����Ŀ¼
C++ȡ����������ķ���
1��c�����м�rand()�C��Χ����0~32767
������Ŀ��ȡֵ��ΧС�Ŀ���rand(),ʡȥ�˸��ඨ����鷳
���÷�Ϊ:���ȡ[n,m)֮�����,����÷���Ϊ:rand()%(m-n+1) + n
int ans = rand() % 5 +1; //��Χָ��1��ʼ��5��--1,2,3,4,5
int ans = rand() %5;//��Χָ��0��ʼ��5��--0,1,2,3,4
2��mt19937�����C������
1���������������mtָ����Mersenne Twister�㷨,��α�����������֮һ,����Ҫ����������α���������19937����Ϊ�������������ٶȿ졢���ڳ�,��Χ�ܵ�2^19937-1�����÷���rand()�������ơ�
2������������������ӡ����е����������������һ������:������ѭ����λ�ȡ�����ʱ,����������й������ʹ���˶��̵߳ȷ���,����ʹ�����ظ��Ӷ�������ظ�����˿�������C++11�е���������������������������ӡ�random_device��(��ֱ����������Ϊ�����ٶȺ���)
3��ȡ������rand()����%���������ȡֵ��Χ,��mt19937��Ҫ����һ��ר�ŵĺ�������ȡ������ķ�Χ:
//��Ŀ�о��������Ҫ��ɾ��Ǵ�����ʵ�ֵ�.ע��real�Ǹ�����,��int������
template <class IntType = int> class uniform_int_distribution(a,b);
template <class IntType = double> class uniform_real_distribution(a,b);
������ݷ�����,�����ȵĸ�������a��b֮�����[a,b],���DZ�����!
���,�����һ�����һ��ģ��:
mt19937 gen{random_device{}()};//����:������+���ӡ�
//--����������Ҫ#include<random>
//����gen�ij�ʼ������Ҳ��һ��������,���Ҫ{}
// random_device�ȼ�{}����һ���������������,��()��������
uniform_int_distribution<int> dis(1,5);//����:ȡ����
int ans = dis(gen);//ans��1~5�о��ȸ���ȡ���ġ�
C++���ھ����������Ӧ��
1����Բ��������ɵ�(ȡֵ��Χ��������)
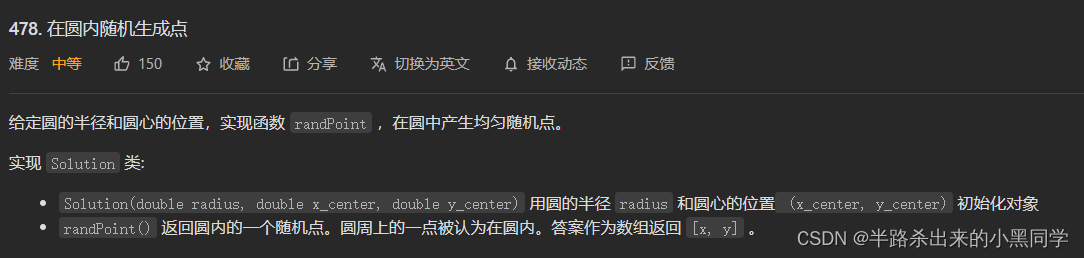
������������д�������ģ��Ҳ����֪��,���������������һ�����εķ�Χ,��ô���ʹ���ΪԲ����,��ʵ��ȫ����ȡ�������εķ�Χ���һ�����εķ�Χ,Ȼ���ټӸ��ж�,��ȥ��Բ��ʱ,������ȡ����!
