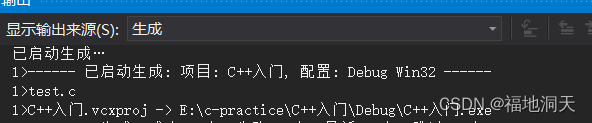
ШЫЩњжаЕквЛИіC++ГЬађ
#include<iostream>
int main()
{
std::cout << "hello world!" << std::endl;
return 0;
}1.C++ЙиМќзж
ИљОн(C++98)БъзМ,C++змМЦ63ИіЙиМќзж,Cгябд32ИіЙиМќзжЁЃ
Mirosoft visual stdio 2022БъЪЖ:

2.УќУћПеМф
дкC/C++жа,БфСП,КЏЪ§КЭРрЖМЪЧДѓСПДцдкЕФ,БфСП,КЏЪ§,РрЕФУћГЦЖМНЋДцдкгкШЋОжзїгУгђжа,ПЩФмЛсЕМжТКмЖрГхЭЛЁЃЪЙгУУќУћПеМфЕФФПЕФ:ЖдБэЪОЕФУћГЦНјааБОЕиЛЏЁЃвдБмУтУќУћГхЭЛЛђУћзжЮлШОЁЃ
ЙиМќзж:namespace
ЙигкУќУћГхЭЛОйР§:
СЫНтCгябдЖМЧхГўmallocгУгкЯђМЦЫуЛњЩъЧыПеМфЕФКЏЪ§ЁЃ
#include<stdio.h>
//#include<stdlib.h>
int malloc = 0;
int main()
{
printf("%d\n", malloc);
return 0;
}
#include<stdio.h>
#include<stdlib.h>
int malloc = 0;
int main()
{
printf("%d\n", malloc);
return 0;
}?
?ЕБАќКЌmallocЫљдкЕФЭЗЮФМўЪБ,дЯШЕФДњТыжБНгБЈДэ,ШчЙћЪЧвђЮЊБфСПУќУћГхЭЛЕМжТБЈДэ,ФЧОЭЗЧГЃЕФИуШЫаФЬЌСЫЁЃ
C++ЬљаФЕФЪЙгУУќУћПеМфИуЕєСЫетИіЮЪЬтЁЃ
2.1УќУћПеМфЖЈвх
ЖЈвхУќУћПеМф,ашвЊЪЙгУЙиМќзжnamespace,КѓУцИњУќУћПеМфЕФУћзж,ШЛКѓИњЩЯвЛЖд{},{}жаМДЮЊУќУћПеМфЕФГЩдБЁЃ
ОйИіРѕзг:
#include<iostream>
//ЦеЭЈЕФУќУћПеМф
namespace T1//вдT1зїЮЊУќУћПеМфЕФУћзж
{
//ФкШнжаПЩвдЖЈвх БфСП,КЏЪ§,НсЙЙЬх
char a;
void test()
{
printf("hello world\n");
}
struct ListNode
{
int val;
struct ListNode* next;
};
}//НјНз
//УќУћПеМфОЭЯёЪЧвЛИіЁАДѓКЏЪ§ЁБ,КЏЪ§ФмЙЛЧЖЬз,ФЧУДУќУћПеМфвВФмЧЖЬз
namespace T2
{
char q;
namespace T3
{
int val;
}
}//ЭЌвЛИіЙЄГЬжаПЩДцдкЖрИіУћГЦЯрЭЌЕФУќУћПеМф,БрвыЦїдкСДНгЪБЛсНЋЦфздЖЏКЯВЂ
namespace T1
{
int num;
double e;
}?
дкnamespaceжаЖЈвхЕФБфСП,КЏЪ§,НсЙЙЬхЕШФкШнЕФзїгУгђЖМНЋЪмЯодкИЩИУУќУћПеМфжаЁЃ
зЂвт:дкЭЌвЛИігђжа,ВЛФмгаЭЌУћБфСПЁЃ
2.2УќУћПеМфЕФЪЙгУ
ДДНЈСЫУќУћПеМф,НтОіСЫПЩФмДцдкЕФУќУћГхЭЛЮЪЬт,ФЧУДИУдѕУДЪЙгУетаЉЖЈвхЕФБфСПЁЃЩЯЮФЬсМАЙ§,ЖЈвхЕФЫљгУФкШнЕФзїгУгђЖМНЋЪмЯогкЦфУќУћПеМфжа,ЫљвджБНгдкЦфЫћКЏЪ§ФкЪЧЮоЗЈБЛЪЙгУЕФЁЃ
C++ЬсЙЉСЫВйзїЗћ:зїгУгђЯоЖЈВйзїЗћ::
1.МгУќУћПеМфУћГЦМАзїгУгђВйзїЗћ

етОЭЪЧРЯЪЕШЫЪжЖЏЗУЮЪ
2.ЪЙгУusingНЋУќУћПеМфжаГЩдБв§Шы
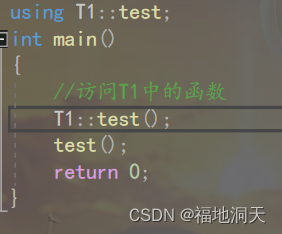
?
