Java ЛљДЁ
1. JDK КЭ JRE гаЪВУДЧјБ№?
-
JDK:Java Development Kit ЕФМђГЦ,java ПЊЗЂЙЄОпАќ,ЬсЙЉСЫ java ЕФПЊЗЂЛЗОГКЭдЫааЛЗОГЁЃ
-
JRE:Java Runtime Environment ЕФМђГЦ,java дЫааЛЗОГ,ЮЊ java ЕФдЫааЬсЙЉСЫЫљашЛЗОГЁЃ
ОпЬхРДЫЕ JDK ЦфЪЕАќКЌСЫ JRE,ЭЌЪБЛЙАќКЌСЫБрвы java дДТыЕФБрвыЦї javac,ЛЙАќКЌСЫКмЖр java ГЬађЕїЪдКЭЗжЮіЕФЙЄОпЁЃМђЕЅРДЫЕ:ШчЙћФуашвЊдЫаа java ГЬађ,жЛашАВзА JRE ОЭПЩвдСЫ,ШчЙћФуашвЊБраД java ГЬађ,ашвЊАВзА JDKЁЃ
2. == КЭ equals ЕФЧјБ№ЪЧЪВУД?
== НтЖС
ЖдгкЛљБОРраЭКЭв§гУРраЭ == ЕФзїгУаЇЙћЪЧВЛЭЌЕФ,ШчЯТЫљЪО:
-
ЛљБОРраЭ:БШНЯЕФЪЧжЕЪЧЗёЯрЭЌ;
-
в§гУРраЭ:БШНЯЕФЪЧв§гУЪЧЗёЯрЭЌ;
ДњТыЪОР§:
String x = "string";String y = "string";String z = new String("string");System.out.println(x==y); // trueSystem.out.println(x==z); // falseSystem.out.println(x.equals(y)); // trueSystem.out.println(x.equals(z)); // true
ДњТыНтЖС:вђЮЊ x КЭ y жИЯђЕФЪЧЭЌвЛИів§гУ,Ыљвд == вВЪЧ true,Жј new String()ЗНЗЈдђжиаДПЊБйСЫФкДцПеМф,Ыљвд == НсЙћЮЊ false,Жј equals БШНЯЕФвЛжБЪЧжЕ,ЫљвдНсЙћЖМЮЊ trueЁЃ
equals НтЖС
equals БОжЪЩЯОЭЪЧ ==,жЛВЛЙ§ String КЭ Integer ЕШжиаДСЫ equals ЗНЗЈ,АбЫќБфГЩСЫжЕБШНЯЁЃПДЯТУцЕФДњТыОЭУїАзСЫЁЃ
ЪзЯШРДПДФЌШЯЧщПіЯТ equals БШНЯвЛИігаЯрЭЌжЕЕФЖдЯѓ,ДњТыШчЯТ:
class Cat {public Cat(String name) {this.name = name;}private String name;public String getName() {return name;}public void setName(String name) {this.name = name;}}Cat c1 = new Cat("ЭѕРк");Cat c2 = new Cat("ЭѕРк");System.out.println(c1.equals(c2)); // false
ЪфГіНсЙћГіКѕЮвУЧЕФвтСЯ,ОЙШЛЪЧ false?етЪЧдѕУДЛиЪТ,ПДСЫ equals дДТыОЭжЊЕРСЫ,дДТыШчЯТ:
public boolean equals(Object obj) {return (this == obj);}
дРД equals БОжЪЩЯОЭЪЧ ==ЁЃ
ФЧЮЪЬтРДСЫ,СНИіЯрЭЌжЕЕФ String ЖдЯѓ,ЮЊЪВУДЗЕЛиЕФЪЧ true?ДњТыШчЯТ:
String s1 = new String("РЯЭѕ");String s2 = new String("РЯЭѕ");System.out.println(s1.equals(s2)); // true
ЭЌбљЕФ,ЕБЮвУЧНјШы String ЕФ equals ЗНЗЈ,евЕНСЫД№АИ,ДњТыШчЯТ:
public boolean equals(Object anObject) {if (this == anObject) {return true;}if (anObject instanceof String) {String anotherString = (String)anObject;int n = value.length;if (n == anotherString.value.length) {char v1[] = value;char v2[] = anotherString.value;int i = 0;while (n-- != 0) {if (v1[i] != v2[i])return false;i++;}return true;}}return false;}
дРДЪЧ String жиаДСЫ Object ЕФ equals ЗНЗЈ,Абв§гУБШНЯИФГЩСЫжЕБШНЯЁЃ
змНс?:== ЖдгкЛљБОРраЭРДЫЕЪЧжЕБШНЯ,Ждгкв§гУРраЭРДЫЕЪЧБШНЯЕФЪЧв§гУ;Жј equals ФЌШЯЧщПіЯТЪЧв§гУБШНЯ,жЛЪЧКмЖрРржиаТСЫ equals ЗНЗЈ,БШШч StringЁЂInteger ЕШАбЫќБфГЩСЫжЕБШНЯ,ЫљвдвЛАуЧщПіЯТ equals БШНЯЕФЪЧжЕЪЧЗёЯрЕШЁЃ
3. СНИіЖдЯѓЕФ hashCode()ЯрЭЌ,дђ equals()вВвЛЖЈЮЊ true,ЖдТ№?
ВЛЖд,СНИіЖдЯѓЕФ hashCode()ЯрЭЌ,equals()ВЛвЛЖЈ trueЁЃ
ДњТыЪОР§:
String str1 = "ЭЈЛА";String str2 = "жиЕи";System.out.println(String.format("str1:%d | str2:%d", str1.hashCode(),str2.hashCode()));System.out.println(str1.equals(str2));
жДааЕФНсЙћ:
str1:1179395 | str2:1179395
false
ДњТыНтЖС:КмЯдШЛЁАЭЈЛАЁБКЭЁАжиЕиЁБЕФ hashCode() ЯрЭЌ,ШЛЖј equals() дђЮЊ false,вђЮЊдкЩЂСаБэжа,hashCode()ЯрЕШМДСНИіМќжЕЖдЕФЙўЯЃжЕЯрЕШ,ШЛЖјЙўЯЃжЕЯрЕШ,ВЂВЛвЛЖЈФмЕУГіМќжЕЖдЯрЕШЁЃ
4. final дк java жагаЪВУДзїгУ?
-
final аоЪЮЕФРрНазюжеРр,ИУРрВЛФмБЛМЬГаЁЃ
-
final аоЪЮЕФЗНЗЈВЛФмБЛжиаДЁЃ
-
final аоЪЮЕФБфСПНаГЃСП,ГЃСПБиаыГѕЪМЛЏ,ГѕЪМЛЏжЎКѓжЕОЭВЛФмБЛаоИФЁЃ
5. java жаЕФ Math.round(-1.5) ЕШгкЖрЩй?
ЕШгк -1,вђЮЊдкЪ§жсЩЯШЁжЕЪБ,жаМфжЕ(0.5)ЯђгвШЁећ,Ыљвде§ 0.5 ЪЧЭљЩЯШЁећ,ИК 0.5 ЪЧжБНгЩсЦњЁЃ
6. String ЪєгкЛљДЁЕФЪ§ОнРраЭТ№?
String ВЛЪєгкЛљДЁРраЭ,ЛљДЁРраЭга 8 жж:byteЁЂbooleanЁЂcharЁЂshortЁЂintЁЂfloatЁЂlongЁЂdouble,Жј String ЪєгкЖдЯѓЁЃ
7. java жаВйзїзжЗћДЎЖМгаФФаЉРр?ЫќУЧжЎМфгаЪВУДЧјБ№?
ВйзїзжЗћДЎЕФРрга:StringЁЂStringBufferЁЂStringBuilderЁЃ
String КЭ StringBufferЁЂStringBuilder ЕФЧјБ№дкгк String ЩљУїЕФЪЧВЛПЩБфЕФЖдЯѓ,УПДЮВйзїЖМЛсЩњГЩаТЕФ String ЖдЯѓ,ШЛКѓНЋжИеыжИЯђаТЕФ String ЖдЯѓ,Жј StringBufferЁЂStringBuilder ПЩвддкдгаЖдЯѓЕФЛљДЁЩЯНјааВйзї,ЫљвддкОГЃИФБфзжЗћДЎФкШнЕФЧщПіЯТзюКУВЛвЊЪЙгУ StringЁЃ
StringBuffer КЭ StringBuilder зюДѓЕФЧјБ№дкгк,StringBuffer ЪЧЯпГЬАВШЋЕФ,Жј StringBuilder ЪЧЗЧЯпГЬАВШЋЕФ,ЕЋ StringBuilder ЕФадФмШДИпгк StringBuffer,ЫљвддкЕЅЯпГЬЛЗОГЯТЭЦМіЪЙгУ StringBuilder,ЖрЯпГЬЛЗОГЯТЭЦМіЪЙгУ StringBufferЁЃ
8. String str="i"гы String str=new String("i")вЛбљТ№?
ВЛвЛбљ,вђЮЊФкДцЕФЗжХфЗНЪНВЛвЛбљЁЃString str="i"ЕФЗНЪН,java ащФтЛњЛсНЋЦфЗжХфЕНГЃСПГижа;Жј String str=new String("i") дђЛсБЛЗжЕНЖбФкДцжаЁЃ
9. ШчКЮНЋзжЗћДЎЗДзЊ?
ЪЙгУ StringBuilder Лђеп stringBuffer ЕФ reverse() ЗНЗЈЁЃ
ЪОР§ДњТы:
// StringBuffer reverseStringBuffer stringBuffer = new StringBuffer();stringBuffer.append("abcdefg");System.out.println(stringBuffer.reverse()); // gfedcba// StringBuilder reverseStringBuilder stringBuilder = new StringBuilder();stringBuilder.append("abcdefg");System.out.println(stringBuilder.reverse()); // gfedcba
10. String РрЕФГЃгУЗНЗЈЖМгаФЧаЉ?
-
indexOf():ЗЕЛижИЖЈзжЗћЕФЫїв§ЁЃ
-
charAt():ЗЕЛижИЖЈЫїв§ДІЕФзжЗћЁЃ
-
replace():зжЗћДЎЬцЛЛЁЃ
-
trim():ШЅГ§зжЗћДЎСНЖЫПеАзЁЃ
-
split():ЗжИюзжЗћДЎ,ЗЕЛивЛИіЗжИюКѓЕФзжЗћДЎЪ§зщЁЃ
-
getBytes():ЗЕЛизжЗћДЎЕФ byte РраЭЪ§зщЁЃ
-
length():ЗЕЛизжЗћДЎГЄЖШЁЃ
-
toLowerCase():НЋзжЗћДЎзЊГЩаЁаДзжФИЁЃ
-
toUpperCase():НЋзжЗћДЎзЊГЩДѓаДзжЗћЁЃ
-
substring():НиШЁзжЗћДЎЁЃ
-
equals():зжЗћДЎБШНЯЁЃ
11. ГщЯѓРрБиаывЊгаГщЯѓЗНЗЈТ№?
ВЛашвЊ,ГщЯѓРрВЛвЛЖЈЗЧвЊгаГщЯѓЗНЗЈЁЃ
ЪОР§ДњТы:
abstract class Cat {public static void sayHi() {System.out.println("hi~");}}
ЩЯУцДњТы,ГщЯѓРрВЂУЛгаГщЯѓЗНЗЈЕЋЭъШЋПЩвде§ГЃдЫааЁЃ
12. ЦеЭЈРрКЭГщЯѓРргаФФаЉЧјБ№?
-
ЦеЭЈРрВЛФмАќКЌГщЯѓЗНЗЈ,ГщЯѓРрПЩвдАќКЌГщЯѓЗНЗЈЁЃ
-
ГщЯѓРрВЛФмжБНгЪЕР§ЛЏ,ЦеЭЈРрПЩвджБНгЪЕР§ЛЏЁЃ
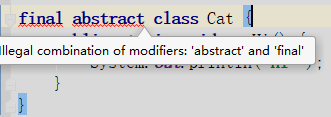
13. ГщЯѓРрФмЪЙгУ final аоЪЮТ№?
ВЛФм,ЖЈвхГщЯѓРрОЭЪЧШУЦфЫћРрМЬГаЕФ,ШчЙћЖЈвхЮЊ final ИУРрОЭВЛФмБЛМЬГа,етбљБЫДЫОЭЛсВњЩњУЌЖм,Ыљвд final ВЛФмаоЪЮГщЯѓРр,ШчЯТЭМЫљЪО,БрМЦївВЛсЬсЪОДэЮѓаХЯЂ:
14. НгПкКЭГщЯѓРргаЪВУДЧјБ№?
-
ЪЕЯж:ГщЯѓРрЕФзгРрЪЙгУ extends РДМЬГа;НгПкБиаыЪЙгУ implements РДЪЕЯжНгПкЁЃ
-
ЙЙдьКЏЪ§:ГщЯѓРрПЩвдгаЙЙдьКЏЪ§;НгПкВЛФмгаЁЃ
-
main ЗНЗЈ:ГщЯѓРрПЩвдга main ЗНЗЈ,ВЂЧвЮвУЧФмдЫааЫќ;НгПкВЛФмга main ЗНЗЈЁЃ
-
ЪЕЯжЪ§СП:РрПЩвдЪЕЯжКмЖрИіНгПк;ЕЋЪЧжЛФмМЬГавЛИіГщЯѓРрЁЃ
-
ЗУЮЪаоЪЮЗћ:НгПкжаЕФЗНЗЈФЌШЯЪЙгУ public аоЪЮ;ГщЯѓРржаЕФЗНЗЈПЩвдЪЧШЮвтЗУЮЪаоЪЮЗћЁЃ
15. java жа IO СїЗжЮЊМИжж?
АДЙІФмРДЗж:ЪфШыСї(input)ЁЂЪфГіСї(output)ЁЃ
АДРраЭРДЗж:зжНкСїКЭзжЗћСїЁЃ
зжНкСїКЭзжЗћСїЕФЧјБ№ЪЧ:зжНкСїАД 8 ЮЛДЋЪфвдзжНкЮЊЕЅЮЛЪфШыЪфГіЪ§Он,зжЗћСїАД 16 ЮЛДЋЪфвдзжЗћЮЊЕЅЮЛЪфШыЪфГіЪ§ОнЁЃ
16. BIOЁЂNIOЁЂAIO гаЪВУДЧјБ№?
-
BIO:Block IO ЭЌВНзшШћЪН IO,ОЭЪЧЮвУЧЦНГЃЪЙгУЕФДЋЭГ IO,ЫќЕФЬиЕуЪЧФЃЪНМђЕЅЪЙгУЗНБу,ВЂЗЂДІРэФмСІЕЭЁЃ
-
NIO:New IO ЭЌВНЗЧзшШћ IO,ЪЧДЋЭГ IO ЕФЩ§МЖ,ПЭЛЇЖЫКЭЗўЮёЦїЖЫЭЈЙ§ Channel(ЭЈЕР)ЭЈбЖ,ЪЕЯжСЫЖрТЗИДгУЁЃ
-
AIO:Asynchronous IO ЪЧ NIO ЕФЩ§МЖ,вВНа NIO2,ЪЕЯжСЫвьВНЗЧЖТШћ IO ,вьВН IO ЕФВйзїЛљгкЪТМўКЭЛиЕїЛњжЦЁЃ
17. FilesЕФГЃгУЗНЗЈЖМгаФФаЉ?
-
Files.exists():МьВтЮФМўТЗОЖЪЧЗёДцдкЁЃ
-
Files.createFile():ДДНЈЮФМўЁЃ
-
Files.createDirectory():ДДНЈЮФМўМаЁЃ
-
Files.delete():ЩОГ§вЛИіЮФМўЛђФПТМЁЃ
-
Files.copy():ИДжЦЮФМўЁЃ
-
Files.move():вЦЖЏЮФМўЁЃ
-
Files.size():ВщПДЮФМўИіЪ§ЁЃ
-
Files.read():ЖСШЁЮФМўЁЃ
-
Files.write():аДШыЮФМўЁЃ
ШнЦї
18. java ШнЦїЖМгаФФаЉ?
ГЃгУШнЦїЕФЭМТМ:
19. Collection КЭ Collections гаЪВУДЧјБ№?
-
java.util.Collection ЪЧвЛИіМЏКЯНгПк(МЏКЯРрЕФвЛИіЖЅМЖНгПк)ЁЃЫќЬсЙЉСЫЖдМЏКЯЖдЯѓНјааЛљБОВйзїЕФЭЈгУНгПкЗНЗЈЁЃCollectionНгПкдкJava РрПтжагаКмЖрОпЬхЕФЪЕЯжЁЃCollectionНгПкЕФвтвхЪЧЮЊИїжжОпЬхЕФМЏКЯЬсЙЉСЫзюДѓЛЏЕФЭГвЛВйзїЗНЪН,ЦфжБНгМЬГаНгПкгаListгыSetЁЃ
-
CollectionsдђЪЧМЏКЯРрЕФвЛИіЙЄОпРр/АяжњРр,ЦфжаЬсЙЉСЫвЛЯЕСаОВЬЌЗНЗЈ,гУгкЖдМЏКЯжадЊЫиНјааХХађЁЂЫбЫївдМАЯпГЬАВШЋЕШИїжжВйзїЁЃ
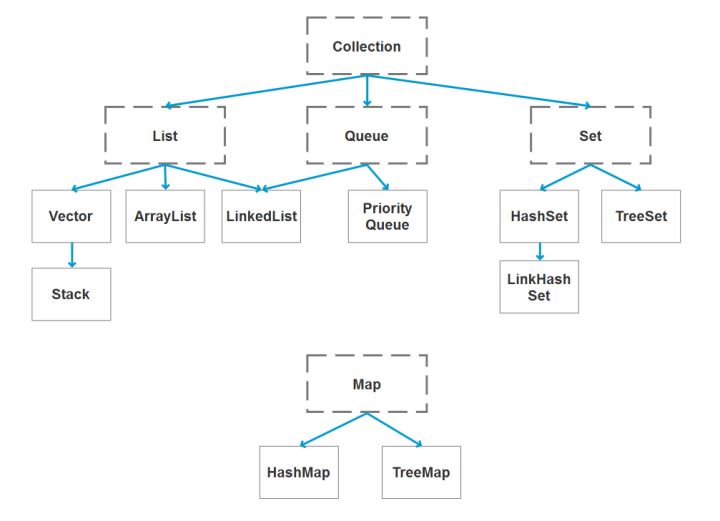
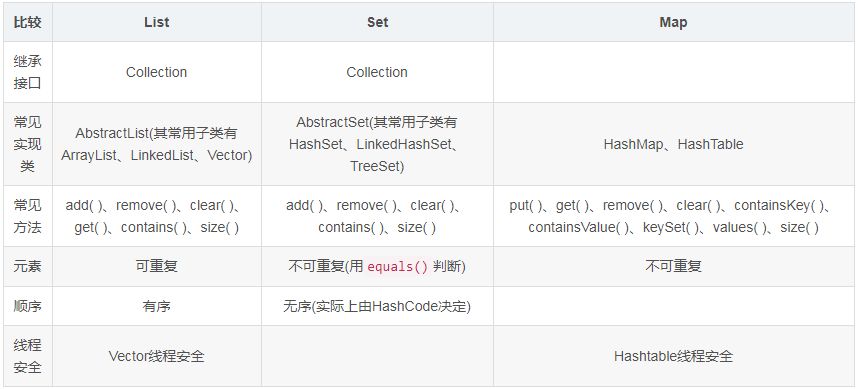
20. ListЁЂSetЁЂMap жЎМфЕФЧјБ№ЪЧЪВУД?
21. HashMap КЭ Hashtable гаЪВУДЧјБ№?
-
hashMapШЅЕєСЫHashTable ЕФcontainsЗНЗЈ,ЕЋЪЧМгЩЯСЫcontainsValue()КЭcontainsKey()ЗНЗЈЁЃ
-
hashTableЭЌВНЕФ,ЖјHashMapЪЧЗЧЭЌВНЕФ,аЇТЪЩЯБЦhashTableвЊИпЁЃ
-
hashMapдЪаэПеМќжЕ,ЖјhashTableВЛдЪаэЁЃ
22. ШчКЮОіЖЈЪЙгУ HashMap ЛЙЪЧ TreeMap?
ЖдгкдкMapжаВхШыЁЂЩОГ§КЭЖЈЮЛдЊЫиетРрВйзї,HashMapЪЧзюКУЕФбЁдёЁЃШЛЖј,МйШчФуашвЊЖдвЛИігаађЕФkeyМЏКЯНјааБщРњ,TreeMapЪЧИќКУЕФбЁдёЁЃЛљгкФуЕФcollectionЕФДѓаЁ,вВаэЯђHashMapжаЬэМгдЊЫиЛсИќПь,НЋmapЛЛЮЊTreeMapНјаагаађkeyЕФБщРњЁЃ
23. ЫЕвЛЯТ HashMap ЕФЪЕЯждРэ?
HashMapИХЪі:HashMapЪЧЛљгкЙўЯЃБэЕФMapНгПкЕФЗЧЭЌВНЪЕЯжЁЃДЫЪЕЯжЬсЙЉЫљгаПЩбЁЕФгГЩфВйзї,ВЂдЪаэЪЙгУnullжЕКЭnullМќЁЃДЫРрВЛБЃжЄгГЩфЕФЫГађ,ЬиБ№ЪЧЫќВЛБЃжЄИУЫГађКуОУВЛБфЁЃ?
HashMapЕФЪ§ОнНсЙЙ:дкjavaБрГЬгябджа,зюЛљБОЕФНсЙЙОЭЪЧСНжж,вЛИіЪЧЪ§зщ,СэЭтвЛИіЪЧФЃФтжИеы(в§гУ),ЫљгаЕФЪ§ОнНсЙЙЖМПЩвдгУетСНИіЛљБОНсЙЙРДЙЙдьЕФ,HashMapвВВЛР§ЭтЁЃHashMapЪЕМЪЩЯЪЧвЛИіЁАСДБэЩЂСаЁБЕФЪ§ОнНсЙЙ,МДЪ§зщКЭСДБэЕФНсКЯЬхЁЃ
ЕБЮвУЧЭљHashmapжаputдЊЫиЪБ,ЪзЯШИљОнkeyЕФhashcodeжиаТМЦЫуhashжЕ,ИљОјhashжЕЕУЕНетИідЊЫидкЪ§зщжаЕФЮЛжУ(ЯТБъ),ШчЙћИУЪ§зщдкИУЮЛжУЩЯвбОДцЗХСЫЦфЫћдЊЫи,ФЧУДдкетИіЮЛжУЩЯЕФдЊЫиНЋвдСДБэЕФаЮЪНДцЗХ,аТМгШыЕФЗХдкСДЭЗ,зюЯШМгШыЕФЗХШыСДЮВ.ШчЙћЪ§зщжаИУЮЛжУУЛгадЊЫи,ОЭжБНгНЋИУдЊЫиЗХЕНЪ§зщЕФИУЮЛжУЩЯЁЃ
ашвЊзЂвтJdk 1.8жаЖдHashMapЕФЪЕЯжзіСЫгХЛЏ,ЕБСДБэжаЕФНкЕуЪ§ОнГЌЙ§АЫИіжЎКѓ,ИУСДБэЛсзЊЮЊКьКкЪїРДЬсИпВщбЏаЇТЪ,ДгдРДЕФO(n)ЕНO(logn)
24. ЫЕвЛЯТ HashSet ЕФЪЕЯждРэ?
-
HashSetЕзВугЩHashMapЪЕЯж
-
HashSetЕФжЕДцЗХгкHashMapЕФkeyЩЯ
-
HashMapЕФvalueЭГвЛЮЊPRESENT
25. ArrayList КЭ LinkedList ЕФЧјБ№ЪЧЪВУД?
зюУїЯдЕФЧјБ№ЪЧ ArrrayListЕзВуЕФЪ§ОнНсЙЙЪЧЪ§зщ,жЇГжЫцЛњЗУЮЪ,Жј LinkedList ЕФЕзВуЪ§ОнНсЙЙЪЧЫЋЯђбЛЗСДБэ,ВЛжЇГжЫцЛњЗУЮЪЁЃЪЙгУЯТБъЗУЮЪвЛИідЊЫи,ArrayList ЕФЪБМфИДдгЖШЪЧ O(1),Жј LinkedList ЪЧ O(n)ЁЃ
26. ШчКЮЪЕЯжЪ§зщКЭ List жЎМфЕФзЊЛЛ?
-
ListзЊЛЛГЩЮЊЪ§зщ:ЕїгУArrayListЕФtoArrayЗНЗЈЁЃ
-
Ъ§зщзЊЛЛГЩЮЊList:ЕїгУArraysЕФasListЗНЗЈЁЃ
27. ArrayList КЭ Vector ЕФЧјБ№ЪЧЪВУД?
-
VectorЪЧЭЌВНЕФ,ЖјArrayListВЛЪЧЁЃШЛЖј,ШчЙћФубАЧѓдкЕќДњЕФЪБКђЖдСаБэНјааИФБф,ФугІИУЪЙгУCopyOnWriteArrayListЁЃ?
-
ArrayListБШVectorПь,ЫќвђЮЊгаЭЌВН,ВЛЛсЙ§диЁЃ?
-
ArrayListИќМгЭЈгУ,вђЮЊЮвУЧПЩвдЪЙгУCollectionsЙЄОпРрЧсвзЕиЛёШЁЭЌВНСаБэКЭжЛЖССаБэЁЃ
28. Array КЭ ArrayList гаКЮЧјБ№?
-
ArrayПЩвдШнФЩЛљБОРраЭКЭЖдЯѓ,ЖјArrayListжЛФмШнФЩЖдЯѓЁЃ?
-
ArrayЪЧжИЖЈДѓаЁЕФ,ЖјArrayListДѓаЁЪЧЙЬЖЈЕФЁЃ?
-
ArrayУЛгаЬсЙЉArrayListФЧУДЖрЙІФм,БШШчaddAllЁЂremoveAllКЭiteratorЕШЁЃ
29. дк Queue жа poll()КЭ remove()гаЪВУДЧјБ№?
poll() КЭ remove() ЖМЪЧДгЖгСажаШЁГівЛИідЊЫи,ЕЋЪЧ poll() дкЛёШЁдЊЫиЪЇАмЕФЪБКђЛсЗЕЛиПе,ЕЋЪЧ remove() ЪЇАмЕФЪБКђЛсХзГівьГЃЁЃ
30. ФФаЉМЏКЯРрЪЧЯпГЬАВШЋЕФ?
-
vector:ОЭБШarraylistЖрСЫИіЭЌВНЛЏЛњжЦ(ЯпГЬАВШЋ),вђЮЊаЇТЪНЯЕЭ,ЯждквбОВЛЬЋНЈвщЪЙгУЁЃдкwebгІгУжа,ЬиБ№ЪЧЧАЬЈвГУц,ЭљЭљаЇТЪ(вГУцЯьгІЫйЖШ)ЪЧгХЯШПМТЧЕФЁЃ
-
statck:ЖбеЛРр,ЯШНјКѓГіЁЃ
-
hashtable:ОЭБШhashmapЖрСЫИіЯпГЬАВШЋЁЃ
-
enumeration:УЖОй,ЯрЕБгкЕќДњЦїЁЃ
31. ЕќДњЦї Iterator ЪЧЪВУД?
ЕќДњЦїЪЧвЛжжЩшМЦФЃЪН,ЫќЪЧвЛИіЖдЯѓ,ЫќПЩвдБщРњВЂбЁдёађСажаЕФЖдЯѓ,ЖјПЊЗЂШЫдБВЛашвЊСЫНтИУађСаЕФЕзВуНсЙЙЁЃЕќДњЦїЭЈГЃБЛГЦЮЊЁАЧсСПМЖЁБЖдЯѓ,вђЮЊДДНЈЫќЕФДњМлаЁЁЃ
32. Iterator дѕУДЪЙгУ?гаЪВУДЬиЕу?
JavaжаЕФIteratorЙІФмБШНЯМђЕЅ,ВЂЧвжЛФмЕЅЯђвЦЖЏ:
ЁЁЁЁ
(1) ЪЙгУЗНЗЈiterator()вЊЧѓШнЦїЗЕЛивЛИіIteratorЁЃЕквЛДЮЕїгУIteratorЕФnext()ЗНЗЈЪБ,ЫќЗЕЛиађСаЕФЕквЛИідЊЫиЁЃзЂвт:iterator()ЗНЗЈЪЧjava.lang.IterableНгПк,БЛCollectionМЬГаЁЃ
ЁЁЁЁ
(2) ЪЙгУnext()ЛёЕУађСажаЕФЯТвЛИідЊЫиЁЃ
ЁЁЁЁ
(3) ЪЙгУhasNext()МьВщађСажаЪЧЗёЛЙгадЊЫиЁЃ
ЁЁЁЁ
(4) ЪЙгУremove()НЋЕќДњЦїаТЗЕЛиЕФдЊЫиЩОГ§ЁЃ
ЁЁЁЁ
IteratorЪЧJavaЕќДњЦїзюМђЕЅЕФЪЕЯж,ЮЊListЩшМЦЕФListIteratorОпгаИќЖрЕФЙІФм,ЫќПЩвдДгСНИіЗНЯђБщРњList,вВПЩвдДгListжаВхШыКЭЩОГ§дЊЫиЁЃ
33. Iterator КЭ ListIterator гаЪВУДЧјБ№?
-
IteratorПЩгУРДБщРњSetКЭListМЏКЯ,ЕЋЪЧListIteratorжЛФмгУРДБщРњListЁЃ?
-
IteratorЖдМЏКЯжЛФмЪЧЧАЯђБщРњ,ListIteratorМШПЩвдЧАЯђвВПЩвдКѓЯђЁЃ?
-
ListIteratorЪЕЯжСЫIteratorНгПк,ВЂАќКЌЦфЫћЕФЙІФм,БШШч:діМгдЊЫи,ЬцЛЛдЊЫи,ЛёШЁЧАвЛИіКЭКѓвЛИідЊЫиЕФЫїв§,ЕШЕШЁЃ
ЖрЯпГЬ
35. ВЂааКЭВЂЗЂгаЪВУДЧјБ№?
-
ВЂааЪЧжИСНИіЛђепЖрИіЪТМўдкЭЌвЛЪБПЬЗЂЩњ;ЖјВЂЗЂЪЧжИСНИіЛђЖрИіЪТМўдкЭЌвЛЪБМфМфИєЗЂЩњЁЃ
-
ВЂааЪЧдкВЛЭЌЪЕЬхЩЯЕФЖрИіЪТМў,ВЂЗЂЪЧдкЭЌвЛЪЕЬхЩЯЕФЖрИіЪТМўЁЃ
-
дквЛЬЈДІРэЦїЩЯЁАЭЌЪБЁБДІРэЖрИіШЮЮё,дкЖрЬЈДІРэЦїЩЯЭЌЪБДІРэЖрИіШЮЮёЁЃШчhadoopЗжВМЪНМЏШКЁЃ
ЫљвдВЂЗЂБрГЬЕФФПБъЪЧГфЗжЕФРћгУДІРэЦїЕФУПвЛИіКЫ,вдДяЕНзюИпЕФДІРэадФмЁЃ
36. ЯпГЬКЭНјГЬЕФЧјБ№?
МђЖјбджЎ,НјГЬЪЧГЬађдЫааКЭзЪдДЗжХфЕФЛљБОЕЅЮЛ,вЛИіГЬађжСЩйгавЛИіНјГЬ,вЛИіНјГЬжСЩйгавЛИіЯпГЬЁЃНјГЬдкжДааЙ§ГЬжагЕгаЖРСЂЕФФкДцЕЅдЊ,ЖјЖрИіЯпГЬЙВЯэФкДцзЪдД,МѕЩйЧаЛЛДЮЪ§,ДгЖјаЇТЪИќИпЁЃЯпГЬЪЧНјГЬЕФвЛИіЪЕЬх,ЪЧcpuЕїЖШКЭЗжХЩЕФЛљБОЕЅЮЛ,ЪЧБШГЬађИќаЁЕФФмЖРСЂдЫааЕФЛљБОЕЅЮЛЁЃЭЌвЛНјГЬжаЕФЖрИіЯпГЬжЎМфПЩвдВЂЗЂжДааЁЃ
37. ЪиЛЄЯпГЬЪЧЪВУД?
ЪиЛЄЯпГЬ(МДdaemon thread),ЪЧИіЗўЮёЯпГЬ,зМШЗЕиРДЫЕОЭЪЧЗўЮёЦфЫћЕФЯпГЬЁЃ
38. ДДНЈЯпГЬгаФФМИжжЗНЪН?
Ђй. МЬГаThreadРрДДНЈЯпГЬРр
-
ЖЈвхThreadРрЕФзгРр,ВЂжиаДИУРрЕФrunЗНЗЈ,ИУrunЗНЗЈЕФЗНЗЈЬхОЭДњБэСЫЯпГЬвЊЭъГЩЕФШЮЮёЁЃвђДЫАбrun()ЗНЗЈГЦЮЊжДааЬхЁЃ
-
ДДНЈThreadзгРрЕФЪЕР§,МДДДНЈСЫЯпГЬЖдЯѓЁЃ
-
ЕїгУЯпГЬЖдЯѓЕФstart()ЗНЗЈРДЦєЖЏИУЯпГЬЁЃ
Ђк. ЭЈЙ§RunnableНгПкДДНЈЯпГЬРр
-
ЖЈвхrunnableНгПкЕФЪЕЯжРр,ВЂжиаДИУНгПкЕФrun()ЗНЗЈ,ИУrun()ЗНЗЈЕФЗНЗЈЬхЭЌбљЪЧИУЯпГЬЕФЯпГЬжДааЬхЁЃ
-
ДДНЈ RunnableЪЕЯжРрЕФЪЕР§,ВЂвРДЫЪЕР§зїЮЊThreadЕФtargetРДДДНЈThreadЖдЯѓ,ИУThreadЖдЯѓВХЪЧеце§ЕФЯпГЬЖдЯѓЁЃ
-
ЕїгУЯпГЬЖдЯѓЕФstart()ЗНЗЈРДЦєЖЏИУЯпГЬЁЃ
Ђл. ЭЈЙ§CallableКЭFutureДДНЈЯпГЬ
-
ДДНЈCallableНгПкЕФЪЕЯжРр,ВЂЪЕЯжcall()ЗНЗЈ,ИУcall()ЗНЗЈНЋзїЮЊЯпГЬжДааЬх,ВЂЧвгаЗЕЛижЕЁЃ
-
ДДНЈCallableЪЕЯжРрЕФЪЕР§,ЪЙгУFutureTaskРрРДАќзАCallableЖдЯѓ,ИУFutureTaskЖдЯѓЗтзАСЫИУCallableЖдЯѓЕФcall()ЗНЗЈЕФЗЕЛижЕЁЃ
-
ЪЙгУFutureTaskЖдЯѓзїЮЊThreadЖдЯѓЕФtargetДДНЈВЂЦєЖЏаТЯпГЬЁЃ
-
ЕїгУFutureTaskЖдЯѓЕФget()ЗНЗЈРДЛёЕУзгЯпГЬжДааНсЪјКѓЕФЗЕЛижЕЁЃ
39. ЫЕвЛЯТ runnable КЭ callable гаЪВУДЧјБ№?
гаЕуЩюЕФЮЪЬтСЫ,вВПДГівЛИіJavaГЬађдБбЇЯАжЊЪЖЕФЙуЖШЁЃ
-
RunnableНгПкжаЕФrun()ЗНЗЈЕФЗЕЛижЕЪЧvoid,ЫќзіЕФЪТЧщжЛЪЧДПДтЕиШЅжДааrun()ЗНЗЈжаЕФДњТыЖјвб;
-
CallableНгПкжаЕФcall()ЗНЗЈЪЧгаЗЕЛижЕЕФ,ЪЧвЛИіЗКаЭ,КЭFutureЁЂFutureTaskХфКЯПЩвдгУРДЛёШЁвьВНжДааЕФНсЙћЁЃ
40. ЯпГЬгаФФаЉзДЬЌ?
ЯпГЬЭЈГЃЖМгаЮхжжзДЬЌ,ДДНЈЁЂОЭаїЁЂдЫааЁЂзшШћКЭЫРЭіЁЃ
-
ДДНЈзДЬЌЁЃдкЩњГЩЯпГЬЖдЯѓ,ВЂУЛгаЕїгУИУЖдЯѓЕФstartЗНЗЈ,етЪЧЯпГЬДІгкДДНЈзДЬЌЁЃ
-
ОЭаїзДЬЌЁЃЕБЕїгУСЫЯпГЬЖдЯѓЕФstartЗНЗЈжЎКѓ,ИУЯпГЬОЭНјШыСЫОЭаїзДЬЌ,ЕЋЪЧДЫЪБЯпГЬЕїЖШГЬађЛЙУЛгаАбИУЯпГЬЩшжУЮЊЕБЧАЯпГЬ,ДЫЪБДІгкОЭаїзДЬЌЁЃдкЯпГЬдЫаажЎКѓ,ДгЕШД§ЛђепЫЏУпжаЛиРДжЎКѓ,вВЛсДІгкОЭаїзДЬЌЁЃ
-
дЫаазДЬЌЁЃЯпГЬЕїЖШГЬађНЋДІгкОЭаїзДЬЌЕФЯпГЬЩшжУЮЊЕБЧАЯпГЬ,ДЫЪБЯпГЬОЭНјШыСЫдЫаазДЬЌ,ПЊЪМдЫааrunКЏЪ§ЕБжаЕФДњТыЁЃ
-
зшШћзДЬЌЁЃЯпГЬе§дкдЫааЕФЪБКђ,БЛднЭЃ,ЭЈГЃЪЧЮЊСЫЕШД§ФГИіЪБМфЕФЗЂЩњ(БШШчЫЕФГЯюзЪдДОЭаї)жЎКѓдйМЬајдЫааЁЃsleep,suspend,waitЕШЗНЗЈЖМПЩвдЕМжТЯпГЬзшШћЁЃ
-
ЫРЭізДЬЌЁЃШчЙћвЛИіЯпГЬЕФrunЗНЗЈжДааНсЪјЛђепЕїгУstopЗНЗЈКѓ,ИУЯпГЬОЭЛсЫРЭіЁЃЖдгквбОЫРЭіЕФЯпГЬ,ЮоЗЈдйЪЙгУstartЗНЗЈСюЦфНјШыОЭаї ЁЁЁЁ
41. sleep() КЭ wait() гаЪВУДЧјБ№?
sleep():ЗНЗЈЪЧЯпГЬРр(Thread)ЕФОВЬЌЗНЗЈ,ШУЕїгУЯпГЬНјШыЫЏУпзДЬЌ,ШУГіжДааЛњЛсИјЦфЫћЯпГЬ,ЕШЕНанУпЪБМфНсЪјКѓ,ЯпГЬНјШыОЭаїзДЬЌКЭЦфЫћЯпГЬвЛЦ№ОКељcpuЕФжДааЪБМфЁЃвђЮЊsleep() ЪЧstaticОВЬЌЕФЗНЗЈ,ЫћВЛФмИФБфЖдЯѓЕФЛњЫј,ЕБвЛИіsynchronizedПщжаЕїгУСЫsleep() ЗНЗЈ,ЯпГЬЫфШЛНјШыанУп,ЕЋЪЧЖдЯѓЕФЛњЫјУЛгаБЛЪЭЗХ,ЦфЫћЯпГЬвРШЛЮоЗЈЗУЮЪетИіЖдЯѓЁЃ
wait():wait()ЪЧObjectРрЕФЗНЗЈ,ЕБвЛИіЯпГЬжДааЕНwaitЗНЗЈЪБ,ЫќОЭНјШыЕНвЛИіКЭИУЖдЯѓЯрЙиЕФЕШД§Ги,ЭЌЪБЪЭЗХЖдЯѓЕФЛњЫј,ЪЙЕУЦфЫћЯпГЬФмЙЛЗУЮЪ,ПЩвдЭЈЙ§notify,notifyAllЗНЗЈРДЛНабЕШД§ЕФЯпГЬ
42. notify()КЭ notifyAll()гаЪВУДЧјБ№?
-
ШчЙћЯпГЬЕїгУСЫЖдЯѓЕФ wait()ЗНЗЈ,ФЧУДЯпГЬБуЛсДІгкИУЖдЯѓЕФЕШД§Гижа,ЕШД§ГижаЕФЯпГЬВЛЛсШЅОКељИУЖдЯѓЕФЫјЁЃ
-
ЕБгаЯпГЬЕїгУСЫЖдЯѓЕФ notifyAll()ЗНЗЈ(ЛНабЫљга wait ЯпГЬ)Лђ notify()ЗНЗЈ(жЛЫцЛњЛНабвЛИі wait ЯпГЬ),БЛЛНабЕФЕФЯпГЬБуЛсНјШыИУЖдЯѓЕФЫјГижа,ЫјГижаЕФЯпГЬЛсШЅОКељИУЖдЯѓЫјЁЃвВОЭЪЧЫЕ,ЕїгУСЫnotifyКѓжЛвЊвЛИіЯпГЬЛсгЩЕШД§ГиНјШыЫјГи,ЖјnotifyAllЛсНЋИУЖдЯѓЕШД§ГиФкЕФЫљгаЯпГЬвЦЖЏЕНЫјГижа,ЕШД§ЫјОКељЁЃ
-
гХЯШМЖИпЕФЯпГЬОКељЕНЖдЯѓЫјЕФИХТЪДѓ,МйШєФГЯпГЬУЛгаОКељЕНИУЖдЯѓЫј,ЫќЛЙЛсСєдкЫјГижа,ЮЈгаЯпГЬдйДЮЕїгУ wait()ЗНЗЈ,ЫќВХЛсжиаТЛиЕНЕШД§ГижаЁЃЖјОКељЕНЖдЯѓЫјЕФЯпГЬдђМЬајЭљЯТжДаа,жБЕНжДааЭъСЫ synchronized ДњТыПщ,ЫќЛсЪЭЗХЕєИУЖдЯѓЫј,етЪБЫјГижаЕФЯпГЬЛсМЬајОКељИУЖдЯѓЫјЁЃ
43. ЯпГЬЕФ run()КЭ start()гаЪВУДЧјБ№?
УПИіЯпГЬЖМЪЧЭЈЙ§ФГИіЬиЖЈThreadЖдЯѓЫљЖдгІЕФЗНЗЈrun()РДЭъГЩЦфВйзїЕФ,ЗНЗЈrun()ГЦЮЊЯпГЬЬхЁЃЭЈЙ§ЕїгУThreadРрЕФstart()ЗНЗЈРДЦєЖЏвЛИіЯпГЬЁЃ
start()ЗНЗЈРДЦєЖЏвЛИіЯпГЬ,еце§ЪЕЯжСЫЖрЯпГЬдЫааЁЃетЪБЮоашЕШД§runЗНЗЈЬхДњТыжДааЭъБЯ,ПЩвджБНгМЬајжДааЯТУцЕФДњТы; етЪБДЫЯпГЬЪЧДІгкОЭаїзДЬЌ, ВЂУЛгадЫааЁЃ ШЛКѓЭЈЙ§ДЫThreadРрЕїгУЗНЗЈrun()РДЭъГЩЦфдЫаазДЬЌ, етРяЗНЗЈrun()ГЦЮЊЯпГЬЬх,ЫќАќКЌСЫвЊжДааЕФетИіЯпГЬЕФФкШн, RunЗНЗЈдЫааНсЪј, ДЫЯпГЬжежЙЁЃШЛКѓCPUдйЕїЖШЦфЫќЯпГЬЁЃ
run()ЗНЗЈЪЧдкБОЯпГЬРяЕФ,жЛЪЧЯпГЬРяЕФвЛИіКЏЪ§,ЖјВЛЪЧЖрЯпГЬЕФЁЃ?ШчЙћжБНгЕїгУrun(),ЦфЪЕОЭЯрЕБгкЪЧЕїгУСЫвЛИіЦеЭЈКЏЪ§Жјвб,жБНгД§гУrun()ЗНЗЈБиаыЕШД§run()ЗНЗЈжДааЭъБЯВХФмжДааЯТУцЕФДњТы,ЫљвджДааТЗОЖЛЙЪЧжЛгавЛЬѕ,ИљБООЭУЛгаЯпГЬЕФЬиеї,ЫљвддкЖрЯпГЬжДааЪБвЊЪЙгУstart()ЗНЗЈЖјВЛЪЧrun()ЗНЗЈЁЃ
44. ДДНЈЯпГЬГигаФФМИжжЗНЪН?
Ђй. newFixedThreadPool(int nThreads)
ДДНЈвЛИіЙЬЖЈГЄЖШЕФЯпГЬГи,УПЕБЬсНЛвЛИіШЮЮёОЭДДНЈвЛИіЯпГЬ,жБЕНДяЕНЯпГЬГиЕФзюДѓЪ§СП,етЪБЯпГЬЙцФЃНЋВЛдйБфЛЏ,ЕБЯпГЬЗЂЩњЮДдЄЦкЕФДэЮѓЖјНсЪјЪБ,ЯпГЬГиЛсВЙГфвЛИіаТЕФЯпГЬЁЃ
Ђк. newCachedThreadPool()
ДДНЈвЛИіПЩЛКДцЕФЯпГЬГи,ШчЙћЯпГЬГиЕФЙцФЃГЌЙ§СЫДІРэашЧѓ,НЋздЖЏЛиЪеПеЯаЯпГЬ,ЖјЕБашЧѓдіМгЪБ,дђПЩвдздЖЏЬэМгаТЯпГЬ,ЯпГЬГиЕФЙцФЃВЛДцдкШЮКЮЯожЦЁЃ
Ђл. newSingleThreadExecutor()
етЪЧвЛИіЕЅЯпГЬЕФExecutor,ЫќДДНЈЕЅИіЙЄзїЯпГЬРДжДааШЮЮё,ШчЙћетИіЯпГЬвьГЃНсЪј,ЛсДДНЈвЛИіаТЕФРДЬцДњЫќ;ЫќЕФЬиЕуЪЧФмШЗБЃвРееШЮЮёдкЖгСажаЕФЫГађРДДЎаажДааЁЃ
Ђм. newScheduledThreadPool(int corePoolSize)
ДДНЈСЫвЛИіЙЬЖЈГЄЖШЕФЯпГЬГи,ЖјЧввдбгГйЛђЖЈЪБЕФЗНЪНРДжДааШЮЮё,РрЫЦгкTimerЁЃ
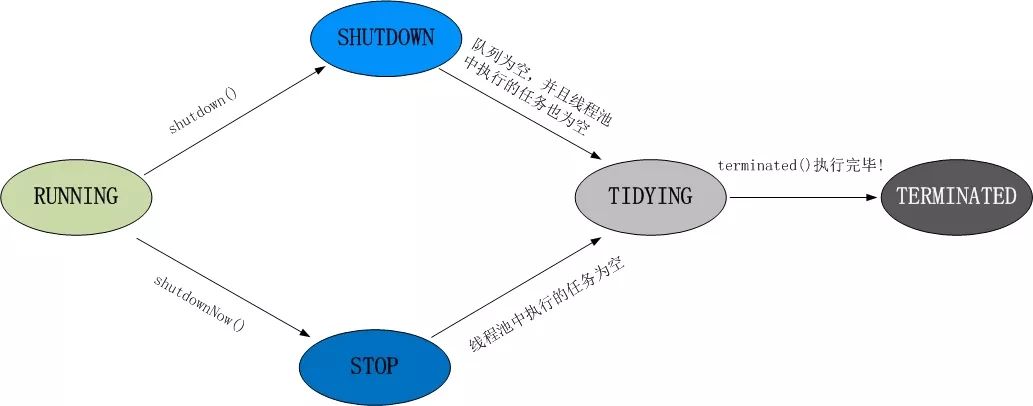
45. ЯпГЬГиЖМгаФФаЉзДЬЌ?
ЯпГЬГига5жжзДЬЌ:RunningЁЂShutDownЁЂStopЁЂTidyingЁЂTerminatedЁЃ
ЯпГЬГиИїИізДЬЌЧаЛЛПђМмЭМ:
46. ЯпГЬГижа submit()КЭ execute()ЗНЗЈгаЪВУДЧјБ№?
-
НгЪеЕФВЮЪ§ВЛвЛбљ
-
submitгаЗЕЛижЕ,ЖјexecuteУЛга
-
submitЗНБуExceptionДІРэ
47. дк java ГЬађжадѕУДБЃжЄЖрЯпГЬЕФдЫааАВШЋ?
ЯпГЬАВШЋдкШ§ИіЗНУцЬхЯж:
-
дзгад:ЬсЙЉЛЅГтЗУЮЪ,ЭЌвЛЪБПЬжЛФмгавЛИіЯпГЬЖдЪ§ОнНјааВйзї,(atomic,synchronized);
-
ПЩМћад:вЛИіЯпГЬЖджїФкДцЕФаоИФПЩвдМАЪБЕиБЛЦфЫћЯпГЬПДЕН,(synchronized,volatile);
-
гаађад:вЛИіЯпГЬЙлВьЦфЫћЯпГЬжаЕФжИСюжДааЫГађ,гЩгкжИСюжиХХађ,ИУЙлВьНсЙћвЛАудгТвЮоађ,(happens-beforeддђ)ЁЃ
48. ЖрЯпГЬЫјЕФЩ§МЖдРэЪЧЪВУД?
дкJavaжа,ЫјЙВга4жжзДЬЌ,МЖБ№ДгЕЭЕНИпвРДЮЮЊ:ЮозДЬЌЫј,ЦЋЯђЫј,ЧсСПМЖЫјКЭжиСПМЖЫјзДЬЌ,етМИИізДЬЌЛсЫцзХОКељЧщПіж№НЅЩ§МЖЁЃЫјПЩвдЩ§МЖЕЋВЛФмНЕМЖЁЃ
ЫјЩ§МЖЕФЭМЪОЙ§ГЬ:?
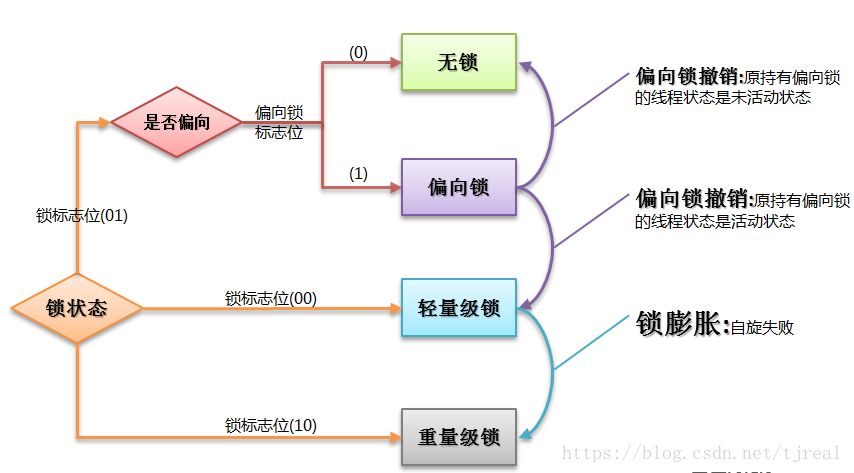
49. ЪВУДЪЧЫРЫј?
ЫРЫјЪЧжИСНИіЛђСНИівдЩЯЕФНјГЬдкжДааЙ§ГЬжа,гЩгкОКељзЪдДЛђепгЩгкБЫДЫЭЈаХЖјдьГЩЕФвЛжжзшШћЕФЯжЯѓ,ШєЮоЭтСІзїгУ,ЫќУЧЖМНЋЮоЗЈЭЦНјЯТШЅЁЃДЫЪБГЦЯЕЭГДІгкЫРЫјзДЬЌЛђЯЕЭГВњЩњСЫЫРЫј,етаЉгРдЖдкЛЅЯрЕШД§ЕФНјГЬГЦЮЊЫРЫјНјГЬЁЃЪЧВйзїЯЕЭГВуУцЕФвЛИіДэЮѓ,ЪЧНјГЬЫРЫјЕФМђГЦ,зюдчдк 1965 ФъгЩ Dijkstra дкбаОПвјааМвЫуЗЈЪБЬсГіЕФ,ЫќЪЧМЦЫуЛњВйзїЯЕЭГФЫжСећИіВЂЗЂГЬађЩшМЦСьгђзюФбДІРэЕФЮЪЬтжЎвЛЁЃ
50. дѕУДЗРжЙЫРЫј?
ЫРЫјЕФЫФИіБивЊЬѕМў:
-
ЛЅГтЬѕМў:НјГЬЖдЫљЗжХфЕНЕФзЪдДВЛдЪаэЦфЫћНјГЬНјааЗУЮЪ,ШєЦфЫћНјГЬЗУЮЪИУзЪдД,жЛФмЕШД§,жБжСеМгаИУзЪдДЕФНјГЬЪЙгУЭъГЩКѓЪЭЗХИУзЪдД
-
ЧыЧѓКЭБЃГжЬѕМў:НјГЬЛёЕУвЛЖЈЕФзЪдДжЎКѓ,гжЖдЦфЫћзЪдДЗЂГіЧыЧѓ,ЕЋЪЧИУзЪдДПЩФмБЛЦфЫћНјГЬеМга,ДЫЪТЧыЧѓзшШћ,ЕЋгжЖдздМКЛёЕУЕФзЪдДБЃГжВЛЗХ
-
ВЛПЩАўЖсЬѕМў:ЪЧжИНјГЬвбЛёЕУЕФзЪдД,дкЮДЭъГЩЪЙгУжЎЧА,ВЛПЩБЛАўЖс,жЛФмдкЪЙгУЭъКѓздМКЪЭЗХ
-
ЛЗТЗЕШД§ЬѕМў:ЪЧжИНјГЬЗЂЩњЫРЫјКѓ,ШєИЩНјГЬжЎМфаЮГЩвЛжжЭЗЮВЯрНгЕФбЛЗЕШД§зЪдДЙиЯЕ
етЫФИіЬѕМўЪЧЫРЫјЕФБивЊЬѕМў,жЛвЊЯЕЭГЗЂЩњЫРЫј,етаЉЬѕМўБиШЛГЩСЂ,ЖјжЛвЊЩЯЪіЬѕМўжЎ вЛВЛТњзу,ОЭВЛЛсЗЂЩњЫРЫјЁЃ
РэНтСЫЫРЫјЕФдвђ,гШЦфЪЧВњЩњЫРЫјЕФЫФИіБивЊЬѕМў,ОЭПЩвдзюДѓПЩФмЕиБмУтЁЂдЄЗРКЭ НтГ§ЫРЫјЁЃ
Ыљвд,дкЯЕЭГЩшМЦЁЂНјГЬЕїЖШЕШЗНУцзЂвтШчКЮВЛШУетЫФИіБивЊЬѕМўГЩСЂ,ШчКЮШЗ ЖЈзЪдДЕФКЯРэЗжХфЫуЗЈ,БмУтНјГЬгРОУеМОнЯЕЭГзЪдДЁЃ
ДЫЭт,вВвЊЗРжЙНјГЬдкДІгкЕШД§зДЬЌЕФЧщПіЯТеМгУзЪдДЁЃвђДЫ,ЖдзЪдДЕФЗжХфвЊИјгшКЯРэЕФЙцЛЎЁЃ
51. ThreadLocal ЪЧЪВУД?гаФФаЉЪЙгУГЁОА?
ЯпГЬОжВПБфСПЪЧОжЯогкЯпГЬФкВПЕФБфСП,ЪєгкЯпГЬздЩэЫљга,ВЛдкЖрИіЯпГЬМфЙВЯэЁЃJavaЬсЙЉThreadLocalРрРДжЇГжЯпГЬОжВПБфСП,ЪЧвЛжжЪЕЯжЯпГЬАВШЋЕФЗНЪНЁЃЕЋЪЧдкЙмРэЛЗОГЯТ(Шч web ЗўЮёЦї)ЪЙгУЯпГЬОжВПБфСПЕФЪБКђвЊЬиБ№аЁаФ,дкетжжЧщПіЯТ,ЙЄзїЯпГЬЕФЩњУќжмЦкБШШЮКЮгІгУБфСПЕФЩњУќжмЦкЖМвЊГЄЁЃШЮКЮЯпГЬОжВПБфСПвЛЕЉдкЙЄзїЭъГЩКѓУЛгаЪЭЗХ,Java гІгУОЭДцдкФкДцаЙТЖЕФЗчЯеЁЃ
52.ЫЕвЛЯТ synchronized ЕзВуЪЕЯждРэ?
synchronizedПЩвдБЃжЄЗНЗЈЛђепДњТыПщдкдЫааЪБ,ЭЌвЛЪБПЬжЛгавЛИіЗНЗЈПЩвдНјШыЕНСйНчЧј,ЭЌЪБЫќЛЙПЩвдБЃжЄЙВЯэБфСПЕФФкДцПЩМћадЁЃ
JavaжаУПвЛИіЖдЯѓЖМПЩвдзїЮЊЫј,етЪЧsynchronizedЪЕЯжЭЌВНЕФЛљДЁ:
-
ЦеЭЈЭЌВНЗНЗЈ,ЫјЪЧЕБЧАЪЕР§ЖдЯѓ
-
ОВЬЌЭЌВНЗНЗЈ,ЫјЪЧЕБЧАРрЕФclassЖдЯѓ
-
ЭЌВНЗНЗЈПщ,ЫјЪЧРЈКХРяУцЕФЖдЯѓ
53. synchronized КЭ volatile ЕФЧјБ№ЪЧЪВУД?
-
volatileБОжЪЪЧдкИцЫпjvmЕБЧАБфСПдкМФДцЦї(ЙЄзїФкДц)жаЕФжЕЪЧВЛШЗЖЈЕФ,ашвЊДгжїДцжаЖСШЁ; synchronizedдђЪЧЫјЖЈЕБЧАБфСП,жЛгаЕБЧАЯпГЬПЩвдЗУЮЪИУБфСП,ЦфЫћЯпГЬБЛзшШћзЁЁЃ
-
volatileНіФмЪЙгУдкБфСПМЖБ№;synchronizedдђПЩвдЪЙгУдкБфСПЁЂЗНЗЈЁЂКЭРрМЖБ№ЕФЁЃ
-
volatileНіФмЪЕЯжБфСПЕФаоИФПЩМћад,ВЛФмБЃжЄдзгад;ЖјsynchronizedдђПЩвдБЃжЄБфСПЕФаоИФПЩМћадКЭдзгадЁЃ
-
volatileВЛЛсдьГЩЯпГЬЕФзшШћ;synchronizedПЩФмЛсдьГЩЯпГЬЕФзшШћЁЃ
-
volatileБъМЧЕФБфСПВЛЛсБЛБрвыЦїгХЛЏ;synchronizedБъМЧЕФБфСППЩвдБЛБрвыЦїгХЛЏЁЃ
54. synchronized КЭ Lock гаЪВУДЧјБ№?
-
ЪзЯШsynchronizedЪЧjavaФкжУЙиМќзж,дкjvmВуУц,LockЪЧИіjavaРр;
-
synchronizedЮоЗЈХаЖЯЪЧЗёЛёШЁЫјЕФзДЬЌ,LockПЩвдХаЖЯЪЧЗёЛёШЁЕНЫј;
-
synchronizedЛсздЖЏЪЭЗХЫј(a?ЯпГЬжДааЭъЭЌВНДњТыЛсЪЭЗХЫј ;b ЯпГЬжДааЙ§ГЬжаЗЂЩњвьГЃЛсЪЭЗХЫј),LockашдкfinallyжаЪжЙЄЪЭЗХЫј(unlock()ЗНЗЈЪЭЗХЫј),ЗёдђШнвздьГЩЯпГЬЫРЫј;
-
гУsynchronizedЙиМќзжЕФСНИіЯпГЬ1КЭЯпГЬ2,ШчЙћЕБЧАЯпГЬ1ЛёЕУЫј,ЯпГЬ2ЯпГЬЕШД§ЁЃШчЙћЯпГЬ1зшШћ,ЯпГЬ2дђЛсвЛжБЕШД§ЯТШЅ,ЖјLockЫјОЭВЛвЛЖЈЛсЕШД§ЯТШЅ,ШчЙћГЂЪдЛёШЁВЛЕНЫј,ЯпГЬПЩвдВЛгУвЛжБЕШД§ОЭНсЪјСЫ;
-
synchronizedЕФЫјПЩжиШыЁЂВЛПЩжаЖЯЁЂЗЧЙЋЦН,ЖјLockЫјПЩжиШыЁЂПЩХаЖЯЁЂПЩЙЋЦН(СНепНдПЩ);
-
LockЫјЪЪКЯДѓСПЭЌВНЕФДњТыЕФЭЌВНЮЪЬт,synchronizedЫјЪЪКЯДњТыЩйСПЕФЭЌВНЮЪЬтЁЃ
55. synchronized КЭ ReentrantLock ЧјБ№ЪЧЪВУД?
synchronizedЪЧКЭifЁЂelseЁЂforЁЂwhileвЛбљЕФЙиМќзж,ReentrantLockЪЧРр,етЪЧЖўепЕФБОжЪЧјБ№ЁЃМШШЛReentrantLockЪЧРр,ФЧУДЫќОЭЬсЙЉСЫБШsynchronizedИќЖрИќСщЛюЕФЬиад,ПЩвдБЛМЬГаЁЂПЩвдгаЗНЗЈЁЂПЩвдгаИїжжИїбљЕФРрБфСП,ReentrantLockБШsynchronizedЕФРЉеЙадЬхЯждкМИЕуЩЯ:?
-
ReentrantLockПЩвдЖдЛёШЁЫјЕФЕШД§ЪБМфНјааЩшжУ,етбљОЭБмУтСЫЫРЫј?
-
ReentrantLockПЩвдЛёШЁИїжжЫјЕФаХЯЂ
-
ReentrantLockПЩвдСщЛюЕиЪЕЯжЖрТЗЭЈжЊ?
СэЭт,ЖўепЕФЫјЛњжЦЦфЪЕвВЪЧВЛвЛбљЕФ:ReentrantLockЕзВуЕїгУЕФЪЧUnsafeЕФparkЗНЗЈМгЫј,synchronizedВйзїЕФгІИУЪЧЖдЯѓЭЗжаmark wordЁЃ
56. ЫЕвЛЯТ atomic ЕФдРэ?
AtomicАќжаЕФРрЛљБОЕФЬиадОЭЪЧдкЖрЯпГЬЛЗОГЯТ,ЕБгаЖрИіЯпГЬЭЌЪБЖдЕЅИі(АќРЈЛљБОРраЭМАв§гУРраЭ)БфСПНјааВйзїЪБ,ОпгаХХЫћад,МДЕБЖрИіЯпГЬЭЌЪБЖдИУБфСПЕФжЕНјааИќаТЪБ,НігавЛИіЯпГЬФмГЩЙІ,ЖјЮДГЩЙІЕФЯпГЬПЩвдЯђзда§ЫјвЛбљ,МЬајГЂЪд,вЛжБЕШЕНжДааГЩЙІЁЃ
AtomicЯЕСаЕФРржаЕФКЫаФЗНЗЈЖМЛсЕїгУunsafeРржаЕФМИИіБОЕиЗНЗЈЁЃЮвУЧашвЊЯШжЊЕРвЛИіЖЋЮїОЭЪЧUnsafeРр,ШЋУћЮЊ:sun.misc.Unsafe,етИіРрАќКЌСЫДѓСПЕФЖдCДњТыЕФВйзї,АќРЈКмЖржБНгФкДцЗжХфвдМАдзгВйзїЕФЕїгУ,ЖјЫќжЎЫљвдБъМЧЮЊЗЧАВШЋЕФ,ЪЧИцЫпФуетИіРяУцДѓСПЕФЗНЗЈЕїгУЖМЛсДцдкАВШЋвўЛМ,ашвЊаЁаФЪЙгУ,ЗёдђЛсЕМжТбЯжиЕФКѓЙћ,Р§ШчдкЭЈЙ§unsafeЗжХфФкДцЕФЪБКђ,ШчЙћздМКжИЖЈФГаЉЧјгђПЩФмЛсЕМжТвЛаЉРрЫЦC++вЛбљЕФжИеыдННчЕНЦфЫћНјГЬЕФЮЪЬтЁЃ
ЗДЩф
57. ЪВУДЪЧЗДЩф?
ЗДЩфжївЊЪЧжИГЬађПЩвдЗУЮЪЁЂМьВтКЭаоИФЫќБОЩэзДЬЌЛђааЮЊЕФвЛжжФмСІ
JavaЗДЩф:
дкJavaдЫааЪБЛЗОГжа,ЖдгкШЮвтвЛИіРр,ФмЗёжЊЕРетИіРргаФФаЉЪєадКЭЗНЗЈ?ЖдгкШЮвтвЛИіЖдЯѓ,ФмЗёЕїгУЫќЕФШЮвтвЛИіЗНЗЈ
JavaЗДЩфЛњжЦжївЊЬсЙЉСЫвдЯТЙІФм:
-
дкдЫааЪБХаЖЯШЮвтвЛИіЖдЯѓЫљЪєЕФРрЁЃ
-
дкдЫааЪБЙЙдьШЮвтвЛИіРрЕФЖдЯѓЁЃ
-
дкдЫааЪБХаЖЯШЮвтвЛИіРрЫљОпгаЕФГЩдББфСПКЭЗНЗЈЁЃ
-
дкдЫааЪБЕїгУШЮвтвЛИіЖдЯѓЕФЗНЗЈЁЃ?
58. ЪВУДЪЧ java ађСаЛЏ?ЪВУДЧщПіЯТашвЊађСаЛЏ?
МђЕЅЫЕОЭЪЧЮЊСЫБЃДцдкФкДцжаЕФИїжжЖдЯѓЕФзДЬЌ(вВОЭЪЧЪЕР§БфСП,ВЛЪЧЗНЗЈ),ВЂЧвПЩвдАбБЃДцЕФЖдЯѓзДЬЌдйЖСГіРДЁЃЫфШЛФуПЩвдгУФуздМКЕФИїжжИїбљЕФЗНЗЈРДБЃДцobject states,ЕЋЪЧJavaИјФуЬсЙЉвЛжжгІИУБШФуздМККУЕФБЃДцЖдЯѓзДЬЌЕФЛњжЦ,ФЧОЭЪЧађСаЛЏЁЃ
ЪВУДЧщПіЯТашвЊађСаЛЏ:
a)ЕБФуЯыАбЕФФкДцжаЕФЖдЯѓзДЬЌБЃДцЕНвЛИіЮФМўжаЛђепЪ§ОнПтжаЪБКђ;
b)ЕБФуЯыгУЬзНгзждкЭјТчЩЯДЋЫЭЖдЯѓЕФЪБКђ;
c)ЕБФуЯыЭЈЙ§RMIДЋЪфЖдЯѓЕФЪБКђ;
59. ЖЏЬЌДњРэЪЧЪВУД?гаФФаЉгІгУ?
ЖЏЬЌДњРэ:
ЕБЯывЊИјЪЕЯжСЫФГИіНгПкЕФРржаЕФЗНЗЈ,МгвЛаЉЖюЭтЕФДІРэЁЃБШШчЫЕМгШежО,МгЪТЮёЕШЁЃПЩвдИјетИіРрДДНЈвЛИіДњРэ,ЙЪУћЫМвщОЭЪЧДДНЈвЛИіаТЕФРр,етИіРрВЛНіАќКЌдРДРрЗНЗЈЕФЙІФм,ЖјЧвЛЙдкдРДЕФЛљДЁЩЯЬэМгСЫЖюЭтДІРэЕФаТРрЁЃетИіДњРэРрВЂВЛЪЧЖЈвхКУЕФ,ЪЧЖЏЬЌЩњГЩЕФЁЃОпгаНтёювтвх,СщЛю,РЉеЙадЧПЁЃ
ЖЏЬЌДњРэЕФгІгУ:
-
SpringЕФAOP
-
МгЪТЮё
-
МгШЈЯо
-
МгШежО
60. дѕУДЪЕЯжЖЏЬЌДњРэ?
ЪзЯШБиаыЖЈвхвЛИіНгПк,ЛЙвЊгавЛИіInvocationHandler(НЋЪЕЯжНгПкЕФРрЕФЖдЯѓДЋЕнИјЫќ)ДІРэРрЁЃдйгавЛИіЙЄОпРрProxy(ЯАЙпадНЋЦфГЦЮЊДњРэРр,вђЮЊЕїгУЫћЕФnewInstance()ПЩвдВњЩњДњРэЖдЯѓ,ЦфЪЕЫћжЛЪЧвЛИіВњЩњДњРэЖдЯѓЕФЙЄОпРр)ЁЃРћгУЕНInvocationHandler,ЦДНгДњРэРрдДТы,НЋЦфБрвыЩњГЩДњРэРрЕФЖўНјжЦТы,РћгУМгдиЦїМгди,ВЂНЋЦфЪЕР§ЛЏВњЩњДњРэЖдЯѓ,зюКѓЗЕЛиЁЃ
ЕкЮхФЃПщД№АИ
ЖдЯѓПНБД
61. ЮЊЪВУДвЊЪЙгУПЫТЁ?
ЯыЖдвЛИіЖдЯѓНјааДІРэ,гжЯыБЃСєдгаЕФЪ§ОнНјааНгЯТРДЕФВйзї,ОЭашвЊПЫТЁСЫ,JavaгябджаПЫТЁеыЖдЕФЪЧРрЕФЪЕР§ЁЃ
62. ШчКЮЪЕЯжЖдЯѓПЫТЁ?
гаСНжжЗНЪН:
1). ЪЕЯжCloneableНгПкВЂжиаДObjectРржаЕФclone()ЗНЗЈ;
??
2). ЪЕЯжSerializableНгПк,ЭЈЙ§ЖдЯѓЕФађСаЛЏКЭЗДађСаЛЏЪЕЯжПЫТЁ,ПЩвдЪЕЯжеце§ЕФЩюЖШПЫТЁ,ДњТыШчЯТ:
import java.io.ByteArrayInputStream;import java.io.ByteArrayOutputStream;import java.io.ObjectInputStream;import java.io.ObjectOutputStream;import java.io.Serializable;public class MyUtil {private MyUtil() {throw new AssertionError();}@SuppressWarnings("unchecked")public static <T extends Serializable> T clone(T obj) throws Exception {ByteArrayOutputStream bout = new ByteArrayOutputStream();ObjectOutputStream oos = new ObjectOutputStream(bout);oos.writeObject(obj);ByteArrayInputStream bin = new ByteArrayInputStream(bout.toByteArray());ObjectInputStream ois = new ObjectInputStream(bin);return (T) ois.readObject();// ЫЕУї:ЕїгУByteArrayInputStreamЛђByteArrayOutputStreamЖдЯѓЕФcloseЗНЗЈУЛгаШЮКЮвтвх// етСНИіЛљгкФкДцЕФСїжЛвЊРЌЛјЛиЪеЦїЧхРэЖдЯѓОЭФмЙЛЪЭЗХзЪдД,етвЛЕуВЛЭЌгкЖдЭтВПзЪдД(ШчЮФМўСї)ЕФЪЭЗХ}}
ЯТУцЪЧВтЪдДњТы:
import java.io.Serializable;/*** ШЫРр* @author nnngu**/class Person implements Serializable {private static final long serialVersionUID = -9102017020286042305L;private String name; // аеУћprivate int age; // ФъСфprivate Car car; // зљМнpublic Person(String name, int age, Car car) {this.name = name;this.age = age;this.car = car;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public Car getCar() {return car;}public void setCar(Car car) {this.car = car;}@Overridepublic String toString() {return "Person [name=" + name + ", age=" + age + ", car=" + car + "]";}}
/*** аЁЦћГЕРр* @author nnngu**/class Car implements Serializable {private static final long serialVersionUID = -5713945027627603702L;private String brand; // ЦЗХЦprivate int maxSpeed; // зюИпЪБЫйpublic Car(String brand, int maxSpeed) {this.brand = brand;this.maxSpeed = maxSpeed;}public String getBrand() {return brand;}public void setBrand(String brand) {this.brand = brand;}public int getMaxSpeed() {return maxSpeed;}public void setMaxSpeed(int maxSpeed) {this.maxSpeed = maxSpeed;}@Overridepublic String toString() {return "Car [brand=" + brand + ", maxSpeed=" + maxSpeed + "]";}}
class CloneTest {public static void main(String[] args) {try {Person p1 = new Person("ЙљОИ", 33, new Car("Benz", 300));Person p2 = MyUtil.clone(p1); // ЩюЖШПЫТЁp2.getCar().setBrand("BYD");// аоИФПЫТЁЕФPersonЖдЯѓp2ЙиСЊЕФЦћГЕЖдЯѓЕФЦЗХЦЪєад// дРДЕФPersonЖдЯѓp1ЙиСЊЕФЦћГЕВЛЛсЪмЕНШЮКЮгАЯь// вђЮЊдкПЫТЁPersonЖдЯѓЪБЦфЙиСЊЕФЦћГЕЖдЯѓвВБЛПЫТЁСЫSystem.out.println(p1);} catch (Exception e) {e.printStackTrace();}}}
зЂвт:ЛљгкађСаЛЏКЭЗДађСаЛЏЪЕЯжЕФПЫТЁВЛНіНіЪЧЩюЖШПЫТЁ,ИќживЊЕФЪЧЭЈЙ§ЗКаЭЯоЖЈ,ПЩвдМьВщГівЊПЫТЁЕФЖдЯѓЪЧЗёжЇГжађСаЛЏ,етЯюМьВщЪЧБрвыЦїЭъГЩЕФ,ВЛЪЧдкдЫааЪБХзГівьГЃ,етжжЪЧЗНАИУїЯдгХгкЪЙгУObjectРрЕФcloneЗНЗЈПЫТЁЖдЯѓЁЃШУЮЪЬтдкБрвыЕФЪБКђБЉТЖГіРДзмЪЧКУЙ§АбЮЪЬтСєЕНдЫааЪБЁЃ
63. ЩюПНБДКЭЧГПНБДЧјБ№ЪЧЪВУД?
-
ЧГПНБДжЛЪЧИДжЦСЫЖдЯѓЕФв§гУЕижЗ,СНИіЖдЯѓжИЯђЭЌвЛИіФкДцЕижЗ,ЫљвдаоИФЦфжаШЮвтЕФжЕ,СэвЛИіжЕЖМЛсЫцжЎБфЛЏ,етОЭЪЧЧГПНБД(Р§:assign())
-
ЩюПНБДЪЧНЋЖдЯѓМАжЕИДжЦЙ§РД,СНИіЖдЯѓаоИФЦфжаШЮвтЕФжЕСэвЛИіжЕВЛЛсИФБф,етОЭЪЧЩюПНБД(Р§:JSON.parse()КЭJSON.stringify(),ЕЋЪЧДЫЗНЗЈЮоЗЈИДжЦКЏЪ§РраЭ)
Java Web
64. jsp КЭ servlet гаЪВУДЧјБ№?
