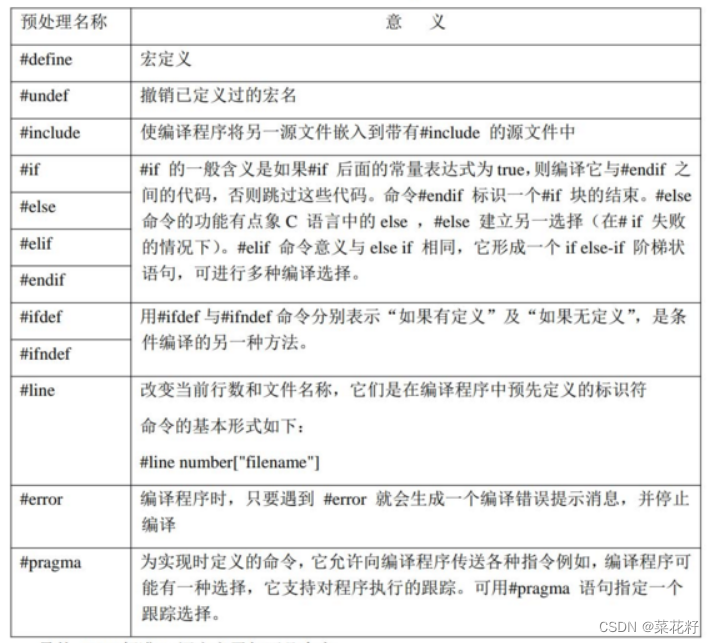
预处理

一.总体概述
预处理本质是将我们的代码进行预先处理。主要分为四个步骤:1.去注释; 2.宏替换; 3.条件编译; 4.头文件展开(以下主要说明去注释和宏替换部分,条件编译在第三点,文件展开在第四点)
1.注释去除
去掉注释的本质其实是将我们注释的内容全部变为了空格,在我们的gcc下可以很明确的看到(因为VS是不能看到预处理阶段的)
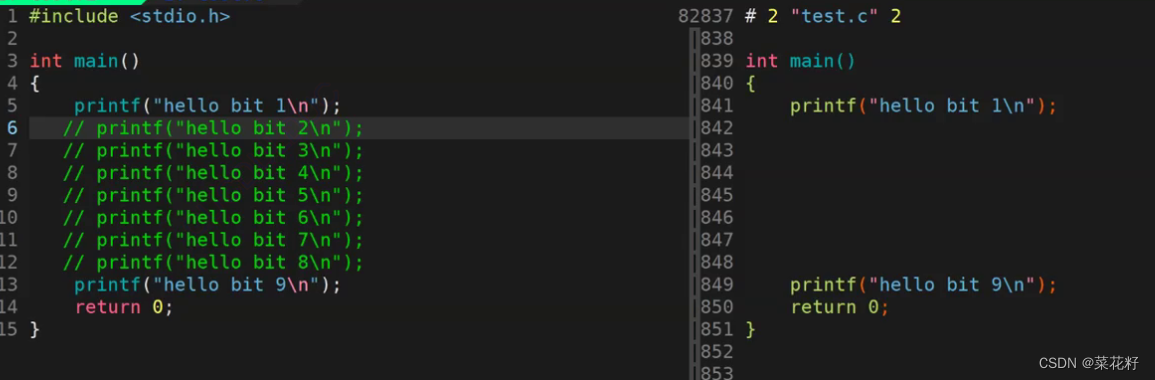
这里就不再多说啦,如果有其他想法可以在gcc里自己看一看哟
2.宏替换
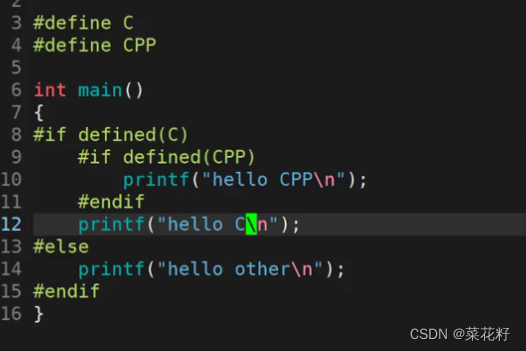
举个例子
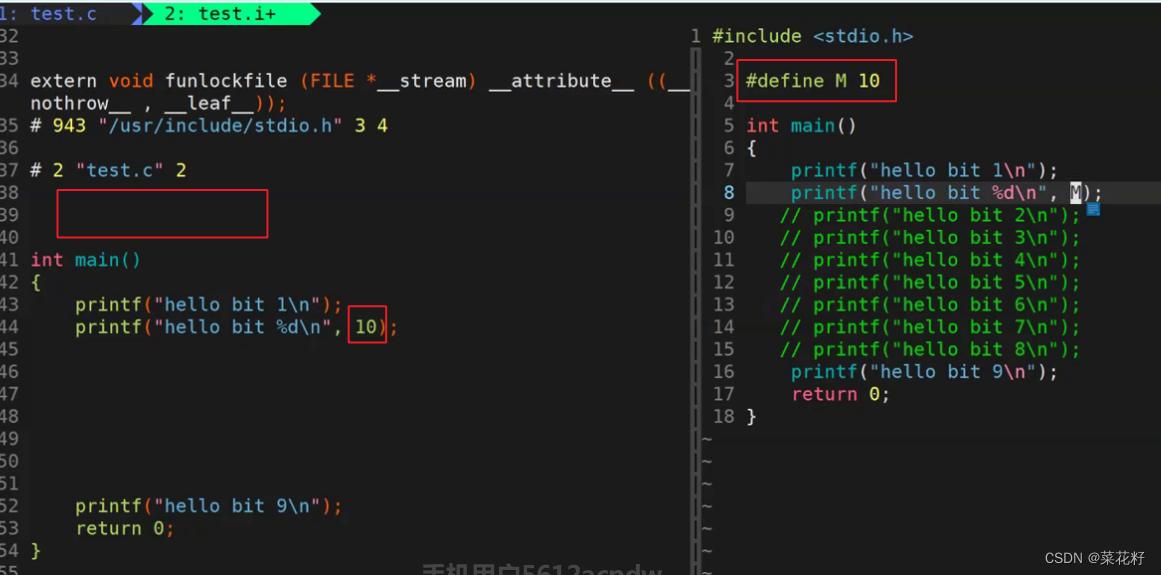
可以看到预处理过后我们所定义的M已经不见了,相反在打印阶段里的M被替换成了10,这就是所谓的宏替换
二.宏定义(宏替换类型)
1.数值宏常量
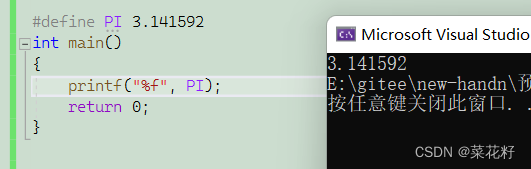
这个概念很简单,无非就是把一些数用一个常量接收罢了。那我们为什么要这样“麻烦”一下呢?
原因当然是为了方便我们“偷懒啦”,首先3.141592这么长的数字写起来当然没有PI这两个字符方便;其次,有可能在你的程序里会出现多个3.141592,而当某一天你想修改这个值时需要把它们挨个挨个的修改,很麻烦(也叫做可维护性差),如果用宏的话,直接修改一个值就可以了。这也是在大型文件里所必须做的事
2.字符串宏常量
如果我用定义数字宏常量的方法去定义一个字符串宏常量,行不行呢?
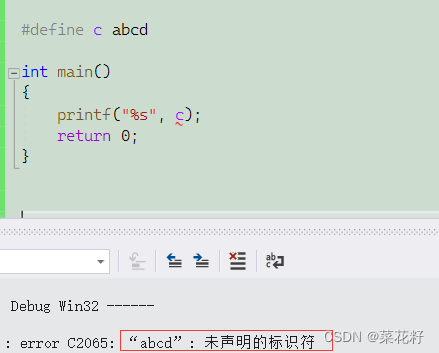
很显然是不行的,知识因为字符串本身是必须带上双引号的(如果不太了解可以看看这篇博客双引号和单引号),所以在定义宏时也必须带上双引号
