目录
内存和数据类型的关系?为什么会引入数据类型?
高级语言都能通过变量名来访问内存中的数据。那么这些变量在内存中是如何存放呢?程序又是如何使用这些变量的呢?
引出两个重要话题:
? ? ?内存四区模型
? ? ?函数调用模型
建立正确程序运行内存布局图是学好C语言关键
有说的不对的地方请朋友们不吝赐教,轻轻地拍!!!
数据类型本质分析
1. 常用数据类型
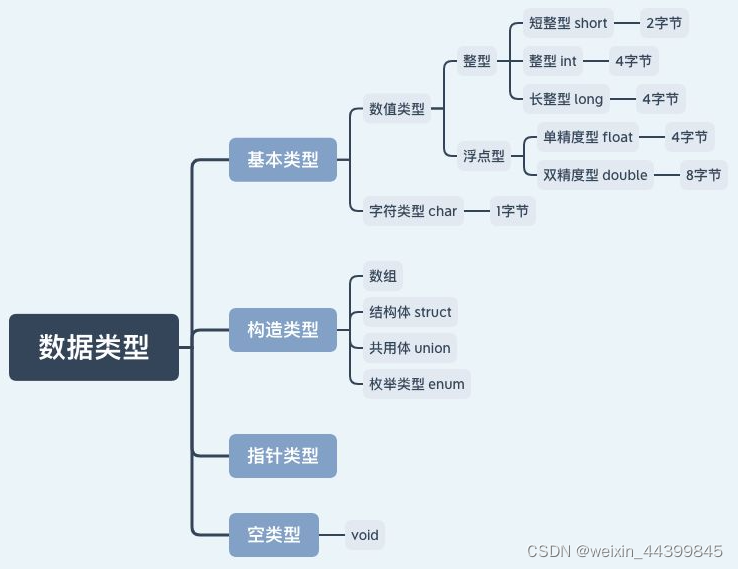
2. 数据类型本质
数据类型可以理解为创建变量的模具(棋子),是固定内存大小的别名。
作用:编译器预算对象(变量)分配内存空间的大小
#include <stdio.h>
void main()
{
int a;
int b[10];
printf("b:%d,b+1:%d,&b:%d,&b+1:%d \n",b,b+1,&b,&b+1);
system("pause");
}编译后的执行结果:
b:2029624,b+1:2029628
&b:2029624,&b+1:2029664b+1? &b+1 步长结果不一样? ?原因是?b 和&b代表的数据类型不一样
b? 表示数组首元素地址? ? ?&b 代表整个数组地址
?3.数据类型大小sizeof(xxx)
int a;
int b[10];
printf("sizeof(b):%d \n", sizeof(b));
printf("sizeof(a):%d \n", sizeof(a));?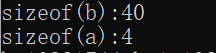
4. 数据类型别名typedef
struct Teacher
{
char name[64];
int age;
}Teacher;
typedef struct Teacher2
{
char name[64];
int age;
}Teacher2;
typedef int u32;
void main()
{
struct Teacher t1;
t1.age = 31;
Teacher2 t2;
t2.age = 32;
printf("u32:%d \n",sizeof(u32));
system("pause");
}5. 数据类型的封装?
-
Void 的字面意思是“无类型”,void* 则为“无类型指针“,void* 可以指向任何类型的指针数据。
- 用法1:数据类型的封装? ? ? ? ? ? ? ?
? ? ? ? ? ? ? ? 典型的如内存操作函数,函数原型如下:
void *memcpy(void *dest, const void *src, size_t n);
void *memccpy(void *dest, const void *src, int c, size_t n);
int memcmp(const void *s1, const void *s2, size_t n);
? ?3. 用法2:修饰函数返回值和参数,仅表示无
? ?4.?Void *指针的意义
- c语言规定只有相同类型的指针才可以相互赋值
- Void* 指针作为左值用于“接受”任意类型的指针
- Void* 指针作为右值复制给其他指针时需要强制类型转换
int *p1 = NULL;
char *p2 = (char *)malloc(sizeof(char)*20)- 不存在void类型的变量
4. 数据类型的总结与扩展
- 数据类型的本质是固定内存大小的别名;是个模具,C语言规定:通过数据类型定义变量
- 数据类型大小统计(sizeof)
- 可以给已存在数据类型起别名(typedef)
- 数据类型 封装概念(void 万能类型)
?变量本质分析
1. 变量概念
概念:既能读又能写的内存对象,成为变量;若一旦初始化后不能修改的对象称为常量。?
