Ŀ¼
ǰ��
��Һ�,������è,������������ʶһ��C�����е��Զ�����������,
C�����е�char,short,int,long,float,double��Щ�������Ǵ�ҿ϶��Ѿ��dz���Ϥ��,
��Щ������C������������������,���������ǵ��ճ�������ֻ���е�һ���Ե�������֮����,
�������ͬʱ���и��ָ����IJ�ͬ����,
������Ϊ��У��ѧ������:��������,�����䡱,���༶��,��ѧ�š�,�����ߡ��ȵȵ�,
�ٱ���һ����:��������,�����ߡ�,����š�,���۸ȵȵ�
��Щ��������һ�����������;Ϳ��Ա�ʾ��,��ô,���Ǿ���Ҫ�õ���Щ�Զ�������
������������Ҫ���������͡�����������Ǵӽṹ�忪ʼ��ʶ��!
һ���ṹ��(struct)
�ṹ��һЩֵ�ļ���,��Щֵ��Ϊ��Ա�������ṹ��ÿ����Ա�����Dz�ͬ���͵ı�����
(һ)�ṹ�������
1.�ṹ������
struct tag{
member��list;
};
member��list�dz�Ա�б�
��������һ���鼮:
struct book{
char title[20];//����
char writer[20];//����
float price;//�۸�
};
�����struct�ǽṹ��ؼ���,book�ǽṹ���ǩ,struct book����һ�������Ľṹ������
�ڴ����ṹ������DZ���д��ȫ��
�����ṹ�������ַ���:
һ����ֱ���������ṹʱֱ�Ӵ���,���ִ�����������ȫ�ֱ���,
��һ����ͨ���ṹ�����ʹ�����
����:
struct book{
char title[20];//����
char writer[20];//����
float price;//�۸�
}b1,b2;
struct book b3,b4;
2.���������(����ȫ����)
����������һ���ṹ��ʱ,���Բ������������֡�,�����Ϊ����ȫ����
����:
struct {
char ch;
char str[20];
int num;
}d1,d2;//ֻ���������ṹ���ͬʱ��������
//struct d3,d4; �����Ǵ����,��Ϊ����ֻ�нṹ��ؼ���,������֪������ṹ�������
struct {
char ch;
char str[20];
int num;
}d3,d4;
//����������Ҫע��:�����d3��d4����ͬ��,
//����d3��d1��d2�Dz�ͬ��,��Ȼ���ǵ����Ϳ���������ȫһ����
//���DZ��������ǻ��ж�Ϊ��ͬ������
3.�ṹ���������
�ڽṹ�а���һ��Ϊ�ṹ�屾�������͵ı���
����:
struct str{
int data;
struct str* ps;
};
//���������ǿ�������һ��ָ���������͵�ָ��,���������ݽṹ�е��������÷�.
//struct str{
//int data;
//struct str s;
//};
//������÷��Dz��е�,����s�����ﻹ��һ���ṹ�����s,s�������滹��һ��s,������������,�������ڴ��С.
