字符指针
在指针的类型中我们知道有一种指针类型为字符指针 char*
int mian()
{
const char* p = "abcdef"; //存在内存的常量区,一但创建好,是只读的不能改,当*p = 'W'这样修改时,就会报错; error,所以要加const,否则会崩溃程序
printf("%c\n",*p);
printf("%s",p); //字符串中一个字符存一个地址,由于字符串是连续存在的,所以指向a也就指向了整个字符串,可直接用%s打印
return 0;
}
上述代码为什么要加const?
假如当要给 *p = ‘w’这样赋值时会报错程序崩溃,因为 *p字符指针创建的字符串,是在内存常量区存储的,只不可更改,所以为了防止error,应该在字符指针前加上const
接下来看示例:
int main()
{
const char* p1 = "abcdef";
const char* p2 = "abcdef";
char arr1[] = "abcde";
char arr2[] = "abcde";
if(p1 == p2)
printf("p1 == p2\n");
else
printf("p1 != p2\n");
if(arr1 == arr2)
printf("arr1 == arr2\n");
else
printf("arr1 != arr2\n");
return 0;
}
输出结果为 p1 == p2, arr1 != arr2
(1)p1,p2字符指针,虽然创建两份,但是在常量区相同的内容只会创建一份并存储,所以p1和p2只是都指向这同一个地址
(2)arr1,arr2字符数组,比较的是两个数组名,而数组名代表的是数组首地址,是在栈区开辟了不同的地址,所以不相同
总结: 字符指针指向的字符是在常量区,而且是只读的,并且相同的内容只会存一份,由于是只读的,为了防止误操作应在指针前加const修饰
字符串虽然是第一个元素的地址,但是他是连续的,指向第一个就等于指向了整个字符串,用%s打印即可(到\0结束)
指针数组
指针数组,在指针初姐介绍过,数的每个元素都是指针
int main()
{
int a = 10;
int b = 20;
int c = 30;
int* arr[3] = {&a,&b,&c};
int i;
for(i=0;i<3;i++)
{
printf("%d ",*(arr[i]));
}
return 0;
}
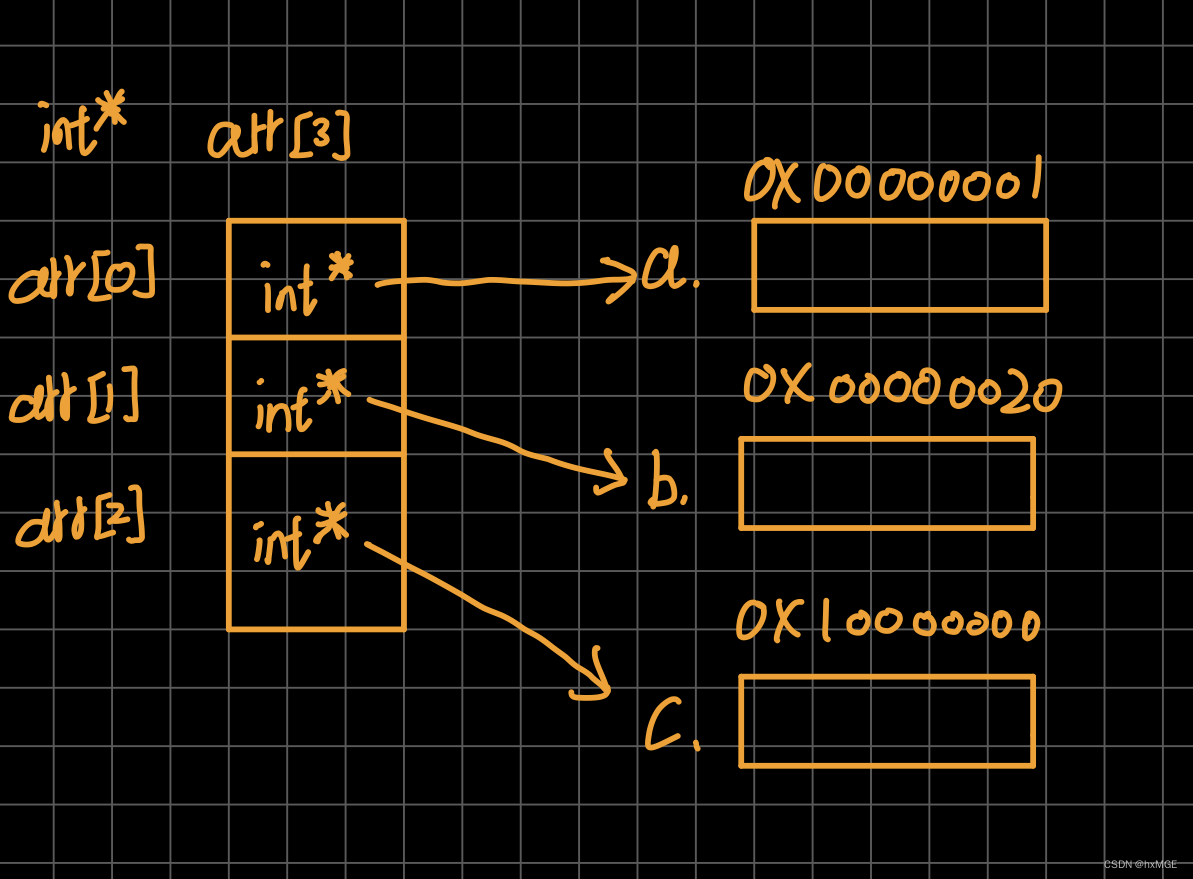
如图所示,arr先与[3]结合说明是指针,类型是int* 型的,说明是指针数组
数组的每个元素都是指针,都是int*类型,分别指向a,b,c,解引用时只需要把数组当成一个指针变量在外面加 * 就行了, *(arr[0])
示例2:
int main()
{