-
jspОБрвыКѓОЭБфГЩСЫServlet.(JSPЕФБОжЪОЭЪЧServlet,JVMжЛФмЪЖБ№javaЕФРр,ВЛФмЪЖБ№JSPЕФДњТы,WebШнЦїНЋJSPЕФДњТыБрвыГЩJVMФмЙЛЪЖБ№ЕФjavaРр)
-
jspИќЩУГЄБэЯжгквГУцЯдЪО,servletИќЩУГЄгкТпМПижЦЁЃ
-
ServletжаУЛгаФкжУЖдЯѓ,JspжаЕФФкжУЖдЯѓЖМЪЧБиаыЭЈЙ§HttpServletRequestЖдЯѓ,HttpServletResponseЖдЯѓвдМАHttpServletЖдЯѓЕУЕНЁЃ
-
JspЪЧServletЕФвЛжжМђЛЏ,ЪЙгУJspжЛашвЊЭъГЩГЬађдБашвЊЪфГіЕНПЭЛЇЖЫЕФФкШн,JspжаЕФJavaНХБОШчКЮЯтЧЖЕНвЛИіРржа,гЩJspШнЦїЭъГЩЁЃЖјServletдђЪЧИіЭъећЕФJavaРр,етИіРрЕФServiceЗНЗЈгУгкЩњГЩЖдПЭЛЇЖЫЕФЯьгІЁЃ
65. jsp гаФФаЉФкжУЖдЯѓ?зїгУЗжБ№ЪЧЪВУД?
JSPга9ИіФкжУЖдЯѓ:
-
request:ЗтзАПЭЛЇЖЫЕФЧыЧѓ,ЦфжаАќКЌРДздGETЛђPOSTЧыЧѓЕФВЮЪ§;
-
response:ЗтзАЗўЮёЦїЖдПЭЛЇЖЫЕФЯьгІ;
-
pageContext:ЭЈЙ§ИУЖдЯѓПЩвдЛёШЁЦфЫћЖдЯѓ;
-
session:ЗтзАгУЛЇЛсЛАЕФЖдЯѓ;
-
application:ЗтзАЗўЮёЦїдЫааЛЗОГЕФЖдЯѓ;
-
out:ЪфГіЗўЮёЦїЯьгІЕФЪфГіСїЖдЯѓ;
-
config:WebгІгУЕФХфжУЖдЯѓ;
-
page:JSPвГУцБОЩэ(ЯрЕБгкJavaГЬађжаЕФthis);
-
exception:ЗтзАвГУцХзГівьГЃЕФЖдЯѓЁЃ
66. ЫЕвЛЯТ jsp ЕФ 4 жжзїгУгђ?
JSPжаЕФЫФжжзїгУгђАќРЈpageЁЂrequestЁЂsessionКЭapplication,ОпЬхРДЫЕ:
-
pageДњБэгывЛИівГУцЯрЙиЕФЖдЯѓКЭЪєадЁЃ
-
requestДњБэгыWebПЭЛЇЛњЗЂГіЕФвЛИіЧыЧѓЯрЙиЕФЖдЯѓКЭЪєадЁЃвЛИіЧыЧѓПЩФмПчдНЖрИівГУц,ЩцМАЖрИіWebзщМў;ашвЊдквГУцЯдЪОЕФСйЪБЪ§ОнПЩвджУгкДЫзїгУгђЁЃ
-
sessionДњБэгыФГИігУЛЇгыЗўЮёЦїНЈСЂЕФвЛДЮЛсЛАЯрЙиЕФЖдЯѓКЭЪєадЁЃИњФГИігУЛЇЯрЙиЕФЪ§ОнгІИУЗХдкгУЛЇздМКЕФsessionжаЁЃ
-
applicationДњБэгыећИіWebгІгУГЬађЯрЙиЕФЖдЯѓКЭЪєад,ЫќЪЕжЪЩЯЪЧПчдНећИіWebгІгУГЬађ,АќРЈЖрИівГУцЁЂЧыЧѓКЭЛсЛАЕФвЛИіШЋОжзїгУгђЁЃ
67. session КЭ cookie гаЪВУДЧјБ№?
-
гЩгкHTTPавщЪЧЮозДЬЌЕФавщ,ЫљвдЗўЮёЖЫашвЊМЧТМгУЛЇЕФзДЬЌЪБ,ОЭашвЊгУФГжжЛњжЦРДЪЖОпЬхЕФгУЛЇ,етИіЛњжЦОЭЪЧSession.ЕфаЭЕФГЁОАБШШчЙКЮяГЕ,ЕБФуЕуЛїЯТЕЅАДХЅЪБ,гЩгкHTTPавщЮозДЬЌ,ЫљвдВЂВЛжЊЕРЪЧФФИігУЛЇВйзїЕФ,ЫљвдЗўЮёЖЫвЊЮЊЬиЖЈЕФгУЛЇДДНЈСЫЬиЖЈЕФSession,гУгУгкБъЪЖетИігУЛЇ,ВЂЧвИњзйгУЛЇ,етбљВХжЊЕРЙКЮяГЕРяУцгаМИБОЪщЁЃетИіSessionЪЧБЃДцдкЗўЮёЖЫЕФ,гавЛИіЮЈвЛБъЪЖЁЃдкЗўЮёЖЫБЃДцSessionЕФЗНЗЈКмЖр,ФкДцЁЂЪ§ОнПтЁЂЮФМўЖМгаЁЃМЏШКЕФЪБКђвВвЊПМТЧSessionЕФзЊвЦ,дкДѓаЭЕФЭјеО,вЛАуЛсгазЈУХЕФSessionЗўЮёЦїМЏШК,гУРДБЃДцгУЛЇЛсЛА,етИіЪБКђ Session аХЯЂЖМЪЧЗХдкФкДцЕФ,ЪЙгУвЛаЉЛКДцЗўЮёБШШчMemcachedжЎРрЕФРДЗХ SessionЁЃ
-
ЫМПМвЛЯТЗўЮёЖЫШчКЮЪЖБ№ЬиЖЈЕФПЭЛЇ?етИіЪБКђCookieОЭЕЧГЁСЫЁЃУПДЮHTTPЧыЧѓЕФЪБКђ,ПЭЛЇЖЫЖМЛсЗЂЫЭЯргІЕФCookieаХЯЂЕНЗўЮёЖЫЁЃЪЕМЪЩЯДѓЖрЪ§ЕФгІгУЖМЪЧгУ Cookie РДЪЕЯжSessionИњзйЕФ,ЕквЛДЮДДНЈSessionЕФЪБКђ,ЗўЮёЖЫЛсдкHTTPавщжаИцЫпПЭЛЇЖЫ,ашвЊдк Cookie РяУцМЧТМвЛИіSession ID,вдКѓУПДЮЧыЧѓАбетИіЛсЛАIDЗЂЫЭЕНЗўЮёЦї,ЮвОЭжЊЕРФуЪЧЫСЫЁЃгаШЫЮЪ,ШчЙћПЭЛЇЖЫЕФфЏРРЦїНћгУСЫ Cookie дѕУДАь?вЛАуетжжЧщПіЯТ,ЛсЪЙгУвЛжжНазіURLжиаДЕФММЪѕРДНјааЛсЛАИњзй,МДУПДЮHTTPНЛЛЅ,URLКѓУцЖМЛсБЛИНМгЩЯвЛИіжюШч sid=xxxxx етбљЕФВЮЪ§,ЗўЮёЖЫОнДЫРДЪЖБ№гУЛЇЁЃ
-
CookieЦфЪЕЛЙПЩвдгУдквЛаЉЗНБугУЛЇЕФГЁОАЯТ,ЩшЯыФуФГДЮЕЧТНЙ§вЛИіЭјеО,ЯТДЮЕЧТМЕФЪБКђВЛЯыдйДЮЪфШыеЫКХСЫ,дѕУДАь?етИіаХЯЂПЩвдаДЕНCookieРяУц,ЗУЮЪЭјеОЕФЪБКђ,ЭјеОвГУцЕФНХБОПЩвдЖСШЁетИіаХЯЂ,ОЭздЖЏАяФуАбгУЛЇУћИјЬюСЫ,ФмЙЛЗНБувЛЯТгУЛЇЁЃетвВЪЧCookieУћГЦЕФгЩРД,ИјгУЛЇЕФвЛЕуЬ№ЭЗЁЃЫљвд,змНсвЛЯТ:SessionЪЧдкЗўЮёЖЫБЃДцЕФвЛИіЪ§ОнНсЙЙ,гУРДИњзйгУЛЇЕФзДЬЌ,етИіЪ§ОнПЩвдБЃДцдкМЏШКЁЂЪ§ОнПтЁЂЮФМўжа;CookieЪЧПЭЛЇЖЫБЃДцгУЛЇаХЯЂЕФвЛжжЛњжЦ,гУРДМЧТМгУЛЇЕФвЛаЉаХЯЂ,вВЪЧЪЕЯжSessionЕФвЛжжЗНЪНЁЃ
68. ЫЕвЛЯТ session ЕФЙЄзїдРэ?
ЦфЪЕsessionЪЧвЛИіДцдкЗўЮёЦїЩЯЕФРрЫЦгквЛИіЩЂСаБэИёЕФЮФМўЁЃРяУцДцгаЮвУЧашвЊЕФаХЯЂ,дкЮвУЧашвЊгУЕФЪБКђПЩвдДгРяУцШЁГіРДЁЃРрЫЦгквЛИіДѓКХЕФmapАЩ,РяУцЕФМќДцДЂЕФЪЧгУЛЇЕФsessionid,гУЛЇЯђЗўЮёЦїЗЂЫЭЧыЧѓЕФЪБКђЛсДјЩЯетИіsessionidЁЃетЪБОЭПЩвдДгжаШЁГіЖдгІЕФжЕСЫЁЃ
69. ШчЙћПЭЛЇЖЫНћжЙ cookie ФмЪЕЯж session ЛЙФмгУТ№?
Cookieгы Session,вЛАуШЯЮЊЪЧСНИіЖРСЂЕФЖЋЮї,SessionВЩгУЕФЪЧдкЗўЮёЦїЖЫБЃГжзДЬЌЕФЗНАИ,ЖјCookieВЩгУЕФЪЧдкПЭЛЇЖЫБЃГжзДЬЌЕФЗНАИЁЃЕЋЮЊЪВУДНћгУCookieОЭВЛФмЕУЕНSessionФи?вђЮЊSessionЪЧгУSession IDРДШЗЖЈЕБЧАЖдЛАЫљЖдгІЕФЗўЮёЦїSession,ЖјSession IDЪЧЭЈЙ§CookieРДДЋЕнЕФ,НћгУCookieЯрЕБгкЪЇШЅСЫSession ID,вВОЭЕУВЛЕНSessionСЫЁЃ
МйЖЈгУЛЇЙиБеCookieЕФЧщПіЯТЪЙгУSession,ЦфЪЕЯжЭООЖгавдЯТМИжж:
-
ЩшжУphp.iniХфжУЮФМўжаЕФЁАsession.use_trans_sid = 1ЁБ,ЛђепБрвыЪБДђПЊДђПЊСЫЁА--enable-trans-sidЁБбЁЯю,ШУPHPздЖЏПчвГДЋЕнSession IDЁЃ
-
ЪжЖЏЭЈЙ§URLДЋжЕЁЂвўВиБэЕЅДЋЕнSession IDЁЃ
-
гУЮФМўЁЂЪ§ОнПтЕШаЮЪНБЃДцSession ID,дкПчвГЙ§ГЬжаЪжЖЏЕїгУЁЃ
70. spring mvc КЭ struts ЕФЧјБ№ЪЧЪВУД?
-
РЙНиЛњжЦЕФВЛЭЌ
Struts2ЪЧРрМЖБ№ЕФРЙНи,УПДЮЧыЧѓОЭЛсДДНЈвЛИіAction,КЭSpringећКЯЪБStruts2ЕФActionBeanзЂШызїгУгђЪЧдаЭФЃЪНprototype,ШЛКѓЭЈЙ§setter,getterАЩrequestЪ§ОнзЂШыЕНЪєадЁЃStruts2жа,вЛИіActionЖдгІвЛИіrequest,responseЩЯЯТЮФ,дкНгЪеВЮЪ§ЪБ,ПЩвдЭЈЙ§ЪєадНгЪе,етЫЕУїЪєадВЮЪ§ЪЧШУЖрИіЗНЗЈЙВЯэЕФЁЃStruts2жаActionЕФвЛИіЗНЗЈПЩвдЖдгІвЛИіurl,ЖјЦфРрЪєадШДБЛЫљгаЗНЗЈЙВЯэ,етвВОЭЮоЗЈгУзЂНтЛђЦфЫћЗНЪНБъЪЖЦфЫљЪєЗНЗЈСЫ,жЛФмЩшМЦЮЊЖрР§ЁЃ
ЁЁЁЁ
SpringMVCЪЧЗНЗЈМЖБ№ЕФРЙНи,вЛИіЗНЗЈЖдгІвЛИіRequestЩЯЯТЮФ,ЫљвдЗНЗЈжБНгЛљБОЩЯЪЧЖРСЂЕФ,ЖРЯэrequest,responseЪ§ОнЁЃЖјУПИіЗНЗЈЭЌЪБгжКЮвЛИіurlЖдгІ,ВЮЪ§ЕФДЋЕнЪЧжБНгзЂШыЕНЗНЗЈжаЕФ,ЪЧЗНЗЈЫљЖРгаЕФЁЃДІРэНсЙћЭЈЙ§ModeMapЗЕЛиИјПђМмЁЃдкSpringећКЯЪБ,SpringMVCЕФController BeanФЌШЯЕЅР§ФЃЪНSingleton,ЫљвдФЌШЯЖдЫљгаЕФЧыЧѓ,жЛЛсДДНЈвЛИіController,гагІЮЊУЛгаЙВЯэЕФЪєад,ЫљвдЪЧЯпГЬАВШЋЕФ,ШчЙћвЊИФБфФЌШЯЕФзїгУгђ,ашвЊЬэМг@ScopeзЂНтаоИФЁЃ
ЁЁЁЁ
Struts2газдМКЕФРЙНиInterceptorЛњжЦ,SpringMVCетЪЧгУЕФЪЧЖРСЂЕФAopЗНЪН,етбљЕМжТStruts2ЕФХфжУЮФМўСПЛЙЪЧБШSpringMVCДѓЁЃ
-
ЕзВуПђМмЕФВЛЭЌ
ЁЁЁЁ
Struts2ВЩгУFilter(StrutsPrepareAndExecuteFilter)ЪЕЯж,SpringMVC(DispatcherServlet)дђВЩгУServletЪЕЯжЁЃFilterдкШнЦїЦєЖЏжЎКѓМДГѕЪМЛЏ;ЗўЮёЭЃжЙвдКѓзЙЛй,ЭэгкServletЁЃServletдкЪЧдкЕїгУЪБГѕЪМЛЏ,ЯШгкFilterЕїгУ,ЗўЮёЭЃжЙКѓЯњЛйЁЃ
-
адФмЗНУц
Struts2ЪЧРрМЖБ№ЕФРЙНи,УПДЮЧыЧѓЖдгІЪЕР§вЛИіаТЕФAction,ашвЊМгдиЫљгаЕФЪєаджЕзЂШы,SpringMVCЪЕЯжСЫСуХфжУ,гЩгкSpringMVCЛљгкЗНЗЈЕФРЙНи,гаМгдивЛДЮЕЅР§ФЃЪНbeanзЂШыЁЃЫљвд,SpringMVCПЊЗЂаЇТЪКЭадФмИпгкStruts2ЁЃ
-
ХфжУЗНУц
ЁЁЁЁ
spring MVCКЭSpringЪЧЮоЗьЕФЁЃДгетИіЯюФПЕФЙмРэКЭАВШЋЩЯвВБШStruts2ИпЁЃ
71. ШчКЮБмУт sql зЂШы?
-
PreparedStatement(МђЕЅгжгааЇЕФЗНЗЈ)
-
ЪЙгУе§дђБэДяЪНЙ§ТЫДЋШыЕФВЮЪ§
-
зжЗћДЎЙ§ТЫ
-
JSPжаЕїгУИУКЏЪ§МьВщЪЧЗёАќКЏЗЧЗЈзжЗћ
-
JSPвГУцХаЖЯДњТы
72. ЪВУДЪЧ XSS ЙЅЛї,ШчКЮБмУт?
XSSЙЅЛїгжГЦCSS,ШЋГЦCross Site Script? (ПчеОНХБОЙЅЛї),ЦфдРэЪЧЙЅЛїепЯђгаXSSТЉЖДЕФЭјеОжаЪфШыЖёвтЕФ HTML ДњТы,ЕБгУЛЇфЏРРИУЭјеОЪБ,етЖЮ HTML ДњТыЛсздЖЏжДаа,ДгЖјДяЕНЙЅЛїЕФФПЕФЁЃXSS ЙЅЛїРрЫЦгк SQL зЂШыЙЅЛї,SQLзЂШыЙЅЛїжавдSQLгяОфзїЮЊгУЛЇЪфШы,ДгЖјДяЕНВщбЏ/аоИФ/ЩОГ§Ъ§ОнЕФФПЕФ,ЖјдкxssЙЅЛїжа,ЭЈЙ§ВхШыЖёвтНХБО,ЪЕЯжЖдгУЛЇгЮРРЦїЕФПижЦ,ЛёШЁгУЛЇЕФвЛаЉаХЯЂЁЃ XSSЪЧ Web ГЬађжаГЃМћЕФТЉЖД,XSS ЪєгкБЛЖЏЪНЧвгУгкПЭЛЇЖЫЕФЙЅЛїЗНЪНЁЃ
XSSЗРЗЖЕФзмЬхЫМТЗЪЧ:ЖдЪфШы(КЭURLВЮЪ§)НјааЙ§ТЫ,ЖдЪфГіНјааБрТыЁЃ
73. ЪВУДЪЧ CSRF ЙЅЛї,ШчКЮБмУт?
CSRF(Cross-site request forgery)вВБЛГЦЮЊ one-click attackЛђеп session riding,жаЮФШЋГЦЪЧНаПчеОЧыЧѓЮБдьЁЃвЛАуРДЫЕ,ЙЅЛїепЭЈЙ§ЮБдьгУЛЇЕФфЏРРЦїЕФЧыЧѓ,ЯђЗУЮЪвЛИігУЛЇздМКдјОШЯжЄЗУЮЪЙ§ЕФЭјеОЗЂЫЭГіШЅ,ЪЙФПБъЭјеОНгЪеВЂЮѓвдЮЊЪЧгУЛЇЕФецЪЕВйзїЖјШЅжДааУќСюЁЃГЃгУгкЕСШЁеЫКХЁЂзЊеЫЁЂЗЂЫЭащМйЯћЯЂЕШЁЃЙЅЛїепРћгУЭјеОЖдЧыЧѓЕФбщжЄТЉЖДЖјЪЕЯжетбљЕФЙЅЛїааЮЊ,ЭјеОФмЙЛШЗШЯЧыЧѓРДдДгкгУЛЇЕФфЏРРЦї,ШДВЛФмбщжЄЧыЧѓЪЧЗёдДгкгУЛЇЕФецЪЕвтдИЯТЕФВйзїааЮЊЁЃ
ШчКЮБмУт:
1. бщжЄ HTTP Referer зжЖЮ
HTTPЭЗжаЕФRefererзжЖЮМЧТМСЫИУ HTTP ЧыЧѓЕФРДдДЕижЗЁЃдкЭЈГЃЧщПіЯТ,ЗУЮЪвЛИіАВШЋЪмЯовГУцЕФЧыЧѓРДздгкЭЌвЛИіЭјеО,ЖјШчЙћКкПЭвЊЖдЦфЪЕЪЉ CSRF
ЙЅЛї,ЫћвЛАужЛФмдкЫћздМКЕФЭјеОЙЙдьЧыЧѓЁЃвђДЫ,ПЩвдЭЈЙ§бщжЄRefererжЕРДЗРгљCSRF ЙЅЛїЁЃ
2. ЪЙгУбщжЄТы
ЙиМќВйзївГУцМгЩЯбщжЄТы,КѓЬЈЪеЕНЧыЧѓКѓЭЈЙ§ХаЖЯбщжЄТыПЩвдЗРгљCSRFЁЃЕЋетжжЗНЗЈЖдгУЛЇВЛЬЋгбКУЁЃ
3. дкЧыЧѓЕижЗжаЬэМгtokenВЂбщжЄ
CSRF ЙЅЛїжЎЫљвдФмЙЛГЩЙІ,ЪЧвђЮЊКкПЭПЩвдЭъШЋЮБдьгУЛЇЕФЧыЧѓ,ИУЧыЧѓжаЫљгаЕФгУЛЇбщжЄаХЯЂЖМЪЧДцдкгкcookieжа,вђДЫКкПЭПЩвддкВЛжЊЕРетаЉбщжЄаХЯЂЕФЧщПіЯТжБНгРћгУгУЛЇздМКЕФcookie РДЭЈЙ§АВШЋбщжЄЁЃвЊЕжгљ CSRF,ЙиМќдкгкдкЧыЧѓжаЗХШыКкПЭЫљВЛФмЮБдьЕФаХЯЂ,ВЂЧвИУаХЯЂВЛДцдкгк cookie жЎжаЁЃПЩвддк HTTP ЧыЧѓжавдВЮЪ§ЕФаЮЪНМгШывЛИіЫцЛњВњЩњЕФ token,ВЂдкЗўЮёЦїЖЫНЈСЂвЛИіРЙНиЦїРДбщжЄетИі token,ШчЙћЧыЧѓжаУЛгаtokenЛђеп token ФкШнВЛе§ШЗ,дђШЯЮЊПЩФмЪЧ CSRF ЙЅЛїЖјОмОјИУЧыЧѓЁЃетжжЗНЗЈвЊБШМьВщ Referer вЊАВШЋвЛаЉ,token ПЩвддкгУЛЇЕЧТНКѓВњЩњВЂЗХгкsessionжЎжа,ШЛКѓдкУПДЮЧыЧѓЪБАбtoken Дг session жаФУГі,гыЧыЧѓжаЕФ token НјааБШЖд,ЕЋетжжЗНЗЈЕФФбЕудкгкШчКЮАб token вдВЮЪ§ЕФаЮЪНМгШыЧыЧѓЁЃ
Ждгк GET ЧыЧѓ,token НЋИНдкЧыЧѓЕижЗжЎКѓ,етбљ URL ОЭБфГЩ http://url?csrftoken=tokenvalueЁЃ
ЖјЖдгк POST ЧыЧѓРДЫЕ,вЊдк form ЕФзюКѓМгЩЯ <input type="hidden" name="csrftoken" value="tokenvalue"/>,етбљОЭАбtokenвдВЮЪ§ЕФаЮЪНМгШыЧыЧѓСЫЁЃ
4. дкHTTP ЭЗжаздЖЈвхЪєадВЂбщжЄ
етжжЗНЗЈвВЪЧЪЙгУ token ВЂНјаабщжЄ,КЭЩЯвЛжжЗНЗЈВЛЭЌЕФЪЧ,етРяВЂВЛЪЧАб token вдВЮЪ§ЕФаЮЪНжУгк HTTP ЧыЧѓжЎжа,ЖјЪЧАбЫќЗХЕН HTTP ЭЗжаздЖЈвхЕФЪєадРяЁЃЭЈЙ§ XMLHttpRequest етИіРр,ПЩвдвЛДЮадИјЫљгаИУРрЧыЧѓМгЩЯ csrftoken етИі HTTP ЭЗЪєад,ВЂАб token жЕЗХШыЦфжаЁЃетбљНтОіСЫЩЯжжЗНЗЈдкЧыЧѓжаМгШы token ЕФВЛБу,ЭЌЪБ,ЭЈЙ§ XMLHttpRequest ЧыЧѓЕФЕижЗВЛЛсБЛМЧТМЕНфЏРРЦїЕФЕижЗРИ,вВВЛгУЕЃаФ token ЛсЭИЙ§ Referer аЙТЖЕНЦфЫћЭјеОжаШЅЁЃ
вьГЃ
74. throw КЭ throws ЕФЧјБ№?
throwsЪЧгУРДЩљУївЛИіЗНЗЈПЩФмХзГіЕФЫљгавьГЃаХЯЂ,throwsЪЧНЋвьГЃЩљУїЕЋЪЧВЛДІРэ,ЖјЪЧНЋвьГЃЭљЩЯДЋ,ЫЕїгУЮвОЭНЛИјЫДІРэЁЃЖјthrowдђЪЧжИХзГіЕФвЛИіОпЬхЕФвьГЃРраЭЁЃ
75. finalЁЂfinallyЁЂfinalize гаЪВУДЧјБ№?
-
finalПЩвдаоЪЮРрЁЂБфСПЁЂЗНЗЈ,аоЪЮРрБэЪОИУРрВЛФмБЛМЬГаЁЂаоЪЮЗНЗЈБэЪОИУЗНЗЈВЛФмБЛжиаДЁЂаоЪЮБфСПБэЪОИУБфСПЪЧвЛИіГЃСПВЛФмБЛжиаТИГжЕЁЃ
-
finallyвЛАузїгУдкtry-catchДњТыПщжа,дкДІРэвьГЃЕФЪБКђ,ЭЈГЃЮвУЧНЋвЛЖЈвЊжДааЕФДњТыЗНЗЈfinallyДњТыПщжа,БэЪОВЛЙмЪЧЗёГіЯжвьГЃ,ИУДњТыПщЖМЛсжДаа,вЛАугУРДДцЗХвЛаЉЙиБезЪдДЕФДњТыЁЃ
-
finalizeЪЧвЛИіЗНЗЈ,ЪєгкObjectРрЕФвЛИіЗНЗЈ,ЖјObjectРрЪЧЫљгаРрЕФИИРр,ИУЗНЗЈвЛАугЩРЌЛјЛиЪеЦїРДЕїгУ,ЕБЮвУЧЕїгУSystemЕФgc()ЗНЗЈЕФЪБКђ,гЩРЌЛјЛиЪеЦїЕїгУfinalize(),ЛиЪеРЌЛјЁЃ?
76. try-catch-finally жаФФИіВПЗжПЩвдЪЁТд?
Д№:catch ПЩвдЪЁТд
двђ:
ИќЮЊбЯИёЕФЫЕЗЈЦфЪЕЪЧ:tryжЛЪЪКЯДІРэдЫааЪБвьГЃ,try+catchЪЪКЯДІРэдЫааЪБвьГЃ+ЦеЭЈвьГЃЁЃвВОЭЪЧЫЕ,ШчЙћФужЛгУtryШЅДІРэЦеЭЈвьГЃШДВЛМгвдcatchДІРэ,БрвыЪЧЭЈВЛЙ§ЕФ,вђЮЊБрвыЦїгВадЙцЖЈ,ЦеЭЈвьГЃШчЙћбЁдёВЖЛё,дђБиаыгУcatchЯдЪОЩљУївдБуНјвЛВНДІРэЁЃЖјдЫааЪБвьГЃдкБрвыЪБУЛгаШчДЫЙцЖЈ,ЫљвдcatchПЩвдЪЁТд,ФуМгЩЯcatchБрвыЦївВОѕЕУЮоПЩКёЗЧЁЃ
?
РэТлЩЯ,БрвыЦїПДШЮКЮДњТыЖМВЛЫГбл,ЖМОѕЕУПЩФмгаЧБдкЕФЮЪЬт,ЫљвдФуМДЪЙЖдЫљгаДњТыМгЩЯtry,ДњТыдкдЫааЦкЪБвВжЛВЛЙ§ЪЧдке§ГЃдЫааЕФЛљДЁЩЯМгвЛВуЦЄЁЃЕЋЪЧФувЛЕЉЖдвЛЖЮДњТыМгЩЯtry,ОЭЕШгкЯдЪОЕиГаХЕБрвыЦї,ЖдетЖЮДњТыПЩФмХзГіЕФвьГЃНјааВЖЛёЖјЗЧЯђЩЯХзГіДІРэЁЃШчЙћЪЧЦеЭЈвьГЃ,БрвыЦївЊЧѓБиаыгУcatchВЖЛёвдБуНјвЛВНДІРэ;ШчЙћдЫааЪБвьГЃ,ВЖЛёШЛКѓЖЊЦњВЂЧв+finallyЩЈЮВДІРэ,ЛђепМгЩЯcatchВЖЛёвдБуНјвЛВНДІРэЁЃ
?
жСгкМгЩЯfinally,дђЪЧдкВЛЙмгаУЛВЖЛёвьГЃ,ЖМвЊНјааЕФЁАЩЈЮВЁБДІРэЁЃ
77. try-catch-finally жа,ШчЙћ catch жа return СЫ,finally ЛЙЛсжДааТ№?
Д№:ЛсжДаа,дк return ЧАжДааЁЃ
ДњТыЪОР§1:
/*?* javaУцЪдЬт--ШчЙћcatchРяУцгаreturnгяОф,finallyРяУцЕФДњТыЛЙЛсжДааТ№?*/public class FinallyDemo2 {public static void main(String[] args) {System.out.println(getInt());}public static int getInt() {int a = 10;try {System.out.println(a / 0);a = 20;} catch (ArithmeticException e) {a = 30;return a;/** return a дкГЬађжДааЕНетвЛВНЕФЪБКђ,етРяВЛЪЧreturn a ЖјЪЧ return 30;етИіЗЕЛиТЗОЖОЭаЮГЩСЫ* ЕЋЪЧФи,ЫќЗЂЯжКѓУцЛЙгаfinally,ЫљвдМЬајжДааfinallyЕФФкШн,a=40* дйДЮЛиЕНвдЧАЕФТЗОЖ,МЬајзпreturn 30,аЮГЩЗЕЛиТЗОЖжЎКѓ,етРяЕФaОЭВЛЪЧaБфСПСЫ,ЖјЪЧГЃСП30*/} finally {a = 40;}// return a;}}
жДааНсЙћ:30
ДњТыЪОР§2:
package com.java_02;/*?* javaУцЪдЬт--ШчЙћcatchРяУцгаreturnгяОф,finallyРяУцЕФДњТыЛЙЛсжДааТ№?*/public class FinallyDemo2 {public static void main(String[] args) {System.out.println(getInt());}public static int getInt() {int a = 10;try {System.out.println(a / 0);a = 20;} catch (ArithmeticException e) {a = 30;return a;/** return a дкГЬађжДааЕНетвЛВНЕФЪБКђ,етРяВЛЪЧreturn a ЖјЪЧ return 30;етИіЗЕЛиТЗОЖОЭаЮГЩСЫ* ЕЋЪЧФи,ЫќЗЂЯжКѓУцЛЙгаfinally,ЫљвдМЬајжДааfinallyЕФФкШн,a=40* дйДЮЛиЕНвдЧАЕФТЗОЖ,МЬајзпreturn 30,аЮГЩЗЕЛиТЗОЖжЎКѓ,етРяЕФaОЭВЛЪЧaБфСПСЫ,ЖјЪЧГЃСП30*/} finally {a = 40;return a; //ШчЙћетбљ,ОЭгжжиаТаЮГЩСЫвЛЬѕЗЕЛиТЗОЖ,гЩгкжЛФмЭЈЙ§1ИіreturnЗЕЛи,ЫљвдетРяжБНгЗЕЛи40}// return a;}}
жДааНсЙћ:40
78. ГЃМћЕФвьГЃРргаФФаЉ?
-
NullPointerException:ЕБгІгУГЬађЪдЭМЗУЮЪПеЖдЯѓЪБ,дђХзГіИУвьГЃЁЃ
-
SQLException:ЬсЙЉЙигкЪ§ОнПтЗУЮЪДэЮѓЛђЦфЫћДэЮѓаХЯЂЕФвьГЃЁЃ
-
IndexOutOfBoundsException:жИЪОФГХХађЫїв§(Р§ШчЖдЪ§зщЁЂзжЗћДЎЛђЯђСПЕФХХађ)ГЌГіЗЖЮЇЪБХзГіЁЃ?
-
NumberFormatException:ЕБгІгУГЬађЪдЭМНЋзжЗћДЎзЊЛЛГЩвЛжжЪ§жЕРраЭ,ЕЋИУзжЗћДЎВЛФмзЊЛЛЮЊЪЪЕБИёЪНЪБ,ХзГіИУвьГЃЁЃ
-
FileNotFoundException:ЕБЪдЭМДђПЊжИЖЈТЗОЖУћБэЪОЕФЮФМўЪЇАмЪБ,ХзГіДЫвьГЃЁЃ
-
IOException:ЕБЗЂЩњФГжжI/OвьГЃЪБ,ХзГіДЫвьГЃЁЃДЫРрЪЧЪЇАмЛђжаЖЯЕФI/OВйзїЩњГЩЕФвьГЃЕФЭЈгУРрЁЃ
-
ClassCastException:ЕБЪдЭМНЋЖдЯѓЧПжЦзЊЛЛЮЊВЛЪЧЪЕР§ЕФзгРрЪБ,ХзГіИУвьГЃЁЃ
-
ArrayStoreException:ЪдЭМНЋДэЮѓРраЭЕФЖдЯѓДцДЂЕНвЛИіЖдЯѓЪ§зщЪБХзГіЕФвьГЃЁЃ
-
IllegalArgumentException:ХзГіЕФвьГЃБэУїЯђЗНЗЈДЋЕнСЫвЛИіВЛКЯЗЈЛђВЛе§ШЗЕФВЮЪ§ЁЃ
-
ArithmeticException:ЕБГіЯжвьГЃЕФдЫЫуЬѕМўЪБ,ХзГіДЫвьГЃЁЃР§Шч,вЛИіећЪ§ЁАГ§вдСуЁБЪБ,ХзГіДЫРрЕФвЛИіЪЕР§ЁЃ?
-
NegativeArraySizeException:ШчЙћгІгУГЬађЪдЭМДДНЈДѓаЁЮЊИКЕФЪ§зщ,дђХзГіИУвьГЃЁЃ
-
NoSuchMethodException:ЮоЗЈевЕНФГвЛЬиЖЈЗНЗЈЪБ,ХзГіИУвьГЃЁЃ
-
SecurityException:гЩАВШЋЙмРэЦїХзГіЕФвьГЃ,жИЪОДцдкАВШЋЧжЗИЁЃ
-
UnsupportedOperationException:ЕБВЛжЇГжЧыЧѓЕФВйзїЪБ,ХзГіИУвьГЃЁЃ
-
RuntimeExceptionRuntimeException:ЪЧФЧаЉПЩФмдкJavaащФтЛње§ГЃдЫааЦкМфХзГіЕФвьГЃЕФГЌРрЁЃ
ЭјТч
79. http ЯьгІТы 301 КЭ 302 ДњБэЕФЪЧЪВУД?гаЪВУДЧјБ№?
Д№:301,302?ЖМЪЧHTTPзДЬЌЕФБрТы,ЖМДњБэзХФГИіURLЗЂЩњСЫзЊвЦЁЃ
ЧјБ№:?
-
301?redirect:?301?ДњБэгРОУадзЊвЦ(Permanently?Moved)ЁЃ
-
302?redirect:?302?ДњБэднЪБадзЊвЦ(Temporarily?Moved?)ЁЃ?
80. forward КЭ redirect ЕФЧјБ№?
ForwardКЭRedirectДњБэСЫСНжжЧыЧѓзЊЗЂЗНЪН:жБНгзЊЗЂКЭМфНгзЊЗЂЁЃ
жБНгзЊЗЂЗНЪН(Forward),ПЭЛЇЖЫКЭфЏРРЦїжЛЗЂГівЛДЮЧыЧѓ,ServletЁЂHTMLЁЂJSPЛђЦфЫќаХЯЂзЪдД,гЩЕкЖўИіаХЯЂзЪдДЯьгІИУЧыЧѓ,дкЧыЧѓЖдЯѓrequestжа,БЃДцЕФЖдЯѓЖдгкУПИіаХЯЂзЪдДЪЧЙВЯэЕФЁЃ
МфНгзЊЗЂЗНЪН(Redirect)ЪЕМЪЪЧСНДЮHTTPЧыЧѓ,ЗўЮёЦїЖЫдкЯьгІЕквЛДЮЧыЧѓЕФЪБКђ,ШУфЏРРЦїдйЯђСэЭтвЛИіURLЗЂГіЧыЧѓ,ДгЖјДяЕНзЊЗЂЕФФПЕФЁЃ
ОйИіЭЈЫзЕФР§зг:
ЁЁЁЁ
жБНгзЊЗЂОЭЯрЕБгк:ЁАAевBНшЧЎ,BЫЕУЛга,BШЅевCНш,НшЕННшВЛЕНЖМЛсАбЯћЯЂДЋЕнИјAЁБ;
ЁЁЁЁ
МфНгзЊЗЂОЭЯрЕБгк:"AевBНшЧЎ,BЫЕУЛга,ШУAШЅевCНш"ЁЃ
81. МђЪі tcp КЭ udpЕФЧјБ№?
