layout: post
title: C++prime读书笔记(二)C++标准库
description: C++prime读书笔记(二)C++标准库
tag: 读书笔记
第8章:IO库
- IO类:C++中有如下IO库类型,表头是它们所属的头文件。常见的cin,cout,这些输入流和输入流对象在头文件iostream中。fstream定义了读写命名文件的类型,sstream定义了读写内存string对象的类型。

- IO对象无拷贝或者赋值,故也不能将形参或者返回类型设置为流类型。但是可以用引用的方法传递和返回流,此外读写一个IO对象会改变其状态,故传递和返回的引用不能是const类型。
- IO类的条件状态
IO操作可能发生错误,有些可以恢复但是有一些不能恢复,IO类定义的一些函数和标志,可以帮助我们访问和操纵流的条件状态。以上的三个流都有一样的标志,标志如下表。


下边是io错误的例子,期望的ival是int类型,假如我们键入“Boo”,读操作就会失败,cin进入错误状态。所以代码通常应该在使用一个流之前检查它是否处于良好的状态,最好的方法就是把它当作一个条件使用,例如下边的while语句,当键入int数字时,条件为真,维持键入状态,否则会退出while。
int ival;
cin << ival;
while(cin << ival)
// ok:读操作成功
- 管理输出缓冲:每个输出流管理着一个缓冲区,用来保存程序读写的数据,运行程序将多个输出操作组合为一个写操作。缓冲区管理方式如下:
- 使用endl操纵符,执行换行并刷新缓冲区。
- 使用flush操纵符,执行刷新缓冲区。
- 使用ends操纵符,执行空格并刷新缓冲区。
- 如果想在每次输出操作后都刷新缓冲区,使用
unitbuf操纵符,告诉流对象接下来每次写操作之后都进行一次flush操作。使用nounitbuf(unitbuf前边加no,取消的意思)操纵符,重置流,恢复默认的刷新机制。
写文件
- 包含头文件
#include<fstream> - 创建流对象
ofstream ofs; - 打开文件
ofs.open("文件路径",打开方式); - 写数据
ofs << "写入的数据"; - 关闭文件
ofs.close();
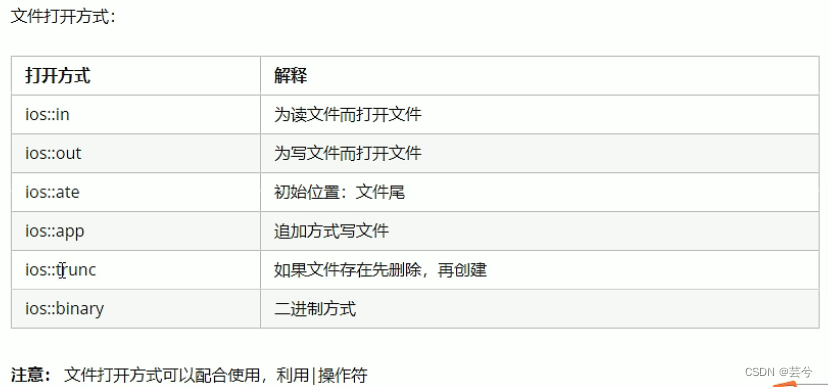
注:打开方式可以配合使用,利用|操作符
eg : 用二进制方式写入文件:
ios::binary | ios::out
读文件
- 包含头文件
#include<fstream> - 创建输入流对象
ofstream ifs; - 打开文件
ifs.open("文件路径",打开方式); - 读数据
- 关闭文件
ofs.close();
#include<fstream>
#include<iostream>
using namespace std;
void main()
{
ifstream ifs;
ifs.open("test.txt", ios::in);
if (!ifs.is_open())
{
cout << "文件打开失败" << endl;
return;
}
// 读数据
/*
第一种
char buf[1024] = { 0 };
while (ifs >> buf)
{
cout << buf << endl;
}
ifs.close();
*/
/*第二种
char buf[1024] = { 0 };
// ifs.getline(buf, sizeof(buf),读取到buf,最多读sizeof(buf)个字节
while (ifs.getline(buf, sizeof(buf)))
{
cout << buf << endl;
}
*/
/*
* 第三种
* string buf;
* while(getline(ifs, buf))
* {
cout << buf << endl;
* }
*
*/
/*第四种
* 一个字符一个字符读取,判断是否到达文件尾部EOF
*/
char c;
while (( c = ifs.get()) != EOF)
{
cout << c;
}
ifs.close();
return;
}
- 读文件可以利用ifstream,或者fstream
- 读文件可以利用ifs.is_open()函数判断文件是否打开成功
- ifs.close(); 关闭文件
string流
下边这段代码用于循环处理下边的信息:
morgan 0003031 324244
drew 12323
lee 9900 33132 331333
文件的每条记录都以人名开始,跟随着一个或者多个电话号码。
最外层的while循环逐行读取数据,直至cin遇到文件尾。
用输入字符串流 istringstream与读取到的文本行line绑定,记录为record。
struct PersonInfo
{
string name;
vector<string> phones;
};
int main() {
string line, word; // 分别保持来自输入的一行和单词
vector<PersonInfo> people;
while (getline(cin, line))
{
PersonInfo info;
istringstream record(line); // 将记录绑定到刚读入的行
record >> info.name; // 读取名字
while (record >> word)
{
info.phones.push_back(word); // 保持它们
}
people.push_back(info);
}
return 0;
}
第9章:顺序容器
顺序容器类型:
* vector
* deque
* list(双向链表)
* forward_list(单向链表)
* array(固定大小的数组)
* string
容器操作
- 成员
- iterator: 容器的迭代器类型
- const_iterator: 容器的只读迭代器类型
