1.РиТЄµДjar°ь
ПлТЄЅшРРJavaЕАіж,РиТЄ¶оНвµјИлТ»Р©jar°ь,ѕЯМеИзПВ
ХвР©jarїЙТФµЅХвёцНшЦ·ЙПИҐПВФШ:https://mvnrepository.com/
µ±И»,¶БХЯИз№ыІ»ПлµјИлХвР©ДЈїй(ЅцЅцПлКµПЦJavaЕАіж),їЙТФїґїґРЎ±аµДХвЖЄІ©ОД,І©ОДБґЅУОЄ:https://blog.csdn.net/qq_45404396/article/details/116203121
ПВФШПВАґЦ®єу,°СХвР©jar°ь·ЕµЅХвёцОДјюјРПВГж,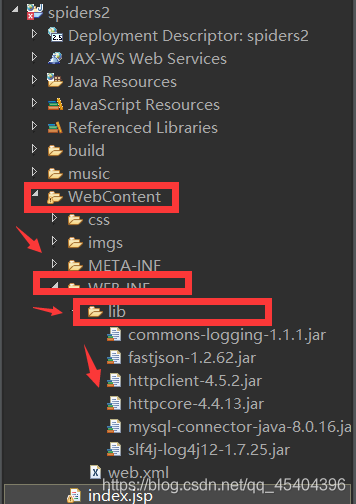
µ±И»,µјИлЦ®З°РиТЄґґЅЁ¶ЇМ¬ПоДї,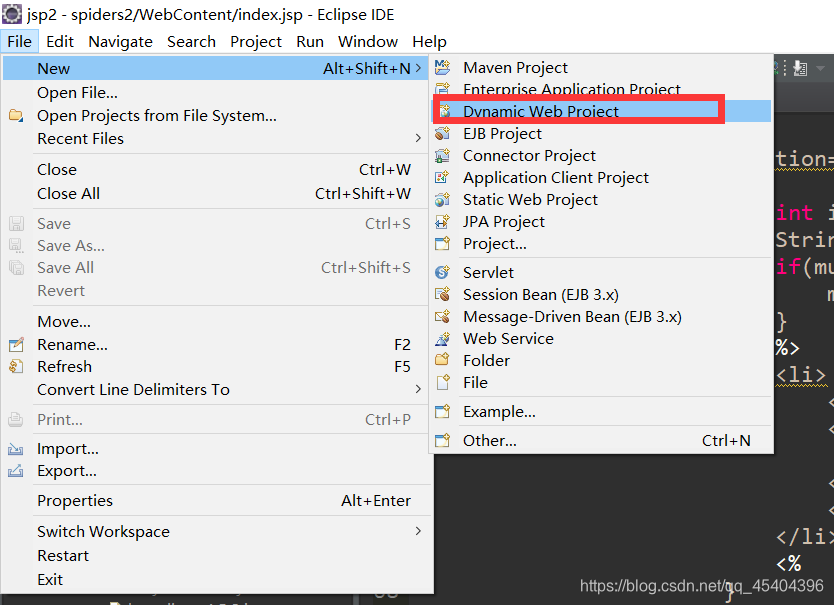
µјИлЦ®єу,РиТЄ№№ЅЁВ·ѕ¶,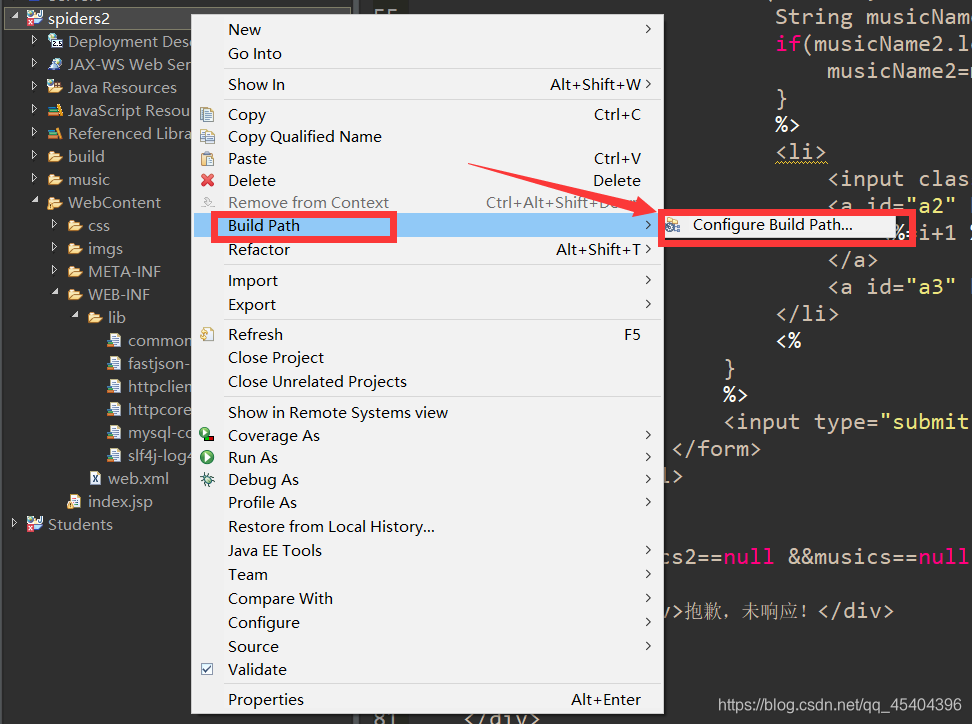
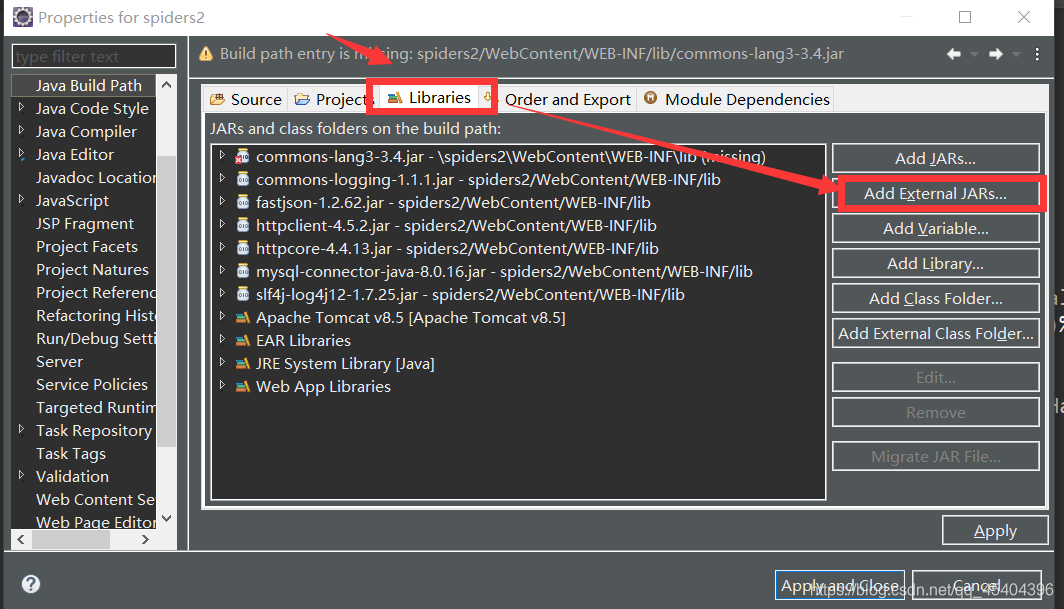
Ц»Ри°СФЪХвёцПоДїОДјюПВµДjar°ьИ«ІїµјИлјґїЙ,ХвСщТ»ёцјтµҐµДJavaЕАіжРиТЄµДjarѕННкіЙБЛЎЈ
2.КµПЦJavaЕАіжµДАа
Хвёц№эіМЧЬµДАґЛµѕНјёѕдґъВл(єЬ¶аµШ·Ѕ¶јКЗґъВлЦШёґ),¶БХЯїЙТФІОїјРЎ±аµДХвЖЄІ©ОД,І©ОДБґЅУОЄ:https://blog.csdn.net/qq_45404396/article/details/116203121,БнНв,ХвАпЅІµЅБЛРиТЄЕАИЎТфАЦ,¶БХЯїЙТФІОїјРЎ±аµДХвЖЄІ©їН,І©їНБґЅУОЄ:https://www.cnblogs.com/liuze-2/p/12409989.html,ЛдИ»ХвКЗУГPythonЕАіжРґµД,µ«КЗКµПЦ№эіМ»№КЗєНJavaЕАіжТ»СщµД№ю!
РЎ±аРиТЄФЪХвАпЗїµчѕНКЗХвАпРиТЄґ¦АнЕАіжµГµЅµДjsonКэѕЭ,
3.КµПЦЦчТЄµДindex.jspОДјю
ХвёцОДјюЦчТЄКµПЦµД№¦ДЬѕНКЗМбЅ»УГ»§КдИлµД№ШјьґК,И»єу·µ»ШТ»ёцЛСЛчµГµЅµДЅб№ы,КµПЦР§№ыИзПВ:

ХвАпРиТЄУГµЅМбЅ»±нµҐ,ѕЯМеИзПВ:

РЎ±аХвАп°СПВФШјЗВј·ЕµЅКэѕЭївАпБЛ,ЛщТФХвАп¶оНвМнјУБЛТ»ёц№¦ДЬ,ѕНКЗіэБЛПВФШТфАЦЦ®Нв,»№їЙТФІйїґЧФјєФшѕµДПВФШјЗВј№ю!µ±И»ПВФШјЗВјТІКЗїЙТФНЁ№эёХІЕДЗёцІЩЧчКµПЦЕъБїЙѕіэєНµҐёцЙѕіэµДЎЈ

ХвёцПВФШјЗВј±ѕЙнКЗТ»ёцa±кЗ©,µг»чТ»ПВ,ТІїЙТФЦ±ЅУАґµЅПВФШЅзГжµД№ю!

Н¬К±РЎ±а»№Ѕ«ёиґКТІПВФШПВАґБЛ,

ХвКЗТ»ёц.mdОДјю,¶БХЯїЙТФПВФШТ»ёцTyporaХвёцИнјю,ѕНїЙТФІйїґБЛЎЈ
ѕЯМеЖдЛыservletОДјюєНjava beanОДјюРЎ°ЧѕНІ»Т»Т»ЧёКцБЛ,Из№ы¶БХЯРиТЄРЎ±аµДХвёцПоДї,їЙТФФЪCSDNЙППВФШ,µ±И»ТІїЙТФАґgiteeЙППВФШ№ю!giteeБґЅУОЄ:https://gitee.com/il_li/Java_web/tree/master/web
АґїґТ»ПВНкХыµДФЛРРЅб№ы°Й!ХвАпµДФЛРРЅб№ы»№Г»УРКµПЦДЗёцПВФШјЗВјµД№¦ДЬ№ю!
JavaЕАіжЅбєПjspКµПЦТфАЦПВФШµДНшЦ·