变量定义形式:? 类型? 标识符,标识符,…,标识符;
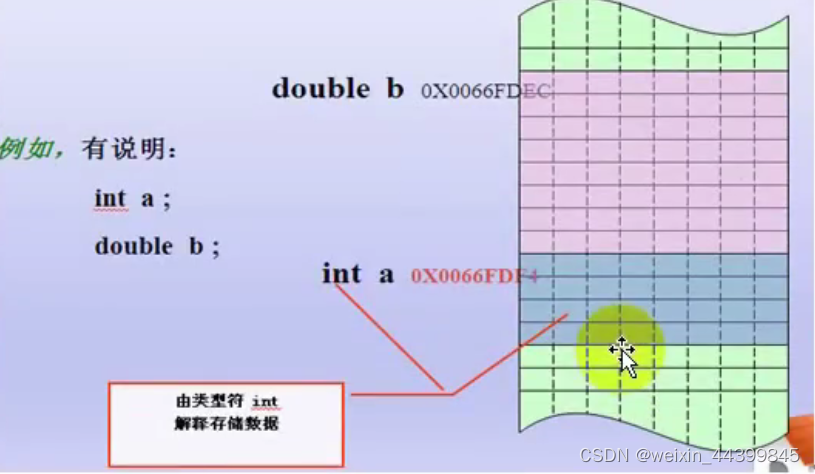
?2. 变量本质
- 程序通过变量来申请和命名内存空间 int a = 0?
- 通过变量名访问内存空间
? ? ? ? ? 变量名是(一段连续)内存空间的别名(是一个门牌号)。
- 修改变量有几种方法? ? ? ? ?
? ? ? ? ? ① 直接
? ? ? ? ? ② 间接:内存有地址编号,拿到地址编号也可以修改内存
? ? ? ? ? ③ 内存空间可以再给取别名吗?
? ? ? ? ? ? ? ? ?对内存空间不能再取别名(typedef是对数据类型取别名),c++中引用可以
- 数据类型和变量关系?
? ? ? ? ? ? ? 通过数据类型定义变量
3. 总结
- 对内存,可读可写;
- ?通过变量往内存读写数据
- 不是向变量读写数据,而是向变量所代表的内存空间中写数据。问: 变量跑哪了?
4. 思考?
- Thingking1:变量三要素(名称、大小、作用域)。变量的生命周期?
- Thingking2:c++编译器如何管理函数 1、函数 2、变量之间的关系
- 高级语言都能通过变量名来访问内存中的数据。那么这些变量在内存中是如何存放呢?程序又是如何使用这些变量的呢?下面会对此进行深入的探讨。
? ===>>引出两个重要话题:
? ? ?内存四区模型
? ? ?函数调用模型
内存四区模型?
1.内存四区建立流程
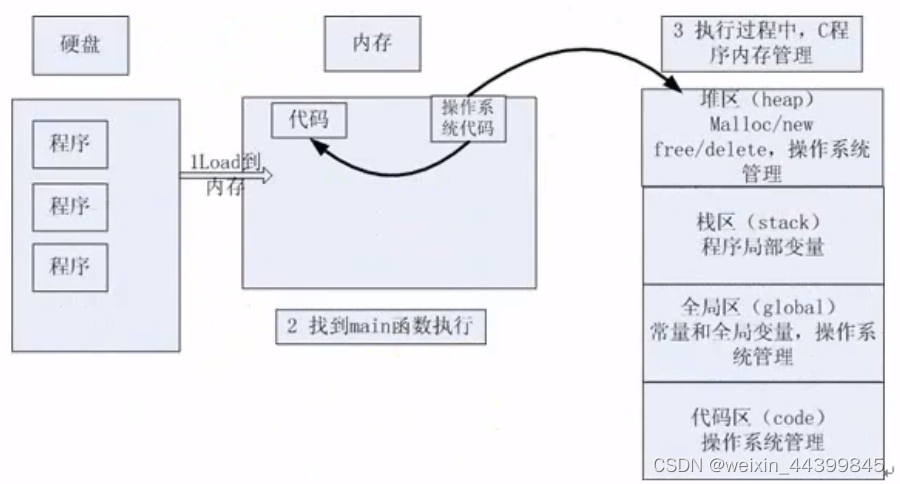
- 流程说明
- 操作系统把物理磁盘代码load到内存
- 操作系统把c代码分成四个区
- 操作系统找到main函数入口执行
?2. 各区元素分析
| 栈区(stack) | 由编译器自动分配释放,存放函数的参数值,局部变量的值等,其操作方式类似数据结构中的栈。 |
| 堆区(heap) | 由程序员分配释放,若程序员不释放(动态内存的分配与释放),程序结束时可能由OS回收。注意它与数据结构中的堆是两回事。 |
| 全局区(静态区)(static) | 全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一个区域,未初始化的全局变量和未初始化的静态变量在相邻的另一个区域,该区域在程序结束后由OS释放。 |
| 常量区 | 字符串常量和其他常量的存储位置,程序结束后由操作系统释放。 |
| 代码区 | 存放函数体的二进制代码 |
- 申请后系统的响应:
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆: 首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
- 申请大小的限制
栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
- 申请效率的比较
栈由系统自动分配,速度较快。但程序员是无法控制的。?
堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便。?
- 堆和栈中的存储内容?
栈:在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。?
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
堆栈属性测试demo
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
//栈的开口向上 or 向下,测试release 和 debug
//一般认为:栈的开口向下
//不管栈的开口向上还是向下,buf的内存地址 buf+1,永远向上 ...
void main()
{
int a;
int b;
char* buf[128]; //静态链接时,buf所代表内存空间标号就已经定义下来了。。。
printf("&a: %d, &b: %d\n",&a, &b);
system("pause");
}执行结果:
Release版:
&a: 7600948, &b: 7600952
Debug版:
&a: 7339304, &b: 7339292?Debug模式,地址逐渐减小。
?Release模式,地址逐渐增大。
一个使用预留的? 一个是使用内存扩展的。
注意:本文中的C语言代码如没有特别声明,默认都使用VC编译的release版。?
?先看下面这段代码
#include <stdio.h>
int g1 = 0, g2 = 0, g3 = 0;
int main()
{
static int s1 = 0, s2 = 0, s3 = 0;
int v1 = 0, v2 = 0, v3 = 0;
//打印出各个变量的内存地址
printf("0x%08x\n", &v1); //打印各本地变量的内存地址
printf("0x%08x\n", &v2);
printf("0x%08x\n\n", &v3);
printf("0x%08x\n", &g1); //打印各全局变量的内存地址
printf("0x%08x\n", &g2);
printf("0x%08x\n\n", &g3);
printf("0x%08x\n", &s1); //打印各静态变量的内存地址
printf("0x%08x\n", &s2);
printf("0x%08x\n\n", &s3);
return 0;
}?编译后的执行结果是:
Debug模式的结果:
&v1:0x00cff788
&v2:0x00cff77c
&v3:0x00cff770
&g1:0x0033f140
&g2:0x0033f144
&g3:0x0033f148
&s1:0x0033f14c
&s2:0x0033f150
&s3:0x0033f154
Release模式的结果:
&v1:0x005cfe98
&v2:0x005cfe94
&v3:0x005cfe90
&g1:0x00453388
&g2:0x00453384
&g3:0x00453380
&s1:0x00453390
&s2:0x0045338c
&s3:0x00453394Release和Debug?两种模式的执行结果不一样,查阅资源也没弄明白,望知道的大佬给出解答。
在此以Debug模式为准:输出的结果就是变量的内存地址。其中v1,v2,v3是局部变量,g1,g2,g3是全局变量,s1,s2,s3是静态变量。可以看到这些变量在内存是连续分布的,但是局部变量和全局变量分配的内存地址差了十万八千里,而全局变量和静态变量分配的内存是连续的。这是因为局部变量和全局/静态变量是分配在不同类型的内存区域中的结果。对于一个进程的内存空间而言,可以在逻辑上分成3个部份:代码区,静态数据区和动态数据区。动态数据区一般就是“堆栈”。“栈(stack)”和“堆(heap)”是两种不同的动态数据区,栈是一种线性结构,堆是一种链式结构。进程的每个线程都有私有的“栈”,所以每个线程虽然代码一样,但局部变量的数据都是互不干扰。一个堆栈可以通过“基地址”和“栈顶”地址来描述。全局变量和静态变量分配在静态数据区,局部变量分配在动态数据区,即堆栈中。程序通过堆栈的基地址和偏移量来访问本地变量。?
