目录
前言:从这里开始就正式进入STL了,STL对与C++是很重要的,接下来将会把STL的重要容器都学习一遍,并且也会包括STL的其它部分。?
一.字符码表
????????我们都知道ASCII码表,但是ASCII码表只有符号和英文字母,并没有中文汉字,或是其它语言的字符,因此就又有了其它的码表。
????????例如:unicode(全世界语言) utf-8 utf-16 utf-32 gbk(国标)
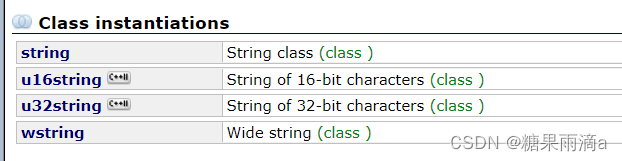
除此之外呢, 在我们搜索string时,会发现string有如下4个实例化,而这4个实例化的作用就是为了支持多种字符
一.为什么用string类
????????C语言中,字符串时以'\0'结尾的 一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户自己管理,容易导致越界访问。
????????因此有了string类的出现。
? ? ? ? 在OJ题中,有关字符串的题目基本以string类的形式出现,而且在常规工作中,为了简单、方便。快捷。基本都使用string类,很少有人去使用C库中的字符串操作函数。
二.使用标准库中的string类
1.string类
①string是表示字符串的字符串类
②该类的接口与常规容器的接口基本相同,但添加了一些专门用来操作string的常规操作
③string在底层实际是:basic_string模板类的别名,typedef basic_string<char,? char_traits, allocator> string;
④不能操作多字节或者变长字符的序列。
在使用string类时,必须包含#include <string>头文件。
2.string中的常用接口说明
(1)string类对象的常见构造
①string()? ? ? ? 构造空的string类对象,即空字符串
②string(const char* s)? ? ? ? 用C格式的string来构造string类对象
③string(size_t n, char c)? ? ? ? string类对象中包含n个字符c
④string(const string& s)? ? ? ? 拷贝构造函数
int main()
{
string s1; // 构造空的string类对象
string s2("hello world"); // 用C格式的字符串构造
string s3(s2); // 拷贝构造
string s4 = s2; // 拷贝构造
string s5("http://m.cplusplus.com/reference/string/string/string/", 4); // 用前4个字符构造
cout << s1 << endl;
cout << s2 << endl;
cout << s3 << endl;
cout << s4 << endl;
cout << s5 << endl;
return 0;
}(2)string类对象访问及遍历操作
①operator[]? ? ? ? 返回pos位置的字符,const string类对象调用
②iterator(begin + end?)? ? ? ?begin获取一个字符的迭代器 +end获取最后一个字符下一个位置的迭代器
③reverse_iterator(rbegin + rend)? ? ? ?begin获取一个字符的迭代器 +end获取最后字符的下一个位置的迭代器
④范围for? ? ? ? C++11支持更简洁的范围for的新遍历方式? ??
(3)string类对象遍历方式
①下标+[]
for (size_t i = 0; i < s1.size(); i++)
{
cout << s1[i] << " ";
}有一个与[]类似的at,使用方法相同,但有一点差别?
s1.at(6); // 使用at看第6个元素
s1[6] // 使用[]看第6个元素
用[]失败了报断言错误,直接结束程序。
而at相对温和,失败会抛异常。
但是一般都是用operator[],几乎不会使用at。
②迭代器
迭代器一共4种:iterator、reverse_iterator、const_iterator、const_reverse_iterator
正向迭代器:?
string s("hello world");
string::iterator it = s.begin();
while (it != s.end())
{
(*it) += 1;
cout << *it << " ";
++it;
}反向迭代器:?
