目录
命名空间
在C++的学习过程中,比起C语言,C++有着更多的函数,关键字等等,但是他们都存在于全局作用域中,就可能会导致很多冲突,有了命名空间,就可以避免命名冲突或名字污染。namespace就是它的关键字。
#include <stdio.h>
#include <stdlib.h>
int rand = 2;
int main()
{
printf("%d\n", rand);
}
//会报错rand重定义,在C语言中,全局变量rand与stdlib.h库中的rand函数重命1.命名空间的定义?
//1.正常的定义
namespace a
{ //在命名空间中可以定义变量、函数、结构体
int rand;
int Add(int x, int y)
{
return x + y;
}
struct Node
{
struct Node* next;
int val;
};
}
//2.嵌套定义
namespace n1
{
int a;
int b;
int Add(int x, int y)
{
return x + y;
}
struct Node
{
struct Node* next;
int val;
};
namespace n2
{
int c;
int Sub(int x, int y)
{
return x - y;
}
}
}
//3.在同一个工程中,如果有多个相同名称的命名空间,最后编译器会将他们合并
//test.h
namespace m1
{
int a;
int Add(int x, int y)
{
return x + y;
}
}
//test.cpp
namespace m1
{
int b;
int Sub(int x, int y)
{
return x - y;
}
}
//合并后
namespace m1
{
int a;
int b;
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
}一个命名空间就是一个作用域,定义的变量只在此作用域内才能使用。?
?2.命名空间的使用
namespace x
{
int a;
int b;
int Add(int x, int y)
{
return x + y;
}
struct Node
{
struct Node* next;
int val;
};
}
//如果想要访问命名空间x中的变量、函数、结构体就要用到作用域限定符::
int main()
{
printf("%d\n", a);//错误
printf("%d\n", X::a);//正确
}
//若使用using namespace可以将命名空间的所有变量直接引入
using namespace x;
int main()
{
printf("%d\n", a);//正确
printf("%d\n", X::a);//正确
}
//若使用using可以将命名空间的某个成员引入
using x::a;
int main()
{
printf("%d\n", a);//正确
printf("%d\n", X::a);//正确
printf("%d\n", b);//错误
printf("%d\n", X::b);//正确
}在日常训练中,我们可以直接将命名空间的变量用using namespace全部引入,在工作时,使用using将常用的几个成员,如C++库中的cout可以引入。
C++的输入与输出
在引入了命名空间这个概念,在C++ 中的输入与输出就与C语言就有不同了。
#include <iostream>
//在C++中标准库被放在了 std 这个命名空间中了
using namespace std;
int main()
{
cout << "hello world!" << endl;
//cout是标准输出对象(控制台),endl类似于C语言的换行符
//<<与>>是流插入运算符
return 0;
}#include <iostream>
using namespace std;
int main()
{
int a;
double b;
char c;
//cin是标准输入对象(键盘)
cin >> a;//输入1
cin >> b >> c;//输入3.14 a
cout << a << endl;//输出的结果为1
cout << b << " " << c << endl;输出结果为3.14 a
//cin与cout都能自动识别变量类型
return 0;
}缺省参数
?缺省参数是在定义或声明函数时为函数的参数提供一个缺省值,调用函数时若没有指定实参贼则采用缺省值,否则采用实参。
#include <iostream>
using namespace std;
void func(int a = 10)
{
cout << "a = " << a << endl;
}
int main()
{
func();//在不给定实参输出10
func(2);//给定实参输出实参2
return 0;
}//全缺省参数
void func1(int a = 10, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
}
//半缺省参数
void func(int a, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
}
int main()
{
func1();
//结果
//a = 10
//b = 20
//c = 30
func2(5);
//结果
//a = 5
//b = 10
//c = 20
}半缺省参数必须从右往左依次给出,不能间隔着给。同时缺省参数不能在函数的声明和定义中同时出现。
//test.h
void func(int a = 10);
//test.cpp
void func(int a =20)
{}
//若声明与定义的缺省值给的不同就导致编译器无法确定缺省值
缺省值必须是全局变量或者是常量。?