int arr1[5] = {1,2,3,4,5};
int arr2[5] = {2,3,4,5,6};
int arr3[5] = {3,4,5,6,7};
int* parr[3] = {arr1,arr2,arr3}; //这里arr是传递的首地址,只有sizeof和&arr才是全地址
int i,j;
for(i=0;i<3;i++)
{
for(j=0;j<5;j++)
{
printf("%d ",parr[i][j]); // parr[0][2] <==> arr1[2]
//printf("%d",*(parr[i]+j)); //*(parr[0]+2) <==> *( *(parr+0) + 2)
}
} //parr[0] 是 arr1,而数组名是首地址,数组想找到下标的内容 一种是 首地址+下标i 解引用,一种是 [ ] 找到
//所以就是 *(parr[0]+i) 或者 parr[0][i] 或者 *(*(parr+0)+i)
//parr[0],*(parr+0),都是arr数组名也就是他的首地址
return 0;
}
上述示例,是把3个数组的首地址分别存到指针数组里
parr[i] 代表找到这个这个数组的第i个元素里的内容( * (parr+i)下标为i的地址里的内容),元素的数据类型是int*的也就是整型指针,因为每个元素都是一个整型指针,所以指针数组下标i里的内容是地址(数组就是首地址);而数组首地址+i代表第i个下标的地址,在通过解引用就是下标i地址存的的内容
指针数组下标0,解引用就会得到数组名也就是首地址例如: parr[0] 就是 arr1
首地址再解引用,就会取到数组首元素的内容 解引用:*(parr[0]) 就是 *(arr1)也就是arr1[0]
只需要把里面的数组看成对应下标的数组名就会好理解了
总结: 指针数组,是变量先与指针结合,然后看类型,是指针类型,指针数组里的每一个元素都是对应的数据类型指针,是存放地址的,可以使变量地址,数组名等
数组指针
数组指针是指向数组的指针
例如 :int( * p2)[10];p2先和*结合所以是个指针,然后指向的是数组 ,数组有10个元素,数据类型是int,最后认为是一个 指向整型具有10个元素数组 的 指针,也就是数组指针
例1:数组指针对一维数组的使用
int main()
{
int ar[5] = {1,2,3};
int i;
int (*p)[5] = &ar;
printf("ar的总地址: %p\n",&ar);
printf("ar的总地址大小+1:%p\n",&ar+1);
//说明+1是p移动到下一个未使用的位置,
//因为ar是5个元素共20字节,所以移动了20个字节,而取地址就是下一个未使用的地址的位置
putchar('\n');
printf("ar的首地址: %p\n",ar);