-
TCPУцЯђСЌНг(ШчДђЕчЛАвЊЯШВІКХНЈСЂСЌНг);UDPЪЧЮоСЌНгЕФ,МДЗЂЫЭЪ§ОнжЎЧАВЛашвЊНЈСЂСЌНгЁЃ
-
TCPЬсЙЉПЩППЕФЗўЮёЁЃвВОЭЪЧЫЕ,ЭЈЙ§TCPСЌНгДЋЫЭЕФЪ§Он,ЮоВюДэ,ВЛЖЊЪЇ,ВЛжиИД,ЧвАДађЕНДя;UDPОЁзюДѓХЌСІНЛИЖ,МДВЛБЃжЄПЩППНЛИЖЁЃ
-
TcpЭЈЙ§аЃбщКЭ,жиДЋПижЦ,ађКХБъЪЖ,ЛЌЖЏДАПкЁЂШЗШЯгІД№ЪЕЯжПЩППДЋЪфЁЃШчЖЊАќЪБЕФжиЗЂПижЦ,ЛЙПЩвдЖдДЮађТвЕєЕФЗжАќНјааЫГађПижЦЁЃ
-
UDPОпгаНЯКУЕФЪЕЪБад,ЙЄзїаЇТЪБШTCPИп,ЪЪгУгкЖдИпЫйДЋЪфКЭЪЕЪБадгаНЯИпЕФЭЈаХЛђЙуВЅЭЈаХЁЃ
-
УПвЛЬѕTCPСЌНгжЛФмЪЧЕуЕНЕуЕФ;UDPжЇГжвЛЖдвЛ,вЛЖдЖр,ЖрЖдвЛКЭЖрЖдЖрЕФНЛЛЅЭЈаХЁЃ
-
TCPЖдЯЕЭГзЪдДвЊЧѓНЯЖр,UDPЖдЯЕЭГзЪдДвЊЧѓНЯЩйЁЃ
82. tcp ЮЊЪВУДвЊШ§ДЮЮеЪж,СНДЮВЛааТ№?ЮЊЪВУД?
ЮЊСЫЪЕЯжПЩППЪ§ОнДЋЪф, TCP авщЕФЭЈаХЫЋЗН, ЖМБиаыЮЌЛЄвЛИіађСаКХ, вдБъЪЖЗЂЫЭГіШЅЕФЪ§ОнАќжа, ФФаЉЪЧвбОБЛЖдЗНЪеЕНЕФЁЃ Ш§ДЮЮеЪжЕФЙ§ГЬМДЪЧЭЈаХЫЋЗНЯрЛЅИцжЊађСаКХЦ№ЪМжЕ, ВЂШЗШЯЖдЗНвбОЪеЕНСЫађСаКХЦ№ЪМжЕЕФБиОВНжшЁЃ
ШчЙћжЛЪЧСНДЮЮеЪж, жСЖржЛгаСЌНгЗЂЦ№ЗНЕФЦ№ЪМађСаКХФмБЛШЗШЯ, СэвЛЗНбЁдёЕФађСаКХдђЕУВЛЕНШЗШЯЁЃ
83. ЫЕвЛЯТ tcp еГАќЪЧдѕУДВњЩњЕФ?
Ђй. ЗЂЫЭЗНВњЩњеГАќ
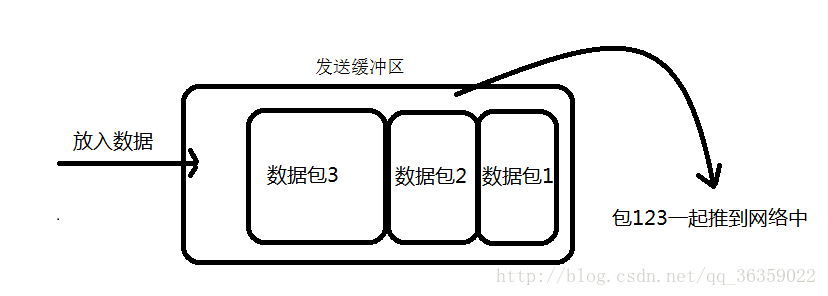
ВЩгУTCPавщДЋЪфЪ§ОнЕФПЭЛЇЖЫгыЗўЮёЦїОГЃЪЧБЃГжвЛИіГЄСЌНгЕФзДЬЌ(вЛДЮСЌНгЗЂвЛДЮЪ§ОнВЛДцдкеГАќ),ЫЋЗНдкСЌНгВЛЖЯПЊЕФЧщПіЯТ,ПЩвдвЛжБДЋЪфЪ§Он;ЕЋЕБЗЂЫЭЕФЪ§ОнАќЙ§гкЕФаЁЪБ,ФЧУДTCPавщФЌШЯЕФЛсЦєгУNagleЫуЗЈ,НЋетаЉНЯаЁЕФЪ§ОнАќНјааКЯВЂЗЂЫЭ(ЛКГхЧјЪ§ОнЗЂЫЭЪЧвЛИіЖббЙЕФЙ§ГЬ);етИіКЯВЂЙ§ГЬОЭЪЧдкЗЂЫЭЛКГхЧјжаНјааЕФ,вВОЭЪЧЫЕЪ§ОнЗЂЫЭГіРДЫќвбОЪЧеГАќЕФзДЬЌСЫЁЃ
Ђк. НгЪеЗНВњЩњеГАќ
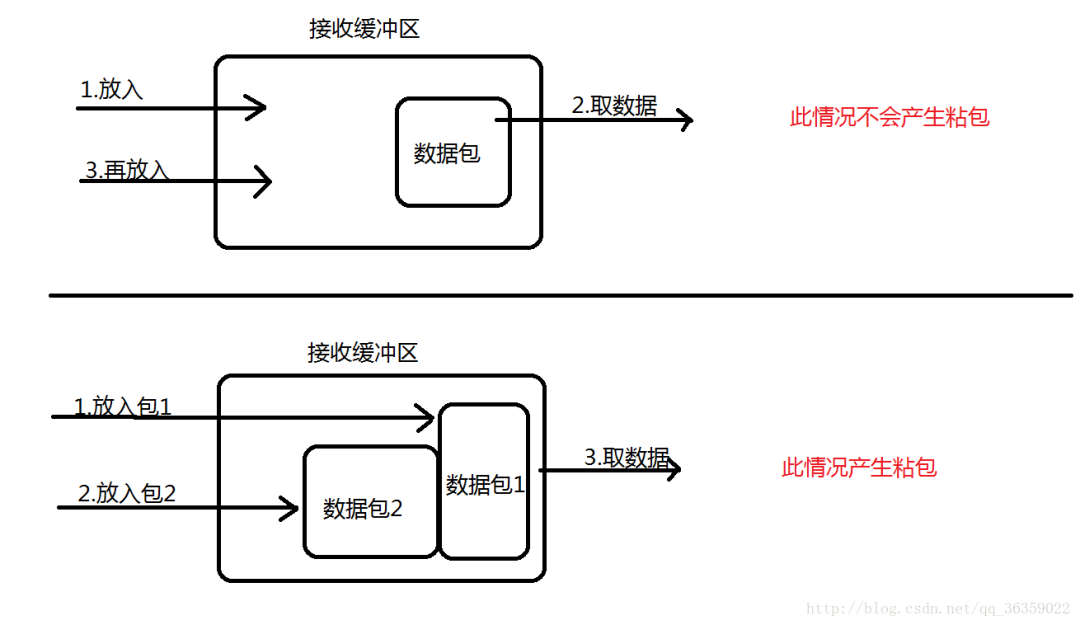
НгЪеЗНВЩгУTCPавщНгЪеЪ§ОнЪБЕФЙ§ГЬЪЧетбљЕФ:Ъ§ОнЕНЕзНгЪеЗН,ДгЭјТчФЃаЭЕФЯТЗНДЋЕнжСДЋЪфВу,ДЋЪфВуЕФTCPавщДІРэЪЧНЋЦфЗХжУНгЪеЛКГхЧј,ШЛКѓгЩгІгУВуРДжїЖЏЛёШЁ(CгябдгУrecvЁЂreadЕШКЏЪ§);етЪБЛсГіЯжвЛИіЮЪЬт,ОЭЪЧЮвУЧдкГЬађжаЕїгУЕФЖСШЁЪ§ОнКЏЪ§ВЛФмМАЪБЕФАбЛКГхЧјжаЕФЪ§ОнФУГіРД,ЖјЯТвЛИіЪ§ОнгжЕНРДВЂгавЛВПЗжЗХШыЕФЛКГхЧјФЉЮВ,ЕШЮвУЧЖСШЁЪ§ОнЪБОЭЪЧвЛИіеГАќЁЃ(ЗХЪ§ОнЕФЫйЖШ > гІгУВуФУЪ§ОнЫйЖШ)?
84. OSI ЕФЦпВуФЃаЭЖМгаФФаЉ?
-
гІгУВу:ЭјТчЗўЮёгызюжегУЛЇЕФвЛИіНгПкЁЃ
-
БэЪОВу:Ъ§ОнЕФБэЪОЁЂАВШЋЁЂбЙЫѕЁЃ
-
ЛсЛАВу:НЈСЂЁЂЙмРэЁЂжежЙЛсЛАЁЃ
-
ДЋЪфВу:ЖЈвхДЋЪфЪ§ОнЕФавщЖЫПкКХ,вдМАСїПиКЭВюДэаЃбщЁЃ
-
ЭјТчВу:НјааТпМЕижЗбАжЗ,ЪЕЯжВЛЭЌЭјТчжЎМфЕФТЗОЖбЁдёЁЃ
-
Ъ§ОнСДТЗВу:НЈСЂТпМСЌНгЁЂНјаагВМўЕижЗбАжЗЁЂВюДэаЃбщЕШЙІФмЁЃ
-
ЮяРэВу:НЈСЂЁЂЮЌЛЄЁЂЖЯПЊЮяРэСЌНгЁЃ
85. get КЭ post ЧыЧѓгаФФаЉЧјБ№?
-
GETдкфЏРРЦїЛиЭЫЪБЪЧЮоКІЕФ,ЖјPOSTЛсдйДЮЬсНЛЧыЧѓЁЃ
-
GETВњЩњЕФURLЕижЗПЩвдБЛBookmark,ЖјPOSTВЛПЩвдЁЃ
-
GETЧыЧѓЛсБЛфЏРРЦїжїЖЏcache,ЖјPOSTВЛЛс,Г§ЗЧЪжЖЏЩшжУЁЃ
-
GETЧыЧѓжЛФмНјааurlБрТы,ЖјPOSTжЇГжЖржжБрТыЗНЪНЁЃ
-
GETЧыЧѓВЮЪ§ЛсБЛЭъећБЃСєдкфЏРРЦїРњЪЗМЧТМРя,ЖјPOSTжаЕФВЮЪ§ВЛЛсБЛБЃСєЁЃ
-
GETЧыЧѓдкURLжаДЋЫЭЕФВЮЪ§ЪЧгаГЄЖШЯожЦЕФ,ЖјPOSTУДгаЁЃ
-
ЖдВЮЪ§ЕФЪ§ОнРраЭ,GETжЛНгЪмASCIIзжЗћ,ЖјPOSTУЛгаЯожЦЁЃ
-
GETБШPOSTИќВЛАВШЋ,вђЮЊВЮЪ§жБНгБЉТЖдкURLЩЯ,ЫљвдВЛФмгУРДДЋЕнУєИааХЯЂЁЃ
-
GETВЮЪ§ЭЈЙ§URLДЋЕн,POSTЗХдкRequest bodyжаЁЃ
86. ШчКЮЪЕЯжПчгђ?
ЗНЪНвЛ:ЭМЦЌpingЛђscriptБъЧЉПчгђ
ЭМЦЌpingГЃгУгкИњзйгУЛЇЕуЛївГУцЛђЖЏЬЌЙуИцЦиЙтДЮЪ§ЁЃ?
scriptБъЧЉПЩвдЕУЕНДгЦфЫћРДдДЪ§Он,етвВЪЧJSONPвРРЕЕФИљОнЁЃ?
ЗНЪНЖў:JSONPПчгђ
JSONP(JSON with Padding)ЪЧЪ§ОнИёЪНJSONЕФвЛжжЁАЪЙгУФЃЪНЁБ,ПЩвдШУЭјвГДгБ№ЕФЭјгђвЊЪ§ОнЁЃИљОн XmlHttpRequest ЖдЯѓЪмЕНЭЌдДВпТдЕФгАЯь,ЖјРћгУ <script>дЊЫиЕФетИіПЊЗХВпТд,ЭјвГПЩвдЕУЕНДгЦфЫћРДдДЖЏЬЌВњЩњЕФJSONЪ§Он,ЖјетжжЪЙгУФЃЪНОЭЪЧЫљЮНЕФ JSONPЁЃгУJSONPзЅЕНЕФЪ§ОнВЂВЛЪЧJSON,ЖјЪЧШЮвтЕФJavaScript,гУ JavaScriptНтЪЭЦїдЫааЖјВЛЪЧгУJSONНтЮіЦїНтЮіЁЃЫљга,ЭЈЙ§ChromeВщПДЫљгаJSONPЗЂЫЭЕФGetЧыЧѓЖМЪЧjsРраЭ,ЖјЗЧXHRЁЃ?

ШБЕу:
-
жЛФмЪЙгУGetЧыЧѓ
-
ВЛФмзЂВсsuccessЁЂerrorЕШЪТМўМрЬ§КЏЪ§,ВЛФмКмШнвзЕФШЗЖЈJSONPЧыЧѓЪЧЗёЪЇАм
-
JSONPЪЧДгЦфЫћгђжаМгдиДњТыжДаа,ШнвзЪмЕНПчеОЧыЧѓЮБдьЕФЙЅЛї,ЦфАВШЋадЮоЗЈШЗБЃ
ЗНЪНШ§:CORS
Cross-Origin Resource Sharing(CORS)ПчгђзЪдДЙВЯэЪЧвЛЗнфЏРРЦїММЪѕЕФЙцЗЖ,ЬсЙЉСЫ Web ЗўЮёДгВЛЭЌгђДЋРДЩГКаНХБОЕФЗНЗЈ,вдБмПЊфЏРРЦїЕФЭЌдДВпТд,ШЗБЃАВШЋЕФПчгђЪ§ОнДЋЪфЁЃЯжДњфЏРРЦїЪЙгУCORSдкAPIШнЦїШчXMLHttpRequestРДМѕЩйHTTPЧыЧѓЕФЗчЯеРДдДЁЃгы JSONP ВЛЭЌ,CORS Г§СЫ GET вЊЧѓЗНЗЈвдЭтвВжЇГжЦфЫћЕФ HTTP вЊЧѓЁЃЗўЮёЦївЛАуашвЊдіМгШчЯТЯьгІЭЗЕФвЛжжЛђМИжж:
Access-Control-Allow-Origin: *Access-Control-Allow-Methods: POST, GET, OPTIONSAccess-Control-Allow-Headers: X-PINGOTHER, Content-TypeAccess-Control-Max-Age: 86400
ПчгђЧыЧѓФЌШЯВЛЛсаЏДјCookieаХЯЂ,ШчЙћашвЊаЏДј,ЧыХфжУЯТЪіВЮЪ§:
"Access-Control-Allow-Credentials": true// AjaxЩшжУ"withCredentials": true
ЗНЪНЫФ:window.name+iframe
window.nameЭЈЙ§дкiframe(вЛАуЖЏЬЌДДНЈi)жаМгдиПчгђHTMLЮФМўРДЦ№зїгУЁЃШЛКѓ,HTMLЮФМўНЋДЋЕнИјЧыЧѓепЕФзжЗћДЎФкШнИГжЕИјwindow.nameЁЃШЛКѓ,ЧыЧѓепПЩвдМьЫїwindow.nameжЕзїЮЊЯьгІЁЃ
-
iframeБъЧЉЕФПчгђФмСІ;
-
window.nameЪєаджЕдкЮФЕЕЫЂаТКѓвРОЩДцдкЕФФмСІ(ЧвзюДѓдЪаэ2Mзѓгв)ЁЃ
УПИіiframeЖМгаАќЙќЫќЕФwindow,ЖјетИіwindowЪЧtop windowЕФзгДАПкЁЃcontentWindowЪєадЗЕЛи<iframe>дЊЫиЕФWindowЖдЯѓЁЃФуПЩвдЪЙгУетИіWindowЖдЯѓРДЗУЮЪiframeЕФЮФЕЕМАЦфФкВПDOMЁЃ
<!--ЯТЪігУЖЫПк10000БэЪО:domainA10001БэЪО:domainB--><!-- localhost:10000 --><script>var iframe = document.createElement('iframe');iframe.style.display = 'none'; // вўВиvar state = 0; // ЗРжЙвГУцЮоЯоЫЂаТiframe.onload = function() {if(state === 1) {console.log(JSON.parse(iframe.contentWindow.name));// ЧхГ§ДДНЈЕФiframeiframe.contentWindow.document.write('');iframe.contentWindow.close();document.body.removeChild(iframe);} else if(state === 0) {state = 1;// МгдиЭъГЩ,жИЯђЕБЧАгђ,ЗРжЙДэЮѓ(proxy.htmlЮЊПеАзвГУц)// Blocked a frame with origin "http://localhost:10000" from accessing a cross-origin frame.iframe.contentWindow.location = 'http://localhost:10000/proxy.html';}};iframe.src = 'http://localhost:10001';document.body.appendChild(iframe);</script><!-- localhost:10001 --><!DOCTYPE html>...<script>window.name = JSON.stringify({a: 1, b: 2});</script></html>
ЗНЪНЮх:window.postMessage()
HTML5аТЬиад,ПЩвдгУРДЯђЦфЫћЫљгаЕФ window ЖдЯѓЗЂЫЭЯћЯЂЁЃашвЊзЂвтЕФЪЧЮвУЧБиаывЊБЃжЄЫљгаЕФНХБОжДааЭъВХЗЂЫЭ MessageEvent,ШчЙћдкКЏЪ§жДааЕФЙ§ГЬжаЕїгУСЫЫќ,ОЭЛсШУКѓУцЕФКЏЪ§ГЌЪБЮоЗЈжДааЁЃ
ЯТЪіДњТыЪЕЯжСЫПчгђДцДЂlocalStorage
<!--ЯТЪігУЖЫПк10000БэЪО:domainA10001БэЪО:domainB--><!-- localhost:10000 --><iframe src="http://localhost:10001/msg.html" name="myPostMessage" style="display:none;"></iframe><script>function main() {LSsetItem('test', 'Test: ' + new Date());LSgetItem('test', function(value) {console.log('value: ' + value);});LSremoveItem('test');}var callbacks = {};window.addEventListener('message', function(event) {if (event.source === frames['myPostMessage']) {console.log(event)var data = /^#localStorage#(\d+)(null)?#([\S\s]*)/.exec(event.data);if (data) {if (callbacks[data[1]]) {callbacks[data[1]](data[2] === 'null' ? null : data[3]);}delete callbacks[data[1]];}}}, false);var domain = '*';// діМгfunction LSsetItem(key, value) {var obj = {setItem: key,value: value};frames['myPostMessage'].postMessage(JSON.stringify(obj), domain);}// ЛёШЁfunction LSgetItem(key, callback) {var identifier = new Date().getTime();var obj = {identifier: identifier,getItem: key};callbacks[identifier] = callback;frames['myPostMessage'].postMessage(JSON.stringify(obj), domain);}// ЩОГ§function LSremoveItem(key) {var obj = {removeItem: key};frames['myPostMessage'].postMessage(JSON.stringify(obj), domain);}</script><!-- localhost:10001 --><script>window.addEventListener('message', function(event) {console.log('Receiver debugging', event);if (event.origin == 'http://localhost:10000') {var data = JSON.parse(event.data);if ('setItem' in data) {localStorage.setItem(data.setItem, data.value);} else if ('getItem' in data) {var gotItem = localStorage.getItem(data.getItem);event.source.postMessage('#localStorage#' + data.identifier +(gotItem === null ? 'null#' : '#' + gotItem),event.origin);} else if ('removeItem' in data) {localStorage.removeItem(data.removeItem);}}}, false);</script>
зЂвтSafariвЛЯТ,ЛсБЈДэ:
Blocked?a?frame?with?origin?ЁАhttp://localhost:10001ЁБ?from?accessing?a?frame?with?origin?ЁАhttp://localhost:10000ЁА.?Protocols,?domains,?and?ports?must?match.
БмУтИУДэЮѓ,ПЩвддкSafariфЏРРЦїжаЙДбЁПЊЗЂВЫЕЅ==>ЭЃгУПчгђЯожЦЁЃЛђепжЛФмЪЙгУЗўЮёЦїЖЫзЊДцЕФЗНЪНЪЕЯж,вђЮЊSafariфЏРРЦїФЌШЯжЛжЇГжCORSПчгђЧыЧѓЁЃ
ЗНЪНСљ:аоИФdocument.domainПчзггђ
ЧАЬсЬѕМў:етСНИігђУћБиаыЪєгкЭЌвЛИіЛљДЁгђУћ!ЖјЧвЫљгУЕФавщ,ЖЫПкЖМвЊвЛжТ,ЗёдђЮоЗЈРћгУdocument.domainНјааПчгђ,ЫљвджЛФмПчзггђ
дкИљгђЗЖЮЇФк,дЪаэАбdomainЪєадЕФжЕЩшжУЮЊЫќЕФЩЯвЛМЖгђЁЃР§Шч,дкЁБaaa.xxx.comЁБгђФк,ПЩвдАбdomainЩшжУЮЊ ЁАxxx.comЁБ ЕЋВЛФмЩшжУЮЊ ЁАxxx.orgЁБ ЛђепЁБcomЁБЁЃ
ЯждкДцдкСНИігђУћaaa.xxx.comКЭbbb.xxx.comЁЃдкaaaЯТЧЖШыbbbЕФвГУц,гЩгкЦфdocument.nameВЛвЛжТ,ЮоЗЈдкaaaЯТВйзїbbbЕФjsЁЃПЩвддкaaaКЭbbbЯТЭЈЙ§jsНЋdocument.name?=?'xxx.com';ЩшжУвЛжТ,РДДяЕНЛЅЯрЗУЮЪЕФзїгУЁЃ
ЗНЪНЦп:WebSocket
WebSocket protocol ЪЧHTML5вЛжжаТЕФавщЁЃЫќЪЕЯжСЫфЏРРЦїгыЗўЮёЦїШЋЫЋЙЄЭЈаХ,ЭЌЪБдЪаэПчгђЭЈбЖ,ЪЧserver pushММЪѕЕФвЛжжКмАєЕФЪЕЯжЁЃЯрЙиЮФеТ,ЧыВщПД:WebSocketЁЂWebSocket-SockJS
ашвЊзЂвт:WebSocketЖдЯѓВЛжЇГжDOM 2МЖЪТМўеьЬ§Цї,БиаыЪЙгУDOM 0МЖгяЗЈЗжБ№ЖЈвхИїИіЪТМўЁЃ
ЗНЪНАЫ:ДњРэ
ЭЌдДВпТдЪЧеыЖдфЏРРЦїЖЫНјааЕФЯожЦ,ПЩвдЭЈЙ§ЗўЮёЦїЖЫРДНтОіИУЮЪЬт
DomainAПЭЛЇЖЫ(фЏРРЦї) ==> DomainAЗўЮёЦї ==> DomainBЗўЮёЦї ==> DomainAПЭЛЇЖЫ(фЏРРЦї)
РДдД:blog.csdn.net/ligang2585116/article/details/73072868
87.ЫЕвЛЯТ JSONP ЪЕЯждРэ?
jsonp МД json+padding,ЖЏЬЌДДНЈscriptБъЧЉ,РћгУscriptБъЧЉЕФsrcЪєадПЩвдЛёШЁШЮКЮгђЯТЕФjsНХБО,ЭЈЙ§етИіЬиад(вВПЩвдЫЕТЉЖД),ЗўЮёЦїЖЫВЛдкЗЕЛѕjsonИёЪН,ЖјЪЧЗЕЛивЛЖЮЕїгУФГИіКЏЪ§ЕФjsДњТы,дкsrcжаНјааСЫЕїгУ,етбљЪЕЯжСЫПчгђЁЃ
ОХЁЂЩшМЦФЃЪН
88. ЫЕвЛЯТФуЪьЯЄЕФЩшМЦФЃЪН?
ВЮПМ:ГЃгУЕФЩшМЦФЃЪНЛузм,ГЌЯъЯИ!
89. МђЕЅЙЄГЇКЭГщЯѓЙЄГЇгаЪВУДЧјБ№?
МђЕЅЙЄГЇФЃЪН:
етИіФЃЪНБОЩэКмМђЕЅЖјЧвЪЙгУдквЕЮёНЯМђЕЅЕФЧщПіЯТЁЃвЛАугУгкаЁЯюФПЛђепОпЬхВњЦЗКмЩйРЉеЙЕФЧщПі(етбљЙЄГЇРрВХВЛгУОГЃИќИФ)ЁЃ
ЫќгЩШ§жжНЧЩЋзщГЩ:
?
-
ЙЄГЇРрНЧЩЋ:етЪЧБОФЃЪНЕФКЫаФ,КЌгавЛЖЈЕФЩЬвЕТпМКЭХаЖЯТпМ,ИљОнТпМВЛЭЌ,ВњЩњОпЬхЕФЙЄГЇВњЦЗЁЃШчР§згжаЕФDriverРрЁЃ
-
ГщЯѓВњЦЗНЧЩЋ:ЫќвЛАуЪЧОпЬхВњЦЗМЬГаЕФИИРрЛђепЪЕЯжЕФНгПкЁЃгЩНгПкЛђепГщЯѓРрРДЪЕЯжЁЃШчР§жаЕФCarНгПкЁЃ
-
ОпЬхВњЦЗНЧЩЋ:ЙЄГЇРрЫљДДНЈЕФЖдЯѓОЭЪЧДЫНЧЩЋЕФЪЕР§ЁЃдкjavaжагЩвЛИіОпЬхРрЪЕЯж,ШчР§згжаЕФBenzЁЂBmwРрЁЃ
РДгУРрЭМРДЧхЮњЕФБэЪОЯТЕФЫќУЧжЎМфЕФЙиЯЕ:

ГщЯѓЙЄГЇФЃЪН:
ЯШРДШЯЪЖЯТЪВУДЪЧВњЦЗзх: ЮЛгкВЛЭЌВњЦЗЕШМЖНсЙЙжа,ЙІФмЯрЙиСЊЕФВњЦЗзщГЩЕФМвзхЁЃ
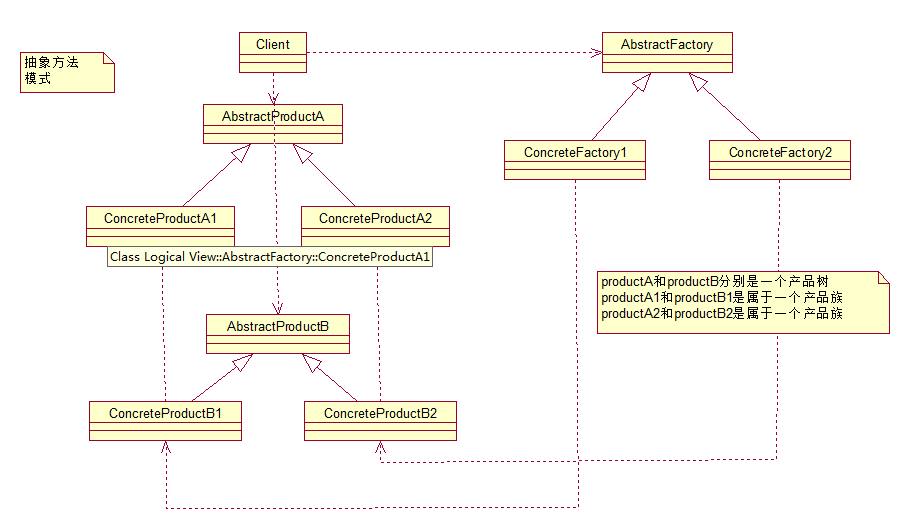
ЭМжаЕФBmwCarКЭBenzCarОЭЪЧСНИіВњЦЗЪї(ВњЦЗВуДЮНсЙЙ);ЖјШчЭМЫљЪОЕФBenzSportsCarКЭBmwSportsCarОЭЪЧвЛИіВњЦЗзхЁЃЫћУЧЖМПЩвдЗХЕНХмГЕМвзхжа,вђДЫЙІФмгаЫљЙиСЊЁЃЭЌРэBmwBussinessCarКЭBenzBusinessCarвВЪЧвЛИіВњЦЗзхЁЃ
?
ПЩвдетУДЫЕ,ЫќКЭЙЄГЇЗНЗЈФЃЪНЕФЧјБ№ОЭдкгкашвЊДДНЈЖдЯѓЕФИДдгГЬЖШЩЯЁЃЖјЧвГщЯѓЙЄГЇФЃЪНЪЧШ§ИіРяУцзюЮЊГщЯѓЁЂзюОпвЛАуадЕФЁЃГщЯѓЙЄГЇФЃЪНЕФгУвтЮЊ:ИјПЭЛЇЖЫЬсЙЉвЛИіНгПк,ПЩвдДДНЈЖрИіВњЦЗзхжаЕФВњЦЗЖдЯѓЁЃ
?
ЖјЧвЪЙгУГщЯѓЙЄГЇФЃЪНЛЙвЊТњзувЛЯТЬѕМў:
?
-
ЯЕЭГжагаЖрИіВњЦЗзх,ЖјЯЕЭГвЛДЮжЛПЩФмЯћЗбЦфжавЛзхВњЦЗ
-
ЭЌЪєгкЭЌвЛИіВњЦЗзхЕФВњЦЗвдЦфЪЙгУЁЃ
РДПДПДГщЯѓЙЄГЇФЃЪНЕФИїИіНЧЩЋ(КЭЙЄГЇЗНЗЈЕФШчГівЛео):
?
-
ГщЯѓЙЄГЇНЧЩЋ: етЪЧЙЄГЇЗНЗЈФЃЪНЕФКЫаФ,ЫќгыгІгУГЬађЮоЙиЁЃЪЧОпЬхЙЄГЇНЧЩЋБиаыЪЕЯжЕФНгПкЛђепБиаыМЬГаЕФИИРрЁЃдкjavaжаЫќгЩГщЯѓРрЛђепНгПкРДЪЕЯжЁЃ
-
ОпЬхЙЄГЇНЧЩЋ:ЫќКЌгаКЭОпЬхвЕЮёТпМгаЙиЕФДњТыЁЃгЩгІгУГЬађЕїгУвдДДНЈЖдгІЕФОпЬхВњЦЗЕФЖдЯѓЁЃдкjavaжаЫќгЩОпЬхЕФРрРДЪЕЯжЁЃ
-
ГщЯѓВњЦЗНЧЩЋ:ЫќЪЧОпЬхВњЦЗМЬГаЕФИИРрЛђепЪЧЪЕЯжЕФНгПкЁЃдкjavaжавЛАугаГщЯѓРрЛђепНгПкРДЪЕЯжЁЃ
-
ОпЬхВњЦЗНЧЩЋ:ОпЬхЙЄГЇНЧЩЋЫљДДНЈЕФЖдЯѓОЭЪЧДЫНЧЩЋЕФЪЕР§ЁЃдкjavaжагЩОпЬхЕФРрРДЪЕЯжЁЃ
ЪЎЁЂSpring / Spring MVC
90. ЮЊЪВУДвЊЪЙгУ spring?
1.МђНщ
-
ФПЕФ:НтОіЦѓвЕгІгУПЊЗЂЕФИДдгад
-
ЙІФм:ЪЙгУЛљБОЕФJavaBeanДњЬцEJB,ВЂЬсЙЉСЫИќЖрЕФЦѓвЕгІгУЙІФм
-
ЗЖЮЇ:ШЮКЮJavaгІгУ
МђЕЅРДЫЕ,SpringЪЧвЛИіЧсСПМЖЕФПижЦЗДзЊ(IoC)КЭУцЯђЧаУц(AOP)ЕФШнЦїПђМмЁЃ
2.ЧсСПЁЁЁЁ
ДгДѓаЁгыПЊЯњСНЗНУцЖјбдSpringЖМЪЧЧсСПЕФЁЃЭъећЕФSpringПђМмПЩвддквЛИіДѓаЁжЛга1MBЖрЕФJARЮФМўРяЗЂВМЁЃВЂЧвSpringЫљашЕФДІРэПЊЯњвВЪЧЮЂВЛзуЕРЕФЁЃДЫЭт,SpringЪЧЗЧЧжШыЪНЕФ:ЕфаЭЕи,SpringгІгУжаЕФЖдЯѓВЛвРРЕгкSpringЕФЬиЖЈРрЁЃ
3.ПижЦЗДзЊЁЁЁЁ
SpringЭЈЙ§вЛжжГЦзїПижЦЗДзЊ(IoC)ЕФММЪѕДйНјСЫЫЩёюКЯЁЃЕБгІгУСЫIoC,вЛИіЖдЯѓвРРЕЕФЦфЫќЖдЯѓЛсЭЈЙ§БЛЖЏЕФЗНЪНДЋЕнНјРД,ЖјВЛЪЧетИіЖдЯѓздМКДДНЈЛђепВщеввРРЕЖдЯѓЁЃФуПЩвдШЯЮЊIoCгыJNDIЯрЗДЁЊЁЊВЛЪЧЖдЯѓДгШнЦїжаВщеввРРЕ,ЖјЪЧШнЦїдкЖдЯѓГѕЪМЛЏЪБВЛЕШЖдЯѓЧыЧѓОЭжїЖЏНЋвРРЕДЋЕнИјЫќЁЃ
4.УцЯђЧаУцЁЁЁЁ
SpringЬсЙЉСЫУцЯђЧаУцБрГЬЕФЗсИЛжЇГж,дЪаэЭЈЙ§ЗжРыгІгУЕФвЕЮёТпМгыЯЕЭГМЖЗўЮё(Р§ШчЩѓМЦ(auditing)КЭЪТЮё(transaction)ЙмРэ)НјааФкОладЕФПЊЗЂЁЃгІгУЖдЯѓжЛЪЕЯжЫќУЧгІИУзіЕФЁЊЁЊЭъГЩвЕЮёТпМЁЊЁЊНіДЫЖјвбЁЃЫќУЧВЂВЛИКд№(ЩѕжСЪЧвтЪЖ)ЦфЫќЕФЯЕЭГМЖЙизЂЕу,Р§ШчШежОЛђЪТЮёжЇГжЁЃ
5.ШнЦї
SpringАќКЌВЂЙмРэгІгУЖдЯѓЕФХфжУКЭЩњУќжмЦк,дкетИівтвхЩЯЫќЪЧвЛжжШнЦї,ФуПЩвдХфжУФуЕФУПИіbeanШчКЮБЛДДНЈЁЊЁЊЛљгквЛИіПЩХфжУдаЭ(prototype),ФуЕФbeanПЩвдДДНЈвЛИіЕЅЖРЕФЪЕР§ЛђепУПДЮашвЊЪБЖМЩњГЩвЛИіаТЕФЪЕР§ЁЊЁЊвдМАЫќУЧЪЧШчКЮЯрЛЅЙиСЊЕФЁЃШЛЖј,SpringВЛгІИУБЛЛьЭЌгкДЋЭГЕФжиСПМЖЕФEJBШнЦї,ЫќУЧОГЃЪЧХгДѓгыБПжиЕФ,ФбвдЪЙгУЁЃ
6.ПђМм
SpringПЩвдНЋМђЕЅЕФзщМўХфжУЁЂзщКЯГЩЮЊИДдгЕФгІгУЁЃдкSpringжа,гІгУЖдЯѓБЛЩљУїЪНЕизщКЯ,ЕфаЭЕиЪЧдквЛИіXMLЮФМўРяЁЃSpringвВЬсЙЉСЫКмЖрЛљДЁЙІФм(ЪТЮёЙмРэЁЂГжОУЛЏПђМмМЏГЩЕШЕШ),НЋгІгУТпМЕФПЊЗЂСєИјСЫФуЁЃ
ЫљгаSpringЕФетаЉЬиеїЪЙФуФмЙЛБраДИќИЩОЛЁЂИќПЩЙмРэЁЂВЂЧвИќвзгкВтЪдЕФДњТыЁЃЫќУЧвВЮЊSpringжаЕФИїжжФЃПщЬсЙЉСЫЛљДЁжЇГжЁЃ
91. НтЪЭвЛЯТЪВУДЪЧ aop?
