��һ��֪ʶ��
- Arraylist ��LinkedList����
- HashMap��put����
- ˵?��ThreadLocal
- ˵?��JVM��,��Щ�ǹ�����,��Щ������Ϊgc root
- ��Ŀ����Ų�JVM����(?)
- ��β鿴�߳�����(?)
- �߳�֮����ν���ͨѶ��(?)
- Spring�����������ʵ�ֵ�?
- ʲô������
- ����ĸ��뼶��
- ����Ĵ�������
- ʲôʱ��@TransactionalʧЧ
- Jdk1.7��Jdk1.8 HashMap ������ʲô�仯(�ײ�)?
- Jdk1.7��Jdk1.8 java�����������ʲô�仯?(?)
- ���ʵ��AOP,��Ŀ��Щ�ط��õ���AOP?
- springboot���õ�ע��?
- �ֲ�ʽ������ʵ��(��Ҫ��ϸ�˽�)
- Redis�����ݽṹ,����ʹ�ó���
- Redis��Ⱥ����(Clusterģʽ��������)
- ����mysql�������֪ʶ��
- Mysql���ݿ���,ʲô�������������������ʹ��?(���֪ʶ�㲻�˽�,ȥ����Ƶ)
- Innodb�����ʵ�������
- �Լ�֪���Ŀ��ʹ�õ����ģʽ(���������ģʽ,���������)
- Java������α���?(����˳��ʽ?)
- ��������ķ�ʽ?(?)
- �����dz����
- ������ύ����ʱ,�̳߳ض�������,��ʱ�ᷢ��ʲô?(�̵߳ľܾ�������???)
Arraylist ��LinkedList����
����,Arraylist�ײ�ά����������,��linkedlist�ײ�ά������������
��ʵ����list�ӿ�,����linkedlist��ʵ����deque�ӿ�,���Ե�������ʹ��!
��ѯ
�����������,���в�ѯ����ԽϿ��,��Ϊ�������Ǵ�����,���Ѿ�������ڴ�ռ�ġ�ֱ�Ӱ��±�˳���������,���±���в����ǿ���ֱ�Ӷ�λ��Ҫ���ҵ����ݡ�
�������������±��ѯ,���Ǵ�ͷ��ʼ����,�ڵõ�����,������������Ҫ��ѯ�����ĵ�һ�������һ������,�Ƿdz����,��Ϊ���ײ������������,ר�ž��Ǽ�¼��һ�������һ�����ݵġ�
����
arraylistֱ�ӽ���add,��Ĭ�Ͻ�����ֱ�Ӳ�������ĩβ(����������),��ܿ졣
����,ִ��ֱ�Ӹ����±����(����������),����������
arraylist.add(1,5);//�������±�Ϊ1��λ��,��������5
��Ϊ�����漰�������,����±�֮������ݶ���������һλ��Ч�ʱ��!
����Linkedist����add����,Ҳ��ֱ�ӽ����ݲ��뵽���,�ܿ�,��������û�����ݵIJ�����
����,ִ��ֱ�Ӹ����±����
linkedlist.add(1,5);//�������±�Ϊ1��λ��,��������5
������Ƚ��б����ҵ���Ӧ���±�,����컹����ȡ������ѡ����±��Dz��Ǻܴ�Ȼ��ִ�в������,�ܿ�,�ı�����ָ����С�
Arraylist ��LinkedListִ�����Ӳ���,���ܲ���ֱ�ӱȽϡ���ʵ���������!
ɾ��,��
ɾ�����Ķ����ҵ���Ӧ��λ�� ������ʽ����������
HashMap��put����
���Ĵ���������,��ͨ��key����hash�㷨Ȼ�������鳤�Ƚ���������,�õ�Ҫ�����ĸ������±��¡�
��ʱ��,���ּ���״��:
-
��������±�λ��Ϊ��:
��Ϊ��,��key��value��װΪnode����(1.7Ϊentry����,1.8Ϊode����),�����λ�á� -
����
a.��jdk1.7,�����ж��Ƿ���Ҫ����,��Ҫ����,���ж��Ƿ�key�ظ�,�ظ��ľͽ�value����֮ǰ��ֵ,û���ظ�,����ͷ�巨���뵱ǰλ�õ������С�
b.��jdk1.8,���жϵ�ǰnode������,�Ǻ����node��������nodei. ����Ǻ�?��Node,��key��value��װΪ?����?���ڵ㲢���ӵ���?����ȥ,������� ���л��жϺ�?�����Ƿ���ڵ�ǰkey,������������value ii. �����λ���ϵ�Node�����������ڵ�,��key��value��װΪ?������Node��ͨ��β�巨���뵽���������λ��ȥ,��Ϊ��β�巨,������Ҫ��������,�ڱ��������Ĺ����л��ж��Ƿ���ڵ�ǰkey,������������value,��������������,��������Node��?��������,��?��������,�ῴ��ǰ�����Ľڵ����,���?�ڵ���8,��ô��Ὣ������ת�ɺ�?�� iii. ��key��value��װΪNode��?���������?���к�,���ж��Ƿ���Ҫ��?����,�����Ҫ������,�������Ҫ�ͽ���PUT?��
˵?��ThreadLocal
����ʲô��?