静态区案例
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
char* getStr1()
{
char* p1 = "abcdefg2";
return p1;
}
char* getStr2()
{
char* p2 = "abcdefg2";
return p2;
}
void main()
{
char* p1 = NULL;
char* p2 = NULL;
p1 = getStr1();
p2 = getStr2();
//打印p1 p2 所指向内存空间的数据
printf("p1:%s, p2:%s \n", p1, p2);
//打印p1 p2的值
printf("p1:%08x, p2:%08x \n", p1, p2);
}编译后的执行结果是:
p1:abcdefg2, p2:abcdefg2
p1:00582100, p2:00582100四区图:
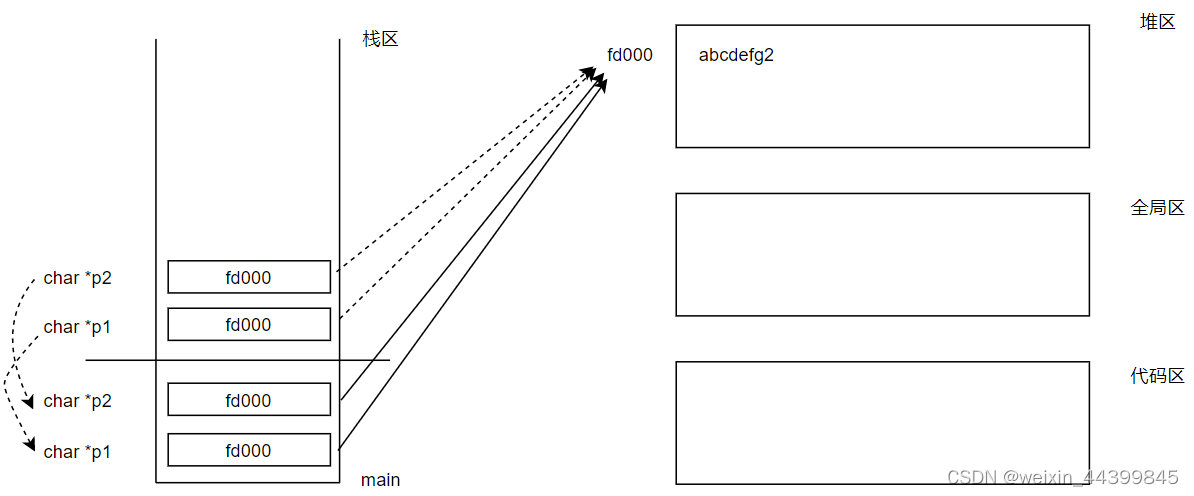
- 指针指向谁就把谁的地址赋给指针
- 指针变量和它所指向的内存空间变量是两个不同概念
注:如果全局区存入相同的值,则编译器会进行优化,存入一个值,指向相同空间。??
堆栈是一个先进后出的数据结构,栈顶地址总是小于等于栈的基地址。我们可以先了解一下函数调用的过程,以便对堆栈在程序中的作用有更深入的了解。?
?函数的调用模式
1. 基本原理
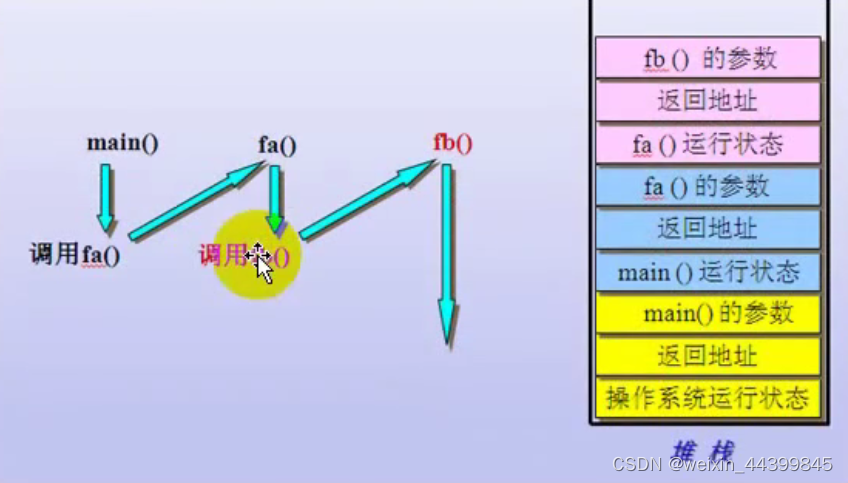
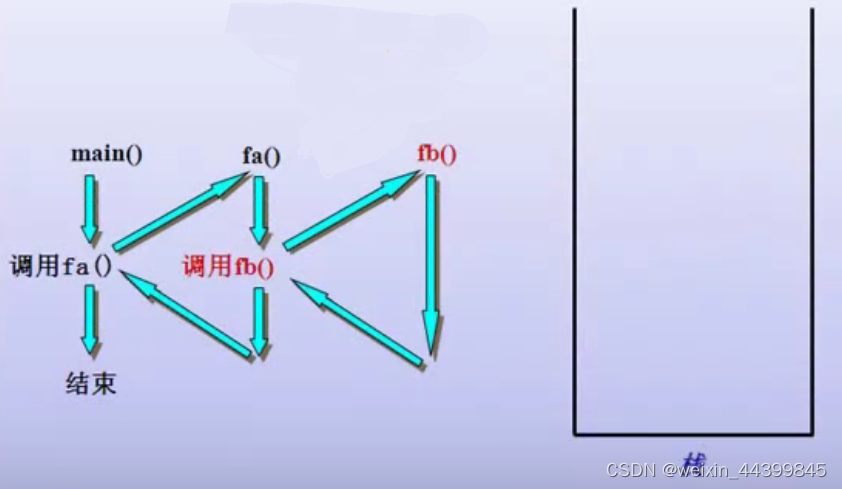
?2. 函数调用的示例代码
我们可以先了解一下函数调用的过程,以便对堆栈在程序中的作用有更深入的了解。不同的语言有不同的函数调用规定,这些因素有参数的压入规则和堆栈的平衡。windows API的调用规则和ANSI C的函数调用规则是不一样的,前者由被调函数调整堆栈,后者由调用者调整堆栈。两者通过“__stdcall”和“__cdecl”前缀区分。先看下面这段代码:
#include <stdio.h>
void __stdcall func(int param1, int param2, int param3)
{
int var1 = param1;
int var2 = param2;
int var3 = param3;
printf("0x%08x\n", ¶m1); //打印出各个变量的内存地址
printf("0x%08x\n", ¶m2);