- reverse_iterator:按逆序寻址的迭代器
- size_type: 无符号整形,足够保存此种容器最大可能容器大小
- difference_type: 带符号整形,足够保存两个迭代器之间的距离
- value_type :元素类型
- reference:元素的左值类型,与value_type &含义相同(元素指针类型)
- const_reference
- 构造
- C c; 默认构造,构造空容器
- C c1(c2);拷贝构造
- C c(b, e); 构造c,将迭代器b和e指定范围内的元素拷贝到c
- C c{a, b, c……} ;初始化列表
- 赋值与交换
- c1 = c2; 将c1中元素替换为c2
- c1 = {a, b, c……};将c1中元素替换为列表中元素
- a.swap(b); 交换容器a和容器b的元素
- swap(a, b);与上一行等价
- 大小
- c.size();
- c.max_size();c可保存的最大元素数目
- c.empty()
- 添加删除元素
- c.insert()
- c.erase()
- c.clear()
- c.emplace()
- 迭代器
- c.begin()
- c.end()
- c.rbegin()
- c.rend() :rbegin()和rend()的类型为reverse_iterator,rbegin()指向末尾元素,rend()指向首元素的前一个地址。
注意1:当用一个容器对另一个容器进行拷贝赋值时,两个容器的类型和容器中元素的类型都必须一致。
注意2: 标准库array与内置数组不同,允许赋值和花括号初始化,但不允许花括号列表赋值,因为花括号列表元素的大小可能与固定数组array不一致。
// ans.rbegin()用法
vector<int>ans({ 1, 2, 3 });
for (vector<int>::reverse_iterator it = ans.rbegin(); it != ans.rend();it++)
{
cout << (*it) << endl;
}
// 拷贝赋值
vector<int>copy_ans(ans);
// 双端队列可以用vector的子序列拷贝赋值,这是由于双端队列的底层有用vector来实现
deque<int> dq(ans.begin(), ans.end());
// 标准库array与内置数组不同,允许赋值和花括号初始化,但不允许花括号列表赋值,因为花括号列表元素的大小可能与固定数组array不一致.
array<int, 10> a1 = {0,1,2,3,4,5};
array<int, 10> a2 = {0}; // 10个0
a1 = a2; //用a2给a1赋值
a2 = {0}; // 错误,不允许用花括号列表给array赋值
assign
assign允许将一个不同但是相容的类型赋值,或者从容器的一个子序列赋值。例如使用assign可以实现将一个vector中的一段char*值赋予一个list中的string:
list<string> names;
vector<const char*> oldstyle;
names = oldstyle; // 错误,容器类型不相符
names.assign(oldstyle.cbegin(), oldstyle.cend());
list<string> slist1(1); // 一个空的字符串元素
slist.assign(10, "Hiya");
swap
swap交换两个相同类型的容器的内容,swap不对任何元素进行拷贝,删除或插入,因此可以在很快的常数时间内完成。假定iter在swap前指向svec1[3]的string,那么在swap交换后,iter指向了svec2[3]的元素。与其他容器不同,对一个string调用swap会导致迭代器,引用和指针失效。
向容器中添加元素insert,emplace
- insert除了可以接收单个元素外,还可以接收指定数量或者范围内的元素
例如:svec.insert(svec.end(), 10, “Anna”),注意,第一个参数必须是迭代器,插入位置是包含第一个参数迭代器指向的位置的。
svec.insert(svec.end(), 10, "Anna"); //从某个位置起(包含),插入10个“Anna”
ans.insert(ans.end(), ans.begin(), ans.end());
C++11引入了三个新成员――emplace_front、emplace、emplace_back();
这些操作对于push_front,push,push_back();二者的区别可以用下边一个例子说明:
假定用容器c保存PersonInfo元素。
test.emplace_back(“lzy”, 22); // 正确
相当于:test.push_back(PersonInfo(“lzy”, 22)); //正确创建一个临时的PersonInfo对象传递给push_back.
emplace_back会在容器管理的内存中直接创建对象,而调用push_back则会创建一个局部临时对象,并将它压入容器,所以emplace是原地构造新的元素对象。
struct PersonInfo
{
PersonInfo(string _name, int _age) : name(_name), age(_age) {}
string name;
int age;
};
int main() {
vector<PersonInfo> test;
test.emplace_back("lzy", 22); // 正确
test.push_back("lzy", 22); // 错误,没有接收2个参数push_back
test.push_back(PersonInfo("lzy", 22)); //正确创建一个临时的PersonInfo对象传递给push_back.