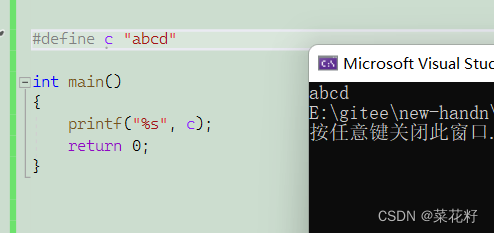
这里如果字符串太长可以使用 \ 进行续航(如果对这个符号不太熟悉的话可以看看这篇博客反斜杠)
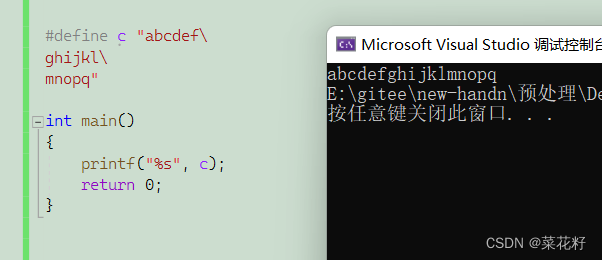
3.用宏定义注释符号
上文我们说到,预处理会进行去注释和宏替换,那么这就有个好玩的东西,如果我们用宏定义注释符号,那么它是会先被去除还是先被替换呢?
我们使用gcc来观察一下(因为VS不能够观察到预处理)
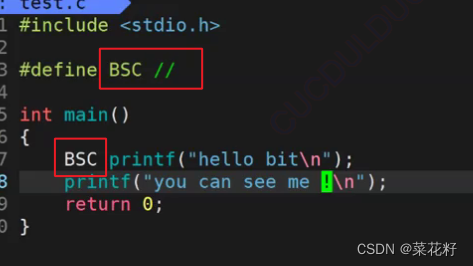
如果我们的宏替换先于去注释,那么BSC就会被替换为双斜杠并且hello bit也就不能看到。反之就都能看到
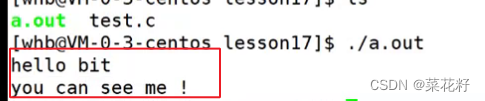
都能打印出来,看起来是我们的第二种情况,那么我们接下来看看深入看看它的预处理情况
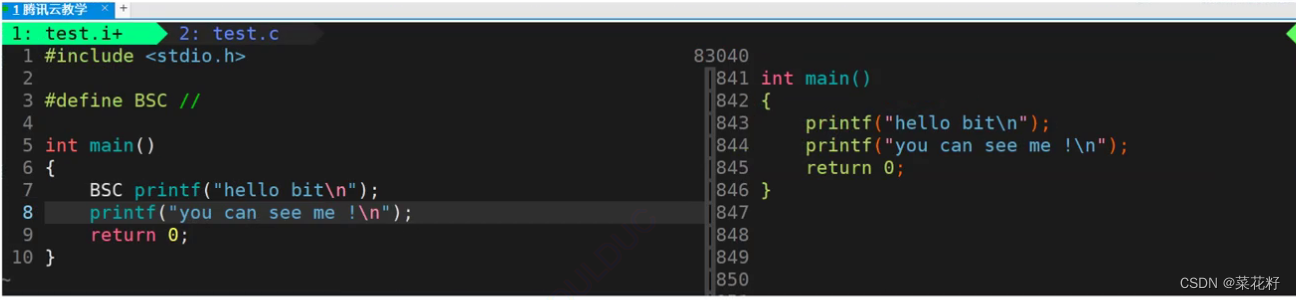
从这里,我们更直观的看出,编译器确实是先将//看为了注释,然后直接去掉,那么整个宏就变为了#define BSC,这时右边没有替换值也就是空,所以它在打印时实际并没有起作用
结论:预处理阶段先去注释,后进行宏替换
上面我们用的是c++风格的注释,那么我们换成c风格的注释,结果会不会不同呢?
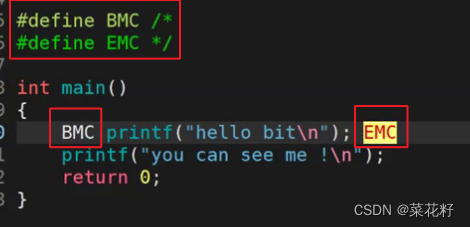
预处理之后
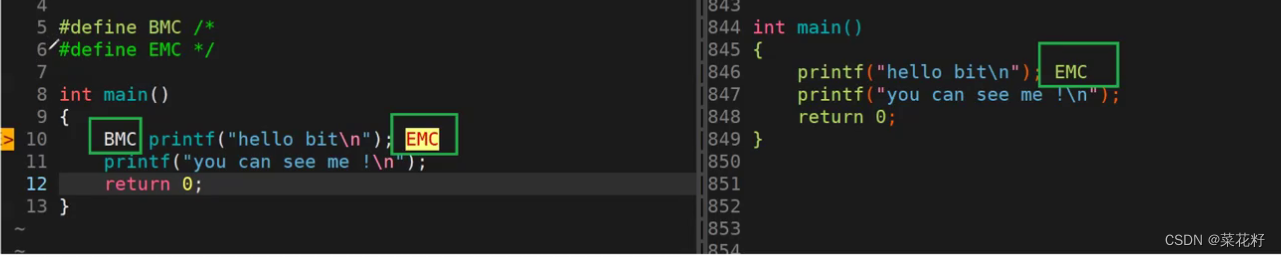
这里我们发现了根c++风格注释不同的 点,它预处理后还剩下一个EMC,这为什么没有宏替换完全呢?这是因为#define EMC被注释掉啦,BMC变成了空所以没有显示,但EMC编译器并不认为它是一个空的宏定义,而是一个未进行声明和初始化的变量。当然这个程序是不能编译的