printf("ar的第二元素地址:%p\n",ar+1);
printf("*p+1解引用: %p\n",*p+1);
//ar,*p解引用是数组名ar,数组名是首地址
//*p+1等同于 ar+1
//说明数组指针解引用就是数组名就是 ,指向的数组首地址
putchar('\n');
printf("*p解引用: %p\n",*p); //0053FDF4
printf("*(p+1)解引用:%p\n",*(p+1)); //0053FE08 相差20,
//说明指针+1,跳过了“一行大小的字节”,
return 0;
}

根据输出结果可知:
1.虽然数组总地址与首地址相同但意义不同,总地址+1跳过的是整个数组大小,首地址+1跳过的是元素数据类型的大小
2.数组指针必须对应指向数组的元素个数
3.对数组指针解引用得到的是传递的数组名,也就是指向的数组名(首地址)
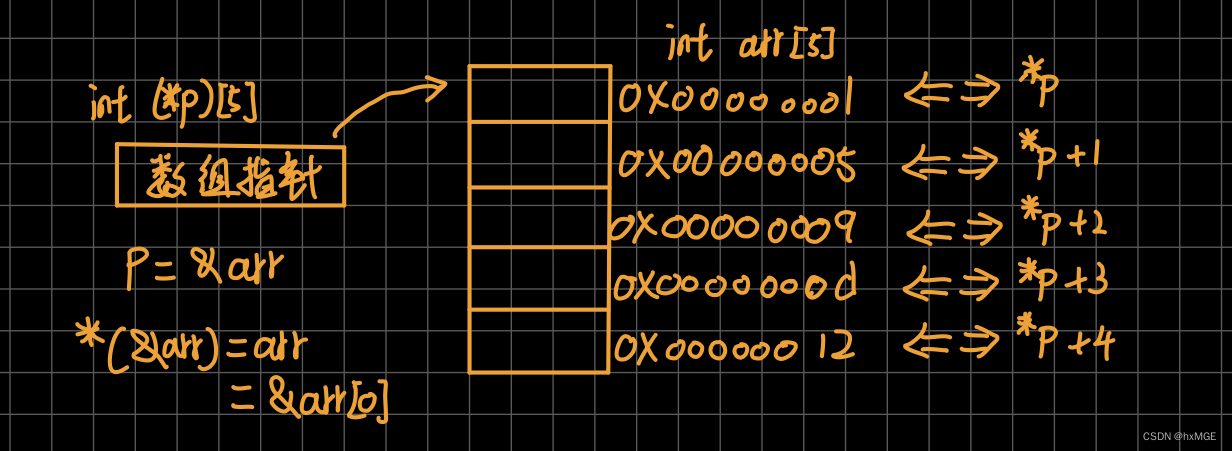
使用数组指针打印一维数组里的内容:
int main()
{
int ar[5] = {1,2,3};
int i;
int (*p)[5] = &ar; //这里是一维数组的全地址给了 数组指针
for(i=0;i<5;i++)
{
printf("%d ",*(*p+i)); //等价于 *(p[0]+i),只不过只有一个数组,所以*p就是他的数组名
//解引用得到数组名,也就是首地址,首地址+i就是第i个元素的地址,再进行解引用,就是第i个元素内容
}
return 0;
}
由于只有一个数组,所以*p就是数组名,可以看成p[0] 或 *(p+0)
例2:数组指针对二维数组的使用
int main()
{
int arr[3][5] = {{1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7}};
int i;
int (*p)[5] = arr; //将首行的地址传递给了数组指针
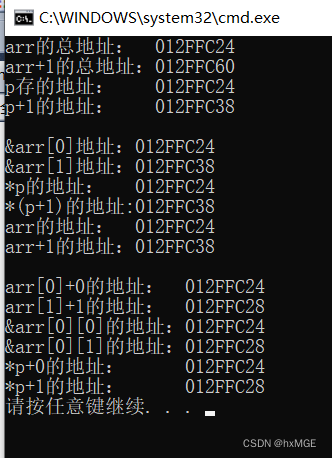
printf("arr的总地址: %p\n",&arr);
printf("arr+1的总地址:%p\n",&arr+1);
printf("p存的地址: %p\n",p);
printf("p+1的地址: %p\n",p+1);
//这里+1表示跳过了整个数组大小
putchar('\n');
printf("&arr[0]地址:%p\n",&arr[0]); //整行的地址
printf("&arr[1]地址:%p\n",&arr[1]);
printf("*p的地址: %p\n",*p); //第一行第一个元素的地址
printf("*(p+1)的地址:%p\n",*(p+1)); //第二行第一个元素的地址
printf("arr的地址: %p\n",arr); //第一行地址
