最近正好有个内存泄露分析的案例,和大家分享下,其带给我的一些思考。
开发模型与问题发现的时机
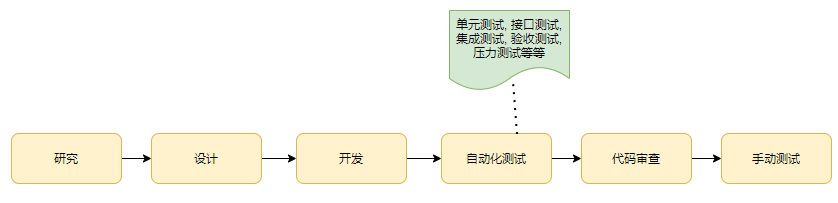
这些年来开发模型从传统的瀑布模型,逐步向敏捷开发过渡。敏捷开发将需求进行细分后,进行更快速的迭代,不断的交付,从原先瀑布模型按半年,甚至几年一次性交付,变成敏捷开发模式的1个月,2周,甚至是几天为一个交付周期。 在这样的开发模式中,可以让客户更快速的使用功能给出反馈,开发人员可以及时做出调整。 但从开发者的角度来看,在快速的迭代开发中,CI/CD (持续集成/持续部署)成为不可或缺的部分,自动化必须替代其中大部分的手动工作。
在瀑布模型时代的时候,当开发者开发完成后,做完基本测试,交由测试人员进行功能测试,性能测试等等。而此时给与测试人员测试和开发人员修复问题的时间,往往比较充足。但在敏捷开发中,假设就以1个月为一个Sprint(冲刺), 那么假设开发人员(RD)设计、开发和单元测试时间为2~3周,1周的测试人员(QA)测试和开发人员修复bug,剩余的时间测试人员进行回归测试,开发人员准备下一个Sprint。如果这个时候等到QA测试出一些比较难处理的棘手问题(比如内存泄露、内存破坏等),那么对于项目的发布将会受到严重的挑战,时间比较短促了。
然而不巧,本人这次碰到的内存泄露案例,就在发布的前一周结束的时候发现的,此时对于即使有一定经验的开发人员无疑是很具有挑战性的。
那么在敏捷开发中,让问题尽早的暴露显得尤为重要,以下是个人的一些感想:
- 在研究(Research)阶段,做好充分的学习和验证,要当问题追踪(Trouble Shooting)一样的细心,不放过任何的蛛丝马迹,尤其是那些想当然的场景,最后也许是让你出乎意料的地方。要做到
明确需求,广泛阅读先关资料与有相关经验的人员谦虚沟通学习,做代码级别的验证,并且不放过蛛丝马迹,还需要及时和相关组员汇报和讨论相关研究进展,发现可能的问题和应对方案。 - 在设计过程中,要做到详细设计,尽量考虑到多种可能的场景,测试以及部署相关的。一般相关的人员(比如QA)或者预备人员,在参与会议过程中,要尽可能的认真聆听,尽量给出自己的建议和想法,让设计方面的问题及早的暴露。
- 开发过程中,开发人员要不断的提高自己的编码能力(比如熟知一些C++常见的避坑写法),做好单元测试,并且在编写代码的时候,笔者也经常有一些疑问或者感觉某个地方未来可能会产生问题的(根据墨菲定律,那一定会产生问题),可以用笔记将其记录下来,或者本人比较喜欢用微软的
To Do(以前叫做Wunder List)去进行记录, 然后在有空闲时间的时候,对这些问题进行仔细查看和测试。 - 代码Review。大家都知道代码review的重要性,然而在项目进行时,却往往没有给代码Review腾出足够时间。那么在一些功能测试很难暴露的问题,比如内存泄露,内存破坏,UAF(Use After Free, 使用释放后的内存)等问题, 在代码Review过程中也许会被发现。
- CI/CD中,集成自动化的相关测试,比如单元测试(Unit Test),接口测试(Interface Test),集成测试(Integration Test),验收测试(User Acceptance Test), 以及压力测试(Stress Test)。像本文所说的内存泄露问题,应该在持续的压力测试过程中很可能会暴露出来。那这样只要RD在开发完代码提交到代码仓库,触发了CI/CD后,便可以自动获取测试报告,发现可疑的问题。
- 如果不能在自动化阶段完成这些测试,那么在RD在进行开发的过程中,RD和QA可以共同准备压力测试的方法和脚本,便于在尽早的时候进行测试,暴露问题。
内存泄露的发现与分析方法
在压力测试中,尽可能时间长的混杂不同的类型的样例进行测试。 本文的案例主要发生在Windows平台, 可以使用Windows自带的任务管理器和性能监视器或者sysinternals工具集中的Process Explorer和vmmap进行观察,首先区分出是常见的句柄泄露,还是堆内存泄露。本文主要讲的是堆内存泄露。
当确定程序有内存泄露,然后又告诉你还有几天就要发布了。这个时候不慌是不可能的,但是很有必要冷静下来想一想该怎么做?
第一步 不是用调试工具,而是先确定问题发生范围。那么先确认是不是这个问题在上一个发布版本已经有了?
- 如果上一个版本已经有这个问题了,并且跑了一段时间,并没有引起太大的问题。那么在综合考虑后,也许你可以不用紧急的修复这个问题,而是可以继续发布,在下一个
Sprint对问题进行查找,进入第三步。 - 如果上一个版本没有这个问题,那么可以集中考虑这个
Sprint编写的代码的问题,走进第二步
第二步 这个时候又要分以下几种可能的情况:
- 代码量不大,那么可以和同事一起进行所有的代码Review,如果还找不出来,进入
第三步 - 代码量比较大,那么这个时候除了和熟悉这部分代码的同事一起Review代码,还可以根据内存泄露的速率和这次新增的业务逻辑,找到可疑的点。如果还是找不到,那么进入
第三步。
第三步 这个时候需要调试工具的介入。之前本人写过几篇内存泄露分析的方法:
- <<微软Debug CRT库是如何追踪C++内存泄露的?>>: 这种做法只适合于小型的项目,而且对于第三方库的内存泄露无法进行检测。本文旨在通过分析微软Debug CRT库的实现的检测内存泄露的方式,从而阐述自我实现简易C++内存泄露检测的思想。
- <<Windows程序内存泄漏(Memory Leak)分析之UMDH>>: 这种方法有一定的局限:当程序复杂,内存频繁的申请释放,通过UMDH对比的文件将会非常的大,并且很难直接看出内存泄露所在; 另外UMDH在收集信息的需要符号文件,不太适合于在客户的机器上进行操作。
- <<Windows程序内存泄漏(Memory Leak)分析之Windbg>>: 这种方法,需要分析者对Windbg和Windows的堆要比较熟悉,分析过程也相对比较麻烦,不是首选方法。
- <<vmmap分析内存泄露问题>>: 虽然也可以用来做内存泄露分析,但是一般本人喜欢用于做辅助分析,可以比较清晰的看出各种类型内存的动态变化。
- <<Windows内存泄露分析之DebugDialog>>: 这种是我目前分析内存泄露问题的首选方法,也是本案例中使用的主要方法, 其主要两个步骤: 收集dump和自动分析,从而找出可疑的内存泄露对应的函数调用栈。读者可以跳转到文章,查看详细的信息,本文将精简原文所做的步骤和讲解。
当本人在准备对内存泄露进行分析的时候,便想到了之前写过的几种方法,由于代码比较复杂,也不太想消费太多的脑力去回忆Windbg的种种指令(毕竟大多数时候,不需要用Windbg分析),综合的考虑后选择了DebugDialog。
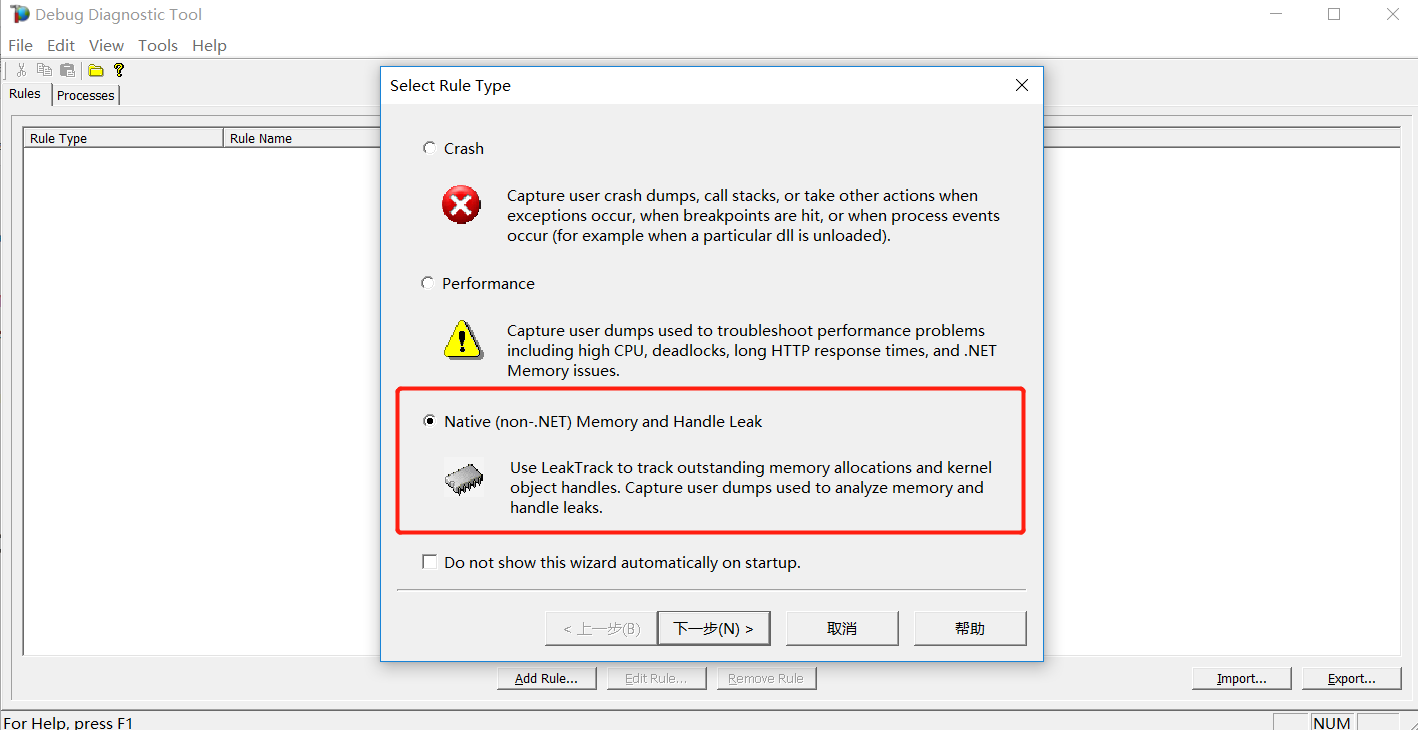
第一步 打开DebugDialog Collection,选择你需要分析的问题的类型,比如我们想要分析的是Native Memory and Handle Leak问题, 然后选择相应的进程:
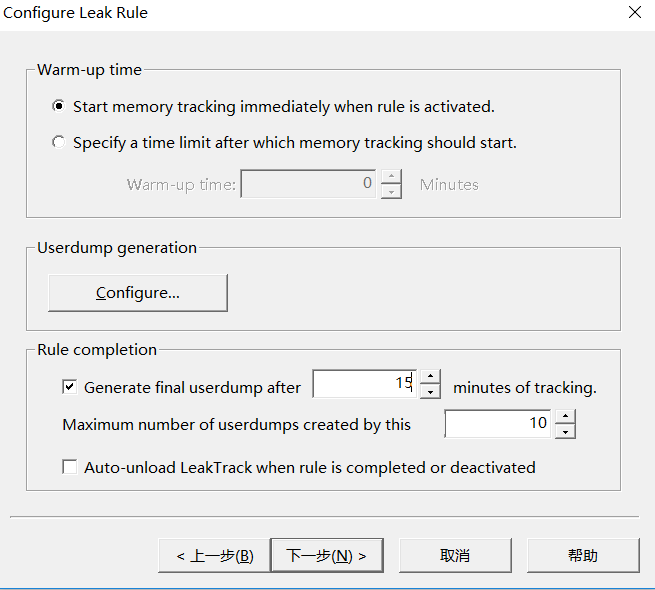
第二步 选择你需要产生Dump的时间,最少要配置15分钟,这个可以根据你项目产生Memory Leak的速度来决定。
第三步 然后Active你配置的Rule,则需要监测的进程被注入LeakTrack.dll用于辅助分析。接下来静心等待,直到产生了Dump文件。然后开启DebugDialog Analysis, 先配置好符号文件目录:
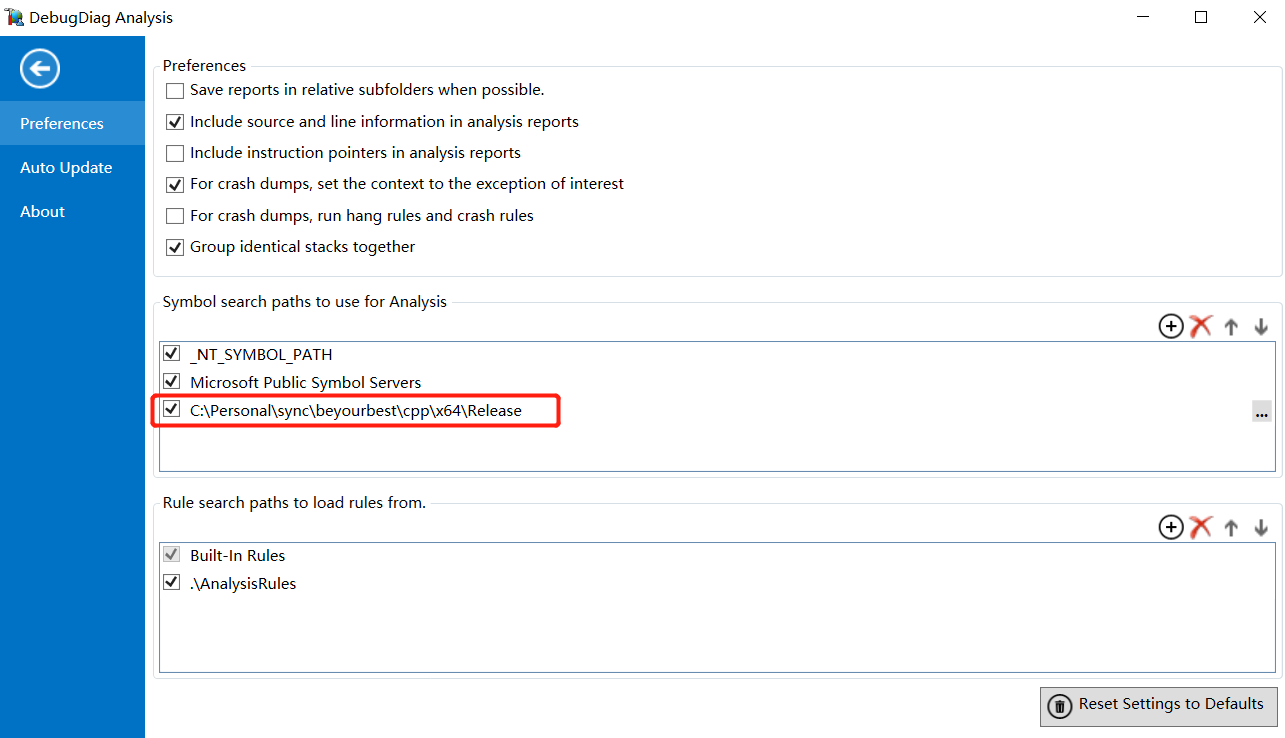
然后选择MemoryAnalysis, 并且添加刚才Monitor后产生的Dump文件。点击Start Analysis进行分析。
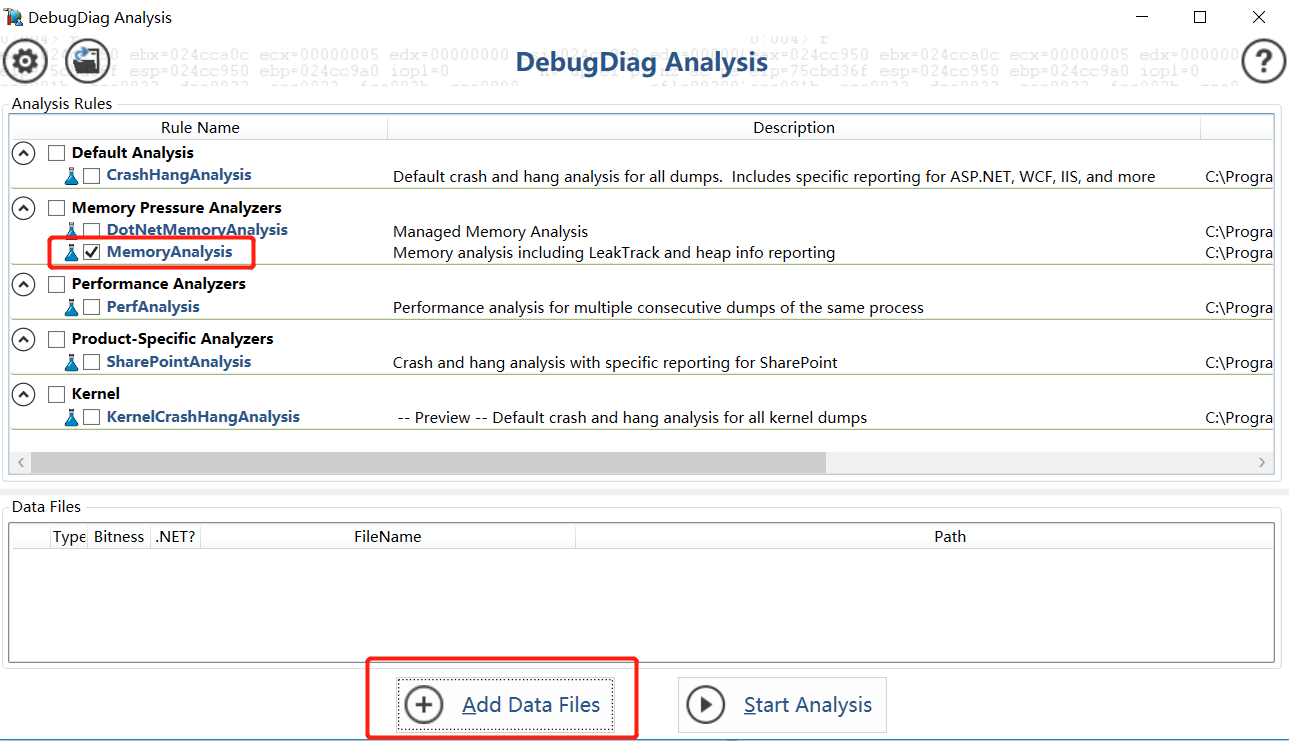
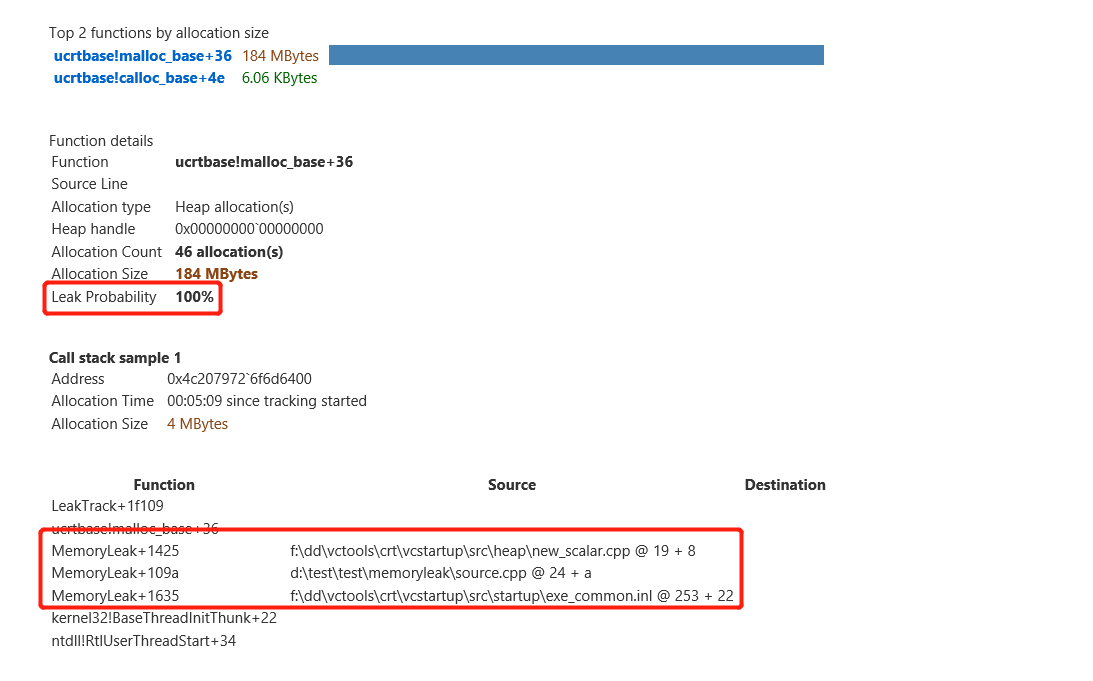
分析结束后,打开报告, 直接拉到Leak Analysis部分:
这一部分才是内存泄露的关键部分,会列出详细的内存申请的位置和大小。首先注意查看的是Leak Probability 显示为100%, 非常值得怀疑的部分,其列举了申请内存为4M的函数调用栈,可以根据函数调用栈(d:\test\test\memoryleak\source.cpp @ 24 + a)寻找到内存泄露的地方。
大功告成,赶紧修复后出一个Debug Build试一试吧。
也有可能很不幸的是,由于一些原因没有分析出问题原因呢? 那这个时候也许还有一种可能,如果可行,这部分代码暂时不进行发布。天塌下来又如何,就当被子盖吧!
内存泄露的原因
本次的案例实在是羞愧和读者朋友们分享,因为本人之前写过一篇<<你踩过几种C++内存泄露的坑?>>,这个案例的原因也就是那篇文章的第一个坑。其中加重字体写着"当你构建一个类的时候,写析构函数一定要切记释放类成员关联的资源。". 不过还是容我解释下,当初在对一个class做修改的时候,正好发现有一个成员变量可以复用,而没有将其改造为智能指针std::unique_ptr,在写的时候还提醒自己,析构函数别忘记写delete哦。 我们不应心存侥幸:记得手动释放内存;而是尽量用正确的方法,智能指针去避免这种可能的问题发生,否则分析的代价比用智能指针可大了很多。
class MemoryLeakClass
{
public:
MemoryLeakClass()
{
m_pObj = new XXX_ResourceClass;
}
void DoSomething()
{
m_pObj->DoSomething();
}
~MemoryLeakClass()
{
;
}
private:
XXX_ResourceClass* m_pObj;
};
总结
纸上得来终觉浅,绝知此事要躬行。当五花八门的方法和思路摆在面前,我们需要的先冷静下来,理清思路,然后再着手使用更合适的方法去解决问题。当然了,作为技术人员,在平时尽量做好技术积累的工作,比如本次案例中,本人之前写过的<<Windows内存泄露分析之DebugDialog>>文章帮助我节省了很多的时间去重新回忆和整理。