�Լ�������һ����Ʊ����,���ܺ�ǿ��,��Ҫ�ĵ����������ӻ�ȡ:
QStockView��Ʊ���ܷ������������������� - һ��ǧ�� - ����
Ŀ¼
1????? ����... 1
1.1????????? ԭ�Ӳ���... 1
1.2????????? ָ��ִ��˳��... 2
1.3????????? ��������CPUָ������... 2
1.4????????? ������ϵ... 3
1.5????????? memoryorder����... 3
2????? �����ڴ�ģʽ... 3
2.1????????? Relaxed ordering. 5
2.2????????? Release �C acquire. 6
2.3????????? Release �C consume. 7
2.4????????? memory_order_acq_rel 10
2.5????????? Sequentially-consistent ordering. 11
2.6????????? �ܽ�... 13
3????? �����... 14
?
1??????? ����
���̱߳���Ѿ��Ǵ����֪��֪ʶ,���̱߳����Ҫ��������Ƕ��߳�ͬʱ����һ������ʱ,�����ͬʱ��дͬһ������������,��������쳣,ͨ����ʹ��mutex���ٽ���������������ʵ�ֶ��߳�ͬ��,������߳�ͬʱ��дͬһ������������������Ҳ��Ӱ������ִ��Ч��,����C++11������ԭ�ӱ���atomic,ʵ�ֱ�����ԭ�Ӳ���,�̶߳Ա����IJ������϶������߳̿ɼ�,����ʹ�����ٽ�����ɵ����ġ�ͬʱC++11�������ڴ�ģ��,����ͬ����ͬ�߳�֮���ԭ�ӱ�������ǰ��Ĵ�����������ơ�
1.1? ԭ�Ӳ���
����,ʲô��ԭ�Ӳ���?ԭ�Ӳ������Ƕ�һ���ڴ��ϱ���(���߽���ֵ)�Ķ�ȡ-���-�洢(load-add-store)��Ϊһ������һ����ɡ�����x++�������ʽ�������ɻ��,��Ӧ����3��ָ��:mov(���ڴ浽�Ĵ���),add,mov(�ӼĴ������ڴ�)��ô�ڶ��̻߳�����,�ʹ��������Ŀ���:���߳�A�ո�ִ����ڶ���addָ���ʱ��,��û��ִ�е�����movָ��,�߳�B��ͬʱ��ʼִ�е�һ��ָ���ôB���������ݻ���0,Aִ�е�����ָ���д���ڴ�,xֵ��1,B��ִ�е�����ָ��ӼĴ���д���ڴ�,x����1�������ԭ�Ӳ���,mov(���ڴ浽�Ĵ���),add,mov(�ӼĴ������ڴ�)������ָ�����һ�����,�߳�Aִ������֮��,x=1,�߳�B��ִ������ָ��,�õ�x=2��atomic��������һ����,���Լ����Ѿ��������ԭ�Ӳ��������á��ڴ�˳���ǿ��Ʋ�ͬԭ�Ӳ���֮���ִ��˳��,�������߳�B�ȼ�1�����߳�A�ȼ�1��
1.2? ָ��ִ��˳��
Ϊ�˾����ܵ���������Դ�����ʺ�����,��������Դ��������������, CPU ���ָ��������������ӻ�ִ�С����ֻ���ȵ�,�Դﵽ���õ�ִ��Ч�������߳����ǰ����߳��еĴ���˳��ִ��ָ��,���߳�ʱ,�����߳�֮��ִ��ָ���˳�������Ż�����,��������֤�����߳���ָ��ִ�е����˳��,�����߳�1��ָ��A,B,�߳�2��ָ��C,D,�����߳�ͬʱִ��,��ô���ܵ�ִ��˳����ABCD,ACBD,CDAB,CABD��;����C++11�����ڴ�˳�����,ʵ�ֿ��ƶ��߳���ָ��ִ��˳��,ʵ�ֶ��߳�ͬ�����ܹ����������˳��ִ��ָ�
happens-before��ϵ,˵���˾��Ǵ����д˳��,һ����ָ���߳��ڲ��Ĵ���˳��Synchronized-with��ϵ���Ƕ��߳�֮���ͬ����ϵ,ͨ��6��ģʽ,ʵ�ֶ��߳���ָ��ִ��˳��IJ�ͬԼ����
1.3? ��������CPUָ������
����˳��:�����㰴�մ���һ��һ�д������µ�˳��;