结论:无论是哪种风格的注释,都是先去注释再进行宏替换
4.用宏定义表达式(难点)
1.第一种情况
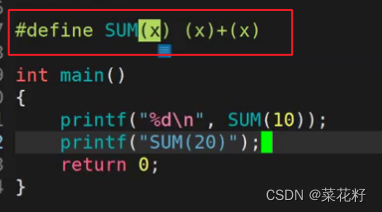
这里可以看出这里的宏跟我们之前写的宏不一样,之前的宏都是一个数直接替换很简单。而这种宏是带参的,而参数在预处理时是等价的,这里的10就等价于x。并且后面的表达式会替换前面的x。

第一个式子确实如我们所想的那样,10替换了x,x+x替换了前面的x,最终就输出10+10的结果。但第二个为什么没有被替换呢?这是因为在c语言中,双引号括起来的是严格意义上的字符串,故编译器直接将双引号里面的内容认为是字符啦,所以并未发生替换(如果不太理解双引号可以看看这篇博客 双引号 )
我们也可以来看看它预处理后的结果
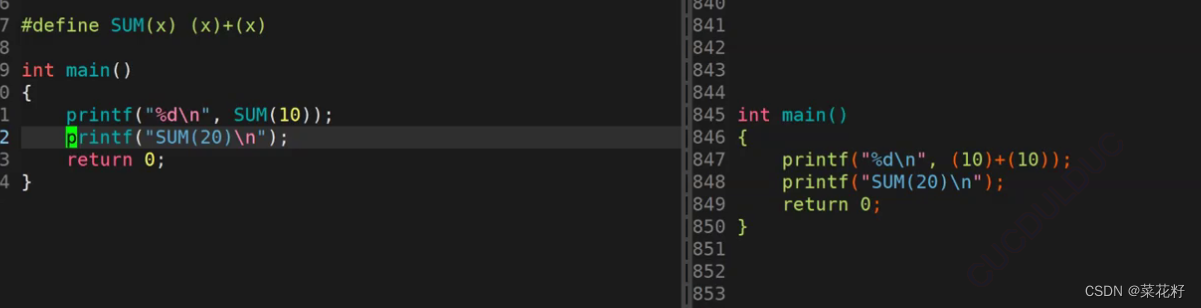
以上是不是就很直观了呢
2.第二种情况
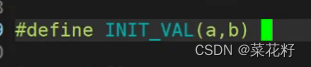
这里我对a和b两个变量进行初始化,初始化很简单在后面直接加就可以了

这里为了美观,我使用了反斜杠进行续航(如果不太了解这个作用,可以看看这篇博客反斜杠)
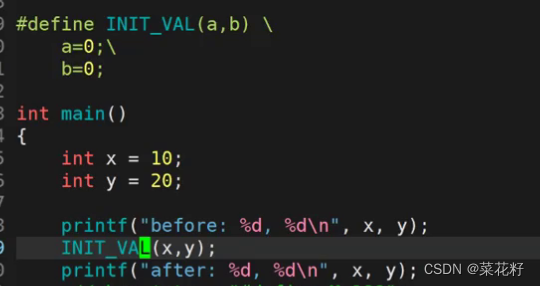
之后我想修改x和y的值,将它们变成0。根据我们上文的经验,#define(a,b)中的a和b首先应该被替换为x和y,然后后面的表达式替换前面的,也就是0会替换x和y。理论上应该是这样的,那究竟行不行呢?

根据我们的结果,x和y确实都被改为0了,接下来我们继续看看它的预处理结果
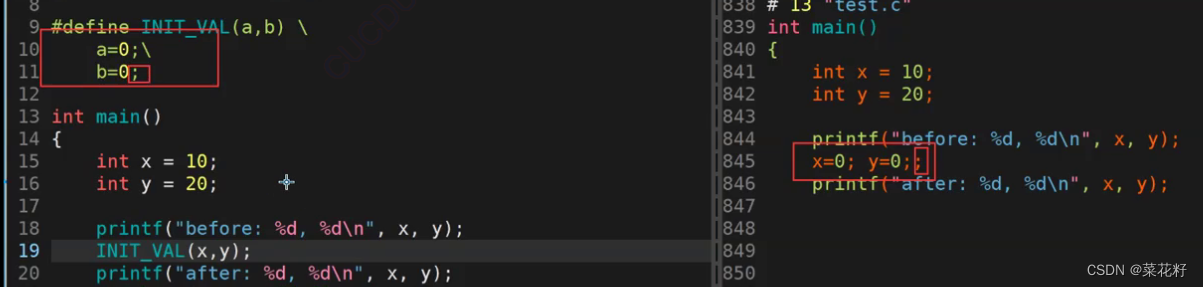
根据预处理结果看出,它确实进行了宏替换,并且修改了x和y的值。这也符合我们的预期,接下来深入理解一下这样的代码会出现什么问题
有什么问题
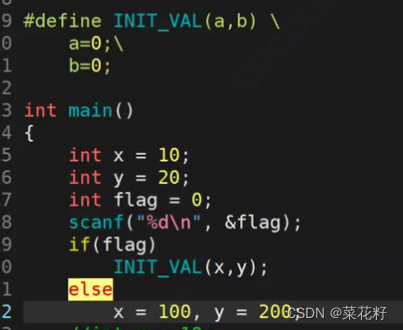