4.�ṹ��ij�ʼ���븳ֵ
������:
//�ṹ��ij�ʼ��
struct str{
char ch;
int data;
}s1={'a',10}; // 1
struct str s2={'b',20}; // 2
struct str s3={.data=30,.ch='c'}; // 3
//�ṹ��ĸ�ֵ
struct str s4;
scanf("%c %d",&s4.ch,&s4.data);
//����ǽṹ��ָ��,�Ǿ������ָ�ֵ��ʽ
struct *p=s4;
scanf("%c %d",&(*p).ch,&(*p).data);// *p��ͬ��s4
scanf("%c %d",&p->ch,&p->data);//->Ϊ��ͷ�����,������ṹ��ָ��ֱ��ָ��ṹ���Ա
5.�ṹ���ڴ����
�ṹ����ڴ�����ǽṹ���һ������Ҫ��֪ʶ,�����ṹ�����ڴ��еĴ洢��ʽ�й�
����������������һ�������������ṹ��Ĵ�С:
struct str1
{
char ch;
short sh;
int num;
};
struct str2
{
char ch;
int num;
short sh;
};
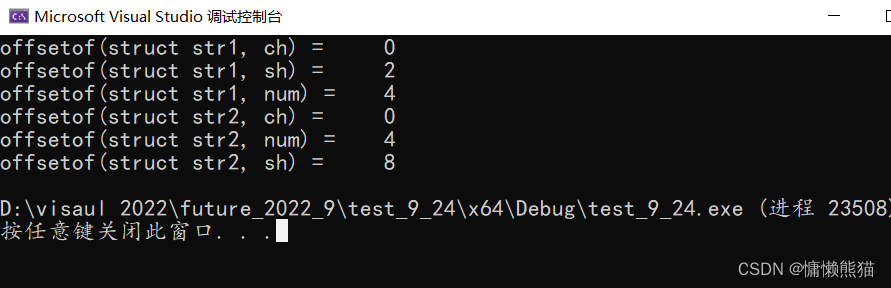
����������Dz�֪���ṹ����ڴ�������,��ô�϶��кܶ����ѻ���Ϊ�������ṹ��Ĵ�С����7,
sizeof(str1)=1+2+4=7,
sizeof(str2)=1+4+2=7;
��ô��Ȼ����ר�Ž���������ӵĻ��Ǿ�˵�����Ǵ���Ľ����,
��ô�����ǵ�һ�����˻��ǵڶ������˻���������С��������,
���濴ʵ�����н��:

����Ϊʲô����������Ľ����?
�������������˽�һ�½ṹ���ڴ����Ĺ���
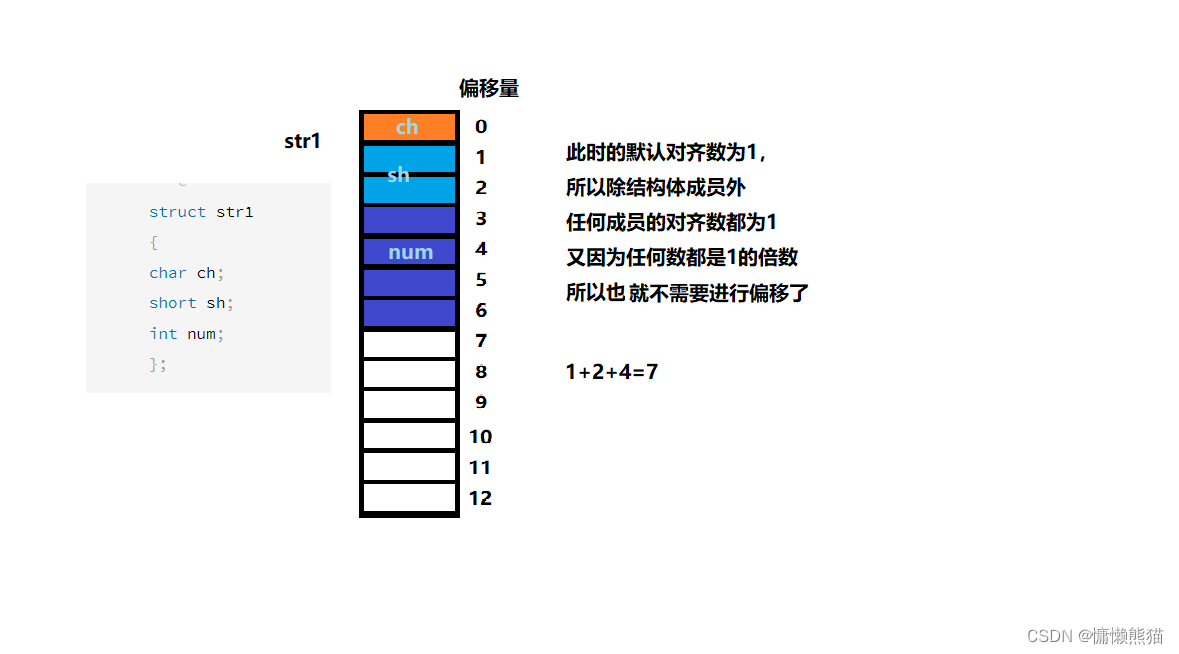
�ڴ�������:
- ��һ����Ա����ṹ�����ƫ����Ϊ0�ĵ�ַ����
2.�ӵڶ�����Ա��ʼ,ƫ���������� ������(Ĭ�϶���������������С�еĽ�С��) ����������
3.�ṹ���ܴ�СΪ������������������
4.���Ƕ���˽ṹ������,Ƕ�Ľṹ����뵽�Լ���������������������,�ṹ�����
���С����������������(��Ƕ�ṹ��Ķ�����)����������
��������ͨ����ͼ������ϸ�˽�:

����Ҳ����ͨ��offsetof()�������õ�����Ա��ƫ������������֤:
��������:
#include<stdio.h>
#include<stdlib.h>
struct str1
{
char ch;
short sh;
int num;
};
struct str2
{
char ch;
int num;
short sh;
};
int main()
{
printf("offsetof(struct str1, ch) = \t%d\n", offsetof(struct str1, ch));
printf("offsetof(struct str1, sh) = \t%d\n", offsetof(struct str1, sh));
printf("offsetof(struct str1, num) = \t%d\n", offsetof(struct str1, num));
printf("offsetof(struct str2, ch) = \t%d\n", offsetof(struct str2, ch));
printf("offsetof(struct str2, num) = \t%d\n", offsetof(struct str2, num));
printf("offsetof(struct str2, sh) = \t%d\n", offsetof(struct str2, sh));
return 0;
}
Ϊʲô�����ڴ����?
�ֵIJο����϶�������˵��:
1.ƽ̨ԭ��(��ֲԭ��):
�������е�Ӳ��ƽ̨���ܷ��������ַ�ϵ��������ݵ�;
ijЩӲ��ƽֻ̨����ijЩ��ַ��ȡijЩ�ض����͵�����,�����׳�Ӳ���쳣��
2. ����ԭ��:
���ݽṹ(������ջ)Ӧ�þ����ܵ�����Ȼ�߽��϶��롣
ԭ������,Ϊ�˷���δ������ڴ�,��������Ҫ�������ڴ����;��������ڴ���ʽ���Ҫһ�η��ʡ�
������˵:
�ṹ����ڴ�������ÿռ�����ȡʱ���������
������������������г�Ա����ȫ��ͬ��,����һ����СΪ8,һ��ȴΪ12;
������ƽṹ���ʱ��,���Ǽ�Ҫ�������,��Ҫ��ʡ�ռ�,�������:
��ռ�ÿռ�С�ij�Ա����������һ��
6.��Ĭ�϶�����
�Ķ�������Ҫ�õ�Ԥ����ָ��#pragma
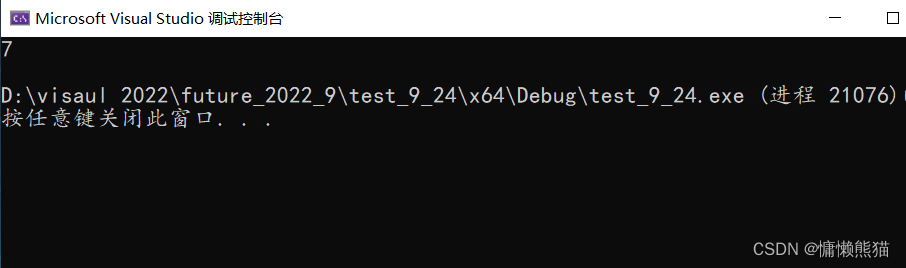
����ʵ��:
#include<stdio.h>
#pragma pack(1)//����Ĭ�϶�����Ϊ1
struct str1
{
char ch;
short sh;
int num;
};
struct str2
{
char ch;
int num;
short sh;
};
int main()
{
printf("%d\n", sizeof(struct str2));
return 0;
}
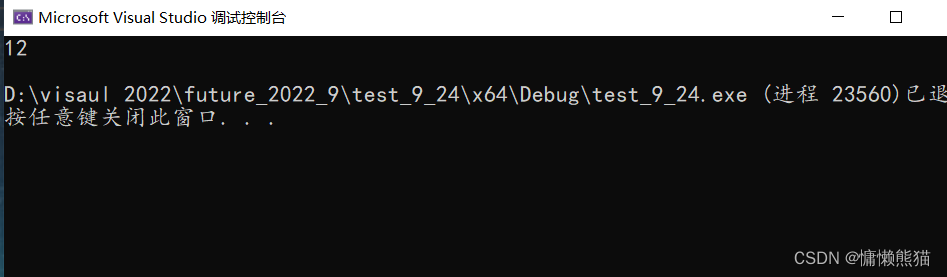
��ԭĬ�϶�����:
#include<stdio.h>
#pragma pack(1)//����Ĭ�϶�����Ϊ1
#pragma pack()//��ԭĬ�϶�����
struct str1
{
char ch;
short sh;
int num;
};
struct str2
{
char ch;
int num;
short sh;
};
int main()
{
printf("%d\n", sizeof(struct str2));
return 0;
}
7.�ṹ�崫��
�����ڽ��к�������ʱ�ȿ��Խ��д�ֵ����Ҳ���Խ��д�ַ����
�ṹ��Ҳͬ������ʹ���������ַ���
struct S {
int data[1000];
int num;
};
struct S s = {{1,2,3,4}, 1000};
//��ֵ����
void print1(struct S s) {
printf("%d\n", s.num);
}
//��ַ����
void print2(struct S* ps) {
printf("%d\n", ps->num);
}
int main()
{
print1(s); //���ṹ��
print2(&s); //����ַ
return 0; }
�������������,
�ṹ��dz���,������ǽ��д�ַ���εĻ��β���ʵ�ε�һ����ʱ����,
