目录
引入
我们知道,相比移位运算,除法运算的开销比较大。
在 Leetcode 做题的时候,当除数是 2 的 n 次幂时,大家通常会用移位来代替除法运算,并且希望这样能够提升运算效率――这似乎已成为了算法题解中的“标配”。
那么问题来了,使用移位操作代替乘除运算,真的效率更高吗?
对于这个灵魂拷问,本文 分别以 C++ / Java 为例,从汇编层面带你一探究竟。
C++ 编译器对除法的优化
在 Optimizations in C++ Compilers [中文译文在此] 这篇文章中,作者建议不要在代码中用 >> 代替除法运算,原因有两个。一方面,编译器已经帮你做了这个优化,能够帮你正确处理符号;另一方面,我们希望代码的可读性更高。
Integer division by a constant
It may be surprising to learn that―until very recently―about the most expensive thing you could do on a modern CPU is an integer divide. Division is more than 50 times more expensive than addition and more than 10 times more expensive than multiplication. (This was true until Intel’s release of the Cannon Lake microarchitecture, where the maximum latency of a 64-bit divide was reduced from 96 cycles to 18.6 This is only around 20 times slower than an addition, and 5 times more expensive than multiplication.)
Thankfully, compiler authors have some strength reduction tricks up their sleeves when it comes to division by a constant. I’m sure we’ve all realized that division by a power of two can often be replaced by a logical shift right―rest assured the compiler will do this for you. I would advise not writing a >> in your code to do division; let the compiler work it out for you. It’s clearer, and the compiler also knows how to account properly for signed values: integer division truncates toward zero, and shifting down by itself truncates toward negative infinity.
来,举个例子,方便理解。先写一段 C++ 代码用来测试:
// test.cpp
#include <stdio.h>
int main(void){
int a = 64;
int b = a >> 3;
int c = a / 8;
return 0;
}
然后编译成汇编代码:
gcc -S test.cpp
cat test.cpp
由于篇幅原因,我们只截取部分汇编结果,来看一看生成的汇编码是啥样的。
movl $64, -12(%rbp) # a=64
movl -12(%rbp), %eax
sarl $3, %eax # a>>3
movl %eax, -8(%rbp)
movl -12(%rbp), %eax
leal 7(%rax), %edx
testl %eax, %eax
cmovs %edx, %eax
sarl $3, %eax # a/8 优化后等同于 a>>3
movl %eax, -4(%rbp)
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
可以看到,a/8 经过编译器优化后,是等同于 a>>3 的。简而言之,我们可以依靠编译器来很好地优化除法。
况且编译器对于除法的优化不仅限于除数为 2 的 n 次幂的情况,例如对于 x/3 这样的运算,编译器将除法替换为了更廉价的定点乘法逆运算,本文不再详述。
如果感兴趣的话,仍然可以参考 Optimizations in C++ Compilers 这篇文章,里面有详细的讲解。
Java 编译器对除法的优化
尽管上面这个例子只是众多优化中的一点皮毛,但已经能让我们感受到 C++ 编译器的强大之处了。如此看来,在 C++ 编译器的优化下,我们现在很难再通过位移操作来榨取乘除运算的性能了。
然后回到我们文章最开始的灵魂拷问,使用移位操作代替乘除运算,真的效率更高吗??
