参考书籍《深入理解计算机系统》
1 信息存储基本概念
- 存储单位:大多数计算机使用8位(bit)的块 [ 称之为字节(byte)] 作为最小的可寻址存储器单位;
- 地址:机器级程序(常说的用户进程)讲存储器视为非常大的字节数组(称为虚拟存储器),存储器的每个字节都由一个唯一的数字来标识,称之为地址,所有可能地址的集合就是虚拟地址空间;
- 字节的二进制表示法:一个字节包括8位,在二进制表示法种,一个字节可以表示的域为 0000 0000b ~ 1111 1111b,其十六进制的表示方法为 0x00~0xFF;
- 字长:每台计算机都有一个字长,可以用来指明整数和指针数据的标称大小。因为虚拟地址是以这样的字来编码的,所以 字长决定了虚拟地址空间的最大大小。
2 数据的表示
- 如上所述,字节为最小的寻址单位,一个字节所能表示的域有限,无法表示所有对象,这个时候就会采用多字节来表示,在几乎所有的机器上,多字节对象都被存储为连续的字节序连,对象的地址为字节序列种的最小地址。
如:C++种 int 常常被定义为4个字节表示的数据格式,假设有一个类型为 int 的变量 x 的地址为0x100,也就是说 x 的四个字节将被存储在0x100,0x101,0x102,0x103这四个位置。 - 由于历史原因,字节存放的顺序,有两种:
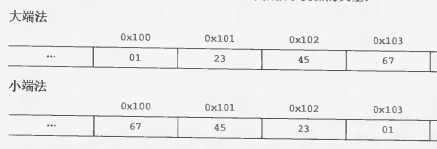
大端字节序列:高位字节存在低地址端
小端字节序列:低位字节存在低地址端
假如 x 的值为0x01234567,大小端字节序列的0x100,0x101,0x102,0x103对应的数据如下图:
3 整数的编码方式
- 整数数据类型:C/C++支持多种整数数据类型,有 (unsigned)char、 (unsigned)short、 (unsigned)int、 (unsigned)long等;
- 整数有两种不同的编码方式:一种只能表示非负数(无符号编码),另一种可以表示负数、零、正数(二进制补码编码);
- 无符号编码:有效位全部用来编码值,表示的整数为二进制数直接转换的数值,比如 1111 1111 1111 1111 111 1111 1111 1111字节序表示整数 4294967295;
- 二进制补码编码:最高位为负权,又称符号位,0为非负数,1为负数。当最高位为0时,值为剩下的位编码值,当最高位为1时,值为剩下的位的补码所表示的编码值,
如:1111 1111 1111 1111 111 1111 1111 1111的最高位为1,则值为(111 1111 1111 1111 111 1111 1111 1111)的补码(000 0000 0000 0000 0000 0000 0000 0001),表示 -1; - 不同数据类型之间的转换:所谓的数据转换,就是对相同地址的字节序列,采用不同的编码解析方式,比如unsigned int 转 int ,转换的时候,地址种的字节序列不会发生改变,都是1111 1111 1111 1111 111 1111 1111 1111,但是对这段地址的解析方式不同了,类型为unsigned int 时解析为 4294967295,转换成 int 时解析为的值为 -1。
4 浮点数的编码方式
- 二进制小数:形如1101.1101的二进制数转十进制数为:
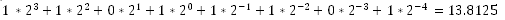
所以小数的二进制表示法只能表示能够写成 (x * 2^y)的数,像 1/3,5/7这样的数不能准确表达,只能够被近似表示; - IEEE浮点表示:
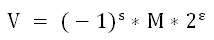
s:决定V是正数还是负数
M:有效数,是一个二进制小数
E:是指数(可能是负数),作用是对浮点数加权 - 浮点编码的特殊情况:
1 非规格化值:全为0,表示非常接近于0.0的数
2 特殊数值:指数域全为1,小数域全为0,得到的值表示无穷;指数域全为1,小数域为非零时,结果值为“NaN”,用来表示未初始化的数据 - 舍入:因为浮点的表示方法限制了浮点数的范围和精度,浮点运算只能近似的表示实数运算,因此所以要定义一个舍入方向,IEEE浮点格式定义了如下图的四种舍入方式:

- float:C/C++种,用s占1位,M占23位,E占8位
- double:C/C++种,用s占1位,M占52位,E占11位
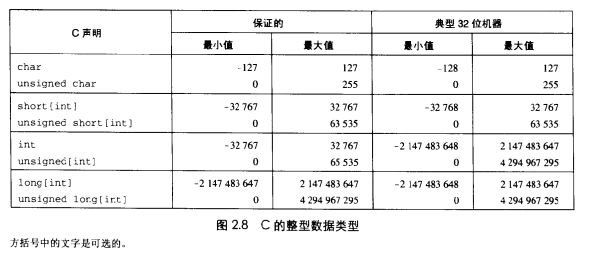
5 不同数据类型的值域
- 如上所述,所谓的数据类型,其实是限定了解析字节序的长度和编码解析方式,所以数据类型都会有一个值域,即这种数据类型能表示的最大值和最小值,常用数据类型的值域如下:
- 做算术运算时,如果得到的结果超过了上下限,就会发生溢出,会得到预期之外的值,比如两个很大的 int 型整数相加得到一个负数。