一、包含对象成员的类
valarray类:
valarray类由头文件<valarray>支持。它是个模块类。模板特性意味着声明对象时,必须指定具体的数据类型。
valarray<int> q_values;// an array of int
valarray<double> weights;// an array of doubledouble gpa[5] = {3.1, 3.5, 3.8, 2.9, 3.3};
valarray<double> v1;// an array of double, size 0
valarray<int> v2(8);// an array of 8 int elements
valarray<int> v3(10, 8);// an array of 8 int elements, each set to 10
valarray<double> v4(gpa, 4);// an array of 4 elements,
// initialized to the first 4 elements of gpa下面是这个类的一些方法:
- operator[ ]():让你能够访问各个元素。
- size():返回包含的元素数。
- sum():返回所有元素的总和。
- max():返回最大的元素。
- min():返回最小的元素。
has-a:用于建立has-a关系的C++技术是组合(包含),即创建一个包含其他类对象的类。
对于has-a关系来说,类对象不能自动获得被包含对象的接口是一件好事。例如,string类将+运算符重载为将两个字符串连接起来;但从概念上说,将两个Student对象串接起来是没有意义的。这也是这里不使用公有继承的原因之一。另一方面,被包含的类的接口部分对新类来说可能是有意义的。例如,可能希望使用string接口中的operator<()方法将Student对象按姓名进行排序,为此可以定义Student::Operator<()成员函数,它在内部使用函数string::Operator<()。
// studentc.h -- defining a Student class using containment
#ifndef STUDENTC_H_
#define STUDENTC_H_
#include <iostream>
#include <string>
#include <valarray>
class Student {
private:
typedef std::valarray<double> ArrayDb;
std::string name; // contained object
ArrayDb scores; // contained object
// private method for scores output
std::ostream & arr_out(std::ostream & os) const;
public:
Student() : name("Null Student"), scores() {}
explicit Student(const std::string & s)
: name(s), scores() {}
explicit Student(int n) : name("Nully"), scores(n) {}
Student(const std::string & s, int n)
: name(s), scores(n) {}
Student(const std::string & s, const ArrayDb & a)
: name(s), scores(a) {}
Student(const char * str, const double * pd, int n)
: name(str), scores(pd, n) {}
~Student() {}
double Average() const;
const std::string& Name() const;
double& operator[](int i);
double operator[](int i) const;
// friends
// input
friend std::istream & operator>>(std::istream & is, Student & stu); // 1 word
friend std::istream & getline(std::istream & is, Student & stu); // 1 line
// output
friend std::ostream & operator<<(std::ostream & os, const Student & stu);
};
#endif请注意关键字explicit的用法:
可以用只有一个参数调用的构造函数将用作从参数类型到类类型的隐式转换函数;但这通常不是好主意。在上述第二个构造函数中,第一个参数表示数组的元素个数,而不是数组中的值,因此将一个构造函数用作int到Student的转换函数是没有意义的,所以使用explicit关闭隐式转换。
如果省略该关键字,则可以编写如下所示的代码:
Student doh("Homer", 10);
doh = 5;// 隐式转换
Student st = Student(8);// 8将转换为一个临时Student对象在这里,马虎的程序员键入了doh而不是doh[0]。如果构造函数省略了explicit,则将使用构造函数调用Student(5)将5转换为一个临时Student对象,并使用“Nully”来设置成员name的值。因此赋值操作将使用临时对象替换原来的doh值。使用了explicit后,编译器将认为上述赋值运算符是错误的。
C++和约束:C++包含让程序员能够限制程序结构的特性――使用explicit防止单参数构造函数的隐式转换,使用const限制方法修改数据,等等。这样做的根本原因是:在编译阶段出现错误优于在运行阶段出现错误。
注意最后一个构造函数:
Student(const char * str, const double * pd, int n)
: name(str), scores(pd, n) {}因为该构造函数初始化的是成员对象,而不是继承的对象,所以在初始化列表中使用的是成员名,而不是类名。初始化列表中的每一项都调用与之匹配的构造函数,即name(str)调用构造函数string(const char *),scores(pd, n)调用构造函数ArrayDb(const double *, int)。
成员列表项初始化顺序:与排列顺序无关,谁先在类中被声明,就先初始化谁!