从上面这个例子来看,并没有。可我不甘心啊――既然有人这么写,就一定是有它的道理的!于是我把希望寄托在 Java 编译器上,希望 javac 没有做过这个优化。
话不多说,直接上例子。我们在两个方法 test1, test2 中分别使用 i >> 3 运算与 i / 8 运算,比较二者的运行时间以及编译生成的字节码。
public class Solution {
public int test1() {
int sum = 0;
for (int i = 0; i < 1000000000; i++) {
sum += i >> 3;
}
return sum;
}
public int test2() {
int sum = 0;
for (int i = 0; i < 1000000000; i++) {
sum += i / 8;
}
return sum;
}
public static void main(String[] args) {
Solution solution = new Solution();
long start, end;
for (int i = 0; i < 10; i++) {
System.out.println("=== loop " + i+" ===");
start = System.currentTimeMillis();
solution.test1();
end = System.currentTimeMillis();
System.out.println(end - start);
start = System.currentTimeMillis();
solution.test2();
end = System.currentTimeMillis();
System.out.println(end - start);
}
}
}
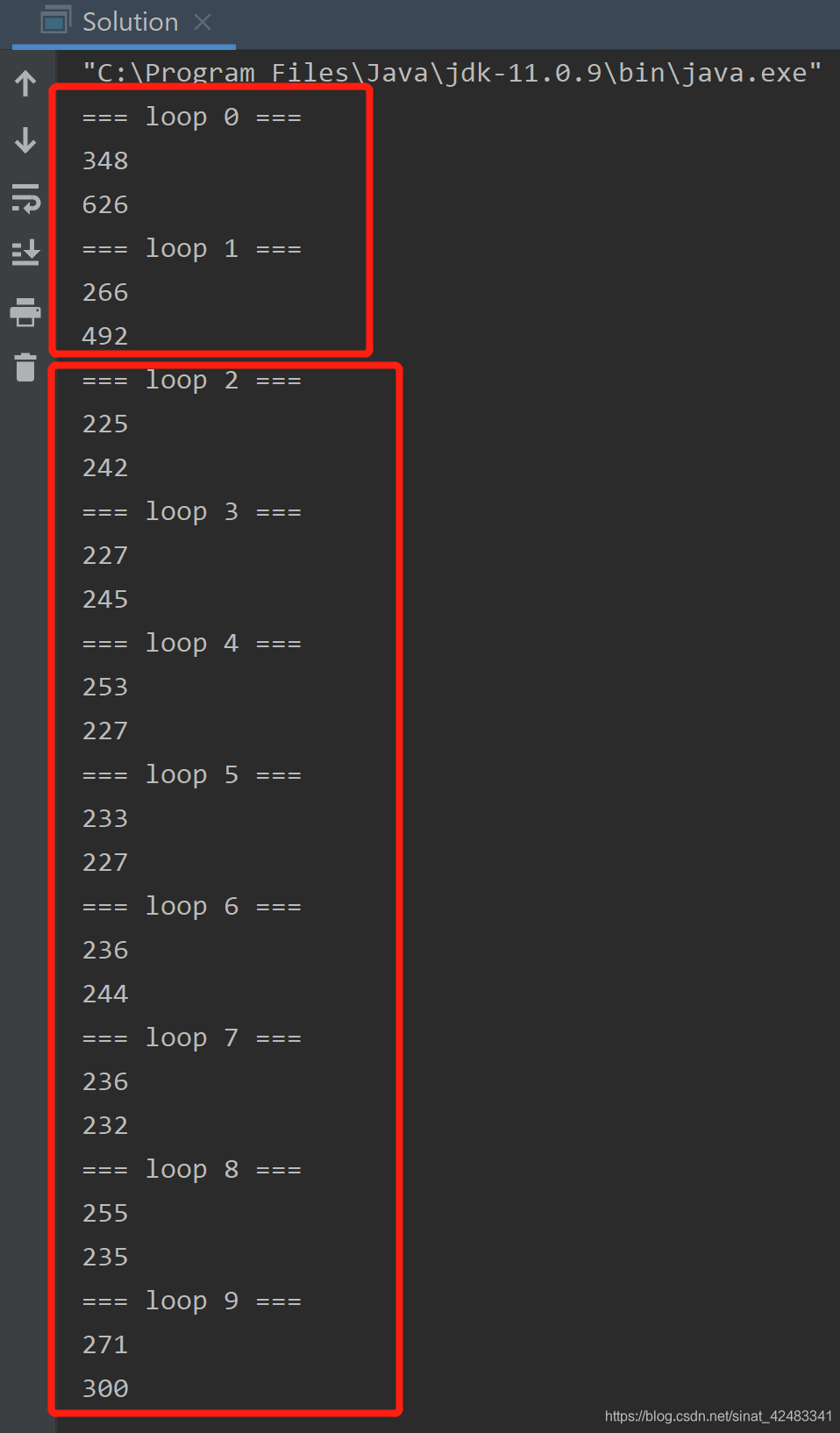
从下面的运行时间上来看,在前两个 loop 中,test1 明显比 test2 效率高,但在后面 8 个 loop 中,两种方法的耗时几乎没有区别。
=== loop 0 ===
348
626
=== loop 1 ===
266
492
=== loop 2 ===
225
242
=== loop 3 ===
227
245
=== loop 4 ===
253
227
=== loop 5 ===
233
227
=== loop 6 ===
236
244
=== loop 7 ===
236
232
=== loop 8 ===
255
235
=== loop 9 ===
271
300
在查看字节码时,我们用到了一个 IDEA 插件叫 Jclasslib。在 Settings -> Plugin 里搜一下即可安装。
然后,我们来见证奇迹,看看经过编译之后生成的字节码。
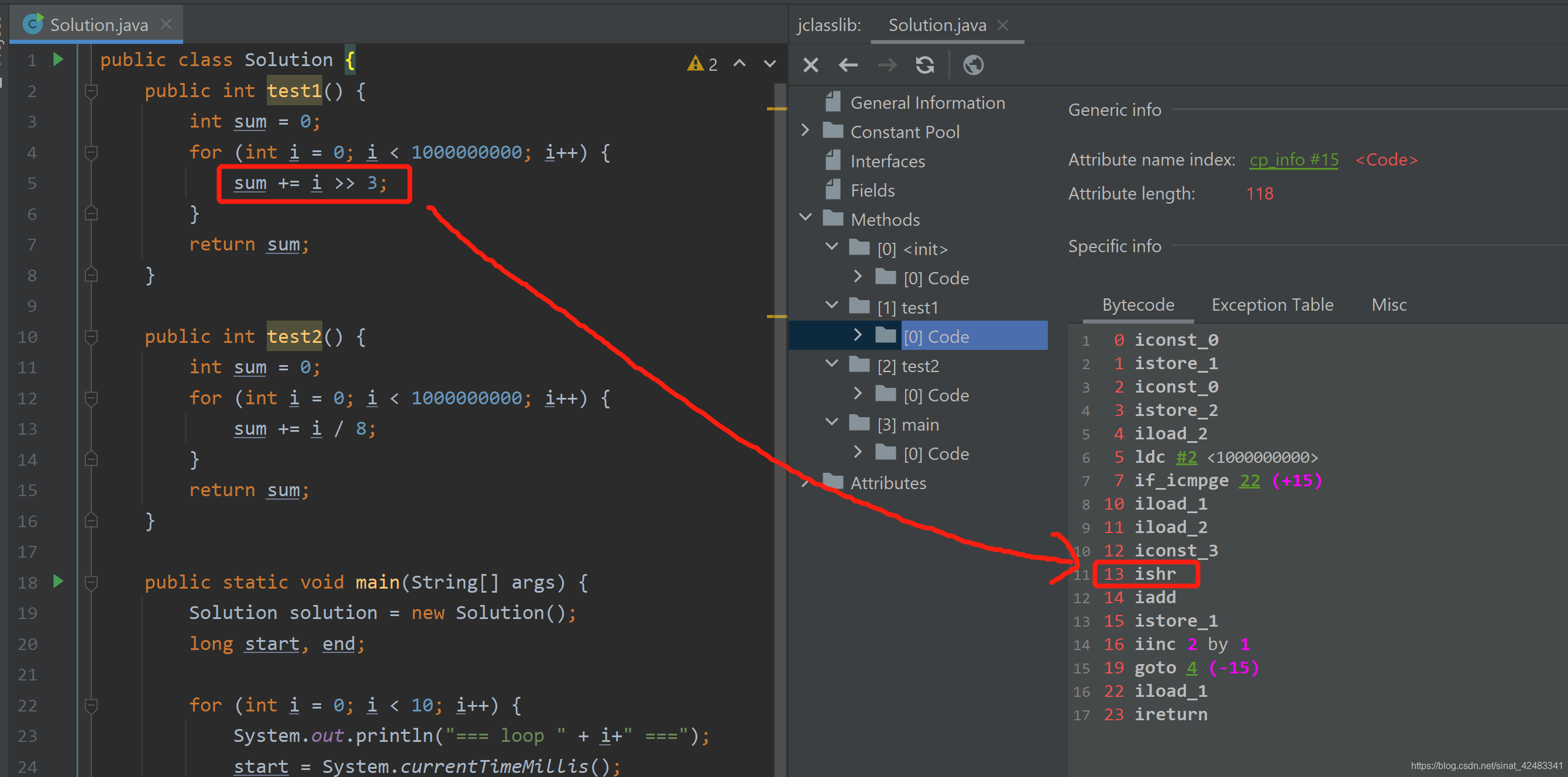
移位运算对应的字节码
除法操作对应的字节码
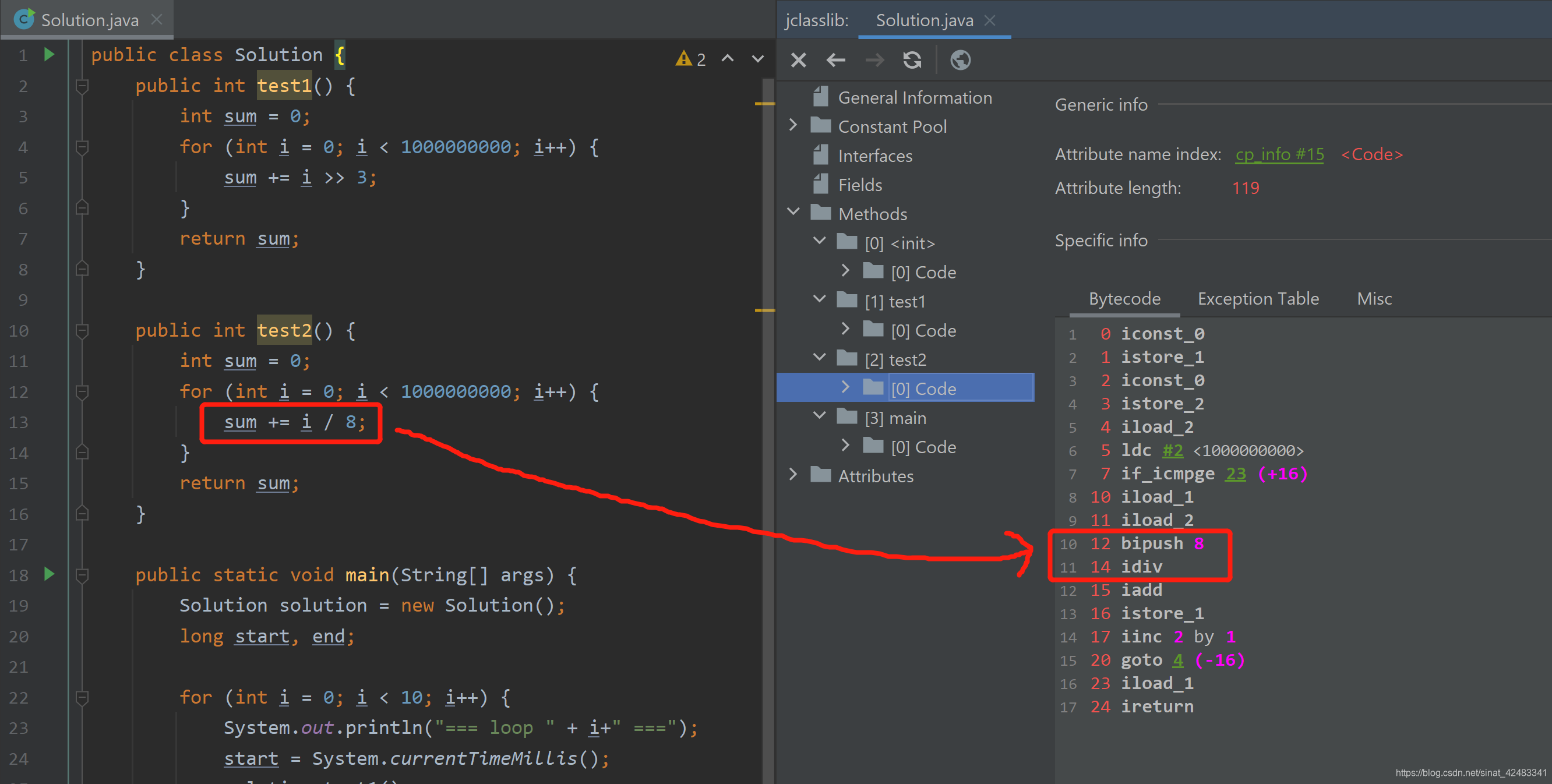
从字节码上来看,Java 编译器是没有对除法做优化的。移位是 ishr,除法是 idiv。然后虚拟机对这些字节码进行解释执行,然后就没有然后了。
真的就没有然后了吗?Java 在优化上做的这么挫吗?看到这里,你是不是有一种想要优化 javac 的冲动?如果真是这样的话,后 8 次循环中两方法耗时相同怎么解释呢?…
直到我看到了这段话:
因为Javac这类前端编译器对代码的运行效率几乎没有任何优化措施可言(在JDK 1.3之后,Javac的-O优化参数就不再有意义),哪怕是编译器真的采取了优化措施也不会产生什么实质的效果。因为Java虚拟机设计团队选择把对性能的优化全部集中到运行期的即时编译器中,这样可以让那些不是由Javac产生的Class文件(如JRuby、Groovy等语言的Class文件)也同样能享受到编译器优化措施所带来的性能红利。但是,如果把“优化”的定义放宽,把对开发阶段的优化也计算进来的话,Javac确实是做了许多针对Java语言编码过程的优化措施来降低程序员的编码复杂度、提高编码效率。相当多新生的Java语法特性,都是靠编译器的“语法糖”来实现,而不是依赖字节码或者Java虚拟机的底层改进来支持。我们可以这样认为,Java中即时编译器在运行期的优化过程,支撑了程序执行效率的不断提升;而前端编译器在编译期的优化过程,则是支撑着程序员的编码效率和语言使用者的幸福感的提高。
―― 摘自《深入理解Java虚拟机 第10章 前端编译与优化》
哦!要想知道 Java 究竟有没有做除法优化,我们需要去看 JIT 的编译产物!
查看及分析 JIT 即时编译结果
一般来说,虚拟机的即时编译过程对用户程序是完全透明的,我们也不需要知道。但如果一定要看,当然是有办法的。
步骤比较复杂,网上教程也有不少坑,让我们慢慢道来~
1、手动编译 OpenJDK
本文使用的部分运行参数输出反汇编信息需要 FastDebug 或者 SlowDebug 优化的虚拟机才能支持,所以首先要编译自己的 JDK。
OpenJDK 官网上的速度太慢了,可以从我的 gitee 直接 clone,然后根据里面的 doc/building.html 文档进行编译。
需要提前安装一些依赖:
sudo apt-get update
sudo apt-get install build-essential