AOP(Aspect-Oriented Programming,УцЯђЗНУцБрГЬ),ПЩвдЫЕЪЧOOP(Object-Oriented Programing,УцЯђЖдЯѓБрГЬ)ЕФВЙГфКЭЭъЩЦЁЃOOPв§ШыЗтзАЁЂМЬГаКЭЖрЬЌадЕШИХФюРДНЈСЂвЛжжЖдЯѓВуДЮНсЙЙ,гУвдФЃФтЙЋЙВааЮЊЕФвЛИіМЏКЯЁЃЕБЮвУЧашвЊЮЊЗжЩЂЕФЖдЯѓв§ШыЙЋЙВааЮЊЕФЪБКђ,OOPдђЯдЕУЮоФмЮЊСІЁЃвВОЭЪЧЫЕ,OOPдЪаэФуЖЈвхДгЩЯЕНЯТЕФЙиЯЕ,ЕЋВЂВЛЪЪКЯЖЈвхДгзѓЕНгвЕФЙиЯЕЁЃР§ШчШежОЙІФмЁЃШежОДњТыЭљЭљЫЎЦНЕиЩЂВМдкЫљгаЖдЯѓВуДЮжа,ЖјгыЫќЫљЩЂВМЕНЕФЖдЯѓЕФКЫаФЙІФмКСЮоЙиЯЕЁЃЖдгкЦфЫћРраЭЕФДњТы,ШчАВШЋадЁЂвьГЃДІРэКЭЭИУїЕФГжајадвВЪЧШчДЫЁЃетжжЩЂВМдкИїДІЕФЮоЙиЕФДњТыБЛГЦЮЊКсЧа(cross-cutting)ДњТы,дкOOPЩшМЦжа,ЫќЕМжТСЫДѓСПДњТыЕФжиИД,ЖјВЛРћгкИїИіФЃПщЕФжигУЁЃ
ЖјAOPММЪѕдђЧЁЧЁЯрЗД,ЫќРћгУвЛжжГЦЮЊЁАКсЧаЁБЕФММЪѕ,ЦЪНтПЊЗтзАЕФЖдЯѓФкВП,ВЂНЋФЧаЉгАЯьСЫЖрИіРрЕФЙЋЙВааЮЊЗтзАЕНвЛИіПЩжигУФЃПщ,ВЂНЋЦфУћЮЊЁАAspectЁБ,МДЗНУцЁЃЫљЮНЁАЗНУцЁБ,МђЕЅЕиЫЕ,ОЭЪЧНЋФЧаЉгывЕЮёЮоЙи,ШДЮЊвЕЮёФЃПщЫљЙВЭЌЕїгУЕФТпМЛђд№ШЮЗтзАЦ№РД,БугкМѕЩйЯЕЭГЕФжиИДДњТы,НЕЕЭФЃПщМфЕФёюКЯЖШ,ВЂгаРћгкЮДРДЕФПЩВйзїадКЭПЩЮЌЛЄадЁЃAOPДњБэЕФЪЧвЛИіКсЯђЕФЙиЯЕ,ШчЙћЫЕЁАЖдЯѓЁБЪЧвЛИіПеаФЕФдВжљЬх,ЦфжаЗтзАЕФЪЧЖдЯѓЕФЪєадКЭааЮЊ;ФЧУДУцЯђЗНУцБрГЬЕФЗНЗЈ,ОЭЗТЗ№вЛАбРћШа,НЋетаЉПеаФдВжљЬхЦЪПЊ,вдЛёЕУЦфФкВПЕФЯћЯЂЁЃЖјЦЪПЊЕФЧаУц,вВОЭЪЧЫљЮНЕФЁАЗНУцЁБСЫЁЃШЛКѓЫќгжвдЧЩЖсЬьЙІЕФУюЪжНЋетаЉЦЪПЊЕФЧаУцИДд,ВЛСєКлМЃЁЃ
ЪЙгУЁАКсЧаЁБММЪѕ,AOPАбШэМўЯЕЭГЗжЮЊСНИіВПЗж:КЫаФЙизЂЕуКЭКсЧаЙизЂЕуЁЃвЕЮёДІРэЕФжївЊСїГЬЪЧКЫаФЙизЂЕу,гыжЎЙиЯЕВЛДѓЕФВПЗжЪЧКсЧаЙизЂЕуЁЃКсЧаЙизЂЕуЕФвЛИіЬиЕуЪЧ,ЫћУЧОГЃЗЂЩњдкКЫаФЙизЂЕуЕФЖрДІ,ЖјИїДІЖМЛљБОЯрЫЦЁЃБШШчШЈЯоШЯжЄЁЂШежОЁЂЪТЮёДІРэЁЃAop ЕФзїгУдкгкЗжРыЯЕЭГжаЕФИїжжЙизЂЕу,НЋКЫаФЙизЂЕуКЭКсЧаЙизЂЕуЗжРыПЊРДЁЃе§ШчAvanadeЙЋЫОЕФИпМЖЗНАИЙЙМмЪІAdam MageeЫљЫЕ,AOPЕФКЫаФЫМЯыОЭЪЧЁАНЋгІгУГЬађжаЕФЩЬвЕТпМЭЌЖдЦфЬсЙЉжЇГжЕФЭЈгУЗўЮёНјааЗжРыЁЃЁБ
92. НтЪЭвЛЯТЪВУДЪЧ ioc?
IOCЪЧInversion of ControlЕФЫѕаД,ЖрЪ§ЪщМЎЗвыГЩЁАПижЦЗДзЊЁБЁЃ
ЁЁЁЁ
1996Фъ,Michael MattsonдквЛЦЊгаЙиЬНЬжУцЯђЖдЯѓПђМмЕФЮФеТжа,ЪзЯШЬсГіСЫIOC етИіИХФюЁЃЖдгкУцЯђЖдЯѓЩшМЦМАБрГЬЕФЛљБОЫМЯы,ЧАУцЮвУЧвбОНВСЫКмЖрСЫ,ВЛдйзИЪі,МђЕЅРДЫЕОЭЪЧАбИДдгЯЕЭГЗжНтГЩЯрЛЅКЯзїЕФЖдЯѓ,етаЉЖдЯѓРрЭЈЙ§ЗтзАвдКѓ,ФкВПЪЕЯжЖдЭтВПЪЧЭИУїЕФ,ДгЖјНЕЕЭСЫНтОіЮЪЬтЕФИДдгЖШ,ЖјЧвПЩвдСщЛюЕиБЛжигУКЭРЉеЙЁЃ
ЁЁЁЁ
IOCРэТлЬсГіЕФЙлЕуДѓЬхЪЧетбљЕФ:НшжњгкЁАЕкШ§ЗНЁБЪЕЯжОпгавРРЕЙиЯЕЕФЖдЯѓжЎМфЕФНтёюЁЃШчЯТЭМ:
ЭМ IOCНтёюЙ§ГЬ
ЁЁЁЁ
ДѓМвПДЕНСЫАЩ,гЩгкв§НјСЫжаМфЮЛжУЕФЁАЕкШ§ЗНЁБ,вВОЭЪЧIOCШнЦї,ЪЙЕУAЁЂBЁЂCЁЂDет4ИіЖдЯѓУЛгаСЫёюКЯЙиЯЕ,ГнТжжЎМфЕФДЋЖЏШЋВПвРППЁАЕкШ§ЗНЁБСЫ,ШЋВПЖдЯѓЕФПижЦШЈШЋВПЩЯНЩИјЁАЕкШ§ЗНЁБIOCШнЦї,Ыљвд,IOCШнЦїГЩСЫећИіЯЕЭГЕФЙиМќКЫаФ,ЫќЦ№ЕНСЫвЛжжРрЫЦЁАеГКЯМСЁБЕФзїгУ,АбЯЕЭГжаЕФЫљгаЖдЯѓеГКЯдквЛЦ№ЗЂЛгзїгУ,ШчЙћУЛгаетИіЁАеГКЯМСЁБ,ЖдЯѓгыЖдЯѓжЎМфЛсБЫДЫЪЇШЅСЊЯЕ,етОЭЪЧгаШЫАбIOCШнЦїБШгїГЩЁАеГКЯМСЁБЕФгЩРДЁЃ
ЁЁЁЁ
ЮвУЧдйРДзіИіЪдбщ:АбЩЯЭМжаМфЕФIOCШнЦїФУЕє,ШЛКѓдйРДПДПДетЬзЯЕЭГ:
ЭМ ФУЕєIOCШнЦїКѓЕФЯЕЭГ
ЁЁЁЁ
ЮвУЧЯждкПДЕНЕФЛУц,ОЭЪЧЮвУЧвЊЪЕЯжећИіЯЕЭГЫљашвЊЭъГЩЕФШЋВПФкШнЁЃетЪБКђ,AЁЂBЁЂCЁЂDет4ИіЖдЯѓжЎМфвбОУЛгаСЫёюКЯЙиЯЕ,БЫДЫКСЮоСЊЯЕ,етбљЕФЛА,ЕБФудкЪЕЯжAЕФЪБКђ,ИљБОЮоаыдйШЅПМТЧBЁЂCКЭDСЫ,ЖдЯѓжЎМфЕФвРРЕЙиЯЕвбОНЕЕЭЕНСЫзюЕЭГЬЖШЁЃЫљвд,ШчЙћецФмЪЕЯжIOCШнЦї,ЖдгкЯЕЭГПЊЗЂЖјбд,етНЋЪЧвЛМўЖрУДУРКУЕФЪТЧщ,ВЮгыПЊЗЂЕФУПвЛГЩдБжЛвЊЪЕЯжздМКЕФРрОЭПЩвдСЫ,ИњБ№ШЫУЛгаШЮКЮЙиЯЕ!
????
ЮвУЧдйРДПДПД,ПижЦЗДзЊ(IOC)ЕНЕзЮЊЪВУДвЊЦ№етУДИіУћзж?ЮвУЧРДЖдБШвЛЯТ:
????
ШэМўЯЕЭГдкУЛгав§ШыIOCШнЦїжЎЧА,ШчЭМ1ЫљЪО,ЖдЯѓAвРРЕгкЖдЯѓB,ФЧУДЖдЯѓAдкГѕЪМЛЏЛђепдЫааЕНФГвЛЕуЕФЪБКђ,здМКБиаыжїЖЏШЅДДНЈЖдЯѓBЛђепЪЙгУвбОДДНЈЕФЖдЯѓBЁЃЮоТлЪЧДДНЈЛЙЪЧЪЙгУЖдЯѓB,ПижЦШЈЖМдкздМКЪжЩЯЁЃ
????
ШэМўЯЕЭГдкв§ШыIOCШнЦїжЎКѓ,етжжЧщаЮОЭЭъШЋИФБфСЫ,ШчЭМ3ЫљЪО,гЩгкIOCШнЦїЕФМгШы,ЖдЯѓAгыЖдЯѓBжЎМфЪЇШЅСЫжБНгСЊЯЕ,Ыљвд,ЕБЖдЯѓAдЫааЕНашвЊЖдЯѓBЕФЪБКђ,IOCШнЦїЛсжїЖЏДДНЈвЛИіЖдЯѓBзЂШыЕНЖдЯѓAашвЊЕФЕиЗНЁЃ
????
ЭЈЙ§ЧАКѓЕФЖдБШ,ЮвУЧВЛФбПДГіРД:ЖдЯѓAЛёЕУвРРЕЖдЯѓBЕФЙ§ГЬ,гЩжїЖЏааЮЊБфЮЊСЫБЛЖЏааЮЊ,ПижЦШЈЕпЕЙЙ§РДСЫ,етОЭЪЧЁАПижЦЗДзЊЁБетИіУћГЦЕФгЩРДЁЃ
93. spring гаФФаЉжївЊФЃПщ?
SpringПђМмжСНёвбМЏГЩСЫ20ЖрИіФЃПщЁЃетаЉФЃПщжївЊБЛЗжШчЯТЭМЫљЪОЕФКЫаФШнЦїЁЂЪ§ОнЗУЮЪ/МЏГЩ,ЁЂWebЁЂAOP(УцЯђЧаУцБрГЬ)ЁЂЙЄОпЁЂЯћЯЂКЭВтЪдФЃПщЁЃ
ИќЖраХЯЂ:howtodoinjava.com/java-spring-framework-tutorials/
94. spring ГЃгУЕФзЂШыЗНЪНгаФФаЉ?
SpringЭЈЙ§DI(вРРЕзЂШы)ЪЕЯжIOC(ПижЦЗДзЊ),ГЃгУЕФзЂШыЗНЪНжївЊгаШ§жж:
-
ЙЙдьЗНЗЈзЂШы
-
setterзЂШы
-
ЛљгкзЂНтЕФзЂШы
95. spring жаЕФ bean ЪЧЯпГЬАВШЋЕФТ№?
SpringШнЦїжаЕФBeanЪЧЗёЯпГЬАВШЋ,ШнЦїБОЩэВЂУЛгаЬсЙЉBeanЕФЯпГЬАВШЋВпТд,вђДЫПЩвдЫЕspringШнЦїжаЕФBeanБОЩэВЛОпБИЯпГЬАВШЋЕФЬиад,ЕЋЪЧОпЬхЛЙЪЧвЊНсКЯОпЬхscopeЕФBeanШЅбаОПЁЃ
96. spring жЇГжМИжж bean ЕФзїгУгђ?
ЕБЭЈЙ§springШнЦїДДНЈвЛИіBeanЪЕР§ЪБ,ВЛНіПЩвдЭъГЩBeanЪЕР§ЕФЪЕР§ЛЏ,ЛЙПЩвдЮЊBeanжИЖЈЬиЖЈЕФзїгУгђЁЃSpringжЇГжШчЯТ5жжзїгУгђ:
-
singleton:ЕЅР§ФЃЪН,дкећИіSpring IoCШнЦїжа,ЪЙгУsingletonЖЈвхЕФBeanНЋжЛгавЛИіЪЕР§
-
prototype:даЭФЃЪН,УПДЮЭЈЙ§ШнЦїЕФgetBeanЗНЗЈЛёШЁprototypeЖЈвхЕФBeanЪБ,ЖМНЋВњЩњвЛИіаТЕФBeanЪЕР§
-
request:ЖдгкУПДЮHTTPЧыЧѓ,ЪЙгУrequestЖЈвхЕФBeanЖМНЋВњЩњвЛИіаТЪЕР§,МДУПДЮHTTPЧыЧѓНЋЛсВњЩњВЛЭЌЕФBeanЪЕР§ЁЃжЛгадкWebгІгУжаЪЙгУSpringЪБ,ИУзїгУгђВХгааЇ
-
session:ЖдгкУПДЮHTTP Session,ЪЙгУsessionЖЈвхЕФBeanЖЙНЌВњЩњвЛИіаТЪЕР§ЁЃЭЌбљжЛгадкWebгІгУжаЪЙгУSpringЪБ,ИУзїгУгђВХгааЇ
-
globalsession:УПИіШЋОжЕФHTTP Session,ЪЙгУsessionЖЈвхЕФBeanЖМНЋВњЩњвЛИіаТЪЕР§ЁЃЕфаЭЧщПіЯТ,НідкЪЙгУportlet contextЕФЪБКђгааЇЁЃЭЌбљжЛгадкWebгІгУжаЪЙгУSpringЪБ,ИУзїгУгђВХгааЇ
ЦфжаБШНЯГЃгУЕФЪЧsingletonКЭprototypeСНжжзїгУгђЁЃЖдгкsingletonзїгУгђЕФBean,УПДЮЧыЧѓИУBeanЖМНЋЛёЕУЯрЭЌЕФЪЕР§ЁЃШнЦїИКд№ИњзйBeanЪЕР§ЕФзДЬЌ,ИКд№ЮЌЛЄBeanЪЕР§ЕФЩњУќжмЦкааЮЊ;ШчЙћвЛИіBeanБЛЩшжУГЩprototypeзїгУгђ,ГЬађУПДЮЧыЧѓИУidЕФBean,SpringЖМЛсаТНЈвЛИіBeanЪЕР§,ШЛКѓЗЕЛиИјГЬађЁЃдкетжжЧщПіЯТ,SpringШнЦїНіНіЪЙгУnew ЙиМќзжДДНЈBeanЪЕР§,вЛЕЉДДНЈГЩЙІ,ШнЦїВЛдкИњзйЪЕР§,вВВЛЛсЮЌЛЄBeanЪЕР§ЕФзДЬЌЁЃ
ШчЙћВЛжИЖЈBeanЕФзїгУгђ,SpringФЌШЯЪЙгУsingletonзїгУгђЁЃJavaдкДДНЈJavaЪЕР§ЪБ,ашвЊНјааФкДцЩъЧы;ЯњЛйЪЕР§ЪБ,ашвЊЭъГЩРЌЛјЛиЪе,етаЉЙЄзїЖМЛсЕМжТЯЕЭГПЊЯњЕФдіМгЁЃвђДЫ,prototypeзїгУгђBeanЕФДДНЈЁЂЯњЛйДњМлБШНЯДѓЁЃЖјsingletonзїгУгђЕФBeanЪЕР§вЛЕЉДДНЈГЩЙІ,ПЩвджиИДЪЙгУЁЃвђДЫ,Г§ЗЧБивЊ,ЗёдђОЁСПБмУтНЋBeanБЛЩшжУГЩprototypeзїгУгђЁЃ
97. spring здЖЏзАХф bean гаФФаЉЗНЪН?
SpringШнЦїИКд№ДДНЈгІгУГЬађжаЕФbeanЭЌЪБЭЈЙ§IDРДаЕїетаЉЖдЯѓжЎМфЕФЙиЯЕЁЃзїЮЊПЊЗЂШЫдБ,ЮвУЧашвЊИцЫпSpringвЊДДНЈФФаЉbeanВЂЧвШчКЮНЋЦфзАХфЕНвЛЦ№ЁЃ
springжаbeanзАХфгаСНжжЗНЪН:
-
вўЪНЕФbeanЗЂЯжЛњжЦКЭздЖЏзАХф
-
дкjavaДњТыЛђепXMLжаНјааЯдЪОХфжУ
ЕБШЛетаЉЗНЪНвВПЩвдХфКЯЪЙгУЁЃ
98. spring ЪТЮёЪЕЯжЗНЪНгаФФаЉ?
-
БрГЬЪНЪТЮёЙмРэЖдЛљгк POJO ЕФгІгУРДЫЕЪЧЮЈвЛбЁдёЁЃЮвУЧашвЊдкДњТыжаЕїгУbeginTransaction()ЁЂcommit()ЁЂrollback()ЕШЪТЮёЙмРэЯрЙиЕФЗНЗЈ,етОЭЪЧБрГЬЪНЪТЮёЙмРэЁЃ
-
Лљгк TransactionProxyFactoryBean ЕФЩљУїЪНЪТЮёЙмРэ
-
Лљгк @Transactional ЕФЩљУїЪНЪТЮёЙмРэ
-
Лљгк Aspectj AOP ХфжУЪТЮё
99. ЫЕвЛЯТ spring ЕФЪТЮёИєРы?
ЪТЮёИєРыМЖБ№жИЕФЪЧвЛИіЪТЮёЖдЪ§ОнЕФаоИФгыСэвЛИіВЂааЕФЪТЮёЕФИєРыГЬЖШ,ЕБЖрИіЪТЮёЭЌЪБЗУЮЪЯрЭЌЪ§ОнЪБ,ШчЙћУЛгаВЩШЁБивЊЕФИєРыЛњжЦ,ОЭПЩФмЗЂЩњвдЯТЮЪЬт:
-
дрЖС:вЛИіЪТЮёЖСЕНСэвЛИіЪТЮёЮДЬсНЛЕФИќаТЪ§ОнЁЃ
-
ЛУЖС:Р§ШчЕквЛИіЪТЮёЖдвЛИіБэжаЕФЪ§ОнНјааСЫаоИФ,БШШчетжжаоИФЩцМАЕНБэжаЕФЁАШЋВПЪ§ОнааЁБЁЃЭЌЪБ,ЕкЖўИіЪТЮёвВаоИФетИіБэжаЕФЪ§Он,етжжаоИФЪЧЯђБэжаВхШыЁАвЛаааТЪ§ОнЁБЁЃФЧУД,вдКѓОЭЛсЗЂЩњВйзїЕквЛИіЪТЮёЕФгУЛЇЗЂЯжБэжаЛЙДцдкУЛгааоИФЕФЪ§Онаа,ОЭКУЯѓЗЂЩњСЫЛУОѕвЛбљЁЃ
-
ВЛПЩжиИДЖС:БШЗНЫЕдкЭЌвЛИіЪТЮёжаЯШКѓжДааСНЬѕвЛФЃвЛбљЕФselectгяОф,ЦкМфдкДЫДЮЪТЮёжаУЛгажДааЙ§ШЮКЮDDLгяОф,ЕЋЯШКѓЕУЕНЕФНсЙћВЛвЛжТ,етОЭЪЧВЛПЩжиИДЖСЁЃ
100. ЫЕвЛЯТ spring mvc дЫааСїГЬ?
Spring MVCдЫааСїГЬЭМ:
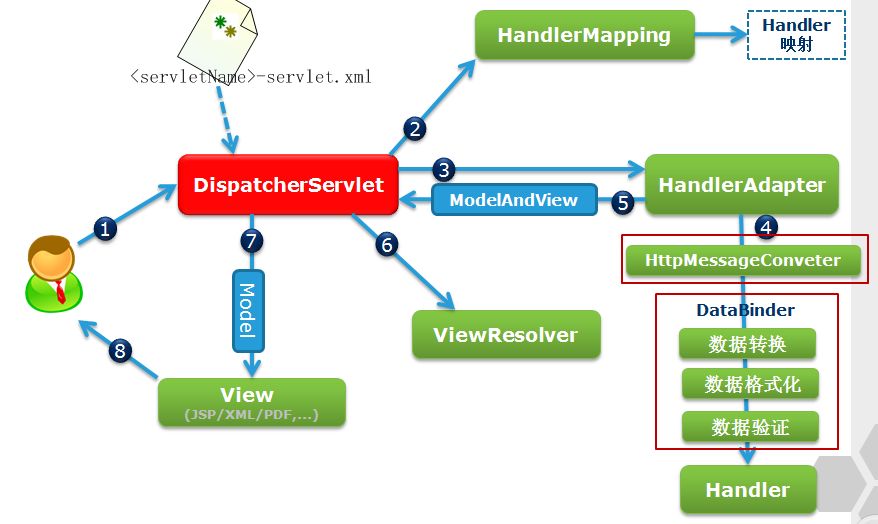
SpringдЫааСїГЬУшЪі:
? ? ??
1. гУЛЇЯђЗўЮёЦїЗЂЫЭЧыЧѓ,ЧыЧѓБЛSpring ЧАЖЫПижЦServelt DispatcherServletВЖЛё;
? ? ??
2.?DispatcherServletЖдЧыЧѓURLНјааНтЮі,ЕУЕНЧыЧѓзЪдДБъЪЖЗћ(URI)ЁЃШЛКѓИљОнИУURI,ЕїгУHandlerMappingЛёЕУИУHandlerХфжУЕФЫљгаЯрЙиЕФЖдЯѓ(АќРЈHandlerЖдЯѓвдМАHandlerЖдЯѓЖдгІЕФРЙНиЦї),зюКѓвдHandlerExecutionChainЖдЯѓЕФаЮЪНЗЕЛи;
? ????
3.?DispatcherServlet ИљОнЛёЕУЕФHandler,бЁдёвЛИіКЯЪЪЕФHandlerAdapter;(ИНзЂ:ШчЙћГЩЙІЛёЕУHandlerAdapterКѓ,ДЫЪБНЋПЊЪМжДааРЙНиЦїЕФpreHandler(...)ЗНЗЈ)
? ? ???
4. ?ЬсШЁRequestжаЕФФЃаЭЪ§Он,ЬюГфHandlerШыВЮ,ПЊЪМжДааHandler(Controller)ЁЃ дкЬюГфHandlerЕФШыВЮЙ§ГЬжа,ИљОнФуЕФХфжУ,SpringНЋАяФузівЛаЉЖюЭтЕФЙЄзї:
-
HttpMessageConveter: НЋЧыЧѓЯћЯЂ(ШчJsonЁЂxmlЕШЪ§Он)зЊЛЛГЩвЛИіЖдЯѓ,НЋЖдЯѓзЊЛЛЮЊжИЖЈЕФЯьгІаХЯЂ
-
Ъ§ОнзЊЛЛ:ЖдЧыЧѓЯћЯЂНјааЪ§ОнзЊЛЛЁЃШчStringзЊЛЛГЩIntegerЁЂDoubleЕШ
-
Ъ§ОнИљЪНЛЏ:ЖдЧыЧѓЯћЯЂНјааЪ§ОнИёЪНЛЏЁЃ ШчНЋзжЗћДЎзЊЛЛГЩИёЪНЛЏЪ§зжЛђИёЪНЛЏШеЦкЕШ
-
Ъ§ОнбщжЄ: бщжЄЪ§ОнЕФгааЇад(ГЄЖШЁЂИёЪНЕШ),бщжЄНсЙћДцДЂЕНBindingResultЛђErrorжа
? ????
5. ?HandlerжДааЭъГЩКѓ,ЯђDispatcherServlet?ЗЕЛивЛИіModelAndViewЖдЯѓ;
? ????
6. ?ИљОнЗЕЛиЕФModelAndView,бЁдёвЛИіЪЪКЯЕФViewResolver(БиаыЪЧвбОзЂВсЕНSpringШнЦїжаЕФViewResolver)ЗЕЛиИјDispatcherServlet?;
? ????
7.?ViewResolver НсКЯModelКЭView,РДфжШОЪгЭМ;
? ? ??
8. НЋфжШОНсЙћЗЕЛиИјПЭЛЇЖЫЁЃ
101. spring mvc гаФФаЉзщМў?
Spring MVCЕФКЫаФзщМў:
-
DispatcherServlet:жабыПижЦЦї,АбЧыЧѓИјзЊЗЂЕНОпЬхЕФПижЦРр
-
Controller:ОпЬхДІРэЧыЧѓЕФПижЦЦї
-
HandlerMapping:гГЩфДІРэЦї,ИКд№гГЩфжабыДІРэЦїзЊЗЂИјcontrollerЪБЕФгГЩфВпТд
-
ModelAndView:ЗўЮёВуЗЕЛиЕФЪ§ОнКЭЪгЭМВуЕФЗтзАРр
-
ViewResolver:ЪгЭМНтЮіЦї,НтЮіОпЬхЕФЪгЭМ
-
Interceptors :РЙНиЦї,ИКд№РЙНиЮвУЧЖЈвхЕФЧыЧѓШЛКѓзіДІРэЙЄзї
102. @RequestMapping ЕФзїгУЪЧЪВУД?
RequestMappingЪЧвЛИігУРДДІРэЧыЧѓЕижЗгГЩфЕФзЂНт,ПЩгУгкРрЛђЗНЗЈЩЯЁЃгУгкРрЩЯ,БэЪОРржаЕФЫљгаЯьгІЧыЧѓЕФЗНЗЈЖМЪЧвдИУЕижЗзїЮЊИИТЗОЖЁЃ
RequestMappingзЂНтгаСљИіЪєад,ЯТУцЮвУЧАбЫ§ЗжГЩШ§РрНјааЫЕУїЁЃ
value, method:
-
value:жИЖЈЧыЧѓЕФЪЕМЪЕижЗ,жИЖЈЕФЕижЗПЩвдЪЧURI Template ФЃЪН(КѓУцНЋЛсЫЕУї);
-
method:жИЖЈЧыЧѓЕФmethodРраЭ, GETЁЂPOSTЁЂPUTЁЂDELETEЕШ;
consumes,produces
-
consumes:жИЖЈДІРэЧыЧѓЕФЬсНЛФкШнРраЭ(Content-Type),Р§Шчapplication/json, text/html;
-
produces:жИЖЈЗЕЛиЕФФкШнРраЭ,НіЕБrequestЧыЧѓЭЗжаЕФ(Accept)РраЭжаАќКЌИУжИЖЈРраЭВХЗЕЛи;
params,headers
-
params: жИЖЈrequestжаБиаыАќКЌФГаЉВЮЪ§жЕЪЧ,ВХШУИУЗНЗЈДІРэЁЃ
-
headers:жИЖЈrequestжаБиаыАќКЌФГаЉжИЖЈЕФheaderжЕ,ВХФмШУИУЗНЗЈДІРэЧыЧѓЁЃ
103. @Autowired ЕФзїгУЪЧЪВУД?
ЁЖ@AutowiredгУЗЈЯъНтЁЗ:blog.csdn.net/u013257679/article/details/52295106
ЪЎвЛЁЂSpring Boot / Spring Cloud
104. ЪВУДЪЧ spring boot?
дкSpringПђМметИіДѓМвзхжа,ВњЩњСЫКмЖрбмЩњПђМм,БШШч SpringЁЂSpringMvcПђМмЕШ,SpringЕФКЫаФФкШндкгкПижЦЗДзЊ(IOC)КЭвРРЕзЂШы(DI),ЫљЮНПижЦЗДзЊВЂЗЧЪЧвЛжжММЪѕ,ЖјЪЧвЛжжЫМЯы,дкВйзїЗНУцЪЧжИдкspringХфжУЮФМўжаДДНЈ<bean>,вРРЕзЂШыМДЮЊгЩspringШнЦїЮЊгІгУГЬађЕФФГИіЖдЯѓЬсЙЉзЪдД,БШШч в§гУЖдЯѓЁЂГЃСПЪ§ОнЕШЁЃ
? ?
SpringBootЪЧвЛИіПђМм,вЛжжШЋаТЕФБрГЬЙцЗЖ,ЫћЕФВњЩњМђЛЏСЫПђМмЕФЪЙгУ,ЫљЮНМђЛЏЪЧжИМђЛЏСЫSpringжкЖрПђМмжаЫљашЕФДѓСПЧвЗБЫіЕФХфжУЮФМў,Ыљвд SpringBootЪЧвЛИіЗўЮёгкПђМмЕФПђМм,ЗўЮёЗЖЮЇЪЧМђЛЏХфжУЮФМўЁЃ
105. ЮЊЪВУДвЊгУ spring boot?
-
Spring BootЪЙБрТыБфМђЕЅ
-
Spring BootЪЙХфжУБфМђЕЅ
-
Spring BootЪЙВПЪ№БфМђЕЅ
-
Spring BootЪЙМрПиБфМђЕЅ
-
SpringЕФВЛзу
106. spring boot КЫаФХфжУЮФМўЪЧЪВУД?
Spring BootЬсЙЉСЫСНжжГЃгУЕФХфжУЮФМў:
-
propertiesЮФМў
-
ymlЮФМў
107. spring boot ХфжУЮФМўгаФФМИжжРраЭ?ЫќУЧгаЪВУДЧјБ№?
Spring BootЬсЙЉСЫСНжжГЃгУЕФХфжУЮФМў,ЗжБ№ЪЧpropertiesЮФМўКЭymlЮФМўЁЃЯрЖдгкpropertiesЮФМўЖјбд,ymlЮФМўИќФъЧс,вВгаКмЖрЕФПгЁЃПЩЮНГЩвВЯєКЮАмЯєКЮ,ymlЭЈЙ§ПеИёРДШЗЖЈВуМЖЙиЯЕ,ЪЙХфжУЮФМўНсЙЙИњЧхЮњ,ЕЋвВЛсвђЮЊЮЂВЛзуЕРЕФПеИёЖјЦЦЛЕСЫВуМЖЙиЯЕЁЃ
108. spring boot гаФФаЉЗНЪНПЩвдЪЕЯжШШВПЪ№?
SpringBootШШВПЪ№ЪЕЯжгаСНжжЗНЪН:
Ђй. ЪЙгУspring loaded
дкЯюФПжаЬэМгШчЯТДњТы:???????
<build><plugins><plugin><!-- springBootБрвыВхМў--><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><dependencies><!-- springШШВПЪ№ --><!-- ИУвРРЕдкДЫДІЯТдиВЛЯТРД,ПЩвдЗХжУдкbuildБъЧЉЭтВПЯТдиЭъГЩКѓдйеГЬљНјpluginжа --><dependency><groupId>org.springframework</groupId><artifactId>springloaded</artifactId><version>1.2.6.RELEASE</version></dependency></dependencies></plugin></plugins></build>
ЬэМгЭъБЯКѓашвЊЪЙгУmvnжИСюдЫаа:
ЁЁЁЁЁЁЁЁ
ЪзЯШевЕНIDEAжаЕФEdit configurations ,ШЛКѓНјааШчЯТВйзї:(ЕуЛїзѓЩЯНЧЕФ"+",ШЛКѓбЁдёmavenНЋГіЯжгвВрУцАх,дкКьЩЋЛЎЯпВПЮЛЪфШыШчЭМЫљЪОжИСю,ФуПЩвдЮЊИУжИСюУќУћ(ДЫДІУќУћЮЊMvnSpringBootRun))
ЁЁЁЁЁЁЁЁ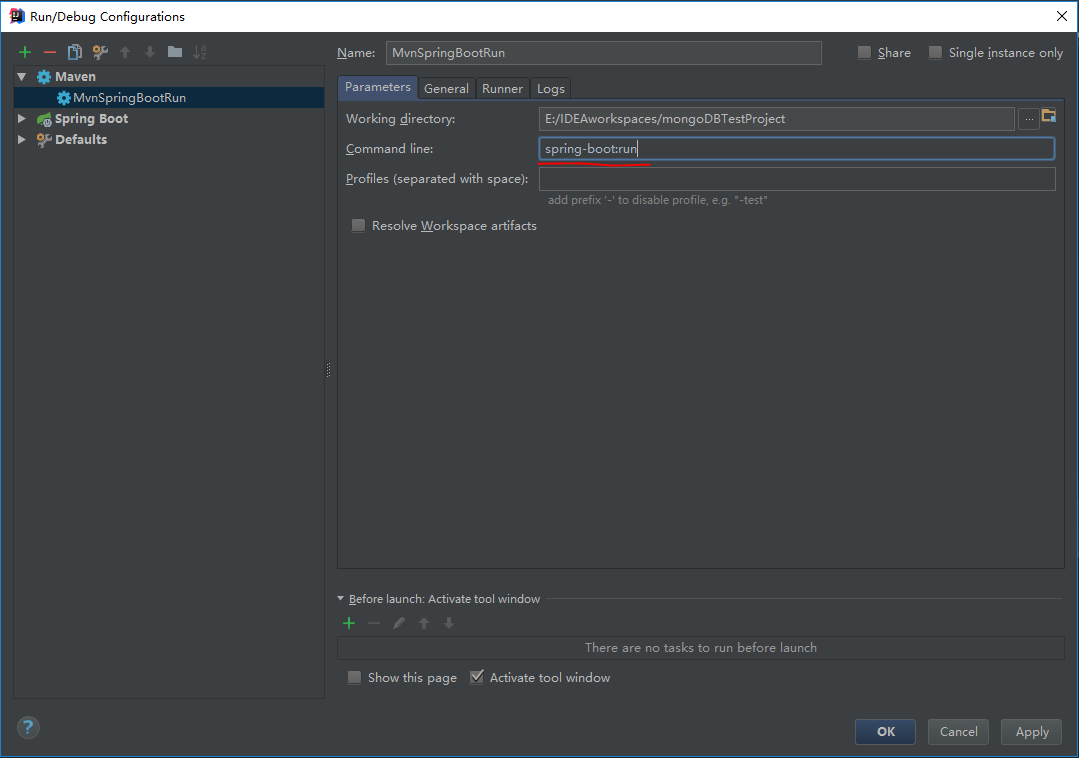
ЁЁ
ЕуЛїБЃДцНЋЛсдкIDEAЯюФПдЫааВПЮЛГіЯж,ЕуЛїТЬЩЋМ§ЭЗдЫааМДПЩ
![]()
Ђк. ЪЙгУspring-boot-devtools
дкЯюФПЕФpomЮФМўжаЬэМгвРРЕ:???????
?<!--ШШВПЪ№jar-->?<dependency>?????<groupId>org.springframework.boot</groupId>?????<artifactId>spring-boot-devtools</artifactId>?</dependency>
ШЛКѓ:ЪЙгУ shift+ctrl+alt+"/" (IDEAжаЕФПьНнМќ) бЁдё"Registry" ШЛКѓЙДбЁ?compiler.automake.allow.when.app.running
109. jpa КЭ hibernate гаЪВУДЧјБ№?
-
JPA Java Persistence API,ЪЧJava EE 5ЕФБъзМORMНгПк,вВЪЧejb3ЙцЗЖЕФвЛВПЗжЁЃ
-
Hibernate,ЕБНёКмСїааЕФORMПђМм,ЪЧJPAЕФвЛИіЪЕЯж,ЕЋЪЧЦфЙІФмЪЧJPAЕФГЌМЏЁЃ
-
JPAКЭHibernateжЎМфЕФЙиЯЕ,ПЩвдМђЕЅЕФРэНтЮЊJPAЪЧБъзМНгПк,HibernateЪЧЪЕЯжЁЃФЧУДHibernateЪЧШчКЮЪЕЯжгыJPAЕФетжжЙиЯЕЕФФиЁЃHibernateжївЊЪЧЭЈЙ§Ш§ИізщМўРДЪЕЯжЕФ,МАhibernate-annotationЁЂhibernate-entitymanagerКЭhibernate-coreЁЃ
-
hibernate-annotationЪЧHibernateжЇГжannotationЗНЪНХфжУЕФЛљДЁ,ЫќАќРЈСЫБъзМЕФJPA annotationвдМАHibernateздЩэЬиЪтЙІФмЕФannotationЁЃ
-
hibernate-coreЪЧHibernateЕФКЫаФЪЕЯж,ЬсЙЉСЫHibernateЫљгаЕФКЫаФЙІФмЁЃ
-
hibernate-entitymanagerЪЕЯжСЫБъзМЕФJPA,ПЩвдАбЫќПДГЩhibernate-coreКЭJPAжЎМфЕФЪЪХфЦї,ЫќВЂВЛжБНгЬсЙЉORMЕФЙІФм,ЖјЪЧЖдhibernate-coreНјааЗтзА,ЪЙЕУHibernateЗћКЯJPAЕФЙцЗЖЁЃ
110. ЪВУДЪЧ spring cloud?