printf("arr+1的地址:%p\n",arr+1); //第二行地址
//上述现象可以看出,arr代表第一行的地址,所以指针p指向的是第一行地址,指针p+1指向第二行
//可以把一行当作一个一维数组(因为p或arr取的都是一行的总地址)
//对一个一维数组解引用就等于他的数组名,是一维数组第一个元素地址
putchar('\n');
printf("arr[0]+0的地址: %p\n",arr[0]+0);
printf("arr[0]+1的地址: %p\n",arr[0]+1);
printf("&arr[0][0]的地址:%p\n",&arr[0][0]);
printf("&arr[0][1]的地址:%p\n",&arr[0][1]);
printf("*p+0的地址: %p\n",*p+0);
printf("*p+1的地址: %p\n",*p+1);
//上述为,第一行第一列,和第一行第二列的地址
return 0;
}
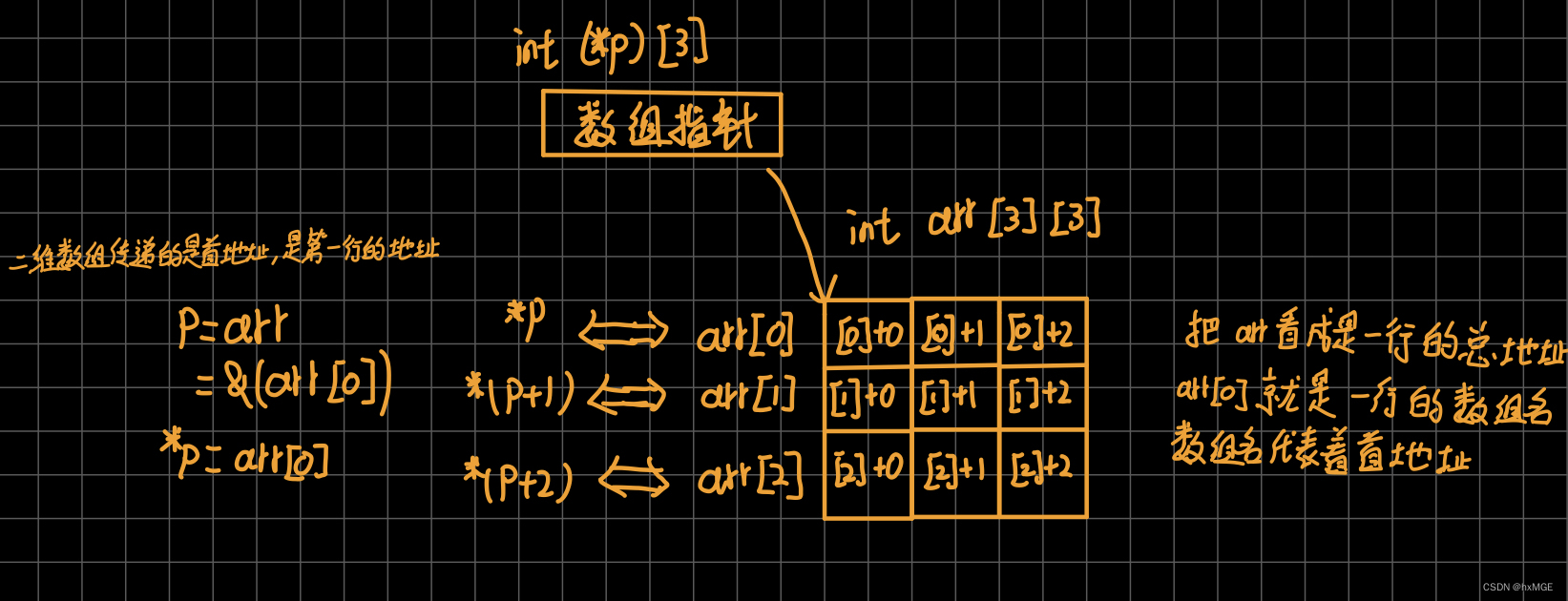
总结:
(1)将二维数组传给数组指针接收,传递的是一行的地址
(2)可以将二维数组的行地址,看成是一个一维数组处理,或将数组指针看成指向行的(因为接收的整行地址)
(3)对行的总地址解引用,相当于对一维数组的总地址解引用,得到的是一维数组名相当于一维数组首元素地址,这时候列标就可看作一维数组元素下标了
(4)几种格式:* (* (p+0)+0) <=> p[0][0] <=> arr[0][0] <===> *( *(arr+0)+0)
(5)对行标解引用+列标,再解引用,就是当前行 “一维数组“ 的列下标指向的元素内容
例如:arr就代表一维数组的总地址,解引用后arr[ ]就是一维数组数组名,一维数组的数组名就是一维数组的首地址相当于arr[ ]+0 ,arr[ ][ ] 就是引用一维数组的元素
可以理解为,数组指针是对二维数组的降维,也可以将传递的二维数组行地址看成一个完整的一维数组,具体看自己怎么方便理解
数组指针指向的元素个数必须与二维数组列相等
使用数组指针打印二维数组里的内容:
int main()
{
int arr[3][5] = {{1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7}};
int i;
int (*p)[5] = arr;
for(i = 0;i<3;i++)
{
int j;
for(j=0;j<5;j++)
printf("%d ",*(*(p+i)+j)); //等价为p[i][j]或 *(p[i]+j)
putchar('\n');
}
return 0;
}
p+i是指向第i行
*(p+i)、p[i] 相当于拿到了第i行,也相当于第i行的数组名,也就是第i行一维数组的首元素地址
