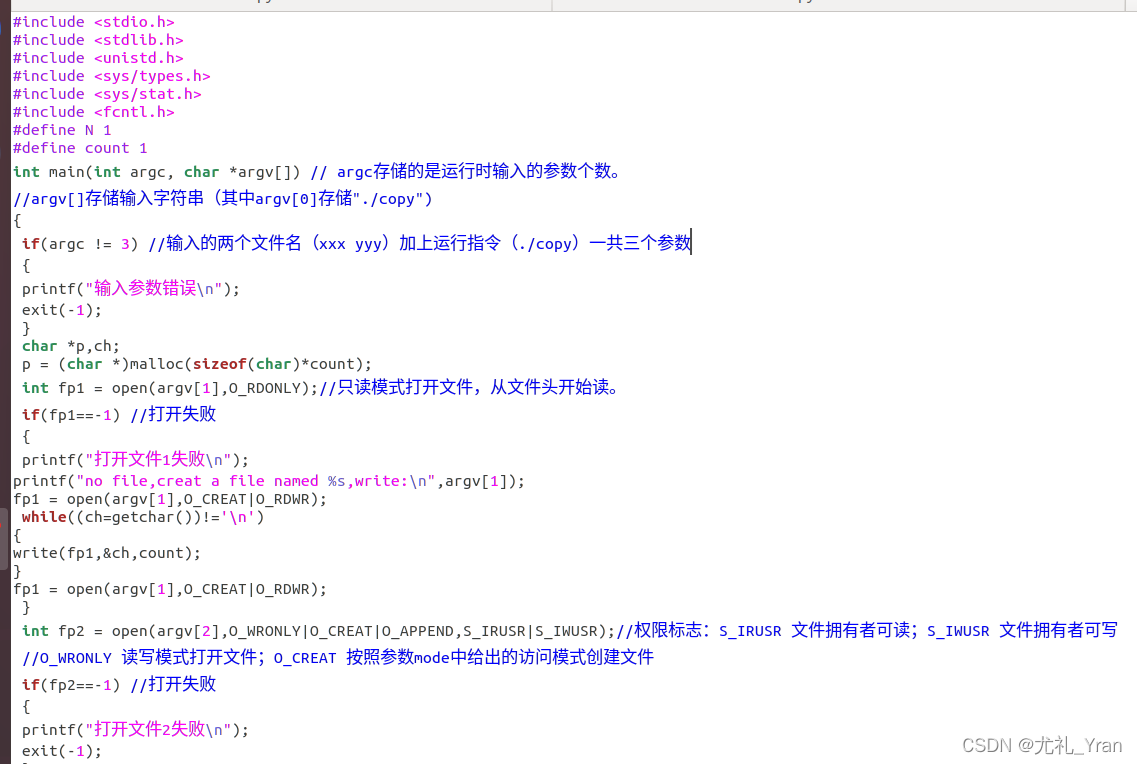
8)执行第(5)步:gcc copyread.c -o copyread_exe
9)同一目录下创建copyread1024.c文件,将第7步源文件中的 #define count 1 改为 #define count 1024后复制粘贴到此文件中,保存并执行第5步。
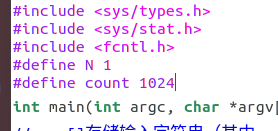
gcc copyread1024.c -o copyread1024_exe
10) 分别执行下图命令:
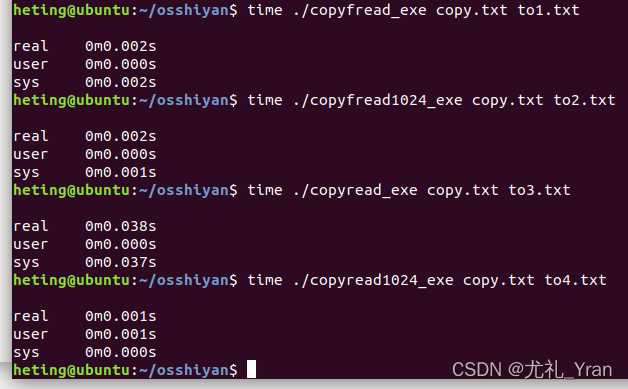
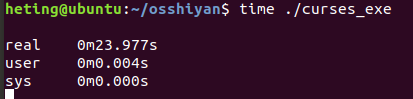
上图的4次运行分别对应用 fread/fwrite 、read/write 缓冲区大下为 1 和 1024 的耗时。
结论:库函数实现文件复制比文件的系统调用效率更高,读取1024字节程序比读取1字节效率更高;
原因:1. 对比分析库函数与系统调用对执行时间的影响; 要实现文件拷贝,必须嵌入内核,从磁盘读取文件内容,然后存储到另一个文件。