![]()
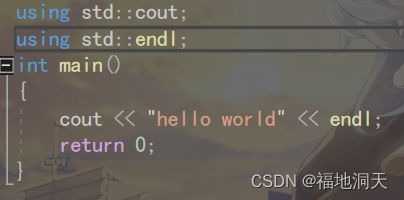
етРяЪЧжЛАбT1жаЕФtestКЏЪ§ЗХГіРДЁЃ
3.ЪЙгУusing namespace УќУћПеМфУћГЦв§Шы
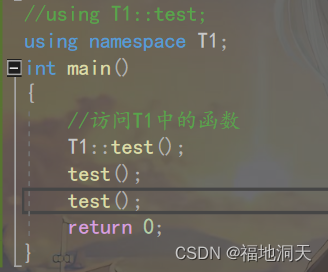

етРяЪЧНЋT1жаЖЈвхЕФЖЋЮїШЋВПЪЭЗХГіРДЁЃ
ЫљвдПЩвдНтОіжЎЧАЕФвЩЮЪ:ЮЊЩЖвЊдкЮФМўжаМгusing namespace std;
ШчЙћВЛМгФи?

ПЩжЊ,cout КЭ endl ЪЧАќКЌдкC++БъзМПтжаЕФ,ЖјЧветИіПтЛЙЪЧвЛИіЕЅЖР
ЕФУќУћПеМфЁЃ
дкФГаЉЧщПіЯТ,НЋПтЭъШЋЗХГіРДЛсГіЯжУќУћЮлШОЕФЧщПі,ашвЊзЂвтЁЃ
ВЛНЋБъзМПтжаЕФЫљгаЗХГіРД,ПЩвдПМТЧЪЙ 1 гУКЭ 2.
?
?
?
3.C++ЪфШыКЭЪфГі
еыЖдШЫЩњЕквЛИіC++ГЬађ,hello worldЕФЫЕУї:
- ЪЙгУcoutБъзМЪфГі(ПижЦЬЈ)КЭcinБъзМЪфШы(МќХЬ)ЪБ,БиаыАќКЌ<iostream>ЭЗЮФМўвдМАstdБъзМУќУћПеМфЁЃ
- ЪЙгУC++ЪфШыЪфГіИќЗНБу,ВЛашвЊМгЪ§ОнИёЪНЛЏПижЦЁЃ
4.ШБЪЁВЮЪ§
гаИіБИЬЅ,зпдкТЗЩЯЖМАВаФСЫКУЖр(doge)
C++жаЕФКЏЪ§ВЮЪ§вВЪЧПЩвдгаБИЬЅЕФЁЃ
4.1ШБЪЁКЏЪ§ЕФИХФю
ШБЪЁКЏЪ§ЪЧЩњУќЛђепЖЈвхКЏЪ§ЪБЮЊКЏЪ§ЕФВЮЪ§жИЖЈвЛИіФЌШЯжЕЁЃдкЕїгУИУКЏЪ§ЪБ,ШчЙћУЛгажИЖЈЪЕВЮдђ
ВЩгУФЌШЯжЕ,ЗёдђЪЙгУжИЖЈЕФЪЕВЮЁЃ
ОйР§зг:
void test(int i = 1)
{
cout << i << endl;
}
int main()
{
test();
test(20);
return 0;
}?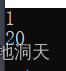
?ПЩМћ:УЛгаДЋВЮЪБ,ЪЙгУВЮЪ§ЮЊФЌШЯжЕ,ДЋВЮЪБ,ЪЙгУжИЖЈЕФЪЕВЮЁЃ
4.2ШБЪЁВЮЪ§ЗжРр
- ШЋШБЪЁВЮЪ§
void fun(int a = 10, int b = 20, int c = 30) { cout << "a = " << a << endl; cout << "b = " << b << endl; cout << "c = " << c << endl; } int main() { fun(); return 0; }
-
АыШБЪЁВЮЪ§
void fun(int a = 10, int b = 20, int c = 30) { cout << "a = " << a << endl; cout << "b = " << b << endl; cout << "c = " << c << endl; } int main() { fun(1,2); return 0; }
?