数组传参和指针传参
一维数组传参
void test(int temp[])
{}
void test(int temp[100]) //没错,但不提倡
{}
void test(int* temp)
{}
int main()
{
int arr[10] = {0};
test(arr);
}
数组传参时,形参不会真的创建一个[100]的地址,只在栈区随机创建一个指针大小的地址(32位=4字节)用于接收地址
因为传递参数时,传递数组名只是传递一个int型数组的首地址
因为对首地址通过遍历即可得到全部元素,所以传参时,本质上形参是指针,接收的只是一个首地址
指针数组传参
void test2(int* temp[])
{}
void tese2(int* temp[10]) //不会真的创建10个
{}
void tese2(int** temp)
由于是指针数组,每个元素的地址就是指针地址,传递的首地址可看成是一个指针的地址,对于接收指针的地址,需要二级指针来接收
说明传参形参只是传递一个地址
int main()
{
int* arr2[10] = {0};
test2(arr2);
}
void tese2(int** temp) 解释:
由于是指针数组,每个元素的地址就是指针地址,传递的首地址可看成是一个指针的地址,对于接收指针的地址,需要二级指针来接收
又说明了传参形参只传递是一个地址,并不会真的创建数组大小的地址
二维数组传参
void test3(int temp[3][5])
{}
void test3(int temp[][5])
{}
void test3(int (*temp)[5])
{}
数组指针的形式,是接收二维数组的第一行的地址,数组指针+1就是行+1
数组指针*(temp+0)解引用得到“一维数组名”也就是该行首元素地址
int main()
{
int a[3][5] = {0};
test3(a);
return 0;
}
注意:
可以没有行标 但不能没有列标,因为二维数组在内存中是横着排序(一共就一行),先排列完第一行,再排列第二行以此类推
就是将二维数组看成若干个一维数组,通过确定列数,来确定一维数组里有多少个元素,只有确定好所有的一维数组中存多少元素,才能确定二维数组,如果没有列标,操作系统不知道该给行(一维数组)分配多少元素地址,只有给出列,操作系统就根据一共多少元素,结合一行多少列的元素,自动分配出行数
所以二维数组,至少确定第二维度的长度才能正确运行
如:第一行00000000…|第二行00000000…不确定列,无法确定行,但确定列可以自动分配行
二级指针传参
void test4(char** temp)
{}
void test4(char* temp[]) //temp[] = *temp, char* temp[] = char**temp