string::reverse_iterator rit = s.rbegin();
while (rit != s.rend())
{
(*rit) += 1;
cout << *rit << " ";
++rit;
}?这里我们可以发现正向迭代器和反向迭代器都可以对string类对象内部字符进行修改,因此迭代器还有两种:const_iterator和const_reverse_iterator,这两种迭代器都只能遍历,而不能修改
string::const_iterator it = rs.begin();
while (it != rs.end())
{
//*it += 1; // 无法进行修改
cout << *it << " ";
++it;
}
cout << endl;
const_reverse_iterator rit = rs.rbegin(); // auto rit = rs.rbegin()
while (rit != rs.rend())
{
//(*rit) -= 1; // 无法进行修改
cout << *rit << " ";
++rit;
}③范围for(原理:替换成迭代器)
for (auto ch : s1)
{
cout << ch << " ";
}(4)string类对象的容量操作
①size? ? ? ? 返回字符串有效字符长度
????????length与size作用相同,只是length是最开始出现的,后面为了让string与其它STL容器差不多,便添加了size,但是length也不能删去
? ? ? ? max_size可以得到最大容量大小
②capacity? ? ? ? 返回空间总大小
③empty? ? ? ? 检测字符串是否为空串,是就返回true,不是就返回false
④clear? ? ? ? 清空有效字符
⑤reverse? ? ? ? 为字符串预留空间
⑥resize? ? ? ? 将有效字符的个数改成n个,多余的空间用字符c填充
int main()
{
string s("hello world");
cout << s.length() << endl;
cout << s.size() << endl;
cout << s.max_size() << endl;
cout << s.capacity() << endl;
string s;
//s.reserve(1000); // 扩空间
s.resize(1000, 'x'); // 扩空间+初始化
size_t sz = s.capacity(); // 得到当前容量大小
cout << "making s grow:\n";
cout << "capacity changed: " << sz << '\n';
for (int i = 0; i < 1000; ++i)
{
s.push_back('c');
if (sz != s.capacity())
{
sz = s.capacity(); // 容量满了
cout << "capacity changed: " << sz << '\n';
}
}
string s("hello");
//s.reserve(100);
s.resize(100, 'x');
// vs下他们都不会缩容量
s.reserve(10);
s.resize(10);
return 0;
}(5)string类对象的修改操作
①push_back? ? ? ? 在字符串后尾插字符
②append? ? ? ? 在字符串后追加一个字符串
③operator+=? ? ? ? 在字符串后追加字符串
④c str? ? ? ? 返回C语言格式的字符串
⑤find + npos? ? ? ? (从前往后) 从字符串pos位置开始往后找字符c,返回该字符在字符串中的位置
⑥rfind? ? ? ? (从后往前)
⑦substr? ? ? ? 在str中从pos位置开始,截取n个字符,然后将其返回
void test_string8()
{
string s;
s.push_back('x');
s.append("hello");
string str("world");
s.append(str);
cout << s << endl;
s += 'x';
s += "hello";
s += str;
cout << s << endl;
cout << str << endl;
cout << str.c_str() << endl; // 以C语言的方式打印字符串
}
void test_string9()
{
string s1("hello world");
string s2("string");
// C++98
s1.swap(s2); // 效率高
swap(s1, s2); // 效率低
cout << s1 << endl;
cout << s1.c_str() << endl;
// 要求取出文件的后缀
//string file("string.cpp");
//string file("string.c");
string file("string.c.tar.zip");
//size_t pos = file.find('.');
size_t pos = file.rfind('.');
if (pos != string::npos)
{
//string suffix = file.substr(pos, file.size() - pos);
string suffix = file.substr(pos);
cout << file << "后缀:" << suffix << endl;
}
else
{
cout << "没有后缀" << endl;
}
// 取出url中的域名
string url1("http://www.cplusplus.com/reference/string/string/find/");
string url2("https://leetcode.cn/problems/design-skiplist/solution/tiao-biao-probabilistic-alternative-to-b-0cd8/");
string& url = url2;
// 协议 域名 uri
string protocol;
size_t pos1 = url.find("://");
if (pos1 != string::npos)
{
protocol = url.substr(0, pos1);
cout << "protocol:" << protocol << endl;
}
else
{
cout << "非法url" << endl;
}
string domain;
size_t pos2 = url.find('/', pos1 + 3);
if (pos2 != string::npos)
{
domain = url.substr(pos1 + 3, pos2 - (pos1 + 3));
cout << "domain:" << domain << endl;
}
else
{
cout << "非法url" << endl;
}
string uri = url.substr(pos2 + 1);
cout << "uri:" << uri << endl;
}????????在string尾部追加字符串,一般用+=比较多,+=既可以连接单个字符,还可以连接字符串。
? ? ? ? 对string操作时,如果能大概预估放多少字符,可以先通过reserve把空间预留好。
(6)string类非成员函数
①getline? ? ? ? 获取一行字符串
②operator+? ? ? ? 传值返回,导致深拷贝效率低,应尽量少用
③operator>>? ? ? ? 输入运算符重载
④operator<<? ? ? ? 输出运算符重载
⑤find + npos? ? ? ? (从前往后) 从字符串pos位置开始往后找字符c,返回该字符在字符串中的位置
三.浅拷贝与深拷贝
1.浅拷贝
????????浅拷贝也称位拷贝,编译器只是将对象中的值拷贝过来。如果在对象中管理资源,最后就会导致多个对象共享同一份资源,当一个对象销毁时就会将该资源释放掉,尔此时另一些对象不知道该资源已经被释放,以为还有效,所以当继续对资源进行操作时,就会发生了访问违规。要解决浅拷贝问题,就要用深拷贝。
? ? ? ? 如果没有显式定义构函数、拷贝构造函数、赋值运算符重载,那么编译器就会合成默认的,就是浅拷贝。浅拷贝会导致两个类对象s1、s2共用同一块内存空间,在释放时同一块空间被多次释放而引起程序崩溃。
string(const char* str = "")
: _size(strlen(str))
, _capacity(_size)
{
// 浅拷贝
_str = str;
}2.深拷贝
? ? ? ? 如果一个类中涉及到资源的管理,其拷贝构造函数、赋值运算符重载以及析构函数必须要显式给出。给每个对象独立分配资源,保证多个对象之间不会因共享资源而造成多次释放造成程序崩溃问题。
string(const char* str = "")
: _size(strlen(str))
, _capacity(_size)
{
// 深拷贝
_str = new char[_capacity + 1];
strcpy(_str, str);
}四.string类的分部模拟实现(包括传统写法和现代写法)
注意:模拟实现之前需要自己定义一个命名空间
namespace hb
{
// ...
}要在命名空间里面模拟实现?
1.私有成员
private:
char* _str;
size_t _size; // 有效字符个数
size_t _capacity; // 实际存储有效字符的空间2.构造函数
?????????构造函数要采用深拷贝,防止因共用同一块内存空间,导致释放时多次释放而报错。
string(const char* str = "")
: _size(strlen(str))
, _capacity(_size)
{
_str = new char[_capacity + 1];
strcpy(_str, str);
}3.拷贝构造函数
(1)传统写法
????????传统写法就如名字一样,很传统,该开空间就自己开空间,该拷贝数据就自己拷贝数据。同样是深拷贝。
string(const string& s)
: _size(s._size)
, _capacity(s._capacity)
{
_str = new char[_capacity + 1];
strcpy(_str, s._str);
}(2)现代写法
????????先实现一个swap为了方便所有的现代写法:
void swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}????????这里为什么要自己实现一个swap,而不是用库里的swap函数呢?
? ? ? ? 原因呢是库里的swap的函数在swap该string类成员时,每次都会进行深拷贝,效率很低。因此自己实现一个swap就可以避免这种损耗。
????????现代写法是自己不想做,就让别人去做,这里就是定义一个tmp,然后让tmp去拷贝,之后再窃取tmp的成果之后,tmp自动析构。
string(const string& s)
: _str(nullptr)
, _size(0)
, _capacity(0)
{
string tmp(s._str);
swap(tmp);
}4.赋值运算符重载
(1)传统写法
? ? ? ? 在模拟实现赋值运算符重载时,要注意如果自己赋值自己的情况,通过一个if (this != &s)就是当自己赋值自己时,直接返回自己,可以避免报错。
string& operator=(const string& s)
{
if (this != &s)
{
char* tmp = new char[s._capacity + 1];
strcpy(tmp, s._str);
delete[] _str;
_str = tmp;
_size = s._size;
_capacity = s._capacity;
}
return *this;
}(2)现代写法
现代写法有两种:
①第一种和传统写法比较相似
string& operator=(const string& s)
{
if (this != &s)
{
string tmp(s._str);
swap(tmp);
}
return *this;
}②第二种可以说是将现代写法发挥到了极致,在形参就开始拷贝,然后下面直接调用swap函数。
string operator=(string s)
{
swap(s);
return *this;
}5.析构函数
~string()
{
if (_str)
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
}6.下标[]运算符重载
????????这里要实现两种,第一种是因为下标运算符要可以被修改,第二种是为了让const类型的string类对象可以使用下标运算符重载。
? ? ? ? 这里的const放在函数后面是因为this指针自动隐藏,而无法加在this前,因此C++让本应该加在this前的const放在函数后面。
实际相当于 const char& operator[](const string* this, size_t pos)
?
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
const char& operator[](size_t pos) const
{
assert(pos < _size);
return _str[pos];
}7.有效字符个数和存储空间容量
????????直接返回,加上const,让const类对象成员也可以调用。
size_t size() const
{
return _size;
}
size_t capacity() const
{
return capacity();
}8.reserve函数
? ? ? ? 增容函数,实现时里面要创建一个临时变量,将临时变量变为新的容量,然后通过strcpy函数将_str转换为tmp,再delete掉tmp
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete _str;
_str = tmp;
_capacity = n;
}
}9.resize函数
? ? ? ? 分情况讨论,想要resize的大小 < 当前有效字符个数时,可直接将n位置变为\0;当 n > 当前容量大小时,要先增容,然后再依次让n之后都变为传来的ch字符。
void resize(size_t n, char ch = '\0')
{
if (n < _size)
{
_size = n;
_str[_size] = '\0';
}
else
{
if (n > _capacity)
{
reserve(n);
}
for (size_t i = _size; i < n; ++i)
{
_str[i] = ch;
}
_size = n;
_str[_size] = '\0';
}
}10.尾插字符push_back函数
? ? ? ? 注意扩容
void push_back(char ch)
{
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size] = ch;
++_size;
_str[_size] = '\0';
}当insert字符函数实现之后,可直接复用:
void push_back(char ch)
{
insert(_size, ch);
}11.尾插字符串append函数
? ? ? ? 注意扩容
void append(const char* str)
{
size_t len = _size + strlen(str);
if (len > _capacity)
{
reserve(len);
}
strcpy(_str + _size, str);
_size = len;
}当insert字符串函数实现后 ,可直接复用:
void append(const char* str)
{
insert(_size, str);
}12.+=运算符重载
????????+=有两个,一个是+=字符的,另一个是+=字符串的,这里前面实现了puch_back和append函数,可以直接复用:
string& operator+=(const char* str)
{
append(str);
return *this;
}
string& operator+=(char ch)
{
push_back(ch);
return *this;
}13.插入函数
????????插入有两个,一个是插入字符的,另一个是插入字符串的。
这里插入函数的实现参考顺序表的插入函数实现。
? ? ? ? 第一个:
? ? ? ? 如果size_t end = _size时,下面写成end >= pos,_str[end + 1] = _str[end]时,会导致end变为-1,又因为end是size_t类型,就会变为一个很大的数4294967295导致报错。
? ? ? ? 因此像我这种写法可以避免出现-1的情况。
string& insert(size_t pos, char ch)
{
assert(pos <= _size);
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
_size++;
return *this;
}????????第二个:
? ? ? ? 同上,需要注意size_t,这里用了strncpy去连接新插入的字符串。
string& insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
size_t end = _size + len;
while (end > pos + len - 1)
{
_str[end] = _str[end - len];
--end;
}
strncpy(_str + pos, str, len);
_size += len;
return *this;
}14.删除函数
? ? ? ? 实现删除前,要先定义一个静态成员变量npos。
private:
char* _str;
size_t _size; // 有效字符个数
size_t _capacity; // 实际存储有效字符的空间
const static size_t npos;
};
// 初始化
const size_t string::npos = -1;? ? ? ? npos是size_t类型的,定义其为-1,就相当于4294967295。
? ? ? ? 删除也参考之前顺序表中的删除函数。
void earse(size_t pos, size_t len = npos)
{
assert(pos < _size);
if (len == npos || pos + len >= _size)
{
_str[pos] = '\0';
_size = pos;
}
else
{
size_t begin = pos + len;
while (begin <= _size)
{
_str[begin - len] = _str[begin];
++begin;
}
_size -= len;
}
}15.查找函数
? ? ? ? 查找分为查找字符和字符串两种。
? ? ? ? 第一种:
size_t find(char ch, size_t pos = 0)
{
for (; pos < _size; ++pos)
{
if (_str[pos] == ch)
{
return pos;
}
}
return npos;
}? ? ? ? 第二种:
? ? ? ? 可以直接用strstr去查找子字符串?。
size_t find(const char* str, size_t pos = 0)
{
const char* p = strstr(_str + pos, str);
if (p == nullptr)
{
return npos;
}
else
{
return p - _str;
}
}16.清除函数
void clear()
{
_str[0] = '\0';
_size = 0;
}17.C语言形式返回字符串
? ? ? ? 实现成const类型,const成员和非const成员都可以调用。
const char* c_str() const
{
return _str;
}18.迭代器
????????要实现const类型和非const类型两种。
typedef char* iterator;
typedef const char* const_iterator;
const_iterator begin() const
{
return _str;
}
const_iterator end() const
{
return _str + _size;
}
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}19.>、<、==等运算符重载
? ? ? ? 这个要写在类外面。
bool operator<(const string& s1, const string& s2)
{
return strcmp(s1.c_str(), s2.c_str()) < 0;
}
bool operator==(const string& s1, const string& s2)
{
return strcmp(s1.c_str(), s2.c_str()) == 0;
}
bool operator<=(const string& s1, const string& s2)
{
return s1 < s2 || s1 == s2;
}
bool operator>(const string& s1, const string& s2)
{
return !(s1 <= s2);
}
bool operator>=(const string& s1, const string& s2)
{
return !(s1 < s2);
}
bool operator!=(const string& s1, const string& s2)
{
return !(s1 == s2);
}20.流插入、流提取运算符重载
流插入:
????????这里用范围for,而不是c_str是为了能识别出字符串中\0这种隐藏字符。
ostream& operator<<(ostream& out, const string& s)
{
// 不能写成这种形式
/*out << s.c_str();*/
for (auto ch : s)
{
out << ch;
}
return out;
}流提取:
第一种:
????????这里我们用ch = in.get()是为了在输入时,可以识别出 空格' ' 和 回车'\n' ,否则将无法结束输入。
istream& operator>>(istream& in, string& s)
{
char ch;
// 不能写成这种形式
//in >> ch;
ch = in.get();.
while (ch != ' ' && ch != '\n')
{
s += ch;
in >> ch;
}
return in;
}第二种:
????????这里的buff数组以及while循环是为了提高效率的。
? ? ? ? 我们不知道输入的字符串是长还是短,当字符串比较短时,那么上面第一种方法是可以的。而当字符串很长时,每当输入一个字符就+=一次,会导致效率较低,因此这里是每满128个字符时,进行一次+=,可以提升一定的效率。
istream& operator>>(istream& in, string& s)
{
char ch;
ch = in.get();
char buff[128] = { '\0' };
size_t i = 0;
while (ch != ' ' && ch != '\n')
{
buff[i++] = ch;
if (i == 127)
{
s += buff;
memset(buff, '\0', 128);
i = 0;
}
ch = in.get();
}
s += buff;
return in;
}五.string类模拟实现总代码
#pragma once
#include <assert.h>
namespace hb
{
class string
{
public:
typedef char* iterator;
typedef const char* const_iterator;
const_iterator begin() const
{
return _str;
}
const_iterator end() const
{
return _str + _size;
}
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
string(const char* str = "")
: _size(strlen(str))
, _capacity(_size)
{
_str = new char[_capacity + 1];
strcpy(_str, str);
}
// 传统写法:
/*string(const string& s)
: _size(s._size)
, _capacity(s._capacity)
{
_str = new char[_capacity + 1];
strcpy(_str, s._str);
}
string& operator=(const string& s)
{
if (this != &s)
{
char* tmp = new char[s._capacity + 1];
strcpy(tmp, s._str);
delete[] _str;
_str = tmp;
_size = s._size;
_capacity = s._capacity;
}
return *this;
}*/
void swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
// 现代写法:
string(const string& s)
: _str(nullptr)
, _size(0)
, _capacity(0)
{
string tmp(s._str);
swap(tmp);
}
// 1.