return 0;
}
容器中删除元素
删除单个元素:
注意下边语句中迭代器仅在不需要删除元素时后移,这是因为删除操作会动态改变容器数据,迭代器指向的元素会发生变化。
list<int> lst = {0,1,2,3,4,5};
auto it = lst.begin();
while(it != lst.end()){
if(*it % 2){
it = lst.erase(it); // 删除此元素
}else{
++it;
}
}
删除多个元素:
接首两个迭代器参数的erase允许我们删除一个范围内的元素。同样因为删除会改变数据结构长度,迭代器指向的元素会变化。它可以由返回值,返回指向最后一个被删元素之后位置的迭代器。
elem1指向删除的第一个元素位置,elem2指向删除的最后一个元素之后的位置。(左闭右开)
删除完毕后,返回的迭代器就是elem2,故最后elem1 = elem2
elem1 = slist.erase(elem1, elem2);
容器操作可能使得迭代器失效
- 向容器添加元素后:
- 如果容器是vector或string,且存储空间被重新分配,则指向容器的迭代器、指针和引用都会失效。如果存储空间未重新分配(
vector与string都是动态增长存储空间,空间增长后就会重新分配存储空间),指向插入位置之前的元素的迭代器,指针和引用仍然有效,但指向插入位置之后元素的迭代器、指针和引用失效。 - 对于deque,插入到除首尾位置之外的任何位置都会导致迭代器,指针和引用失效。如果在首尾位置添加元素,迭代器会失效,但是指向存在的元素的引用和指针不会失效。
- 对于list和forward_list,指向容器的迭代器(包括尾后迭代器和首前迭代器),指针和引用都仍有效。
- 如果容器是vector或string,且存储空间被重新分配,则指向容器的迭代器、指针和引用都会失效。如果存储空间未重新分配(
- 当从容器删除元素后。
- 对于vector和string,指向被删除元素之前的元素的 迭代器、引用和指针任然有效
- 对于deque,如果在首尾之外任何位置删除元素,那么指向被删除元素外的其他元素的迭代器、指针和引用都会失效。删除deque的尾部元素,尾后迭代器也会失效,其他迭代器、引用、指针不受影响。删除首元素,这些不受影响。
- 对于list和forward_list,指向容器的迭代器(包括尾后迭代器和首前迭代器),指针和引用都仍有效。
vector与string的空间分配
vector和string通常会分配比新空间需求更大的内存空间,以预留空间备用。这种分配策略避免了每次添加新元素时都需要重新分配内存空间。
vector中string提供了一些成员函数,允许我们与它实现中的内存分配互动。
- c.shrink_to_fit:只适用于vector、string和deque,用于将capacity减少为与size()相同大小
- c.capacity() 不重新分配内存空间的话,c可以保存多少元素
- c.resize():重新指定容器大小,多余元素赋值0
- c.reserve(n) 分配至少能容纳n个元素的内存空间。(reserve并不改变容器中元素的数目,仅影响预先分配的多大的内存,它与resize是相对的。resize划定的大小范围是可以通过下标访问的,reserve则不行)
额外的string操作
构造string的其他方法
- string s(cp, n); s是cp指向的数组中前n个字符的拷贝,此数组至少包含n个字符
- string s(s2, pos); s是从字符串s2从下标pos开始的字符子串的拷贝
- string s(s2, pos, len);s是字符串s2从pos开始,长len的字符子串的拷贝,至多拷贝s2.size() - pos个字符。
const char *cp = "Hello world!!!"; // 以空字符结束的数组
char noNull[] = {'H', 'i'}; //不是空字符结束的数组
string s1(cp); // 拷贝cp中的字符,直到遇到空字符
string s2(noNull, 2); // 从noNull拷贝两个字符
string s3(noNull); // 可以会出现问题,因为noNull不以空字符结尾,所以拷贝时不知何时结束
string s4(cp + 6, 5) // 从cp[6]开始拷贝5个字符,得到"world"
string s5(s1,6, 5 ) // 从s1[6]开始拷贝5个字符
string s6(s1, 6) // 从s1[6]开始拷贝到结束
string s7(s1, 6, 20); // 正确,只会拷贝到结尾
string s8(s1, 16); // 错误,抛出一个越界的错误
substr操作
s.substr(pos, n); // 返回从字符串s的下标pos开始,长为n的子字符串,n的默认大小为s.size() - pos
append和replace函数
append操作在string末尾插入字符串
replace操作是调用erase和insert的一种简写形式
string s("C++ prime"), s2 = s;
s.insert(s.size(), " 4th Ed."); // s == "C++ prime 4th Ed."
s2.append(" 4th Ed."); // 与上一行含义一致
s.erase(11, 3);
s.insert(11, "5th")
s2.replace(11, 3, "5th"); // 从s2的11开始删除3个字符替换为5th,等价上边两句
string的搜索操作
args必须是以下形式之一:
-
c, pos 从s中位置pos开始查找字符c,pos默认为0
-
s2, pos从s中位置pos开始查找字符串s2.pos默认为0
-
cp,pos从s中位置pos开始查找指针cp指向的以空字符结尾的c风格字符串,pos默认为0
-
cp, pos, n,从s中位置pos开始查找指针cp指向数组前n个字符,pos和n无默认值
- s.find(args); //查找s中第一次出现args的位置
- s.rfind(args);// 查找s中最后一次出现args的位置
- s.find_first_of(args);//在s中查找args中任何一个字符第一次出现的位置
- s.find_last_of(args);// 在s中查找args中任何一个字符最后一次出现的位置
- s.find_first_not_of(args); //在s中查找第一个不在args中的字符
- s.find_last_not_of(args);//在s中查找最后一个不在args中的字符
数值转换
- to_string(val):返回数值val的string的string表示,val可以是任何算术类型
- stoi(a, p, b):返回s的起始子串(表示整数内容)的数值,返回值类型分别是int,long,unsigned_long……p是size_t指针,用来保存s中第一个非数值字符的下标,p默认为0,即函数不保存下标,而b是转换所用的基数。
- stol(a p,b)
- stoul(a p,b)
- stoll(a p,b)
- stoull(a p,b)
- stof(s, p)
- stod(s, p)
- stold(s, p)
容器适配器
除了顺序容器,标准库还定义了三个顺序容器适配器:stack,queue和priority_queue。
- 每个适配器都定义两个构造函数:默认构造函数创建一个空对象,接受一个容器的构造函数拷贝该容器来初始化适配器。假定deq是一个deque,我们可以用deq来初始化一个新的stack:
stack<int> stk(deq); // 从deq拷贝元素构造stk - 默认情况下,stack和queue都是基于deque实现的,priority_queue是在vector之上实现的。我们可以在创建一个适配器时将一个命名的顺序容器作为第二个类型参数,来重载默认容器类型。
// 在vector上实现的空栈
stack<string, vector<string>> str_stk;
// str_stk2在vector上实现,初始化时保存svec的拷贝
stack<string, vector<string>>str_stk2(svec);
第10章:泛型算法
概念
大多数算法都定义在头文件algorithm中,标准库还在头文件numeric中定义了一组数值泛型算法。一般情况下算法并不直接操作容器,而是遍历由两个迭代器指定的一个元素范围。迭代器令算法不依赖于容器,算法永远不会执行容器的操作。
常见算法
标准库提供超过100个算法,但这些算法有一致的结构,理解结构可以帮助我们更容易地学习和使用这些算法
只读算法
一些算法只读取输入范围的元素,但不改变元素。例如find,count和定义在numeric中的accumulate,它接受3个参数,前两个指定了求和的元素的范围,第三个参数是和的初始值。例如下边这条语句sum求取了vec中所有元素的和。
int sum = accumulate(vec.cbegin(), vec.cend(), 0);
accumulate将第三个参数作为求和的起点,这里隐含地假设了元素类型是可以求和的操作的,故上例中元素类型可以是int,long,double,long long等。
由于string定义了+运算符,因此可以调用accumulate来将vector中的string元素连接起来:
string sum = accumulate(v.cbegin(), v.cend(), string(""));
注意这里最后一个参数显式地创建了一个string,而非直接将字面值""作为参数传递,原因在于如果我们传递的是字符串字面值,用于保存和的对象的类型将是const char *.这样便会产生矛盾,所以应该构建一个临时的string变量作为参数传递,而不能使用字面值常量。
equal是另一个只读算法,用于确定两个序列是否保存相同的值。如果两序列所有对应元素相等,返回true,否则返回false,此算法也可以接受三个迭代器,前两个表示第一个序列的元素范围,第三个表示第二个序列的首元素。这些只接受一个单一迭代器来表示第二个序列的算法,都假定第二个序列至少与第一个序列一样长,并且比较的长度基于第一个序列的长度。例如下边的例子,str1与str2的equal结果是1.