使用被包含对象的接口,被包含对象的接口不是公有的,但可以在类方法中使用它。如下面代码中实现的Average()函数,就使用了被包含对象――scores的sum()和size()方法。
// studentc.cpp -- Student class using containment
#include "studentc.h"
using std::ostream;
using std::endl;
using std::istream;
using std::string;
//public methods
double Student::Average() const {
if (scores.size() > 0)
return scores.sum() / scores.size();
else
return 0;
}
const string& Student::Name() const {
return name;
}
double& Student::operator[](int i) {
return scores[i]; // use valarray<double>::operator[]()
}
double Student::operator[](int i) const {
return scores[i];
}
// private method
ostream& Student::arr_out(ostream &os) const {
int i;
int lim = scores.size();
if (lim > 0) {
for (i = 0; i < lim; i++) {
os << scores[i] << " ";
if (i % 5 == 4)
os << endl;
}
if (i % 5 != 0)
os << endl;
} else
os << " empty array ";
return os;
}
// friends
// use string version of operator>>()
istream& operator>>(istream &is, Student &stu) {
is >> stu.name;
return is;
}
// use string friend getline(ostream &, const string &)
istream& getline(istream &is, Student &stu) {
getline(is, stu.name);
return is;
}
// use string version of operator<<()
ostream& operator<<(ostream &os, const Student &stu) {
os << "Scores for " << stu.name << ":\n";
stu.arr_out(os); // use private method for scores
return os;
}// use_stuc.cpp -- using a composite class
// compile with studentc.cpp
#include <iostream>
#include "studentc.h"
using std::cin;
using std::cout;
using std::endl;
void set(Student &sa, int n);
const int pupils = 3;
const int quizzes = 5;
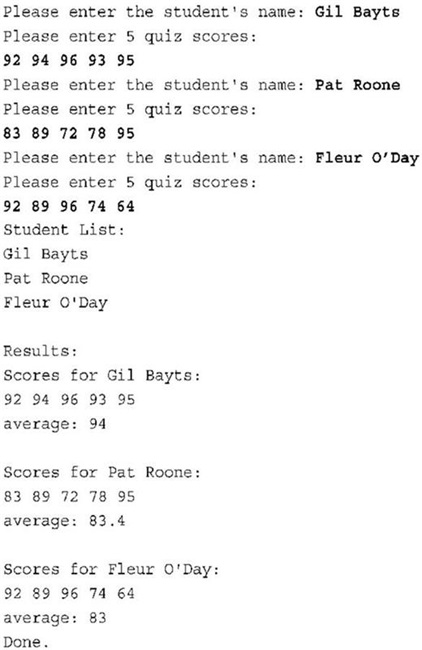
int main() {
Student ada[pupils] =
{Student(quizzes), Student(quizzes), Student(quizzes)};
int i;
for (i = 0; i < pupils; ++i)
set(ada[i], quizzes);
cout << "\nStudent List:\n";
for (i = 0; i < pupils; ++i)
cout << ada[i].Name() << endl;
cout << "\nResults:";
for (i = 0; i < pupils; ++i) {
cout << endl << ada[i];
cout << "average: " << ada[i].Average() << endl;
}
cout << "Done.\n";
return 0;
}
void set(Student &sa, int n) {
cout << "Please enter the student's name: ";
getline(cin, sa);
cout << "Please enter " << n << " quiz scores:\n";
for (int i = 0; i < n; i++)
cin >> sa[i];
while (cin.get() != '\n')
continue;
}
二、私有继承
C++还有另一种实现has-a关系的途径――私有继承。使用私有继承,基类的公有成员和保护成员都将成为派生类的私有成员。这意味着基类方法将不会成为派生对象公有接口的一部分,但可以在派生类的成员函数中使用它们。
下面更深入地探讨接口问题。使用公有继承,基类的公有方法将成为派生类的公有方法。总之,派生类将继承基类的接口;这是is-a关系的一部分。使用私有继承,基类的公有方法将成为派生类的私有方法。总之,派生类不继承基类的接口。正如从被包含对象中看到的,这种不完全继承是has-a关系的一部分。
使用私有继承,类将继承实现。例如,如果从String类派生出Student类,后者将有一个String类组件,可用于保存字符串。另外,Student方法可以使用String方法来访问String组件。
包含将对象作为一个命名的成员对象添加到类中,而私有继承将对象作为一个未被命名的继承对象添加到类中。我们将使用术语子对象(subobject)来表示通过继承或包含添加的对象。
因此私有继承提供的特性与包含相同:获得实现,但不获得接口。所以,私有继承也可以用来实现has-a关系。接下来介绍如何使用私有继承来重新设计Student类。
// studenti.h -- defining a Student class using private inheritance
#ifndef STUDENTC_H_
#define STUDENTC_H_
#include <iostream>
#include <valarray>
#include <string>
class Student : private std::string, private std::valarray<double> {
private:
typedef std::valarray<double> ArrayDb;
// private method for scores output
std::ostream & arr_out(std::ostream & os) const;
