ǰ��
����ʽ����,����:vector��list��deque��forward_list(C++11)��,��ײ�Ϊ�������е����ݽṹ,����洢����Ԫ�ر�������ʲô�ǹ���ʽ����?��������ʽ������ʲô����?
����ʽ����Ҳ�������洢���ݵ�,������ʽ������ͬ����,������洢���� <key, value> �ṹ�ļ�ֵ��,�����ݼ���ʱ������ʽ����Ч�ʸ�����
-
����Ӧ�ó����IJ�ͬ,STL�ܹ�ʵ�������ֲ�ͬ�ṹ�Ĺ���ʽ����:�����ͽṹ���롸��ϣ�ṹ����
-
���ͽṹ�Ĺ���ʽ������Ҫ������:map��set��multimap��multiset�������������Ĺ�ͬ����:ʹ��ƽ�����������(�������)��Ϊ��ײ�ṹ,�����е�Ԫ����һ�������������
һ��set(����)
1.1 set��������
�ٷ��ĵ�:set - C++ Reference (cplusplus.com)
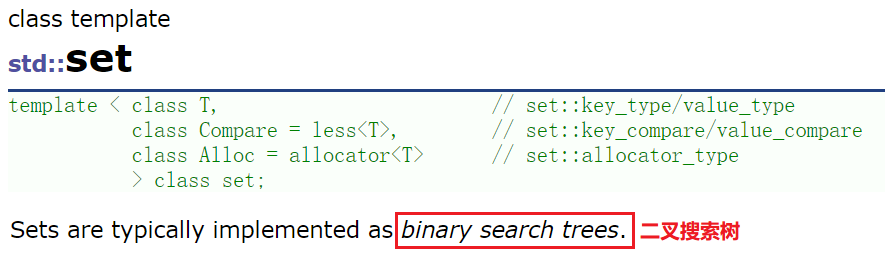
set��ģ������б�:
��������:
- T:set�д��Ԫ�ص�����,ʵ���ڵײ�洢���� <value, value> ��ֵ�ԡ�
- Compare:�Ƚ���������,set��Ԫ��Ĭ�ϰ���С��(< ����)���Ƚϡ�һ�������(��������Ԫ��)�ò�������Ҫ����,������Ƚ�ʱ(�����Զ�������),��Ҫ�û��Լ���ʽ���ݱȽϹ���(һ������°��պ���ָ����߷º���������)
- ��(< ����),less
- ����(> ����),����setʱģ�������Ҫд�� greater
- Alloc:set��Ԫ�ؿռ�Ĺ�����ʽ,ʹ��STL�ṩ�Ŀռ�������������
- ʹ��setʱ,��Ҫ����ͷ�ļ� #include��
1.2 set��ʹ��
�� set�ij��ýӿ�
set�ĵ�����:
| Iterators: | |
|---|---|
| begin | ����ָ��set�е�һ��Ԫ�صĵ����� |
| end | ����ָ��set�����һ��Ԫ�غ���ĵ����� |
set����:
| Modifiers: | |
|---|---|
| insert | Insert element(����Ԫ��) |
| erase | Erase elements(ɾ��Ԫ��) |
set�IJ���:
| Operations: | |
|---|---|
| find | ����ҵ�,�ظ�Ԫ�صĵ�����,����set::end�ĵ������� |
�� ʹ�þ���
void test_set1()
{
// ������array�е�Ԫ�ع���set
int array[] = { 1, 3, 5, 4, 2 };
set<int> s(array, array + sizeof(array) / sizeof(array[0]));
s.insert(4); // 4�Ѿ���set����,�������
cout << s.size() << endl; // ��ȡsetԪ�ظ���
// ����������set
set<int>::iterator it = s.begin();
while (it != s.end())
{
cout << *it << " ";
it++;
}
cout << endl;
// ���ֲ���Ԫ�ط�ʽ:
// 1��algorithm�ļ��е�find����,�ײ��DZ�������,ȫ���ڵ����һ��,Ч�ʵ�,O(N)
// auto ret = find(s.begin(), s.end(), 4);
// 2��set�ij�Ա����,����Ϊ:O(logN)
auto ret = s.find(4);
// ������Ҫ�ж�һ��,���ҵ�,���ظ�Ԫ�صĵ�����,��û���ҵ�,����s�����һ��Ԫ�غ���ĵ�����
if (ret != s.end())
{
s.erase(ret); // ɾ��Ԫ�ط�ʽ1,ɾ��������retָ���Ԫ��
}
s.erase(5); // ɾ��Ԫ�ط�ʽ2:ɾ��ֵΪ5��Ԫ��
}
����+ȥ��
set �Dz��������������,ʹ�� set ���������� set �е�Ԫ��,���Եõ�һ����������,�����ʹﵽ�˶�һ����������+ȥ�ص�Ч����
1.3 �ܽ�
- �� map/multimap ��ͬ,map/multimap �д洢���������ļ�ֵ��<key, value>,�� set ��ֻ�� value,���ڵײ�ʵ�ʴ�ŵ����� <value, value> ���ɵļ�ֵ�ԡ�
- set �в���Ԫ��ʱ,ֻ��Ҫ���� value ����,����Ҫ�����ֵ�ԡ�
- set �е�Ԫ�ز������ظ�(��˿���ʹ�� set ����ȥ��)
- ʹ�� set �ĵ��������� set �е�Ԫ��,���Եõ��������С�
- set �е�Ԫ��Ĭ�ϰ���С�����Ƚϡ�
- set �в���ij��Ԫ��,ʱ�临�Ӷ�Ϊ:O(log2N),set ����ɾ��Ķ���O(log2N)
- set �е�Ԫ�ز�����������ΪsetҪ��֤������,���set��Ԫ�ز��ܱ�ֱ����,��Ҫ�Ŀ�����ɾ��,�ڲ���
- set �еĵײ���ʹ��ƽ�����������(�����)��ʵ�֡�
����multiset
multiset ��ʹ�ú� set ����һ��,����֮����������:
set �Dz��������������,�� multiset ������������,�����ж����ֵͬ��Ԫ�ء�
ע��:multiset �� find() ����һ��ֵ,�������4,�ҵ���һ��4�Ժ�,����ֹͣ,Ҫ�������ҵ�����ĵ�һ��4,���ҵ���һ��4�Ժ�,Ҫ���������������Dz���4,�������,�ͷ��ص�ǰ���4;�����,���ߵ��������4,�������±������жϡ�
ʹ�þ���:
multiset<int> s;
s.insert(4);
s.insert(3);
s.insert(5);
s.insert(4);
s.insert(6);
s.insert(4);
s.insert(2);
// ����multiset
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
// ����:2 3 4 4 4 5 6
�����Ҫ�鿴������,ij��ֵΪkey��Ԫ���ж��ٸ�,������ count() �ӿ�:
cout << s.count(4) << endl; // ����:3
cout << s.count(3) << endl; // ����:1
����map(ӳ��)
3.1 map��������
�ٷ��ĵ�:map - C++ Reference (cplusplus.com)
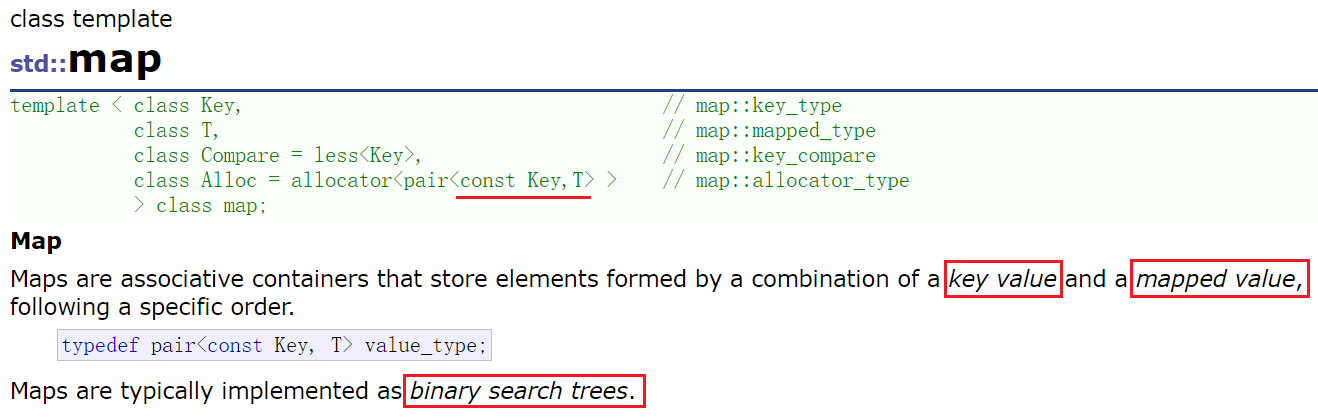
map��ģ������б�:
��������:
- key:��ֵ���� key ������
- T: ��ֵ���� value ������
- Compare:�Ƚ���������,map�е�Ԫ���ǰ��� key ���Ƚϵ�,ȱʡ����°���С�� ( < ����) ���Ƚ�,һ�������(��������Ԫ��)�ò�������Ҫ����,������Ƚ�ʱ(�����Զ�������),��Ҫ�û��Լ���ʽ���ݱȽϹ���(һ������°��պ���ָ����߷º���������)
- ��(< ����),less
- ����(> ����),����mapʱģ�������Ҫд�� greater
- Alloc:ͨ���ռ�������������ײ�ռ�,����Ҫ�û�����,�����û�����ʹ�ñ����ṩ�Ŀռ�������
- ��ʹ��mapʱ,��Ҫ����ͷ�ļ� #include
3.2 ��ֵ�� - pair(?���� - �dz���Ҫ)
������ʾ����һһ��Ӧ��ϵ��һ�ֽṹ,�ýṹ��һ��ֻ����������Ա���� key �� value,key ������ֵ,value ��ʾ�� key ��Ӧ����Ϣ��
SGI-STL�й��� ��ֵ�� �Ķ���:map�д�ŵ�Ԫ����һ�����ļ�ֵ��(�� pair ����)��
// map�д����һ��pair�ṹ��,key��value����װ������
template <class T1, class T2>
struct pair
{
typedef T1 first_type; // ��ֵ����key������
typedef T2 second_type; // ��ֵ����value������
T1 first; // first�൱��key
T2 second; // second�൱��value
pair(): first(T1()), second(T2()) {} // ���캯��
pair(const T1& a, const T2& b): first(a), second(b) {} // �������캯��
};
����һ��pair����(��ֵ��):
std::pair<int, int> p(10, 20);
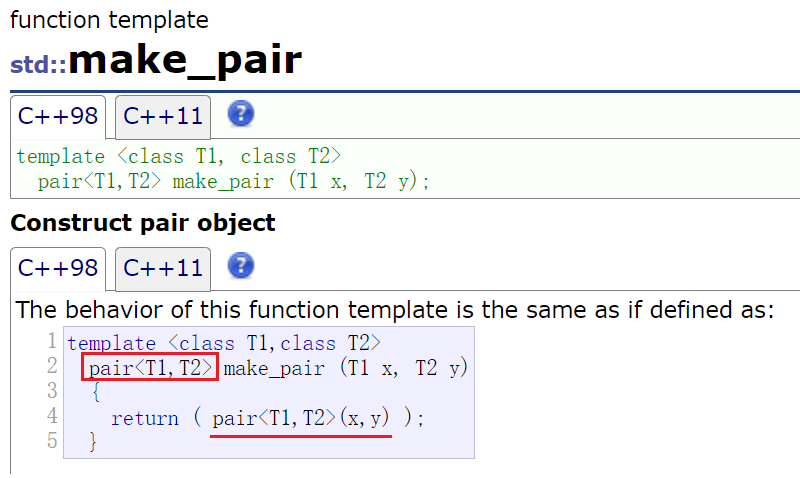
���� make_pair ����ģ�幹��һ��pair����(��ֵ��),ͨ�����ݸ�make_pair�IJ�����ʽ�Ƶ�������
std::pair<int,int> p = std::make_pair(10,20); // �������ֹ��췽ʽ
3.3 map��ʹ��
����:map�����в�������ͨ������ƥ��Ԫ�صļ� key ����ɵ�,�����Ӧӳ��ֵ value �ء���Ϊ map ��������������,����ÿ��Ԫ�ص� key ֵ��Ψһ�ġ�
�� map�ij��ýӿ�
map�ĵ�����,�� set ����,ֻ����map������ָ���Ԫ����һ��pair����
map�ķ���:
| Element access: | |
|---|---|
| operator[ ] | Access element(����Ԫ��) |
| at (C++11) | Access element(����Ԫ��) |
1��operator[] ��������(?)
ǰ��ѧϰ�� vector ��������� vector::operator[] �Ǵ���Ԫ���±�,���ضԸ�Ԫ�ص����á�
�� map �е� operator[] ����Ԫ�غ���,������������ͦ�������,�Ѿ����Ǵ�ͳ�������±������:
operator[]�ײ�ʵ���ϵ��õ�insert()������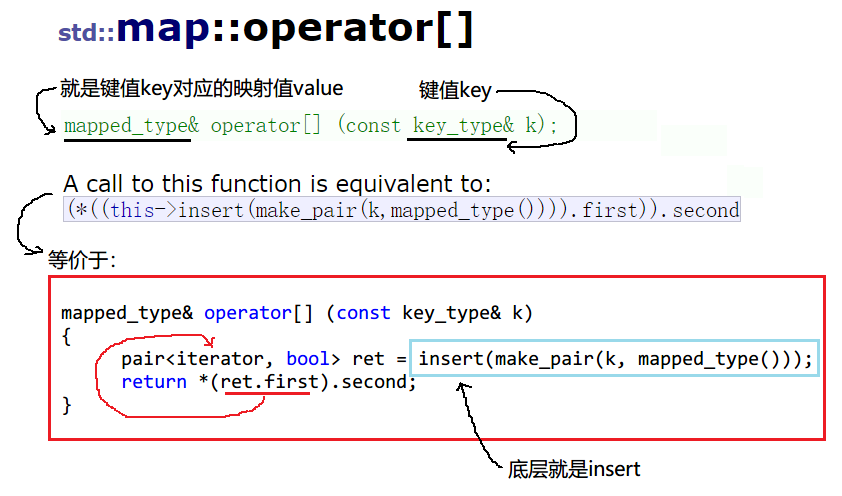
map�����е� map::operator[] �Ǵ����ֵ key,ͨ����Ԫ�ص� key ���Ҳ��ж��Ƿ��� map ��:
-
����� map ��,˵�� insert ����ʧ��,insert�������ص� pair ��������ָ���Ԫ�صĵ�����,ͨ�����������,���ǿ����õ���Ԫ�� key ��Ӧ��ӳ��ֵ value,Ȼ�����������Ӧӳ��ֵ value ��������
-
������� map ��,˵�� insert ����ɹ�,�����������Ԫ��
< key, value() >,Ȼ�����������Ӧӳ��ֵ value �������� -
ע��:���������Ԫ��ʱ,��
value()��һ��ȱʡֵ,�ǵ��� value ���͵�Ĭ�Ϲ��캯�������һ����������(������ string ���;͵��� string ��Ĭ�Ϲ���)
��operator[ ] �ܽ���
ʹ�� map::operator[] ����,����Ԫ�صļ�ֵ key:
- ��� key ��map��,���� key ��Ӧӳ��ֵ value �����á�
- ��� key ����map��,�����Ԫ��
< key, value() >,���� key ��Ӧӳ��ֵ value �����á� - �õ��������ص�ӳ��ֵ value,���ǿ��Զ�������
��������dz���ǿ��,���в��ҹ���,Ҳ�в��빦��,����������
����˵��:
map<string, string> dict;
// �������˼��,�Ȳ���pair("tree", ""),����"tree"��Ӧ��valueֵΪ"��"
dict["tree"] = "��";
// �ȼ���:
dict["tree"]; // ����pair("string", "")
dict["tree"] = "��"; // "tree"�Ѵ���,����"tree"��Ӧ��valueֵΪ"��"
��������
���Ƶij�Ա���� map::at ��Ԫ�ش���ʱ�� map::operator[] ������ͬ����Ϊ,��������,��Ԫ�ز�����ʱ map::at ���׳��쳣��
map����:
| Modifiers: | |
|---|---|
| insert | Insert element(����Ԫ��) |
| erase | Erase elements(ɾ��Ԫ��) |
2��insert ��������(?)
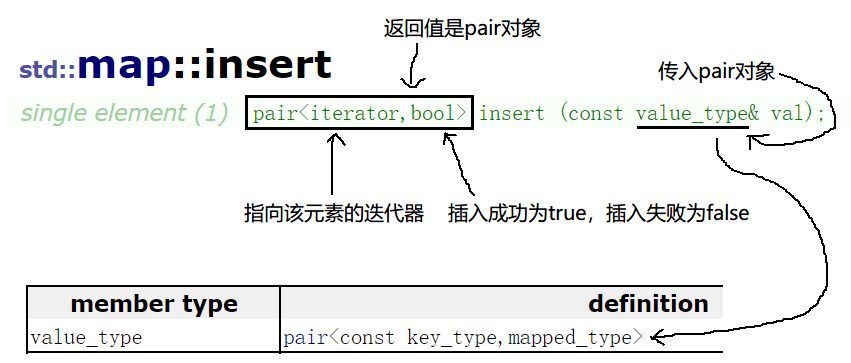
pair<iterator,bool> insert (const value_type& val);
����:�� map �в���Ԫ��(pair����)ʱ,��ͨ����Ԫ�ص� key ���Ҳ��ж��Ƿ��� map ��:
- �����,����һ�� pair ����:<ָ���Ԫ�صĵ�����, false>
- �������,�����Ԫ��<key, value>,����һ�� pair ����:<ָ���Ԫ�صĵ�����, true>
map�IJ���:
| Operations: | |
|---|---|
| find | ����ҵ�����ָ����(key)��Ԫ��,�ظ�Ԫ�صĵ�����,����map::end�ĵ������� |
�� ʹ�þ���
1��ʵ��һ���ֵ� �C ��ͨ�����ʲ��ҵ���Ӧ�����ĺ���
����map,��map�в���Ԫ��(��ֵ��),map�����ֲ���Ԫ�ط�ʽ:һ���õڶ���
// ����map
map<string, string> dict;
// ��map�в���Ԫ��,2�ַ�ʽ:
// 1������ֵ��<"sort", "����">����map��,ֱ�ӹ���pair��������(��ֵ��)
dict.insert(pair<string, string>("sort", "����"));
// 2������ֵ��<"sort", "����">����map��,��make_pair����������pair����(��ֵ��)
dict.insert(make_pair("left", "���"));
dict.insert(make_pair("tree", "��"));
�õ���������mapԪ��:
��Ҫע�����,����map��Ԫ�صķ�ʽ��������������Щ��ͬ,��������������ʾ��:
// error:�����it��ָ��ǰԪ�صĵ�����,������*it��һ��pair����(��ֵ��),��map��û�������������������,���Բ����������
map<string, string>::iterator it = dict.begin();
while (it != dict.end())
{
/* ������õ��� it.operator*() ��������������غ���,
* ���� *it ֻ�ǵõ��˵�ǰ�ڵ��д洢 pair<key,value> �ṹ��
* key��value��һ���װ��pair�ṹ���е�,����ֱ�Ӱ�key��value�������
* ����������ר�������� pair<key,value> �ṹ�������ݵ������������,����:
* ostream& operator<<(ostream& out, const pair<K, V>& kv);
*/
// cout << *it << endl; // error!!!
it++;
}
����������mapԪ�������ַ�ʽ:
// ����������map
map<string, string>::iterator it = dict.begin();
while (it != dict.end())
{
/* ���ֱ���map��Ԫ�صķ�ʽ:*/
/* 1��
* ����������ָ��һ��������
* �Ե�ǰԪ�صĵ�����it������(*it)���Եõ���ǰ�ڵ��д洢������:��pair����(��ֵ��),
* Ȼ����'.'��ȥ����pair�����е�kvֵ
* ������õ���it.operator*() ��������������غ���,����ֵΪ:pair���������
*/
cout << (*it).first << ", " << (*it).second << endl;
/* 2��
* ��������ͷ->,���ص�ǰ������ָ��j�ĵ�ַ(ָ��):pair<string, int>*
* ʵ�����ǵ��õ�operator->()����
* ��ָ����ʹ��'->'�Ϳ���ȡ��(pair����)�����kvֵ,��first��second
* ����Ϊ:it->->first,���ɶ���̫��,�����������������,ʡ�Ե���һ����ͷ
* �����˳���Ŀɶ���
*/
// һ��ṹ���ָ��Ż�ʹ��'->'�����ʳ�Ա
// ���Ե������������Ľڵ��е������ǽṹ���ʱ��,�Ϳ�����'->'
cout << it->first << ", " << it->second << endl; // ���������
it++;
}
�������:

2��ͳ�Ƶ��ʳ��ֵĴ���
����map,����str,��map�в���Ԫ��(��ֵ��):
string str[] = { "sort","sort", "tree","sort", "node", "tree","sort", "sort", };
// ����map
map<string, int> Map;
// ����str
for (auto& e : str) // ������,����string���
{
// �Ȳ����жϵ�ǰ�����Ƿ��Ѿ���Map����
auto ret = Map.find(e);
if (ret == Map.end()) // �������Map��,����Map�����һ��Ԫ�غ���ĵ�����
{
Map.insert(make_pair(e, 1)); // ����pair����(��ֵ��),��<����,���ʳ��ִ���>
}
else // �����Map��,���ظ�Ԫ�صĵ�����
{
ret->second++; // ���ʳ��ֵĴ���+1
}
}
// ����map,�����e��map��Ԫ��(��pair����),��ӡ<����,���ʳ��ִ���>
for (auto& e : Map)
{
cout << e.first << ", " << e.second << endl;
}
�����ⷨ,�Ȳ��ҵ�ǰ�����Ƿ���map��,�������,�����,�����ڲ��뺯�����ֻ����һ��,�ҵ������λ��,�е����ࡣ
����һ�ֽⷨ,����Ԫ��ʱ,insert�������в��ҹ���:
void test_map()
{
string str[] = { "sort","sort", "tree","sort", "node", "tree","sort", "sort", };
// ����map
map<string, int> count_map;
// ����str
for (auto& e : str)
{
// ����Ԫ��
auto ret = count_map.insert(make_pair(e, 1));
// insert����ֵ������:pair<map<string, int>::iterator, bool>
// ����ʧ��,˵����Ԫ���Ѵ�����map��,��������һ��pair����
// ��:pair<ָ���Ԫ�صĵ�����, false>
if (ret.second == false)
{
(ret.first)->second++; // �Ե�ǰԪ�ص�valueֵ��1
}
}
// ����map,�����e��map��Ԫ��(��pair����)
for (auto& e : count_map)
{
cout << e.first << ", " << e.second << endl;
}
}
�����ֽⷨ:
ʹ�� map::operator[] �������ݵ�ǰԪ�صļ�ֵ key ����,�жϸ�Ԫ���Ƿ��� map ��,�����,������ӳ��ֵ value ������,�������,������Ԫ�ز���,��������ӳ��ֵ value �����á�
string str[] = { "sort","sort", "tree","sort", "node", "tree","sort", "sort", };
// ����map
map<string, int> Map;
// ʹ��operator[]����
// ��Ԫ��e����,�������Ӧӳ��ֵvalue,����1
// ��Ԫ��e������,�����,�������Ӧӳ��ֵvalue,����1
for (auto& e : str)
{
Map[e]++;
}
// ����map,��ӡ< ����,���ʳ��ִ��� >
for (auto& e : Map)
{
cout << e.first << ", " << e.second << endl;
}
����:

3����һ������ȥ��
map��������������,���Բ���Ԫ��ʱ,����Ѵ�����ͬkeyֵ��Ԫ��,�������롣�ɶ�һ������ȥ�ء�
3.4 �ܽ�
-
map�еĵ�Ԫ���Ǽ�ֵ��(pair�ṹ��)
-
map�е�key��Ψһ��,���Ҳ�����,ֻ����key��Ӧ��ӳ��ֵvalue
-
��map��,��ֵ key ͨ�����������Ωһ�ر�ʶԪ��,��ֵ key ��ֵ value �����Ϳ��ܲ�ͬ,�� map ���ڲ�,key �� value ͨ����Ա���� value_type ����һ��,Ϊ��ȡ����Ϊ pair:
typedef pair<const Key, T> value_type; -
Ĭ�ϰ���С�ڵķ�ʽ�� key ���бȽ�
-
map ��ͨ����ֵ���ʵ���Ԫ�ص��ٶ�ͨ���� unordered_map ������,�� map ��������˳���Ԫ�ؽ���ֱ�ӵ���(��==��map�е�Ԫ�ؽ��е���ʱ,���Եõ�һ�����������==)��
-
map֧��
[]������,operator[]��ʵ���ǽ��в��Ҳ���,����[]�з��� key,�Ϳ����ҵ��� key ��Ӧ�� value�� -
map�ĵײ�Ϊƽ�����������(�����),����Ч�ʱȽϸ�
�ġ�multimap
multimap ��ʹ�ú� map ����һ��,����֮����������:
-
map �Dz��������������,�� multimap ������������,�����ж����ͬ key ֵ��Ԫ�ء�
-
multimap��û������
operator[]������(������,�ж����ͬ key,�������ĸ� key ��ӳ��ֵ value ��?)