string str1 = "abc";
string str2 = "abcd";
cout << equal(str1.begin(), str1.end(), str2.begin()); // 打印结果为1,相等
写容器元素的算法
一些算法将新值赋予序列中的元素,当使用这类算法时,必须确保序列的大小,至少不小于我们要求算法写入的元素的数目。例如fill,它接受一对迭代器表示一个范围,还接受一个值作为第三个参数,将这个给定值赋予输入序列范围中每个元素。
fill(vec.begin(), vec.end(), 0); // 将每个元素重置为0
fill(vec.begin(), vec.begin() + vec.size() / 2, 10;)
一些算法接受一个迭代器指出一个单独的目的位置,从该位置开始赋值。例如fill_n
fill_n(vec.begin(), vec.size(), 0);
back_inserter插入迭代器
一种保证算法有足够元素空间来容纳输出数据的方法是使用插入迭代器back_inserter,它是定义在头文件iterator中的一个函数。它接受一个指向容器的引用,返回一个与该容器绑定的插入迭代器,当我们向此迭代器赋值时,赋值运算符会调用push_back将一个具有给定值的元素添加到容器中。
vector<int>vec;
auto it = back_inserter(vec); // 通过它赋值,会将元素添加到vec中
*it = 42; // vec中现有一个元素,值为42
我们常常使用back_inserter来创建一个迭代器,作为算法的目的位置来使用:
vector<int>vec;
fill_n(back_inserter(vec), 10, 0); // 添加10个元素到vec
在每步迭代中,fill_n向给定序列的一个元素赋值,由于我们传递的参数是back_inserter返回的迭代器,因此每次赋值都会在vec上调用push_back.
拷贝算法
copy算法接受三个迭代器,前两个表示一个输入范围,第三个表示目的序列的起始位置,此算法将输入范围中的元素拷贝到目的序列中,传递给copy的目的序列至少要包含与输入序列一样多的元素。可以使用copy实现内置数组的拷贝:
int a1[] = {0,1,2,3,4,5};
int a2[sizeof(a1) / sizeof(*a1)];
auto ret = copy(begin(a1), end(a1), a2); // 把a1的内容拷贝给a2,ret指向a2尾元素下一个位置
replace算法读入一个序列,并将其中所有等于给定值的元素都改为另一个值。此算法接受4个参数,前两个是迭代器,后两个一个是要搜索的值,另一个是新值。
如果希望保留原序列不变,可以调用replace_copy算法,此算法额外接受第三个迭代器参数,指向调整后序列的保存位置:
replace(ilst.begin(), ilst.end(), 0, 42); // 将ilst中所有的0替换为42
replace_copy(ilst.cbegin(), ilst.cend(), back_inserter(ivec), 0, 42);
// 此调用后,ilst并未改变,ivec包含ilst的一份拷贝,不过原来在ilst中0替换为了42
重排容器元素的算法
某些算法会重排容器中的元素的顺序,比如sort。
为了消除重复单词,首先将vector排序,使得重复的单词相邻出现,一旦vector排序完毕,使用unique算法重排vector,使得不重复的元素出现在vector的开始部分,返回一个迭代器,指向元素不重复出现序列尾部的下一个位置。由于算法不能执行容器的操作,所有我们使用erase成员函数来完成真正的删除操作。
void elimDumps(vector<string> &words){
// 按字典序排序words
sort(words.begin(), words.end());
auto end_unique = unique(words.begin(), words.end());
// 使用向量操作erase删除重复单词
words.erase(end_unique, words.end());
}
自定义操作
向算法传递函数
sort算法默认使用元素类型的<运算符,但可能我们希望的排序顺序与<所定义的顺序不同,或是我们的序列可能保存的是未定义<运算符的元素类型,在这两种情况下,都需要重载sort的默认行为。重载的sort接收第三个参数,它是一个谓词。
谓词
谓词是一个可调用的表达式,其返回结果是一个能用作条件的值。谓词分为两类:一元谓词,二元谓词(意味着它有两个参数)。接受谓词参数的算法对输入序列中的元素调用谓词。因此元素类型必须能转换为谓词的参数类型。
接受一个二元谓词的sort使用这个谓词来代替**<**来比较元素。
例如:下边这段函数可以按长度由短到长排序words
bool isShorter(const string &s1, const string &s2){
return s1.size() < s2.size();
}
sort(words.begin(), words.end(), isShorter); // 按长度由短到长排序words
排序算法
在words按大小重排的同时,还希望具有相同长度的元素按字典序重排,为了保存相同长度的单词按字典序排列,可以使用stable_sort算法。稳定排序算法维持相等元素的原有顺序。
elimDups(words); // 将words按照字典序重排并消除重复单词
stable_sort(word.begin(), word.end(), isShorter);
for(const auto &s : words){
cout << s << " ";
}
cout << endl;
lambda表达式
根据算法接受一元谓词还是二元谓词,我们传递给算法的谓词必须验证接受一个或两个参数。但有时,我们希望进行的操作需要更多参数。以下边这个需求为例:
求大于等于一个给定长度的单词有多少。
使用标准库find_if算法来查找第一个具有特定大小是元素,find_if算法接受三个参数,前两个是一对迭代器,表示一个范围,第三个参数是一个谓词,返回第一个使得谓词非0的元素,如果不存在这样的元素,返回尾迭代器。find_fi接受一个参数。没有办法再传递给他第二个参数表示长度。为此,需要引用lambda表达式。
void biggies(vector<string>& words, vector<string>::size_type sz){
elimDups(words); // 字典序排序,去重
stable_sort(words.begin(), words.end(), isShorter);
// 获取一个迭代器,指向第一个满足size() >= sz的元素
// 计算满足size >= sz的元素的数目