ПЩжЊ:етЪЧвЛжжВПЮЛ,ЧветжжВПЮЛЪЧЫГађЕФ,МДЮоЗЈЙцЖЈДЋЕнЕФЪЕВЮ2гЩcРДНгЪмЁЃ
зЂвт:
1.АцШБЪЁВЮЪ§БиаыДггвЭљзѓвРДЮРДИјГі,ВЛФмМфИєзХЁЃ
2.ШБЪЁВЮЪ§ВЛФмдйКЏЪ§ЩљУїКЭЖЈвхжаЭЌЪБГіЯжЁЃ
3.ШБЪЁжЕБиаыЪЧГЃСПЛђепШЋОжБфСПЁЃ
4.CгябдВЛжЇГж
5.КЏЪ§жиди
5.1ИХФю
КЏЪ§жиди:КЏЪ§ЕФвЛИіЬиЪтЧщПі,C++дЪаэдкЭЌвЛзїгУгђжаЩљУїМИИіЙІФмРрЫЦЕФЭЌУћКЏЪ§,
етаЉЭЌУћКЏЪ§ЕФаЮВЮСаБэ(ВЮЪ§ИіЪ§/РраЭ/ЫГађ)БиаыВЛЭЌ,ГЃгУРДДІРэЪЕЯжЙІФмРрЫЦЪ§ОнРраЭВЛЭЌЕФЮЪЬтЁЃ
ОйИіРѕзг:
int Add(int a, int b)
{
return a + b;
}
double Add(double a, int b)
{
return a + b;
}
int main()
{
Add(1, 2);
Add(1.6, 2);
cout << "Add(1,2) = " << Add(1, 2) << endl;
cout << "Add(1.6,2) = " << Add(1.6, 2) << endl;
return 0;
}

?
етРяПЩвдПДЕН:ЫфШЛЕїгУСЫЁАЯрЭЌЕФКЏЪ§НгПкЁБ,ЕЋЪЧЪЕМЪЩЯЕїгУЕФКЏЪ§НгПкЪЧВЛЭЌЕФЁЃ
ЙЙГЩКЏЪ§жидиЕФЙиМќ:
ВЮЪ§ИіЪ§,РраЭ,ЫГађжаЕФжСЩйвЛИіМДПЩЁЃ
6.в§гУ
6.1в§гУИХФю
в§гУВЛЪЧаТЖЈвхвЛИіБфСП,ЖјЪЧИјвбДцдкЕФБфСПШЁСЫвЛИіБ№Ућ,БрвыЦїВЛЛсЮЊв§гУЕФБфСППЊБйФкДцПеМф,
ЫќКЭЫќв§гУЕФБфСПЙВгУвЛПщФкДцПеМфЁЃ
БШШч:ЁЖЮїгЮМЧЁЗРяЕФКязг,ОДГЦЁАЦыЬьДѓЪЅЁБ,ЗЈКХЁАЮђПеЁБЁЃжИЕФЖМЪЧЭЌвЛШЫЁЃ
РраЭ& в§гУБфСПУћ(ЖдЯѓУћ)= в§гУЪЕЬх;
ОйИіР§зг:
int main()
{
int a = 10;
int& b = a;
cout << "a = " << a<< endl;
cout << "b = " << b << endl;
cout << "a: " << &a << endl;
cout << "b: " << &b << endl;
b = 20;
cout << "a = " << a << endl;
return 0;
}
?
гЩДЫПЩвдХаЖЈ:в§гУВЂВЛЪЧвЛжжИГжЕВйзї,ЖјЪЧвЛжжАѓЖЈВйзїЁЃ
6.2в§гУЬиад
1.в§гУдкЖЈвхЪББиаыГѕЪМЛЏЁЃ
2.вЛИіБфСППЩвдгаЖрИів§гУЁЃ
3.в§гУвЛЕЉв§гУвЛИіЪЕЬх,ОЭВЛФмдйв§гУЦфЫќЪЕЬхЁЃ
int main()
{
int a = 10;
//int& b;//ЛсБЈДэ
int& c = a;
int& d = c;
printf("%p\n%p\n%p\n",&a,&c,&d);
return 0;
}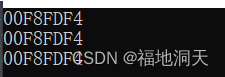
?
6.3ГЃв§гУ
в§гУеыЖдБфСПгавЛЬзгяЗЈ,ФЧЖдгкГЃСПгяЗЈЛЙФмЪЙгУТ№?
