在C语言中,我们时常需要计算和统计一个对象的空间大小或“长度”,我们便可以运用sizeof 和 strlen 来简便地得到结果,但是这俩在使用的时候仍有不少值得注意的细节。
sizeof
在C语言中,sizeof是一个判断数据类型或者表达式长度的操作符,而并非一个函数。起初我以为sizeof是一个函数,在后面查阅资料才知道并不是函数而是操作符。
其返回值是一个对象或类型所占用的内存字节数,返回类型为size_t,也就是unsigned int。

sizeof的语法:sizeof (data type),data type 是要计算大小的数据类型,包括类、结构、共用体和其他用户自定义数据类型。也可以是sizeof(变量名)。
在不同环境下,sizeof对同一类型的结果可能会有不同,例如指针,我们知道,在x86环境下,也就是32位系统,指针的大小都是4个字节,而在x64系统下指针的大小是8个字节。
strlen
strlen是C语言string.h库的函数。
返回值是该string字符串的长度,判断标志为’\0’,即读取到’\0’后便停止计数。假如初始化数组时数组中没有存放’\0’,使用strlen时,strlen会在内存中一直向后读取,直到在随机的内存空间中读到’\0’为止,因此计算该数组长度会是随机值。
sizeof 和 strlen 实际运用
通过一些代码加强对sizeof和strlen的运用和理解。
在这之前补充一点,在C语言中, sizeof(数组名),数组名是表示整个数组,计算的是整个数组的大小,单位是字节。
&数组名,这里的数组名表示整个数组,取出的是数组的地址。
除此之外所有的数组名都是数组首元素的地址
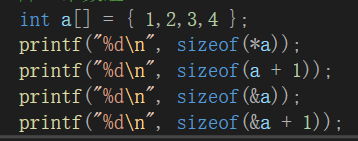
第一行结果为4,表示对数组首元素地址解引用,即得到数字1,大小为4个字节。
第二行结果为4,表示a[0] + 1,即得到数字2,大小为4个字节。
第三行结果为4,表示得到整个数组的地址,即是一个指针,指针大小为4/8个字节。
第四行结果为4,表示跳过整个a数组后的地址,也是一个指针,大小为4/8个字节。

第一行的结果为6,表示数组中一个有6个元素,大小为6个字节。
第二行的结果为4,表示arr[0]的地址,因此是一个指针,指针大小为4/8个字节。
第三行的结果为1,表示*arr[0],得到的是字符’a’,大小为1个字节。
第四行的结果为4,表示arr[1]的地址,指针大小为4/8个字节。
第五行的结果为随机值,因为arr中没有’\0’字符,因此为随机值。
第六行的结果为Err,因为 *arr得到的是字符’a’,字符’a’的ASCII值为97,因此strlen会把97当作起始地址进行访问,会引发访问冲突,因此编译器会报错,这是值得注意的一点。
第七行的结果为随机值,&arr是arr数组的地址,虽然类型和strlen的参数类型有所差异,但是传参过去后,还是从第一个字符的地址,结果同第五行。

第一行的结果为7,因为字符串初始化时会自带’\0’,sizeof会读取’\0’,因此大小为4个字节。
第二行的结果为4,表示arr2[1]的地址,指针大小为4/8个字节。
第三行的结果为6,表示从arr2[0]的位置开始往后计数,strlen不读取’\0’,因此结果为6。
第四行的结果为Err,得到的是字符’a’,strlen会引发访问冲突,因此编译器会报错。
第五行的结果为6,原理同上图的第七行。
第六行的结果为随机值,表示跳过整个arr2后进行计数直到读取到’\0’,因此为随机值。
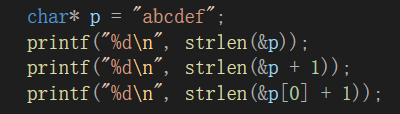
这个表达式要区分于上图表达式,意思为,在内存中有一个字符串为"abcdef",指针p指向字符串的起始地址,即"a"的地址。
 (草图。。)
(草图。。)
因此第一行的结果会是随机值,而不是6,因为是从p的位置开始从后读取’\0’,而不是从字符串的地址开始。
第二行的结果也为随机值,表示跳过整个数组。
第三行的结果为5,表示从字符’b’的位置开始往后计数,因此结果为5。

第一行的结果为48,表示整个a2数组的大小。
第二行的结果为16,表示二维数组中第一行数组的大小。
第三行的结果为4,表示二维数组中第一行数组的第二个元素的大小。
第四行的结果为4,a2是第一行数组的地址,加1表示第二行数组的地址,类型为int (*)[4],表示一个数组指针,因此大小为4/8个字节。
第五行的结果为16,表示第二行数组整个数组的大小。
第六行的结果为16,&a2[0] + 1表示第二行的地址,对地址进行解引用,得到第二行数组,即大小为16个字节。
第七行的结果为16,a表示首元素的地址,*a2表示第一行数组。
第七行的结果为16,a2[3]显然是越界了,但是sizeof的操作对象是数据类型,因此编译器会自动推断类型后得到大小,而不会对这块空间进行访问。因此大小仍然是16个字节。