我们来看看它的预处理后的结果
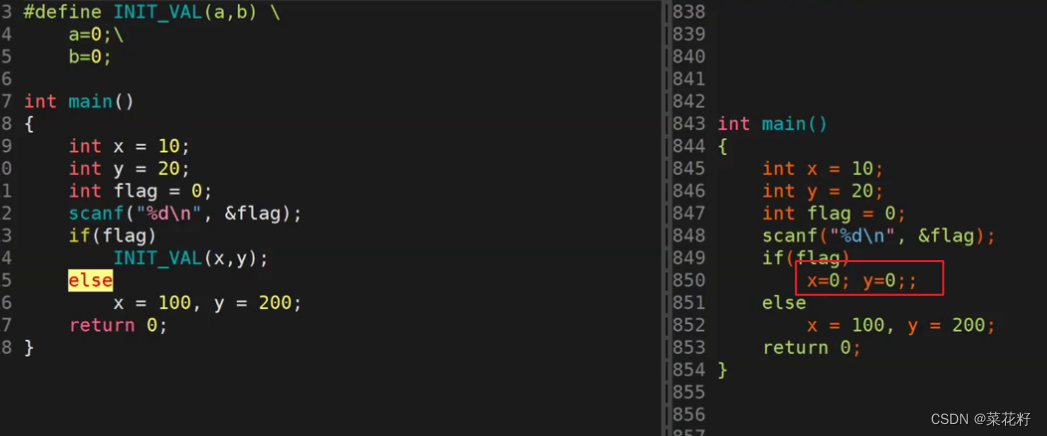
我们可以看到,首先x和y确实是被替换了(是被完全替换连分号也会被替换)。我们知道if如果不加花括号的话只能处理一条语句,也就是一个分号。而else又需要紧跟if,但是我们的if中间多出来了一个y=0;;这样的语句。相当于是if(flag){x=0;} y=0;;else{x=100,y=100;}。这样写不符合我们的语法规定,自然就报错了
结论:用宏来充当多条语句的时候,在一些较为复杂的场景中可能并不能达到我们想要的结果
怎样修改
我们是不是带上花括号就可以了呢
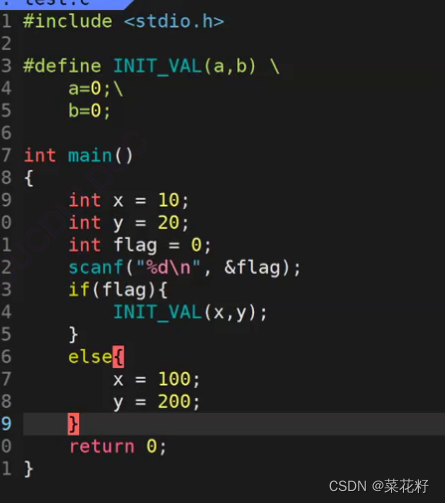
以下是预处理后的结果
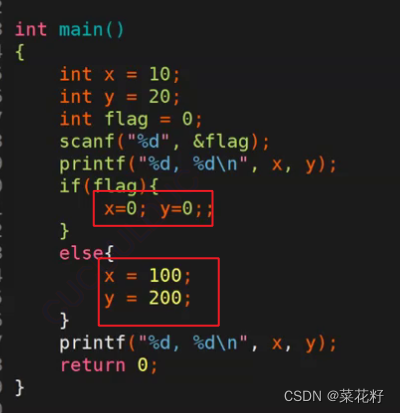
上述的带话括号确实是一种解决方案,但是不够好。因为这是在给程序员提要求,要他遵守好的代码规范,但如果这个程序员不遵守呢?所以这种方案是不具备普适性的
接下来我们进行一个尝试,不是缺花括号吗,我们直接在宏定义时就加上花括号行不行呢?
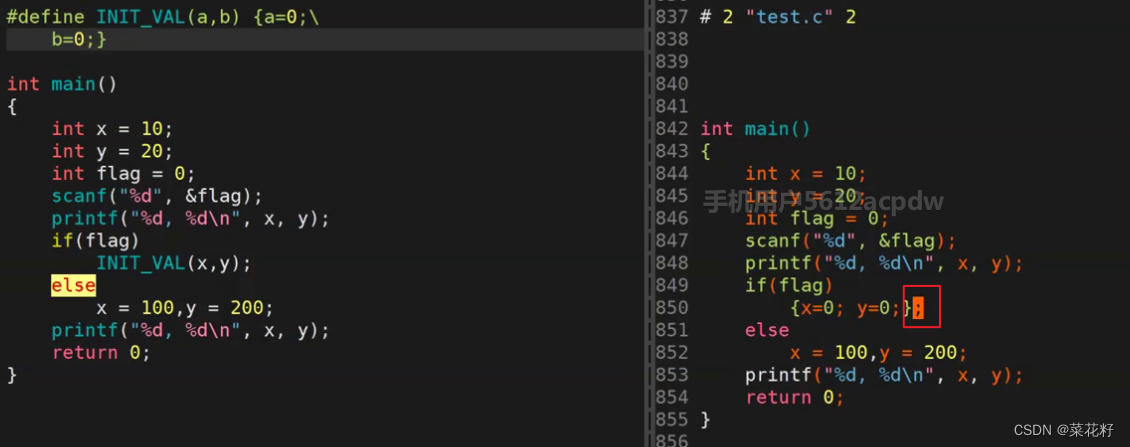
这样做其实存在两个问题,一是程序员可能自己会写花括号,导致花括号重复。二是程序员自己在写完一条语句后会带上分号,导致花括号后带分号。这样写是不行的
以下是最终解决方案,为了方便看我们先将续航符去掉
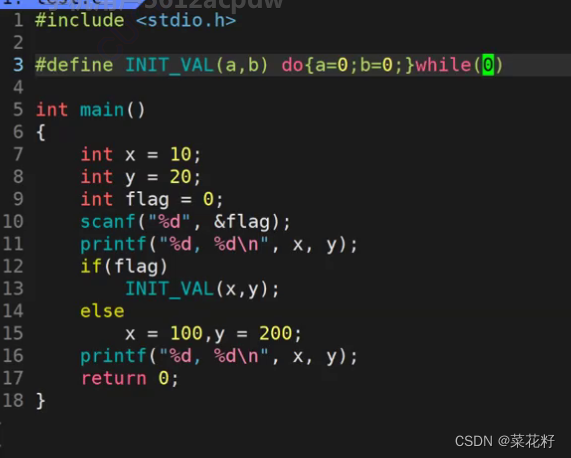
这是预处理后的结果
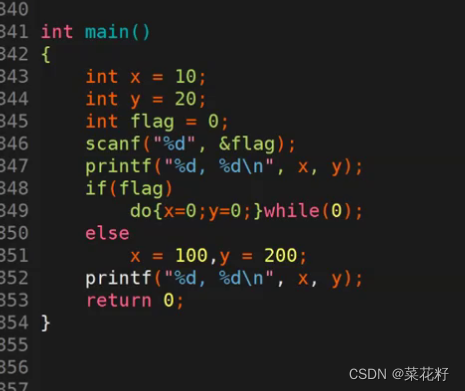
这其实就在我们上一个方案中做了改进,修改了上面存在的两个问题。1.do…while是一条语句,所以在外面带不带上花括号都没有影响,这解决了花括号重复问题。2.多余的分号会自动到while(0)后面,这也解决了分号问题
同理,这里再加上我们的续航符,也没有任何影响,并且如果你的宏里有多条语句,也建议如下写
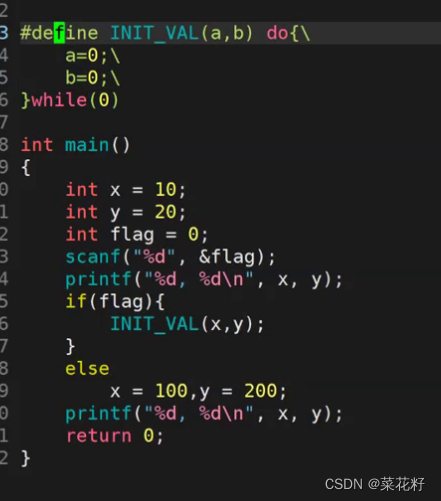
为什么do里可以容纳多条语句呢?因为它带有花括号。为什么while(0)呢?因为我们并不需要它循环,我们需要的只是这种语法结构。
这种结构被称为do―while―zero结构
5.#undef(宏的有效范围)
1.两个问题
#undef是用来撤销宏定义的,具体是如何做到的呢?
在说明这个问题前先来讨论两个问题。1.宏只能在main上面定义吗? 2.在一个源文件里,宏的有效范围是多少?
下面是第一个问题的探索
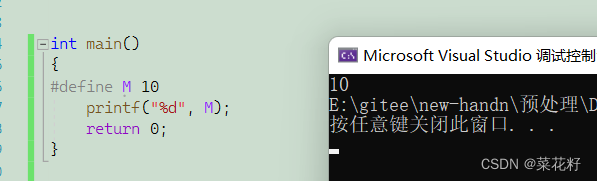
上面的宏是在main函数内定义的并且我们发现它是可以正常使用的
接下来我们进行更多的尝试,如果定义在其他函数里,另一个函数能不能调用它呢
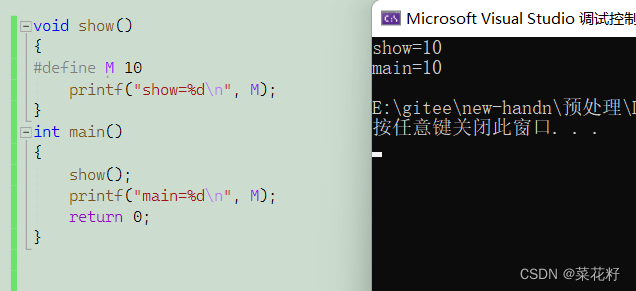
得出结论:宏可以在任何地方定义,与在函数体内还是函数体外都没有任何关系
下面是第二个问题的探索
我们像下面的方式书写能编过吗?