ThreadLocal��Java�����ṩ���̱߳��ش洢����,������?�û��ƽ����ݻ�����ij���߳��ڲ�,���� �̿���������ʱ�̡�����?���л�ȡ���������
����ͨ�����һ��person��,��һ�����Ա���:
String name;
��������ThreadLocal��,�������������:
public class Person {
ThreadLocal<String> name = new ThreadLocal<>();
public String getName() {
return this.name.get();
}
public void setName(String name) {
this.name.set(name);
}
}
ThreadLocal�ײ���ͨ��ThreadLocalMap��ʵ�ֵ�,ÿ��Thread����(ע�ⲻ��ThreadLocal ����)�ж�����?��ThreadLocalMap,Map��keyΪThreadLocal����,Map��valueΪ��Ҫ�����ֵ
���DZ�дһ��������:
import java.util.concurrent.TimeUnit;
public class Tesst {
public static void main(String[] args) {
Person person = new Person();
new Thread(new Runnable() {
@Override
public void run() {
person.setName("��˧��");
try {
TimeUnit.SECONDS.sleep(3); //���߳�˯3��,Ϊ���������̶߳�ִ����,set����,ע�����Լ���ֵ
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() +" ==>" +person.getName());
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
person.setName("����");
try {
TimeUnit.SECONDS.sleep(3); //���߳�˯3��
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() +" ==>" +person.getName());
}
}).start();
}
}

���ǵIJ�����,��Ӧ��һ��person����,�ٲ�ͬ���߳������ò�ͬ������ֵ,Ȼ���ٴ�����ȡ����,���ֲ���ִ�ж��ٴ�,�ó�����ֵ,����֮ǰ�������Լ����߳������ô��ֵ��
��Ϊÿ���̶߳����Լ���ThreadLocalMap,����Լ���map,key��value�� ���������߳��ò����Է��̵߳����ݡ�
����ThreadLocal���и���������ڴ�й¶,��Ϊ��ThreadLocal����ʹ?��֮��,Ӧ��Ҫ�����õ�key,value,Ҳ����Entry�����?����,���̳߳��е��̲߳������,�ᱻ����ʹ��,?�̶߳�����ͨ��ǿ��?ָ��ThreadLocalMap,ThreadLocalMapҲ��ͨ��ǿ��?ָ��Entry����,�̲߳�������,Entry����Ҳ�Ͳ��ᱻ����,��?�����ڴ�й©,����취��,��ʹ?�� ThreadLocal����֮��,?����?ThreadLocal��remove?��,?�����Entry����
ThreadLocal�����Ӧ?�����������ӹ���(?���̳߳���?������,�����Ӷ�������ڲ�ͬ��?��֮ ���?����,�߳�֮�䲻����ͬ?������)��
˵?��JVM��,��Щ�ǹ�����,��Щ������Ϊgc root
������?�����������̹߳�����,ջ������?��ջ�������������ÿ���̶߳��е�

ʲô��gc root,JVM�ڽ�?��������ʱ,��Ҫ�ҵ�������������,Ҳ����û�б���?�Ķ���,����ֱ�� �ҡ�������������?�Ϻ�ʱ��,���Է�����,���ҡ�?����������,Ҳ������������,��ô����Ҫ��ij Щ��������ʼȥ��,������Щ����������?·���ҵ���������,?��Щ��������?������,������ֻ����?���� ����,?���ᱻ����������?,����:ջ�еı��ر���(�����ֲ�����)��?�����еľ�̬����������?��ջ�еı������� ����?���̵߳ȿ�����Ϊgc root��
��Ŀ����Ų�JVM����(?)
���ڻ���������?��ϵͳ:
- ����ʹ?jmap���鿴JVM�и��������ʹ?���
- ����ͨ��jstack���鿴�̵߳���?���,?����Щ�߳��������Ƿ����������
- ����ͨ��jstat�������鿴�������յ����,�ر���fullgc,�������fullgc?��Ƶ��,��ô�͵ý�?������
- ͨ����������Ľ��,����jvisualvm��?������?����
- ?��,�����²�Ƶ������fullgc��ԭ��,���Ƶ����?fullgc����??ֱû�г����ڴ����,��ô��ʾ fullgcʵ�����ǻ����˺ܶ������,������Щ�����������younggc�����о�ֱ�ӻ��յ�,������Щ�� ���?��?���,�����������,��Ҫ������Щ���ʱ�䲻?�Ķ����Dz���?��?,����������Ų� ��,ֱ�ӽ�?����?���,���Լ�?�������??,�������֮��,fullgc����,��֤������Ч
- ͬʱ,�������ҵ�ռ?CPU�����߳�,��λ�������?��,�Ż����?����ִ?,���Ƿ��ܱ���ijЩ ����Ĵ���,��?��ʡ�ڴ�
�����Ѿ���?��OOM(�ڴ����)��ϵͳ:
- ?��?��ϵͳ�ж������õ�ϵͳ��?��OOMʱ,?�ɵ�ʱ��dump?��(-XX:+HeapDumpOnOutOfMemoryError XX:HeapDumpPath=/usr/local/base)
- ���ǿ�����?jsisualvm��?��������dump?��
- ����dump?���ҵ��쳣��ʵ������,���쳣���߳�(ռ?CPU?),��λ������Ĵ���
- Ȼ���ٽ�?��ϸ�ķ����͵��� ��֮,���Ų���?��?�͵�,��Ҫ������������ʵ�����ܽᡢ�ٷ���,���ն�λ�����������
��β鿴�߳�����(?)
