使用C语言编写程序对C语言程序进行语法和词法分析。
注注注注注:Dev需先配置C++11的环境,lex.h与语法分析程序同一目录下
目录
1.程序要求
1.1词法分析
已知待分析的C语言子集的词法:
1. 关键字: main ?if ?else ?int ?while ?char 均为小写。
2.专用符号: = + - * / < <= > >= ?== ?!= ? ; , { ?} ?( ?)
3、其他标记ID和NUM通过以下正则式定义: ID: letter(letter|digit)* NUM: digitdigit* letter→a|b|c|d…|z|A|B|C…|Z digit →0|1|2|3|4|5|6|7|8|9
4、空格由空白、制表符、换行符组成,用来分隔ID、NUM、专用符号与关键字,词法分析阶段常被忽略。
要求:?设计、编制并调试一个词法分析程序
输入:源程序文件
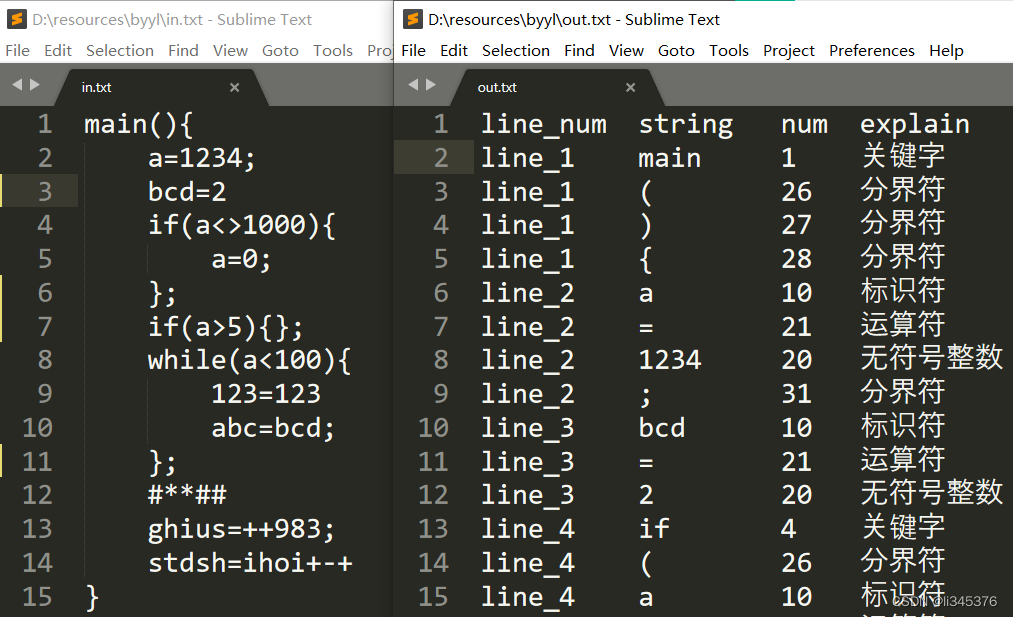
输出:二元组(syn,token或sum)构成的序列(文件),其中:syn为单词种别码,token为存放的单词自身字符串,sum为整型常量。
1.2语法分析
在上机(一)词法分析的基础上,采用递归子程序法或其他适合的语法分析方法,实现其语法分析程序。要求编译后能检查出语法错误。
2.原理图
2.1词法

2.2种别码表
| 单词符号 | 种别码 | 单词符号 | 种别码 | 单词符号 | 种别码 |
| main | 1 | + | 22 | ; | 31 |
| ?int | 2 | - | 23 | > | 32 |
| ?char | 3 | * | 24 | < | 33 |
| if | 4 | / | 25 | >= | 34 |
| else | 5 | ( | 26 | <= | 35 |
| while | 6 | ) | 27 | == | 36 |
| ID | 10 | { | 28 | != | 37 |
| NUM | 20 | } | 29 | ||
| = | 21 | , | 30 |
2.3语法

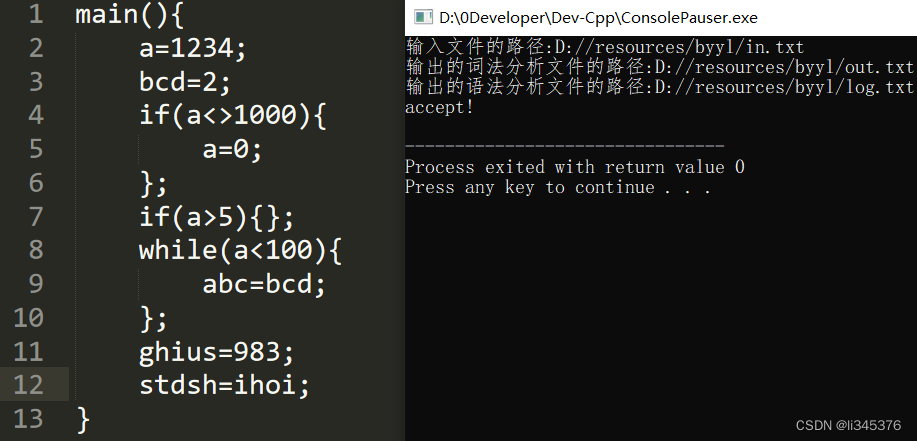
?3.运行截图
3.1词法分析
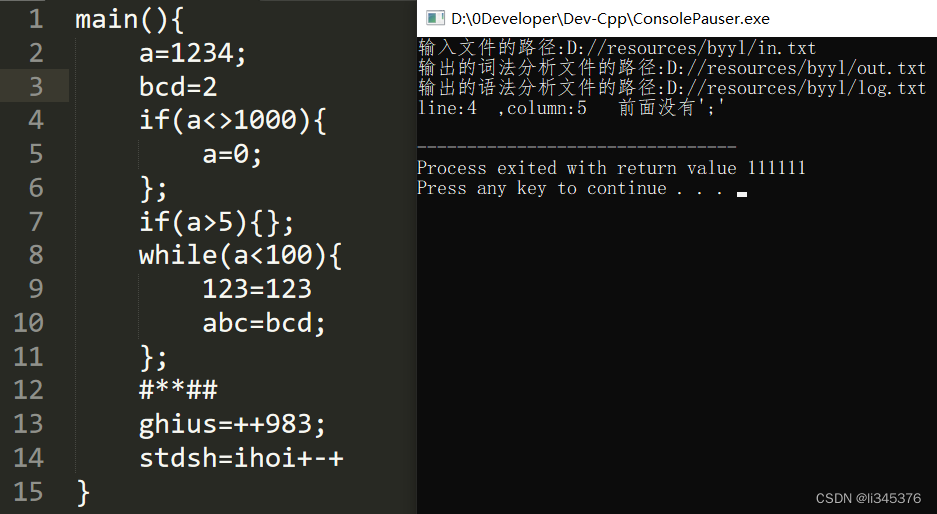
3.2语法分析
?
?
?
?
4.源码
4.1词法分析(lex.h)
#ifndef LEX_H
#define LEX_H
#include"lex.h"
#define E 65535
#define EOI -1
#include<iostream>
#include<cstdio>
#include<cstring>
#include<string>
#include<cctype>
#include<vector>
#include<map>
using namespace std;
int line;
int column,cc;
typedef struct CI{
int line;
int column;
int type;
}Ci;
map<string,int> mp{{"ID",10},{"INT",20},{"<",33},{"<=",35},{"<>",36},{"!=",37},
{">",32},{">=",34},{"=",21},{"+",22},{"-",23},
{"*",24},{"/",25},{"(",26},{")",27},{"{",28},
{"}",29},{",",30},{";",31},{"[",32},{"]",33},
{"int",2},{"char",3},{"float",7},{"main",1},{"switch",12},
{"double",8},{"case",10},{"for",9},{"if",4},{"auto",9},
{"else",5},{"do",11},{"while",6},{"void",13},{"static",14},
{"return",15},{"break",16},{"struct",17},{"const",18},
{"union",19},{"typedef",20},{"enum",21}};
int lookup(string TOKEN){
if(mp.find(TOKEN)==mp.end())return -1;
else return mp[TOKEN];
}
void out(FILE* fout,string str,int id,string explain,vector<Ci> &v){
fprintf(fout,"line_%-5d%-9s%-5d%-9s\n",(line+1),str.c_str(),id,explain.c_str());
v.push_back({line+1,column,id});
}
void print_error(FILE* fout,char ch,vector<Ci> &v){
fprintf(fout,"line_%-5d%-9c%-5c%-9s\n",(line+1),ch,'E',"异常字符");
v.push_back({line+1,column,E});
}
vector<Ci> analysis(FILE* fin,FILE* fout){
char ch;
int i,c;
string TOKEN;
vector<Ci> v;
column=1;
fprintf(fout,"%-10s%-9s%-5s%-9s\n","line_num","string","num","explain");
while((ch=fgetc(fin))!=EOF){
if(ch==' '){
column++;
continue;
}
if(ch=='\t'){
column+=4;
continue;
}
if(ch=='\n'){
line++;
column=1;
continue;
}
if(isalpha(ch)){//标识符或关键字
cc=column;
TOKEN=string(1,ch);
ch=fgetc(fin);
cc++;
while(isalnum(ch)){
cc++;
TOKEN+=ch;
ch=fgetc(fin);
}
fseek(fin,-1,1);//回退
c=lookup(TOKEN);
if(c==-1)out(fout,TOKEN,mp["ID"],"标识符",v);//是标识符(1)
else out(fout,TOKEN,c,"关键字",v);//是关键字
column=cc;
}else if(isdigit(ch)){
cc=column;
TOKEN=string(1,ch);
ch=fgetc(fin);
cc++;
while(isdigit(ch)){
cc++;
TOKEN+=ch;
ch=fgetc(fin);
}
fseek(fin,-1,1);//回退
out(fout,TOKEN,mp["INT"],"无符号整数",v);
column=cc;
}else{
switch(ch){
//运算符
case '<':{
ch=fgetc(fin);
cc=column+2;
if(ch=='=')out(fout,"<=",mp["<="],"运算符",v);
else if(ch=='>')out(fout,"<>",mp["<>"],"运算符",v);
else{
cc--;
fseek(fin,-1,1);//回退
out(fout,"<",mp["<"],"运算符",v);
}
column=cc;
break;
}
case '>':{
ch=fgetc(fin);
cc=column+2;
if(ch=='=')out(fout,">=",mp[">="],"运算符",v);
else{
cc--;
fseek(fin,-1,1);//回退
out(fout,">",mp[">"],"运算符",v);
}
column=cc;
break;
}
case '=':out(fout,string(1,ch),mp["="],"运算符",v);column++;break;
case '+':out(fout,string(1,ch),mp["+"],"运算符",v);column++;break;
case '-':out(fout,string(1,ch),mp["-"],"运算符",v);column++;break;
case '*':out(fout,string(1,ch),mp["*"],"运算符",v);column++;break;
case '/':out(fout,string(1,ch),mp["/"],"运算符",v);column++;break;
//分界符
case '(':out(fout,string(1,ch),mp["("],"分界符",v);column++;break;
case ')':out(fout,string(1,ch),mp[")"],"分界符",v);column++;break;
case '[':out(fout,string(1,ch),mp["["],"分界符",v);column++;break;
case ']':out(fout,string(1,ch),mp["]"],"分界符",v);column++;break;
case '{':out(fout,string(1,ch),mp["{"],"分界符",v);column++;break;
case '}':out(fout,string(1,ch),mp["}"],"分界符",v);column++;break;
case ',':out(fout,string(1,ch),mp[","],"分界符",v);column++;break;
case ';':out(fout,string(1,ch),mp[";"],"分界符",v);column++;break;
default:print_error(fout,ch,v);column++;break;
}
}
}
v.push_back({line+1,column,EOI});
return v;
}
#endif4.2语法分析
#include<iostream>
#include"lex.h"
using namespace std;
int index;
FILE *fin,*fout,*flog;
vector<Ci> v;
void advance(){
index++;
}
bool match(string s){
if(index>=v.size())return 0;
if(v[index].type==E){
printf("line:%-3d,column:%-3d 语法错误\n",v[index].line,v[index].column);
advance();
return 0;
}
else return v[index].type==mp[s];
}
bool match(int ch){
if(index>v.size())return 0;
else return v[index].type==ch;
}
void ERROR(string e){
printf("line:%-3d,column:%-3d %s\n",v[index].line,v[index].column,e.c_str());
fprintf(flog,"line:%-3d,column:%-3d %s\n",v[index].line,v[index].column,e.c_str());
fclose(flog);
exit(111111);
}
void expression();
void block();
void cacu_operator(){
if(match("<")||match("<=")||match(">")||match(">=")||match("<>")||match("!=")){
advance();
}else{
ERROR("错误的运算符");
}
}
void condition(){
expression();
cacu_operator();
expression();
}
void Y(){
if(match("ID")||match("INT")){
advance();
}else if(match("(")){
advance();
expression();
if(!match(")"))ERROR("括号不匹配 缺少')'");
else advance();
}else{
ERROR("缺数字或变量");
}
}
void X(){
while(1){
Y();
if(match("*")||match("/")){
advance();
continue;
}else{
break;
}
}
}
void giveValue(){
advance();
if(match("=")){
advance();
expression();
}else{
ERROR("没有'='");
}
}
void check(){
advance();
if(match("(")){
advance();
condition();
if(match(")")){
advance();
block();
}else{
ERROR("无')'");
}
}else{
ERROR("无'('");
}
}
void circulation(){
advance();
if(match("(")){
advance();
condition();
if(match(")")){
advance();
block();
}else{
ERROR("无')'");
}
}else{
ERROR("无'('");
}
}
void expression(){
while(1){
X();
if(match("+")||match("-")){
advance();
continue;
}else{
break;
}
}
}
void sentence(){
if(match("ID")){
giveValue();
}else if(match("if")){
check();
}else if(match("while")){
circulation();
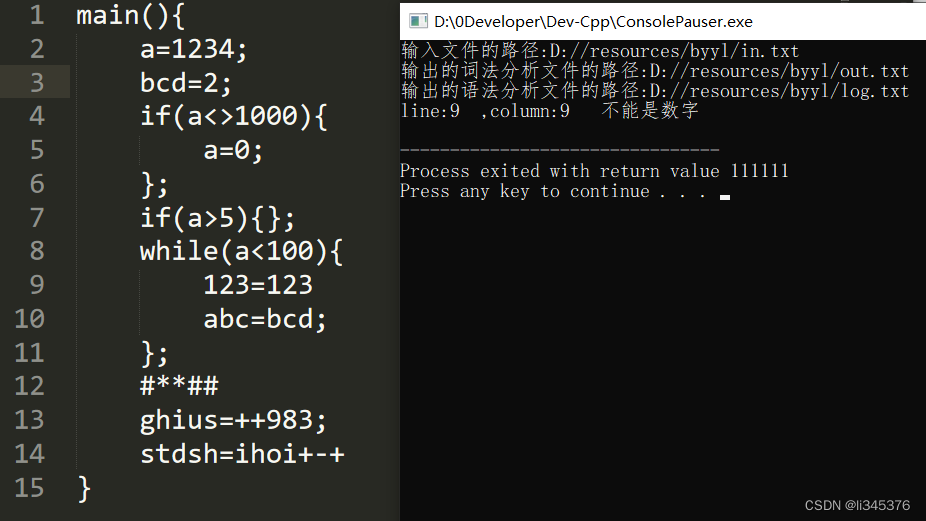
}else if(match("INT")){
ERROR("不能是数字");
}else if(match(E)){
ERROR("语法错误");
advance();
sentence();
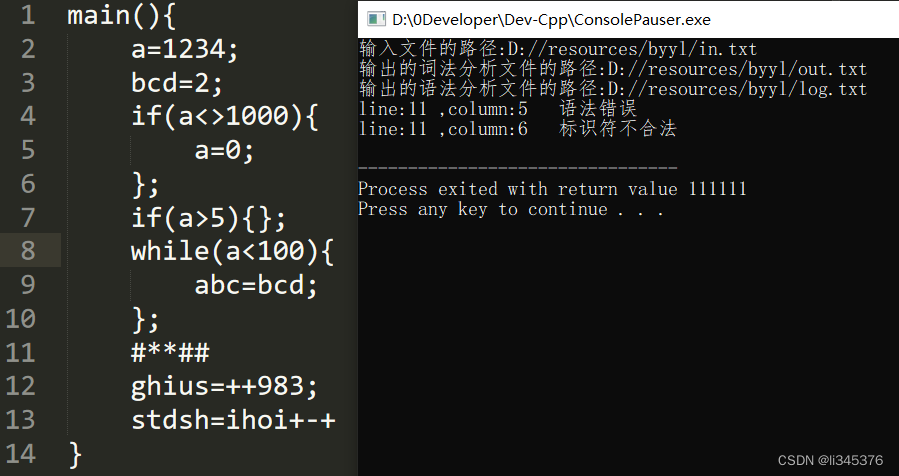
}else{
ERROR("标识符不合法");
}
}
void sentences(){
while(1){
sentence();
if(match(";")){
advance();
if(match("}")){
break;
}
else continue;
}else{
ERROR("前面没有';'");
}
}
}
void block(){
if(match("{")){
advance();
if(match("}")){
advance();
return;
}
sentences();
if(!match("}"))ERROR("无'}'");
else advance();
}else ERROR("无'{'");
}
void process(){
if(match("main")){
advance();
if(match("(")){
advance();
if(match(")")){
advance();
block();
}else ERROR("无')'");
}else ERROR("无'('");
}else ERROR("无 main方法");
}
char finname[64],foutname[64],flogname[64];
int main(){
cout<<"输入文件的路径:";
cin>>finname;
cout<<"输出的词法分析文件的路径:";
cin>>foutname;
cout<<"输出的语法分析文件的路径:";
cin>>flogname;
fin=fopen(finname,"r");
fout=fopen(foutname,"w");
v=analysis(fin,fout);
fclose(fin);
fclose(fout);
flog=fopen(flogname,"w");
process();
fclose(flog);
cout<<"accept!"<<endl;
return 0;
}5.总结
? ? ? ? 语法分析程序不是很完善,可以考虑在排查到错误后继续往后识别。