答案是不行的,为什么呢?接下来为了更直观的观看,我使用gcc来演示
下面是gcc预处理后的结果
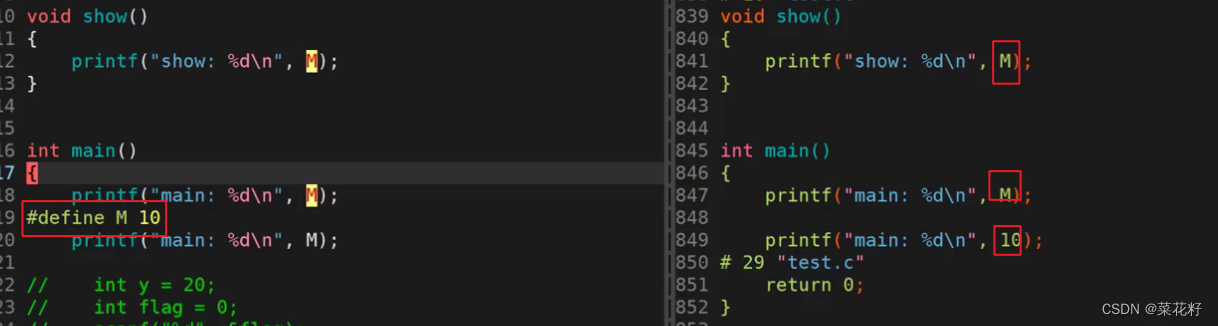
可以很明显的看到,在宏定义上面的M并没有被替换掉,而在下面的M则被替换了。
得出结论:宏从定义处向下都是有效的,与函数调用无关(因为宏替换在函数调用之前),只是简单的文本替换
2.#undef的使用
上文说到#undef就是用来取消宏定义的,那是如何取消的呢?直接看预处理结果
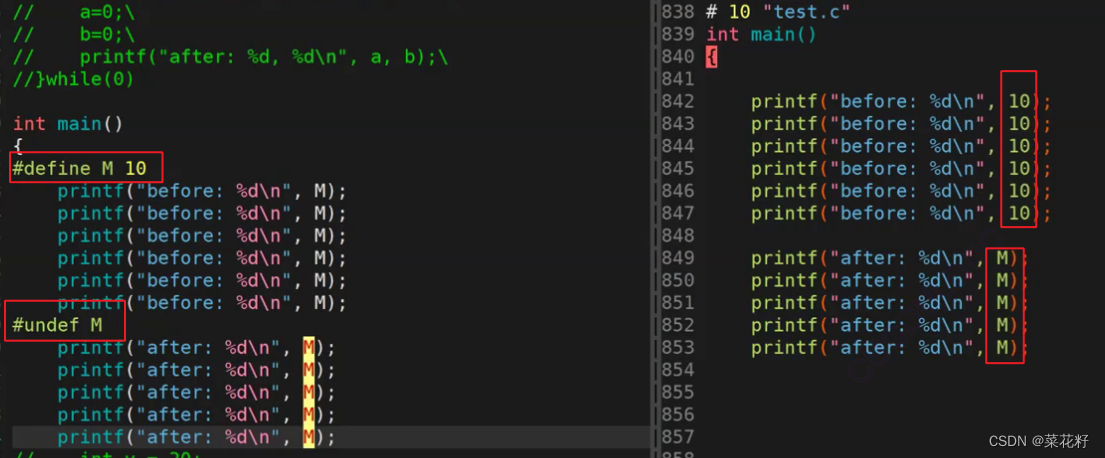
我们可以看到在#undef的上面部分,M是被替换掉了而下面则没有。
结论:#undef又可以称为限制宏,在宏定义的下面,#undef的上面才是宏的有效范围
3.一段代码的理解

以上这段代码最终打印的结果是什么呢?
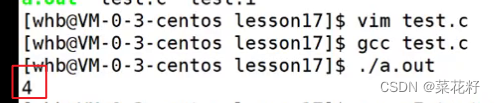
废话不多说,直接转到预处理结果

这是因为第一个宏#define x 3的有效范围只有#define Y x*2这一行,而当代码向下走到Int z=Y时,#define x 3早已失效,故当Y进行宏替换时所看到的宏其实是#define x 2,所以就不难理解最后的答案是4啦
三.条件编译
必须明确的是,1.条件编译是预处理的一个步骤。2.条件编译更多的是为了进行代码裁剪。
1.#ifdef和#ifndef的用法
通常用于检测一个宏是否被定义(主要与宏为真为假区分开来)。这两个通常与#else,#endif一起用(看起来跟if,else类似)
#ifdef是表肯定。如果宏被定义,则该代码保留
#ifndef表示否定。如果没有被定义,则该代码保留
举个例子
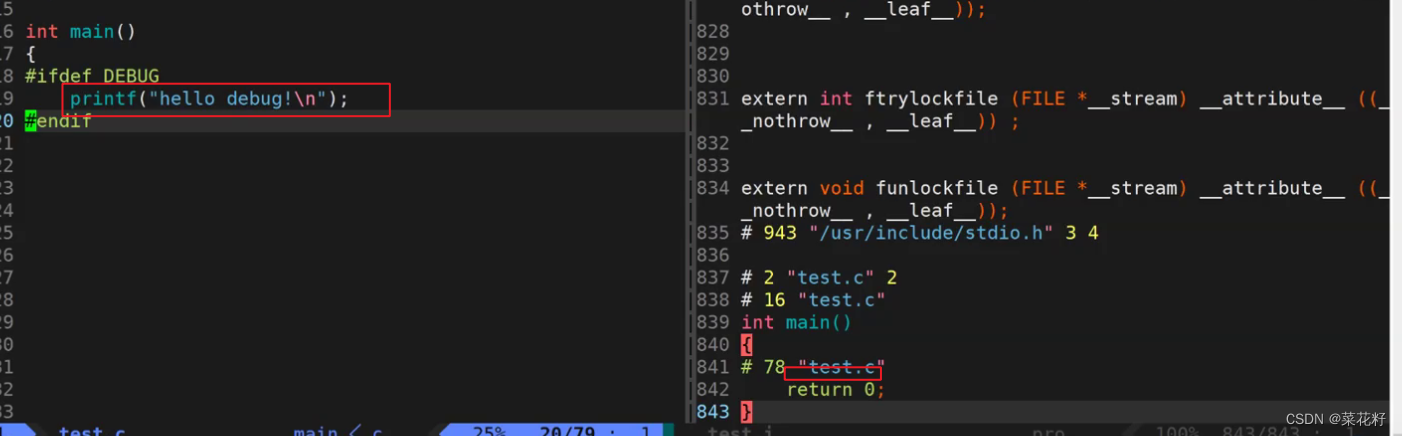
补充一下#endif是结束标志,表示该条件结束。我们可以看到printf这条语句被裁掉了。这是因为我们的宏DEBUG并没有被定义。如果像保留的话需要定义一下
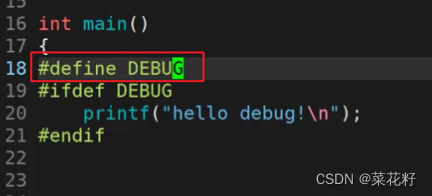
#define就是定义,这里定义成多少不重要(我这里就没有初识化),重要的是只要定义了,该代码就能被保留

