在之前,我已经学完了C语言,数据结构初阶(C实现)。从本篇博客开始,正式进入C++的学习历程。C++的学习要结合之前C语言以及数据结构的知识,在学习C++的过程中顺便复习巩固已经学过的知识。
愿自己能够持续努力,输出更多关于C++的优质文章。
通过看完本篇解决以下问题:
1. using namespace std;是什么意思?
2. 你了解命名空间吗?会使用吗?
3.? <<? 符号是什么?
4.函数重载是什么?使用有什么注意事项?
目录
3.3.3使用using namespace 命名空间名称引入
1.helloworld的实现代码
(本篇看完就能知道每一行代表的意思)
#include <iostream>
using namespace std;
int main()
{
cout << "hello world!" << endl;
return 0;
}结果显示:

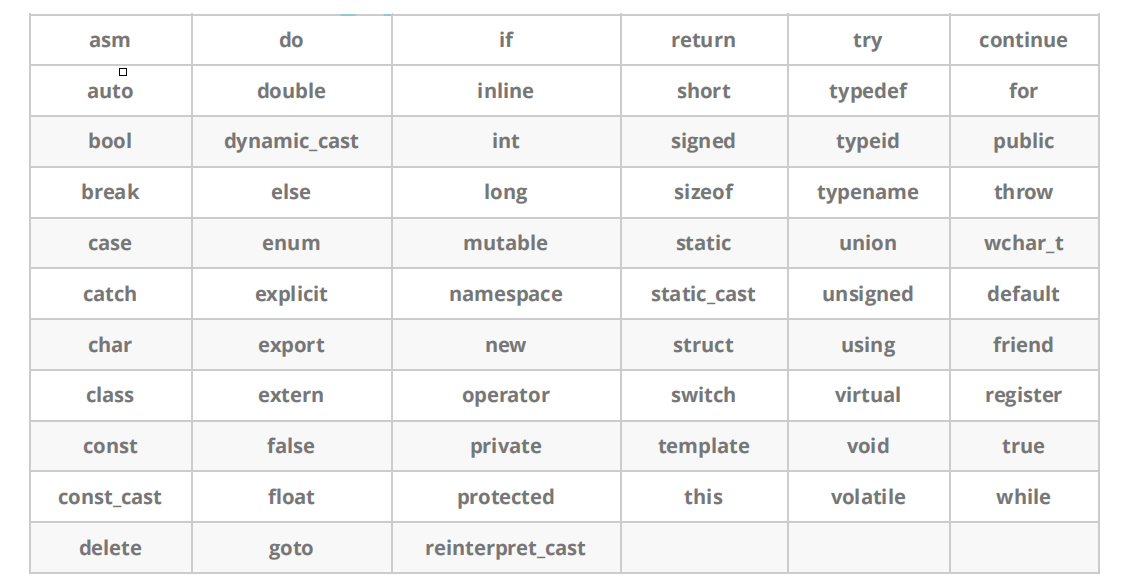
2.C++关键字
3.命名空间?
3.1问题引入
1.我们在看过或者学过C++的小伙伴们都遇到过C++程序都会包括这个头文件
#include <iostream>?这个类似于我们C语言中的
#include <stdio.h>?这是用来和控制台进行输入和输出的。我们也可以使用C语言的这个头文件
2.那么这个是什么东西呢?
using namespace std;我们发现其中包含了我们的一个关键字 namespace。这就是命名空间。这是对C语言的补充,那我们一起来了解一下namespace。
首先,我们都知道C语言中存在一个问题:命名冲突
#include <stdio.h>
//命名冲突
int a = 10;//第一个人
int a = 10;//第二个人
int main()
{
printf("%d\n",a);
return 0;
}我们运行发现明显了明显的命名冲突错误
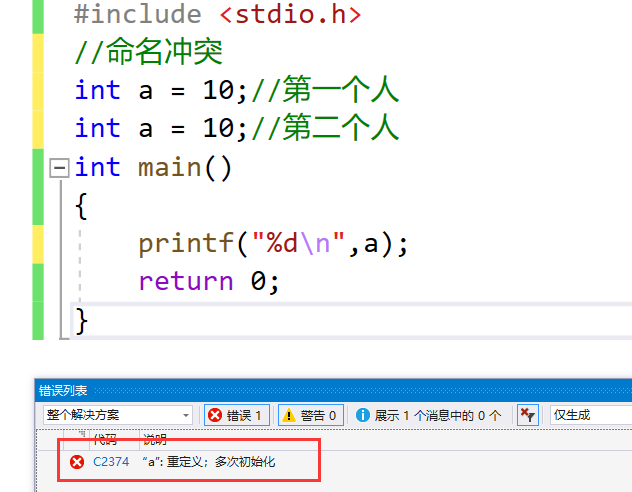
同一个作用域中变量是不能出现重复的命名的,但是如果一个小组同时开发,不知道彼此使用什么命名,这时就可能就造成命名冲突。
此时C++就引入了namespace命名空间。
定义命名空间,需要使用到 namespace 关键字 ,后面跟 命名空间的名字 ,然 后接一对 {} 即可,{}中即为命名空间的成员。
3.2命名空间的定义
3.2.1? :: 域作用限定符
我们来看看这段代码,他的输出结果是多少?
#include <stdio.h>
int a = 0;
int main()
{
int a = 1;
printf("%d\n", a);//局部a
return 0;
}我们在C语言学习过知道这里 肯定会输出 1,在之前作用域的学习过程中我们知道局部优先。
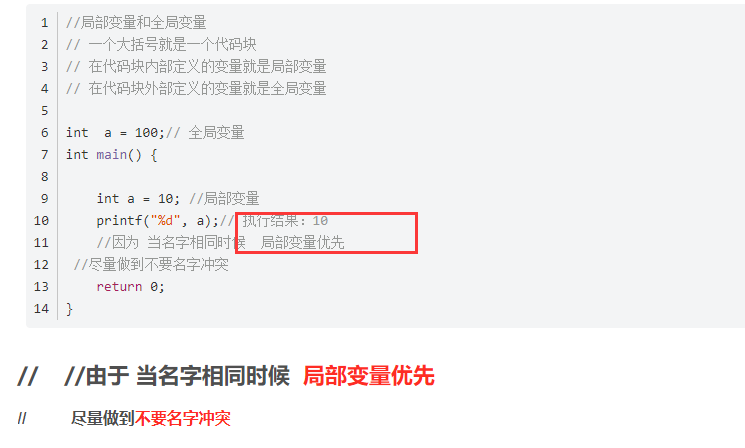
那么我现在就想访问全局的a,应该怎么办呢?
此时我们就要使用域作用限定符(::),::这个符号叫做域作用限定符,他的功能是根据::左边的域找变量,如果左边空白就默认全局域
#include <stdio.h>
int a = 0;
int main()
{
int a = 1;
printf("%d\n", a);//局部a
printf("%d\n", ::a);//::域作用限定符 全局a
return 0;
}我们看输出结果发现拿到了全局的a

3.2.2命名空间的使用
如果我们要避免这个a变量的重复出现,这时就可以使用命名空间。
命名空间的格式:
//1. 普通的命名空间
namespace N1 // N1为命名空间的名称
{
// 命名空间中的内容,既可以定义变量,也可以定义函数
int a;
int Add(int left, int right)
{
return left + right;
}
//也可以定义类型
struct ListNode//可以定义类型
{
int val;
struct ListNode* next;
};
}那么刚刚不同人写的两段代码我们就可以使用命名空间来包含起来:
#include <stdio.h>
//命名冲突
namespace N1
{
int a = 10;//第一个人
}
namespace N2
{
int a = 20;//第二个人
}
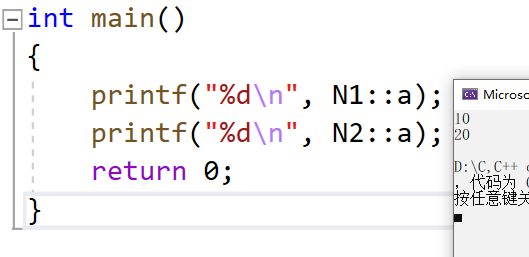
int main()
{
printf("%d\n",N1::a);
return 0;
}此时我们看到我们输入的是N1::a,这时我们就是拿到的N1空间域内部的a,如果我们想拿到N2空间域的a,N2::a就得到了这样的结果:
3.2.3命名空间的嵌套使用
?命名空间也是可以嵌套使用的,结构如下:
namespace N2
{
int a;
int b;
int Add(int left, int right)
{
return left + right;
}
namespace N3
{
int c;
int d;
int Sub(int left, int right)
{
return left - right;
}
}
}?我们也举个例子方便理解:
//命名空间还可以嵌套使用
namespace lxy
{
int c = 1;
namespace data
{
//数据组
int d = 5;
}
namespace cache
{
//缓存组
int e = 10;
}
}我们发现lxy下的空间内部又嵌套了data和cache,那使用的时候怎么使用其实也非常简单

注意:一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间中。
3.3命名空间的使用方式
?命名空间的使用有三种方式:
3.3.1加命名空间名称及作用域限定符
这就是我们刚刚一直所使用的方式,我们再看看其结构:
int main()
{
printf("%d\n", N::a);
return 0;
}3.3.2使用using将命名空间中成员引入?
假设我们要经常使用某一个命名空间中的定义的东西,那我们每次使用的时候都要使用:: 我们发现这是很不方便的,因此我们使用using 就相当于把这个命名空间的作用域放开了。
namespace lxy
{
namespace data
{
//数据组
int d = 5;
}
}
using lxy::data::d;
int main()
{
printf("%d\n", d);
return 0;
}我们发现使用using lxy::data::d之后,我们发现主函数就可以直接使用d。
3.3.3使用using namespace 命名空间名称引入
namespace lxy
{
namespace data
{
//数据组
int d = 5;
}
}
using namespace lxy;
using namespace data;
int main()
{
printf("%d\n", d);
return 0;
}?我们这样也是可以在main函数直接使用的。
因此我们可以回看helloworld程序中的第二行,我们就知道了这是放开了C++中标准库的命名空间。
#include <iostream>
using namespace std;//std 封C++库的命名空间
int main()
{
cout << "hello world" << std::endl;
return 0;
}4.C++输入和输出
这里先简单的了解一下C++的输入和输出,后续还会专门学习输入输出流。
我们先以这个helloworld为例来进行简单的了解:
#include <iostream>
using namespace std;
int main()
{
cout << "hello world!" << endl;
return 0;
}在这里我们知道cin是输入,cout是输出,那其中的<< 和>>又分别指的是什么呢?
答:>>是流提取运算符,<<流插入运算符。其中输入和输出都是可以输入多个和输出多个的。其中endl是换行符。其中在C语言中的'\n'仍然是可以使用的。

?
说明:1. 使用 cout 标准输出 ( 控制台 ) 和 cin 标准输入 ( 键盘 ) 时,必须 包含 < iostream > 头文件 以及 std 标准命名空间。注意:早期标准库将所有功能在全局域中实现,声明在 .h 后缀的头文件中,使用时只需包含对应头文件即可,后来将其实现在std 命名空间下,为了和 C 头文件区分,也为了正确使用命名空间,规定 C++ 头文件不带.h ;旧编译器 (vc 6.0) 中还支持 <iostream.h> 格式,后续编译器已不支持,因此 推荐 使用 <iostream>+std 的方式。2. 使用 C++ 输入输出更方便,不需增加数据格式控制,比如:整形 --%d ,字符 --%c
4.1缺省参数
缺省参数在C语言中也是不支持的,它具体是什么?
缺省参数是 声明或定义函数时 为函数的 参数指定一个默认值 。在调用该函数时,如果没有指定实参则采用该默认值,否则使用指定的实参。
我们举个例子可以看看:
缺省参数
void TestFunc(int a = 0)
{
cout << a << endl;
}
int main()
{
TestFunc();//没有参数时,是用参数的默认值
TestFunc(1);
return 0;
}?在这段代码中第一个TestFunc函数是没有传参的,在C语言中,这是显然错误的,但是在C++语言中如果函数有默认值,当函数不传参时,就会使用默认值。但是一旦传参,函数就会以传入的参数为准。因此缺省参数好比是一个备胎。
4.2缺省参数的分类
4.2.1全缺省参数
全缺省参数就是每个参数都有默认值,因此可以都不传,不传参数就会使用默认值,但是如果要传参数,传入的参数必须是从左往右传,如果想跳过a,使用a的默认值,传b这是不可以的。
全缺省
// 可以都不传,但是要传是从左往右传
void TestFunc(int a = 10, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl<<endl;
}
int main()
{
TestFunc();
TestFunc(1);
TestFunc(1,2);
TestFunc(1, 2,3);
return 0;
}运行结果: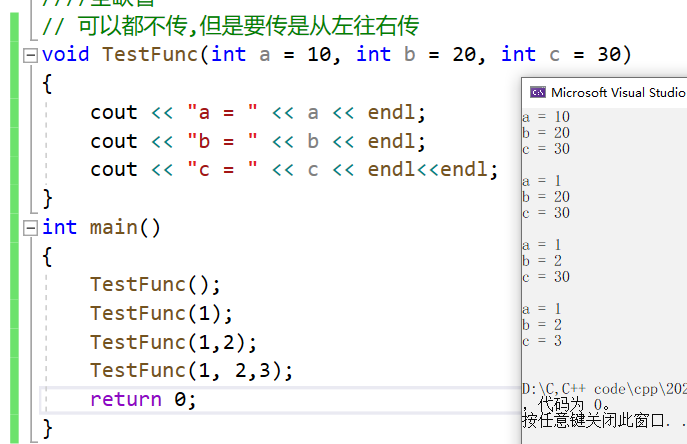
?
4.2.2半缺省参数?
半缺省参数就是必须至少传一个,并且按照顺序从左往右传。
void TestFunc(int a, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl<<endl;
}
int main()
{
TestFunc(1);
TestFunc(1, 2);
TestFunc(1, 2, 3);
return 0;
}此时我们观察上述代码:TestFunc函数的第一个参数a是没有默认值的,这时必须给a传值,否则就会出错。
半缺省参数在栈中的灵活使用:
我们知道栈的初始化要开辟空间,如果我们默认让栈的空间是4,如果我们不传参就使用默认的4个空间,如果我们想要多大,再传多大,这时我们就不用每次都需要开辟,我们只需要更改空间大小的参数值即可。
struct Stack
{
int* a;
int size;
int capacity;
};
void StackInit(struct Stack* ps, int n = 4)
{
assert(ps);
ps->a = (int*)malloc(sizeof(int) * n);
ps->size = 0;
ps->capacity = n;
}
int main()
{
Stack st;
StackInit(&st, 100);
return 0;
}5.函数重载
5.1函数重载的概念
函数重载 : 是函数的一种特殊情况, C++ 允许在 同一作用域中 声明几个功能类似 的同名函数 ,这些同名函数的 形参列表 ( 参数个数 或 类型 或 顺序 ) 必须不同 ,常用来处理实现功能类似数据类型不同的问题。
?我们可以根据参数列表的不用选择同名但不同的函数进行调用。
int Add(int left, int right)
{
return left + right;
}
double Add(double left, double right)
{
return left + right;
}
int main()
{
cout << Add(1, 2) << endl;
cout << Add(1.1, 2.2) << endl;
return 0;
}
我们发现上述两个函数名都是Add,但是我们显然可以看成他们的参数类型是不同的,因此当我们传入不同的参数是就会进入对应数据类型的函数。这就是函数重载。

我们再举一个例子看看:
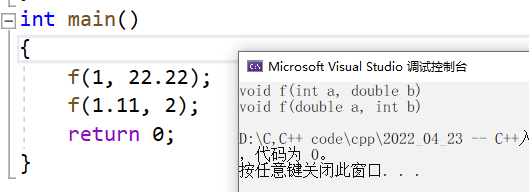
在这个例子中我们可以发现,他们的返回类型都是void,但是他们也属于函数重载,因为他们参数的顺序不同。
void f(int a, double b)
{
cout << "void f(int a, double b)" << endl;
}
void f(double a, int b)
{
cout << "void f(double a, int b)" << endl;
}
int main()
{
f(1, 22.22);
f(1.11, 2);
return 0;
}
5.2函数重载总结
总结:
函数重载要求函数名相同,参数不同
参数不同:1、参数个数不同。 2、参数的类型。3、参数的顺序(形参的类型)
?其中只要有一个不同就可构成函数重载。
(本篇完)?