// 打印长度大于等于给定值的单词,每个单词后边接一个空格
}
一个lambda表达式表示一个可以调用的代码单元,可以把他理解为一个未命名的内联函数。与任何函数类似,一个lambda具有一个返回类型,一个参数列表和一个函数体。但与函数不同的是,lambda可能定义在函数内部。
一个lambda表达式具有如下形式:
[capture list] (parameter list) ->return type{function body}
其中capture list(捕获列表)是一个lambda所在函数中定义的局部变量列表,参数列表与函数体与普通函数一样。不同的是,lambda必须使用尾置返回来指定返回类型。我们可以忽略参数列表与返回类型,但是必须永远包含捕获列表和函数体。
auto f = [] {return 42;};
上边这句代码定义了一个可调用对象f,不接受参数,返回42.
cout << f() << endl; // 打印42
在lambda中忽略括号和参数列表等价指定一个空参数列表。
下边采用lambda表达式来编写一个功能与isShorter函数相同的函数:
空捕获列表表明此lambda不使用它所在函数中任何局部变量,lambda的参数与isShorter是类似的
[] (const string& a, const string& b){return a.size() < b.size()}
// 使用lambda调用算法
stable_sort(words.begin(), words.end(), [](const string & a, const string &b){return a.size() < b.size();});
for_each算法
for_each算法接受一个可调用对象,并对输入序列中每个元素调用此对象:
例如下边这条语句,前面两个参数是气质迭代器,第三个参数是一个lambda表达式,它的参数类型与迭代器解引用后一致。
// 打印长度大于等于给定值的单词,每个单词后边接一个空格
for_each(wc, words.end(), [](const string &s){cout << s << " ";});
使用捕获列表
一个lambda可以使用一个函数中的局部变量,但必须明确地在捕获列表中指明:
[sz](const string &a, const string &b){return a.size() >= sz;}
完整的biggies
void biggies(vector<string>& words, vector<string>::size_type sz){
elimDups(words); // 字典序排序,去重
stable_sort(words.begin(), words.end(), [](const string &a, const string &b) {return a.size() < b.size();}); // 使用lambda按照长度排序
// 获取一个迭代器,指向第一个满足size() >= sz的元素
auto wc = find_if(words.begin(), words.end(), [sz](const string &a){return a.size() >= sz;})
// 计算满足size >= sz的元素的数目
auto count = words.end() - wc;
cout << count << " " << make_plural(count, "word", "s");
<< "of length" << sz << "or longer" << endl;
// 打印长度大于等于给定值的单词,每个单词后边接一个空格
for_each(wc, words.end(), [](const string &s){cout << s << " ";});
cout << endl;
}
类似参数传递。变量的捕获方式可以是值或者引用,采用值捕获的前提是变量可以拷贝,与参数传递不同的是,被捕获的变量是在lambda创建时拷贝,而不是调用时拷贝。下边这个例子,创建的lambda拷贝了v1为42的值,后边v1虽然被修改了,但不会影响lambda内对应的值,因为它是在创建lambda时执行的拷贝。
void fcn1(){
size_t v1 = 42;
auto f = [v1] {return v1;};
v1 = 0;
auto j = f();
}
如果想要在创建lambda后还能修改捕获参数,那么就应该采用引用捕获的方式:
下边的fcn2则会输出0,因为传递的是引用。
void fcn2(){
size_t v1 = 42;
auto f2 = [&v1] {return v1;};
v1 = 0;
auto j = f2();
}
注意:
- 引用捕获与返回引用有着相同的问题和限制,需保证引用的对象在执行lambda时是存在的。lambda捕获的都是局部变量,这些变量在函数结束后就不复存在了,如果lambda可能在函数结束后执行,捕获的引用指向的局部变量已经消失。
- 一些不能拷贝的类型如ostream,捕获的唯一方式就是引用捕获或指向os的指针。
- 应尽量保存lambda的变量捕获简单化,避免捕获潜在的问题。
除了显式列出我们希望使用的来自所在函数的变量之外,还可以让编译器根据lambda体中的代码推断我们要使用的变量,称为隐式捕获,为了指示编译器推断,应该在捕获列表写一个=或&告诉编译器是采用值捕获还是引用捕获。例如我们可以重写传递给find_if的lambda:
// sz为隐式捕获
wc = find_if(words.begin(), words.end(), [=](const string &s){return s.size() >= sz});
如果希望对一部分变量采用值捕获,其他变量采用引用捕获,可以混合使用隐式捕获和显示捕获,当使用混合捕获时,捕获列表第一个参数必须是=或&,指定默认捕获方式是值或是引用。
// os隐式捕获,指明了是&引用捕获,c是显示捕获
for_each(words.begin(), words.end(), [&, c](const string &s){ os << s << c;});
// c隐式捕获,值捕获,os显式引用捕获
for_each(words.begin(), words.end(), [=, &os](const string &s){os << s << c;});
默认情况下,值拷贝的变量,lambda不会改变其值,如果希望改变,需在参数列表首加上mutable关键字。
size_t v1 = 42;
auto f = [v1]()mutable {return ++v1;};
v1 = 0;
auto j = f(); // j = 43
指定lambda返回类型必须是尾置的