{} //二级指针传参是传的一级指针地址
//虽然是数组的形式,但不会真的创建数组,只会接收一个地址,所以可看成一个指针
int main()
{
char** pa;
test4(pa); //pa的内容是一级指针的地址
return 0;
}
练习:下列代码的类型
int arr[5]; 整型数组,有5个元素
int *parr1[10]; 指针数组,有10个元素,元素类型都是int型指针
int (*parr2)[10]; 数组指针,指向10个元素的
int (*parr3[10])[5]; 存放数组指针的数组
parr3[10]是一个数组有10个元素,类型是int (*)[5],也就是每个元素都是int (*)[5]数组指针指向5个元素
总结:
-
字符指针指向的字符串是在常量区的,只读不可更所以最好有const修饰;而且在常量区,字符串不管创建几份只会保存一份的地址,也就是多个字符指针指向的字符串内容相同时,地址都是同一个
-
字符指针虽然是指向第一个元素的地址,但是他是连续的,指向第一个就等于指向了整个字符串,用%s打印即可(到\0结束)
-
指针数组,数组里的每个元素都是一个指针,可以存放变量的地址、数组首地址等,但是最好是相同数据类型
-
数组指针是指向数组的指针
(1)数组指针接收的一维数组是一维数组名取地址,是总地址;对数组指针解引用得到一维数组数组名,也就是一维数组的首地址
(2)数组指针接收的二维数组是二维数组名,是他的首地址;二维数组的首地址就是行地址,一整行的地址,对数组指针解引用可看成是对整行地址解引用,得到的是整行的首地址;相当于把二维数组的每一行看成是一个一维数组,对一维数组的总地址解引用得到一维数组名,列标就是一维数组的元素下标
(3)数组指针必须与一维数组的元素个数个数一致,数组指针对于二维数组是列标必须一致 -
一维数组的传参:传递的只是一个首地址,所以不论形参是指针还是数组(不管数组是几个元素如[100]),都只在栈区随机创建一个指针大小的地址(32位=4字节)用于接收地址
-
指针数组传参:传递的是指针数组的首地址,除了用指针数组接收,还可使用二级指针接收;因为指针数组的元素是指针,而传递的首地址可以看成是传递的指针地址,接收指针地址必须用二级指针
-
二维数组传参:二维数组传参必须要有列标,因为在实际存储中是横向排序的,通过每一行里的(列的个数)元素才能确定下一行;因为传递的是首行地址,所以可使用二维数组、数组指针来接收,但列必须相同
-
二级指针传参:二级指针传递的是一级指针的地址,除了用二级指针接收,还可以用数组指针接收,因为传递的只是一个地址,所以在形参中虽然写的是指针数组形式,但实际只有一个元素,数组的形式就可以看成一级指针,再加上数据类型就是个二级指针了,例如char* temp[] =>temp[] = *temp+char *=>char** temp