class Solution {
private:
mt19937 gen{random_device{}()};
uniform_real_distribution<double> dis;
double xc, yc, r;
public:
Solution(double radius, double x_center, double y_center): dis(-radius, radius), xc(x_center), yc(y_center), r(radius) {}
vector<double> randPoint() {
//�����wile(true)�����ϳ���,ֱ�������Բ�ڵĵ��ٷ���
while (true) {
double x = dis(gen), y = dis(gen);
if (x * x + y * y <= r * r) {
return {xc + x, yc + y};
}
}
}
};
2�����ص������е������(��ȡֵ��Χ)
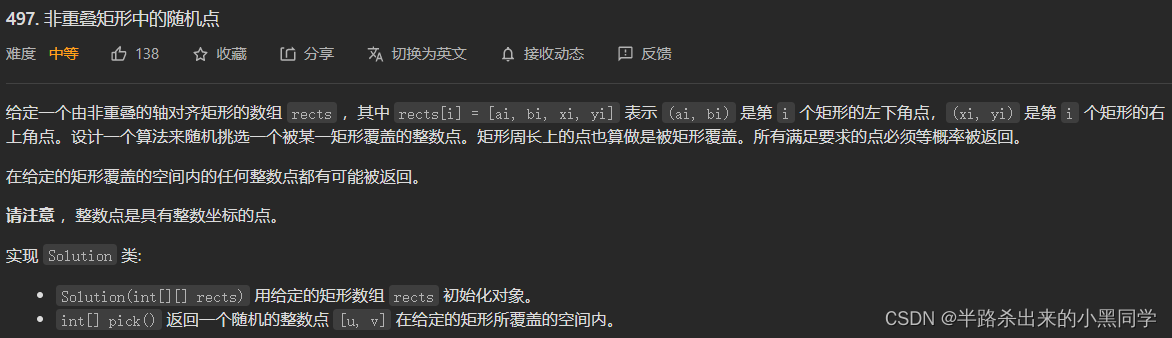
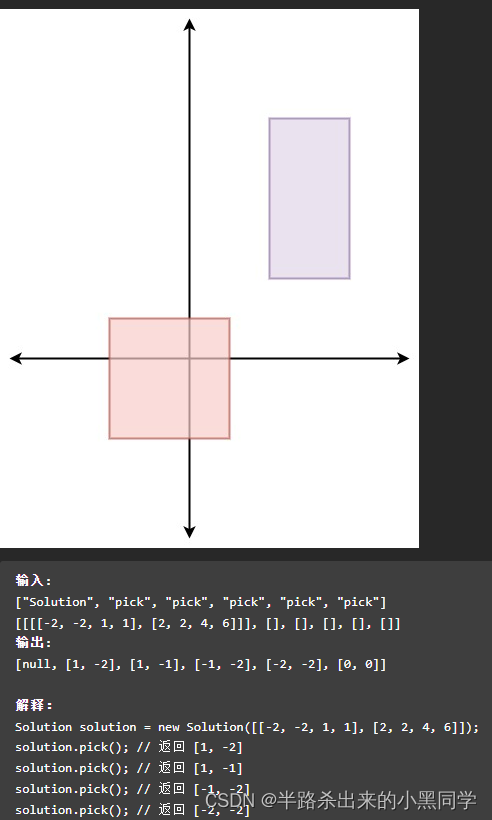
�������������е�,��˴�����ȷֲ������ķ�ΧӦ�������о��θ��ǵ�������(�������о��ζ����һ����������ɵ���,���Ǹ���ά�IJ���,���ٺ�~)������㹫ʽ����(x-a+1)*(y-b+1)
��һ�������е��������ص���������Ϊ(�ر�):
//��ǰ������������е�������½ǵ��������
int x = idx%rowPoints;
int y = idx/rowPoints;
���ʾ���ǰ�ͽ��,ֻ�������������ǰ�͵Ĺ������ö��ַ���!!!����,���ֲ��Ҽǵ�Ҫ���Ҷ����right_bound���ֲ������ҵ����ñ����ٵĵط�,���+1���Ǹ�����������ص�,���ڵľ��������
��ԭ��Ŀ��Ԫ�� target ���������� nums ��ʱ,�������߽�Ķ��������ķ���ֵ���������¼��ֽ��:
1�����ص����ֵ�� nums �����ڵ��� target ����СԪ��������
2�����ص����ֵ�� target Ӧ�ò����� nums �е�����λ�á�
3�����ص����ֵ�� nums ��С�� target ��Ԫ�ظ�����
�������������� nums = [2,3,5,7] ������ target = 4,������߽�Ķ����㷨�᷵�� 2(Ҳ����ָ��5),����������˵��,���ǶԵġ��������ұ߽�Ķ����㷨�ͻ᷵��1(Ҳ����ָ��3)��
�����ɡ������ȡ [1, sum[w]] ��Ӧ����߽�,��� [0, sum[w] - 1] ��ʹ����߶�ռһ��,�����ұ���ռһ��;
�����ȡ [0, sum[w] - 1] ��Ӧ���ұ߽�+1,��� [1, sum[w]] ��ʹ�������ռһ��,�������������
class Solution {
public:
int n=0;
vector<int> sum_point;//ǰ��
mt19937 gen{random_device{}()};
vector<vector<int>>rects;
Solution(vector<vector<int>>& rects): rects{rects} {
n = rects.size();
sum_point.resize(n,0);
//baseline��ǰ�������~!