函数重载
函数重载是一种特殊的情况,在C++中允许在同一个域中声明有着相似功能的但是名字相同的函数,这些同名函数的参数列表(参数类型,参数个数,类型顺序)是不同的,这样就构成了函数重载。
#include <iostream>
using namespace std;
//参数类型不同
int Add(int x, int y)
{
return x + y;
}
double Add(double x, double y)
{
return x + y;
}
//参数个数不同
void func()
{
cout << "func()" << endl;
}
void func(int a)
{
cout << "func(int a)" << endl;
}
//参数类型顺序不同
void a(int x, char y)
{
cout << "a(int x, char y)" << endl;
}
void a(char y, int x)
{
cout << "a(char a, int x)" << endl;
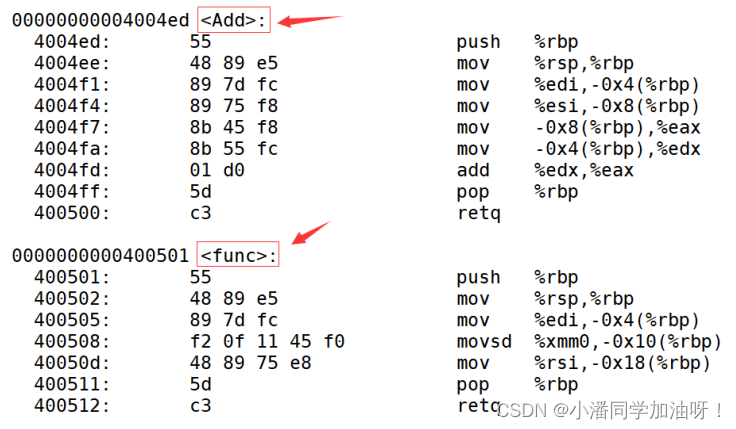
}C++支持函数重载是因为相对于C语言,C++某个程序在调用函数时,是根据一个函数的命名修饰来找的,C语言对于函数的命名修饰仅仅只是记录了函数的函数名,而C++对于函数的修饰有函数名加上参数的修饰。
 ?
?
这是gcc采用C语言编译器编译后的结果,对于函数的命名修饰仅仅只是函数名。? ? ? ???
 ?
?
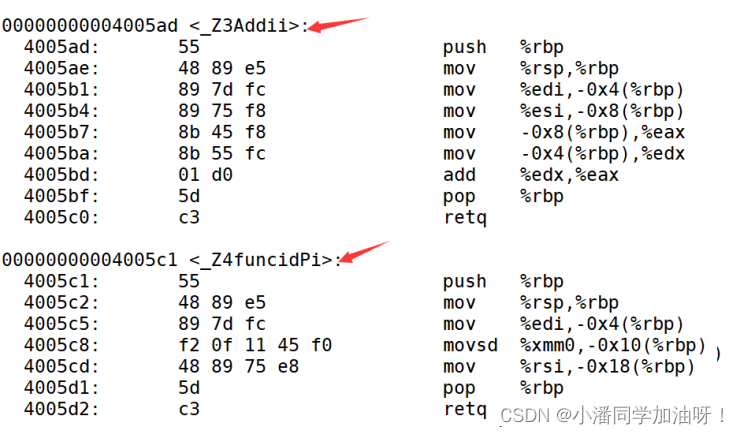
而在Linux环境下利用g++编译完成后,对于函数的命名修饰大概就是 函数名+参数类型。
引用?
引用不是定义一个新的变量,而是给一个已经存在的变量取“别名”,它与它引用的变量共用同一块空间。
在定义引用时,应该遵循 引用类型& 引用变量名 = 引用实体;
void test()
{
int a = 10;
int& ra = a;
printf("%p\n", &a);
printf("%p\n", &ra);
}
//可以利用这段代码去测试他们的储存空间的地址注意:引用类型必须和引用实体的类型时同一种类型。?
引用的特性:?
1.引用必须在定义时初始化。
2.一个变量可以有多个引用。
3.引用一旦引用了一个实体,就不能引用其他实体。
void test2()
{
int a = 10;
int& ra = a;
int& rra = ra;
printf("%p\n", &a);
printf("%p\n", &ra);
printf("%p\n", &rra);
}//多重引用都是一个变量实体常引用的一些问题:?
void test3()
{
const int a = 10;
//int& ra = a; // 该语句编译时会出错,a为常量
const int& ra = a;
// int& b = 10; // 该语句编译时会出错,b为常量
const int& b = 10;
double d = 12.34;
//int& rd = d; // 该语句编译时会出错,类型不同
const int& rd = d;
}如果引用const修饰的常变量时,被const修饰的常变量的权限被进行了放大,这样就会报错。同理在引用一个常量时,也发生了权限放大,也会报错。如果引用的引用类型与被引用变量类型不同则也会报错。
引用的使用场景:?
1.做参数
void swap(int& ra, int& rb)
{
int tmp = ra;
ra = rb;
rb = tmp;
}
//使用引用作为参数
void swap(int* pa, int* pb)
{
int tmp = *pa;
*pa = *pb;
*pb = tmp;
}
//使用指针作为参数在C语言中,我们要在一个函数体内可以改变函数外的变量的值,只能使用指针来改变,但是有了引用,引用就相当于变量的别名,传过去的参数,也就是变量本身,可以简化指针作为参数的麻烦。?