/*string& operator=(const string& s)
{
if (this != &s)
{
string tmp(s._str);
swap(tmp);
}
return *this;
}*/
// 2.
string operator=(string s)
{
swap(s);
return *this;
}
~string()
{
if (_str)
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
}
const char* c_str() const
{
return _str;
}
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
const char& operator[](size_t pos) const
{
assert(pos < _size);
return _str[pos];
}
size_t size() const
{
return _size;
}
size_t capacity() const
{
return capacity();
}
string& operator+=(const char* str)
{
append(str);
return *this;
}
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete _str;
_str = tmp;
_capacity = n;
}
}
void resize(size_t n, char ch = '\0')
{
if (n < _size)
{
_size = n;
_str[_size] = '\0';
}
else
{
if (n > _capacity)
{
reserve(n);
}
for (size_t i = _size; i < n; ++i)
{
_str[i] = ch;
}
_size = n;
_str[_size] = '\0';
}
}
void push_back(char ch)
{
/*if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size] = ch;
++_size;
_str[_size] = '\0';*/
insert(_size, ch);
}
void append(const char* str)
{
/*size_t len = _size + strlen(str);
if (len > _capacity)
{
reserve(len);
}
strcpy(_str + _size, str);
_size = len;*/
insert(_size, str);
}
string& insert(size_t pos, char ch)
{
assert(pos <= _size);
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
_size++;
return *this;
}
string& insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
size_t end = _size + len;
while (end > pos + len - 1)
{
_str[end] = _str[end - len];
--end;
}
strncpy(_str + pos, str, len);
_size += len;
return *this;
}
void earse(size_t pos, size_t len = npos)
{
assert(pos < _size);
if (len == npos || pos + len >= _size)
{
_str[pos] = '\0';
_size = pos;
}
else
{
size_t begin = pos + len;
while (begin <= _size)
{
_str[begin - len] = _str[begin];
++begin;
}
_size -= len;
}
}
size_t find(char ch, size_t pos = 0)
{
for (; pos < _size; ++pos)
{
if (_str[pos] == ch)
{
return pos;
}
}
return npos;
}
size_t find(const char* str, size_t pos = 0)
{
const char* p = strstr(_str + pos, str);
if (p == nullptr)
{
return npos;
}
else
{
return p - _str;
}
}
void clear()
{
_str[0] = '\0';
_size = 0;
}
private:
char* _str;
size_t _size; // 有效字符个数
size_t _capacity; // 实际存储有效字符的空间
const static size_t npos;
};
const size_t string::npos = -1;
ostream& operator<<(ostream& out, const string& s)
{
/*out << s.c_str();*/
for (auto ch : s)
{
out << ch;
}
return out;
}
istream& operator>>(istream& in, string& s)
{
//char ch;
in >> ch;
//ch = in.get();.
//while (ch != ' ' && ch != '\n')
//{
// s += ch;
// in >> ch;
//}
//return in;
char ch;
ch = in.get();
char buff[128] = { '\0' };
size_t i = 0;
while (ch != ' ' && ch != '\n')
{
buff[i++] = ch;
if (i == 127)
{
s += buff;
memset(buff, '\0', 128);
i = 0;
}
ch = in.get();
}
s += buff;
return in;
}
bool operator<(const string& s1, const string& s2)
{
return strcmp(s1.c_str(), s2.c_str()) < 0;
}
bool operator==(const string& s1, const string& s2)
{
return strcmp(s1.c_str(), s2.c_str()) == 0;
}
bool operator<=(const string& s1, const string& s2)
{
return s1 < s2 || s1 == s2;
}
bool operator>(const string& s1, const string& s2)
{
return !(s1 <= s2);
}
bool operator>=(const string& s1, const string& s2)
{
return !(s1 < s2);
}
bool operator!=(const string& s1, const string& s2)
{
return !(s1 == s2);
}
}