实现文件拷贝最通常的做法是:
读取文件用系统调用read()函数,读取到一定长度的连续的用户层缓冲区,然后使用write()函数将缓冲区内容写入文件。也可以用标准库函数fread()和fwrite(),但这两个函数最终还是通过系统调用read()和write()实现拷贝的,因此可以归为一类,不过效率肯定没有直接进行系统调用的高。
- 对比分析缓冲区大小对执行时间的影响,其大致原因如下: 本来系统读取数据的缓存区是较大的,可以读取多个字节数据,这样能够解释为何多(更多)字节数据的读取高的原因。又由于读取单(低)字节,需要系统额外地设置和读取缓存区,导致比读取更多字节更高的时间开销,所以单(低)字节的效率便低于多字节的时间效率了。
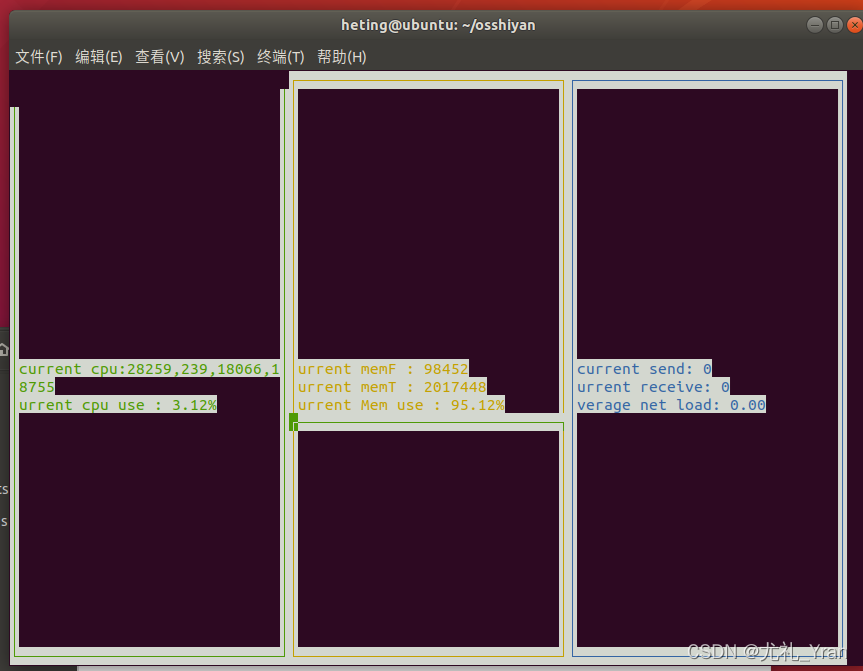
2.编写一个C程序,使用Ubuntu下基于文本的终端图形编程库curses,分窗口实时监测(即周期性刷新显示)CPU、内存和网络的详细使用情况和它们的利用率。
