LZW 编解码算法实现与分析(词典编码)
词典编码的基本原理,用C/C++/Python等语言编程实现LZW解码器并分析编解码算法。
二话不说,上代码:
首先是主函数:
int main( int argc, char **argv){
FILE *fp;
BITFILE *bf;
if( 4>argc){
fprintf( stdout, "usage: \n%s <o> <ifile> <ofile>\n", argv[0]);
fprintf( stdout, "\t<o>: E or D reffers encode or decode\n");
fprintf( stdout, "\t<ifile>: input file name\n");
fprintf( stdout, "\t<ofile>: output file name\n");
return -1;
}
if( 'E' == argv[1][0]){ // do encoding
fp=fopen( argv[2], "rb");
bf = OpenBitFileOutput( argv[3]);//以字节文件形式打开
if( NULL!=fp && NULL!=bf){
LZWEncode( fp, bf);
fclose( fp);
CloseBitFileOutput( bf);
fprintf( stdout, "encoding done\n");
}
}else if( 'D' == argv[1][0]){ // do decoding
bf = OpenBitFileInput( argv[2]);
fp=fopen( argv[3], "wb");
if( NULL!=fp && NULL!=bf){
LZWDecode( bf, fp);
fclose( fp);
CloseBitFileInput( bf);
fprintf( stdout, "decoding done\n");
}
}else{ // otherwise
fprintf( stderr, "not supported operation\n");
}
return 0;
}
解析:非常地浅显易懂,就是三个输入:编解码模式选择(E or D),源文件名,目标文件名。
注意两个指针:
bf是指向我们编码后的字节型文件,
fp是指向压缩前的文件或还原后的文件
编码程序:
void LZWEncode( FILE *fp, BITFILE *bf){
int character;
int string_code;
int index;
unsigned long file_length;
fseek( fp, 0, SEEK_END);//指针指向最后位置
file_length = ftell( fp);//ftell得到流式文件的当前读写位置,其返回值是当前读写位置偏离文件头部的字节数.
fseek( fp, 0, SEEK_SET);//指针指向开头位置
BitsOutput( bf, file_length, 4*8);
InitDictionary();
string_code = -1;
while( EOF!=(character=fgetc( fp))){//fgetc()返回一个整数值,该值是无符号char的转换
index = InDictionary( character, string_code);
if( 0<=index){ // string+character in dictionary
string_code = index;
}else{ // string+character not in dictionary
output( bf, string_code);//先将已有的前缀索引写入
if( MAX_CODE > next_code){ // free space in dictionary
// add string+character to dictionary
AddToDictionary( character, string_code);
}
string_code = character;//当前字符变为前缀字符
}
}
output( bf, string_code);
}
其实就是首先初始化字典,此时其实单个char字符都已经在字典中,字符索引和对应的字符其实对计算机来说从根本上是相等的。
初始化字典代码:
void InitDictionary( void){
int i;
for( i=0; i<256; i++){
dictionary[i].suffix = i;
dictionary[i].parent = -1;
dictionary[i].firstchild = -1;
dictionary[i].nextsibling = i+1;
}
dictionary[255].nextsibling = -1;
next_code = 256;
}
逐个取出char字符,判断是否在字典中:
是:就再将该字符变为前缀字符索引,等待下一个字符
不是:就将已有的前缀字符索引写入输出,判断字典是否有多余的位置,将此时的字符和前缀字符共同加入字典,再将当前的字符变为前缀字符索引。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-317yAlTm-1650616377526)(C:\Users\86183\AppData\Roaming\Typora\typora-user-images\image-20220422120825777.png)]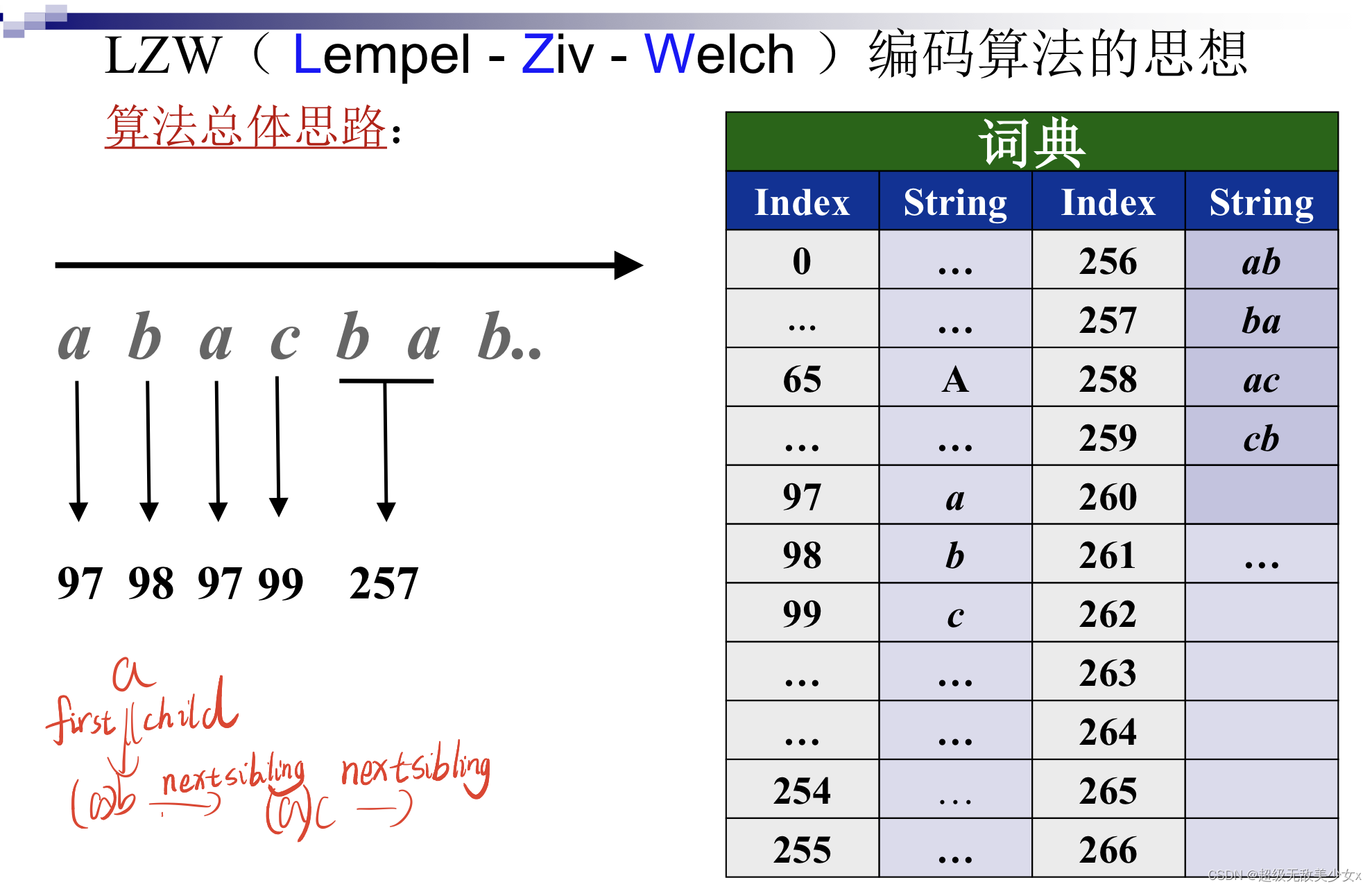
加入字典的代码:
输入:字符,前缀字符索引(前缀字符)
void AddToDictionary( int character, int string_code){
int firstsibling, nextsibling;
if( 0>string_code) return;
dictionary[next_code].suffix = character;//当前字符
dictionary[next_code].parent = string_code;//前缀字符
dictionary[next_code].nextsibling = -1;