printf("0x%08x\n\n", ¶m3);
printf("0x%08x\n", &var1);
printf("0x%08x\n", &var2);
printf("0x%08x\n\n", &var3);
return;
}
int main()
{
func(1, 2, 3);
return 0;
}编译后的执行结果是:
¶m1:0x0081f894
¶m2:0x0081f898
¶m3:0x0081f89c
&var1:0x0081f880
&var2:0x0081f874
&var3:0x0081f868├―――――――┤<―函数执行时的栈顶(ESP)、低端内存区域?
│ …… │?
├―――――――┤?
│ var 3?│?
├―――――――┤?
│ var 2 │?
├―――――――┤?
│ var 1 │?
├―――――――┤?
│ RET │?
├―――――――┤<―“__cdecl”函数返回后的栈顶(ESP)?
│ parameter 1 │?
├―――――――┤?
│ parameter 2 │?
├―――――――┤?
│ parameter 3 │?
├―――――――┤<―“__stdcall”函数返回后的栈顶(ESP)?
│ …… │?
├―――――――┤<―栈底(基地址 EBP)、高端内存区域?
上图就是函数调用过程中堆栈的样子了。首先,三个参数以从右到左的次序压入堆栈,先压“param3”,再压“param2”,最后压入“param1”;然后压入函数的返回地址(RET),接着跳转到函数地址接着执行;第三步,将栈顶(ESP)减去一个数,为本地变量分配内存空间,上例中是减去12字节(ESP=ESP-3*4,每个int变量占用4个字节);接着就初始化本地变量的内存空间。由于“__stdcall”调用由被调函数调整堆栈,所以在函数返回前要恢复堆栈,先回收本地变量占用的内存(ESP=ESP+3*4),然后取出返回地址,填入EIP寄存器,回收先前压入参数占用的内存(ESP=ESP+3*4),继续执行调用者的代码。
?2. 建立正确的程序运行内存布局图
- ?内存四区模式&函数调用模式
- 函数内元素
- 深入理解数据类型和变量“内存”属性
- 一级指针 内存布局图(int *? char *)
- 二级指针内存布局图(int **? ? char**)
- 函数间接
- 主调函数分配内存还是被调函数分配内存
- 主调函数如何使用 被调函数分配的内存(技术关键点,指针做函数参数)
参考文章链接: