����Ŀ¼
- �ı��ļ��Ͷ������ļ�������ʲô����?
- C����fgetc��fputc�����÷����(���ַ���ʽ��д�ļ�)
- C����fgets��fputs�������÷����(���ַ�������ʽ��д�ļ�)
- C����fread��fwrite���÷����(�����ݿ����ʽ��д�ļ�)
- C����fscanf��fprintf�������÷����(��ʽ����д�ļ�)
- C����rewind��fseek�������÷����(�����д�ļ�)
- C����ʵ���ļ����ƹ���(�����ı��ļ��Ͷ������ļ�)
- C����FILE�ṹ���Լ�����������̽��
- C���Ի�ȡ�ļ���С(����)
- C���Բ��롢ɾ���������ļ�����
- ������ļ�������ʲô(ͨ����)?
- C++�ļ���(�ļ�����)���÷����
- C++ open ���ļ�(����ģʽһ����)
- �ı���ʽ�Ͷ����ƴ�ʽ��������ʲô?
- C++ close()�ر��ļ��������
- C++���ļ�һ��Ҫ��close()�����ر�!
- C++�ı��ļ���д�������
- C++ get()��put()��д�ļ����
- C++ getline():���ļ��ж�ȡһ���ַ���
- C++�ƶ��ͻ�ȡ�ļ���дָ��(seekp��seekg��tellg��tellp)
֮ǰд��һƪ�й��ļ���һƪ����: ��C/C++�������������ļ�,�ļ�������,I/O��·����,select / poll / epoll ���.
���Ժ���ƪһ���Ķ���
һ���ļ����ļ�ϵͳ
���Կ������⼸ƪ����:
һ�����㶮���ļ�ϵͳ��,�Ϳ��� 25 ��ͼ��
�ļ�ϵͳ��ʲô?���ܼ��ּ�����ļ�ϵͳ��������ԭ��
ת����:http://c.biancheng.net/view/vip_2079.html,http://c.biancheng.net/view/309.html
����C�����ļ��������
C���Ծ��в����ļ�������,������ļ�����ȡ�������ݡ������ɾ�����ݡ��ر��ļ���ɾ���ļ��ȡ�
����������������,C�����ļ������Ľӿ��൱����ѧ����C������,Ϊ��ͳһ�Ը���Ӳ���IJ���,�ӿ�,��ͬ��Ӳ���豸Ҳ��������һ���ļ�������Щ�ļ��IJ���,��ͬ�ڶԴ�������ͨ�ļ��IJ�����
C�����е��ļ���ʲô?
���Ƕ��ļ��ĸ����Ѿ��dz���Ϥ��,���糣���� Word �ĵ���txt �ļ���Դ�ļ��ȡ��ļ�������Դ��һ��,����Ҫ�������DZ������ݡ�
�ڲ���ϵͳ��,Ϊ��ͳһ�Ը���Ӳ���IJ���,�ӿ�,��ͬ��Ӳ���豸Ҳ��������һ���ļ�������Щ�ļ��IJ���,��ͬ�ڶԴ�������ͨ�ļ��IJ���������:
- ͨ������ʾ����Ϊ������ļ�,printf ����������ļ��������;
- ͨ���Ѽ��̳�Ϊ�������ļ�,scanf ���Ǵ�����ļ���ȡ���ݡ�
| �ļ� | Ӳ���豸 |
|---|---|
| stdin | �������ļ�,һ��ָ����;scanf()��getchar() �Ⱥ���Ĭ�ϴ� stdin ��ȡ���롣 |
| stdout | ������ļ�,һ��ָ��ʾ��;printf()��putchar() �Ⱥ���Ĭ���� stdout ������ݡ� |
| stderr | �������ļ�,һ��ָ��ʾ��;perror() �Ⱥ���Ĭ���� stderr �������(�����ὲ��)�� |
| stdprn | ����ӡ�ļ�,һ��ָ��ӡ���� |
���Dz�ȥ̽��Ӳ���豸����α�ӳ����ļ���,���ֻ��Ҫ��ס,��C������Ӳ���豸���Կ����ļ�,��Щ���������������Ҫ��ָ������д�ĸ��ļ�,ϵͳ�Ѿ�Ϊ����������Ĭ�ϵ��ļ�,��Ȼ��Ҳ���Ը���,������ printf ������ϵ��ļ�������ݡ�
�����ļ�����ȷ����Ϊ:���ļ� --> ��д�ļ� --> �ر��ļ����ļ��ڽ��ж�д����֮ǰҪ�ȴ�,ʹ�����Ҫ�رա�
��ν���ļ�,���ǻ�ȡ�ļ����й���Ϣ,�����ļ������ļ�״̬����ǰ��дλ�õ�,��Щ��Ϣ�ᱻ���浽һ�� FILE ���͵Ľṹ������С��ر��ļ����ǶϿ����ļ�֮�����ϵ,�ͷŽṹ�����,ͬʱ��ֹ�ٶԸ��ļ����в�����
��C������,�ļ��ж��ֶ�д��ʽ,����һ���ַ�һ���ַ��ض�ȡ,Ҳ���Զ�ȡһ����,�����Զ�ȡ���ɸ��ֽڡ��ļ��Ķ�дλ��Ҳ�dz����,���Դ��ļ���ͷ��ȡ,Ҳ���Դ��м�λ�ö�ȡ��
�ļ���
�ڡ������ڴ�,�ó�������������һ�����ᵽ,���е��ļ�(�����ڴ���)��Ҫ�����ڴ���ܴ���,���е����ݱ���д���ļ�(����)�Ų��ᶪʧ���������ļ����ڴ�֮�䴫�ݵĹ��̽����ļ���,����ˮ��һ���ط���������һ���ط������ݴ��ļ����Ƶ��ڴ�Ĺ��̽���������,���ڴ汣�浽�ļ��Ĺ��̽����������
�ļ�������Դ��һ��,�����ļ�,�������ݿ⡢���硢���̵�;���ݴ��ݵ��ڴ�Ҳ���DZ��浽C���Եı���(�����������ַ��������顢��������)�����ǰ�����������Դ�ͳ���(�ڴ�)֮�䴫�ݵĹ��̽���������(Data Stream)����Ӧ��,���ݴ�����Դ������(�ڴ�)�Ĺ��̽���������(Input Stream),�ӳ���(�ڴ�)������Դ�Ĺ��̽��������(Output Stream)��
�������(Input output,IO)��ָ����(�ڴ�)���ⲿ�豸(���̡���ʾ�������̡������������)���н����IJ������������еij������������������,��Ӽ����϶�ȡ����,�ӱ��ػ������ϵ��ļ���ȡ���ݻ�д�����ݵȡ�ͨ�����������������Դ���������Ϣ,�����ǰ���Ϣ���ݸ���硣
���ǿ���˵,���ļ����Ǵ���һ������
C����fopen�������÷�,C���Դ��ļ����
��C������,�����ļ�֮ǰ�����ȴ��ļ�;��ν�����ļ���,�����ó�����ļ��������ӵĹ��̡�
���ļ�֮��,������Եõ��ļ��������Ϣ,�����С�����͡�Ȩ�ޡ������ߡ�����ʱ��ȡ��ں�����д�ļ��Ĺ�����,�����Լ�¼��ǰ��д�����ĸ�λ��,�´ο����ڴ˻����ϼ���������
�������ļ� stdin(��ʾ����)��������ļ� stdout(��ʾ��ʾ��)���������ļ� stderr(��ʾ��ʾ��)����ϵͳ��,��ֱ��ʹ�á�
ʹ�� <stdio.h> ͷ�ļ��е� fopen() �������ɴ��ļ�,�����÷�Ϊ:
FILE *fopen(char *filename, char *mode);
filenameΪ�ļ���(�����ļ�·��),modeΪ��ʽ,���Ƕ����ַ�����
fopen() �����ķ���ֵ
fopen() ���ȡ�ļ���Ϣ,�����ļ������ļ�״̬����ǰ��дλ�õ�,������Щ��Ϣ���浽һ�� FILE ���͵Ľṹ�������,Ȼ�ñ����ĵ�ַ���ء�
FILE �� <stdio.h> ͷ�ļ��е�һ���ṹ��,��ר�����������ļ���Ϣ�����Dz��ù��� FILE �ľ���ṹ,ֻ��Ҫ֪�������÷����С�
���ϣ������ fopen() �ķ���ֵ,����Ҫ����һ�� FILE ���͵�ָ��������:
FILE *fp = fopen("demo.txt", "r");
��ʾ�ԡ�ֻ������ʽ��ǰĿ¼�µ� demo.txt �ļ�,��ʹ fp ָ����ļ�,�����Ϳ���ͨ�� fp ������ demo.txt �ˡ�fp ͨ������Ϊ�ļ�ָ�롣
������һ������:
FILE *fp = fopen("D:\\demo.txt","rb+");
��ʾ�Զ����Ʒ�ʽ�� D ���µ� demo.txt �ļ�,��������д��
�ж��ļ��Ƿ�ɹ�
���ļ�����ʱ,fopen() ������һ����ָ��,Ҳ���� NULL,���ǿ���������һ�����ж��ļ��Ƿ�ɹ�,�뿴����Ĵ���:
FILE *fp;
if( (fp=fopen("D:\\demo.txt","rb")) == NULL ){
printf("Fail to open file!\n");
exit(0); //�˳�����(��������)
}
����ͨ���ж� fopen() �ķ���ֵ�Ƿ�� NULL ������ж��Ƿ��ʧ��:��� fopen() �ķ���ֵΪ NULL,��ô fp ��ֵҲΪ NULL,��ʱ if ���ж���������,��ʾ�ļ���ʧ�ܡ�
���ϴ������ļ������Ĺ淶д��,�����ڴ��ļ�ʱһ��Ҫ�ж��ļ��Ƿ�ɹ�,��Ϊһ����ʧ��,���������Ͷ�û��������,�����ԡ����������ա�
fopen() �����Ĵ�ʽ
��ͬ�IJ�����Ҫ��ͬ���ļ�Ȩ�ޡ�����,ֻ���ȡ�ļ��е����ݵĻ�,��ֻ����Ȩ����;�����ȡ����д�����ݵĻ�,����д��Ȩ���DZ�����ˡ�
����,�ļ�Ҳ�в�ͬ������,�������ݵĴ洢��ʽ���Է�Ϊ�������ļ����ı��ļ�,���ǵIJ���ϸ���Dz�ͬ�ġ�
�ڵ��� fopen() ����ʱ,��Щ��Ϣ�������ṩ,��Ϊ���ļ���ʽ������������ļ���ʽ�����¼���:
| ���ƶ�дȨ���ַ���(����ָ��) | |
|---|---|
| ��ʽ | ˵�� |
| ��r�� | �ԡ�ֻ������ʽ���ļ���ֻ������ȡ,������д�롣�ļ��������,�����ʧ�ܡ� |
| ��w�� | �ԡ�д�롱��ʽ���ļ�������ļ�������,��ô����һ�����ļ�;����ļ�����,��ô����ļ�����(�൱��ɾ��ԭ�ļ�,�ٴ���һ�����ļ�)�� |
| ��a�� | �ԡ��ӡ���ʽ���ļ�������ļ�������,��ô����һ�����ļ�;����ļ�����,��ô��д��������ӵ��ļ���ĩβ(�ļ�ԭ�е����ݱ���)�� |
| ��r+�� | �ԡ���д����ʽ���ļ����ȿ��Զ�ȡҲ����д��,Ҳ������������ļ����ļ��������,�����ʧ�ܡ� |
| ��w+�� | �ԡ�д��/���¡���ʽ���ļ�,�൱��w��r+���ӵ�Ч�����ȿ��Զ�ȡҲ����д��,Ҳ������������ļ�������ļ�������,��ô����һ�����ļ�;����ļ�����,��ô����ļ�����(�൱��ɾ��ԭ�ļ�,�ٴ���һ�����ļ�)�� |
| ��a+�� | �ԡ���/���¡���ʽ���ļ�,�൱��a��r+���ӵ�Ч�����ȿ��Զ�ȡҲ����д��,Ҳ������������ļ�������ļ�������,��ô����һ�����ļ�;����ļ�����,��ô��д��������ӵ��ļ���ĩβ(�ļ�ԭ�е����ݱ���)�� |
| ���ƶ�д��ʽ���ַ���(���Բ�д) | |
| ��ʽ | ˵�� |
| ��t�� | �ı��ļ��������д,Ĭ��Ϊ"t"�� |
| ��b�� | �������ļ��� |
���� fopen() ����ʱ����ָ����дȨ��,���ǿ��Բ�ָ����д��ʽ(��ʱĬ��Ϊ"t")��
��дȨ�Ͷ�д��ʽ�������ʹ��,���DZ��뽫��д��ʽ���ڶ�дȨ���м����β��(���仰˵,���ܽ���д��ʽ���ڶ�дȨ�Ŀ�ͷ)������:
- ����д��ʽ���ڶ�дȨ��ĩβ:��rb������wt������ab������r+b������w+t������a+t��
- ����д��ʽ���ڶ�дȨ���м�:��rb+������wt+������ab+��
������˵,�ļ���ʽ�� r��w��a��t��b��+ �����ַ�ƴ��,���ַ��ĺ�����:
- r(read):��
- w(write):д
- a(append):��
- t(text):�ı��ļ�
- b(binary):�������ļ�
- +:����д
�ر��ļ�
�ļ�һ��ʹ�����,Ӧ���� fclose() �������ļ��ر�,���ͷ������Դ,�������ݶ�ʧ��fclose() ���÷�Ϊ:
int fclose(FILE *fp);
fp Ϊ�ļ�ָ�롣����:
fclose(fp);
�ļ������ر�ʱ,fclose() �ķ���ֵΪ0,������ط���ֵ���ʾ�д�������
ʵ����ʾ
���,����ͨ��һ�������Ĵ�������ʾ fopen �������÷�,������ӻ�һ��һ�еض�ȡ�ı��ļ�����������:
#include <stdio.h>
#include <stdlib.h>
#define N 100
int main() {
FILE *fp;
char str[N + 1];
//�ж��ļ��Ƿ��ʧ��
if ( (fp = fopen("d:\\demo.txt", "rt")) == NULL ) {
puts("Fail to open file!");
exit(0);
}
//ѭ����ȡ�ļ���ÿһ������
while( fgets(str, N, fp) != NULL ) {
printf("%s", str);
}
//����������ر��ļ�
fclose(fp);
return 0;
}
����ֻ��Ҫ�����ļ����ֵĴ���,��ʱ���ù����ļ���ȡ���ֵĴ���,�������ǻ���һ���⡣
�ı��ļ��Ͷ������ļ�������ʲô����?
��ѧϰ�� fopen() ������,����֪�����ĵڶ���������һ���ַ���,������ʾ�ļ���ʽ������ַ����г���b,���ʾ�Զ����Ʒ�ʽ���ļ�;����ַ����г���t,�������߶�������,���ʾ���ı���ʽ���ļ���
�ı��ļ��Ͷ������ļ�������
�������������ľ���,�ı��ļ�ͨ�������������ۿɼ����ַ�,����.txt�ļ���.c�ļ���.dat�ļ���,���ı��༭������Щ�ļ�,�����ܹ�˳�������ļ������ݡ�
�������ļ�ͨ������������Ƶ��ͼƬ������Ȳ����Ķ�������,���ı��༭������Щ�ļ�,�ῴ��һ������,������������
���Ǵ������Ͻ�,�������ļ����ַ��ļ���û��ʲô����,���Ƕ����Զ����Ƶ���ʽ�����ڴ����ϵ����ݡ�
����֮�����ܿ����ı��ļ�������,����Ϊ�ı��ļ��в��õ��� ASCII��UTF-8��GBK ���ַ�����,�ı��༭������ʶ�����Щ�����ʽ,��������ֵת�����ַ�չʾ������
���������ļ�ʹ�õ��� mp4��gif��exe ����������ʽ,�ı��༭��������ʶ��Щ�����ʽ,ֻ�ܰ����ַ������ʽ���ҽ���,���Ծͳ���һ�����߰�����ַ�,�е�������û������
��������½�һ�� mp4 �ļ�,����д��һ���ַ�,Ȼ�������ı��༭����,��һ�����Զ��ö�,����Ȥ�Ķ��߿����Լ����ԡ�
������˵,��ͬ���͵��ļ��в�ͬ�ı����ʽ,����ʹ�ö�Ӧ�ij���(����)������ȷ����,�������һ������,������ʹ�á�
fopen() �е��ı���ʽ�Ͷ����Ʒ�ʽ
��C������,�����Ʒ�ʽ�ܼ�,��ȡ�ļ�ʱ,��ԭ�ⲻ���Ķ����ļ���ȫ������,д������ʱ,Ҳ�ǰѻ������еă���ԭ�ⲻ����д���ļ��С�
�ı���ʽ�Ͷ����Ʒ�ʽ��û�б����ϵ�����,ֻ�Ƕ��ڻ��з��Ĵ�����ͬ��
C���Գ���\n��Ϊ���з�,�� UNIX/Linux ϵͳ�ڴ����ı��ļ�ʱҲ��\n��Ϊ���з�,���Գ����е����ݻ�ԭ�ⲻ����д���ı��ļ���,��֮��Ȼ��
���� Windows ϵͳȴ��ͬ,����\r\n��Ϊ�ı��ļ��Ļ��з���
�� Windows ϵͳ��,������ı���ʽ���ļ�,����ȡ�ļ�ʱ,����Ὣ�ļ������е�\r\nת����һ���ַ�\n��Ҳ����˵,����ı��ļ����������������ַ���\r\n,�����ᶪ��ǰ���\r,ֻ����\n��
��д���ļ�ʱ,����Ὣ\nת����\r\nд�롣Ҳ����˵,���Ҫд������������ַ�\n,����д����ַ�ǰ,������Զ���д��һ��\r��
���,������ı���ʽ�������ļ����ж�д,��д�����ݾͿ��ܺ��ļ��������г��롣
������˵,���� Windows ƽ̨,Ϊ�˱������,���������"t"�����ı��ļ�,��"b"���������ļ������� Linux ƽ̨,ʹ��"r"����"b"������ν,��ȻĬ����"r",������ʲô����д�����ˡ�
C����fgetc��fputc�����÷����(���ַ���ʽ��д�ļ�)
��C������,��д�ļ��Ƚ����,�ȿ���ÿ�ζ�дһ���ַ�,Ҳ���Զ�дһ���ַ���,�����������ֽڵ�����(���ݿ�)�����ڽ������ַ���ʽ��д�ļ���
���ַ���ʽ��д�ļ�ʱ,ÿ�ο��Դ��ļ��ж�ȡһ���ַ�,�������ļ���д��һ���ַ�����Ҫʹ����������,�ֱ��� fgetc() �� fputc()��
�ַ���ȡ���� fgetc
fgetc �� file get char ����д,��˼�Ǵ�ָ�����ļ��ж�ȡһ���ַ���fgetc() ���÷�Ϊ:
int fgetc (FILE *fp);
fp Ϊ�ļ�ָ����fgetc() ��ȡ�ɹ�ʱ���ض�ȡ�����ַ�,��ȡ���ļ�ĩβ���ȡʧ��ʱ����EOF��
EOF �� end of file ����д,��ʾ�ļ�ĩβ,���� stdio.h �ж���ĺ�,����ֵ��һ������,������ -1��fgetc() �ķ���ֵ����֮����Ϊ int,����Ϊ�������������(char�����Ǹ���)��
EOF �������� -1,Ҳ��������������,��Ҫ����������ʵ�֡�
fgetc() ���÷�����:
char ch;
FILE *fp = fopen("D:\\demo.txt", "r+");
ch = fgetc(fp);
��ʾ��D:\\demo.txt�ļ��ж�ȡһ���ַ�,�����浽���� ch �С�
���ļ��ڲ���һ��λ��ָ��,����ָ��ǰ��д����λ��,Ҳ���Ƕ�д���ڼ����ֽڡ����ļ���ʱ,��ָ������ָ���ļ��ĵ�һ���ֽڡ�ʹ�� fgetc() ������,��ָ�������ƶ�һ���ֽ�,���Կ����������ʹ�� fgetc() ��ȡ����ַ���
ע��:����ļ��ڲ���λ��ָ����C�����е�ָ�벻��һ���¡�λ��ָ�������һ����־,��ʾ�ļ���д����λ��,Ҳ���Ƕ�д���ڼ����ֽ�,������ʾ��ַ���ļ�ÿ��дһ��,λ��ָ��ͻ��ƶ�һ��,������Ҫ���ڳ����ж����ֵ,������ϵͳ�Զ�����,���û������صġ�
��ʾ��������Ļ����ʾ D:\demo.txt �ļ������ݡ�
#include<stdio.h>
int main(){
FILE *fp;
char ch;
//����ļ�������,������ʾ���˳�
if( (fp=fopen("D:\\demo.txt","rt")) == NULL ){
puts("Fail to open file!");
exit(0);
}
//ÿ�ζ�ȡһ���ֽ�,ֱ����ȡ���
while( (ch=fgetc(fp)) != EOF ){
putchar(ch);
}
putchar('\n'); //������з�
fclose(fp);
return 0;
}
��D���´��� demo.txt �ļ�,�����������ݲ�����,���г���,�ͻῴ���ղ����������ȫ������ʾ����Ļ�ϡ�
�ó���Ĺ����Ǵ��ļ��������ȡ�ַ�,����Ļ����ʾ,ֱ����ȡ��ϡ�
����� 13 ���ǹؼ�,while ѭ��������Ϊ(ch=fgetc(fp)) != EOF��fget() ÿ�δ�λ��ָ�����ڵ�λ�ö�ȡһ���ַ�,�����浽���� ch,λ��ָ������ƶ�һ���ֽڡ����ļ�ָ���ƶ����ļ�ĩβʱ,fget() ������ȡ�ַ���,���Ƿ��� EOF,��ʾ�ļ���ȡ�����ˡ�
�� EOF ��˵��
EOF ������ʾ�ļ�ĩβ,��ζ�Ŷ�ȡ����,���Ǻܶຯ���ڶ�ȡ����ʱҲ���� EOF,��ô������ EOF ʱ,�������ļ���ȡ����˻��Ƕ�ȡ������?���ǿ��Խ��� stdio.h �е������������ж�,�ֱ��� feof() �� ferror()��
feof() ���������ж��ļ��ڲ�ָ���Ƿ�ָ�����ļ�ĩβ,����ԭ����:
int feof ( FILE * fp );
��ָ���ļ�ĩβʱ���ط���ֵ,������ֵ��
ferror() ���������ж��ļ������Ƿ����,����ԭ����:
int ferror ( FILE *fp );
����ʱ���ط���ֵ,������ֵ��
��Ҫ˵������,�ļ������Ƿdz��ټ������,�����ʾ�������ܹ���֤���ļ��ڵ����ݶ�ȡ��ϡ����������,Ҳ���Լ����жϲ�������ʾ:
#include<stdio.h>
int main(){
FILE *fp;
char ch;
//����ļ�������,������ʾ���˳�
if( (fp=fopen("D:\\demo.txt","rt")) == NULL ){
puts("Fail to open file!");
exit(0);
}
//ÿ�ζ�ȡһ���ֽ�,ֱ����ȡ���
while( (ch=fgetc(fp)) != EOF ){
putchar(ch);
}
putchar('\n'); //������з�
if(ferror(fp)){
puts("��ȡ����");
}else{
puts("��ȡ�ɹ�");
}
fclose(fp);
return 0;
}
����,�����dz�������������ȡ,���ܹ���������������
�ַ�д�뺯�� fputc
fputc �� file output char ������,��˼����ָ�����ļ���д��һ���ַ���fputc() ���÷�Ϊ:
int fputc ( int ch, FILE *fp );
ch ΪҪд����ַ�,fp Ϊ�ļ�ָ�롣fputc() д��ɹ�ʱ����д����ַ�,ʧ��ʱ���� EOF,����ֵ����Ϊ int Ҳ��Ϊ�������������������:
fputc('a', fp);
����:
char ch = 'a';
fputc(ch, fp);
��ʾ���ַ� ��a�� д��fp��ָ����ļ��С�
����˵��
-
��д����ļ�������д����д���ӷ�ʽ��,��д���д��ʽ��һ���Ѵ��ڵ��ļ�ʱ�����ԭ�е��ļ�����,����д����ַ������ļ���ͷ�����豣��ԭ���ļ�����,����д����ַ������ļ�ĩβ,�ͱ������ӷ�ʽ���ļ��������Ժ��ַ�ʽ��,��д����ļ���������ʱ�����ļ���
-
ÿд��һ���ַ�,�ļ��ڲ�λ��ָ������ƶ�һ���ֽڡ�
��ʾ�����Ӽ�������һ���ַ�,д���ļ���
#include<stdio.h>
int main(){
FILE *fp;
char ch;
//�ж��ļ��Ƿ�ɹ���
if( (fp=fopen("D:\\demo.txt","wt+")) == NULL ){
puts("Fail to open file!");
exit(0);
}
printf("Input a string:\n");
//ÿ�δӼ��̶�ȡһ���ַ���д���ļ�
while ( (ch=getchar()) != '\n' ){
fputc(ch,fp);
}
fclose(fp);
return 0;
}
���г���,����һ���ַ������س�������,��D���µ� demo.txt �ļ�,�Ϳ��Կ����ղ���������ݡ�
����ÿ�δӼ��̶�ȡһ���ַ���д���ļ�,ֱ�����»س���,while ����������,������ȡ��
C����fgets��fputs�������÷����(���ַ�������ʽ��д�ļ�)
fgetc() �� fputc() ����ÿ��ֻ�ܶ�дһ���ַ�,�ٶȽ���;ʵ�ʿ�����������ÿ�ζ�дһ���ַ�������һ�����ݿ�,�������������Ч�ʡ�
���ַ������� fgets
fgets() ����������ָ�����ļ��ж�ȡһ���ַ���,�����浽�ַ�������,�����÷�Ϊ:
char *fgets ( char *str, int n, FILE *fp );
str Ϊ�ַ�����,n ΪҪ��ȡ���ַ���Ŀ,fp Ϊ�ļ�ָ����
����ֵ:��ȡ�ɹ�ʱ�����ַ�������ַ,Ҳ�� str;��ȡʧ��ʱ���� NULL;�����ʼ��ȡʱ�ļ��ڲ�ָ���Ѿ�ָ�����ļ�ĩβ,��ô����ȡ�����κ��ַ�,Ҳ���� NULL��
ע��,��ȡ�����ַ�������ĩβ�Զ����� ��\0��,n ���ַ�Ҳ���� ��\0����Ҳ����˵,ʵ��ֻ��ȡ���� n-1 ���ַ�,���ϣ����ȡ 100 ���ַ�,n ��ֵӦ��Ϊ 101������:
#define N 101
char str[N];
FILE *fp = fopen("D:\\demo.txt", "r");
fgets(str, N, fp);
��ʾ�� D:\demo.txt �ж�ȡ 100 ���ַ�,�����浽�ַ����� str �С�
��Ҫ�ص�˵������,�ڶ�ȡ�� n-1 ���ַ�֮ǰ��������˻���,���߶������ļ�ĩβ,���ȡ�����������ζ��,���� n ��ֵ���,fgets() ���ֻ�ܶ�ȡһ������,���ܿ��С���C������,û�а��ж�ȡ�ļ��ĺ���,���ǿ��Խ��� fgets(),�� n ��ֵ���õ��㹻��,ÿ�ξͿ��Զ�ȡ��һ�����ݡ�
��ʾ����һ��һ�еض�ȡ�ļ���
#include <stdio.h>
#include <stdlib.h>
#define N 100
int main(){
FILE *fp;
char str[N+1];
if( (fp=fopen("d:\\demo.txt","rt")) == NULL ){
puts("Fail to open file!");
exit(0);
}
while(fgets(str, N, fp) != NULL){
printf("%s", str);
}
fclose(fp);
return 0;
}
����������ݸ��Ƶ� D:\demo.txt:
C����������
http://c.biancheng.net
һ��ѧϰ��̵ĺ���վ!
��ô���н��Ϊ:
fgets() ��������ʱ,�Ὣ���з�һ����ȡ����ǰ�ַ�������ʾ����������֮���Ժ� demo.txt ����һ��,�û��еĵط�����,������Ϊ fgets() �ܹ���ȡ�����з����� gets() ��һ��,������Ի��з���
д�ַ������� fputs
fputs() ����������ָ�����ļ�д��һ���ַ���,�����÷�Ϊ:
int fputs( char *str, FILE *fp );
str ΪҪд����ַ���,fp Ϊ�ļ�ָ�롣д��ɹ����طǸ���,ʧ�ܷ��� EOF������:
char *str = "http://c.biancheng.net";
FILE *fp = fopen("D:\\demo.txt", "at+");
fputs(str, fp);
��ʾ�Ѱ��ַ��� str д�뵽 D:\demo.txt �ļ��С�
��ʾ�����������н����� d:\demo.txt �ļ�����һ���ַ�����
#include<stdio.h>
int main(){
FILE *fp;
char str[102] = {0}, strTemp[100];
if( (fp=fopen("D:\\demo.txt", "at+")) == NULL ){
puts("Fail to open file!");
exit(0);
}
printf("Input a string:");
gets(strTemp);
strcat(str, "\n");
strcat(str, strTemp);
fputs(str, fp);
fclose(fp);
return 0;
}
���г���,����C C++ Java Linux Shell,�� D:\demo.txt,�ļ�����Ϊ:
C����������
http://c.biancheng.net
һ��ѧϰ��̵ĺ���վ!
C C++ Java Linux Shell
C����fread��fwrite���÷����(�����ݿ����ʽ��д�ļ�)
fgets() �о�����,ÿ�����ֻ�ܴ��ļ��ж�ȡһ������,��Ϊ fgets() �������з��ͽ�����ȡ�����ϣ����ȡ��������,��Ҫʹ�� fread() ����;��Ӧ��д�뺯��Ϊ fwrite()��
���� Windows ϵͳ,ʹ�� fread() �� fwrite() ʱӦ���Զ����Ƶ���ʽ���ļ�,����ԭ���������ڡ��ı��ļ��Ͷ������ļ�������ʲô������һ���н�����˵����
fread() ����������ָ���ļ��ж�ȡ�����ݡ���ν������,Ҳ�������ɸ��ֽڵ�����,������һ���ַ�,������һ���ַ���,�����Ƕ�������,��û��ʲô���ơ�fread() ��ԭ��Ϊ:
size_t fread ( void *ptr, size_t size, size_t count, FILE *fp );
fwrite() �����������ļ���д�������,����ԭ��Ϊ:
size_t fwrite ( void * ptr, size_t size, size_t count, FILE *fp );
�Բ�����˵��:
- ptr Ϊ�ڴ������ָ��,�����������顢�������ṹ��ȡ�fread() �е� ptr ������Ŷ�ȡ��������,fwrite() �е� ptr �������Ҫд������ݡ�
- size:��ʾÿ�����ݿ���ֽ�����
- count:��ʾҪ��д�����ݿ�Ŀ�����
- fp:��ʾ�ļ�ָ�롣
- ������,ÿ�ζ�д size*count ���ֽڵ����ݡ�
size_t ���� stdio.h �� stdlib.h ͷ�ļ���ʹ�� typedef �������������,��ʾ��������,Ҳ���Ǹ���,��������ʾ������
����ֵ:���سɹ���д�Ŀ���,Ҳ�� count���������ֵС�� count:
- ���� fwrite() ��˵,�϶�������д�����,������ ferror() ������⡣
- ���� fread() ��˵,���ܶ������ļ�ĩβ,���ܷ����˴���,������ ferror() �� feof() ��⡣
��ʾ�����Ӽ�������һ������,������д���ļ��ٶ�ȡ������
#include<stdio.h>
#define N 5
int main(){
//�Ӽ�����������ݷ���a,���ļ���ȡ�����ݷ���b
int a[N], b[N];
int i, size = sizeof(int);
FILE *fp;
if( (fp=fopen("D:\\demo.txt", "rb+")) == NULL ){ //�Զ����Ʒ�ʽ��
puts("Fail to open file!");
exit(0);
}
//�Ӽ����������� �����浽����a
for(i=0; i<N; i++){
scanf("%d", &a[i]);
}
//������a������д�뵽�ļ�
fwrite(a, size, N, fp);
//���ļ��е�λ��ָ�����¶�λ���ļ���ͷ
rewind(fp);
//���ļ���ȡ���ݲ����浽����b
fread(b, size, N, fp);
//����Ļ����ʾ����b������
for(i=0; i<N; i++){
printf("%d ", b[i]);
}
printf("\n");
fclose(fp);
return 0;
}
����:
23 409 500 100 222�L
23 409 500 100 222
�� D:\demo.txt,�����ļ����ݸ������Ķ���������Ϊ����ʹ��"rb+"��ʽ���ļ�,�����ԭ�ⲻ�����Զ�������ʽд���ļ�,һ�����Ķ���
����д����Ϻ�,λ��ָ�����ļ���ĩβ,Ҫ���ȡ����,���뽫�ļ�ָ���ƶ����ļ���ͷ,�����rewind(fp);�����á��������rewind��������������:C����rewind������
�ļ��ĺ���һ���� .txt,�������������,������Լ�����,���� demo.ddd��demo.doc��demo.diy �ȡ�
��ʾ�����Ӽ�����������ѧ������,д��һ���ļ���,�ٶ���������ѧ����������ʾ����Ļ�ϡ�
#include<stdio.h>
#define N 2
struct stu{
char name[10]; //����
int num; //ѧ��
int age; //����
float score; //�ɼ�
}boya[N], boyb[N], *pa, *pb;
int main(){
FILE *fp;
int i;
pa = boya;
pb = boyb;
if( (fp=fopen("d:\\demo.txt", "wb+")) == NULL ){
puts("Fail to open file!");
exit(0);
}
//�Ӽ�����������
printf("Input data:\n");
for(i=0; i<N; i++,pa++){
scanf("%s %d %d %f",pa->name, &pa->num,&pa->age, &pa->score);
}
//������ boya ������д���ļ�
fwrite(boya, sizeof(struct stu), N, fp);
//���ļ�ָ�����õ��ļ���ͷ
rewind(fp);
//���ļ���ȡ���ݲ����浽���� boyb
fread(boyb, sizeof(struct stu), N, fp);
//������� boyb �����
for(i=0; i<N; i++,pb++){
printf("%s %d %d %f\n", pb->name, pb->num, pb->age, pb->score);
}
fclose(fp);
return 0;
}
����:
Input data:
Tom 2 15 90.5�L
Hua 1 14 99�L
Tom 2 15 90.500000
Hua 1 14 99.000000
C����fscanf��fprintf�������÷����(��ʽ����д�ļ�)
fscanf() �� fprintf() ������ǰ��ʹ�õ� scanf() �� printf() ��������,���Ǹ�ʽ����д����,���ߵ��������� fscanf() �� fprintf() �Ķ�д�����Ǽ��̺���ʾ��,���Ǵ����ļ���
������������ԭ��Ϊ:
int fscanf ( FILE *fp, char * format, ... );
int fprintf ( FILE *fp, char * format, ... );
fp Ϊ�ļ�ָ��,format Ϊ��ʽ�����ַ���,�� ��ʾ�����б����� scanf() �� printf() ���,���ǽ�������һ�� fp ����������:
FILE *fp;
int i, j;
char *str, ch;
fscanf(fp, "%d %s", &i, str);
fprintf(fp,"%d %c", j, ch);
fprintf() ���سɹ�д����ַ��ĸ���,ʧ���ظ�����fscanf() ���ز����б��б��ɹ���ֵ�IJ���������
��ʾ������ fscanf �� fprintf ��������ɶ�ѧ����Ϣ�Ķ�д��
#include<stdio.h>
#define N 2
struct stu{
char name[10];
int num;
int age;
float score;
} boya[N], boyb[N], *pa, *pb;
int main(){
FILE *fp;
int i;
pa=boya;
pb=boyb;
if( (fp=fopen("D:\\demo.txt","wt+")) == NULL ){
puts("Fail to open file!");
exit(0);
}
//�Ӽ��̶�������,���浽boya
printf("Input data:\n");
for(i=0; i<N; i++,pa++){
scanf("%s %d %d %f", pa->name, &pa->num, &pa->age, &pa->score);
}
pa = boya;
//��boya�е�����д�뵽�ļ�
for(i=0; i<N; i++,pa++){
fprintf(fp,"%s %d %d %f\n", pa->name, pa->num, pa->age, pa->score);
}
//�����ļ�ָ��
rewind(fp);
//���ļ��ж�ȡ����,���浽boyb
for(i=0; i<N; i++,pb++){
fscanf(fp, "%s %d %d %f\n", pb->name, &pb->num, &pb->age, &pb->score);
}
pb=boyb;
//��boyb�е������������ʾ��
for(i=0; i<N; i++,pb++){
printf("%s %d %d %f\n", pb->name, pb->num, pb->age, pb->score);
}
fclose(fp);
return 0;
}
����:
Input data:
Tom 2 15 90.5�L
Hua 1 14 99�L
Tom 2 15 90.500000
Hua 1 14 99.000000
�� D:\demo.txt,�����ļ��������ǿ����Ķ���,��ʽ�dz��������� fprintf() �� fscanf() ������д�����ļ�����־�ļ���dz�����,���������ܹ�ʶ��,�û�Ҳ���Կ���,�����ֶ��ġ�
����� fp ����Ϊ stdin,��ô fscanf() ��������Ӽ��̶�ȡ����,�� scanf ��������ͬ;����Ϊ stdout,��ô fprintf() ������������ʾ���������,�� printf ��������ͬ������:
#include<stdio.h>
int main(){
int a, b, sum;
fprintf(stdout, "Input two numbers: ");
fscanf(stdin, "%d %d", &a, &b);
sum = a + b;
fprintf(stdout, "sum=%d\n", sum);
return 0;
}
����:
Input two numbers: 10 20�L
sum=30
C����rewind��fseek�������÷����(�����д�ļ�)
ǰ����ܵ��ļ���д��������˳���д,����д�ļ�ֻ�ܴ�ͷ��ʼ,���ζ�д�������ݡ�����ʵ�ʿ����о�����Ҫ��д�ļ����м䲿��,Ҫ����������,�͵����ƶ��ļ��ڲ���λ��ָ��,�ٽ��ж�д�����ֶ�д��ʽ��Ϊ�����д,Ҳ����˵���ļ�������λ�ÿ�ʼ��д��
ʵ�������д�Ĺؼ���Ҫ��Ҫ���ƶ�λ��ָ��,���Ϊ�ļ��Ķ�λ��
�ļ���λ����rewind��fseek
�ƶ��ļ��ڲ�λ��ָ��ĺ�����Ҫ������,�� rewind() �� fseek()��
rewind() ������λ��ָ���ƶ����ļ���ͷ,ǰ���Ѿ����ʹ�ù�,����ԭ��Ϊ:
void rewind ( FILE *fp );
fseek() ������λ��ָ���ƶ�������λ��,����ԭ��Ϊ:
int fseek ( FILE *fp, long offset, int origin );
����˵��:
-
fp Ϊ�ļ�ָ��,Ҳ���DZ��ƶ����ļ���
-
offset Ϊƫ����,Ҳ����Ҫ�ƶ����ֽ�����֮����Ϊ long ����,��ϣ���ƶ��ķ�Χ����,�ܴ������ļ�����offset Ϊ��ʱ,����ƶ�;offset Ϊ��ʱ,��ǰ�ƶ���
-
origin Ϊ��ʼλ��,Ҳ���ǴӺδ���ʼ����ƫ������C���Թ涨����ʼλ��������,�ֱ�Ϊ�ļ���ͷ����ǰλ�ú��ļ�ĩβ,ÿ��λ�ö��ö�Ӧ�ij�������ʾ:
| ��ʼ�� | ������ | ����ֵ |
|---|---|---|
| �ļ���ͷ | SEEK_SET | 0 |
| ��ǰλ�� | SEEK_CUR | 1 |
| �ļ�ĩβ | SEEK_END | 2 |
����,��λ��ָ���ƶ������ļ���ͷ100���ֽڴ�:
fseek(fp, 100, 0);
ֵ��˵������,fseek() һ�����ڶ������ļ�,���ı��ļ�������Ҫ����ת��,�����λ����ʱ�������
�ļ��������д
���ƶ�λ��ָ��֮��,�Ϳ�����ǰ����ܵ��κ�һ�ֶ�д�������ж�д�ˡ������Ƕ������ļ�,��˳��� fread() �� fwrite() ��д��
��ʾ�����Ӽ�����������ѧ����Ϣ,���浽�ļ���,Ȼ���ȡ�ڶ���ѧ������Ϣ��
#include<stdio.h>
#define N 3
struct stu{
char name[10]; //����
int num; //ѧ��
int age; //����
float score; //�ɼ�
}boys[N], boy, *pboys;
int main(){
FILE *fp;
int i;
pboys = boys;
if( (fp=fopen("d:\\demo.txt", "wb+")) == NULL ){
printf("Cannot open file, press any key to exit!\n");
getch();
exit(1);
}
printf("Input data:\n");
for(i=0; i<N; i++,pboys++){
scanf("%s %d %d %f", pboys->name, &pboys->num, &pboys->age, &pboys->score);
}
fwrite(boys, sizeof(struct stu), N, fp); //д������ѧ����Ϣ
fseek(fp, sizeof(struct stu), SEEK_SET); //�ƶ�λ��ָ��
fread(&boy, sizeof(struct stu), 1, fp); //��ȡһ��ѧ����Ϣ
printf("%s %d %d %f\n", boy.name, boy.num, boy.age, boy.score);
fclose(fp);
return 0;
}
����:
Input data:
Tom 2 15 90.5�L
Hua 1 14 99�L
Zhao 10 16 95.5�L
Hua 1 14 99.000000
C����ʵ���ļ����ƹ���(�����ı��ļ��Ͷ������ļ�)
�ļ��ĸ����dz��õĹ���,Ҫ��дһ�δ���,���û�����Ҫ���Ƶ��ļ��Լ��½����ļ�,Ȼ����ļ����и��ơ��ܹ����Ƶ��ļ������ı��ļ��Ͷ������ļ�,����Ը���1G�ĵ�Ӱ,Ҳ���Ը���1Byte��txt�ĵ���
ʵ���ļ����Ƶ���Ҫ˼·��:����һ��������,���ϴ�ԭ�ļ��ж�ȡ���ݵ�������,ÿ��ȡ��һ�ξͽ��������е�����д�뵽�½����ļ�,ֱ����ԭ�ļ������ݶ�ȡ�ꡣ
�����������ؼ���������Ҫ���:
-
���ٶ��Ļ���������?��������С����ɶ�д����������,����Ҳ�����������Ч�ʡ�Ŀǰ�ִ��̵���������4K�����,�����д�����ݲ���4K��������,�ͻ��������ȡ,����Ч��,�������ǿ���4K�Ļ�������
-
�������е�������û�н�����־��,�����������䲻��,���ȷ��д����ֽ���?��õİ취����ÿ�ζ�ȡ���ܷ��ض�ȡ�����ֽ�����
fread() ��ԭ��Ϊ:
size_t fread ( void *ptr, size_t size, size_t count, FILE *fp );
�����سɹ���д�Ŀ���,��ֵС�ڵ��� count����������ò��� size ����1,��ô���صľ��Ƕ�ȡ���ֽ�����
ע��:fopen()һ��Ҫ�Զ����Ƶ���ʽ���ļ�,�������ı���ʽ��,����ϵͳ����ļ�����һЩ����,������ı��ļ�,��.txt��,����û������,�������������ʽ���ļ�,��.mp4, .rmvb, .jpg��,���ƺ�ͻ����,����ȡ��
����ʵ��:
#include <stdio.h>
#include <stdlib.h>
int copyFile(char *fileRead, char *fileWrite);
int main(){
char fileRead[100]; // Ҫ���Ƶ��ļ���
char fileWrite[100]; // ���ƺ���ļ���
// ��ȡ�û�����
printf("Ҫ���Ƶ��ļ�:");
scanf("%s", fileRead);
printf("���ļ����Ƶ�:");
scanf("%s", fileWrite);
// ���и��Ʋ���
if( copyFile(fileRead, fileWrite) ){
printf("��ϲ��,�ļ����Ƴɹ�!\n");
}else{
printf("�ļ�����ʧ��!\n");
}
return 0;
}
/**
* �ļ����ƺ���
* @param fileRead Ҫ���Ƶ��ļ�
* @param fileWrite ���ƺ��ļ��ı���·��
* @return int 1: ���Ƴɹ�;2: ����ʧ��
**/
int copyFile(char *fileRead, char *fileWrite){
FILE *fpRead; // ָ��Ҫ���Ƶ��ļ�
FILE *fpWrite; // ָ���ƺ���ļ�
int bufferLen = 1024*4; // ����������
char *buffer = (char*)malloc(bufferLen); // ���ٻ���
int readCount; // ʵ�ʶ�ȡ���ֽ���
if( (fpRead=fopen(fileRead, "rb")) == NULL || (fpWrite=fopen(fileWrite, "wb")) == NULL ){
printf("Cannot open file, press any key to exit!\n");
getch();
exit(1);
}
// ���ϴ�fileRead��ȡ����,���ڻ�����,�ٽ�������������д��fileWrite
while( (readCount=fread(buffer, 1, bufferLen, fpRead)) > 0 ){
fwrite(buffer, readCount, 1, fpWrite);
}
free(buffer);
fclose(fpRead);
fclose(fpWrite);
return 1;
}
����:
Ҫ���Ƶ��ļ�:d://1.mp4
���ļ����Ƶ�:d://2.mp4
��ϲ��,�ļ����Ƴɹ�!
����ļ�������,�������ʾ,����ֹ����:
Ҫ���Ƶ��ļ�:d://123.mp4
���ļ����Ƶ�:d://333.mp4
d://cyuyan.txt: No such file or directory
��46�����ļ����Ƶĺ��Ĵ��롣ͨ��fread()����,ÿ�δ� fileRead �ļ��ж�ȡ bufferLen ���ֽ�,�ŵ�������,��ͨ��fwrite()������������������д��fileWrite�ļ���
���������,ÿ�λ��ȡbufferLen���ֽ�,��readCount=bufferLen;����ļ���С����bufferLen���ֽ�,���߶�ȡ���ļ�ĩβ,ʵ�ʶ�ȡ�����ֽھͻ�С��bufferLen,��readCount<bufferLen������ͨ��fwrite()д���ļ�ʱ,Ӧ����readCountΪ��
C����FILE�ṹ���Լ�����������̽��
��C������,��һ��ָ�����ָ��һ���ļ�,���ָ���Ϊ�ļ�ָ�롣ͨ���ļ�ָ��Ϳɶ�����ָ���ļ����и��ֲ�����
�����ļ�ָ���һ����ʽΪ:
FILE *fp;
�����FILE,ʵ��������stdio.h�ж����һ���ṹ��,�ýṹ���к����ļ������ļ�״̬���ļ���ǰλ�õ���Ϣ,fopen ���صľ���FILE���͵�ָ�롣
ע��:FILE���ļ��������Ľṹ,fpҲ��ָ���ļ���������ָ�롣
��ͬ������ stdio.h ͷ�ļ��ж� FILE �Ķ������в���,�����Ա�C����˵��:
typedef struct _iobuf {
int cnt; // ʣ����ַ�,��������뻺����,��ô�ͱ�ʾ�������л��ж��ٸ��ַ�δ����ȡ
char *ptr; // ��һ��Ҫ����ȡ���ַ��ĵ�ַ
char *base; // ����������ַ
int flag; // ��д״̬��־λ
int fd; // �ļ�������
// ������Ա
} FILE;
����˵һ��������ƻ�������
����֪��,�����ǴӼ����������ݵ�ʱ��,���ݲ�����ֱ�ӱ����ǵõ�,���Ƿ����˻�������,Ȼ�����Ǵӻ������еõ�������Ҫ������ ���������ͨ��setbuf()��setvbuf()����������������10���ֽڵĴ�С,�����ǴӼ���������20���ֽڴ�С������,�������������ǰ10�����ݻ���ڻ�������,��Ϊ�������õĻ������Ĵ�Сֻ�ܹ�װ��10���ֽڴ�С������,װ����20���ֽڴ�С�����ݡ���ôʣ�µ���10���ֽڴ�С��������ô����?��ʱ�������������С��뿴��ͼ:

����ļ�ͷ��ʾ��������൱��һ��������,��ɫ�ĵط��൱��һ������,������ؿ��Կ���������ɫ����(��ע���ǻ�����)��Ž�ȥ������,����20���ֽڵ�����ֻ���������зŽ�ȥ��10���ֽ�,ʣ�µ�10���ֽڵ����ݾͱ�ͣ��������������!�ȴ���ȥ���������з���!������ϵͳ����������������������?
��˵һ�� FILE �ṹ���м�����س�Ա�ĺ���:
cnt // ʣ����ַ�,��������뻺����,��ô�ͱ�ʾ�������л��ж��ٸ��ַ�δ����ȡ
ptr // ��һ��Ҫ����ȡ���ַ��ĵ�ַ
base // ����������ַ
���������������з�����10���ֽڴ�С������,FILE�ṹ���е� cnt ��Ϊ��10 ,˵����ʱ����������10���ֽڴ�С�����ݿ��Զ�,ͬʱ���Ǽ��軺�����Ļ���ַҲ���� base ��0x00428e60 ,���Dz���� ,����ʱ ptr ��ֵҲΪ0x00428e60 ,��ʾ��0x00428e60���λ�ÿ�ʼ��ȡ����,�����Ǵӻ������ж�ȡ5�����ݵ�ʱ��,cnt ��Ϊ��5 ,��ʾ����������5�����ݿ��Զ�,ptr ���Ϊ��0x0042e865��ʾ�´�Ӧ�ô����λ�ÿ�ʼ��ȡ�������е����� ,��������������ٶ�ȡ5�����ݵ�ʱ��,cnt ���Ϊ��0 ,��ʾ���������Ѿ�û���κ�������,ptr ��Ϊ��0x0042869��ʾ�´�Ӧ�ô����λ�ÿ�ʼ�ӻ������ж�ȡ����,���Ǵ�ʱ���������Ѿ�û���κ�������,����Ҫ���������е�ʣ�µ���10�����ݷŽ���,������������������10������,��ʱ cnt ��Ϊ��10 ,ע���˸ղ����ǽ��� ptr ��ֵ��0x00428e69 ,���������������·Ž������ݵ�ʱ����� ptr ��ֵ��Ϊ��0x00428e60 ,������Ϊ����������û���κ����ݵ�ʱ��Ҫ�� ptr ���ֵ����һ��ˢ��,ʹ��ָ�����Ļ���ַҲ����0x0042e860���ֵ!��Ϊ�´�Ҫ�����λ�ÿ�ʼ��ȡ����!
�������е���Ҫ˵��:�����ǴӼ��������ַ�����ʱ����Ҫ��һ�»س������ܹ�������ַ������뵽��������,��ô���������س���(\r)�ᱻת��Ϊһ�����з�\n,������з�\nҲ�ᱻ�洢�ڻ������в��ұ�����һ���ַ�������!���������ڼ�����������123456����ַ���,Ȼ����һ�»س���(\r)������ַ��������˻�������,��ô��ʱ�������е��ֽڸ�����7 ,������6��
��������ˢ�¾��ǽ�ָ�� ptr ��Ϊ�������Ļ���ַ ,ͬʱ cnt ��ֵ��Ϊ0 ,��Ϊ������ˢ�º�������û�����ݵ�!
C���Ի�ȡ�ļ���С(����)
ʵ�ʿ�����,��ʱ����Ҫ�Ȼ�ȡ�ļ���С�ٽ�����һ��������C����û���ṩ��ȡ�ļ���С�ĺ���,Ҫ��ʵ�ָù���,�����Լ���д������
ftell()����
ftell() ����������ȡ�ļ��ڲ�ָ��(λ��ָ��)�����ļ���ͷ���ֽ���,����ԭ��Ϊ:
long int ftell ( FILE * fp );
ע��:fp Ҫ�Զ����Ʒ�ʽ��,������ı���ʽ��,�����ķ���ֵ����û�����塣
��ʹ�� fseek() ���ļ��ڲ�ָ�붨λ���ļ�ĩβ,��ʹ�� ftell() �����ڲ�ָ������ļ���ͷ���ֽ���,�������ֵ�͵����ļ��Ĵ�С���뿴����Ĵ���:
long fsize(FILE *fp){
fseek(fp, 0, SEEK_END);
return ftell(fp);
}
��δ��벢����׳,���ƶ����ļ��ڲ�ָ��,���ܻᵼ�½��������ļ�������������:
long size = fsize(fp);
fread(buffer, 1, 1, fp);
fread() ��������Զ��ȡ�������ݡ�
����,��ȡ���ļ���С����Ҫ�ָ��ļ��ڲ�ָ��,�뿴����Ĵ���:
long fsize(FILE *fp){
long n;
fpos_t fpos; //��ǰλ��
fgetpos(fp, &fpos); //��ȡ��ǰλ��
fseek(fp, 0, SEEK_END);
n = ftell(fp);
fsetpos(fp,&fpos); //�ָ�֮ǰ��λ��
return n;
}
fpos_t ���� stdio.h �ж���Ľṹ��,���������ļ����ڲ�ָ�롣fgetpos() ������ȡ�ļ��ڲ�ָ��,fsetpos() ���������ļ��ڲ�ָ�롣
������ʾ��:
#include<stdio.h>
#include<stdlib.h>
#include<conio.h>
long fsize(FILE *fp);
int main(){
long size = 0;
FILE *fp = NULL;
char filename[30] = "D:\\1.mp4";
if( (fp = fopen(filename, "rb")) == NULL ){ //�Զ����Ʒ�ʽ���ļ�
printf("Failed to open %s...", filename);
getch();
exit(EXIT_SUCCESS);
}
printf("%ld\n", fsize(fp));
return 0;
}
long fsize(FILE *fp){
long n;
fpos_t fpos; //��ǰλ��
fgetpos(fp, &fpos); //��ȡ��ǰλ��
fseek(fp, 0, SEEK_END);
n = ftell(fp);
fsetpos(fp,&fpos); //�ָ�֮ǰ��λ��
return n;
}
C���Բ��롢ɾ���������ļ�����
����ƽʱ�������ļ�,���� txt��doc��mp4 ��,�ļ������ǰ��մ�ͷ��β��˳�����δ洢�ڴ����ϵ�,��������һ�������Ķ���,��Ϊ˳���ļ���
����˳���ļ�,���������ļ���ɢ���ļ���,һ��������������,�������ݿ⡢��Ч�ļ�ϵͳ�ȡ�
˳���ļ��Ĵ洢�ṹ���������ܹ���Ч��ȡ����,�����ܹ�������롢ɾ���������ݡ��������ļ���ͷ����100���ֽڵ�����,��ôԭ���ļ����������ݶ�Ҫ����ƶ�100���ֽ�,�ⲻ���Ƿdz���Ч�IJ���,���һ����ܸ��������ļ������C����û���ṩ���롢ɾ�������ļ����ݵĺ���,Ҫ��ʵ����Щ����,ֻ���Լ���д������
�Բ�������Ϊ��,����ԭ���ļ��Ĵ�СΪ 1000 �ֽ�,����Ҫ����500�ֽڴ������û�������ַ���,��ô����������ʵ��:
- ����һ����ʱ�ļ�,������500�ֽڵ����ݸ��Ƶ���ʱ�ļ�;
- ��ԭ���ļ����ڲ�ָ�������500�ֽڴ�,д���ַ���;
- �ٽ���ʱ�ļ��е�����д�뵽ԭ�����ļ�(�����ַ����ij���Ϊ100,��ô��ʱ�ļ��ڲ�ָ����600�ֽڴ�)��
ɾ������ʱ,Ҳ�����Ƶ�˼·������ԭ���ļ���СΪ1000�ֽ�,����Ϊ demo.mp4,����Ҫ����500�ֽڴ�����ɾ��100�ֽڵ�����,��ô����������ʵ��:
- ����һ����ʱ�ļ�,�Ƚ�ǰ500�ֽڵ����ݸ��Ƶ���ʱ�ļ�,�ٽ�600�ֽ�֮����������ݸ��Ƶ���ʱ�ļ�;
- ɾ��ԭ�����ļ�,������һ�����ļ�,����Ϊ demo.mp4;
- ����ʱ�ļ��е��������ݸ��Ƶ� demo.mp4��
������ʱ,��������ݺ;����ݳ�����ͬ,��ô���ú��ڲ�ָ��,ֱ��д�뼴��;��������ݱȾ����ݳ�,�൱������������,˼·�Ͳ�����������;��������ݱȾ����ݶ�,�൱�ڼ�������,˼·��ɾ���������ơ�ʵ�ʿ�����,���������ᱣ���¾����ݳ���һ��,�Լ��ٱ�̵Ĺ�����,�������Dz��������¾����ݳ��Ȳ�ͬ�������
������˵,�����ص��������ݵIJ����ɾ����
�ļ����ƺ���
�����ݵIJ���ɾ��������,��Ҫ��θ����ļ�����,�����б�Ҫ���ù���ʵ��Ϊһ������,������ʾ:
/**
* �ļ����ƺ���
* @param fSource Ҫ���Ƶ�ԭ�ļ�
* @param offsetSource ԭ�ļ���λ��ƫ��(����ļ���ͷ),Ҳ���Ǵ����↑ʼ����
* @param len Ҫ���Ƶ����ݳ���,С��0��ʾ����offsetSource��ߵ���������
* @param fTarget Ŀ���ļ�,Ҳ���ǽ��ļ����Ƶ�����
* @param offsetTarget Ŀ���ļ���λ��ƫ��,Ҳ���Ǹ��Ƶ�Ŀ���ļ���ʲôλ��
* @return �ɹ����Ƶ��ֽ���
**/
long fcopy(FILE *fSource, long offsetSource, long len, FILE *fTarget, long offsetTarget){
int bufferLen = 1024*4; // ����������
char *buffer = (char*)malloc(bufferLen); // ���ٻ���
int readCount; // ÿ�ε���fread()��ȡ���ֽ���
long nBytes = 0; //�ܹ������˶��ٸ��ֽ�
int n = 0; //��Ҫ���ö��ٴ�fread()����
int i; //ѭ�����Ʊ���
fseek(fSource, offsetSource, SEEK_SET);
fseek(fTarget, offsetTarget, SEEK_SET);
if(len<0){ //������������
while( (readCount=fread(buffer, 1, bufferLen, fSource)) > 0 ){
nBytes += readCount;
fwrite(buffer, readCount, 1, fTarget);
}
}else{ //����len���ֽڵ�����
n = (int)ceil((double)((double)len/bufferLen));
for(i=1; i<=n; i++){
if(len-nBytes < bufferLen){ bufferLen = len-nBytes; }
readCount = fread(buffer, 1, bufferLen, fSource);
fwrite(buffer, readCount, 1, fTarget);
nBytes += readCount;
}
}
fflush(fTarget);
free(buffer);
return nBytes;
}
�ú������Խ�ԭ�ļ�����λ�õ����ⳤ�ȵ����ݸ��Ƶ�Ŀ���ļ�������λ��,�dz������ϣ��ʵ�֡�C����ʵ���ļ����ƹ���(�����ı��ļ��Ͷ������ļ�)��һ���еĹ���,��ô������������������:
fcopy(fSource, 0, -1, fTarget, 0);
�ļ����ݲ��뺯��
���ȿ�����:
/**
* ���ļ��в�������
* @param fp Ҫ�������ݵ��ļ�
* @param buffer ������,Ҳ����Ҫ���������
* @param offset ƫ����(����ļ���ͷ),Ҳ���Ǵ����↑ʼ����
* @param len Ҫ��������ݳ���
* @return �ɹ�������ֽ���
**/
int finsert(FILE *fp, long offset, void *buffer, int len){
long fileSize = fsize(fp);
FILE *fpTemp; //��ʱ�ļ�
if(offset>fileSize || offset<0 || len<0){ //�������
return -1;
}
if(offset == fileSize){ //���ļ�ĩβ����
fseek(fp, offset, SEEK_SET);
if(!fwrite(buffer, len, 1, fp)){
return -1;
}
}
if(offset < fileSize){ //�ӿ�ͷ�����м�λ�ò���
fpTemp = tmpfile();
fcopy(fp, 0, offset, fpTemp, 0);
fwrite(buffer, len, 1, fpTemp);
fcopy(fp, offset, -1, fpTemp, offset+len);
freopen(FILENAME, "wb+", fp );
fcopy(fpTemp, 0, -1, fp, 0);
fclose(fpTemp);
}
return 0;
}
����˵��:
-
fsize() ���ڡ�C���Ի�ȡ�ļ���С(����)���Զ���ĺ���,������ȡ�ļ���С(���ֽڼ�)��
-
��17���ж����ݵIJ���λ��,��������ļ�ĩβ,�ͷdz�����,ֱ���� fwrite() д�뼴�ɡ�
-
������ļ���ͷ���м����,�͵ô�����ʱ�ļ���
tmpfile() ������������һ����ʱ�Ķ������ļ�,���Զ�ȡ��д������,�൱�� fopen() ������"wb+"��ʽ���ļ�������ʱ�ļ�����͵�ǰ�Ѵ��ڵ��κ��ļ�����,���һ��ڵ��� fclose() ������������Զ�ɾ����
�ļ�����ɾ������
�뿴����Ĵ���:
int fdelete(FILE *fp, long offset, int len){
long fileSize = getFileSize(fp);
FILE *fpTemp;
if(offset>fileSize || offset<0 || len<0){ //����
return -1;
}
fpTemp = tmpfile();
fcopy(fp, 0, offset, fpTemp, 0); //��ǰoffset�ֽڵ����ݸ��Ƶ���ʱ�ļ�
fcopy(fp, offset+len, -1, fpTemp, offset); //��offset+len֮����������ݶ����Ƶ���ʱ�ļ�
freopen(FILENAME, "wb+", fp ); //���´��ļ�
fcopy(fpTemp, 0, -1, fp, 0);
fclose(fpTemp);
return 0;
}
�ļ���5~7�������жϴ���IJ����Ƿ�Ϸ���freopen() ��"w+"��ʽ���ļ�ʱ,�����ͬ�����ļ�����,��ô�Ƚ��ļ�����ɾ��,��Ϊһ�����ļ��Դ���
����C++�ļ�����
C++�ļ�������Ҫ��Ϊ 2 ��,�����ļ���д�ļ�,���½����ܳ�����C++�ļ�����,����(��������)���ļ�����ȡ�������ݡ������ɾ�����ݡ��ر��ļ���ɾ���ļ��ȡ�
Ϊ�˷����û�ʵ���ļ�����,C++�ṩ�� 3 ���ļ�����,�ֱ��� ofstream(ʵ��д�ļ�)��ifstream(ʵ�ֶ��ļ�)�Լ� fstream(ʵ�ֶ�д�ļ�),����ͳ��Ϊ���ļ����ࡱ��
�����ļ�����,��Ȼ�� C++ �����п��Լ������� C ���Ե������ļ�������ʽ,�����Ƽ�ʹ���ʵ����ļ���������д�ļ���
������ļ�������ʲô(ͨ����)?
�ڴ��д�ŵ������ڼ�����ػ���ͻ���ʧ��Ҫ���ñ�������,��Ҫʹ��Ӳ�̡����̡�U �̵��豸��Ϊ�˱������ݵĹ����ͼ���,�����ˡ��ļ����ĸ��
һƪ���¡�һ����Ƶ��һ����ִ�г���,�����Ա�����Ϊһ���ļ�,������һ���ļ���������ϵͳ���ļ�Ϊ��λ���������е����ݡ�
��ǧ������ļ�������ӷ������һ��,�û�ʹ��������Ȼ�dz�����,���������������Ŀ¼(Ŀ¼Ҳ���ļ���)�Ļ���,�����ļ����ڲ�ͬ���ļ�����,�ļ����л�����Ƕ���ļ���,��ͱ����û����ļ����й�����ʹ��,���� Windows ����Դ���������ֵ�������
һ����˵,�ļ��ɷ�Ϊ�ı��ļ�����Ƶ�ļ�����Ƶ�ļ���ͼ���ļ�����ִ���ļ��ȶ������,���Ǵ��ļ��Ĺ��ܽ��з���ġ������ݴ洢�ĽǶ���˵,���е��ļ������϶���һ����,������һ�����ֽ���ɵ�,��������� 0��1 ���ش�����ͬ���ļ����ֳ���ͬ����̬(�е����ı�,�е�����Ƶ�ȵ�),����Ҫ���ļ��Ĵ����ߺͽ�����(ʹ���ļ�������)Լ�������ļ���ʽ��
��ν����ʽ��,���ǹ����ļ���ÿһ���ֵ����ݴ���ʲô�����һ��Լ��������,�����Ĵ��ı��ļ�(Ҳ���ı��ļ�,��չ��ͨ���ǡ�.txt��),ָ�����ܹ��� Windows �ġ����±��������д�,�����ܿ�����һ������������ֵ��ļ����ı��ļ��ĸ�ʽ������һ�仰������:�ļ��е�ÿ���ֽڶ���һ���ɼ��ַ��� ASCII �롣
���˴��ı��ļ���,ͼ����Ƶ����ִ���ļ���һ�㱻�������������ļ������������ļ�����á����±��������,��������һƬ���롣
��ν���ı��ļ����͡��������ļ���,ֻ��Լ���׳ɵġ��Ӽ�����û��Ƕȳ������еķ���,�����Ǽ������ѧ�ķ��ࡣ��Ϊ�Ӽ������ѧ�ĽǶ�����,���е��ļ������ɶ�����λ��ɵ�,���Ƕ������ļ����ı��ļ��������������ļ�ֻ�Ǹ�ʽ��ͬ���ѡ�
ʵ����,ֻҪ�涨�ø�ʽ,���Ҳ����˷ѿռ�,���ı��ļ�һ�����Ա�ʾͼ����������Ƶ������ִ�г���˵,���Լ�����ַ� ��1������2����������7�� ��ʾ�߸�����,��ô����Щ�ַ���ɵ��ı��ļ��Ϳ��Ա���Ӹ�Լ�����������������һ�����ӡ�
�����ٿ�һ�����ı��ļ���ʾһ��ͼ�������:һ��ͼ��ʵ���Ͼ���һ���ɵ㹹�ɵľ���,ÿ��������в�ͬ����ɫ,��Ϊ���ء��е�ͼ���� 256 ɫ��,�е��� 32 λ���ɫ(��һ �����ص���ɫ��һ�� 32 λ��������ʾ)�ġ�
�� 256 ɫͼ��Ϊ��,������ 0~255 �� 256 �������� 256 ����ɫ,��ôÿ�����ؾͿ�����һ��������ʾ����Լ���ļ���ʼ������������ͼ��Ŀ��Ⱥ߶�(������Ϊ��λ),�������ı��ļ��Ϳ��Ա�ʾһ������Ϊ 6 ���ء��߶�Ϊ 4 ���ص� 256 ɫͼ��:
6 4
24 0 38 129 4 154
12 73 227 40 0 0
12 173 127 20 0 0
21 73 87 230 1 0
������ı�ͼ���ļ��ĸ�ʽ��������Ϊ:��һ�е��������ֱ����ˮƽ�����������Ŀ�ʹ�ֱ�����������Ŀ,�˺�ÿ�д���ͼ���һ������,һ���е�ÿ������Ӧ��һ������,��ʾ����ɫ��������һ��ʽ��ͼ���������Ϳ��������ı��ļ�����Ϊһ��ͼ����Ƶ����ÿ�� 24 ��ͼ����ɵ�,������ı��ļ�Ҳ���Ա�ʾ��Ƶ��
�������ı��ļ���ʾͼ��ķ����Ƿdz���Ч��,�˷���̫��Ŀռ䡣�ļ��д����Ŀո���һ���˷ѡ�����,����Ҫ�� 2 ������ 3 ���ַ�����ʾһ������,Ҳ��ɴ����˷�,��Ϊ��һ���ֽھ����Ա�ʾ 0~255 �� 256 ���������,����Լ��һ������ʡ�ռ�ĸ�ʽ����ʾһ�� 256 ɫ��ͼ��,�����ļ���ʽ����������:�ļ��еĵ� 0 �͵� 1 ���ֽ������� n,����ͼ��Ŀ���(2 �ֽڵ� n ��ȡֵ��Χ�� 0~65 535,˵��ͼ�����ֻ���� 65 535 �����ؿ�),�� 2 �͵� 3 ���ֽڴ���ͼ��ĸ߶ȡ�������,ÿ n ���ֽڱ�ʾͼ���һ������,����ÿ���ֽڶ�Ӧ��һ�����ص���ɫ��
�����ָ�ʽ�洢 256 ɫͼ��,����������ı���ʽ�洢ͼ���ܹ�����ʡ�ռ䡣�ڡ����±��������д���,�����ľͻ�������,���ͼ���ļ�Ҳ������ν�ġ��������ļ�����
������ͼ���ļ�����Ƶ�ļ�����Ƶ�ļ��ĸ�ʽ���Ƚϸ���,�еĻ�������ѹ��,��ֻҪ�ļ������������ͽ������(��ͼ��鿴����,��Ƶ����Ƶ��������)��ѭ��ͬ�ĸ�ʽԼ��,�û��Ϳ������ļ���������п����ļ������ݡ�
C++�ļ���(�ļ�����)���÷����
��C++�����������һ���н���,�ض����� cin �� cout �ɷֱ����ڶ�ȡ�ļ��е����ݺ����ļ���д�����ݡ�����֮��,C++ �����л�ר���ṩ�� 3 ��������ʵ���ļ�����,����ͳ��Ϊ�ļ�����,�� 3 ����ֱ�Ϊ:
- ifstream:ר���ڴ��ļ��ж�ȡ����;
- ofstream:ר�������ļ���д������;
- fstream:�ȿ����ڴ��ļ��ж�ȡ����,�ֿ��������ļ���д�����ݡ�
ֵ��һ�����,�� 3 ���ļ����λ�� ͷ�ļ���,�����ʹ������֮ǰ,������Ӧ�������ͷ�ļ���
�� 3 ���ļ�����ļ̳й�ϵ,��ͼ 1 ��ʾ��
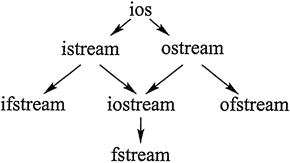
ͼ1:C++����е�����
���Կ���,ifstream ��� fstream ���Ǵ� istream ������������,��� ifstream ��ӵ�� istream ���ȫ����Ա������ͬ����,ofstream �� fstream ��Ҳӵ�� ostream ���ȫ����Ա��������Ҳ����ζ��,istream �� ostream ���ṩ�Ĺ� cin �� cout ���õij�Ա����,Ҳͬ���������ļ����������� 3 ��������Щ��Ա��������ͬ��,���� operator <<()��operator >>()��peek()��ignore()��getline()��get() �ȡ�
ֵ��һ�����,�� ͷ�ļ��ж����� ostream �� istream ��Ķ��� cin �� cout ��ͬ, ͷ�ļ��в�û�ж����ֱ��ʹ�õ� fstream��ifstream �� ofstream ��������,���������ʹ�ø�������ļ�,��Ҫ�Լ�������Ӧ��Ķ���
Ϊʲô C++ ���ⲻ�ṩ�ֳɵ����� fin ���� fout �Ķ�����?��ʵ�ܼ�,�ļ������������������������豸��Ӳ���е��ļ�,Ӳ�����кܶ��ļ�,����Ӧ��ʹ����һ����?����,C++ ����ͰѴ����ļ�������������û��ˡ�
fstream ��ӵ�� ifstream �� ofstream �������еij�Ա����,�� 2 ������ fstream ��һЩ���õij�Ա������
| ��Ա������ | ��������� | �� �� |
|---|---|---|
| open() | fstream ifstream ofstream | ��ָ���ļ�,ʹ�����ļ�������������� |
| is_open() | ���ָ���ļ��Ƿ��Ѵ� | |
| close() | �ر��ļ�,�жϺ��ļ�������Ĺ����� | |
| swap() | ���� 2 ���ļ������� | |
| operator>> | fstream ifstream | ���� >> �����,���ڴ�ָ���ļ��ж�ȡ���ݡ� |
| gcount() | �����ϴδ��ļ�����ȡ�����ַ��������ú������� get()��getline()��ignore()��peek()��read()��readsome()��putback() �� unget() ���á� | |
| get() | ���ļ����ж�ȡһ���ַ�,ͬʱ���ַ��������������ʧ�� | |
| getline(str,n,ch) | ���ļ����н��� n-1 ���ַ��� str ����,������ָ�� ch �ַ�ʱ��ֹͣ��ȡ,Ĭ������� ch Ϊ ��\0���� | |
| ignore(n,ch) | ���ļ����������ȡ�ַ�,����ȡ�����ַ�������,����ʹ��,ֱ����ȡ�� n ���ַ�,���ߵ�ǰ��ȡ���ַ�Ϊ ch�� | |
| peek() | �����ļ����еĵ�һ���ַ�,����������ȡ���ַ��� | |
| putback? | ���ַ� c �����ļ���(������)�� | |
| operator<< | fstream ofstream | ���� << �����,�������ļ���д��ָ�����ݡ� |
| put() | ��ָ���ļ�����д�뵥���ַ��� | |
| write() | ��ָ���ļ���д���ַ����� | |
| tellp() | ���ڻ�ȡ��ǰ�ļ������ָ���λ�á� | |
| seekp() | ��������ļ������ָ���λ�á� | |
| flush() | ˢ���ļ�������������� | |
| good() | fstream ofstream ifstream | �����ɹ�,û�з����κδ��� |
| eof() | ��������ĩβ���ļ�β�� |
�� 2 �н��оٵ��˲��ֳ��õij�Ա����,����ϸ�Ľ���,���߿ɲ鿴 C++�����ֲ���
������� fstream �����,����ʾһ�����ʹ�ñ� 2 �е�һЩ��Ա���������ļ�:
#include <iostream>
#include <fstream>
using namespace std;
int main() {
const char *url ="http://c.biancheng.net/cplus/";
//����һ�� fstream �����
fstream fs;
//�� test.txt �ļ��� fs �ļ�������
fs.open("test.txt", ios::out);
//��test.txt�ļ���д�� url �ַ���
fs.write(url, 30);
fs.close();
return 0;
}
ִ�г���,�ó���ͬĿ¼�»�����һ�� test.txt �ļ�,���ļ�������Ϊ:
http://c.biancheng.net/cplus/
ע��,��ѧ��ֻ�����ע�Ϳ�������ִ�����̼���,����Ĵ���ʵ�ֲ����,�����½ڻ�����ϸ���⡣
ֵ��һ�����,�����Ƕ�ȡ�ļ��е�����,�������ļ���д������,����Ҫ���ľ��ǵ��� open() ��Ա�������ļ���ͬʱ�ڲ����ļ�������,������Ҫ���� close() ��Ա�����ر��ļ����������ʹ�� open() ������һ���ļ�,��һ�ڻ�����ϸ���ܡ�
C++ open ���ļ�(����ģʽһ����)
�ڶ��ļ����ж�д����֮ǰ,��Ҫ���ļ������ļ�����������Ŀ��:
- ͨ��ָ���ļ���,�������ļ����ļ�������Ĺ���,�Ժ�Ҫ���ļ����в���ʱ,�Ϳ���ͨ����֮�����������������С�
- ָ���ļ���ʹ�÷�ʽ��ʹ�÷�ʽ��ֻ����ֻд���ȶ���д�����ļ�ĩβ�������ݡ����ı���ʽʹ�á��Զ����Ʒ�ʽʹ�õȶ��֡�
���ļ�����ͨ���������ַ�ʽ����:
- ����������� open ��Ա�������ļ���
- �����ļ�������ʱ,ͨ�����캯�����ļ���
ʹ�� open �������ļ�
�ȿ���һ���ļ���ʽ���� ifstream ��Ϊ��,������һ�� open ��Ա����,���������ļ�����Ҳ��ͬ���� open ��Ա����:
void open(const char* szFileName, int mode)
��һ��������ָ���ļ�����ָ��,�ڶ����������ļ��Ĵ�ģʽ��ǡ�
�ļ��Ĵ�ģʽ��Ǵ������ļ���ʹ�÷�ʽ,��Щ��ǿ��Ե���ʹ��,Ҳ�������ʹ�á��� 1 �г��˸���ģʽ��ǵ���ʹ��ʱ������,�Լ�����������ģʽ�����ϵ����á�
| ģʽ��� | ���ö��� | ���� |
|---|---|---|
| ios::in | ifstream fstream | ���ļ����ڶ�ȡ���ݡ�����ļ�������,������� |
| ios::out | ofstream fstream | ���ļ�����д�����ݡ�����ļ�������,���½����ļ�;����ļ�ԭ���ʹ���,���ʱ���ԭ�������ݡ� |
| ios::app | ofstream fstream | ���ļ�,��������β���������ݡ�����ļ�������,���½����ļ��� |
| ios::ate | ifstream | ��һ�����е��ļ�,�����ļ���ָ��ָ���ļ�ĩβ(��дָ �ĸ���������)������ļ�������,������� |
| ios:: trunc | ofstream | ���ļ�ʱ������ڲ��洢����������,����ʹ��ʱ�� ios::out ��ͬ�� |
| ios::binary | ifstream ofstream fstream | �Զ����Ʒ�ʽ���ļ�������ָ����ģʽ,�����ı�ģʽ�� |
| ios::in | ios::out | fstream | ���Ѵ��ڵ��ļ�,�ȿɶ�ȡ������,Ҳ������д�����ݡ��ļ��մ�ʱ,ԭ�����ݱ��ֲ��䡣����ļ�������,������� |
| ios::in | ios::out | ofstream | ���Ѵ��ڵ��ļ�,��������д�����ݡ��ļ��մ�ʱ,ԭ�����ݱ��ֲ��䡣����ļ�������,������� |
| ios::in | ios::out | ios::trunc | fstream | ���ļ�,�ȿɶ�ȡ������,Ҳ������д�����ݡ�����ļ������ʹ���,���ʱ���ԭ��������;����ļ�������,���½����ļ��� |
ios::binary ���Ժ�����ģʽ������ʹ��,����:
ios::in | ios::binary��ʾ�ö�����ģʽ,�Զ�ȡ�ķ�ʽ���ļ���ios::out | ios::binary��ʾ�ö�����ģʽ,��д��ķ�ʽ���ļ���
�ı���ʽ������Ʒ�ʽ���ļ���������ʵ�dz�С,�һ��ڡ��ļ����ı���ʽ�Ͷ����ƴ�ʽ��������һ����ר�Ž��͡�һ����˵,������������ı��ļ�,��ô���ı���ʽ�᷽��һЩ������ʵ�κ��ļ��������Զ����Ʒ�ʽ������д��
����������ִ�� open ��Ա����,�����ļ����ʹ�ģʽ,�Ϳ��Դ��ļ����ж��ļ����Ƿ�ɹ�,���Կ������������������ʽ��ֵ�Ƿ�Ϊ true,���Ϊ true,���ʾ�ļ��ɹ���
����ij�����ʾ����δ��ļ�:
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
ifstream inFile;
inFile.open("c:\\tmp\\test.txt", ios::in);
if (inFile) //��������,��˵���ļ��ɹ�
inFile.close();
else
cout << "test.txt doesn't exist" << endl;
ofstream oFile;
oFile.open("test1.txt", ios::out);
if (!oFile) //��������,��˵���ļ�����
cout << "error 1" << endl;
else
oFile.close();
oFile.open("tmp\\test2.txt", ios::out | ios::in);
if (oFile) //��������,��˵���ļ��ɹ�
oFile.close();
else
cout << "error 2" << endl;
fstream ioFile;
ioFile.open("..\\test3.txt", ios::out | ios::in | ios::trunc);
if (!ioFile)
cout << "error 3" << endl;
else
ioFile.close();
return 0;
}
���� open ��Ա����ʱ,�������ļ���������ȫ·����,��� 7 �е�c:\\tmp\\test.txt, ָ���ļ��� c �̵� tmp �ļ�����;Ҳ����ֻ�����ļ���,��� 13 �е�test1.txt,��������³�����ڵ�ǰ�ļ���(Ҳ���ǿ�ִ�г������ڵ��ļ���)��Ѱ��Ҫ���ļ���
�� 18 �е�tmp\\test2.txt�����������·��,˵�� test2.txt λ�ڵ�ǰ�ļ��е� tmp ���ļ����С��� 24 �е�..\\test3.txtҲ�����·��,������һ���ļ���,��ʱҪ����ǰ�ļ��е���һ���ļ����в��� test3.txt������,..\\..\\test4.txt��..\\tmp\\test4.txt�ȶ��ǺϷ��Ĵ����·�����ļ�����
ʹ������Ĺ��캯�����ļ�
����������ʱ,�ڹ��캯���и����ļ����ʹ�ģʽҲ���Դ��ļ����� ifstream ��Ϊ��,�������¹��캯��:
ifstream::ifstream (const char* szFileName, int mode = ios::in, int);
��һ��������ָ���ļ�����ָ��;�ڶ��������Ǵ��ļ���ģʽ���,Ĭ��ֵΪios::in; ���������������͵�,Ҳ��Ĭ��ֵ,һ�㼫��ʹ�á�
�ڶ���������ʱ���ļ���ʾ����������(������Ĺ��캯�����ļ�):
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
ifstream inFile("c:\\tmp\\test.txt", ios::in);
if (inFile)
inFile.close();
else
cout << "test.txt doesn't exist" << endl;
ofstream oFile("test1.txt", ios::out);
if (!oFile)
cout << "error 1";
else
oFile.close();
fstream oFile2("tmp\\test2.txt", ios::out | ios::in);
if (!oFile2)
cout << "error 2";
else
oFile.close();
return 0;
}
ע��,�����ٶԴ��ļ������κβ���ʱ,Ӧ��ʱ���� close() ��Ա�����ر��ļ����йظ÷������÷�,����������ϸ���⡣
�ı���ʽ�Ͷ����ƴ�ʽ��������ʲô?
��ѧϰ�� C++ �ļ�������ʹ�� open() ���ļ���,����֪�����ĵڶ���������һ���ַ���,������ʾ�ļ���ʽ,�����ʹ�� ios::binary,���ʾ�Զ����Ʒ�ʽ���ļ�;��֮,�����ı��ļ��ķ�ʽ���ļ���
�ı��ļ��Ͷ������ļ�������
�������������ľ���,�ı��ļ�ͨ�������������ۿɼ����ַ�,���� .txt�ļ���.c�ļ���.dat�ļ���,���ı��༭������Щ�ļ�,�����ܹ�˳�������ļ������ݡ�
�������ļ�ͨ������������Ƶ��ͼƬ������Ȳ����Ķ�������,���ı��༭������Щ�ļ�,�ῴ��һ������,������������
���Ǵ������Ͻ�,�������ļ����ַ��ļ���û��ʲô����,���Ƕ����Զ����Ƶ���ʽ�����ڴ����ϵ����ݡ�
����֮�����ܿ����ı��ļ�������,����Ϊ�ı��ļ��в��õ��� ASCII��UTF-8��GBK ���ַ�����,�ı��༭������ʶ�����Щ�����ʽ,��������ֵת�����ַ�չʾ������
���������ļ�ʹ�õ��� mp4��gif��exe ����������ʽ,�ı��༭��������ʶ��Щ�����ʽ,ֻ�ܰ����ַ������ʽ���ҽ���,���Ծͳ���һ�����߰�����ַ�,�е�������û������
��������½�һ�� mp4 �ļ�,����д��һ���ַ�,Ȼ�������ı��༭����,��һ�����Զ��ö�,����Ȥ�Ķ��߿����Լ����ԡ�
�ܵ���˵,��ͬ���͵��ļ��в�ͬ�ı����ʽ,����ʹ�ö�Ӧ�ij���(����)������ȷ����,�������һ������,������ʹ�á�
���ִ�ʽ������
�ı���ʽ�Ͷ����Ʒ�ʽ��û�б����ϵ�����,ֻ�Ƕ��ڻ��з��Ĵ�����ͬ��
�� UNIX/Linux ƽ̨��,���ı���ʽ������Ʒ�ʽ���ļ�û���κ�����,��Ϊ�ı��ļ��� \n(ASCII ��Ϊ 0x0a)��Ϊ���з��š�
���� Windows ƽ̨��,�ı��ļ�������һ��� \r\n ��Ϊ���з��š�������ı���ʽ���ļ�,����ȡ�ļ�ʱ,����Ὣ�ļ������е� \r\n ת����һ���ַ� \n��Ҳ����˵,����ı��ļ����������������ַ��� \r\n,�����ᶪ��ǰ��� \r,ֻ���� \n��
ͬ����д���ļ�ʱ,����Ὣ \n ת���� \r\n д�롣Ҳ����˵,���Ҫд������������ַ� \n,����д����ַ�ǰ,������Զ���д��һ�� \r��
����� Windows ƽ̨��,������ı���ʽ�������ļ����ж�д,��д�����ݾͿ��ܺ��ļ��������г��롣
�ܵ���˵,Linux ƽ̨ʹ�����ִ�ʽ����;Windows ƽ̨������� ��ios::in | ios::out�� �ȴ��ı��ļ�,�� ��ios::binary�� �������ļ�������������ƽ̨,�ö����Ʒ�ʽ���ļ�������յġ�
C++ close()�ر��ļ��������
��C++ open���ļ���һ����,��ϸ�������ļ���������ε��� open() ��Ա������ָ���ļ������Ӧ��,�ļ��������������ر���ǰ���ļ�,������ close() ��Ա������
����֪��,���� open() �������ļ�,���ļ���������ļ�֮�佨�������Ĺ��̡���ô,���� close() �����ر��Ѵ��ļ�,�Ϳ�������Ϊ���ж��ļ���������ļ�֮��Ĺ�����ע��,close() �����Ĺ��ܽ����ж��ļ������ļ�֮��Ĺ���,���ļ������ᱻ����,������������ڹ����������ļ���
close() �������÷��ܼ�,�����ʽ����:
void close( )
���Կ���,�÷����Ȳ���Ҫ�����κβ���,Ҳû�з���ֵ��
�ٸ�����:
#include <fstream>
using namespace std;
int main()
{
const char *url="http://c.biancheng.net/cplus/";
ofstream outFile("url.txt", ios::out);
//�� url.txt �ļ���д���ַ���
outFile.write(url, 30);
//�ر��Ѵ��ļ�
outFile.close();
return 0;
}
���г���,�ڸó���ͬĿ¼�»�����һ�� url.txt �ļ�,���ڲ��洢������Ϊ:
http://c.biancheng.net/cplus/
��Щ���߿��ܷ���,������������в����� close() ����,Ҳ�ܳɹ��� url.txt �ļ���д�� url �ַ�����������Ϊ,���ļ���������������ڽ���ʱ,�����е�������������,�ú����ڲ������ٶ���֮ǰ,���ȵ��� close() �����ж������κ��ļ��Ĺ���,������������
ǿ�ҽ������,ʹ�� open() �������ļ�,һ��Ҫ�ֶ����� close() �����ر�,�������Ա��������һЩ����Ĵ���!
ֵ��һ�����,��C++�����������������һ���н����� 4 ����״̬,����Ҳͬ���������ļ��������ļ�������δ�����κ��ļ�ʱ,���� close() ������ʧ��,���Ϊ�ļ������� failbit ״̬��־,�ñ�־���Ա� fail() ��Ա������������:
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
const char *url="http://c.biancheng.net/cplus/";
ofstream outFile;
outFile.close();
if (outFile.fail()) {
cout << "�ļ��������̷����˴���!";
}
return 0;
}
����ִ�н��Ϊ:
�ļ��������̷����˴���!
C++���ļ�һ��Ҫ��close()�����ر�!
ͨ��ǰ���ѧϰ����֪��,C++ ʹ�� open() �������ļ�,ʹ�� close() �����ر��ļ�������(����һ):
#include <iostream> //std::cout
#include <fstream> //std::ofstream
using namespace std;
int main()
{
const char * url = "http://c.biancheng.net/cplus/";
//���ı�ģʽ��out.txt
ofstream destFile("out.txt", ios::out);
if (!destFile) {
cout << "�ļ���ʧ��" << endl;
return 0;
}
//��out.txt�ļ���д�� url �ַ���
destFile << url;
//�رմ� out.txt �ļ�
destFile.close();
return 0;
}
ִ�иó���,������һ�� out.txt �ļ�,�ڲ�������������:
http://c.biancheng.net/cplus/
ǰ���ᵽ,��ijЩ�����(�������������),���㲻��ʽ���� close() ����,�ļ��Ķ�д����Ҳ�ܳɹ�ִ�С���Ϊ���ļ���������������ڽ���ʱ,�����е�����������,�˺����ڲ����ȵ��� close() �����ж��ļ����������κ��ļ��Ĺ���,������������
��ô,��Ȼ�ļ���������������ʱ����ʽ���� close() ����,�Dz��ǾͲ�����ʽ���� close() ��������?