sum_point[0] = (rects[0][2] - rects[0][0] + 1) * (rects[0][3] - rects[0][1] + 1);
for(int i=1;i<n;++i)
{
int length = rects[i][2]-rects[i][0]+1;
int height = rects[i][3]-rects[i][1]+1;
sum_point[i] = height*length+sum_point[i-1];
}
}
vector<int> pick() {
uniform_int_distribution<int> dis_point(0,sum_point[n-1]-1);
int point = dis_point(gen);
int lp=0,rp=n-1;
while(lp<=rp)
{
int mid = lp+(rp-lp)/2;
if(sum_point[mid]>point) rp=mid-1;
else lp = mid+1;
}
int num = rp+1;
if (num > 0) point -= sum_point[num-1];
int length = rects[num][2]-rects[num][0]+1;
int x = point % length;
int y = point / length;
return{rects[num][0]+x,rects[num][1]+y};
}
};
C++��Ȩ�ص����ѡ���㷨(ȡֵ��Χ����)
ǰ��+���������㶨ȡֵ��Χ����
�����Ͻڵĵ�2��,��ʵ���ǿ�������ͬ�ķ���,�������Ȩ�صĻ��ɾ��ȳ�ȡ��,���������W=[1,3]����,���ǾͿ��Կ�������[0,1,1,1]�Ͼ��ȳ�ȡ����˷���������������,ǰ��+��������,����ɷ�Ϊ���¼���:
1������Ȩ������ǰ������
2������һ����ǰ�������ڵ������
3��ͨ���������������߽�����(ԭ������Ҳ�ᵽ��)�ҵ�������������СԪ��������
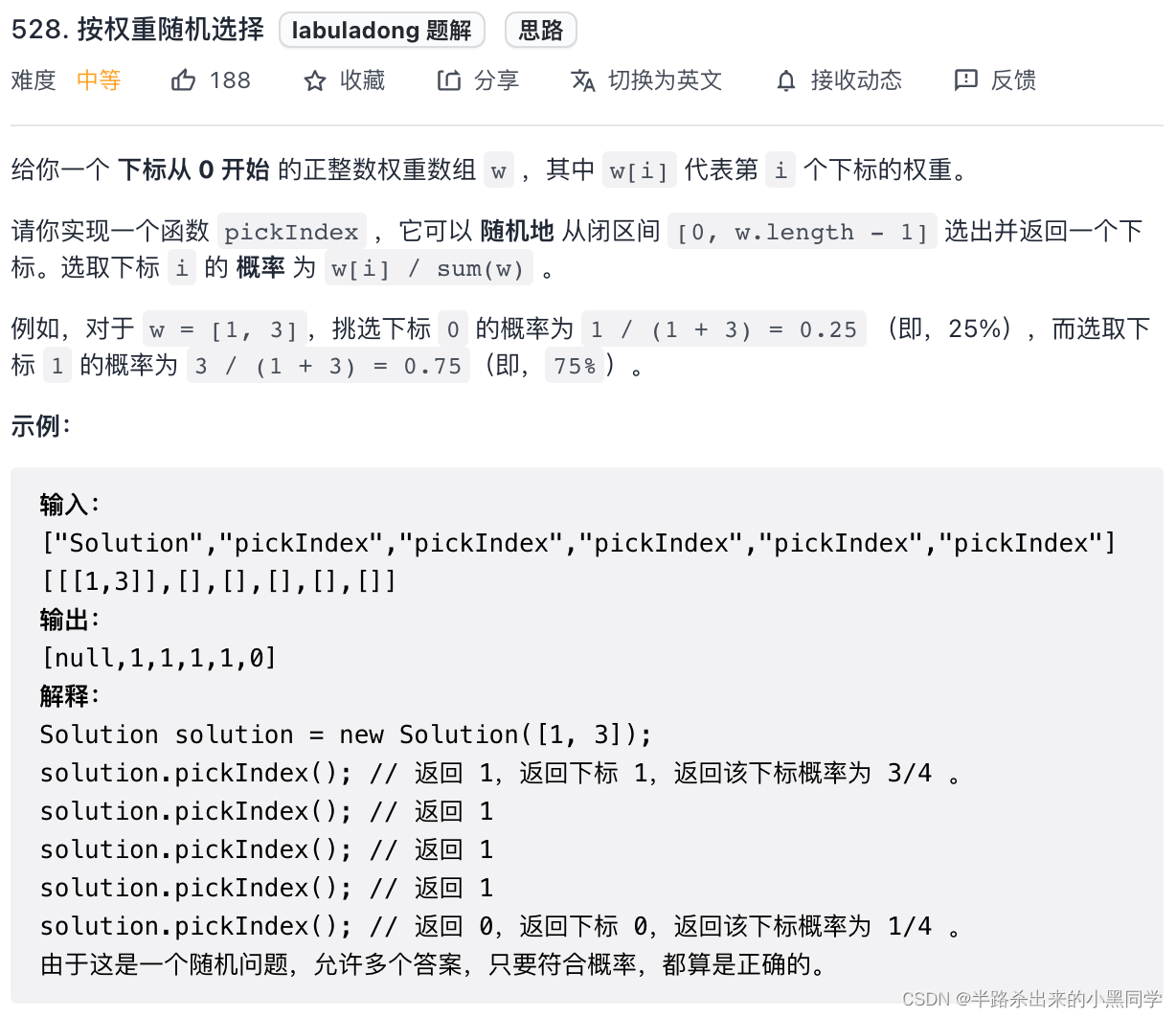
�������Ҷ��յĶ�������,ѡ�����������ҵļ���
�����ɡ������ȡ [1, sum[w]] ��Ӧ����߽�,��� [0, sum[w] - 1] ��ʹ����߶�ռһ��,�����ұ���ռһ��;