�������Դ�����ܽ���ָ�����š�Ҳ���DZ������ɵĶ�����(������)��˳����Դ������ܲ�ͬ,����һ���߳��������д���x++;y++;��Ȼy++��x++֮��,���DZ��������ܻ��y++�ŵ�x++֮ǰ������CPU�ڲ�Ҳ��ָ������,Ҳ����˵,CPUִ��ָ���˳��,Ҳ����������ȫ�ϸ��ջ������˳����CPU��IPC(ÿʱ��ִ��ָ����)һ�㶼Զ����1,Ҳ������ν�Ķ��,�ܶ������ͬʱִ�еġ�����,����CPU����(һ������)һ�����2�����ϵ�����ALU(�ӷ���),2�����ϵĸ���ALU(�ӷ���),�������ж����ij˷���,�Լ�,������Load��Storeִ������Load��Storeģ����������8�����ϵĶ���,Ҳ���ǿ���ͬʱ����8�������ڴ��ַ(cache line)�Ķ�д������
1.4? ������ϵ
���߳���ָ������Ҳ��������,����ص�ָ���������,��ص�ָ�������;�����߳�1��������ָ��x++;y++;������ָ������ȫ����ص�,�����������˳���������x++;y=x;��������ָ����������ϵ,��ôһ���ǰ��մ���˳��ȥִ�С�
1.5? memoryorder����
memory order,��ʵ�������Ʊ������Լ�CPU�Ե��̵߳��е�ָ��ִ��˳��������ŵij̶�(���������cache�Ŀ��Ʒ���)����������,��������atomic����Ϊ����(�߽�),����֮ǰ����ڴ��������,�ܹ��ڶ��ķ�Χ����������(���߷�����,��Ҫʩ�Ӷ��ı�������),Ҳ����Ϊդ�����Ӷ��γ���6��ģʽ������������߳���,�����Ƶĵ�һ�̵߳���ָ��ִ��˳��
�����
������� C++11 ������ memory order? - ֪��
2??????? �����ڴ�ģʽ
| ��� | ˳���ϵ | ˵�� |
| 1 | Relaxed order������ر�����ԭ�Ӳ����� | ֻ��֤�߳�1�е�g.Store���߳�2�е�g.load������ԭ�Ӳ���������֤�߳�֮���g����ָ��ͬ��˳��Ҳ����������������˳�� |
| 2 | Release-acquireͬ�����߳�˳��,ǿ������������˳����ϵ�� | (1)??? �߳�1��,g.store(release)֮ǰ��д�������������ŵ�g.store(release)���档 (2)??? g.load(acquire)֮��Ķ�д���������������ŵ�g.load(acquire)֮ǰ�� (3)??? ���g.store()��gload()֮ǰִ��,��ôg.store(release)֮ǰ������д������g.load(acquire)֮�������ɼ��� |
| 3 | Release-consumeֻͬ��ͬ��˳��,ǿ������������˳����ϵ�� | (1)??? ֻ��֤ԭ�Ӳ���,����Ӱ���������ϵ����������˳�����ơ� (2)??? ����������ϵ�ı���,���g.store()��gload()֮ǰִ��,����g.store(release)֮ǰ������д������g.load(acquire)֮�������ɼ��� |
| 4 | memory_order_acq_rel: | (1)�ڵ�ǰ�̶߳Զ�ȡ��д��ʩ�� acquire-release ����,����IJ������ŵ�ǰ��,���ǰ�IJ������ŵ����档 (2)���Կ��������߳�ʩ�� release ����֮ǰ������д��,ͬʱ�Լ��� release ����������д�������ʩ�� acquire ������߳̿ɼ��� |
| 5 | memory_order_seq_cst | ˳��һ����ģ��,(1)�Ա���ʩ��acq_rel�������Ƶ�����,(2)ͬʱ������һ��������ԭ�ӱ���������ȫ��Ψһ��˳��,�����߳̿������ڴ������˳����һ���ġ� |
?
