ps:以下为个人收集、整理和总结,如有错误请见谅! ?(・ω・)ノ
一.string
- 应用:
代替一般字符数组char str[];
- 访问:通过下标访问
注:如果要读入或者输出,只能用cin,cout
迭代器访问:string::iterator it;
string和vector一样,支持直接对迭代器进行加减某个数。如:str.begin()+3;
- 函数:
#include<string>
using namespace std;
string str;
str1+=str2;//直接将str1,str2连起来,拼到str1上
str1==str2;//类似的操作还有:!=,<,<=,>,>=
length(str);//=size(str);
insert(pos,str);//在pos位置上插入str
insert(it,it1,it2)//it为字符串要插入的位置,it1和it2分别是待插入字符串的首尾
str.erase(it); // 迭代器
str.erase(first,last); // [first,last)区间的字符删除掉
str.erase(pos,len);//pos是开始删除的位置,len是要删除的字符串的长度
str.clear();
Str.substr(pos,len);//返回从pos开始,长度为len的字符串
str.substr(5) //获得字符串s中 从第5位开始到尾的字符串
string::npos//一个常数,值为-1,实际也可做unsigned_int的最大值
查找相关(查找成功返回位置 ,查找失败,返回-1)―― find函数:从头查找
str.find('A')――查找 'A' //返回’A’第一次出现的位置,否则返回string::npos
str.find("ABC")――查找 "ABC" // 例:int n=s4.find("ABC"); s4:ABCD -> n = 0
str.find('B',1)――从 位置1 处,查找'B'
str.find("ABC",1,2)――从 位置1 处,开始查找 'ABC' 的前 2个 字符
str.replace(pos,len,str2);//将从pos位置开始长为len的子串替换为str2
下面三个函数的返回类型为size_t,可以强制转换为int类型:
1. size_t find (const string& str, size_t pos = 0)
str.find(str1)
说明:从pos(默认是是0,即从头开始查找)开始查找,找到第一个和str1相匹配的子串,返回该子串的起始索引位置;如果没有找到则返回string::npos
2. size_t find_first_of (const string& str, size_t pos = 0)
str.find_first_of(str1)
说明:从pos(默认是是0,即从头开始查找)开始查找,找到第一个和str1相匹配的子串,返回该子串的起始索引位置;如果没有找到则返回string::npos
3.size_t find_last_of (const string& str, size_t pos = npos)
str.find_last_of(str1)
说明:从npos(默认是字符串最后一个,即从后向前查找)开始查找,找到第一个和str1相匹配的子串,返回该子串的最后一个字符的索引位置;如果没有找到则返回string::npos
判断字符串为空:
str.empty() str.size()==0 str==””
(注意:不能使用str==NULL来判断)
- Next_permutation也可以用于string
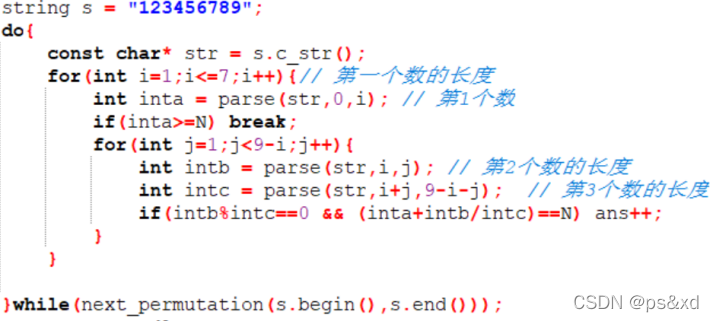
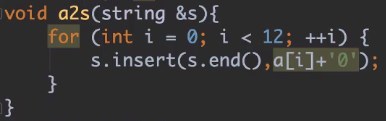
5.Int数组转化为字符串(B2016.7):
6.字符串查找特定的字符:

7.截断字符串后面的部分:

8.考察%*s的用法
printf("%*s%s%*s",(width-2-strlen(buf))/2,"",buf,width-strlen(buf)-2-(width-strlen(buf)-2)/2,"");
考察%*s的用法: printf("%*s",5,"22")相当于printf("%5s","22"),字符串宽度为5,内容为"22"
9.整型与字符串的转换

10.对字符串进行特定的处理(istringstream)

或:

11.去掉字符串中的空格

12.对字符串直接进行大小写转换
#include <string>
#include <algorithm>
transform(strA.begin(), strA.end(), strA.begin(), ::toupper);
transform(strB.begin(), strB.end(), strB.begin(), ::toupper);
13.查找字符串中某一特定字符最后出现的下标
char p[50];
strcpy(p, s.c_str());
C 库函数- strrchr() 头文件:<string.h>
char *strrchr(const char *str, int c) 在参数 str 所指向的字符串中搜索最后一次出现字符 c(一个无符号字符)的位置。如果未能找到指定字符,那么函数将返回NULL。
二.vector(元素允许重复)
- 应用
① 用于普通数组会超内存的情况
② 以邻接矩阵的方式存储图
- 定义:
typename可以是int,double,char,结构体 - 元素访问
① 下标访问(0~n-1)
② 迭代器访问:vector< typename >::iterator it;
- 函数
#include<vector>
using namespace std;
vector<typename>name; //定义
vector<vector<int> >name;//如果typename也是一个vector,>>之间要有空格
vector<typename>name[maxn];
//二维vector< typename >name[maxn],有一维长度固定为maxn,无法改变
push_back(); //vector后加一个元素
pop_back(); //删去vector的尾元素
size(); //获得vector中元素个数
clear(); //清空
insert(it,x); //向vector任意迭代器it处插入一个元素x
v.insert(v.begin() + position, x); // 在下标position处插入元素x
erase(it); //删去单个元素
erase(first,last); //删去区间[first,last)内的所有元素
erase(position); //删去位置为position的元素
vector<pair<int, string> > vec;
vec.push_back(make_pair<int, string>(5, "hello"));
sort(vec.begin(), vec.end(), strict_weak_ordering);
vector<pair<int, string> >::iterator it = vec.begin(), end = vec.end();
for(; it != end; ++it) cout<<it->second<<endl;
for (auto i = vec.begin(); i != vec.end(); i++)
for (auto i : vec)
vector::front() // 返回第一个元素 如: 1 2 3 4 5 返回1
vector::back() // 返回最后一个元素 如: 1 2 3 4 5 返回5
不同于map(map有find方法),vector本身是没有find这一方法,其find是依靠algorithm来实现的。
vector<string> nameList1;
//给nameList1赋值
string name;
if(find(nameList1.begin(),nameList1.end(),name) == nameList1.end()){
//没有找到
}
else{
//找到了
}
5.Vector 可排序
三、map
1.应用:可将任何基本类型映射到任何基本类型;存储“键-值对”
2.访问:
① 通过下标访问:mp[‘c’]=a,注意引号
② 通过迭代器访问:map<typename1,typename2>::iterator it;
③ 可用it->first访问键,it->second访问值
④ map会以键的自小到大排序。适用于那些有顺序要求的问题
⑤ 时间复杂度为 lg n;空间占用较大
3.函数:
#include<map>
using namespace std;
map<typename1,typename2>mp;//name1是键的类型,name2是值的类型
mp.find(key);//返回key映射的迭代器
mp.erase(it);//同上,删除迭代器位置处的单个字符, 并返回下个元素的迭代器
mp.erase(key);//key为要删除的映射的键
mp.erase(first,last);//同上
size();
clear(); // 清空
mp[key][pos]; // 当键为key时对应的值(假设是string)的下标为pos的字符
// 插入
#include <iostream>
#include <map>
C++:map.insert插入重复键(已存在键)将忽略,而非值覆盖。
因此需要先删除,再插入! 或用 []=
map<char, int> mymap;
// 插入单个值
mymap.insert(pair<char, int>('a', 100));
mymap.insert(pair<char, int>('z', 200));
//返回插入位置以及是否插入成功
pair<map<char, int>::iterator, bool> ret;
ret = mymap.insert(pair<char, int>('z', 500));
if (ret.second == false) {
cout << "element 'z' already existed";
cout << " with a value of " << ret.first->second << '\n';
}
//指定位置插入
map<char, int>::iterator it = mymap.begin();
mymap.insert(it, pair<char, int>('b', 300)); //效率更高
mymap.insert(it, pair<char, int>('c', 400)); //效率非最高
mymap.insert(make_pair(string,vector<string,int>));
//范围多值插入
map<char, int> anothermap;
anothermap.insert(mymap.begin(), mymap.find('c'));
// 列表形式插入
anothermap.insert({ { 'd', 100 }, {'e', 200} });
// 查找
iter = mapStudent.find(1);
if(iter != mapStudent.end()) Cout<<”Find, the value is ”<<iter->second<<endl;
Else Cout<<”Do not Find”<<endl;
4.迭代:
map<int,int>::iterator itu; // u向量迭代器
map<int,int>::iterator itv; // v向量迭代器
// 遍历(以短者为根据)
for(itu=u.begin(),itv=v.begin();itu!=u.end()&&itv!=v.end();){
// 比较键
if(itu->first==itv->first) { // 键相等(下标相等)
ans += itu->second * itv->second; // 加入结果
itu++;
itv++;
}
else if(itu->first < itv->first) itu++;
else itv++;
}
5.unordered_map (头文件 #include<unordered_map>)
① unordered_map内部实现了一个哈希表
② 查找的时间复杂度可达到O(1),其在海量数据处理中有着广泛应用
③ 元素的排列顺序是无序的
④ 适用于查找问题
⑤ unordered_map的用法和map是一样的,提供了 insert,size,count等操作,并且里面的元素也是以pair类型来存贮的。其底层实现是完全不同的,上方已经解释了,但是就外部使用来说却是一致的。
四、set
- 应用:
去重,自动排序,不允许有下标 - 定义:
typename类型同vector; - 元素访问:
只能用迭代器set< typename >::iterator it; - 函数:
#include<set>//头文件
using namespace std;
set<typename>name;//定义
s.size(); //元素的数目
s.max_size(); //可容纳的最大元素的数量
s.empty(); //判断容器是否为空
s.find(elem); //返回值是迭代器类型
s.count(elem); //elem的个数,要么是1,要么是0,multiset可以大于一
s.begin();
s.end();
s.rbegin();
s.rend();
s.insert(elem);
s.insert(pos, elem);
s.insert(begin, end);
s.erase(pos);
s.erase(begin,end);
s.erase(elem);
s.clear();//清除a中所有元素;
五、stack
stack<int> s;
stack< int, vector<int> > stk; //覆盖基础容器类型,使用vector实现stk
s.empty(); //判断stack是否为空,为空返回true,否则返回false
s.size(); //返回stack中元素的个数
s.pop(); //删除栈顶元素,但不返回其值
s.top(); //返回栈顶元素的值,但不删除此元素
s.push(item); //在栈顶压入新元素item
六、cctype头文件
七、输入
1. cin(包含头文件#include <iostream>)
C++,当遇到空格或者回车键即停止。
2. getline()(包含头文件#include <string>)
若定义变量为string类型,则要考虑getline()函数。注意不是字符型数组,用法如下:
string st; getline(cin,st);
cin.ignore(); 吃掉一个字符 相当于 getline(cin,s);
3.cin.get (char *str, int maxnum)
cin.get()函数可以接收空格,遇回车结束输入。
4.cin.getline (char *str, int maxnum)(包含头文件#include <string>)
cin.getline()函数可以同cin.get()函数类似,也可接收空格,遇回车结束输入。
5.字符串类型转换为字符数组
char p[50];
string str="I Love Ningbo!";
strcpy(p, str.c_str());
strcpy(p, str.data());
八、map
1.应用:可将任何基本类型映射到任何基本类型
2.访问:
通过下标访问:mp[‘c’]=a,注意引号
通过迭代器访问:map<typename1,typename2>::iterator it;
可用it->first访问键,it->second访问值
另外,map会以键的自大到小排序。每个关键字只能在map中出现一次;第二个称之为该关键字的对应值。
3.函数
begin() 返回指向map头部的迭代器
clear() 删除所有元素
count() 返回指定元素出现的次数
empty() 如果map为空则返回true
end() 返回指向map末尾的迭代器
equal_range() 返回特殊条目的迭代器对
erase() 删除一个元素
find() 查找一个元素
get_allocator() 返回map的配置器
insert() 插入元素
key_comp() 返回比较元素key的函数
lower_bound() 返回键值>=给定元素的第一个位置
max_size() 返回可以容纳的最大元素个数
rbegin() 返回一个指向map尾部的逆向迭代器
rend() 返回一个指向map头部的逆向迭代器
size() 返回map中元素的个数
swap() 交换两个map
upper_bound() 返回键值>给定元素的第一个位置
value_comp() 返回比较元素value的函数
九、queue
queue的基本操作有:
1.入队:如q.push(x):将x元素接到队列的末端;
2.出队:如q.pop() 弹出队列的第一个元素,并不会返回元素的值;
3,访问队首元素:如q.front()
4,访问队尾元素,如q.back();
5,访问队中的元素个数,如q.size();
十、list
非连续存储结构,具有双链表结构,每个元素维护一对前向和后向指针,因此支持前向/后向遍历。 支持高效的随机插入/删除操作,但随机访问效率低下,且由于需要额外维护指针 ,开销也比较大。每一个结点都包括一个信息快Info、一个前驱指针Pre、一个后驱指针Post。可以不分配必须的内存大小方便的进行添加和删除操作。使用的是非连续的内存空间进行存储。
优点:(1) 不使用连续内存完成动态操作。
(2) 在内部方便的进行插入和删除操作
(3) 可在两端进行push、pop
缺点:(1) 不能进行内部的随机访问,即不支持[ ]操作符和vector.at()
(2) 相对于verctor占用内存多
使用区别:
(1)如果你需要高效的随即存取,而不在乎插入和删除的效率,使用vector
(2)如果你需要大量的插入和删除,而不关心随机存取,则应使用list
(3)如果你需要随机存取,而且关心两端数据的插入和删除,则应使用deque
list适合有大量的插入和删除操作,并且不关心随机访问的场景.
Lists将元素按顺序储存在链表中. 与 向量(vectors)相比, 它允许快速的插入和删除,但是随机访问却比较慢.
assign() 给list赋值
back() 返回最后一个元素
begin() 返回指向第一个元素的迭代器
clear() 删除所有元素
empty() 如果list是空的则返回true
end() 返回末尾的迭代器
erase() 删除一个元素
front() 返回第一个元素
get_allocator() 返回list的配置器
insert() 插入一个元素到list中
max_size() 返回list能容纳的最大元素数量
merge() 合并两个list
pop_back() 删除最后一个元素
pop_front() 删除第一个元素
push_back() 在list的末尾添加一个元素
push_front() 在list的头部添加一个元素
rbegin() 返回指向第一个元素的逆向迭代器
remove() 从list删除元素
remove_if() 按指定条件删除元素
rend() 指向list末尾的逆向迭代器
resize() 改变list的大小
reverse() 把list的元素倒转
size() 返回list中的元素个数
sort() 给list排序
splice() 合并两个list
swap() 交换两个list
unique() 删除list中重复的元素
list和vector的区别:
(1)vector为存储的对象分配一块连续的地址空间 ,随机访问效率很高。但是 插入和删除需要移动大量的数据,效率较低。尤其当vector中存储
的对象较大,或者构造函数复杂,则在对现有的元素进行拷贝的时候会执行拷贝构造函数。
(2)list中的对象是离散的,随机访问需要遍历整个链表, 访问效率比vector低。但是在list中插入元素,尤其在首尾 插入,效率很高,只需要改变元素的指针。
(3)vector是单向的,而list是双向的.