�������ͻ����ڴ��п���һ���ʵ��һ������������β�,���������˷Ѻܴ�Ŀռ�,
��ʹ�ô�ַ���ξ�ֻ�Ǵ���һ��ָ��,��һ��ָ���С����4/8���ֽ�,
���,�����ڽ��нṹ�崫��ʱ������ʹ�ô�ַ���Ρ�
(��)�
�ṹ�彲��͵ý����ṹ��ʵ�� λ�� ��������
����,�����ͬѧ��û����˵��λ����������,���Խ��������ǾͲ�������,
ֱ��ͨ�������ʵ�����˽�����
1.λ�ε�����
λ�ε������ͽṹ�����Ƶ�,��������ͬ:
1.λ�εij�Ա������ int��unsigned int ��signed int �� char �����μ��塣
2.λ�εij�Ա�������һ��ð�ź�һ�����֡�
����ʵ��:
#include<stdio.h>
struct str
{
int a:4;
int b:10;
int c:20;
int d:8;
};
int main()
{
printf("%d\n",sizeof(struct str));
return 0;
}
����:
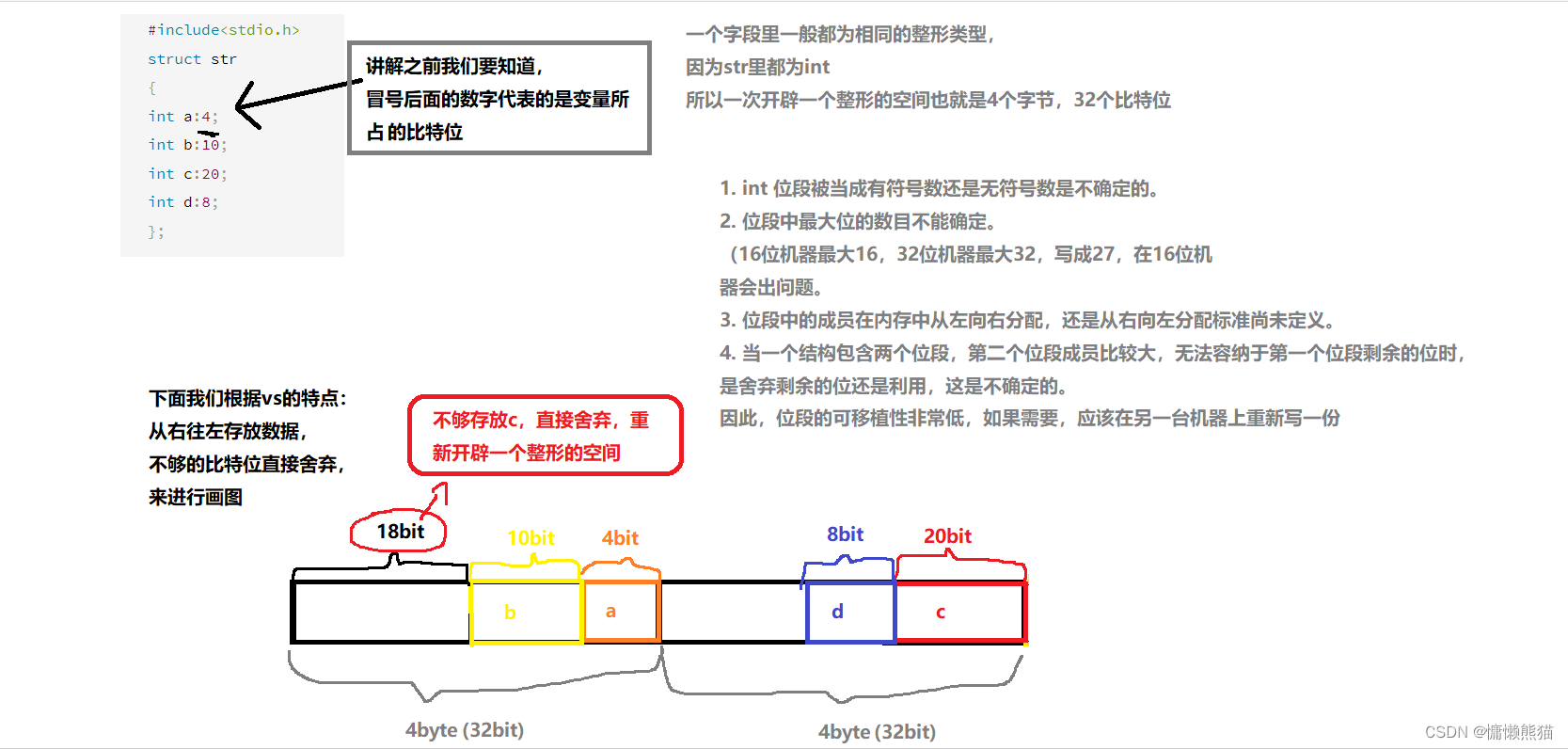
2.λ�ε�ʹ��
�������λ�ε�֪ʶ�����й�����,����֪�������֪ʶ��ͺ�,
��Ȼ��Ҳ���Լ���ʹ�ó���:���������������ݵķֶδ���ʱ��Ҫ����������Ϣ,��ʱ�Ϳ���ʹ��λ��,
���ԶԿռ���к�����ʹ�á�

����ö��(enum)
ö�ٹ���˼����ǨCһһ�о�,�ѿ��ܵ����ȫ�����оٳ���
һ��������,����һһ�о�,
һ���ж�ʮ�ĸ�Сʱ,����һһ�о�,
Ӣ����ĸ�ж�ʮ����,Ҳ����һһ�о١�
1.ö�����͵Ķ���
enum Day//����
{
MON,
TUES,
WED,
THUR,
FRI,
SAT,
SUN
};
����ö������Ĭ�ϴ�0��ʼ,��:
MON == 0 , TUES == 1 , WED == 2 ����
�ڳ�ʼ��ʱ���Ը������ǵ�ֵ,eg:
MON = 3,
��ôTUES�ͻ��Ϊ4,������������1
2.ö�ٵ��ŵ�
Ϊʲôʹ��ö��?