2.做返回值(重点)
int& count()
{
static int n = 0;
n++;
return n;
}
int main()
{
int& ret = count();
printf("%d\n", ret);
return 0;
}//答案是1
//这是一个正确使用引用返回的代码大家看下面代码
 ?
?
在vs2022下,如果我们的Add函数中c是int出来的而没有带static修饰,main函数中两次输出ret的值就会不一样,为什么呢?其实由于c是int出来的,是存在于Add函数栈帧里的,在函数结束时会随着函数栈帧的销毁一同销毁掉,它的返回值时int&类型的,返回值就是原本在函数栈帧中int出来的c,但是由于销毁后,我们利用ret接受返回值,ret就是原本函数栈帧里的c,第一次输出,操作系统并没有回收,则打印出的值就是30,第二次的操作系统回收后打印的就是随机值。
结论:如果函数返回时,出来函数作用域,如果返回对象没有随着函数栈帧一起销毁,就可以使用引用返回,如果返回对象随着函数栈帧一起销毁,则使用传值返回。
传值与传引用的效率比较
#include <time.h>
struct A { int a[10000]; };
void TestFunc1(A a) {}
void TestFunc2(A& a) {}
void TestRefAndValue()
{
A a;
// 以值作为函数参数
size_t begin1 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc1(a);
size_t end1 = clock();
// 以引用作为函数参数
size_t begin2 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc2(a);
size_t end2 = clock();
// 分别计算两个函数运行结束后的时间
cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;
cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}上面代码段,可以用来测试传值与传引用的效率。由于传值时,函数会创建一个临时变量来保存传过去的值,而传引用时,传过去的是一个变量的”别名“也就是变量本身,故不用创建临时变量,所以传引用要比传值运行更快。
值返回与引用返回的性能比较:?
#include <time.h>
struct A { int a[10000]; };
A a;
// 值返回
A TestFunc1() { return a; }
// 引用返回
A& TestFunc2() { return a; }
void TestReturnByRefOrValue()
{
// 以值作为函数的返回值类型
size_t begin1 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc1();
size_t end1 = clock();
// 以引用作为函数的返回值类型
size_t begin2 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc2();
size_t end2 = clock();
// 计算两个函数运算完成之后的时间
cout << "TestFunc1 time:" << end1 - begin1 << endl;
cout << "TestFunc2 time:" << end2 - begin2 << endl;
}上面代码是用来测试它们的性能的。对于值返回,在函数栈帧销毁时,会创建一个临时变量来保存返回值,如果外面有变量接收再进行拷贝。对于引用返回,在函数栈帧销毁时,若正确使用引用返回,返回值就是不随着函数栈帧销毁而销毁的变量本身,所以不需要创建临时变量来保存返回值,如果在外面有变量接收也就拷贝一次。总结:值返回一次拷贝一次,?引用返回一次不需要拷贝,若外面有变量接收返回值它们都需要拷贝。对于返回的变量占很大空间时,引用返回效率远远高于值返回。
?引用与指针的区别:
?在语法层面上,引用就是一个变量的”别名“,没有独立空间,与引用实体共用同一块空间。但是实际上在底层上,引用是利用指针的方式来实现的,要占用空间。
不同点:
1.引用在概念上只是一个变量的”别名“不占储存空间,指针储存变量的地址,占用储存空间。
2.引用在定义时必须初始化,指针不用。
3.引用在引用一个实体后就不能改变引用对象,指针可以任意改变。
4.引用没有NULL这个概念,指针有NULL。
5.在利用sizeof计算大小时,引用就是引用实体的大小,指针始终是地址的所占的字节数(32位平台为4字节,64位为8字节)
6.引用自增一就是引用实体自增一,指针自增一就是向后偏移一个类型的大小。
7.指针有多级指针,而引用没有,引用就是引用实体的别名。
8.指针要解引用,而引用编译器自己处理。
9.引用比起指针更加安全,可以避免野指针。
内联函数?
内联函数是以inline修饰的函数,在编译时C++编译器会在调用内联函数的地方展开,展开没有栈帧的建立与开销,可以提升程序的运行效率。
 ?
?