public:
Student() : std::string("Null Student"), ArrayDb() {}
explicit Student(const std::string & s)
: std::string(s), ArrayDb() {}
explicit Student(int n) : std::string("Nully"), ArrayDb(n) {}
Student(const std::string & s, int n)
: std::string(s), ArrayDb(n) {}
Student(const std::string & s, const ArrayDb & a)
: std::string(s), ArrayDb(a) {}
Student(const char * str, const double * pd, int n)
: std::string(str), ArrayDb(pd, n) {}
~Student() {}
double Average() const;
double & operator[](int i);
double operator[](int i) const;
const std::string & Name() const;
// friends
// input
friend std::istream & operator>>(std::istream & is, Student & stu); // 1 word
friend std::istream & getline(std::istream & is, Student & stu); // 1 line
// output
friend std::ostream & operator<<(std::ostream & os, const Student & stu);
};
#endif// studenti.cpp -- Student class using private inheritance
#include "studenti.h"
using std::ostream;
using std::endl;
using std::istream;
using std::string;
// public methods
double Student::Average() const {
if (ArrayDb::size() > 0)
return ArrayDb::sum() / ArrayDb::size();
else
return 0;
}
const string &Student::Name() const {
return (const string &) *this;
}
double & Student::operator[](int i) {
return ArrayDb::operator[](i); // use ArrayDb::operator[]()
}
double Student::operator[](int i) const {
return ArrayDb::operator[](i);
}
// private method
ostream & Student::arr_out(ostream &os) const {
int i;
int lim = ArrayDb::size();
if (lim > 0) {
for (i = 0; i < lim; i++) {
os << ArrayDb::operator[](i) << " ";
if (i % 5 == 4)
os << endl;
}
if (i % 5 != 0)
os << endl;
} else
os << " empty array ";
return os;
}
// friends
// use String version of operator>>()
istream & operator>>(istream &is, Student &stu) {
is >> (string &) stu;
return is;
}
// use string friend getline(ostream &, const string &)
istream & getline(istream &is, Student &stu) {
getline(is, (string &) stu);
return is;
}
// use string version of operator<<()
ostream & operator<<(ostream &os, const Student &stu) {
os << "Scores for " << (const string &) stu << ":\n";
stu.arr_out(os); // use private method for scores
return os;
}1.初始化基类组件
?对于继承类,新版本的构造函数将使用成员初始化列表语法,它使用类名而不是成员名来标识构造函数:
Student(const char * str, const double * pd, int n)
: std::string(str), ArrayDb(pd, n) {}?在这里,ArrayDb是std::valarray<double>的别名。成员初始化列表使用std::string(str),而不是name(str)。
2.访问基类的方法
使用私有继承时,只能在派生类的方法中使用基类的方法。但有时候可能希望基类工具是公有的。例如,在类声明中提出可以使用average()函数。和包含一样,要实现这样的目的,可以在公有Student::average()函数中使用私有Student::Average()函数。
私有继承使得能够使用类名和作用域解析运算符来调用基类的方法。

对比最先前的Student类与现在Student类的Average()函数的实现:
// 先前版本(有成员变量private ArrayDb scores;)
double Student::Average() const {
if (scores.size() > 0)
return scores.sum()/scores.size();
else
return 0;
}
// 私有继承版本
double Student::Average() const {
if (ArrayDb::size() > 0)
return ArrayDb::sum()/ArrayDb::size();
else
return 0;
}?总之,使用包含时将使用对象名来调用方法,而使用私有继承时将使用类名和作用域解析运算符来调用方法。
3.访问基类对象
使用作用域解析运算符可以访问基类的方法,但如果要使用基类对象本身,该如何做呢?例如,Student类的包含版本实现了Name()方法,它返回string对象成员name;但使用私有继承时,该string对象没有名称。那么,Student类的代码如何访问内部的string对象呢?