dictionary[next_code].firstchild = -1;
firstsibling = dictionary[string_code].firstchild;//前缀字符的有无组队
if( -1<firstsibling){ // the parent has child,有组队,寻找同辈
nextsibling = firstsibling;
while( -1<dictionary[nextsibling].nextsibling )
nextsibling = dictionary[nextsibling].nextsibling;//不停的找到没有同辈的同辈
dictionary[nextsibling].nextsibling = next_code;//跟上做同辈
}else{// no child before, modify it to be the first
dictionary[string_code].firstchild = next_code;
}
next_code ++;
}
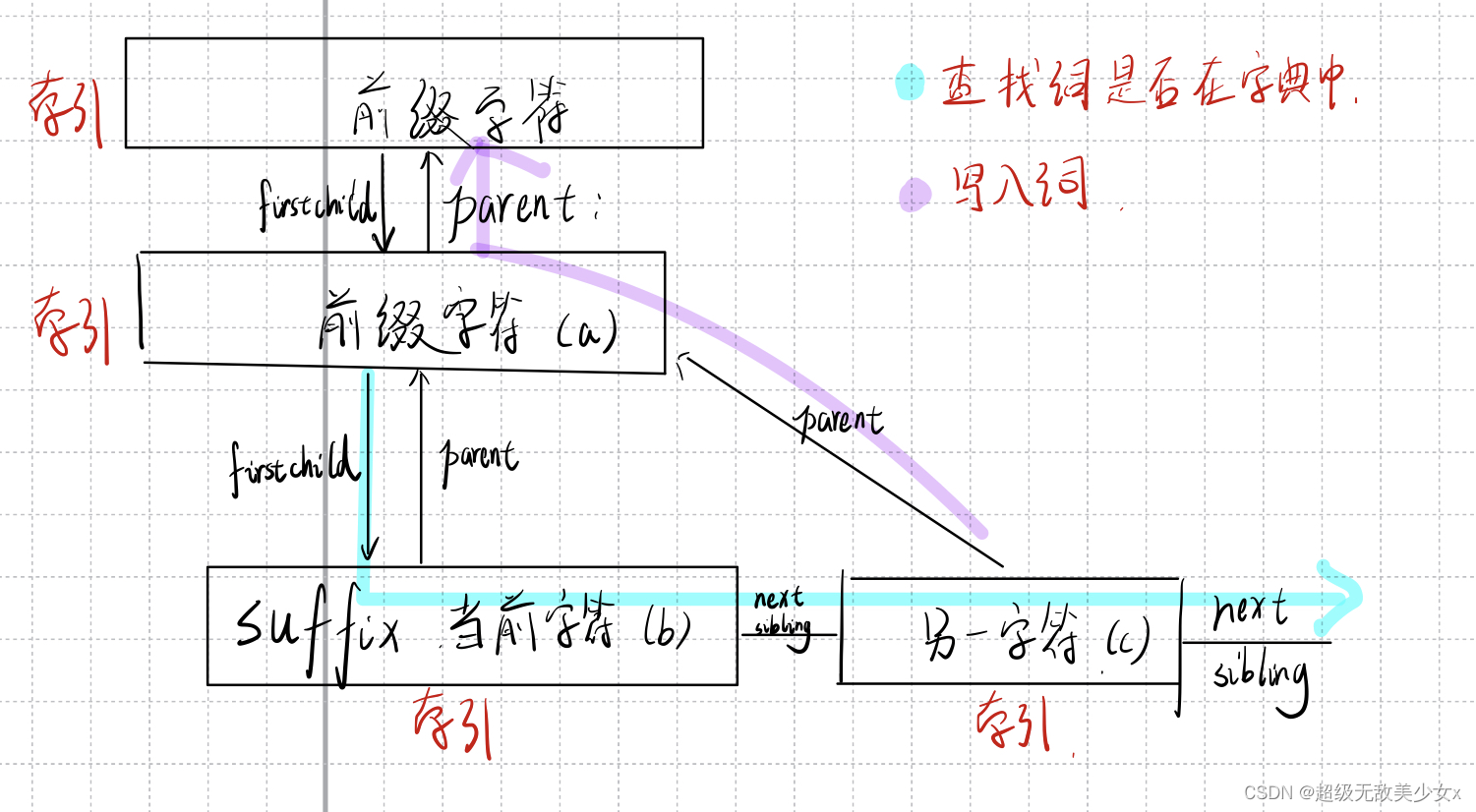
我本人数据结构学的不好,所以字典中的关系看了好久。。。。
firstchild、sibling节点主要用于查找词,parent主要用于写入词
解码:
void LZWDecode( BITFILE *bf, FILE *fp){
//需填充
int character;
int new_code, last_code;
int phrase_length;
unsigned long file_length;
file_length = BitsInput(bf, 4 * 8);
if (-1 == file_length) file_length = 0;
InitDictionary();//初始化字典
last_code = -1;//初始化前缀索引
while (0 < file_length) {
new_code = input(bf);