���ǿ���ʹ�� #define ���峣��,Ϊʲô��Ҫʹ��ö��?
ö�ٵ��ŵ�:
1.���Ӵ���Ŀɶ��ԺͿ�ά����
2.��#define����ı�ʶ���Ƚ�ö�������ͼ��,�����Ͻ���
3.��ֹ��������Ⱦ(��װ)
4.���ڵ���
5.ʹ�÷���,һ�ο��Զ���������
3.ö�ٵ�ʹ��
enum Day
{
MON,
TUES,
WED
THUR,
FRI,
SAT,
SUN
};
int main()
{
enum Day d;
scanf("%d",&d);
switch(d)
{
case MON:
printf("����һ\n");
break;
case TUES:
printf("���ڶ�\n");
break;
case WED:
printf("������\n");
break;
case THUR:
printf("������\n");
break;
case FRI:
printf("������\n");
break;
case SAT:
printf("������\n");
break;
case SUN:
printf("������\n");
break;
}
return 0;
}
��������(union)
1.�������͵Ķ���
����������Ҳ����˼��һ���Ǿ��ǨCվ��һ��,��ͬʹ�á�
������Ҳ��һ��������Զ�������,��������ͬ�ij�Ա,����Щ��Ա��ͬʹ��ͬһ���ڴ�ռ䡣(����Ҳ�й�����)
union un
{
int num;
float fa;
char str[10];
};
2.���ϵ��ص�
���ϵij�Ա�ǹ���ͬһ���ڴ�ռ��,����һ�����ϱ����Ĵ�С,����������Ա�Ĵ�С(��Ϊ��
�����ٵ����������������Ǹ���Ա)��
3.���ϵ�ʹ��
��������:�жϸü�����Ǵ�˴洢����С�˴洢
int main()
{
int a=0x1;
//p��ŵ��DZ���a����ַ(Ҳ���ǵ͵�ַ),
//��ΪС�˴洢ʱ��λ���ڵ͵�ַ��,���Ե�*pΪ1����ΪС�˴洢,*pΪ0���Ǵ�˴洢
char*p=(char*)&a;
printf("%d\n",*p);
return 0;
}