下边这个例子使用标准库中的transform算法和一个lambda来将一个序列中的每个负数替换为它的绝对值:
transform(vi.begin(), vi.end(), vi.begin(), [](int i){return i < 0 ? -i : i});
函数transform接受3个迭代器和一个可调用对象,前两个迭代器表示输入序列,第三个迭代器表示目的位置,算法对输入序列中每个元素调用可调用对象,并将结果写在目的位置。如上边的例子所示,目的迭代器位置是可以与表示输入序列开始的位置相同的。
因为lambda可以根据条件运算符的类型推断返回值类型,所以lambda忽略了返回值类型的声明。如果使用看似等价的if代替上面的三目运算符,则会出错,因为编译器无法推断返回值类型。
transform(vi.begin(), vi.end(), vi.begin(), [](int i){if(i < 0 return -i; else return i;});
当需要为一个lambda定义返回值类型时,必须使用尾置返回值类型:
transform(vi.begin(), vi.end(), vi.begin(), [](int i) -> int{if(i < 0 return -i; else return i;});
参数绑定
在头文件functional中有名为bind的标准库函数,可以将bind视为一个通用的函数适配器,它接受一个可调用对象,生成一个新的可调用对象来“适应”原对象的参数列表。调用bind的一般形式为:
auto newCallable = bind(callable, arg_list);
arg_list是一个逗号分隔的参数列表,对应给定的callable的参数,当我们调用newCallable时,newCallable会调用callable,并传递给它arg_list中的参数。
举个简单的例子,check_size是一个可调用对象,它接受两个参数,如果我们想要一个固定大小参数版本的check6,就可以使用bind来完成:
此bind调用只有一个占位符_1,表示check6只接受单一参数,占位符出现在arg_list的第一个位置,表示check6的此参数对应check_size的第一个参数const string &s。
因此调用check6必须传递它一个string类型的参数,它会将此参数传递给check_size.
bool check_size(const string &s, string::size_type sz){
return s.size() >= sz;
}
auto check6 = bind(check_size, _1, 6);
使用bind我们可以将原来基于lambda的find_if,进行替换:
auto wc = find_if(words.begin(), words.end(), [sz] (const string & s));
auto wc = find_if(words.begin(), words.end(), bind(check_size, _1, sz));
使用_n绑定bind的参数或者重排参数顺序
名字_n都定义在一个名为placeholders的命名空间中,而这个命名空间本身定义在std命名空间。
_n指示了参数位置。
利用bind可以绑定给定可调用对象中的参数或者重新安排顺序.
假定f是一个可调用对象,接受5个参数。
g = bind(f ,a ,b ,_2, _c, _1)
bind绑定后的新可调用对象接受两个参数,第一个位置的参数会赋值给f的第5个位置,而新可调用对象的第二个位置参数会赋值给f的第3个位置。
即g(_1, _2)将被映射为:
f(a,b,_2,c,_1)
下面举一个使用bind重排参数顺序的例子:
bind(isShorter, _2, _1))使得传递给新的可调用对象的第一个位置参数,赋予给了isShort的第二个位置,因此重排参数顺序的结果是,下边第二条语句返回的是按单词长度由长到短排序。
// 按单词长度由短到长排序
sort(words.begin(), words.end(), isShorter);
// 按单词长度由长到短排序。
sort(words.begin(), words.end(), bind(isShorter, _2, _1));
绑定引用参数
与lambda一样,有时需要用引用的方式绑定参数。
而bind本身是对参数进行拷贝,这时需要用到与bind一样处于头文件functional中的ref函数或者cref函数。
函数ref返回一个对象,包含给定的引用,此对象是可以拷贝的,cref生成保存const引用的类。
for_each(words.begin(), words.end(), bind(print, ref(os), _1, ' '));
迭代器
迭代器类别
- 插入迭代器:绑定在容器上用于向容器插入元素
- 流迭代器:绑定在输入或输出流上,用于遍历关联的IO流
- 反向迭代器:向后而不是向前移动
- 移动迭代器:不拷贝元素,而是移动它们
第11章:关联容器
访问容器
在multiset和multimap中如果有多个元素具有给定关键字,则这些元素在容器中会相邻存储。
假定一个容器c,可以使用成员函数lower_bound(),upper_bound(),equal_range()来获取所有具有相同关键字K的元素范围。
lower_bound(key)返回大于等于key的第一个元素的迭代器
upper_bound(key)返回大于key的第一个元素的迭代器
所有例如这两个函数可以获取所有等于key的元素范围
而这样获取的范围还可直接利用equal_range(key),它返回一个迭代器pair,直接表示了关键字等于key的元素范围。
第12章:动态内存
头文件memory中有三种类型的智能指针:shared_ptr、unique_ptr、weak_ptr
- shared_ptr允许多个指针指向同一个对象
- unique_ptr则独占所指的对象。
- weak_ptr是一种弱引用,指向shared_ptr所管理的对象。
shared_ptr
智能指针也是模板,在创建时需指明指针可以指向的类型:
shared _ptr< string >p1;
shared_ptr< list< int > > p2;
shared_ptr与unique_ptr都支持如下操作:

shared_ptr独有地支持下边的操作:

make_shared函数
最安全的分配和使用动态内存的方法是调用一个名为make_shared的标准库函数,此函数在动态内存中分配一个对象并初始化它,返回指向次对象的shared_ptr,此函数同样在memory头文件中。使用make_shared必须指向创建的对象的类型:
// 指向一个值为42的int的shared_ptr
shared_ptr < int > p3 = make_shared< int >(42);