- ����ͨ��jstack��������?�鿴,jstack�����л���ʾ��?���������߳�
- ���������߳�ȥ�������ݿ�ʱ,���ݿⷢ?������,���ǿ��Բ�ѯ���ݿ���������
1����ѯ�Ƿ�����
show OPEN TABLES where In_use > 0;
2����ѯ����
show processlist;
3���鿴������������
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
4���鿴�ȴ���������
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
�߳�֮����ν���ͨѶ��(?)
- �߳�֮�����ͨ�������ڴ�(Ҳ����ͬһ��������)�����?������?ͨ��
- �����ͨ�������ڴ�����?ͨ��,����Ҫ���Dz�������,ʲôʱ������,ʲôʱ���� ��Java�е�wait()��notify()���������ͻ���
- ͨ��?���?�ϼ���,ͨ��?�����ӽ�ͨ�����ݷ�����?,��ȻҲҪ���ǵ���������,����?ʽ���Ǽ�����?ʽ
Spring�����������ʵ�ֵ�?
Spring�ڲ�ͬ���������API֮�϶�����һ�������,ʹ�ÿ�����Ա�����˽�ײ���������API�Ϳ���ʹ��Spring������������ơ�Spring֧�ֱ��ʽ�������������ʽ�����������
���ʽ�������:
�������������Ƕ��ҵ����������������ύ�ͻع�
ȱ��:������ÿ���������ҵ�����а�������������������
����ʽ�������
һ������±ȱ��ʽ������á�
��������������ҵ���з������,�������ķ�ʽ��ʵ�����������
�����������Ϊ���й�ע��,ͨ��aop����ģ�黯��Spring��ͨ��Spring AOP���֧������ʽ���������
��ϸʵ��:
<!--��������ʽ���� ����ʽ���ﲻͬ ���ʽ�������ڴ�����ֱ��try catch ����ֱ�Ӹı���벻�Ƽ� ���ʹ������ʽ������-->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="datasouce"/>
</bean>
<!-- ���aopʵ������֯��-->
<!-- ��������֪ͨ-->
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<!-- ����������������-->
<tx:method name="getUserList"/>
<tx:method name="add" propagation="REQUIRED"/>
<tx:method name="delete" propagation="REQUIRED"/>
<!-- �����еķ�����������-->
<tx:method name="*" propagation="REQUIRED"/>
</tx:attributes>
</tx:advice>
<!-- ���������-->
<aop:config>
<aop:pointcut id="expoincut" expression="execution(* com.hzf.dao.*.*(..))"/>
<aop:advisor advice-ref="txAdvice" pointcut-ref="expoincut"/>
</aop:config>
</beans>
�������ʽ��������,����aop���������,����Ҫʵ������ķ����������롣
�ֶ��ύ����,��try catch try'�� commit catch�� rollback
ʲô������
�����Ƿ������ݿ��һ����������,���ݿ�Ӧ��ϵͳͨ����������ɶ����ݿ�Ĵ�ȡ���������ȷִ��ʹ�����ݿ��һ��״̬ת��Ϊ��һ��״̬�� ���������
�������������ҵ��Ӧ�ö���������Ҫ,����֤���û���ÿһ�β������ǿɿ���,����������쳣�ķ������,Ҳ�������ƻ���̨���ݵ������ԡ��������е��Զ�����ATM,ͨ��ATM����������Ϊ�ͻ�����,����Ҳ�����������������м���ͻȻ�����ϵ����,��ʱ,����ͱ���ȷ��������ǰ���˻��IJ�������Ч,�����û��ղ���ȫû��ʹ�ù�ATM��һ��,�Ա�֤�û������е����涼������ʧ��
���������(*):
| ���� | ˵�� |
|---|---|
| ԭ����(A) | һ�������е����в���,Ҫôȫ���ɹ�,Ҫôȫ�����ɹ�,����������м�ij������; |