����������ʹ����ǿ������ת���ķ���ȡ����a�ĵ�ַ,���Ǹ��ݽ������ǽ��Ĺ�����,���ǾͿ������һ�ָ�����ķ��������ж�
����:
union un
{
int a;
char ch;
};
int main()
{
union un d = { 0 };
scanf("%d", &d.a);
printf("%d\n", d.ch);
return 0;
}
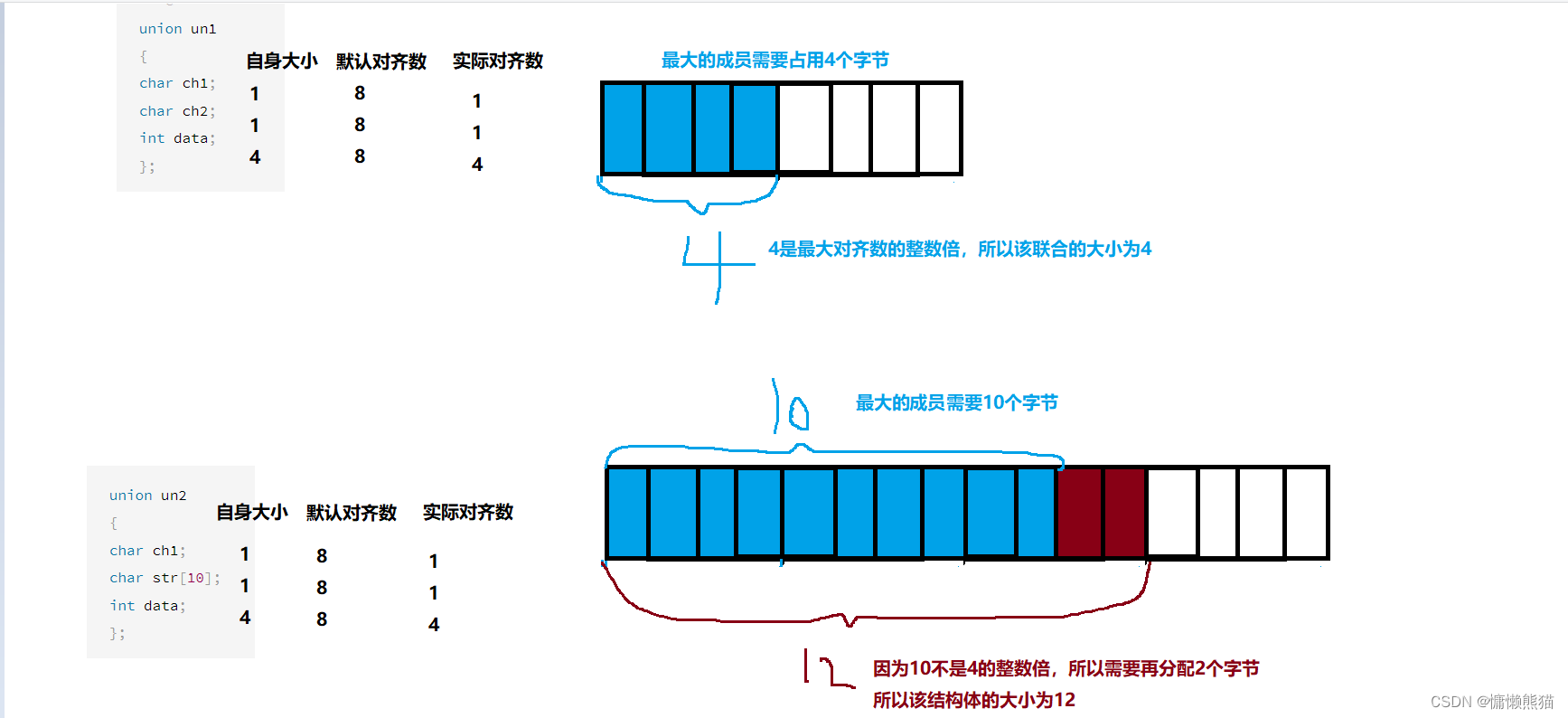
4.���ϴ�С�ļ���
������Ҳ�ж�����,
���ϵĴ�С����������Ա�Ĵ�С��
������Ա��С����������������������ʱ��,��Ҫ���뵽������������������
union un1
{
char ch1;
char ch2;
int data;
};
union un2
{
char ch1;
char str[10];
int data;
};
int main()
{
printf("%zu\n",sizeof(union un1));
printf("%zu\n",sizeof(union un2));
return 0;
}
����:
������VS�²��Ե�,VS��Ĭ�϶�����Ϊ8
���濴ͼ��:
�ܽ�
���Ͼ��ǹ��ڽṹ�塢ö�١��Լ����ϵ�֪ʶ�ܽ�,��������д������è�Լ����ܽ�:
- �ṹ������϶���Ҫ�ڴ����,���ʱ������С��������һ��,�ڴ������ʱ������ڴ���˷�,����ȴ������߳�Ա�����ٶ�,
Ҳ�������dz�˵�����ڴ滻ʱ�䡣- �ṹ��λ�εĴ��ھ���Ϊ�˽�ʡ�ռ�,����λ�β���Ҫ�ڴ����,ʹ��λ��ʱҪע���Ա����ġ� : '�Լ�������ֽ�����
- ö����������Ա֮����ͨ���� , '���ӵ�,Ҳ����˵ö������ʵ����ֻ��һ������,���:sizeof(enum day)== 4��
- �ڶ����Զ�������ʱҪע������ź���ġ� ; ',����һ���������ı�־,����еı�����û���Զ���������Ҳ�������ǡ�
��ô��������ݾ�д������,��л��ҵ�֧��,��ӭ�����������һ��̽��,��ҵĹ����� �������µľ�����
�������µľ�����