if (new_code >= next_code) {
//不在词典中
d_stack[0] = character;
phrase_length = DecodeString(1, last_code);//说明此时为上一个刚写入的前缀+前缀第一个字符所以才会找不到
}
else {
phrase_length = DecodeString(0, new_code);//寻找该索引的所有parent,返回总共有几个字符,并存入d_stack缓冲中
}
character = d_stack[phrase_length - 1];
while (0 < phrase_length) {
phrase_length--;
fputc(d_stack[phrase_length], fp);//倒着写入输出
file_length--;
}
if (MAX_CODE > next_code) {
AddToDictionary(character, last_code);
}
last_code = new_code;
}
}
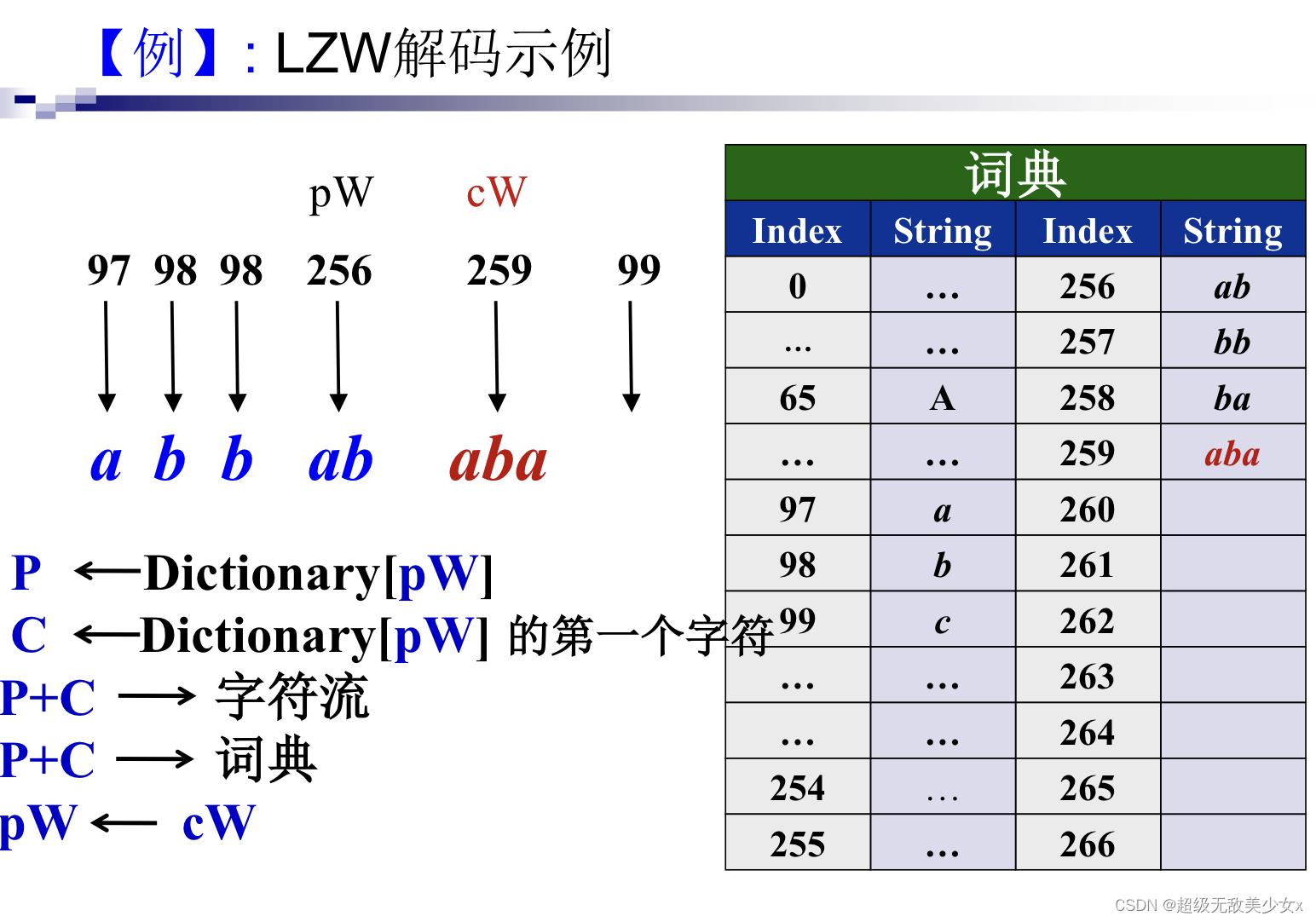
其中:
int DecodeString( int start, int code){
//需填充
int count;
count = start;
while (0 <= code) {
d_stack[count] = dictionary[code].suffix;
code = dictionary[code].parent;
count++;
}
return count;
}
首先初始化字典,将输入的索引判断是否在字典中:
是:找到该索引对应字符和他所有的parent对应的字符,存入缓冲区
? 定位该索引对应的字符,和旧索引一起加入字典中,同样调用加入字典的方法
? 再将此索引存入旧索引
否:则说明遇见特殊情况
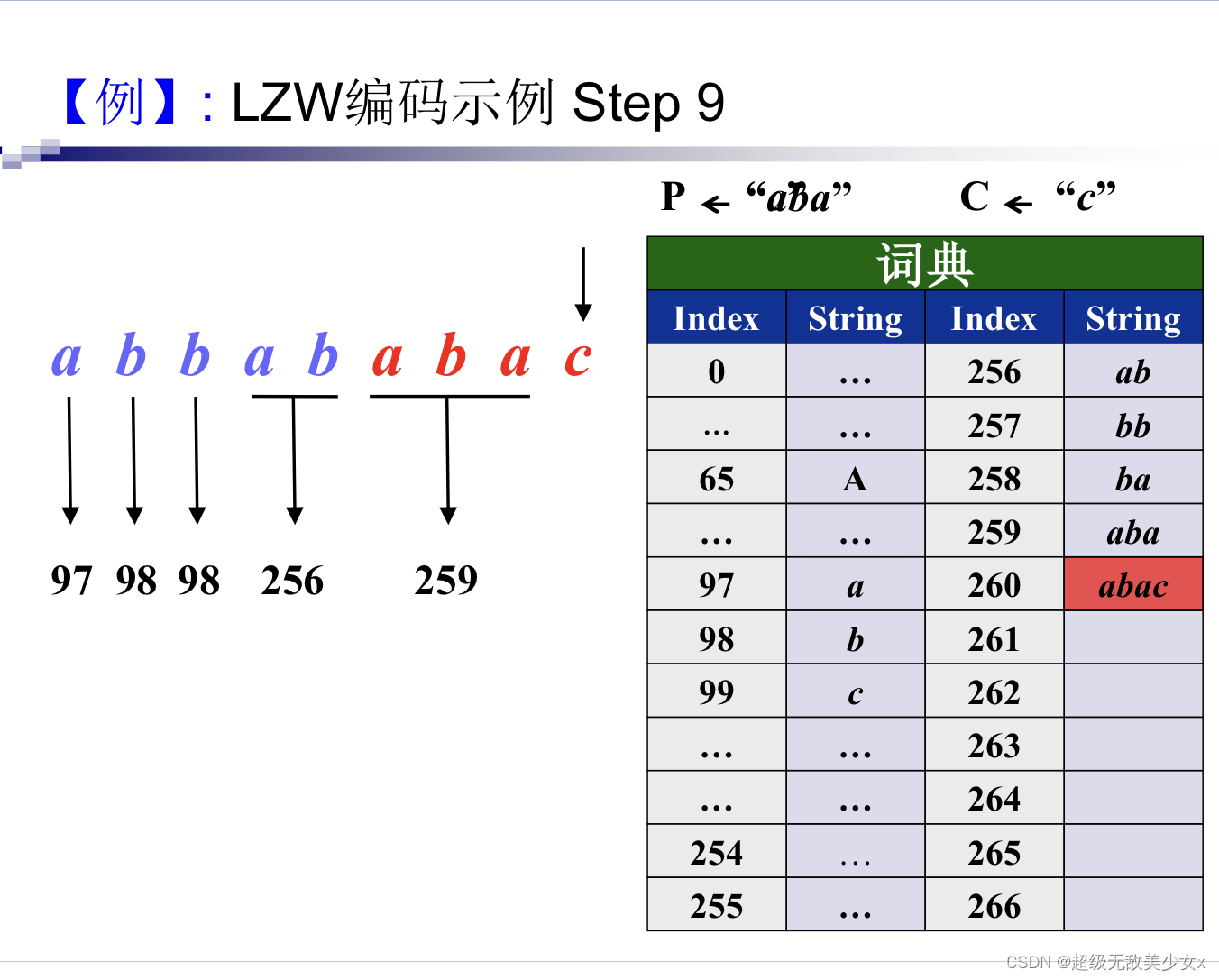
为什么解码会遇见没有在动态构造的字典的索引呢?