2.1? Relaxed ordering
?
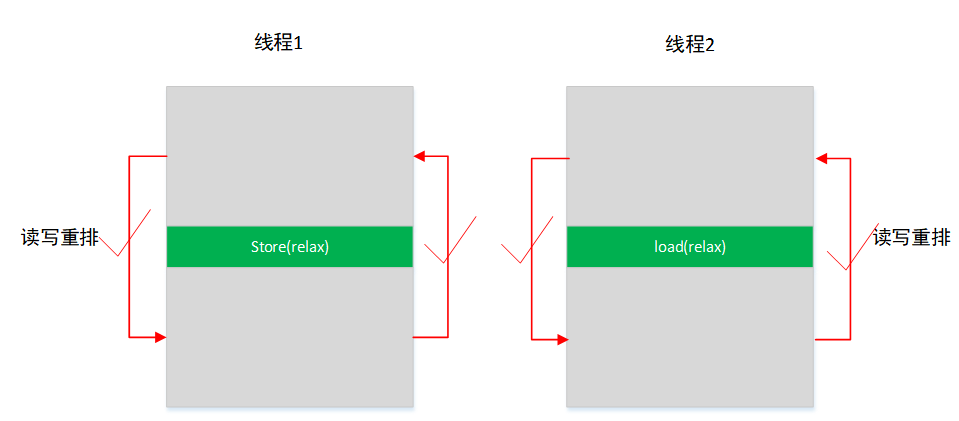
Relaxed ordering,���ɵ�����,ֻ��֤������ԭ�Ӳ���,���Dz���֤�κ�˳��,���߳��г���������ϵ�İ��մ���˳��,û��������ϵ�����������⡣�ٸ����ӡ����½�������ԭ�ӱ���,�߳�1��ִ�и�ֵ����A,B,�߳�2��ִ�ж�ȡ����C,D����ΪRelaxed orderingֻ��֤����A,B,C,D��ԭ�Ӳ���,A,B֮��û��������ϵ,C,D֮��Ҳû��������ϵ,�����߳�1��ִ��˳�������A,B,Ҳ������B,A,�߳�2��ִ��˳�������C,D,Ҳ������D,C,�߳�1���߳�2֮��Ҳû���κ�ͬ����ϵ,�����߳�1���߳�2ͬʱִ��ʱ,A,B,C,D����������˳��,���D��A֮ǰִ��,����ִ��˳����B,D,C,A,��Dָ����Ի����ʧ��,��ΪA������û��д��fΪtrue��������C������ whileѭ��,ֻ�DZ�֤B����ִ���ꡣʵ��Ӧ���п��Բ���ѭ����
atomic<bool> f=false;
atomic<bool> g=false;
// thread1
f.store(true, memory_order_relaxed);//A
g.store(true, memory_order_relaxed);//B
?
// thread2
while(!g.load(memory_order_relaxed));//C??
assert(f.load(memory_order_relaxed));//D
�������������ϵ,��B�ij�g.store(f, memory_order_relaxed);,g������f,���߳�1��ִ��˳��ֻ����A,B,�߳�2�л�������˳��CD,����DC���߳�1���߳�2��ִ��˳��������˳��,ֻ��A������Bǰ�档������ABCD��ACBD,DABC��;D�����п�����A֮ǰִ��,����D���ǻ���ֶ���ʧ�ܡ���ô��֤Aһ����D֮ǰִ��,�ö��Բ�ʧ����,Ҳ��Ҫ���������߳��е�����ָ���˳��,����ʹ��Release �C acquire˳���ϵ��ʵ�֡�
?