�����ȡ [0, sum[w] - 1] ��Ӧ���ұ߽�+1,��� [1, sum[w]] ��ʹ�������ռһ��,�������������
class Solution {
public:
vector<int>add_num;
mt19937 gen{random_device{}()};
Solution(vector<int>& w) {
int tem=0;
for(auto a:w)
{
tem+=a;
add_num.push_back(tem);
}
}
int pickIndex() {
uniform_int_distribution<int> dis(1,add_num.back());
int x = dis(gen);
int lp = 0,rp = add_num.size()-1;
while(lp<=rp)
{
int mid = lp+(rp-lp)/2;
if(add_num[mid]>=x) rp = mid-1;
else lp = mid+1;
}
return lp;
}
};
����������STL�����Ż�һ��:
class Solution {
private:
mt19937 gen{random_device{}()};
uniform_int_distribution<int> dis;
vector<int> add_num;
public:
//accumulate ͷ�ļ���<numeric>��,���ض���Χ������Ԫ�صĺ͡�
Solution(vector<int>& w):dis(1, accumulate(w.begin(), w.end(), 0)) {
partial_sum(w.begin(), w.end(), back_inserter(pre));
//back_inserter����ͷ�ļ�<iterator>,������ĩβ����Ԫ�ء�
}
//spartial_sum������ͷ�ļ���<numeric>,��(first, last)�ڵ�Ԫ��������ۼƺ�,����result������
int pickIndex() {
int x = dis(gen);
return lower_bound(pre.begin(), pre.end(), x) - pre.begin();
//lower_boundͷ�ļ���<algorithm>,�����ҳ���Χ�ڲ�С��num�ĵ�һ��Ԫ�صĵ�����,Ҳ�����,��ȥ.begin()�ĵ����������±���!��!!��Ҳ�ǵ��������ٵõ��±��һ������,ѧ����!
