学习spring源码,BeanDifinition是一个重要的基础。spring把(几乎)所有的要管理的对象都定义为Bean,在对Bean初始化之前,会把对spring配置转换为BeanDifinition对象,把所有的BeanDifinition放入到一个Map中,key为Bean的名字,value为BeanDifinition对象
1、Bean
先看一下Spring官网中对Bean的描述

Bean是通过我们提供给spring的配置文件来创建的,这些文件包括xml文件,注解,java config配置这三种形式。
我们可以理解为spring管理对象的单位就是Bean,比如有下面这个xml配置:
<beans>
<bean id="bean1" class="..."/>
<bean id="bean2" class="..."/>
</beans>
里面的定义最终都会被创建为Bean
2、BeanDifinition
简单来说,BeanDifinition就是定义bean的一个描述模型,里面描述了Bean的各种信息,下面来自于spring官网
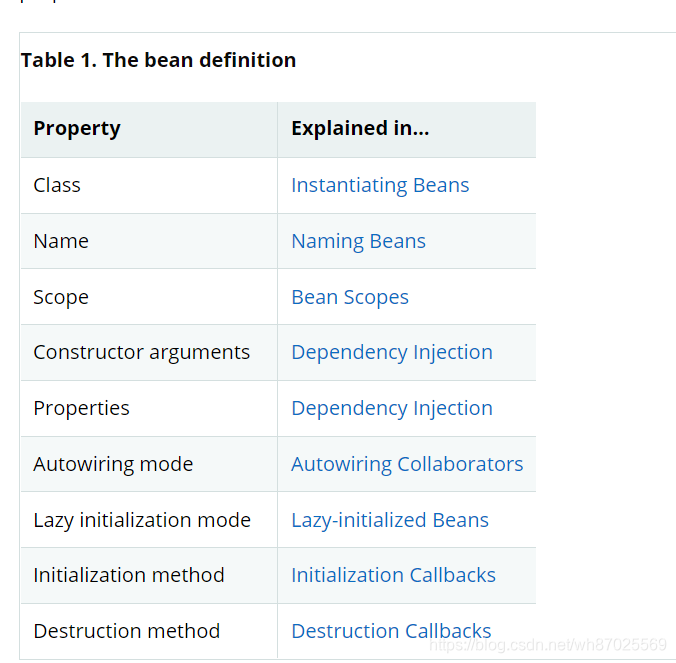
| 参数 | 含义 |
|---|---|
| Class | Bean要实现的类 |
| Name | Bean的名字 |
| Scope | 作用域 |
| Constructor arguments | 构造方法注入时的参数 |
| Properties | setter注入时的参数 |
| Autowiring mode | 自动注入模型 |
| Lazy initialization mode | 懒加载模型 |
| Initialization method | 初始化方法 |
| Destruction method | 销毁方法 |
我们看到BeanDifinition里面保存了一些Bean创建时一些必要的信息,既然我们已经通过xml文件、注解或java config这三种方法定义了Bean,那为什么还要把这些信息再存一个BeanDifinition呢?
1、首先来说xml文件,我们配置的这个xml是一个文件,java想要读取里面的信息肯定要创建流来读取,然后还有对xml进行解析,如果每次需要xml里面信息都要这么操作未免太浪费资源了,不如统一解析出来放到一个map里面保存。
2、那注解和java config好像没有上述的问题,为什么也用了BeanDifinition呢,因为从上面的表格我们看到BeanDifinition中并不是所有属性都是从配置中读出来的,有的是经过了对配置的处理得到的,这种的就没法暂存的原来的注解和java config中了。
3、还有一个原因就是spring支持这三种方式的配置,如果某一天多出了一种配置方式(比如使用json),那么只需要添加从json转换为BeanDifinition的逻辑,就不需要动原来的代码,这也是编程中常常使用的多加一层实现提高抽象程度的方法。
不知道这三个理由能不能说服你,也欢迎大家讨论谈谈自己的理解!