接下来加上一起用
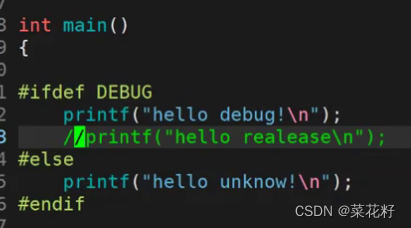
这里的意思是,如果定义了DEBUG,就打印出hello debug;否则就打印出hello unkown(注意不能加#elif,这个是用于判断真假的)
具体的结果就不再演示了,大家有兴趣的话可以自己打印一下(#ifndef的用法与#ifndef相同)
2.#if的用法
#if是用来判断我们的宏的真假(与#ifdef区分开来),如果为真就保留该代码,否则就裁剪(这里的用法其实与if从句类似)
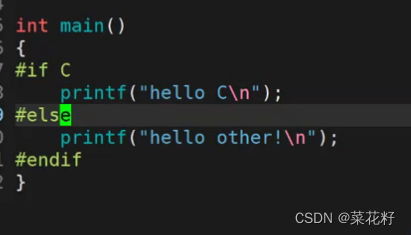
这里我没有定义c,那么c就被默认认为是假了

接下来我们来定义一下,如果定义为0
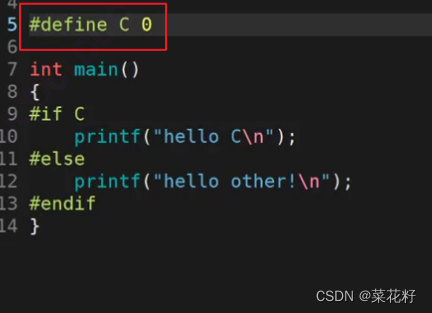

如果定义为1
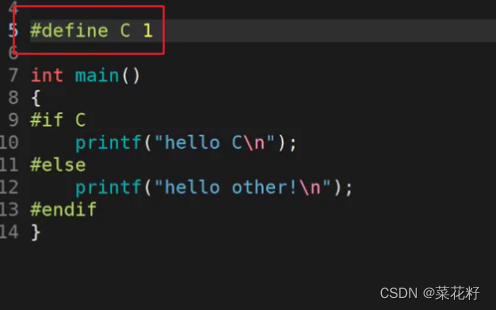

如果我们只定义不初始化呢?
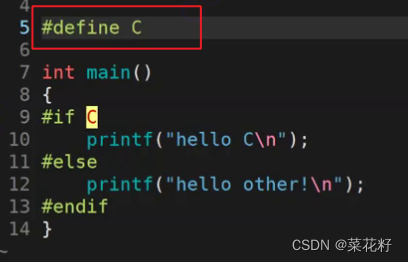
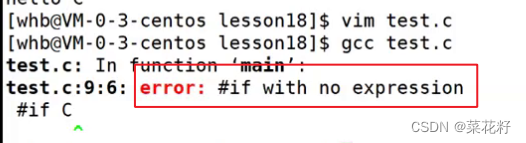
这里就直接报错了,这是因为c被替换后什么也没有,所以编译器会报错说#if后没有表达式
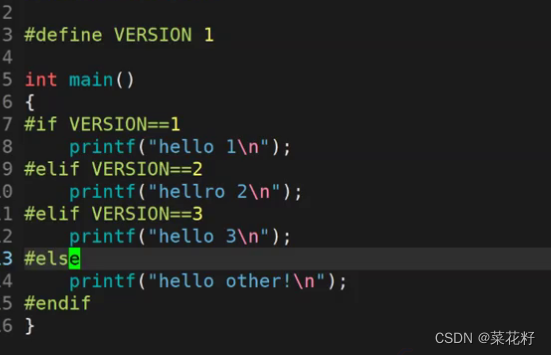
多条件判断
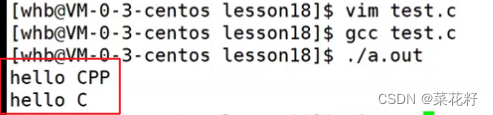
除此之外我们也可以加上#elif,用于多条件判断,具体用法就跟if,else if,类似。
上述的所有代码均可在VS里实现并且没有差别。
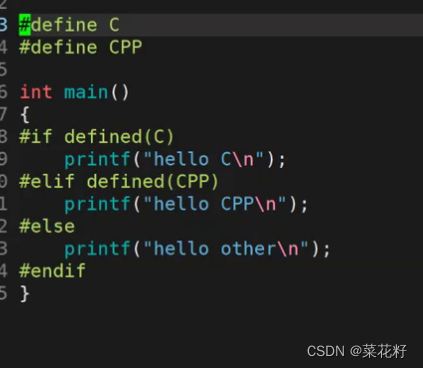
3.如何用#if来取代#ifdef
其实只需要在#if后面加上defined(),括号里就是要判断的元素。
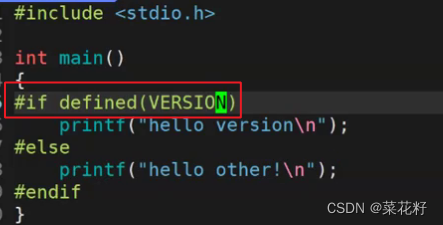
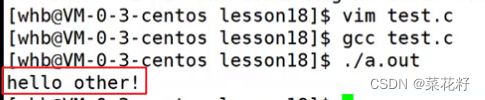
因为我们的VERSION并未被定义,所以输出的就是hello other。其实仔细观察,#ifdef就是#if defined()的缩写。如果想模拟实现#ifndef呢?
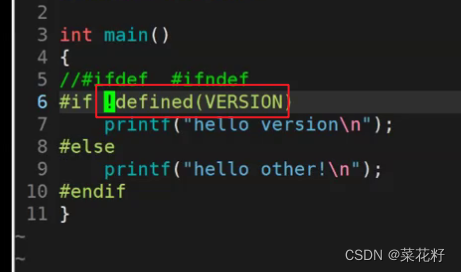
直接带个感叹号,取反就可以啦。
结论
1.#ifdef等价于#if defined()
2.#ifndef等价于#if !defined()
3.不管是哪一种写法必须以#endif 结尾
4 .裁剪的意义
对于程序员来说,我们如果不需要某行代码,直接删除或者注释掉就可以了,为什么需要这些语句呢?
本质上就是通过代码裁剪,快速实现某种目的(版本维护,功能裁剪,跨平台性)
举个例子
现在很多软件都分为免费版和收费版。毫无疑问,收费版的功能更多,开发商做这两个版本的时候难道用的是两份不同的代码吗?当然不是,这样的话维护成本太高了,如果一个版本出现了问题我们不仅需要改这个bug还需要相应修改另一个版本的bug。所以其实他们使用的就是代码裁剪,如果不需要哪个功能,直接剪掉就可以了。并且这样只需要维护一份代码,成本较低。
5.深入理解奇怪的情况
第一种:同时检测两个定义
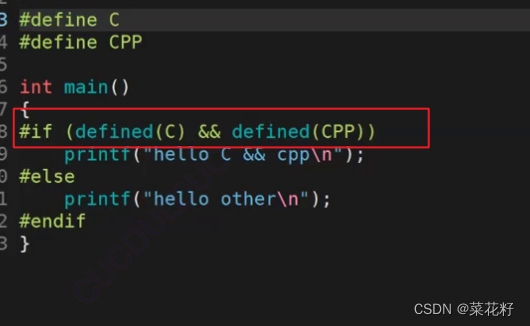