答案是使用强制类型转换。由于Student类是从string类派生而来的,因此可以通过强制类型转换,将Student对象转换为string对象;结果为继承而来的string对象。本书前面介绍过,指针this指向用来调用方法的对象,因此*this为用来调用方法的对象,在这个例子中,为类型为Student的对象。为避免调用构造函数创建新的对象,可使用强制类型转换来创建一个引用:
const string & Student::Name() const {
return (const string &) *this;
}上述方法返回一个引用,该引用指向用于调用该方法的Student对象中的继承而来的string对象。?
4.访问基类的友元函数
用类名显式地限定函数名不适合于友元函数,这是因为友元不属于类。然而,可以通过显式地转换为基类来调用正确的函数。例如,对于下面的友元函数定义:
ostream& operator<<(ostream& os, const Student& stu) {
os << "Scores for " << (const String&) stu << ":\n";
...
}如果plato是一个Student对象,则下面的语句将调用上述函数,stu将是指向plato的引用,而os将是指向cout的引用:?cout << plato;
下面的代码:
os << "Scores for " << (const String&) stu << ":\n";?显式地将stu转换为string对象引用,进而调用函数operator<<(ostream &, const String &)。
// use_stui.cpp -- using a class with private inheritance
// compile with studenti.cpp
#include <iostream>
#include "studenti.h"
using std::cin;
using std::cout;
using std::endl;
void set(Student &sa, int n);
const int pupils = 3;
const int quizzes = 5;
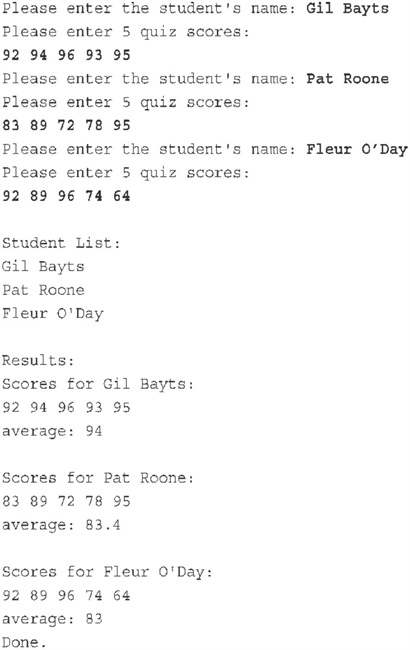
int main() {
Student ada[pupils] =
{Student(quizzes), Student(quizzes), Student(quizzes)};
int i;
for (i = 0; i < pupils; i++)
set(ada[i], quizzes);
cout << "\nStudent List:\n";
for (i = 0; i < pupils; ++i)
cout << ada[i].Name() << endl;
cout << "\nResults:";
for (i = 0; i < pupils; i++) {
cout << endl << ada[i];
cout << "average: " << ada[i].Average() << endl;
}
cout << "Done.\n";
// cin.get();
return 0;
}
void set(Student &sa, int n) {
cout << "Please enter the student's name: ";
getline(cin, sa);
cout << "Please enter " << n << " quiz scores:\n";
for (int i = 0; i < n; i++)
cin >> sa[i];
while (cin.get() != '\n')
continue;
}
使用包含还是私有继承:
由于既可以使用包含,也可以使用私有继承来建立has-a关系,那么应使用种方式呢?大多数C++程序员倾向于使用包含。首先,它易于理解。类声明中包含表示被包含类的显式命名对象,代码可以通过名称引用这些对象,而使用继承将使关系更抽象。其次,继承会引起很多问题,尤其从多个基类继承时,可能必须处理很多问题,如包含同名方法的独立的基类或共享祖先的独立基类。总之,使用包含不太可能遇到这样的麻烦。另外,包含能够包括多个同类的子对象。如果某个类需要3个string对象,可以使用包含声明3个独立的string成员。而继承则只能使用一个这样的对象(当对象都没有名称时,将难以区分)。
然而,私有继承所提供的特性确实比包含多。例如,假设类包含保护成员(可以是数据成员,也可以是成员函数),则这样的成员在派生类中是可用的,但在继承层次结构外是不可用的。如果使用组合将这样的类包含在另一个类中,则后者将不是派生类,而是位于继承层次结构之外,因此不能访问保护成员。但通过继承得到的将是派生类,因此它能够访问保护成员。
另一种需要使用私有继承的情况是需要重新定义虚函数。派生类可以重新定义虚函数,但包含类不能。使用私有继承,重新定义的函数将只能在类中使用,而不是公有的。
提示:通常,应使用包含来建立has-a关系;如果新类需要访问原有类的保护成员,或需要重新定义虚函数,则应使用私有继承。
保护继承:
保护继承是私有继承的变体。保护继承在列出基类时使用关键字protected:
class Student : protected std::string,
protected std::valarray<double> {
...