那必然说明,这个字符串是最新构造出来的呀
那最新构造出来的是什么字符串?
那就是上一个字符串再加上这个索引对应字符串的第一个字符,是最新的字符串
可以分析一下,上一个字符串的第一个字符和这个索引对应的字符串的第一个字符是一样的,一定是首尾相同
至此,基本上都分析完了
字典编码涉及到的知识面好多!!
有比特流的输入输出!
有数据结构!
还有编码能力!
还有对部分重复调用的函数封装能力!我老是直线思维!
呜呜呜呜希望自己能早日写出这么漂亮的代码!
压缩结果!!
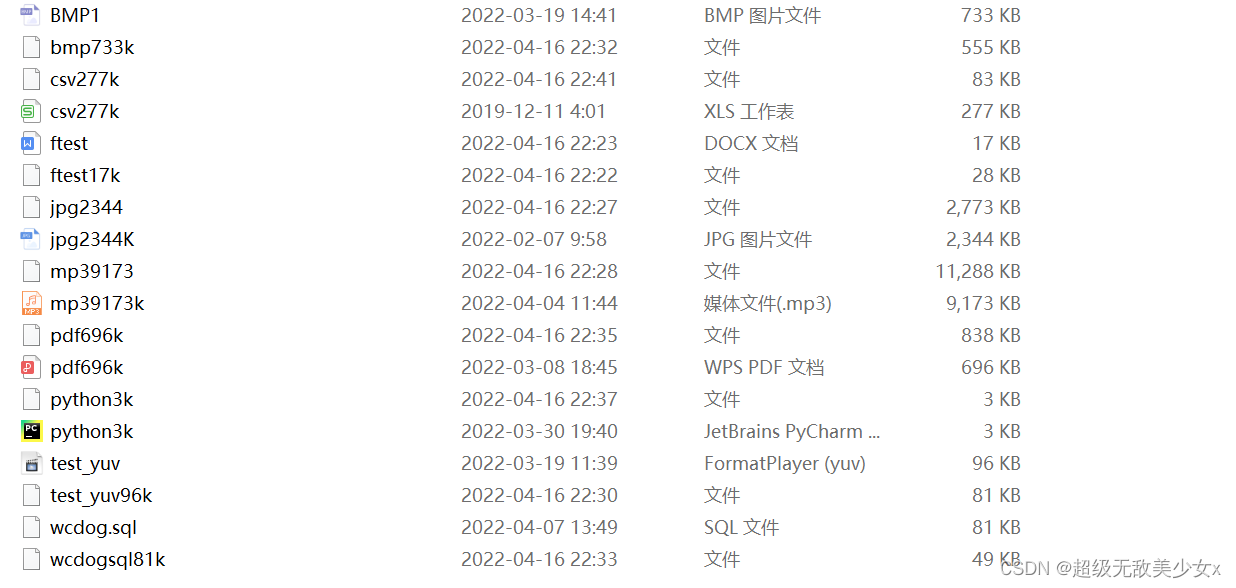
压缩效果最显著的是sql文件,可能因为很多重复的词语,还有随便找的csv文件
一个字符是一样的,一定是首尾相同
至此,基本上都分析完了
字典编码涉及到的知识面好多!!
有比特流的输入输出!
有数据结构!
还有编码能力!
还有对部分重复调用的函数封装能力!我老是直线思维!
呜呜呜呜希望自己能早日写出这么漂亮的代码!
压缩结果!!
[外链图片转存中…(img-6XumsZFP-1650616377527)]
压缩效果最显著的是sql文件,可能因为很多重复的词语,还有随便找的csv文件
最惨的是mp3和word文件,还不如没压缩