}
};
����lower_bound��upper_bound������
��ʵһ���Ǵ��ڵ���,һ������,���������:
��Ŀ��ֵ����ʱ,upper_bound-1(Ҫ��1Ŷ)�����൱������������Ķ��ֲ��ҵ�rightָ�롣lower_bound�����൱������������Ķ��ֲ��ҵ�leftָ�롣
��Ŀ��ֵ������ʱ,�����������ķ���ֵ��ͬ,�䶼����������Ķ��ֲ��ҵ�leftָ���Ч��(ָ���һ������Ŀ��ֵ�ĵط�)
C++����ʱ��ɾ��/���������е�����Ԫ��
1������ij���ʱ��ɾ�����������Ԫ��

1����Ҫ�����ɾ��Ԫ�������Ե�ʱ����,��ô���������ݽṹ��������,һ���ǹ�ϣ������һ�����ǽ��յ����顣����ϣ���������ȡ��,���ڸ��ֽ����ϣ��ͻ�Ļ���,��������O(1)ʱ�������ȡ,��˾��������顣���ǾͿ���ֱ�������������Ϊ����,��������ȡ�������������Ӧ��Ԫ��,��Ϊ���Ԫ�ء�
2����ô�������ô����մӶ�ʵ�ֿ��ٲ���ɾ����,�����˵,ɾ���Ļ���ֻ����β�����н���Ȼ��pop������˾���Ҫ��һ����ϣ������¼ÿ��ÿ��Ԫ�ض�Ӧ��������
class RandomizedSet {
public:
RandomizedSet() {
}
bool insert(int val)
{
if(!record.count(val))
{
record[val] = ans.size();
ans.push_back(val);
return true;
}
else return false;
}
bool remove(int val) {
if(record.count(val))
{
int i = record[val];
record[ans.back()] = i;
swap(ans[i],ans.back());
ans.pop_back();
record.erase(val);
return true;
}
else return false;
}
int getRandom() {
uniform_int_distribution<int>dis(0,ans.size()-1);
int x = dis(gen);
return ans[x];
}
private:
unordered_map<int,int>record;
vector<int>ans;
mt19937 gen{random_device{}()};
};
2���������������(������Բ���������,�ظ������������)
��Ŀ����һ�仰**�Ż�����㷨,ʹ����С���������� ���� ��������Ĵ�����**��仰�ͼ�ֱ�ӵ�˵���˲�����Բ����,�ظ��������������
��ʵ�����������������!
ǰ��+���ֲ���
����һ�֡���Ȼ��ǰ��+���ֲ���,ֻҪȥ��������������,����������
class Solution
{
public:
using T = pair<int, int>;
vector<T> m; // ��Ÿ�������
vector<int> s; // ���ǰ��, ��m�������䳤�ȵ�ǰ��
Solution(int n, vector<int>& blacklist)
{
sort(blacklist.begin(), blacklist.end()); // ���ȶԺ�������������
int b_n = blacklist.size();
int st = 0; // st��ʾһ�����������˵�, Ĭ��Ϊ0
s.push_back(0);
for(auto v : blacklist)
{
if(v == st) // ��������Ĵ������������˵��Ǻ�����������++
{
++st;
continue;
}
m.push_back({st, v - 1}); // ����һ��������
s.push_back(s.back() + v - st); // (v - 1) - st + 1 ��ʾ��������ij���
st = v + 1;
}
// ���һ������ļ��� st ~ n - 1, ��Ҫע���ж��Ƿ�ɼ���
if(st != n)
{
m.push_back({st, n - 1});
s.push_back(s.back() + n - st);
}
}
int pick()
{
int N = s.back();
int t = rand() % N + 1; // ���߶εõ�һ�������, ��Ϊ���䳤������Ϊ1, ������Ҫ+1, ��1��ʼ
// ���ֲ���, �� t �������Ǹ������ϵ�
int l = 1, r = s.size() - 1;
while(r >= l)
{
int mid = l + r >> 1;
if(s[mid] >= t) r = mid-1;
else l = mid + 1;
}
auto iter = m[l - 1]; // ע�� r - 1, ��Ϊm�������Ǵ�0�±꿪ʼ�洢��
int n = iter.second - iter.first + 1; // �õ��������������ij���
return iter.first + rand() % n; // �������(��˵���ֵ + �����) ��Ϊ���մ�
}
};
��ϣӳ��
�������ù�ϣ�������ӳ���ϵ,�������������ǽ��յ�,�������ȡԪ�ء����ǰѺ�����������ӳ�䵽��n��ȥ,Ȼ���ǰn������������,���ȡ���ֵ�ʱ��,ֻ��ǰn������ȡ��ok�ˡ�
class Solution {
public:
Solution(int n, vector<int>& blacklist) {
sort(blacklist.begin(),blacklist.end(),greater<int>());
//������,������ֹһ��ѭ������
int num = blacklist.size();
range = n-num-1;//ȷ���������ͺ������Ľ���
int last = n-1;//�ӽ������ʼ��
for(auto black:blacklist)
{
if(black>range)//���Ǻ������������ں�������������
{
list_map[black] = black;
continue;
}
//��ֹ���������ڵ�����ռλ
while(list_map.count(last)) --last;
list_map[black] = last--;
}
}
int pick() {
uniform_int_distribution<int>dis(0,range);
int x = dis(gen);
//������������,��ӳ�伴��
if (list_map.count(x)) return list_map[x];
else return x;
}
private:
unordered_map<int,int>list_map;
mt19937 gen{random_device{}()};
int range;
};
C++�����������������ȡԪ��
����ļ�������,��������ͨ��ǰ�ͺͶ��ֲ��Ҷ��㶨,���Ƕ�����������,��û�а취ͨ��һ��0,n�ķ�Χ����ȥ�����!
