ЮФеТФПТМ
1ЁЂМђНщ
1.1 ANSI
ANSIЪЧвЛжжзжЗћДњТы,ЮЊЪЙМЦЫуЛњжЇГжИќЖргябд,ЭЈГЃЪЙгУ 0x00~0x7f ЗЖЮЇЕФ1 ИізжНкРДБэЪО 1 ИігЂЮФзжЗћЁЃГЌГіДЫЗЖЮЇЕФЪЙгУ0x80~0xFFFFРДБрТы,МДРЉеЙЕФASCIIБрТыЁЃ
дкМђЬхжаЮФWindowsВйзїЯЕЭГжа,ANSI БрТыДњБэ GBK БрТы;дкЗБЬхжаЮФWindowsВйзїЯЕЭГжа,ANSIБрТыДњБэBig5;дкШеЮФWindowsВйзїЯЕЭГжа,ANSI БрТыДњБэ Shift_JIS БрТыЁЃ
ASCIIдкФкЕФ1зжНкзжЗћ128Иі,МДcharаЭЕФе§Ъ§,ККзж2зжНк,ЕквЛИізжНкЪЧ0X80вдЩЯ,МДcharаЭИКЪ§ЕквЛзжНк,ЮФМўПЊЭЗУЛгаБъжО,жБНгЪЧФкШнЁЃжБНгЖСШЁ,МЦЫуЛњЛсНсКЯБОЕиЕФБрТы(ШчGBKНјааЯдЪО)ЁЃ
🍺ASCIIЯрЙиЮФеТЛузмШчЯТ🍺:
- 🎈ASCIIТыЖдееБэ(255ИіasciiзжЗћЛузм)🎈
- 🎈ASCIIТыЖдееБэ(PythonДњТыЪЕЯжДђгЁ)🎈
- 🎈ASCIIТыЖдееБэ(emojiБэЧщЗћКХ)🎈
1.2 Unicode
ЖдгкгЂЮФРДНВ,ASCIIТыОЭзувдБрТыЫљгазжЗћ,ЕЋЖдгкжаЮФ,дђБиаыЪЙгУСНИізжНкРДДњБэвЛИіККзж,етжжБэЪОККзжЕФЗНЪНЯАЙпЩЯГЦЮЊЫЋзжНкЁЃЫфШЛЫЋзжНкПЩвдНтОіжагЂЮФзжЗћЛьКЯЪЙгУЕФЧщПі,ЕЋЖдгкВЛЭЌзжЗћЯЕЭГЖјбд,ОЭвЊОЙ§зжЗћТызЊЛЛ,ЗЧГЃТщЗГ,ШчжагЂЁЂжаШеЁЂШеКЋЛьКЯЕФЧщПіЁЃЮЊНтОіетвЛЮЪЬт,КмЖрЙЋЫОСЊКЯЦ№РДжЦЖЈСЫвЛЬзПЩвдЪЪгУгкШЋЪРНчЫљгаЙњМвЕФзжЗћТы,ВЛЙмЪЧЖЋЗНЮФзжЛЙЪЧЮїЗНЮФзж,вЛТЩгУСНИізжНкРДБэЪО,етОЭЪЧUNICODEЁЃ
- UnicodeзжЗћМЏПЩвдМђаДЮЊUCS(Unicode Character Set)ЁЃ
- UnicodeПЊЪМЦєгУ2ИізжНкБэЪОЁЃбмЩњГіUSC-2LE ЁЂUSC-2BEЁЂUTF8ЕШЁЃ
- етИіОЭЪЧЙЬЖЈЕФ2зжНкБэЪОзжЗћ,АќРЈгЂЮФзжЗћвВЪЧ2зжНкЁЃПЊЭЗгаЬиеї:вд0xFFEF(аЁЖЫ)КЭ0xEFFF(ДѓЖЫ)ПЊЭЗЮЊБъжОЁЃ
UnicodeБрТыЯЕЭГПЩЗжЮЊБрТыЗНЪНКЭЪЕЯжЗНЪНСНИіВуДЮЁЃ
- БрТыЗНЪН
UnicodeЪЧЙњМЪзщжЏжЦЖЈЕФПЩвдШнФЩЪРНчЩЯЫљгаЮФзжКЭЗћКХЕФзжЗћБрТыЗНАИЁЃUnicodeгУЪ§зж0-0x10FFFFРДгГЩфетаЉзжЗћ,зюЖрПЩвдШнФЩ1114112ИізжЗћ,ЛђепЫЕга1114112ИіТыЮЛЁЃТыЮЛОЭЪЧПЩвдЗжХфИјзжЗћЕФЪ§зжЁЃUTF-8ЁЂUTF-16ЁЂUTF-32ЖМЪЧНЋЪ§зжзЊЛЛЕНГЬађЪ§ОнЕФБрТыЗНАИЁЃ - ЪЕЯжЗНЪН
дкUnicodeжа:ККзжЁАзжЁБЖдгІЕФЪ§зжЪЧ23383ЁЃдкUnicodeжа,ЮвУЧгаКмЖрЗНЪННЋЪ§зж23383БэЪОГЩГЬађжаЕФЪ§Он,АќРЈ:UTF-8ЁЂUTF-16ЁЂUTF-32ЁЃUTFЪЧЁАUCS Transformation FormatЁБЕФЫѕаД,ПЩвдЗвыГЩUnicodeзжЗћМЏзЊЛЛИёЪН,МДдѕбљНЋUnicodeЖЈвхЕФЪ§зжзЊЛЛГЩГЬађЪ§ОнЁЃ
Р§Шч,ЁАККзжЁБЖдгІЕФЪ§зжЪЧ0x6c49КЭ0x5b57,ЖјБрТыЕФГЬађЪ§ОнЪЧ:
BYTE data_utf8[] = {0xE6, 0xB1, 0x89, 0xE5, 0xAD, 0x97}; // UTF-8БрТы
WORD data_utf16[] = {0x6c49, 0x5b57}; // UTF-16БрТы
DWORD data_utf32[] = {0x6c49, 0x5b57}; // UTF-32БрТы
1.3 UTF8
UTF-8вдзжНкЮЊЕЅЮЛЖдUnicodeНјааБрТыЁЃ
UTF8ЪЧБфГЄЕФБрТы,гЂЮФзжЗћЛЙга1зжНк,ККзжКЭЦфЫћИїЙњзжЗћгУ2зжНкЛђеп3зжНкЁЃ
UTF8БрТыЕФЗжЮЊДјBOMКЭВЛДјBOMЕФ,BOM(Byte Order Mark)ОЭЪЧЮФМўПЊЭЗЕФБъжОСЫЁЃ
- ДјBOMЕФUTF-8ЮФМўЪЧ:ПЊЭЗШ§зжНк,EE BB EF
- ВЛДјBOMЕФUTF-8,ПЊЭЗЮЊЬиеї,жБНгЪЧФкШн,дьГЩКЭANSIЕФвЛбљЁЃ
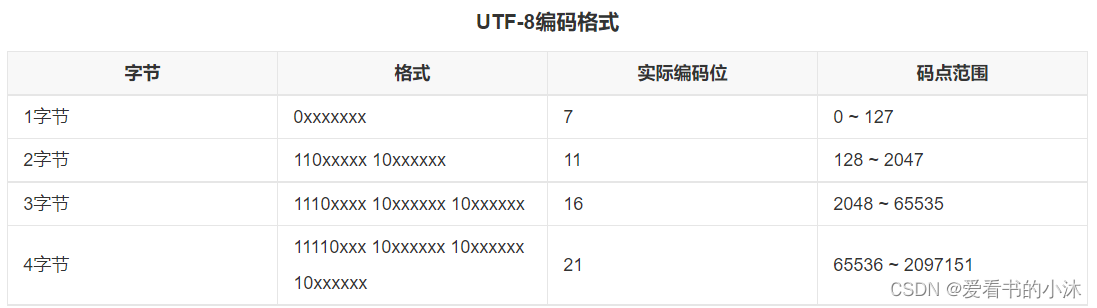