2.2? Release �C acquire

���̲߳�����Ϊ�����Ч��,���߳�ͬ����Ϊ�˽��ͬʱ����ͬһ������������,�߳�1��g.store(release)д�������߳�2��g.load(acquire)���������ʹ��,�����DZ�֤g.store(release)һ����g.load(acquire)֮ǰִ��,����߳�1һֱsleep����,�߳�2��ִ��g.load(acquire)��������ͬ����ָ�߳�1��g.store(release)֮ǰ��д���ܱ����ŵ�g.store(release)֮��,�߳�2 g.load(acquire)֮��Ķ�д���ܱ����ŵ�g.load(acquire)֮ǰ,���g.store(release)����g.load(acquire)֮ǰִ��(ǰ��),��ô�߳�1��g.store(release)֮ǰ�Ķ�д���߳�2��g.load(acquire)֮��Ķ�д�ɼ������g.load(acquire)����g.store(release)֮ǰִ��,��ô����֤�߳�1��g.store(release)֮ǰ�Ķ�д���߳�2��g.load(acquire)֮��Ķ�д�ɼ����ܽ���������:
(1)??? load(acquire)���ڵ��߳���load(acquire)֮�������д����(������������ϵ),���������ƶ������load()��ǰ��,һ����load֮��ִ�С�
(2)??? store(release)֮ǰ�����ж�д����(������������ϵ),�����������ŵ����store(release)�ĺ���,һ����store֮ǰִ�С�
(3)??? ���store(release)��load(acquire)֮ǰִ����(ǰ��),��ôstore(release)֮ǰ��д������ load(acquire)֮��Ķ�д�����ɼ���
?
����
bool f=false;
atomic<bool> g=false;
// thread1
f=true//A
g.store(true, memory_order_release);//B
?
// thread2
while(!g.load(memory_order_ acquire));//C
assert(f));//D
���ݹ���(1),�߳�1��A�����������ŵ�B֮��,���ݹ���(2)D�����������ŵ�C֮ǰ,���ݹ���(3),��ΪC����whileѭ��,һֱ�ȴ�,�ȵ�Bִ������,C��ѭ�����˳�,��֤B��C֮ǰִ����,A��һ����B֮ǰִ����,��ôD��������Զ��true,��Զ����ʧ�ܡ����Cû ѭ��,��ʹ����release��acquire,Ҳ���ܱ�֤B��C֮ǰִ��,DҲ���ܻ����ʧ�ܡ�
release -- acquire �и�ţ�Ƶĸ�����:�߳� 1 �����з����� B ֮ǰ��A����,������B֮ǰִ��,DҲһ����C֮��ִ��,A,D�������,��Ե�ʵľͱ�ǿ��˳���ˡ����������A,D��˳��ǿ��˳��,����ʹ��Release �C consume��
2.3? Release �C consume
?

(1)Release �C consumeʵ��
Release �C consumeҲ��ʵ�ֶ��߳�֮��ָ���ͬ������,��Release �C acquire��ͬ����,Release �C consume���������߳�������������˳������,����˳��ǿ����ǰ������ָ��(��������ϵ)��˳����������ָ��ǿ��˳������Ķ����������:
bool f=false;
atomic<bool> g=false;
// thread1
f=true//A
g.store(true, memory_order_release);//B
?
