结构体
自定义类型(设计类型):结构体类型、联合体类型、枚举类型
1、结构体类型的设计
C 语言提供了基本数据类型,如 char、short、int、float … 等类型,我们称之为内置类型。程序开发人员可以使用结构体来封装一些属性,设计出新的类型,在 C 语言中称为结构体类型
结构体类型的设计:
- 在 C 语言中,结构体是一种数据类型(由程序开发者自己设计的类型)
- 可以使用 结构体(struct) 来存放一组不同类型的数据。
结构体的定义形式为:
struct 结构体名
{
成员列表(可以是基本数据类型,指针,数组或其它结构类型)
};
1.1 设计一个学生结构体类型
客观事物(实体)是复杂的,要描述它必须从多方面进行,也就是用不同的数据类型来描述不同的方面。如学生实体可以这样来描述:
- 学生学号:可以用 字符串 描述
- 学生姓名:可以用 字符串 描述
- 性别:字符串 描述
- 年龄:整型 描述
这里用了属于 2 种不同的数据类型,以及 4 个数据成员来描述学生实体
struct Student
{
char stu_id[10]; // 学生学号
char stu_name[20]; // 学生姓名
char stu_sex[4]; // 性别
int stu_age; // 年龄
};
图示:
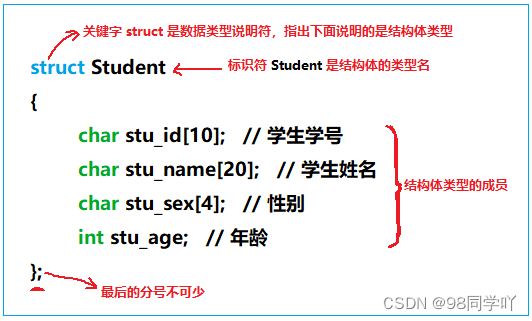
【注意】函数定义的花括号 { } 后面没有分号
2 、结构体变量的定义和初始化
既然结构体是一种数据类型,那么就可以用它来定义变量。结构体就像是一个 “模板”,定义出来的变量都具有相同的性质。也可以将结构体比作 “图纸”,将结构体变量比作 “零件”,根据同一张图纸生产出来的零件的特性都是一样的。
结构体是一种数据类型,是创建变量的模板,不占用内存空间;结构体变量才包含了实实在在的数据,需要存储空间
2.1 结构体变量在内存中表示(不考虑内存对齐的问题)
示例:
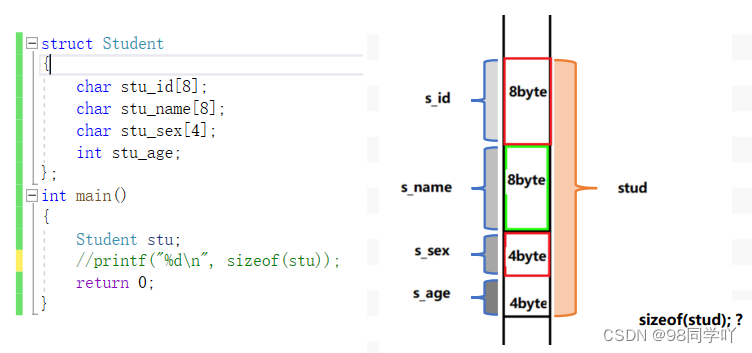
从 Student 结构体可以看出,有 4 个成员,大小分别占 8、8、4、4 个字节,所以用学生 Student 结构体定义的变量所占字节为 24(不考虑内存对齐)
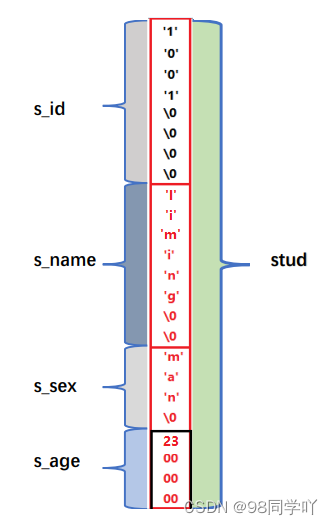
2.2 结构体变量初始化
struct Student
{
char stu_id[8];
char stu_name[8];
char stu_sex[4];
int stu_age;
};
int main()
{
Student stu = {"1001", "liming", "man", 23};
return 0;
}
图示:
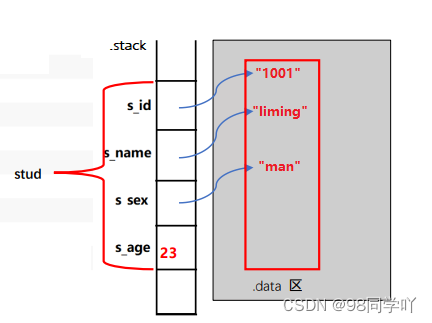
再举个简单的栗子:
struct Student
{
char* stu_id;
char* stu_name;
char* stu_sex;
int stu_age;
};
int main()
{
// 在 .c 文件中需要加上 struct
struct Student stu = {"1001", "liming", "man", 23};
return 0;
}
图示:
2.3 结构体嵌套结构体
示例:
#include <stdio.h>
#include <string.h>
struct Date
{
int year;
int month;
int day;
};
struct Student
{
char stu_name[20]; // 姓名
struct Date birthday; // 生日
float score; // 成绩
};
int main()
{
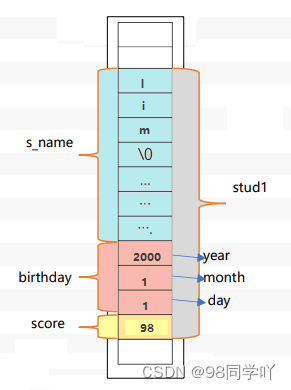
struct Student stud1 = {"Xiaoming", 2000, 1, 1, 98};
struct Student stud2 = {"Xiaoqiang", 2002, 9, 21, 100};
Date date;
return 0;
}
图示:
2.4 结构体自定义
示例1:
struct Student
{
char stu_name[8];
int stu_age;
float score;
struct Student studx;
};
思考: sizeof(Student) ?
示例2:
struct Student
{
char stu_name[8];
int stu_age;
float score;
struct Student *next;
};
思考: sizeof(Student) ?
3、结构体成员访问(获取和访问)
- 结构体变量的成员使用 ‘.’ 访问
- 获取和赋值结构体变量成员的一般格式为
- 结构体变量 . 成员名;
3.1 结构体变量成员的访问
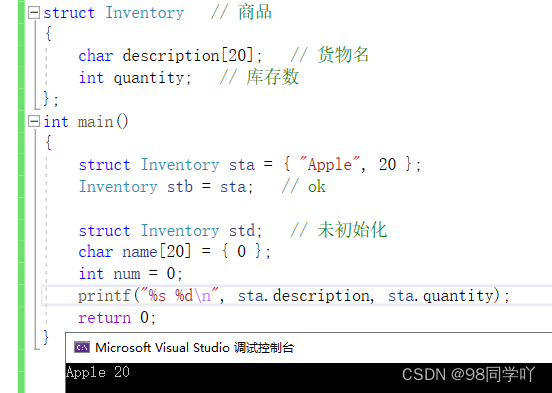
struct Inventory // 商品
{
char description[20]; // 货物名
int quantity; // 库存数
};
int main()
{
struct Inventory sta = { "Apple", 20 };
Inventory stb = sta; // ok
struct Inventory stc; // 未初始化
char name[20] = { 0 };
int num = 0;
printf("%s %d\n", sta.description, sta.quantity);
num = stc.quantity; // ok
//name = stc.description; // error 字符串不能直接赋值
strcpy_s(name, sta.description); // ok 要调用字符串拷贝函数
//stc.description = "auto"; // error
strcpy_s(sta.description, "auto"); // ok
sta.quantity = 100; // ok 整数可以直接赋值
struct Inventory std;
std = sta; // ok
printf("%s %d\n", std.description, std.quantity);
return 0;
}
注意:对结构体变量整体赋值有三种情况:
- 定义结构体变量(
用 { } 初始化) - 用已定义的结构体变量初始化
- 结构体类型相同的变量可以作为整体相互赋值
在其它情况的使用过程中只能对成员逐一赋值
在 C 语言中不存在对结构体类型的强制转换(和内置类型的区别)
3.2 结构体变量和指针
内置类型能够定义指针变量,结构体类型也可以定义结构体类型指针
结构体类型指针访问成员的获取和赋值形式:
- (
*p).成员名 ( . 的优先级高于*,(*p)两边的括号不能少) p ->成员名 (-> 是减号加大于号,中间没有空格,称为指向符)
示例:
struct Inventory // 商品
{
char description[20]; // 货物名
int quantity; // 库存数
};
int main()
{
struct Inventory sta = { "Apple", 20 };
// 定义结构体类型指针变量
struct Inventory* stp = &sta;
char name[20] = { 0 };
int num = 0;
(*stp).quantity = 30; // 对结构体类型指针通过解引用并使用 . 访问结构体成员
stp->quantity = 50; // 也可以直接使用 指向符 去访问结构体成员
strcpy(name, stp->description);
printf("%s %d\n", stp->description, stp->quantity);
printf("%s %d\n", (*stp).description, (*stp).quantity);
// 注意:(*stp) 的括号不能少
// *stp 和 (*stp) 完全不一样
return 0;
}
3.3 结构体变量和函数
示例1:首先分析代码
#include <stdio.h>
#include <string.h>
struct School