ЁАККзжЁБЕФUTF-8БрТыашвЊ6ИізжНкЁЃЁАККзжЁБЕФUTF-16БрТыашвЊСНИіWORD,ДѓаЁЪЧ4ИізжНкЁЃЁАККзжЁБЕФUTF-32БрТыашвЊСНИіDWORD,ДѓаЁЪЧ8ИізжНкЁЃИљОнзжНкађЕФВЛЭЌ,UTF-16ПЩвдБЛЪЕЯжЮЊUTF-16LEЛђUTF-16BE,UTF-32ПЩвдБЛЪЕЯжЮЊUTF-32LEЛђUTF-32BEЁЃ
2ЁЂДњТыЪЕЯж
- FxEncodeUtil.h:
/***************************************************************
* @file FxEncodeUtil.h
* @brief C++ЪЕЯжGB2312(ANSI)ЁЂUTF8ЁЂUnicodeзжЗћБрТыЛЅзЊ
* @author АЎПДЪщЕФаЁух
* @version 1.0
* @date 2022-5-18
* @platform Visual Studio 2017 / Win10 win64
* @languages C++
**************************************************************/
#pragma once
#include <assert.h>
#include <iostream>
#include <locale>
#include <codecvt>
class FxEncodeUtil
{
public:
static std::string UnicodeToUTF8(const std::wstring & wstr);
static std::wstring UTF8ToUnicode(const std::string & str);
static std::string UnicodeToANSI(const std::wstring & wstr);
static std::wstring ANSIToUnicode(const std::string & str);
static std::string UTF8ToANSI(const std::string & str);
static std::string ANSIToUTF8(const std::string & str);
static std::wstring ANSIToUnicode2(const std::string & str);
static std::string UnicodeToANSI2(const std::wstring & str);
static std::wstring UTF8ToUnicode2(const std::string & str);
static std::string UnicodeToUTF82(const std::wstring & str);
static std::string UTF8ToANSI2(const std::string & str);
static std::string ANSIToUTF82(const std::string & str);
};
- FxEncodeUtil.cpp:
/***************************************************************
* @file FxEncodeUtil.cpp
* @brief C++ЪЕЯжGB2312(ANSI)ЁЂUTF8ЁЂUnicodeзжЗћБрТыЛЅзЊ
* @author АЎПДЪщЕФаЁух
* @version 1.0
* @date 2022-5-18
* @platform Visual Studio 2017 / Win10 win64
* @languages C++
**************************************************************/
#include "FxEncodeUtil.h"
#include "gtest/gtest.h"
#include "FxUnicode.h"
#define _AMD64_
#include <winnls.h>
std::string FxEncodeUtil::UnicodeToUTF8(const std::wstring &wstr)
{
std::string ret;
try
{
std::wstring_convert<std::codecvt_utf8<wchar_t>> wcv;
ret = wcv.to_bytes(wstr);
}
catch (const std::exception &e)
{
std::cerr << e.what() << std::endl;
}
return ret;
}
std::wstring FxEncodeUtil::UTF8ToUnicode(const std::string &str)
{
std::wstring ret;
try
{
std::wstring_convert<std::codecvt_utf8<wchar_t>> wcv;
ret = wcv.from_bytes(str);
}
catch (const std::exception &e)
{
std::cerr << e.what() << std::endl;
}
return ret;
}