// thread2
while(!g.load(memory_order_consume);//C
assert(f));//D
ͬ��������������ʹ����release��consume��ϵ,��������A��B��C��Dָ���˳��,������������,�߳�1�п�����AB,BA,�߳�2�п�����CD,DC���߳�1���߳�2�����������������ϡ�����D�п��ܶ���ʧ�ܡ����������relax��һ���ġ�
(2)Release �C consume������ϵ������������
��������ϵ�ı�����ָ��˳���ǻᰴ�մ���˳��ȥִ��,���AB֮����������ϵ�������������:
bool f=false;
atomic<bool> g=false;
// thread1
f=true//A
g.store(f, memory_order_release);//B?? g������f
?
// thread2
while(!g.load(memory_order_consume);//C
assert(f));//D
��ΪB�еı���g������f,�����߳�1��ָ��˳��ֻ����AB,�߳�2��Dһ���ɹ�,��Ϊ���߳�1��g������f,����Aһ����B֮ǰִ��,�߳�2��DҲ�����Ʋ������ŵ�C֮ǰ,C�е�whileѭ����һֱ�ȵ�g��Ϊtrue,˵��f�Ѿ�Ϊtrue,��ôD��Զ�ɹ���
(3)relax��consume������
��ôrelax��consume����һ����?�����߳�����������ϵ�Ͱ��մ���˳���������������,relax��consume��������ʲô?�������������ʾ,��release��consume������relax��
bool f=false;
atomic<bool> g=false;
// thread1
f=true//A
g.store(f, memory_order_relax);//B?? g������f
?
// thread2
while(!g.load(memory_order_?relax);//C
assert(f));//D
�߳�1��g������f,�����մ���˳��,A��B֮ǰִ�С���Ϊ���߳�2��CD֮��û��������ϵ,�����߳�2��CD�����������š��������consume,��ô�߳�2�о�ֻ����CD˳��,���ܱ����š���Ϊ�߳�1��������ϵҲӰ�����߳�2�е�ָ����������,�߳���B֮ǰ����������д����߳�2��C֮������������Ķ�ȡ�ɼ��������relax��consume������
2.4? memory_order_acq_rel
?
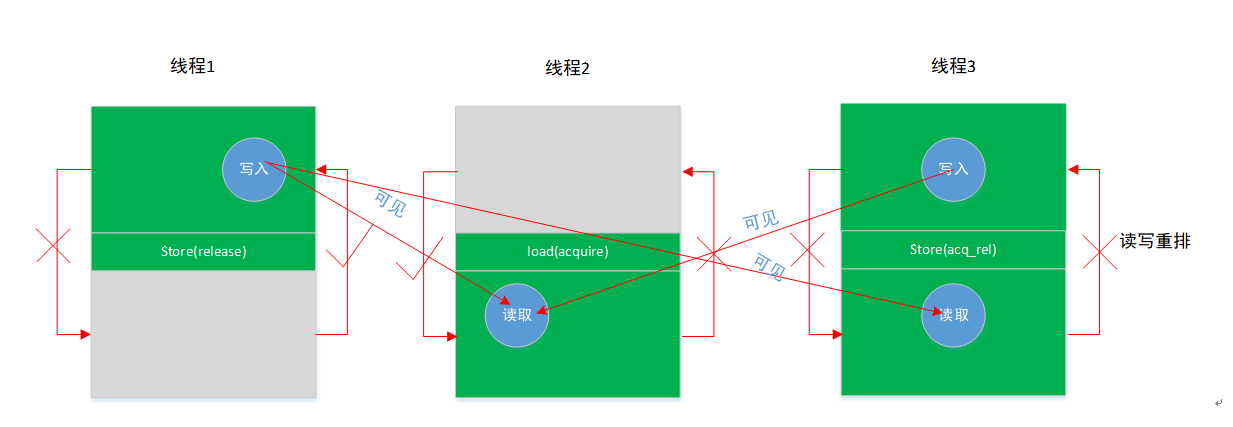
?�Զ�ȡ��д��ʩ�� acquire-release ����,Ҳ����g.store(acquire-release)����g.load(acquire-release)ǰ���������ŵ�����,�����������ŵ�ǰ�档
���Կ��������߳�ʩ�� release ֮ǰ������д��,ͬʱ�Լ�֮ǰ����д�������ʩ�� acquire ������߳̿ɼ����������������:
bool f=false;
atomic<bool> g=false;
bool h=false;
// thread1
f=true//A
g.store(true, memory_order_release);//B?