}使用保护继承时,基类的公有成员和保护成员都将成为派生类的保护成员。和私有私有继承一样,基类的接口在派生类中也是可用的,但在继承层次结构之外是不可用的。当从派生类派生出另一个类时,私有继承和保护继承之间的主要区别便呈现出来了。使用私有继承时,第三代类将不能使用基类的接口,这是因为基类的公有方法在派生类中将变成私有方法;使用保护继承时,基类的公有方法在第二代中将变成受保护的,因此第三代派生类可以使用它们。
使用using重新定义访问权限:
class Student : private std::string, private std::valarray<double> {
public: ?????
using std::valarray<double>::min;
using std::valarray<double>::max;
...
};上述using声明使得valarray<double>::min()和valarray<double>::max()可用,就像它们是Student的公有方法一样:
cout << "high score:" << ada[i].max() << endl;注意,using声明只使用成员名――没有圆括号、函数特征标和返回类型。例如,为使Student类可以使用valarray的operator?方法,只需在Student类声明的公有部分包含下面的using声明:
using std::valarray<double>::operator[];这将使两个版本(const和非const)都可用。这样,便可以删除Student::operator[] ( )的原型和定义。using声明只适用于继承,而不适用于包含。
有一种老式方式可用于在私有派生类中重新声明基类方法,即将方法名放在派生类的公有部分,如下所示:
class Student : private std::string, private std::valarray<double> {
public:
std::valarray<double>::operator[];// redeclare as public, just use name
...
}这看起来像不包含关键字using的using声明。这种方法已被摒弃,即将停止使用。因此,如果编译器支持using声明,应使用它来使派生类可以使用私有基类中的方法。
多重继承(MI):
MI描述的是有多个直接基类的类。与单继承一样,公有MI表示的也是is-a关系。例如,可以从Waiter类和Singer类派生出SingingWaiter类:
class SingingWaiter : public Waiter, public Singer { ... };必须使用关键字public来限定每一个基类。因为缺省情况下,默认是私有派生。
MI可能会给程序员带来很多新问题。其中两个主要的问题是:从两个不同的基类继承同名方法;从两个或更多相关基类那里继承同一个类的多个实例。为解决这些问题,需要使用一些新规则和不同的语法。因此,与使用单继承相比,使用MI更困难,也更容易出现问题。由于这个原因,很多C++用户强烈反对使用MI,一些人甚至希望删除MI;而喜欢MI的人则认为,对一些特殊的工程来说,MI很有用,甚至是必不可少的;也有一些人建议谨慎、适度地使用MI。
看一个例子,要使用MI,需要几个类。我们将定义一个抽象基类Worker,并使用它派生出Waiter类和Singer类。然后,便可以使用MI从Waiter类和Singer类派生出SingingWaiter类。

// worker0.h -- working classes
#ifndef WORKER0_H_
#define WORKER0_H_
#include <string>
class Worker { // an abstract base class
private:
std::string fullname;
long id;
public:
Worker() : fullname("no one"), id(0L) {}
Worker(const std::string& s, long n) : fullname(s), id(n) {}
virtual ~Worker() = 0; // pure virtual destructor
virtual void Set();
virtual void Show() const;
};
class Waiter : public Worker {
private:
int panache;
public:
Waiter() : Worker(), panache(0) {}
Waiter(const std::string& s, long n, int p = 0) : Worker(s, n), panache(p) {}
Waiter(const Worker& wk, int p = 0) : Worker(wk), panache(p) {}
void Set();
void Show() const;
};
class Singer : public Worker {
protected:
enum { other, alto, contralto, soprano, bass, baritone, tenor };
enum { Vtypes = 7 };
private:
static char* pv[Vtypes]; // string equivs of voice types