| һ����(C) | ����ʼ֮ǰ�ͽ���֮��,���ݿ��������û�б��ƻ�; |
| ������(I) | Ҫ��ÿ����д����IJ�����������������IJ��������������; |
| �־���(D) | ����һ���ύ,�����ͻ�־û�,���㷢��崻�Ҳ�ָܻ�����; |
��������������������
�ٸ�����,����A������B���ݵ���ͬһ����Դ,����A�����ɸ�������,����BҲ�����ɸ�������,����A������B�ڸ߲����������,����ָ��ָ��������⡣�����ָ��������⡱,�ܽ�һ����Ҫ��������:��һ�ඪʧ���¡��ڶ��ඪʧ���¡�����������ظ������ö�������֮��,��һ�ඪʧ���¡��ڶ��ඪʧ���²���Ҫ,������,��һ������������ظ����ͻö���
1�����
��ν���,����ָ����A����������B��û���ύ������,��������ȡǮ,����A��������,��ʱ�л�������B,����B��������C>ȡ��100Ԫ,��ʱ�л�������A,����A��ȡ�Ŀ϶������ݿ������ԭʼ����,��Ϊ����Bȡ����100��Ǯ,��û���ύ,���ݿ�������������϶�����ԭʼ���,����������
2�������ظ���
��ν�����ظ���,����ָ��һ�����������ȡ������ij������,�����������ݲ�һ�¡�����������ȡǮΪ��,����A��������C>������п����Ϊ1000Ԫ,��ʱ�л�������B����B��������C>����Bȡ��100Ԫ�C>�ύ,���ݿ���������Ϊ900Ԫ,��ʱ�л�������A,����A�ٲ�һ�β���˻����Ϊ900Ԫ,����������A����,��ͬһ�����������ζ�ȡ�˻�������ݲ�һ��,����Dz����ظ�����
3���ö�
��ν�ö�,����ָ��һ����������IJ����з�����δ�����������ݡ�����ѧ����Ϣ,����A��������C>������ѧ������ǩ��״��Ϊfalse,��ʱ�л�������B,����B��������C>����B������һ��ѧ������,��ʱ�л�������A,����A�ύ��ʱ������һ���Լ�û���Ĺ�������,����ǻö�,�ͺ������˻þ�һ�����ö����ֵ�ǰ���Dz��������������������˲��롢ɾ��������
����ĸ��뼶��
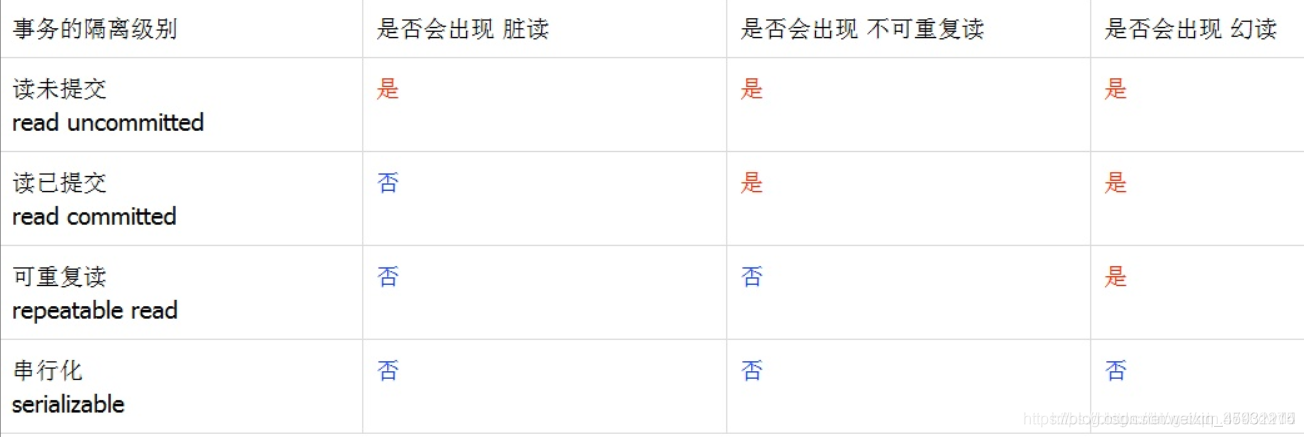
DEFAULT
ʹ�����ݿⱾ��ʹ�õĸ��뼶��
ORACLE(�����ύ) MySQL(���ظ���)
Read uncommitted
��δ�ύ,����˼��,����һ��������Զ�ȡ��һ��δ�ύ��������ݡ�
Read committed
���ύ,����˼��,����һ������Ҫ����һ�������ύ����ܶ�ȡ���ݡ�
��������,�����ܽ�������ظ����ͻö���
Repeatable read
�ظ���,�����ڿ�ʼ��ȡ����(������)ʱ,���������IJ���
����˲����ظ���,�����ܽ���ö���
Serializable ���л�
==Serializable ==����ߵ�������뼶��,�ڸü�����,�����л�˳��ִ��,���Ա�������������ظ�����ö�����������������뼶��Ч�ʵ���,�ȽϺ����ݿ�����,һ�㲻ʹ�á�
����Ĵ�������
����Ĵ�����Ϊ��ָ,����ڿ�ʼ��ǰ����֮ǰ,һ�������������Ѿ�����,��ʱ������ѡ�����ָ��һ�������Է�����ִ����Ϊ��
��:��ִ��һ��@Transactinalע���ע�ķ���ʱ,����������;���÷�������ִ����ʱ,��һ����Ҳ�����˸÷���; ��ô��ʱ��ô��������,��ʱ�Ϳ���ͨ������Ĵ���������ָ��������ʽ��
| ���� | ���� |
|---|---|
| TransactionDefinition.PROPAGATION_REQUIRED | �����ǰ��������,����������;�����ǰû������,��һ���µ���������Ĭ��ֵ�� |
| TransactionDefinition.PROPAGATION_REQUIRES_NEW | ����һ���µ�����,�����ǰ��������,��ѵ�ǰ������� |
| TransactionDefinition.PROPAGATION_SUPPORTS | �����ǰ��������,����������;�����ǰû������,���Է�����ķ�ʽ�������С� |
| TransactionDefinition.PROPAGATION_NOT_SUPPORTED | �Է�����ʽ����,�����ǰ��������,��ѵ�ǰ������� |
| TransactionDefinition.PROPAGATION_NEVER | �Է�����ʽ����,�����ǰ��������,���׳��쳣�� |
| TransactionDefinition.PROPAGATION_MANDATORY | �����ǰ��������,����������;�����ǰû������,���׳��쳣�� |
| TransactionDefinition.PROPAGATION_NESTED | �����ǰ��������,��һ��������Ϊ��ǰ�����Ƕ������������;�����ǰû������,���ȡֵ�ȼ���TransactionDefinition.PROPAGATION_REQUIRED�� |
ʲôʱ��@TransactionalʧЧ
Transactional ע��ֻ��Ӧ�õ� public �ɼ��ȵķ����ϡ� ���Ӧ����protected��private���� package�ɼ��ȵķ�����,Ҳ���ᱨ��,�����������ò���������
��ΪSpring�����ǻ��ڴ�����ʵ�ֵ�,Ҳ�������Ǽ��˸�ע���,����һ����������,��������������÷�������������,����ij������@Transactional��?��ֻ�������������?ʱ,��ô���ע��Ż�?Ч��
ͬʱ���ij��?����private��,��ô@TransactionalҲ��ʧЧ,��Ϊ�ײ�cglib (Ҳ��һ�ִ�����java�Ķ�̬��������,���Ǹ�ǿ��)�ǻ���??����ʵ�ֵ�,��Ϊ�������ɵĶ���ײ㻹��Է����������� ?���Dz�������?���private?����,����?���ܺõ���?����,Ҳ�ᵼ��@TransactianalʧЧ��
Jdk1.7��Jdk1.8 HashMap ������ʲô�仯(�ײ�)?
- 1.7�еײ�������+����,1.8�еײ�������+����+��?��,�Ӻ�?����?������?HashMap��?�Ͳ�ѯ ����Ч��
- 1.7��������?ʹ?����ͷ�巨,1.8��������?ʹ?����β�巨,��Ϊ1.8�в�?key��valueʱ��Ҫ�ж�����Ԫ�ظ���,������Ҫ��������ͳ������Ԫ�ظ���,�������þ�ֱ��ʹ?β�巨
- 1.7�й�ϣ�㷨?�ϸ���,���ڸ����������������,1.8�н�?�˼�,��Ϊ���ӵĹ�ϣ�㷨��?�ľ�����?ɢ����,���ṩHashMap������Ч��,?1.8�������˺�?��,���Կ����ʵ��ļ�ϣ�㷨, ��ʡCPU��Դ.
Jdk1.7��Jdk1.8 java�����������ʲô�仯?(?)
1.7�д������ô�,1.8��û�����ô�,�滻������Ԫ�ռ�,Ԫ�ռ���ռ���ڴ治����������ڲ�,?�DZ����ڴ�ռ�,��ô����ԭ����,���������ô�����Ԫ�ռ�,���Ƕ���?�����ľ���ʵ��,֮����Ԫ�ռ���ռ���ڴ�ijɱ����ڴ�,��?��˵����Ϊ�˺�JRockitͳ?,���������?Щԭ��,?��?�������洢������Ϣͨ����?����ȷ����,���Զ���?������??��?����ָ����,̫?�����׳���?�������,̫?�� ?��ռ?��̫����������ڴ�ռ�,?ת�Ƶ������ڴ����Ӱ���������ռ?���ڴ档
���ʵ��AOP,��Ŀ��Щ�ط��õ���AOP?
AOP�ĵײ�ʵ��ԭ��������̬����ģʽ��
�������ij���� ?�ɴ�������,����?���������ij��?��ʱ,����������Ƹ�?����ִ?,?������ȴ�ӡִ?ʱ��, ��ִ?��?��,���Ҹ�?��ִ?��ɺ�,�ٴδ�ӡִ?ʱ�䡣
AOP(Aspect Oriented Programming)��Ϊ:����������,ͨ��Ԥ���뷽ʽ�������ڶ�̬����ʵ�ֳ����ܵ�ͳһά����һ�ּ�����AOP��OOP������,�����������е�һ���ȵ�,Ҳ��Spring����е�һ����Ҫ����,�Ǻ���ʽ��̵�һ���������͡�����AOP���Զ�ҵ�����ĸ������ֽ��и���,�Ӷ�ʹ��ҵ����������֮�����϶Ƚ���,��߳���Ŀ�������,ͬʱ����˿�����Ч�ʡ�
��Ŀ��Щ�ط��õ���AOP?(�ײ�����ԭ������̫�˽�)
�ṩ����ʽ����;�������������ᵽ��spring��������
�����û��Զ������档
��?��,?������Ȩ���ơ�?��ִ?ʱ??־����ͨ��AOP������ʵ�ֵ�,������Ҫ��ijЩ?����ͳ ?�����Ķ�����?AOP��ʵ��,��?AOP��������ҵ��?��?��
springboot���õ�ע��?