// thread2
while(!g.load(memory_order_?acquire);//C
assert(f));//D
assert(h);//E
?
//thread3
h=true;//F
while(!g.load(memory_order_acq_rel);//G
assert(f));//H
���ݹ���,�߳�1��A���������������ŵ�B֮��,�߳�2��DE���������������ŵ�C֮ǰ���߳�3��F���������������ŵ�G֮��,H���������������ŵ�G֮ǰ��
�߳�1��A����д����߳�2��D��ȡ�Լ��߳�3��H�����Ķ�ȡ���ǿɼ�,��DH��gΪtrue��ǰ����,������һ����true;ͬʱ�߳�3��F������д����߳�2��E�����Ķ�ȡ�ɼ�,��E������gΪtrue��ǰ����,������һ����true��
2.5? ?Sequentially-consistent ordering
?
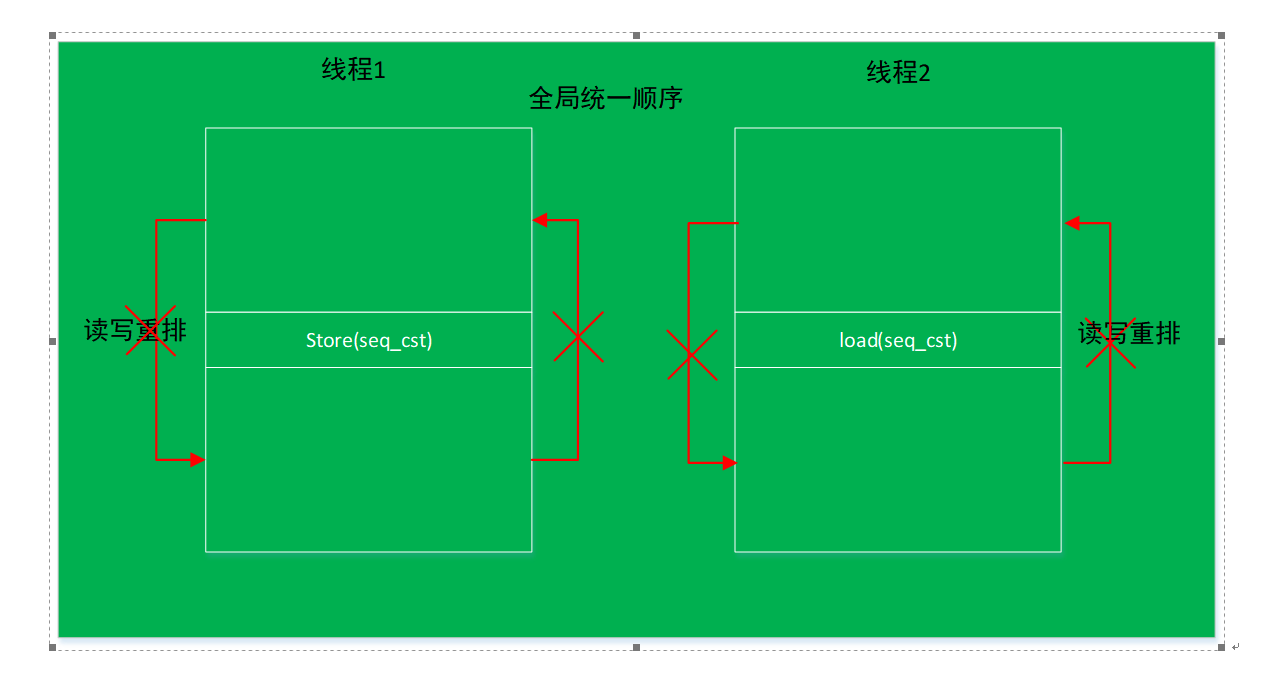
Ĭ�������,std::atomicʹ�õ��� Sequentially-consistent ordering,���˰���release/acquire������,ͬʱ������һ��������ԭ�ӱ���������ȫ��Ψһ��˳������ͳһ��ȫ��˳��,���е��߳̿�����˳����һ�µġ����ڶ���̼߳��л�,�ﵽ����̷߳·���һ���߳���˳��ִ�е�Ч���������߳��а��մ���˳��,���߳�֮�䰴��һ��ȫ��ͳһ˳��,����ʲô˳����ʱ��Ƭ�ķ��䡣
��������
// ˳��һ��
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x()
{
?? x.store(true,std::memory_order_seq_cst);//A
}
void write_y()
{
??? y.store(true,std::memory_order_seq_cst);//B
}
void read_x_then_y()
{
??? while(!x.load(std::memory_order_seq_cst));//C
??? if(y.load(std::memory_order_seq_cst))//D
??????? ++z;
}
void read_y_then_x()
{
??? while(!y.load(std::memory_order_seq_cst));//E
??? if(x.load(std::memory_order_seq_cst))F
??????? ++z;
}
int main()