int voice;
public:
Singer() : Worker(), voice(other) {}
Singer(const std::string& s, long n, int v = other) : Worker(s, n), voice(v) {}
Singer(const Worker& wk, int v = other) : Worker(wk), voice(v) {}
void Set();
void Show() const;
};
#endif// worker0.cpp -- working class methods
#include "worker0.h"
#include <iostream>
using std::cout;
using std::cin;
using std::endl;
// Worker methods
Worker::~Worker() {}// 【must】 implement virtual destructor, even if pure
void Worker::Set() {
cout << "Enter worker's name: ";
getline(cin, fullname);
cout << "Enter worker's ID: ";
cin >> id;
while (cin.get() != '\n')
continue;
}
void Worker::Show() const {
cout << "Name: " << fullname << "\n";
cout << "Employee ID: " << id << "\n";
}
// Waiter methods
void Waiter::Set() {
Worker::Set();
cout << "Enter waiter's panache rating: ";
cin >> panache;
while (cin.get() != '\n')
continue;
}
void Waiter::Show() const {
cout << "Category: waiter\n";
Worker::Show();
cout << "Panache rating: " << panache << "\n";
}
// Singer methods
char* Singer::pv[] = { "other", "alto", "contralto",
"soprano", "bass", "baritone", "tenor" };
void Singer::Set() {
Worker::Set();
cout << "Enter number for singer's vocal range:\n";
int i;
for (i = 0; i < Vtypes; i++) {
cout << i << ": " << pv[i] << " ";
if (i % 4 == 3)
cout << endl;
}
if (i % 4 != 0)
cout << endl;
while (cin >> voice && (voice < 0 || voice >= Vtypes))
cout << "Please enter a value >= 0 and < " << Vtypes << endl;
while (cin.get() != '\n')
continue;
}
void Singer::Show() const {
cout << "Category: singer\n";
Worker::Show();
cout << "Vocal range: " << pv[voice] << endl;
}// worktest.cpp -- test worker class hierarchy
#include <iostream>
#include "worker0.h"
const int LIM = 4;
int main() {
Waiter bob("Bob Apple", 314L, 5);
Singer bev("Beverly Hills", 522L, 3);
Waiter w_temp;
Singer s_temp;
Worker* pw[LIM] = { &bob, &bev, &w_temp, &s_temp };
int i;
for (i = 2; i < LIM; i++)
pw[i]->Set();
for (i = 0; i < LIM; i++) {
pw[i]->Show();
std::cout << std::endl;
}
return 0;
}
?
假设首先从Singer和Waiter公有派生出SingingWaiter:
class SingingWaiter : public Singer, public Waiter {...};因为Singer和Waiter都继承了一个Worker组件,因此SingingWaiter将包含两个Worker组件,如下图:
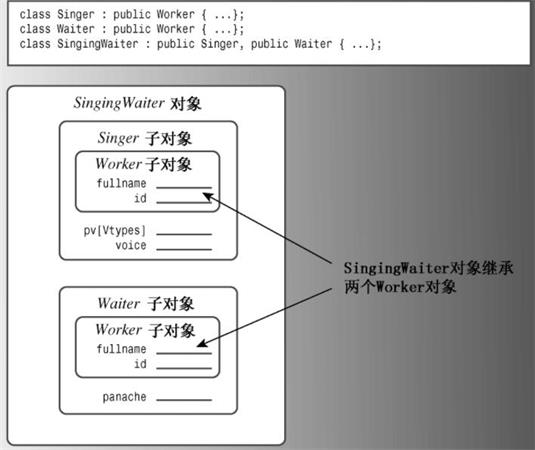
?通常可以将派生类对象的地址赋给基类指针,但现在将出现二义性:
SingingWaiter ed;
Worker * pw = &ed;// ambiguous通常,这种赋值将把基类指针设置为派生对象中的基类对象的地址。但ed中包含两个Worker对象,有两个地址可供选择,所以应使用类型转换来指定对象:
?