shared_ptr< string > p4 = make_shared<string>(10, '9');
// p5指向一个值初始化的int,值为0;
shared_ptr<int> p5 = make_shared<int>();
auto p6 = make_shared<vector<string>>();
由上可见,类似顺序容器的emplace成员,make_shared用其参数构造给定类型的对象。
shared_ptr的拷贝和赋值
当进行拷贝或者赋值操作时,每个shared_ptr都会记录有多少个其他shared_ptr指向相同的对象。
auto p = make_shared<int>(42); //p指向的对象只有p一个引用者
auto q(p); // p和q指向相同对象,此对象有两个引用者
我们可以认为每个shared_ptr都有一个关联的计数器,通常称其为引用计数,无论我们何时拷贝了一个shared_ptr,计数器都会递增。例如用一个shared_ptr初始化另一个shared_ptr或将它作为参数传递给一个函数,以及作为函数的返回值,它所管理的计数器就会递增。当我们给shared_ptr赋予一个新值或是shared_ptr被销毁(例如一个局部的shared_ptr离开其作用域)时,计数器就会递减。
一旦一个shared_ptr的计数器变为0,它就会自动释放自己所管理的对象。
下边的例子第一条语句创建了share_ptr r,随后在给r赋值时,shared_ptr的计数器递减为0,因此int会被自动释放。
auto r = make_shared<int>(42);
r = q;
shared_ptr自动销毁所管理的对象
当指向一个对象的最后一个shared_ptr被销毁时,shared_ptr类会自动销毁此对象。它是通过另一个特殊的成员函数析构函数完成销毁工作的。
shared_ptr的析构函数会递减它所指向的对象的引用计数,如果计数变为0,shared_ptr的析构函数就会销毁对象,并释放它占用的内存。
void use_factory(T arg){
shared_ptr<T> p = factory(arg)
}// p离开了作用域,它指向的内存就会被自动释放掉
使用了动态生存期的资源的类
程序使用动态内存出于以下三种原因之一:
- 程序不知道自己需要使用多少对象
- 程序不知道所需对象的准确类型
- 程序需要在多个对象间共享数据
容器类是出于第一种原因而使用动态内存的典型例子。
下边这个例子,两个对象共享底层的数据,当某个对象被销毁时,我们不能单方面销毁底层数据:
Blob<string> b1; // 空blob
{
Blob<string> b2 = {"a", "an", "the"};
b1 = b2;
}// b2被销毁了,但b2中的元素不能销毁,因为b1由最初的b2创建的
为了实现数据共享,我们应该给每个对象设置一个shared_ptr来管理动态分配的底层数据,假如用vector存储底层数据,shared_ptr记录有多少个对象共享相同的vector,并在vector的最后一个使用者被销毁时释放vector。
下面我们定义一个StrBlob类,来模拟所希望的数据共享机制:
class StrBlob{
public:
typedef std::vector<std::string>::size_type size_type;
StrBlob();
StrBlob(std::initializer_list<std::string> il);
size_type size() const {return data->size();}
bool empty() const {return data->empty();}
// 添加和删除元素
void push_back(const std::string &t) {data->push_back(t);}
void pop_back();
//元素访问
std::string & front();
std::string & back();
private:
std::shared_ptr <std::vector<std::string>> data;
// 如果data[i]不合法,抛出异常
void check(size_type i, const std::string &msg)const;
}
// 构造函数
StrBlob::StrBlob():data(make_shared<vector<string>>()){}
StrBlob::StrBlob(initializer_list<string> il): data(make_shared<vector<string>>(il)){}
void StrBlob::check(size_type i, const string &msg) const
{
if(i >= data->size())
throw out_of_range(msg);
}
string& StrBlob::front()
{
check(0, "front on empty StrBlob");
return data->front();
}
string& StrBlob::back()
{
check(0, "back on empty StrBlob");
return data->back();
}
void StrBlob::pop_back()
{
check(0, "pop back on empty StrBlob");
data->pop_back();
}
StrBlob类只有一个数据成员,它是shared_ptr类型,因此当我们拷贝、赋值或者销毁一个StrBlob对象时,它的shared_ptr成员会被拷贝,赋值或销毁。而拷贝shared_ptr会增加其引用计数,=赋值会递增=右侧shared_ptr的引用计数,递减=左侧shared_ptr的引用计数。如果一个shared_ptr的引用计数变为0,它所指向的对象会自动销毁,因此对于StrBlob构造函数分配的vector,当最后一个指向它的StrBlob对象被销毁时,它会随之被销毁。
使用new和delete直接管理内存
由内置指针(new返回的指针)管理动态内存在被显式释放前(delete)都会一直存在,返回指向动态内存的指针(而不是智能指针)的函数给函数调用者增加了一个额外负担――调用者必须记得释放内存,然而调用者经常忘记释放对象:
Foo* factory(T arg)
{
// 视情况处理arg
return new Foo(arg); //调用者负责释放此内存
}
void use_factory(T arg)
{
Foo *p = factory(arg);
// 使用了p,但不delete它
}// p离开了它的作用域,但它所指向的内存没有被释放!!!