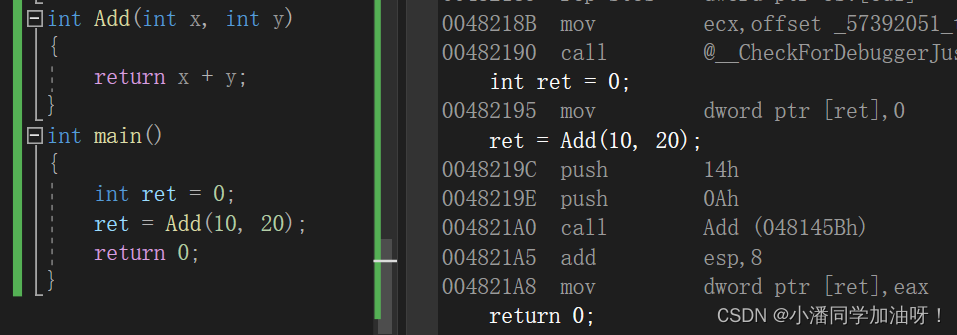
上图中,普通函数调用在底层反汇编时会call函数(也就是调用函数),有了函数栈帧的开销。?
 ?
?
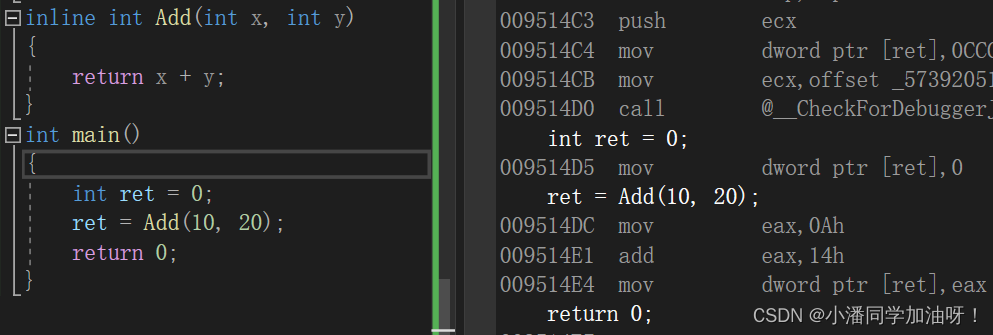
在vs2022环境下,想要看到内联函数是否被展开要将编译器属性中设置C/C++下常规调试信息格式设置为程序数据库,优化设置为只适用于inline才能查看是否展开,上图是底层反汇编时函数直接在调用位置展开,而不会call函数,没有建立函数栈帧,无开销,程序运行会比call快。但是由于是在调用位置展开,空间就会增加,所以内联函数是以空间换时间的一个手段。
特性:
1.inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会
用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运
行效率。
2. inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建
议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不
是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。
3. inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址
了,链接就会找不到。(程序运行要经过预处理、编译、汇编、链接,在链接前会形成符号表,如果是内敛函数的话,由于是在调用处展开,并不会被符号表记录,链接的时候就会出错)如下面代码:
?
// F.h
#include <iostream>
using namespace std;
inline void f(int i);
// F.cpp
#include "F.h"
void f(int i)
{
cout << i << endl;
}
// main.cpp
#include "F.h"
int main()
{
f(10);
return 0;
}
// 链接错误:main.obj : error LNK2019: 无法解析的外部符号 "void __cdecl
//f(int)" (?f@@YAXH@Z),该符号在函数 _main 中被引用auto关键字?
auto简介:?
在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,但遗憾的
是一直没有人去使用它,大家可思考下为什么?
C++11中,标准委员会赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一
个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
//auto自动推导类型
int main()
{
int x = 10;
auto a = &x;
auto* b = &x;
auto& c = x;
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
*a = 20;
*b = 30;
c = 40;
return 0;
}//typeid().name()可以打印出对于变量的类型使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto
的实际类型。因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编
译期会将auto替换为变量实际的类型。
注意:
1.利用auto声明指针类型的时候auto与auto*无区别,但是声明引用的时候要加上&。
2.如果在同一行auto声明多个变量,这些变量必须是同类型的否则会报错。
void TestAuto()
{
auto a = 1, b = 2;
auto c = 3, d = 4.0; // 该行代码会编译失败,因为c和d的初始化表达式类型不同
}3.auto不能作为函数参数,因为编译器无法推导出类型。
4.auto也不能用来声明数组。
利用auto的范围for(一颗语法“糖”)
//一般遍历,将数组元素每个值乘以2再遍历输出
void Testfor()
{
int array[] = { 1,2,3,4,5,6 };
for (int i = 0; i < sizeof(array) / sizeof(array[0]); i++)
{
array[i] *= 2;
}
for (int i = 0; i < sizeof(array) / sizeof(array[0]); i++)
{
cout << array[i] << ' ';
}
}
//范围for遍历,将数组元素每个值乘以2再遍历输出
void Testfor()
{
int array[] = { 1,2,3,4,5,6 };
for (auto& e : array)
{
e *= 2;
}
for (auto e:array)
{
cout << e << ' ';
}
}for循环后的括号由冒号“ :”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围。注意:范围for能够使用必须要知道遍历的范围。
谢谢各位的观看,创作不易,一键三连。如有错误欢迎指正!