(1) 使用curses库,使用命令:sudo apt-get install libncurses5-dev,下载相关软件包
(2) gedit 2win-curses.c 编辑源文件。
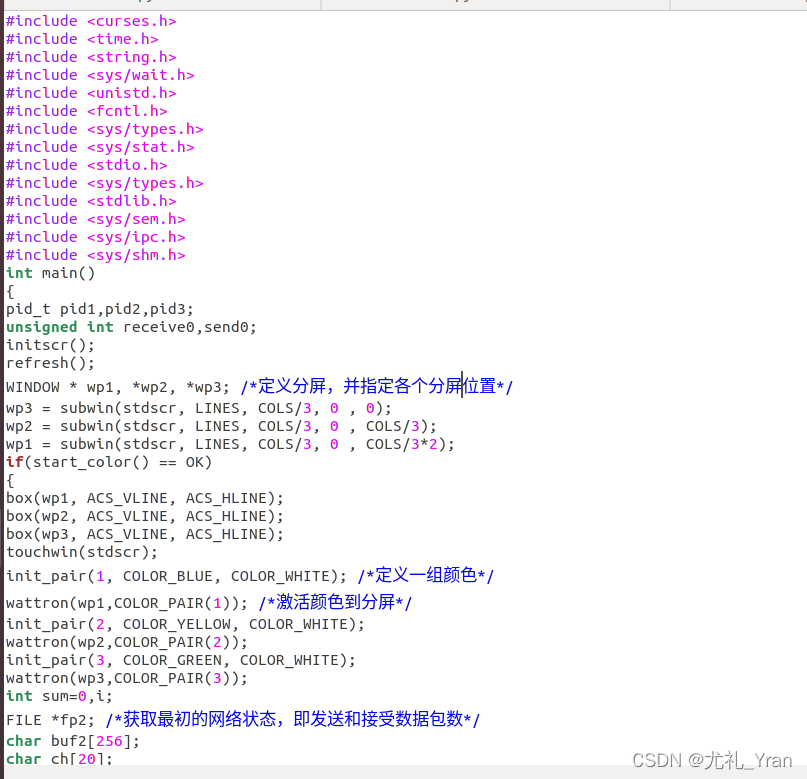
(3) 编译调试gcc -o curses_exe 2win-curses.c -lcurses (如果没有后面 的-lcurses,会提示 一系列的 undefined reference to `initscr’)
执行 ./curses_exe 即可弹出多窗口性能对比。
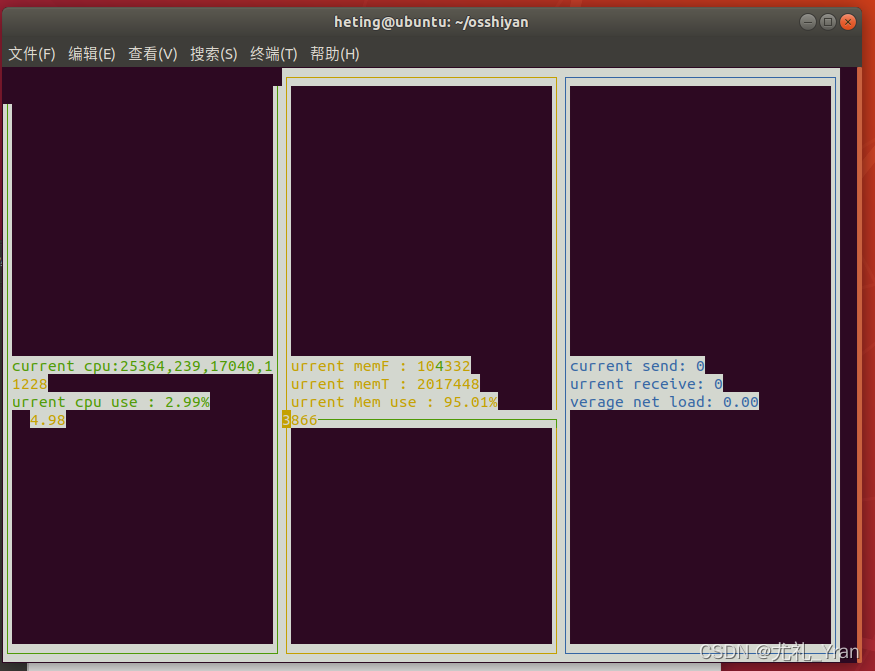
(4) 查看CPU使用效率
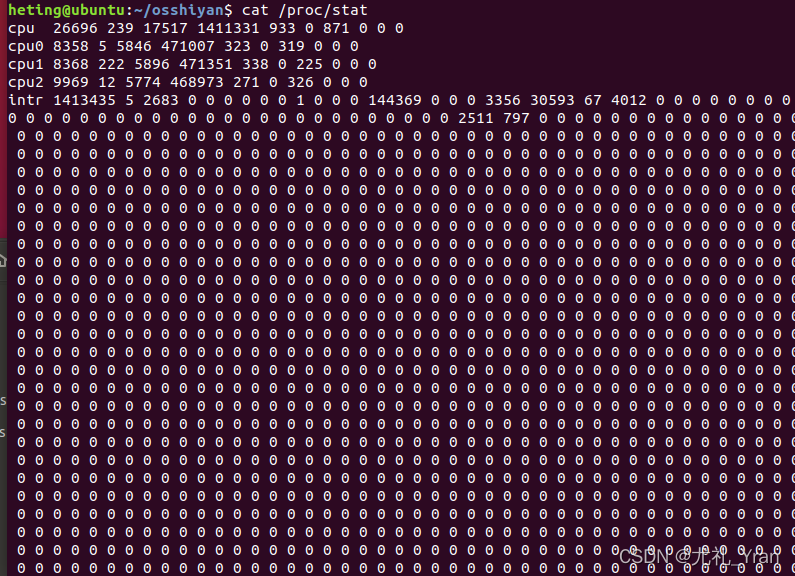
利用命令:cat /proc/stat,截图如下:
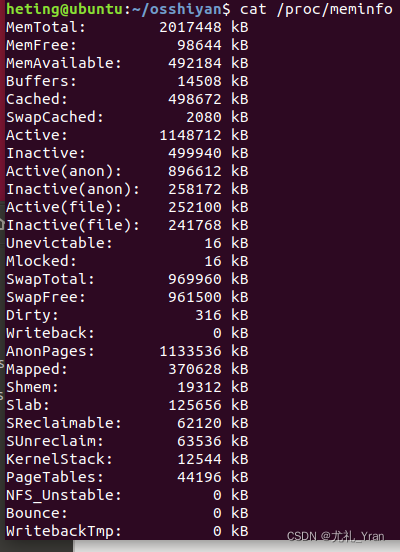
(5)查看内存利用
利用命令:cat /proc/meminfo,实现截图:
(6)计算程序执行的时间
利用命令:time ./curses_exe,执行截图如下: