文章目录
泛型编程
- 问题引入:如何实现一个通用的交换函数?
我们目前首先想到的就是函数重载:
乍一看好像还可以实现,仔细想想,函数重载只能实现内置类型的重载,对于用户提供的自定义类型,就不会适用了。并且只有参数不同的“同一份代码”需要些多遍,成本很高。因此淘汰!
我们现在又有另一个想法:给编译器一个模子,让编译器根据不同的类型利用该模子来生成代码
这个就是今天要介绍的内容―模板 ,分为函数模板和类模板
所谓泛型编程指的是:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础。
函数模板
函数模板的概念&&格式
- 概念
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生函数的特定类型版本 - 格式
template<typename T1,typename T2.....,typename Tn>
返回值类型 函数名 (参数列表)
{
//实现的具体代码
}
比如下面就是一个交换函数的模板:
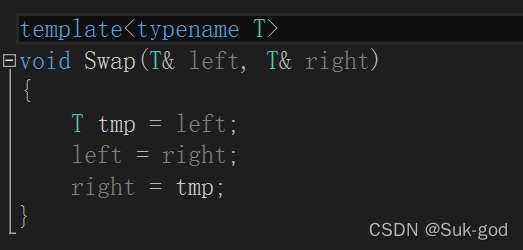
typename是用来定义模板参数的关键字,也可以使用class,但是切记不能使用struct
函数模板的原理
函数模板是一个蓝图,它本身并不是函数,是编译器根据使用方式产生特定具体类型函数的模具。
本质上模板就是将本来有我们自己做的重复事情交给了编译器
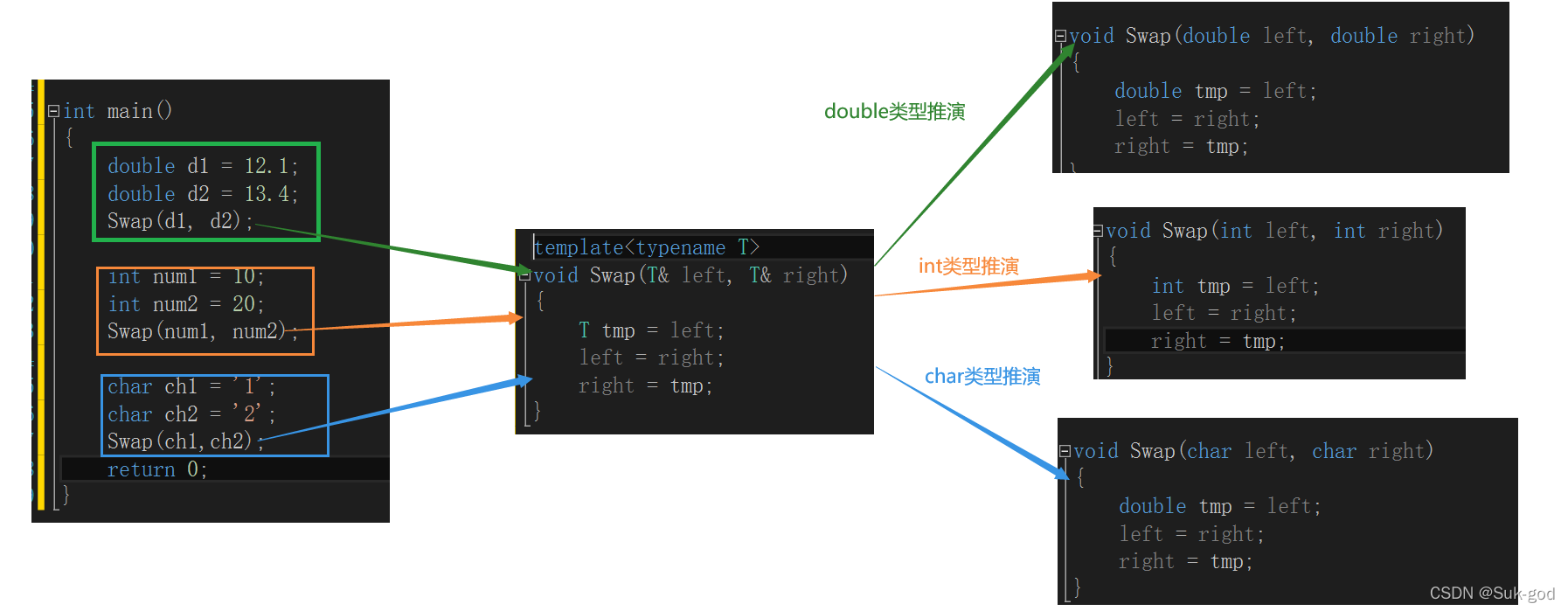
在编译器编译阶段,对于模板函数的使用,编译器需要根据出传入的实参类型来推演生成对应类型的函数以供调用。
下面画图理解一下:
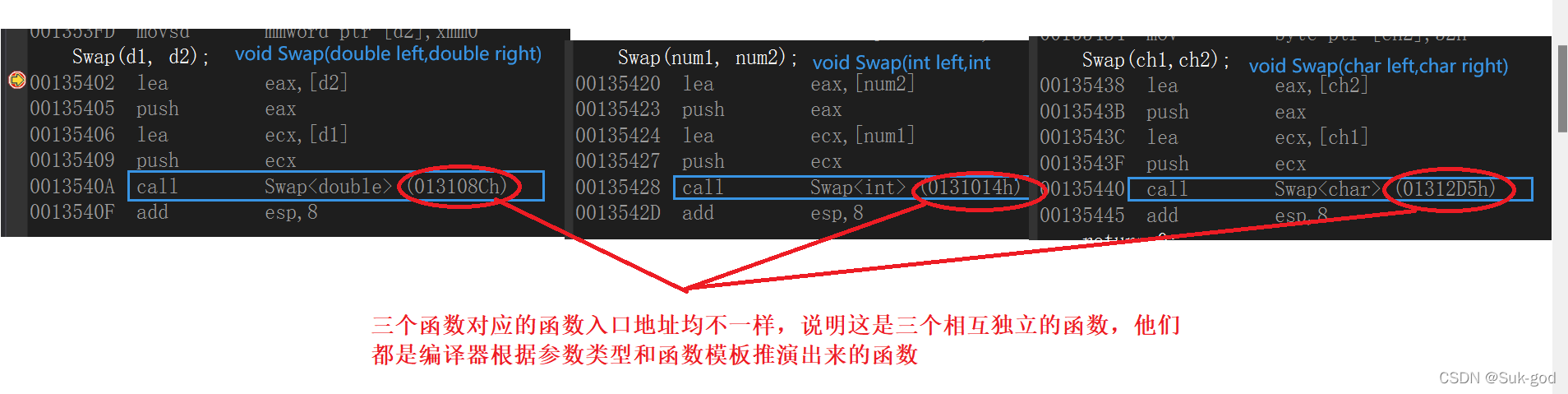
汇编层面验证上图的说法:
函数模板的实例化
- 什么是实例化
用不同类型的参数使用函数模板时,称为函数模板的实例化 - 分类
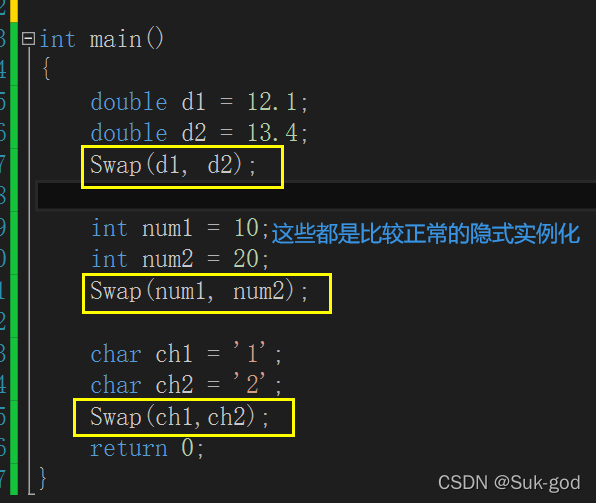
隐式实例化 和 显式实例化 - 隐式实例化
让编译器根据实参推演模板参数的实际类型
就好比刚才上面的那张图,都是属于隐式实例化
这里再列举一些隐式实例化的例子

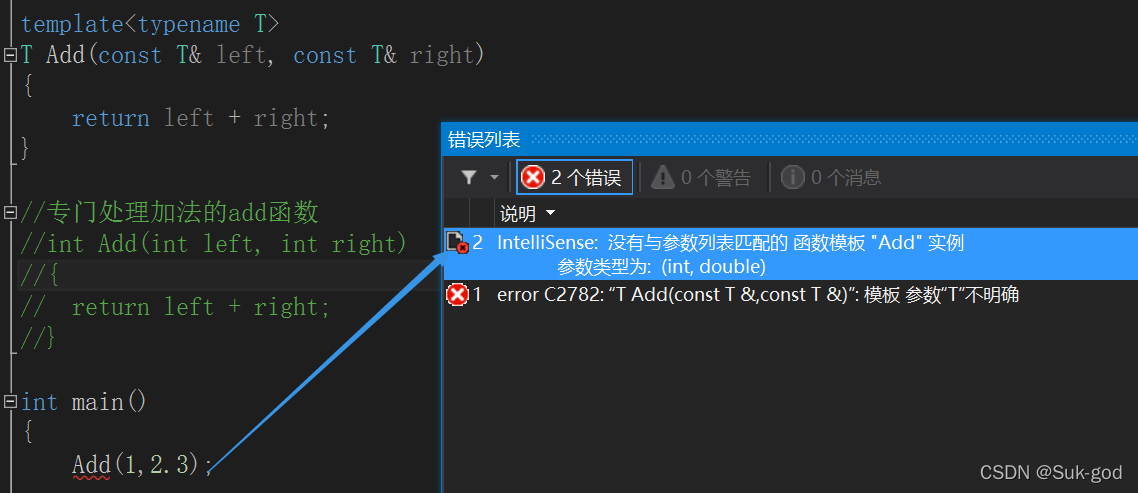
下面来几个比较棘手的:

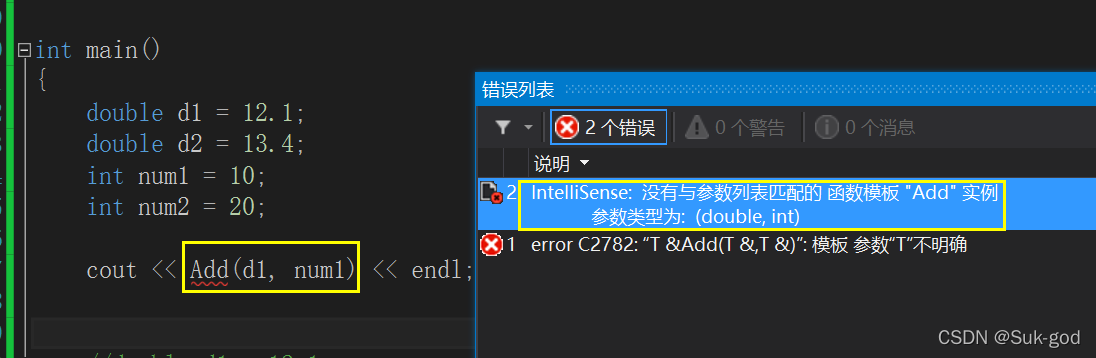
我们发现,Add函数在参数列表类型不一样时,编译器无法通过隐式实例化确定相应的Add函数。那怎么解决这样的场景呢?
有两种方法
1、用户自己来强制转化
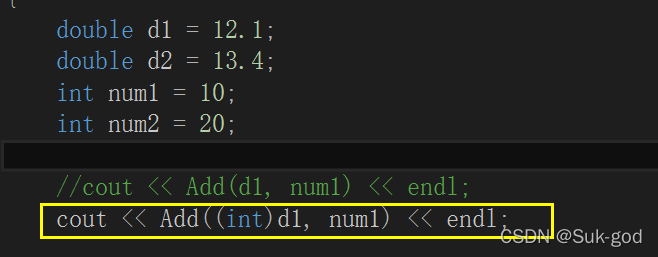
2、使用显示实例化的方式告知编译器如何去产生Add函数
下面,我们来介绍一下显示实例化 - 显式实例化
在函数名后加上<>并在<>里面指定模板参数的实际类型
如果类型不匹配,编译器会尝试进行隐式类型转换。若无法转换成功,就会报错
下面我们通过显式实例化处理上面的代码
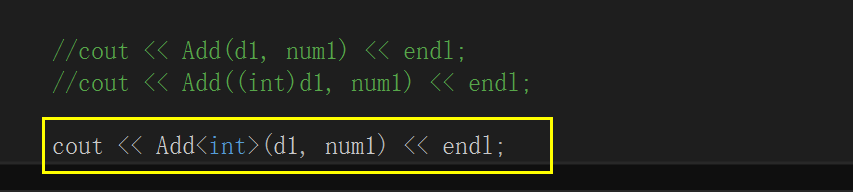
这样就能够解决上述的问题了.
模板参数的匹配原则
-
一个非模板函数可以和一个同名的函数模板同时存在,而且该函数模板还可以被实例化为这个非模板函数
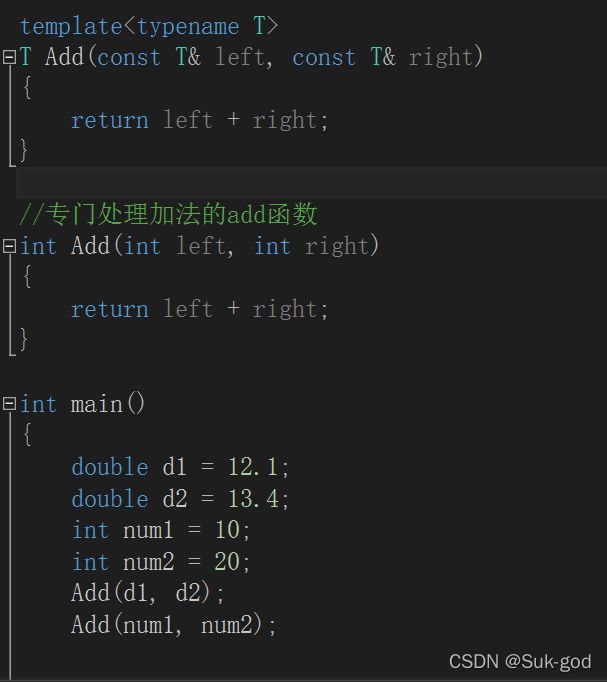
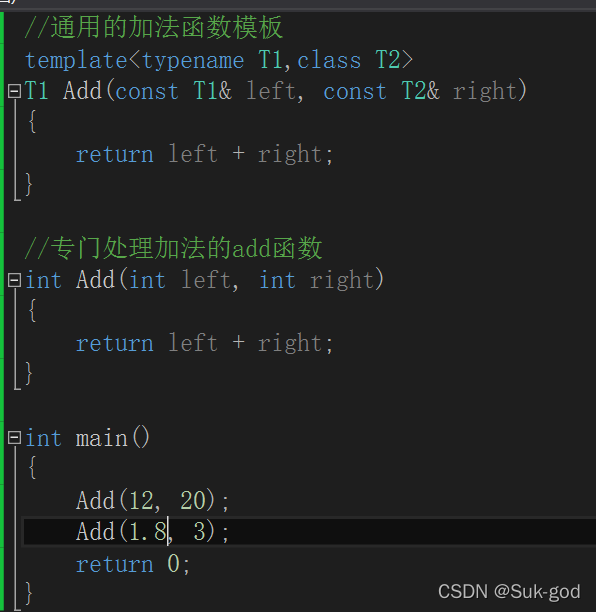
对于上述的情形,编译器会为d1,d2创建一个函数,而对于num1和num2来说,就会直接调用已经定义好的Add函数
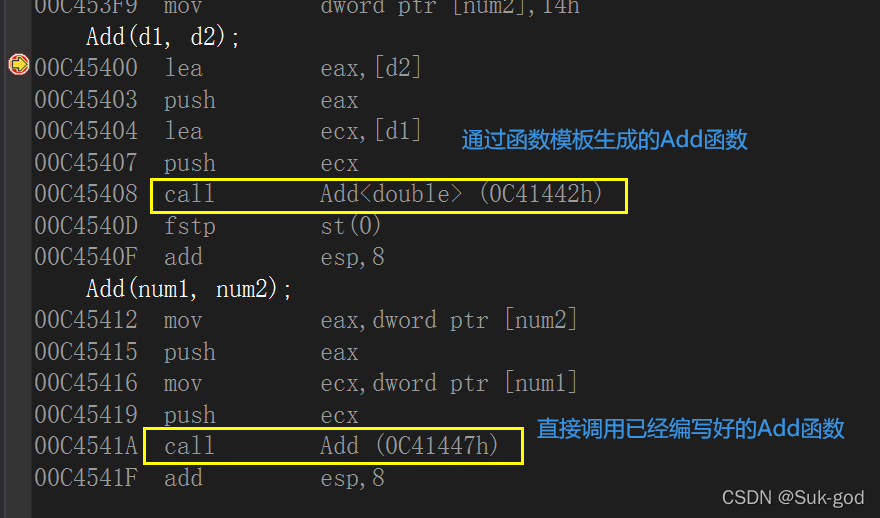
-
对于非模板函数和同名函数模板,如果其他条件都相同,在调用时会优先调用非模板函数,而不会从该模板产生出一个实例。如果模板可以产生一个具有更好匹配度的函数,那么将选择模板
Add(12,20)与非函数模板类型完全匹配,不需要函数模板实例化
Add(1.8,3)函数模板可以生成更加匹配的版本,编译器会根据实参生成更加匹配的Add函数。
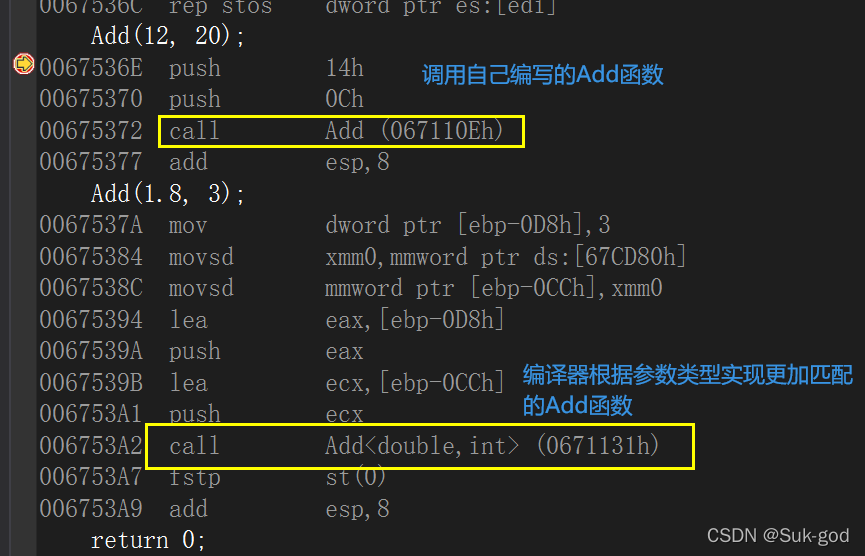
-
模板函数不允许自动类型转换,但普通函数可以进行自动类型转换
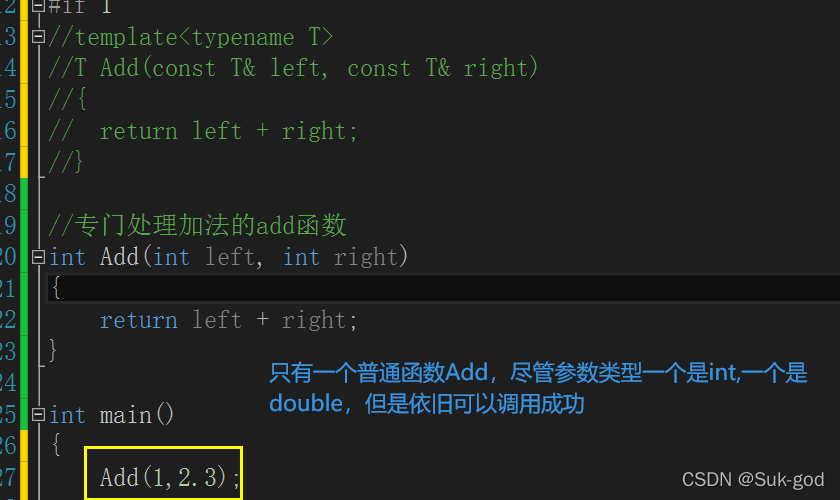
如果是没有普通函数Add,只有一个函数模板Add的话,就会报错!
类模板
- 定义格式
template<class T1,class T2, ...,class T3>
class 类模板名
{
//类内成员定义
}
- 动态顺序表的实现
template<class T>
class SeqList
{
public:
SeqList(size_t initCapacity = 4)
:_array(new T[initCapacity])
,_capacity(initCapacity)
, _size(0)
{}
~SeqList()
{
if (_array)
{
delete[] _array;
_array = nullptr;
_capacity = 0;
_size = 0;
}
}
void PushBack(const T& data);//尾插函数放在类外进行定义
void PopBack()
{
if (IsEmpty())
{
return;
}
--_size;
}
T& GetFront()const
{
return _array[0];
}
T& GetBack()const
{
return _array[_size - 1];
}
size_t GetSize()const
{
return _size;
}
bool IsEmpty()const
{
return _size == 0;
}
private:
void ExpandCapacity()
{
size_t newCapacity = _capacity * 2;
T* tmp = new T[newCapacity];
for (size_t i = 0; i < _size; i++)
{
tmp[i] = _array[i];
}
delete[] _array;
_array = tmp;
_capacity = newCapacity;
}
private:
T* _array;
size_t _capacity;
size_t _size;
};
//类模板中的函数放在类外进行定义的时候。需要加上模板参数列表
template<class T>
void SeqList<T>::PushBack(const T& data)//尾插函数放在类外进行定义
{
if (_capacity == _size)
{
//扩容
ExpandCapacity();
}
_array[_size++] = data;
}
class Date
{
friend ostream& operator <<(ostream& _cout, const Date& d);
public:
Date(int year = 1900,int month = 1,int day = 1)
:_year(year)
, _month(month)
, _day(day)
{}
private:
int _year;
int _month;
int _day;
};
//在使用的时候,需要将其声明为Date类的友元函数,否则在该函数内部无法访问Date类的成员变量
ostream& operator <<(ostream& _cout, const Date& d)
{
_cout << d._year << "-" << d._month << "-" << d._day;
return _cout;
}
int main()
{
//测试内置类型
SeqList<int> s1;
s1.PushBack(1);
s1.PushBack(3);
s1.PushBack(5);
s1.PushBack(7);
s1.PushBack(9);
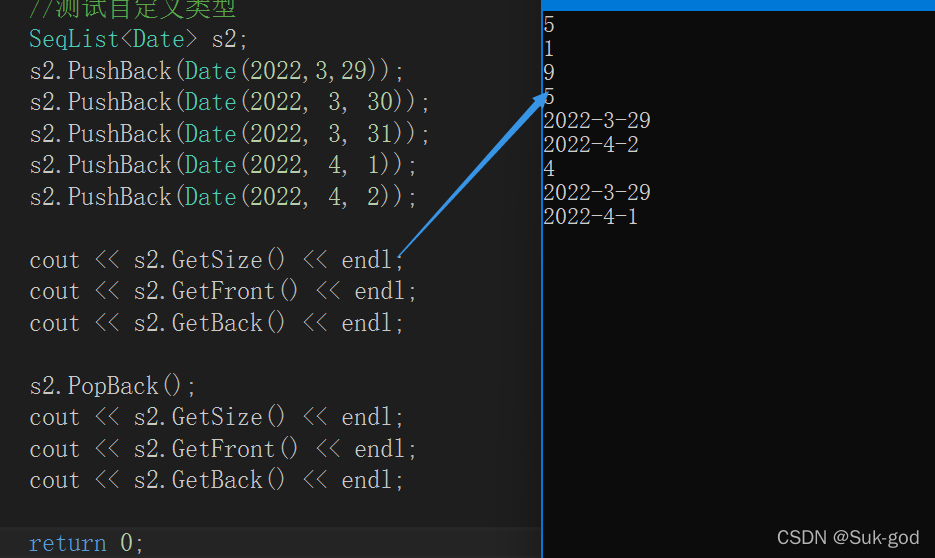
cout << s1.GetSize() << endl;
cout << s1.GetFront() << endl;
cout << s1.GetBack() << endl;
//测试自定义类型
SeqList<Date> s2;
s2.PushBack(Date(2022,3,29));
s2.PushBack(Date(2022, 3, 30));
s2.PushBack(Date(2022, 3, 31));
s2.PushBack(Date(2022, 4, 1));
s2.PushBack(Date(2022, 4, 2));
cout << s2.GetSize() << endl;
cout << s2.GetFront() << endl;
cout << s2.GetBack() << endl;
s2.PopBack();
cout << s2.GetSize() << endl;
cout << s2.GetFront() << endl;
cout << s2.GetBack() << endl;
return 0;
}
两点注意事项:
1、类模板名是一个类名,并不是类型,不能用来实例化对象。要实例化对象需要用 类模板名<具体类型>来进行实例化
2、类模板中的函数若在类外定义,需要加上模板参数列表,并且需要加上所属类和作用域限定符
非类型参数模板
模板参数分为两大类:
类型形参:出现在模板参数列表中,跟在class或者typename之后的参数类型名称
非类型形参:用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可以将该参数当作常量来使用
例如:定义一个模板类型的静态数组(数组大小一旦被确定,不会改变)
template<class T,size_t N = 10>
class List
{
public:
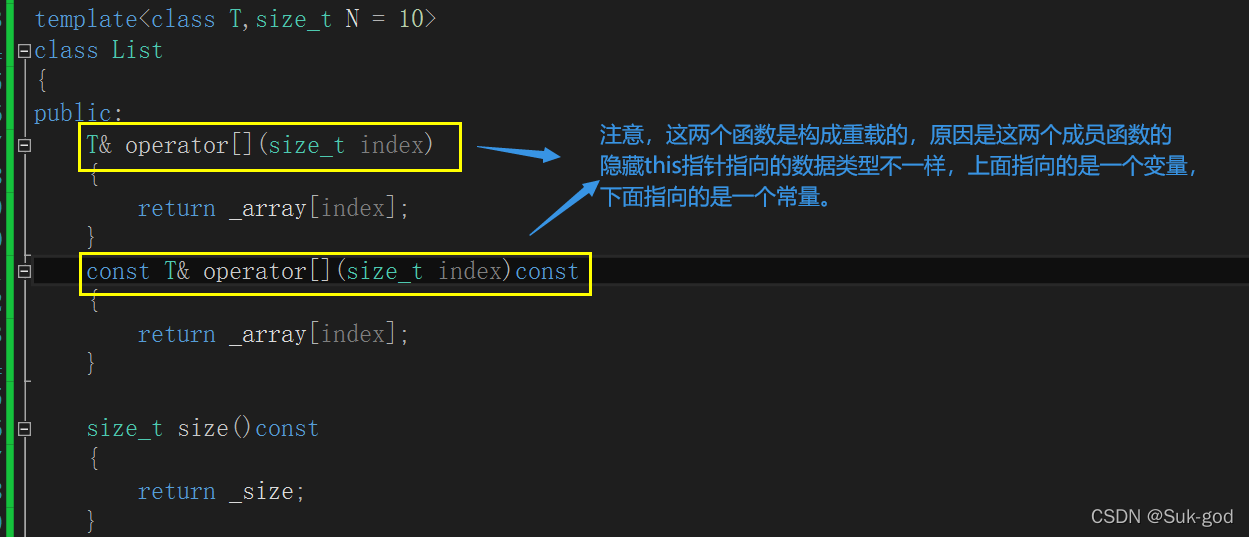
T& operator[](size_t index)
{
return _array[index];
}
const T& operator[](size_t index)const
{
return _array[index];
}
size_t size()const
{
return _size;
}
bool IsEmpty()const
{
return _size == 0;
}
private:
T _array[N];
size_t _size;
};
int main()
{
List<int> s1;
s1[0] = 100;
s1[1] = 200;
cout << s1[1] << endl;
const int ret = s1[0];
cout << ret << endl;
List<double,20>s2;
s2[19] = 12.34;
cout << s2[19] << endl;
return 0;
}
具体有关const的用法请参考const关键字详解
两点注意事项:
1、浮点数、类对象以及字符串是不允许作为非类型模板参数的
2、非类型的模板参数必须在编译期就能确认结果
模板的特化
为什么要有模板特化
通常情况下,使用模板可以实现与类型无关的代码,但对于一些特殊类型的可能会得到一些错误的结果,此时就需要进行模板特化。
所谓模板特化就是在原来模板的基础之上,针对特殊类型所进行特殊化的实现方式。
模板特化分为两类
1、函数模板特化
2、类模板特化
下面我们详细介绍一下这两类模板特化
函数模板的特化
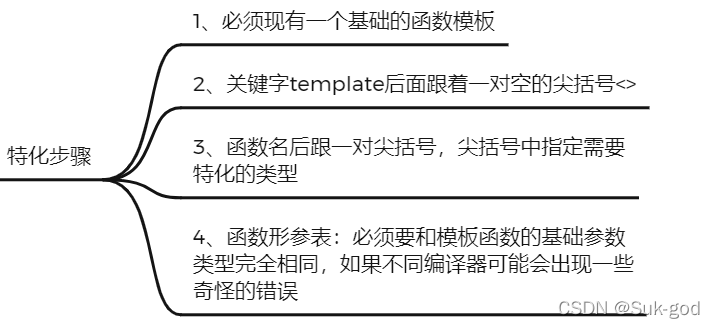
特化步骤如下:
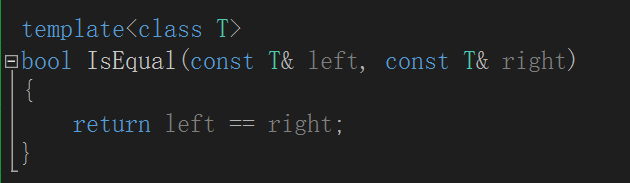
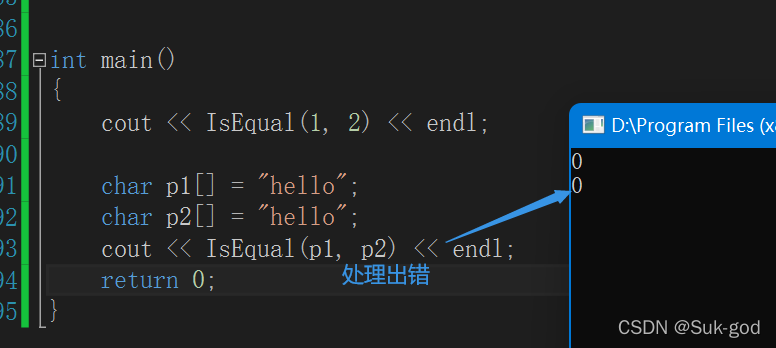
此时我们有两种解决办法:
1、给出函数模板的特化
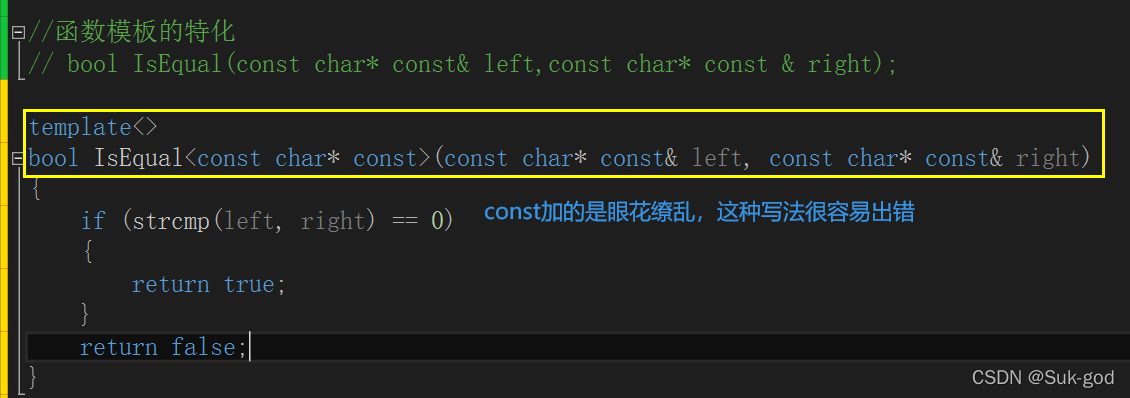
2、针对无法处理的类型直接给出的处理函数

注意事项:一般情况下如果函数模板遇到不能处理或者处理有误的类型,为了实现简单,通常就是将该函数直接给出。
类模板的特化
全特化
将模板参数列表中所有的参数都确定化
template<class T1, class T2>
class Data
{
public:
Data()
{
cout << "Data<T1, T2>" << endl;
}
private:
T1 _d1;
T2 _d2;
};
template<>
class Data<int, char> {
public:
Data()
{
cout << "Data<int, char>" << endl;
}
private:
int _d1;
char _d2;
};
void TestVector()
{
Data<int, int> d1;//会通过默认的类模板创建一个类对象。
Data<int, char> d2;//按照全特化的类模板来创建类对象
}
偏特化
任何针对模板参数进一步进行条件限制设计的特化版本都属于是偏特化
有两种表现方式
1、部分特化
将模板参数列表中一部分参数特化

2、参数更进一步限制
偏特化并不仅仅是特化部分参数,而是针对模板参数更进一步的条件限制所设计出来的一个特化版本
//两个参数偏特化为指针类型
template<class T1,class T2>
class Data<T1*, T2*>
{
public:
Data()
{
cout << "Data<T1*, T2*>" << endl;
}
private:
T1* _d1;
T2* _d2;
};
//两个参数偏特化为引用类型
template<class T1, class T2>
class Data<T1&, T2&>
{
public:
Data(const T1& d1,const T2& d2)
:_d1(d1)
, _d2(d2)
{
cout << "Data<T1&, T2&>" << endl;
}
private:
const T1& _d1;//注意const
const T2& _d2;
};
int main()
{
Data<int*, int*>d1;
Data<int&, int&>d2(1,2);
return 0;
}
模板的分离编译
前提知识铺垫
生成一份可执行程序经历的过程
预处理、编译、汇编、链接
下面我们对这四个步骤做进一步的理解:
预处理
主要做6件事情,分别是:
①头文件展开: 处理“#include”预编译指令,将被包含的文件插入到该预编译指令的位置。
注意:这个过程是递归进行的,也就是说被包含的文件还可以包含其他文件
②宏替换:将所有的“#define”删除,并且展开所有的宏定义
③条件编译:处理所有的条件编译指令,比如“#if”、“#ifdef”、“#elif”、“#else” 、“#endif”
④去注释:删除所有注释 “//”和“/**/”
⑤添加行号和文件名标识: 目的是以便于编译时编译器产生调试用的行号信息以及用于编译时产生编译错误或者警告时能够显示行号
⑥保留所有的#pragma编译器指令,因为编译器要使用它们编译
编译器将预处理完的文件进行一系列词法分析、语法分析、语义分析以及优化后生成相应的汇编代码文件。这个过程往往是整个程序构建的核心部分汇编
通过汇编器将汇编代码转变成机器可以执行的指令,相较于编译器的工作,该过程是一种比较简单的翻译。链接
主要内容是把各个模块之间相互作用的部分都处理好,使得各个模块之间能够正确的衔接
该过程主要包括三个方面:
①地址和空间分配
引入几个名称概念:
变量,函数----没错,这可能是我们再熟悉不过的名称了。就不再介绍
模块:由若干个变量和函数构成
对于一个项目来说(拿C举例),它有若干个.c文件,每一个.c源文件由若干个模块构成。这些源代码按照文件目录结构来组织。
每个模块之间相互依赖又相互独立。这样的存储方式使得代码更容易阅读、理解和重用。每个模块可以单独开发、编译、测试,改变部分代码不需要编译整个程序
这些模块被编译好之后如何组合在一起形成一个单一的程序是需要解决的问题。模块之间的组合问题可以归结为模块之间如何通信的问题。最常见的属于静态语言的C/C++模块之间的通信方式有两种“
Ⅰ:模块间的函数调用:需要知道目标函数的入口地址
Ⅱ:模块间的变量访问:需要知道目标变量的地址
综上:这两种方式可以归结为一种方式,那就是模块间符号的引用。这种通过符号来通信的方式类似于”拼图“,而这个拼接的过程就是链接的过程!
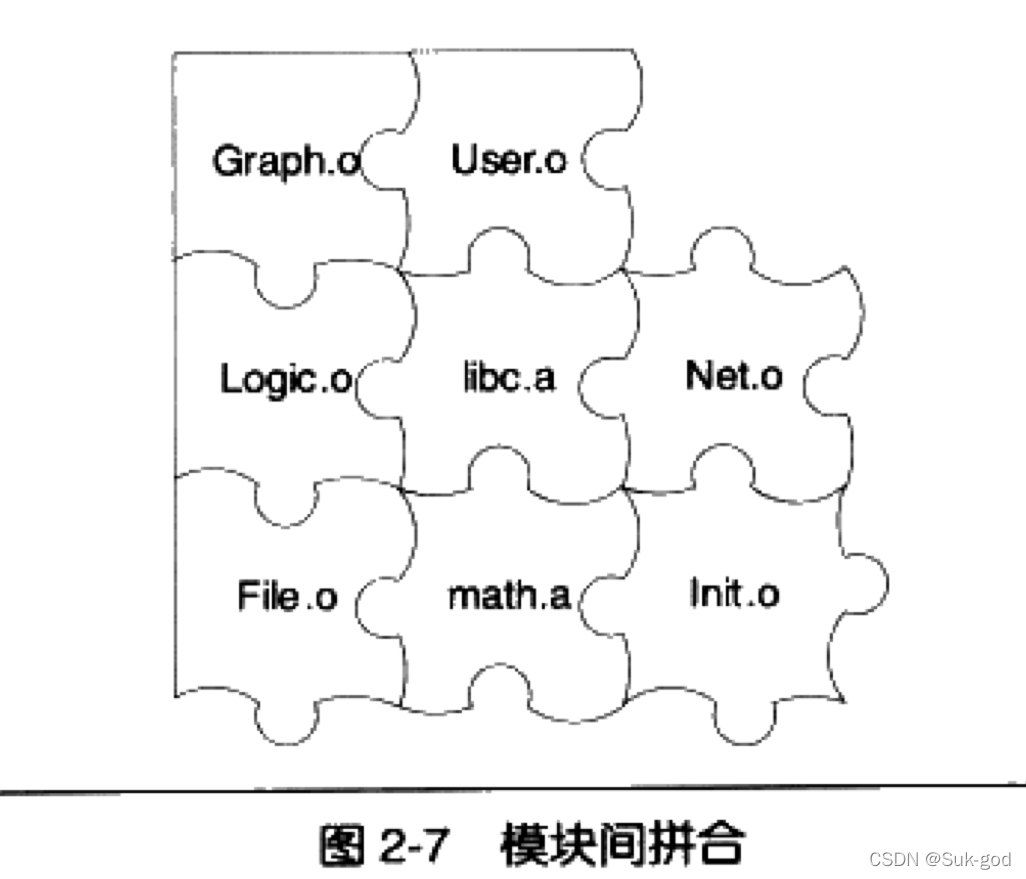
②符号决议
符号决议有时候也被称为符号绑定(Symbol Binding)、名称绑定(Name Binding)、名称决议(Name Resolution),甚至还有叫做地址绑定(Address Binding) 、指令绑定(Instruction Binding)的,但是大体上他们都是一个意思。但是从细节上来说还是有些许差别的,比如“决议”更倾向于静态链接,“绑定”更倾向于动态链接。在静态链接部分,我们统一称为符号决议。
下图是最基本的静态链接的过程,每个模块的源代码经过编译器编译成目标代码,目标文件和库一起链接成最终的可执行文件。
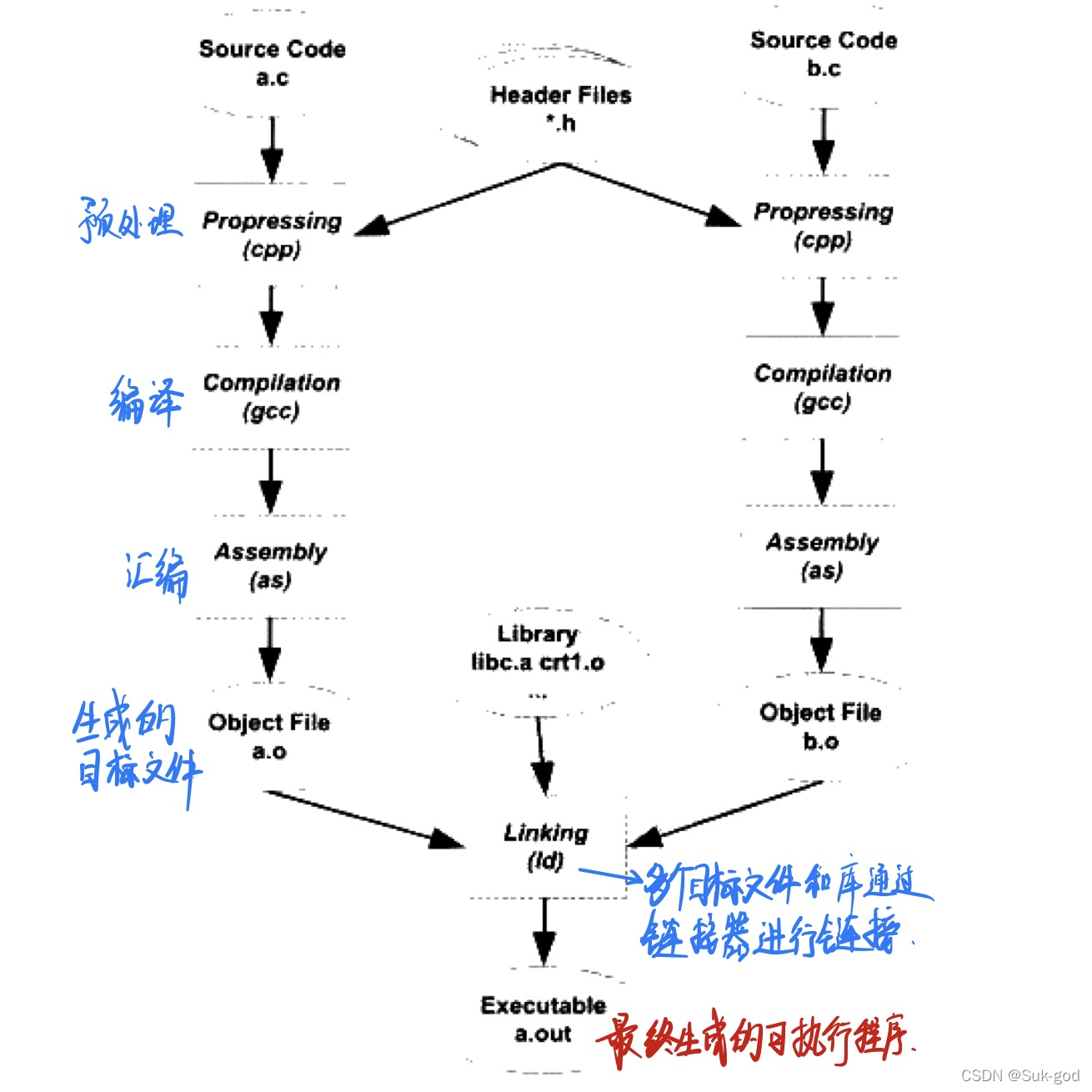
这里有一个新名词,库:是一组目标文件的包,其实就是一些最常用的代码编译成目标文件后打包存放。最常见的库就是运行时库,他是支持程序运行的基本函数的集合。
③重定向

很简单解释一下上图的文字描述:
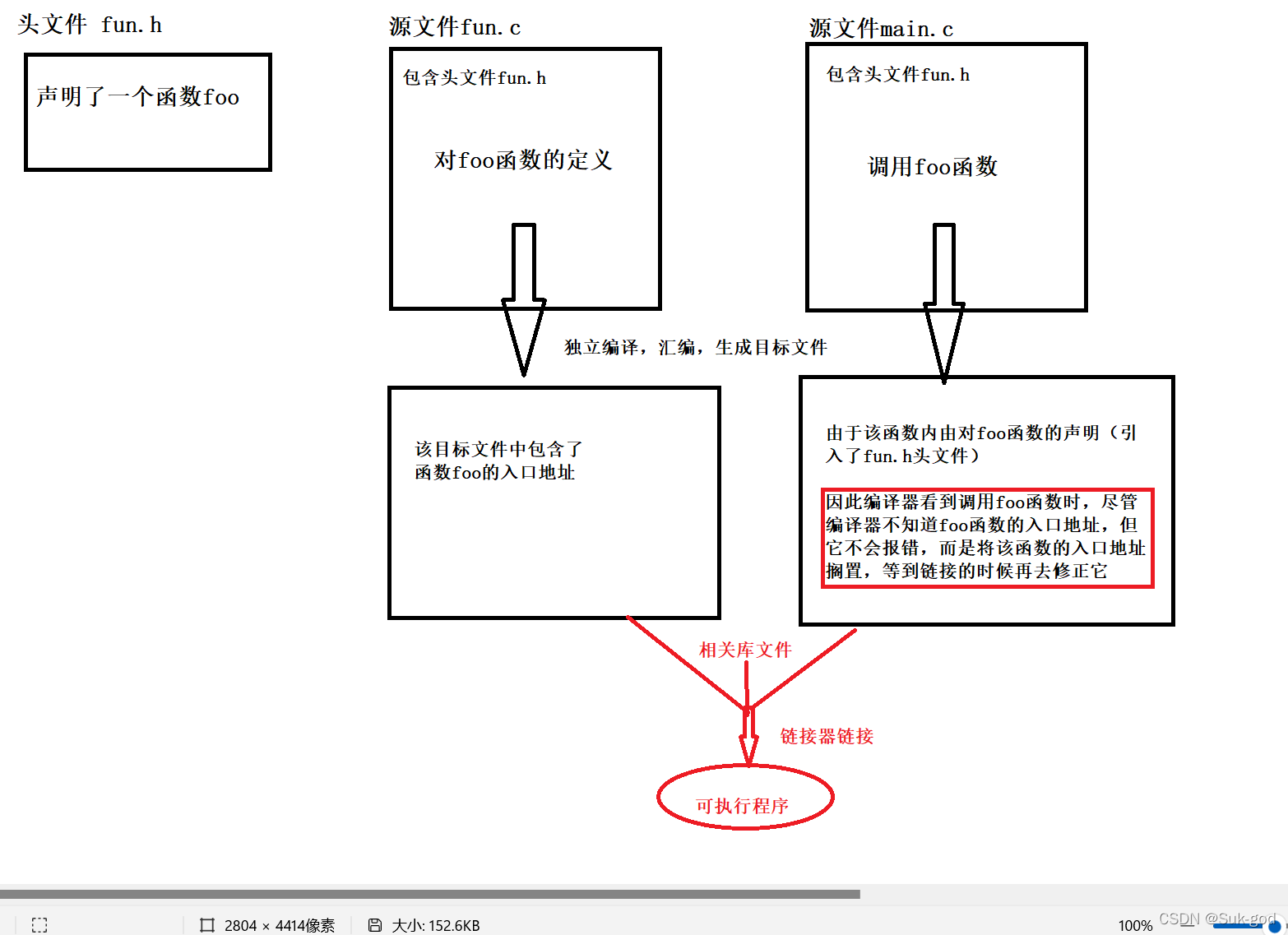
对于一些变量,例如全局变量,也是如此。
上述讲的 地址的修正过程 被称为重定位.每个要被修正的目标地址叫做重定位入口。重定位所做的就是给程序中每个这样的绝对地址引用的位置“打补丁”,使他们指向正确的地址。
上述内容的介绍,有兴趣深入了解的读友们可以参考《程序员的自我修养》。
分离编译的概念
终于,我们可以直奔主题了~
一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程
模板的分离编译过程
假如有以下场景,模板的声明与定义分离开,在头文件中进行声明,源文件中完成定义
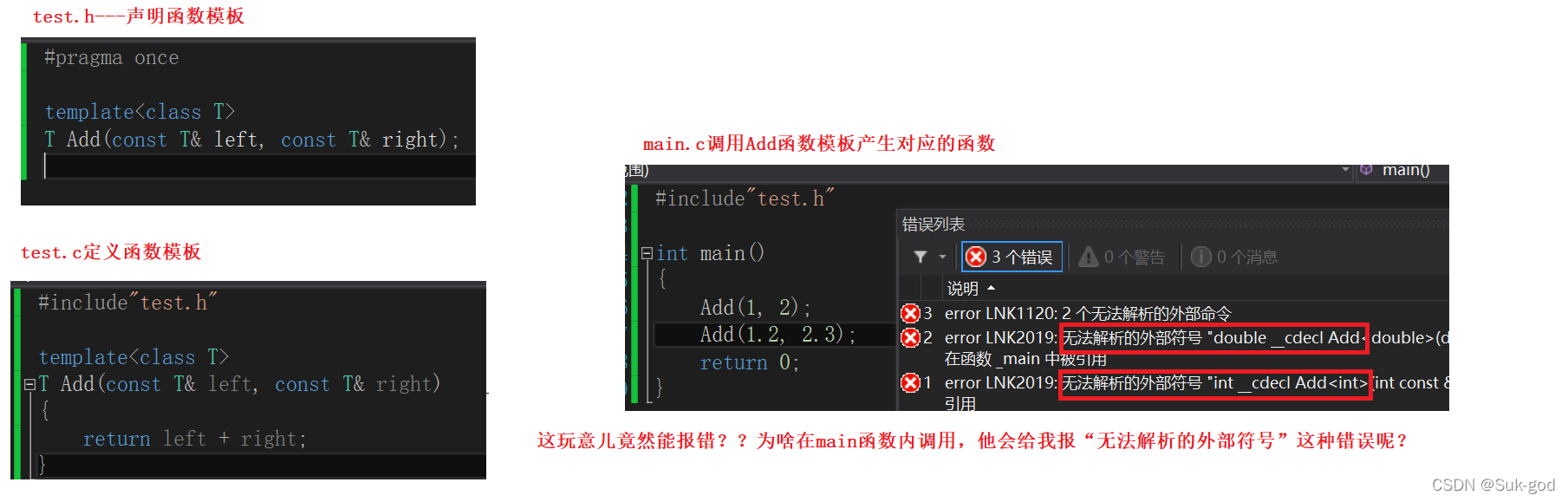
好,这个棘手问题先放一放,我们再来看一种现象:
我现在在test.c源文件内实例化一下Add(xxx,xxx);再来观察现象
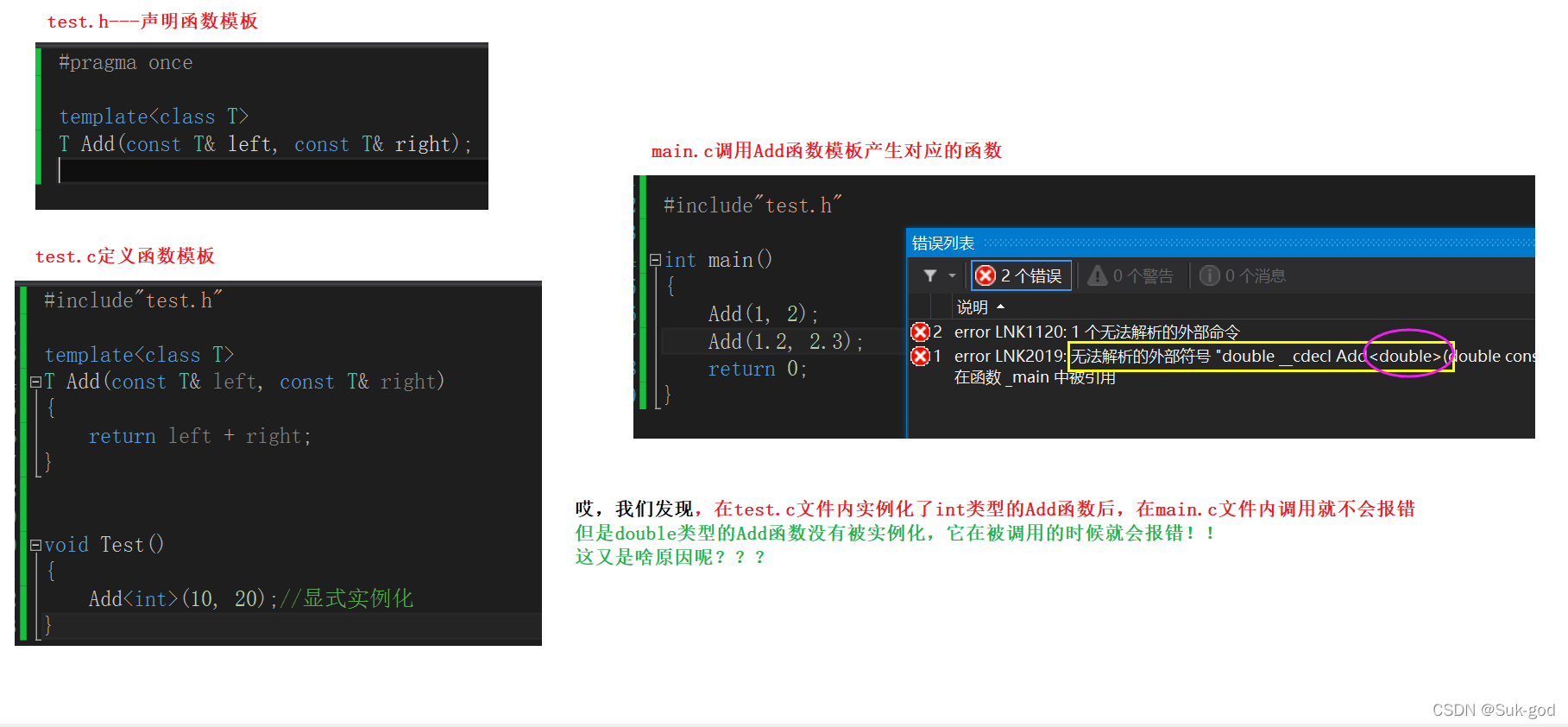
看到这里,我们要解决的矛盾点也就出来了。
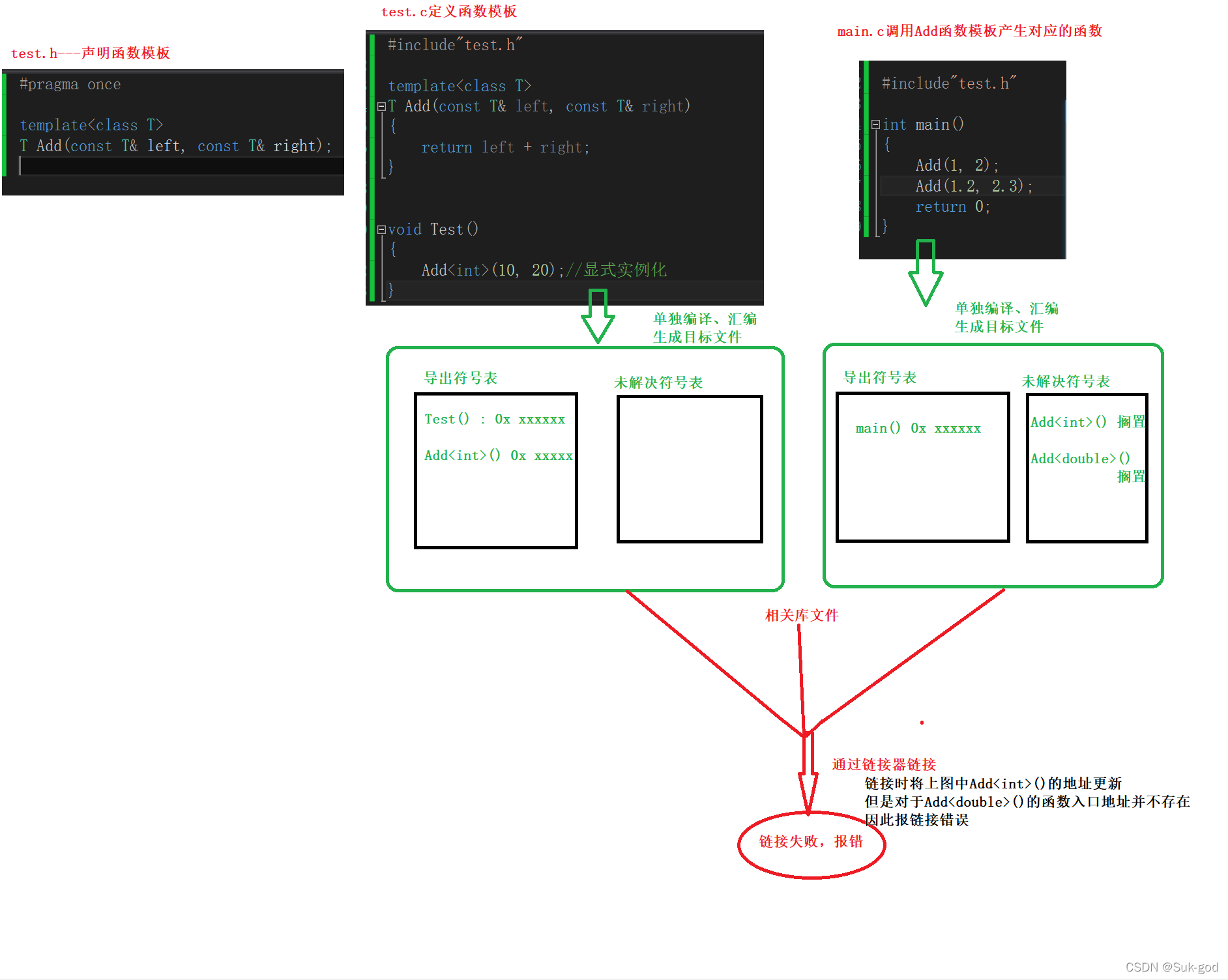
目前我们通过现象得到的时:在定义模板的源文件内实例化过的Add函数,在其他源文件内可以正常使用。未实例化的,就不能被使用。
分析原因:
本质上是因为每个源文件都是单独编译的!对于该文件中未定义并且使用到的函数(变量)地址,会在链接的时候通过重定向来找到这些目标地址。如果找到了,也就不会报错。对于找不到的地址,编译器会报链接错误的标识!(如果这段话你无法理解,那么请看前面的前提知识铺垫,在里面讲了有关知识以及书籍推荐)
下面通过图示的方式解释一下:
解决办法
针对上述问题,如何解决呢?
有两种方式:
1、将申明和定义放到一个文件“xxx.hpp”里面或者“xxx.h”里面(推荐使用,一般放在“xxx.hpp”)
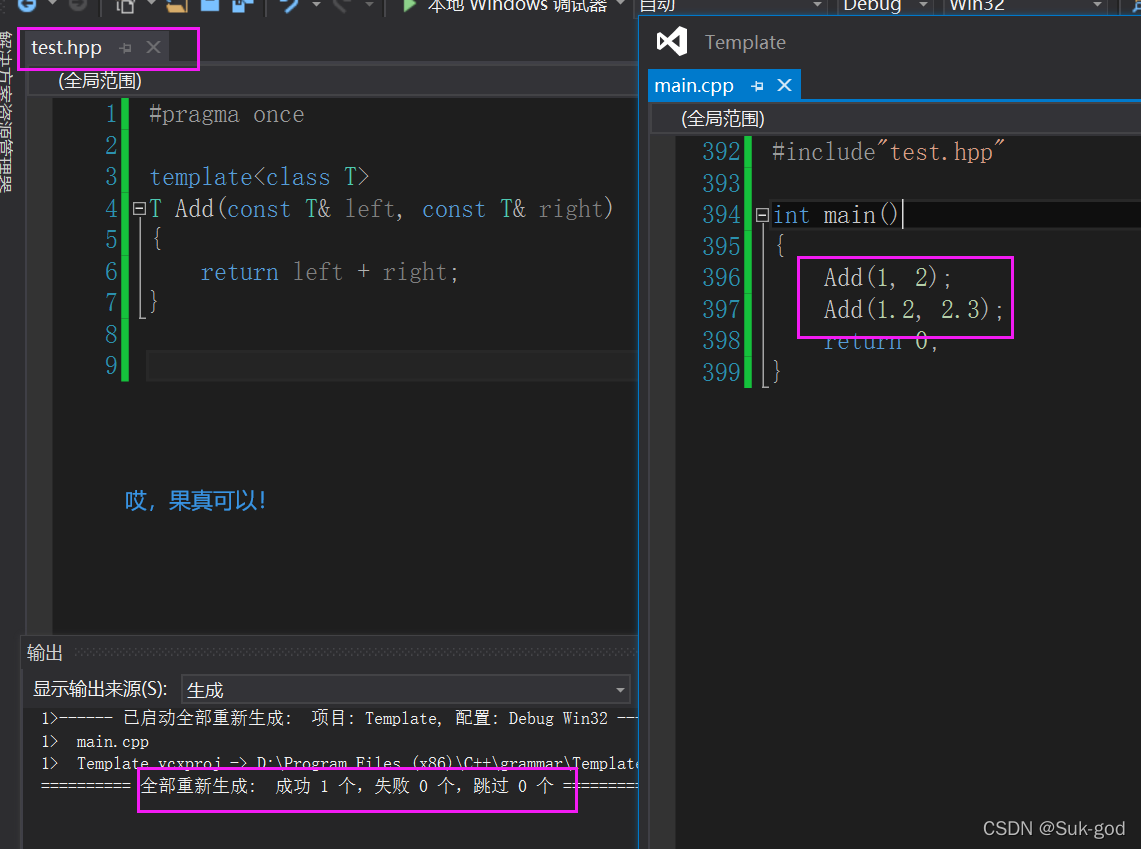
2、模板定义的位置显示实例化(该方法不实用,不推荐使用)
模板总结

以上就是对模板这块知识的总结归纳,感觉有所帮助的小伙伴们请留下你的足迹~~
我们下期再见!