Worker * pw1 = (Waiter *) &ed;// the Worker in Waiter
Worker * pw2 = (Singer *) &ed;// the Worker in Singer包含两个Worker对象拷贝还会导致其他的问题。然而,真正的问题是:为什么需要Worker对象的两个拷贝?唱歌的侍者和其他Worker对象一样,也应只包含一个姓名和一个ID。C++引入多重继承的同时,引入了一种新技术――虚基类(virtual base class),使MI成为可能。
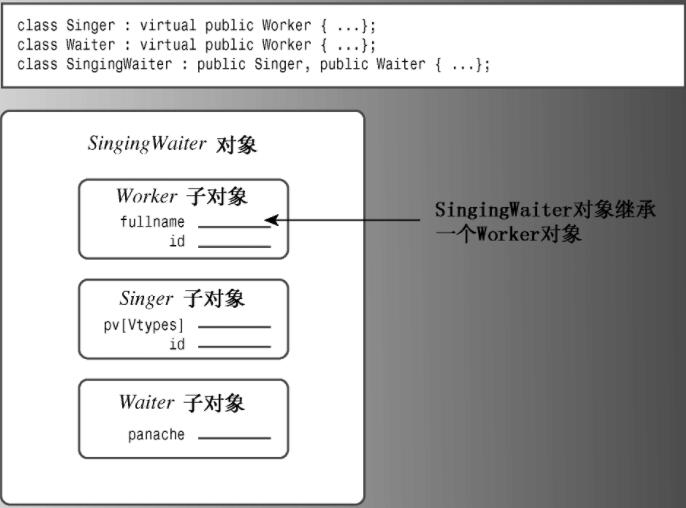
?虚基类
虚基类使得从多个类(它们的基类相同)派生出的对象只继承一个基类对象。例如,通过在类声明中使用关键字virtual,可以使Worker被用作Singer和Waiter的虚基类(virtual和public的次序无关紧要):
class Singer : virtual public Worker {...};
class Waiter : public virtual Worker {...};?然后,可以将SingingWaiter类定义为:
class SingingWaiter : public Singer, public Waiter {...};现在,SingingWaiter对象将只包含Worker对象的一个副本。从本质上说,继承的Singer和Waiter对象共享一个Worker对象,而不是各自引入自己的Worker对象副本(请参见下图)。因为SingingWaiter现在只包含了一个Worker子对象,所以可以使用多态。
?新的构造函数规则
使用虚基类时,需要对类构造函数采用一种新的方法。对于非虚基类,唯一可以出现在初始化列表中的构造函数是即时基类构造函数。但这些构造函数可能需要将信息传递给其基类。例如,可能有下面一组构造函数:
class A {
int a;
public:
A(int n = 0) : a(n) {}
...
};
class B : public A {
int b;
public:
B(int m = 0; int n = 0) : A(n), b(m) {}
...
};
class C : public B {
int c;
public:
C(int q = 0, int m = 0, int n = 0) : B(m, n), c(q) {}
...
};C类的构造函数只能调用B类的构造函数,而B类的构造函数只能调用A类的构造函数。这里,C类的构造函数使用值q,并将值m和n传递给B类的构造函数;而B类的构造函数使用值m,并将值n传递给A类的构造函数。
如果Worker是虚基类,则这种信息自动传递将不起作用。例如,对于下面的MI构造函数:
SingingWaiter(const Worker& wk, int p = 0, int v = Singer::other)
: Waiter(wk, p), Singer(wk, v) {} // 有缺陷存在的问题是,自动传递信息时,将通过2条不同的途径(Waiter和Singer)将wk传递给Worker对象。为避免这种冲突,C++在基类是虚的时,禁止信息通过中间类自动传递给基类。因此,上述构造函数将初始化成员panache和voice,但wk参数中的信息将不会传递给子对象Waiter。然而,编译器必须在构造派生对象之前构造基类对象组件;在上述情况下,编译器将使用Worker的默认构造函数。如果不希望默认构造函数来构造虚基类对象,则需要显式地调用所需的基类构造函数。因此,构造函数应该是这样:
SingingWaiter(const Worker& wk, int p = 0, int v = Singer::other)
: Worker(wk), Waiter(wk, p), Singer(wk, v) {}上述代码将显式地调用构造函数Worker(const Worker &)。请注意,这种用法是合法的,对于虚基类,必须这样做;但对于非虚基类,则是非法的。
警告:如果类有间接虚基类,则除非只需使用该虚基类的默认构造函数,否则必须显式地调用该虚基类的某个构造函数。
未完待续。。。。。。?