sudo apt-get install libfreetype6-dev
sudo apt-get install libcups2-dev
sudo apt-get install libx11-dev libxext-dev libxrender-dev libxrandr-dev libxtst-dev libxt-dev
sudo apt-get install libasound2-dev
sudo apt-get install libffi-dev
sudo apt-get install autoconf
sudo apt-get install openjdk-11-jdk # 自举,需要安装前一版本JDK,相当于“先有鸡还是先有蛋”问题
装好依赖之后,cd 到刚下载好的 OpenJDK12 目录,先初始化配置
bash configure --enable-debug --disable-warnings-as-errors
然后编译
make images
在我的 6c 16g 机器上,完成编译需要 15 分钟左右,喝水等一下吧。
编完之后,完整的编译结果在 OpenJDK12/build/配置名称/jdk 目录下,把它加到环境变量里,就可以作为一个完整的 JDK 使用啦。
# 环境变量示例
export JAVA_HOME=/home/hanquan/OpenJDK12/build/linux-x86_64-server-fastdebug/jdk
export PATH=$JAVA_HOME/bin:$PATH
2、编译 hsdis-amd64.so 反汇编适配器
OpenJDK 源码中已经包含了 hsdis 工具,但是需要我们自己编译。
hsdis 源码在 OpenJDK12/src/utils/hsdis 目录下,里面有个 README,直接根据这个文档来编就可以了(网上教程都不好使)。
里面说需要用到一个工具 binutils,直接从它给你的链接就可以下载,或者使用 清华镜像,注意要和 README 里面的版本匹配。解压后,放在你喜欢的地方就好了,后面可以显示指定路径。
显示指定 binutils 的路径,然后 编译 hsdis:
make BINUTILS=/home/hanquan/OpenJDK12/build/binutils-2.30 ARCH=amd64
编译完成之后,会生成一个 build 目录。

编译产物叫 hsdis-amd64.so,找到它,复制到和 libjvm.so 相同的目录下(一般会在OpenJDK12/build/linux-x86_64-server-fastdebug/jdk/lib/server),就可以被虚拟机自动找到了。
cp hsdis-amd64.so /home/hanquan/OpenJDK12/build/linux-x86_64-server-fastdebug/jdk/lib/server
3、编写测试代码
至此,工具都准备好了,后面就是常规操作。
测试代码中,为了触发 JIT 的即时编译,所以写了两个循环。重点还是看其中的移位和除法操作。
public class Solution {
public int test1() {
int sum = 0;
for (int i = 0; i < 1000000000; i++) {
sum += i >> 3;
}
return sum;
}
public int test2() {
int sum = 0;
for (int i = 0; i < 1000000000; i++) {
sum += i / 8;
}
return sum;
}
public static void main(String[] args) {
Solution solution = new Solution();
long start, end;
for (int i = 0; i < 10; i++) {
solution.test1();
solution.test2();
}
}
}
4、javac 编译 & JIT 即时编译
终于到了关键一步,这一步就能看到 JIT 即时编译的汇编代码了。
# 编译得到字节码
javac Solution.java
# 使用参数 -XX:CompileCommand=compileonly,<类名>.<方法名> 这样可以只编译指定类的指定方法
java -XX:+PrintAssembly -XX:CompileCommand=compileonly,Solution.test* Solution > assembly.log
输出被存到了 assembly.log 中,这就是我们一直想看的 JIT 即时编译的汇编代码。
来,看看它长啥样,到底有没有做除法优化。
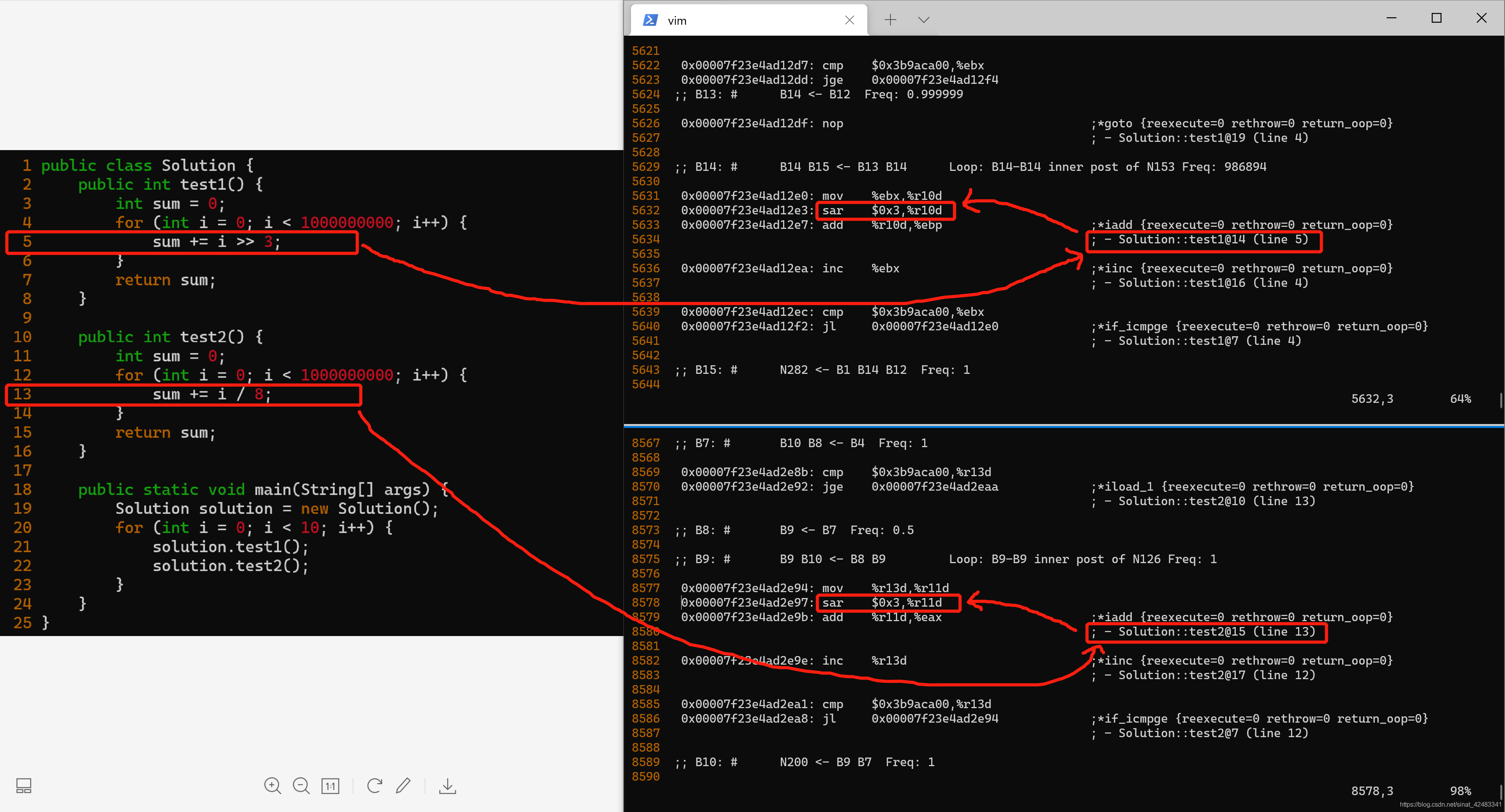
好吧,Java 诚不我欺,在 JIT 的即时编译阶段是做了除法优化的,具体是,将除法运算改为了移位运算。
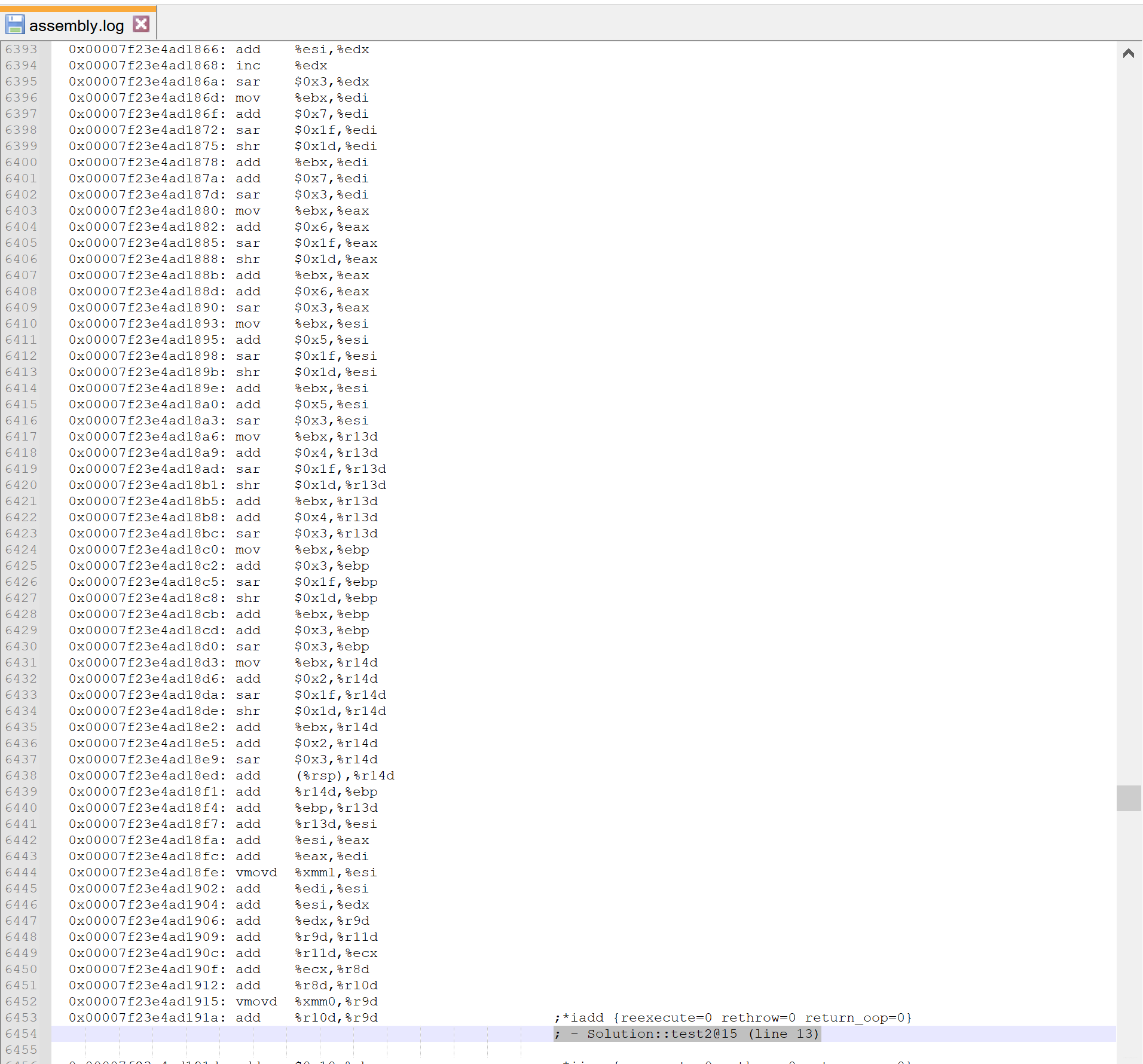
另外,如上图所示,也看到了一些其他的优化,比如循环展开,本文就不细讲了。
补充
上面我们使用的 Java 测试代码,10 次循环中消耗的时间并不相同。
在 前两次循环 中,test2 耗时明显较长,我们猜测是由于短时间内 JIT 未完成编译,虚拟机在编译器还未完成编译之前,仍然按照解释方式继续执行代码,所以前两个 loop 的这段时间仍然是解释执行的过程。从 loop2 开始,编译完成了,才开始执行编译器输出的本地代码。