{
??? x=false;
??? y=false;
??? z=0;
??? std::thread a(write_x);
??? std::thread b(write_y);
??? std::thread c(read_x_then_y);
??? std::thread d(read_y_then_x);
??? a.join();
??? b.join();
??? c.join();
??? d.join();
??? assert(z.load()!=0);
}
����һ���ĸ��߳�,�����ĸ��߳�ͬʱ����,��ABCDEF6��ָ���ʲô˳��ִ����?�ĸ��̲߳���ִ��,��������ִ��,�ܵ�ȫ��˳���ѡ����ͼ�е�һ������˳��ʼִ��,���Ҷ����е��߳���˵���ǰ������ȫ��˳��ִ�С�
���簴��ACDBEF��˳��ִ��,�����߳�write_x�ȷ��䵽ʱ��Ƭ,A��ִ��,x��Ϊtrue,�߳�read_x_then_y��C����whileѭ���˳�,D����ִ��,Bִ��,y��Ϊtrue,E��whileѭ���˳�,ִ��F��
�ٱ���ABCDEF,ACBEDF��,ֻ��Cһ����D֮ǰ,Eһ����F֮ǰ��
?
?
2.6? �ܽ�
����ģ�Ͳ��������������Ƶ��߳��ڲ���ָ������˳��,������ͬ����ͬ�߳�֮���ָ��˳��,����ͨ�����Ƶ��߳���ָ�������,�Կ��ƴ���ģ�Ͳ����ı���ǰ���ָ�����˳�����ơ���������,��������atomic����Ϊ����(�߽�),����֮ǰ���ڴ��������,�Լ�֮����ڴ��������,�ܹ��ڶ��ķ�Χ���������š������������,ʹ��whileѭ��,��һֱ�ȴ�,��Ϊ�˱�֤storeΪtrue��,loadΪtrue,�Ӷ��˳�whileѭ��,��Ϊstore֮ǰ��дָ����store֮ǰ���,����store֮ǰ��дָ���while(load(acquire))֮���дָ��ɼ�,whileѭ��һֱ�ȴ�,ǿ���˶��̼߳�����ָ���˳��,����дֻ��Ϊ��˵��ԭ��,ʵ��Ӧ���в�������ȥ��̡�
3??????? �����
������� C++11 ������ memory order? - ֪��
https://en.cppreference.com/w/cpp/atomic/memory_order
C++11��6���ڴ����ܽ�_Andrew LD-CSDN����_memory_order_relaxed
���� C++ �� Memory Order | Senlin's Blog
?
?