std::string FxEncodeUtil::UnicodeToANSI(const std::wstring &wstr)
{
char *curLocale = setlocale(LC_ALL, NULL);
setlocale(LC_ALL, "chs");
std::string ret;
std::mbstate_t state = {};
const wchar_t *src = wstr.data();
size_t len = std::wcsrtombs(nullptr, &src, 0, &state);
if (static_cast<size_t>(-1) != len)
{
std::unique_ptr<char[]> buff(new char[len + 1]);
len = std::wcsrtombs(buff.get(), &src, len, &state);
if (static_cast<size_t>(-1) != len)
{
ret.assign(buff.get(), len);
}
}
setlocale(LC_ALL, curLocale);
return ret;
}
std::wstring FxEncodeUtil::ANSIToUnicode(const std::string &str)
{
char *curLocale = setlocale(LC_ALL, NULL);
setlocale(LC_ALL, "chs");
std::wstring ret;
std::mbstate_t state = {};
const char *src = str.data();
size_t len = std::mbsrtowcs(nullptr, &src, 0, &state);
if (static_cast<size_t>(-1) != len)
{
std::unique_ptr<wchar_t[]> buff(new wchar_t[len + 1]);
len = std::mbsrtowcs(buff.get(), &src, len, &state);
if (static_cast<size_t>(-1) != len)
{
ret.assign(buff.get(), len);
}
}
setlocale(LC_ALL, curLocale);
return ret;
}
std::string FxEncodeUtil::UTF8ToANSI(const std::string &str)
{
return UnicodeToANSI(UTF8ToUnicode(str));
}
std::string FxEncodeUtil::ANSIToUTF8(const std::string &str)
{
return UnicodeToUTF8(ANSIToUnicode(str));
}
///
///
///
std::wstring FxEncodeUtil::ANSIToUnicode2(const std::string &str)
{
size_t len = str.length();
int iTextLen = ::MultiByteToWideChar(CP_ACP, 0, str.c_str(), -1, NULL, 0);
wchar_t *pUnicodeText;
pUnicodeText = new wchar_t[iTextLen + 1];
memset(pUnicodeText, 0, (iTextLen + 1) * sizeof(wchar_t));
::MultiByteToWideChar(CP_ACP, 0, str.c_str(), -1, (LPWSTR)pUnicodeText, iTextLen);
std::wstring ret;
ret = (wchar_t *)pUnicodeText;
delete pUnicodeText;
return ret;
}
std::string FxEncodeUtil::UnicodeToANSI2(const std::wstring &str)
{
char *pAnsiText;
int iTextLen = WideCharToMultiByte(CP_ACP, 0, str.c_str(), -1, NULL, 0, NULL, NULL);
pAnsiText = new char[iTextLen + 1];
memset((void *)pAnsiText, 0, sizeof(char) * (iTextLen + 1));
::WideCharToMultiByte(CP_ACP, 0, str.c_str(), -1, pAnsiText, iTextLen, NULL, NULL);
std::string ret;
ret = pAnsiText;
delete[] pAnsiText;
return ret;
}
std::wstring FxEncodeUtil::UTF8ToUnicode2(const std::string &str)
{
size_t len = str.length();
int iTextLen = ::MultiByteToWideChar(CP_UTF8, 0, str.c_str(), -1, NULL, 0);
wchar_t *pUnicode;
pUnicode = new wchar_t[iTextLen + 1];
memset(pUnicode, 0, (iTextLen + 1) * sizeof(wchar_t));
::MultiByteToWideChar(CP_UTF8, 0, str.c_str(), -1, (LPWSTR)pUnicode, iTextLen);
std::wstring ret;
ret = (wchar_t *)pUnicode;
delete[] pUnicode;
return ret;
}
std::string FxEncodeUtil::UnicodeToUTF82(const std::wstring &str)
{
char *pUtf8Text;
int iTextLen = WideCharToMultiByte(CP_UTF8, 0, str.c_str(), -1, NULL, 0, NULL, NULL);
pUtf8Text = new char[iTextLen + 1];
memset((void *)pUtf8Text, 0, sizeof(char) * (iTextLen + 1));
::WideCharToMultiByte(CP_UTF8, 0, str.c_str(), -1, pUtf8Text, iTextLen, NULL, NULL);
std::string strText;
strText = pUtf8Text;
delete[] pUtf8Text;
return strText;
}
std::string FxEncodeUtil::UTF8ToANSI2(const std::string &str)
{
return UnicodeToANSI2(UTF8ToUnicode2(str));
}
std::string FxEncodeUtil::ANSIToUTF82(const std::string &str)
{
return UnicodeToUTF82(ANSIToUnicode2(str));
}
///
///
///
TEST(FxEncodeUtilTest, StringComparison)
{
/*LCID lciid = GetUserDefaultLCID();
wchar_t szLocName[255] = L"\0";
int len = 255;
GetUserDefaultLocaleName(szLocName, len);
char *curLocale = setlocale(LC_ALL, NULL);
// setlocale(LC_ALL, NULL);
// setlocale( LC_ALL, "en-US" );
// setlocale(LC_ALL, "chs");
setlocale(LC_ALL, "zh-CN");*/
char strZhong[] = {-28, -72, -83, 0}; //жа
ASSERT_STREQ(strZhong, FxEncodeUtil::ANSIToUTF8("жа").c_str());
ASSERT_STREQ(strZhong, FxEncodeUtil::ANSIToUTF82("жа").c_str());
EXPECT_EQ(FxEncodeUtil::ANSIToUTF82("жаЙњ"), FxEncodeUtil::ANSIToUTF82("жаЙњ"));
EXPECT_EQ(FxEncodeUtil::ANSIToUTF82("ФуКУЪРНч,2022"), FxEncodeUtil::ANSIToUTF82("ФуКУЪРНч,2022"));
}
3ЁЂiconv
http://gnuwin32.sourceforge.net/packages/libiconv.htm
iconvЪЧlinuxЯТЕФБрТызЊЛЛЕФЙЄОп,ЫќЬсЙЉУќСюааЕФЪЙгУКЭКЏЪ§НгПкжЇГжЁЃ
3.1 УќСюаа
-f, --from-code=УћГЦ дЪМЮФБОБрТы
-t, --to-code=УћГЦ ЪфГіБрТы
-l, --list СаОйЫљгавбжЊЕФзжЗћМЏ
-c ДгЪфГіжаКіТдЮоаЇЕФзжЗћ
-o, --output=FILE ЪфГіЮФМў
-s, --silent ЙиБеОЏИц
--verbose ДђгЁНјЖШаХЯЂ
iconv -f encoding -t encoding inputfile
iconv -f utf-8 -t unicode utf8file.txt> unicodefile.txt
iconv -f utf-8 -t gb2312 /server_test/reports/t1.txt > /server_test/reports/t2.txt
iconv -f utf8 -t gb18030 -oresult.xls result_tmp.xls
iconv -f utf8 -t gb18030 result_tmp.xls> result.xls
iconv -f utf8 -t gb2312 result_tmp.xls> result.xls
iconv -f latin1 -t ascii//TRANSLIT file
iconv -f UTF-8 -t ascii//TRANSLIT file
iconv -f "ISO_8859-1" -t "GBK" ./test
cmake -G "Visual Studio 15 2017 Win64" ..
https://www.gnu.org/software/libiconv/
3.2 C++ДњТыЪЕЯжвЛ
//***********************************************************************
// Purpose: ЛљгкlibiconvПтЕФC++ЪЕЯжзжЗћБрТыЛЅзЊ(ВтЪдгУР§1)
// Author: АЎПДЪщЕФаЁух
// Date: 2022-5-19
// Languages: C++
// Platform: Visual Studio 2017
// OS: Win10 win64
// ***********************************************************************
#include <iostream>
#include "libiconv/iconv.h"
#pragma comment(lib, "libiconv.lib")
int test_libiconv1()
{
char *curLocale = setlocale(LC_ALL, NULL);
setlocale(LC_ALL, "chs");
/* дДБрТы */
const char *encFrom = "GBK";
/* ФПЕФБрТы, TRANSLIT:гіЕНЮоЗЈзЊЛЛЕФзжЗћОЭевЯрНќзжЗћЬцЛЛ
* IGNORE :гіЕНЮоЗЈзЊЛЛзжЗћЬјЙ§*/
//const char *encTo = "UNICODE//TRANSLIT";
//const char *encTo = "GBK//TRANSLIT";
//const char *encTo = "latin1//TRANSLIT";
//const char *encTo = "ISO_8859-1//TRANSLIT";
//const char *encTo = "UNICODE//IGNORE";
const char *encTo = "UTF-8//TRANSLIT";
/* ЛёЕУзЊЛЛОфБњ
*@param encTo ФПБъБрТыЗНЪН
*@param encFrom дДБрТыЗНЪН
*
* */
iconv_t cd = iconv_open(encTo, encFrom);
if (cd == (iconv_t)-1)
{
perror("iconv_open");
return -1;
}
/* ашвЊзЊЛЛЕФзжЗћДЎ */
char inbuf[1024] = "ТнЫПжа123abc";
size_t inlen = strlen(inbuf);
/* ДцЗХзЊЛЛКѓЕФзжЗћДЎ */
size_t outlen = 1024;
char outbuf[1024] = "\0";
memset(outbuf, 0, sizeof(outbuf));
/* гЩгкiconv()КЏЪ§ЛсаоИФжИеы,ЫљвдвЊБЃДцдДжИеы */
char *srcstart = inbuf;
char *tempoutbuf = outbuf;
size_t ret = iconv(cd, (const char **)&srcstart, &inlen, &tempoutbuf, &outlen);
if (ret == -1)
{
perror("iconv");
return -1;
}
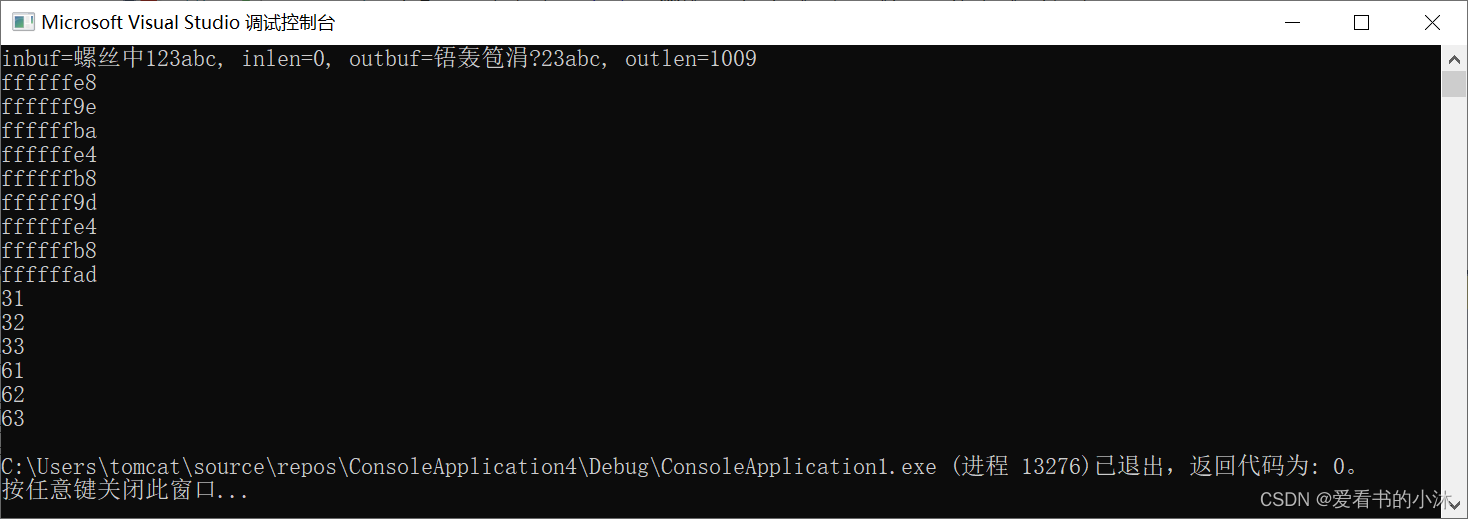
printf("inbuf=%s, inlen=%d, outbuf=%s, outlen=%d\n", inbuf, inlen, outbuf, outlen);
for (int i = 0; i < strlen(outbuf); i++)
{
printf("%x\n", outbuf[i]);
}
/* ЙиБеОфБњ */
iconv_close(cd);
return 0;
}
дЫааНсЙћШчЯТ:
3.3 C++ДњТыЪЕЯжЖў
//***********************************************************************
// Purpose: ЛљгкlibiconvПтЕФC++ЪЕЯжзжЗћБрТыЛЅзЊ(ВтЪдгУР§2)
// Author: АЎПДЪщЕФаЁух
// Date: 2022-5-19
// Languages: C++
// Platform: Visual Studio 2017
// OS: Win10 win64
// ***********************************************************************
#include <iostream>
#include "libiconv/iconv.h"
#pragma comment(lib, "libiconv.lib")
char * test_libiconv2(const char *encFrom, const char *encTo, const char * inStr)
{
char *curLocale = setlocale(LC_ALL, NULL);
setlocale(LC_ALL, "chs");
char buf_out[1024];
char *str_in, *str_out;
int len_in, len_out, ret;
iconv_t c_pt;
if ((c_pt = iconv_open(encTo, encFrom)) == (iconv_t)-1)
{
printf("iconv_open false: %s ==> %s\n", encFrom, encTo);
return NULL;
}
iconv(c_pt, NULL, NULL, NULL, NULL);
len_in = strlen(inStr) + 1;
len_out = 1024;
str_in = (char *)inStr;
str_out = buf_out;
ret = iconv(c_pt, (const char**)&str_in, (size_t *)&len_in, &str_out, (size_t *)&len_out);
if (ret == -1)
{
perror("iconv");
return NULL;
}
iconv_close(c_pt);
return buf_out;
}
int main()
{
char* p = NULL;
p = test_libiconv2("GBK", "UTF-8//TRANSLIT", "ТнЫПжа123abc+-=,.?*$%#@");
if(p) std::cout << p << std::endl;
p = test_libiconv2("GBK", "UTF-8//TRANSLIT", "ПЊЗЂепЛЙЬсЙЉСЫвЛеХGeForce RTX 3090ЕчФдЕФНиЭМ,");
if (p) std::cout << p << std::endl;
p = test_libiconv2("GBK", "UTF-8//TRANSLIT", "ИУЕчФддкгы гЂЬиЖћ Core i9-12900KЕФзщКЯЯТ,ХмГіСЫ35fpsЕФжЁЫйЁЃ");
if (p) std::cout << p << std::endl;
}
дЫааНсЙћШчЯТ:
3.4 C++ДњТыЪЕЯжШ§
//***********************************************************************
// Purpose: ЛљгкlibiconvПтЕФC++ЪЕЯжзжЗћБрТыЛЅзЊ(ВтЪдгУР§3)
// Author: АЎПДЪщЕФаЁух
// Date: 2022-5-19
// Languages: C++
// Platform: Visual Studio 2017
// OS: Win10 win64
// ***********************************************************************
#include <iostream>
#include "libiconv/iconv.h"
#pragma comment(lib, "libiconv.lib")
bool test_libiconv3(const char *encFrom, const char *encTo, const char *inbuf, size_t *inlen, char *outbuf, size_t *outlen)
{
/* ФПЕФБрТы, TRANSLIT:гіЕНЮоЗЈзЊЛЛЕФзжЗћОЭевЯрНќзжЗћЬцЛЛ
* IGNORE :гіЕНЮоЗЈзЊЛЛзжЗћЬјЙ§*/
//const char *encTo = "UTF-8//IGNORE";
/* дДБрТы */
//const char *encFrom = "UNICODE";
/* ЛёЕУзЊЛЛОфБњ
*@param encTo ФПБъБрТыЗНЪН
*@param encFrom дДБрТыЗНЪН
*
* */
iconv_t cd = iconv_open(encTo, encFrom);
if (cd == (iconv_t)-1)
{
perror("iconv_open");
}
/* ашвЊзЊЛЛЕФзжЗћДЎ */
printf("in_buf=%s\n", inbuf);
/* ДђгЁашвЊзЊЛЛЕФзжЗћДЎЕФГЄЖШ */
printf("in_len=%d\n", *inlen);
/* гЩгкiconv()КЏЪ§ЛсаоИФжИеы,ЫљвдвЊБЃДцдДжИеы */
char *tmpin = (char *)inbuf;
char *tmpout = outbuf;
size_t insize = *inlen;
size_t outsize = *outlen;
size_t ret = iconv(cd, &tmpin, inlen, &tmpout, outlen);
if (ret == -1)
{
perror("iconv");
}
/* ДцЗХзЊЛЛКѓЕФзжЗћДЎ */
printf("out_buf=%s\n", outbuf);
//ДцЗХзЊЛЛКѓoutbufеМгУЕФПеМф
int outlen_real = outsize - (*outlen);
*outlen = outlen_real;
printf("out_len=%d\n", outlen_real);
for (int i = 0; i < outlen_real; i++)
{
//printf("%2c", outbuf[i]);
//printf("%x\n", outbuf[i]);
}
/* ЙиБеОфБњ */
iconv_close(cd);
return outlen_real;
}
//unicodeзЊUTF-8
bool unicode_to_utf8(const char *inbuf, size_t *inlen, char *outbuf, size_t *outlen)
{
return test_libiconv3("UCS-2LE", "UTF-8//IGNORE", inbuf, inlen, outbuf, outlen);
}
//UTF-8зЊunicode
bool utf8_to_unicode(const char *inbuf, size_t *inlen, char *outbuf, size_t *outlen)
{
return test_libiconv3("UTF-8", "UCS-2LE//IGNORE", inbuf, inlen, outbuf, outlen);
}
//gbkзЊunicode,"UCS-2LE"ДњБэunicodeаЁЖЫФЃЪН
bool gbk_to_unicode(const char *inbuf, size_t *inlen, char *outbuf, size_t *outlen)
{
return test_libiconv3("gb2312", "UCS-2LE//IGNORE", inbuf, inlen, outbuf, outlen);
}
//unicodeзЊgbk
bool unicode_to_gbk(const char *inbuf, size_t *inlen, char *outbuf, size_t *outlen)
{
return test_libiconv3("UCS-2LE", "gb2312//IGNORE", inbuf, inlen, outbuf, outlen);
}
//gbkзЊUTF-8
bool gbk_to_utf8(const char *inbuf, size_t *inlen, char *outbuf, size_t *outlen)
{
return test_libiconv3("GBK", "UTF-8//IGNORE", inbuf, inlen, outbuf, outlen);
}
//UTF-8зЊgbk
bool utf8_to_gbk(const char *inbuf, size_t *inlen, char *outbuf, size_t *outlen)
{
return test_libiconv3("UTF-8", "GBK//IGNORE", inbuf, inlen, outbuf, outlen);
}
//вдЪЎСљНјжЦДђгЁзжЗћДЎ
void printChars(const char *buffer, int len)
{
for (int i = 0; i < len; i++)
{
printf("%0x,", *buffer++);
}
printf("\n");
}