��Ȼ���ǡ���ʵ�ʽ����ļ������Ĺ�����,���ڴ��ļ�,Ҫ��ʱ���� close() ��������ر�,����ܿ��ܻᵼ�¶�д�ļ�ʧ�ܡ�
�ٸ�����(�����):
#include <iostream> //std::cout
#include <fstream> //std::ofstream
using namespace std;
int main()
{
const char * url = "http://c.biancheng.net/cplus/";
//���ı�ģʽ��out.txt
ofstream destFile("out.txt", ios::out);
if (!destFile) {
cout << "�ļ���ʧ��" << endl;
return 0;
}
//��out.txt�ļ���д�� url �ַ���
destFile << url;
//�����׳�һ���쳣
throw "Exception";
//�رմ� out.txt �ļ�
destFile.close();
return 0;
}
ͨ���ԱȲ��ѷ���,�˳���ͳ���һΨһ����������,�� 17 ���������׳��쳣����䡣���ڳ�����û�ж��׳����쳣���д���,��˵�����ִ�е�����ʱ�������
����Ҫ����,�� 17 �лᵼ���ļ�д�����ʧ�ܡ�ִ�д˳���,ͬ�������� out.txt �ļ�,�� ��http:c.biancheng.net/cplus/�� �ַ�����û�гɹ���д�롣
Ҳ����˵,�����Ѿ����ļ�,�������ʱ�ر�,һ����������쳣,��ܿ��ܻᵼ��֮ǰ��д�ļ������в���ʧЧ���ڳ�����Ļ�����,������� 17 �д���͵� 19 �д��뻥��,�ٴ�ִ�г���ᷢ��,��Ȼ����ִ���Ի����,�� ��http:c.biancheng.net/cplus/�� �ַ������Ա��ɹ�д�뵽 out.txt �ļ��С�
C++ flush()ˢ�»�����
�ںܶ�ʵ�ʳ�����,�����Ѿ����ļ�ִ����д����,�����������ܻ�ִ��������д�����������������,���ǿ��ܲ�����Ƶ���ش�/�ر��ļ�,����ʹ�� flush() ������ʱˢ�������������,Ҳ����ֹд���ļ�ʧ�ܵ����á�
�����֮����д���ļ�ʧ��,����Ϊ << д����������Ƚ� url �ַ���д�뵽�������������,�������������߹ر��ļ�ʱ,���ݲŻ��ɻ�����д�뵽�ļ��С���ֱ���������,close() ����Ҳû�еõ�ִ��,�� destFile ����Ҳû����������,���� url �ַ���һֱ�洢�ڻ�������,û��д�뵽�ļ��С�
����,�ij�����Ĵ���:
#include <iostream> //std::cout
#include <fstream> //std::ofstream
using namespace std;
int main()
{
const char * url = "http://c.biancheng.net/cplus/";
//���ı�ģʽ��out.txt
ofstream destFile("out.txt", ios::out);
if (!destFile) {
cout << "�ļ���ʧ��" << endl;
return 0;
}
//��out.txt�ļ���д�� url �ַ���
destFile << url;
//ˢ�������������
destFile.flush();
//�����׳�һ���쳣
throw "Exception";
//�رմ� out.txt �ļ�
destFile.close();
return 0;
}
���Կ���,�ڳ�����Ļ�����,�ڵ� 17 �е����� flush() �������ٴ�ִ�г���,��Ȼ��ִ�б���,�� ��http://c.baincheng.net/cplus/�� �ַ����ɹ�д�뵽�� out.txt �ļ��С�
��֮,C++ ��ʹ�� open() ���ļ�,�ڶ�д����ִ����Ϻ�,Ӧ��ʱ���� close() �����ر��ļ�,���߶��ļ�ִ��д������ʱ���� flush() ����ˢ���������������
C++�ı��ļ���д�������
ǰ���½���,�Ѿ�����ҽ������ļ���������ε��� open() �������ļ�,�����ڶ�д(�ֳ� I/O )�ļ�����������,Ӧ���� close() �����ر���ǰ���ļ�����ô,���ʵ�ֶ��ļ����ݵĶ�д��?�������ͶԴ���������ϸ�Ľ��⡣
�ڽ�������д�ļ��ķ���֮ǰ,��������Ҫ���������,���ļ��Ķ�/д�����ֿ���ϸ��Ϊ 2 ��,�ֱ������ı���ʽ��д�ļ����Զ�������ʽ��д�ļ���
-
����֪��,�ļ��д洢�����ݲ�û�������ϵķֱ�,ͳͳ�����ַ�����ν���ı���ʽ��/д�ļ�,����ֱ�ؽ��ļ��д洢���ַ�(���ַ���)��ȡ����,�Լ���Ŀ���ַ�(���ַ���)�洢���ļ��С�
-
���Զ�������ʽ��/д�ļ�,�����Ķ������Ǵ��ļ����ܿ������ַ�,�����ļ��ײ�洢�Ķ��������ݡ�����ϸ�ؽ�,���Ը���ʽ��ȡ�ļ�ʱ,��ȡ���Ǹ��ļ��ײ�洢�Ķ���������;ͬ��,����ij�����Զ�������ʽд�뵽�ļ���ʱ,д���Ҳ�����Ӧ�Ķ��������ݡ�
�ٸ�����,�����������ı���ʽ�������� 19.625 д���ļ�,����ļ���ֱ�ӽ� ��19.625�� ����ַ����洢������������˫�����ļ�,Ҳ���Կ��� 19.625��ֵ��һ�����,�ɷ��ַ�������(��������ĸ����� 19.625)ת��Ϊ��Ӧ�ַ���(ת��Ϊ ��19.625��)�Ĺ���,C++ �����Ѿ�ʵ�ֺ���,����Ҫ���Dz��ġ�
������Զ�������ʽ�������� 19.625 д���ļ�,����ļ��洢�IJ����� ��19.625�� ����ַ���,���� 19.625 ��������Ӧ�Ķ��������ݡ��� float ���͵� 19.625 ��˵,�ļ����մ洢������������ʾ:
0100 0001 1001 1101 0000 0000 0000 0000
������εó� float ���͵� 19.625 ��Ӧ�Ķ�����,����Ȥ�Ķ��߿��Ķ���С�����ڴ�������δ洢����һ�ڡ�
��Ȼ,���ֱ�ӽ����϶���������ת��Ϊ float ����,�Կ��Եõ������� 19.625���������ļ���˵,��ֻ�Ὣ�洢�Ķ��������ݸ��ݼȶ��ı����ʽ(�� utf-8��gbk ��)ת��Ϊһ�����ַ�����Ҳ����ζ��,�������ֱ�Ӵ��ļ�,�����IJ������� 19.625,������һ�����롣
C++ ������,�ṩ�� 2 ��д�ļ��ķ������,�ֱ���:
- ʹ�� >> �� << ��д�ļ�:���������ı���ʽ��д�ļ�;
- ʹ�� read() �� write() ��Ա������д�ļ�:�������Զ�������ʽ��д�ļ���
�����Ƚ�������� >> �� << ʵ�����ı���ʽ��д�ļ�,�������ʵ���Զ�������ʽ��д�ļ�,��һ�ڻ�����ϸ���ܡ�
C++ >>��<<��д�ı��ļ�
ͨ����C++�ļ�������һ�ڵ�ѧϰ����֪��,fstream ���� ifstream �ฺ��ʵ�ֶ��ļ��Ķ�ȡ,�����ڲ����� >> ������������������;ͬ��,fstream �� ofstream �ฺ��ʵ�ֶ��ļ���д��,���ǵ��ڲ�Ҳ���� << �����������������ء�
����,�� fstream ���� ifstream �������ļ�(ͨ���� ios::in ��Ϊ��ģʽ)֮��,�Ϳ���ֱ�ӽ��� >> �����������,��ȡ�ļ��д洢���ַ�(���ַ���);�� fstream ���� ofstream �������ļ�(ͨ���� ios::out ��Ϊ��ģʽ)��,����ֱ�ӽ��� << �������������ļ���д���ַ�(���ַ���)��
�ٸ�����:
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
int x,sum=0;
ifstream srcFile("in.txt", ios::in); //���ı�ģʽ��in.txt����
if (!srcFile) { //��ʧ��
cout << "error opening source file." << endl;
return 0;
}
ofstream destFile("out.txt", ios::out); //���ı�ģʽ��out.txt��д
if (!destFile) {
srcFile.close(); //�������ǰ�������ǹر���ǰ�����ļ�
cout << "error opening destination file." << endl;
return 0;
}
//��������cin������ifstream����
while (srcFile >> x) {
sum += x;
//������ cout ����ʹ�� ofstream ����
destFile << x << " ";
}
cout << "sum:" << sum << endl;
destFile.close();
srcFile.close();
return 0;
}
ע��,�˳����зֱ���� ios::in �� ios::out ���ļ�,�����ı�ģʽ���Ƕ�����ģʽ���ļ�������Ȥ�Ķ��߿�������������� ios::binary,���Զ�����ģʽ���ļ�,�������ɻ�����ִ�С�������Ϊ,���ı�ģʽ���ļ����Զ�����ģʽ���ļ�,��û�кܴ������(�����½ڻ�����ϸ����)��
ִ�д˳���֮ǰ,�����ںó���Դ�ļ�ͬĿ¼���ֶ�����һ�� in.txt �ļ�,�������ڲ��洢���ַ���Ϊ:
10 20 30 40 50
����֮��,ִ�г���,��ִ�н��Ϊ:
sum:150
ͬʱ�� in.txt �ļ�ͬĿ¼��,������һ�� out.txt �ļ�,���ڲ��洢���ַ��� in.txt �ļ���ȫһ��,���߿����д��ļ��鿴��
ͨ�����������ִ�н����������,���� in.txt �ļ��е� ��10 20 30 40 50�� �ַ���,srcFile ��������ν� ��10������20������30������40������50�� ��ȡ����,�����ǽ����� int ���͵����� 10��20��30��40��50 ����ֵ�� x,ͬʱ��ɺ� sum �ļӺͲ�����
ͬ��,����ÿ�δ� in.txt �ļ���ȡ�������������� x,destFile ����ԭ�ⲻ���ؽ����ٽ����ɶ�Ӧ���ַ���(������ 10 �������ַ��� ��10��),Ȼ��� " " �ո��һ��д�� out.txt �ļ���
ͨ����C++�ı��ļ���д������һ�ڵ�ѧϰ,�����˽������ı���ʽ��д�ļ����Զ�������ʽ��д�ļ�������,�������������ص� >> �� << �����ʵ�����ı���ʽ��д�ļ����ڴ˻�����,���ڼ�����������Զ�������ʽ��д�ļ���
�������ܾ����ʵ�ַ���ǰ,�ȸ����߽���һ��������ı���ʽ��д�ļ�,�Զ�������ʽ��д�ļ�����Щ�ô�?
�ٸ�����,����Ҫ��һ��ѧ����������,����һ����Ҫ�Ĺ������Ǽ�¼ѧ����ѧ�š��������������Ϣ������ζ��,������Ҫ��һ��������ʾѧ��,������ʾ:
class CStudent
{
char szName[20]; //����ѧ������������19���ַ�,�� '\0' ��β
char szId[l0]; //����ѧ��Ϊ9λ,�� '\0' ��β
int age; //����
};
ǰ���½���,����ѧ����������ı���ʽ��д�ļ�,���ʹ�ô˷�ʽ�洢ѧ������Ϣ,�����յ��ļ��д洢��ѧ����Ϣ�������������:
Micheal Jackson 110923412 17
Tom Hanks 110923413 18
��
Ҫ֪��,���ִ洢ѧ����Ϣ�ķ�ʽ�����˷ѿռ�,���Һ��ڲ����ڲ���ָ��ѧ������Ϣ(����Ч�ʵ���),��Ϊÿ��ѧ������Ϣ��ռ�õ��ֽ�����ͬ��
���������,�Զ�������ʽ��ѧ����Ϣ�洢���ļ���,�Ƿdz�������ѡ��,��Ϊ�Դ���ʽ�洢ѧ����Ϣ,����ֱ�Ӱ� CStudent ����д���ļ���,����ζ��ÿ��ѧ������Ϣ��ֻռ�� sizeof(CStudent) ���ֽڡ�
ֵ��һ�����,Ҫʵ���Զ�������ʽ��д�ļ�,<< �� >> ����������,��Ҫʹ�� C++ ����ר���ṩ�� read() �� write() ��Ա����������,read() ���������Զ�������ʽ���ļ��ж�ȡ����;write() ���������Զ�������ʽ������д���ļ���
C++ ostream::write()����д�ļ�
ofstream �� fstream �� write() ��Ա����ʵ���ϼ̳��� ostream ��,�书���ǽ��ڴ��� buffer ָ��� count ���ֽڵ�����д���ļ�,������ʽ����:
ostream & write(char* buffer, int count);
����,buffer ����ָ��Ҫд���ļ��Ķ��������ݵ���ʼλ��;count ����ָ��д���ֽڵĸ�����
Ҳ����˵,�÷������Ա� ostream ��� cout �������,����������Ļ������ַ�����ͬʱ,�������Ա� ofstream ���� fstream �������,���ڽ�ָ�������Ķ���������д���ļ���
ͬʱ,�÷����᷵��һ�������ڸú�����������ʽ�Ķ��ٸ�����,obj.write() �����ķ���ֵ���Ƕ� obj ��������á�
��Ҫע���һ����,write() ��Ա�������ļ���д�������ֽ�,���ǵ��� write() ����ʱ��û��ָ����Щ�ֽ�д���ļ��еľ���λ�á���ʵ��,write() ��������ļ�дָ��ָ���λ�ý�����������д�롣��ν�ļ�дָ��,���� ofstream �� fstream �����ڲ�ά����һ������,�ļ��մ�ʱ,�ļ�дָ��ָ������ļ��Ŀ�ͷ(����� ios::app ��ʽ��,��ָ���ļ�ĩβ),�� write() ����д�� n ���ֽ�,дָ��ָ���λ�þ�����ƶ� n ���ֽڡ�
����ij�����ʾ����ν�ѧ����Ϣ�Զ�������ʽд���ļ�:
#include <iostream>
#include <fstream>
using namespace std;
class CStudent
{
public:
char szName[20];
int age;
};
int main()
{
CStudent s;
ofstream outFile("students.dat", ios::out | ios::binary);
while (cin >> s.szName >> s.age)
outFile.write((char*)&s, sizeof(s));
outFile.close();
return 0;
}
����:
Tom 60�L
Jack 80�L
Jane 40�L
^Z�L
����,�L��ʾ������з�,^Z ��ʾ����Ctrl+Z��ϼ��������롣
ִ�г����,���Զ�����һ�� students.dat �ļ�,���ڲ����� 72 �ֽڵ�����,����á����±������ļ�,���ܿ�����������:
Tom ����������������< Jack ���������������P Jane ��������������?