{
char s_name[20];
int s_age;
};
void Print_a(struct School sx)
{
printf("%s %d\n", sx.s_name, sx.s_age);
}
void Print_b(struct School* sp)
{
printf("%s %d\n", sp->s_name, sp->s_age);
}
int main()
{
struct School sx = { "Beijing", 100 };
Print_a(sx);
Print_b(&sx);
return 0;
}
比较两个打印函数的优缺点
4、结构体与数组
所谓结构体数组,是指数组中的每个元素都是一个结构体类型。在实际应用中,C语言结构体数组常被用来表示一个拥有相同数据结构的群体,比如一个班的学生、一个公司的员工等
举个简单的栗子:
#include <stdio.h>
#include <string.h>
struct Student
{
char s_name[20];
int age;
float score;
};
int main()
{
struct Student cla[] =
{
{"xiaoming", 18, 98},
{"xiaoqiang", 23, 96},
{"xaiohong", 16, 99},
};
return 0;
}
5、结构体大小
5.1 如何计算结构体大小
由于存储变量地址对齐的问题,计算结构体大小的 3 条规则:
1、结构体变量的首地址,必须是结构体变量中的 “最大基本数据类型成员所占字节数” 的整数倍2、结构体变量中的每个成员相对于结构体首地址的偏移量,都是该成员基本数据类型所占字节数的整数倍3、结构体变量的总大小,为结构体变量中 “最大基本数据类型成员所占字节数” 的整数倍
6、联合体(共用体)
联合体(union)与结构体(struct)有一些相似之处。但两者有本质上的不同。在结构体中,个成员有各自的内存空间。而在联合体中,各成员共享同一段内存空间,一个联合变量的长度等于各成员中最长的长度
应该说明的是,这里所谓的共享不是指把多个成员同时装入一个联合变量内,而是指该联合变量可被赋予任一成员值,但是每次只能赋一种值,赋入新值则冲去旧值
一个联合体类型必须经过定义之后,才能使用它,才能把一个变量声明定义为该联合体类型
总结
1、为什么要理解字节对齐问题
1)内存大小的基本单位是字节(byte),理论上来讲,可以从任意地址访问变量,但是实际上,cup 并非逐字节读写内存,而是以 2、4 或 8 的倍数的字节块来读写内存,因此就会对基本数据类型的地址作出一些限制,即它的地址必须是 2、4 或 8 的倍数。那么就要求各种数据类型按照一定的规则在空间上排列,这就是内存对齐
2)有些平台每次读取都是从偶地址开始,如果一个 int 型(假设为 32 位系统)如果存放在偶地址开始的地方,那么一个读周期就可以读出这 32bit,而如果存放在奇地址开始的地方,就需要 2 个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该 32 bit 数据。显然在读取效率上下降很多
3)由于不同平台对齐方式可能不同,如此一来 ,同样的结构在不同的平台其大小可能不同,在无意识的情况下,互相发送的数据可能出现错乱,甚至引发严重的问题
指定对齐值
预处理命令:#pragma pack(n) 可以改变默认对齐数。n 取值是 1、2、4、8、16
vs 中默认值是 8,gcc 中默认值是 4
2、总结
- 结构体变量的首地址,必须是 MIN { “结构体最大基本数据类型成员所占字节数”, 指定对齐方式 } 大小的整数倍
- 结构体每个成员相对于结构体首地址的偏移量,都是 MIN { 基本数据类型成员, 指定对齐方式 } 大小的整数倍
- 结构体的总大小,为 MIN { 结构体 “最大基本数据类型成员所占字节数” (将嵌套结构体里的基本类型也算上,得出 最大基本数据类型成员所占字节数), 指定对齐方式 } 大小的整数倍
3、思考题
1)在设计结构体的时候,我们既要满足对齐,又要节省空间,如何做到?
2)不定义结构体变量,如何计算结构体成员的相对偏移量?