- @SpringBootApplicationע��:���ע���ʶ��?��SpringBoot?��,��ʵ��������������ע����� ��,������ע����:
a. @SpringBootConfiguration:���ע��ʵ�ʾ���?��@Configuration,��ʾ������Ҳ��?��������
b. @EnableAutoConfiguration:��Spring�����е�?��?��Selector,?������ClassPath�� SpringFactories���������?��������,����Щ?������Ϊ����Bean
c. @ComponentScan:��ʶɨ��·��,��ΪĬ����û������ʵ��ɨ��·��,����SpringBootɨ��� ·�������������ڵĵ�ǰ?¼ - @Beanע��:?������Bean,������XML�еı�ǩ,Spring������ʱ,��Լ���@Beanע�� ��?����?����,��?����������ΪbeanName,��ͨ��ִ??���õ�bean����
- @Controller��@Service��@ResponseBody��@Autowired������˵
- ������˵һϵ�е�@Enable*ע��,����һϵ�еĹ���
- ��redis����,���������@EnableCaching//ע���������û���
- @EnableTransactionManagement ��������(Ĭ�Ͽ���)
- @EnableScheduling //��ʱ����
- ��springcloud����
@EnableEurekaClient //�ڷ���������,�Զ�ע�ᵽEureka��
@EnableDiscoveryClient //������
@EnableEurekaServer //EnableEurekaServer ����˵�������,���Խ��ܱ���ע�����
�ȵȵȵȡ�������������
�ֲ�ʽ������ʵ��(��Ҫ��ϸ�˽�)
ʲô�Ƿֲ�ʽ��?
�����ڿ���Ӧ�õ�ʱ��,�����Ҫ��ijһ�������������ж��߳�ͬ�����ʵ�ʱ��,����ʹ������ѧ����Java���̵߳�18�����ս��д���,���ҿ�������������,����Bug!
ע�����ǵ���Ӧ��,Ҳ�������е�������䵽��ǰ��������JVM�ڲ�,Ȼ��ӳ��Ϊ����ϵͳ���߳̽��д���!�������������ֻ�������JVM�ڲ���һ���ڴ�ռ�!
����ҵ��չ,��Ҫ����Ⱥ,һ��Ӧ����Ҫ����̨������Ȼ�������ؾ���,��������ͼ:
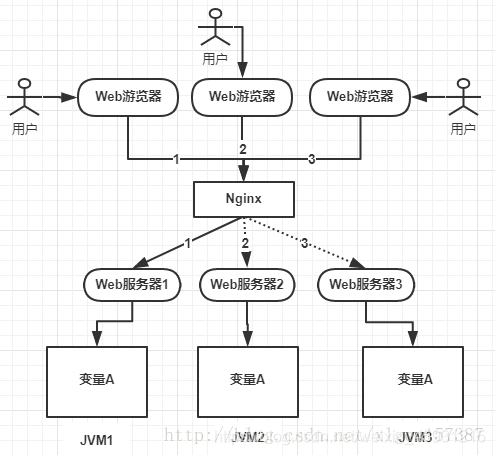
��ͼ���Կ���,����A����JVM1��JVM2��JVM3����JVM�ڴ���,��������κο��ƵĻ�,����Aͬʱ������JVM����һ���ڴ�,����������ͬʱ�������������,��Ȼ����Dz��Ե�!��ʹ����ͬʱ������,��������ֱ����������ͬJVM�ڴ����������,����A֮�䲻���ڹ���,Ҳ�����пɼ���,�����Ľ��Ҳ�Dz��Ե�!
Ϊ�˱�֤һ�������������ڸ߲�������µ�ͬһʱ��ֻ�ܱ�ͬһ���߳�ִ��,�ڴ�ͳ����Ӧ�õ�������������,����ʹ��Java����������ص�API(��ReentrantLock��Synchronized)���л�����ơ��ڵ���������,Java���ṩ�˺ܶಢ��������ص�API������,����ҵ��չ����Ҫ,ԭ���嵥�������ϵͳ���ݻ��ɷֲ�ʽ��Ⱥϵͳ��,���ڷֲ�ʽϵͳ���̡߳�����̲��ҷֲ��ڲ�ͬ������,�⽫ʹԭ������������µIJ�������������ʧЧ,������Java API�������ṩ�ֲ�ʽ����������Ϊ�˽������������Ҫһ�ֿ�JVM�Ļ�����������ƹ�����Դ�ķ���,����Ƿֲ�ʽ��Ҫ���������!
�ֲ�ʽ��Ӧ�þ߱���Щ����?
1���ڷֲ�ʽϵͳ������,һ��������ͬһʱ��ֻ�ܱ�һ��������һ���߳�ִ��;
2���߿��õĻ�ȡ�����ͷ���;
3�������ܵĻ�ȡ�����ͷ���;
4���߱�����������;
5���߱���ʧЧ����,��ֹ����;
6���߱�������������,��û�л�ȡ������ֱ�ӷ��ػ�ȡ��ʧ�ܡ�
�ֲ�ʽ��������ʵ�ַ�ʽ
Ŀǰ�����ܶ������վ��Ӧ�ö��Ƿֲ�ʽ�����,�ֲ�ʽ�����е�����һ��������һֱ��һ���Ƚ���Ҫ�Ļ��⡣�ֲ�ʽ��CAP���۸������ǡ��κ�һ���ֲ�ʽϵͳ����ͬʱ����һ����(Consistency)��������(Availability)�ͷ����ݴ���(Partition tolerance),���ֻ��ͬʱ�������������,�ܶ�ϵͳ�����֮����Ҫ������������ȡ�ᡣ�ڻ���������ľ�������ij�����,����Ҫ����ǿһ��������ȡϵͳ�ĸ߿�����,ϵͳ����ֻ��Ҫ��֤������һ���ԡ�,ֻҪ�������ʱ�������û����Խ��ܵķ�Χ�ڼ��ɡ�
�ںܶೡ����,����Ϊ�˱�֤���ݵ�����һ����,��Ҫ�ܶ�ļ���������֧��,����ֲ�ʽ���ֲ�ʽ���ȡ��е�ʱ��,������Ҫ��֤һ��������ͬһʱ����ֻ�ܱ�ͬһ���߳�ִ�С�
�������ݿ�ʵ�ֲַ�ʽ��;
���ڻ���(Redis��)ʵ�ֲַ�ʽ��;
����Zookeeperʵ�ֲַ�ʽ��;
����ʵ�ַ�ʽ:
https://blog.csdn.net/wuzhiwei549/article/details/80692278
Redis�����ݽṹ,����ʹ�ó���
Redis�����ݽṹ����,ָ����redis��ֵ��value����;
Redis�����ݽṹ��:
- �ַ���:����?����������ݻ���,���Ի���ij�����ַ���,Ҳ���Ի���ij��json��ʽ���ַ� ��,Redis�ֲ�ʽ����ʵ�־���?���������ݽṹ,����������ʵ�ּ�������Session�������ֲ�ʽID
- ��ϣ��:����?���洢?Щkey-value��,���ʺ�?���洢����
- �б�:Redis���б�ͨ����������,�ȿ��Ե���ջ,Ҳ���Ե���������ʹ?,����?������������ ���ںš�������Ϣ������
- ����:���б�����,Ҳ���Դ洢���Ԫ��,���Dz����ظ�,���Ͽ��Խ�?�����������������,�Ӷ�����ʵ������,�Һ�ij?��ͬ��ע��?������Ȧ���ȹ���
- ����:������?���,���Ͽ�������˳��,����?��ʵ����?����
Redis��Ⱥ����(Clusterģʽ��������)
Redis�ṩ�����ּ�Ⱥ����:
- ����ģʽ:����ģʽ?�ϼ�,������Զ�д,���һ�ʹӿ��?����ͬ��,����ģʽ��,�ͻ���ֱ�� �������ij���ӿ�,���ǵ������ӿ�崻���,�ͻ�����Ҫ?����IP,����,����ģʽҲ?���ѽ�? ����,������Ⱥ���ܴ洢�������ܵ�ij̨�������ڴ�����,���Բ�����?����?������
- �ڱ�ģʽ:����ģʽ�����ӵĻ������������ڱ��ڵ�,������ڵ�崻���,�ڱ��ᷢ������ڵ�崻�, Ȼ���ڴӿ���ѡ��?������Ϊ��������,�����ڱ�Ҳ��������Ⱥ,��?���Ա�֤��ij?���ڱ��ڵ�崻� ��,���������ڱ��ڵ���Լ���?��,����ģʽ����?�Ϻõı�֤Redis��Ⱥ��?��?,������Ȼ���� �ܺõĽ��Redis�������������⡣
- Clusterģʽ:Clusterģʽ��?��?�϶��ģʽ,��?�ֶ������,����ģʽ�ᰴ��key��?��λ�ķ���,����ʹ�ò�ͬ��key��ɢ����ͬ�����ڵ���,��?����ģʽ����ʹ��������Ⱥ?�ָ�?����������,ͬʱÿ�����ڵ����ӵ���Լ��Ķ���ӽڵ�,��������ڵ�崻�,������Ĵӽڵ���ѡ��?���µ����ڵ㡣
����������ģʽ,���RedisҪ�����������?,����ѡ���ڱ�ģʽ,���RedisҪ���������?,������Ҫ����������,��ôѡ��Clusterģʽ��
����mysql�������֪ʶ��
Mysql���ݿ���,ʲô�������������������ʹ��?(���֪ʶ�㲻�˽�,ȥ����Ƶ)
- û�з�������ǰԭ��(��ʹ�ø��������������)
- �ֶν�?����ʽ��������ת��
- ?����û��ȫ��ɨ��Ч��?