Д№АИЪЧВЛФмЁЃ
int main()
{
int a = 10;
int& b = a;
//ФЧвЊжБНгИјГЃСП10ШЁБ№Ућ,ЖјВЛЪЧЖдБфСПaШЁБ№УћЁЃ
//int& c = 10;//БЈДэ
//ЮЊЪВУД?
//ГЃСП10жЛФмЖСВЛФмаД,ФЧжБНгв§гУЛсНЋЦфШЈЯоРЉДѓ,ЪЧВЛБЛдЪаэЕФЁЃ
const int& c = 10;
const int& d = a;
return 0;
}МгЩЯconst ПЩвдНтОіЮЪЬт,ФЧЖдгкБфСПв§гУФмЗёЪЙгУconstаоЪЮ?
Д№АИЪЧПЩвдЕФЁЃ

ПЩвдЕУжЊ:
ШЁБ№Ућддђ:Жддв§гУБфСП,ШЈЯо(ЖСаДШЈЯо)жЛФмЫѕаЁ,ВЛФмЗХДѓЁЃ
дйПДвЛзщДњТы:
int main()
{
double a = 1.6;
//int& b = a; //РраЭВЛвЛбљ,ЛсБЈДэЁЃ
const int& b = a;//ВЛЛсБЈДэ
cout << "a = " << a << endl;
cout << "b = " << b << endl;
}
?![]()
?
ЕЋЪЧЦфжаЕФЛњжЦгжЪЧЪВУД?
aЮЊИЁЕуаЭ,bЮЊећаЮ,жЎМфЕФзЊЛЛЩцМАРраЭзЊЛЛ,ЛсЩњГЩвЛИіСйЪББфСПДцЗХдкМФДцЦїжаЁЃ
ЮвУЧв§гУЕФbЪЕМЪЩЯЪЧФЧИіСйЪББфСПЕФЁЃ
бщжЄ:


ПЩМћЫфШЛbЪЧaЕФв§гУ,ЕЋЪЧЕижЗЪЧВЛЭЌЕФЁЃ
етРявВПЩвдЕУжЊ:СйЪББфСПЪЧОпгаГЃадЕФЁЃ
6.4ЪЙгУГЁОА
1.зіВЮЪ§
ЪЙгУв§гУПЩвдЙцБмжИеыЮЪЬт
ГѕЪМCгябдЪБ:аДЙ§НЛЛЛКЏЪ§
void Swap(int a, int b)
{
int tmp = a;
a = b;
b = tmp;
}
int main()
{
int a = 1, b = 2;
Swap(a ,b);
cout << "a = " << a << endl;
cout << "b = " << b << endl;
return 0;
}етИіаДЗЈЪЧДэЮѓЕФ
НЛЛЛСЫСйЪББфСПЕЋЪЕВЮШДУЛгаНтОіЁЃЕЋв§гУОЭПЩвдЭъУРНтОіЁЃ
void Swap(int& a, int& b)
{
int tmp = a;
a = b;
b = tmp;
}
int main()
{
int a = 1, b = 2;
Swap(a ,b);
cout << "a = " << a << endl;
cout << "b = " << b << endl;
return 0;
}
?
2.зіЗЕЛижЕ
КЏЪ§ЗЕЛижЕдкГіСЫзїгУгђЪБ,ЛсЯњЛйеЛжЁ,дЯШЕФЗЕЛижЕЛсЗХдкМФДцЦїжа(ПНБД)
зюКѓВХЛсНЋНсЙћИГжЕИјФуЫљДДНЈдкЕїгУКЏЪ§НгПкЕФБфСПжа(ПНБД)
int& f()
{
static int a = 0;
a++;
return a;
}
int main()
{
int b = f();
return 0;
}ДЋжЕЗЕЛи:ЛсГіЯжвЛИіПНБДЁЃ
ДЋв§гУЗЕЛи:УЛгаетИіПНБДСЫ,КЏЪ§ЗЕЛиЕФжБНгОЭЪЧЗЕЛиБфСПЕФБ№УћЁЃ
етЫЦКѕФмЬсИпМЦЫуЛњЕФЫйЖШ,ЕЋЪЧгавЛИіжТУќЕФЮЪЬт,в§гУЕФдЖдЯѓБиаы
ЁБЛюзХЁА,ЗёдђетИів§гУОЭЛсдННчЗУЮЪ,ЪЧЮЅЗЈЕФЁЃ
етРяЪЙгУСЫstaticНЋaЗХНјСЫОВЬЌЧј,ЩњУќжмЦкЮЊећИіГЬађЕФЩњУќжмЦк,ЕБШЛВЛЛсГіЯждННчЗУЮЪЁЃ
ЬхбщСйЪББфСПЩњУќжмЦкНсЪјЕФЧщПі:
int& Add(int a, int b)
{
int c = 0;
c = a + b;
return c;
}
int main()
{
int& ret = Add(1, 2);//retЮЊcЕФБ№Ућ
Add(3, 4);//дйДЮЕїгУКЏЪ§,ЗЕЛиЪЧБЛаоИФЕФc
cout << "Add(1,2) : " << ret << endl;//ЕквЛДЮДђгЁ
cout << "Add(1,2) : " << ret << endl;//ЕкЖўДЮДђгЁЪБ,дЯШЕФcЕФеЛжЁвбБЛЯњЛйЁЃ
cout << "Add(1,2) : " << ret << endl;//ЭЌЕкЖўДЮ
return 0;
}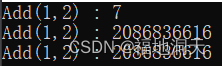
?
Ыљвд:ШчЙћКЏЪ§ЗЕЛиЪБ,ГіСЫКЏЪ§зїгУгђ,ШчЙћЗЕЛиЖдЯѓЛЙЮДНЛЛЙИјЯЕЭГ,дђПЩвдЪЙгУв§гУЗЕЛи,
ШчЙћвбОЗЕЛиИјЯЕЭГРя,ФЧОЭБиаыЪЙгУДЋжЕЗЕЛиЁЃ
6.5еыЖджЕ,жИеыКЭв§гУзюЗЕЛижЕРраЭдкадФмЩЯЕФБШНЯ
#include<time.h>
typedef struct Test
{
int Arr[100000];
}ST;
ST st;
ST test1()
{
return st;
}
ST& test2()
{
return st;
}
ST* test3()
{
return &st;
}
int main()
{
//жЕЗЕЛи
size_t begin1 = clock();
for (int i = 0; i < 10000; i++)
{
test1();
}
size_t end1 = clock();
//в§гУЗЕЛи
size_t begin2 = clock();
for (int i = 0; i < 10000; i++)
{
test2();
}
size_t end2 = clock();
//жИеыЗЕЛи
size_t begin3 = clock();
for (int i = 0; i < 10000; i++)
{
test3();
}
size_t end3 = clock();
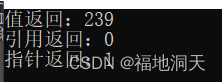
cout << "жЕЗЕЛи:" << end1 - begin1 << endl;
cout << "в§гУЗЕЛи:" << end2 - begin2 << endl;
cout << "жИеыЗЕЛи:" << end3 - begin3 << endl;
return 0;
}
?
ЭЈЙ§ЩЯЪіБШНЯ,ПЩжЊжИеыЗЕЛиКЭв§гУЗЕЛиЕФаЇТЪВюВЛЖр,жЕЗЕЛиаЇТЪзюВюЁЃ
6.6в§гУКЭжИеыЕФЧјБ№
в§гУ:дкИХФюЩЯв§гУжЛЪЧдБфСПЕФвЛИіБ№Ућ,УЛгаЖРСЂЕФПеМф,КЭв§гУЪЕЬхЙЋгУЭЌвЛПщПеМфЁЃ
жИеы:вЊПЊБйПеМф,ЮЊ4/8зжНкЁЃ
ЖјЕзВуЪЕЯжЩЯ,в§гУЪЧгаПеМфЕФ,вђЮЊв§гУЪЧАДеежИеыЕФЗНЪНЪЕЯжЕФЁЃ
| в§гУ | жИеы | |
| ГѕЪМЛЏ | БиаыГѕЪМЛЏ | ЮовЊЧѓ |
| жИЯђад | ВЛФмв§гУЖрИіЪЕЬх | ПЩжИЯђШЮвЛЪЕЬх |
| NULL | ЮоNULLв§гУ | NULLжИеы |
| sizeofКЌвх | в§гУРраЭЕФДѓаЁ | жИеыЕижЗПеМфЫљеМзжНкИіЪ§ |
| здМг | ЪЕЬхдіМг1 | ЯђКѓЦЋвЦвЛИіРраЭЕФДѓаЁ |
| ЖрМЖ | ЮоЖрМЖв§гУ | гаЖрМЖжИеы |
| ЗУЮЪЪЕЬхЗНЪН | БрвыЦїздааДІРэ | ашвЊНтв§гУ |
| АВШЋад | в§гУБШжИеыЪЙгУЦ№РДИќМгАВШЋ |
ВщПДв§гУКЭжИеыЕФЛуБрДњТы

7.ФкСЊКЏЪ§
7.1ИХФю
вдinlineаоЪЮЕФКЏЪ§НазіФкСЊКЏЪ§,БрвыЪБC++БрвыЦїЛсдкЕєХЖгУФкСЊКЏЪ§ЕФЕиЗНеЙПЊЁЃ
УЛгаКЏЪ§бЙеЛЕФвЛЯЕСаЯћКФ,ФкСЊКЏЪ§ПЩМЋДѓЕФЬсИпаЇТЪЁЃ
ИљОнФкСЊКЏЪ§ЕФЛљБОИХФю,ПЩжЊЦфгыCгябджаЕФКъгаЯрЫЦжЎДІЁЃ
ЖдБШCгябдКЭC++ФкСЊКЏЪ§
КъЖЈвхAddКЏЪ§
#define ADD(X,Y) ((X) + (Y))
int main()
{
ADD(1, 2);
cout << ADD(1, 2) << endl;
return 0;
}
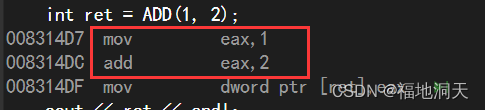
int main()
{
int ret = ADD(1, 2);
cout << ret << endl;
return 0;
}//ФкСЊКЏЪ§
inline int ADD(int x, int y)
{
return x + y;
}
int main()
{
int ret = ADD(1, 2);
cout << ret << endl;
return 0;
}
?
7.2Ьиад
1.inlineЪЧвЛжжвдПеМфЛЛЪБМфЕФзіЗЈ,ЪЁШЅКЏЪ§ЕїгУеЛжЁЕФПЊЯњЁЃЫљвдДњТыКмГЄЛђепгабЛЗ/ЕнЙщЕФКЏЪ§ВЛЪЪКЯзїЮЊФкСЊКЏЪ§ЁЃ
2.inlineЖдгкБрвыЦїЪЧвЛжжНЈвщ,ЫљвдШчЙћЖЈвхЮЊinlineЕФКЏЪ§ЬхФкгабЛЗ/ЕнЙщЕШ,БрвыЦїгХЛЏЪБЛсКіТдФкСЊЁЃ
3.inlineВЛЭЦМіЩљУїКЭЖЈвхЗжРы,ЗжРыЛсЕМжТСЌНгДэЮѓЁЃвђЮЊinlineБЛеЙПЊОЭУЛгаКЏЪ§ЕижЗСЫ,СДНгЪБОЭЛсБЈДэЁЃ
C++ЭЦГіФкСЊКЏЪ§ЪЧЮЊСЫНтОіCгябдКъЕФЛоЩЌФбЖЎ,ШнвзГіДэ,ВЛЗНБуЕїЪдЕФШБЕуЁЃ
гХЕу:ТњзуCгябдКъЕФЫљгагХЕу,
ФкСЊЕФаДЗЈгыЦеЭЈКЏЪ§ЭъШЋЯрЭЌ,МЋДѓЕФМѕЩйСЫБраДЕФЙЄГЬСПЁЃ
ЁОУцЪдЬтЁП
КъЕФгХШБЕу?
| гХЕу | ШБЕу |
| діЧПДњТыЕФПЩЖСад | ВЛЗНБуЕїЪдКъ(дЄБрвыНзЖЮКъЛсБЛЬцЛЛ) |
| ЬсИпадФм | ДњТыПЩЖСадБфВю,ЮЌЛЄадБфВю,взБЛЮѓгУ |
| УЛгаРраЭАВШЋЕФМьВщ |
C++еыЖдCгябдКъЕФгХЛЏЬцДњ?
1.ГЃСПЖЈвх ЛЛгУconst
2.КЏЪ§ЖЈвх ЛЛгУФкСЊКЏЪ§
8.autoЙиМќзж
8.1autoМђНщ
дкC/C++ИГгшautoЕФКЌвхЪЧ:ЪЙгУautoаоЪЮЕФБфСП,ЪЧОпгаздЖЏДцДЂЦїЕФОжВПБфСП,ЕЋЫцзХБрвыЦїЕФгХЛЏ
autoЫЦКѕУЛдйГіЯжЙ§ЁЃ
C++11жа,autoБЛИГгшСЫШЋаТЕФКЌвх:autoВЛдйЪЧвЛИіДЂДцРраЭЕФжИЪОЗћ,ЖјЪЧзїЮЊвЛИіаТЕФ
РраЭЕФжИЪОЗћРДжИЪОБрвыЦї,autoЩњУќЕФБфСПБиаыгЩБрвыЦїдкБрвыЪБЦкЭЦЕМЖјЕУЁЃ
int main()
{
int a = 10;
auto b = a;//int
auto c = 'a';//char
auto d = &a;//int*
auto* e = &a;//int*
auto& f = a;//int
//typeid(a).name();гУгкВщПДБфСПРраЭ
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
cout << typeid(d).name() << endl;
cout << typeid(e).name() << endl;
cout << typeid(f).name() << endl;
//d = 20;
return 0;
}
?
зЂвт: auto g;ЗЧЗЈ,gЕФРраЭЮоЗЈБЛЪЖБ№ЁЃ
ЁОзЂвтЁПЪЙгУautoЖЈвхБфСПЪББиаыЖдЦфНјааГѕЪМЛЏ,дкБрвыНзЖЮашвЊИљОнГѕЪМЛЏБэДяЪНРД
ЭЦЕМautoЕФЪЕМЪРраЭЁЃвђДЫautoВЂЗЧЪЧвЛжжЁАРраЭЁБЕФЩљУї,ЖјЪЧвЛИіРраЭЩљУїЪБЕФеМЮЛЗћ,
БрвыЦїдкдЄБрвыЦкНЋautoЬцЛЛЮЊБфСПЪЕМЪЕФРраЭЁЃ
ФЧautoЪЧЗёПЩвдзїЮЊШБЪЁВЮЪ§НјааДЋВЮ?
void AutoTest(auto a = 10)
{}
int main()
{
AutoTest();
return 0;
}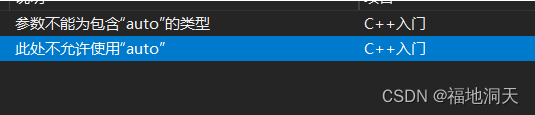
Д№АИЪЧВЛдЪаэЕФЁЃ
8.2autoЕФЪЙгУЯИдђ
1.autoгыжИеыКЭв§гУНсКЯЦ№РДЪЙгУ
гУautoЩљУїжИеыРраЭЪБ,гУautoЛђauto*УЛгаШЮКЮЧјБ№,ЕЋгУautoЩљУїв§гУБфСПЪББиаыМг&
int main()
{
int a = 10;
auto b = &a;
auto* c = &a;
auto& x = a;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
cout << typeid(x).name() << endl;
return 0;
}
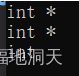
?
2.дкЭЌвЛааЖЈвхЖрИіБфСП
дкЭЌвЛааЩљУїЖрИіБфСПЪБ,етаЉБфСПБиаыЪЧЯрЭЌЕФРраЭ,ЗёдђБрвыЦїЛсБЈДэЁЃ
двђ:БрвыЦїЪЕМЪжЛЛсЖдЕквЛИіРраЭНјааЭЦЕМ,ШЛКѓгУЭЦЕМГіРДЕФРраЭЖЈвхЦфЫћБфСПЁЃ
ВтЪд:
void AutoTest()
{
auto a = 10, b = 20;
auto c = 10.0, d = 20;
}
int main()
{
AutoTest();
return 0;
}

?
8.3autoВЛФмЭЦЕМЕФГЁОА
- autoВЛФмзїЮЊКЏЪ§ВЮЪ§
- autoВЛФмгУРДЩљУїЪ§зщ
- C++11жЛБЃСєСЫautoзїЮЊРраЭжИЪОЗћЕФгУЗЈ
- autoзюГЃгУЕФЪЧХфКЯЗЖЮЇforбЛЗ,КЭlambdaБэДяЪНХфКЯЪЙгУЁЃ
9.ЛљгкЗЖЮЇЕФforбЛЗ(C++11)
9.1ЗЖЮЇforЕФгяЗЈ
вдБщРњЪ§зщЮЊР§:
C++98гяЗЈЙцдђБщРњ
int main()
{
int a[] = { 1,2,3,4,5,6,7,8,9 };
for (int i = 0; i < sizeof(a)/sizeof(int); i++)
{
cout << a[i] << " ";
}
cout << endl;
return 0;
}
C++11гяЗЈЙцдђЗЖЮЇforБщРњ
int main()
{
int a[] = { 1,2,3,4,5,6,7,8,9 };
for (auto e : a)//ЗЖЮЇfor (auto БфСП : Ъ§зщУћ}
{
cout << e << " ";
}
cout << endl;
return 0;
}![]()
?ЖдгквЛИігаЗЖЮЇЕФМЏКЯЖјбд,ЪЙгУЗЖЮЇforЪББШНЯгХЕФбЁдёЁЃ
forбЛЗКѓЕФРЈКХгЩУАКХЁБ:ЁАЗжЮЊСНВПЗж:вЛВПЗжЪБЗЖЮЇФкгУгкЕќДњЕФБфСП,
ЕкЖўВПЗждђБэЪОБЛЕќДњЕФЗЖЮЇЁЃ
зЂвт:гыЦеЭЈбЛЗРрЫЦ,ПЩвдгУcontinueРДНсЪјБОДЮбЛЗ,вВПЩвдгІbreakЬјГіећИібЛЗЁЃ
9.2ЗЖЮЇforЕФЪЙгУЬѕМў
1.forбЛЗЕФЕќДњЕФЗЖЮЇБиаыЪЧШЗЖЈЕФЁЃ
ЖдЪ§зщЖјбд,ОЭЪЧЪ§зщжаЕквЛИідЊЫиКЭзюКѓвЛИідЊЫиЕФЗЖЮЇ;
ЖдРрЖјбд,ЬсЙЉbeginКЭendЕФЗЖЮЇ,beginКЭendОЭЪЧforбЛЗЕќДњЕФЗЖЮЇЁЃ
ДэЮѓЪОЗЖ:
void ForTest(int a[])
{
for (auto e : a)
{
cout << e << " " << endl;
}
cout << endl;
}
int main()
{
int a[] = { 1,2,3,4,5,6,7,8,9 };
ForTest(a);
return 0;
}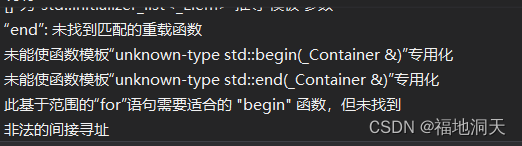
?
двђ:Ъ§зщДЋВЮДЋЕнЕФЪЧЪздЊЫиЕижЗ,УЛгажБНгПЩШЗЖЈЕФЗЖЮЇ,здШЛЗЖЮЇforОЭЪЧДэЮѓЕФЁЃ
2.ЕќДњЦїЕФЖдЯѓЪЕЯж++КЭ==ЕФВйзїЁЃ
10.жИеыПежЕnullptr(C++11)
10.1C++98жаЕФжИеыПежЕ
дкC++98жаПЩвдетбљЖЈвхПежИеы
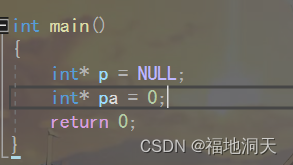
NULLЪЕМЪЩЯЪЧвЛИіКъ,АќКЌдкCЭЗЮФМў(stddef.h)жа,зЊЕНЖЈвхПЩжЊ:
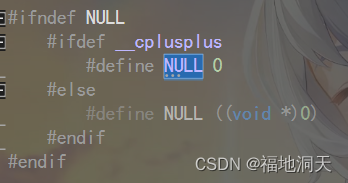
NULLПЩФмБЛЖЈвхЮЊзжУцГЃСП0ЛђепБЛЖЈвхЮЊ(void*)ГЃСП,ЕЋетПЩФмЛсГіЯжжИДњВЛУїЕФЧщПіЁЃ
void NULLTest(int)//зжУцГЃСП
{
cout << "int" << endl;
}
void NULLTest(int*)//(void*)ГЃСП
{
cout << "int*" << endl;
}
int main()
{
NULLTest(0);//~int
NULLTest(NULL);//ЯЃЭћЕїгУint*
NULLTest((int*)NULL);//~~int*
NULLTest(nullptr);
return 0;
}
?
ПЩвдПДЕН,ЪТгыдИЮЅ,NULLЕїгУЕФЪЧintРраЭЕФзжУцГЃСПЁЃ
дкC++98жа,зжУцГЃСПМШПЩвдЪЧвЛИіећаЭЪ§зж,вВПЩвдЪЧИіЮоРраЭЕФжИеы(void*)ГЃСП,
БрвыЦїФЌШЯЧщПіЯТНЋЦфПДГЩвЛИіећаЭГЃСП,ШчЙћвЊАДеежИеыЕФЗНЪНРДЪЙгУ,БиаыЖдЦфЪЙгУ
ЧПзЊЁЃ
C++11ЭЦГіСЫаТЕФnullptrРДЬцДњдгаЕФNULL/0.
зЂвт:
1.дкЪЙгУnullptrБэЪОжИеыЮЊПеЪБ,ВЛгывЊАќКЌЭЗЮФМў,вђЮЊnullptrдкC++11АцБОЯТЪЧЙиМќзжЁЃ
2.дкC++жа,sizeof(nullptr)гыsizeof((void*))ЫљеМзжНкЯрЭЌЁЃ
3.ЮЊСЫЬсИпДњТыЕФНЁзГад,nullptrдкc++жаПЩвдЭъШЋЬцДњNULL/0.
ШчгаДэЮѓ,ЛЙЧыДѓРажИГі!!