ДгзжУцРэНт,Spring Cloud ОЭЪЧжТСІгкЗжВМЪНЯЕЭГЁЂдЦЗўЮёЕФПђМмЁЃ
Spring Cloud ЪЧећИі Spring МвзхжааТЕФГЩдБ,ЪЧзюНќдЦЗўЮёЛ№БЌЕФБиШЛВњЮяЁЃ
Spring Cloud ЮЊПЊЗЂШЫдБЬсЙЉСЫПьЫйЙЙНЈЗжВМЪНЯЕЭГжавЛаЉГЃМћФЃЪНЕФЙЄОп,Р§Шч:
-
ХфжУЙмРэ
-
ЗўЮёзЂВсгыЗЂЯж
-
ЖЯТЗЦї
-
жЧФмТЗгЩ
-
ЗўЮёМфЕїгУ
-
ИКдиОљКт
-
ЮЂДњРэ
-
ПижЦзмЯп
-
вЛДЮадСюХЦ
-
ШЋОжЫј
-
СьЕМбЁОй
-
ЗжВМЪНЛсЛА
-
МЏШКзДЬЌ
-
ЗжВМЪНЯћЯЂ
-
ЁЁ
ЪЙгУ Spring Cloud ПЊЗЂШЫдБПЩвдПЊЯфМДгУЕФЪЕЯжетаЉФЃЪНЕФЗўЮёКЭгІгУГЬађЁЃетаЉЗўЮёПЩвдШЮКЮЛЗОГЯТдЫаа,АќРЈЗжВМЪНЛЗОГ,вВАќРЈПЊЗЂШЫдБздМКЕФБЪМЧБОЕчФдвдМАИїжжЭаЙмЦНЬЈЁЃ
111. spring cloud ЖЯТЗЦїЕФзїгУЪЧЪВУД?
дкSpring CloudжаЪЙгУСЫHystrix?РДЪЕЯжЖЯТЗЦїЕФЙІФм,ЖЯТЗЦїПЩвдЗРжЙвЛИігІгУГЬађЖрДЮЪдЭМжДаавЛИіВйзї,МДКмПЩФмЪЇАм,дЪаэЫќМЬајЖјВЛЕШД§ЙЪеЯЛжИДЛђепРЫЗб CPU жмЦк,ЖјЫќШЗЖЈИУЙЪеЯЪЧГжОУЕФЁЃЖЯТЗЦїФЃЪНвВЪЙгІгУГЬађФмЙЛМьВтЙЪеЯЪЧЗёвбОНтОі,ШчЙћЮЪЬтЫЦКѕвбОЕУЕНОРе§,гІгУГЬађПЩвдГЂЪдЕїгУВйзїЁЃ
ЖЯТЗЦїдіМгСЫЮШЖЈадКЭСщЛюад,вдвЛИіЯЕЭГ,ЬсЙЉЮШЖЈад,ЖјЯЕЭГДгЙЪеЯжаЛжИД,ВЂОЁСПМѕЩйДЫЙЪеЯЕФЖдадФмЕФгАЯьЁЃЫќПЩвдАяжњПьЫйЕиОмОјЖдвЛИіВйзї,МДКмПЩФмЪЇАм,ЖјВЛЪЧЕШД§ВйзїГЌЪБ(ЛђепВЛЗЕЛи)ЕФЧыЧѓ,вдБЃГжЯЕЭГЕФЯьгІЪБМфЁЃШчЙћЖЯТЗЦїЬсИпУПДЮИФБфзДЬЌЕФЪБМфЕФЪТМў,ИУаХЯЂПЩвдБЛгУРДМрВтгЩЖЯТЗЦїБЃЛЄЯЕЭГЕФВПМўЕФНЁПЕзДПі,ЛђвдЬсабЙмРэдБЕБЖЯТЗЦїЬјеЂ,вддкДђПЊзДЬЌЁЃ
112. spring cloud ЕФКЫаФзщМўгаФФаЉ?
Ђй. ЗўЮёЗЂЯжЁЊЁЊNetflix Eureka
вЛИіRESTfulЗўЮё,гУРДЖЈЮЛдЫаадкAWSЕиЧј(Region)жаЕФжаМфВуЗўЮёЁЃгЩСНИізщМўзщГЩ:EurekaЗўЮёЦїКЭEurekaПЭЛЇЖЫЁЃEurekaЗўЮёЦїгУзїЗўЮёзЂВсЗўЮёЦїЁЃEurekaПЭЛЇЖЫЪЧвЛИіjavaПЭЛЇЖЫ,гУРДМђЛЏгыЗўЮёЦїЕФНЛЛЅЁЂзїЮЊТжбЏИКдиОљКтЦї,ВЂЬсЙЉЗўЮёЕФЙЪеЯЧаЛЛжЇГжЁЃNetflixдкЦфЩњВњЛЗОГжаЪЙгУЕФЪЧСэЭтЕФПЭЛЇЖЫ,ЫќЬсЙЉЛљгкСїСПЁЂзЪдДРћгУТЪвдМАГіДэзДЬЌЕФМгШЈИКдиОљКтЁЃ
Ђк. ПЭЗўЖЫИКдиОљКтЁЊЁЊNetflix Ribbon
Ribbon,жївЊЬсЙЉПЭЛЇВрЕФШэМўИКдиОљКтЫуЗЈЁЃRibbonПЭЛЇЖЫзщМўЬсЙЉвЛЯЕСаЭъЩЦЕФХфжУбЁЯю,БШШчСЌНгГЌЪБЁЂжиЪдЁЂжиЪдЫуЗЈЕШЁЃRibbonФкжУПЩВхАЮЁЂПЩЖЈжЦЕФИКдиОљКтзщМўЁЃ
Ђл. ЖЯТЗЦїЁЊЁЊNetflix Hystrix
ЖЯТЗЦїПЩвдЗРжЙвЛИігІгУГЬађЖрДЮЪдЭМжДаавЛИіВйзї,МДКмПЩФмЪЇАм,дЪаэЫќМЬајЖјВЛЕШД§ЙЪеЯЛжИДЛђепРЫЗб CPU жмЦк,ЖјЫќШЗЖЈИУЙЪеЯЪЧГжОУЕФЁЃЖЯТЗЦїФЃЪНвВЪЙгІгУГЬађФмЙЛМьВтЙЪеЯЪЧЗёвбОНтОіЁЃШчЙћЮЪЬтЫЦКѕвбОЕУЕНОРе§,гІгУГЬађПЩвдГЂЪдЕїгУВйзїЁЃ
ЪЎвЛЁЂSpring Boot / Spring Cloud
104. ЪВУДЪЧ spring boot?
дкSpringПђМметИіДѓМвзхжа,ВњЩњСЫКмЖрбмЩњПђМм,БШШч SpringЁЂSpringMvcПђМмЕШ,SpringЕФКЫаФФкШндкгкПижЦЗДзЊ(IOC)КЭвРРЕзЂШы(DI),ЫљЮНПижЦЗДзЊВЂЗЧЪЧвЛжжММЪѕ,ЖјЪЧвЛжжЫМЯы,дкВйзїЗНУцЪЧжИдкspringХфжУЮФМўжаДДНЈ<bean>,вРРЕзЂШыМДЮЊгЩspringШнЦїЮЊгІгУГЬађЕФФГИіЖдЯѓЬсЙЉзЪдД,БШШч в§гУЖдЯѓЁЂГЃСПЪ§ОнЕШЁЃ
? ?
SpringBootЪЧвЛИіПђМм,вЛжжШЋаТЕФБрГЬЙцЗЖ,ЫћЕФВњЩњМђЛЏСЫПђМмЕФЪЙгУ,ЫљЮНМђЛЏЪЧжИМђЛЏСЫSpringжкЖрПђМмжаЫљашЕФДѓСПЧвЗБЫіЕФХфжУЮФМў,Ыљвд SpringBootЪЧвЛИіЗўЮёгкПђМмЕФПђМм,ЗўЮёЗЖЮЇЪЧМђЛЏХфжУЮФМўЁЃ
105. ЮЊЪВУДвЊгУ spring boot?
-
Spring BootЪЙБрТыБфМђЕЅ
-
Spring BootЪЙХфжУБфМђЕЅ
-
Spring BootЪЙВПЪ№БфМђЕЅ
-
Spring BootЪЙМрПиБфМђЕЅ
-
SpringЕФВЛзу
106. spring boot КЫаФХфжУЮФМўЪЧЪВУД?
Spring BootЬсЙЉСЫСНжжГЃгУЕФХфжУЮФМў:
-
propertiesЮФМў
-
ymlЮФМў
107. spring boot ХфжУЮФМўгаФФМИжжРраЭ?ЫќУЧгаЪВУДЧјБ№?
Spring BootЬсЙЉСЫСНжжГЃгУЕФХфжУЮФМў,ЗжБ№ЪЧpropertiesЮФМўКЭymlЮФМўЁЃЯрЖдгкpropertiesЮФМўЖјбд,ymlЮФМўИќФъЧс,вВгаКмЖрЕФПгЁЃПЩЮНГЩвВЯєКЮАмЯєКЮ,ymlЭЈЙ§ПеИёРДШЗЖЈВуМЖЙиЯЕ,ЪЙХфжУЮФМўНсЙЙИњЧхЮњ,ЕЋвВЛсвђЮЊЮЂВЛзуЕРЕФПеИёЖјЦЦЛЕСЫВуМЖЙиЯЕЁЃ
108. spring boot гаФФаЉЗНЪНПЩвдЪЕЯжШШВПЪ№?
SpringBootШШВПЪ№ЪЕЯжгаСНжжЗНЪН:
Ђй. ЪЙгУspring loaded
дкЯюФПжаЬэМгШчЯТДњТы:
<build><plugins><plugin><!-- springBootБрвыВхМў--><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><dependencies><!-- springШШВПЪ№ --><!-- ИУвРРЕдкДЫДІЯТдиВЛЯТРД,ПЩвдЗХжУдкbuildБъЧЉЭтВПЯТдиЭъГЩКѓдйеГЬљНјpluginжа --><dependency><groupId>org.springframework</groupId><artifactId>springloaded</artifactId><version>1.2.6.RELEASE</version></dependency></dependencies></plugin></plugins></build>
ЬэМгЭъБЯКѓашвЊЪЙгУmvnжИСюдЫаа:
ЁЁЁЁЁЁЁЁ
ЪзЯШевЕНIDEAжаЕФEdit configurations ,ШЛКѓНјааШчЯТВйзї:(ЕуЛїзѓЩЯНЧЕФ"+",ШЛКѓбЁдёmavenНЋГіЯжгвВрУцАх,дкКьЩЋЛЎЯпВПЮЛЪфШыШчЭМЫљЪОжИСю,ФуПЩвдЮЊИУжИСюУќУћ(ДЫДІУќУћЮЊMvnSpringBootRun))
ЁЁЁЁЁЁЁЁ
ЁЁ
ЕуЛїБЃДцНЋЛсдкIDEAЯюФПдЫааВПЮЛГіЯж,ЕуЛїТЬЩЋМ§ЭЗдЫааМДПЩ
![]()
Ђк. ЪЙгУspring-boot-devtools
дкЯюФПЕФpomЮФМўжаЬэМгвРРЕ:???????
?<!--ШШВПЪ№jar-->?<dependency>?????<groupId>org.springframework.boot</groupId>?????<artifactId>spring-boot-devtools</artifactId>?</dependency>
ШЛКѓ:ЪЙгУ shift+ctrl+alt+"/" (IDEAжаЕФПьНнМќ) бЁдё"Registry" ШЛКѓЙДбЁ?compiler.automake.allow.when.app.running
109. jpa КЭ hibernate гаЪВУДЧјБ№?
-
JPA Java Persistence API,ЪЧJava EE 5ЕФБъзМORMНгПк,вВЪЧejb3ЙцЗЖЕФвЛВПЗжЁЃ
-
Hibernate,ЕБНёКмСїааЕФORMПђМм,ЪЧJPAЕФвЛИіЪЕЯж,ЕЋЪЧЦфЙІФмЪЧJPAЕФГЌМЏЁЃ
-
JPAКЭHibernateжЎМфЕФЙиЯЕ,ПЩвдМђЕЅЕФРэНтЮЊJPAЪЧБъзМНгПк,HibernateЪЧЪЕЯжЁЃФЧУДHibernateЪЧШчКЮЪЕЯжгыJPAЕФетжжЙиЯЕЕФФиЁЃHibernateжївЊЪЧЭЈЙ§Ш§ИізщМўРДЪЕЯжЕФ,МАhibernate-annotationЁЂhibernate-entitymanagerКЭhibernate-coreЁЃ
-
hibernate-annotationЪЧHibernateжЇГжannotationЗНЪНХфжУЕФЛљДЁ,ЫќАќРЈСЫБъзМЕФJPA annotationвдМАHibernateздЩэЬиЪтЙІФмЕФannotationЁЃ
-
hibernate-coreЪЧHibernateЕФКЫаФЪЕЯж,ЬсЙЉСЫHibernateЫљгаЕФКЫаФЙІФмЁЃ
-
hibernate-entitymanagerЪЕЯжСЫБъзМЕФJPA,ПЩвдАбЫќПДГЩhibernate-coreКЭJPAжЎМфЕФЪЪХфЦї,ЫќВЂВЛжБНгЬсЙЉORMЕФЙІФм,ЖјЪЧЖдhibernate-coreНјааЗтзА,ЪЙЕУHibernateЗћКЯJPAЕФЙцЗЖЁЃ
110. ЪВУДЪЧ spring cloud?
ДгзжУцРэНт,Spring Cloud ОЭЪЧжТСІгкЗжВМЪНЯЕЭГЁЂдЦЗўЮёЕФПђМмЁЃ
Spring Cloud ЪЧећИі Spring МвзхжааТЕФГЩдБ,ЪЧзюНќдЦЗўЮёЛ№БЌЕФБиШЛВњЮяЁЃ
Spring Cloud ЮЊПЊЗЂШЫдБЬсЙЉСЫПьЫйЙЙНЈЗжВМЪНЯЕЭГжавЛаЉГЃМћФЃЪНЕФЙЄОп,Р§Шч:
-
ХфжУЙмРэ
-
ЗўЮёзЂВсгыЗЂЯж
-
ЖЯТЗЦї
-
жЧФмТЗгЩ
-
ЗўЮёМфЕїгУ
-
ИКдиОљКт
-
ЮЂДњРэ
-
ПижЦзмЯп
-
вЛДЮадСюХЦ
-
ШЋОжЫј
-
СьЕМбЁОй
-
ЗжВМЪНЛсЛА
-
МЏШКзДЬЌ
-
ЗжВМЪНЯћЯЂ
-
ЁЁ
ЪЙгУ Spring Cloud ПЊЗЂШЫдБПЩвдПЊЯфМДгУЕФЪЕЯжетаЉФЃЪНЕФЗўЮёКЭгІгУГЬађЁЃетаЉЗўЮёПЩвдШЮКЮЛЗОГЯТдЫаа,АќРЈЗжВМЪНЛЗОГ,вВАќРЈПЊЗЂШЫдБздМКЕФБЪМЧБОЕчФдвдМАИїжжЭаЙмЦНЬЈЁЃ
111. spring cloud ЖЯТЗЦїЕФзїгУЪЧЪВУД?
дкSpring CloudжаЪЙгУСЫHystrix?РДЪЕЯжЖЯТЗЦїЕФЙІФм,ЖЯТЗЦїПЩвдЗРжЙвЛИігІгУГЬађЖрДЮЪдЭМжДаавЛИіВйзї,МДКмПЩФмЪЇАм,дЪаэЫќМЬајЖјВЛЕШД§ЙЪеЯЛжИДЛђепРЫЗб CPU жмЦк,ЖјЫќШЗЖЈИУЙЪеЯЪЧГжОУЕФЁЃЖЯТЗЦїФЃЪНвВЪЙгІгУГЬађФмЙЛМьВтЙЪеЯЪЧЗёвбОНтОі,ШчЙћЮЪЬтЫЦКѕвбОЕУЕНОРе§,гІгУГЬађПЩвдГЂЪдЕїгУВйзїЁЃ
ЖЯТЗЦїдіМгСЫЮШЖЈадКЭСщЛюад,вдвЛИіЯЕЭГ,ЬсЙЉЮШЖЈад,ЖјЯЕЭГДгЙЪеЯжаЛжИД,ВЂОЁСПМѕЩйДЫЙЪеЯЕФЖдадФмЕФгАЯьЁЃЫќПЩвдАяжњПьЫйЕиОмОјЖдвЛИіВйзї,МДКмПЩФмЪЇАм,ЖјВЛЪЧЕШД§ВйзїГЌЪБ(ЛђепВЛЗЕЛи)ЕФЧыЧѓ,вдБЃГжЯЕЭГЕФЯьгІЪБМфЁЃШчЙћЖЯТЗЦїЬсИпУПДЮИФБфзДЬЌЕФЪБМфЕФЪТМў,ИУаХЯЂПЩвдБЛгУРДМрВтгЩЖЯТЗЦїБЃЛЄЯЕЭГЕФВПМўЕФНЁПЕзДПі,ЛђвдЬсабЙмРэдБЕБЖЯТЗЦїЬјеЂ,вддкДђПЊзДЬЌЁЃ
112. spring cloud ЕФКЫаФзщМўгаФФаЉ?
Ђй. ЗўЮёЗЂЯжЁЊЁЊNetflix Eureka
вЛИіRESTfulЗўЮё,гУРДЖЈЮЛдЫаадкAWSЕиЧј(Region)жаЕФжаМфВуЗўЮёЁЃгЩСНИізщМўзщГЩ:EurekaЗўЮёЦїКЭEurekaПЭЛЇЖЫЁЃEurekaЗўЮёЦїгУзїЗўЮёзЂВсЗўЮёЦїЁЃEurekaПЭЛЇЖЫЪЧвЛИіjavaПЭЛЇЖЫ,гУРДМђЛЏгыЗўЮёЦїЕФНЛЛЅЁЂзїЮЊТжбЏИКдиОљКтЦї,ВЂЬсЙЉЗўЮёЕФЙЪеЯЧаЛЛжЇГжЁЃNetflixдкЦфЩњВњЛЗОГжаЪЙгУЕФЪЧСэЭтЕФПЭЛЇЖЫ,ЫќЬсЙЉЛљгкСїСПЁЂзЪдДРћгУТЪвдМАГіДэзДЬЌЕФМгШЈИКдиОљКтЁЃ
Ђк. ПЭЗўЖЫИКдиОљКтЁЊЁЊNetflix Ribbon
Ribbon,жївЊЬсЙЉПЭЛЇВрЕФШэМўИКдиОљКтЫуЗЈЁЃRibbonПЭЛЇЖЫзщМўЬсЙЉвЛЯЕСаЭъЩЦЕФХфжУбЁЯю,БШШчСЌНгГЌЪБЁЂжиЪдЁЂжиЪдЫуЗЈЕШЁЃRibbonФкжУПЩВхАЮЁЂПЩЖЈжЦЕФИКдиОљКтзщМўЁЃ
Ђл. ЖЯТЗЦїЁЊЁЊNetflix Hystrix
ЖЯТЗЦїПЩвдЗРжЙвЛИігІгУГЬађЖрДЮЪдЭМжДаавЛИіВйзї,МДКмПЩФмЪЇАм,дЪаэЫќМЬајЖјВЛЕШД§ЙЪеЯЛжИДЛђепРЫЗб CPU жмЦк,ЖјЫќШЗЖЈИУЙЪеЯЪЧГжОУЕФЁЃЖЯТЗЦїФЃЪНвВЪЙгІгУГЬађФмЙЛМьВтЙЪеЯЪЧЗёвбОНтОіЁЃШчЙћЮЪЬтЫЦКѕвбОЕУЕНОРе§,гІгУГЬађПЩвдГЂЪдЕїгУВйзїЁЃ
Ђм. ЗўЮёЭјЙиЁЊЁЊNetflix Zuul
РрЫЦnginx,ЗДЯђДњРэЕФЙІФм,ВЛЙ§netflixздМКдіМгСЫвЛаЉХфКЯЦфЫћзщМўЕФЬиадЁЃ
Ђн. ЗжВМЪНХфжУЁЊЁЊSpring Cloud Config
етИіЛЙЪЧОВЬЌЕФ,ЕУХфКЯSpring Cloud BusЪЕЯжЖЏЬЌЕФХфжУИќаТЁЃ
Ђм. ЗўЮёЭјЙиЁЊЁЊNetflix Zuul
РрЫЦnginx,ЗДЯђДњРэЕФЙІФм,ВЛЙ§netflixздМКдіМгСЫвЛаЉХфКЯЦфЫћзщМўЕФЬиадЁЃ
Ђн. ЗжВМЪНХфжУЁЊЁЊSpring Cloud Config
етИіЛЙЪЧОВЬЌЕФ,ЕУХфКЯSpring Cloud BusЪЕЯжЖЏЬЌЕФХфжУИќаТЁЃ
ЪЎЖўЁЂHibernate
113. ЮЊЪВУДвЊЪЙгУ hibernate?
-
ЖдJDBCЗУЮЪЪ§ОнПтЕФДњТызіСЫЗтзА,ДѓДѓМђЛЏСЫЪ§ОнЗУЮЪВуЗБЫіЕФжиИДадДњТыЁЃ
-
HibernateЪЧвЛИіЛљгкJDBCЕФжїСїГжОУЛЏПђМм,ЪЧвЛИігХауЕФORMЪЕЯжЁЃЫћКмДѓГЬЖШЕФМђЛЏDAOВуЕФБрТыЙЄзї
-
hibernateЪЙгУJavaЗДЩфЛњжЦ,ЖјВЛЪЧзжНкТыдіЧПГЬађРДЪЕЯжЭИУїадЁЃ
-
hibernateЕФадФмЗЧГЃКУ,вђЮЊЫќЪЧИіЧсСПМЖПђМмЁЃгГЩфЕФСщЛюадКмГіЩЋЁЃЫќжЇГжИїжжЙиЯЕЪ§ОнПт,ДгвЛЖдвЛЕНЖрЖдЖрЕФИїжжИДдгЙиЯЕЁЃ
114. ЪВУДЪЧ ORM ПђМм?
ЖдЯѓ-ЙиЯЕгГЩф(Object-Relational Mapping,МђГЦORM),УцЯђЖдЯѓЕФПЊЗЂЗНЗЈЪЧЕБНёЦѓвЕМЖгІгУПЊЗЂЛЗОГжаЕФжїСїПЊЗЂЗНЗЈ,ЙиЯЕЪ§ОнПтЪЧЦѓвЕМЖгІгУЛЗОГжагРОУДцЗХЪ§ОнЕФжїСїЪ§ОнДцДЂЯЕЭГЁЃЖдЯѓКЭЙиЯЕЪ§ОнЪЧвЕЮёЪЕЬхЕФСНжжБэЯжаЮЪН,вЕЮёЪЕЬхдкФкДцжаБэЯжЮЊЖдЯѓ,дкЪ§ОнПтжаБэЯжЮЊЙиЯЕЪ§ОнЁЃФкДцжаЕФЖдЯѓжЎМфДцдкЙиСЊКЭМЬГаЙиЯЕ,ЖјдкЪ§ОнПтжа,ЙиЯЕЪ§ОнЮоЗЈжБНгБэДяЖрЖдЖрЙиСЊКЭМЬГаЙиЯЕЁЃвђДЫ,ЖдЯѓ-ЙиЯЕгГЩф(ORM)ЯЕЭГвЛАувджаМфМўЕФаЮЪНДцдк,жївЊЪЕЯжГЬађЖдЯѓЕНЙиЯЕЪ§ОнПтЪ§ОнЕФгГЩфЁЃ
115. hibernate жаШчКЮдкПижЦЬЈВщПДДђгЁЕФ sql гяОф?
ВЮПМ:blog.csdn.net/Randy_Wang_/article/details/79460306
116. hibernate гаМИжжВщбЏЗНЪН?
-
hqlВщбЏ
-
sqlВщбЏ
-
ЬѕМўВщбЏ
hqlВщбЏ,sqlВщбЏ,ЬѕМўВщбЏHQL: Hibernate Query Language. УцЯђЖдЯѓЕФаДЗЈ:Query query = session.createQuery("from Customer where name = ?");query.setParameter(0, "ВдРЯЪІ");Query.list();QBC: Query By Criteria.(ЬѕМўВщбЏ)Criteria criteria = session.createCriteria(Customer.class);criteria.add(Restrictions.eq("name", "ЛЈНу"));List<Customer> list = criteria.list();SQL:SQLQuery query = session.createSQLQuery("select * from customer");List<Object[]> list = query.list();SQLQuery query = session.createSQLQuery("select * from customer");query.addEntity(Customer.class);List<Customer> list = query.list();Hql: ОпЬхЗжРр1ЁЂ ЪєадВщбЏ 2ЁЂ ВЮЪ§ВщбЏЁЂУќУћВЮЪ§ВщбЏ 3ЁЂ ЙиСЊВщбЏ 4ЁЂ ЗжвГВщбЏ 5ЁЂ ЭГМЦКЏЪ§HQLКЭSQLЕФЧјБ№HQLЪЧУцЯђЖдЯѓВщбЏВйзїЕФ,SQLЪЧНсЙЙЛЏВщбЏгябд ЪЧУцЯђЪ§ОнПтБэНсЙЙЕФ
117. hibernate ЪЕЬхРрПЩвдБЛЖЈвхЮЊ final Т№?
ПЩвдНЋHibernateЕФЪЕЬхРрЖЈвхЮЊfinalРр,ЕЋетжжзіЗЈВЂВЛКУЁЃвђЮЊHibernateЛсЪЙгУДњРэФЃЪНдкбгГйЙиСЊЕФЧщПіЯТЬсИпадФм,ШчЙћФуАбЪЕЬхРрЖЈвхГЩfinalРржЎКѓ,вђЮЊ?JavaВЛдЪаэЖдfinalРрНјааРЉеЙ,ЫљвдHibernateОЭЮоЗЈдйЪЙгУДњРэСЫ,ШчДЫвЛРДОЭЯожЦСЫЪЙгУПЩвдЬсЩ§адФмЕФЪжЖЮЁЃВЛЙ§,ШчЙћФуЕФГжОУЛЏРрЪЕЯжСЫвЛИіНгПкЖјЧвдкИУНгПкжаЩљУїСЫЫљгаЖЈвхгкЪЕЬхРржаЕФЫљгаpublicЕФЗНЗЈТжЕНЛА,ФуОЭФмЙЛБмУтГіЯжЧАУцЫљЫЕЕФВЛРћКѓЙћЁЃ
118. дк hibernate жаЪЙгУ Integer КЭ int зігГЩфгаЪВУДЧјБ№?
дкHibernateжа,ШчЙћНЋOIDЖЈвхЮЊIntegerРраЭ,ФЧУДHibernateОЭПЩвдИљОнЦфжЕЪЧЗёЮЊnullЖјХаЖЯвЛИіЖдЯѓЪЧЗёЪЧСйЪБЕФ,ШчЙћНЋOIDЖЈвхЮЊСЫintРраЭ,ЛЙашвЊдкhbmгГЩфЮФМўжаЩшжУЦфunsaved-valueЪєадЮЊ0ЁЃ
119. hibernate ЪЧШчКЮЙЄзїЕФ?
hibernateЙЄзїдРэ:
-
ЭЈЙ§Configuration config = new Configuration().configure();//ЖСШЁВЂНтЮіhibernate.cfg.xmlХфжУЮФМў
-
гЩhibernate.cfg.xmlжаЕФ<mapping resource="com/xx/User.hbm.xml"/>ЖСШЁВЂНтЮігГЩфаХЯЂ
-
ЭЈЙ§SessionFactory sf = config.buildSessionFactory();//ДДНЈSessionFactory
-
Session session = sf.openSession();//ДђПЊSesssion
-
Transaction tx = session.beginTransaction();//ДДНЈВЂЦєЖЏЪТЮёTransation
-
persistent operateВйзїЪ§Он,ГжОУЛЏВйзї
-
tx.commit();//ЬсНЛЪТЮё
-
ЙиБеSession
-
ЙиБеSesstionFactory
120. get()КЭ load()ЕФЧјБ№?
-
load() УЛгаЪЙгУЖдЯѓЕФЦфЫћЪєадЕФЪБКђ,УЛгаSQL ?бгГйМгди
-
get() УЛгаЪЙгУЖдЯѓЕФЦфЫћЪєадЕФЪБКђ,вВЩњГЩСЫSQL ?СЂМДМгди
121. ЫЕвЛЯТ hibernate ЕФЛКДцЛњжЦ?
HibernateжаЕФЛКДцЗжЮЊвЛМЖЛКДцКЭЖўМЖЛКДцЁЃ
вЛМЖЛКДцОЭЪЧ? Session МЖБ№ЕФЛКДц,дкЪТЮёЗЖЮЇФкгааЇЪЧ,ФкжУЕФВЛФмБЛаЖдиЁЃЖўМЖЛКДцЪЧ SesionFactoryМЖБ№ЕФЛКДц,ДггІгУЦєЖЏЕНгІгУНсЪјгааЇЁЃЪЧПЩбЁЕФ,ФЌШЯУЛгаЖўМЖЛКДц,ашвЊЪжЖЏПЊЦєЁЃБЃДцЪ§ОнПтКѓ,ЛКДцдкФкДцжаБЃДцвЛЗн,ШчЙћИќаТСЫЪ§ОнПтОЭвЊЭЌВНИќаТЁЃ
ЪВУДбљЕФЪ§ОнЪЪКЯДцЗХЕНЕкЖўМЖЛКДцжа?
-
КмЩйБЛаоИФЕФЪ§Он? ?ЬћзгЕФзюКѓЛиИДЪБМф
-
ОГЃБЛВщбЏЕФЪ§Он? ?ЕчЩЬЕФЕиЕу
-
ВЛЪЧКмживЊЕФЪ§Он,дЪаэГіЯжХМЖћВЂЗЂЕФЪ§Он
-
ВЛЛсБЛВЂЗЂЗУЮЪЕФЪ§Он
-
ГЃСПЪ§Он
РЉеЙ:hibernateЕФЖўМЖЛКДцФЌШЯЪЧВЛжЇГжЗжВМЪНЛКДцЕФЁЃЪЙгУ? memcahe,redisЕШжабыЛКДцРДДњЬцЖўМЖЛКДцЁЃ
122. hibernate ЖдЯѓгаФФаЉзДЬЌ?
hibernateРяЖдЯѓгаШ§жжзДЬЌ:
-
Transient(ЫВЪБ):ЖдЯѓИеnewГіРД,ЛЙУЛЩшid,ЩшСЫЦфЫћжЕЁЃ
-
Persistent(ГжОУ):ЕїгУСЫsave()ЁЂsaveOrUpdate(),ОЭБфГЩPersistent,гаidЁЃ
-
Detached(ЭбЙм):ЕБsession ?close()ЭъжЎКѓ,БфГЩDetachedЁЃ
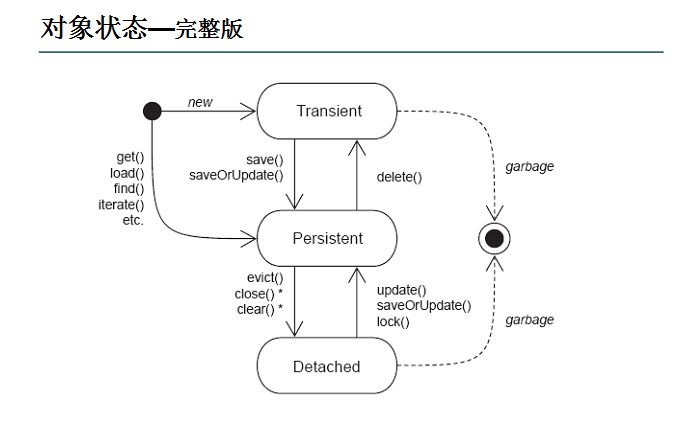
123. дк hibernate жа getCurrentSession КЭ openSession ЕФЧјБ№ЪЧЪВУД?
openSession ДгзжУцЩЯПЩвдПДЕУГіРД,ЪЧДђПЊвЛИіаТЕФsessionЖдЯѓ,ЖјЧвУПДЮЪЙгУЖМЪЧДђПЊвЛИіаТЕФsession,МйШчСЌајЪЙгУЖрДЮ,дђЛёЕУЕФsessionВЛЪЧЭЌвЛИіЖдЯѓ,ВЂЧвЪЙгУЭъашвЊЕїгУcloseЗНЗЈЙиБеsessionЁЃ
getCurrentSession ,ДгзжУцЩЯПЩвдПДЕУГіРД,ЪЧЛёШЁЕБЧАЩЯЯТЮФвЛИіsessionЖдЯѓ,ЕБЕквЛДЮЪЙгУДЫЗНЗЈЪБ,ЛсздЖЏВњЩњвЛИіsessionЖдЯѓ,ВЂЧвСЌајЪЙгУЖрДЮЪБ,ЕУЕНЕФsessionЖМЪЧЭЌвЛИіЖдЯѓ,етОЭЪЧгыopenSessionЕФЧјБ№жЎвЛ,МђЕЅЖјбд,getCurrentSession ОЭЪЧ:ШчЙћгавбОЪЙгУЕФ,гУОЩЕФ,ШчЙћУЛга,НЈаТЕФЁЃ
зЂвт:дкЪЕМЪПЊЗЂжа,ЭљЭљЪЙгУgetCurrentSessionЖр,вђЮЊвЛАуЪЧДІРэЭЌвЛИіЪТЮё(МДЪЧЪЙгУвЛИіЪ§ОнПтЕФЧщПі),ЫљвддквЛАуЧщПіЯТБШНЯЩйЪЙгУopenSessionЛђепЫЕopenSessionЪЧБШНЯРЯОЩЕФвЛЬзНгПкСЫЁЃ
124. hibernate ЪЕЬхРрБиаывЊгаЮоВЮЙЙдьКЏЪ§Т№?ЮЊЪВУД?
Биаы,вђЮЊhibernateПђМмЛсЕїгУетИіФЌШЯЙЙдьЗНЗЈРДЙЙдьЪЕР§ЖдЯѓ,МДClassРрЕФnewInstanceЗНЗЈ,етИіЗНЗЈОЭЪЧЭЈЙ§ЕїгУФЌШЯЙЙдьЗНЗЈРДДДНЈЪЕР§ЖдЯѓЕФЁЃ
?
СэЭтдйЬсабвЛЕу,ШчЙћФуУЛгаЬсЙЉШЮКЮЙЙдьЗНЗЈ,ащФтЛњЛсздЖЏЬсЙЉФЌШЯЙЙдьЗНЗЈ(ЮоВЮЙЙдьЦї),ЕЋЪЧШчЙћФуЬсЙЉСЫЦфЫћгаВЮЪ§ЕФЙЙдьЗНЗЈЕФЛА,ащФтЛњОЭВЛдйЮЊФуЬсЙЉФЌШЯЙЙдьЗНЗЈ,етЪББиаыЪжЖЏАбЮоВЮЙЙдьЦїаДдкДњТыРя,Зёдђnew Xxxx()ЪЧЛсБЈДэЕФ,ЫљвдФЌШЯЕФЙЙдьЗНЗЈВЛЪЧБиаыЕФ,жЛдкгаЖрИіЙЙдьЗНЗЈЪБВХЪЧБиаыЕФ,етРяЁАБиаыЁБжИЕФЪЧЁАБиаыЪжЖЏаДГіРДЁБЁЃ
ЪЎШ§ЁЂMybatis
125. mybatis жа #{}КЭ ${}ЕФЧјБ№ЪЧЪВУД?
-
#{}ЪЧдЄБрвыДІРэ,${}ЪЧзжЗћДЎЬцЛЛ;
-
MybatisдкДІРэ#{}ЪБ,ЛсНЋsqlжаЕФ#{}ЬцЛЛЮЊ?КХ,ЕїгУPreparedStatementЕФsetЗНЗЈРДИГжЕ;
-
MybatisдкДІРэ${}ЪБ,ОЭЪЧАб${}ЬцЛЛГЩБфСПЕФжЕ;
-
ЪЙгУ#{}ПЩвдгааЇЕФЗРжЙSQLзЂШы,ЬсИпЯЕЭГАВШЋадЁЃ
126. mybatis гаМИжжЗжвГЗНЪН?
-
Ъ§зщЗжвГ
-
sqlЗжвГ
-
РЙНиЦїЗжвГ
-
RowBoundsЗжвГ
128. mybatis ТпМЗжвГКЭЮяРэЗжвГЕФЧјБ№ЪЧЪВУД?
-
ЮяРэЗжвГЫйЖШЩЯВЂВЛвЛЖЈПьгкТпМЗжвГ,ТпМЗжвГЫйЖШЩЯвВВЂВЛвЛЖЈПьгкЮяРэЗжвГЁЃ
-
ЮяРэЗжвГзмЪЧгХгкТпМЗжвГ:УЛгаБивЊНЋЪєгкЪ§ОнПтЖЫЕФбЙСІМгжюЕНгІгУЖЫРД,ОЭЫуЫйЖШЩЯДцдкгХЪЦ,ШЛЖјЦфЫќадФмЩЯЕФгХЕузувдУжВЙетИіШБЕуЁЃ
129. mybatis ЪЧЗёжЇГжбгГйМгди?бгГйМгдиЕФдРэЪЧЪВУД?