本文不足
我们的结论是,尽管 javac 前端编译对字节码的优化几乎为 0,但在 JIT 即时编译的时候,确实进行了一些优化,这其中包括对除法的优化。
JIT 中的 Server Compiler 模式是一个充分优化过的高级编译器,几乎能达到 GNU C++编译器使用-O2 参数时的优化强度,它会执行所有的经典的优化动作,如无用代码消除(Dead Code Elimination)、循环展开(Loop Unrolling)、循环表达式外提(Loop Expression Hoisting)、消除公共子表达式(Common Subexpression Elimination)、常量传播(Constant Propagation)、基本块冲排序(Basic Block Reordering)等,还会实施一些与Java 语言特性密切相关的优化技术,如范围检查消除(Range Check Elimination)、空值检查消除(Null Check Elimination ,不过并非所有的空值检查消除都是依赖编译器优化的,有一些是在代码运行过程中自动优化 了)等。另外,还可能根据解释器或Client Compiler提供的性能监控信息,进行一些不稳定的激进优化,如守护内联(Guarded Inlining)、分支频率预测(Branch Frequency Prediction)等。
―― 摘自《深入理解Java虚拟机 第11章 后端编译与优化》
最后要说的是,为了触发即时编译,写测试样例的时候,我们 只在循环中 使用了除法,并没有对 除法独立出现 的情况进行测试。这将是本文可以完善的一个方向。
感谢阅读 ~ 笔者才疏学浅,如有不足之处,请多多指教,欢迎评论区探讨。