�����ǻص��������,����һ����������:
һ��δ֪���ȵ�����,�������һ���㷨,ֻ�ܱ���һ��,������������������е�һ���ڵ㡣
ˮ�������㷨
��ʵ������̬���������ѡ��,��Ӧ����ѭ���¹���(������������֤������,�Ƿ�����ѧ������):
������һ��һ���ض�̬ѡ��ʱ������������ i ��Ԫ��ʱ,Ӧ���� 1/i �ĸ���ѡ���Ԫ��,1 - 1/i �ĸ��ʱ���ԭ�е�ѡ��
�����ڶ����һ��һ�εض�̬ѡ��ʱ�����Ҫ���ѡ�� k ����,ֻҪ�ڵ� i ��Ԫ�ش��� k/i �ĸ���ѡ���Ԫ��,�� 1 - k/i �ĸ��ʱ���ԭ��ѡ��
������ֱ��ʵս����һ��:
1�� ��������ڵ�
������������������ɲ�һ��,һ��ʼʱ��֪�����ж��,������ǿ�����ˮ�������㷨��
class Solution {
public:
Solution(ListNode* head) {
this -> head = head;
}
int getRandom() {
ListNode* root = head;
//ע�������head����,�������һ��head��ԶΪ��
int ans=0;i=0;
while(root!=nullptr)
{
i++;//ע�����i���Ǵ�1��ʼ��,0��û����Ϊ��ĸ
uniform_int_distribution<int>dis(0,i-1);
//��Ϊ��0,����i���Ǵ�0~i-1
//���ڱ���涨valС��10���Ĵη�,��ʵ������rand()%i���жϿ��ٽ��
if(dis(gen) == 0) ans = root->val;
root = root->next;
}
return ans;
}
private:
mt19937 gen{random_device{}()};
ListNode* head;
int i;
};
2�����������
��������1 <= nums.length <= 2 * 10��4�η�,С��30000,��˾�ֱ����С��Χ��rand()͵�����ˡ�
�����������ȱ������ֱ���ù�ϣ������ɱ,һ����¼ֵ,��һ��������ÿ��ֵ���±ꡣ����pick,����ֱ��ȡ������,ֱ������±ꡣ
��ϣ��ɱ
class Solution {
public:
unordered_map<int,vector<int>> record;
Solution(vector<int>& nums) {
for(int i=0;i<nums.size();++i)
{
record[nums[i]].push_back(i);
}
}
int pick(int target) {
vector<int> ans = record[target];
int n = ans.size();
return ans[rand()%n];//͵������ʵû����
}
};
ˮ����������ʱ�˾�Ȼ
���ûɶ��˵��,ֻ�����ȵ�������nums�е���target��ֵʱ��ȥ�����,��Ȼ��ʱ��,û�취,���ǹ�ϣ��ɱ��~��������ѧѧӦ�á�
class Solution {
public:
vector<int> nums;
Solution(vector<int>& nums) {
this -> nums = nums;
}
int pick(int target) {
int i = 0,ans = 0;
for(int index = 0;index<nums.size();++index)
{
if(nums[index] == target)
{
++i;
if(rand()%i==0) ans = index;
}
}
return ans;
}
};