文章目录
【写在前面】
模板的进阶会涉及模板的一些更深入的知识。在此之前,我们可以看到模板在 C++ 中是随处可见的,它能支持 C++ 泛型编程,模板包括函数模板和类模板,注意,有些人可能会说模板函数和模板类,但严格来说这种说法是错误的。实际中类模板要比函数模板用的场景多,比如说 STL 中的 vector、list、stack 等是类模板;algorithm 中的 sort、find 等是函数模板。
一、非类型模板参数
模板参数分为类型形参与非类型形参。
- 类型形参:出现在模板参数列表中,跟在 class 或者 typename 之类的参数类型名称之后。
- 非类型形参,就是用一个常量作为类 (函数) 模板的一个参数,在类 (函数) 模板中可将该参数当成常量来使用。
#include<iostream>
using namespace std;
#define N 10
//实现一个静态的栈,这里的T叫做类型模板参数,定义的是一个类型
template<class T>
class Stack
{
private:
_a[N];
size_t _top;
};
int main()
{
Stack<int> st1;
Stack<int> st2;
return 0;
}
📝说明
可以看到如上问题,如果我们想更改 st1 里 _a 数组的大小,可以更改宏,但是如果希望 st1 _a 是 100,st2 _a 是 1000,只能再定义一个 Stack 类,那么分别控制 Stack 类,让它完成需求,但是如果还想要 st3 _a 是 2000、st4 _a 是 3000 呢 … …,那代码可太冗余了。针对这种问题,我们就可以使用非类型模板参数去解决。
#include<iostream>
using namespace std;
//实现一个静态的栈,这里的N叫做非类型模板参数,它是一个常量
template<class T, size_t N>
class Stack
{
private:
_a[N];
size_t _top;
};
int main()
{
Stack<int, 100> st1;
Stack<int, 1000> st2;
//验证N是常量,err,VS2017中不支持C99中的变长数组
int n;
cin >> n;
Stack<int, n> st2;
return 0;
}
📝说明
-
List item
模板这里可以想象它跟函数参数是相似的,只不过这里不仅可以使用非类型,还可以使用类型。为什么这里的 N 认定是常量呢 ―― 因为我这里的编译器是 C89 所支持的 VisualStudio2017,而 C99 才支持变长数组,而我这里依然支持 _a[N],说明 N 是常量 (已验)。
-
List item
非类型模板参数使用场景 ?
deque 里就使用到了非类型模板参数,它要传一个一个常量来控制 buff 的大小,其次 C++11 里的 array 容器也使用到了非类型模板参数。

-
List item
浅谈 array 容器 ?
array 是 C++11 所支持的,array 的结构类似于 vector,但是 array 相比 vector 它是静态的,并且没有提供头插、头删、尾插、尾删、任意位置插入删除,因为它不存在这种说法,也没必要,它可以使用 operator[]。但是 array 容器是不推荐使用的,比如明确知道需要多少空间,也不建议使用,说明它是有缺陷的。
array 的大概结构:

array 的缺陷:array 容器的底层是在栈上开辟空间的,而栈空间又是极其有限的,在 32 位机器的 Linux 下栈空间一般只有 8M,很容易造成栈溢出,所以一般开大容量的空间时,是极其不推荐使用 array 的,相比情况下就更推荐使用 vector,可以看到如果小空间还好,其实干脆一点什么场景都不用 array 了,array 相比 vector 也没啥优势,在知道要开多大空间的情况下,vector 也可以一次性开好空间,避免 vector 增容的劣势。
这里就可以看到静态的数据结构有两大缺陷,a) 空间固定,不够灵活。 b) 消耗栈空间
那为啥还要有 array 的存在呢 ?
这也是 C++ 被吐槽最多的一个角度 (你说你增加了很多无用的东西也就算了,刚需的东西却也迟迟不到,比如网络库)。你要说这个 array 有无价值,当然有,也可以这么说 array 要比 vector 要快一点,但是其实有点微乎其微,还把这门语言变 “ 重 ” 了,反而让弊大于利。
-
List item
浅谈 forward_list 容器 ?
同样没啥价值,它是单链表,也是 C++11 所提供的。
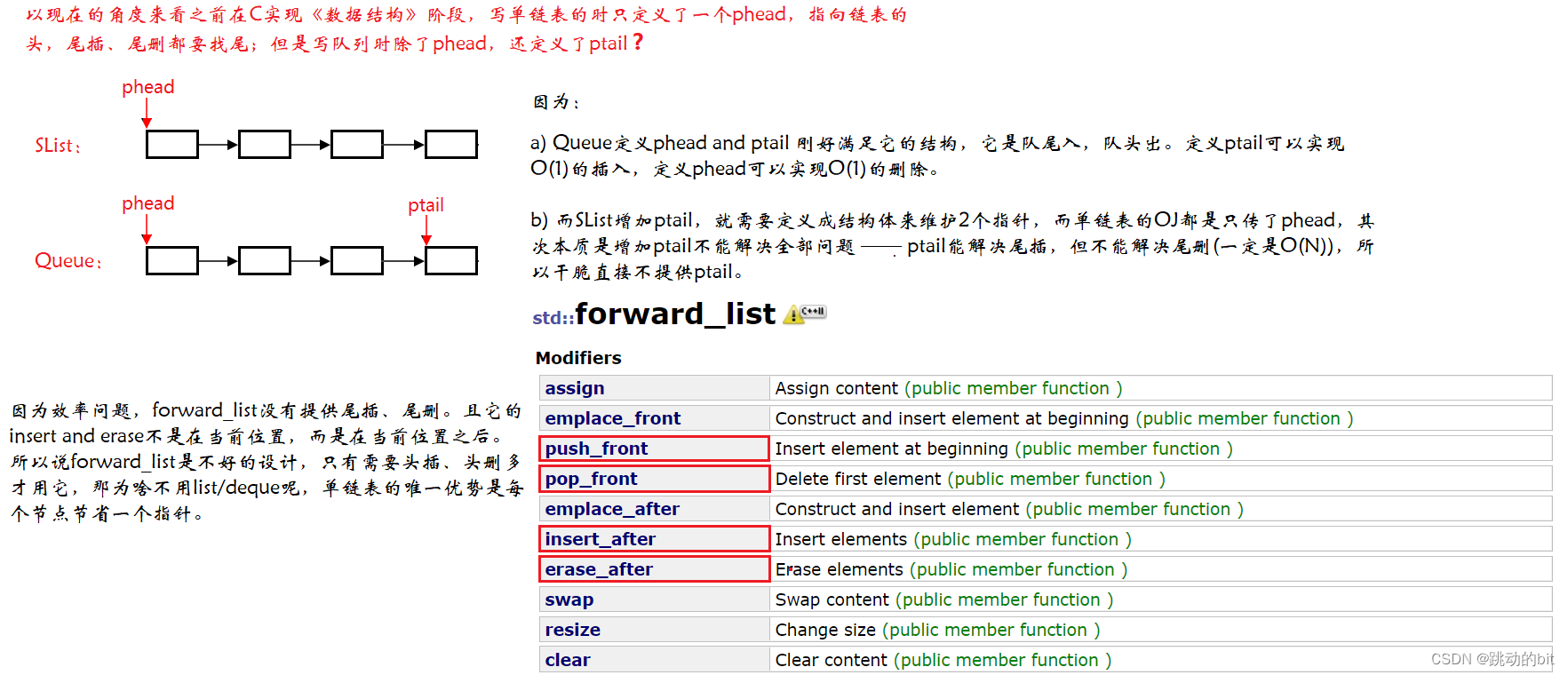
C++11 增加了 4 个容器,其中 <array>、<forward_list> 比较鸡肋,<unordered_map>、<unordered_set> 是哈希表,比较有用,后面我们会学。
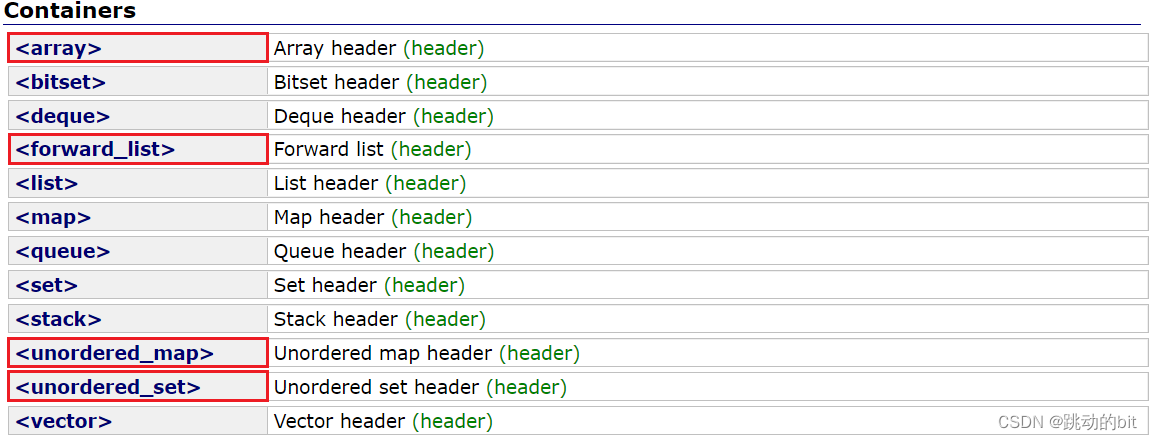
非类型模板参数补充 ?
#include<iostream>
using namespace std;
//template<size_t N = 10, class Container = deque<T>>//不管是非类型模板参数,还是类型模板参数都可以给缺省值,且与函数参数的缺省值是完全类似的(全缺省、半缺省(从右至左))。
//template<class T, string s>//err,不支持类对象作为非类型模板参数
//template<class T, double d>//err,不支持浮点数及字符串作为非类型模板参数
template<class T = int, size_t N = 10>//全缺省的模板参数调用方式如下
class Stack
{
private:
_a[N];
size_t _top;
};
int main()
{
//全缺省模板参数调用方式
Stack<> s1;
Stack<int> s2;
Stack<int, 100> s3;
return 0;
}
二、模板的特化
💦 概念
通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型可能会得到一些错误的结果,比如:
template<class T>
bool IsEqual(const T& left, const T& right)
{
//C/C++不支持用类型比较
/*if(T == const char*)//string
{}
else//int
{}*/
return left == right;
}
int main()
{
cout << IsEqual(1, 2) << endl;//ok
char p1[] = "hello";
char p2[] = "hello";
cout << IsEqual(p1, p2) << endl;//err
return 0;
}
📝说明
可以看到对于 IsEqual 函数,它支持用 2 个整型去比较,但是它不支持字符串比较,且这里的 p1 and p2 比的是地址。大聪明们一般会判断类型,但是在 C/C++ 中不可以使用类型去比较,所以 C/C++ 里针对这种场景给出了 " 模板特化 " ―― 在原模板类的基础上,针对某些类型进行特殊化处理。模板特化又分为函数模板特化和类模板特化。
💦 函数模板特化
函数模板的特化步骤:
- 必须要先有一个基础的函数模板。
- 关键字 template 后面接一对空的尖括号 <>。
- 函数名后跟一对尖括号,尖括号中指定需要特化的类型。
- 函数形参表必须要和函数模板的基础参数类型完全相同,如果是不同编译器可能会报一些奇怪的错误。
template<class T>
bool IsEqual(const T& left, const T& right)
{
return left == right;
}
//函数模板匹配原则
//err,表达式必须是可修改的左值,p1 and p2做为形参传给left and right,并且是p1 and p2的别名,这里 p1 and p2 是数组名,带有const属性,注意实参的const修饰的是*left,这里属于权限放大。
//bool IsEqual(const char*& left, const char*& right)
/*bool IsEqual(const char* const& left, const char* const& right)//ok,这里就非常考验咱基础扎实与否了,const在*左边,修饰*left,const在*右边,修饰left。
{
return strcmp(left, right) == 0;
}*/
//同上,不使用引用就可以不用const,因为这时是值拷贝,并不会影响实参。
/*bool IsEqual(const char* left, const char* right)
{
return strcmp(left, right) == 0;
}*/
//函数模板的特化,有bug,待改
template<>
bool IsEqual<const char*>(const char* const& left, const char* const& right)
{
return strcmp(left, right) == 0;
}
int main()
{
cout << IsEqual(1, 2) << endl;//ok
char p1[] = "hello";
char p2[] = "hello";
cout << IsEqual(p1, p2) << endl;
return 0;
}
📝说明
严格的说,以上 2 种写法不是特化,而是模板的匹配原则 ―― a) 有现成完全匹配的,就直接调用,没有现成调用的,实例化模板生成。 b) 有需要转换匹配的,那么它会优先选择去实例化模板生成。
再来看一个例子:
template<class T>
void Swap(T& a, T& b)
{
//对于v1 and v2对象虽然Swap能成功,但是Swap里会完成3次深拷贝,所以针对v1 and v2我们有必要做特殊处理。
T tmp = a;
a = b;
b = tmp;
}
//模板匹配原则来进行特殊处理
/*void Swap(vector<int>& a, vector<int>& b)
{
a.swap(b);
}*/
//函数模板的特化,标准的特殊化处理
template<>
void Swap<vector<int>>(vector<int>& a, vector<int>& b)
{
a.swap(b);
}
//对于下面的v3 and v4,目前好像只能这样特化
template<>
void Swap<vector<double>>(vector<double>& a, vector<double>& b)
{
a.swap(b);
}
int main()
{
int x = 1, y = 2;
Swap(x, y);
vector<int> v1 = { 1, 2, 3, 4 };
vector<int> v2 = { 10, 20, 30 };
Swap(v1, v2);
vector<double> v3 = { 1.1, 2.2, 3.3, 4.4 };
vector<double> v4 = { 10.1, 20.2, 30.3 };
Swap(v3, v4);
return 0;
}
📝说明
对于模板匹配原则 and 函数模板特化,两者底层并无差别,如果能使用模板匹配原则特化就更推荐使用模板匹配原则来进行特化。
💦 类模板特化
1、全特化
全特化:即是将模板参数列表中所有的参数确定化。
template<class T1, class T2>
class Data
{
public:
Data(){cout << "Data<T1, T2>" << endl;}
private:
T1 _d1;
T2 _d2;
};
//全特化
template<>
class Data<double, double>
{
public:
Data(){cout << "Data<double, double>" << endl;}
private:
};
int main()
{
Data<int, int> d1;
Data<double, double> d2;
return 0;
}
2、偏特化
偏特化 (半特化):任何针对模版参数进一步进行条件限制设计的特化版本。比如对于以下模板类:
template<class T1, class T2>
class Data
{
public:
Data(){cout << "Data<T1, T2>" << endl;}
private:
T1 _d1;
T2 _d2;
};
//偏特化(半特化)
//只要第二个模板参数是char,那么它就会匹配
template<class T1>
class Data<T1, char>
{
public:
Data(){cout << "Data<T1, char>" << endl;}
private:
T1 _d1;
};
//当两个模板参数是指针就会匹配,不管是什么类型的指针
template<class T1, class T2>
class Data<T1*, T2*>
{
public:
Data(){cout << "Data<T1*, T2*>" << endl;}
private:
T1 _d1;
T2 _d2;
};
//T1&, T2&
template<class T1, class T2>
class Data<T1&, T2&>
{
public:
Data(){cout << "Data<T1&, T2&>" << endl;}
private:
T1 _d1;
T2 _d2;
};
//T1&, T2*
template<class T1, class T2>
class Data<T1&, T2*>
{
public:
Data(){cout << "Data<T1&, T2*>" << endl;}
private:
T1 _d1;
T2 _d2;
};
int main()
{
Data<double, int> d1;
Data<double, char> d2;
Data<int*, char*> d3;
Data<int&, char&> d4;
Data<int&, char*> d5;
return 0;
}
📝说明
偏特化并不仅仅是指特化部分参数,而是针对模板参数更进一步的条件限制所设计出来的一个特化版本,比如说限定你的类型是指针。
在前面谈到的类型萃取本质就是特化,关于特化的场景我们现在还不好举例,等后面的哈希表会再见面。
三、模板分离编译
💦 什么是分离编译
一个程序 (项目) 由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程称为分离编译模式。
💦 模板的分离编译
假如有以下场景,模板的声明与定义分离开,在头文件中进行声明,源文件中完成定义:
背景 ?
在 C语言实现数据结构时,我们写的顺序表、链表等,都是写一个 SeqList.h 文件用于声明,SeqList.c 用于定义,test.c 用于测试。而到 STL 这里都是定义 vector.h 用于声明定义或定义,test.cpp 用于测试。这是因为 C++ 里的模板不支持分离编译。
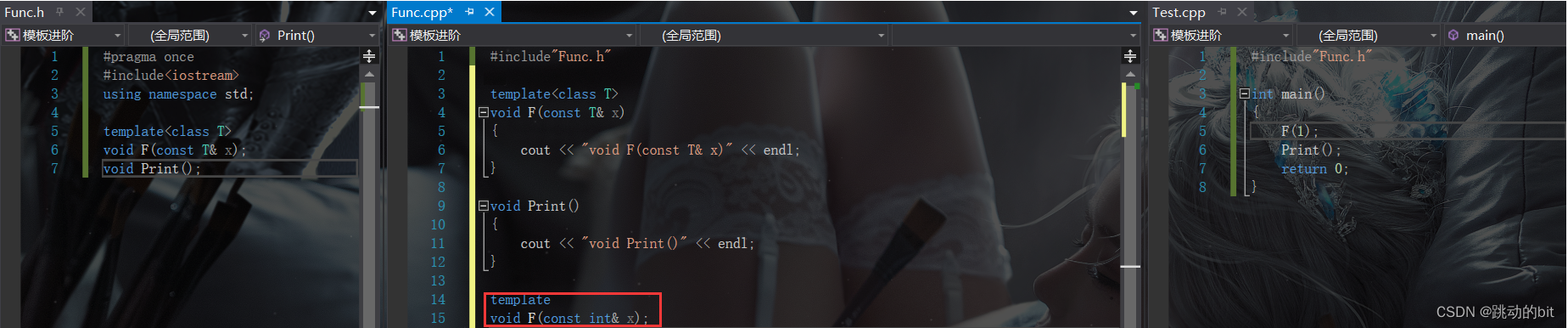
可以看到这里调用 F 后报了链接错误,链接错误一般都是在链接时找不到它的定义,但是我这里有定义 F 的呀,相比 Print 都找的到,而 F 为啥找不到 ?
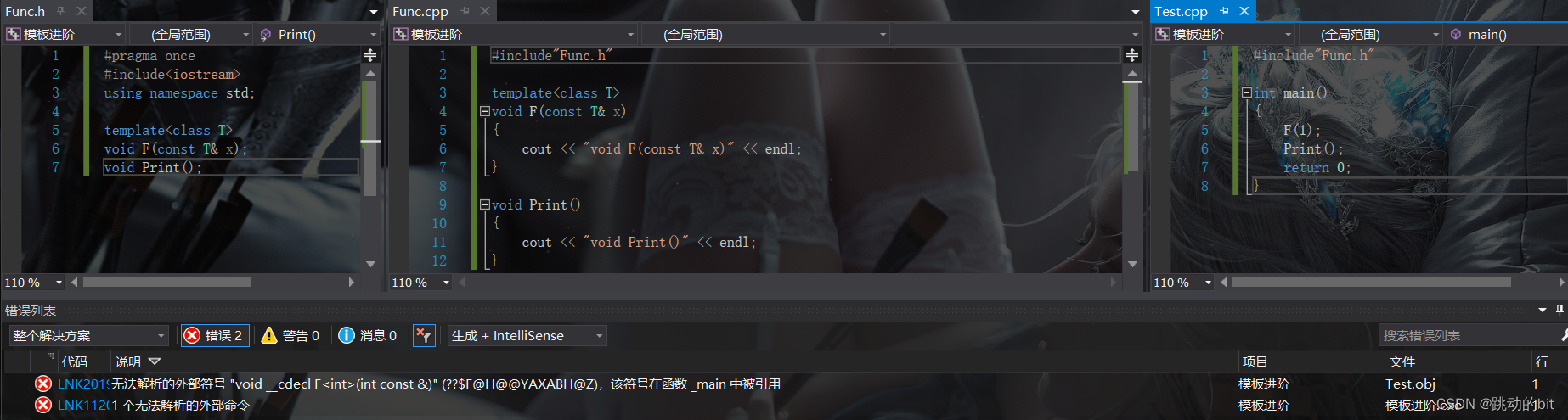
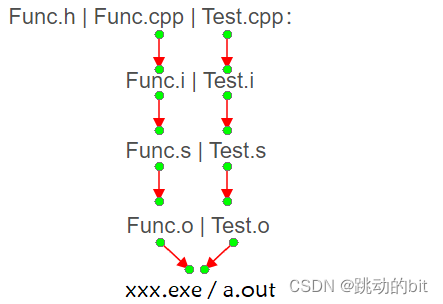
我们先回顾下程序的编译过程 Func.h | Func.cpp | Test.cpp:
-
预处理 ―― 头文件展开、宏替换、条件编译、去掉注释后,生成一份干净的 C 原始程序。
Func.i | Test.i

-
编译 ―― 语法检查后,生成汇编代码。
Func.s | Test.s
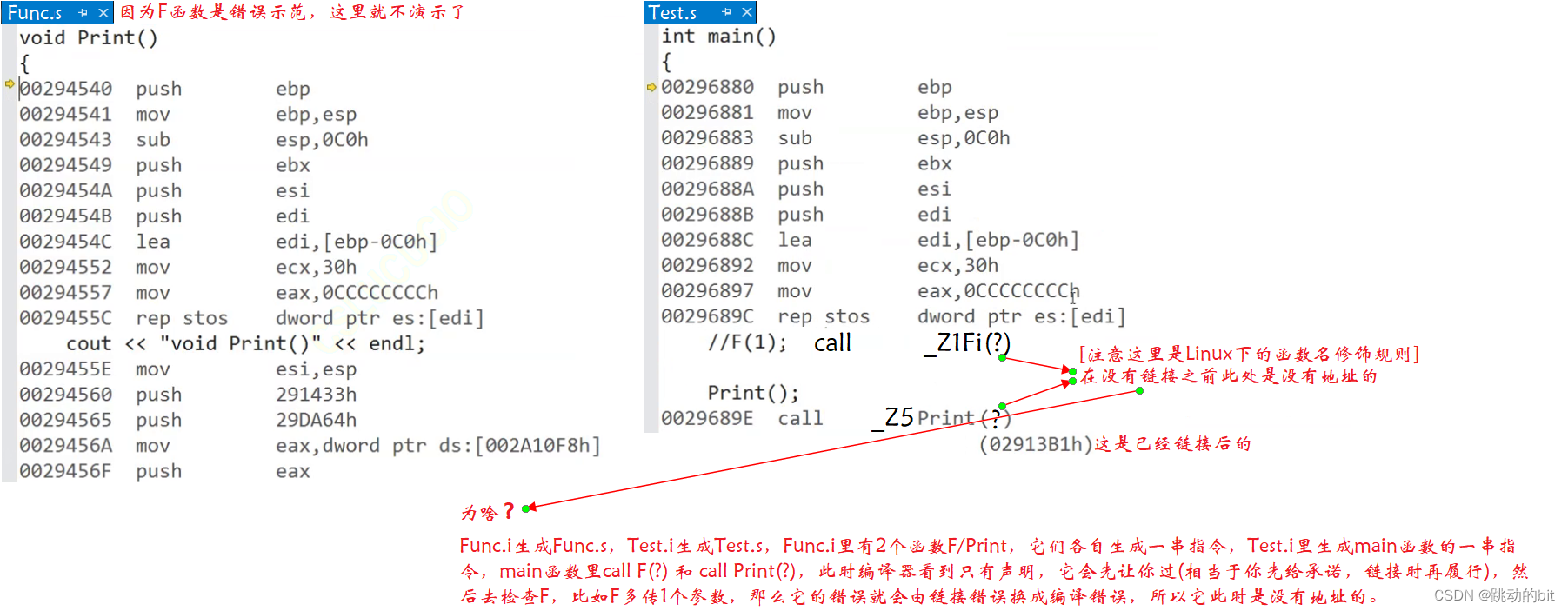
-
汇编 ―― 把汇编代码转成二进制机器码
Func.o | Test.o
-
链接 ―― 把类似 Test.o 里面 F and Print 这样没有地址的地方,拿修饰过的函数名去 Func.o (符号表里会把函数名和对应地址建立起来) 中查找,找到后填上地址。再把目标文件合并到一起,生成可执行程序。
为什么不能分离编译 ?
用函数名去查找时 Print 能找到,但是 F 找不到,如下标识处就是 Windows 下函数名 F 的修饰规则修饰出来的函数名。

因为在链接之前,这 2 个文件都是各自玩各自的,只有在链接时才会交汇。Func.i 编译成 Func.s 时就存在一个问题,Print 有定义可以生成,但是 F 是 1 个模板,它不能生成,因为不知道 T 是什么类型,这里只有 Test.i 才知道 T 是什么类型,等到链接时就晚了,所以它找不到 F 的定义。
💦 解决方法
? A):
先说一下不可行的方法,让编译器在编译的时候去各个地方查找实例化,比如说在 Func.i 里看到有 1 个模板,然后去 Test.i 里找实例化,但是这样对于编译器的实现就复杂了,这样说的原因是如果是大项目,有几百个文件的情况下,那么成本就非常高了。所以说在链接之前,它们是不会互相交互的。
? B):
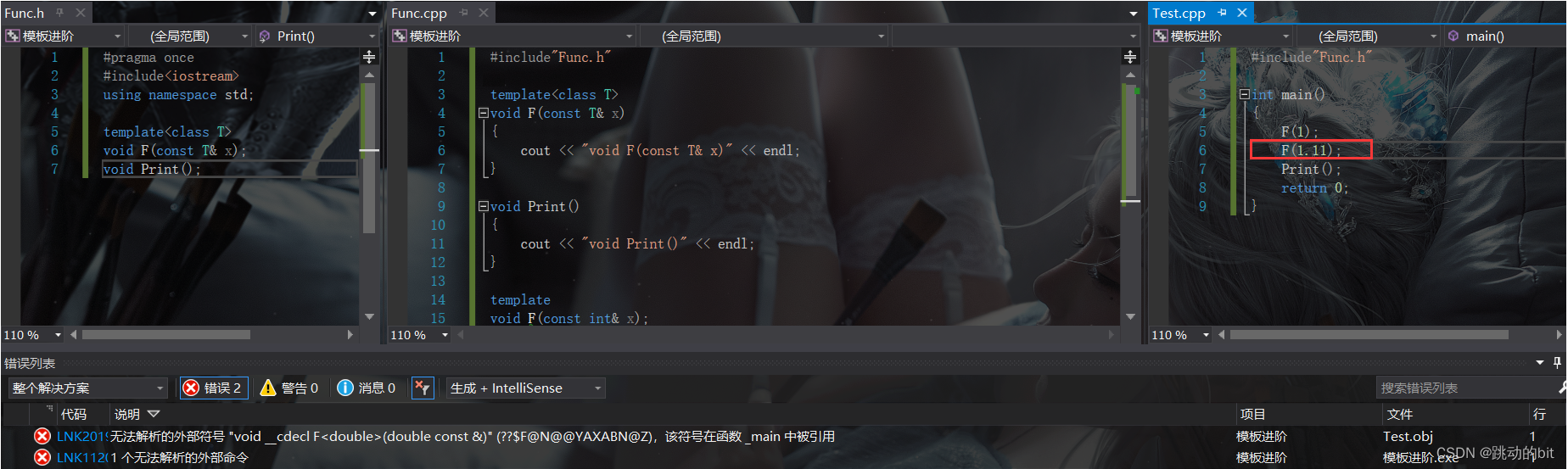
显示指定实例化,编译器看到后会就知道你要把这个 T 实例化什么类型。
但是显示实例化带来的问题是我换个类型就又链接不上了,因为你这里只显示实例化了 int,解决方法是再显示实例化对应类型,这种方式的缺陷也很明显 ―― 使用一种类型就得显示实例化一个,很麻烦,一点也不通用。
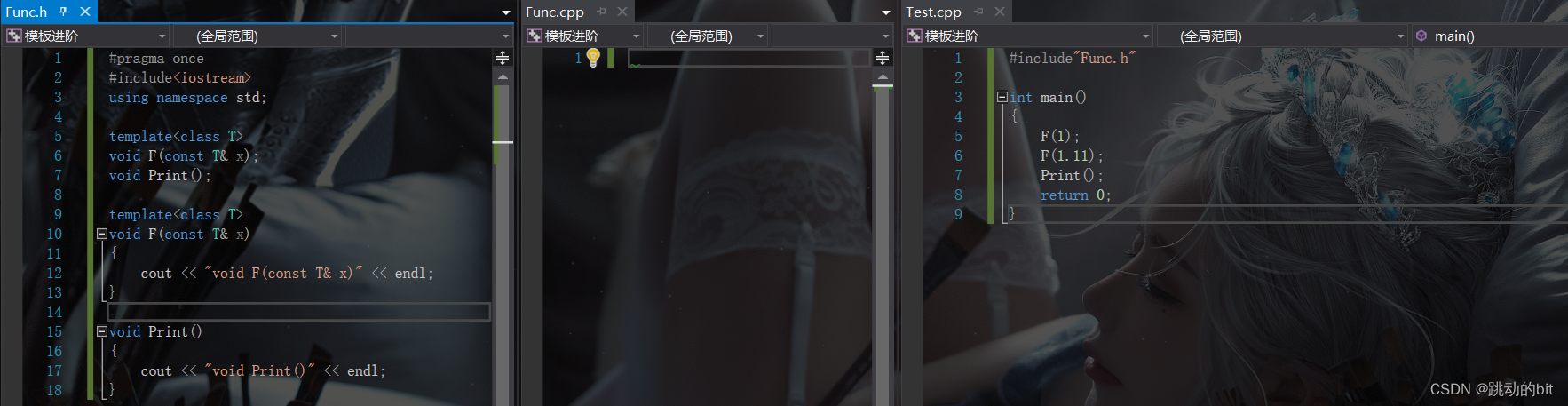
? C) 推荐:
这种方法非常的粗暴,STL 源码中也是使用这种粗暴的方案,不分离编译,声明和定义或者直接定义在 Func.h 中。因为 Func.h 中包含了模板的定义,就不需要链接的时候去查找了,直接在编译阶段就直接填地址了。有些地方可能会把就种声明和定义放一起的模板,它会定义成 Func.hpp,也就是说它既是 .h,也是 .cpp。
分离编译扩展阅读
💦 补充
同样我们的类模板也不支持分离编译,最好的办法就是不分离,要调用构造、析构,需要找它们的地址,此时就不需要在链接时去找了,在编译时既有声明也有定义,然后这里编译成指令的同时就可以拿到它们的地址了。
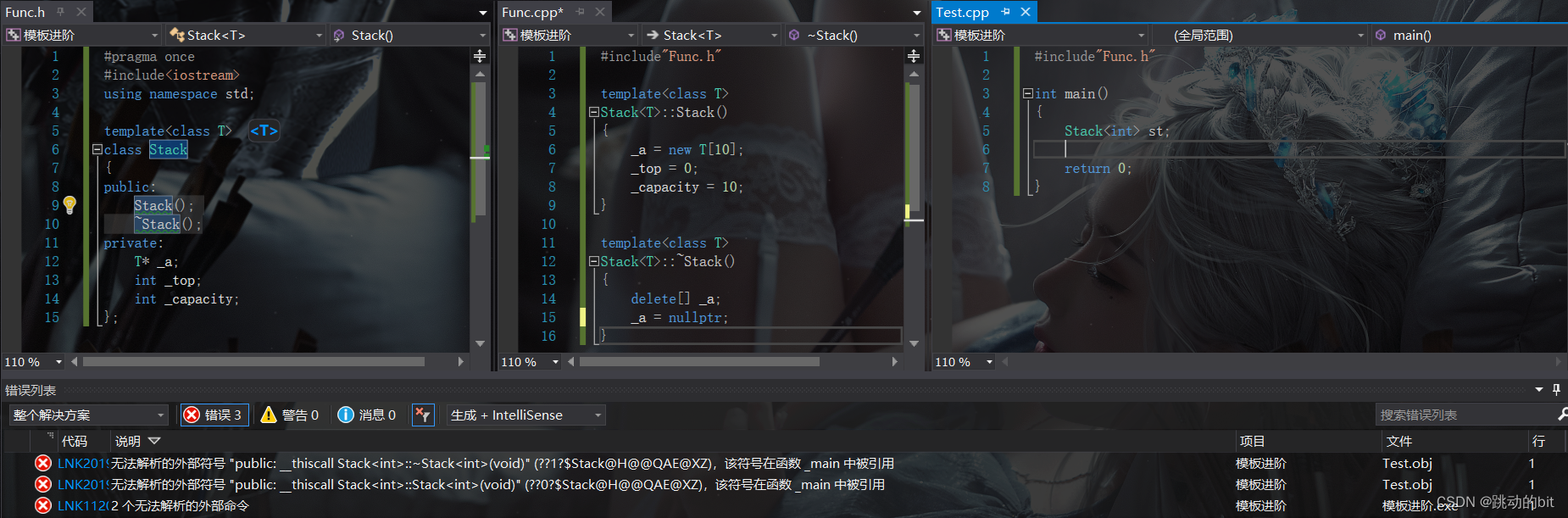
按需实例化 ?
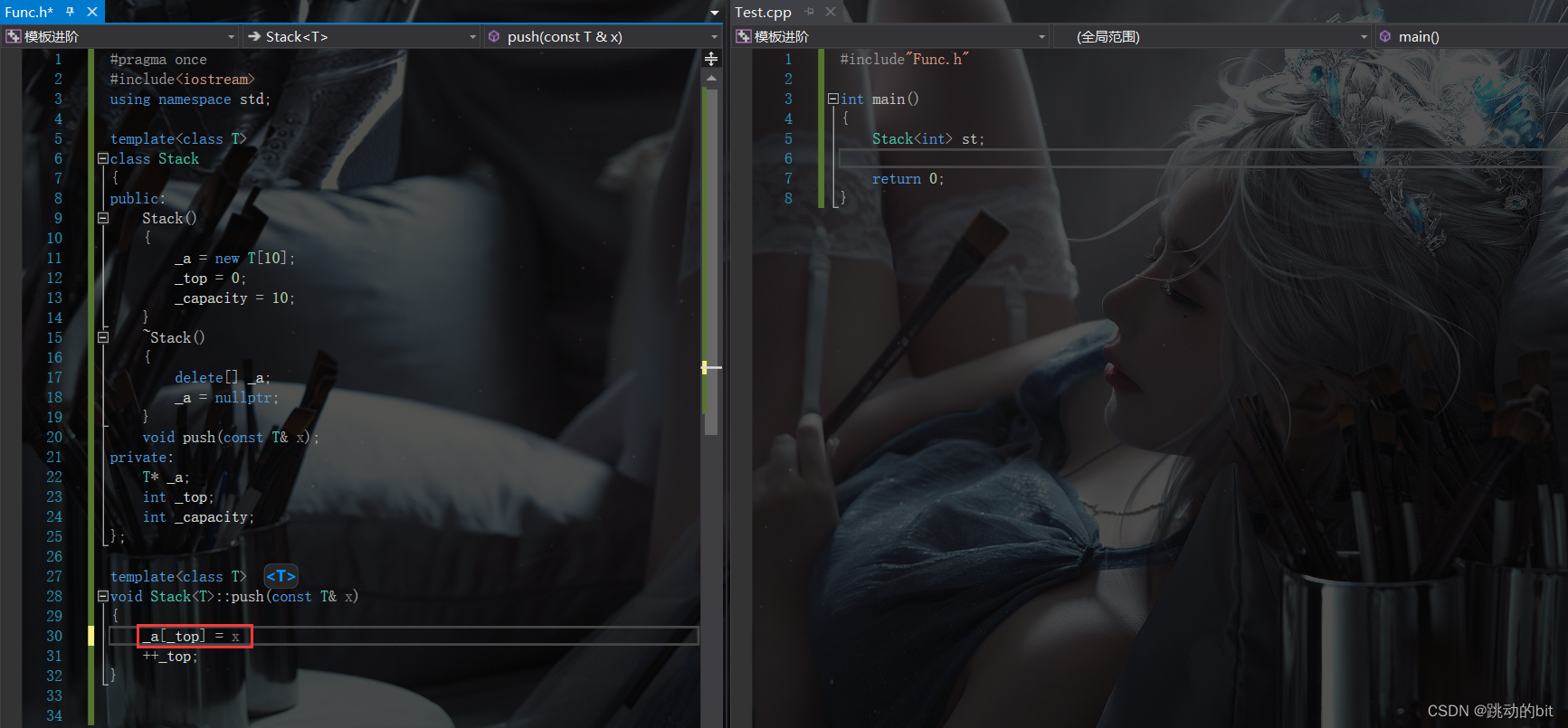
紧接着,我们又实现了一个 push,并且 push 的定义里有一个语法错误 ―― 少一个分号,但是奇怪的是我竟然能编译通过。原因其实也很简单,模板如果没有实例化,编译器不会去检查模板函数内部的语法错误。
四、模板总结
【优点】
- 模板复用了代码,节省资源,更快的迭代开发,C++ 的标准模板库 (STL) 也因此而产生。
- 增强了代码的灵活性
【缺点】
-
模板会导致代码膨胀问题,也会导致编译时间变长。
-
出现模板编译错误时,错误信息非常凌乱,且准确度不高 (不要轻易去相信模板的报错),不易定位错误。可能只是一个小错误,却报出一大串的错误 (深有体会),此时一定要优先看第一个错误。
但是整体而言,模板肯定是优点远大于缺点的。