MybatisНіжЇГжassociationЙиСЊЖдЯѓКЭcollectionЙиСЊМЏКЯЖдЯѓЕФбгГйМгди,associationжИЕФОЭЪЧвЛЖдвЛ,collectionжИЕФОЭЪЧвЛЖдЖрВщбЏЁЃдкMybatisХфжУЮФМўжа,ПЩвдХфжУЪЧЗёЦєгУбгГйМгдиlazyLoadingEnabled=true|falseЁЃ
ЫќЕФдРэЪЧ,ЪЙгУCGLIBДДНЈФПБъЖдЯѓЕФДњРэЖдЯѓ,ЕБЕїгУФПБъЗНЗЈЪБ,НјШыРЙНиЦїЗНЗЈ,БШШчЕїгУa.getB().getName(),РЙНиЦїinvoke()ЗНЗЈЗЂЯжa.getB()ЪЧnullжЕ,ФЧУДОЭЛсЕЅЖРЗЂЫЭЪТЯШБЃДцКУЕФВщбЏЙиСЊBЖдЯѓЕФsql,АбBВщбЏЩЯРД,ШЛКѓЕїгУa.setB(b),гкЪЧaЕФЖдЯѓbЪєадОЭгажЕСЫ,НгзХЭъГЩa.getB().getName()ЗНЗЈЕФЕїгУЁЃетОЭЪЧбгГйМгдиЕФЛљБОдРэЁЃ
ЕБШЛСЫ,ВЛЙтЪЧMybatis,МИКѕЫљгаЕФАќРЈHibernate,жЇГжбгГйМгдиЕФдРэЖМЪЧвЛбљЕФЁЃ
130. ЫЕвЛЯТ mybatis ЕФвЛМЖЛКДцКЭЖўМЖЛКДц?
вЛМЖЛКДц: Лљгк PerpetualCache ЕФ HashMap БОЕиЛКДц,ЦфДцДЂзїгУгђЮЊ Session,ЕБ Session flush Лђ close жЎКѓ,ИУ Session жаЕФЫљга Cache ОЭНЋЧхПе,ФЌШЯДђПЊвЛМЖЛКДцЁЃ
ЖўМЖЛКДцгывЛМЖЛКДцЦфЛњжЦЯрЭЌ,ФЌШЯвВЪЧВЩгУ PerpetualCache,HashMap ДцДЂ,ВЛЭЌдкгкЦфДцДЂзїгУгђЮЊ Mapper(Namespace),ВЂЧвПЩздЖЈвхДцДЂдД,Шч EhcacheЁЃФЌШЯВЛДђПЊЖўМЖЛКДц,вЊПЊЦєЖўМЖЛКДц,ЪЙгУЖўМЖЛКДцЪєадРрашвЊЪЕЯжSerializableађСаЛЏНгПк(ПЩгУРДБЃДцЖдЯѓЕФзДЬЌ),ПЩдкЫќЕФгГЩфЮФМўжаХфжУ<cache/> ;
ЖдгкЛКДцЪ§ОнИќаТЛњжЦ,ЕБФГвЛИізїгУгђ(вЛМЖЛКДц Session/ЖўМЖЛКДцNamespaces)ЕФНјааСЫC/U/D ВйзїКѓ,ФЌШЯИУзїгУгђЯТЫљга select жаЕФЛКДцНЋБЛ clearЁЃ
131. mybatis КЭ hibernate ЕФЧјБ№гаФФаЉ?
(1)MybatisКЭhibernateВЛЭЌ,ЫќВЛЭъШЋЪЧвЛИіORMПђМм,вђЮЊMyBatisашвЊГЬађдБздМКБраДSqlгяОфЁЃ
(2)MybatisжБНгБраДдЩњЬЌsql,ПЩвдбЯИёПижЦsqlжДааадФм,СщЛюЖШИп,ЗЧГЃЪЪКЯЖдЙиЯЕЪ§ОнФЃаЭвЊЧѓВЛИпЕФШэМўПЊЗЂ,вђЮЊетРрШэМўашЧѓБфЛЏЦЕЗБ,вЛЕЋашЧѓБфЛЏвЊЧѓбИЫйЪфГіГЩЙћЁЃЕЋЪЧСщЛюЕФЧАЬсЪЧmybatisЮоЗЈзіЕНЪ§ОнПтЮоЙиад,ШчЙћашвЊЪЕЯжжЇГжЖржжЪ§ОнПтЕФШэМў,дђашвЊздЖЈвхЖрЬзsqlгГЩфЮФМў,ЙЄзїСПДѓЁЃ?
(3)HibernateЖдЯѓ/ЙиЯЕгГЩфФмСІЧП,Ъ§ОнПтЮоЙиадКУ,ЖдгкЙиЯЕФЃаЭвЊЧѓИпЕФШэМў,ШчЙћгУhibernateПЊЗЂПЩвдНкЪЁКмЖрДњТы,ЬсИпаЇТЪЁЃ?
132. mybatis гаФФаЉжДааЦї(Executor)?
MybatisгаШ§жжЛљБОЕФжДааЦї(Executor):
-
SimpleExecutor:УПжДаавЛДЮupdateЛђselect,ОЭПЊЦєвЛИіStatementЖдЯѓ,гУЭъСЂПЬЙиБеStatementЖдЯѓЁЃ
-
ReuseExecutor:жДааupdateЛђselect,вдsqlзїЮЊkeyВщевStatementЖдЯѓ,ДцдкОЭЪЙгУ,ВЛДцдкОЭДДНЈ,гУЭъКѓ,ВЛЙиБеStatementЖдЯѓ,ЖјЪЧЗХжУгкMapФк,ЙЉЯТвЛДЮЪЙгУЁЃМђбджЎ,ОЭЪЧжиИДЪЙгУStatementЖдЯѓЁЃ
-
BatchExecutor:жДааupdate(УЛгаselect,JDBCХњДІРэВЛжЇГжselect),НЋЫљгаsqlЖМЬэМгЕНХњДІРэжа(addBatch()),ЕШД§ЭГвЛжДаа(executeBatch()),ЫќЛКДцСЫЖрИіStatementЖдЯѓ,УПИіStatementЖдЯѓЖМЪЧaddBatch()ЭъБЯКѓ,ЕШД§ж№вЛжДааexecuteBatch()ХњДІРэЁЃгыJDBCХњДІРэЯрЭЌЁЃ
133. mybatis ЗжвГВхМўЕФЪЕЯждРэЪЧЪВУД?
ЗжвГВхМўЕФЛљБОдРэЪЧЪЙгУMybatisЬсЙЉЕФВхМўНгПк,ЪЕЯжздЖЈвхВхМў,дкВхМўЕФРЙНиЗНЗЈФкРЙНиД§жДааЕФsql,ШЛКѓжиаДsql,ИљОнdialectЗНбд,ЬэМгЖдгІЕФЮяРэЗжвГгяОфКЭЮяРэЗжвГВЮЪ§ЁЃ
134. mybatis ШчКЮБраДвЛИіздЖЈвхВхМў?
зЊзд:blog.csdn.net/qq_30051265/article/details/80266434
MybatisздЖЈвхВхМўеыЖдMybatisЫФДѓЖдЯѓ(ExecutorЁЂStatementHandler ЁЂParameterHandler ЁЂResultSetHandler )НјааРЙНи,ОпЬхРЙНиЗНЪНЮЊ:?
-
Executor:РЙНижДааЦїЕФЗНЗЈ(logМЧТМ)?
-
StatementHandler :РЙНиSqlгяЗЈЙЙНЈЕФДІРэ?
-
ParameterHandler :РЙНиВЮЪ§ЕФДІРэ?
-
ResultSetHandler :РЙНиНсЙћМЏЕФДІРэ?
MybatisздЖЈвхВхМўБиаыЪЕЯжInterceptorНгПк:
public interface Interceptor {Object intercept(Invocation invocation) throws Throwable;Object plugin(Object target);void setProperties(Properties properties);}
interceptЗНЗЈ:РЙНиЦїОпЬхДІРэТпМЗНЗЈ?
pluginЗНЗЈ:ИљОнЧЉУћsignatureMapЩњГЩЖЏЬЌДњРэЖдЯѓ?
setPropertiesЗНЗЈ:ЩшжУPropertiesЪєад
здЖЈвхВхМўdemo:
// ExamplePlugin.java@Intercepts({@Signature(type= Executor.class,method = "update",args = {MappedStatement.class,Object.class})})public class ExamplePlugin implements Interceptor {public Object intercept(Invocation invocation) throws Throwable {Object target = invocation.getTarget(); //БЛДњРэЖдЯѓMethod method = invocation.getMethod(); //ДњРэЗНЗЈObject[] args = invocation.getArgs(); //ЗНЗЈВЮЪ§// do something ...... ЗНЗЈРЙНиЧАжДааДњТыПщObject result = invocation.proceed();// do something .......ЗНЗЈРЙНиКѓжДааДњТыПщreturn result;}public Object plugin(Object target) {return Plugin.wrap(target, this);}public void setProperties(Properties properties) {}}
вЛИі@InterceptsПЩвдХфжУЖрИі@Signature,@SignatureжаЕФВЮЪ§ЖЈвхШчЯТ:?
-
type:БэЪОРЙНиЕФРр,етРяЪЧExecutorЕФЪЕЯжРр;
-
method:БэЪОРЙНиЕФЗНЗЈ,етРяЪЧРЙНиExecutorЕФupdateЗНЗЈ;
-
args:БэЪОЗНЗЈВЮЪ§ЁЃ
ЪЎЫФЁЂRabbitMQ
135. rabbitmq ЕФЪЙгУГЁОАгаФФаЉ?
Ђй. ПчЯЕЭГЕФвьВНЭЈаХ,ЫљгаашвЊвьВННЛЛЅЕФЕиЗНЖМПЩвдЪЙгУЯћЯЂЖгСаЁЃОЭЯёЮвУЧГ§СЫДђЕчЛА(ЭЌВН)вдЭт,ЛЙашвЊЗЂЖЬаХ,ЗЂЕчзггЪМў(вьВН)ЕФЭЈбЖЗНЪНЁЃ
Ђк. ЖрИігІгУжЎМфЕФёюКЯ,гЩгкЯћЯЂЪЧЦНЬЈЮоЙиКЭгябдЮоЙиЕФ,ЖјЧвгявхЩЯвВВЛдйЪЧКЏЪ§ЕїгУ,вђДЫИќЪЪКЯзїЮЊЖрИігІгУжЎМфЕФЫЩёюКЯЕФНгПкЁЃЛљгкЯћЯЂЖгСаЕФёюКЯ,ВЛашвЊЗЂЫЭЗНКЭНгЪеЗНЭЌЪБдкЯпЁЃдкЦѓвЕгІгУМЏГЩ(EAI)жа,ЮФМўДЋЪф,ЙВЯэЪ§ОнПт,ЯћЯЂЖгСа,дЖГЬЙ§ГЬЕїгУЖМПЩвдзїЮЊМЏГЩЕФЗНЗЈЁЃ
Ђл. гІгУФкЕФЭЌВНБфвьВН,БШШчЖЉЕЅДІРэ,ОЭПЩвдгЩЧАЖЫгІгУНЋЖЉЕЅаХЯЂЗХЕНЖгСа,КѓЖЫгІгУДгЖгСаРявРДЮЛёЕУЯћЯЂДІРэ,ИпЗхЪБЕФДѓСПЖЉЕЅПЩвдЛ§бЙдкЖгСаРяТ§Т§ДІРэЕєЁЃгЩгкЭЌВНЭЈГЃвтЮЖзХзшШћ,ЖјДѓСПЯпГЬЕФзшШћЛсНЕЕЭМЦЫуЛњЕФадФмЁЃ
Ђм. ЯћЯЂЧ§ЖЏЕФМмЙЙ(EDA),ЯЕЭГЗжНтЮЊЯћЯЂЖгСа,КЭЯћЯЂжЦдьепКЭЯћЯЂЯћЗбеп,вЛИіДІРэСїГЬПЩвдИљОнашвЊВ№ГЩЖрИіНзЖЮ(Stage),НзЖЮжЎМфгУЖгСаСЌНгЦ№РД,ЧАвЛИіНзЖЮДІРэЕФНсЙћЗХШыЖгСа,КѓвЛИіНзЖЮДгЖгСажаЛёШЁЯћЯЂМЬајДІРэЁЃ
Ђн. гІгУашвЊИќСщЛюЕФёюКЯЗНЪН,ШчЗЂВМЖЉдФ,БШШчПЩвджИЖЈТЗгЩЙцдђЁЃ
Ђо. ПчОжгђЭј,ЩѕжСПчГЧЪаЕФЭЈбЖ(CDNаавЕ),БШШчББОЉЛњЗПгыЙужнЛњЗПЕФгІгУГЬађЕФЭЈаХЁЃ
136. rabbitmq гаФФаЉживЊЕФНЧЩЋ?
RabbitMQ жаживЊЕФНЧЩЋга:ЩњВњепЁЂЯћЗбепКЭДњРэ:
-
ЩњВњеп:ЯћЯЂЕФДДНЈеп,ИКд№ДДНЈКЭЭЦЫЭЪ§ОнЕНЯћЯЂЗўЮёЦї;
-
ЯћЗбеп:ЯћЯЂЕФНгЪеЗН,гУгкДІРэЪ§ОнКЭШЗШЯЯћЯЂ;
-
ДњРэ:ОЭЪЧ RabbitMQ БОЩэ,гУгкАчбнЁАПьЕнЁБЕФНЧЩЋ,БОЩэВЛЩњВњЯћЯЂ,жЛЪЧАчбнЁАПьЕнЁБЕФНЧЩЋЁЃ
137. rabbitmq гаФФаЉживЊЕФзщМў?
-
ConnectionFactory(СЌНгЙмРэЦї):гІгУГЬађгыRabbitжЎМфНЈСЂСЌНгЕФЙмРэЦї,ГЬађДњТыжаЪЙгУЁЃ
-
Channel(аХЕР):ЯћЯЂЭЦЫЭЪЙгУЕФЭЈЕРЁЃ
-
Exchange(НЛЛЛЦї):гУгкНгЪмЁЂЗжХфЯћЯЂЁЃ
-
Queue(ЖгСа):гУгкДцДЂЩњВњепЕФЯћЯЂЁЃ
-
RoutingKey(ТЗгЩМќ):гУгкАбЩњГЩепЕФЪ§ОнЗжХфЕННЛЛЛЦїЩЯЁЃ
-
BindingKey(АѓЖЈМќ):гУгкАбНЛЛЛЦїЕФЯћЯЂАѓЖЈЕНЖгСаЩЯЁЃ
138. rabbitmq жа vhost ЕФзїгУЪЧЪВУД?
vhost ПЩвдРэНтЮЊащФт broker ,МД mini-RabbitMQ? serverЁЃЦфФкВПОљКЌгаЖРСЂЕФ queueЁЂexchange КЭ binding ЕШ,ЕЋзюзюживЊЕФЪЧ,ЦфгЕгаЖРСЂЕФШЈЯоЯЕЭГ,ПЩвдзіЕН vhost ЗЖЮЇЕФгУЛЇПижЦЁЃЕБШЛ,Дг RabbitMQ ЕФШЋОжНЧЖШ,vhost ПЩвдзїЮЊВЛЭЌШЈЯоИєРыЕФЪжЖЮ(вЛИіЕфаЭЕФР§згОЭЪЧВЛЭЌЕФгІгУПЩвдХмдкВЛЭЌЕФ vhost жа)ЁЃ?
139. rabbitmq ЕФЯћЯЂЪЧдѕУДЗЂЫЭЕФ?
ЪзЯШПЭЛЇЖЫБиаыСЌНгЕН RabbitMQ ЗўЮёЦїВХФмЗЂВМКЭЯћЗбЯћЯЂ,ПЭЛЇЖЫКЭ rabbit server жЎМфЛсДДНЈвЛИі tcp СЌНг,вЛЕЉ tcp ДђПЊВЂЭЈЙ§СЫШЯжЄ(ШЯжЄОЭЪЧФуЗЂЫЭИј rabbit ЗўЮёЦїЕФгУЛЇУћКЭУмТы),ФуЕФПЭЛЇЖЫКЭ RabbitMQ ОЭДДНЈСЫвЛЬѕ amqp аХЕР(channel),аХЕРЪЧДДНЈдкЁАецЪЕЁБ tcp ЩЯЕФащФтСЌНг,amqp УќСюЖМЪЧЭЈЙ§аХЕРЗЂЫЭГіШЅЕФ,УПИіаХЕРЖМЛсгавЛИіЮЈвЛЕФ id,ВЛТлЪЧЗЂВМЯћЯЂ,ЖЉдФЖгСаЖМЪЧЭЈЙ§етИіаХЕРЭъГЩЕФЁЃ
140. rabbitmq дѕУДБЃжЄЯћЯЂЕФЮШЖЈад?
-
ЬсЙЉСЫЪТЮёЕФЙІФмЁЃ
-
ЭЈЙ§НЋ channel ЩшжУЮЊ confirm(ШЗШЯ)ФЃЪНЁЃ
141. rabbitmq дѕУДБмУтЯћЯЂЖЊЪЇ?
-
ЯћЯЂГжОУЛЏ
-
ACKШЗШЯЛњжЦ
-
ЩшжУМЏШКОЕЯёФЃЪН
-
ЯћЯЂВЙГЅЛњжЦ
142. вЊБЃжЄЯћЯЂГжОУЛЏГЩЙІЕФЬѕМўгаФФаЉ?
-
ЩљУїЖгСаБиаыЩшжУГжОУЛЏ durable ЩшжУЮЊ true.
-
ЯћЯЂЭЦЫЭЭЖЕнФЃЪНБиаыЩшжУГжОУЛЏ,deliveryMode ЩшжУЮЊ 2(ГжОУ)ЁЃ
-
ЯћЯЂвбОЕНДяГжОУЛЏНЛЛЛЦїЁЃ
-
ЯћЯЂвбОЕНДяГжОУЛЏЖгСаЁЃ
вдЩЯЫФИіЬѕМўЖМТњзуВХФмБЃжЄЯћЯЂГжОУЛЏГЩЙІЁЃ
143. rabbitmq ГжОУЛЏгаЪВУДШБЕу?
ГжОУЛЏЕФШБЕиОЭЪЧНЕЕЭСЫЗўЮёЦїЕФЭЬЭТСП,вђЮЊЪЙгУЕФЪЧДХХЬЖјЗЧФкДцДцДЂ,ДгЖјНЕЕЭСЫЭЬЭТСПЁЃПЩОЁСПЪЙгУ ssd гВХЬРДЛКНтЭЬЭТСПЕФЮЪЬтЁЃ
144. rabbitmq гаМИжжЙуВЅРраЭ?
Ш§жжЙуВЅФЃЪН:
-
fanout: ЫљгаbindЕНДЫexchangeЕФqueueЖМПЩвдНгЪеЯћЯЂ(ДПЙуВЅ,АѓЖЈЕНRabbitMQЕФНгЪмепЖМФмЪеЕНЯћЯЂ);
-
direct: ЭЈЙ§routingKeyКЭexchangeОіЖЈЕФФЧИіЮЈвЛЕФqueueПЩвдНгЪеЯћЯЂ;
-
topic:ЫљгаЗћКЯroutingKey(ДЫЪБПЩвдЪЧвЛИіБэДяЪН)ЕФroutingKeyЫљbindЕФqueueПЩвдНгЪеЯћЯЂ;
145. rabbitmq дѕУДЪЕЯжбгГйЯћЯЂЖгСа?
-
ЭЈЙ§ЯћЯЂЙ§ЦкКѓНјШыЫРаХНЛЛЛЦї,дйгЩНЛЛЛЦїзЊЗЂЕНбгГйЯћЗбЖгСа,ЪЕЯжбгГйЙІФм;
-
ЪЙгУ RabbitMQ-delayed-message-exchange ВхМўЪЕЯжбгГйЙІФмЁЃ
146. rabbitmq МЏШКгаЪВУДгУ?
МЏШКжївЊгавдЯТСНИігУЭО:
-
ИпПЩгУ:ФГИіЗўЮёЦїГіЯжЮЪЬт,ећИі RabbitMQ ЛЙПЩвдМЬајЪЙгУ;
-
ИпШнСП:МЏШКПЩвдГадиИќЖрЕФЯћЯЂСПЁЃ
147. rabbitmq НкЕуЕФРраЭгаФФаЉ?
-
ДХХЬНкЕу:ЯћЯЂЛсДцДЂЕНДХХЬЁЃ
-
ФкДцНкЕу:ЯћЯЂЖМДцДЂдкФкДцжа,жиЦєЗўЮёЦїЯћЯЂЖЊЪЇ,адФмИпгкДХХЬРраЭЁЃ
148. rabbitmq МЏШКДюНЈашвЊзЂвтФФаЉЮЪЬт?
-
ИїНкЕужЎМфЪЙгУЁА--linkЁБСЌНг,ДЫЪєадВЛФмКіТдЁЃ
-
ИїНкЕуЪЙгУЕФ erlang cookie жЕБиаыЯрЭЌ,ДЫжЕЯрЕБгкЁАУидПЁБЕФЙІФм,гУгкИїНкЕуЕФШЯжЄЁЃ
-
ећИіМЏШКжаБиаыАќКЌвЛИіДХХЬНкЕуЁЃ
149. rabbitmq УПИіНкЕуЪЧЦфЫћНкЕуЕФЭъећПНБДТ№?ЮЊЪВУД?
ВЛЪЧ,двђгавдЯТСНИі:
-
ДцДЂПеМфЕФПМТЧ:ШчЙћУПИіНкЕуЖМгЕгаЫљгаЖгСаЕФЭъШЋПНБД,етбљаТдіНкЕуВЛЕЋУЛгааТдіДцДЂПеМф,ЗДЖјдіМгСЫИќЖрЕФШпгрЪ§Он;
-
адФмЕФПМТЧ:ШчЙћУПЬѕЯћЯЂЖМашвЊЭъећПНБДЕНУПвЛИіМЏШКНкЕу,ФЧаТдіНкЕуВЂУЛгаЬсЩ§ДІРэЯћЯЂЕФФмСІ,зюЖрЪЧБЃГжКЭЕЅНкЕуЯрЭЌЕФадФмЩѕжСЪЧИќдуЁЃ
150. rabbitmq МЏШКжаЮЈвЛвЛИіДХХЬНкЕуБРРЃСЫЛсЗЂЩњЪВУДЧщПі?
ШчЙћЮЈвЛДХХЬЕФДХХЬНкЕуБРРЃСЫ,ВЛФмНјаавдЯТВйзї:
-
ВЛФмДДНЈЖгСа
-
ВЛФмДДНЈНЛЛЛЦї
-
ВЛФмДДНЈАѓЖЈ
-
ВЛФмЬэМггУЛЇ
-
ВЛФмИќИФШЈЯо
-
ВЛФмЬэМгКЭЩОГ§МЏШКНкЕу
ЮЈвЛДХХЬНкЕуБРРЃСЫ,МЏШКЪЧПЩвдБЃГждЫааЕФ,ЕЋФуВЛФмИќИФШЮКЮЖЋЮїЁЃ
151. rabbitmq ЖдМЏШКНкЕуЭЃжЙЫГађгавЊЧѓТ№?
RabbitMQ ЖдМЏШКЕФЭЃжЙЕФЫГађЪЧгавЊЧѓЕФ,гІИУЯШЙиБеФкДцНкЕу,зюКѓдйЙиБеДХХЬНкЕуЁЃШчЙћЫГађЧЁКУЯрЗДЕФЛА,ПЩФмЛсдьГЩЯћЯЂЕФЖЊЪЇЁЃ
ЪЎЮхЁЂKafka
152. kafka ПЩвдЭбРы zookeeper ЕЅЖРЪЙгУТ№?ЮЊЪВУД?
kafka ВЛФмЭбРы zookeeper ЕЅЖРЪЙгУ,вђЮЊ kafka ЪЙгУ zookeeper ЙмРэКЭаЕї kafka ЕФНкЕуЗўЮёЦїЁЃ
153. kafka гаМИжжЪ§ОнБЃСєЕФВпТд?
kafka гаСНжжЪ§ОнБЃДцВпТд:АДееЙ§ЦкЪБМфБЃСєКЭАДееДцДЂЕФЯћЯЂДѓаЁБЃСєЁЃ
154. kafka ЭЌЪБЩшжУСЫ 7 ЬьКЭ 10G ЧхГ§Ъ§Он,ЕНЕкЮхЬьЕФЪБКђЯћЯЂДяЕНСЫ 10G,етИіЪБКђ kafka НЋШчКЮДІРэ?
етИіЪБКђ kafka ЛсжДааЪ§ОнЧхГ§ЙЄзї,ЪБМфКЭДѓаЁВЛТлФЧИіТњзуЬѕМў,ЖМЛсЧхПеЪ§ОнЁЃ
155. ЪВУДЧщПіЛсЕМжТ kafka дЫааБфТ§?
-
cpu адФмЦПОБ
-
ДХХЬЖСаДЦПОБ
-
ЭјТчЦПОБ
156. ЪЙгУ kafka МЏШКашвЊзЂвтЪВУД?
-
МЏШКЕФЪ§СПВЛЪЧдНЖрдНКУ,зюКУВЛвЊГЌЙ§ 7 Иі,вђЮЊНкЕудНЖр,ЯћЯЂИДжЦашвЊЕФЪБМфОЭдНГЄ,ећИіШКзщЕФЭЬЭТСПОЭдНЕЭЁЃ
-
МЏШКЪ§СПзюКУЪЧЕЅЪ§,вђЮЊГЌЙ§вЛАыЙЪеЯМЏШКОЭВЛФмгУСЫ,ЩшжУЮЊЕЅЪ§ШнДэТЪИќИпЁЃ
ЪЎСљЁЂZookeeper
157. zookeeper ЪЧЪВУД?
zookeeper ЪЧвЛИіЗжВМЪНЕФ,ПЊЗХдДТыЕФЗжВМЪНгІгУГЬађаЕїЗўЮё,ЪЧ google chubby ЕФПЊдДЪЕЯж,ЪЧ hadoop КЭ hbase ЕФживЊзщМўЁЃЫќЪЧвЛИіЮЊЗжВМЪНгІгУЬсЙЉвЛжТадЗўЮёЕФШэМў,ЬсЙЉЕФЙІФмАќРЈ:ХфжУЮЌЛЄЁЂгђУћЗўЮёЁЂЗжВМЪНЭЌВНЁЂзщЗўЮёЕШЁЃ
158. zookeeper ЖМгаФФаЉЙІФм?
-
МЏШКЙмРэ:МрПиНкЕуДцЛюзДЬЌЁЂдЫааЧыЧѓЕШЁЃ
-
жїНкЕубЁОй:жїНкЕуЙвЕєСЫжЎКѓПЩвдДгБИгУЕФНкЕуПЊЪМаТвЛТжбЁжї,жїНкЕубЁОйЫЕЕФОЭЪЧетИібЁОйЕФЙ§ГЬ,ЪЙгУ zookeeper ПЩвдажњЭъГЩетИіЙ§ГЬЁЃ
-
ЗжВМЪНЫј:zookeeper ЬсЙЉСНжжЫј:ЖРеМЫјЁЂЙВЯэЫјЁЃЖРеМЫјМДвЛДЮжЛФмгавЛИіЯпГЬЪЙгУзЪдД,ЙВЯэЫјЪЧЖСЫјЙВЯэ,ЖСаДЛЅГт,МДПЩвдгаЖрЯпЯпГЬЭЌЪБЖСЭЌвЛИізЪдД,ШчЙћвЊЪЙгУаДЫјвВжЛФмгавЛИіЯпГЬЪЙгУЁЃzookeeperПЩвдЖдЗжВМЪНЫјНјааПижЦЁЃ
-
УќУћЗўЮё:дкЗжВМЪНЯЕЭГжа,ЭЈЙ§ЪЙгУУќУћЗўЮё,ПЭЛЇЖЫгІгУФмЙЛИљОнжИЖЈУћзжРДЛёШЁзЪдДЛђЗўЮёЕФЕижЗ,ЬсЙЉепЕШаХЯЂЁЃ
159. zookeeper гаМИжжВПЪ№ФЃЪН?
zookeeper гаШ§жжВПЪ№ФЃЪН:
-
ЕЅЛњВПЪ№:вЛЬЈМЏШКЩЯдЫаа;
-
МЏШКВПЪ№:ЖрЬЈМЏШКдЫаа;
-
ЮБМЏШКВПЪ№:вЛЬЈМЏШКЦєЖЏЖрИі zookeeper ЪЕР§дЫааЁЃ
160. zookeeper дѕУДБЃжЄжїДгНкЕуЕФзДЬЌЭЌВН?
zookeeper ЕФКЫаФЪЧдзгЙуВЅ,етИіЛњжЦБЃжЄСЫИїИі server жЎМфЕФЭЌВНЁЃЪЕЯжетИіЛњжЦЕФавщНазі zab авщЁЃ zab авщгаСНжжФЃЪН,ЗжБ№ЪЧЛжИДФЃЪН(бЁжї)КЭЙуВЅФЃЪН(ЭЌВН)ЁЃЕБЗўЮёЦєЖЏЛђепдкСьЕМепБРРЃКѓ,zab ОЭНјШыСЫЛжИДФЃЪН,ЕБСьЕМепБЛбЁОйГіРД,ЧвДѓЖрЪ§ server ЭъГЩСЫКЭ leader ЕФзДЬЌЭЌВНвдКѓ,ЛжИДФЃЪНОЭНсЪјСЫЁЃзДЬЌЭЌВНБЃжЄСЫ leader КЭ server ОпгаЯрЭЌЕФЯЕЭГзДЬЌЁЃ
161. МЏШКжаЮЊЪВУДвЊгажїНкЕу?
дкЗжВМЪНЛЗОГжа,гааЉвЕЮёТпМжЛашвЊМЏШКжаЕФФГвЛЬЈЛњЦїНјаажДаа,ЦфЫћЕФЛњЦїПЩвдЙВЯэетИіНсЙћ,етбљПЩвдДѓДѓМѕЩйжиИДМЦЫу,ЬсИпадФм,ЫљвдОЭашвЊжїНкЕуЁЃ
162. МЏШКжага 3 ЬЈЗўЮёЦї,ЦфжавЛИіНкЕухДЛњ,етИіЪБКђ zookeeper ЛЙПЩвдЪЙгУТ№?
ПЩвдМЬајЪЙгУ,ЕЅЪ§ЗўЮёЦїжЛвЊУЛГЌЙ§вЛАыЕФЗўЮёЦїхДЛњОЭПЩвдМЬајЪЙгУЁЃ
163. ЫЕвЛЯТ zookeeper ЕФЭЈжЊЛњжЦ?
ПЭЛЇЖЫЖЫЛсЖдФГИі znode НЈСЂвЛИі watcher ЪТМў,ЕБИУ znode ЗЂЩњБфЛЏЪБ,етаЉПЭЛЇЖЫЛсЪеЕН zookeeper ЕФЭЈжЊ,ШЛКѓПЭЛЇЖЫПЩвдИљОн znode БфЛЏРДзіГівЕЮёЩЯЕФИФБфЁЃ
ЪЎЦпЁЂMySql
164. Ъ§ОнПтЕФШ§ЗЖЪНЪЧЪВУД?
-
ЕквЛЗЖЪН:ЧПЕїЕФЪЧСаЕФдзгад,МДЪ§ОнПтБэЕФУПвЛСаЖМЪЧВЛПЩЗжИюЕФдзгЪ§ОнЯюЁЃ
-
ЕкЖўЗЖЪН:вЊЧѓЪЕЬхЕФЪєадЭъШЋвРРЕгкжїЙиМќзжЁЃЫљЮНЭъШЋвРРЕЪЧжИВЛФмДцдкНівРРЕжїЙиМќзжвЛВПЗжЕФЪєадЁЃ
-
ЕкШ§ЗЖЪН:ШЮКЮЗЧжїЪєадВЛвРРЕгкЦфЫќЗЧжїЪєадЁЃ
165. вЛеХзддіБэРяУцзмЙВга 7 ЬѕЪ§Он,ЩОГ§СЫзюКѓ 2 ЬѕЪ§Он,жиЦє mysql Ъ§ОнПт,гжВхШыСЫвЛЬѕЪ§Он,ДЫЪБ id ЪЧМИ?
-
БэРраЭШчЙћЪЧ MyISAM ,ФЧ id ОЭЪЧ 18ЁЃ
-
БэРраЭШчЙћЪЧ InnoDB,ФЧ id ОЭЪЧ 15ЁЃ
InnoDB БэжЛЛсАбзддіжїМќЕФзюДѓ id МЧТМдкФкДцжа,ЫљвджиЦєжЎКѓЛсЕМжТзюДѓ id ЖЊЪЇЁЃ
166. ШчКЮЛёШЁЕБЧАЪ§ОнПтАцБО?
ЪЙгУ select version() ЛёШЁЕБЧА MySQL Ъ§ОнПтАцБОЁЃ
167. ЫЕвЛЯТ ACID ЪЧЪВУД?
-
Atomicity(дзгад):вЛИіЪТЮё(transaction)жаЕФЫљгаВйзї,ЛђепШЋВПЭъГЩ,ЛђепШЋВПВЛЭъГЩ,ВЛЛсНсЪјдкжаМфФГИіЛЗНкЁЃЪТЮёдкжДааЙ§ГЬжаЗЂЩњДэЮѓ,ЛсБЛЛжИД(Rollback)ЕНЪТЮёПЊЪМЧАЕФзДЬЌ,ОЭЯёетИіЪТЮёДгРДУЛгажДааЙ§вЛбљЁЃМД,ЪТЮёВЛПЩЗжИюЁЂВЛПЩдММђЁЃ
-
Consistency(вЛжТад):дкЪТЮёПЊЪМжЎЧАКЭЪТЮёНсЪјвдКѓ,Ъ§ОнПтЕФЭъећадУЛгаБЛЦЦЛЕЁЃетБэЪОаДШыЕФзЪСЯБиаыЭъШЋЗћКЯЫљгаЕФдЄЩшдМЪјЁЂДЅЗЂЦїЁЂМЖСЊЛиЙіЕШЁЃ
-
Isolation(ИєРыад):Ъ§ОнПтдЪаэЖрИіВЂЗЂЪТЮёЭЌЪБЖдЦфЪ§ОнНјааЖСаДКЭаоИФЕФФмСІ,ИєРыадПЩвдЗРжЙЖрИіЪТЮёВЂЗЂжДааЪБгЩгкНЛВцжДааЖјЕМжТЪ§ОнЕФВЛвЛжТЁЃЪТЮёИєРыЗжЮЊВЛЭЌМЖБ№,АќРЈЖСЮДЬсНЛ(Read uncommitted)ЁЂЖСЬсНЛ(read committed)ЁЂПЩжиИДЖС(repeatable read)КЭДЎааЛЏ(Serializable)ЁЃ
-
Durability(ГжОУад):ЪТЮёДІРэНсЪјКѓ,ЖдЪ§ОнЕФаоИФОЭЪЧгРОУЕФ,МДБуЯЕЭГЙЪеЯвВВЛЛсЖЊЪЇЁЃ
168. char КЭ varchar ЕФЧјБ№ЪЧЪВУД?
char(n) :ЙЬЖЈГЄЖШРраЭ,БШШчЖЉдФ char(10),ЕБФуЪфШы"abc"Ш§ИізжЗћЕФЪБКђ,ЫќУЧеМЕФПеМфЛЙЪЧ 10 ИізжНк,ЦфЫћ 7 ИіЪЧПезжНкЁЃ
chat гХЕу:аЇТЪИп;ШБЕу:еМгУПеМф;ЪЪгУГЁОА:ДцДЂУмТыЕФ md5 жЕ,ЙЬЖЈГЄЖШЕФ,ЪЙгУ char ЗЧГЃКЯЪЪЁЃ
varchar(n) :ПЩБфГЄЖШ,ДцДЂЕФжЕЪЧУПИіжЕеМгУЕФзжНкдйМгЩЯвЛИігУРДМЧТМЦфГЄЖШЕФзжНкЕФГЄЖШЁЃ
Ыљвд,ДгПеМфЩЯПМТЧ varcahr БШНЯКЯЪЪ;ДгаЇТЪЩЯПМТЧ char БШНЯКЯЪЪ,ЖўепЪЙгУашвЊШЈКтЁЃ
169. float КЭ double ЕФЧјБ№ЪЧЪВУД?
-
float зюЖрПЩвдДцДЂ 8 ЮЛЕФЪЎНјжЦЪ§,ВЂдкФкДцжаеМ 4 зжНкЁЃ
-
double зюПЩПЩвдДцДЂ 16 ЮЛЕФЪЎНјжЦЪ§,ВЂдкФкДцжаеМ 8 зжНкЁЃ
170. mysql ЕФФкСЌНгЁЂзѓСЌНгЁЂгвСЌНггаЪВУДЧјБ№?
ФкСЌНгЙиМќзж:inner join;зѓСЌНг:left join;гвСЌНг:right joinЁЃ
ФкСЌНгЪЧАбЦЅХфЕФЙиСЊЪ§ОнЯдЪОГіРД;зѓСЌНгЪЧзѓБпЕФБэШЋВПЯдЪОГіРД,гвБпЕФБэЯдЪОГіЗћКЯЬѕМўЕФЪ§Он;гвСЌНге§КУЯрЗДЁЃ
171. mysql Ыїв§ЪЧдѕУДЪЕЯжЕФ?
Ыїв§ЪЧТњзуФГжжЬиЖЈВщевЫуЗЈЕФЪ§ОнНсЙЙ,ЖјетаЉЪ§ОнНсЙЙЛсвдФГжжЗНЪНжИЯђЪ§Он,ДгЖјЪЕЯжИпаЇВщевЪ§ОнЁЃ
ОпЬхРДЫЕ MySQL жаЕФЫїв§,ВЛЭЌЕФЪ§Онв§ЧцЪЕЯжгаЫљВЛЭЌ,ЕЋФПЧАжїСїЕФЪ§ОнПтв§ЧцЕФЫїв§ЖМЪЧ B+ ЪїЪЕЯжЕФ,B+ ЪїЕФЫбЫїаЇТЪ,ПЩвдЕНДяЖўЗжЗЈЕФадФм,евЕНЪ§ОнЧјгђжЎКѓОЭевЕНСЫЭъећЕФЪ§ОнНсЙЙСЫ,ЫљгаЫїв§ЕФадФмвВЪЧИќКУЕФЁЃ
172. дѕУДбщжЄ mysql ЕФЫїв§ЪЧЗёТњзуашЧѓ?