ֵ��һ�����,�����е� 13 ��ָ���ļ��Ĵ�ģʽΪ ios::out | ios::binary,���Զ�����дģʽ���� Windowsƽ̨��,�Զ�����ģʽ���ļ��Ƿdz��б�Ҫ��,������ܳ���,ԭ����ڡ��ļ����ı���ʽ�Ͷ����ƴ�ʽ��������һ���н��ܡ�
����,�� 15 �н� s ����д���ļ���s �ĵ�ַ����Ҫд���ļ����ڴ滺�����ĵ�ַ,���� &s ���� char * ����,���Ҫ����ǿ������ת��;�� 16 ��,�ļ�ʹ�����һ��Ҫ�ر�,�������������ļ������ݿ��ܲ�������
C++ istream::read()�������ļ�
ifstream �� fstream �� read() ����ʵ���ϼ̳��� istream ��,�书�����ú� write() �����෴,�����ļ��ж�ȡ count ���ֽڵ����ݡ��÷��������ʽ����:
istream & read(char* buffer, int count);
����,buffer ����ָ����ȡ�ֽڵ���ʼλ��,count ָ����ȡ�ֽڵĸ�����ͬ��,�÷���Ҳ�᷵��һ�����ø÷����Ķ�������á�
�� write() ��������,read() �������ļ���ָ��ָ���λ�ÿ�ʼ��ȡ�����ֽڡ���ν�ļ���ָ��,��������Ϊ�� ifstream �� fstream �����ڲ�ά����һ���������ļ��մ�ʱ,�ļ���ָ��ָ���ļ��Ŀ�ͷ(����� ios::app ��ʽ��,��ָ���ļ�ĩβ),�� read() ������ȡ n ���ֽ�,��ָ��ָ���λ�þ�����ƶ� n ���ֽڡ����,��һ���ļ����������� read() ����,���ܽ������ļ������ݶ�ȡ������
ͨ��ִ�� write() ������ʾ������,���ǽ� 3 ��ѧ������Ϣ�洢���� students.dat �ļ���,���������ʾ�����ʹ�� read() ���������Ƕ�ȡ����:
#include <iostream>
#include <fstream>
using namespace std;
class CStudent
{
public:
char szName[20];
int age;
};
int main()
{
CStudent s;
ifstream inFile("students.dat",ios::in|ios::binary); //�����ƶ���ʽ��
if(!inFile) {
cout << "error" <<endl;
return 0;
}
while(inFile.read((char *)&s, sizeof(s))) { //һֱ�����ļ�����
cout << s.szName << " " << s.age << endl;
}
inFile.close();
return 0;
}
�������������:
Tom 60
Jack 80
Jane 40
ע��,�����е� 18 ��ֱ�ӽ� read() ������Ϊ while ѭ�����ж�����,����ζ��,read() ������һֱ��ȡ���ļ���ĩβ,�������ֽ�ȫ����ȡ���,while ѭ���Ż���ֹ��
����,��ʹ�� read() ������ͬʱ,�����֪��һ���ɹ���ȡ�˶��ٸ��ֽ�(�����ļ�βʱ,δ���ܶ�ȡ count ���ֽ�),������ read() ����ִ�к����������ļ�������� gcount() ��Ա����,�䷵��ֵ�������һ�� read() �����ɹ���ȡ���ֽ���������Ȥ�Ķ��߿����г���,���ﲻ����������ʾ��
C++ get()��put()��д�ļ����
��ijЩ����ij�����,���ǿ�����Ҫ�����ȡ�ļ��д洢���ַ�,����������ַ��洢���ļ��С����������,�Ϳ��Ե��� get() �� put() ��Ա����ʵ�֡�
C++ ostream::put()��Ա����
ͨ����C++ cout.put()��һ�ڵ�ѧϰ,�������������ͨ��ִ�� cout.put() ��������Ļ��������ַ�������֪��,fstream �� ofstream ��̳��� ostream ��,��� fstream �� ofstream ������Ե��� put() ������
�� fstream �� ofstream �ļ���������� put() ����ʱ,�÷����Ĺ��ܾͱ������ָ���ļ���д�뵥���ַ���put() ���������ʽ����:
ostream& put (char c);
����,c ����ָ��Ҫд���ļ����ַ����÷����᷵��һ�����ø÷����Ķ����������ʽ������,obj.put() �����᷵�� obj �����������á�
�ٸ�����:
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
char c;
//�Զ�������ʽ���ļ�
ofstream outFile("out.txt", ios::out | ios::binary);
if (!outFile) {
cout << "error" << endl;
return 0;
}
while (cin >> c) {
//���ַ� c д�� out.txt �ļ�
outFile.put(c);
}
outFile.close();
return 0;
}
ִ�г���,����:
http://c.biancheng.net/cplus/�L
^Z�L
����,
�L��ʾ���뻻�з�;^Z�� Ctrl+Z ����ϼ�,��ʾ���������
�ɴ�,������ͨ��ִ�� while ѭ��,�Ὣ ��http://c.biancheng.net/cplus/�� �ַ������ַ�������Ƹ����� c,�����д�뵽 out.txt �ļ���
ע��,�����ļ������Ӳ����,Ӳ�̵ķ����ٶ�ԶԶ�����ڴ档���ÿ��дһ���ֽڶ�Ҫ����Ӳ��,��ô�ļ��Ķ�д�ٶȾͻ����ò������ܡ����,����ϵͳ�ڽ��յ� put() ����д�ļ�������ʱ,���Ƚ�ָ���ַ��洢��һ��ָ�����ڴ�ռ���(��Ϊ�ļ������������),��ˢ�¸û�����(�����������ر��ļ����ֶ����� flush() ������,���ᵼ�»�����ˢ��)ʱ,�ŻὫ�������д洢�������ַ���һ���Զ���ȫд���ļ���
C++ istream::get()��Ա����
�� put() ��Ա�����Ĺ�����Ե��� get() ����,�䶨���� istream ����,���� cin.get() ���Զ�ȡ�û�������ַ����ڴ˻�����,fstream �� ifstream ��̳��� istream ��,��� fstream �� ifstream ��Ķ���Ҳ�ܵ��� get() ������
�� fstream �� ifstream �ļ���������� get() ����ʱ,�书�ܾͱ���˴�ָ���ļ��ж�ȡ�����ַ�(�����Զ�ȡָ�����ȵ��ַ���)��ֵ��һ�����,get() ���������ʽ�кܶ�(���ͻ������˽�����),�����������õ� 2 ��:
int get();
istream& get (char& c);
����,��һ�����ʽ�ķ���ֵ���Ƕ�ȡ�����ַ�,ֻ�������ص������� ASCII ��,������������ĩβ,��ֵΪ EOF���ڶ������ʽ��Ҫ����һ���ַ�����,get() ���������н���ȡ�����ַ���ֵ�����������
����ǰ���ڽ��� put() ����ʱ,������һ�� out.txt �ļ�,�����������ʾ�����ͨ�� get() ���������ȡ out.txt �ļ��е��ַ�:
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
char c;
//�Զ�������ʽ���ļ�
ifstream inFile("out.txt", ios::out | ios::binary);
if (!inFile) {
cout << "error" << endl;
return 0;
}
while ( (c=inFile.get())&&c!=EOF ) //���� while(inFile.get(c)),��Ӧ�ڶ������ʽ
{
cout << c ;
}
inFile.close();
return 0;
}
����ִ�н��Ϊ:
http://c.biancheng.net/cplus/
ע��,�� put() ����һ��,����ϵͳ�ڽ��յ� get() �����������,����ֻ��ȡһ���ַ�,Ҳ��һ���Դ��ļ��н��ܶ�����(ͨ�������� 512 ���ֽ�,��ΪӲ�̵�һ�������� 512 B)����һ���ڴ�ռ���(�ɳ�Ϊ�ļ������뻺����),��������ȡ��һ���ַ�ʱ,�Ͳ���Ҫ�ٷ���Ӳ���е��ļ�,ֱ�ӴӸû������ж�ȡ���ɡ�
C++ getline():���ļ��ж�ȡһ���ַ���
��cin.getline()��һ����,��ϸ���������ʹ�� getline() ������ cin �������������ж�ȡһ���ַ������ڴ˻�����,getline() �����������ڶ�ȡָ���ļ��е�һ������,���ھ��������ϸ�Ľ��⡣
����֪��,getline() ���������� istream ����,�� fstream �� ifstream ��̳��� istream ��,��� fstream �� ifstream ���������Ե��� getline() ��Ա������
���ļ���������� getline() ����ʱ,�÷����Ĺ��ܾͱ���˴�ָ���ļ��ж�ȡһ���ַ������÷��������� 2 �����ʽ:
istream & getline(char* buf, int bufSize);
istream & getline(char* buf, int bufSize, char delim);
����,��һ�����ʽ���ڴ��ļ��������������ж�ȡ bufSize-1 ���ַ��� buf,������ \n Ϊֹ(�ĸ�����������Ͱ��ĸ�ִ��),�÷������Զ��� buf �ж������ݵĽ�β���� ��\0����
�ڶ������ʽ�͵�һ�ֵ���������,��һ���汾�Ƕ��� \n Ϊֹ,�ڶ����汾�Ƕ��� delim �ַ�Ϊֹ��\n �� delim �����ᱻ���� buf,���ᱻ���ļ���������������ȡ�ߡ�
���� 2 �ָ�ʽ��,getline() �������᷵��һ����ǰ�����ö�������á�����,obj.getline() �᷵�� obj �����á�
ע��,����ļ��������� \n �� delim ֮ǰ���ַ������ﵽ�� bufSize,�ͻᵼ�¶�ȡʧ�ܡ�
�ٸ�����:
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
char c[40];
//�Զ�����ģʽ�� in.txt �ļ�
ifstream inFile("in.txt", ios::in | ios::binary);
//�ж��ļ��Ƿ�������
if (!inFile) {
cout << "error" << endl;
return 0;
}
//�� in.txt �ļ��ж�ȡһ���ַ���,������ 39 ��
inFile.getline(c, 40);
cout << c ;
inFile.close();
return 0;
}
���� in.txt �ļ��д��������ַ���:
http://c.biancheng.net/cplus/
�����ִ�н��Ϊ:
http://c.biancheng.net/cplus/
��Ȼ,����Ҳ����ʹ�� getline() �����ĵڶ������ʽ������,������������е� 15 �д���Ϊ:
inFile.getline(c,40,'c');
����ζ��,һ�������ַ� ��c��,getline() �����ͻ�ֹͣ��ȡ�� �ٴ����г���,��������Ϊ:
http://
����,������ȡ�ļ��еĶ�������,����������:
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
char c[40];
ifstream inFile("in.txt", ios::in | ios::binary);
if (!inFile) {
cout << "error" << endl;
return 0;
}
//��������Ϊ��λ,��ȡ in.txt �ļ��е�����
while (inFile.getline(c, 40)) {
cout << c << endl;
}
inFile.close();
return 0;
}
���� in.txt �ļ��д�����������:
http://c.biancheng.net/cplus/
http://c.biancheng.net/python/
http://c.biancheng.net/java/
�����ִ�н��Ϊ:
http://c.biancheng.net/cplus/
http://c.biancheng.net/python/
http://c.biancheng.net/java/
C++�ƶ��ͻ�ȡ�ļ���дָ��(seekp��seekg��tellg��tellp)
�ڶ�д�ļ�ʱ,��ʱϣ��ֱ�������ļ��е�ij����ʼ��д,�����Ҫ�Ƚ��ļ��Ķ�дָ��ָ��ô�,Ȼ���ٽ��ж�д��
- ifstream ��� fstream ���� seekg ��Ա����,���������ļ���ָ���λ��;
- ofstream ��� fstream ���� seekp ��Ա����,���������ļ�дָ���λ�á�
��ν��λ�á�,����ָ�����ļ���ͷ�ж��ٸ��ֽڡ��ļ���ͷ��λ���� 0��
������������ԭ������:
ostream & seekp (int offset, int mode);
istream & seekg (int offset, int mode);
mode �����ļ���дָ�������ģʽ,����������ѡ��:
- ios::beg:���ļ���ָ��(��дָ��)ָ����ļ���ʼ���� offset �ֽڴ���offset ���� 0 �������ļ���ͷ���ڴ������,offset ֻ���ǷǸ�����
- ios::cur:�ڴ������,offset Ϊ�������ʾ����ָ��(��дָ��)�ӵ�ǰλ�ó��ļ���ͷ�����ƶ� offset �ֽ�,Ϊ�������ʾ����ָ��(��дָ��)�ӵ�ǰλ�ó��ļ�β���ƶ� offset�ֽ�,Ϊ 0 ���ƶ���
- ios::end:���ļ���ָ��(��дָ��)ָ����ļ���β��ǰ�� |offset|(offset �ľ���ֵ)�ֽڴ����ڴ������,offset ֻ���� 0 ���߸�����
����,���ǻ����Եõ���ǰ��дָ��ľ���λ��:
- ifstream ��� fstream ��� tellg ��Ա����,�ܹ������ļ���ָ���λ��;
- ofstream ��� fstream ��� tellp ��Ա����,�ܹ������ļ�дָ���λ�á�
��������Ա������ԭ������:
int tellg();
int tellp();
Ҫ��ȡ�ļ�����,������ seekg �������ļ���ָ�붨λ���ļ�β��,���� tellg ������ȡ�ļ���ָ���λ��,��λ�ü�Ϊ�ļ����ȡ�
����:����ѧ����¼�ļ� students.dat �ǰ��������ź����,��д����,�� students.dat �ļ������۰���ҵķ����ҵ�����Ϊ Jack ��ѧ����¼,�����������Ϊ 20(�����ļ��ܴ�,��ȫ�������ڴ�)����������:
#include <iostream>
#include <fstream>
#include <cstring>
using namespace std;
class CStudent
{
public:
char szName[20];
int age;
};
int main()
{
CStudent s;
fstream ioFile("students.dat", ios::in|ios::out);//�üȶ���д�ķ�ʽ��
if(!ioFile) {
cout << "error" ;
return 0;
}
ioFile.seekg(0,ios::end); //��λ��ָ�뵽�ļ�β��,
//�Ա����Ժ�tellg ��ȡ�ļ�����
int L = 0,R; // L���۰���ҷ�Χ�ڵ�һ����¼�����
// R���۰���ҷ�Χ�����һ����¼�����
R = ioFile.tellg() / sizeof(CStudent) - 1;
//�״β��ҷ�Χ�����һ����¼����ž���: ��¼����- 1
do {
int mid = (L + R)/2; //Ҫ�ò��ҷ�Χ���еļ�¼�ʹ����ҵ����ֱȶ�
ioFile.seekg(mid *sizeof(CStudent),ios::beg); //��λ�����еļ�¼
ioFile.read((char *)&s, sizeof(s));
int tmp = strcmp( s.szName,"Jack");
if(tmp == 0) { //�ҵ���
s.age = 20;
ioFile.seekp(mid*sizeof(CStudent),ios::beg);
ioFile.write((char*)&s, sizeof(s));
break;
}
else if (tmp > 0) //������ǰһ�����
R = mid - 1 ;
else //��������һ�����
L = mid + 1;
}while(L <= R);
ioFile.close();
return 0;
}

