首先我们来思考拷贝和移动的区别,这样你能更深刻的理解c++11为什么要推出右值引用和move了。
现来说说拷贝,以下面的例子来说明:
int f(){
int tmp=10;
return tmp;
}
int mian(){
int b=f();
return 0;
}
在主函数中,调用f()函数,为临时变量tmp申请了一块内存用来存储数据,当函数即将结束时,临时申请的这块内存要被释放掉,所以需要拷贝一份用于作为 f()函数的返回值。此时涉及了一次拷贝,还有一次拷贝是在主函数中,需要为b申请一块内存,存放f()返回值。当main函数结束,上述过程一共执行1次自主申请内存,两次拷贝,三次释放。(当然由于编译器优化,上面在实际情况中只涉及了一次申请,一次释放,这个过程对程序员是透明的。)
考虑一下,当拷贝的数据量足够大时,这些无意义的拷贝和释放,大大的降低了性能,所以引入右值引用和move的作用是为了减少无意义的拷贝,实现资源的移动,减少内存的申请与释放。
先来说一下什么是右值。在c++11中,右值是由两个概念构成的,一个是将亡值,另一个是纯右值。其中纯右值就是c++98标准中的右值概念,讲的是用于辨识变量和一些不跟对象关联的值。比如非引用返回的函数返回的临时变量值,就是一个纯右值 。一些运算表达式,如(1+3)产生的临时变量,也是纯右值。而不跟对象关联的纯右值,比如:2,‘c’,true,也是纯右值。此外类型转换函数的返回值,lambda表达式等,也都是右值。
move的作用: move可以将左值转化为右值,进行一个资源的转移,但是我们需要确定这个左值,之后不会再次使用,我们才可以进行这个操作来提升性能。
举个例子:
int main(){
string foo="abcdef";
vector<string>v;
v.push_back(foo);
cout<<foo<<endl;
return 0;
}
以上这个过程是一个拷贝过程,向push_back里面传入foo这个变量,vector容器中会对这个变量进行一个拷贝,我们之后还能用foo进行其他操作。
结果:

当我们使用move时,看以下代码:
int main(){
string foo="abcdef";
vector<string>v;
v.push_back(move(foo));
cout<<foo<<endl;
return 0;
}

这个过程中foo无法继续使用。
其实move本身是一个强制转换,作用便是将左值转换为右值,并无神奇之处,进行转移的过程,其实是类本身里面写的移动构造函数起的作用,通过延长右值的生命周期,通过引用将资源给新的变量,实现一个浅拷贝过程。
move应用实际场景
#include <bits/stdc++.h>
using namespace std;
class A {
public:
A(int sz) : sz(sz), s(new int[sz]) {
s[0] = 10;
// cout << "sc a" << endl;
}
~A() {
delete[] s;
// cout << "xg a" << endl;
}
A(const A& b) {
sz = b.sz;
s = new int[sz];
memcpy(s, b.s, sz * sizeof(int));
// cout << "fz a" << endl;
}
A(A&& b) : sz(b.sz), s(b.s) {
// cout << "mov a" << endl;
b.s = nullptr;
}
int* s;
int sz;
};
int main() {
/*A资源经过一系列使用后,不在使用A资源,但需要保存在智能指针中*/
A tmp(500000000);
int start1 = clock();
shared_ptr<A> up(new A(tmp));
int end1 = clock();
int start2 = clock();
shared_ptr<A> usp(new A(move(tmp)));
int end2 = clock();
cout << "copy times = " << (end1 - start1) << endl;
cout << "move times = " << (end2 - start2) << endl;
return 0;
}
性能对比:
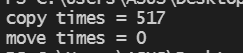
再来看以下他们的执行过程;
shared_ptr<A> up(new A(tmp));
他的执行过程:
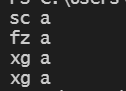
fz a 执行了拷贝构造函数,实行深拷贝
shared_ptr<A> usp(new A(move(tmp)));
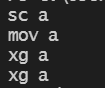
mov a 执行了移动构造函数,可以理解为浅拷贝,但是所有权从tmp转移到新建的对象上了,管理的资源是同一份,tmp对类内指针的管理权丧失