ЪЙгУ explain ВщПД SQL ЪЧШчКЮжДааВщбЏгяОфЕФ,ДгЖјЗжЮіФуЕФЫїв§ЪЧЗёТњзуашЧѓЁЃ
explain гяЗЈ:explain select * from table where type=1ЁЃ
173. ЫЕвЛЯТЪ§ОнПтЕФЪТЮёИєРы?
MySQL ЕФЪТЮёИєРыЪЧдк MySQL. ini ХфжУЮФМўРяЬэМгЕФ,дкЮФМўЕФзюКѓЬэМг:transaction-isolation = REPEATABLE-READ
ПЩгУЕФХфжУжЕ:READ-UNCOMMITTEDЁЂREAD-COMMITTEDЁЂREPEATABLE-READЁЂSERIALIZABLEЁЃ
-
READ-UNCOMMITTED:ЮДЬсНЛЖС,зюЕЭИєРыМЖБ№ЁЂЪТЮёЮДЬсНЛЧА,ОЭПЩБЛЦфЫћЪТЮёЖСШЁ(ЛсГіЯжЛУЖСЁЂдрЖСЁЂВЛПЩжиИДЖС)ЁЃ
-
READ-COMMITTED:ЬсНЛЖС,вЛИіЪТЮёЬсНЛКѓВХФмБЛЦфЫћЪТЮёЖСШЁЕН(ЛсдьГЩЛУЖСЁЂВЛПЩжиИДЖС)ЁЃ
-
REPEATABLE-READ:ПЩжиИДЖС,ФЌШЯМЖБ№,БЃжЄЖрДЮЖСШЁЭЌвЛИіЪ§ОнЪБ,ЦфжЕЖМКЭЪТЮёПЊЪМЪБКђЕФФкШнЪЧвЛжТ,НћжЙЖСШЁЕНБ№ЕФЪТЮёЮДЬсНЛЕФЪ§Он(ЛсдьГЩЛУЖС)ЁЃ
-
SERIALIZABLE:ађСаЛЏ,ДњМлзюИпзюПЩППЕФИєРыМЖБ№,ИУИєРыМЖБ№ФмЗРжЙдрЖСЁЂВЛПЩжиИДЖСЁЂЛУЖСЁЃ
дрЖС :БэЪОвЛИіЪТЮёФмЙЛЖСШЁСэвЛИіЪТЮёжаЛЙЮДЬсНЛЕФЪ§ОнЁЃБШШч,ФГИіЪТЮёГЂЪдВхШыМЧТМ A,ДЫЪБИУЪТЮёЛЙЮДЬсНЛ,ШЛКѓСэвЛИіЪТЮёГЂЪдЖСШЁЕНСЫМЧТМ AЁЃ
ВЛПЩжиИДЖС :ЪЧжИдквЛИіЪТЮёФк,ЖрДЮЖСЭЌвЛЪ§ОнЁЃ
ЛУЖС :жИЭЌвЛИіЪТЮёФкЖрДЮВщбЏЗЕЛиЕФНсЙћМЏВЛвЛбљЁЃБШШчЭЌвЛИіЪТЮё A ЕквЛДЮВщбЏЪБКђга n ЬѕМЧТМ,ЕЋЪЧЕкЖўДЮЭЌЕШЬѕМўЯТВщбЏШДга n+1 ЬѕМЧТМ,етОЭКУЯёВњЩњСЫЛУОѕЁЃЗЂЩњЛУЖСЕФдвђвВЪЧСэЭтвЛИіЪТЮёаТдіЛђепЩОГ§ЛђепаоИФСЫЕквЛИіЪТЮёНсЙћМЏРяУцЕФЪ§Он,ЭЌвЛИіМЧТМЕФЪ§ОнФкШнБЛаоИФСЫ,ЫљгаЪ§ОнааЕФМЧТМОЭБфЖрЛђепБфЩйСЫЁЃ
174. ЫЕвЛЯТ mysql ГЃгУЕФв§Чц?
InnoDB в§Чц:InnoDB в§ЧцЬсЙЉСЫЖдЪ§ОнПт acid ЪТЮёЕФжЇГж,ВЂЧвЛЙЬсЙЉСЫааМЖЫјКЭЭтМќЕФдМЪј,ЫќЕФЩшМЦЕФФПБъОЭЪЧДІРэДѓЪ§ОнШнСПЕФЪ§ОнПтЯЕЭГЁЃMySQL дЫааЕФЪБКђ,InnoDB ЛсдкФкДцжаНЈСЂЛКГхГи,гУгкЛКГхЪ§ОнКЭЫїв§ЁЃЕЋЪЧИУв§ЧцЪЧВЛжЇГжШЋЮФЫбЫї,ЭЌЪБЦєЖЏвВБШНЯЕФТ§,ЫќЪЧВЛЛсБЃДцБэЕФааЪ§ЕФ,ЫљвдЕБНјаа select count(*) from table жИСюЕФЪБКђ,ашвЊНјааЩЈУшШЋБэЁЃгЩгкЫјЕФСЃЖШаЁ,аДВйзїЪЧВЛЛсЫјЖЈШЋБэЕФ,ЫљвддкВЂЗЂЖШНЯИпЕФГЁОАЯТЪЙгУЛсЬсЩ§аЇТЪЕФЁЃ
MyIASM в§Чц:MySQL ЕФФЌШЯв§Чц,ЕЋВЛЬсЙЉЪТЮёЕФжЇГж,вВВЛжЇГжааМЖЫјКЭЭтМќЁЃвђДЫЕБжДааВхШыКЭИќаТгяОфЪБ,МДжДаааДВйзїЕФЪБКђашвЊЫјЖЈетИіБэ,ЫљвдЛсЕМжТаЇТЪЛсНЕЕЭЁЃВЛЙ§КЭ InnoDB ВЛЭЌЕФЪЧ,MyIASM в§ЧцЪЧБЃДцСЫБэЕФааЪ§,гкЪЧЕБНјаа select count(*) from table гяОфЪБ,ПЩвджБНгЕФЖСШЁвбОБЃДцЕФжЕЖјВЛашвЊНјааЩЈУшШЋБэЁЃЫљвд,ШчЙћБэЕФЖСВйзїдЖдЖЖргкаДВйзїЪБ,ВЂЧвВЛашвЊЪТЮёЕФжЇГжЕФ,ПЩвдНЋ MyIASM зїЮЊЪ§ОнПтв§ЧцЕФЪзбЁЁЃ
175. ЫЕвЛЯТ mysql ЕФааЫјКЭБэЫј?
MyISAM жЛжЇГжБэЫј,InnoDB жЇГжБэЫјКЭааЫј,ФЌШЯЮЊааЫјЁЃ
-
БэМЖЫј:ПЊЯњаЁ,МгЫјПь,ВЛЛсГіЯжЫРЫјЁЃЫјЖЈСЃЖШДѓ,ЗЂЩњЫјГхЭЛЕФИХТЪзюИп,ВЂЗЂСПзюЕЭЁЃ
-
ааМЖЫј:ПЊЯњДѓ,МгЫјТ§,ЛсГіЯжЫРЫјЁЃЫјСІЖШаЁ,ЗЂЩњЫјГхЭЛЕФИХТЪаЁ,ВЂЗЂЖШзюИпЁЃ
176. ЫЕвЛЯТРжЙлЫјКЭБЏЙлЫј?
-
РжЙлЫј:УПДЮШЅФУЪ§ОнЕФЪБКђЖМШЯЮЊБ№ШЫВЛЛсаоИФ,ЫљвдВЛЛсЩЯЫј,ЕЋЪЧдкЬсНЛИќаТЕФЪБКђЛсХаЖЯвЛЯТдкДЫЦкМфБ№ШЫгаУЛгаШЅИќаТетИіЪ§ОнЁЃ
-
БЏЙлЫј:УПДЮШЅФУЪ§ОнЕФЪБКђЖМШЯЮЊБ№ШЫЛсаоИФ,ЫљвдУПДЮдкФУЪ§ОнЕФЪБКђЖМЛсЩЯЫј,етбљБ№ШЫЯыФУетИіЪ§ОнОЭЛсзшжЙ,жБЕНетИіЫјБЛЪЭЗХЁЃ
Ъ§ОнПтЕФРжЙлЫјашвЊздМКЪЕЯж,дкБэРяУцЬэМгвЛИі version зжЖЮ,УПДЮаоИФГЩЙІжЕМг 1,етбљУПДЮаоИФЕФЪБКђЯШЖдБШвЛЯТ,здМКгЕгаЕФ version КЭЪ§ОнПтЯждкЕФ version ЪЧЗёвЛжТ,ШчЙћВЛвЛжТОЭВЛаоИФ,етбљОЭЪЕЯжСЫРжЙлЫјЁЃ
177. mysql ЮЪЬтХХВщЖМгаФФаЉЪжЖЮ?
-
ЪЙгУ show processlist УќСюВщПДЕБЧАЫљгаСЌНгаХЯЂЁЃ
-
ЪЙгУ explain УќСюВщбЏ SQL гяОфжДааМЦЛЎЁЃ
-
ПЊЦєТ§ВщбЏШежО,ВщПДТ§ВщбЏЕФ SQLЁЃ
178. ШчКЮзі mysql ЕФадФмгХЛЏ?
-
ЮЊЫбЫїзжЖЮДДНЈЫїв§ЁЃ
-
БмУтЪЙгУ select *,СаГіашвЊВщбЏЕФзжЖЮЁЃ
-
ДЙжБЗжИюЗжБэЁЃ
-
бЁдёе§ШЗЕФДцДЂв§ЧцЁЃ
ЪЎАЫЁЂRedis
179.?redis?ЪЧЪВУД?ЖМгаФФаЉЪЙгУГЁОА?
RedisЪЧвЛИіПЊдДЕФЪЙгУANSI?CгябдБраДЁЂжЇГжЭјТчЁЂПЩЛљгкФкДцврПЩГжОУЛЏЕФШежОаЭЁЂKey-ValueЪ§ОнПт,ВЂЬсЙЉЖржжгябдЕФAPIЁЃ
Redis?ЪЙгУГЁОА:
-
Ъ§ОнИпВЂЗЂЕФЖСаД
-
КЃСПЪ§ОнЕФЖСаД
-
ЖдРЉеЙадвЊЧѓИпЕФЪ§Он
180.?redis?гаФФаЉЙІФм?
-
Ъ§ОнЛКДцЙІФм
-
ЗжВМЪНЫјЕФЙІФм
-
жЇГжЪ§ОнГжОУЛЏ
-
жЇГжЪТЮё
-
жЇГжЯћЯЂЖгСа
181.?redis?КЭ?memecache?гаЪВУДЧјБ№?
-
memcachedЫљгаЕФжЕОљЪЧМђЕЅЕФзжЗћДЎ,redisзїЮЊЦфЬцДњеп,жЇГжИќЮЊЗсИЛЕФЪ§ОнРраЭ
-
redisЕФЫйЖШБШmemcachedПьКмЖр
-
redisПЩвдГжОУЛЏЦфЪ§Он
182.?redis?ЮЊЪВУДЪЧЕЅЯпГЬЕФ?
вђЮЊ?cpu?ВЛЪЧ?Redis?ЕФЦПОБ,Redis?ЕФЦПОБзюгаПЩФмЪЧЛњЦїФкДцЛђепЭјТчДјПэЁЃМШШЛЕЅЯпГЬШнвзЪЕЯж,ЖјЧв?cpu?гжВЛЛсГЩЮЊЦПОБ,ФЧОЭЫГРэГЩеТЕиВЩгУЕЅЯпГЬЕФЗНАИСЫЁЃ
Йигк?Redis?ЕФадФм,ЙйЗНЭјеОвВга,ЦеЭЈБЪМЧБОЧсЫЩДІРэУПУыМИЪЎЭђЕФЧыЧѓЁЃ
ЖјЧвЕЅЯпГЬВЂВЛДњБэОЭТ§?nginx?КЭ?nodejs?вВЖМЪЧИпадФмЕЅЯпГЬЕФДњБэЁЃ
183.?ЪВУДЪЧЛКДцДЉЭИ?дѕУДНтОі?
ЛКДцДЉЭИ:жИВщбЏвЛИівЛЖЈВЛДцдкЕФЪ§Он,гЩгкЛКДцЪЧВЛУќжаЪБашвЊДгЪ§ОнПтВщбЏ,ВщВЛЕНЪ§ОндђВЛаДШыЛКДц,етНЋЕМжТетИіВЛДцдкЕФЪ§ОнУПДЮЧыЧѓЖМвЊЕНЪ§ОнПтШЅВщбЏ,дьГЩЛКДцДЉЭИЁЃ
НтОіЗНАИ:зюМђЕЅДжБЉЕФЗНЗЈШчЙћвЛИіВщбЏЗЕЛиЕФЪ§ОнЮЊПе(ВЛЙмЪЧЪ§ОнВЛДцдк,ЛЙЪЧЯЕЭГЙЪеЯ),ЮвУЧОЭАбетИіПеНсЙћНјааЛКДц,ЕЋЫќЕФЙ§ЦкЪБМфЛсКмЖЬ,зюГЄВЛГЌЙ§ЮхЗжжгЁЃ
184.?redis?жЇГжЕФЪ§ОнРраЭгаФФаЉ?
stringЁЂlistЁЂhashЁЂsetЁЂzsetЁЃ
185.?redis?жЇГжЕФ?java?ПЭЛЇЖЫЖМгаФФаЉ?
RedissonЁЂJedisЁЂlettuceЕШЕШ,ЙйЗНЭЦМіЪЙгУRedissonЁЃ
186.?jedis?КЭ?redisson?гаФФаЉЧјБ№?
JedisЪЧRedisЕФJavaЪЕЯжЕФПЭЛЇЖЫ,ЦфAPIЬсЙЉСЫБШНЯШЋУцЕФRedisУќСюЕФжЇГжЁЃ
RedissonЪЕЯжСЫЗжВМЪНКЭПЩРЉеЙЕФJavaЪ§ОнНсЙЙ,КЭJedisЯрБШ,ЙІФмНЯЮЊМђЕЅ,ВЛжЇГжзжЗћДЎВйзї,ВЛжЇГжХХађЁЂЪТЮёЁЂЙмЕРЁЂЗжЧјЕШRedisЬиадЁЃRedissonЕФзкжМЪЧДйНјЪЙгУепЖдRedisЕФЙизЂЗжРы,ДгЖјШУЪЙгУепФмЙЛНЋОЋСІИќМЏжаЕиЗХдкДІРэвЕЮёТпМЩЯЁЃ
187.?дѕУДБЃжЄЛКДцКЭЪ§ОнПтЪ§ОнЕФвЛжТад?
-
КЯРэЩшжУЛКДцЕФЙ§ЦкЪБМфЁЃ
-
аТдіЁЂИќИФЁЂЩОГ§Ъ§ОнПтВйзїЪБЭЌВНИќаТ?Redis,ПЩвдЪЙгУЪТЮяЛњжЦРДБЃжЄЪ§ОнЕФвЛжТадЁЃ
188.?redis?ГжОУЛЏгаМИжжЗНЪН?
Redis?ЕФГжОУЛЏгаСНжжЗНЪН,ЛђепЫЕгаСНжжВпТд:
-
RDB(Redis?Database):жИЖЈЕФЪБМфМфИєФмЖдФуЕФЪ§ОнНјааПьееДцДЂЁЃ
-
AOF(Append?Only?File):УПвЛИіЪеЕНЕФаДУќСюЖМЭЈЙ§writeКЏЪ§зЗМгЕНЮФМўжаЁЃ
189.?redis?дѕУДЪЕЯжЗжВМЪНЫј?
Redis?ЗжВМЪНЫјЦфЪЕОЭЪЧдкЯЕЭГРяУцеМвЛИіЁАПгЁБ,ЦфЫћГЬађвВвЊеМЁАПгЁБЕФЪБКђ,еМгУГЩЙІСЫОЭПЩвдМЬајжДаа,ЪЇАмСЫОЭжЛФмЗХЦњЛђЩдКѓжиЪдЁЃ
еМПгвЛАуЪЙгУ?setnx(set?if?not?exists)жИСю,жЛдЪаэБЛвЛИіГЬађеМга,ЪЙгУЭъЕїгУ?del?ЪЭЗХЫјЁЃ
190.?redis?ЗжВМЪНЫјгаЪВУДШБЯн?
Redis?ЗжВМЪНЫјВЛФмНтОіГЌЪБЕФЮЪЬт,ЗжВМЪНЫјгавЛИіГЌЪБЪБМф,ГЬађЕФжДааШчЙћГЌГіСЫЫјЕФГЌЪБЪБМфОЭЛсГіЯжЮЪЬтЁЃ
191.?redis?ШчКЮзіФкДцгХЛЏ?
ОЁПЩФмЪЙгУЩЂСаБэ(hashes),ЩЂСаБэ(ЪЧЫЕЩЂСаБэРяУцДцДЂЕФЪ§Щй)ЪЙгУЕФФкДцЗЧГЃаЁ,ЫљвдФугІИУОЁПЩФмЕФНЋФуЕФЪ§ОнФЃаЭГщЯѓЕНвЛИіЩЂСаБэРяУцЁЃ
БШШчФуЕФwebЯЕЭГжагавЛИігУЛЇЖдЯѓ,ВЛвЊЮЊетИігУЛЇЕФУћГЦ,аеЪЯ,гЪЯф,УмТыЩшжУЕЅЖРЕФkey,ЖјЪЧгІИУАбетИігУЛЇЕФЫљгааХЯЂДцДЂЕНвЛеХЩЂСаБэРяУцЁЃ
192.?redis?ЬдЬВпТдгаФФаЉ?
-
volatile-lru:ДгвбЩшжУЙ§ЦкЪБМфЕФЪ§ОнМЏ(server.?db[i].?expires)жаЬєбЁзюНќзюЩйЪЙгУЕФЪ§ОнЬдЬЁЃ
-
volatile-ttl:ДгвбЩшжУЙ§ЦкЪБМфЕФЪ§ОнМЏ(server.?db[i].?expires)жаЬєбЁНЋвЊЙ§ЦкЕФЪ§ОнЬдЬЁЃ
-
volatile-random:ДгвбЩшжУЙ§ЦкЪБМфЕФЪ§ОнМЏ(server.?db[i].?expires)жаШЮвтбЁдёЪ§ОнЬдЬЁЃ
-
allkeys-lru:ДгЪ§ОнМЏ(server.?db[i].?dict)жаЬєбЁзюНќзюЩйЪЙгУЕФЪ§ОнЬдЬЁЃ
-
allkeys-random:ДгЪ§ОнМЏ(server.?db[i].?dict)жаШЮвтбЁдёЪ§ОнЬдЬЁЃ
-
no-enviction(Ч§ж№):НћжЙЧ§ж№Ъ§ОнЁЃ
193.?redis?ГЃМћЕФадФмЮЪЬтгаФФаЉ?ИУШчКЮНтОі?
-
жїЗўЮёЦїаДФкДцПьее,ЛсзшШћжїЯпГЬЕФЙЄзї,ЕБПьееБШНЯДѓЪБЖдадФмгАЯьЪЧЗЧГЃДѓЕФ,ЛсМфЖЯадднЭЃЗўЮё,ЫљвджїЗўЮёЦїзюКУВЛвЊаДФкДцПьееЁЃ
-
Redis?жїДгИДжЦЕФадФмЮЪЬт,ЮЊСЫжїДгИДжЦЕФЫйЖШКЭСЌНгЕФЮШЖЈад,жїДгПтзюКУдкЭЌвЛИіОжгђЭјФкЁЃ
ЪЎОХЁЂJVM
194.?ЫЕвЛЯТ?jvm?ЕФжївЊзщГЩВПЗж?МАЦфзїгУ?
-
РрМгдиЦї(ClassLoader)
-
дЫааЪБЪ§ОнЧј(Runtime Data Area)
-
жДаав§Чц(Execution Engine)
-
БОЕиПтНгПк(Native Interface)
зщМўЕФзїгУ:?ЪзЯШЭЈЙ§РрМгдиЦї(ClassLoader)ЛсАб?Java?ДњТызЊЛЛГЩзжНкТы,дЫааЪБЪ§ОнЧј(Runtime?Data?Area)дйАбзжНкТыМгдиЕНФкДцжа,ЖјзжНкТыЮФМўжЛЪЧ?JVM?ЕФвЛЬзжИСюМЏЙцЗЖ,ВЂВЛФмжБНгНЛИіЕзВуВйзїЯЕЭГШЅжДаа,вђДЫашвЊЬиЖЈЕФУќСюНтЮіЦїжДаав§Чц(Execution?Engine),НЋзжНкТыЗвыГЩЕзВуЯЕЭГжИСю,дйНЛгЩ?CPU?ШЅжДаа,ЖјетИіЙ§ГЬжаашвЊЕїгУЦфЫћгябдЕФБОЕиПтНгПк(Native?Interface)РДЪЕЯжећИіГЬађЕФЙІФмЁЃ
195.?ЫЕвЛЯТ?jvm?дЫааЪБЪ§ОнЧј?
-
ГЬађМЦЪ§Цї
-
ащФтЛњеЛ
-
БОЕиЗНЗЈеЛ
-
Жб
-
ЗНЗЈЧј
гаЕФЧјгђЫцзХащФтЛњНјГЬЕФЦєЖЏЖјДцдк,гаЕФЧјгђдђвРРЕгУЛЇНјГЬЕФЦєЖЏКЭНсЪјЖјДДНЈКЭЯњЛйЁЃ
196.?ЫЕвЛЯТЖбеЛЕФЧјБ№?
1. еЛФкДцДцДЂЕФЪЧОжВПБфСПЖјЖбФкДцДцДЂЕФЪЧЪЕЬх;
2. еЛФкДцЕФИќаТЫйЖШвЊПьгкЖбФкДц,вђЮЊОжВПБфСПЕФЩњУќжмЦкКмЖЬ;
3. еЛФкДцДцЗХЕФБфСПЩњУќжмЦквЛЕЉНсЪјОЭЛсБЛЪЭЗХ,ЖјЖбФкДцДцЗХЕФЪЕЬхЛсБЛРЌЛјЛиЪеЛњжЦВЛЖЈЪБЕФЛиЪеЁЃ
197.?ЖгСаКЭеЛЪЧЪВУД?гаЪВУДЧјБ№?
-
ЖгСаКЭеЛЖМЪЧБЛгУРДдЄДцДЂЪ§ОнЕФЁЃ
-
ЖгСадЪаэЯШНјЯШГіМьЫїдЊЫи,ЕЋвВгаР§ЭтЕФЧщПі,Deque?НгПкдЪаэДгСНЖЫМьЫїдЊЫиЁЃ
-
еЛКЭЖгСаКмЯрЫЦ,ЕЋЫќдЫааЖддЊЫиНјааКѓНјЯШГіНјааМьЫїЁЃ
198.?ЪВУДЪЧЫЋЧзЮЏХЩФЃаЭ?
дкНщЩмЫЋЧзЮЏХЩФЃаЭжЎЧАЯШЫЕЯТРрМгдиЦїЁЃЖдгкШЮвтвЛИіРр,ЖМашвЊгЩМгдиЫќЕФРрМгдиЦїКЭетИіРрБОЩэвЛЭЌШЗСЂдк?JVM?жаЕФЮЈвЛад,УПвЛИіРрМгдиЦї,ЖМгавЛИіЖРСЂЕФРрУћГЦПеМфЁЃРрМгдиЦїОЭЪЧИљОнжИЖЈШЋЯоЖЈУћГЦНЋ?class?ЮФМўМгдиЕН?JVM?ФкДц,ШЛКѓдйзЊЛЏЮЊ?class?ЖдЯѓЁЃ
РрМгдиЦїЗжРр:
-
ЦєЖЏРрМгдиЦї(Bootstrap?ClassLoader),ЪЧащФтЛњздЩэЕФвЛВПЗж,гУРДМгдиJava_HOME/lib/ФПТМжаЕФ,ЛђепБЛ?-Xbootclasspath?ВЮЪ§ЫљжИЖЈЕФТЗОЖжаВЂЧвБЛащФтЛњЪЖБ№ЕФРрПт;
-
ЦфЫћРрМгдиЦї:
-
РЉеЙРрМгдиЦї(Extension?ClassLoader):ИКд№Мгди<java_home?style="box-sizing:?border-box;?-webkit-tap-highlight-color:?transparent;?text-size-adjust:?none;?-webkit-font-smoothing:?antialiased;?outline:?0px?!important;">\lib\extФПТМЛђJava.?ext.?dirsЯЕЭГБфСПжИЖЈЕФТЗОЖжаЕФЫљгаРрПт;</java_home>
-
гІгУГЬађРрМгдиЦї(Application?ClassLoader)ЁЃИКд№МгдигУЛЇРрТЗОЖ(classpath)ЩЯЕФжИЖЈРрПт,ЮвУЧПЩвджБНгЪЙгУетИіРрМгдиЦїЁЃвЛАуЧщПі,ШчЙћЮвУЧУЛгаздЖЈвхРрМгдиЦїФЌШЯОЭЪЧгУетИіМгдиЦїЁЃ
ЫЋЧзЮЏХЩФЃаЭ:ШчЙћвЛИіРрМгдиЦїЪеЕНСЫРрМгдиЕФЧыЧѓ,ЫќЪзЯШВЛЛсздМКШЅМгдиетИіРр,ЖјЪЧАбетИіЧыЧѓЮЏХЩИјИИРрМгдиЦїШЅЭъГЩ,УПвЛВуЕФРрМгдиЦїЖМЪЧШчДЫ,етбљЫљгаЕФМгдиЧыЧѓЖМЛсБЛДЋЫЭЕНЖЅВуЕФЦєЖЏРрМгдиЦїжа,жЛгаЕБИИМгдиЮоЗЈЭъГЩМгдиЧыЧѓ(ЫќЕФЫбЫїЗЖЮЇжаУЛевЕНЫљашЕФРр)ЪБ,згМгдиЦїВХЛсГЂЪдШЅМгдиРрЁЃ
199.?ЫЕвЛЯТРрМгдиЕФжДааЙ§ГЬ?
РрМгдиЗжЮЊвдЯТ?5?ИіВНжш:
-
Мгди:ИљОнВщевТЗОЖевЕНЯргІЕФ?class?ЮФМўШЛКѓЕМШы;
-
МьВщ:МьВщМгдиЕФ?class?ЮФМўЕФе§ШЗад;
-
зМБИ:ИјРржаЕФОВЬЌБфСПЗжХфФкДцПеМф;
-
НтЮі:ащФтЛњНЋГЃСПГижаЕФЗћКХв§гУЬцЛЛГЩжБНгв§гУЕФЙ§ГЬЁЃЗћКХв§гУОЭРэНтЮЊвЛИіБъЪО,ЖјдкжБНгв§гУжБНгжИЯђФкДцжаЕФЕижЗ;
-
ГѕЪМЛЏ:ЖдОВЬЌБфСПКЭОВЬЌДњТыПщжДааГѕЪМЛЏЙЄзїЁЃ
200.?дѕУДХаЖЯЖдЯѓЪЧЗёПЩвдБЛЛиЪе?
вЛАугаСНжжЗНЗЈРДХаЖЯ:
-
в§гУМЦЪ§Цї:ЮЊУПИіЖдЯѓДДНЈвЛИів§гУМЦЪ§,гаЖдЯѓв§гУЪБМЦЪ§Цї?+1,в§гУБЛЪЭЗХЪБМЦЪ§?-1,ЕБМЦЪ§ЦїЮЊ?0?ЪБОЭПЩвдБЛЛиЪеЁЃЫќгавЛИіШБЕуВЛФмНтОібЛЗв§гУЕФЮЪЬт;
-
ПЩДяадЗжЮі:Дг?GC?Roots?ПЊЪМЯђЯТЫбЫї,ЫбЫїЫљзпЙ§ЕФТЗОЖГЦЮЊв§гУСДЁЃЕБвЛИіЖдЯѓЕН?GC?Roots?УЛгаШЮКЮв§гУСДЯрСЌЪБ,дђжЄУїДЫЖдЯѓЪЧПЩвдБЛЛиЪеЕФЁЃ
201.?java?жаЖМгаФФаЉв§гУРраЭ?
-
ЧПв§гУ
-
Шэв§гУ
-
Шѕв§гУ
-
ащв§гУ(гФСщв§гУ/ЛУгАв§гУ)
202.?ЫЕвЛЯТ?jvm?гаФФаЉРЌЛјЛиЪеЫуЗЈ?
-
БъМЧ-ЧхГ§ЫуЗЈ
-
БъМЧ-ећРэЫуЗЈ
-
ИДжЦЫуЗЈ
-
ЗжДњЫуЗЈ
203.?ЫЕвЛЯТ?jvm?гаФФаЉРЌЛјЛиЪеЦї?
-
Serial:зюдчЕФЕЅЯпГЬДЎааРЌЛјЛиЪеЦїЁЃ
-
Serial?Old:Serial?РЌЛјЛиЪеЦїЕФРЯФъАцБО,ЭЌбљвВЪЧЕЅЯпГЬЕФ,ПЩвдзїЮЊ?CMS?РЌЛјЛиЪеЦїЕФБИбЁдЄАИЁЃ
-
ParNew:ЪЧ?Serial?ЕФЖрЯпГЬАцБОЁЃ
-
Parallel?КЭ?ParNew?ЪеМЏЦїРрЫЦЪЧЖрЯпГЬЕФ,ЕЋ?Parallel?ЪЧЭЬЭТСПгХЯШЕФЪеМЏЦї,ПЩвдЮўЩќЕШД§ЪБМфЛЛШЁЯЕЭГЕФЭЬЭТСПЁЃ
-
Parallel?Old?ЪЧ?Parallel?РЯЩњДњАцБО,Parallel?ЪЙгУЕФЪЧИДжЦЕФФкДцЛиЪеЫуЗЈ,Parallel?Old?ЪЙгУЕФЪЧБъМЧ-ећРэЕФФкДцЛиЪеЫуЗЈЁЃ
-
CMS:вЛжжвдЛёЕУзюЖЬЭЃЖйЪБМфЮЊФПБъЕФЪеМЏЦї,ЗЧГЃЪЪгУ?B/S?ЯЕЭГЁЃ
-
G1:вЛжжМцЙЫЭЬЭТСПКЭЭЃЖйЪБМфЕФ?GC?ЪЕЯж,ЪЧ?JDK?9?вдКѓЕФФЌШЯ?GC?бЁЯюЁЃ
204.?ЯъЯИНщЩмвЛЯТ?CMS?РЌЛјЛиЪеЦї?
CMS?ЪЧгЂЮФ?Concurrent?Mark-Sweep?ЕФМђГЦ,ЪЧвдЮўЩќЭЬЭТСПЮЊДњМлРДЛёЕУзюЖЬЛиЪеЭЃЖйЪБМфЕФРЌЛјЛиЪеЦїЁЃЖдгквЊЧѓЗўЮёЦїЯьгІЫйЖШЕФгІгУЩЯ,етжжРЌЛјЛиЪеЦїЗЧГЃЪЪКЯЁЃдкЦєЖЏ?JVM?ЕФВЮЪ§МгЩЯЁА-XX:+UseConcMarkSweepGCЁБРДжИЖЈЪЙгУ?CMS?РЌЛјЛиЪеЦїЁЃ
CMS?ЪЙгУЕФЪЧБъМЧ-ЧхГ§ЕФЫуЗЈЪЕЯжЕФ,Ыљвддк?gc?ЕФЪБКђЛиВњЩњДѓСПЕФФкДцЫщЦЌ,ЕБЪЃгрФкДцВЛФмТњзуГЬађдЫаавЊЧѓЪБ,ЯЕЭГНЋЛсГіЯж?Concurrent?Mode?Failure,СйЪБ?CMS?ЛсВЩгУ?Serial?Old?ЛиЪеЦїНјааРЌЛјЧхГ§,ДЫЪБЕФадФмНЋЛсБЛНЕЕЭЁЃ
205.аТЩњДњРЌЛјЛиЪеЦїКЭРЯЩњДњРЌЛјЛиЪеЦїЖМгаФФаЉ?гаЪВУДЧјБ№?
-
аТЩњДњЛиЪеЦї:SerialЁЂParNewЁЂParallel?Scavenge
-
РЯФъДњЛиЪеЦї:Serial?OldЁЂParallel?OldЁЂCMS
-
ећЖбЛиЪеЦї:G1
аТЩњДњРЌЛјЛиЪеЦївЛАуВЩгУЕФЪЧИДжЦЫуЗЈ,ИДжЦЫуЗЈЕФгХЕуЪЧаЇТЪИп,ШБЕуЪЧФкДцРћгУТЪЕЭ;РЯФъДњЛиЪеЦївЛАуВЩгУЕФЪЧБъМЧ-ећРэЕФЫуЗЈНјааРЌЛјЛиЪеЁЃ
206.?МђЪіЗжДњРЌЛјЛиЪеЦїЪЧдѕУДЙЄзїЕФ?
ЗжДњЛиЪеЦїгаСНИіЗжЧј:РЯЩњДњКЭаТЩњДњ,аТЩњДњФЌШЯЕФПеМфеМБШзмПеМфЕФ?1/3,РЯЩњДњЕФФЌШЯеМБШЪЧ?2/3ЁЃ
аТЩњДњЪЙгУЕФЪЧИДжЦЫуЗЈ,аТЩњДњРяга?3?ИіЗжЧј:EdenЁЂTo?SurvivorЁЂFrom?Survivor,ЫќУЧЕФФЌШЯеМБШЪЧ?8:1:1,ЫќЕФжДааСїГЬШчЯТ:
-
Аб?Eden?+?From?Survivor?ДцЛюЕФЖдЯѓЗХШы?To?Survivor?Чј;
-
ЧхПе?Eden?КЭ?From?Survivor?ЗжЧј;
-
From?Survivor?КЭ?To?Survivor?ЗжЧјНЛЛЛ,From?Survivor?Бф?To?Survivor,To?Survivor?Бф?From?SurvivorЁЃ
УПДЮдк?From?Survivor?ЕН?To?Survivor?вЦЖЏЪБЖМДцЛюЕФЖдЯѓ,ФъСфОЭ?+1,ЕБФъСфЕНДя?15(ФЌШЯХфжУЪЧ?15)ЪБ,Щ§МЖЮЊРЯЩњДњЁЃДѓЖдЯѓвВЛсжБНгНјШыРЯЩњДњЁЃ
РЯЩњДњЕБПеМфеМгУЕНДяФГИіжЕжЎКѓОЭЛсДЅЗЂШЋОжРЌЛјЪеЛи,вЛАуЪЙгУБъМЧећРэЕФжДааЫуЗЈЁЃвдЩЯетаЉбЛЗЭљИДОЭЙЙГЩСЫећИіЗжДњРЌЛјЛиЪеЕФећЬхжДааСїГЬЁЃ
207.?ЫЕвЛЯТ?jvm?ЕїгХЕФЙЄОп?
JDK?здДјСЫКмЖрМрПиЙЄОп,ЖМЮЛгк?JDK?ЕФ?bin?ФПТМЯТ,ЦфжазюГЃгУЕФЪЧ?jconsole?КЭ?jvisualvm?етСНПюЪгЭММрПиЙЄОпЁЃ
-
jconsole:гУгкЖд?JVM?жаЕФФкДцЁЂЯпГЬКЭРрЕШНјааМрПи;
-
jvisualvm:JDK?здДјЕФШЋФмЗжЮіЙЄОп,ПЩвдЗжЮі:ФкДцПьееЁЂЯпГЬПьееЁЂГЬађЫРЫјЁЂМрПиФкДцЕФБфЛЏЁЂgc?БфЛЏЕШЁЃ
208.?ГЃгУЕФ?jvm?ЕїгХЕФВЮЪ§ЖМгаФФаЉ?
-
-Xms2g:ГѕЪМЛЏЭЦДѓаЁЮЊ?2g;
-
-Xmx2g:ЖбзюДѓФкДцЮЊ?2g;
-
-XX:NewRatio=4:ЩшжУФъЧсЕФКЭРЯФъДњЕФФкДцБШР§ЮЊ?1:4;
-
-XX:SurvivorRatio=8:ЩшжУаТЩњДњ?Eden?КЭ?Survivor?БШР§ЮЊ?8:2;
-
ЈCXX:+UseParNewGC:жИЖЈЪЙгУ?ParNew?+?Serial?Old?РЌЛјЛиЪеЦїзщКЯ;
-
-XX:+UseParallelOldGC:жИЖЈЪЙгУ?ParNew?+?ParNew?Old?РЌЛјЛиЪеЦїзщКЯ;
-
-XX:+UseConcMarkSweepGC:жИЖЈЪЙгУ?CMS?+?Serial?Old?РЌЛјЛиЪеЦїзщКЯ;
-
-XX:+PrintGC:ПЊЦєДђгЁ?gc?аХЯЂ;
-
-XX:+PrintGCDetails:ДђгЁ?gc?ЯъЯИаХЯЂЁЃ