在本例中p是指向factory分配的内存的唯一指针,一旦use_factory返回,程序就没有办法释放这块内存了,根据程序的逻辑,修正这个错误的正确方法是在use_factory中记得释放内存:
void use_factory(T arg)
{
Foo *p = factory(arg);
// 使用p
delete p; //现在记得释放内存,我们已经不需要它了
}
注意:使用new和delete管理动态存在3个常见问题
- 忘记delete内存。忘记释放动态内存会导致人们常说的“内存泄露”问题。因为这种内存永远不可能归还给自由空间了。查找内存泄露的错误是非常困难的。因为通常应用程序运行很长时间,真正耗尽内存时,才能检测到这种错误。
- 使用已经释放掉的对象。通过在释放内存后将指针置为空,有时可以检测出这种错误。
- 同一块内存释放两次,当有两个指针指向相同的动态分配对象时,可能发生这种错误。如果对其中一个指针进行了delete将内存归还给自由空间,随后又delete了第二个指针,自由空间就可能被破坏。
在delete后,指针变成了空悬状态,未初始化指针的所有缺点,空悬指针都有。有一种方法可以避免空悬指针的问题:
在指针即将要离开其作用域之前释放掉它所关联的内存,这样在指针关联的内存释放之后就没有机会继续使用该指针了。如果我们需要保留指针,可以在delete后将nullptr赋予指针,这样就清楚地指出指针不指向任务对象。
但这只是提供了有限的保存
动态内存的一个基本问题是可能有多个指针指向相同的内存,在delete内存之后重置指针的方法只对这个指针有效,对其他任何指向(已释放)内存的指针是没有作用的。
int *p(new int(42));
auto q = p;
delete p; // p和q均变为了空悬指针
p = nullptr; // p被重置为空指针,但重置对q无效,q任然是空悬指针!
shared_ptr和new结合使用
我们可以用new返回的指针来初始化智能指针
shared_ptr<double> p1; // shared_ptr可以指向一个double
shared_ptr<int> p2(new int(42)); // p2指向一个值为42的int
接受指针参数的智能指针构造函数是explicit的,必须使用直接初始化形式(构造函数是explicit的)来初始化一个智能指针
shared_ptr<int> p1 = new int(1024); // 错误:必须直接初始化形式
shared_ptr<int> p2(new int(1024));
p1的初始化隐式地要求编译器用一个new返回的int *来创建shared_ptr,由于我们不能进行内置指针到智能指针的隐式转换,因此这条初始化语句是错误的,出于相同 的原因,一个返回shared_ptr的函数,不能在其返回语句中隐式转换一个普通指针:
shared_ptr<int> clone(int p){
return new int(p); // 错误普通指针无法隐式转为shared_ptr
}
shared_ptr<int> clone(int p){
return shared_ptr<int>(new int(p)); // 正确,直接显示绑定普通指针给shared_ptr
}
定义和改变shared_ptr的其他方法
- share_ptr< T > p(q):p管理内置指针q所指向的对象,q必须指向new分配的内存且能够转为T类型
- share_ptr< T > p(u):p从unique_ptr那里接管了对象所有权,将u置为空
- share_ptr< T > p(q, d):p接管了内置指针q的所有权,q必须能转为T类型,p将使用可调用对象d来代替delete
- share_ptr< T > p(p2, d):p是shared_ptr p2的拷贝,唯一的区别是p将用可调用对象d来代替delete
- p.reset():若p是唯一指向对象的shared_ptr,reset会释放此对象,若传递了可选参数内置指针q,会令p指向q,否则会将p置空,若还传递了参数d,将会调用d而不是delete来释放q。
- p.reset(q)
- p.reset(q, d)
不要混合使用普通指针和智能指针
shared_ptr可以协调对象的析构,但这仅限于其自身的拷贝,也就是shared_ptr之间,这也是为什么我们推荐使用make_shared而不是new的原因。这样我们就能在分配对象的同时就讲shared_ptr与之绑定,从而避免了无意中将同一块内存绑定到多个独立创建的shared_ptr上。
考虑下面的对shared_ptr操作的函数:
// 在函数被调用时ptr被创建并初始化
void process(shared_ptr<int> ptr)
{
// 使用ptr
} // 离开作用域,被撤销
process是值传递,因此实参会拷贝到ptr中,因此在process函数体中,引用计数值至少为2,当process结束,ptr引用计数会递减,但不会变为0,因此局部变量ptr被销毁时,ptr指向的内存不会被释放。
shared_ptr<int> p (new int(42)); // 引用计数为1
process(p); // 拷贝p增加它的引用计数,在process中引用计数为2
int i = *p // 正确:引用计数为1,可以解引用
虽然不能传递给process一个内置指针,但可以传递给他一个临时的shared_ptr,这个shared_ptr是用一个内置指针显示构造的:
int *x(new int (1024)); // 危险,x是一个普通指针,不是智能指针
process(x); //错误,不能将普通指针转为shared_ptr
process(shared_ptr<int>(x)); // 合法的,但内存会被释放
int j = *x; // 未定义的,x的引用此时变为了0,是空悬指针
在上边的调用中,我们将一个临时的shared_ptr传递给process,当调用所在的表达式结束时,这个临时对象就被销毁了,所指内存被释放。
智能指针类型定义了一个名为get的函数,它返回一个内置指针,指向智能指针管理的对象。此函数是为了这样一种情况设计:
我们需要向不能使用智能指针的代码传递一个内置指针,使用get返回的指针的代码不能delete此指针!
下边这个例子中,p和q指向相同的内存,由于它们是独立创建的,因此各自的引用计数都是1,当q所在的程序块结束,q被销毁,导致内存被delete,从而p也变成了空悬指针。所以后边再试图使用p时,将发生未定义的行为。
shard_ptr<int> p(new int(42));
int *q = p.get();
{
shared_ptr<int>(q);
}// 程序块结束,q被销毁,它指向的内存被释放
int foo = *p; //未定义:p指向的内存已经被释放了。
其他的shared_ptr操作
p.reset(new int(1024)); //重置p,并执行新的int
if(!p.unique())
p.reset(new string(*p)); //如果p不是唯一用户,分配新的拷贝
*p += newVal; //现在我们知道自己是唯一用户,可以改变对象的值,避免影响其他指针。