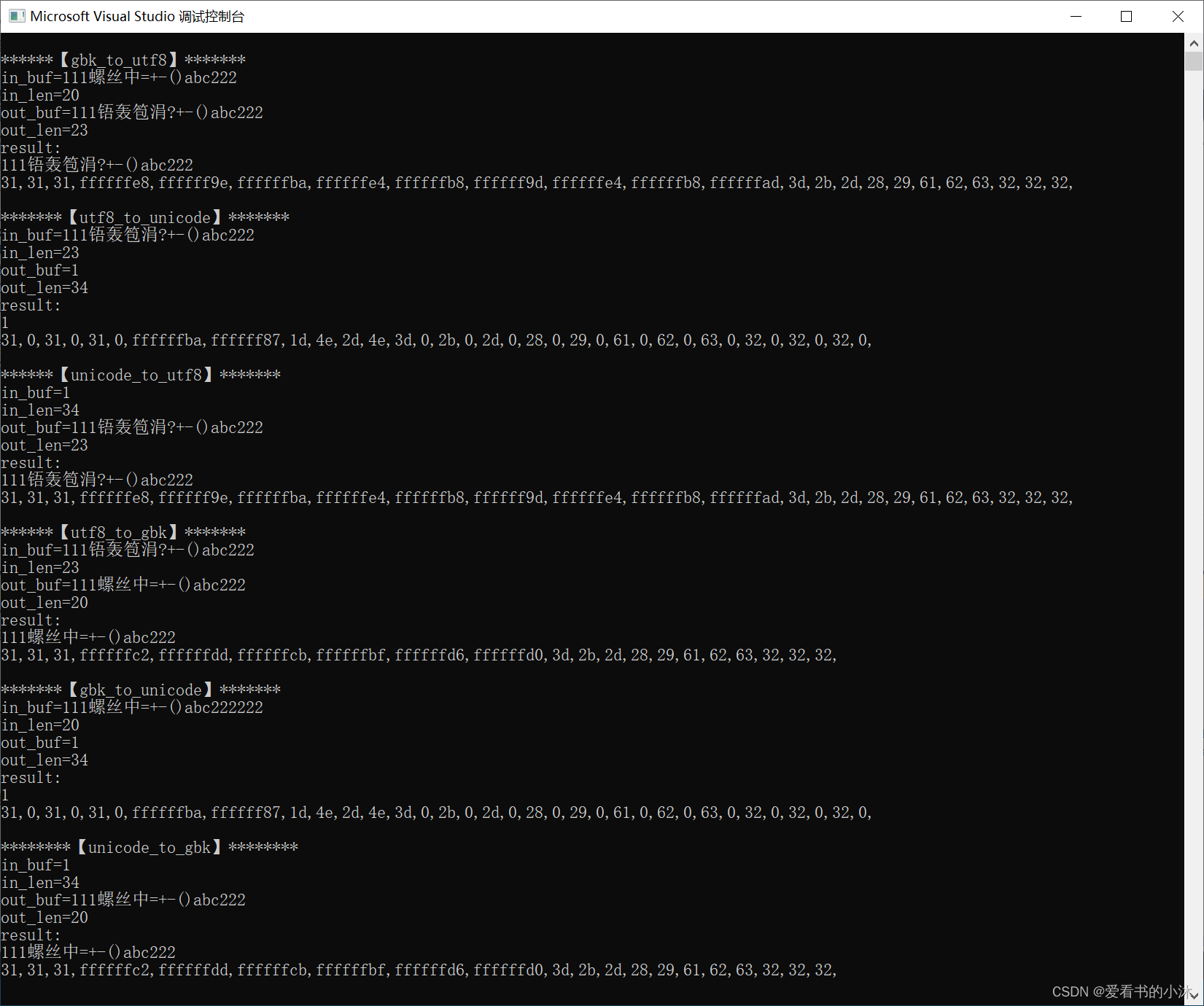
ВтЪдДњТыШчЯТ:
int main()
{
// gbk_to_utf8
printf("\n******ЁОgbk_to_utf8ЁП*******\n");
char inbuf[1024] = "111ТнЫПжа=+-()abc222";
size_t inlen = strlen(inbuf);
char outbuf[1024] = {};
size_t outlen = sizeof(outbuf);
gbk_to_utf8(inbuf, &inlen, outbuf, &outlen);
printf("result:\n%s\n", outbuf);
printChars(outbuf, outlen);
// utf8_to_unicode
printf("\n*******ЁОutf8_to_unicodeЁП*******\n");
inlen = outlen;
outlen = sizeof(outbuf);
memcpy(inbuf, outbuf, inlen);
memset(outbuf, 0, outlen);
utf8_to_unicode(inbuf, &inlen, outbuf, &outlen);
printf("result:\n%s\n", outbuf);
printChars(outbuf, outlen);
// unicode_to_utf8
printf("\n******ЁОunicode_to_utf8ЁП*******\n");
inlen = outlen;
outlen = sizeof(outbuf);
memcpy(inbuf, outbuf, inlen);
memset(outbuf, 0, outlen);
unicode_to_utf8(inbuf, &inlen, outbuf, &outlen);
printf("result:\n%s\n", outbuf);
printChars(outbuf, outlen);
// utf8_to_gbk
printf("\n******ЁОutf8_to_gbkЁП*******\n");
inlen = outlen;
outlen = sizeof(outbuf);
memcpy(inbuf, outbuf, inlen);
memset(outbuf,0, outlen);
utf8_to_gbk(inbuf, &inlen, outbuf, &outlen);
printf("result:\n%s\n", outbuf);
printChars(outbuf, outlen);
// gbk_to_unicode
printf("\n*******ЁОgbk_to_unicodeЁП*******\n");
inlen = outlen;
outlen = sizeof(outbuf);
memcpy(inbuf, outbuf, inlen);
memset(outbuf, 0, outlen);
gbk_to_unicode(inbuf, &inlen, outbuf, &outlen);
printf("result:\n%s\n", outbuf);
printChars(outbuf, outlen);
// unicode_to_gbk
printf("\n********ЁОunicode_to_gbkЁП********\n");
inlen = outlen;
outlen = sizeof(outbuf);
memcpy(inbuf, outbuf, inlen);
memset(outbuf, 0, outlen);
unicode_to_gbk(inbuf, &inlen, outbuf, &outlen);
printf("result:\n%s\n", outbuf);
printChars(outbuf, outlen);
}
libiconvЕФЯрЙиВтЪддДТыМћШчЯТСДНг:
https://download.csdn.net/download/hhy321/85419981
Нсгя
ШчЙћФњОѕЕУИУЗНЗЈЛђДњТыгавЛЕуЕугУДІ,ПЩвдИјзїепЕуИідо,ЛђДђЩЭБПЇЗШ;Јr( ̄Ј ̄)Јq
ШчЙћФњИаОѕЗНЗЈЛђДњТыВЛеІЕи//(ЈвoЈв)//,ОЭдкЦРТлДІСєбд,зїепМЬајИФНјЁЃo_O???
ШчЙћФњашвЊЯрЙиЙІФмЕФДњТыЖЈжЦЛЏПЊЗЂ,ПЩвдСєбдЫНСФзїепЁЃ(????)
ИааЛИїЮЛЭЏаЌУЧЕФжЇГж!( Ёф ЈЁф )ノ ( Ёф ЈЁф)ЄУ!!!