与平常我们所使用的语句相同,直接用&&就可以啦。同时这里推荐最外面加上圆括号,这样会更加规范
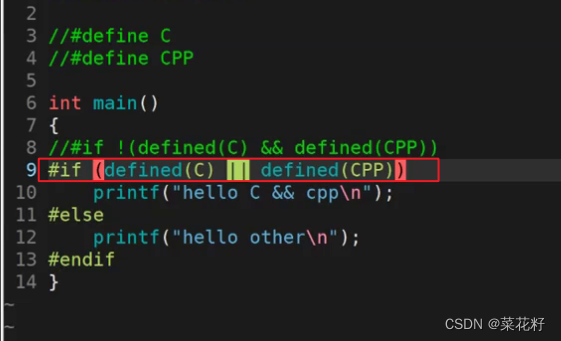
同理既然可以判断“和”,那也可以判断“或”

嵌套情况
这个与我们的if从句里的嵌套类似,我们可以类似的看为下面的代码

当然上面的代码并不够准确,只是为了方便我们理解。
多条件检测宏定义

这种情况也是符号if …else…语句的顺序的。也就是如果#if条件成立就不会判断#elif里的内容
四.头文件展开
在gcc里创建了两个文件,一个是test.h,用于包含所有头文件;一个是test.c,用于我们代码的实现
1.一种现象
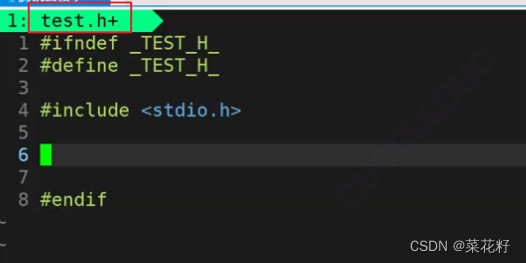
这里的意思是如果没有定义TEST_H_,那么就定义TEST_H_。为什么我们经常在头文件项目里看到这样写呢?
这是为了防止头文件被重复包含。那么是如何做到的呢?
第一次包含时,我们的TEST_H_没有被定义,那么它下面的就会被保留。
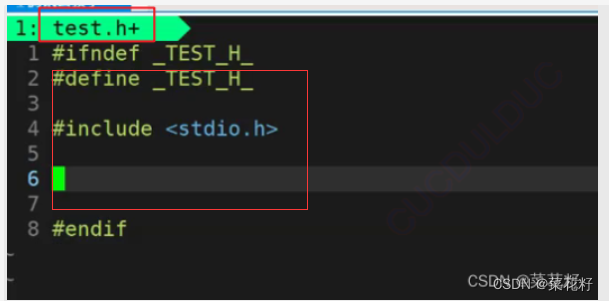
当我们第二次,第三次想要包含该文件时,由于_TEST_H_已经被定义,那么它之下的就不会被保留,从而做到避免被重复包含。
2.什么叫做头文件展开
其实每次在进行预处理结果查看时会出现很多我并没有写并且不认识的函数(上文我们所看的预处理结果都在最下面),我们直接只写了六行代码,但展开后却有八百多行代码。这是为什么呢?
我们仔细观察,其实它的第11行就是我们所写的头文件stdio.h
它之后的代码可以简单理解成收stdio.h自己所包含的内容。
结论:头文件展开就是把头文件内容拷贝到目标源文件(当然这种拷贝是进行过优化的)
一个小问题:重复包含一定是错误的吗?
并不是的。甚至可以不算一种错误。因为头文件里的很多内容并不是定义,而是声明,声明是可以重复进行的。但也可能引起一些定义类的错误,但特别特别少。重复包含主要会引起重复拷贝,影响运行效率
四.一些好玩的预处理符号
1.预处理符号
以下内容简单了解一下,所以我还是回到熟悉的VS
#error
作用是只要遇到#error,就会生成一个编译错误提示信息并停止编译
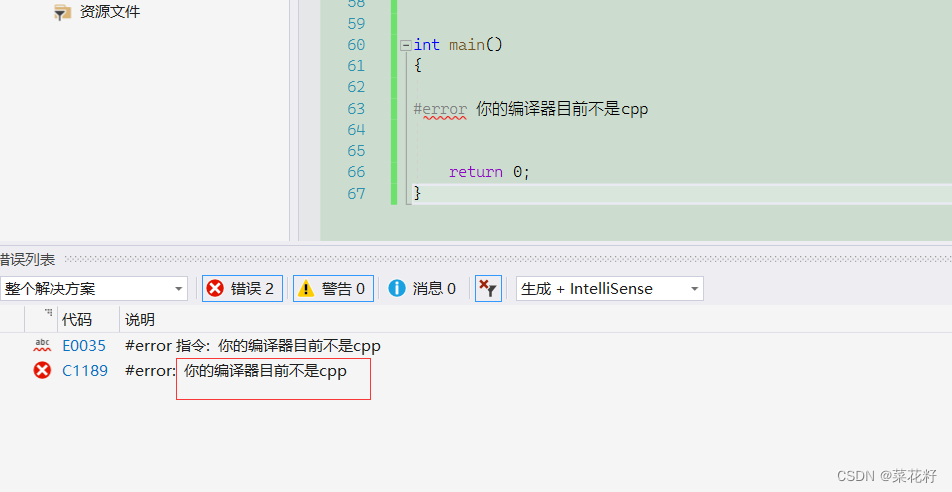
这就相当于你自定义了一个错误。
#line
作用是改变当前行数和文件名称

可以看到前面打印的就是我的文件名,后面打印的就是行号。那么#line的作用是什么呢?