https://www.bilibili.com/video/BV1W64y1u761?p=47
Innodb�����ʵ�������
�����ع���־(undo log) �� ������־(redo log)���ֱ�ʵ������,��ʵ�� MVCC (��汾��������);
��ִ�������ÿ��SQLʱ,���Ƚ�����ԭֵд��undo log ��, Ȼ��ִ��SQL�����ݽ�����,����ĺ��ֵд��redo log�С�
redo log ������־����������:1 ���ڴ��е�������־���� ;2 ��������־�ļ����������ύʱ,�����Ƚ��������������־д�뵽������־�ļ����г־û�,������commit������ɲ�����ɡ�
��һ�������е�����SQL��ִ�гɹ���,�Ὣredo log �����е�����ˢ�����,Ȼ���ύ��
��������ع�,�����undo log�ָ����ݡ�
| ���� | INNODBʵ�ַ�ʽ |
|---|---|
| ԭ����(A) | �ع���־(undo log):���ڼ�¼������ǰ��״̬; |
| һ����(C) | ������־(redo log):���ڼ�¼�о��ĺ��״̬; |
| ������(I) | ��:������Դ����,��Ϊ��������������; |
| �־���(D) | ������־(redo log) + �ع���־(undo log); |
MVCC (��汾��������)(����������,�����)
��ѯ��Ҫ����Դ�ӹ�����(S),��������Ҫ����Դ��������(X)
�Լ�֪���Ŀ��ʹ�õ����ģʽ(���������ģʽ,���������)
��ѧϰ?Щ��ܻ��м���ĵײ�Դ���ʱ��������?Щ���ģʽ:
- ����ģʽ:Mybatis��?��JDK��̬������?��Mapper�Ĵ�������,��ִ?���������?��ʱ��ȥִ ?SQL,Spring��AOP������@Configurationע��ĵײ�ʵ��Ҳ��?���˴���ģʽ
- ������ģʽ:Tomcat�е�Pipelineʵ��,�Լ�Dubbo�е�Filter���ƶ�ʹ?��������ģʽ
- ??ģʽ:Spring�е�BeanFactory����?��??ģʽ��ʵ��
- ������ģʽ:Spring�е�Bean���ٵ�?��������?����������ģʽ,?���������Bean��������ִ ?ʽ
- ���ģʽ:Tomcat�е�Request��RequestFacade֮�����ֵľ������ģʽ
- ģ��?��ģʽ:Spring�е�refresh?���о��ṩ�˸�?��̳���д��?��,��?����ģ��?��ģʽ
Java������α���?(����˳��ʽ?)
���������?��ԭ��:
- ��������:?����Դÿ��ֻ�ܱ�?���߳�ʹ?
- �����뱣������: ?���߳��������ȴ�ij����Դʱ,���ͷ���ռ����Դ
- ����������:?���߳��Ѿ���õ���Դ,��δʹ?��֮ǰ,���ܱ�ǿ?����
- ѭ���ȴ�����:��?�߳��γ�ͷβ��ӵ�ѭ���ȴ���Դ��ϵ
���������������Ҫ�ﵽ��4������,���Ҫ��������,ֻ��Ҫ����?����ij?���������ɡ�?����ǰ3�� ��������Ϊ��Ҫ���ϵ�����,����Ҫ������������Ҫ���Ƶ�4������,������ѭ���ȴ����Ĺ�ϵ��
��ô���ѭ�ȴ���?
�ڿ���������:
- Ҫע�����˳��,��֤ÿ���̰߳�ͬ����˳���?����()
- Ҫע�����ʱ��,�������������?����ʱʱ��
- Ҫע���������,����?��Ԥ������,ȷ���ڵ�?ʱ�䷢����������?���
��������ķ�ʽ?(?)
�����dz����
�?��dz��?����ָ����Ŀ�?,?�������д����������͵�����,?���ǻ�����������,?����ʵ�� �������?��
- dz��?��ָ,ֻ�´?�����������͵�ֵ,�Լ�ʵ���������?��ַ,�����Ḵ��?����?��ַ��ָ�� �Ķ���,Ҳ����dz��?�����Ķ���,�ڲ���������ָ�����ͬ?������
- �?��ָ,�Ȼ´?�����������͵�ֵ,Ҳ�����ʵ���������?��ַ��ָ��Ķ����?����,� ?�����Ķ���,�ڲ�������ָ��IJ���ͬ?������
������ύ����ʱ,�̳߳ض�������,��ʱ�ᷢ��ʲô?(�̵߳ľܾ�������???)
https://blog.csdn.net/Fly_as_tadpole/article/details/86483898
��������û�н��,�����Ƚ������,�ڸ�ϰ����֪ʶ��!!!