可以看到的是,就是强制改变了我的文件名和行数
#pragma
作用是用来对代码中特定的符号进行是否存在编译时消息提醒
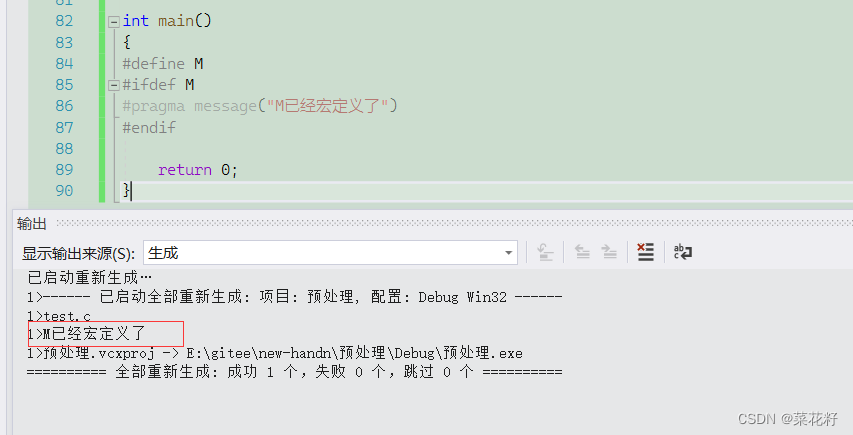
主要用途就是来检测某些宏是否存在。补充一点#pragma message是让编译器编译时在输出窗口输出相应的信息
2.#运算符

我们可以看到这三种打印都能通过。在c语言中一对双引号看着一个字符串,但如果两对双引号连在一起编译器也会认为这是一个字符串。
这种特性被叫做:相邻字符串具有连接特性
一个例子
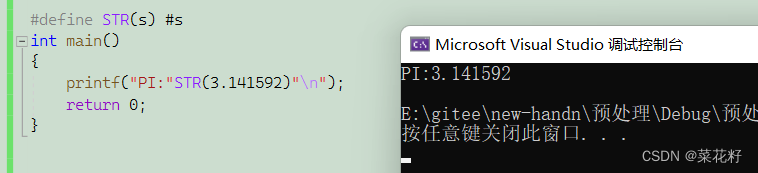
结论是:在宏中直接使用单井号是将参数符号s对应的文本内容转义成字符串
其实就是拿3.1415926这个值来充当s,那么s就被替换为#3.1415926。而在c语言中,碰到单井号就会被解释为字符串。也就是3.1415926不再是数字了,而是一个字符串
为了更直观,再次使用gcc
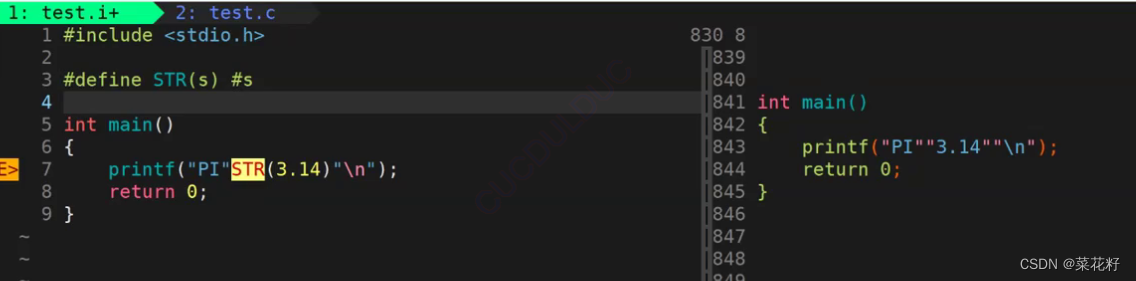
之后再根据字符串的连接性,打印出来就是一个字符串啦
一个应用
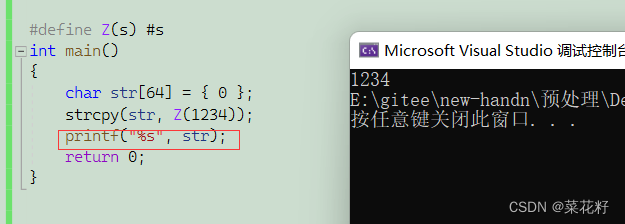
我想要把1234这一串数字转换为字符串,以前的话我们是需要写算法的,但现在只需要使用#就可以了
3.##预算符
和#一样,##也可以运用在宏替换部分。这个运算符将两个语言符号组合成单个语言符号(俗称粘合剂)
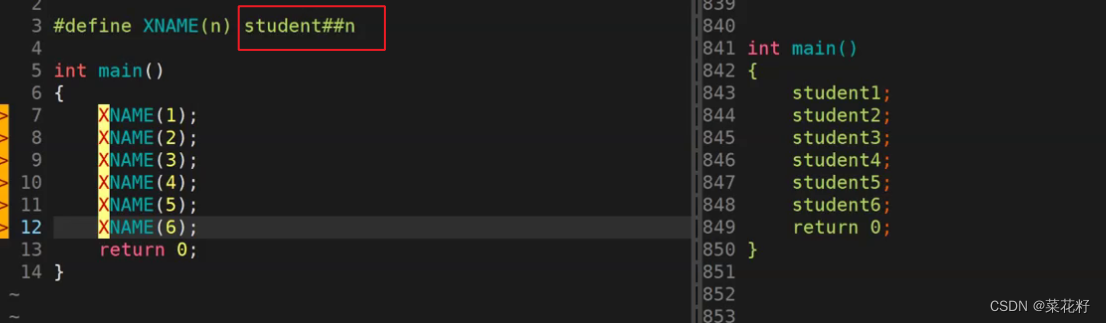
这里的student是一个符号,n是一个符号。而student##n就又是另一种新的符号啦。通过预处理结果我们可以直观的看到student和n被连接到一起了。后面n的值发生改变,所以student依次和1,2,3…连接,输出了我们所看到的结果
需要格外注意的是:这里的student1…之类的既不是整数也不是字符串,它是一个符号于int,char类似
例子
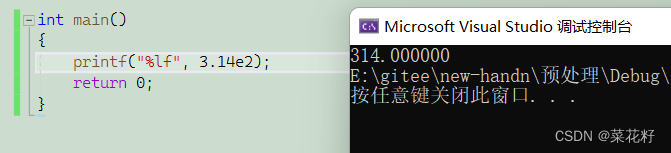
这里的e2就是科学计数法,如果我们模拟实现这它呢?当然我们可以使用pow函数,但是我们今天也可以使用我们的粘合剂
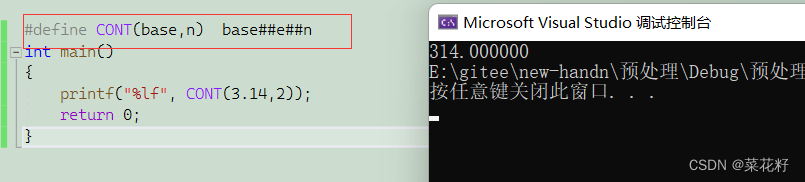
由于后面的是粘在一起的,所以我们可以直接看为(base)(e)(n),如果我们令base=3.14,n=2那其实就相当于3.14e2。当然,我们也可以看看它的预处理结果

